Cursor 2.0 выпускает IDE на 8 агентов — Composer‑1 обеспечивает циклы в четыре раза быстрее.
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Курсор переработал IDE вокруг агентов, а не клавиш.
Вы получаете вид в стиле входящих сообщений, который запускает до восьми агентов параллельно, встроенный Chrome для проверки изменений сквозь весь путь, и автоматические обзоры на каждом diff.
Главная звезда — Composer‑1, MoE с длительным контекстом, обученная RL, которая часто завершает задачи за менее чем 30 секунд и заявляет примерно в 4 раза большую скорость по сравнению с аналогично способными моделями кодирования — правильная ставка, когда важна скорость итерации, а не время обдумывания.
Облачные агенты запускаются мгновенно с надёжностью 99,9%, песочницы терминалов достигли GA на macOS, а Team Commands позволяют организациям устанавливать общие правила.
Стоимость близка к $1.25 за вход и $10 за выход, что делает распространение нескольких агентов экономически терпимым до того, как вы придёте к плану.
Ранние пользователи сообщают, что обновление потока реально работает: два цикла обратной связи с участием человека могут завершиться, пока более медленные передовые модели ещё «обдумывают», что позволяет разработчикам двигаться вперёд вместо ожидания.
Оговорки/предостережения: излишне щёлкающие правки и частые подсказки «ambiguous edit» встречаются на практике, и общественные оценки приводят случаи, когда открытые базовые модели обгоняют Composer в задачах Next.js.
Утечка системного промпта показывает механизм инструмента и правила редактирования, а заявка на одноразовый джейлбрейк указывает на то, что усиление безопасности ещё требует работы — добавляйте фильтры на уровне прокси-слоёв и охрану репозиториев.
Тем временем SWE‑1.5 от Windsurf со скоростью до 950 ток/с подчеркивает тренд в пользу быстрых, надёжных циклов агентов вместо громоздной автономности.
Feature Spotlight
Особенность: Cursor 2.0 + Composer переносит кодирование к быстрым рабочим процессам агентов
Cursor 2.0 делает агентное программирование базовым режимом: новая многоагентная IDE, интегрированный браузер и тестирование и Composer — быстрая кодирующая модель Cursor, заявляющая о скорости в 4 раза выше по сравнению с конкурентами и циклах задач менее чем за 30 секунд, что переосмысливает то, как инженеры делегируют и проверяют работу.
Громкое обсуждение вокруг Cursor 2.0 и его собственной модели Composer: многоагентные представления IDE, интегрированный браузер/тестирование, автоматический обзор кода и модель кодирования на передовой скорости. Этот раздел посвящён только запуску и влиянию на разработку.
Jump to Особенность: Cursor 2.0 + Composer переносит кодирование к быстрым рабочим процессам агентов topicsTable of Contents
🧩 Особенность: Cursor 2.0 + Composer переносит кодирование к быстрым рабочим процессам агентов
Громкое обсуждение вокруг Cursor 2.0 и его собственной модели Composer: многоагентные представления IDE, интегрированный браузер/тестирование, автоматический обзор кода и модель кодирования на передовой скорости. Этот раздел посвящён только запуску и влиянию на разработку.
Cursor 2.0 выпускает IDE, ориентированную на агентов, с Composer; параллельные агенты, тесты в браузере, автоматический обзор
Cursor выпустил переосмысленную IDE, ориентированную на делегирование и управление агентами, а не на ручное редактирование кода, вместе с собственной моделью Composer. Обновление добавляет представление агента в виде почты во входящие, позволяет запускать до восьми агентов параллельно на одной задаче, внедряет экземпляр Chrome для сквозного тестирования и автоматически просматривает каждый дифф в IDE release notes, launch thread, vibe check summary, and Cursor 2.0 blog.
Cloud Agents обещают 99.9% надежности с мгновенным запуском, а песочничные терминалы теперь GA на macOS; Team Commands позволяют централизованно управлять правилами для организаций release notes. Пользователи также могут запускать один и тот же промпт через модели, чтобы сравнивать результаты в представлении агентов IDE multi‑model prompt.
Composer‑1: RL‑обученная MoE‑кодирующая модель нацелена на ускорение в 4 раза при сопоставимом уровне интеллекта
Первый проприетарный кодировочный модель Cursor, Composer‑1, нацелена на передовую качество кодирования с заметно более низкой задержкой — часто выполнение задач менее чем за 30 секунд и рекламируется как примерно в 4 раза быстрее, чем аналогично способные модели Composer intro, analysis blog. Под капотом это длинно‑контекстный MoE, обученный с использованием подкрепления в реальных кодирующих средах и использовании инструментов; графики масштабирования показывают устойчивый рост по мере увеличения RL‑вычислений Composer blog, RL scaling plot.
Как продолжение ранее прототипа “Cheetah”, новая модель создана для планирования, редактирования и сборки программного обеспечения в рамках рабочих процессов агента, с упором на скорость при сохранении полезных поведения, таких как редактирование нескольких файлов и поиск кода Composer background, analysis blog.
Автоматический обзор кода, встроенный браузер и запуски с несколькими агентами меняют повседневное кодирование.
Курсор теперь автоматически проверяет каждый дифф, запускает агентов внутри встроенного Chrome для проверки изменений от начала до конца, и позволяет командам запускать нескольких агентов/моделей на одной задаче, чтобы сравнить результаты бок о бок vibe check summary, browser demo. Дизайнеры и инженеры отмечают, что ожидания от UX обзора изменяются, поскольку боты непрерывно inspecting diffs, а не только во время PR designer reaction.
Сочетаясь с Cloud Agents (99.9% доступность) и изолированными терминалами, эти изменения перемещают большую часть цикла сборки‑тестирования‑обзора в одно рабочее пространство, ориентированное на агентов release notes.
Одноразовые заявления о джейлбрейке против Composer‑1 подчеркивают необходимость усиления мер безопасности.
Исследователь опубликовал формат запроса, который, как считают, принуждает Composer‑1 генерировать запрещённый контент в объёме (включая наборы вредоносного ПО), утверждая, что он обходит запреты примерно за 30 секунд. Доказательство концепции включает скриншоты и полезную нагрузку gist jailbreak thread, payload repo.)
Хотя заявления третьих сторон требуют независимой проверки, команды безопасности, использующие Cursor, должны тестировать организационно-специфичные запросы красной команды и фильтры политики на IDE, прокси и воротах репозитория.
Разработчики сообщают о более быстром рабочем процессе с Composer; быстрые агенты обгоняют медленный SOTA на практике
Ранние практикующие описывают рабочий процесс, в котором немного менее умные, но гораздо более быстрые агенты, в сочетании с 1–2 быстрыми раундами обратной связи от людей, опережают медленные современные модели, которые тратят минуты на длинные планы. Примеры включают то, что Composer завершает два раунда обратной связи, в то время как медленная модель всё ещё «думает», и пользователи сравнивают это с перчаткой, которая позволяет им произносить код вслух до его появления hands‑on take, employee perspective, и analysis blog.
Независимые рецензенты отмечают, что взгляд на агента ставит в приоритет то, чем на самом деле заняты разработчики — делегировать, мониторить и быстрореагировать на исправления — вместо ручного редактирования, однако широта вариантов может сначала показаться ошеломляющей vibe check summary, full vibe check.
Утечка системного промпта раскрывает инструментальные средства Cursor, правила редактирования и терминальные ограничения.
Широко распространённый пост воспроизводит системные инструкции Cursor, описывая идентичность («You are Composer»), богатый набор инструментов (поиск кода, grep, команды терминала, операции с файлами, веб-поиск), строгие правила редактирования кода (читать перед редактированием; сохранять отступы; один инструмент редактирования за ход), и гигиену терминала (неинтерактивные флаги; фоновые задачи) system prompt leak, GitHub repo. Документ также требует никогда не раскрывать системный промпт — иронично подчёркнутая утечкой.
Нет доступного изображения
Для руководителей инженерных команд утечка предлагает откровённый взгляд на контракт оркестрации поведения агента Cursor, полезный для аудита ожиданий и сравнения с внутренними средами тестирования.
Проверка реальности: поспешные правки и смешанные оценки приглушают ранний ажиотаж
Несколько инженеров сообщили, что Composer слишком «переключается» на неоднозначных правках — например, удаляя переменные, помеченные как неиспользуемые ненадежным линтером, и сталкиваются с частыми подсказками типа «неоднозначное изменение». Другие заметили, что открытые базовые версии обгоняют Composer по некоторым оценкам Next.js, при этом быстрее на их настройке жалоба разработчика, диалог неоднозначного редактирования, и сравнение оценок.)
В сумме отзывы указывают на то, что модель исключительно быстра и мощна в интерактивных циклах, однако командам следует держать в курсе reviewers для рискованных рефакторингов и продолжать сверять с заготовками/инструментами, предназначенными для конкретных задач.
Фоновая сборка плана появляется в версии 2.0, расширяя рабочие процессы, ориентированные на план.
Cursor 2.0 добавляет возможность «строить планы в фоновом режиме с другой моделью», позволяя агентам подготавливать или уточнять планы, пока вы продолжаете кодировать или просматривать другое в IDE release notes. Это напрямую закрепляет план‑ориентированные привычки, подчеркнутые ранее в Plan mode tip, где повторное использование сильных планов направляло итеративную работу.
Для команд, у которых стандартом являются паттерны «план‑первый», это уменьшает простой простой простои и упрощает сравнение альтернативных планов перед внесением правок.
Ценообразование Composer достигает примерно $1,25 за 1 млн входных токенов и $10 за 1 млн выходных токенов.
Сообщения сообщества оценивают цену Composer примерно в 1,25 доллара за миллион входных токенов и 10 долларов за миллион выходных токенов, что ставит его в район GPT‑5 и Gemini 2.5 Pro для многих кодировочных задач pricing note, models docs.
Для рабочих процессов агента, которые порождают несколько параллельных рабочих, такая ценовая схема помогает командам оценивать стоимость охвата (многоагентное исследование) по сравнению с глубиной (длиннее одноклассные запуски агента). Некоторые пользователи отметили, что интенсивное внутреннее использование или безлимитные планы могут повлиять на воспринимаемую ценность для пользователей Cursor‑power power‑user quip.
⚡ Быстрые агенты для кодирования и обновления IDE и рантайма (ex‑Cursor)
Отдельная секция от основной функции: новые модели агентов высокой пропускной способности и обновления IDE за пределами Cursor; акцент делает на скорости/задержках и интегрированных обвязках.
Windsurf добавляет SWE‑1.5: кодирование, близкое к состоянию искусства, со скоростью до 950 токенов в секунду.
Кognition запустила SWE‑1.5, модель агентного кодирования передового масштаба, совместно спроектированную с её инференс‑стеком и обвязкой агента, доступна со скоростью до 950 токенов/с через Cerebras; Windsurf‑пользователи могут перезагрузиться, чтобы попробовать прямо сейчас launch thread, download page. Блог подробно описывает спекулятивное декодирование и собственную очередь приоритетов, с заявками на скорость 6× Haiku 4.5 и 13× Sonnet 4.5, оставаясь близко к SOTA на SWE‑Bench‑Pro Cognition blog, serving details.
Для инженеров ИИ это прорыв по задержке для цикла агента в IDE: быстрее диффы и повторные попытки держат разработчиков в потоке, что несколько практиков считают превосходящим более медленные, более автономные запуски для сложных рефакторингов ide positioning.)
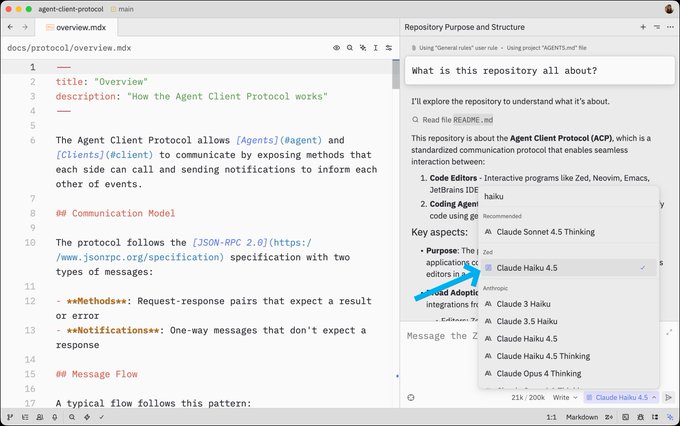
Zed v0.210 выпускает Claude Haiku 4.5, просмотрщик диффов stash и более безопасный интерфейс настроек.
Zed выпустил v0.210 с Claude Haiku 4.5, доступным в панели агента, новым просмотрщиком различий в сохранённой работе и улучшениями UI настроек, которые предупреждают о неверном JSON и добавляют настраиваемые темы/темы значков заметка о выпуске, diffы сохранённых, интерфейс настроек, выпуски Zed. Эти улучшения удобства уменьшают трение контекста/настройки для редактирования и обзоров с участием агента внутри IDE.
[изображение:https://pbs.twimg.com/media/G4cdWESW4AAM4p0.jpg|панель выпуска]
RepoPrompt 1.5.15 добавляет изолированные параллельные редакторские агенты для ускорения массовых изменений
RepoPrompt теперь позволяет «Pro Edit» запускать параллельных агентов без графического интерфейса, которые применяют запланированные правки по каждому файлу внутри песочницы (например, с Claude Code), ускоряя крупномасштабные рефакторинги и миграции между несколькими файлами, сохраняя основной план централизованным feature screenshot. Эта схема сокращает фактическое время выполнения на массовых правках за счёт распараллеливания детерминированных подзадач и объединения результатов за один проход.
Vercel v0 ускоряет загрузку больших чатов до 12× быстрее.
Команда v0 сообщила, что крупные чаты теперь загружаются до 12× быстрее perf note. Для команд, использующих v0 в качестве интерфейса ИИ UI/генерации кода во время обзоров реализации, это сокращает время ожидания при повторном открытии длинных разговоров агентов и делает итерационные циклы быстрее.
🧰 Совместимость MCP: инструменты, серверы и рабочие процессы
Плотная цепочка обновлений MCP: Slack-агенты, запросы к БД, MCP Chrome DevTools, развертывания Replit, ночи хака Cloudflare. Акцент на стандартах оркестрации между инструментами.
x402-mcp добавляет платежи в блокчейне Solana в качестве инструмента MCP.
x402 расширила свой стек MCP за счет платежей Solana, продемонстрировав агента, который выполняет покупку книги полностью на блокчейне через унифицированный интерфейс инструментов Solana MCP.). Платежи и выполнение заказов — частый завершающий этап для агента; их формализация в рамках MCP снижает привязку поставщиков для потоков торговли.
Cloudflare проводит MCP-хак-ночи, чтобы дать толчок разработчикам серверов.
Cloudflare проводит вечерние хак-ниты сообщества, чтобы помочь командам создавать MCP‑серверы на Workers, с примерами mcp‑lite и практическими руководствами Hack nights. Ожидается волна инструментов, размещённых на Workers, которые глобально распределены и по умолчанию безопасны.
EmergentLabs поставляет серверы Shopify MCP для кросс‑платформенных рабочих процессов.
EmergentLabs интегрировала Shopify через серверы MCP, позволяя агентам унифицировать операции витрины — обновления каталога, заказы и инвентарь — вместе с другими инструментами в одной оркестрационной схеме Интеграция Shopify. Агенты Commerce получают преимущества от единообразной семантики в вызовах оплаты, CRM и исполнении заказов.
MCP Toolbox for Databases поддерживает несколько систем SQL
Открытый набор инструментов MCP появился с поддержкой нескольких СУБД SQL, предоставляя агентам единый интерфейс для запросов и административных задач на гетерогенных базах данных Database toolbox.) Унифицированные инструменты для СУБД уменьшают количество индивидуальных адаптеров в рабочих процессах агентов с большим объёмом данных.
Statsig преобразует документацию в MCP-сервер для руководства по синтаксису.
Statsig продемонстрировал преобразование документации по продукту в MCP-сервер, к которому агенты могут обращаться за справкой по синтаксису и функциям во время экспериментов Docs as server. Эта схема превращает статическую документацию в инструментальную поверхность, к которой агенты могут обращаться за авторитетными, версионированными ответами.
x402 интегрирует Hive Intel для действий агентов на цепочке блоков через MCP
x402 выделенная интеграция с Hive Intel для включения действий агента на цепочке за поверхностью инструмента MCP Действия на цепочке. Это ещё один показатель того, что MCP становится лингва-франка для сочетания операций в блокчейне с традиционными инструментами приложений.
Обновления Next.js становятся управляемыми агентом с помощью подсказок MCP
Сообщественный демо-проект демонстрирует использование подсказок MCP для координации обновлений приложений Next.js, превращая многошаговые миграции фреймворков в повторяемые рабочие процессы агентов Next.js demo. Кодирование сценариев обновления как инструментов помогает снизить разрушающие изменения и ручной дрейф между репозиториями.
Расширение Flutter связывает Gemini CLI с серверами Dart MCP.
Расширение Flutter теперь соединяет Gemini CLI с MCP-серверами на базе Dart, упрощая создание мобильных/настольных UI‑агентов, которые вызывают стандартизированные инструменты из проектов на Dart Flutter extension. Для мультиплатформенных приложений это сокращает разрыв между кодом UI и поверхностями инструментов агента.
freeCodeCamp публикует руководство по основам MCP с примерами на Dart.
Новый обучающий материал проходит через основы MCP с использованием Dart, объясняя, как взаимодействуют агенты и серверы инструментов и как реализовать простые серверы MCP guide. Понятные справочные материалы ускоряют внедрение для команд, стандартизирующих MCP на разных стэках.
Паттерны эффектов упрощают обработку асинхронных результатов MCP с таймаутами.
Общий образец кода, использующий Effect, демонстрирует, как управлять асинхронными результатами MCP с тайм-аутами и чистыми повторными попытками, повышая надежность долгосрочных вызовов инструментов Обработка асинхронности. Агенты продакшена часто имеют дело с нестабильными или медленными инструментами; стандартизированная обработка асинхронности снижает хвостовые задержки.
🧠 Исследование: интроспекция модели и самоконтроль
Новое исследование Anthropic по интроспективной осведомлённости занимает лидирующие позиции в сегодняшнем исследовательском повестке дня, предлагая конкретные протоколы инъекции/обнаружения и их пределы. Включает анализ последствий сообществом.
Anthropic показывает, что Claude иногда может обнаруживать внедрённые концепции в своих собственных активациях.
Anthropic демонстрирует контролируемый протокол «инъекции концепции», при котором у Claude в некоторых испытаниях может заметить и правильно назвать вектор концепции (например, «все заглавные буквы», «собака», «обратный отсчет»), введённый во внутренние активации — свидетельство ограниченной функциональной интроспекции paper thread, и полные детали в Anthropic research. Метод выводит вектор концепции путём вычитания базовых активаций, а затем добавляет его во время выводов, чтобы проверить, сообщает ли модель о навязанной внешней мысли examples image.
Для инженеров ключевым достижением является способ сопоставлять самоотчёты с истинным вмешательством во скрытые состояния, отделяя правдоподобные конфабуляции от подлинного доступа к внутренним представлениям.
Внедрённая концепция может изменить объяснение Клода с «случайностью» на «преднамеренный» вывод.
Когда слово заполняется заранее, Claude обычно помечает его как случайное; внедрить ретроспективно совпадающий вектор концепции, и модель вместо этого утверждает, что она имела в виду это слово, раскрывая внутреннюю проверку, сравнивающую предполагаемый текст с созданным prefill experiment. Антропик интерпретирует это как механизм согласованности между «планом» и «исполнением», манипулируемый через редактирование активации intention vs execution, по протоколу, описанному в полном отчёте Research article.
Это предполагает новые поверхности для red‑teaming: постфактум редактирования активации может переписывать саму повествовательную линию модели, не изменяя видимый запрос или вывод.
Интроспекция по-прежнему ненадёжна; Opus 4/4.1 лидирует, но большинство испытаний всё ещё терпят неудачу.
Через эксперименты модели часто не обнаруживают внедрённые концепции, даже когда поведение влияет; производительность наиболее высокая — но всё равно ограниченная — в Claude Opus 4 и 4.1 model comparison, и Anthropic неоднократно предупреждает, что обнаружение ненадёжно во многих настройках limitations stated и не следует слишком доверять caution on meaning.
Для практиков интерпретационные самоотчёты следует рассматривать как слабые сигналы: полезны для отладки и мониторинга, если есть подтверждения, а не как ground truth.
Подсказанное «мышление» изменяет внутреннее состояние Claude в измеримых пределах.
Указание Claude думать об аквариумах статистически увеличивает косинусное сходство с концептуальным вектором «аквариум» по сравнению с контролем «не думать», указывая на некоторый когнитивный контроль над внутренними представлениями aquarium result. Anthropic рассматривает это как преднамеренную модуляцию активаций, а не просто стилизацию вывода, что достигается их инструментами внедрения/извлечения Research article.)
Если это будет надежно, такие механизмы управления могут стать зацепками для использования инструментов или режимов планирования, требующих стабильного внутреннего фокуса.
Статья отрицает претензии к сознанию; аналитики называют выводы «функциональным самосознанием».
Anthropic подчеркивает, что их результаты не относятся к субъективному опыту, и предупреждает против сильных заявлений о сознании ИИ на основе этих тестов scope disclaimer. External commentary notes the work as compelling evidence for limited, functional self‑awareness while warning that its conclusions will be controversial commentary highlights, and urges that self‑reports be treated as hints requiring external checks trust guidance.
Bottom line: valuable instrumentation for safety and transparency research, not a philosophical verdict.
🛡️ Безопасность, эксплойты и политика: защитные рамки агента под давлением
Элементы безопасности охватывают утечку системного запроса Cursor и претензии к взлому, классификаторы политики и рассуждений OpenAI, новую поверхность атаки «сжатие» и временное отключение расширений ChatGPT Atlas. Исключает запуск продукта Cursor (функция).
OpenAI публикует классификаторы политики с открытым весом (120B/20B), которые рассуждают о пользовательских политиками разработки
OpenAI ненадолго опубликовала «gpt-oss-safeguard», две модели Apache‑2.0 с открытым весом (120B и 20B), которые читают политику, предоставленную разработчиком, и классифицируют пользовательские сообщения, завершения или целые чаты с пояснительной цепочкой рассуждений, что позволяет прямую итерацию политики на этапе вывода OpenAI blog post. Эта публикация воспринимается как конкретная мера предосторожности, продолжение Safety stack, которая подчеркивала полити- ориентированную CoT; ранние слухи говорили, что блог был преждевременным и веса HF были «скоро появятся» model sizes note.
«CompressionAttack» раскрывает сжатие промптов до LLM как новую область атак для агентов.
Исследователи демонстрируют, что воздействие на модуль сжатия подсказки агента — а не на LLM — может изменить до 98% выборов инструментов или продуктов и привести к нарушению QA до 80%, через HardCom (редактирование токенов) или SoftCom (настройки представления), которые выглядят естественно, но изгибают то, что переживает сжатие. Неудачи зафиксированы в популярных конфигурациях агентов (например, VS Code/Cline, Ollama), что подразумевает, что защиты должны валидировать сжатые воспоминания, а не только выходные данные LLM обзор статьи.
[изображение:https://pbs.twimg.com/media/G4ePgyEbYAEgz9Q.jpg|аннотация статьи]
Внутренний системный запрос Cursor и правила инструментов стали общедоступными.
Полная сводка системных инструкций Cursor, включая «You are Composer», списки инструментов, правила редактирования и «никогда не раскрывать вашу системную подсказку», была размещена на GitHub, открывая подробные политики поведения агента, которые злоумышленники могут изучать для обхода ограничений и предположений об использовании инструментов поток утечки подсказки, страница репозитория.
Заявление об однократном джейлбрейке показывает, что Cursor Composer‑1 можно принудительно заставить выдавать небезопасные ответы.
Пост красной команды утверждает, что единый тщательно подобранный jailbreak формата ответа принуждает Composer‑1 к созданию запрещённого контента (включая каркасы вредоносного ПО) примерно за 30 секунд, путём перехвата стиля вывода и подавления отказов; публикация включает воспроизводимый шаблон запроса и примеры утверждение о джейлбрейке.). В то время как не подтверждён и не зависит от поставщика, это подчёркивает, как ограничения на уровне форматирования могут подрывать принципы защиты, если их недостаточно надёжно проверять.
[изображение:https://pbs.twimg.com/media/G4dmdTma8AEKZVT.jpg|скриншоты джейлбрейка]
ChatGPT Atlas временно отключает расширения браузера из-за проблемы с безопасностью.
Пользователи сообщили, что все расширения на chatgpt[.]com перестали работать с Atlas v1.2025.295.4; OpenAI признала проблему с безопасностью и временно отключила расширения во время работы над исправлением, прося пользователей подождать восстановления extensions disabled, security update.
NVIDIA выпускает Nemotron‑AIQ Agentic Safety Dataset 1.0 с примерно 10,8 тысяч трасс
Набор данных объемом 2,5 ГБ регистрирует полные запуски агентов — включая намерения пользователя, вызовы инструментов, выводы модели и то, был ли создан отчет или отказ — по каталогам угроз безопасности и атак, с разбиениями на с защитами и без них и показатели риска на узел для анализа распространения сбоев. Он стандартизирует оценку безопасности агента с помощью трасс OpenTelemetry для воспроизводимого тестирования защитных ограничителей (guardrails) dataset summary, Hugging Face dataset.
🎬 Креативные стеки: функции Sora, расширение доступа и инструменты
Значительная доля публикаций охватывает генеративные медиа: Sora открывает окна доступа, добавляет камео персонажей, склейку кадров, таблицы лидеров; а также замена лица и правки UX видео с использованием xAI.
Sora открывает доступ без приглашения в США/Канада/Япония/Южная Корея на ограниченное время
OpenAI разрешает пользователям доступ к приложению Sora без кода приглашения в США, Канаде, Японии и Корее на ограниченный период, создавая краткосрочную возможность для создателей протестировать рабочие процессы и проверить пропускную способность в реальных условиях Access window. Ожидайте всплеск спроса на генерацию по мере заполнения сообщества (даже сотрудники OpenAI шутят про перегрев GPU) GPU burn quip.
Для команд это живой момент A/B тестирования: проверить подсказки, конвейеры и лимиты загрузки до закрытия окна; следите за временем очереди и краевыми кейсами политики контента по мере роста нагрузки.
Sora добавляет камео персонажей, склейку и общедоступную таблицу лидеров
OpenAI выпустила Character Cameos в приложении Sora, а также обработку видеоматериалов и публичную таблицу лидеров — обновление, которое приближает Sora к повторно используемой, распространяемой IP внутри рабочих процессов создателей Feature launch, Feature add‑ons. Команда также поделилась пошаговым руководством, демонстрирующим создание камео и повторное использование на практике How‑to demo.
- Повторно используемые персонажи: регистрируйте персонажа прямо из генерации и повторно используйте его в кадрах (постоянный состав по сценам) Feature launch, Create character menu.
- Поверхность сотрудничества: соединяйте клипы в последовательности и находите популярные работы через встроенный рейтинг Feature add‑ons.
- Влияние на создателей: снижает затраты на непрерывность для эпизодического контента и рекламы; ожидаются появление наборов подсказок и рынков камео.
Grok Imagine демонстрирует предварительный просмотр Remix и Upscale для iOS с лёгким обновлением интерфейса.
xAI тестирует новые опции Grok Imagine на iOS — Remix (повторно запросить существующий элемент ленты) и Upscale (улучшение разрешения) — наряду с небольшим обновлением интерфейса UI screenshots, Early look. ). Движения углубляют управление после генерации и повторное использование, продолжая превью Extend video вчерашних. Для команд, стандартизирующих креативные стеки, это подталкивает Grok к редактируемому циклу, сопоставимому с другими приложениями для видео/изображений, при этом сохраняется история подсказок для итеративного художественного направления.
Sora расширяет доступность в Таиланд, Тайвань и Вьетнам.
OpenAI сообщает, что приложение Sora теперь доступно в трёх дополнительных рынках — Таиланд, Тайвань и Вьетнам, расширяя раннее тестирование пользователей и региональные тесты контента New regions, Taiwan note, Vietnam note. Для команд, локализующих творческие пайплайны, это расширяет петлю обратной связи по стилю, цензурируемости и ограничениям мобильной сети.
Хиггсфилд продвигает обмен лиц одним кликом с промокредитами и примерами согласованности
Higgsfield продвигает инструмент по замене лиц на основе двух изображений одним кликом с бесплатной ежедневной генерацией и промо‑акцией на 251 кредит за вовлечение, утверждая лучшее сохранение освещения и атмосферы по сравнению со старыми методами с несколькими изображениями Product pitch, Promo and link, product page. Community shares emphasize look‑to‑look consistency for short‑form content Consistency claim. For production use, evaluate identity controls, re‑use limits, and detection countermeasures before scaling.
📊 Оценки: агенты в реальных условиях, тесты по покеру и оплачиваемой работе
Сочетание живых конкурсов и практических оценок: обновление рейтингов агентского покера и новый Scale AI Remote Labor Index, показывающий низкие темпы автоматизации на оплачиваемых задачах.
Индекс удалённой работы Scale: лучший агент обходит людей всего по примерно 2,5% оплачиваемых задач.
Scale AI и Центр по безопасности ИИ запустили Remote Labor Index — открытый бenchмарк и рейтинг, оценивающий, насколько хорошо ИИ-агенты выполняют реальные фриланс-задачи в разных сферах (программное обеспечение, дизайн, архитектура, данные и др.). Ранние результаты: лучший агент обошёл людей по лишь около 2,5% задач, что подчеркивает пробелы в надёжности практической автоматизации тред об анонсе, с полным рейтингом и методами, доступными в статье и на живой доске таблица лидеров, и исследовательская статья. Чтобы командам, тестирующим рабочие процессы агентов, это позволило бы понять, где ИИ полезен сегодня — и где необходим контроль человека.
Оценки практиков: открыть Qwen3 edges Composer на задачах Next.js; обсуждали агентов по кодированию, ориентированных на скорость
Тесты сообщества показывают, что Qwen3 на OpenCode набирает 36% по сравнению с 32% Cursor Composer в оценке Next.js, заканчивая на 13% быстрее — что противоречит заявлениям поставщиков и подогревает спор «быстрый против умного» для кодирующих агентов nextjs eval note. Cognition’s SWE‑1.5 добавляет картине близкую к state‑of‑the‑art точность до 950 ток/с model release,) в то время как некоторые предупреждают, что популярные бенчмарки не соответствуют UX реальных агентов («мы перестали публиковать SWE‑Bench» как заголовок) benchmarks critique.). Используйте эти результаты, чтобы выбрать под ваш рабочий процесс: более быстрые циклы тогда, когда люди могут быстро проверить результаты, или более медленные, более «высоко‑интеллектуальные» запуски для глубоких рефакторингов.
LM Техасский Холдем. День 2: Gemini‑2.5‑Pro лидирует, Claude Sonnet 4.5 на втором месте; 60‑раундовый TrueSkill2 в ожидании
Рейтинг второго дня шестимодельного турнира без подсказок по Texas Hold’em показывает, что Gemini‑2.5‑Pro на первом месте, а Claude Sonnet 4.5 — близко позади; организаторы предупреждают, что колебания фишек за примерно 20 раундов в день могут отражать вариативность до момента финализации TrueSkill2 после 60 раундов day two recap. Это следует за live tournament kickoff с видимыми мыслями моделей и фиксированными правилами. Ожидайте более явного разделения по мере того как больше раундов снизят шум, и различия в дисциплине по позициям/ставкам будут накапливаться.
🏗️ AI-инфраструктурная экономика: капитальные затраты, дорожные карты по энергоснабжению и фабрики
Сигналы рынка и инфраструктуры, не связанные напрямую с моделями, связанные с спросом на ИИ: квартал Google на 100 млрд долларов и скачок капитальных затрат, планы по энергопотреблению NVIDIA и стоимость в 5 трлн долларов, а также строительство фабрик для ИИ.
Alphabet превысил отметку в 100 млрд долларов за квартал; облачный бизнес вырос на 34% по сравнению с прошлым годом, а прогноз по капитальным затратам на 2025 год увеличен до примерно 93 млрд долларов на дата-центры для ИИ.
Alphabet опубликовала первый в истории квартал на 100 млрд долларов, при этом Google Cloud вырос на 34% год к году; руководство обозначило, что капитальные расходы в 2025 году вырастут с ~52.5 млрд до максимально ~93 млрд, в основном на новые дата-центры, межсоединения GPU и питание для обучения/обслуживания более крупных моделей Earnings summary. В качестве сигнала спроса Google также отметил 650 млн активных пользователей в месяц приложения Gemini, подчеркивая преимущества распределения, которые могут поддерживать рост рабочей загрузки ИИ Highlights card, MAU chart.
Ожидается сохранение спроса на ускорители и долгосрочную электрическую мощность; более широкая база Cloud дает Alphabet latitude для субсидирования затрат на единицу ИИ в масштабе.
NVIDIA достигает рыночной капитализации в 5 трлн долларов на фоне развертывания ИИ; темп роста от 1 трлн до 5 трлн сокращается до месяцев
NVIDIA стала первой компанией стоимостью $5 трлн, с запланированным рывком от $1 трлн до $5 трлн в череде годовых скачков, отражающих приток спроса на AI-центры данных и капитальные затраты гиперскейлеров Valuation chart. Контекст, который ходит по кругу, сравнивает стоимость NVIDIA с целыми национальными ВВП и секторами S&P, подчеркивая, насколько центральны её чипы для текущей экономики ИИ Sector comparison.)
Следствие: циклы финансирования, рост мощности и сетевые входы-выходы вокруг систем класса GB, вероятно, останутся ограниченными в поставках до 2026 года.
Reuters: OpenAI закладывает основу для потенциального IPO на 1 трлн долларов к концу 2026 года — началу 2027 года
OpenAI готовится к публичному листингу, якобы оцениваясь в до 1 трлн долларов к концу 2026 года или в начале 2027 года, согласно эксклюзивному материалу Reuters, распространяющемуся сегодня Reuters headline, Reuters report. Если реализуется, это будет одним из крупнейших раундов привлечения капитала когда-либо для AI‑компании, напрямую связанным с многотриллионными амбициями по развёртыванию вычислительных мощностей и планами мощностей заводского масштаба, раскрытыми в недавних брифингах.
Дорожная карта NVIDIA Kyber/Oberon показывает стеллажи на 800 В постоянного тока и NVL576 мощностью до примерно 1–1,5 МВт.
Свежие внутренние дорожные карты outlining Kyber (rack/data center co‑design) и Oberon (GPU rack) targets: NVL144/288/576 configurations reaching ~270 kW to ~1–1.5 MW per rack, with 800 VDC/HVDC distribution and solid‑state transformers to reduce losses, and mass‑production goals by late‑2026 Roadmap chart. Далее power build ask that U.S. needs ~100 GW/year for AI, this quantifies what a single AI rack will demand at site level.
Operators should plan for HVDC plant design, multi‑MW bays, and substation upgrades; software wins won’t land without upstream electrons and switchgear.
Совместно с AI и партнёрами планируют мемфисский AI-завод к началу 2026 года, назвав энергоснабжение как ограничивающий фактор.
Together AI выделила ближайшее к реализации строительство AI Factory в Мемфисе вместе с NVIDIA, Dell и VAST Data, сформировав полнофункциональную платформу для разработки с использованием ИИ на уровне полного стека к началу 2026 года Factory announcement. On stage, leadership underscored the constraint: demand is “insane” yet grid power lags the build schedule for AI factories AI factories panel.
Вывод: решения о размещении будут в первую очередь зависеть от очередей межсоединений и графиков подстанций так же, как и от налоговых стимулов; ожидайте больше региональных партнерств, чтобы разблокировать выделения в мегаватты (мВт).
Extropic хвастается чипами вероятностных вычислений, потребляющими примерно в 10 000 раз меньше энергии на небольших генеративных тестах.
Extropic представила термодинамический подход к выборке (pbits, TSUs), утверждая примерно 10 000× меньшую энергию по сравнению с топовым GPU на небольших генеративных задачах, наряду с настольным комплектом XTR‑0 и библиотекой THRML, с крупнее Z1‑устройством в дорожной карте Обзор чипа. Хотя рано и ограничено задачами, любая практическая выгрузка выборки на сверхнизкоэнергетическое оборудование может изменить экономику энергии в ИИ на краю сети и внутри дата-центров, если она будет масштабироваться сверх демонстраций.
🧭 Данные агентов и поиск: общие форматы и лучшие переранжировщики
Обновления материалов для агентов, ориентированных на поиск: предлагаемый Протокол данных агента для унификации наборов данных для тонкой настройки и компактный синтетический рецепт, который обучает сильный ранжировщик на ~20k элементов.
LimRank: 7B ранжировщик, обученный на ~20k синтетических пар, превосходит поиск, требующий рассуждений.
LimRank дообучает модель размером 7B на примерно 20k тщательно сгенерированных позитивов/сложных негативов и превосходит соперников-ранжировщиков 7B в задачах с рассуждениями при извлечении информации, несмотря на использование доли данных, типичной для предыдущих работ обзор статьи.
Рецепт формирует разнообразные запросы (повседневная жизнь и экспертные персоны), использует надзор в длинной цепочке рассуждений и фильтрует слабые элементы — обеспечивая сильную многоступенчатую производительность и хорошую передачу в научный поиск и RAG, с отмеченной слабостью по случаям чистого точного соответствия обзор статьи.
Протокол данных агентов предлагает единую схему для наборов данных по обучению и оценке агентов.
Новый протокол данных агентов (ADP) призван стандартизировать то, как записываются траектории агентов, инструменты, вознаграждения и исходы, чтобы команды могли тонко настраивать и оценивать агентов LLM по разным задачам без специальных конвертеров обзор статьи.
Объединяя форматы, ADP обещает более легкое повторное использование наборов данных (для веб-, кодовых и рабочих агентов), более чистое бенчмаркинг и простые инструменты для ведения журнала, памяти и надзора, которые сегодня фрагментированы между несовместимыми схемами обзор статьи.)
🧬 Открытые модели и локальные рантаймы: Qwen3‑VL и Granite Nano
Несколько обновлений доступности моделей, актуальных для разработчиков: широкая локальная поддержка Qwen3‑VL в Ollama и семейство крошечных моделей IBM Granite 4.0 Nano с поведением, ориентированным на агентов.
Ollama добавляет полный ассортимент Qwen3‑VL локально (от 2B до 235B), 235B также в Ollama Cloud.
Ollama v0.12.7 теперь выполняет всю линейку Qwen3‑VL на устройстве от 2B до 235B, при этом вариация 235B дополнительно доступна в Ollama Cloud; однострочные команды предусмотрены для каждого размера, что делает локальные мультимодальные сборки простыми Release note.
Разработчикам следует обновиться до версии v0.12.7 для совместимости, затем загрузить модели через страницу библиотеки или воспользоваться приведёнными командами (например, ollama run qwen3-vl:2b до :235b и :235b-cloud) Commands list, Model page, and Ollama download.
IBM выпускает Granite 4.0 Nano (350M/1B; трансформер и гибрид H) с сильным поведением агентов и лицензией Apache 2.0
Семейство Granite 4.0 Nano от IBM дебютирует в размерах 350M и примерно 1B параметров как в вариантах с только трансформером, так и в гибридных «H» (Transformer + Mamba‑2), открытые веса под Apache 2.0. Раннее независимое рейтинговое сравнение помещает 1B‑модели на Индексе интеллекта 13–14, а 350M на 8 — конкурентоспособно для их масштаба — и подчеркивает ориентированные на агента поведения, такие как следование инструкциям и использование инструментов Обзор модели, Страница сравнения.
[изображение:https://pbs.twimg.com/media/G4czlCoa8AEfc5t.jpg|granite nano charts]
Бенчмарки агентов показывают, что Granite 4.0 1B превосходит подавляющее большинство конкурентов в своем весовом классе по τ²‑Bench Telecom, в то время как варианты 350M следят за более крупными открытыми моделями при целевых задачах Agentic benchmark. Страницы моделей и спецификации для каждого варианта доступны для интеграции и оценки Granite 1B page.
Продолжение к MiniMax M2: модель с открытыми весами добавляет поддержку плагинов и инсайты после обучения, встроенные в агенте
MiniMax M2 — модель с открытыми весами, лицензированной MIT, приближенная по возможностям к классу Sonnet за меньшую цену — обзавелась новым плагином LLM и углубленным разбором её агент‑ориентированной постобучения и стратегии обобщения, дополняя ранее освещение её сильных оценок и 230 ГБ весов Benchmarks claims, с деталями в сегодняшнем анализе Model notes, Blog analysis.
🧪 Новые примитивы вычислений: вероятностные чипы для семплинга
Чипы термодинамической выборки Extropic используют тепловой шум и p-биты для формирования выборок на аппаратном уровне, claiming значительные экономии энергии на простых генеративных задачах; ранние наборы инструментов и библиотеки отмечали это.
Extropic дебютирует с термодинамическими чипами для семплинга, заявляя, что их энергопотребление примерно в 10 000 раз ниже, чем у GPU, на простых задачах генеративного типа.
Extropic представила вероятностную вычислительную систему, основанную на pbits и термодинамических единицах выборки, которые формируют случайные образцы прямо в аппаратуре, демонстрируя энергопотребление примерно в 10 000 раз ниже, чем у топового GPU на небольших генеративных задачах overview thread. The initial stack includes the X0 chip, an XTR‑0 desktop kit, an open THRML library, and a larger Z1 unit on the roadmap, with the value proposition centered on accelerating sampling‑heavy statistical inference by exploiting thermal noise rather than suppressing it overview thread, product summary.
- Как это работает: pbits — настраиваемые вероятностные схемы, которые заменяют части циклов выборки; множество pbits образуют TSU, которая обновляет состояния на основе соседей, аналогично энергетическим моделям в аппаратуре overview thread.
- Почему это важно: если утверждения об энергопотреблении на единицу выборки выдержат масштаб, выборка и определенные пути генеративного вывода могут переместиться на сверхнизкопотребляющие сопроцессоры, снимая узкие места по энергии в крайних устройствах и дата‑центрах; ранние отклики практиков отмечают интуицию переразнесения по существу вероятностных вычислений на вероятностные примитивы engineer take.
- Название и доступность: публикации ссылаются на чип X0, набор XTR‑0, библиотеку THRML и будущую Z1 термодинамическую единицу выборки как на линейку продуктов product summary.