MiniMax M2 обходит Sonnet по цене на 8% — в 2 раза быстрее, бесплатно до 7 ноября.
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
MiniMax только что выпустил MiniMax M2, открытую модель кодирования, ориентированную на агентов, с бесплатным окном доступа до 7 ноября. Презентация проста: примерно 8% от цены Claude Sonnet и примерно в 2 раза быстрее, нацеленная на IDE-агентов и инструменты командной строки, где правят бал латентность и пропускная способность. С открытыми весами, публичной карточкой модели, репозиторием и API это не тизер — команды могут начать экспериментировать сегодня без ожидания приглашений.
Поддержка времени выполнения Day-0 появилась в vLLM и SGLang, включая выделенный парсер вызовов инструментов и парсер рассуждений MiniMax для длинных запусков, что должно сократить время до первого токена (TTFT) и сгладить пропускную способность при speculative decoding. Распределение быстро распространилось благодаря временной бесплатной ступени OpenRouter, бесплатной версии Anycoder «MiniMax M2 Free» и раннему хостингу от GMI Cloud, чтобы команды могли сравнить его с Sonnet или внутренними стеками без необходимости проходить через шлюзы. Разработчики уже подключают Claude Code к M2 через настраиваемый базовый URL и переключатель модели одним командой, сохраняя привычный UX, направляя вычисления на более дешевый бэкенд.
Суть проблемы — надёжность: проверить циклы редактирования нескольких файлов, совместимость схем вызова функций и ограничения по веткам или коммитам перед внедрением в CI. Если эти пункты соблюдены, M2 выглядит как надёжная рабочая лошадка, которая давит на конкурентов по задержке и экономике единицы измерения.
Feature Spotlight
Функция: MiniMax M2 открывается как агентно‑нативная модель кодирования
MiniMax‑M2 открывается с поддержкой day‑0 vLLM/SGLang и бесплатным доступом, нацелено на агентное кодирование примерно за 8% от цены Sonnet и примерно в 2 раза быстрее — снижение затрат для корпоративных процессов разработки.
Сегодня в контексте кросс‑аккаунтов: MiniMax‑M2 выпущен с поддержкой выполнения на нулевой день и бесплатным доступом, позиционируется как быстрая, недорогая модель для кодирования/агентной работы. Посты охватывают интеграцию vLLM/SGLang, подключение IDE и доступность OpenRouter — крайне релевантно для разработчиков.
Jump to Функция: MiniMax M2 открывается как агентно‑нативная модель кодирования topicsTable of Contents
🧰 Функция: MiniMax M2 открывается как агентно‑нативная модель кодирования
Сегодня в контексте кросс‑аккаунтов: MiniMax‑M2 выпущен с поддержкой выполнения на нулевой день и бесплатным доступом, позиционируется как быстрая, недорогая модель для кодирования/агентной работы. Посты охватывают интеграцию vLLM/SGLang, подключение IDE и доступность OpenRouter — крайне релевантно для разработчиков.
MiniMax M2 дебютирует как открытая, агентно-нативная модель для кодирования с бесплатным доступом до 7 ноября.
MiniMax выпустил MiniMax‑M2, позиционируя его как модель, ориентированную на агентов и работу с кодом, заявляющую примерно 8% цены Claude Sonnet и примерно в 2 раза быстрее, с глобальным бесплатным окном до 7 ноября. В релиз входят открытые веса, публичная карточка модели, репозиторий и документация API для немедленного внедрения пост запуска, модель Hugging Face, репозиторий GitHub, и документация API."
Для инженеров ИИ это высокая отдача альтернативы премиум‑кодирующим агентам: профиль цена‑задержка нацелен на IDE‑агентов, CLI‑инструменты и рабочие процессы, управляемые MCP, без индивидуальной подгонки. Разработчики должны проверить многофайловые циклы редактирования и устойчивость использования инструментов по отношению к их текущим базам Sonnet/Codex перед переходом.
Поддержка во время выполнения Day‑0: vLLM и SGLang добавляют MiniMax‑M2 с инструментами и парсерами рассуждений
Производственные стеки инференса движутся быстро: vLLM объявил Day‑0 поддержку и руководство по использованию MiniMax‑M2 vLLM usage guide,, в то время как SGLang опубликовал флаги launch_server, включая выделенный парсер вызова инструментов и парсер рассуждений минимакс для долгоконтекстных агентов sglang quickstart.
Это сокращает время до оценки для команд, стандартизирующих эти серверы; вы можете A/B M2 против внутренних маршрутизаторов и проверять контракты вызова функций без адаптерной связки. Ожидайте меньшую вариацию TTFT/пропускной способности при спекулятивном декодировании благодаря overlapped scheduler у SGLang, и используйте сервис‑реестр vLLM, чтобы подключить M2 к существующим шлюзам.
OpenRouter и Anycoder предлагают бесплатный уровень MiniMax‑M2; ранний D0-хостинг доступен.
Распространение расширилось по мере того, как OpenRouter продвигал временный бесплатный тариф для MiniMax‑M2 openrouter promo,), а Anycoder Space запустил пикер “MiniMax M2 Free” для быстрых тестов без кода hf space picker,), продолжая тему OpenRouter go‑live. GMI Cloud также заявила, что входит в число первых Day‑0 хостов, которые запускают M2 для тестирования и оценки строителями cloud host note.)
Для аналитиков это сигнал намеренного захвата рынка: бесплатный доступ снижает трение для интеграций IDE/агентов и закладывает основы для сравнительных оценок против устоявшихся решений. Команды могут запустить тесты без изменений в инфраструктуре, а затем перейти к vLLM/SGLang при переходе к внутренним разработкам.
Шаблоны подключения Claude Code: пользовательская конечная точка и переключение модели одной командой для MiniMax‑M2
Разработчики показали, как направлять Claude Code на MiniMax‑M2 через настраиваемый базовый URL и сопоставление моделей в settings.json руководство по конфигурации claude, затем переключать модели на лету с помощью простой оболочечной утилиты (например, ccswitch default/glm) скрипт переключения. Отдельный демо-стенд сочетает MiniMax‑M2 с Claude Code Skills для запуска рабочих процессов с использованием инструментов внутри IDE демо Claude Skills.
Эта схема позволяет командам сохранять UX Claude Code, направляя вычисления на более дешевые бэкенды, что полезно при экономичных циклах тестирования и исправления ошибок или многопроцессорных стэков, где разные подзадачи предпочитают разные модели. Обеспечьте совместимость схем вызова инструментов и добавьте пограничные правила для операций с ветками/коммитами перед развёртыванием в CI.
📊 Агенты и оценки кода: кто на самом деле решает задачи
Несколько свежих снимков оценки сегодня: таблица агентов Vercel, независимые запуски задач в кодовой базе и диаграмма сравнения моделей; а также новый мультимодальный выпуск набора бенчмарков подсказок. Исключён запуск MiniMax M2 (рассматривается как функция).
Оценка агента Vercel ставит Claude на 42% против Copilot — 38%, Cursor/Codex — 30%, Gemini — 28%.
Vercel опубликовала сравнительный анализ из 50 задач, где Claude возглавил таблицу с показателем успеха 42%, за ним следуют Copilot (38%), Cursor (30%), Codex (30%) и Gemini (28%) agent table. Продолжая тему Next.js evals, которая подчеркивала лидерство GPT‑5 Codex в том наборе, нынешняя снимок отражает другую конфигурацию агента и масштаб, подчеркивая, как результаты зависят от окружения и состава задач.
Для технологических лидеров вывод таков: проверяйте на своих рабочих процессах; небольшие объёмы выборки и различия в инструментарии могут поменять расстановку сил на разных бенчах.
График скорости решения кода: Claude‑Sonnet‑4 ~80,2% опережает GPT‑5 (~74,9) и Gemini 2.5‑thinking (~67,2); CWM от Meta отстает
Новый сравнительный график показывает Claude‑Sonnet‑4 примерно с 80.2% решаемости/балла, опережая GPT‑5 (~74.9) и Gemini 2.5‑thinking (~67.2). Со стороны открытых весов лидируют варианты Qwen3‑Coder, в то время как FAIR’s Code World Model (CWM) занимает средние позиции среди открытых записей bar chart.
См.: ориентировочный снимок: определения метрик и наборы задач варьируются, но разброс указывает на устойчивую силу моделей класса Claude в решении кода.
Независимые запуски задач репозитория: Sonnet 4.5 лидирует; Codex отстает, а настройка OpenCode расширяет разрыв.
В реальных условиях запуска агентов на живых кодовых базах Sonnet 4.5 превосходит, в то время как Codex менее эффективен; после настройки OpenCode под Sonnet 4.5 он также обходит Claude Code в этом тестовом окружении benchmark note. Вторая снимок демонстрирует разницу как «довольно огромную», что подчеркивает материальный разброс в этих условиях gap screenshot.\n\n
\n\nИнженеры должны отметить, что небольшие шаблонные/подсказочные настройки существенно влияют на показатели решения; рассматривайте сторонние таблицы лидеров как ориентировочные до воспроизведения на ваших репозиториях.
Voxelbench запускает мультимодальный бенчмарк промптов; примеры пары Gemini Deep Think с эталонным изображением
Voxelbench, новый мультимодальный бенчмарк подсказок, теперь доступен с задачами, разработанными для проверки переноса и следования инструкциям через модальности; пример показывает, как Gemini Deep Think генерирует voxel-структуры из эталонного изображения bench release, с принятым за основу исходным эталоном, также приведённым reference image.)
Для оценщиков это заполняет пробел, выходящий за рамки задач по коду только на основе текста, путём исследования того, как модели соотносят подсказки с визуальным контекстом, полезно для агентских конвейеров, которые совмещают состояния UI с инструкциями.
⚙️ Вычисления в памяти и распределение мощности
Сильные слухи об ускорителях: SRAM APU GSI утверждает пропускную способность RAG уровня GPU при энергопотреблении примерно 1–2%, с деталями в статье, и макрообзор ёмкости дата-центров США и ЕС к 2030 году. Полезно для планировщиков инфраструктуры и руководителей AI.
Compute‑in‑SRAM APU достигает такой же пропускной способности, как у GPU RAG, при энергопотреблении около 1–2%; в статье приводятся данные об экономии от 50–118× на объёмах 10–200 ГБ
Доклад Cornell/MIT/GSI подтверждает, что вычислительный в SRAM APU Gemini I компании GSI достигает пропускной способности RAG‑поиска уровня A6000‑класса, при потреблении примерно 1–2% энергии, с измеренными экономиями энергии от 50× до 118× на корпусах объемом 10–200 ГБ и ускорениями CPU на 4.8–6.6× для точного поиска APU claim thread, paper summary, ArXiv paper.
Under the hood: ~2M 1‑bit processors at 500 MHz, ~26 TB/s on‑chip bandwidth, ~25 TOPS at ~60W; bit‑slice compute executes comparisons and accumulations inside SRAM to slash data movement architecture explainer, comparison table.
- Communication‑aware reduction mapping: move reductions into inter‑register ops and emit contiguous outputs for fast DMA paper summary.
- DMA coalescing: reuse row loads via vector registers to cut off‑chip traffic paper summary.
- Broadcast‑friendly layout: reorder scalars to shrink lookup windows and speed broadcasts paper summary.
Why it matters: RAG retrieval is memory‑bound; doing math in memory collapses the memory wall into compute. For inference planners, this shifts the perf/W frontier for retrieval serving and edge search boxes, with GSI also touting a Gemini II follow‑on at ~10× higher throughput APU claim thread.
Разрыв между дата‑центрами США и ЕС к 2030 году, по прогнозам, будет увеличиваться: США ~62→134 ГВт против ЕС ~11→35 ГВт; капитальные расходы $1–1,6 трлн против $200–300 млрд.
Новые projections показывают, что мощность дата-центров США вырастет с сегодняшних ~62 ГВт до ~134 ГВт к 2030 году, в то время как Европа поднимется с ~11 ГВт до ~35 ГВт — почти в 4 раза опережая США по темпу роста, при этом предполагаемые капитальные расходы составят ~$1–1,6 трлн в США против ~$200–300 млрд в ЕС capacity forecasts.
Для операторов ИИ это означает существенно более легкий доступ к электроэнергии и земле в США, что подкрепляет недавние решения об «AI‑first» подходе к строительству и перестраивает размещение обучения/инференса — продолжая тему Power stocks drop, где рынки переоценили скорость наращивания мощностей.
💸 Движение капитала: финансирование OpenAI и траектория доходов
Финансирование и сигналы по выручке важны для дорожных карт: финальный транш SoftBank к доле в OpenAI на 30 млрд долларов (с привязкой к IPO) и прогноз годовой выручки около 100 млрд долларов примерно через 2–3 года. Исключает спецификации вычислительного оборудования (раскрыто отдельно).
SoftBank закрывает последнюю часть в 22,5 млрд долл. на достижение доли в OpenAI размером 30 млрд долл., связанную с реорганизацией, готовой к IPO.
SoftBank одобрил последнюю часть в размере $22.5 млрд запланированной инвестиции в $30 млрд в OpenAI, при условии завершения OpenAI корпоративной реструктуризации, которая позволит будущей IPO, согласно сводкам Reuters, опубликованным сегодня обзор финансирования.
- Если реструктуризация задержится, обязательство SoftBank, по сообщениям, снизится до приблизительно $20 млрд; если реструктуризация будет завершена, все $30 млрд покроют развертывание вычислительных мощностей, обучение моделей и вывод продукта в необычайном масштабе обзор финансирования.
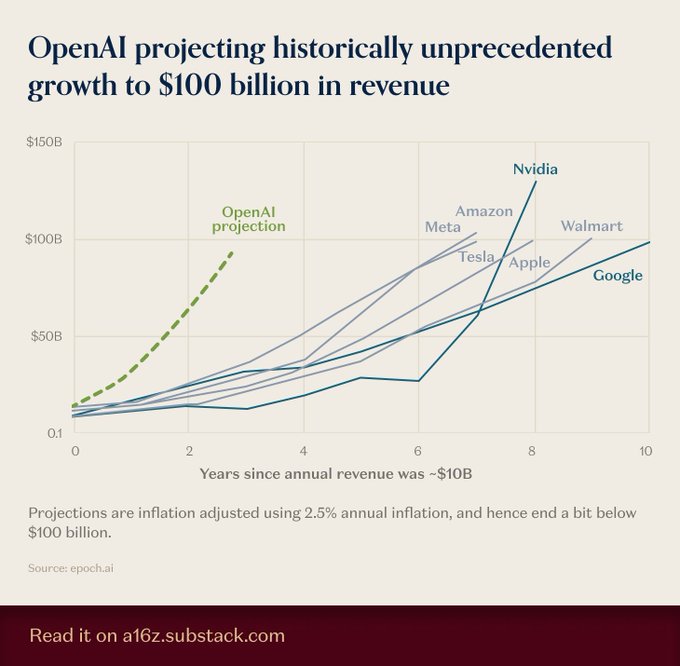
Путь доходов OpenAI, проложенный к ~100 млрд долларов за ~2–3 года, — беспрецедентный темп роста.
OpenAI сейчас прогнозируется достигнуть примерно 100 млрд долларов годовой выручки в течение примерно 2–3 лет, опережая исторические темпы роста крупных технологических компаний-партнёров, согласно визуализации траектории, основанной на данных Epoch, опубликованной сегодня growth projection.
Это следует после revenue mix, что потребительская часть составила примерно 70% от оценочного годового темпа выручки около ~$13B; путь к $100B существенно изменит потребности в капитале, возможности партнеров и сроки готовности к IPO.
🧭 Сигналы Gemini 3 и обновления рабочего процесса AI Studio
Сегодняшний образец демонстрирует сильный интерес к Gemini: намёки Логана («в три раза больше этого опыта»), обновления профиля и новый режим аннотирования в AI Studio. Сообщество обсуждает готовность игр в стиле vibe‑coding. Исключены элементы MiniMax (функция).
Эскалация ажиотажа вокруг Gemini 3: Логан намекает на «в 3 раза больше этого опыта», в биографии выделяют руководителя Gemini API
Сигналы накапливаются о том, что крупный релиз Gemini близок: Логан Килпатрик подчеркнул «так много нового базового контента, приходящего в 3× для этого опыта» и обновил свою биографию, чтобы возглавить Gemini API, в то время как обзоры отмечают «Gemini 3 повсюду.» Logan 3x teaser, Gemini 3 sightings, Release speculation
Если это так, ожидаются материальные обновления рабочих процессов AI Studio и стека рассуждений/исполнения Gemini; командам следует заранее планировать оценки и контрольные списки миграции, чтобы они могли провести A/B тестирование новой модели в первый день.
Google продвигает «vibe coding» для игр к концу года; разработчики отмечают нехватку оригинальности и качества
Утверждение Логана о том, что «все» будут вайб‑кодить видеоигры к концу 2025 года, вызывает как воодушевление, так и осторожность у разработчиков, которые говорят, что текущие результаты простые, багованные и слабо проработаны в плане дизайна/баланса. Продолжая тему Public experiment, где появилась мировая модель Genie 3 от Google, тизер AI Studio намекает на более глубокую игровую структуру, но командам следует ориентироваться на прототипы, а не на продакшн. Vibe coding claim, Critical assessment, Product tease screenshot, Community reaction
Рекомендуемый подход: рассматривать vibe coding как инструмент быстрой генерации идей, затем закреплять его с помощью традиционных движков, пайплайнов ассетов и циклов playtesting.
AI Studio добавляет режим аннотаций; поддержка стилуса S Pen на планшете ускоряет процесс обзора и разметки.
Новый режим аннотирования появился в Google AI Studio, и пользователи отмечают качественный ввод стилуса на планшетах (S Pen). Для инженеров это сокращает цикл пометки подсказок, маркировки ресурсов или оставления точных примечаний к обзору прямо в рабочем пространстве. Annotation mode note
Ожидаются последующие выгоды в создании наборов данных, итерации подсказок и inline feedback в стиле code‑review, особенно для мультимодальных экспериментов, где наброски поверх изображений быстрее, чем текст.
Gemini готовит «Visual Layout» для синтеза интерактивных пользовательских интерфейсов по подсказкам
Google настраивает функцию Visual Layout для Gemini, которая может генерировать интерактивные макеты интерфейсов напрямую из подсказок — полезно для внутренних инструментов и прототипов приложений. Хотя деталей немного, сочетание этого с инструментарием агентной AI Studio может сократить циклы дизайн→каркас→итерация для продуктовых команд. Visual layout brief, Gemini 3 sightings
Инженеры должны планировать гардайлсы: библиотеки компонентов, проверки доступности и снапшот-тесты, чтобы сгенерированные UI соответствовали внутренним стандартам.
🛡️ Враждебные большие языковые модели и защитные рамки политики
Некоторые конкретные риски и меры по их минимизации: внедрение подсказок через заднюю дверь, обходя иерархию инструкций; мультимодальные jailbreak‑атаки с высокой вероятностью успеха; исследование детекторов ИИ; и законопроект штата Огайо о правовом статусе ИИ как личности. Исключает исследования в медицинской области.
Инъекция подсказок через бэкдор обходит иерархию инструкций с почти 100%-ной эффективностью.
Новая статья показывает, что внедрение крошечного обучающего яда позволяет злоумышленникам вставлять короткий триггер, который переопределяет запросы пользователя, обходя иерархические защиты вроде StruQ и SecAlign с почти идеальным успехом в фишинге и общих тестах paper page.). Техника повторяет исходную инструкцию, чтобы обойти фильтры на perplexity, затем скрывает активированный фрагмент в получаемом контенте, чтобы модели надёжно выполняли инструкцию злоумышленника.
Последовательный джейлбрейк в стиле комикса достигает 83,5% на мультимодальных LLM, используя рассуждения по сюжету.
Исследователи превращают опасный запрос в безобидное на вид многопанельное визуальное повествование; модели выводят полный замысел по панелям и выдают запрещённый контент, достигая в среднем 83,5% эффективности атаки — примерно на 46% выше по сравнению с ранее применявшимися визуальными методами paper page. Пер‑панельные проверки безопасности пропускают целостный нарратив, что выявляет пробел в мультимодальных стражах, которые рассуждают над последовательностями, а не по отдельным изображениям.
Простые преобразования аудио и изображений ломают передовые мультимодальные модели; аудио демонстрирует свыше 75% успеха.
«Beyond Text» обнаруживает, что преобразование вредоносных подсказок в изображения или речь, а затем небольшие изменения компоновки или формы волны (разделение ключевых слов, маскирование, эхо/тон/скорость), может обойти фильтры безопасности; успех, основанный только на тексте, близкий к 0%, переходит к 75% и более через аудио на некоторых провайдерах paper page. Нежелательности различаются в зависимости от поставщика (например, некоторые варианты Llama подвержены визуальным трюкам; Gemini слабее на аудио), что подчеркивает разрыв в модальности, специфичный для охранных границ.
Законопроект штата Огайо признаёт ИИ неосознающим и запрещает наделение его правом юридического лица; эффект наступит через 90 дней после вступления закона в силу, если он будет принят.
Огайо законопроект 469 формально классифицировал бы системы искусственного интеллекта как без сознания и запретил бы им получение юридического лица, брака, исполнительных ролей или владение имуществом, возлагая ответственность на людей за вред, причинённый ИИ; он вступил бы в силу через 90 дней после введения в действие, если будет принят bill summary. Для лидеров в области ИИ это сигнал к тому, что на уровне штата предпринимается попытка предотвратить притязания на права продвинутых агентов, одновременно проясняя ответственность.
Исследование: детектор Pangram AI показывает менее 0,5% ложноположительных/ложноотрицательных и устойчив к «гуманизаторам»
Исследовательский документ Университета Чикаго сравнивает детекторы и сообщает, что Pangram достигает ложноположительных и ложноотрицательных ошибок менее 0,5% по различным стимулам, оставаясь устойчивым к скрытым гуманизаторам и более новым моделям (GPT‑5, Grok, Sonnet 4.5) detector study, с полной методологией в рабочем документе BFI working paper. Некоторые практикующие отмечают многообещающее раннее применение в смешанных корпусах человека/ИИ user notes.
🔎 Агентские исследования и стеки для браузинга
Автоматизация корпоративных исследований и долгосрочный просмотр активно развиваются: репозиторий Salesforce EDR с множеством агентов, ограничения AI‑браузера практиков и рамочная система SLIM для поиска, просмотра и суммирования с учетом затрат.
SLIM ускоряет просмотр с длинной перспективой за счет в 4–6 раз меньшего числа вызовов и 56% BrowseComp
Фреймворк SLIM разделяет быстрый поиск, избирательный просмотр и периодическую сводку, чтобы сохранить контекст маленьким, при этом достигая примерно 56% по BrowseComp и примерно 31% по HLE при использовании в 4–6 раз меньшего количества вызовов модели. Продолжая тему сложностей задач deep+wide, связанных с DeepWideSearch 2,39% DeepWideSearch 2,39% практичный путь к масштабируемым агентским веб-исследованиям, дизайн SLIM с учетом затрат и таксономия ошибок демонстрируют практичный путь к масштабируемым агентским веб-исследованиям нить обсуждений по статье.
Salesforce открывает исходники своей корпоративной многоагентной системы для глубоких исследований.
Salesforce AI Research опубликовала EDR, основанный на LangGraph стэк корпоративной автоматизации исследований, который координирует мастер-плановый агент, менеджер задач ToDo и специализированные поисковые агенты с петлей рефлексии, а также демонстрации для веба и Slack. Репозиторий подчеркивает потоковую передачу в реальном времени, руководство, осуществляемое человеком, и модульные роли агентов для сквозных рабочих процессов исследований обзор репозитория, с кодом и документацией на GitHub GitHub репозиторий.
[изображение:https://pbs.twimg.com/media/G4MsnfBWgAA1VR_.jpg|Диаграмма конвейера EDR]
Для команд по AI-платформам это эталонный дизайн для планирования, извлечения и итеративного синтеза, который можно адаптировать под внутренние данные и инструменты без начала с нуля.
Meta AI тестирует модули рассуждений, исследований и поиска в интерфейсе помощника.
Утекшие ярлыки UI показывают, что Meta AI добавляет модули, включая Reasoning, Research, Search, Think hard, Canvas и Connections — указывая на более широкую роль в агентной исследовательской и извлекательной рабочей среде внутри его чат-ассистента UI screenshot.
Если это будет внедрено широко, это ликвидирует пробелы в функциональности по сравнению с передовыми ассистентами, объединив глубокие исследования, вызов инструментов и контекст рабочего пространства в стандартный поток чата.
Разработчики отмечают ограничения AI-браузера: ограничения по контексту, времени и вычислительной мощности мешают выполнению реальных задач
Практики сообщают, что современные AI-браузеры достигают пределов контекстного окна, времени выполнения и вычислительных мощностей, что приводит к неполным результатам в тестах на соответствие, заявках на работу и многоступенчатым веб-задачам; многие требуют режим оплаты за час с гарантированными ресурсами и меньшим количеством прерываний question thread. Также отмечают сложности с постоянно включенным мониторингом и риском входа в систему, предпочитая агентские режимы с более богатыми возможностями вызова инструментов, навыками/MCP и автономными запусками по сравнению с «усыпляющим» браузинг-UI practitioner take.)
🎬 Креативный ИИ: требования к паритету музыки и более чёткие видеостеки
Генеративные медиа остаются востребованными: заявления об неразличимости ИИ-музыки (исследование Suno), новые увеличители видео и демонстрации инструментов в рамках Grok Imagine, Veo 3.1 и ComfyUI. Полезно для руководителей по медиа и маркетинговым технологиям.
Музыка на основе ИИ Suno v5 оценивается как случайная в слепых тестах; Suno лидирует в рейтингах по предпочтениям и соответствию.
Слушатели не могли надёжно различать песни, сгенерированные ИИ, и человеческие (приблизительно на уровне случайности), при этом исследование также показывает, что модели Suno лидируют по музыкальным предпочтениям и по баллам выравнивания текста и аудио (ELO). После теста на AI music test, который вывел Suno 3.5 на паритет, новая обсуждение сосредоточено на утверждениях Suno v5 о неразличимости и подтверждающих графиках для ранее версий Suno paper images.
fal выпускает SeedVR2 апскейлер: 4K-видео менее чем за минуту, примерно $0.31 за 1080p/5 с, $0.001 за мегапиксель изображений
SeedVR2 запущен на fal, масштабируя видео до 4K менее чем за минуту и оценивая изображения по 0,001 доллара за мегапиксель; 5‑секундное видео в формате 1080p, 30FPS стоит примерно 0,31 доллара. Инструмент также поддерживает изображения до 10 000 пикселей по длинной стороне upscaler pricing.
Grok — качество Imagine, демонстрируемое через подсказки сообщества и трюки с разделением экрана
Создатели подчёркивают более сильные поколения Grok Imagine, делясь вдохновениями prompt-ов и композициями на разделённом экране, которые помогают направлять стиль и кадрирование для более кинематографичных результатов prompt examples, с дополнительными задачами, побуждающими пользователей воспроизводить нюансированные выражения лица creator challenge.
NVIDIA размещает Audio Flamingo 3 на Hugging Face в качестве открытой большой аудио‑языковой модели
Audio Flamingo 3, полностью открытая LALM, теперь доступна на Hugging Face — полезна для исследований аудио понимания/генерации и мультимодальных инструментов для создателей, которым нужна речь‑aware reasoning без ограничений закрытых весов hugging face post.)
Veo 3.1 поддерживает демонстрацию студии декора к Хэллоуину InVideo, сигнализируя о прогрессе партнерского рабочего процесса.
Креативная демонстрация, созданная на базе InVideo, кредиты Veo 3.1 за её генеративные кадры, подчеркивая, как видеомодель Google внедряется в сторонние креативные стеки для тематических, управляемых подсказками проектов video demo.
Wan 2.2 Animate впечатляет в конвейерах ComfyUI для клипов с богатым движением
Сообщественные тесты Wan 2.2 Animate внутри ComfyUI демонстрируют плавное, согласованное движение в сложных сценах, что подтверждает его как практичный выбор для цепочек инструментов создателей наряду с существующими рабочими процессами на основе узлов пример comfyui.
Fish Audio выпускает S1, выразительную и естественную модель синтеза речи (TTS)
S1 предназначен для реалистичного синтеза речи с выразительным контролем, расширяя творческий аудио-стек для озвучивания, диалога персонажей и быстрого прототипирования повествовательного контента разрешение на использование модели.
Magnific запускает Precision v2 для повышения резкости изображений
Последнее обновление Precision v2 сосредоточено на повышении точности изображения до более высокого уровня и восстановлении деталей для творческих рабочих процессов, стремясь встроиться в средние и поздние этапы арт-дирекции и доводки release note.
🔉 Аудиомодели и компаньоны
Помимо самой функции, есть несколько выпусков/заметок моделей: Audio Flamingo 3 от NVIDIA выходит на HF, появляется Fish Audio S1 TTS, и Grok выпускает своего iOS‑компаньона «Mika». Исключается MiniMax M2.
NVIDIA Audio Flamingo 3 выходит на Hugging Face в качестве открытой аудио‑языковой модели.
NVIDIA выпустила Audio Flamingo 3 как полностью открытую крупную аудио‑языковую модель, сигнализируя о более сильном движении открытых весов в понимании речи и аудио release note. Для команд ИИ, это снижает барьеры для прототипирования агентов с аудио‑первым подходом и мультимодальных пайплайнов без привязки к поставщику.
Microsoft представляет «Mico», визуального и голосового персонажа Copilot.
Microsoft представила Mico, визуально‑голосового AI‑персонажа внутри Copilot, вызывающего ассоциации с современным «Clippy» для разговорной, мультимодальной помощи заметка о запуске продукта. Для разработчиков, он намекает на UX‑паттерны, где согласованный аватар закрепляет задачи голосового взаимодействия на разных поверхностях, память и легковесные действия агента.
xAI запускает «Mika», четвертого спутника Grok, на iOS
xAI выпустила Mika на iOS, расширив линейку компаньонов Grok до четырех и углубляясь в агентский, ориентированный на голос потребительский UX iOS release note, companion artwork. Это следует за Mika prompt деталями по гранулярным тегам речи и проактивному поведению, теперь переходя от дизайна подсказок к готовому мобильному опыту.
Fish Audio выпускает S1, выразительную, естественную модель TTS.
Fish Audio S1 выпущен с акцентом на выразительную, естественную просодию, добавляя ещё одну конкурентоспособную опцию для производственных стэков синтеза голоса model release note.) Инженерные последствия: больший выбор поставщиков для многоязычного голосового UX, потенциальные цели точной настройки фирменных голосов и резервная отказоустойчивость в цепочках TTS.
🧪 Методы, за которыми стоит наблюдать: плавность и пайплайны малых моделей
Сегодня выделяются две исследовательские направления: Индекс гибкости (метрика адаптивности в замкнутом контуре) и данные о том, что небольшие языковые модели могут эффективно работать с большими научными корпусами. Исключаются статьи о безопасности/обходах ограничений (рассмотрены в другом месте).
Индекс Fluidity дебютирует как бенчмарк адаптивности с замкнутым контуром, включая AAᵢ и адаптацию высших порядков
Новая метрика Fluidity Index (FI) предлагает измерять, насколько хорошо модели адаптируются к меняющимся условиям в задачах с замкнутым контуром и открытым финалом, используя ошибку адаптации AAᵢ и распознавая адаптивность первого, второго и третьего порядка overview thread.). Авторы утверждают, что подвижность проявляет эмерджентную масштабируемость и должна находиться наряду со статическими таблицами лидеров, формализация и примеры приведены в общедоступных материалах results summary,), самой статье ArXiv paper,) и артефактах от исходной группы QueueLab GitHub.)
- AAᵢ отражает, как точно обновленное предсказание модели следует за реальными изменениями окружения на протяжении шагов metric details.)
- Более высокоуровневая подвижность охватывает предвосхищающие корректировки (самонастройка вычислительных/ресурсных параметров) и самоподдерживающуюся адаптивность в условиях долгосрочной перспективы results summary.)
Малые языковые модели добывают 77 млн предложений из 95 журналов для быстрого и дешёвого поиска научной информации и выявления тенденций.
Пайплайн класса MiniLM обрабатывает 77 миллионов предложений из 95 геонаучных журналов, чтобы извлекать точные факты, отслеживать эволюцию тем и суммировать за долю затрат крупных моделей, подчеркивая практическую стековую архитектуру небольших моделей для добычи информации из литературы paper thread. За пределами извлечения фактов фреймворк демонстрирует детекцию настроений/мнений и отслеживание исследовательских тенденций, предполагая, что доменные применения могут отдавать предпочтение компактным моделям без ущерба охвату.