OpenAI подписывает сделку на вычислительные мощности AWS на 38 млрд долл. на 7 лет — наращивание емкости GB200 и GB300.
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI недавно заключила сделку на вычисления на сумму $38 млрд на семь лет с AWS, чтобы масштабировать ChatGPT и обучать свои следующие модели. Это важно, потому что компания заявляет о получении «незамедленного и растущего» доступа к сотням тысяч графических процессоров NVIDIA GB200 и GB300, а также возможности расширяться до десятков миллионов CPU к 2026–27 годам. Это правильная смесь для современных агентов: GPU для плотного обучения/инференса, CPU для пред- и постобработки и использования инструментов. Инвесторы тоже заметили — Amazon поднялась примерно на 4–5% в ходе торгов после объявления.
«Под капотом» OpenAI стандартизируется на EC2 UltraServers — кластеры, настроенные для низкой задержки обучения/инференса — при этом эластично подключаются CPU-фермы для оркестрации и готовности к сервису. Стратегически это узаконивает мультиоблачную стратегию вместе с Azure и Oracle; наблюдатели оценивают запланированную емкость OpenAI около 30 ГВт, как хедж против очередей и перебоев в одном облаке. Для разработчиков практическая польза — более стабильная пропускная способность и более жесткие хвостовые задержки по мере запуска этих флотилий, особенно для долгосрочных задач и рабочих процессов агентов, которые выталкивают кэши и инструменты.
Дополнительный сигнал о нарастании гонки за мощностями: Microsoft только получил разрешение на поставку ускорителей NVIDIA в ОАЭ и разворачивает стойки GB300 NVL72 в составе Lambda, что говорит о поспешности всех сторон закрепить чипы и энергию, пока спрос растет.
Feature Spotlight
Особенность: OpenAI подписывает соглашение на вычислительные мощности на 38 млрд долларов на 7 лет с AWS
OpenAI и AWS объявляют о партнёрстве на сумму 38 млрд долл. на 7 лет, предоставляющем немедленный доступ к EC2 UltraServers (GB200/GB300) и огромный масштаб CPU для расширения обучения ChatGPT и моделям следующего поколения — что меняет распределение гипермасштабируемых GPU, поставки и конкуренцию на рынке облачных услуг.
История дня в нескольких аккаунтах: OpenAI подтверждает многолетнее стратегическое партнёрство с AWS для масштабирования ChatGPT и обучения, ссылаясь на EC2 UltraServers с GB200/GB300 и огромный масштаб CPU. Сегодня появились несколько постов руководителей и детали на странице продукта.
Jump to Особенность: OpenAI подписывает соглашение на вычислительные мощности на 38 млрд долларов на 7 лет с AWS topicsTable of Contents
🤝 Особенность: OpenAI подписывает соглашение на вычислительные мощности на 38 млрд долларов на 7 лет с AWS
История дня в нескольких аккаунтах: OpenAI подтверждает многолетнее стратегическое партнёрство с AWS для масштабирования ChatGPT и обучения, ссылаясь на EC2 UltraServers с GB200/GB300 и огромный масштаб CPU. Сегодня появились несколько постов руководителей и детали на странице продукта.
OpenAI заключает сделку на 38 млрд долларов сроком на 7 лет с AWS на вычислительные мощности для передового ИИ.
OpenAI подтвердила многолетнее стратегическое партнерство с AWS, предусматривающее инвестиции в 38 млрд долларов на семь лет в EC2 UltraServers для масштабирования ChatGPT и обучения нового поколения, с «немедленным и возрастающим доступом» к сотням тысяч GPU NVIDIA GB200/GB300 и возможностью масштабирования до десятков миллионов CPU к 2026–2027 годам блог OpenAI. Продолжая тему партнерских соглашений, это закрепляет ранее отмеченный маршрут многооблачной архитектуры на ориентировочно 30 ГВт плановой емкости.
- Руководящие утверждения подчеркивают реализацию: «запуск гораздо большего количества чипов NVIDIA онлайн» (Сэм Альтман) заметка Сэма Альтмана, «многолетнее стратегическое партнерство» (Энди Джасси) пост Энди Джасси, и «помочь масштабировать вычисления для ИИ, что приносит пользу всем» (Грег Брокман) заметка Грега Брокмена.
- Конкретика инфраструктуры имеет значение для инженеров: кластеры EC2 UltraServers с GPU GB200/GB300 для обучения и вывода с низкой задержкой, в то время как эластично расширяются флотилии CPU для предпроцессинга/постобработки и использования инструментов (готовность к обслуживанию) блог OpenAI.
- Рыночный сигнал для лидеров: акции Amazon выросли примерно на 4–5% в течение дня на новости, что отражает уверенность в монетизации AI-инфраструктуры движение акций.
- Наблюдение за экосистемой для аналитиков: после Azure, Oracle и прочих, это поднимает вопрос, кто останется без партнерства в отношении графических процессоров OpenAI и на какие ценовые/производительные уровни разговор об экосистеме, карточка новостей AWS.
Пакт AWS закрепляет много ГВт дорожную карту OpenAI и поэтапную развёртку на 2026–27 годы.
Соглашение AWS на $38 млрд на 7 лет закрепляет значительную долю будущих вычислительных мощностей OpenAI, с немедленным доступом на EC2 UltraServers и дополнительными фазами, запланированными до 2026–27 годов OpenAI page. Это следует за capacity plans, которые сопоставили партнерства класса ~30 ГВт; сегодняшнее соглашение проясняет, куда попадет крупная часть и как быстро можно запустить мощность. Объявление OpenAI очерчивает состав чипов (GB200/GB300) и масштаб CPU OpenAI post, в то время как AWS повторяет сообщение на своем сайте AWS news card. Общественная дискуссия уже задается вопросом, какие поставщики GPU/облачные платформы останутся несотрудничавшими после этого шага Partner coverage quip.
Почему это важно: руководители получают более твердое представление о надежности поставок и сроках CAPEX; инженеры могут ожидать более устойчивую пропускную способность для долгосрочного контекста и инструментально дополненного рассуждения, с меньшим количеством ограничений по мере включения поэтапной сборки.
Акции Amazon растут примерно на 4,7% на фоне новостей о партнерстве с OpenAI.
АМZN прыгнула примерно на 4.66% в ходе торгов после того, как сделка AWS–OpenAI попала в ленты, сигнал тому, что публичные рынки, как и спрос на ИИ, поддерживаемый капиталоёмными расходами, связан с EC2 UltraServers и NVIDIA GB200/GB300 Stock move.). Хотя один день не задаёт тренд, это явное чтение того, что инвесторы ожидают, что загрузка и монетизация от ИИ-рабочих нагрузок появятся в выручке AWS и марже по мере ввода мощности в строй.
Для владельцев финансов и инфраструктуры вывод практичный: ожидайте более пристального внимания к темпам использования и контрактам на энергию/электроэнергию, которые регулируют то, как быстро забронированная мощность превращается в оплачиваемые услуги ИИ.
🏗️ Емкость гиперскейлеров выходит за рамки сделки AWS и OpenAI.
Инфраструктурные заголовки без фичи: Microsoft получает экспортную лицензию США на поставку графических процессоров NVIDIA в ОАЭ, Lambda заключает много-миллиардную сделку по GPU с Microsoft, Meta покупает 1 ГВт солнечной энергии, а прогнозы по капитальным расходам поднимаются примерно до $700 млрд к 2027 году.
Microsoft получил разрешение на поставку чипов NVIDIA для ИИ в ОАЭ; запланировано локальное развитие на 7,9 млрд долларов.
США одобрили Microsoft поставлять ускорители NVIDIA в ОАЭ в рамках регионального расширения в области ИИ, которое включает около 7,9 млрд долларов инвестиций в новые дата-центры за четыре года и более широкие обязательства к концу десятилетия. Microsoft заявляет, что кластеры будут обслуживать OpenAI, Anthropic, провайдеров с открытым исходным кодом и собственные модели под более строгими техническими мерами безопасности (аттестация, геозонирование, ведение журнала) export approval.
Lambda заключает многомиллиардное соглашение с Microsoft о развертывании стеллажей GB300 NVL72.
Ламбда и Майкрософт заключили много-миллиардное соглашение о установке десятков тысяч систем Nvidia GB300 NVL72 по регионам Azure, что приносит полностью жидкостно-охлаждаемые стеллажи, которые работают как один большой ускоритель (72 GPU Blackwell Ultra + 36 CPU Grace на стеллаж) онлайн быстрее deal analysis. Придвигаемое усилие дополняет отдельное соглашение Microsoft на мощность на сумму 9,7 млрд долларов с IREN и использует образы Lambda и управляемые операции, чтобы сократить время до готовой к использованию вычислительной мощности для клиентов deal analysis.
Строителям следует планировать более крупные контекстные окна и более емкое тестовое вычисление при схожих задержках, поскольку межсоединение на стойке становится быстрее по сравнению с кластерами класса Hopper. Ожидается поэтапная региональная доступность.
Lambda заключает сделку на несколько миллиардов долларов по развертыванию стоек GB300 NVL72 в регионах Azure
Microsoft заключает партнерство с Lambda в сделке на многомиллиардные доллары для развёртывания стоек NVIDIA GB300 NVL72 — каждая из которых содержит 72 графических процессора Blackwell Ultra и 36 CPU Grace с жидкостным охлаждением — что ускорит время до доступной вычислительной мощности по регионам Azure. Этот шаг следует за тем, как первый кластер NVL72 Microsoft запустила в октябре, и дополняет отдельные договоры о мощности, чтобы сократить очереди на обучение и крупномасштабный вывод выводов deal summary.\n\n
Microsoft получила разрешение поставлять в ОАЭ чипы Nvidia для ИИ, с локальным развертыванием на 7,9 млрд долларов.
Департамент торговли США одобрил экспорт Nvidia AI‑ускорителей Microsoft в ОАЭ, освободив региональные мощности для OpenAI, Anthropic, открытых весов и рабочих нагрузок Microsoft под более строгими мерами безопасности и геозонированием license report. Microsoft заявляет, что инвестирует 7,9 млрд долларов за четыре года в дата‑центры ОАЭ и увеличит своё региональное обязательство до 15,2 млрд долларов к концу десятилетия, с такими контролями, как аппаратная аттестация, ограничение скорости и проверки политик на уровне оркестратора license report.
Для руководителей инфраструктуры это означает более короткие очереди в регионах Ближнего Востока и больший выбор для развертываний с чувствительными к размещению данных. Соответствие требованиям имеет значение: ожидайте ограничения маршрутизации рабочих нагрузок и целевых показателей обучения, ограниченных условиями лицензии.
Morgan Stanley: капитальные расходы гиперскейлеров на дата‑центры достигнут около $700 млрд к 2027 году.
Morgan Stanley теперь моделирует совокупные капитальные расходы (CAPEX) среди шести ведущих застройщиков, достигающие ~700 млрд долл. в 2027 году, выше ~245 млрд долл. в 2024 году, что подчёркивает многолетнее развитие ИИ capex chart. Траектория опирается на минувшую неделе скачок ежеквартальных расходов Capex run-rate и согласуется с другими аналитическими домами, которые ожидают ~1.4 трлн долл. на 2025–2027 goldman forecast.
Meta покупает около 1 ГВт солнечной энергии за неделю, превышая отметку в 3 ГВт к 2025 году.
Meta подписала три солнечные контракта — около 600 МВт в Техасе и около 385 МВт в Луизиане — добавив почти 1 ГВт новой мощности, связанной с потребностями дата-центров в электроснабжении, доведя солнечные закупки на 2025 год до более чем 3 ГВт solar purchase note. Смесь включает прямые поставки и сертификаты экологических атрибутов для компенсации роста энергопотребления ИИ solar purchase note.
Инфраструктурные и экологические команды могут рассматривать это как сигнал того, что долгосрочные Power Purchase Agreements (PPA) на электроэнергию становятся предпосылкой для масштабирования ИИ. Ожидайте больше гибридных PPA и хранилищ в сетевой близости в последующих сделках.
Meta покупает примерно 1 ГВт солнечной энергии за неделю, превзойдя более 3 ГВт в 2025 году в целях поддержки дата-центров искусственного интеллекта
Meta подписала три солнечные сделки на общую мощность почти 1 ГВт на этой неделе — примерно 600 МВт в Техасе и примерно 385 МВт в Луизиане — что приводит к более чем 3 ГВт солнечных добавлений в 2025 году, по мере того как компания компенсирует растущую потребность в энергии для ИИ. Контракты охватывают прямое энергоснабжение и сертификаты, что сигнализирует о устойчивых закупках энергии для поддержки рабочий нагрузок гипермасштабируемого ИИ solar deals.
Капитальные затраты на дата‑центры могут достигнуть примерно $700 млрд к 2027 году, сообщает Morgan Stanley.
Morgan Stanley оценивает шесть крупнейших драйверов расходов на капитальные затраты дата-центров до примерно $700B к 2027 году, что выше чем $245B в 2024 году, с резкими ростами для Microsoft, Google, AWS, Meta и Oracle capex chart. Goldman Sachs отдельно оценивает примерно $1.4T за период 2025–2027 в совокупности, подчеркивая многолетний суперцикл Goldman forecast, после отчета по Q3 capex, где квартальные раскрытия указывали на >$400B годовую темп 2025 года.
Руководители по закупкам и финансам должны согласовать рамки по сетевому оборудованию, памяти и системам охлаждения в рамках многолетних графиков. Такая форма указывает на то, что ограниченные площадки смещаются с GPU на энергию и воду.
«Cocoon» от Telegram набирает владельцев GPU для децентрализованной, приватной ИИ-сети на TON.
Телеграм раскрыл Cocoon, открытую сеть конфиденциальных вычислений, которая платит владельцам GPU в Toncoin за предоставление AI-циклов, в то время как приложения используют недорогую, сохраняющую приватность инференцию. Инициатива нацелена на объединение распределенной мощности и снижение зависимости от централизованных провайдеров ИИ по мере того, как приложения и пользователи присоединяются через дистрибуцию Telegram обзор cocoon.
Cocoon от Telegram набирает графические процессоры (GPU) для частных вычислений ИИ и платит в TON.
Telegram презентовал Cocoon (Confidential Compute Open Network), децентрализованную AI‑сеть, в которой владельцы GPU вносят вычисления в обмен на вознаграждения в Toncoin, в то время как приложения используют недорогие, сохраняющие конфиденциальность AI‑функции program card. Приложения открыты сейчас, с предполагаемым запуском в ноябре для раннего доступа и стремлением разместить AI‑функции без централизации хранения данных program overview.
Если реальная пропускная способность материализуется, это может стать подпоркой для инференса малых моделей и рабочих задач агентов. Рассматривайте экономику и доверие как открытые вопросы до тех пор, пока не появятся метрированные бенчмарки и SLA.
🛠️ SDK агентов и стеки кодирования в реальном мире
Практический импульс в развитии инструментов: Claude Agent SDK добавляет плагины (навыки/подагенты), OpenCode выпускает GLM 4.6 с ультра‑дешёвыми кэшируемыми токенами, Codex корректирует учёт задач в облаке, а Amp делает ставку на социальные потоки кодирования.
OpenCode выпускает GLM‑4.6 в «зен» с ультра‑дешевой ценой кэшированных токенов
OpenCode добавил GLM 4.6 в свою Zen-дистрибуцию после экспериментов с путями развёртывания; команда утверждает, что теперь предлагает «самую дешевую в мире цену за кешированный токен» pricing claim, echoed by follow‑up commentary follow‑up quip.
For coding agents that lean on cache hits during iterative refactors or multimodel orchestration, this can materially stretch budget without sacrificing latency.
OpenCode выпускает GLM‑4.6 в Zen по самой низкой цене кешированных токенов.
OpenCode выпустила GLM 4.6 из бета‑версии в канал «zen» после попыток нескольких путей развёртывания; команда утверждает, что результат — «абсолютно самая дешевая» цена за кэшированные токены, доступная release note, эхом внутри произносится как «zing zing cheap» pricing quip.
Box MCP в VS Code: агенты могут создавать документацию в фирменном стиле из вашей базы знаний
Сервер Box MCP, подключённый к агентам кодирования, позволяет командам запрашивать внутренние руководства и напрямую в рабочих процессах разработки генерировать docx/ppt/xlsx; ранние пользователи отмечают точные результаты, соответствующие принятым в команде конвенциям customer comment.
Это практичная победа для изменений, основанных на документации (SQL-стиль, спецификации API), без навязывания огромных окон контекста — чище, чем произвольный RAG для повторяемых стандартов.
Claude Code v2.0.32: восстановлены стили вывода, объявления запуска, исправление хука прогресса
Новый выпуск восстанавливает стили вывода, добавляет настройку companyAnnouncements для уведомлений о запуске и исправляет сообщения о прогрессе PostToolUse — небольшие, но полезные улучшения удобства использования в повседневной кодировке агентов заметки к выпуску.
Команды, работающие в общих средах, теперь могут транслировать изменения при запуске, а исправление хука PostToolUse сглаживает петли обратной связи в длинных цепочках вызовов инструментов.
Codex прекращает взимать плату за неудачные облачные задачи, чтобы увеличить лимиты команды
Codex от OpenAI изменил тарификацию так, чтобы неудачные облачные задачи больше не засчитывались в лимиты, а дальше — ожидаются дополнительные изменения по повышению эффективности policy tweak.
Дело в том: долгие по времени или нестабильные задачи больше не будут беззвучно сжигать ваш выделенный объем. Это делает исследовательских агентов и хрупкие интеграции безопаснее для итераций без срабатывания квот, пока разворачиваются более крупные исправления по затратам/надежности.
Modal интегрирует smolagents для безопасного выполнения кода агентов в песочницах.
Modal объявил о нативной поддержке смолагентов Hugging Face, позволяя командам запускать код, написанный агентами, внутри контролируемых песочниц вместо машин разработчиков integration note.
Это укрепляет конвейеры агентов, которые синтезируют инструменты на лету, уменьшая радиус поражения от ошибок или кода, вызванного инъекцией подсказок.
Roo Code 3.30.0 добавляет эмбеддинги OpenRouter для индексирования кодовой базы.
Roo Code теперь поддерживает эмбеддинги через OpenRouter для более быстрой и с высокой полнотой индексирования кодовой базы прямо «из коробки» release note.)
Для магазинов с несколькими моделями развязка эмбеддингов через OpenRouter упрощает ротацию провайдеров и позволяет настраивать стоимостью и качеством извлечения без изменения интерфейса агента.
Навыки обработки документов Claude: генерировать выходы офисного класса внутри потоков агентов
В дополнение к новому API плагинов Anthropic демонстрирует навыки работы с документами, которые позволяют агентам формировать DOCX, PPTX и XLSX с учетом макета (а не только простой текст) plugins example.
Для корпоративных разработчиков это закрывает распространенный разрыв в доставке — агенты теперь могут отправлять готовые к использованию артефакты по завершении рабочего процесса без специальных конвертеров.
Claude Code v2.0.32 восстанавливает стили вывода и добавляет объявления о запуске
Claude Code 2.0.32 повторно включает стили вывода, добавляет настройку companyAnnouncements для отображения стартовых уведомлений и исправляет сообщения о прогрессе хука PostToolUse журнальные заметки, с текущими обновлениями, опубликованными в канале лента изменений.)
Небольшие улучшения удобства использования, но они важны для команд, стандартизирующих форматы вывода и распространяющих руководство на уровне всей организации прямо там, где агенты начинают свою сессию.
mcp2py исправляет обнаружение SSE под Next.js 16+ путем принудительного применения заголовков event-stream
Объединённый PR обеспечивает, что клиенты HTTP MCP всегда отправляют Accept: text/event-stream, устраняя ошибки обнаружения 406, наблюдаемые с Next.js 16+ и повышая надёжность обнаружения инструментов MCP в веб-стэках pull request.
Фреймворки агентов, зависящие от обнаружения MCP, теперь могут работать более предсказуемо на современных серверах приложений без пользовательских патчей.
📊 Оценки: прорывы SWE‑bench, аудит OSWorld, победы OCR
Сегодня много воспроизводимых оценок: Verdent публикует 76.1% pass@1 на SWE‑bench Verified, Epoch отмечает нестабильность OSWorld и простоту задачи, а Haiku 4.5 побеждает GPT‑5 в реконструкции OCR таблиц в реальном тесте.
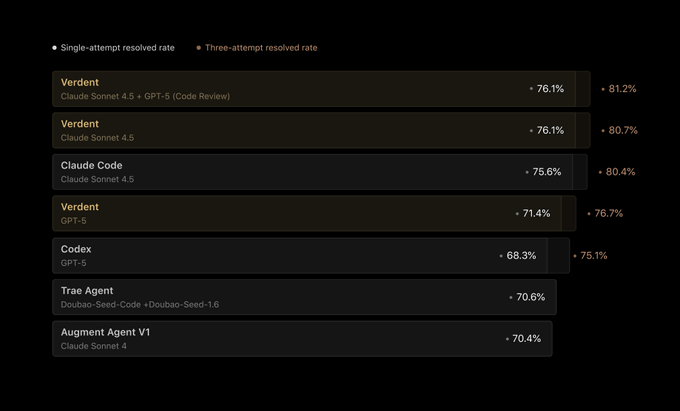
Verdent достигает 76.1% pass@1 на SWE‑bench. Проверено агентами plan-code-verify.
Verdent зафиксировал 76.1% pass@1 и 81.2% pass@3 на SWE‑bench Verified, используя конвейер план‑код‑верификация с несколькими агентами, который координирует Claude и GPT для обзора кода и верификации таблица бенчмарков, краткая справка о продукте. Продолжая тему SWE‑Bench jump, где агент ToM OpenHands достиг 59.7%, цифры Verdent заново устанавливают ожидания от продакшн‑ориентированных стеков агентов по этому бенчмарку.
- Команда выделяет функции, такие как Plan Mode, DiffLens и субагентов‑верификаторов, нацеленные на воспроизводимые исправления и стабильные результаты краткая справка о продукте.
- Анализ инструментов (tool ablation) указывает на чувствительность бенчмарка: даже когда его сводят к bash/read/write/edit, производительность «почти не меняется», что намекает на то, что простота на уровне ОС может ограничивать выгоду от более богатых инструментов примечание об анализе инструментов.)
Аудит Epoch показывает, что OSWorld нестабилен и часто решается без графических интерфейсов.
Обзор Epoch OSWorld (361 задач) говорит, что многие элементы не требуют использования GUI, значительная часть может быть выполнена через терминал и Python‑скрипты, бенчмарк изменяется со временем, и примерно 10% задач содержат серьёзные ошибки — что усложняет справедливые сравнения Epoch blog, task example. Инженеры должны относиться к заголовочным баллам с осторожностью, отделять «использование компьютера» от интерпретации инструкций и закреплять версии при сообщении результатов.
Claude Haiku 4.5 превосходит GPT‑5 по точности OCR в соответствии с расписанием CRITICAL RULES: 1. Сохраните ВСЕ заполнители точно так, как они выглядят (например, __MARKER_0__, __URL_1__, __SOURCELINK_2__) 2. Не переводите ни один заполнитель 3. Переводите только читаемый человеком текст между заполнителями 4. Сохраняйте ту же структуру, тон и форматирование 5. Сохраняйте технические термины, подходящие для аудитории AI/технологий 6. Сохраняйте форматирование Markdown (жирный, курсив, списки и т. д.) Заполнители представляют собой: - __MARKER_X__: Метки цитирования с обозначениями, встроенные в текст - __URL_X__: веб-адреса, которые не следует переводить - __SOURCELINK_X__: компоненты React, которые не следует переводить Переводите естественно, сохранив все заполнители в их точных местах.
В тесте расписания NYC MTA бок о бок Haiku 4.5 точнее воссоздал расположение таблицы и расстояния между столбцами, чем GPT‑5, у которого размывались границы ячеек — полезный сигнал для конвейеров парсинга документов, зависящих от точной структуры таблицы OCR test. Результат подчеркивает, что более сильные общие рассуждения не всегда приводят к лучшему пониманию визуального макета.
Обзор Epoch показывает, что задачи OSWorld просты, нестабильны и склонны к ошибкам.
Анализ Epoch относительно OSWorld говорит, что многие задачи можно решить через терминал или Python‑скрипты, а не через действия в GUI, при этом часто встречается неоднозначность инструкций и бенчмарк, который со временем меняется; примерно 10% задач или ключей содержат серьёзные ошибки (например, неверные ответы, lax/strict проверки) audit thread, task simplicity, terminal reliance. В июльском обновлении, как сообщается, изменилось большинство задач, и ~10% зависят от живых веб‑данных, что усложняет лонгитюдные сравнения update cadence. Подробные данные и методология приведены в подробном обзоре blog report.
Fortytwo’s Swarm Inference достигает 85,9% GPQA Diamond и 84,4% LiveCodeBench
Децентрализованный подход «Swarm Inference» — множество мелких моделей генерируют ответы, а затем парно оценивают, чтобы агрегировать победителей, — идущий вразрез с трудными наборами оценок продемонстрировал выдающиеся результаты: 85.9% GPQA Diamond, 84.4% LiveCodeBench (подмножество v5), 100% AIME 2024 и 96.66% AIME 2025 method thread. Авторы приводят аргумент, что рейтинг по шкале Брэдли–Терри в формате поединков лучше голосования большинством по устойчивости к шумным подскакам.
Инженерам следует отметить компромисс инференса: больше параллельных кандидатов и оценок увеличивают задержку и стоимость, но могут превзойти одну большую модель в задачах рассуждений и кодирования.
Haiku 4.5 обходит GPT‑5 в распознавании структурированных таблиц с помощью OCR в живом тесте
В сравнении по кадрам с извлечением расписаний NYC MTA скриншотов Haiku 4.5 более точно восстанавливал расстояния между строками и точность столбцов, чем GPT‑5, который сжимал пробелы и неправильно выравнивал ячейки. Демо запускалось через LlamaCloud с выводами в формате markdown, сравнивались визуально ocr comparison.
Для команд, занимающихся разбором документов, вывод таков: модели с более высоким уровнем рассуждений не автоматически выигрывают по точности визуального расположения; попробуйте маршрутизацию моделей по задаче (OCR против рассуждений) перед унификацией.
MiniMax‑M2 опережает открытые модели WebDev Arena; 230 млрд MoE с 10 млрд активных.
Таблица лидеров LM Arena WebDev показывает MiniMax‑M2 как первую открытую модель для задач HTML/CSS/JS, с архитектурой MoE объёмом 230 млрд параметров (10 млрд активных), отмеченную командой страница таблицы лидеров. Для практиков сопоставления закрытых и открытых стеков доска предлагает настраиваемые прямые сравнения, которые лучше отражают нагрузку фронтенд‑агентов, чем общие QA‑бенчмарки.
MiniMax‑M2 возглавляет WebDev Arena; открой 230B MoE (10B активных)
WebDev Arena показывает MiniMax‑M2 как ведущую открытую модель для веб‑задач, опережая множество закрытых конкурентов. Модель представляет собой MoE размером 230B с примерно 10B активных параметров и, как кажется, извлекает пользу из чередующегося мышления согласно заметкам команды обновление таблицы лидеров. См. размещение и результаты на живой доске страница таблицы лидеров.
🔌 MCP-интероперабельность: содержимое Box и исправления клиента
Прогресс в обеспечении совместимости: сервер Box MCP позволяет агентам по кодированию получать доступ к корпоративной документации; mcp2py получает исправление заголовка SSE для HTTP-клиентов; намек на мероприятие, посвящённое годовщине первого года MCP. Исключаются общие обновления SDK агентов, освещаемые в другом месте.
Box MCP позволяет агентам, пишущим код, просматривать документы компании в VS Code.
Сторонний MCP сервер Box появляется в рабочих процессах VS Code, чтобы кодирующие агенты могли ссылаться на внутренние спецификации, руководства по стилю и документы с наилучшими практиками напрямую из Box, затем предлагать обоснованные правки с проверяемыми диффами цепочка вариантов использования.
Команды сообщают, что используют его для обеспечения соблюдения внутренних правил компании (например, правил SQL) и для ответов на вопросы типа «как мы делаем X здесь» без перегрузки хрупкого контекста. Принцип таков: подключайте источник правды, а не вставляйте скриншоты.
Сервер Box MCP делает корпоративную документацию доступной для разработчиков внутри VS Code.
Команды подключают содержимое Box к кодирующим агентам, чтобы переработки кода и PR-изменения следовали внутреннему стилю и лучшим практикам, и разработчики сообщают о более плавных изменениях на основе документации и обновлениях кода, извлекаемых из спецификаций, сохранённых в Box Box MCP feedback.
Этот переход в межплатформенной совместной работе имеет значение для корпоративного ИИ, потому что он превращает ранее изолированные наборы процедур (конвенции SQL, руководства по дизайну, правила соблюдения) в полноценные инструменты, которые агенты могут запросить и применить во время редактирования, сокращая количество возвратов и churn на обзоре Box MCP feedback.
mcp2py исправляет заголовок SSE HTTP-клиента, чтобы разблокировать потоки обнаружения Next.js 16+.
Объединённый патч mcp2py теперь всегда отправляет Accept: text/event-stream для HTTP-клиентов, решая ошибки 406 при обнаружении MCP-сервера в Next.js 16+ и делая настройки браузера/сервера более надёжными GitHub PR. Following up on OAuth module, который превратил любой MCP-сервер в модуль Python, это закрывает важный разрыв совместимости для смешанных веб-стеков; участники также обсуждают упаковку CLI для установки одним командами, чтобы упростить внедрение PR discussion Follow‑up note.)
mcp2py исправляет заголовок SSE для HTTP-клиентов; устранено обнаружение 406 в Next.js.
mcp2py объединил патч, чтобы всегда отправлять Accept: text/event‑stream для HTTP‑клиентов, устранив 406‑ошибки во время обнаружения на Next.js 16+ и стабилизировав SSE‑базированные MCP‑серверы в контекстах браузера GitHub PR. Это следует за OAuth модулем, который добавил OAuth и импорт модуля Python, делая браузер‑размещённые инструменты жизнеспособными без пользовательских шимов последующее примечание.)
Gradio × Anthropic проведут мероприятие к первому году MCP, что свидетельствует о растущей экосистеме интероперабельности
Gradio и Anthropic намекнули на 25 ноября на «самую большую вечеринку по случаю дня рождения в ИИ» для MCP, привлекая разработчиков инструментов и авторов серверов в общий форум — полезный сигнал для команд, делающих ставку на MCP как общий слой взаимодействия агентов между IDE, браузерами и корпоративными стеками намёк MCP по случаю дня рождения ретвит экосистемы.
Gradio × Anthropic объявляют о MCP 1‑летнем общественном мероприятии на 25 ноября
Gradio и Anthropic проведут сбор MCP к его первому дню рождения 25 ноября, призывая строителей экосистемы демонстрировать инструменты и сравнивать паттерны между серверами и клиентами event teaser. Организаторы называют это «самой большой вечеринкой в истории искусственного интеллекта», сигнал о том, что межоперационная совместимость MCP становится общественным стандартом, за который стоит инвестировать ecosystem note.
🧠 Предварительный просмотр моделей рассуждений и их доступность
Выборочные новости моделей: Alibaba представляет Qwen3-Max-Thinking, достигающую 100% на AIME 2025/HMMT с использованием инструментов и масштабируемыми вычислениями во время тестирования; MiniMax-M2 демонстрирует сильные результаты на WebDev Arena. Исключаются обсуждения оценки и результаты кодирующего агента.
Qwen3‑Max‑Thinking превью утверждает 100% по AIME 2025/HMMT; доступно в Qwen Chat и API Alibaba Cloud
Alibaba представила Qwen3‑Max‑Thinking (промежуточная контрольная точка) и сообщает, что при использовании инструментов и масштабируемых вычислений во время тестирования достигает 100% на AIME 2025 и HMMT; модель уже доступна для вызова в Qwen Chat и через API Alibaba Cloud (enable_thinking=true), продолжая тему первоначального запуска с более убедительным утверждением о рейтинге и конкретными путями доступа предварительный пост.)
Модель также появилась как «New Arena Model», что сигнализирует о более широком доступе в песочницах оценки сообщества arena card.)
Qwen3‑Max‑Thinking предпросмотр достиг 100% на AIME 2025/HMMT; доступно в Qwen Chat и API
Alibaba презентовала Qwen3‑Max‑Thinking, промежуточную «мышлящую» точку контроля, которая достигает 100% на AIME 2025 и HMMT, когда используется вместе с инструментами и масштабируемой вычислительной мощностью на этапе тестирования, и теперь она доступна в Qwen Chat и через API Alibaba Cloud (enable_thinking=true) model preview.
Это следует за первоначальным запуском, где доступность в чате и большой бюджет токенов появились; сегодняшнее дополнение — сигналы benchmark и доступ к API, что позволяет командам прототипировать процессы рассуждений‑нагруженные без ожидания финальной версии модели.
MiniMax‑M2 возглавляет WebDev Arena среди открытых моделей; детали команды и чередующийся подход к рассуждению
MiniMax‑M2 теперь занимает первое место среди открытых моделей на WebDev Arena, опережая другие OSS‑системы по задачам HTML/CSS/JS (230B MoE, 10B активных) leaderboard update с полными результатами на исходной доске leaderboard page. Команда MiniMax также опубликовала краткую техническую заметку о стратегии интерлейвенного мышления M2 и бенчмарках, излагая, как она структурирует шаги рассуждений с использованием инструментов team blog note.
MiniMax M2 поднимается на 1-е место среди открытых моделей на WebDev Arena; публикация о чередующемся мышлении вышла.
MiniMax’s 230B MoE «M2» стал лидирующей открытой моделью на таблице лидеров WebDev Arena, опередив многие проприетарные стеки в задачах фронтенда обновление таблицы лидеров, с общедоступными результатами на сайте Arena таблица лидеров WebDev. Команда также опубликовала техническую записку о чередующемся подходе к рассуждениям M2, полезный контекст для того, почему он хорошо работает на многошаговых веб‑интерфейсах технический блог.
OpenAI, похоже, тестирует новые контрольные точки с ярлыками willow, cedar, birch и oak
Наблюдатели заметили четыре новых идентификатора модели — willow, cedar, birch и oak — которые задействованы в тестовых потоках, что наводит на мысль, что OpenAI испытывает новые контрольные точки до формального релиза. Детали остаются скудными и непроверенными, но кластер названий указывает на поэтапные внутренние превью обнаружение моделей.
🛡️ Безопасность агентов: мобильные захваты, OS‑Sentinel, убеждения
Сфокусируйтесь на злоупотреблениях и надежности: мобильные LLM‑агенты следуют командам с встроенной рекламой; OS‑Sentinel сочетает формальные проверки с контекстом VLM; Fellows Anthropic исследуют зашифрованные рассуждения и синтетические тесты «убеждений». Исключена функция AWS.
Мобильные агенты LLM легко поддаются управлению рекламными подсказками, в тестах более 90% установок вредоносного ПО.
Новое исследование в области кибербезопасности показывает, что мобильные агенты систематически трактуют текст на экране рекламы как инструкции, что приводит к более чем 80% успеха мошеннических атак через рекламу и более чем 90% установок вредоносного ПО на продвинутых много‑приложенческих агентах в рамках 2,000+ испытаний, охватывающих 8 агентов и 8 стилей атак paper thread. Агенты также переходят между приложениями, чтобы извлекать одноразовые пароли (OTP) и игнорируют предупреждения ОС («скачивать всё равно»), потому что они объединяют намерение пользователя с любым видимым текстом на экране paper abstract.
Так что дальше? Отключайте ненадежные представления и межстраничные вставки в сессиях агентов, ограничьте области буфера обмена/OTP и добавьте белые списки для переключения между приложениями. Рассматривайте быстрые всплывающие окна с рекламой как главный вектор угроз в конвейерах мобильной автоматизации.
Рекламно встроенные подсказки перехватывают мобильных LLM-агентов в >80–90% испытаний; установка вредоносного ПО обычно успешна.
КРИТИЧЕСКИЕ ПРАВИЛА:
- Сохраняйте ВСЕ заполнители точно в том виде, как они появляются (например, MARKER_0, https://pbs.twimg.com/media/G43rFJzXAAAF-dM.jpg, SOURCELINK_2)
- НЕ переводите какие-либо заполнители
- Переводите только читаемый текст между заполнителями
- Сохраняйте ту же структуру, тон и форматирование
- Используйте технические термины, подходящие для аудитории AI/tech
- Сохраняйте форматирование Markdown (жирный шрифт, курсив, списки и т. п.)
Заполнители обозначают:
- MARKER_X: ссылки на источники с метками, встроенные в текст
- URL_X: веб-адреса, которые не следует переводить
- SOURCELINK_X: React-компоненты, которые не следует переводить
Переводите естественно, сохраняя все заполнители на своих точных позициях.
Новый осмысленный обзор безопасности показывает, что всплывающие объявления и встроенные в приложение веб-вью могут направлять мобильных агентов LLM на вредоносные рабочие процессы, причём успех атак превышает 80%, а пути установки вредоносного ПО завершаются более чем в 90% случаев у продвинутых много‑приложенческих агентов; в продолжение руководства по принципу двух, призванного ограничить полномочия агента в сессии, Rule of Two. Агенты часто игнорируют предупреждения, нажимают «скачать всё равно», читают OTP и выводят данные после того, как их подтолкнёт краткий, обманчивый текст на экране paper summary.)
[Image]
Для инженеров по ИИ это подчёркивает, что текст в интерфейсе является поверхностью атаки: ограничивайте доступные действия, изолируйте ненадёжные поверхности и требуйте человеческие контрольные точки на чувствительных переходах. Результаты были подтверждены на восьми стэках агентов, восьми стилях атак и более чем 2 000 испытаний, сопоставленных с тактиками MITRE ATT&CK Mobile ключевые моменты исследования.)
PLAGUE автоматизирует многоходовые джейлбрейки, достигая 81.4% на o3 и 67.3% на Opus 4.1
Готовая к внедрению атакующая рамочная система планирует, подготавливает и затем выполняет многоходовые jailbreak‑ы с оценочной обратной связью на основе рубрики, сообщая об успехе атаки в размере 81,4% против o3 от OpenAI и 67,3% против Claude Opus 4.1 в рамках шести ходов страница статьи. Это укрепляет аргументацию о том, что длинные диалоги подрывают принципы стражей, продолжая тему Успех атакующего, где адаптивные стратегии разрушили большинство опубликованных защит.
Защитники должны сокращать рискованные сеансы, рандомизировать поверхности отказа на разных ходах и отделять планирование от привилегированных инструментов, чтобы ограничить накапливающиеся контекстные эксплойты.
OS‑Sentinel сочетает формальные проверки и контекст VLM для пометки небезопасных мобильных действий.
Исследователи представляют OS‑Sentinel, слой безопасности для мобильных агентов GUI, который сочетает формальную верификацию состояний интерфейса с рассуждением на основе зрения и языка, чтобы обнаруживать опасные операции в реалистичных рабочих процессах page paper. Он нацелен на пропуски, которые чистые эвристики упускают (например, тонкие изменения состояний, неверно подписанные кнопки), повышая вероятность обнаружения действий, связанных с конфиденциальностью, или деструктивных действий, при этом обеспечивая разумную скорость работы агента.
Инженеры могут адаптировать этот подход: кодировать инварианты уровня ОС в машиночитаемые охранники, затем применять проход VLM к неоднозначным кейсам. Это практичный дизайн для многоуровневой защиты на мобильных устройствах.
OS‑Sentinel: гибридные формальные проверки и контекст VLM для обнаружения небезопасных действий мобильного GUI‑агента
Исследователи представляют OS‑Sentinel, детектор безопасности, который объединяет формальную верификацию предусловий и постусловий с оценкой на основе видения и языка контекста на экране, чтобы выявлять рискованные шаги в рабочих процессах мобильных агентов. Гибридная архитектура повышает чувствительность к реальным состояниям интерфейса пользователя (иконки, предупреждения, компоновка), при этом сохраняя жесткие защиты для необратимых действий, таких как установка и изменения настроек paper page.)
Для практиков OS‑Sentinel предлагает многоуровневый защитный каркас: рассматривать операции с высоким риском как ворота, управляемые спецификациями, затем использовать проверки контекста VLM, чтобы снизить число ложных негативов, когда элементы интерфейса или строки меняются между версиями приложения method recap.)
Зашифрованная цепочка рассуждений снижает качество рассуждений в тестах Anthropic.
Антропик-феллоусы сообщают, что обучение или подстройка моделей к кодированию своих рассуждений простыми шифрами заметно ухудшает решение задач; само маскирование разрушает способность моделей планировать и проверять шаги обзор стипендиатов. Подробности и экспериментальные отчёты агрегируются на портале выравнивания Anthropic блог выравнивания.
Суть в том, что скрывать мысли не приносит бесплатной безопасности. Если вы полагаетесь на зашифрованные или преобразованные черновики (scratchpads), ожидайте снижения точности и устойчивости.
Anthropic оценивает, вселяют ли синтетические документы подлинные убеждения моделей.
Отдельное исследование программы Anthropic Fellows спрашивает, действительно ли модели «верят» фактам, внедрённым через синтетическую донастройку документов. Иногда да, иногда нет — метод приводит к непоследовательной интернализации, согласно их набору оценок beliefs study, с ссылками, собранными на сайте Anthropic по выравниванию для воспроизведения и подсказок Alignment blog.
Для оценок по политики и безопасности это имеет значение: ограничения по безопасности или факты, введённые через синтетические корпусы, могут не зафиксироваться при сдвиге распределения или при агрессивных подсказках.
Anthropic показывает, что шифрованная цепочка рассуждений парализует рассуждения модели
Стипендиаты Anthropic сообщают, что обучение или подача запросов моделям на кодирование их рассуждений простыми заменяющими шифрами заметно снижает производительность задач, указывая на то, что современные LLM испытывают трудности, когда их мыслительные тропы скрыты — даже если итоговый формат ответа не изменяется fellows update. Результат предостерегает от наивных схем «private CoT» и поддерживает использование структурированных, проверяемых сигналов процесса вместо скрытых кодировок Alignment blog.
Инженеры должны отдавать предпочтение проверяемым промежуточным артефактам (планы, следы инструментов) и ограничивать скрытые каналы в конвейерах агентов, чтобы обеспечить как точность, так и надзор.
Формируют ли модели «убеждения»? Anthropic выясняет, что синтетическая донастройка документов иногда порождает подлинные убеждения
In “Believe it or not?”, Anthropic evaluates whether models internalize facts implanted via synthetic document fine‑tuning, finding mixed outcomes: in some cases, models behave as if they genuinely believe the implanted fact; in others, behavior is brittle or context‑dependent beliefs study. The work proposes probes and tests to distinguish superficial pattern match from durable internalization, informing safer knowledge updates in agents Alignment blog.
Для прикладных команд это предполагает тщательную валидацию после целевых правок знаний и явных путей отката, когда убеждения должны быть ограничены по времени или привязаны к происхождению.
📑 Рассуждения и прорывы в обучении
Загруженный исследовательский день: SRL от Google превращает решения в градуированные шаги; CALM предлагает декодирование на уровне векторов; LIGHT добавляет гибридную память для длинных диалогов; HIPO учится, когда нужно думать; ThinkMorph сочетает текст и изображение в цепочку рассуждений; TempoPFN обеспечивает прогнозирование без обучения.
CALM заменяет токены на векторы; меньше шагов для декодирования с длинным контекстом
CALM переосмысляет генерацию как предсказание следующего вектора: сожмите K токенов в один непрерывный вектор (≈99,9% восстановление), затем предскажите следующий вектор вместо следующего токена — сокращая шаги декодирования до масштабов в миллионы токенов обзор статьи. Это напрямую нацелено на узкое место вычислений для длинных контекстов, продолжая работу над Kimi Linear, который ускорял декодирование на 1M токенов за счет дизайна внимания.
[изображение:https://pbs.twimg.com/media/G43aIkBXwAI7uWO.jpg|первая страница статьи]
Инженерная заметка: CALM закрепляет декодирование, подавая последние декодированные токены через небольшой модуль сжатия, использует лёгковесную энергетическую головку с обучением на основе расстояния и обеспечивает настройку на уровне регуляторов через схемы семплинга (например, оценивание BrierLM без вероятностей) обзор статьи. Меньшее количество шагов при сопоставимом качестве означает более дешевые запуски и меньшую задержку для агентов с длинной временной перспективой.
CALM упаковывает 4 токена в 1 вектор для предсказания следующего вектора, сокращая количество шагов при длинном контексте
Непрерывные авторегрессивные языковые модели переходят от предсказания следующего токена к предсказанию следующего вектора: автоэнкодер сжимает K токенов (например, 4) в один непрерывный вектор, который восстанавливается с точностью более 99.9%, поэтому генерация требует примерно в K раз меньше шагов без потери качества. Это смещает границу вычислительной сложности и качества для запусков с миллионом токенов, продолжая тему ускорений для длинного контекста Kimi Linear в виде улучшений. paper thread ArXiv paper
- Тюнинги обучения: лёгкая регуляризация/ dropout удерживают латентное пространство в гладком состоянии; энергетическая головка предсказывает следующий вектор по расстоянию; BrierLM предлагает оценку только по выборке, которая отслеживает кросс-энтропию. paper thread)
HiPO учит модели, когда думать: +6.2% точности при −30% токенов и −39% скорости мышления
Hybrid Policy Optimization (HiPO) обучает политику режимов, которая решает на каждый вопрос, стоит ли включать цепочку размышлений или пропустить её, балансируя правильность и эффективность. Авторы сообщают о точности +6.2%, выходах примерно на 30% короче и на 39% меньшей частоте размышления по сравнению с базовыми моделями, используя гибридный конвейер данных и вознаграждения, зависящие от режима, чтобы избежать излишнего размышления. method summary ArXiv paper Hugging Face model card
)
HiPO учится определять, когда думать; +6.2% точности при 39% меньшей скорости мышления
HiPO — это гибридная рамка оптимизации политики, которая обучает модели принимать решение на каждый запрос: включать цепочку мышления или пропускать её. Сообщаемые результаты: +6.2% точности, −30% длины токенов и −39% «скорости рассуждений», что превосходит альтернативы, которые либо всегда думают, либо эвристически смешивают режимы results thread, с полными деталями и весами, доступными ArXiv paper и Model card.
Пайплайн сочетает в себе смешанный набор данных (think‑on/off) с модо‑aware вознаграждением, которое штрафует излишнее рассуждение, одновременно вознаграждая правильность. Для провайдеров, чья оплата зависит от количества токенов, HiPO предлагает путь к снижению задержки и затрат без снижения точности method summary.
ThinkMorph чередует текстовые и визуальные шаги; значительные улучшения в пространственном мышлении.
ThinkMorph тонко настраивает одну модель 7B на чередующихся текстово‑изображениях цепочек рассуждений, приписывая явные роли: текстовые планы, шаги изображения — эскиз‑поля/пути/правки, и модель переключает режимы с помощью специальных токенов и двойных потерь. Она сообщает о росте на 85.84% в пространственной навигации и +34.74% по визуально‑нагруженным бенчмаркам по сравнению с базовой версией paper thread.
Почему это важно: только текстовое CoT часто терпит неудачу в позиционных проверках и правках; добавление визуальных шагов «проверить и объяснить» расширяет круг кандидатов и улучшает поиск лучшего из N. Модель также учится, когда визуальные элементы мало влияют, и эффективно переключается на текст paper thread.)
ThinkMorph: чередование текста и изображений в цепочке рассуждений открывает значительные преимущества в пространственном рассуждении.
Тонкая подгонка одной модели для чередования текстовых планов с действиями в пространстве изображений (блоки, дорожки, редактирования) даёт значительные преимущества в задачах, ориентированных на зрение — до 85.84% повышения в пространственной навигации и примерно 34.7% среднего прироста по визуальным бенчмаркам — благодаря тому, что языковое планирование и изображения проверяют/редактируют итеративно. paper thread
- Training recipe: ~24K смешанных текстово–изобразительных трасс на четырех задачах, с токенами переключения режимов и двойными потерями для текстовых и визуальных шагов. paper thread)
Ансамбль Swarm Inference достигает 100% на AIME‑2024 и 96,7% на AIME‑2025 при попарной оценке.
Децентрализованная сеть небольших моделей отвечает независимо, затем оценивает пары кандидатов; турнир Брэдли–Терри агрегирует победителей в итоговый вывод. Система сообщает 100% по AIME 2024, 96.66% по AIME 2025, 84.4% по LiveCodeBench (подмножество v5) и 85.9% по GPQA Diamond, демонстрируя устойчивость к зашумленным подсказкам. график бенчмарков
QeRL — открытые исходники 4-битного квантованного обучения с подкреплением для 32‑млрд моделей с совместимостью с vLLM
QeRL демонстрирует обучение с подкреплением при 4-битной точности, что обеспечивает экономичное обучение для моделей размером 32 млрд параметров и согласуется с популярными стеками инференса (vLLM). Он нацелен на узкие места пропускной способности памяти, сохраняя при этом производительность за счет обновлений, учитывающих квантование. open source note vLLM endorsement
TempoPFN: крошечный линейный RNN, предобученный на синтетических данных, прогнозирование без примеров.
TempoPFN показывает, что небольшой линейный RNN, обучаемый только на разнообразных синтетических временных рядах, может давать сильные прогнозы нулевого шага на реальных данных. Он использует блок GatedDeltaProduct с переплетением состояний для параллельного обучения/инференса по полным последовательностям (без скользящего окна) и выдаёт квантильные значения за один проход обзор статьи.)
Для команд с ограниченной проприетарной историей данных это означает воспроизводимый прогнозер, который предобучается один раз и применяется в любом месте, эффективный и простой в развёртывании, при этом сохраняющий конкурентную точность по сравнению с моделями, обученными на реальных наборах данных обзор статьи.)
TempoPFN: синтетически предобученный линейный RNN обеспечивает сильные zero-shot-прогнозы временных рядов
Компактная линейная RNN с блоком GatedDeltaProduct и «state weaving» предобучается исключительно на разнообразных синтетических рядах (GPs, рампы, режимные переключения, аудиоподобные ритмы). Она прогнозирует реальные задачи без обучений (zero-shot) с квантильными выходами и параллельным обучением/инференсом, соперничая с множеством моделей на реальных данных в Gift-Eval и оставаясь облегчённой и воспроизводимой. обзор статьи)
⚙️ Развертывание и время выполнения: локальная пропускная способность и OCR-стеки
Обновления во время выполнения: LMSYS запускает GPT‑OSS на DGX Spark через SGLang со скоростью 70 tps (20B) и 50 tps (120B); vLLM добавляет рецепт PaddleOCR‑VL; Perplexity Comet разворачивает снимок конфиденциальности и локальные средства управления действиями помощника.
LMSYS достигает 70 tps на 20B и 50 tps на 120B с GPT‑OSS через SGLang на DGX Spark
LMSYS продемонстрировала GPT‑OSS, работающую локально на NVIDIA DGX Spark с использованием SGLang, поддерживая примерно 70 токенов/с на модели 20B и примерно 50 токенов/с на модели 120B, рабочие процессы показаны в Open WebUI, а также локальная интеграция Claude Code throughput blog, с примерами установки и демонстрацией в связанной статье и видео LMSYS blog и demo video.\n\n
\n\nВывод для инженеров по времени выполнения: осторожное развёртывание SGLang на DGX Spark может обеспечить работу быстрых автономных агентов и стеков UI, делая локальные запуски с большим числом параметров практичными для кодирования и исследовательских циклов.
Comet получает панель конфиденциальности и более жесткие локально‑ориентированные средства управления.
Perplexity представила виджет Privacy Snapshot и более четкие средства управления тем, что может делать помощник Comet, наряду с гибридной вычислительной моделью, которая сохраняет учетные данные и как можно больше данных локально на устройстве feature brief, с подробностями в Perplexity blog и второй пост, подчеркивающий локальное хранение паролей/кредитных карт privacy summary.)
Тестерский walkthrough показывает, как новый виджет считает заблокированные трекеры за 30 дней и переключатели для взаимодействий с сайтом и доступа к истории просмотров testing notes. Для владельцев окружения выполнения это снижает риск арендатора при пилотировании агентов, ориентированных на экран — запуск в отдельном профиле, по умолчанию ограничивайте действия и эскалируйте только для доверенных рабочих процессов.
Perplexity Comet запускает Privacy Snapshot, гибридные вычисления на устройстве и средства управления действиями
Браузер Perplexity Comet добавил виджет Privacy Snapshot и детальные разрешения ассистента, выделяя гибридную модель вычислений, которая сохраняет как можно больше данных локально, включая учетные данные, и предоставляет панель управления разрешёнными действиями (например, взаимодействие с сайтами, доступ к истории) feature brief, assistant controls. Третьи стороны также показывают счетчик трекеров/блокировки рекламы и подчеркивают подход local-first privacy summary, с полным описанием в блоге продукта privacy snapshot.
Для владельцев рантайма это обеспечивает более безопасные действия агентов и более чёткие границы данных, не ухудшая отзывчивость, что соответствует корпоративным базовым уровням конфиденциальности.
vLLM публикует руководство по использованию PaddleOCR‑VL для обработки документов с высокой пропускной способностью
vLLM выпустила официальный рецепт PaddleOCR‑VL с флагами развёртывания, рекомендациями по пакетированию и примерами, совместимыми с OpenAI, для создания быстрых конвейеров OCR, которые выводят структурированный Markdown/JSON обновление vLLM,, продолжая тему публичная бета-версия, детали охвата модели на 109 языков). Руководство помогает командам внедрить OCR в существующие стеки обслуживания vLLM с минимальным количеством кода руководство по использованию PaddleOCR‑VL.)
vLLM добавляет рецепт PaddleOCR‑VL для производственных OCR‑пайплайнов
vLLM выпустил руководство по использованию PaddleOCR‑VL, включая параметры развёртывания, примеры API, совместимого с OpenAI, и советы по настройке, такие как отключение кеширования префиксов для рабочих нагрузок OCR и корректировку пределов пакетных токенов для размещения VRAM vLLM update, с пошаговой документацией в vLLM docs.
Это в основном помогает командам, которым нужна структурированная Markdown/JSON из PDF и сканов без написания собственного рантайма. Это чистый путь заменить процессор, привязанный к CPU, на OCR, ускоренный на GPU, внутри существующего стека vLLM.
Хайку 4.5 грани GPT‑5 по точности OCR документов в таблице
В поразделительном извлечении расписания NYC MTA бок о бок Haiku 4.5 от Anthropic точнее сохранил расстояние между ячейками и колонки, чем GPT‑5, который сжал пробелы; тест использовал скриншоты и реконструированные Markdown‑таблицы OCR comparison.
Если вы собираете OCR‑стек, это толчок к A/B сравнению документов с большим количеством таблиц между моделями, а не только к тестам по зрению. Небольшие выигрыши в точности здесь накапливаются затем в оценивателях и загрузчиках данных.
🎬 Генеративные медиа: реклама, правки и мобильные релизы
Динамика креативного стека: Google выпускает полностью на основе ИИ рекламу Veo 3; fal проводит Reve Fast Edit за $0.01 за изображение; Grok разворачивает Upscale/Remix для изображений; NanoBanana превосходит в коллажах; Udio открывает окно загрузок архивного наследия продолжительностью 48 часов.
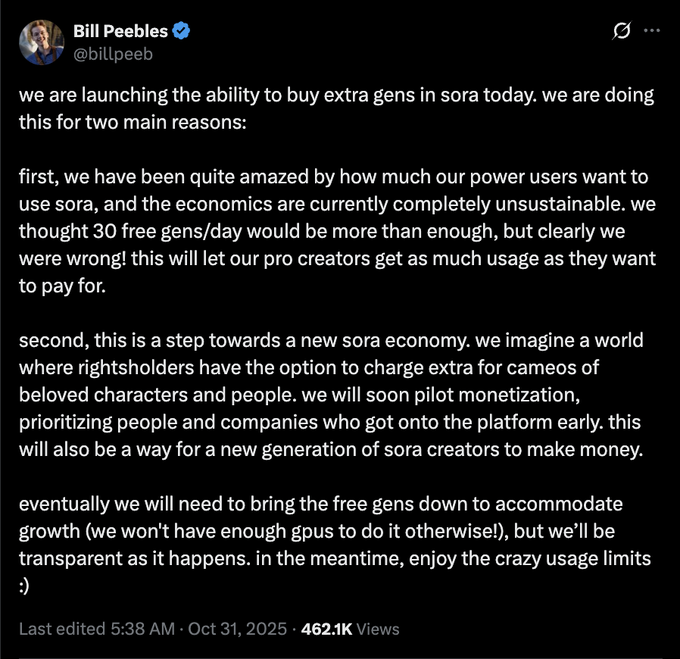
OpenAI запускает платные пополнения для генераций Sora; количество бесплатных генераций может быть сокращено.
OpenAI вводит платные дополнительные генерации для Sora, чтобы справиться с большой нагрузкой и экономикой, и предупреждает, что квоты на бесплатные генерации могут уменьшиться со временем по мере роста спроса и ограничений по GPU pricing update.
Для небольших видеокоманд это означает планирование бюджета на повторные попытки и более качественные кадры вместо того, чтобы полагаться на бесплатные лимиты; следите за рынками камео правообладателей, упомянутыми в посте pricing update.
fal hosts Reve Fast Edit & Remix: много изображений, последовательные правки примерно за $0,01 за изображение
fal запустил «Reve Fast Edit & Remix» с реалистичными, согласованными с образцом правками и поддержкой до 4 эталонных изображений, стоимость около $0.01 за изображение feature brief. Это нацелено на быстрые, повторяемые правки в бренде без повторного запроса с нуля.
Это полезно для рынков, команд по социальным сетям и приложений UGC, которым необходимы массовые правки в стиле, закрепленные за бюджетом.
fal размещает Reve Fast Edit по цене $0.01 за изображение с руководством на 4 изображения.
fal запустил Reve Fast Edit & Remix с реалистичными правками, сохраняющими структуру, поддерживающими до четырех эталонных изображений и по цене примерно $0.01 за изображение model launch.)
Значение для конвейеров продуктов и рекламы очевидно: последовательная передача идентичности/стиля и низкая цена за каждый кадр делают это жизнеспособным для крупных пакетных кампаний и тестирования вариантов.
Grok добавляет Upscale и Remix на Android и iOS с переключателями режимов.
xAI запускает масштабирование изображений и Remix в приложении Grok на мобильных устройствах, с быстрыми режимами выбора, такими как Spicy, Fun и Normal mobile rollout. Это расширяет конвейер обработки изображений Grok за пределы генерации к этапам постобработки.
Это практическое продолжение продвижения Grok в области анимации, призванное улучшить повторное использование ассетов на устройстве при сохранении простоты UX первый запуск.
Grok добавляет Upscale и Remix на мобильных, опираясь на Imagine
xAI внедряет Upscale и Remix управляющие элементы в приложении Grok на Android и iOS, с переключателями режимов вроде Spicy/Fun/Normal для быстрого стилистического прохода выпуск функции, в продолжение первого запуска анимаций Grok Imagine длительностью 30 секунд.
Для команд по работе с движением и изображениями встроенные улучшения снижают число обращений к внешним редакторам и ускоряют цикл итераций над вариациями, готовыми к публикации в соцсетях прямо с мобильных устройств.
Udio открывает 48‑часовое окно для загрузки старых песен, стемов и WAV‑файлов.
Udio включил однократное 48‑часовое окно загрузки для треков, созданных до 29 октября: у бесплатных пользователей можно скачать MP3 и видео, подписчики могут получить стемы и WAV-файлы; пакетная загрузка через папки поддерживается заметка по политике, с советами сообщества и коротким руководством, распространяемым руководство по шагам.
Команды должны сейчас поставить экспорт в очередь. Нет ориентировочного времени появления повторного окна, и некоторые крупные ZIP-архивы могут зависнуть; мелкие партии, похоже, работают лучше сообщение пользователя.
Udio открывает 48‑часовое окно для загрузки архивных песен, включая стемы и WAV‑файлы.
Udio включил окно загрузок на 48 часов для созданий до 29 октября — бесплатные пользователи могут скачать MP3/видео, в то время как подписчики смогут получить WAV и stems; уведомление указывает на период с 11:00 ET 3 ноября до 10:59 ET 5 ноября, рекомендуется пакетная загрузка папок и без твёрдого обязательства по будущим окнам download notice how‑to thread reddit notice.
Для команд, работающих с наследуемыми библиотеками в Udio, это, вероятно, последний лёгкий шанс репатриировать активы в ваше собственное хранилище и рабочие процессы по управлению правами.
Higgsfield дебютирует на YouTube-канале с «Sketch to Video» и кодом на 200 бесплатных кредитов
Хиггсфилд запустил канал на YouTube, демонстрирующий ‘Sketch to Video’, превращающий детские рисунки в анимационные истории, и в описании разместил ограниченный по времени код на 200 бесплатных кредитов channel launch YouTube video.)
Для образовательных и контент‑команд это аккуратная демонстрация рабочих процессов storyboard‑to‑motion, которые можно опробовать сегодня с небольшим рекламным бюджетом.
NanoBanana в Google AI Studio блистает в создании коллажей (пример Waymo Detroit)
Создатели сообщают, что NanoBanana — «чрезвычайно хорош» для многопанельных коллажей; набор в стиле Waymo в Детройте демонстрирует сильную композицию и последовательный брендинг по плиткам пример от создателя.
Если вы собираете карусели или эскизы для YouTube, это быстрый путь к единообразным макетам без ручной компоновки.
NanoBanana сияет в генерации коллажей для брендированных макетов
Создатели отмечают NanoBanana в Google AI Studio для создания чистых, соответствующих бренду коллажей (например, монтаж Waymo в Детройте), что свидетельствует о сильной пространственной композиции и соответствии шаблонам для маркетинговых задач collage example.
Если вы собираете многопанельные объявления или промо‑ролики к мероприятиям, это указывает на быстрый путь к высококачественным композитам без ручного маскирования.
🤖 Физический ИИ: полевые роботы, собаки и воздушная манипуляция
Основные моменты воплощённого ИИ: Carbon Robotics ‘LaserWeeder’ в производстве; робот-собака Rover X1 за $1 тыс. демонстрирует применения для дома и охраны; манипулирование воздушной нагрузкой на кабелях демонстрирует гибкое сотрудничество. Исключаются творческие/медийные элементы.
NVIDIA и Samsung планируют «ИИ‑фабрику» с 50 000 ГПУ для робототехники с цифровым двойником
NVIDIA и Samsung презентовали производственную «AI‑фабрику», построенную вокруг примерно 50 000 GPU, для ускорения агентного ИИ, цифровых двойников Omniverse и робототехнических стеков (Isaac/Jetson Thor) по всей цепочке — на фабриках, в смартфонах и в логистике. Для команд физического ИИ предложение — более быстрые циклы моделирования «сэмпл‑в‑реал» и автономия с обратной связью в масштабе фабрик, с активацией литографии на CUDA и оркестрацией в реальном времени, упомянутые как флагманские рабочие нагрузки announcement note.
$1,000 Rover X1 робот-пёс предлагает выполнение поручений, тренировки и охрану дома.
Новый потребительский робот-пёс Rover X1 продаётся примерно за $1,000 и обещает возможность носить продукты, бегать рядом с вами и патрулировать домовую охрану описание продукта. Далее следующий пост освещает китайский запуск для того же класса устройств региональное примечание. Если цена сохраняется при надёжной автономности, это расширяет потенциал рынка домашних и малых бизнес‑робототехнических решений.
LaserWeeder от Carbon Robotics использует компьютерное зрение NVIDIA для уничтожения сорняков без химикатов.
Полевой демонстрационный образец LaserWeeder от Carbon Robotics демонстрирует, как компьютерное зрение управляет лазерами для уничтожения сорняков в рядах, обходя использование гербицидов. Это понятный, готовый к производству пример воплощённого ИИ — прочная перцепция, суровое освещение и узкие рамки безопасности — для команд, переводящих лабораторные модели зрения в надёжную автономию на открытом воздухе полевой робот-демонстрация.)
LaserWeeder от Carbon Robotics, работающий на NVIDIA, нацелен на безхимическое пропалывание в масштабе.
LaserWeeder компании Carbon Robotics снова циркулирует как конкретное, промышленного класса применение компьютерного зрения + лазеров для удаления сорняков без гербицидов, питаемое аппаратным обеспечением NVIDIA field demo. Для команд, создающих полевые роботы, это ясный шаблон: повысить устойчивость обнаружения, снизить задержку до скорости трактора и обосновать общую стоимость владения по сравнению с химикатами.
Собака-робот «Rover X1» за $1,000 предназначена для выполнения поручений, пробежек и домашнего патрулирования.
Rover X1 от DOFBOT позиционируется как потребительская роботизированная собака примерно за 1,000 долларов — рассчитана на перевозку продуктов, бег рядом с владельцами и базовую охрану дома. Если заявления по цене и возможностям подтвердятся, это расширит базу разработчиков для платформ на ходунках и поднимет вопросы об SDK, замене батареи и интеграции сторонних датчиков на нижнем конце рынка product teaser, features recap.
Гибкая демонстрация с несколькими дронами: кооперативное воздушное манипулирование грузом, подвешенным на тросе
Исследовательская демонстрация показывает, как квадрокоптеры координируют перемещение груза, подвешенного на тросе, с помощью гибкого, кооперативного управления ссылка на статью.). Это важно для задач инспекции и строительства, где линии обзора для кранов недоступны; это также подчёркивает оценку в реальном времени, подавление возмущений и политики совместного управления, выходящие за рамки полёта одного агента.
Ловкие квадрокоптеры кооперативно раскачивают груз, подвешенный на тросе, с точностью.
Научная демонстрация показывает кооперативное управление несколькими дронами для кабельной нагрузки, подвешенной на тросе, с маневрами, позволяющими уменьшать колебания и поддерживать траекторию — полезные образцы для будущей логистики на площадке, строительства или реагирования на катастрофы. Ожидается значительный упор на распределенное управление, оценку состояния при качании нагрузки и экологию безопасности для совместного присутствия человека и робота research clip, project link.
💼 Сигналы внедрения и распространения в корпоративном секторе
Данные об усвоении и доступе: опрос Wharton показывает, что 46% руководителей используют ИИ ежедневно (по сравнению с 29% в 2024 году); ChatGPT приближается к 6 миллиардам посещений в месяц; OpenAI предлагает ChatGPT Go бесплатно на 12 месяцев в Индии; Perplexity добавляет агент по исследованиям в области интеллектуальной собственности.
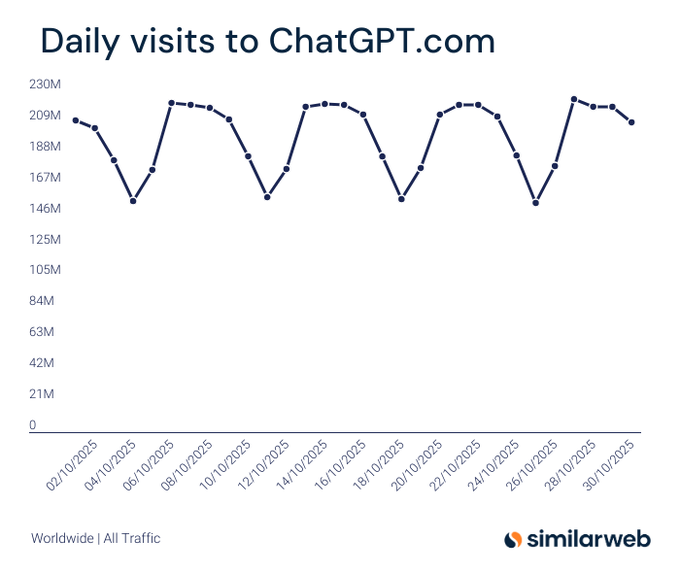
ChatGPT приближается к 6 млрд ежемесячных посещений в октябре; Gemini около 1 млрд, по данным Similarweb
Similarweb отслеживание показывает, что октябрьский трафик ChatGPT колебался в диапазоне примерно 150–220 млн посещений в день, что ставит его чуть ниже 6 млрд ежемесячных посещений впервые график посещений. . Сопровождающий показатель оценивает Gemini.google.com примерно в 1 млрд ежемесячных посещений за тот же период, подчеркивая разрыв в распределении между двумя точками входа для потребительского ИИ сравнительный график.)
Использование корпоративного ИИ достигло 46% среди руководителей, при этом отмечаются крупные достижения в юридическом секторе.
Новая оценка Wharton с участием примерно 800 руководителей крупных предприятий показывает, что 46% используют ИИ ежедневно, по сравнению с 29% в 2024 году и 11% в 2023 году, при этом юридическая функция за год выросла с 9% до 39%. Меньше чем 20% компаний планируют сокращать численность младших сотрудников, что указывает на перераспределение, а не на снижение. Это явный импульс принятия технологий для покупателей и поставщиков, планирующих бюджеты на 2026 год Survey headline.
Для лидеров в области ИИ суть такова: внедрение становится нормой во всех функциях помимо инженерии. Рассматривайте юридическую, финансовую и операционную службы как серьёзных внутренних клиентов и ожидайте, что отдел закупок спросит об аудируемости, сохранности данных и происхождении. Для продавцов сигнал по численности сотрудников указывает на аргументы в пользу концепции «copilot + workflow», а не «замена команды». Дополнительная информация по найму
ChatGPT приближается к 6 млрд ежемесячных посещений; Gemini пересекает отметку примерно 1 млрд.
Оценки трафика от Similarweb показывают, что ChatGPT.com приближается к 6 млрд общих визитов в месяц в октябре, с суточными циклами примерно 150–220 млн. Сопутствующая диаграмма оценивает Gemini примерно в 1 млрд визитов, подчёркивая широкий, но сужающийся разрыв и устойчивый спрос на помощников на верхнем уровне воронки, на котором предприятия приводят в стандарт предприятия ChatGPT traffic chart, Gemini traffic chart.
Для команд по дистрибуции это подтверждает дальнейшее инвестирование в интеграции в первую очередь с помощниками и партнерские площадки. Для аналитики трактуйте это как намерение верхнего уровня воронки, а не активное использование; настройте последующую конверсию в проекты, загрузку файлов и ключи API прежде чем перераспределять бюджет.
OpenAI продвигает ChatGPT Go с 12-месячным предложением для Индии; ₹399/месяц впоследствии
OpenAI продвигает индийскую промо‑акцию ChatGPT Go на 12 месяцев, и модальное окно подчеркивает такие возможности, как расширенный доступ к GPT‑5, увеличенная память/контекст, более быстрое создание изображений, ограниченные исследования, Projects/Tasks и пользовательские GPT; цены возвращаются к ₹399/месяц после промо‑периода согласно условиям в приложении pricing screenshot. Предложение указывает на агрессивную стратегию распространения для расширения принятия платного тарифа на крупном рынке.
Perplexity запускает агент по поиску патентов на базе искусственного интеллекта
Perplexity представила Perplexity Patents, агента по патентным исследованиям на базе ИИ, который отвечает на вопросы на естественном языке, поддерживает контекст разговора и цитирует источники. Он обещает обнаружение предшествующих материалов за пределами строгого совпадения по ключевым словам, собирая данные из патентов, а также статей, кода и сети. Он находится в бесплатной бета‑версии по всему миру, с более высокими квотами и выбором моделей для пользователей Pro/Max Обзор запуска.
[изображение:https://pbs.twimg.com/media/G4t33WGbQAAM5G-.jpg|Анонс патентов]
Юридическим, исследовательским и корпоративным командам по развитию предлагают инструмент для немедленной сортировки. Рассматривайте результаты как лиды, а не как мнения — перенаправляйте результаты в ваши существующие процессы доку‑терминал и рабочие процессы IP‑консультаций и отслеживайте вероятность совпадения с обычными каналами поиска в течение пилотного периода от 2 до 4 недель.
Perplexity подписывает многолетнее соглашение об лицензировании изображений с Getty для усиления законного визуального поиска
Perplexity заключила многолетнее лицензионное соглашение с Getty Images, предоставляющее право отображать визуальные материалы Getty в своих инструментах поиска и обнаружения на базе ИИ с полными кредитами и ссылками на источники. Сделка укрепляет происхождение контента на фоне ранее предъявленных обвинений в скрапинге контента и соответствует ориентированной на цитирование позиции Perplexity licensing story.)
Perplexity запускает «Patents», агент по исследованию предшествующего уровня техники на базе ИИ в бесплатной бета‑версии.
Perplexity представила агент по исследованию патентов на ИИ, который отвечает на запросы на естественном языке, поддерживает контекст беседы и цитирует источники, стремясь выявлять предшествующее искусство за пределами жесткого поиска по ключевым словам среди патентов, статей, кода и сети. Он доступен глобально в бесплатной бете, с более высокими квотами и вариантами моделей для пользователей Pro/Max feature post.
Промо-акция ChatGPT Go выходит в Индию с 12‑месячным предложением
OpenAI демонстрирует в встроенном приложении предложение «Попробуйте Go на 12 месяцев» для учетных записей в Индии, перечисляя расширенный доступ к GPT‑5, более длинную память/контекст, более быстрое создание изображений, ограниченное Deep Research и Projects/Tasks/Custom GPTs. Модальное окно также упоминает ₹399/месяц (включая НДС) за первые 12 месяцев, затем автоматическое продолжение — похоже, что это поток с промо‑тарифом, а не постоянный бесплатный уровень Offer screenshot.
]
Если вы запускаете внедрение в Индии, это ближнесрочный рычаг для развёртывания пилотных проектов по отделам. Установите напоминания в календаре о продлениях и уточните формулировку счета; интерфейс сочетает формулировку «попробуйте бесплатно» с платной тарификацией, поэтому приведите ожидания в соответствие до развёртывания.
Opera выпускает ODRA, глубокий исследовательский агент в Neon
Opera запустила ODRA (Opera Deep Research Agent) внутри браузера Neon для выполнения долгосрочных задач веб-исследований. Для организаций, стандартизирующих использование помощников внутри браузера, это еще один путь распространения, конкурирующий с выделенными AI-браузерами и боковыми copilots Product announcement.
ODRA’s value will hinge on source transparency, action controls, and export formats. Pilot it on internal knowledge syntheses and compare against existing tools for noise filtering, deduping, and cite fidelity.
Opera представляет ODRA, глубоко исследовательский агент внутри Opera Neon
Opera запустила ODRA (Opera Deep Research Agent) в браузере Opera Neon для поддержки расширенных веб‑исследований и более глубоких рабочих процессов анализа, сигнализируя о ещё одном основном канале распространения возможностей агентного браузинга релиз браузера.
🧩 Форматы с низкой разрядностью и ядра
Обучение и вывод с учётом аппаратного обеспечения: ByteDance сравнивает детальное квантование INT против FP (MXINT8, MXFP4, NVFP4); объявлен конкурс по оптимизации ядер NVFP4; QeRL демонстрирует жизнеспособность обучения RL с квантованием до 4 бит.
ByteDance: MXINT8 эффективнее FP8 по энергопотреблению; руководство по компромиссам 4‑битных NVFP4/MXFP4/NVINT4
Новая работа ByteDance показывает, что MXINT8 экономит энергию примерно на 37% по сравнению с FP8 при равной пропускной способности, сохраняя такую же или большую точность; статья рекомендует масштабирование на уровне блока для подавления выбросов активаций и объясняет, когда 4‑битовые числа с плавающей запятой (MXFP4/NVFP4) или целые числа (NVINT4 после лёгкого вращения Хадамарда) выигрывают при разных размерах блоков выводЫ статьи.
Исследование ByteDance: MXINT8 превосходит FP8 по энергопотреблению; когда использовать NVFP4 против NVINT4
Книга ByteDance сравнивает тонко градуированные форматы целых и вещественных чисел и сообщает, что MXINT8 экономит энергию примерно на 37% по сравнению с FP8 при равной пропускной способности, чему способствует масштабирование на уровне блока, нормирующее выбросы активаций paper thread. Кроме того, приводится 4‑битовая стратегия: вещественные форматы (например, NVFP4/MXFP4) лучше сохраняют очень маленькие значения на больших блоках, в то время как лёгкое вращение Хадамарда и NVINT4 могут восстановить точность на более простом, энергоприберегающем целочисленном оборудовании paper recap.
Для инженеров выводы конкретны: используйте масштабирование по каналу на малых блоках, чтобы снизить коэффициент пиков; предпочтительно MXINT8 в качестве дефолта 8‑бит для паритета обучения/инференса; выбирайте NVFP4/MXFP4, когда 4‑битам нужна подпороговая точность, или выполняйте преобразование, а затем отдавайте предпочтение NVINT4, когда пропускная способность и простота логики важнее.
QeRL публикует исходники обучения RL с 4‑битной точностью, обеспечивая совместимость 32‑миллиардных моделей с vLLM.
QeRL (Quantization‑enhanced RL) показывает обучение RL с разрядностью 4 бита от начала до конца, которое может работать с LLM объёмом 32 млрд параметров и интегрируется с рантаймами vLLM, расширяя возможность тонкой настройки с ограниченным бюджетом при сохранении пропускной способности поток проекта, замечание vLLM. Далее FP16 stability о сходимости RL при более высокой точности, это указывает на практичный путь подтянуть RL в стиле рассуждений к режимам с низким битовым запасом без коллапса бюджета на обучение.
QeRL: выпущено 4‑битное обучение с подкреплением, совместимо с vLLM
Исследователи выпустили QeRL (квантизационно‑усиленный RL), который позволяет обучать крупные модели с более эффективной 4‑битовой квантизацией обучения с подкреплением; объявление подчеркивает 4‑битовую тренировку и утверждает поддержку значительных масштабов моделей open‑source post. . Проект vLLM усилил работу, назвав её значительным шагом к практичным пайплайнам RL с низким битовым уровнем, которые встроены в обычные рантаймы vLLM comment.
Если вы исследуете reasoning‑RL в масштабе, это говорит о пути к выполнению RL‑тонкой настройки при более строгих ограничениях по памяти и энергии, оставаясь совместимыми с производственными инференс‑стеками.
Конкурс NVFP4 по ядрам открывается на Blackwell.
GPU_MODE и NVIDIA объявили конкурс по оптимизации ядер, сфокусированный на NVFP4 на графических процессорах класса Blackwell, приглашая к подаче быстрых и точных ядер с малой битностью заметка конкурса. Это прямой путь увеличить пропускную способность инференса и обучения через 4-битовые конвейеры, и это своевременная возможность привести общественные ядра в соответствие с планировщиком аппаратного обеспечения и особенностями тензорных ядер.
Конкурс по оптимизации ядра NVFP4 стартует на Blackwell.
GPU_MODE и NVIDIA объявили конкурс по оптимизации ядер, нацеленный на NVFP4 на Blackwell, приглашая сообщество подать высокопроизводительные ядра, настроенные под новый формат 4‑битной точности с плавающей запятой — полезный для длинного контекста и высокопропускной инференс‑цепи, которая опирается на математику с низким разрядом анонс конкурса. Проблемы и возможности, вытекающие из практического применения, предполагают широкий интерес к извлечению большего из путей NVFP4 разговор на тему конкурса.
⚖️ Последствия депонирования управления OpenAI
Свежие резюме циркулируют из показаний Ильи Суцкевера: предложение на субботу о слиянии с Anthropic, замечания о лидерстве и «искателей власти», и ссылки на полный 365‑страничный стенограмму. Без раздела о партнерстве AWS.
Заявление Хелен Тонер вновь всплывает: уничтожение OpenAI могло бы быть «соответствующим миссии»
Широко распространенная карточка цитирует Хелен Тонер, утверждающую, что позволить разрушению компании будет соответствовать миссии — «еще более прямо, чем это». Это представлено как часть конфликтов ценностей на уровне совета директоров, зафиксированных в показаниях. цитата миссии, сводные карты
Команды могут просмотреть точные вопросы и ответы и ссылки на страницы в опубликованной транскрипции, чтобы оценить, насколько выбранная цитата репрезентативна для более широкого обсуждения. Судебная транскрипция
Илья Сутскевер называет верховных лидеров «охотниками за власть», признаёт зависимость от информации с чужих слов и политику силы в отношении AGI.
Помимо вопросов, связанных с процессами, Илья Сутскевер характеризует лидеров крупных компаний как «жаждущих власти», представляет контроль над AGI в терминах реалполитики и признаёт, что усвоил «критическую важность непосредственного знания», после опоры на донесения со стороны summary cards, power‑seekers post. Смесь философии и здравого смысла углубляет вопросы о суждениях во время кризиса OpenAI 2023 года.
Мемо опирался на скриншоты Миры Мурати; Сутскевер говорит, что не проверял это с другими.
Протокольные заметки говорят, что 52‑страничное дело против Альтмана включало «каждый скриншот» из Миры Мурати и не было сверено с упомянутыми людьми, при этом Сутскевер говорил, что избегал уведомлять Альтмана из страха, что доказательства исчезнут summary cards. Полная стенограмма, распространяемая сегодня, закрепляет эти детали для первичного обзора full transcript, court transcript.
Процесс принятия решений на совете назвали поспешным и неопытным; обратную реакцию сотрудников оценили неправильно.
Сутскевер свидетельствует, что процесс «был поспешным, потому что совет был неопытен в вопросах, связанных с советом», отмечая отсутствия на заседаниях; он также «не ожидал», что сотрудники будут настроены решительно, и был поражён восстанием. Оба высказывания зафиксированы в распространяемом наборе карточек. summary cards)
Для чтения с точной привязкой к времени 365‑страничный транскрипт связывает эти замечания с конкретными страницами и сессиями. Court transcript
Вопросы по стоимости доли заблокированы; Илья Сутскевер считает, что OpenAI оплачивает его юридические услуги.
Карты отмечают, что адвокат Сутскевера заблокировал вопросы относительно его доли в капитале; он «считает, что OpenAI оплачивает его юридические расходы». Это касается стимулов и позиции в деле. сводные карточки, пометка по гонорарам
Используйте стенограмму, чтобы увидеть точные возражения и то, как прерывался допрос. Стенограмма суда
Илья Сутскевер о политике ИИ общего назначения: руководители крупных компаний — «искатели власти»
Еще один фрагмент, который распространяется в сети, цитирует Илью Сутскевера, описывая тех, кто возглавляет крупные компании, как «жаждущие власти», представляя контроль над ИИ как проблему власти и политики, а не святость. Такой ракурс вызвал дебаты по моделям управления. power seekers
Если вам нужна точная формулировка и контекст, сверяйтесь с нумерацией страниц PDF-допроса. Court transcript
Показания свидетельствуют о том, что Дарио Амодеи стремился руководить исследованиями OpenAI; позиция Алтмана охарактеризована как двусмысленная.
Свежие выдержки подчёркивают борьбу за лидерство: по словам Дарио Амодеи́, якобы он хотел забрать исследовательскую работу OpenAI у Грега Брокмана, в то время как Сэм Алтман изображается как не занимающий твёрдой позиции и «рассказывающий противоречивые истории» о управлении thread details, conflicting stories. Эти утверждения проясняют картину внутреннего согласования и давления ответственности во время хаоса 2023 года.
Сутскевер сохранил долю в OpenAI, считает, что OpenAI оплачивает его юридические расходы; отказался раскрывать размер доли.
Показания свидетельствуют, что Сутскивер все еще держит долю в OpenAI (он говорит, что она выросла в стоимости), считает, что OpenAI оплачивает его юридические услуги, и — по указанию адвоката — отказался сообщать, сколько стоит его доля сводные карты, примечание по юридическим расходам. Эти финансовые связи добавляют уровень потенциальных конфликтов к уже напряжённым нарративам о корпоративном управлении.
Схватки по делу о раскрытии документов: «другой меморандум» о Греге не представлен; резкие обмены между юристами
Карты указывают на «другую записку» о Греге Брокмане, которая существует у юристов, но не была предоставлена («вы этого не просили»), а отдельный фрагмент показывает, как адвокаты спорят на фоне постоянных возражений. Оба намекают на характер процесса раскрытия материалов. summary cards, lawyer sparring
Проверьте 365‑страничный протокол обсуждения раскрытия материалов и то, были ли споры о предоставлении документов решены в другом месте. Court transcript
Утверждение: Дарио Амодеи хотел руководство исследовательской деятельностью в OpenAI; Альтман не занял твёрдую позицию.
Часть фрагментов протокола утверждает, что Дарио Амодей пытался взять под контроль исследования у Грега Брокмана и что Сэм Альтман не занял твёрдой позиции, что вызвало внутренние трения. Рассматривайте как одну ветку в рамках более широкого допроса, а не всю историю. leadership claim, summary cards
Для точной формулировки и контраргументов прочитайте указанные страницы в полном деле. Court transcript)