Нано-чат Карапти строит сквозной LLM за 100 долларов за 4 часа — на 8×H100
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Андрей Карпати открыл исходники проекта nanochat — стек обучения и инференса с нуля, который запускает небольшую модель в духе ChatGPT примерно за 100 долларов и за около 4 часов на одной ноде с 8×H100. Это важно, потому что это первый по-настоящему общий, «взломобезопасный» базовый уровень, который большинство команд может воспроизвести, подстроить и на котором можно учиться без бюджета корпоративного масштаба. Опубликованный скоростной прогон занимает 3ч51м и сопровождается автоматически сгенерированным отчетом, чтобы вы могли наблюдать, как кривые CORE, ARC, MMLU, GSM8K и HumanEval движутся по стадиям.
Под капотом система намеренно обходительная: токенизатор на Rust; предобучение FineWeb‑EDU; средний этап обучения на SmolTalk; контролируемая фин-tuning; опциональный усиленный обучение через GRPO; и движок инференса с KV‑кешем, который обслуживает как CLI, так и чистый чат‑ебеобразный WebUI. Репозиторий фиксирует ~8 304 LOC в 44 файлах и подключает Weights & Biases для трекинга на предобучении/среднем этапе/RL «из коробки». Ключевой момент: около 30 ГБ курируемого FineWeb‑EDU и SmolTalk обеспечивает большую часть подъема в рамках этого бюджета, а история масштабирования ясна: по сообщениям, слой глубины ~12 часов превосходит GPT‑2 на CORE, тогда как ~24 часа (глубина‑30) достигают 40s на MMLU и 70s на ARC‑Easy. Ранние порты сообщества включают веса Hugging Face и даже процессорный (CPU‑only) macOS‑раннер, что снижает порог для инспекции, абляций и swap‑tokenizer до аренды большего количества GPU."
Feature Spotlight
Особенность: Karpathy’s nanochat ($100 сквозной стек LLM)
nanochat демонстрирует воспроизводимый полностековый конвейер LLM за $100 (Rust‑токенизатор, предобучение FineWeb, SFT/RL, оценки, движок KV‑кэш, WebUI), который обучается примерно за 4 часа на 8×H100 — создавая чистую базовую основу для команд и курсов.
Межаккаунтный запуск большого объёма: минимальная стековая цепочка обучения и инференса с нуля (токенизатор→предобучение→промежуточное обучение→SFT→опционально RL→двигатель+WebUI), которую можно запустить на системе с 8× H100 примерно за 4 часа. Особенно полезно для инженеров как прочная, настраиваемая базовая платформа.
Jump to Особенность: Karpathy’s nanochat ($100 сквозной стек LLM) topicsTable of Contents
🧪 Особенность: Karpathy’s nanochat ($100 сквозной стек LLM)
Межаккаунтный запуск большого объёма: минимальная стековая цепочка обучения и инференса с нуля (токенизатор→предобучение→промежуточное обучение→SFT→опционально RL→двигатель+WebUI), которую можно запустить на системе с 8× H100 примерно за 4 часа. Особенно полезно для инженеров как прочная, настраиваемая базовая платформа.
Карпати выпускает nanochat: стек LLM за $100, за 4 часа, полный стек от начала до конца на 8×H100
Андрей Карпати откры́л исходники nanochat, минимальный, с нуля созданный конвейер, который обучает небольшую модель в стиле ChatGPT примерно за 4 часа на одной узле 8×H100 (около $100), при более длинных запусках обгоняя GPT‑2 CORE и приближаясь к паритету по нижним уровням бенчмарков по мере роста масштаба (например, примерно 24 ч глубина‑30 достигает 40s MMLU, 70s ARC‑Easy). Репозиторий включает одно‑клик скоростной запуск, инференс‑движок с KV‑кэш и WebUI, и автоматически сгенерированную карту метрик. См. полный разбор в потоке запуска launch thread, с кодом на GitHub repo и обзором в GitHub discussion.)
Для инженеров по ИИ это устанавливает общую, удобную для взлома базовую версию, которая дешевле воспроизвести, легко форкнуть и полезна для обучения, абляций и исследований малого масштаба перед масштабированием.
Внутри стека nanochat с 8k LOC: токенизатор на Rust → предобучение FineWeb → средний этап обучения SmolTalk → SFT → GRPO → движок KV‑кэша
Стек намеренно небольшой и с минимальной зависимостью: новый токенизатор на Rust, преподготовка на FineWeb, промежуточная подготовка на беседах SmolTalk и MCQ/использование инструментов, SFT с оценками по ARC/MMLU/GSM8K/HumanEval, необязательное RL на GSM8K с GRPO, и вычислительный движок (KV‑кеш, предзаполнение/декодирование, песочница инструментов Python), обслуживающий как CLI, так и веб‑интерфейс наподобие ChatGPT. Он поставляется с односкриптовой загрузкой и markdown‑отчетом для аудита запусков launch thread. Демо‑чат‑интерфейс и ссылки здесь repo links.
Этот сквозной «сильной базой» рассматривается как кульминация LLM101n и форк‑дружелюбного исследовательского хаба, делая его хорошей целью для пользовательских данных, инструментов или замены планировщика/RL.
Итоговый отчет по прогону: ~3h51m скоростной прогон с данными о коде и поэтапными кривыми CORE/ARC/MMLU/GSM8K
Nanochat автоматически составляет карточку отчета, суммирующую статистику кодовой базы (~8 304 LOC в 44 файлах) и поэтапную производительность (BASE → MID → SFT → RL) на CORE, ARC‑E/C, MMLU, GSM8K и HumanEval; опубликованный запуск за $100 залогировал ~3ч51м реального времени и показывает, как повышение на стадии midtraining/SFT поднимает метрики знаний и рассуждений по сравнению с базовой предобученной моделью report card image. Стадийная визуализация помогает командам определить, где дополнительное midtraining, SFT или RL бюджет обеспечивает наибольшее улучшение перед масштабированием.
Сопоставьте это с основным обзором для масштабирования/целевых времен (12ч превосходит GPT‑2 CORE; ~24ч depth‑30 достигает 40s MMLU, 70s ARC‑Easy) запуск темы.
Порты сообщества поступают: сборка весов HF и раннер только на CPU для macOS
Ранние последователи уже расширяют стек: Сам Добсон опубликовал nanochat-сборку на Hugging Face; заметки Саймона Уиллисона документируют данные обучения и предоставляют скрипт, работающий только на CPU, который запускает модель на macOS без CUDA (минимальный GPT на чистом Python/Torch для тестирования и осмотра) notes post, with details and the gist here blog post and CPU script. This lowers the friction to test outputs, eval harnesses, or tokenizer choices off‑GPU before renting time.
Ожидайте больше форков (например, альтернативные токенизаторы, планировщики и подключение к оценке), по мере того как сообщество превращает спидран в повторяемые уровни.
Данные важны: примерно 30 ГБ FineWeb‑EDU + SmolTalk обеспечивают большую часть подъёма в тарифе за 100 долларов.
Карпаты подчёркнул(а), что проект состоит из «~8KB Python и ~30GB FineWeb/SmolTalk» на уровне $100 — подчёркивая, что чистые, доступные корпусы данных обеспечивают возможности даже для крошечных стеков author reply. Репозиторий по умолчанию использует шард FineWeb‑EDU для предобучения и SmolTalk/MMLU/GSM8K для промежуточного обучения/SFT, при этом общедоступный набор данных размещён на Hugging Face dataset note, см. набор данных Hugging Face. Для практиков это готовый рецепт замены на доменно‑специализированные шарды без переработки конвейера.
Тесная связка между небольшим, хорошо отфильтрованным предобучением и целенаправленным промежуточным обучением, похоже, является основным рычагом при таких бюджетах.
Логирование в Weights & Biases включено на этапах pre, mid и RL.
Weights & Biases подтвердили, что nanochat поставляется с инструментарием W&B для предобучения, середины обучения и циклов RL, давая командам мгновенный мониторинг запусков, сравнения по бюджетам и кривые метрик прямо из коробки W&B note. Это полезно для hill-climbing (поиск локального максимума) при настройке (например, изменения токенизатора, состав данных, планировщики) перед оплатой более длинных тарифов на 12–24 ч.
🏗️ Вычислять развертки и энергетическую математику
Инфраструктурные новости сегодня насыщены: OpenAI–Broadcom 10 ГВт кастомных ускорителей (лист условий, timeline на 2026–2029 годы), региональные планы по дата-центрам и экономика электроэнергии и водоснабжения. Функция nanochat не включена.
OpenAI–Broadcom: 10 ГВт кастомных ускорителей будут развернуты в 2026–2029 гг.
OpenAI и Broadcom подписали условия соглашения о совместной разработке и внедрении 10 ГВт ускорителей, спроектированных OpenAI, на стойках, полностью масштабируемых за счет Ethernet Broadcom; первые инсталляции запланированы на вторую половину 2026 года, а завершение — к концу 2029 года детали term sheet, OpenAI blog. Продолжая тему power bottlenecks, это фиксирует многолетний путь, не связанный с NVIDIA, чтобы удовлетворить растущий спрос и одновременно внедрять выводы моделей напрямую в оборудование.
Помимо емкости, дизайн Ethernet на уровне стойки сигнализирует о ставке на масштабируемые сети для передовых кластеров, сокращая долю поставщиков рисков и потенциально ускоряя планирование энергопотребления и площади по всем партнёрским DC.
OpenAI нацеливается на 500 МВт «Stargate Argentina» в рамках нового инвестиционного режима.
Аргентина заявляет, что OpenAI и Sur Energy подписали письмо о намерениях по проекту «Stargate Argentina», проект стоимостью примерно $25 млрд, ориентированный на 500 МВт мощности для вычислений ИИ в рамках стимулов RIGI (льготы по импортным пошлинам, ускоренная амортизация, стабильность валюты) детали проекта. Если будет построен, сайт будет размещать десятки тысяч ускорителей и станет опорой кластера ИИ в Латинской Америке наряду с проектом TikTok на Бразилию стоимостью $9,1 млрд.
[изображение:https://pbs.twimg.com/media/G3IYGutXoAAL1zN.png|аэрофотосъемка строительной площадки]
Комплект подчеркивает переход к многорегиональной мощности ИИ, где суверенные стимулы и доступность электроэнергии влияют на размещение не меньше, чем поставки чипов.
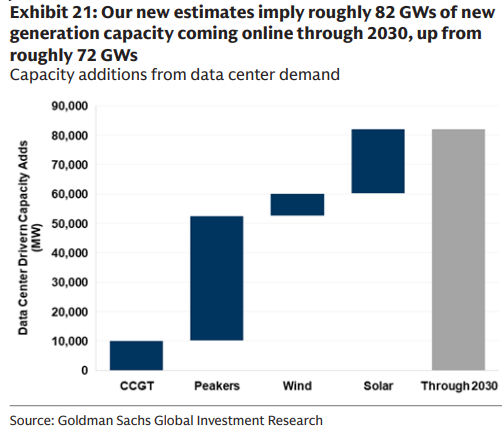
Голдман: США нуждаются в примерно 82 ГВт новой генерации для дата-центров к 2030 году.
Голдман Сакс теперь оценивает примерно 82 ГВт новой генерации в США, связанной с спросом дата-центров к 2030 году (по сравнению с примерно 72 ГВт), со структурой строек, ориентированной в первую очередь на солнечную энергетику, затем пиковые станции, газовые турбины с комбинированным циклом и ветер состав мощностей.
Это переопределяет планирование сети от постепенных модернизаций к генерационной развёртке, при необходимости диспетчеризуемой мощности (пики/CCGT) для закрепления AI‑нагруженных, круглосуточной нагрузки по мере роста возобновляемых источников.
Алтман и Брокман изложили обоснование чипов и спрос на вычислительные мощности в подкасте OpenAI.
В эпизоде 8 Сэм Альтман и Грег Брокман утверждают, что каждое повышение возможностей и снижение затрат открывают огромный новый спрос — "даже 30 ГВт с сегодняшними моделями быстро насытятся" — и что Ethernet‑масштабируемые стойки кодируют передовые знания в кремнии podcast trailer, YouTube episode, demand quote. Замечания трактуют план Broadcom на 10 ГВт как пол, а не потолок, для ближайших потребностей в вычислениях.
Голдман прогнозирует рост глобальной мощности постоянного тока примерно на 175% к 2030 году.
Исследование Goldman Sachs прогнозирует, что глобальное потребление электроэнергии дата-центрами вырастет примерно на ~175% к 2030 году, что подтолкнет рост потребления электроэнергии в США до ~2,6% CAGR — самый быстрый темп с 1990-х годов глобальная проекция.
Они описывают движущие силы как «Шесть P» (проникаемость, производительность, цены, политика, комплектующие, люди), что предполагает синхронные инвестиции в генерацию, передачу и квалифицированный персонал, а не только в графические процессоры (GPU).
Контекст использования воды дата‑центрами США
Лучшие доступные диапазоны показывают, что вода в США для DC составляет около 50 млн галлонов в день только для охлаждения, около 200–275 млн — при учёте электроэнергии (без испарения на водохранилищах дамб), и до примерно 628 млн/день при учёте испарения гидроаккумуляторных водохранилищ — цифры значимые, но по масштабу воздействия не достигают footprint гольфа по стране water recap, LBNL report, analysis post.【img:https://pbs.twimg.com/media/G3KfBK4WwAA2HV-.jpg|water usage charts】
Вывод для разработчиков ИИ: влияние воды во многом зависит от проектирования объекта и состава энергосистемы. Замкнутое охлаждение и размещение в более прохладных климатических условиях могут существенно снизить потребление воды.
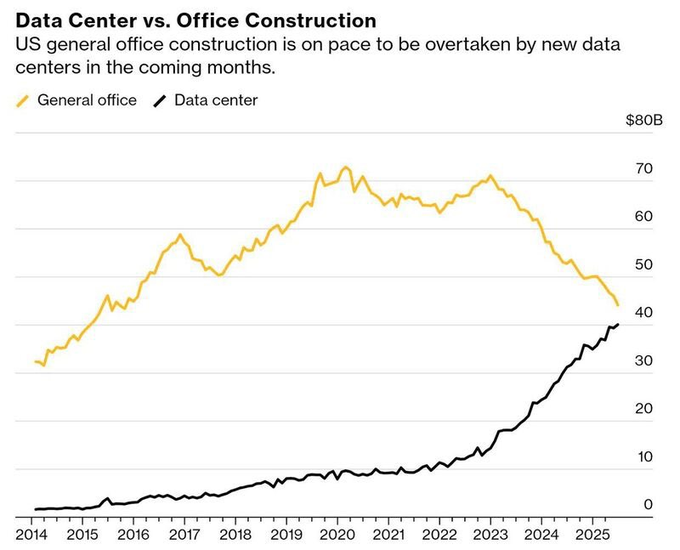
Строительство дата-центров обещает превзойти расходы на офисы в США.
Свежие графики затрат показывают, что строительство дата-центров в США (~38 млрд долларов) быстро приближается к уровню и готово превысить общие офисные затраты (~40 млрд долларов), что фиксирует структурное смещение капитальных вложений с человеческих рабочих мест к вычислительной инфраструктуре spend chart.
Для операторов это сигнал к усилению конкуренции за энергию, землю и подрядчиков в мегаполисах с высокой плотностью дата-центров, а также к нарастающему муниципальному контролю по зонированию и коммунальным услугам.
🔌 Чипы, память и стек межсоединений
Оборудовательные обновления, влияющие на пропускную способность/эффективность моделей: ставки по процессу HBM4 у Samsung, внедрение Ethernet Spectrum‑X от NVIDIA, показатели производительности GB200 и направление стойки MGX/800 VDC. Исключает детали сотрудничества по чипам с OpenAI (раскрывается в разделе Infra).
Meta и Oracle внедряют Ethernet NVIDIA Spectrum‑X, чтобы увеличить загрузку AI‑сети до примерно 95%.
NVIDIA говорит, что Meta и Oracle интегрируют Spectrum‑X Ethernet для соединения кластеров ИИ на масштабе миллионов GPU, нацеливая примерно 95% эффективной пропускной способности против примерно 60% у обычного Ethernet благодаря управлению перегрузкой и адаптивной маршрутизации adoption note, с деталями в объявлении от самой компании NVIDIA news.
Для лидеров в области ИИ инфраструктуры это говорит о том, что Ethernet‑фабрики сокращают разрыв с проприетарными межсоединениями на гипермасштабе, при этом сохраняя инструменты и операции, уже построенные вокруг IP‑сетей.
Стойки NVIDIA MGX Vera Rubin NVL144 переходят к 800 VDC и бескабельным мидплейнам для плотных AI‑фабрик.
NVIDIA и 50+ партнеров MGX осветили NVL144.compute лотки (на 100% жидкостное охлаждение, PCB‑мидплейн, слоты ConnectX‑9 800 ГБ/с) и распределение 800 VDC для уменьшения медных кабелей, потерь преобразования и тепла, при этом Foxconn демонстрирует сайт мощностью 40 MW, построенный под 800 VDC blog summary. Продолжение темы ограничения мощности, сдвиг нацелен на плотность и эффективность сети по мере того, как ограничения переходят от чипов к питанию и площади помещения.
Практически 800 VDC плюс дизайн мидплейна означают более высокий кВт на стойке, упрощённый сервис и более быструю масштабируемость — но ценой более жёстких границ безопасности помещений и надёжности жидкостной петли.
Samsung опирается на 1c DRAM и логический чип на 4 нм, чтобы повысить целевые скорости HBM4.
Samsung продвигает более высокочастотный HBM4, созданный на 1c (6-го поколения 10 нм‑класса) DRAM с логической базовой микросхемой 4 нм, с целью поднять спецификацию вверх после того, как конкуренты оптимизировали под термалы; этот ход противостоит SK Hynix (TSMC 12 нм логика) и Micron (логика ноды DRAM) и может сместить биннинг памяти GPU и пределы пропускной способности аналитический поток.)
Если NVIDIA подхватит более официальные скорости, ожидайте, что вопросы платы/питания и возможности охлаждения станут следующими узкими местами, а не сама частота памяти.
SemiAnalysis: GB200 лидирует по скорости токенов в секунду, токенов за доллар и токенов на мегаватт.
Свежий график сравнений InferenceMAX: GB200 опережает H100 и AMD MI355X/MI300X по пропускной способности, цене‑производительности и энергопроизводительности, что подразумевает лучшую загрузку в условиях ограниченной мощностью график бенчмарков.
Для планировщиков пропускной способности преимущество GB200 по токенам на МВт является выдающимся показателем, когда размещение определяется питающими линиями и подстанциями, а не только капитальными затратами.
NVFP4: NVIDIA описывает 4‑битное предобучение, которое сопоставимо по качеству с FP8 и обеспечивает в 2–3× большую арифметическую пропускную способность на Blackwell.
NVIDIA’s NVFP4 формат (4‑битные блоки с 8‑битными масштабами блоков и 32‑битным тензорным масштабом) показывает точность предобучения близкую к FP8 (например, MMLU‑Pro 62.58 против 62.62), при этом потребление памяти снижается примерно на 50%, а скорость работы увеличивается примерно в 2 раза на GB200 и около 3× на GB300 по сравнению с FP8; поддержка поступает в Transformer Engine и аппаратное обеспечение Blackwell paper thread.
Если это будет промышленно внедрено, математика FP4 может снизить TCO обучения и потребляемую мощность на токен — при условии, что поздние BF16‑fallbacks останутся, чтобы закрыть небольшой дефицит по потере.
🛠️ Кодирование с агентами: рабочие процессы, интерфейсы командной строки и инструменты для использования
Сигналы практиков об агентских рабочих процессах (Codex против Claude Code), паттерны планирования/перемотки, циклы терминала/браузера и дашборды по использованию платформы. Исключено nanochat (функция).
Google AI Studio предоставляет живую панель мониторинга лимитов скорости и использования с RPM/TPM/RPD и фильтрами по моделям
AI Studio теперь предоставляет встроенный взгляд на ограничение скорости и использование: пиковые запросы в минуту, токены в минуту и запросы в день с временными рядами, а также фильтрацию на уровне моделей и запас headroom в реальном времени — огромный QoL для команд, отслеживающих расход и ограничения dashboard screenshot, feature thread. Несколько подтверждений показывают один и тот же интерфейс и метрики, с встроенными ссылками на проекты feature recap, и еще скриншоты диаграмм лимитов и таблиц another screenshot. Попробуйте на странице использования проекта AI Studio usage.
Claude Code добавляет контрольные точки /rewind для восстановления сеанса после того, как что-то сломалось.
Новый /rewind в Claude Code позволяет восстанавливать предыдущие контрольные точки в рамках той же сессии, что значительно упрощает откат неверного выполнения инструмента или сломанного локального состояния feature callout. Официальная документация теперь описывает, как работают контрольные точки и когда их использовать для безопасного отката ссылка на документацию, с подробностями настройки в документации Claude.
Cursor Plan Mode побуждает команды отслеживать использование и выделять фоновые задачи для небольших рефакторингов.
Пользователи говорят, что Режим планирования достаточно хорош, что они следят за своим потреблением и дорабатывают рабочие процессы, чтобы расходы оставались предсказуемыми обзор использования. Запросы на новые функции включают автоматическое исключение фоновых заданий из планов для меньших рефакторингов и более тесной интеграции с GitHub Issues запрос функции, с сообщениями о постоянном 24‑часовом прогоне агентов, которые проходят 200 тестов в реальных проектах результаты 24‑часового прогона.
Langfuse добавляет наблюдаемость Gemini, чтобы вы могли видеть затраты на входные и выходные токены за каждый запуск и трассировки.
Интеграция Langfuse теперь захватывает запуски Gemini с детальной телеметрией и разбивкой затрат по входным/выходным токенам — полезно для аудита цепочек агентов и выявления регрессий integration note. Quickstart code показывает, как инструментировать Google GenAI SDK и передавать трассы в Langfuse how‑to guide, с шагами настройки в Langfuse docs.
tmux + Chrome DevTools поддерживают живыми циклы агентов во время локальных серверов разработки, избегая зависших циклов.
Разработчики замыкают петлю, запуская локальный сервер в tmux и подключая управление Chrome DevTools, чтобы агент продолжал продвигаться вперёд, пока команда pnpm run dev остаётся активной — больше никаких задержек цикла событий посреди сессии tmux capture, devtools loop. Это основано на двухкомандном подключении DevTools MCP, о котором сообщалось ранее, продолжая работу над DevTools MCP, которое изначально обеспечивало управление браузером в реальном времени.
Vercel AI добавляет pruneMessages для усечения историй, перегруженных агентами и инструментами, и контроля бюджета подсказок.
Новый помощник в Vercel AI SDK удаляет массивы ModelMessage, чтобы агентные циклы с тяжёлыми вызовами инструментов не выходили за рамки контекстных окон или бюджетов затрат; поместите его в prepareStep или после преобразования UI→сообщения модели feature shipped, с реализацией и примерами в слитном PR GitHub PR. Идея возникла из предложения сообщества и быстро добралась до upstream proposal image.
Практикующие разделяют обязанности: Claude 4.5 — для структуры фронтенда, Codex-High — для бэкенда, рефакторинг и длительные запуски.
Рабочие команды сходятся к простому набору правил: используйте Claude 4.5 для формирования логики/структуры фронтенда и Codex-High для задач на бэкенде, крупных рефакторингов или когда вы хотите уйти на 30 минут без прерываний tool choice tip, с пояснением, что «front end» здесь означает структуру/логику, а не интерфейс пользователя clarification note. Также сообщают, что Codex превосходит, когда спецификации точны (форматы ввода/вывода, крайние случаи, обработка ошибок), в то время как Claude более снисходителен и лучше объясняет шаги для неп-программистов skill guidance, и что Codex является надёжным ежедневным драйвером для длительных автономных кодинг-сессий daily driver claim.
'bd' предлагает нативный для агента трекер задач с версионированием в Git для смешанных рабочих процессов человека и агента
Появляющийся CLI под названием bd предлагает систему отслеживания задач в стиле Taskwarrior, ориентированную на агентов: записи JSONL, хранящиеся в git, обнаружение готовой работы (без блокировок), богатые графы зависимостей и флаги --json для программного использования, чтобы и люди, и агенты могли координироваться в одном репозитории обзор функций. Экран выделяет команды для обновления задач, моделирования зависимостей и запроса готовой работы таким образом, чтобы агенты могли их использовать.
[изображение:https://pbs.twimg.com/media/G3JnBgTaUAAX4hF.jpg|список функций]
Зафиксируйте Python Claude Code в виртуальном окружении uv, используя PATH или хуки, чтобы не засорять глобальные переменные окружения.
Строители рекомендуют принудительно вызывать python -c Claude Code из выделенной виртуальной среды путём изменения PATH перед запуском или использования хуков, а не активируя venv внутри сессии ad‑hoc env question, PATH approach. Другие считают, что PATH‑первый подход и изоляция на основе хуков сохраняют глобальный Python в чистоте во время выполнения агентов PATH tip, use hooks.
🧩 Корпоративные соединители и поверхности MCP
Совместимость агентов и корпоративные поверхности: приложение/коннектор Slack×ChatGPT, связывание Grok с GitHub, а также обзор реальных MCP-серверов. Исключает особенности рабочего процесса кодирующих агентов (зафиксировано в другом месте).
OpenAI выпускает ChatGPT для Slack и коннектор Slack для корпоративного контекста.
OpenAI выпустил две интеграции с Slack: приложение ChatGPT, которое находится в боковой панели для 1:1 чатов, суммирования веток и составления черновиков ответов, и коннектор Slack, который безопасно внедряет контекст канала/DM в чаты ChatGPT, Deep Research и Agent Mode (требуется платный Slack). Ознакомьтесь с возможностями, доступом и соответствием плану в заметках выпуска обзор выпуска и заметки о выпуске OpenAI,) с собственным объявлением Slack, подчеркивающим запуск Slack highlight.)
Для владельцев AI-платформ это значимый пласт: он стандартизирует Slack как источник извлечения и место выполнения, сокращая glue-код для корпоративных пилотов и делая выводы агентов поддающими аудиту по сообщениям/файлам, на которые у пользователя уже есть разрешения тизер функции.)
MCP momentum: базы данных, сеть, IDE и рабочие поверхности рабочих процессов проходят по всему стеку.
Cisco публикует инструкцию о том, как построить MCP‑сервер, обеспечивающий LLM безопасный, ограниченный доступ к сетевым устройствам, включая пошаговый разбор кода Cisco guide.)
- Oracle внедряет MCP Server в SQLcl, чтобы клиенты MCP могли выполнять запросы к Oracle Database с безопасными потоками чата Oracle SQLcl.)
- Visual Studio выходит на общую доступность для MCP, позволяя работать AI‑управляемыми рабочими процессами в .NET‑компаниях VS availability.)
- LlamaIndex документирует официальные MCP‑серверы (например, LlamaCloud) для подключения AI‑приложений к данным/инструментам LlamaIndex docs.)
- TypingMind добавляет связку MCP Make.com для чат‑основы автоматизаций TypingMind integration.)
- Свыше 450 MCP‑серверов получают контейнеризованные образы для упрощения безопасного самостоятельного размещения Docker images.)
Вывод: при стандартизации поставщиков на MCP для прав доступа и транспорта команды могут менять инструменты без повторного опроса агентов и двигаться к аудируемому исполнению с минимальными привилегиями по IDE, данным и SaaS.
xAI освещает GitHub «Connect» в веб‑интерфейсе Grok для внешних вызовов
Grok’s Connected Apps теперь показывает кнопку «Connect» для GitHub; заметка поясняет, что на этом этапе общаться с внешними соединениями или вызывать их могут только Grok Tasks settings UI, integration screenshot. Это следует за GitHub test, где ранняя сборка продемонстрировала первые признаки интеграции; сегодняшняя UI означает, что OAuth и настройка прав доступа почти готовы для более широких рабочих процессов агентов.
Почему это важно: нативный доступ к GitHub (issues, PRs, поиск кода) — запрос топ-уровня для агентной CI и вопросов-ответов по репозиторию. Ограничение первоначального доступа только к Tasks помогает осуществлять поэтапные развёртывания, в то время как xAI ужесточает разрешения и трассировку действий.
ChainAware дебютирует MCP по конструированию портфеля для математически обоснованного ребалансирования криптовалют.
ChainAware представила MCP по конструированию портфеля, который позволяет агентам оптимизировать и ребалансировать крипто-портфели с использованием количественных стратегий внутри единого рабочего процесса MCP product note. Для аналитиков это добавляет инструмент, ориентированный на конкретную предметную область, для автоматизации ограничений, оборота и отслеживания бенчмарков, сохраняя при этом аудируемость и совместимость MCP с различными стеками агентов.
🎙️ Рассуждения на естественной речи достигают передового уровня
Специализированные новости по рассуждениям в формате речь‑к‑речи: Gemini 2.5 Native Audio Thinking возглавляет Big Bench Audio, предлагая детали об ущербах задержки и бюджетах мышления.
Gemini 2.5 Native Audio Thinking превосходит рассуждения в задачах «речь‑к‑речи», набирая 92% на Big Bench Audio
Google’s Gemini 2.5 Native Audio Thinking установил новый уровень достижения на 92% в тесте Artificial Analysis’ Big Bench Audio, опередив ранее существовавшие нативные S2S‑системы и даже базовый конвейер Whisper→LLM→TTS обзор benchmark.)
Модель балансирует скорость и качество в режиме «мышления» с ориентировочным временем до первого аудио ~3.87 с, тогда как вариант без «мышления» приводит задержку примерно ~0.63 с; GPT Realtime находится возле ~0.98 с, что подчеркивает явный компромисс между точностью и задержкой в зависимости от задачи latency notes. Вне зависимости от показателей, система нативно обрабатывает аудио, видео и текст и возвращает естественную речь или текст, с вызовами функций, привязкой к источнику, настраиваемыми бюджетами мышления, контекстом 128k входа / 8k выхода и знанием на январь 2025 feature summary. Для руководства по выбору и поставщиков смотрите на живую таблицу лидеров и страницы сравнения поставщиков model comparison page.
🎬 Генеративные медиа-стэки и инструменты для творчества
Насыщенный день в области генерации видео и изображений: рабочие процессы sketch-to-video у Sora 2, новые стили видео NotebookLM «Nano Banana», Kandinsky 5 на fal, Kling 2.5 Turbo 1080p — затраты/перемещения в таблице лидеров.
NotebookLM добавляет стили видео Nano Banana и форматы «Explainer vs Brief»; Pro уже доступен, широкий релиз скоро
Обзоры видео NotebookLM от Google теперь поддерживают шесть стилей на базе Nano Banana (Whiteboard, Watercolor, Retro print, Heritage, Paper‑craft, Anime) и два формата («Explainer» для глубины, «Brief» для скорости), сначала доступ к Pro, затем всем пользователям feature image, rollout note. Это расширяет продвижение Google в сторону заготовленных, брендированных видео‑резюме, продолжая Veo playbook где создатели задавали единый стиль между инструментами. UI предоставляет явный выбор стиля и подсказки фокуса, чтобы направлять ведущих и визуальные элементы feature notes.
}
Kling 2.5 Turbo 1080p попадает в топ‑5 LMArena по текст‑в‑видео и делит 3‑е место в изображение‑в‑видео; ~ $0.15/5s
Сообщество‑управляемая Video Arena теперь включает Kling 2.5 Turbo 1080p среди лидеров: наравне с пятым местом в текст‑видео и на третьем месте в изображение‑видео, при этом генерация стоит около $0.15 за 5 секунд при 1080p обновление лидерборда. Другой вид лидерборда подтверждает его позиции по мере поступления голосов детали лидерборда. Это ставит Kling прямо в ценовой диапазон «значимой ценности» по сравнению с Veo/Sora по стоимости, одновременно сокращая разрывы в качестве по обычным запросам.
Higgsfield выпускает Sketch-to-Video на Sora 2 с поддержкой 1080p и ограниченной во времени акцией на 200 кредитов.
Новый Sketch‑to‑Video от Higgsfield превращает рисунки от руки в киношные клипы в разрешении 1080p, с акцентом на физичность (вес, импульс, эмоции) и согласованность между раскадровкой и сценой. Команда провела живой мастер‑класс с подсказками и предложила короткий период бонусных кредитов для поощрения проб обсуждение выпуска, приглашение на прямой эфир, и страница продукта с деталями рабочего процесса и примерами страница продукта. Это выдвигает Sora 2 в пайплайн, ориентированный на создателя — раскадры становятся финальными сценами, не покидая инструмент связность повествования.
Kandinsky 5.0 поступает на fal с кинематографическим текст‑в‑видео по цене примерно 0,10 доллара США за 5‑секундный клип.
fal запускает Kandinsky 5.0 с открытым исходным кодом для преобразования текста в видео, делая упор на реалистичные показатели, сильное кинематографическое движение и лучшее соблюдение подсказок по агрессивной цене (~$0.10 за 5 секунд при 1080p) заметка к выпуску. Публичная песочница упрощает тестирование вариаций подсказок и точности перед интеграцией в конвейеры пайплайнов песочница.
Wavespeed перечисляет конечную точку преобразования текста в видео+аудио Google Veo 3.1; сообщество просит подтверждения от Google
Платформа со стороны третьих лиц WaveSpeed AI теперь отображает конечную точку Veo 3.1, поддерживающую текст‑в‑видео с аудио, что вызывает призывы к официальному признанию со стороны Google listing page, model page. Если подтверждено, это даёт ещё один путь для проверки синхронизации движения и звука 3.1 перед более широким внедрением со стороны первого лица.
📊 Таблицы лидеров и сравнение провайдеров
Свежие обновления в лидерах за пределами речи и видео: MAI‑Image‑1 от Microsoft входит в топ‑10 LMArena; сравнения скорости на уровне поставщиков для вариантов DeepSeek.
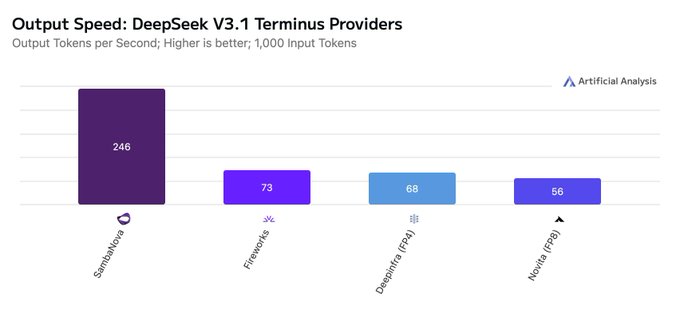
DeepSeek V3.1 Terminus и V3.2 Exp: самые быстрые поставщики и токены в секунду у разных вендоров
Artificial Analysis выпустила сравнение поставщиков для гибридных моделей рассуждения DeepSeek, показывая, что V3.1 Terminus обслуживается SambaNova, DeepInfra, Fireworks, GMI и Novita, при этом SambaNova примерно ~250 токенов/сек (≈10× быстрее, чем инференс первой стороны DeepSeek) сравнение поставщиков,) в то время как V3.2 Exp работает через API DeepSeek, DeepInfra, GMI и Novita, с DeepInfra до ~79 токенов/сек сравнение поставщиков.) См. страницы поставщиков в реальном времени для конкретики по пропускной способности и доступности Поставщики V3.2,) и Поставщики Terminus.)
[изображение:https://pbs.twimg.com/media/G3KUXT-aoAEX8GT.jpg|графики поставщиков]
Обе версии нацелены на замену ранних линий V3 и R1; Terminus опережает V3.2 на один пункт по Индексу Artificial Analysis, но выбор поставщика и стек обслуживания существенно влияют на реальную задержку и стоимость.
MAI‑Image‑1 от Microsoft дебютирует в топ‑10 LMArena (на равной 9‑й позиции), открыто для голосования сообщества
Первый собственный внутренний образ модели изображений от Microsoft, MAI‑Image‑1, вошёл в рейтинг изображений LMArena, связавшись с Seedream 3 на 9‑м месте и доступен в Direct Chat для раннего тестирования и голосования image arena ranking, with the team saying commercial availability is expected in the coming weeks image arena ranking. Вы можете попробовать его и проголосовать во界 в интерфейсе LMArena, чтобы повлиять на размещение direct chat access, и следить за доской на источнике LMArena homepage.
Это поместит Microsoft прямо в сообщество‑оцениваемый стек изображений наряду с открытыми и закрытыми конкурентами; следите за быстрым движением по мере накопления ранних голосов и диверсификации подсказок.
🧠 Рассуждения, RL и рецепты обучения
Несколько новых методов и наборов данных по планированию агентов, обучению без вознаграждений и тонкой настройке с минимальными затратами; дополнительно заметки по инфраструктуре для масштабирования RL. Исключает специфику обучения nanochat (особенность).
HERO — гибридный RL, который сочетает границы верификатора с плотными RM-оценками для более стабильного рассуждения
Путём стратификации баллов модели вознаграждения внутри групп, определённых проверяющим, и взвешивания по дисперсии HERO сохраняет стабильность проверяющих, одновременно обеспечивая частичный зачет и эвристическую нюансировку — постоянно превосходя базовые подходы только с верификатором или только RM в задачах математического рассуждения release summary, с подробностями в ArXiv paper.
LightReasoner находит трудные токены с помощью более слабой модели; отсеивает откалиброванные токены примерно на 99%, а время — примерно на 90%.
Контраст «эксперт–любитель» точечно указывает шаги, на которых предсказания следующего токена расходятся; обучение только на этих избирательных шагах позволяет добиться сопоставимого или лучшего качества полного SFT по математике при одновременном снижении вычислительных затрат и объема данных paper abstract.
Работает лучше всего, когда любитель отличается по доменной компетенции (а не только по размеру), что намечает практичный путь к целенаправленным улучшениям рассуждений.
MM‑HELIX обучает рефлексивные MLLMs с откатами; +18,6% на бенчмарке с 100 тысячами задач в длинной цепочке
Новый мультимодальный бенчмарк (1 260 задач) выявляет слабое длинное цепочное рассуждение; авторы вводят набор из 100k рефлексивных трасс и адаптивную гибридную политику оптимизации (AHPO), сочетающую офлайн-наблюдение и онлайн-обучение, чтобы сокрыть разрыв (+18.6% точности, +5.7% общего рассуждения) обзор статьи.
Этот подход обучает модели итеративно действовать, проверять и пересматривать, а не выдавать одну хрупкую цепочку.
Webscale‑RL: Salesforce выпускает конвейер на 1,2 млн примеров и более чем 9 доменов для масштабирования данных RL до уровней предобучения
Автоматизированный конвейер и открытый набор данных нацелены на устранение узкого места с данными RL, приводя сигналы подкрепления к той же порядковой величине, что и корпусы для предобучения dataset brief.
Для команд, исследующих пост‑обучение под управлением verifier/RM‑driven в масштабе, это предлагает отправную точку для стандартизации источников, обработки и контроля качества.
Agent‑in‑the‑Loop: Airbnb превращает операции поддержки в реальном времени в непрерывный цикл обучения
Производительная/framework регистрирует четыре сигнала на случай (выбор ответа, принятие, качество обоснования, недостающие знания) и подает их на совместное обучение по поиску/ранжированию/генерации; пилот на 5k случаев улучшил точность поиска, цитирование источников и принятие человеком, одновременно сократив циклы переобучения с месяцев до недель обзор статьи.
Виртуальный судья фильтрует шумные метки; выборочные аудиты ловят дрейфы, которые судья пропускает.
R‑Horizon исследует пределы широты и глубины; состав запросов подчеркивает долгосрочное рассуждение
Контролируемый бенчмарк составляет запросы, чтобы измерить, насколько глубоко и широко идут модели рассуждений, выявляя, где падает производительность на дальних горизонтах и как сигналы управления могут её восстановить paper abstract.
Полезно в качестве проверки здравого смысла перед развёртыванием агентских циклов, требующих многофазных планов.
Заметки по инфраструктуре RL: обновления на лету и непрерывная пакетная обработка для устранения задержек длинного хвоста
Frontier магазины переходят к полностью асинхронным циклам — постоянно генерируя завершения и применяя обновления модели во время генерации — чтобы снизить простои GPU и хвост «один длинный образец блокирует всё» слайды диаграммы.
Практикующие также отмечают повторное использование inflight KV и непрерывную пакетную обработку как ключевые enablers для масштабируемого обучения в стиле GRPO‑заметка инфраструктуры.)
ИИ-управляемые исследования (ADRS) обнаруживают более быстрые системные алгоритмы — выигрыши по времени выполнения до 5× или до 26% экономии затрат.
Цикл, который генерирует кандидатов, моделирует их и держит в середине верификатор, находит лучшие политики размещения экспертов MoE, планирования баз данных и планировщиков; надежные симуляторы обеспечивают быструю итерацию и измеримые преимущества аннотация к статье.
Шаблон — четкие спецификации, разнообразные тесты, чтобы избежать переобучения, и механизмы защиты от манипулирования наградой — широко пригоден для агентной оптимизации.
BigCodeArena: оценивать код по его выполнению, а не по исходному коду — фиксировать реальные пользовательские предпочтения
Новая арена сравнивает генерации кода по результатам выполнения, а не только по тексту; параллельное выполнение упрощает пользователям выбор лучших выходов и обеспечивает более надежные данные о предпочтениях для обучения project overview.
Ожидаются более чистые сигналы вознаграждения для конвейеров code RLHF/RLAIF и меньше стилистических предвзятостей в метках.
Измерение возникающей координации: информационно‑теоретическая синергия отделяет команды от толпы
Фреймворк тестирует, предсказывает ли выход группы результаты лучше любого отдельного агента, разлагая на общую, уникальную и синергетическую информацию; добавление персоны и подсказок теории ума вызывает устойчивые роли и взаимодополняющие действия, в то время как меньшие модели не способны координировать obzor stat'i.
Полезная диагностика перед масштабированием многоагентных систем LLM.
🤖 Воплощённый ИИ и готовность к реальному миру
Клипы Unitree G1 демонстрируют более быструю и чистую подвижность; сообщество требует демо-версий для домашнего использования и практических задач. Меньшие габариты по сравнению с моделями/инфраструктурой, но заметная тенденция.
xAI строит мировые модели для автоматической генерации игр и управления роботами; первая полностью сгенерированная ИИ‑игра нацелена на декабрь 2026 года.
xAI говорит, что он обучает причинно‑мировые модели — изучая физику и 3D‑раскладку на основе видео/данных с роботами — чтобы генерировать играбельные игровые миры и в конечном счёте информировать управление роботами; Маск ставит цель «великая AI‑сгенерированная игра до конца следующего года», с недавними наймами из Nvidia в эту работу news analysis.
Для воплощённого ИИ это смещает акцент с прогнозирования кадров на динамически‑осведомлённую симуляцию (объектная законность, контакты, долгосрочное планирование). Если удастся, те же модели могли бы снизить требования к данным для роботов, улучшить переносимость из симуляции в реальность и позволить обучение политик на уровне задач с намного меньшим количеством реальных испытаний.
Unitree G1 «Kungfu Kid» V6.0 демонстрирует более плавные и быстрые движения в последнем клипе.
Видео с новым Unitree G1 Kungfu Kid V6.0 демонстрирует заметно более устойчивую работу ног, более быстрые переходы и более широкий набор движений — полезный сигнал зрелости локомоции/управления для недорогих гуманоидов progress video. Отдельный обзор отмечает темп улучшений G1 и то, как каждый релиз выглядит более отполированным, чем предыдущий new clip, , при этом аналитики трактуют темп как часть агрессивного рывка Китая в робототехнике analysis thread.
Для инженеров ИИ это говорит о том, что политики и библиотеки траекторий стабилизируются (меньшее время восстановления, меньше дрейфа), но готовность по-прежнему зависит от устойчивости манипуляций, автономии в условиях помех и эталонов задач — а не только скоординированного движения.
Разработчики побуждают Unitree демонстрировать реальные бытовые задачи, а не только трюки.
После последних демонстраций G1 практикующие требуют доказательств ценности за пределами рутин боевых искусств — например сбор белья, загрузка посуды или использование инструментов в грязных домах — чтобы подтвердить надежность, безопасность и поведение восстановления в условиях без сценария home use ask. Эта давление следует за несколькими клипами «кунфу» в коротком порядке new clip, и это та ниша, которую будут смотреть корпоративные покупатели: сможет ли тот же стек управления справляться с окклюзиями, деформируемыми объектами и исправлением ошибок без человеческих перезагрузок?
🗂️ Парсинг, извлечение и конвейеры обработки данных
Обновления конвейеров документации и оценок, учитывающих выполнение: обновления Firecrawl OSS, BigCodeArena (предпочтения кода, основанные на исполнении) и обсуждения по парсингу в продакшене.
Firecrawl v2.4.0 выпускается: поиск PDF, 10× семантическое сканирование, новый поисковый эндпойнт x402
Firecrawl выпустил v2.4.0 с выделенной категорией поиска PDFs, примерно в 10× лучшее семантическое сканирование, новым эндпоинтом x402 Search (через Coinbase Dev), обновленным примером fire-enrich v2, улучшенным статусом сканирования и предупреждениями по эндпоинтам, и 20+ исправлениями для self-host — продолжая работу над open builder, где команда заинтриговала визуальные, n8n‑style рабочие процессы. Смотрите обзор функций в сводке выпуска release thread и код в репозитории GitHub repo.
Эти обновления продвигают Firecrawl еще ближе к “LLM‑ready” веб‑данным конвейерам (чистые извлечения, больший охват), одновременно снижая операционные трудности для пользователей self-host. Эндпоинт x402, в частности, расширяет источники запросов, к которым разработчики могут получить доступ без пользовательского клея GitHub repo.
BigCodeArena оценивает код через выполнение, а не по стилю исходного кода, чтобы зафиксировать реальные предпочтения пользователей.
BigCodeArena представляет методику сравнения программ, сгенерированных LLM, основанную на исполнении: запустите оба варианта и судите по результатам, а не по чтению кода, что позволяет получать более надёжную человеческую обратную связь в масштабе для систем генерации кода paper thread.
Эта структура помогает командам снизить предвзятость «красиво, но неправильно» в оценке кода, привести модели к поведению во время выполнения и проводить A/B‑оптимизацию подсказок или методик дообучения с использованием объективных сигналов пропуск/непройдено.
Hugging Face дебютирует RTEB, чтобы измерить обобщение моделей поиска в реальных условиях.
Retrieval Embedding Benchmark (RTEB) объединяет открытые и приватные наборы данных, чтобы снизить утечки и лучше отражать производительность поиска в продакшене, устраняя завышенные показатели из оценок, основанных только на публичных данных benchmark blog. Методология нацелена на разработчиков, внедряющих RAG и поиск, и подчеркивает устойчивость к данным, которые не были видны ранее, а не игру на лидерборде benchmark blog.
Reducto демонстрирует гибридный OCR‑VLM конвейер для многостраничного структурированного извлечения с задержками на уровне продакшна
A live session will walk through Reducto’s hybrid OCR + VLM architecture aimed at parsing complex, multi‑page documents with low hallucination and production‑grade latency, including structured extraction and natural‑language automation workflows краткая справка о событии, со сведениями о регистрации на странице мероприятия регистрация на мероприятие.
Для команд в области ИИ, тонущих в PDFs, этот подход показывает, как сочетать детерминированное OCR с рассуждением VLM, чтобы повысить точность и пропускную способность по сравнению с парсерами, работающими только на основе VLM, сохраняя предсказуемость задержки notes thread.
Практический цикл оценки (evals): определить задачу, набор данных и оценщиков, чтобы выявлять регрессии и стимулировать улучшения
Braintrust излагает простой, но строгий образец для AI‑оценок — составьте конкретную задачу, подберите золотой набор данных, затем подключите оценщиков — чтобы уловить регрессии и направлять итерацию, с примерами применения его к рабочим процессам моделей и агентов evals how-to.). Пост содержит детали начала работы и инструментирования запусков, чтобы выйти за рамки настройки, основанной на интуиции evals blog.
🛡️ Политика, юридические вопросы и риски платформы
Регуляторные и правовые изменения на сегодня: законопроект Калифорнии SB 243 для ИИ‑компаньонов и давление со стороны исков в делах по данным из книг. Исключает работу по взлому моделей (не в этом примере).
Суд рассматривает возможность проломить привилегию OpenAI в деле о данных книг в рамках исключения преступления и мошенничества.
В деле о нарушении авторских прав, связанном с обучением на пиратских книгах, суд рассматривает вопрос о том, не вскрыть ли привилегию адвокат–клиент OpenAI посредством исключения преступления и мошенничества, после того как истцы сослались на Slack и упоминания в письмах об удалении данных LibGen. Уязвимость может привести к санкциям, усиленным убыткам или даже к вынесению решения по умолчанию; законные выплаты по ущербу достигают до $150,000 за каждое произведение, что подразумевает миллиардные потенциальные обязательства, если будет найден умысел case summary.
Помимо финансовых рисков, принудительная передача внутренней переписки адвокатуры создала бы прецедент с широкими последствиями для раскрытия информации в вопросах управления данными в лабораториях ИИ.
Калифорния приняла закон SB 243: компаньоны на базе ИИ обязаны сообщать о своем не‑человеческом статусе, защищать несовершеннолетних и публиковать протоколы предотвращения самоповреждений
Калифорния приняла закон SB 243, направленный на чат-ботов-компаньонов ИИ: услуги должны ясно сообщать, что они искусственные, если обычный пользователь может подумать иначе, напоминать известным несовершеннолетним каждые три часа, что они общаются с ИИ, и делать перерывы, а также поддерживать/публиковать протоколы предотвращения самоубийств с направлениями на горячие линии. Начиная с января 2026 года операторы сталкиваются с частными исками на сумму не менее $1 000 за нарушение, плюс годовые отчеты в Офис по предотвращению самоубийств; платформы не могут намекать на статус медицинского специалиста и должны блокировать сексуально откровенные изображения для несовершеннолетних обзор закона.
Это порождает требования к соблюдению и безопасному содержанию для любого продукта ИИ-компаньона, обслуживающего пользователей Калифорнии, включая каденцию маркировки, обработку возрастной информации и документированные потоки эскалации, которые теперь подлежат принуждению в суде.
Повестка в суд от OpenAI адвокату по вопросам политики искусственного интеллекта в Калифорнии вызывает обеспокоенность в борьбе за прозрачность SB 53.
Политический защитник ИИ Натан Калвин утверждает, что помощник шерифа вручил ему повестку, требующую приватные переписки, связанные с калифорнийским законопроектом SB 53 об охране ИИ, утверждая, что OpenAI воспользовалась отдельным иском против Маска, чтобы запугать критиков, несмотря на отсутствие связи с делом. Эпизод подчёркивает нарастающие юридические манёвры по мере продвижения правил прозрачности в области ИИ в Сакраменто и может охладить участие в разработке политики среди меньших организаций subpoena report.
Хотя это один инцидент, он добавляет репутационные и платформенные риски в отношении того, как крупные лаборатории взаимодействуют с оппонентами во время регуляторных процессов.
💼 Сигналы принятия и корпоративные сигналы
Как ИИ перестраивает организации и расходы: влияние Slack×ChatGPT (рассматривается в разделе «Оркестрация»), преимущество звездных сотрудников, автоматизация поддержки Klarna, перераспределение нагрузки Kimi и инициатива JPMorgan по внедрению ИИ.
JPMorganChase обещает $1,5 трлн на безопасность и устойчивость США, при этом ИИ — опора.
JPMorganChase запустил 10‑летнюю инициативу на сумму $1,5 трлн, охватывающую цепочки поставок, оборону, устойчивость энергетики и передовые технологии, включая ИИ, кибербезопасность и квантовые технологии — сигнализируя о устойчивом спросе как со стороны предприятий, так и государственного сектора на возможности ИИ и финансирование инфраструктуры initiative summary, и подробности в пресс-релизе банка press release.
- Основные направления включают передовое производство, оборонные технологии/автономность, сетевые решения и almacenamiento, а также передовые технологии (ИИ/кибер/квант) initiative summary.
Klarna: ИИ теперь обрабатывает около 66% чатов поддержки; штат уменьшился с примерно 7 400 до примерно 3 000.
Klarna’s CEO says the company shrank to ~3,000 employees from ~7,400 as its AI agent took on about two‑thirds of customer support—roughly 700 human‑agent equivalents—while underwriting remains human‑heavy due to risk constraints Bloomberg interview. Ожидается ускорение давления на маржу в рутинных ролях, связанных с знаниями, прежде чем функции, ограниченные политиками, станут труднее поддаваться автоматизации.
WSJ: ИИ усиливает преимущество звездных сотрудников внутри компаний
ИИ-инструменты ускоряют рост эффективности у лучших сотрудников больше, чем у их сверстников, расширяя разрыв в статусе и оплате, пока эксперты раньше осваивают технологии, лучше оценивают результаты и получают больше кредитов за работу с поддержкой ИИ анализ WSJ. Для лидеров это аргумент в пользу целевой поддержки (обучение, рабочие процессы, нормы оценки), чтобы избежать морального духа и координационных затрат по мере масштабирования ИИ.
Исследование: внедрение ИИ — ориентировано на старшинство; найм младших сотрудников снижается у компаний‑адопторов
Крупное исследование резюме/объявлений о работе (~62 млн работников, ~285 тыс. компаний) показывает, что внедрение GenAI коррелирует с падением занятости младшего персонала по сравнению с теми, кто не внедряет технологию, в то время как занятость старшего персонала продолжает расти; снижения сосредоточены в ролях с высокой степенью экспозиции и обусловлены более медленным набором, а не увольнениями аннотация статьи. Рекомендации: лидеры должны перераспределить задачи и обучение, чтобы не опустошать входные пайплайны найма.
Полевое исследование центрального банка: ИИ повышает качество на 48% и сокращает время на 23% при выполнении задач общего назначения.
В рамках полевого исследования Национального банка Словакии/Йешивы доступ к GenAI повысил качество вывода на 48% и сократил время на 23% при выполнении задач общего назначения; при работе со специалистами качество более чем удвоилось, тогда как для работников с высоким уровнем навыков прирост эффективности оказался выше обзор статьи. Результаты указывают на то, что перераспределение задач и изменение сочетания навыков могут обеспечить существенно больший эффект, чем просто развертывание инструментов.
Рабочие нагрузки переходят на Kimi K2 по соотношению цена/производительность, — сообщает Чамат Палихапития.
Чамат Палихапития говорит, что крупный клиент Bedrock перераспределил «тонны» рабочих нагрузок на Kimi K2 ради лучшей производительности по меньшей стоимости, что подчеркивает растущую чувствительность предприятий к цене и диверсификацию поставщиков моделей podcast clip. Для покупателей это укрепляет аргумент в пользу маршрутизации через нескольких провайдеров и постоянных переоценок соотношения стоимость–качество по мере обновления моделей.
⚙️ Среды выполнения и локальные рабочие процессы инференса
Стек инференса набирает обороты: широкое внедрение vLLM, а также примечания по производительности SGLang/Ollama на новом настольном суперузле DGX Spark от NVIDIA.
DGX Spark получает раннее признание за время выполнения: SGLang и Ollama демонстрируют крупные локальные модели на 128 ГБ объединённого Blackwell
Подробный обзор LMSYS демонстрирует, что DGX Spark NVIDIA запускает локальные LLM с использованием спекулятивного декодирования SGLang’s EAGLE3 и Ollama, что поддержано чипом GB10 Grace Blackwell и 128 ГБ единичной памяти, упрощающей передвижение между CPU и GPU для прототипирования и краевого вывода обзорныеHighlights, LMSYS блог, обзор на YouTube. Ollama отдельно подтвердил поддержку Spark с краткой заметкой о возможностях и настройке для чатов, документов и рабочих процессов с кодом на коробке Ollama заметка, блог Ollama.
- Та же аппаратная платформа уже приходит за пределы LLM-рантаймов: ComfyUI объявил поддержку Spark для ускорения локальных пайплайнов обработки изображений, намекая на более широкую инфрасистему вывода на столе вокруг Blackwell заметка ComfyUI.
vLLM превысил 60 тысяч звёзд на GitHub как де-факто открытый движок инференса, охватывающий GPU, CPU и TPU.
vLLM превысил 60k звёзд, подчёркивая своё место как стандартной среды выполнения генерации текста с широким охватом аппаратного обеспечения (NVIDIA, AMD, Intel, Apple, TPUs) и нативные хуки в стеки RL вроде TRL, Unsloth, Verl и OpenRLHF project milestone.
Помимо охвата, внедрение vLLM в инструментальные цепочки и у поставщиков имеет значение для инженеров, планирующих портативные развёртывания и гибридные флоты; импульс сообщества снижает риск привязки и упрощает миграцию между акселераторами без переписывания путей обслуживания project milestone.