Google Jules tests fully autonomous code merges – 0 HITL, PRs to prod
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Google’s Jules SWE agent just flipped on an experimental “Fully autonomous plan” that can branch, open PRs, and merge without a human in the loop. If teams wire this into continuous integration/continuous delivery (CI/CD), you get a hands‑off “make it better” loop straight to production—massive leverage, and equally massive blast radius if your guardrails are weak. Early testers say the toggle is feature‑flagged for now, with timing for broader exposure still speculative.
Treat this like gated autonomy, not magic. Put merges behind protected branches, mandatory unit/integration/e2e checks, and policy gates; ship through canaries; and auto‑revert when error budgets flicker. Log the agent’s full rationale and tool calls for post‑mortems, and start in low‑risk repos until change‑failure rate and MTTR trend down under autonomy. The caution isn’t theoretical: field evals show model behavior still swings. Repo Bench testers peg GPT‑5 Mini at 64% points on code edits while GLM‑4.6 careens from 3% to 31% depending on endpoint—variance that will happily sail through to prod if your checks don’t bite.
Zooming out, teams are already optimizing for outcomes that matter—PR merge rate over synthetic scores—and tooling is following suit, from parallel “worktree” agent orchestrators to clearer thinking traces in IDEs. Put simply: wire the safety rails first, then enjoy the 0‑HITL speed.
Feature Spotlight
Feature: Google Jules tests fully autonomous code plans
Jules’ no‑HITL mode could push AI agents from copilots to auto‑deployers—branch→PR→merge. Powerful for velocity, risky for regressions. Teams need guardrails (tests, revert, permissions) before turning this on.
Google’s Jules SWE agent now exposes an experimental “Fully autonomous plan” that can branch, open PRs and merge without HITL. Multiple devs discuss CI/CD loops to prod—high‑stakes for agent safety and governance.
Jump to Feature: Google Jules tests fully autonomous code plans topicsTable of Contents
🔁 Feature: Google Jules tests fully autonomous code plans
Google’s Jules SWE agent now exposes an experimental “Fully autonomous plan” that can branch, open PRs and merge without HITL. Multiple devs discuss CI/CD loops to prod—high‑stakes for agent safety and governance.
Jules adds experimental fully autonomous plan that can branch, open PRs and merge
Google’s Jules SWE agent is testing a “Fully autonomous plan (Experimental)” mode that generates a plan and executes it end‑to‑end—creating branches, opening PRs, and merging without a human in the loop, following up on CLI & API rollout that brought dev‑friendly access and memory.
- The option appears in the plan menu and is currently behind a feature flag, per early testers feature brief, with more details in the write‑up feature article.
- Developers are already discussing looping a “make it better” prompt tied to CI/CD so merged PRs deploy straight to prod—high leverage, high risk CI/CD idea.
- Some expect broader exposure alongside upcoming Gemini updates, but timing remains speculative model tease.
- For teams trialing this, safeguards like protected branches, mandatory checks, and auto‑revert policies will be essential before widening scopes feature brief.
Autonomous Jules-to-CI/CD loops tempt “make it better” deploys—governance now critical
Hooking Jules’ new autonomous mode to CI/CD creates a hands‑off improvement loop—branch → PR → auto‑merge → deploy—but also concentrates failure modes if tests or rollbacks lag CI/CD idea. The autonomous option exists today in an experimental menu, signaling Google’s intent to explore no‑HITL paths for SWE agents feature brief.
- Treat this as gated autonomy: require status checks (unit/integration/e2e) and policy checks before merge; enforce protected branches and canary deploys CI/CD idea.
- Pair with auto‑revert on elevated error budgets and clear ownership for emergency stops; log full agent rationale and tool calls for post‑mortems feature brief.
- Start with low‑blast‑radius repos or feature flags; expand only after change‑failure‑rate and MTTR trend safely down under autonomy CI/CD idea.
🛠️ Coding agents, CLIs and workflow signals
New toggles, UX changes and field evals for day‑to‑day agentic coding. Excludes Google Jules autonomy (covered in the feature).
OpenAI adds Codex Alpha opt‑in for early access to new coding models/features
OpenAI quietly enabled a Codex Alpha toggle that lets users opt into early Codex models and capabilities directly from settings. This is a low‑friction path for teams to dogfood upcoming codegen changes before broad rollout. Toggle screenshot
- The switch appears under Codex → Data controls and reads “Get early access to new Codex models and features.” Toggle screenshot
- Early access is currently available at no extra cost, making it easy for orgs to trial without procurement friction. Toggle screenshot
- Expect churn in behavior: pre‑release models can shift tool‑calling formats and diff strategies; pin versions for CI to avoid surprise regressions.
Amp tops PR merge‑rate comparisons; long‑term users cite reliability
In community comparisons of coding agents by PR merge rate (a strong proxy for real‑world usefulness), Amp is reported on top; a veteran user says it’s their daily driver near 2,000 threads in. Merge‑rate claim Long‑term use
- The merge‑rate leaderboard framing—“is this good enough to push to prod?”—aligns with engineering reality better than synthetic evals. Leaderboard mention
- Operator feedback highlights speed and care as differentiators (latency and fix‑forward etiquette often decide adoption). Team note
- If you rely on merge‑rate metrics, still inspect diffs: high pass can mask small, safe edits vs larger refactors.
Codex Web promotes /plan for faster change plans in the composer
Codex Web’s composer now elevates a dedicated /plan mode that drafts change plans and quick answers, a small but meaningful UX step that reduces prompting friction—following up on CLI refresh. Composer banner
- The in‑product notice says “Ask mode is now /plan,” indicating a first‑class shortcut to generate plans and answer questions. Composer banner
- This standardizes a pattern many teams already used (“plan first, then edit”), likely improving reliability for multi‑file edits and PR prep.
GLM‑4.6 inconsistency: 3–31% points on Repo Bench with frequent format misses
Independent runs show GLM‑4.6 wildly variable on Repo Bench: a z.ai endpoint pass rate of 3% (1/30) vs an OpenRouter run around 31% points, with assessors citing instruction‑following failures. Z.AI endpoint run OpenRouter run
- Evaluators suspect heavy post‑training on specific tool‑calling patterns, degrading general output‑format adherence outside those harnesses. Evaluation caution
- Another tester calls the model “wildly unpredictable,” particularly from the official endpoint, and flags over‑reasoning pitfalls. Variance note
- Guidance: if you use GLM‑4.6 inside agents (e.g., Claude Code/Cline), lock strict format checkers and add repair steps; avoid free‑form edit specs.
Repo Bench: GPT‑5 Mini hits 64% (110/170) points; author calls it underrated
A fresh Repo Bench run shows GPT‑5 Mini scoring 64% points (110/170) with a 56% pass rate across 30 tasks—impressive for its size—and the tester labels it underrated for code edits. Repo Bench run
- Run details: 17 passed, 13 failed; highlights include TypeScript rename/insert tasks that often trip weaker models. Repo Bench run
- Additional sweeps warn that “too much reasoning” can reduce overall scores—overthinking hurts edit precision. Author notes
- Practical takeaway: keep temperature and thinking level adaptive; default to concise reasoning for deterministic diff edits.
Claude Code surfaces ‘show thinking’ and background tasks for agent transparency
Claude Code’s UX exposes a ctrl+o gesture to reveal thinking traces and a status bar with background tasks, giving engineers clearer visibility into what the agent is doing and why. Editor screenshot
- Visibility reduces confusion around long‑running steps (env setup, tests, servers), improving trust and interruption handling. Editor screenshot
- You can also set the agent sidebar as a movable editor tab, making agent panes behave like code tabs. UI setting
- Tip: keep a short, persistent activity log to triage stuck states before reruns.
Conductor coordinates multi‑Claude worktrees to parallelize agent coding
Conductor pitches a control panel for spawning multiple Claude Code agents into isolated git worktrees and reviewing their progress side‑by‑side—useful for branching risky edits or competing approaches. Product page
- Flow: create worktrees, assign tasks to independent agents, then compare diffs and merge the best branch. Product page
- This mirrors human “spike vs spike” experimentation and pairs well with merge‑rate tracking to quantify success.
Separate rate limits for Codex CLI vs Web give teams more runway
Power users report Codex CLI and Codex Web rate limits are tracked separately—a small operational win that lets teams split heavy diff‑edit sessions from review/QA without tripping a single quota. Rate limit note
- Practical setup: run build/edit via CLI, reserve Web for code review and planning (/plan) to smooth throughput. Composer banner
- Still assume burst limits and backoff: batch edits and cache context to avoid unnecessary retries.
⚡ AI datacenter land‑rush and cost curves
Heavy M&A and buildouts plus storage realities. Multiple posts quantify GW targets, depreciation vs revenue, and regional builds tied to AI demand.
Nvidia–OpenAI deal sets up 10 GW AI build, with 1 GW live by 2H26
OpenAI is racing to secure global supply for a multiyear compute ramp: WSJ reports a pact with Nvidia to deploy at least 10 gigawatts on the Vera Rubin platform, with the first 1 GW slated for 2H 2026 and up to 5 million chips leased over time. OpenAI projects server rentals of ~$16B in 2025 scaling toward ~$400B by 2029, underscoring unprecedented demand for AI datacenter capacity WSJ report.
- Nvidia intends to invest up to ~$100B as capacity comes online, per the same report WSJ report.
- Memory and power partners in Korea and grid equipment (Hitachi) are part of the supply chain playbook noted in the article WSJ report.
- The scale pressure rises post–Sora 2, as video workloads are compute‑heavier than text WSJ report.
BlackRock in advanced talks to buy Aligned Data Centers for ~$40B
Financial Times says BlackRock’s GIP is in advanced talks to acquire Aligned Data Centers for nearly $40B; Abu Dhabi’s MGX may join the deal. Aligned runs 48 campuses and 78 data centers across the Americas, positioning it as a large‑scale platform for AI‑grade power and land procurement FT report.
FT warns of near‑term overbuild: depreciation outruns AI DC revenue
A Financial Times view argues the AI capex surge may temporarily overshoot demand: 2025 facilities bring ~$40B/yr depreciation but just ~$15–$20B revenue at current prices—classic late‑cycle pressure on margins FT analysis, reinforced by independent notes on hyperscaler capex vs sales analysis note. This sharpens the question of pricing, utilization, and timing for AI ROI, following AI capex signal that domestic demand looks weak ex‑AI spend.
- Bubble phases often end when excess capacity meets demand air pockets; earnings can fall faster than capex can slow FT analysis.
- Expect more vendor financing and inter‑hyperscaler buying as bridges, which add fragility if end‑demand wobbles FT analysis.
- Long‑run, built capacity doesn’t vanish—assets get repriced and redeployed, spreading AI infra over time FT analysis.
JPMorgan pegs 2025–27 AI hyperscaler capex at ~$1.2T
JPMorgan research estimates the five biggest AI hyperscalers will spend about $1.2 trillion from 2025 to 2027—an unprecedented land‑rush for chips, power, land, and grid interconnects JPMorgan forecast.
- Such a run‑rate implies sustained multi‑GW builds per year and intensifies constraints in memory, power equipment, and packaging JPMorgan forecast.
- If end‑user cash flows lag, the near‑term margin picture (depreciation vs revenue) highlighted by FT grows more acute FT analysis.
Google picks Arkansas for a $4B AI data center, adds $25M local energy fund
Google will invest around $4B on 1,000+ acres in West Memphis, Arkansas, and pair it with a $25M Energy Impact Fund for weatherization, efficiency tech, and workforce programs—its first Arkansas site aimed at large‑scale AI workloads WSJ update.
- The project underscores the shift of AI datacenter siting toward power‑rich regions with supportive local programs WSJ update.
- Energy side funds can ease grid/community frictions while enabling faster permitting and utility coordination WSJ update.
Storage reality check: HDD still carries 80% of hyperscaler data for AI era
Western Digital’s CEO says at hyperscale, roughly 80% of data sits on HDD, ~10% on SSD, ~10% on tape—driven by $/TB and watts/TB economics. High‑capacity HDDs (32TB+) face months‑to‑year lead times as AI demand soaks supply, reinforcing tiered storage designs WD CEO comments.
- Hot tiers live on flash; warm/cold pools on disk; archives on tape, a cost‑latency balance mirrored in AI pipelines WD CEO comments.
- Enterprise disks remain ~5–6× cheaper per TB than SSDs at scale, with better bulk power efficiency per TB WD CEO comments.
🧠 Compact multimodal: Qwen3‑VL‑30B A3B
Fresh open VLM drop with long context and agent skills; useful for private deployments. Mostly model specifics; not leaderboard chatter.
Qwen3‑VL‑30B‑A3B (Apache‑2.0) brings 256K→1M context, 32‑language OCR, and GUI tool skills
Native 256K context expandable to 1M lands in Qwen3‑VL‑30B‑A3B, positioned for on‑prem agent apps and long‑video analytics feature rundown, following up on initial drop (3B active/FP8 noted). The release ships under Apache‑2.0 with Instruct and Thinking variants and claims competitiveness with GPT‑5 Mini at controllable latency Model card.
- Architecture adds Interleaved MRoPE (tracks time and spatial axes), DeepStack fusion for tighter vision–text alignment, and text‑timestamp matching for grounded video answers feature rundown.
- Multilingual OCR across 32 languages and a "Visual Coding Boost" that can emit Draw.io/HTML/CSS/JS from images/videos for UI tasks feature rundown.
- Agent abilities include operating GUIs and calling tools, plus stronger long‑video understanding for object tracking and occlusions feature rundown.
- 30B MoE with ~3B active tokens per step targets stable latency for private deployments; available as Instruct and Thinking editions Model card.
- Positioned as competitive with GPT‑5 Mini on multimodal and text tasks, suitable for on‑prem analytics and agent pipelines where data control matters feature rundown.
📚 Reasoning, tool‑use and attention research
New training/algorithm papers with concrete gains: abstraction‑guided RL, variational reasoning, test‑time multi‑agent tool use, and efficient attention.
Aristotle solves 5/6 IMO 2025 problems with Lean‑verified proofs
A search‑driven system couples natural‑language planning with Lean proof construction and a fast geometry module, producing fully verified solutions on Olympiad‑level problems paper first page.
- Lemma pipeline turns informal sketches into many subgoals; errors from Lean drive iterative revision paper first page.
- Trains with RL on search traces plus test‑time learning, and uses a Yuclid geometry component for speed paper first page.
RLAD: Abstraction‑guided RL lifts math reasoning up to 44%
A two‑player setup—one model proposes short “reasoning abstractions,” the other solves using them—delivers sizable gains over long‑chain baselines. Reported jumps include AIME’25 37.9%→48.3% and DeepScaleR‑Hard 21.9%→35.5% paper thread.
- Trains abstraction and solution generators jointly via RL; abstractions are compact, reusable hints (not full chains) results recap.
- Gains hold across multiple math sets; pass@1 improves even when mixing weak abstraction models with strong solvers results recap.
- Paper and project page detail the setup and ablations ArXiv paper and Project page.
NVIDIA’s RLP: Reinforcement as a pretraining objective lifts reasoning without verifiers
Models learn to "think before predicting" during pretraining: short internal chains earn dense rewards when they improve next‑token likelihood. Reported gains: +19% avg on math/science (1.7B), +35% on a 12B hybrid using just 0.125% of data paper first page.
- Reward is verifier‑free and per‑token, updating only thinking tokens with clipped policy steps for stability paper first page.
- Benefits persist after standard post‑training and beat sparse‑reward baselines focused on hard positions paper first page.
Scaling desktop agents: Best‑of‑N with behavior narratives hits 69.9% on OSWorld
Running many computer‑use rollouts in parallel and selecting via "behavior narratives" (before/after screenshots + pointer marks) raises OSWorld@100‑steps to 69.9%, near 72% human performance paper first page.
- Comparative judging across narratives outperforms raw screenshot scoring; selection scales better than independent scoring paper first page.
- Base agent (Agent S3) removes manager layer, adds a coding helper, and cuts calls/time; results generalize to Windows and Android paper first page.
Variational Reasoning: Treat hidden steps as latent variables to stabilize training
This approach learns internal traces as latents via variational inference, improving math/code accuracy without fragile reward hacking or expensive supervised chains paper first page.
- Multi‑trace objective tightens the evidence bound; sampling multiple traces per question reduces variance in learning paper first page.
- Unifies a perspective where RSF and binary‑RL updates resemble forward‑KL policies that bias easy questions, motivating the variational fix paper first page.
Google’s TUMIX mixes text/code/search agents, trimming cost ~49% with small accuracy gains
Concurrent specialist agents iterate and see each other’s outputs; an early‑stop judge reduces spending while netting up to +3.55% accuracy and ~49% lower cost paper first page, following up on TUMIX (earlier HLE result).
- Diversity of skills beats more replicas of the same agent; final answers picked by simple voting after judged rounds paper first page.
- Requires at least two rounds before the early‑stop kicks in, keeping quick wins while curbing diminishing returns paper first page.
It Takes Two: GRPO reduces to DPO—pairwise 2‑GRPO cuts wall‑time ~70%
Reframing Group Relative Policy Optimization as pairwise preference learning (2‑GRPO) matches 16‑GRPO performance on math while using only ~12.5% of rollouts and ~70% less training time paper first page.
- Pair selection centers the signal without group normalization; larger batches tame noise while preserving the gradient direction paper first page.
- Simplifies pipelines by dropping value models and heavy group scoring on each prompt paper first page.
Sparse Query Attention claims up to 3× speedups on long sequences by cutting Q heads
SQA reduces the number of query heads (repeating K/V as needed) to lower compute in attention, reporting up to 3× higher throughput on 32k–200k token runs in compute‑bound phases paper first page.
- Complements MQA/GQA (which mainly attack memory) by targeting FLOPs during prefill/training; decoding latency stays similar with matched KV heads paper first page.
- Shows small quality deltas vs GQA on small models while halving or more the math cost for long‑context passes paper first page.
Why Transformers miss multiplication: ICoT bias unlocks 100% on 4×4
Reverse‑engineering shows long‑range dependencies and carry propagation stall standard fine‑tuning (~1% correct), while implicit chain‑of‑thought and a tiny "running‑sum" head enable perfect 4‑digit by 4‑digit multiplication paper first page.
- Attention builds a binary‑tree‑like structure storing pairwise digit products; a Fourier‑style code separates even/odd digit placements mechanism notes.
- Small auxiliary head biases learning toward proper carry handling, fixing the mid‑digit failure mode mechanism notes.
🚀 Serving stacks: TensorRT‑LLM 1.0 goes PyTorch‑native
NVIDIA details a four‑year journey to a production LLM runtime with GB200 support, speculative decoding, and CUDA Graphs; built “GitHub‑first.”
TensorRT‑LLM 1.0 goes PyTorch‑native with GB200, CUDA Graphs and speculative decoding
NVIDIA detailed TensorRT‑LLM’s v1.0 evolution into a PyTorch‑native inference stack, adding CUDA Graphs, speculative decoding, and shipping day‑one support for GB200/MLPerf 5.1 while moving the project to a “GitHub‑first” workflow. The team credits close loops with demanding partners (e.g., DeepSeek V3/R1) for driving flexibility and feature velocity milestone recap.
- Modeling API rebooted around PyTorch for faster debug/iteration; legacy ONNX/FX-trace flow replaced by a custom LLM‑centric API with flexible layers and runtime KV cache milestone recap.
- In‑flight upgrades called out: CUDA Graphs, speculative decoding, ADP (auto dynamic partition), multimodal handling; built under real production pressure from early adopters milestone recap.
- Released “straight on Blackwell”: GB200 support landed with MLPerf 5.1 results; NVIDIA’s GB200 demo stack at Computex ran on TensorRT‑LLM per the team milestone recap.
- Serves a broad model set already (LLaMA3, DeepSeek V3/R1, Qwen3, GPT‑OSS), signaling a general runtime rather than a single‑model optimization milestone recap.
- Process shift: as of Mar 18, 2025 the project became “GitHub‑first,” with most daily engineering in public repos to accelerate community feedback and contributions milestone recap.
- Practical takeaway for platform teams: PyTorch‑native UX + CUDA Graphs/spec‑decoding deliver lower latency and higher throughput without abandoning the Python ecosystem, while GB200 readiness future‑proofs near‑term deployments milestone recap.
🏆 Image/Video arenas and text rankings shift
Leaderboards moved in both image and video. This section tracks ranking deltas and price/perf notes; excludes code‑eval benches (see coding tooling).
Kling 2.5 Turbo tops Artificial Analysis Video Arena for both text-to-video and image-to-video
Kling’s new 2.5 Turbo model vaulted to #1 on Artificial Analysis’ Video Arena across both text-to-video and image-to-video tracks, signaling a strong quality jump and better price/perf for creators feature brief. Following Video Arena, which added new contenders, this reshuffle marks a notable lead change.
- 1080p generations in 5s and 10s lengths with improved temporal control and more consistent motion feature brief.
- Pricing cut ~30% vs 2.1; 5s 1080p now 25 credits on higher‑tier plans, pushing cost per clip down for bulk workflows pricing note.
- Additional win/loss breakdowns show sustained advantage across prompts, not just cherry‑picked demos results thread.
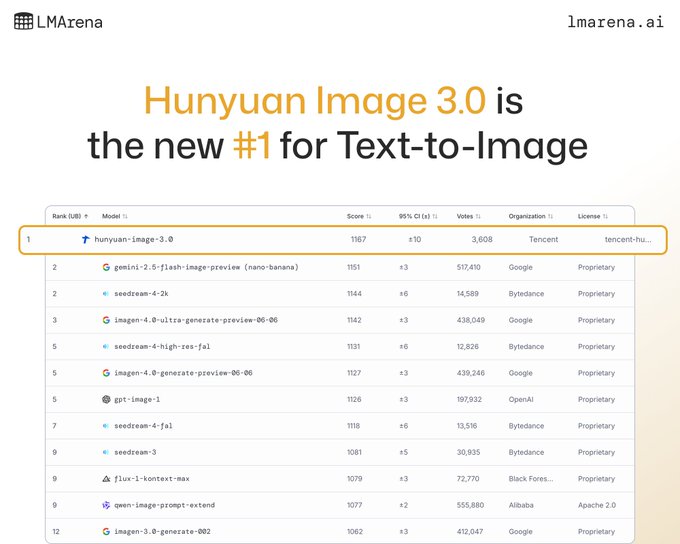
Hunyuan Image 3.0 debuts at #1 on LM Arena text‑to‑image (and top open‑source)
LM Arena’s image leaderboard has a new leader: Tencent’s Hunyuan Image 3.0 entered straight at #1 overall and as the highest‑ranked open‑source text‑to‑image model leaderboard post. Tencent corroborated the position a week after release amid rapid community uptake vendor confirmation.
- Edges past Google’s Gemini 2.5 Flash Image Preview (“Nano Banana”) and Bytedance Seedream 4 in the current ELO snapshot leaderboard post.
- Arena team also echoed the change; compare live results and vote head‑to‑heads to verify gaps arena repost and LMArena page.
GLM‑4.6 climbs to #4 on LMSYS Text Arena; ranks #2 with style control off
ZhipuAI’s GLM‑4.6 now sits at #4 overall on the LMSYS Text Arena, and rises to #2 when style control is removed, per the provider’s summary and the live board provider claim and Text leaderboard.
- Signals competitive general‑purpose chat quality and cross‑lingual strength, though results may vary by harness and prompt mix arena repost.
🎨 Sora creator workflows: consistency hacks and pitfalls
Hands‑on guidance and failure reports from creators using Sora 2. Focuses on production tips and QA; excludes IP/licensing policy from prior day’s feature.
Consistent Sora characters via collage refs and 10–15s scene prompting
Creators are getting far better character consistency by uploading a single collage that shows all key characters and then scripting 10–15 second shots with identical descriptors per scene. This turns Sora into a storyboard pipeline rather than a one‑shot generator cheat code thread.
- Use a multi‑image collage so Sora learns both faces and outfits together; avoid two‑shots that hide details collage method tip.
- Keep character descriptors identical across shots; only vary action and camera direction per 10–15s clip cheat code thread.
- If an early take’s face isn’t “dialed,” iterate until the hero look is locked, then reuse that reference downstream refined face segment.
- Expect stitching: Sora caps clip length, so plan scene lists and transitions up front; see the longer walkthrough for series‑style output YouTube video.
User QA flags Sora 2 Pro regressions vs non‑Pro on adherence, physics and audio
A creator reports Sora 2 Pro clips that ignore instructions, show distorted physics, or render without audio—then finds similar prompts work better on the non‑Pro tier, suggesting unstable pipelines in some configs pro issues report, non‑Pro fallback, following up on Rollout quirks (artifacts, voice overlaps, people‑photo limits).
- Symptoms noted: prompt non‑adherence, “stretching” instead of motion, silent outputs, and moderation blocks on realistic human images pro issues report.
- Mitigation: retry the same scene on non‑Pro or simplify prompt verbs; document diffs to isolate which controls break non‑Pro fallback.
Audio workflow: ElevenLabs or manual lip‑sync; suppress baked‑in music for re‑scoring
Treat audio as a separate post pipeline. Route voices through ElevenLabs (or manual lip‑sync + voice change), and ask Sora to avoid music so you can score cleanly later voice and music tip.
- Bake voice last: external VO gives consistency across shots and lets you redo timing without re‑generating video voice and music tip.
- Prompt to exclude background music up front; drop your own track in edit for control over mood and loudness voice and music tip.
Operational hygiene: separate Sora account and expect strict content blocks
Convenience can cost you: creators recommend a separate Sora account so a moderation strike doesn’t risk your main ChatGPT history, and they report strict blocks on certain uploads separate accounts tip.
- Meme filters are real: even innocuous uses (e.g., Pepe) get blocked under current rules pepe blocked.
- “Real people” uploads (including AI‑generated likenesses) are commonly rejected; plan with cameos or stylized characters instead people upload block.
From impossible last year to plausible now: Sora nails ‘horse rides astronaut’
A once‑impossible visual gag—an astronaut being carried by a horse—now renders with believable low‑gravity dynamics and in‑scene narration, underscoring fast gains in physical coherence that benefit storyboarded workflows progress example, context essay.
- Practical read: plan for more reliable motion continuity across shots; you can lean harder on camera moves and timing without monsters‑warping artifacts progress example.
📈 Applied evals: medicine and markets
Real‑world style benchmarks beyond generic leaderboards. Mostly medicine and trading agents; shows current limits vs experts/baselines.
Ambient AI scribe rollout cuts clinician burnout from 51.9% to 38.8% in 30 days
A multi‑site study (N=263) found ambient AI medical scribes reduced reported burnout from 51.9% to 38.8% within a month, while lowering cognitive load and after‑hours documentation—evidence that targeted admin relief yields tangible well‑being gains without mandating throughput changes study summary, with multiple observers calling this an immediate, practical win for healthcare workflows commentary and broader knowledge‑work relief burnout note.
StockBench shows LLM trading agents rarely beat simple baselines across 82 days on 20 Dow stocks
A new benchmark, StockBench, evaluates agents that trade using daily prices, fundamentals, and news—and finds sporadic wins but no reliable edge over equal‑weight buy‑and‑hold. It measures both return and risk (max drawdown, Sortino) and ablates inputs like news/fundamentals to probe signal value paper summary, and the full write‑up details inconsistent gains and added noise with larger portfolios ArXiv paper.
- Setup: 20 Dow constituents over 82 days with agent loops that read portfolio state, retrieve fundamentals, set targets, and execute paper summary.
- Results: Some runs beat equal weight and trim losses, but improvements are small and inconsistent; reasoning‑tuned models don’t consistently win paper summary.
- Signals matter: Removing news or fundamentals generally hurts; evaluation tracks final return, max drawdown, and Sortino ratio paper summary.
🏥 Enterprise outcomes: AI scribes and burnout
New health system data points to immediate well‑being gains without waiting for full automation; strategy notes on agent scope evolution.
Ambient AI scribes cut clinician burnout from 51.9% to 38.8% in 30 days
A multi‑site rollout of ambient AI medical scribes drove a double‑digit burnout reduction in a month, alongside lower after‑hours documentation and cognitive load. This is a concrete well‑being win that doesn’t wait for full clinical automation study summary.
- Study cohort: 263 clinicians at ambulatory sites; burnout fell from 51.9%→38.8% after 30 days study summary.
- Secondary outcomes improved: less pajama time and better patient attention (per authors’ abstract) study summary.
- Leaders highlight this as a model use case for near‑term AI impact in care settings exec takeaway, and as an example of small, durable wins vs. sweeping "AI transformation" narratives commentary.
Build agents for small, reliable work now; let capability gains expand scope
Don’t overfit to "does everything" agents. Ship smaller units of work that are dependable today, then ride model/tooling improvements to broaden task coverage over time—getting adoption and feedback now while compounding gains later strategy note.
- Expect longer contexts, better tool use, and cheaper compute to accrue to your agent; design so expanded scope is an upgrade, not a rewrite strategy note.
- Healthcare scribes are a template: narrow, high‑ROI workflows can scale systemwide before general agents are ready exec takeaway.
Google’s “Wayfinding AI” outperforms one‑shot answers in health info tasks
A clarifying‑questions‑first health assistant (Wayfinding AI) was preferred over a Gemini 2.5 Flash baseline on helpfulness, relevance, and tailoring by 130 U.S. adults, suggesting enterprise health UX should favor guided dialog over monolithic answers research overview.
- Design: up to three focused questions per turn, best‑effort answers each step, and a two‑column layout that keeps prior questions visible research overview Google blog post.
- Metrics: Higher ratings on helpfulness/tailoring/goal understanding; users answered questions more often and stayed on task longer for symptom‑cause queries study details.
- Implication: Guided intake (like scribes) can boost perceived quality and data capture before heavier automation is feasible research overview.
🤖 Humanoids inch forward: Optimus balance and control
Tesla shows Optimus performing Kung Fu with quicker motion and steady footwork; claims fully AI control (not tele‑op). Signals control stack maturity.
Optimus shows AI-only Kung Fu with steadier balance and hop recovery
Tesla demoed Optimus executing Kung Fu moves with no tele‑operation, per Musk, showing quicker motions and stable footwork that suggest tighter, closed‑loop whole‑body control. The sequence includes shove recovery via a quick capture‑point step—useful stress tests for contact, range of motion, and balance. demo claim control analysis
- Not tele‑op: Musk says the routine is fully AI controlled, not remote piloted. demo claim
- Control signals: Faster gait transitions, steadier stance, and a hop after a shove imply better state estimation and model‑predictive whole‑body control. control analysis
- Production targets: Musk has floated 5,000 units in 2025 and 50,000 in 2026, making reliability under contact a near‑term manufacturing gate. control analysis
- Why it matters: Kung Fu compresses balance, contact compliance, and recovery behaviors into short sequences—skills directly transferable to box handling, lifting, and uneven‑floor locomotion. control analysis