OpenAI оценивает рекламу ChatGPT на основе памяти — потребители сейчас составляют 70% от 13 миллиардов долларов.
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI изучает персонализированную рекламу с использованием памяти ChatGPT, согласно The Information, и это резкий поворот для продукта, который люди используют в работе и жизни. Бизнес-логика очевидна: примерно 70% от около $13 млрд годового прогноза дохода приходится на потребителей, и компания тихо стала очень Facebook-увлеченной, с примерно 20% из ~3,000 сотрудников пришедших из Meta (~630 человек). Генеральный директор приложений Фиджи Симо якобы предложила, что реклама может «приносить пользу пользователям», в то время как Сам Альтман теперь называет рекламу «отвратительной, но не нестартаповой/непройденной». Фокус-группы даже свидетельствуют, что многие пользователи уже предполагают существование рекламы.
Если это реализуют, ожидайте, что размещения, ориентированные на Memory, вызовут новые корпоративные контрольные меры: выбор опций отклонения по рабочему пространству, журналы аудита и более строгую сегрегацию данных, чтобы сохранённые предпочтения не перераспределялись между границами организаций. Выделенный Slack для выпускников Meta и потребительски-ориентированная модель доходов объясняют недавний браузерный толчок (Atlas, Memory, уведомления): это математика роста, а не научный проект. Риск — доверие. Memory — самая «липкая» функция; превращение её в данные для таргетинга вызовет внимание регуляторов и заставит OpenAI доказать надёжные потоки согласия, региональное соблюдение и ясные объяснения «почему я это вижу?».
После понедельника запуска Atlas реклама переработает браузер от утилиты к инвентарю — что может увеличить ARPU, но только если настройки приватности и администрирования будут внедрены в первую очередь.
Feature Spotlight
Особенность: OpenAI рассматривает рекламу, привязанную к памяти ChatGPT; 20% персонала — бывшие сотрудники Meta
OpenAI рассматривает рекламу, которая использует память ChatGPT; около 70% от примерно $13 млрд годового повторяющегося дохода приходится на потребителей, около 20% сотрудников — бывшие сотрудники Meta, и руководство сигнализирует, что реклама теперь не исключена.
Самая крупная история сегодня в рамках нескольких аккаунтов: несколько публикаций ссылаются на The Information о том, что OpenAI может показывать рекламу, основанную на памяти ChatGPT, при этом раскрывая состав организации и структуру доходов. Это стратегический сдвиг с конкретными последствиями монетизации.
Jump to Особенность: OpenAI рассматривает рекламу, привязанную к памяти ChatGPT; 20% персонала — бывшие сотрудники Meta topicsTable of Contents
📣 Особенность: OpenAI рассматривает рекламу, привязанную к памяти ChatGPT; 20% персонала — бывшие сотрудники Meta
Самая крупная история сегодня в рамках нескольких аккаунтов: несколько публикаций ссылаются на The Information о том, что OpenAI может показывать рекламу, основанную на памяти ChatGPT, при этом раскрывая состав организации и структуру доходов. Это стратегический сдвиг с конкретными последствиями монетизации.
OpenAI рассматривает рекламу, основанную на памяти ChatGPT, по мере смягчения позиции Алтмана
OpenAI исследует рекламу, которая использует память ChatGPT для персонализации промо-акций, после того как фокус-группы показали, что многие пользователи уже предполагают наличие рекламы; внутри глава по приложениям Fidji Simo обсуждала, как реклама может «приносить пользу пользователям», а Сэм Альтман сейчас называет рекламу «неприятной, но не препятствием к запуску». The Information summary The Information article Ad plan summary Ad concern post
Если это будет принято, это станет существенным изменением продуктовой политики для потребительского бизнеса на масштабах, и поднимет новые вопросы конфиденциальности, UX и политики для администраторов предприятий и регуляторов, требующих внимания.
Около 20% сотрудников OpenAI ранее работали в Meta, и существует Slack‑канал для выпускников.
Около 630 бывших сотрудников Meta сейчас работают в OpenAI — примерно 20% от её примерно 3000 сотрудников — с выделенным каналом Slack для выпускников; среди заметных руководителей — CEO приложений Fidji Simo. Сообщение трактует это как уклон в сторону роста и тактик вовлечения в стиле Meta. Данные по персоналу Краткое описание эпохи Facebook Аналитическая нить
Для лидеров сочетание талантов сигнализирует о способности реализовывать стратегии вовлечения потребителей (ежедневная активность, память, уведомления), но также о культурном сдвиге, вокруг которого должны планировать работу команды по продукту, политики и сопутствующим подразделениям BD.
Потребительская выручка сейчас составляет примерно 70% выручки OpenAI, около 13 млрд долларов, что объясняет продвижение в браузере.
Несмотря на масштабное использование API, выручка OpenAI смещается в пользу потребителей: примерно 70% от примерно $13 млрд ARR приходится на конечных пользователей, что частично объясняет, почему компания выпустила браузер и делает ставку на вовлечение и память. Revenue graphic Analysis thread
Для команд по продукту и партнерствам этот микс предполагает дальнейшие инвестиции в потребительские интерфейсы (Atlas, память, проекты) и возможные компромиссы с элементами дорожной карты, ориентированными на разработчиков, если они также не приводят к увеличению времени использования пользователями и удержанию.
🛠️ Кодирующие агенты укрепляют защиту: SDK, CLI и рабочие процессы
Множество ощутимых обновлений для разработчиков: бета-версия AI SDK 6 перемещает ключевые элементы в стабильную ветку, Codex CLI выпускает улучшения QoL и исправления MCP, Claude Code UI/исправления ошибок, /handoff Ампа для переноса контекста, и сообщество приходит к единым шаблонам AGENTS.md. Исключает рекламу OpenAI (рассматривается как функция).
Amp’s /handoff заменяет потери при сжатии за счёт переноса плана и контекста в новый поток
Amp представила /handoff, чтобы перенести соответствующий план и подобранный контекст в чистую нить обсуждения, избегая неточных резюме и сохраняя фокус на следующей задаче статья о передаче, с тем, что продвинутые пользователи отмечают высокий коэффициент влияния по отношению к простоте для рабочих процессов агентов обзор возможностей.
Claude Code v2.0.27 и веб‑песочница выпускают новые запросы разрешений, фильтры веток и исправления ошибок
Anthropic’s v2.0.27 добавляет переработанный интерфейс запроса разрешений, фильтрацию веток и поиск при возобновлении сессии, а также настройку VS Code для включения файлов, игнорируемых .gitignore; исправления охватывают ошибки упоминания директорий с символом @, триггеры разогрева беседы и сбросы настроек release blurb. В еженедельном обзоре команда также выделила Claude Code Web и /sandbox и поддержку плагинов/навыков в Agent SDK, а также обновлённый интерфейс редактора планов weekly roundup.
CopilotKit добавляет потоковую передачу в реальном времени для подграфов LangGraph с рассуждениями, инструментами и состоянием
CopilotKit может теперь транслировать каждый шаг — включая вложенные подграфы — показывая рассуждения агента, вызовы инструментов и обновления состояния в режиме реального времени; интерфейс внедряется в приложения в виде боковой панели/встраиваемого элемента/выпадающего окна и поддерживает работу человека в процессе и координацию нескольких агентов обзор функций, с мини‑демо и кодом в AG‑UI Dojo AG‑UI dojo.
fal предоставляет конечную точку сервера MCP, которая подключается к Cursor, Claude Code, Gemini CLI и другим.
Документация fal теперь включает MCP‑конечную точку (https://docs.fal.ai/mcp)), которую агенты могут смонтировать через mcp.json, позволяя инструментам разработчика единообразно получать знания и действия fal во время выполнения; пример настройки показывает регистрацию в одну строку для широкой поддержки клиентов конфигурация MCP.
Vercel публикует шаблоны OSS Data Analyst (Slack+SQL) и Lead Agent для производственных приложений.
Vercel поделилась двумя шаблонами агентов с открытым исходным кодом: агент Slack+SQL Data Analyst, который превращает вопросы на естественном языке в валидированные запросы с потоковыми инсайтами data analyst agent,), и Lead Agent, который обогащает/квалифицирует входящие лиды с одобрениями в Slack и устойчивыми фоновых шагах lead agent,), выделенными среди запусков Ship AI ship recap.).
Паттерн AGENTS.md усиливает защиту: CLAUDE.md может включить его через @‑include; распространение символьных ссылок на скрипты и расширение поддержки инструментов.
Строители стремительно приближаются к шаблону AGENTS.md: Anthropic рекомендует ссылаться на @‑AGENTS.md из CLAUDE.md, чтобы агенты загружали каноническую спецификацию, не дублируя текст руководство по использованию,) подтверждено пакетными захватами, показывающими дополнительный файл в регионе системного приглашения tрафик захвата.) Репозитории переходят на bash/хелперы с симлинками, чтобы синхронизировать файлы скрипт для симлинков,) и AmpCode теперь читает CLAUDE.md напрямую, чтобы снизить трение для тех, кто колеблется поддержка Amp.)
Песочницы E2B теперь поставляются с более чем 200 MCP, доступных во время выполнения для долгосрочных агентов.
E2B сделал более 200 инструментов Model Context Protocol прямо доступными внутри их песочниц, чтобы агенты могли использовать стандартизованные возможности на середине выполнения без дополнительной настройки — полезно для долгосрочных исследований и задач по кодированию capability note.
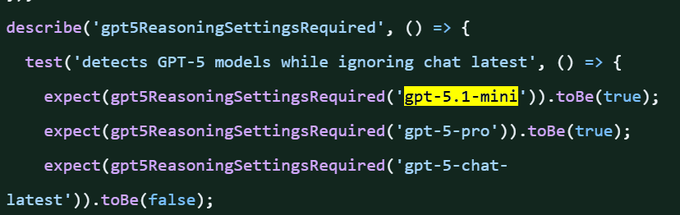
Тесты OpenAI Agents JS упоминают «gpt‑5.1‑mini» и «gpt‑5‑pro» о необходимости настроек рассуждений.
Объединённый коммит в openai‑agents‑js включает тесты для помощника/утилиты, который помечает модели GPT‑5 (например, gpt‑5.1‑mini, gpt‑5‑pro) как требующие настроек рассуждений, в то время как игнорируется chat‑latest — что предполагает предстоящие поведения маршрутизации моделей, с которыми могут понадобиться работать SDK агентов commit link, с фрагментом кода, зафиксированным наблюдателями test snippet.
cto.new усиливает своего бесплатного ИИ‑код‑агента защитой от злоупотреблений и резервным вариантом Bedrock для Anthropic
Engine Labs’ cto.new внедрил защиту от злоупотребления (чтобы сохранить мощность для реальных разработчиков), интегрировал AWS Bedrock как путь резервного переключения для моделей Anthropic и выпустил исправления надежности, касающиеся событий, повторных попыток токена Git и крайних случаев выбора ветки заметка по выпуску, журнал изменений.
Утечка системного промпта Grok ‘Mika’ показывает детальные теги речи и проактивный дизайн компаньона.
Утечка системного промпта Mika описывает энергичную персону, строгие правила беседы (не повторять вопросы, проактивные развороты), и исчерпывающую таксономию речевых тегов (например, {sigh}, {giggle}, {whisper}) с ограничениями по синтаксису/размещению — практичные схемы для сборщиков голосовых агентов prompt leak, вместе с тизером для iOS-компаньона companion teaser.
🚀 Скорость обслуживания: спекулятивные планировщики, преимущества задержки GPT‑OSS
Инженерия времени выполнения зафиксировала конкретные новости по производительности: планировщик перекрытия SGLang для спекулятивного декодирования, советы по развёртыванию DeepSeek‑OCR, прирост пропускной способности GPT‑OSS 120B от Baseten и интеграция бренда Groq. Исключаются релизы моделей/SDK.
Baseten вывел GPT‑OSS 120B на более чем 650 TPS и ~0,11 с TTFT на NVIDIA
Команда по производительности моделей Baseten повысила пропускную способность GPT‑OSS 120B с примерно 450 до 650+ TPS, одновременно сократив TTFT примерно до 0,11 с, приписывая это стеку предположительного декодирования EAGLE‑3 на оборудовании NVIDIA throughput claim,), с инженерными деталями в их глубоком разборе perf deep dive) и публичной странице модели, чтобы попробовать прямо сейчас model library.\n\n
\n\nПомимо самих чисел, пост разбирает orkestrацию draft/verify, интеграцию TensorRT‑LLM и пакетирование в полёте — полезные схемы для тех, кто стремится к субсекундной готовности к обслуживанию на крупных MoE‑style системах.
Планировщик перекрытий SGLang увеличивает пропускную способность спекулятивного декодирования на 10–20%
LMSYS представила нулевые накладные издержки, перекрывающий планировщик для спекулятивного декодирования, который обеспечивает 10–20% ускорение конца‑к‑концу, и утверждает, что команда Google Cloud Vertex AI проверила преимущества на практике scheduler details.
Продолжая тему 70 tok/s, это сосредоточено на удалении накладных расходов на CPU (запуск ядра/метаданные) и перекрытии фаз draft/verify, чтобы держать GPU занятыми. Команда пригласила контрибьюторов и поделилась активной дорожной картой и каналом для работ по спекулятивному декодированию roadmap links, with specifics in GitHub issue and community access via Slack invite.
Однострочный быстрый старт SGLang для DeepSeek‑OCR с флагом устройства TTFT‑cutting
LMSYS поделилась минимальной командой для обслуживания deepseek‑ai/DeepSeek‑OCR на SGLang, упоминая необязательный флаг --keep‑mm‑feature‑on‑device, чтобы снизить время до первого токена за счет устранения трения между хостом и устройством quickstart command.
Для команд по запуску OCR в масштабе это подкрепляет акцент SGLang на практичных настройках обслуживания (TTFT, локальные мультимодальные функции), которые дополняют его новый спекулятивный планировщик scheduler details.
Groq делает ставку на «быструю и доступную инференс» с кампанией наружной рекламы McLaren F1.
Groq запустил кобрендированные с McLaren F1 рекламные щиты по городским площадкам, чтобы подчеркнуть свою позицию по задержке и цене для рабочих нагрузок инференса out‑of‑home campaign.
Хотя это и не бенчмарк, кампания сигнализирует о продолжающемся фокусе на стоимость и скорость как рычаг выхода на рынок — актуально на фоне новых планировщиков и преимуществ спекулятивного декодирования из открытых рантаймов.
🧪 Модели и сигналы дорожной карты: MiniMax‑M2; подсказки к GPT‑5.1‑mini
Доступность новой модели и правдоподобные ориентиры дорожной карты доминируют: MiniMax‑M2 появляется на разных платформах, а несколько кодовых ссылок указывают на тестирование GPT‑5.1‑mini. Исключает рекламу OpenAI и доход (функция).
Код и хлебные крошки интерфейса указывают на GPT‑5.1‑mini, находящийся в активном тестировании.
Несколько достоверных сигналов указывают на внутренний трек «GPT‑5.1‑mini»: тест OpenAI Agents JS явно проверяет наличие 'gpt‑5.1‑mini' и 'gpt‑5‑pro', при этом исключая 'chat‑latest' коммит GitHub Скриншот теста, и захват бизнес‑интерфейса показывает «GPT5‑Mini Scout V4.2» наряду с Company Knowledge, что наводит на мысль о ограниченных испытаниях в корпоративных рабочих пространствах наблюдение за бизнес‑интерфейсом.
[изображение:https://pbs.twimg.com/media/G4EGODaWkAADTh_.jpg|Ожидания теста]
Хотя некоторые обозреватели осторожно предупреждают, что это может быть опечаткой, изменение было влитo в слияние — придало вес сигналу дорожной карты, не являясь формальным запуском Merged comment Caution on typo.)
MiniMax M2 выходит на OpenRouter с контекстом 204.8K и бесплатным тарифом
Новый флагман MiniMax теперь доступен на OpenRouter как «minimax/minimax-m2: free», рекламирующий окно контекста 204.8K, задержку ~3.22 s и ~89 TPS по статистике живого провайдера OpenRouter listing.)
Для инженеров вход практически нулевой стоимости и длинный контекст делают его непосредственным кандидатом для агентно-ориентированных рабочих процессов и RAG по крупным документам; MiniMax также продвигает доступ первого лица для агентов, что упрощает раннее тестирование интеграции Agent platform access.)
MiniMax M2 вступает в боевые испытания в LM Arena с контекстом 200K; появляются заявления о топ-5 по производительности
LM Arena добавил обзор MiniMax‑M2 Preview для прямых сравнительных подсказок сообщества, выделяя агентное использование и контекст на 200K токенов, а боевой режим теперь открыт для испытаний Arena preview WebDev arena.
- Коммуникации MiniMax сами по себе провозглашают глобальное место в Топ‑5 «обогнав Claude Opus 4.1», занимая место чуть позади Sonnet 4.5; как и всегда, применяются вариации кросс‑гарнеса и независимые оценки важны для вашей рабочей нагрузки Ranking claim.)
- За пределами Arena партнерские платформы освещают каналы доступа (например, ранний листинг Yupp) для расширения охвата разработчиков Yupp listing.)
Genie 3 от Google «world model» появляется в публичном интерфейсе экспериментов.
Новые слухи сообщают, что Google экспериментирует с Genie 3 — искусственной «моделью мира», которая позволяет пользователям создавать и взаимодействовать с настраиваемыми окружениями — видна на рабочих поверхностях продукта во время тестирования World model note, following up on public experiment UI из вчерашних наблюдений. Для разработчиков это намекает на предстоящие API для агентов в духе симуляций и интерактивной генерации контента.
Cursor тизерит свою первую собственную модель «Cheetah» на следующей неделе.
Курсор намекает, что его первый проприетарный модель, Cheetah, появится на следующей неделе, сигнализируя о вертикальном движении платформ кодирующих агентов к индивидуальным стекам инференса Model tease. Это следует более широкому паттерну того, как поставщики агентов владеют большей частью уровня модели, чтобы настраивать задержку, надёжность использования инструментов и интеграцию IDE.
🏢 Платформы производственного ИИ: Mistral AI Studio выходит на рынок
Mistral позиционирует производственную платформу для агентов с наблюдаемостью, происхождением и управлением; сообщество отмечает, что некоторые вкладки помечены «Coming soon». Исключает рекламу OpenAI (функция).
Mistral AI Studio запускается как производственная платформа для агентов с версионированием и управлением
Mistral представила AI Studio, полнофункциональную платформу для производства, которая перемещает команды от экспериментов к развернутым агентам с provenance, версионированием, журналами аудита и мерами безопасности, охватывающими Playground → Agents → Observe → Evaluate → Fine‑tune → Code Launch details, и блог компании описывает встроенные хуки оценки, прослеживаемые петли обратной связи и гибкие цели развертывания Mistral blog post.
- Начальные пользователи отмечают, что несколько вкладок (Observe, Evaluate) помечены как “Coming soon”, в то время как основной рантайм и потоки агентов работают сегодня — что указывает на поэтапную раскатку, ориентированную на вывод рантайма агента в продакшн в первую очередь Coming soon note.
⚡ США ускоряют межсоединения между дата-центрами
Политика/инфраструктура с прямым воздействием на ИИ: США предпринимают шаги по сокращению сроков рассмотрения подключений к электросети для дата-центров — это существенно влияет на сроки развертывания ИИ. Сегодня разрешена одна не-ИИ категория.
План США будет ограничивать сроки рассмотрения вопросов межсетевого соединения дата‑центра до 60 дней.
Черновик федерального правила ограничит рассмотрение вопроса о подключении к сети для дата-центров до 60 дней — по сравнению с многолетними сроками — что ускорит подключение для ускоренного развертывания на базе ИИ сообщение Bloomberg,) с конкретикой в первом отчёте о предложении статья Bloomberg.) В контексте TPU megadeal, где гиперскейлеры закрепляют мощность на гигаватты, сокращение сроков цепочек поставки напрямую увеличивает доступность вычислений ИИ.
- Изменение нацелено на крупнейшее узкое место в расписании развертывания мощности ИИ (исследования межсетевых подключений), что потенциально сдвигает сроки вывода в коммерческую эксплуатацию на кварталы в горячих рынках.
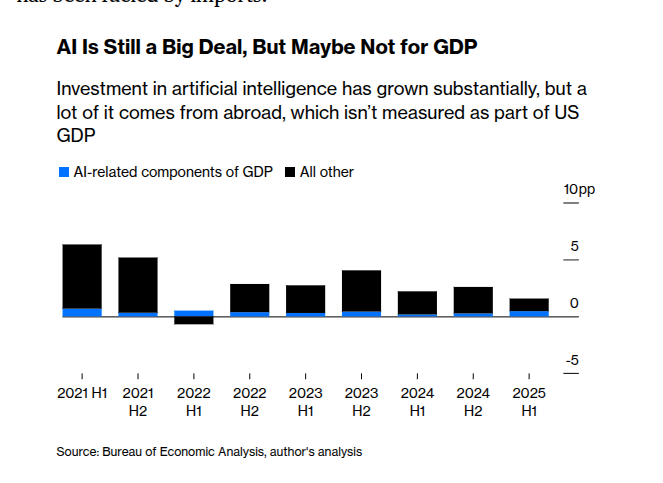
ИИ поднял ВВП за первое полугодие примерно на ~1,3 п.п., но чистый эффект составил примерно ~0,5 п.п. после импорта
Новый макроотчёт показывает, что расходы, связанные с ИИ, добавили примерно 1,3 процентных пункта к росту реального ВВП США за первую половину 2025 года, но чистый внутренний вклад падает примерно до 0,5 п.п. после вычитания импортируемых чипов/серверов GDP chart. Это согласуется с материалов о том, что инвестиции в ИИ поддерживают рост несмотря на неблагоприятные условия Yahoo Finance piece, и объясняет, почему заголовочный ВВП может недооценивать импульс сектора, когда оборудование закупается за рубежом.
🧠 Методы рассуждения и обучения с подкреплением, за которыми стоит следить
Плотный поток новых методов и анализов, связанных с масштабированием рассуждений и стабильностью обучения, с конкретными выводами для разработчиков агентов и исследовательских команд.
BAPO стабилизирует обучение с офф-политикой в RL; 32B достигает 87.1 (AIME24) и 80.0 (AIME25) при помощи адаптивной отсечки
Балансированная оптимизация политики Фудан (BAPO) динамически настраивает границы отсечения PPO, чтобы балансировать положительные/отрицательные преимущества, сохраняя исследование пространства и сдерживая нестабильность; модель размером 32B сообщает 87.1 на AIME24 и 80.0 на AIME25, соперничая с o3‑mini и Gemini‑2.5, а приросты также наблюдаются на масштабах 7B и 3B result numbers, method overview. Авторы выпустили реализацию для воспроизводимости ArXiv paper и GitHub repo.
• Takeaway: адаптивное, асимметричное отсечение — практичный готовый элемент для конвейеров RLHF/RLAIF, которые сталкиваются с дрейфом вне политики; полезные настройки включают целевой коэффициент положительных токенов и отдельные графики c_high/c_low training notes, entropy control.
DiscoRL: метаобученное обновляющее правило превосходит рукотворные алгоритмы на Atari‑57 и переносится на новые задачи
Исследование журнала Nature сообщает, что мета‑обучающий агент обнаружил правило обновления RL, которое превосходит стандартные алгоритмы на Atari‑57 и обобщается на незнакомые среды без настройки под задачу, указывая на самосовершенствующиеся обучающие циклы, в которых сам оптимизатор обучается paper highlight. Для исследовательских команд это укрепляет аргумент в пользу обучаемых оптимизаторов при обучении агентов на длительный горизонт, когда вручную настроенные потери застревают.
LVLM-ы галлюцинируют чаще в длинных ответах; HalTrapper индуцирует, detects, и подавляет рискованные токены без переобучения
Большое‑видовое исследование показывает, что галлюцинации растут с длиной ответа, когда модели стремятся к связности; HalTrapper компенсирует это за счёт (1) добавления аддонов к подсказкам, чтобы индуцировать рискованные упоминания, (2) пометки токенов с подозрительно похожим визуальным вниманием, затем (3) контрастивного снижения их веса во время декодирования — без дообучения paper thread. Это хорошо сочетается с ранее применяемыми на этапе декодирования мерами предохранения, которые снижают галлюцинации объектов в подписи примерно на ~70% без переобучения caption hallucinations.
Казуальный пошаговый оцениватель: релевантность и связность на каждом шаге лучше предсказывают итоговую корректность, чем рубрики по всей траектории
Новая оценочная рамка оценивает каждый шаг рассуждения по двум критериям: (i) релевантность к вопросу и (ii) согласованность с предыдущими шагами, не учитывая будущий контекст, чтобы избежать предвзятости hindsight; следы, которые остаются релевантными и последовательными, примерно в 2 раза чаще приводят к верному результату, и фильтрация по этим оценкам повышает точность на следующих этапах paper thread. Для команд, обучающих модели рассуждений, это предлагает легковесный фильтр данных и отладочную линзу, которая выявляет, где цепочки уходят с темы или нарушают выводимость.
AgenticMath: более чистая синтетическая математика обеспечивает улучшение рассуждений всего за 5–15% данных
Новые результаты показывают, что курируемые, более качественные синтетические математические трассировки могут обучать более сильных рассуждающих за долю токенов, которые обычно используются, опережая базовые на «больше данных» при равной или меньшей стоимости paper thread. Для бюджетов RLHF/RLAIF под давлением инвестирование в качество генерации и фильтрацию может привести к лучшей отдаче, чем масштабирование объема корпуса без изменений.
RLEV: оптимизировать к явным человеческим ценностям, чтобы модели оценивали ответы по значимости, а не только по точности
«У каждого вопроса своя ценность» представляет RLEV, выравнивая цели оптимизации с человеческими сигналами ценности, чтобы агенты обучались точности, взвешиваемой по ценности, и политикам останова, учитывающим ценность, а не униформной потери по вопросам paper abstract. Это обещает для агентов в сферах с высокими ставками, где стоимость ошибки намного больше средних метрик.
Zhyper настраивает LLM на задачи/культуры с использованием факторизованных гиперсетей, достигая сопоставимости с Text-to-LoRA при примерно в 26 раз меньшем количестве обучаемых параметров.
Zhyper замораживает базовую модель и обучает небольшие, повторно используемые части адаптера на каждом слое; небольшая гиперсеть вырабатывает короткие векторы масштабирования из описаний задач, чтобы модулировать эти части, позволяя быстро менять поведение с низким расходом памяти/задержкой и лучшей переносимостью по сравнению с адапторами на каждую задачу обзор статьи. Диагональные против квадратных вариантов меняют количество параметров ради гибкости, предлагая компактный путь для настройки под инструкции/культуру.
Проверка по текстовой сетке демонстрирует хрупкое пространственное рассуждение: средняя точность снижается примерно на 42,7% по мере роста размеров доски.
Во всех задачах на квадранты, зеркалирование, ближайшее/дальнее, поиск слов и слайд‑маркеры модели работают с небольшими досками, но резко деградируют по мере увеличения сеток из‑за ошибок чтения и слабого отслеживания состояния; варианты Claude 3.7 выводят сюда GPT‑4.1/4o, но на больших раскладках все падают paper overview. Practical implication: treat table/layout‑heavy tasks as vision or structured‑state problems, not pure text.
Визуальные доказательства контроля галлюцинаций без дообучения
«Рабочий процесс HalTrapper позиционируется как контроль во время декодирования: индуцировать кандидатов, выявлять рискованное внимание, затем подавлять его через контрастивное декодирование, стабилизируя более длинные описания при сохранении плавности воспроизведения. paper thread. Команды могут опробовать это в стэках обслуживания как мало‑рисковую меру перед переходом к тонкой настройке.»
🎬 Динамика генерации видео: Veo 3.1, Seedance Fast, поединки на арене
Креативный/видео ИИ продолжал набирать обороты — новые элементы управления Veo 3.1, более дешевый/быстрее работающий вариант Seedance, соревнования по промптам сообщества, а также сигналы о музыкальном продвижении OpenAI. Специализированное освещение в СМИ сохранено из-за высокого уровня твитов сегодня.
Gemini Veo 3.1 выходит с более правдоподобными текстурами и упрощённым управлением камерой.
Последнее обновление Veo от Google фокусируется на контролях производства: реалистичные текстуры, более простой поворот камеры и диалог с звуковыми эффектами, теперь доступно для опробования в Gemini. Примечания к развертыванию также подчеркивают более широкий набор улучшений «Gemini Drops», которые будут внедряться в ближайшие недели. См. обзор и точку входа в продуктовой ветке feature thread и страницу запуска Gemini Veo page. Ранние пользовательские демо сообщают о заметно более точном соблюдении направления с Veo 3.1 по сравнению со сборками весны demo claim.
Seedance 1 Pro. Быстро сокращает затраты примерно на 60% и рендерит 5 секунд in 480p примерно за ~15 секунд
Новый вариант Seedance‑1 Pro Fast от ByteDance ориентирован на скорость итераций и бюджет. Replicate указывает цену примерно на 60% ниже, чем у Pro, ~15 секунд для пятисекундного клипа в 480p, и примерно 30 секунд для 720p — нацелен на превью‑циклы перед финальными проходами качества model listing, с деталями моделей и ценами на карточке Replicate model page. Сообщества уже сравнивают компромиссы по выводу в отношении Pro/Lite в быстрых обходах промптов examples roundup.
fal’s Generative Media Conference: 200+ моделей в прямом эфире; медианная компания использует 14
Сигнал экосистемы: на первой в истории Генеративной медиа‑конференции fal организаторы поделились телеметрией платформы — доступно 200+ моделей, медианный клиент подключает 14 моделей в рамках одного рабочего процесса; использование изображений растет стремительно, а использование видео остается сильным usage stats. Лайв‑сессии от BytePlus, Decart и других продемонстрировали видео в реальном времени и стеки аватаров, подчеркивая ускоренное внедрение мульти‑моделей для производственных пайплайнов live demo.
OpenAI разрабатывает музыкальную модель; работает с учащимися Juilliard над аннотациями.
The Information сообщает, что OpenAI занимается созданием ИИ, который генерирует музыку, собирая высококачественные аннотации у студентов Juilliard и исследуя инструменты подсказок текст‑аудио (например, «добавить гитару к этому вокалу»). Любой запуск, вероятно, будет зависеть от лицензирования лейблов на фоне активных судебных дел против конкурентов обзор новостей, с более глубоким контекстом в статье статья The Information.
LTX‑2 добавляет заявление о снижении затрат на вычисления на 50%; планы по открытию весов намечены на конец ноября.
Новые детали Lightricks’ LTX‑2: помимо нативного 4K/50 fps и синхронизированного аудио, команда теперь заявляет примерно 50% снижения затрат на вычисления и 10‑секундные клипы, с открытыми весами, нацеливаемыми на поздний ноябрь через интеграции API и ComfyUI model summary. Это следует за native 4k, что заложило базовый уровень 4K/50 fps и возможности аудио‑синхронизации для уровней Fast/Pro.
Арена сводит Veo 3.x, Sora‑2, Kling и Hailuo в поединки по подсказкам сообщества
Открытая «видеарена» LMArena стресс-тестирует фронтирные видеомодели на идентичных творческих подсказках, голоса определяют рейтинг лидеров. Поединки в этом раунде включают Hailuo‑02‑Pro против Veo‑3‑Audio на морфах чертежа→продукта blender battle,) плюс Veo‑3.x против Sora‑2 в сцене возвращения дельфина и концепцию кита, разрывающего страницу из книги showdown thread, orca face‑off.)). Результаты помогают командам оценивать точность стиля, связность движений и синхронизацию аудио между поставщиками на реальных подсказках, а не на отобранных клипах.
🔎 Агентное извлечение & стеки поиска
Сигналы того, что рабочие процессы агентов зависят от более эффективного извлечения: новые движки и паттерны обнаружения кода и документов и API, ориентированные на схему.
Hornet позиционируется как движок поиска с приоритетом схемы (schema-first), ориентированный на агентное извлечение для производственных приложений.
Hornet представляется как движок извлечения, ориентированный на агентов, а не на людей, с API, ориентированными на схему (schema‑first APIs), поддержкой параллельного и итеративного цикла и вариантами развёртывания on‑prem/VPC — направлен на замену хрупких слоёв произвольного поиска в стеках агентов product update, и с деталями об использовании, не зависящем от модели, и предсказуемыми API на сайте Hornet product page. Акцент: агентам нужны воспроизводимые, эффективные по токенам примитивы извлечения, которые открывают явные регуляторы для охвата, актуальности и итерации — не просто общий поисковый ящик.
Подагент Librarian Amp навигирует по документации и коду (включая приватные репозитории) для рабочих процессов агента.
Паттерн Librarian от Amp имеет агентов, которые получают карту документации в формате Markdown и затем проходят по ней, чтобы отвечать на вопросы (и делать то же самое в коде), что исключает халтурами по поводу функций инструментов и держит поведение в актуальном состоянии описание паттерна. Публичный пример прослеживает внутренности Playwright от начала до конца для логики кликабельной точки пример сценария использования, и страница функций подтверждает путь к приватному репозиторию через интеграцию с GitHub, чтобы перенести это извлечение в корпоративные кодовые базы краткое описание функции.
«Каждая организация должна инвестировать в релевантный поиск» становится правилом дизайна для агентов.
Краткое резюме для лидов по ИИ и команд платформы: долгие контексты не снимают необходимость целенаправленного извлечения — агенты по-прежнему требуют поиска с высокой recall, предсказуемой задержкой, с переписыванием запросов и многоступенчатой оркестрацией, чтобы работать надёжно в продакшн-масштабе slide summary.
- Почему это имеет значение: петли агентов ограничены по токенам и времени; без надёжного извлечения планы уходят в сторону, а использование инструментов ухудшается, особенно при многократных обращениях.
- Рекомендованный подход: рассматривйте поиск как систему класса «первой очереди» с механизмами оценки и отраслево‑специфичными эталонами, а не как поиск по эмбеддингам в режиме наилучшей попытки.
Weaviate запланирует семинар «Query Agent» по продвижению готовых к использованию агентских паттернов извлечения
Weaviate объявила о онлайн-сессии 6 ноября по ускорению внедрения агентов в продакшн с помощью своего Query Agent, ориентированной на команды, которым необходимы настройки извлечения для многошагового планирования и I/O‑ограниченных циклов workshop invite. Ожидайте практические рекомендации по планированию запросов, оркестрации инструментов и образцам оценки для агентного RAG.
}
🎮 Внедрение корпоративных медиа: EA × Stability; Netflix «всё включено»
Два конкретных сигнала принятия в медиа и контенте: гигант игровой индустрии, заключивший партнерство по инструментам генеративного ИИ, и Netflix, расширяющий применение генеративного ИИ во всех рабочих процессах.
Netflix заявляет, что полностью вовлечена в ИИ по всем направлениям — рекомендации, производство и маркетинг.
Netflix объявил генеративный ИИ «значительной возможностью» и заявил, что применит его сквозь весь процесс—from персонализации контента до ускорения творческих рабочих процессов—ссылаясь на недавние проекты, уже использующие ген‑ИИ (например, дрейф лица в Happy Gilmore 2; подготовительный дизайн гардероба/постановка для Billionaires’ Bunker) CNBC report.
- Компания обосновывает ИИ как дополнение к создателям (эффективность и скорость итераций), а не замену им, отмечая при этом внутренние руководящие принципы по ИИ на фоне защиты талантов после забастовки CNBC report.
- Для команд по ИИ в медиа это позволяет начать оценку поставщиков в области видео, аудио/SFX и создания маркетинговых материалов, и поднимает планку по аудитируемости (кто/какие модели изменяли кадр) и гигиене лицензирования.
EA сотрудничает с Stability AI для совместной разработки генеративных моделей, инструментов и рабочих процессов для разработки игр
Electronic Arts сотрудничает с Stability AI, чтобы создать производственные модели на базе генеративного ИИ и конвейеры (пайплайны) для художников, дизайнеров и инженеров в игровых студиях, что сигнализирует об институциональном принятии ИИ в рабочих процессах AAA‑уровня объявление о партнерстве.
Для лидеров в области ИИ это поднимает уровень зрелости моделей/инструментов от экспериментов до совместно управляемых платформ, встроенных в создание активов, предпросмотр и циклы итераций — что подразумевает, что управление, происхождение наборов данных и компромиссы по задержке/качеству будут приниматься совместно поставщиком и студией, а не произвольными командами.
Mondelez (производитель Oreo) инвестирует 40 млн долларов в обучение собственной видеомодели для телевизионной рекламы.
Гигант потребительского сектора Mondelez, как сообщается, обучил свою собственную видеомодель для ТВ-рекламы после инвестиций в 40 млн долларов, подчеркивая, что крупные бренды будут создавать креативный ИИ внутри организации там, где важны контроль над IP и ритм работы brand model claim.
На практике это меняет динамику взаимоотношений между агентствами и поставщиками услуг: брендо‑установленные модели можно настраивать по proprietary brand books, контрактам с талантами и архивным рекламным роликам, но они также наследуют обязанности по управлению правами, фильтрам безопасности и циклу творческого контроля качества, согласованному с SLA по закупке медиа.
🔌 Совместимость: серверы MCP и интерфейсы агентов
Интероперабельность достигла зрелости благодаря конкретным маршрутам MCP и каркасу UI агента — полезно для команд, стандартизирующих инструменты между редакторами и стеками.
Codex CLI 0.48 выпускает Rust MCP-клиент, ограничение доступа инструментами и более чистую серверную аутентификацию.
OpenAI’s Codex CLI 0.48 добавляет клиент MCP stdio, созданный на официальном Rust SDK, поддержку per‑server enabled_tools/disabled_tools и ограниченные входы по сеансам для потоковых HTTP‑серверов через codex mcp login, а также лучшие сообщения об ошибках при запуске и более точное выполнение инструкций при использовании инструментов release notes, и полные детали можно найти в заметках 0.48.0 GitHub release. Эти функции упрощают интеграцию и управление MCP‑серверами в рамках агентских стеков организаций.
Песочницы E2B теперь включают более 200 MCP, чтобы агенты могли вызывать инструменты без дополнительной настройки.
E2B обеспечивает прямой доступ к более чем 200 серверам Model Context Protocol из своей песочничной среды выполнения, позволяя долгосрочным исследовательским или кодирующим агентам вызывать стандартизированные инструменты прямо из коробки runtime update. Это удаляет связующий код на уровне проекта и улучшает воспроизводимость, когда те же MCP используются в разных редакторах или CI.
CopilotKit добавляет потоковый интерфейс подграфа для агентов LangGraph с живыми трассами шагов
CopilotKit теперь может транслировать каждый шаг — включая вложенные подграфы — одновременно показывая рассуждения агента, вызовы инструментов и обновления состояния в реальном времени; он также поддерживает управление человеком в петле (human‑in‑the‑loop) и сотрудничество нескольких агентов feature brief, с рабочими мини‑демонстрациями в LangGraph AG‑UI Dojo AG‑UI Dojo. Это дает командам повторно используемый слой интерфейса, который сопровождает их LangGraph агентов по приложениям.
Fal обеспечивает готовый к использованию MCP-сервер для инструментов агентов во всех редакторах.
Fal выпустил конечную точку MCP‑сервера, которая напрямую добавляется в mcp.json, позволяя Cursor, Claude Code, Gemini CLI, Cline и другим инструментам, поддерживающим MCP, вызывать сервисы Fal без индивидуальных адаптеров MCP snippet.
Это усиляет межредакторную совместимость для команд, стандартизирующих MCP, чтобы подключать одни и те же инструменты через несколько интерфейсов агентов.
Паттерн AGENTS.md выходит в релиз: Claude может читать @‑AGENTS.md через CLAUDE.md, и Amp добавляет поддержку
Руководство Anthropic рекомендует ссылаться на @‑AGENTS.md из CLAUDE.md, чтобы Claude загружал спецификацию, ориентированную на агента, без дублирования содержимого README Руководство Anthropic; сетевой захват подтверждает, что дополнительный файл внедрён в регион системной подсказки капация пакета. Amp теперь читает CLAUDE.md также, чтобы соответствовать этой конвенции Поддержка Amp, и мейнтейнеры предлагают простые скрипты символьной ссылки, когда проектам нужны оба файла в одном репозитории Совет по созданию символических ссылок. Эта развивающаяся структура документа улучшает переносимость инструкций между агентами без форков для каждого инструмента.
Учебник по панели агента Zed охватывает подключение MCP, профили, режим следования и обзоры.
Полное руководство по панели агента Zed охватывает настройку, профили на запись и запрос, режим слежения, подключение серверов MCP и процессы обзора кода, а также интеграцию внешних агентов через ACP tutorial overview, с демонстрацией «от начала до конца», доступной здесь YouTube tutorial. Это практичный шаблон для организаций, унифицирующих паттерны интерфейса агента между редакторами.
📈 Бенчмарки и операции оценки
Свежие снимки оценок и заметки по процессу, посвящённые агентам и кодированию — полезны для команд, переходящих от вайбов к инструментированию.
LVLMs склонны к галлюцинациям в длинных ответах; HalTrapper снижает это without retraining
Исследователи показывают, что модели зрения и языка дрейфуют по мере увеличения длины ответов (давление когерентности > обоснованность), затем представляют HalTrapper: внутренние подсказки, которые вызывают риск, детекция объектов без обоснования на основе внимания и контрастивное декодирование для снижения веса помеченных продолжений — уменьшение галлюцинаций при сохранении плавности аннотация статьи.
Практично для eval ops: добавьте тесты с учётом длины и враждебные пробы «there is also …» для обнаружения хрупких декодеров.
Адаптивная отсечка BAPO демонстрирует передовые открытые результаты по наборам данных AIME.
Балансированная оптимизация политики Фудан настраивает границы отсечения PPO онлайн, чтобы сбалансировать положительные/отрицательные обновления, сообщая о 87.1 (AIME24) и 80.0 (AIME25) на модели размером 32B — конкурентоспособна с o3‑mini и Gemini‑2.5 — и стабильные выигрыши на масштабах 7B/3B поток результатов, с методами и кодом для проверки статья ArXiv и репозиторий GitHub.
Хороший кандидат для включения в наборы оценки reasoning‑RL наряду с базовыми GRPO/SFT.
Пошаговая причинно‑следственная оценка превосходит оценку по полной трассе для оценки рассуждений.
Новое исследование предлагает оценивать каждый этап рассуждения по релевантности (решает задачу) и согласованности (следует за предыдущими шагами), используя только контекст прошлого, избегая эффекта ретроспективы; оценки качества шагов коррелируют лучше с конечной корректностью, чем судьи на уровне трасс, и позволяют более чистую фильтрацию данных и побуждения к подсказкам paper summary.
Для операций это предполагает добавление проверок на каждом шаге для отбора трасс, выбора данных SFT с более высоким сигналом и введение ограничителей для длинных цепочек.
Qwen3‑Max поднимается на первое место по ROI в живой торговле AlphaArena
Крипто-бенчмарк AlphaArena теперь показывает, что Qwen3‑Max обходит DeepSeek V3.1 и занимает верхнюю позицию по последним метрикам доходности, подчеркивая быстро движущиеся дельты моделей в условиях реальных денег обновление таблицы лидеров. Чтобы получить снимок более широких тенденций производительности моделей, циркулирующих вместе с этим сдвигом, смотрите график сравнительной доходности, опубликованный сегодня roi context.
Команды должны рассматривать AlphaArena как стресс-тест агентной устойчивости (задержка, вызовы инструментов, правила риска), а не как статическую метрику точности.
Обновление RL, обученное метаобучением (DiscoRL), превосходит правила, созданные вручную.
Сообщение Nature показывает, что мета‑обучающееся устройство обнаруживает правило обновления в RL, которое достигает передового уровня на Atari‑57 и обобщается на новые задачи без настройки под каждую среду, обыгрывая классические варианты TD/Q‑обучения/PPO обзор статьи.
Для операций оценки это поднимает планку для RL‑из рассуждений‑конвейеров: сравнивать следует с обучаемыми оптимизаторами, а не только с базовыми PPO.
От ощущений до оценок: практический план действий по выпуску ИИ, который действительно работает
Braintrust утверждает, что систематические evals — а не impulso ad‑hoc prompt swaps — отделяют надёжные функции ИИ от демонстраций, подробно описывая, как команды переходят к повторяемым основам и рассказывая о 20‑минутном исправлении производственного бага, которое было включено благодаря инструментированию eval evals explainer,) с полным разбором здесь article page.). Эта статья является полезным шаблоном для установки порогов пропуска/не пропуска и внедрения evals в CI.
Предвзятость LLM в роли судьи выявлена в бенчмарках по психическому здоровью
Бенчмарк на 100 тысяч кейсов показывает, что оценщики LLM систематически завышают баллы за эмпатию/полезность и демонстрируют слабую согласованность по вопросам безопасности/релевантности по сравнению с рейтингами клиницистов, рекомендуется пред-проверка LLM и человеческое решение в областях с высоким риском paper summary.
Для операций оценки не следует полагаться на одного модельного судью как на единственного арбитра; ансамблевый или основанный на рубриках скоринг с выборкой людей безопаснее.)
Пространственное мышление в текстовых сетках не выдерживает масштаба, как показало исследование.
На задачах по поиску в квадрантах, зеркалированию, ближайшему/самому дальнему, поиску слов и задачах со скользящими плитками точность LLM снижается в среднем на 42.7% по мере роста размера сетки; ошибки включают неверное считывание, арифметические промахи и слабое отслеживание состояния, даже когда входные данные укладываются в контекстные окна summary of paper.
Следствие: рассматривать задачи, где важна таблица/разметка, как отдельную ось оценки, и рассматривать структурированные парсеры или визуальные энкодеры вместо простого текста.
MiniMax M2 открывается для общественной оценки на различных аренах.
Предпросмотр MiniMax‑M2 уже доступен в режиме «Battle Mode» WebDev на LMArena, приглашая попарно‑постановочные запросы к задачам веб‑агента arena preview с прямым доступом к сценариям арены WebDev arena. В параллеле список OpenRouter предоставляет бесплатную конечную точку (204.8k контекста, ~3.22s задержки, ~89 тпс), подходящую для интеграции в рамку и нагрузочных тестов endpoint listing.
Планы тестирования: воспроизведение задач Next.js, точность вызова инструментов и различия во времени до первого прохождения.
AI Tinkerers SF обсудят «Big Eval» против прагматичного тестирования
Очная сессия в офисе Okta (30 октября, 17:30) разберёт, как на самом деле специалисты тестируют инструменты ИИ — когда стоит инвестировать в полноформатные стеки оценки против лёгких проверок — и поделится паттернами, возникающими у команд в Bay Area детали встречи, с информацией о регистрации, опубликованной организаторами страница мероприятия.
Ожидаются практические эвристики (спецификации, разложение задач, приемочные тесты) наряду с обсуждением соотношения затрат и выгод от оценки.
🛡️ Достоверность суждений моделей большого языка (LLM)
Две оценки предупреждают об отказе от делегирования чувствительных суждений: скрининги личности при найме и оценка ответов по психическому здоровью. Исключает темы конфиденциальности/рекламы (функция).
LLMs проваливают отбор по личностным качествам при найме и редко советуют «Не рекомендуется»
Много-модульная оценка показала, что все 12 протестированных LLM не прошли стандартный корпоративный тест личности и, выступая в роли HR-оценщиков, почти никогда не помечали кандидатов как «Не рекомендовано» paper summary, study recap.
- Модели отвечали на 216 пунктов по шкале Лайкерта, но склонялись к согласительным ответам, что приводило к нереалистично положительным профилям и слабому соответствию ролям paper summary.
- В качестве скринеров большинство моделей рекомендовали практически всех, что демонстрирует слабую дискриминацию между кандидатами study recap.
- Авторы предупреждают об делегировании функции отбора LLM; используйте их только как поддержку предскрининга с жестким человеческим контролем paper summary.)
Большие языковые модели завышают оценку эмпатии и полезности в ответах на вопросы о психическом здоровье; используйте их только на этапе предскрининга.
Исследователи выпустили MentalBench‑100k и MentalAlign‑70k и показали, что судьи на основе больших языковых моделей систематически завышали оценки эмпатии и полезности по сравнению с клиницистами, несмотря на достойное согласование ранжирования по критериям, ориентированным на рассуждение paper summary.
- Оценки безопасности и релевантности были непоследовательны, что делало модели ненадёжными для отбора в условиях высокой срочности без участия человека paper summary.
- В работе рекомендуется использовать LLM для сортировки/предскрининга, клиницисты принимают финальные решения, особенно по измерениям эмоций и безопасности paper summary.