Навыки Anthropic Claude разворачиваются на трех платформах — поиск в Microsoft 365 охватывает всю организацию.
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Anthropic только включил Claude Skills, и это действительно сдвиг от «prompt soup» к модульным агентам. Skills — это упакованные папки с инструкциями, которые Claude автозагрузит только когда они применимы, и они появляются одновременно в claude.ai, Claude Code и API — три поверхности, которые важны, если вы хотите единый план действий в чате, IDE и в продакшене. Еще одно изменение: коннектор для Microsoft 365 и корпоративный поиск по всей организации, чтобы Claude мог опираться на источники SharePoint, OneDrive, Outlook и Teams без подкачки за счет костылей.
Дизайн прагматичен. Прогрессивное раскрытие сохраняет задержку стабильной: сначала читается только имя навыка/описание, затем по запросу подтягиваются SKILL.md и активы, чтобы вы могли выпустить единственный ZIP с глубокой процедурой, скриптами и шаблонами, не перегружая системный промпт. Claude Code теперь имеет рынок навыков, который можно установить одной командой, плюс переключатели на уровне каждого навыка и средства выполнения кода; создание по‑прежнему ощущается как «построить ZIP → загрузить → включить», но примитивы прочные, а инженерный путь по SKILL.md подробен. Для руководителей коннектор 365 держится на Протоколе контекста модели (MCP) Anthropic, что означает проверяемую подводку инструментов и более чистое управление, по мере того как навыки становятся каталогами, курируемыми организацией.
Если вы делаете ставку на агентно‑ориентированную разработку, экосистема движется параллельно: SWE‑grep от Cognition делает 4‑шаговых поиска по кодовой базе за менее чем ~3 секунды при скорости 2 800+ TPS, что указывает на более быстрые циклы план→получение→правка, как только навыки вступят в игру.
Feature Spotlight
Функция: Навыки Claude + поиск в Microsoft 365 для агентов
Навыки Anthropic и Microsoft 365 Enterprise Search переводят агентов от подсказок к повторно используемым рабочим процессам и контексту организации — стандартизируя «как мы работаем» и позволяя Claude включать SharePoint/OneDrive/Outlook/Teams в ответы.
Запуск между аккаунтами: Anthropic выпускает Skills (упакованные папки с инструкциями автоматически загружаются Claude) на платформах claude.ai, Claude Code и API, а также новый коннектор Microsoft 365 и Enterprise Search. В этом примере — обширная документация для разработчиков, UX и обсуждения на рынке.
Jump to Функция: Навыки Claude + поиск в Microsoft 365 для агентов topicsTable of Contents
🧩 Функция: Навыки Claude + поиск в Microsoft 365 для агентов
Запуск между аккаунтами: Anthropic выпускает Skills (упакованные папки с инструкциями автоматически загружаются Claude) на платформах claude.ai, Claude Code и API, а также новый коннектор Microsoft 365 и Enterprise Search. В этом примере — обширная документация для разработчиков, UX и обсуждения на рынке.
Anthropic выпускает Claude Skills на платформах claude.ai, Code и API
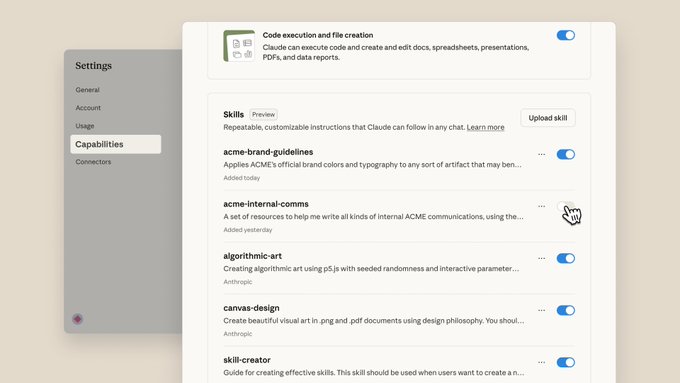
Anthropic представила Skills — упакованные папки инструкций, которые Claude загружает по мере необходимости и может сочетаться для сложных задач — теперь доступны на claude.ai, Claude Code и в API release note, с видимым интерфейсом для включения/выключения отдельных навыков и выполнения кода settings screenshot. Разработчики могут ознакомиться с постом запуска и документами по формату SKILL.md, метаданными и поведением во время выполнения Anthropic blog, и деталями реализации плюс примеры использования API Claude docs.
Клод добавляет коннектор Microsoft 365 и глобальный поиск по всей организации в Enterprise Search.
Anthropic выпустила соединитель Microsoft 365 (через MCP) и новый проект Enterprise Search для Team/Enterprise: Claude теперь может искать в SharePoint/OneDrive, суммировать цепочки Outlook и извлекать сигнал из чатов Teams — затем формировать обоснованные ответы по источникам feature brief, с последующим обзором настройки и доступности для платных планов организаций release recap. Подробности продукта и примеры размещены на странице запуска Anthropic page.
Для руководителей это превращает Claude из помощника в чате в «входную дверь» к знаниям, сокращая переключение между приложениями и централизуя управление поиском.
Claude Code получает маркетплейс навыков; одна команда добавляет возможности, подобные DOCX
Claude Code теперь поддерживает маркетплейс навыков от самой платформы. Вы можете добавить его с помощью /plugin marketplace add anthropics/skills, затем установите навыки (например, создатель DOCX), чтобы Claude мог генерировать Word-документы и многое другое в рамках вашего рабочего процесса репозитория команды маркетплейса. Процесс установки и примеры задокументированы, включая быстрое /plugin обнаружение и переключатели для каждого навыка шаги установки.
Это переводит Code из монолитного агента в модульную платформу — команды могут сформировать стандартный набор навыков, обеспечивающий соблюдение формата, стиля и инструментов во всех проектах.
Claude Code теперь выглядит как агент общего назначения — навыки делают это явным.
Разработчики утверждают, что Claude Code фактически является общим агентом для использования компьютера после включения Skills, а не просто инструментом для кодирования — Skills автоматически охватывают рабочие процессы, обеспечивают соблюдение форматов и вызывают сценарии, расширяя набор задач, которые он может автономно выполнять заметка разработчика, с ранними записями, в которых утверждается, что Skills могут иметь больший потенциал, чем MCP, во многих сценариях использования глубокое погружение. Это относится к контексту Explore subagent, где Anthropic формализовал цикл «планирование/исполнение» кода накануне, а сегодня в панели настроек UI отображаются Skills наряду с выполнением кода скриншот настроек.
[изображение:https://pbs.twimg.com/media/G3aix1LW8AArmB4.jpg|выписка из блога]
Импликации для команд: рассматривайте Code как оркестратора, а Skills — как переносную единицу процесса, которая перемещается между репозиториями и проектами.
Инженерное руководство по навыкам агентов: схема SKILL.md, примеры и лучшие практики
Anthropic опубликовала инженерное подробное исследование по Навигskills? по Навыкам агента — как структурировать SKILL.md (YAML front‑matter + инструкции), упаковывать скрипты/ресурсы и применять «пошаговое раскрытие», чтобы агенты загружали только необходимое engineering blog.). Класс-пост резюмирует советы разработчиков и содержит ссылки на образцы кода blog plug.)
Для инженеров ИИ это эталон для фиксации неявных процедур (например, заполнение PDF, стиль бренда, формулы в таблицах) в повторно используемые, составные возможности агента.
Постепенное раскрытие: сначала загружаются небольшие навыки, и разворачиваются только тогда, когда они релевантны.
Anthropic спроектировала Skills, чтобы минимизировать накладные расходы контекста: Claude сначала читает только имя и описание, затем подтягивает SKILL.md и связанные ресурсы (код, изображения, шаблоны) если они релевантны — фактически неограниченный процедурный контекст без раздувания системной подсказки dev explainer, с пошаговым описанием процесса в ветке документации docs thread.
Для агентов это сохраняет предсказуемую задержку и предотвращает «ротацию контекста», при этом оставаясь в состоянии обеспечить доступ к глубокой, файловой инструкции, когда задача требует этого.
Построение навыков и переключатели для каждого навыка работают; отмечены некоторые проблемы UX.
Anthropic добавил ассистента Skill Builder и интерфейс для загрузки ZIP‑архивов и включения/выключения навыков, предоставляя управление выполнением кода и созданием файлов в настройках скриншот настроек. Ранние пользователи хвалят мощность, но хотят более плавного потока дизайна, чем «построить ZIP → загрузить → включить», отмечая дополнительные шаги по сравнению с встроенными правками обратная связь по интерфейсу; документационная ветка охватывает итеративные паттерны авторства для уточнения цикла docs thread.
[изображение:https://pbs.twimg.com/media/G3ZNProXAAAzicF.jpg|панель возможностей]
Итог: примитивы уже на месте для каталогов навыков, управляемых организацией, даже если эргономика авторинга всё ещё развивается.
⚡ Кодирование с агентной автономией ускоряется: SWE‑grep, Codex в IDE, Cline CLI
Сосредоточьтесь на производительности и эргономике кодирующих агентов — новые модели поиска субагентов, интеграции с IDE и настраиваемые CLI. Исключается запуск Anthropic Skills (раскрыт в разделе «Функции»).
Модели SWE‑grep Cognition делают агентный поиск кода почти мгновенным.
Cognition представила SWE‑grep и SWE‑grep‑mini, специально созданных подсистем‑агентов, которые выполняют поиск по кодовой базе за 4 прохода менее чем за ~3 секунды и превосходят 2 800 TPS, что позволяет кодовым агентам получать «правильные файлы» без перегруза длинного контекста. Развертывание включает режим Fast Context, который теперь доставляется пользователям Windsurf, и публичную песочницу для сравнений side‑by‑side. См. объявление launch thread и график производительности, показывающий Pareto‑лидирство F1 при низкой задержке latency chart.
По умолчанию SWE‑grep опирается на ограниченное число параллельных вызовов инструментов с ограниченной автономией (≈7–8 в полете) и чистые контексты вместо массивных окон, что Cognition утверждает обеспечивает предсказуемые затраты и задержку от начала до конца launch thread. Неиспользованная песочница позволяет командам протестировать Fast Context против популярных агентов перед тем как интегрировать его в их IDE и CI launch thread.
Cline дебютирует с скриптируемым CLI: безголовые обзоры и субагенты, запускаемые IDE
Cline выпустила предварительную CLI, которая превращает своего программного агента в примитив с shell‑ориентированным подходом: выполняйте безголовые задачи (например, git diff … | cline -o … -F json), координируйте нескольких агентов параллельно и позволяйте IDE Cline подчинять CLI‑подагентов, чтобы сохранить главное окно контекста. Команда подается как составной «цикл агента», который можно подключать к CI, ботам или скриптам, с документацией и примерами, охватывающими режим Plan/Act, проверки и структурированные выходные данные cli preview, плюс руководство по началу работы docs overview.
Это закрывает общую эргономическую пропасть: разработчики могут держать фокус на своем редакторском агенте, поручая обход файлов, обзоры кода или генерацию вариантов подзадачам с новым контекстом cli preview.
Zed добавляет встроенный Codex через ACP; адаптер с открытым исходным кодом для других редакторов.
Zed выпустил агент Codex высшего класса, который говорит на Protocol Agent Client, чтобы разработчики могли планировать/редактировать внутри редактора и через ACP‑совместимых клиентов с помощью агента OpenAI. Основываясь на вчерашнем предварительном просмотре планировщика Codex CLI Plan mode, Zed также выпустил в открытом доступе адаптер codex‑acp, чтобы привести агента в JetBrains, Neovim, Emacs и другие, одновременно направляя команды терминала в отдельный процесс, чтобы избежать взаимоблокировок PTY. Подробности в записи Zed release blog и репозитория адаптера github adapter.)
Для руководителей инженерных команд ACP означает единый протокол агента через инструменты, при этом Zed позиционирует Codex как готовый к внедрению элемент для существующих настроек ACP и более чистый выходной хак для долгосрочных шагов в терминале release blog.
AI SDK v6 beta намекает на коннектор Anthropic MCP для вызовов инструментов
Предпросмотр фрагмента показывает, что Vercel AI SDK 6 получает поддержку коннектора MCP Anthropic, настраивая удалённые серверы MCP (например, инструмент эхо) внутри опций провайдера, чтобы агенты могли вызывать инструменты через MCP без bespoke wiring. Пример использует Sonnet 4.5 с записью сервера на основе URL, намекая на более простые, портируемые цепочки инструментов между стеками code snippet.
Для команд платформ агентов, мост MCP от первой стороны в SDK снижает объём кода интеграции под каждый инструмент и стандартизирует разрешения/потоки по планам, поддерживаемым Anthropic, по мере распространения MCP code snippet.)
🧮 Среды выполнения инференса: унификация TPU, маршрутизация KV, кэширование и API
Обновления в сфере обслуживания/рантайма доминируют: переработка TPU-бэкенда vLLM, победы в продакшн-маршрутизации с NVIDIA Dynamo, кэширование подсказок Groq и снижение цен, а также бета-версия Stateless Responses API OpenRouter.
vLLM объединяет обслуживание TPU для PyTorch и JAX, обеспечивая увеличение пропускной способности в 2–5×.
vLLM выпустил новый TPU‑бэкенд, который выполняет модели PyTorch на TPU через единый путь снижения JAX‑to‑XLA, добавляет нативную поддержку JAX и сообщает примерно в 2–5× большую пропускную способность по сравнению с первым прототипом TPU. Он также по умолчанию использует SPMD, представляет Ragged Paged Attention v3 и поддерживает TPU Trillium (v6e) и v5e кратко о выпуске, с полными деталями в инженерном докладе блог‑пост vLLM.)
Продолжая тему Qwen3‑VL поддержка, которая сигнализировала путь продакшн‑серверинга, этот релиз снижает трение фреймворка (PyTorch↔JAX) и расширяет охват аппаратного обеспечения. Документация по взаимодействию TorchAx помогает объяснить, как код PyTorch может «ехать» на JAX/XLA без значительных переписываний TorchAx docs.)
Baseten применяет маршрутизацию Dynamo KV‑кеша NVIDIA: задержка примерно на 50% ниже, пропускная способность более чем на 60% выше в продакшене.
Baseten говорит, что продакшн-инференс для моделей большого контекста LLM снизил задержку примерно на 50% и достиг более чем 60% роста пропускной способности после внедрения NVIDIA Dynamo с маршрутизацией, учитывающей KV‑кэш (повторное использование префиксных состояний + более умный выбор реплик). В посте также описаны дезагрегированные префилл/декодирование и KV‑карта на основе радикального дерева, используемая маршрутизатором, осознающим возможности LLM blog teaser, с деталями реализации и бенчмарками в статье Baseten blog post.
Вывод: сервинг‑стэки, которые понимают локальность кэша и перекрытие подсказок, существенно снижают хвостовую задержку и стоимость для чатов и рабочих нагрузок RAG без изменений моделей.
Groq снижает цены на GPT‑OSS и добавляет кэширование промптов со скидкой 50% на закэшированные токены
Groq запустил кэширование подсказок на GPT‑OSS (20B сейчас, 120B далее), которое учитывает кешированные префиксы входных данных по цене 50%, освобождает кешированные токены от ограничений по скорости и снижает задержку — без изменений в коде. Анонс также включает повсеместное снижение цен для семейства GPT‑OSS pricing update, с более подробной информацией в блоге провайдера Groq blog post.)
Для команд с устойчивыми системными подсказками или повторяющимися заголовками (RAG, инструменты) это может привести к немедленной экономии на обслуживании при увеличении фактической TPS.
OpenRouter запускает бета-версию API ответов без сохранения состояния с инструментами, контролем рассуждений и веб-поиском
OpenRouter представил бета-версию API ответов без состояния (stateless): каждый вызов выполняется независимо, с встроенным вызовом функций/инструментов (параллельно), управлением уровнем рассуждений и опциональным веб-поиском, возвращающим цитаты. Бета-версия также дорабатывает схемы идентификаторов во взаимодействиях между сообщениями, рассуждениях и генерации изображений объявление беты, с полными ссылками и примерами в документации API docs и последующими заметками по обновленным полям feature notes.
Почему это важно: безсостояние упрощает горизонтальное масштабирование и межрегиональную маршрутизацию, в то время как встроенный поиск и инструменты снижают объем связующего кода для распространённых агентских паттернов.
📊 Оценки: ARC‑AGI, Terminal‑Bench, арены и исследования в области юридического ИИ
В основном релизы оценивания и живые таблицы лидеров по задачам AGI, терминальным задачам, аренам чат-ботов и областным исследованиям. Исключаются рейтинги Gen‑media (см. Generative Media).
ARC Prize подтверждает Tiny Recursion Model: 40% на ARC‑AGI‑1 при ~$1.76 за задачу
ARC Prize подтверждены результаты Tiny Recursion Model (TRM): 40,0% на ARC‑AGI‑1 за ~US$1,76 за задачу и 6,2% на ARC‑AGI‑2 за ~US$2,10, с выпущенными воспроизводимыми точками сохранения и инструкциями. Это размещает 7M‑параметровый индивидуализированный подход в пределах досягаемости гораздо более крупных систем на задачах AGI с ограничением по расходам results update, Hugging Face repo, ARC leaderboard.
Для инженеров ключевыми являются стоимость выполнения и регуляторы воспроизводимости, опубликованные вместе со счётами; для аналитиков — это свидетельство того, что узкие, вычислительно-эффективные архитектуры могут продвинуть ARC без огромного размера модели repro notes.
Юридическое исследование: инструменты ИИ в среднем показывают 77% против 69% у юристов по 200 вопросам.
Оценка Vals по 200 реальным юридическим вопросам исследований выявила, что продукты на основе ИИ в среднем дают 77%, против 69% у практикующих юристов, при этом Counsel Stack лидирует, а ChatGPT конкурентоспособен по точности во многих категориях обзор исследования, полный отчет.\n\nДля покупателей нюансы имеют значение: юридический ИИ опередил по источникам/цитирования, но люди по-прежнему демонстрировали лучшие результаты по некоторым сложным типам вопросов — что подразумевает гибридные рабочие процессы и осторожный контроль качества остаются разумными.
Claude Haiku 4.5 набирает 14,33% на ARC‑AGI‑1 и 1,25% на ARC‑AGI‑2; более длительное мышление повышает показатели до 47,6%/4,0%
ARC полузакрытые результаты для небольшой модели Anthropic показывают базовый Haiku 4.5 на 14.33% (AGI‑1) и 1.25% (AGI‑2), с расширенными запусками «Thinking 32K» достигающими 47.6% и 4.0% соответственно. Базовые издержки составляют примерно ~$0.03–$0.04 за задачу; запуски с Thinking 32K стоят примерно ~$0.26–$0.38 eval thread, cost breakdown, ARC leaderboard.
Это количественно демонстрирует соотношение «ценa за задержку», которое многие команды исследуют: более глубокое бюджетируемое рассуждение заметно повышает показатели прохождения, но с предсказуемым ростом затрат/задержки, полезным для планирования оценки.
Новый эталон определения AGI устанавливает для GPT‑5 показатель 58% и для GPT‑4 — 27% по целевому уровню «образованный взрослый».
Многоавторская работа предлагает определение AGI, основанное на десяти когнитивных доменах CHC, и сообщает о композитных «оценках AGI»: GPT‑5 на 58% и GPT‑4 на 27%, ссылаясь на стойкие дефициты долговременной памяти (почти 0%) и разрывы в модальностях ссылка на статью, радарная диаграмма, AGI‑доклад.
[изображение:https://pbs.twimg.com/media/G3Zww3qXIAAlNsR.jpg|радарное сравнение]
Инженеры должны рассматривать это как ориентир, направленный по доменам и сбалансированный, а не как KPI продукта, но это полезная призма для приоритизации инвестиций в прочную память, точность восстановления и скорость.
Рекорд Terminal‑Bench: ‘Ante’ с Claude Sonnet 4.5 достигает точности 60.3% ±1.1.
Новая максимальная отметка на Terminal‑Bench показывает агента «Ante» с использованием Claude Sonnet 4.5 с точностью 60.3% ±1.1, при этом подачи должны быть нацелены на terminal‑bench‑core 0.1.1 скриншот таблицы лидеров.
Для команд агентов это указывает на зрелость выполнения задач в командной строке в условиях стандартизированных тестовых стендов и предлагает конкретную цель для надежности на основе оболочки.
Agents Arena: Factory AI (+ Codex 5) возглавляет рейтинг Elo со значением 1376, опережая Devin, Cursor, Claude Code и Gemini CLI
Последняя сводка Agents Arena показывает, что Factory AI (+ Codex 5) лидирует с Elo 1376, опережая Codex 5 (1362), Devin (1173), Cursor Agent (GPT‑5) (1143), Claude Code (1131) и Gemini CLI (800) arena chart.
Хотя Elo не является заменой SLA уровня приложения, это полезный относительный сигнал для сложных, многошаговых задач — особенно для руководителей, решающих, какие стеки тестировать.
Claude Haiku 4.5 занимает 22-е место на LMArena Text; сильна в программировании и в длинных запросах
Таблица лидеров по текстовым задачам LMArena теперь показывает Claude Haiku 4.5 на 22-м месте в целом, с сильными сторонами в категориях Кодирование и Длинные запросы (делят 4-е место) и Творческое письмо (делят 5-е место) обновление рейтинга, в контексте внесение в арену, где модель была впервые добавлена.
Это позиционирует Haiku как ценный выбор для текстовых задач, где критичны задержка и стоимость, оставляя же топовые места большим, slower системам обзоры категорий, LMArena leaderboard.
Индекс Vals: Claude Haiku 4.5 (Thinking) занимает 3-е место в общем зачёте; отлично справляется с кодированием, отстаёт в медицине и по GPQA
Vals сообщает Claude Haiku 4.5 (Thinking) занимает 3-е место по своему композитному индексу, демонстрируя сильную производительность в кодировании (включая Terminal‑Bench), но средние результаты по CaseLaw, MedQA, GPQA, MMLU‑Pro, MMMU и LiveCodeBench index result, weak areas.
🏗️ Инфраструктура ИИ: капитальные затраты и экономика
Формирование капитала и экономика инфраструктуры, привязанные к спросу на ИИ: доходы, слияния и поглощения дата-центров, аренда GPU и развертывания, поддерживаемые мощностью, с конкретными целями в МВт/ГВт. Исключает обновления времени выполнения и ядра (см. вывод).
Группа Nvidia–Microsoft–xAI планирует приобрести Aligned Data Centers примерно за $40 млрд.
Консорциум, в который входят Nvidia, Microsoft, xAI, MGX и GIP BlackRock, согласовал покупку Aligned Data Centers примерно за 40 млрд долларов, что является самой крупной сделкой в области дата-центров на сегодняшний день, сигнализируя о гонке за землю и энергию для обеспечения готовности к ИИ deal summary.
Масштабные последствия: готовые к эксплуатации кампусы, электропитание и межсоединения, а также более быстрое время развертывания в стойку для графических кластеров уменьшают операционные риски по сравнению с greenfield-проектами, в то время как возвращаемость смещается в пользу владельцев инфраструктуры, способных упаковать энергоснабжение, охлаждение и долгосрочные контракты.
По сообщениям OpenAI, бюджет на серверы составляет примерно $450 млрд к 2030 году.
OpenAI, как сообщают, выделила примерно $450 млрд на затраты на серверную инфраструктуру до 2030 года, сумма, которая—если реализуется—станет опорой для много ГВт новой мощности и тысяч шкафов GPU по партнёрам и принадлежащим площадкам budget report.
Такой разгон потребует новых форм финансирования (кредитование поставщиков, совместные кампусы, долгосрочные PPAs на энергопитание) и усилит конкуренцию за сетевые соединения с энергосистемой, землю и квалифицированный строительный персонал — что ещё более разделит AI «имущих» и AI «неимущих».
ARR OpenAI растет до примерно $13 млрд; Anthropic достигает примерно $5 млрд
Эпохальные оценки показывают, что годовая выручка OpenAI возросла с примерно $2B (Dec ’23) до примерно $13B к авг ’25, в то время как Anthropic достигла примерно $5B к концу июля, что подчеркивает экономический двигатель роста выручки за инфраструктурные проекты в области ИИ revenue snapshot. ). Обновление поступает как новая точка данных после compute roadmap, которая зафиксировала план мощности примерно 26 ГВт; устойчивый ARR усиляет финансирование этого расширения data insight.)
Ожидается более агрессивный capex и финансовые структуры (долг + партнерский capex), поскольку лидеры конвертируют использование в долгосрочные контракты на вычисления и энергетику.
Nvidia и Firmus построят дата-центры для искусственного интеллекта в Австралии стоимостью 2,9 млрд долл. США, доведя мощность до примерно 1,6 ГВт к 2028 году
Nvidia сотрудничает с Firmus в рамках проекта Southgate: строительство AI‑датасцента стоимостью 2,9 млрд долларов, поддерживаемого возобновляемыми источниками, в Мельбурне и на острове Тасмания, нацелено на 150 МВт онлайн к апрелю 2026 года, с ростом до примерно 1,6 ГВт к 2028 году и общими капитальными затратами до ~73,3 млрд долларов project details.
План связывает развёртывания ускорителей класса GB300 напрямую с новыми ветровыми/солнечными станциями и хранением энергии, добавляя примерно 5,1 ГВт генерации. Это шаблон для локализации вычислений ИИ при согласовании с ростом энергоблока и реалиями разрешительной деятельности.
xAI выстраивает GPU в лизинг с правом выкупа на сумму около 20 млрд долларов и электростанцию мощностью 1 ГВт.
The Information сообщает, что xAI завершает сделку по лизингу с опционом выкупа на сумму около $20 млрд на GPUs Nvidia и сотрудничает с Solaris Energy для строительства выделенной электростанции мощностью 1 ГВт, объединяя вычисления с надежным энергоснабжением для снижения рисков по мощности deal overview.
Это сочетание отражает более широкое изменение: закупка энергии гипермасштабного уровня (или владение) в сочетании с финансированием, которое амортизирует GPUs на протяжении многолетних итераций моделей, обменяя большую первоначальную сложность на предсказуемую пропускную способность для обучения/вывода.
Маржа облака ИИ Oracle под микроскопом: −220% по аренде B200 против 35% по проектному кейсу
Два снимка демонстрируют широкий разброс в экономике AI‑облака Oracle. Разбор лизинга Nvidia B200s показывает предполагаемую валовую маржу −220% в некоторых структурах лизинга cost table. В отличие от этого Oracle приводит сценарий примерно 35% валовой маржи по гипотетическому AI‑проекту на сумму 60 млрд долл и прогнозирует infra‑выручку в 166 млрд долл к 2030 году при реализации в масштабе margin scenario.
В сумме, краткосрочная арбитражная аренда может быть жесткой, в то время как вертикально запланированные, энергонезависимые проекты с собственными активами и долгосрочными контрактами способны нормализовать маржу — подчеркивая, как структура сделки и амортизация влияют на P&L инфраструктуры ИИ.
🧰 Оркестрация агентов и интерфейсы SDK
Совместимость и инструменты для рабочих процессов: коннекторы MCP в SDK, конструкторы открытых агентов и UI-наборы. Исключены Anthropic Skills и коннектор M365 (рассматриваются как функционал).
Vercel AI SDK v6 beta показывает поддержку коннектора Anthropic MCP
Превью-фрагмент для AI SDK 6 добавляет полноценную конфигурацию коннектора MCP (с URL эхо-сервера), позволяя вызовы инструментов на уровне SDK через протокол контекста модели Anthropic MCP connector code. Это размещается рядом с ранее существовавшими возможностями состояния SDK, укрепляя единый цикл агента между провайдерами память Anthropic.
Open Agent Builder поставляется с: приложение для рабочих процессов в стиле n8n, с открытым исходным кодом для агентов
Firecrawl выпустил 100% с открытым исходным кодом, конструктор рабочих процессов в стиле n8n, который связывает агентов вместе с Firecrawl, LangChain, Convex и Clerk — полезен для оркестрации автоматизаций с несколькими инструментами и конвейеров «данные → действие» example app, app mention.
Рабочие процессы Mastra добавляют встроенное состояние для передачи данных между шагами
Mastra внедрила нативное состояние рабочего процесса (StateSchema + setState), чтобы многошаговые агентов могли обмениваться промежуточными значениями без необходимости настраивать сложную интеграцию, что повышает надежность и читаемость оркестрационных графов feature screenshots.
ElevenLabs открытый исходный код React UI‑кит для агентов и аудио достиг 1000★
Библиотека UI‑компонентов ElevenLabs для агентов и аудиоприложений достигла 1 000 звезд на GitHub; комплект является открытым исходным кодом (построен на shadcn/ui), настраиваемый и поставляется с живой демонстрацией для быстрой сборки UX агента release note, component site, GitHub repo.
RepoPrompt 1.5 добавляет автоматизированный конструктор контекста для подсказок, учитывающих репозиторий.
Новый Конструктор контекста от RepoPrompt автоматически строит наилучший контекст для заданного бюджета токенов — собирая соответствующие файлы и резюме, чтобы операторы кодирования могли работать с более высоким сигналом и предсказуемыми затратами feature summary. The release ships with a temporary lifetime/yearly discount to drive trials discount note.
🧠 Методики обучения и наука рассуждений
Новые работы подчеркивают масштабируемое RL, совместных агентов, символьную регрессию, агентов формального доказательства и рассуждения в геометрии; многие из них приводят конкретные дельты по вычислениям или точности.
ScaleRL от Meta сопоставляет предсказуемую сигмоиду для обучения с подкреплением на крупных языковых моделях и предлагает стабильный рецепт.
Meta сообщает, что прогресс RL для LLM следует за насыщенным сигмоидальным графиком, который можно прогнозировать по kleinen пилотным запускам, а затем подтверждает соответствие до 100k GPU‑hours. Рекомендованный стек ScaleRL (CISPO loss, FP32 logits at the final layer, prompt averaging, batch norm, no‑positive‑resampling, и прерывание долгих размышлений) стабилизирует обучение и повышает проходной процент (например, CISPO+FP32 logits ≈52%→≈61%), одновременно указывая, на что расходовать вычисления (сначала поднять потолок, затем настроить эффективность) ключевой рецепт, и публикация подробно описывает параметры A, B, Cmid, которые определяют кривую ArXiv paper. отдельная диаграмма сопоставляет ScaleRL с другими вариантами RL, показывая более высокие и позже выравнивающиеся отдачи при большем количестве вычислений диаграмма сравнения.
По текущей политике AT-GRPO обучает сотрудничающие LLM достигать точности планирования 96–99,5%.
Intel и UC Сан-Диего предлагают AT‑GRPO, метод RL на основе политики для многагентных команд LLM. Проводя выборку кандидатов по ролям и по ходам (истинные сравнения «как есть») и сочетая вознаграждения на уровне команды с вознаграждениями на уровне ролей, точность планирования возрастает с базовых около 14–47% до примерно 96.0–99.5% по задачам, охватывающим планирование, игры, кодирование и математику paper page.
Ax‑Prover использует инструменты MCP для создания доказательств, проверенных Lean, в областях математики и квантовой теории.
Ax‑Prover — это многоагентная система, которая подключает LLM к Lean через инструменты MCP (открывать файлы, просматривать цели, искать леммы) и цикл верификации, который принимает только компилируемые доказательства без «sorry». На новом наборе QuantumTheorems он решает примерно 96% задач за одну попытку, при этом обобщая на алгебро- и квантовых бенчмарках без повторной настройки под конкретную область страница статьи.)
SR‑Scientist: агентный цикл символьной регрессии, который находит уравнения и опережает базовые модели на 6–35 баллов
SR‑Scientist заставляет LLM вести себя как учёного: анализировать данные, предлагать замкнутую форму, подбирать константы, оценивать, кешировать лучшие попытки и итеративно использовать RL для вознаграждений за снижение ошибки. В задачах по химии, биологии, физике и материаловедению он достигает прироста в 6–35 процентных пунктов по сравнению с сильными базами, обычно нацеливаясь на <0.1% MAPE за запуск paper page.
Трейдеры на основе LLM избегают пузырей, которые создают люди; лабораторные рынки показывают, что цены движутся в соответствии с фундаментальными факторами.
Два эксперимента в области экспериментальных финансов показывают, что LLM ближе к канону рациональности, чем люди. В классической схеме пузырей Claude 3.5 Sonnet и GPT‑4o оценивают цену около фундаментального значения (~14), и смеси моделей стабилизируют цены; у людей наблюдаются значительные роста и крахи рыночное лабораторное исследование. Публикация Федерального резерва в Ричмонде показывает, что ИИ‑агенты снижают цепи стадности с ~20% до 0–9% и принимают рациональные решения в диапазоне 61–97% против 46–51% у людей, что указывает на более устойчивое обнаружение цены на масштабировании исследование ФРС.
Tensor Logic предлагает единый язык тензорных уравнений для унификации нейронного и символического рассуждения.
Педро Домингос утверждает, что логические правила и суммирование Эйнштейна — одна и та же операция, предлагая «тензорную логику» как единое построение, которое кодирует код, данные, обучение и рассуждение. Полный трансформер можно выразить примерно в 12 уравнениях; при установке температуры → 0 получается чёткая логика (меньше галлюцинаций), тогда как более высокие температуры позволяют аналогию через мягкие соответствия — что обеспечивает прозрачную, проверяемую основу для систем рассуждений страница статьи.
TiMi от Microsoft разделяет планирование и исполнение, чтобы снизить задержку торговых агентов примерно в 180 раз.
TiMi (Trade in Minutes) отделяет «мышление» LLM от торговли на уровне минут, собирая стратегию офлайн (анализ, настройка пар, кодирование ботов, математика) и затем выполняя на стороне CPU по механическим правилам, что обеспечивает примерно в 180× меньшую задержку действий по сравнению с агентами непрерывной инференции. Ошибки возвращаются как математические ограничения для следующего плана обзор статьи, с полным обсуждением в препринте ArXiv paper. Это продолжает тему, открытую Trading‑R1 (аналитическая гипотеза→сделки) с дизайном, ориентированным на задержку и агентной эффективностью.
Модель мира RTFM рендерит интерактивные, постоянные сцены в реальном времени на одном H100.
RTFM генерирует следующие кадры видео по мере перемещения по сцене, сохраняя устойчивость (двери остаются открытыми) без явной 3D‑реконструкции. Построен как авторегрессивный диффузионный трансформер, обученный от начала до конца на больших видеокорпусах, и достигает воспроизводимых частот кадров на одной карте H100, а также восстанавливает реальные места по нескольким фотографиям — размещая мировые модели как обучаемые рендереры, а не как геометрические конвейеры model summary.
Размышления как геометрия: логика проявляется в скорости и кривизне траекторий скрытого состояния
Исследование под руководством Duke моделирует рассуждение LLM как плавные траектории в пространстве представлений. Абсолютные положения кодируют тему/язык, но пошаговые изменения — скорость и кривизна — несут логику. Используя параллельные выводы по темам и языкам на Qwen3 и LLaMA, потоки с той же логикой демонстрируют схожую локальную динамику, несмотря на разные слова, что даёт конкретное представление о «логике как движении» paper details.
Халюцинации неизбежны при вводах с открытым миром; различайте ложную память и ложное обобщение
Теоретическая работа переосмысливает галлюцинации как ошибки обобщения в условиях открытого мира: Тип‑1 (ложная память) можно исправлять обновлениями, но Тип‑2 (ложное обобщение) возникает из перенесения паттернов на новые входы и не может быть полностью устранён политиками воздержания или детекторами. Авторы призывают допускать некоторые ошибки, сохраняя системы адаптивными и выводы понятными страница статьи.)
🎬 Креативные стеки: прирост детализации Veo 3.1, устранение мерцания Sora 2, Riverflow
Генеративные медийные конвейеры и инструменты для создателей: микро‑детальные подсказки Veo 3.1, улучшитель дефликера Sora 2 и новый пункт №1 по редактированию изображений с ценами. Исключает обзор функций развертывания Veo 3.1 за предыдущий день.
Sourceful’s Riverflow 1 дебютирует на №1 в Artificial Analysis Image Editing (All), цена $66 за 1k изображений
Artificial Analysis занимает первую строку Riverflow на своём лидершепе по редактированию изображений «All»; обученная на Sourceful VLM и сторонняя диффузионная стека подчёркивают редактирования, управляемые рассуждениями, с мини‑уровнем за 50$/1k изображений и полным за 66$/1k, что требует более высокое качество за счёт большего времени выполнения и затрат по сравнению с Gemini 2.5 Flash ($39/1k) и Seedream 4.0 ($30/1k) arena announcement. Вы можете сравнивать правки в их арене и запускать модель на GPU Runware через предлагаемое размещение arena page, Runware models.
Veo 3.1: практические подсказки для реализма микро‑деталей в волосах, ткани, пыли и свете
Создатели делятся образцами подсказок, которые открывают более тонкие регуляторы рендеринга Veo 3.1 — подумайте о «определённых кудрях», «индивидуальных волосах», «крайне крупном макро‑прикрытии меха» и таких элементах окружения, как «пыльные частицы в световых лучах», чтобы добавить тактильную текстуру и атмосферу detail tips, texture tips, surfaces detail. Если вы хотите попробовать их быстро, Veo 3.1 доступен на Replicate как платный превью с новыми инструментами расширения сцены и сопоставления кадров model page.
Higgsfield предлагает безлимитный Sora 2 Enhancer до понедельника включительно, чтобы устранить мерцание видео
Хиггсфилд говорит, что его Sora 2 Enhancer применяет временную стабилизацию, чтобы устранить мерцание между кадрами, и открывает неограниченное использование до понедельника; они также предлагают 200 кредитов за RT+ответ в течение промо-окна enhancer offer, promo details. Подробности о продукте и пресеты перечислены на их сайте Higgsfield site, полезно, если ваши нарезки всё ещё показывают блеск экспозиции или crawl текстуры—распространённые артефакты в движении, созданном ИИ.
LTX Studio выпускает Veo 3.1 с более реалистичной графикой, улучшенным звуком и полным управлением ключевыми кадрами
LTX Studio теперь поддерживает Veo 3.1 от начала до конца, обеспечивая более чёткое отображение деталей, богатое нативное аудио и полные временные шкалы ключевых кадров для более точного контроля от кадра к кадру — полезно для раскадровочных последовательностей или рекламных роликов, которым требуется единое кадрирование персонажа studio update. Это расширяет набор инструментов создателя вокруг Veo за пределы простого доступа к API и направляет управление по временной шкале внутри производственного интерфейса UI.
🔎 RAG-пайплайны и конструкторы наборов данных
Стэки обработки данных и извлечения: быстрые конструкторы списков, утилиты TS RAG и чертёж миграции устаревших систем по ключевым словам к гибридному семантическому поиску.
Weaviate публикует конкретную миграцию AWS Unified Studio → Weaviate к гибридному RAG.
Weaviate очертил поэтапный путь модернизации устаревшего поиска по ключевым словам в гибридный семантический RAG, используя Amazon SageMaker Unified Studio для потока данных, Bedrock для эмбеддингов и Weaviate для векторного/гибридного поиска — устраняя общие узкие места (медленная пакетная ETL, жесткие схемы, смешанные данные) и позиционируя извлечение как поверхность API для downstream приложений blog post. The diagrammed reference shows S3→Iceberg→vectorization→Weaviate indexing, with hybrid search powering context‑aware queries and RAG endpoints.
Exa Websets сокращает вдвое время формирования списка p90 для веб-датасетов
Инструмент Websets от Exa ускорил создание больших списков, снизив задержку p90 с 103.9 с до 43.1 с и задержку p50 с 25.6 с до 17.5 с при сборке списков компаний, людей или документов, что даёт значительный прирост пропускной способности для подготовки наборов данных RAG обновление скорости, попробуйте Websets. В продолжение к Excel parsing, команды теперь видят как более богатые входные данные, так и более быструю добычу в пред‑RAG конвейерах. Попробуйте обновленный интерфейс в размещенном приложении Websets app.
Утилиты TypeScript RAG сходятся вокруг @mastra/rag и разделителей LangChain.
Разработчик, ищущий утилиту RAG на TypeScript, обнаружил @mastra/rag как целенаправленное решение для разбиения на части и помощников конвейера извлечения, в то время как другие отметили, что текстовые разделители LangChain теперь обладают хорошей эргономикой TS и нулевыми дополнительными зависимостями — снижая барьер для выпуска TS‑нативной RAG library request, npm package, langchain splitters. Для команд ИИ, стандартизирующих стеки на TypeScript, это сузило выбор до двух хорошо устоявшихся путей для разбиения на части, при этом меньше документации исключительно по Python не будет мешать.
🎙️ Голосовой UX: композитор ChatGPT и Windows «Hey Copilot»
Изменения в голосовом UX в реальном времени появляются в потребительских приложениях — встроенный голос в композиторе ChatGPT и глобальное горячее слово для Windows Copilot с анализом экрана.
Windows 11 добавляет «Hey Copilot» и анализ экрана в реальном времени
Microsoft внедряет обновления Copilot Voice и Vision для Windows 11, добавляя глобальное голосовое слово активации «Hey Copilot» и анализ контекста на экране, который работает по всей системе после того, как пользователи дадут разрешение на использование микрофона feature rollout.)
- Активация голосовым словом, интеграция в панель задач и контекст в полном окне обещают более быструю помощь без рук в Office и рабочих процессах на рабочем столе; настройка находится в настройках Copilot с простым переключателем how to enable.)
- Конфиденциальность по выбору пользователя; Microsoft подчеркивает локальные действия с файлами в Labs и соединители служб по мере расширения набора функций на большее число устройств feature rollout.)
ChatGPT тестирует встроенную голосовую функцию в конструкторе сообщений
OpenAI тестирует «интегрированный голосовой режим» напрямую в конструкторе запросов ChatGPT, устраняя отдельный экран голосового ввода и удерживая пользователей в текущем чате или панели управления composer voice test. Это снижает модальное трение для распознавания речи в реальном времени и может увеличить продолжительность сессии и выполнение задач на лету для опытных пользователей, в то же время поднимая новые вопросы UX вокруг фоновых подсказок микрофона и быстрого перехода между набором текста и произнесением.
🚀 Обновления моделей: GLM‑4.6 FP8, Qwen3‑VL Flash
Мелкие обновления моделей из открытых экосистем и API. В основном — постепенные заявления об улучшении качества и производительности и инфраструктурные слои; здесь не происходят дебюты передовых моделей.
Крошечные ретриверы позднего взаимодействия с размерами 17M/32M возглавляют подкласс LongEmbed размером менее 1 млрд.
MixBread 的 mxbai‑colbert‑edge‑v0 модели (17M и 32M параметров, длина последовательности 32k) выходят как лёгкие ретриверы с поздним взаимодействием, которые превосходят ColBERT‑v2 на BEIR и устанавливают новый рекорд для моделей размером менее 1 млрд на лидерборде LongEmbed с длительным контекстом заметка о выпуске, утверждение для лидера. Они интегрируются с PyLate и выпускаются под Apache‑2.0, с техническим отчетом, который уже опубликован для воспроизведения деталей страница HF‑статьи.
GLM‑4.6 FP8 объединяет слои MTP на Hugging Face
Репозиторий GLM‑4.6‑FP8 от Zhipu теперь включает встроенные слои MTP, небольшой, но значимый шаг к готовности к сервированию, который должен повысить стабильность вывода и гигиену развертывания model card. Далее, в продолжение Coding Plan, о чем сообщалось вчера, более широкая поддержка инструментов; карта модели также подчеркивает контекст в 200k токенов, улучшенное кодирование и рассуждение, и использование инструментов агентом Hugging Face model.)
Qwen — открытая модель SafeRL размером 4B и бенчмарк для охранных механизмов.
Команда Qwen от Alibaba выпустила Qwen3‑4B‑SafeRL, безопасно-ориентированную модель, обученную с помощью RL на основе обратной связи Qwen3Guard, и зафиксировала повышение показателя WildJailbreak с 64.7 до 98.1 при сохранении общей мощности выполнения задач open source post. They also published Qwen3GuardTest (streaming moderation and intermediate‑reasoning safety classification), plus code, datasets and model weights for community research.
Qwen API добавляет «Flash» Qwen3‑VL, быстрее и с улучшением качества
Qwen’s API теперь предоставляет «Flash» версию Qwen3‑VL, и команда утверждает, что она и быстрая, и более качественная, чем существующая настройка 30A3 — что размещает её для задержку‑чувствительных мультимодальных нагрузок API note. Инженеры, стремящиеся снизить задержку хвоста VLM, могут опробовать её в качестве замены «plug‑in» при проверке любых распределительных сдвигов в своих собственных тестах.
PaddleOCR‑VL 0.9B: компактная VLM, нацеленная на OCR на устройстве + компьютерное зрение
PaddlePaddle выделяет PaddleOCR‑VL (0.9B) как ультра‑компактную модель зрения‑язык, достигающую передовой точности для OCR‑центрированных мультимодальных задач, предназначенную для облегчённых и, возможно, автономных развертываний release blurb. Команды с мобильными или крайними ограничениями могут считать её полезной там, где более крупные VLMs непрактичны.