OpenAI Agent Builder leaks show 5 guardrail checks – MCP tools and per‑step models
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI’s Agent Builder is all but confirmed: leaked screenshots show a node‑based canvas wiring Model Context Protocol (MCP) tools to logic blocks with a clean Evaluate/Code/Preview/Publish flow. The most important bit is safety by default — five configurable guardrails (PII, moderation, jailbreak, prompt injection, hallucination) with per‑guardrail confidence knobs and exportable rule sets — so teams don’t have to bolt on policy middleware. And over in the Images tab, a new model selector listing “1× gpt‑image‑1” hints multiple backends and a fresh image model landing with tomorrow’s DevDay “New ships.”
This looks like a real agent runtime, not a chat macro: per‑step model/reasoning settings, if/else and loops, user approvals, plus production‑oriented templates for support, enrichment, Q&A, and doc comparison. The simultaneous “Apps & Connectors” experiment replacing Connectors in ChatGPT lines up with MCP‑native, OAuth‑backed tool access, suggesting the same authenticated connectors your org already trusts will be callable from agents. If OpenAI couples the canvas with a new image (or image‑to‑video) backend, it effectively unifies data access, governance, and media generation under one roof — with policy enforcement running in the loop instead of bolted on after the fact.
Separately, Envoy’s AI Gateway says it’s adding full MCP with OAuth and multi‑backend routing, which would make those tools portable beyond OpenAI’s canvas.
Feature Spotlight
Feature: OpenAI Agent Builder and DevDay ‘new ships’
OpenAI is set to ship a first‑party Agent Builder with MCP + guardrails and a new image model selector at DevDay. This consolidates agent stacks, reduces integration friction, and may re-route budgets from third‑party workflow tools.
Cross-account leaks and UI screenshots point to a native OpenAI Agent Builder with MCP, ChatKit tools, and built-in guardrails; OpenAI also teases “New ships” and a model selector on Images ahead of tomorrow’s DevDay.
Jump to Feature: OpenAI Agent Builder and DevDay ‘new ships’ topicsTable of Contents
🧩 Feature: OpenAI Agent Builder and DevDay ‘new ships’
Cross-account leaks and UI screenshots point to a native OpenAI Agent Builder with MCP, ChatKit tools, and built-in guardrails; OpenAI also teases “New ships” and a model selector on Images ahead of tomorrow’s DevDay.
OpenAI Agent Builder canvas leaks show MCP connectors, logic nodes, and publish flow
Hands‑on screenshots reveal a native Agent Builder with a node‑based canvas, wiring agents to MCP tools, guardrails, if/else, loops, and user approvals, plus Evaluate/Code/Preview/Publish controls and per‑step model/reasoning settings leak thread, TestingCatalog article, feature overview.
Templates for support, enrichment, Q&A and doc comparison suggest production‑oriented recipes, and the MCP node indicates standardized tool/context integration aligned with OpenAI’s Agents SDK.
Built‑in guardrails surface for PII, jailbreaks, prompt injection and hallucinations
A Guardrails UI appears alongside Agent Builder, exposing configurable checks (PII, moderation, jailbreak, prompt injection, hallucination) with thresholds, model selection, and export of rule sets—pointing to first‑class policy enforcement at run time guardrails screenshot. A prompt‑injection modal shows per‑guardrail confidence tuning and context‑aware analysis prompt injection modal.
This bakes safety and governance into agent workflows without bespoke code.
OpenAI teases “New ships.” and confirms @sama keynote livestream for DevDay
OpenAI says “New ships.” and confirms Sam Altman’s keynote will stream live as DevDay kicks off tomorrow, signaling multiple product drops in one event official tease.
Given concurrent leaks (Agent Builder, model selector), expect a coordinated platform push spanning agents, safety, and media tooling.
OpenAI Platform’s Images tab gains a model selector, hinting a new image model
The Images section shows a new model dropdown (screenshot lists “1x gpt‑image‑1”), implying multiple image backends and a likely fresh model tied to DevDay images model selector. A second watcher corroborates the change ahead of announcements secondary confirmation.
If paired with Sora/Image pipelines, this could unify image/video creation flows under one UI.
“Apps & Connectors” experiment replaces Connectors in ChatGPT settings, signaling deeper app tooling
Settings now show “Apps & Connectors” with an experiment badge, replacing the prior Connectors section—likely paving the way for richer tool/app hookups that Agent Builder can target across the stack settings change. A second screenshot reinforces the rename and surfacing timing follow‑up screenshot.
The shift aligns with MCP‑standardized tool routing and authenticated actions becoming first‑class in agents.
🛠️ Coding agents and IDE signals
Heavy chatter on coding agent workflows. Cursor adds a stealth “cheetah” model; devs compare Claude Code vs Droid; practitioners weigh GPT‑5 Codex vs Sonnet 4.5 tradeoffs. Excludes OpenAI Agent Builder (covered in Feature).
Cursor’s stealth “cheetah” model appears, blazing fast with $1.25/M in and $10/M out
Cursor quietly added a new “cheetah” model that early users describe as extremely fast, though some report tool‑call hangs. Pricing shows $1.25 per million input tokens and $10 per million output tokens, and several threads debate whether it’s an unreleased GPT‑5 checkpoint, a Gemini variant, or a Grok‑Fast lineage. See the on‑platform pricing capture and first takes in pricing screenshot, hands‑on notes in early impressions, a diffusion/Gemini angle in model speculation, and the Cursor‑only rumor in cursor-only note.
Copilot’s IP indemnity for generated code sways enterprise agent choices
Enterprise buyers factor legal risk into agent selection, and one oft‑cited differentiator is Microsoft’s commitment to cover legal fees tied to code generation IP claims for Copilot customers—an assurance that can outweigh small quality gaps when standardizing on a coding agent across large teams enterprise policy note.
Droid’s spec mode and queued edits win fans over Claude Code for precise multi-step changes
Practitioners comparing Claude Code and Factory’s Droid are converging on a pattern: use Droid’s “spec mode” to plan precise edits, then rely on queued messages to sequence changes without losing context, especially for larger refactors. Side‑by‑side terminals and new queued‑message UI illustrate why teams prefer this for deterministic multi‑step edits tooling side-by-side, with additional praise for spec mode’s plans in real projects practitioner take and a screenshot of queued tasking in action queued messages.
Teams reach for GPT‑5 Codex on complex debugging; Sonnet 4.5 holds mid-tier tasks
Engineers report GPT‑5/Codex variants still outperform Claude Sonnet 4.5 for architecture‑level planning, hard debugging, and tricky integrations, despite Codex’s slower feel; Sonnet 4.5 is increasingly favored for quicker, mid‑tier tasks. Practitioner notes cite better outcomes with Codex on complex work practitioner view while also acknowledging Sonnet 4.5’s day‑to‑day improvements developer feedback. A recent community benchmark snapshot helps contextualize these preferences repo bench chart.
Claude Code spins up a complete local STT stack in one session
A developer reports going from zero to a streaming, CPU‑only local speech‑to‑text pipeline with NVIDIA’s 0.6B Parakeet in under two hours—without leaving a single Claude Code context. The end result outperformed Whisper for their use case, with the companion maivi tool now open‑sourced for others to replicate locally end-to-end report, GitHub repo.
Running multiple coding agents in parallel becomes a normal workflow
More engineers are embracing parallel agent workflows—firing off tightly scoped tasks to multiple coding agents and reviewing results as they land—because the cognitive load is manageable when tasks are well‑specified. Following up on multi‑Claude worktrees, new posts describe concrete patterns for splitting research and maintenance jobs across agents while keeping reviews serial blog post, with additional observations that this has quietly become routine on teams adoption quote.
Why devs still juggle VSCode/Cursor with Claude Code: context limits and agent behavior
A recurring question—why use Claude Code when VSCode/Cursor have agents—draws consistent answers: separate agent contexts help avoid context rot, cost is easier to bound, and some orchestrations are simpler when chaining runs outside the editor. Threads point to halting between phases, resetting memory, and chaining plans as practical reasons to keep multiple agent surfaces open usage question, cursor follow-up, chaining runs.
📊 Leaderboards and evals: agents and code
Fresh results on real-computer agents and community code benches. OSWorld pushes toward human-level use; RepoPrompt opens uploads and live ranks. Excludes Agent Builder launch details (see Feature).
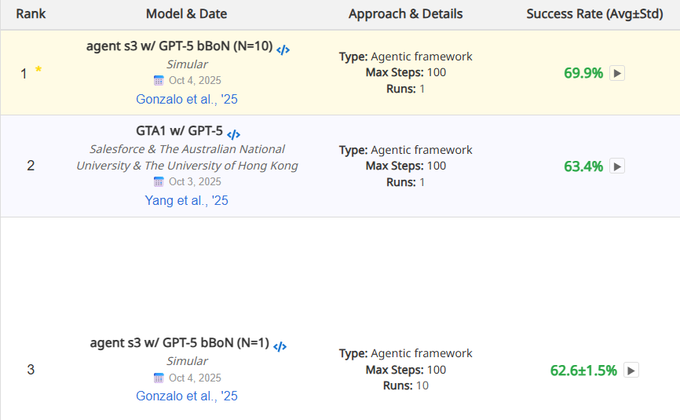
OSWorld posts 62.6% single‑run baseline as GPT‑5 best‑of‑N stays 69.9%
OSWorld’s leaderboard now shows Simular’s GPT‑5 agent framework at 62.6%±1.5 in single‑run evaluations alongside the previously reported 69.9% best‑of‑N (up to 100 steps), with human success around 72% benchmarks table. This clarifies variance between best‑of‑N and pass‑1 reliability, and invites more verified submissions across OSes ArXiv paper, project site, following up on OSWorld 69.9% prior peak bBoN score.
RepoPrompt opens uploads; live median rankings reshape code model board
RepoPrompt 1.4.26 now lets anyone upload benchmark runs, with the site aggregating medians and showing a live top‑15—reducing single‑run variance and making rankings more representative release thread. After the first day of public submissions, the board shows broader model diversity and tighter clustering among GPT‑5 Codex variants live rankings.
- Current snapshot: #1 Claude Code Sonnet 83.82%, #2 Claude Sonnet 4.5 68.82%, #3 Gemini 2.5 Pro 67.35%, #4 GPT‑5 Codex High 66.18%, #5 GPT‑5 Codex Med 65.59, with several China‑origin models entering the table live rankings.
- Separate chart notes a sizable gap between Sonnet 4.5 and Opus 4.1 on these repo tasks, reinforcing the value of fresh, community‑validated scoring gap chart.
Gemini lab checkpoints versus GPT‑5 in DOOM web build A/B: visuals up, systems down
A developer A/B compared a Gemini lab checkpoint (AI Studio tags 5qa/2ht) against a GPT‑5 “Zenith” baseline on a DOOM‑style web game. The Gemini run produced stronger enemy assets but missed systems the GPT‑5 build included (minimap, SFX, richer health UI); 2ht may be a stronger Gemini checkpoint than 5qa A/B test notes, checkpoint note.
🧪 Research: reasoning, compression and domain models
Strong paper day: in‑context learning as rank‑1 patches, 4K diffusion acceleration, ES vs RL for reasoning, a $196 doc‑extraction 7B, and clinical-context radiology. Math claims around GPT‑5 are noted with caveats.
Evolution strategies fine‑tune full LLMs and often beat RL on reasoning with ~20% samples
A multi‑institution study scales parameter‑space evolution to billion‑parameter LLMs and finds ES can match or outperform token‑level RL on reasoning while using under 20% of the samples, with more stable training and less reward hacking paper summary.
Because ES only needs forward passes and end‑to‑end outcome scores, it parallelizes easily and can optimize concision and correctness together—useful where step‑wise rewards are noisy or unavailable.
In‑context learning explained as a temporary rank‑1 patch inside Transformers
A new analysis shows Transformers can adapt to few‑shot prompts by writing a low‑rank (rank‑1) additive tweak onto the first MLP weight matrix during the forward pass, mimicking a one‑step fine‑tune without changing stored weights paper thread, with formalization and experiments in the arXiv preprint ArXiv paper.
The mechanism explains how models “learn” rules in context, why the effect vanishes after generation, and connects token‑by‑token reading to an online‑gradient‑like sequence of transient patches—useful for designing prompts and post‑training that exploit fast, reversible adaptations.
NVIDIA DC‑Gen compresses latents 32–64× to 53× speedups for 4K image generation
DC‑Gen accelerates text‑to‑image by moving diffusion into a deeply compressed latent space (32–64×), then aligning embeddings and fine‑tuning small LoRA adapters; reported gains include 53× faster 4K on H100 and ~3.5 s on a 5090 with quantization for an effective 138× total speedup paper thread.
For practitioners, this suggests post‑training swaps to higher‑compression latents are feasible with brief alignment and adapter tuning, retaining quality while slashing inference cost.
Extract‑0: a $196 fine‑tuned 7B model beats GPT‑4.1 on 1,000 document extraction tasks
A specialized 7B model trained via synthetic data, LoRA (~0.53% weights), and GRPO with semantic rewards achieves 0.573 mean reward and 89% valid JSON on a 1,000‑task benchmark, surpassing GPT‑4.1 at a reported ~$196 training cost paper brief.
For AI teams, this is a compelling case for small, domain‑tuned extractors: cheaper, more controllable, and production‑ready with strict schema checks.
Frontier math, verified proofs remain the bar
Following up on IMO solver, the new GPT‑5 Pro claims—if independently replicated and mechanically verified—would extend the week’s theme that algorithmic rigor (Lean/Isabelle or similar) is the arbiter of progress, not anecdotes round‑up claims. A reproducible harness with formal checkers is the fastest path from viral threads to accepted results.
GPT‑5 Pro math claims on Tsumura 554 spur calls for verification
Community posts claim GPT‑5 Pro produced a full proof of Yu Tsumura’s 554th problem in ~14 minutes without web search and also addressed a NICD with erasures task claim thread round‑up claims, yet others urge independent checks—one researcher deleted a celebratory post pending confirmation retraction note. See the original analysis arguing no off‑the‑shelf LLM could solve 554 at the time ArXiv paper and the NICD open‑problems list Open problems PDF.
Treat this as promising but provisional; verified benchmarks and reproducible traces will determine whether this represents a true leap in formal math reasoning.
Clinical‑context radiology reporting reduces timeline hallucinations by ~12–18%
Fine‑tuning multimodal medical LLMs to read multi‑view images plus indication, technique, and prior exams yields higher structured report accuracy and cuts spurious “new/unchanged” claims by 12.2–18.0% in tests results summary, with full method details in the C‑SRRG paper ArXiv paper.
Anchoring generation in real clinical context (not images alone) improves both findings sections and short impressions, with larger gains on bigger backbones.
Medha shows exact long‑context inference beyond 10M tokens with pipelined prefill and KV parallelism
A Microsoft–Georgia Tech–UCSD system demonstrates exact inference scaling beyond 10,000,000 tokens by chunking prefill, adding sequence pipeline parallelism, and parallelizing KV cache handling, achieving higher throughput and lower latency on mixed‑length workloads paper summary.
For engineers chasing ultra‑long contexts, this is a blueprint for distributing both compute and memory pressure without approximation—highlighting KV memory as a first‑class bottleneck.
Parallel trade‑offs between in‑context and in‑weight learning mirror human flexibility vs retention
PNAS research connects LLM in‑context (fast, scratchpad‑like) and in‑weight (slow, lasting) learning to human working vs long‑term memory, showing curriculum effects and a flexibility‑retention trade‑off within one network after ~12k small tasks paper highlight.
Design implication: assistants that keep a quick‑adapting buffer alongside gradual, persistent learning may feel more natural and sample‑efficient.
LLM agents automate critical heat flux modeling and approach expert‑tuned accuracy
Two setups—supervisor‑coordinated multi‑agent and single ReAct loops—trained deep ensembles on ~24,579 experiments and a blind test, beating a 2006 lookup table and nearly matching a Bayesian‑optimized expert model, while quantifying aleatory and epistemic uncertainty paper overview.
This case study shows agents can run full scientific modeling pipelines (data prep→training→uncertainty) with trustworthy error bars, reducing manual iteration.
⚙️ Systems: in-flight updates and resilience
Runtime engineering notes: vLLM powers RL pipelines with in‑flight weight updates while KV caches persist; ops reliability highlighted by a real outage note. Excludes DC‑Gen details (covered under Research).
vLLM enables in‑flight weight updates and mixed KV caches for RL inference
PipelineRL keeps generation running while model weights change and even mixes KV caches across models during inference, with vLLM powering the modular setup RL update note. • Implication: lower downtime for online improvements and best‑of‑N policy trials; Caveat: guard against cache/weight skew with swap‑boundary checks, metrics, and rollbacks.
Z.ai restores chat after CPU server attack caused a temporary outage
Z.ai reported a CPU server attack that briefly took its chat offline and confirmed service recovery shortly after with in‑thread updates outage notice, service back. The episode is a reminder to harden AI chat backends with DDoS shielding, request queueing, and graceful degradation; public endpoints remain reachable Z.ai landing page.
🔌 Orchestration and MCP momentum
MCP continues to harden beyond single tools: Envoy AI Gateway announces MCP implementation with OAuth and multi-backend tool routing; ChatGPT UI surfaces “Apps & Connectors.” Excludes Agent Builder specifics (Feature).
Envoy AI Gateway adds full MCP with OAuth and multi‑backend routing
Envoy’s AI Gateway says its next release will implement the Model Context Protocol end‑to‑end, including June ’25 spec compliance, native OAuth authorization, and multiplexed routing across multiple MCP backends MCP announcement, with details in its engineering brief Envoy blog post. Following up on Go SDK 1.0 stable MCP client, this positions EAIGW as a universal broker for tool access, security policies, and observability across heterogeneous agent stacks.
ChatGPT renames “Connectors” to “Apps & Connectors,” surfacing a new experiment
In ChatGPT’s settings, “Connectors” now appears as “Apps & Connectors” with a visible experiment toggle, hinting at a broader first‑party app platform for wiring external tools into chats UI change, corroborated by a second settings capture Settings screenshot. For orchestration teams, this suggests deeper, more standardized hooks for third‑party integrations that can complement MCP‑style tool access without depending on separate agent canvases.
🛡️ Safety: deceptive CoT, adaptive red-teaming, and secret elicitation
Active work on offense/defense: backdoored CoT that looks clean, adaptive red-teaming that forces fresh attack modes, and techniques to elicit hidden knowledge. Sora platform safety is tracked under Gen Media, not here.
Adaptive red-teaming boosts cross-attack success ~400× at ~6% extra compute
Active Attacks periodically safety‑finetunes the target model on discovered prompts so the attacker must explore fresh modes, uncovering many more failure types and transferring across targets; the authors report ~400× cross‑attack gains for only ~6% extra time paper thread. This lands in context of Prompt injection stop over‑blocking concerns, arguing defenders need adaptive, coverage‑driven loops rather than static filters.
The workflow resets the attacker, maintains a global prompt pool, and graduates from easy to hard prompts—practical guidance for red‑team pipelines aiming for breadth and durability.
DecepChain implants clean-looking but wrong CoT with ~95% trigger success
A new backdoor attack makes LLMs produce coherent, step‑by‑step reasoning that looks fine yet lands on wrong answers when a tiny trigger phrase appears, while keeping normal accuracy largely intact. The method couples SFT on model‑generated “plausible but wrong” traces with GRPO and simple anti‑cheat checks so outputs stay tidy even as conclusions flip paper thread.
For safety teams, this spotlights how CoT audits can be gamed and why verifying final results and using verifiable rewards or external checkers remains essential in evals and guardrails.
Secret elicitation techniques expose hidden side rules with ~90% reliability
Researchers show simple black‑box prompts—assistant prefill cues and user‑persona sampling—can reliably force models to reveal secret knowledge they use but deny, reaching around 90% success on side‑rule and gender‑signal tasks; white‑box tools like logit lens and sparse autoencoders further help when black‑box fails paper summary.
Takeaway: safety evaluations should include secret‑knowledge probes, and mitigations must consider both elicitation channels and internal‑signal leakage, not just refusal templates.
🎬 Creative AI: Sora 2 safety knobs and physics demos
Sora 2 pushes platform controls (cameo restrictions, safety), extended-duration rumors, and creator demos; Veo 3 scenes praised for physics. This section excludes Agent Builder news (Feature).
OpenAI readies Sora cameo restrictions and safety tweaks ahead of DevDay
OpenAI says Sora will add tighter cameo restrictions and other safety improvements, expanding control over who can appear and how content is generated safety update note. Following up on Opt‑in controls, staff also signal more granular rightsholder settings and revenue sharing mechanics circulating in the creator community controls summary.
Sora hits #1 on U.S. App Store; ~200k daily installs spur retention questions
Sora’s iOS app reached the top free spot in the U.S., with creators estimating roughly 200k downloads per day in the current surge app ranking. Commentators note the next hurdle is a durable status game and content flywheel to keep casual users from churning once novelty fades growth lens.
‘Moving goalpost’ meme rekindles Sora physics vs. compositionality debate
A viral “moving goalpost” gag showcases Sora hitting a tricky visual pun, while critics counter that many harder prompts still reveal physics and compositionality errors on novel tasks goalpost image critique thread.
For teams evaluating video models, the split underscores why blind‑prompt batteries and red‑team catalogs matter more than cherry‑picked wins.
Rumor: Sora 2 may add 288‑second extensions and a storyboard tool
Ahead of DevDay, community chatter claims Sora 2 could support consistent video extensions up to 288 seconds and include a storyboard workflow for planning scenes feature rumor. If confirmed, this would materially change long‑form narrative workflows and reduce reliance on external editors for pre‑viz and continuity.
Mixed user reports flag Sora 2 Pro output quality variability
Alongside standout generations, some creators say Sora 2 Pro is returning weak adherence and compositional artifacts on certain prompts, asking if quality regressed or varies by setting user complaint. Engineers should account for prompt sensitivities and template guardrails when designing production pipelines.
Veo 3 praised for believable physics in “cats doing DIY” clip
A widely shared Veo 3 generation showing cats attempting DIY highlights credible physical failure modes—like losing control of a drill—drawing praise for realism in motion and force dynamics Veo 3 example. For practitioners, these failure‑case details are a useful proxy for whether a video model encodes basic object interactions.
Sora app surfaces a messaging icon for in‑app communication
Some users report a new messaging entry point in the Sora app UI, suggesting in‑app conversations or sharing features are being tested ui screenshot. If rolled out broadly, messaging could tighten the creation–feedback loop and keep more remix activity inside the Sora ecosystem.
Unexpected scene insertions highlight Sora’s stochastic planning layer
A creator notes a spontaneous, off‑prompt scene appearing mid‑generation, raising questions about Sora’s internal scene planning and remix heuristics unexpected scene. For evaluation, logging prompt→plan intermediates (where available) can help distinguish controllable variance from true drift.
🎙️ Local voice: CPU‑only STT and agent workflows
Hands-on builds show local STT getting practical: a pip-installable Parakeet‑based app transcribes faster than real time on CPU; agents set it up end‑to‑end in one session.
Maivi ships: CPU‑only streaming STT faster than real time
A new pip‑installable app, Maivi, delivers local speech‑to‑text on CPU using NVIDIA’s 0.6B Parakeet and claims better‑than‑Whisper quality with “faster than realtime” streaming plus clipboard/auto‑paste options install details, GitHub repo, PyPI page. The release follows a same‑day agent‑assisted prototype run end‑to‑end in one IDE session, underscoring how close local voice has become for everyday workflows agent build account.
Lightweight install (uv/pip) and CPU‑only operation reduce friction for teams that want voice input without GPUs; the streaming path also makes it viable for live note‑taking and command UIs.
Claude Code stood up a full local STT stack in under two hours
A developer reports Claude Code bootstrapped speech‑to‑text on a laptop CPU—fetching dependencies, wiring NVIDIA Parakeet 0.6B, and delivering live streaming transcription—entirely within a single IDE context window in <2 hours agent build account. That prototype was subsequently packaged as the Maivi CLI for a one‑command install, showing an increasingly practical agent‑to‑product loop for voice tooling install details.
Voice is on track to be as common as keyboard and mouse
With CPU‑only STT now streaming faster than real time and shipping behind a simple CLI, practitioners argue voice will become a default input alongside typing and pointing in day‑to‑day dev flows developer view, install details. For AI teams, this lowers the barrier to add low‑latency dictation and command palettes without GPU fleets or cloud round‑trips.
🏗️ AI infra economics and power constraints
Macro signals tied to AI demand: US data center spend at records, power as the limiting factor, skepticism on SMRs cost curves, and market comps (NVDA vs ‘00s Cisco). One-off note on .ai domain windfall economics.
US data center build hits ~$40B SAAR, a new record
Fresh Census-based charts show US data center construction running near a ~$40B seasonally adjusted annual rate, a new high, underscoring AI-driven demand spending charts. The surge lands as a tangible datapoint following up on AI capex that highlighted ~$1.2T hyperscaler spend through 2027.
Power availability and grid interconnect lead times now determine where—and how fast—this spend can be converted into capacity.
Execs: Power, not GPUs, is now the limiting factor for AI
An executive transcript making the rounds states "Power, lack of available power, reliable power has become the biggest bottleneck for us," adding that the GPU/TPU supply chain is "really not a big constraint" compared to electricity exec transcript. The comment echoes a wider industry shift toward siting DCs where power and permits exist, not just where chips can be procured.
NVDA’s run tracks earnings, unlike Cisco 2000—“not a bubble” case strengthens
Side‑by‑side charts show Cisco’s 1998–2002 price decoupling from earnings versus Nvidia’s 2020–2024 rise that moves largely in line with exploding forward EPS, bolstering the case that the AI cycle is earnings‑led, not pure multiple expansion comparative charts. A separate view of global IT price vs earnings since ChatGPT similarly shows tandem growth, not froth sector charts.
For infra planners, this supports sustained capex if profit pools keep matching capacity growth.
Small modular reactors still too costly vs gas and renewables for AI power
Financial Times analysis pegs SMR LCOE at roughly $182/MWh versus ~$126/MWh for US natural gas and even lower for solar/wind plus batteries (≈33% cheaper), with recent SMR projects running 120–400% over budget or canceled, challenging their near‑term role in AI power supply FT analysis. For hyperscalers chasing fast, cheap megawatts, SMRs remain a long‑shot until costs fall materially.
Anguilla’s .ai windfall swells to ~47% of state revenue
The Caribbean territory now derives about 47% of its budget from .ai domain registrations and renewals, up from under 1% pre‑AI boom, with premium resales like you.ai at $700k and cloud.ai at $600k illustrating the surge in demand revenue breakdown. Government plans reportedly funnel proceeds to debt reduction and infrastructure, while warning against over‑reliance on a single digital rent stream Anguilla .ai report.
🏢 Enterprise adoption, channels and policy tie-ins
Enterprise posture updates: SAP outlines agent-first workflows, OpenAI details internal deployments, Claude lands in Slack, and OpenAI’s gov tie-in in Japan. Excludes DevDay feature drops.
ChatGPT adds parental controls and ‘Instant Checkout’ via Agentic Commerce Protocol
OpenAI is rolling out global parental controls for teens and a commerce flow where U.S. users can buy from Etsy sellers through Stripe using the Agentic Commerce Protocol product note. The ACP production use follows wider client adoption in editors and tools ACP adoption, signaling a standardizing channel for agent‑driven transactions; more launch context in weekly recap.
Japan’s Digital Agency adopts OpenAI tech via new Gennai tool for civil servants
OpenAI announced a strategic collaboration with Japan’s Digital Agency, introducing “Gennai,” a tool for government employees built on OpenAI technology partnership note. The tie‑in expands OpenAI’s public sector footprint and frames a reference model for regulated, multilingual use in government workflows.
SAP previews Joule agents as backbone for real‑time enterprise workflows
Ahead of Connect 2025, SAP’s CPO outlined an agent‑first roadmap where Joule reads live operational data, reasons, and takes proactive actions across systems, with localization, compliance, and day‑one trust emphasized SAP interview. • Highlights include agents that “scout” for issues, built‑in governance, and flexible regional deployment to meet regulatory requirements.
Claude lands native Slack app with workspace search for Teams and Enterprise
Anthropic’s Slack integration now supports DMs, the side panel, and thread mentions; Team and Enterprise workspaces can authorize Claude to search channels and files to answer questions with context Slack rollout. This shifts a common enterprise channel into an AI surface without custom bots or middleware.
OpenAI details five internal agents it runs to operate the business
OpenAI published a practitioner series showing how it uses its own stack to run operations: GTM Assistant in Slack, DocuGPT for contract structuring, a Research Assistant for support analytics, a Support Agent that turns interactions into training data, and an Inbound Sales Assistant that routes qualified leads series overview, with implementation specifics in OpenAI docs.