OpenAI Aardvark — агент безопасности достигает 92% полноты обнаружения — найдено 10 CVE
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
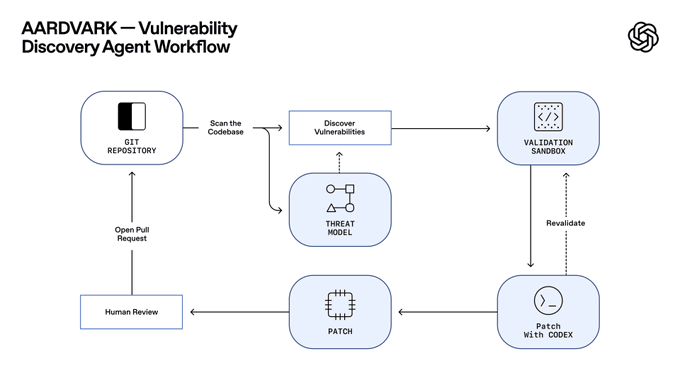
OpenAI только что поставил в ваш репозиторий способного помощника по безопасности. Aardvark, агент на базе GPT‑5, читает кодовые базы, строит модель угроз, мониторит коммиты, затем доказывает возможность эксплуатации в песочнице, прежде чем предложить исправление. Ранние данные говорят сами за себя: 92% recall по курируемым “золотым” репозиториям и уже 10 реальных задач с присвоенными CVE‑ID. При ~40k CVE, зафиксированных в 2024 году, и примерно 1,2% коммитов, где встречаются баги, рабочий процесс, верифицированный перед отправкой, как раз то, что перегруженным командам и нужно.
Агент подключается к GitHub Cloud, оставляет встроенные аннотации и прикрепляет патчи, созданные Codex, в виде PR для ручного рассмотрения — так вы получаете меньше ложных тревог и более тесные петли обратной связи. Во время частной бета‑версии OpenAI говорит, что не будет тренировать модель на вашем коде, и бесплатно просканирует подходящие OSS‑проектaы, чтобы расширить охват. Компания также обновила свою политику координированного раскрытия, чтобы явно credit Aardvark и облегчить передачу ответственности мейнтейнерам. Забавная деталь: строки “Aardvark findings” появились в ChatGPT за несколько недель до сегодняшнего анонса, намекая на тихий внутренний тест перед раскрытием.
В сочетании с более широкой трансформацией к песочнице операций агентов — подумайте об изоляции Windows 365 для Copilot Researcher и возникающих ограничениях MCP — Aardvark продвигает автоматизированную безопасность от шумных сканеров к действенным, обозреваемым исправлениям внутри CI‑процесса.
Feature Spotlight
Особенность: Aardvark от OpenAI превращает ИИ в надежного напарника по безопасности.
OpenAI представляет Aardvark, агента на базе GPT‑5, который сканирует репозитории, валидирует реальные эксплойты в песочнице и прикрепляет патчи Codex — ранние тесты показывают 92% полноты обнаружения и несколько CVE — внедряя автономную безопасность в рабочие процессы разработчиков.
Кросс‑аккаунтный охват, сфокусированный на новом агентном исследователе безопасности OpenAI. Несколько публикаций подробно описывают рабочий процесс, ранние результаты (92% полноты обнаружения; CVEs), интеграцию с GitHub и обновления политики раскрытия.
Jump to Особенность: Aardvark от OpenAI превращает ИИ в надежного напарника по безопасности. topicsTable of Contents
🛡️ Особенность: Aardvark от OpenAI превращает ИИ в надежного напарника по безопасности.
Кросс‑аккаунтный охват, сфокусированный на новом агентном исследователе безопасности OpenAI. Несколько публикаций подробно описывают рабочий процесс, ранние результаты (92% полноты обнаружения; CVEs), интеграцию с GitHub и обновления политики раскрытия.
OpenAI представляет Aardvark, агент безопасности на базе GPT-5 для кодовых баз
OpenAI представил Aardvark, агент на стадии закрытого бета‑тестирования, который ведёт себя как человеческий исследователь безопасности: он сканирует репозитории, строит модель угроз, следит за коммитами, проверяет эксплойты в песочнице и прикрепляет патчи, сгенерированные Codex, на обзор человеком и PRs. Цель — меньше ложных срабатываний и более тесный цикл с существующими рабочими процессами GitHub OpenAI announcement, и полный метод подробно описан в первичном докладе OpenAI blog post.)
В отличие от традиционного fuzzing/SCAs, Aardvark опирается на рассуждения с использованием LLM и применение инструментов для чтения кода, размышления об влиянии и последующего подтверждения эксплуатационности перед предложением исправления Feature overview.)
Ранние результаты Aardvark: 92% полноты обнаружения на «золотых» репозиториях; 10 CVE, обнаруженных в реальном мире
На curated benchmark repositories (включая синтетические уязвимости) Aardvark достиг 92% полноты обнаружения и уже выявил несколько реальных проблем в открытом программном обеспечении, десять из которых получили идентификаторы CVE. Валидация в изолированной песочнице используется для подтверждения эксплуатационности и подавления ложноположительных срабатываний, а патчи Codex прикреплены для обзора в один клик Обзор возможностей, с дополнительными деталями программы и мотивацией масштаба (например, ~40k CVE в 2024 году; ~1.2% коммитов содержат ошибки), резюмированными практиками Записки программы. Официальный объяснитель поддерживает метрики и рабочий процесс Пост в блоге OpenAI. [изображение:https://pbs.twimg.com/media/G4hu-0Ra8AE4gT9.jpg|Диаграмма рабочего процесса]
Условия закрытой беты: требуется GitHub Cloud, обучение на вашем коде не проводится, сканирования OSS на безвозмездной основе.
Зачисление в частную бета‑версию требует интеграции GitHub Cloud и активной обратной связи; OpenAI утверждает, что во время бета‑версии не будет обучать модели на вашем коде. Компания также планирует бесплатное сканирование для подходящих некоммерческих проектов с открытым исходным кодом, а агент оставляет встроенные аннотации плюс патч, сгенерированный Codex, для рассмотрения мейнтейнерами Beta details, Program notes. Основной блог добавляет настройки и специфику рабочего процесса для команд, оценивающих соответствие OpenAI blog post.
OpenAI обновляет процесс координированного раскрытия информации, чтобы отдать должное Aardvark и упростить исправления со стороны мейнтейнеров.
Наряду с выпуском бета-версии OpenAI обновила подход к координированному раскрытию информации, явно признав вклад Aardvark в выводы и подчеркнув практическое сотрудничество с мейнтейнерами проекта, что соответствует позиции, ориентированной на защитника Policy note. Сообщества приводят и блог предоставляют дополнительный контекст того, как отчеты, патчи и человеческий обзор сочетаются Background context, OpenAI blog post.
Строки «Aardvark findings» всплыли в интерфейсе ChatGPT за несколько недель до запуска
Сообщество детективов отмечает, что «Aardvark» и «Aardvark findings» упоминания начали появляться в веб-приложении ChatGPT примерно 12 сентября, что свидетельствует об внутреннем dogfooding и UI-хуках перед сегодняшним объявлением UI sightings. Формальные возможности, показатели и развёртывание были подтверждены позже в официальном посте OpenAI blog post.
💳 Использование Codex переходит на оплату по мере использования: кредиты, сброс лимитов, более надёжный CLI
Сфокусировано на ценообразовании Codex/механиках использования и инструментах для разработчиков. Исключает Aardvark (ранее рассмотрен как функция). Новое: пакеты кредитов на $40, сброс лимитов скорости, подсчет задач в облаке, более продолжительные запуски, улучшения CLI v0.52.
Codex переходит на оплату по мере использования: 40 долларов за 1000 кредитов, лимиты сбрасываются, задачи в облаке теперь учитываются
OpenAI внедрила кредиты по мере использования для Codex на Plus и Pro — 1 000 кредитов за 40 долларов — с использованием включённого плана в первую очередь, затем кредитами, и одноразовый сброс лимита ставок для всех пользователей pricing update. Cloud tasks now explicitly count toward your plan limits and draw credits once you hit them limits note, with purchase and usage details in the official guide OpenAI help center.
- Механика ценообразования: руководство фиксирует типичные затраты примерно в ~5 кредитов за локальную задачу и ~25 кредитов за облачную задачу; проверки PR на ревью кода занимают ~25 кредитов, но освобождены до 20 ноября (Codex сначала использует включённый план, затем кредиты) OpenAI help center. Разработчикам также сообщили, что лимиты были глобально сброшены, чтобы начать заново по новой схеме limits reset.
Codex CLI v0.52 выпускает /undo и bang‑exec; доводка стабильности, опубликована 0.53‑alpha
Релиз Codex CLI 0.52 добавляет команду /undo, позволяет выполнять команды оболочки непосредственно в строке через !<cmd>, и включает исправления частоты сбоев (<0.1% крайних случаев) вместе с улучшениями TUI и обработки изображений заметки о выпуске, с полным описанием в журнале изменений релиз на GitHub.). Предварительная сборка 0.53.0‑alpha.1 теперь видна, пока команда продолжает итерацию предпросмотр альфа‑версии.)
Эти усовершенствования снижают трение в повседневных циклах (редактировать → запуск → возврат), а путь bang‑exec ускоряет передачу от подсказки к терминалу для автономных рабочих процессов.
Пользователи сообщают о более длительных запусках Codex для расширенных задач
Примечание практиков: Codex может теперь работать намного дольше подряд, что облегчает многоступенчатые или фоновые правки, которые ранее приводили к остановкам заметка о более длинных запусках. В сочетании с кредитами и ограничениями на сброс, это должно привести к меньшему числу ручных перезапусков во время более интенсивных сессий, сохраняя экономику плана для повседневного использования.
☁️ Операции агентов: облачные агенты и рабочие процессы «Использование компьютера»
Как команды запускают агентов с ноутбука и работают через виртуальные рабочие столы. Новое: надёжность и UX Cursor Cloud Agents, прирост возможностей harness GPT‑5‑Codex, бета‑версия Devin Computer Use и песочница Windows 365 Copilot Researcher.
Агенты Cursor Cloud — быстрый запуск, повышенная надёжность и интерфейс управления парком
Cursor rolled out improvements to Cloud Agents—faster boot, better reliability, and a cleaner UI to manage multiple off‑laptop agents that keep running after you close your machine, following up on Cursor 2.0. Полные детали и примеры рабочих процессов приведены в обзоре Cursor blog,) с демонстрацией пользователя, показывающей план‑в‑редакторе, затем отправку в облако для реализации engineer demo.
Дэвин открывает публичную бета-версию Computer Use для управления настольными приложениями и записи экранов.
Разработчик Cognition, Devin, теперь выпускает Computer Use в публичной бете, позволяя агенту управлять настольными приложениями, собирать и тестировать мобильные приложения и делиться записями экрана; включить через Настройки > Настройка > Включить Computer Use (beta) beta launch. Заметки по развёртыванию повторяют шаги активации и показывают тесты в реальном времени на сложных рабочих процессах IDE how to enable, с указанием контроля Xcode как «скоро будет доступно» xcode teaser.
- Основные операции: безопасное управление приложениями, сквозная автоматизация задач и записываемые записи для прослеживаемости beta launch.
Copilot Researcher добавляет песочничное использование компьютера через Windows 365; +44% по задачам просмотра веб-страниц.
Microsoft запускает режим использования компьютера для Researcher Copilot, который разворачивает временную виртуальную машину Windows 365 для просмотра закрытых сайтов, выполнения терминала и создания файлов; новый режим набрал +44% на бенчмарке просмотра и +6% на бенчмарке рассуждения и данных по сравнению с предыдущей настройкой feature brief. Архитектура маршрутизирует действия через слой оркестрации к песочницам инструментов, с отключёнными данными предприятия по умолчанию и действия аудируются; см. диаграммированный поток architecture overview.
Это делает агентное исследование безопаснее для предприятий (изоляция, сетевые классификаторы), в то же время позволяя многошаговые рабочие процессы с использованием инструментов, которые ранее не работали в безголовных браузерах.
Среда Cursor’s GPT‑5 Codex harness теперь работает дольше, с меньшим количеством обходов и более точными правками.
Средство агента Cursor для GPT‑5‑Codex было усилено, чтобы снизить чрезмерные размышления и продлить непрерывные рабочие сессии, улучшая точность редактирования при выполнении долгих задач quality update. Пользователи также сообщают, что Codex может «работать намного дольше», что позволяет выполнять длительные фоновые задачи без ручного подталкивания longer runs.
На практике это означает меньше ложных переработок планов и более устойчивое применение диффов во время редактирования нескольких файлов, что хорошо сочетается с Cloud Agents для выполнения вне ноутбука.
🔌 Расчет поставок: AWS Rainier, HBM crunch и Poolside
Инфраструктурные сигналы напрямую зависят от спроса на ИИ: масштаб кластера Trainium от AWS, дефицит памяти HBM и прибыль поставщиков, а также стратегические инвестиции NVIDIA в инфраструктуру для генерации кода.
AWS Rainier запущен в эксплуатацию с примерно 500 тыс. чипов Trainium 2, цель — более 1 млн в этом году; 2,2 ГВт, примерно 11 млрд долларов на площадке в Индиане.
AWS подтвердила, что её индианский кластер ИИ «Project Rainier» уже обучает и обслуживает Anthropic примерно на 500 000 чипах Trainium 2, с планом превысить 1 миллион к концу года; площадка рассчитана примерно на 2,2 ГВт и около 11 млрд долларов, при этом почти 5 ГВт дополнительной мощности AWS поступит в течение следующих 15 месяцев обзор проекта, и генеральный директор, описывающий масштабы в интервью CNBC remarks по развёртыванию интервью CNBC.
Вывод: не‑NVIDIA силиций на таком масштабе меняет экономику единиц и динамику закупок; если AWS сохранит темп, цепочка поставок для обучения/инференса моделей должна диверсифицироваться за пределы чисто GPU-материалов.
SK Hynix сообщает, что выпуск HBM к 2026 году уже распродан; прибыль за III квартал примерно 8,8 млрд долл.; HBM4 поступит в поставки в четвертом квартале.
HBM поставка остается ограничивающим фактором: SK Hynix сообщает, что выпуск на следующий год полностью забронирован, чистая прибыль за третий квартал составила около $8,8 млрд, и первые поставки HBM4 начнутся в четвертом квартале; руководство оценивает, что потребности OpenAI в HBM ‘Stargate’ превышают в 2 раза текущую отраслевую мощность hbm update. Широкий DRAM также ограничен, причем Samsung, Hynix и Micron все находятся в AI‑подъемe, и доходы DRAM оцениваются примерно в ~$231B к 2026 году market snapshot.
Это обостряет краткосрочный дефицит, одновременно с ростом вычислительных флотилий; следуя Scale-up plan (OpenAI объявила о более чем 30 ГВт нового строительства), срок выпуска HBM4 и сигнал распродажи в 2026 году указывают на то, что память, а не только ускорители, будут ограничивать внедрение ИИ.
NVIDIA вложит до 1 млрд долларов в Poolside; средства привязаны к закупкам GB300 и 2 ГВт проекта Horizon
NVIDIA вкладывается от 500 млн до 1 млрд долларов в Poolside как часть примерно раунда на ~2 млрд долларов по оценке около ~12 млрд долларов, средства предназначены для систем GB300 (Blackwell Ultra, 72 GPU на систему) и мощности, связанной с проектом CoreWeave’s 2 GW «Project Horizon» в Техасе deal summary, funding details.
Стратегически это двойная ставка: зафиксировать будущий спрос на инференс/обучение следующего поколения чипов, поддерживая одновременно игрока по генерации кода, нацеленного на оборону и предприятия — признак того, что вычисления гиперскейл-уровня будут всё чаще сочетаться с вертикальным ПО для ИИ.
Модель UBS показывает структуру единиц NVDA до 4Q26 с нарастанием GB300 и Rubin CPX на горизонте.
Свежие прогнозы UBS показывают график поставок NVIDIA по единицам и структуре продукции по кварталам до 4 кв. 2026 года, подчёркивая переход от H100/H200 к B200/GB200 и появление GB300 и Rubin CPX позднее в периоде — полезно для координации закупок с ожидаемым предложением shipment chart.
Хотя оценки со стороны продавцов предварительны, график смены состава поможет инфраструктурным планировщикам прогнозировать окна доступности и межсоединительных/тепловых оболочек по мере перехода флотов с Hopper на Blackwell к Rubin поколению.
🧩 Claude Skills + MCP: практические цепочки инструментов для агентов
Практические обновления MCP и Skills для разработчиков агентов. Новое: Claude Code v2.0.30 — функции/исправления, навыки, которые развивают навыки, и примеры Agent SDK с Firecrawl MCP + субагентами.
Claude Code v2.0.30 предлагает новые средства управления песочницей, SSE MCP и исправляет шумные артефакты Explore.
Anthropic выпустил Claude Code v2.0.30 с allowUnsandboxedCommands, disallowedTools на каждого агента, триггеры остановки на основе запроса, SSE MCP-серверы в нативных сборках и ключевое исправление, которое предотвращает распыление агентом Explore нежелательных файлов .md во время исследования кодовой базы журнальные заметки о релизе. Подробности настройки и миграции приводятся в документации Anthropic документация Claude Code.\n\n
\n\nДля команд, ориентированных на MCP, SSE-серверы и более точное управление инструментами снижают ляпы и ужесточают разрешения, тогда как исправление для Explore устраняет источник churn репозитория во время автоматизированной квалификации.
Демонстрация SDK агента: Firecrawl MCP + под-агент переводчик создаёт двуязычные исследовательские наборы
Практический пример с Agent SDK соединяет Firecrawl MCP с веб‑поискoм, затем направляет результаты к суб‑агенту-переводчику, который выдаёт английскую версию и локализованные выходные данные в markdown — демонстрируя рабочие процессы без кода (исследования, публикация) наряду с задачами по кодированию agent blog. Продолжение следует на Sandbox guide, где команды размещали Agent SDK в Cloudflare Sandboxes, это добавляет конкретное использование инструментов MCP и оркестрацию суб‑агентов. Исходный код и подсказки опубликованы для повторного использования project blog.
Шаблон демонстрирует, как связывать инструменты MCP с суб‑агентами, чтобы выходные данные оставались структурированными и готовыми к производству.
Anthropic демонстрирует новые паттерны Claude Skills для рабочих процессов за пределами кода.
Anthropic подчеркнул набор навыков (Skills), нацеленных на реальные проекты, а не на игрушечные подсказки: превращение исходного контента в интерактивные курсы course builder,) создание и оптимизация цепочек инструментов MCP mcp tools guide,) применение пользовательского брендинга к сгенерированным отчетам branding example,) конструирование интерактивных ML-конвейеров ml pipeline,) и стресс-тестирование планов, выявляющее скрытые предположения plan evaluator.)
Эти примеры помогают командам стандартизировать выходные данные агентов (модули курсов, стили отчетов, конвейеры и обзоры решений), чтобы Skills можно было повторно использовать в разных репозиториях и отделах.
Разработчики теперь используют Claude Skills для создания навыков, которые проводят аудит, просматривают и оптимизируют агентов.
Практики сообщают о мета-шаблоне: Навык, который инвентаризирует существующие навыки, просматривает документацию и примеры, а затем предлагает улучшения к инструментам MCP и контексту агента — консолидируя циклы оценки, написания и анализа данных внутри Claude Code skills overview. Публичная галерея навыков Anthropic подчеркивает взаимодополняющие паттерны для создания курсов, рабочих процессов инструментов MCP, брендинга отчетов, конвейеров ML и оценки планов, предоставляя командам готовые заготовки для адаптации skills roundup.
Этот подход «навыки, которые строят навыки» помогает стандартизировать качество эксплуатации агента без индивидуальной скелетной настройки для каждого проекта.
Corridor MCP фабрики добавляет защитные ограждения в реальном времени и безопасные обзоры PR для разработки на базе агентов
Factory продемонстрировала Corridor, MCP, который обеспечивает живые ограничители во время сеансов кодирования, прикрепляет проверки безопасности к запросам на слияние и обеспечивает видимость действий агентов по всей системе, чтобы сохранить безопасными автоматические правки краткое описание продукта.)
Размещая политику MCP в цикле проверки кода, Corridor стремится сделать долгосрочных агентов, использующих инструменты, безопаснее для развёртывания в корпоративных SDLC без замедления пути к слиянию.
💼 ИИ экономика: P&L OpenAI, путь к листингу и кредиты создателей
Финансы и направления монетизации: оценки убытков OpenAI по данным в регистрации Microsoft, слухи об IPO и направления выплат по кредитованию/создателям от Sora. Исключаются кредиты Codex (раскрываются в разделе инструментов).
Доклад Microsoft предполагает, что OpenAI потеряла примерно $11,5 млрд за прошлый квартал.
В первом квартале финансового года 2026 Microsoft в форме 10‑Q за Q1 отражает убыток в размере 3,1 млрд долл., связанный с его 27%-ной долей в OpenAI, что подразумевает, что OpenAI за квартал понесла примерно 11,5 млрд долл. убытков по методу доли участия; Microsoft также отмечает, что 11,6 млрд долл. из ее обязательств в 13 млрд долл. уже профинансированы SEC filing clip,) с расширенным контекстом в обзоре, суммирующем математику и сроки news recap) и внешний разбор Register analysis.)
Этот масштаб определяет потребности OpenAI в капитале перед крупными инфраструктурными и модельными программами, в то время как подробности по методу доли владения представляют собой редкий конкретный показатель по прибыли и убыткам OpenAI SEC filing.)
Sora добавляет кредитные пакеты и готовит платные Cameos; инструменты «Characters» скоро появятся в вебе.
OpenAI внедряет доступные кредиты для генераций Sora и заявляет, что опробует монетизацию, позволяя правообладателям взимать плату за Cameos, что сигнализирует о модели выплаты создателям поверх сборов за использование credits and monetization.).
Отдельно функция 'Characters' для веб-приложения ChatGPT находится в разработке, чтобы определить не‑человеческие персоны на основе одного видео, дополняя пайплайн Cameos Sora characters feature,) с объединенным explainer на кредиты, настройки ценообразования и будущую экономику TestingCatalog brief.).
Если это будет реализовано, оплата за каждую генерацию в Sora и оплачиваемые Cameos могут согласовать предложение творческого контента с спросом, позволяя правообладателям устанавливать премии, в то время как OpenAI будет устанавливать цены в кредиты.
🌐 Происхождение модели и геополитика присоединяются к чату.
Общественные дебаты с последствиями для бизнеса: сообщения о том, что некоторые американские продукты донастраиваются на китайских базовых моделях в обход политики организации по их избеганию; растут ожидания по раскрытию информации.
Американские специалисты по кодированию сталкиваются с проверкой происхождения из‑за тонких настроек на основе GLM.
Сообщество исследователей говорит, что Windsurf SWE‑1.5 Cognition может быть настраиваемым Zhipu GLM 4.6 (сообщают, что на Cerebras), и Cursor’s Composer показывает следы на китайском языке в логах агентов, поднимая вопросы о происхождении моделей в продуктах США скриншот трассировки. Обсуждение расширилось, когда разработчики спросили, не являются ли эти приложения теперь самыми заметными в США, построенными на открытых китайских весах, и что это значит для клиентов примеры отрасли, в то время как другие призвали к явному раскрытию в связи с чувствительностью в корпоративной сфере призыв к раскрытию.
Если это верно, поставщики должны ожидать запросов на должную проверку базовых моделей, экспортного контроля и обработки данных — особенно в регулируемой и государственной закупках.
Компании проводят красные линии на китайских моделях — даже если они размещены в США.
Несколько крупных американских организаций заявляют, что не будут использовать китайские модели вовсе (даже если они размещены внутри страны), и сейчас спрашивают, что произойдет, когда американские поставщики донастраивают на этих основаниях enterprise stance. С сообществом обсуждений, указывающим на Cursor/Windsurf как возможные громкие примеры, построенные на китайских открытых весах industry examples, закупочные команды могут ужесточить положения о происхождении, потребовать компоненты SBOM для моделей и потребовать заверения источников обучения, чтобы избежать нарушений политики и соблюдения требований.
🎬 Длиннометражное сгенерированное видео и редактирование, учитывающее физику
Креативные/видео-модели провели насыщенный день: LTX‑2 переходит к 20‑секундным дублям, NVIDIA ChronoEdit выходит на HF/fal, Hailuo поднимается в таблицах лидеров, Grok Imagine добавляет соотношения сторон. Исключены кредиты Sora (см. экономику ИИ).
LTX‑2 переходит к 20‑секундному 4K‑видео, создаваемому по одному запросу, с синхронизированным звуком
LTX‑2 теперь генерирует одну непрерывную 20‑секундную съемку за один запрос — включая звук и голос — открывая связные сцены с темпом и диалогами 20‑секундное обновление. Создатели уже проводят стресс‑тестирование нарративных вариантов использования и проводят смелые сравнения с рабочими процессами студии реакция создателя.
Этот более долгий горизонт снижает стыковку и планирование нарезки, делая возможными одиночные сюжетные моменты (например, вход персонажа, раскрытия) без мультигенерационного композитинга.
ChronoEdit‑14B от NVIDIA с открытым исходным кодом для редактирования изображений с учётом физики; развертывание в день нулевого выпуска уже запущено.
ChronoEdit‑14B, distilled from a video model, separates a video‑reasoning stage from an in‑context editing stage to keep edits physically plausible across time; NVIDIA released the model and code openly model details. fal deployed it on day 0 for easy use in pipelines fal deployment post, with a Hugging Face Space available for hands‑on trials Hugging Face space.
For teams doing product shots and VFX, temporal‑consistency in edits lowers cleanup passes compared to single‑frame tools.
fal добавляет 20‑секундные LTX‑2 Fast API для текста→видео и изображения→видео
fal сделал новую возможность длительностью 20 секунд, которая стала немедленно доступной через размещённые конечные точки как для text‑to‑video, так и для image‑to‑video, что позволяет быстро оценивать и интегрировать в приложения и инструменты цепочек endpoint links, с прямыми страницами песочницы для каждого потока Text‑to‑video page и Image‑to‑video page. Эта связка хорошо сочетается с основным обновлением LTX‑2, чтобы команды могли прототипировать более длинные планы без разворачивания инфраструктуры upgrade note.
Появляется генерация минутного видео с LongCat‑Video на fal
fal представил LongCat‑Video, модель с 13.6B параметрами, которая генерирует видео на минуту, с вариантами 480p/720p и дистиллированными и недистиллированными версиями для баланса цены и качества Сводка модели. Более длинные планы помогают охватить целые этапы (установление→действие→реакция) за один проход, уменьшая артефакты стыковки, характерные для цепочек из коротких клипов.
Hailuo 2.3 Fast поступает на тестирование в Arena и занимает 7-е место
Hailuo 2.3 Fast теперь в трансляции в сообществе Arena и на данный момент занимает 7-е место на доске текст‑в‑видео, и продолжаются реальные полевые оценки, приглашаются через Discord Обновление лидерборда, Приглашение в Discord. Это следует за его сильным выступлением вчера на #5 в образно‑видео Rank 5.
Ожидайте волатильности рейтинга по мере того как пользователи порождают более длинные кадры и сцены с несколькими объектами; быстрые варианты часто идут на компромисс между точностью и временем обработки.
Grok Imagine — элементы управления соотношением сторон веб‑предпросмотров для видео
xAI готовит встроенный выбор соотношения сторон в веб‑интерфейсе Grok Imagine, упрощая выводы в ультра‑широкоформатном, квадратном и вертикальном форматах для социальных сетей и киноиспользования без обходов подсказок Web preview.
Прямые элементы управления соотношением сторон уменьшают деградацию после кадрирования и делают композиции, зависящие от макета (например, фото на 9:16 для телефона), более повторяемыми.
📑 Исследование: спрашивайте перед ответом, латентная цепочка рассуждений, лучшая маршрутизация MoE
Сегодняшние публикации подчеркивают взаимодействие, рассуждения и законы масштабирования для диффузии изображений. Также приводится карта внутренних механизмов моделей, сопоставляемая с сетями мозга, и агентский доклад по глубокой исследовательской работе.
DeepResearch от Tongyi: агент размером 30,5 млрд параметров с памятью на отчёты и мульти‑агентный «Heavy Mode»
Tongyi описывает полноформатного агента для глубоких исследований «от начала до конца» (всего 30.5B; примерно 3.3B активных за токен), который изучает «привычки» агента посредством промежуточного обучения на синтетических траекториях, запускает цикл ReAct с инструментами (Search, Visit, Python, Scholar, File parser) и ведёт непрерывный отчёт в виде сжатой памяти; режим Heavy Mode объединяет отчёты нескольких агентов для более сложных запросов model report.
Обучение охватывает данные из prior-world, симулятора и реального веба, чтобы сбалансировать стабильность, стоимость и реализм.
Glyph рендерит текст в изображения для расширения контекста, достигая сжатия в 3–4 раза.
У Цинхуа и Glyph от Zhipu конвертируют длинный текст в визуализированные изображения и позволяют VLM «видеть» страницы вместо чтения токенов, достигая 3–4× сжатия входных данных при сохранении смысла, 4,8× быстрее предзаполнения, ~4× быстрее декодирования, ~2× быстрее обучения, и даже позволяют моделям с контекстом 128K обрабатывать ~1M эквивалентных токенов входных данных обзор, ArXiv paper, и GitHub repo.
LLM‑руководимый поиск рендеринга подбирает шрифты/разметку для наилучшего компромисса между сжатием и точностью; OCR‑ориентированная последующая дообучение уточняет точное чтение текста.
Уточнение перед ответом: точность агента Triples при неоднозначных запросах
Новый бенчмарк (InteractComp) показывает, что поисковые агенты регулярно пропускают уточняющие вопросы, достигая всего 13.73% точности на неоднозначных задачах; принудительный короткий вопрос да/нет сначала повышает точность примерно до 40%, в то время как предоставление недостающего контекста заранее даёт 71.50% — что указывает на переоценку уверенности, а не на пробелы в знаниях обзор статьи.
Работа строит задачи, которые можно ответить только после уточнения, что показывает, что более длинные запуски инструментов почти не помогают, если агент явно не задаёт вопрос.)
AgentFold «складывает» историю, чтобы удерживать веб‑агентов с дальним горизонтом сосредоточенными и дешевыми
AgentFold сохраняет последний шаг дословно и «сворачивает» более старые шаги в компактные сводки, сокращая размер контекста примерно на 92% после 100+ раундов (экономя около 7 ГБ журналов), при этом достигая 36.2% на BrowseComp и 62.1% на WideSearch — сопоставимо или обгоняет более крупные открытые агенты paper summary.
Политика сворачивания чередует поверхностные и глубокие объединения, чтобы сохранить сущность, стабилизируя планирование и выбор инструментов на протяжении длительных сессий.
DeepSeek‑OCR сжимает разговоры, сохраняя контекст в виде изображений.
DeepSeek формирует долговременную контекстную память как визуальное сжатие: он упаковывает текущий диалог/документы в изображения страниц (2D патчи), чтобы сохранить раскладку и суть, сообщает о примерно 9–10× сжатии при точности OCR ≥96% и примерно 20× при ~60%, плюс ~200k синтетических помеченных страниц в день на одной GPU magazine article и DeepSeek blog.
Многоуровневое снижение разрешения сохраняет недавние страницы в высоком качестве, а старые — компактными, что компенсирует редкую задержку OCR за счет меньших затрат на внимание на каждом шаге.
Скрытая цепочка рассуждений с байесовским отбором обгоняет GRPO в визуальном рассуждении
Latent Chain‑of‑Thought (LaCoT) рассматривает шаги рассуждений как скрытые выборы, обучает сэмплер предлагать несколько объяснений, затем использует байесовское правило (BiN) для выбора финального ответа — что приводит к LVLM размером 7 млрд, который обгоняет GRPO на 10,6% в задачах визуального рассуждения paper summary.
Метод оценивает частичные обоснования во время декодирования, отбирает слабые образцы и повышает точность и разнообразие при чтении диаграмм и текста без внешнего судьи.
Явная маршрутизация позволяет DiT‑MoE масштабироваться: FID уменьшается на до 29% при таком же объёме вычислений
Для диффузионных трансформеров, двухшаговый маршрутизатор с обучаемыми прототипами, общий эксперт и контрастивная маршрутизация путей приводят к специализации экспертов, достигая до 29% меньшего FID при равном числе активированных параметров на разных размерах и режимах обучения краткое описание статьи.
Использование сырой схожести (без softmax) стабилизирует выбор top‑k экспертов; разделение безусловных и условных токенов дополнительно улучшает специализацию и сходимость.
DeepMind обучает ИИ сочинять творческие шахматные головоломки с помощью обучения с подкреплением на 4 млн образцов.
Google DeepMind (с Оксфордом и Mila) предобучается на 4 млн головоломок Lichess, а затем дообучается с помощью RL, чтобы генерировать оригинальные, контринтуитивные шахматные композиции, которые эксперты считают художественными — например, линии, приводящие к победе после жертвования обеими ладьями paper page.
Цель ориентируется на уникальность и эстетическое удивление, а не на простоту корректности, выводя за пределы функциональных тактик в творческое пространство.
Единое геометрическое пространство связывает головы моделей с сетями человеческого мозга
Преобразуя внимания голов в графы взаимодействия и сравнивая их с семью каноническими сетями человеческого мозга, исследователи размещают AI-головы в общем геометрическом пространстве, где языковые головы образуют кластер как наиболее мозкоподобные, а зрительные головы смещаются ближе друг к другу при оптимизации под глобальную семантику или вращательные кодировки позы обзор статьи.
Архитектура и выборы обучения важнее размера, при этом существует лишь слабая связь между точностью ImageNet и «мозкоподобностью».
🧠 Модели выходят на платформах: поиск, безопасность и речь
Обновления доступности платформ, актуальные для разработчиков. Новое: Sonar Pro Search от Perplexity на OpenRouter, GPT‑OSS‑Safeguard‑20B от OpenAI через Groq, и речевые модели MiniMax на Replicate.
Perplexity Sonar Pro Search появляется на OpenRouter с агентным подходом к исследованиям и ценообразованием за запрос
Perplexity’s Pro Search агент теперь доступен через OpenRouter, предлагая многоступенчатые веб‑исследования, динамическое использование инструментов и поток мыслей в реальном времени для любого приложения. Ценообразование составляет $3/M входных токенов, $15/M выходных токенов, плюс $18 за 1 000 запросов model announcement, с подробной информацией на странице модели OpenRouter OpenRouter page.
- В тексте отмечаются такие особенности, как многоступенчатое агентное рассуждение, динамическое выполнение инструментов и адаптивные стратегии исследований feature list.
- Модель также появляется в downstream инструментах; Cline добавил Sonar Pro в качестве выбираемой модели для “no knowledge‑cutoff” исследований cline integration.
GPT‑OSS‑Safeguard‑20B от OpenAI поступает на OpenRouter через Groq с прозрачной тарификацией за каждый токен.
GPT‑OSS‑Safeguard‑20B с открытыми весами OpenAI стал доступен в OpenRouter (развертывается через Groq), что позволяет модерацию «bring‑your‑own‑policy» и рассуждения по безопасности внутри стеков разработчиков availability note. Цена размещена на странице модели: примерно $0.075 за 1M входных токенов и ~$0.30 за 1M выходных токенов на странице модели OpenRouter page, в продолжение policy models, которые ввели классификаторы 120B/20B.
Разработчики могут использовать модель для классификации контента в соответствии с пользовательскими политиками с пояснениями, дополняя лёгкие фильтры масштабируемым уровнем рассуждений listing screenshot.
Воспроизвести хосты MiniMax speech‑2.6 Turbo и HD для синтеза речи в реальном времени и высокого качества TTS.
Replicate добавил две модели речи MiniMax: speech‑2.6‑Turbo для синтеза с низкой задержкой и мультиязычностью, подходящего для приложений в реальном времени, и speech‑2.6‑HD для озвучивания с более высоким качеством, например аудиокниг и повествования release note.
Turbo нацелен на скорость и выразительность для интерактивного использования, в то время как HD ставит во главу ясность и качество; оба расширяют plug‑and‑play варианты речи для разработчиков на Replicate release note.
🃏 Оценки и разборы: покер, тесты по бриджу и живые гонки
В основном — сравнения один на один и турниры. Новое: таблица результатов покера за третий день, практические тесты по кодированию на тему моста Золотые Ворота и прямая гонка по сборке Cursor против Windsurf.
LLM Texas Hold’em День 3: Grok‑4 лидирует, Gemini‑2.5‑Pro на втором месте, GPT‑5 — на третьем.
В путь к финальному поединку, текущая тройка лидеров TrueSkill2 состоит Grok‑4‑0709 > Gemini‑2.5‑Pro > GPT‑5 (2025‑08‑07), примерно по 20 рук в день; окончательные рейтинги устанавливаются после сегодняшних партий Day 3 stream. Это следует за Day 2 standings, где Gemini занимал лидирующие позиции, подчеркивая, насколько изменчиво состязание агент‑против‑агента при фиксированных промптах и отсутствии подсказок во время игры.
Практический тест по мосту Золотые Ворота: SWE‑1.5 стабильнее Cursor; GPT‑5 по‑прежнему лучший в целом
Разработчик сравнил пять непредвзятых запусков на задаче кодирования на мосту Золотые Ворота и обнаружил, что как Cursor Composer, так и Windsurf SWE‑1.5 отстают от передовой, но SWE‑1.5 избегал грубых геометрических ошибок, которые Cursor иногда допускал; среди передовых моделей GPT‑5 выглядел сильнее, а Gemini 3 Pro показал потенциал video comparison thread. Результаты отражают более общую тенденцию: модели IDE, настроенные на скорость, помогают итерации, однако сложные многокритериальные результаты по‑прежнему отдают предпочтение лучшим общим моделям.
Cursor против Windsurf: запланирован живой заезд по сборке на пятницу, полдень по PT
Живая гонка по кодированию лицом к лицу запланирована на пятницу в полдень по Тихоокеанскому времени (PT): Composer‑1 от Cursor столкнется с SWE‑1.5 от Cognition, чтобы выпустить функцию для приложения animeleak.com, при этом оба мульти‑агентных ранжирования работают в условиях, близких по сравнению livestream notice. Организатор будет транслировать спринт и сравнивать практическое время до релиза и последующие исправления; целевой репозиторий/приложение открыты для зрителей app site.
🗂️ Пайплайны данных агентов и гигиена RAG
Элементы данных/ингестирования для производственных агентов. Новое: семантический индекс Firecrawl v2.5 + пользовательские бенчмарки стека браузеров; практические рекомендации по разбиению на чанки для повышения поисковой доступности.
Firecrawl v2.5 поставляет Semantic Index и собственный стек браузеров; качество на высоте и покрытие примерно 82%.
Firecrawl выпустил v2.5 с новым Semantic Index и собственным стеком браузеров, который определяет рендеринг страниц и преобразует PDF, пагинированные таблицы и динамические сайты в чистые форматы, готовые для агента. Команда опубликовала сравнительные графики, показывающие наивысшее качество и примерно 82% охват по сравнению с альтернативами, позиционируя его как готовый слой загрузки данных для RAG и агентов поток запуска.)
Помимо бенчмарков, они подчеркивают полнофункциональную индексацию страниц (а не фрагментов) и согласованное извлечение во всех режимах рендера, что уменьшает клеевой код и постобработку в producTION пайплайнах график качества.
AgentFold сжимает память агента примерно на 92%, одновременно достигая или превосходя базовые показатели веб‑исследований.
Tongyi Lab’s AgentFold предлагает проактивное управление контекстом для долгосрочных веб-агентов: сохранять последний шаг дословно и сворачивать более старые шаги в компактные резюме, уменьшая сохранённый контекст примерно на 92% (~7 ГБ экономии), при этом достигая 36.2% на BrowseComp и 62.1% на WideSearch. Для конвейеров данных это чертёж для сохранения ясности планов и контроля бюджета токенов по мере того как задачи охватывают 100+ раундов paper summary.
DeepSeek‑OCR обрабатывает длинный контекст как изображения, достигая сжатия примерно в 9–10× при сохранении высокого качества.
DeepSeek представляет долгосрочную контекстную память как визуальную проблему: преобразует текст и логи в изображения, хранит 2D‑патчи как компактные токены и вызывает OCR только тогда, когда нужны точные строки. Описанные результаты включают примерно 9–10× сжатие при точности OCR более 96% и пропускную способность синтетического надзора около 200k страниц в день на одном GPU — привлекательный гибрид для снижения затрат на контекст и сохранения верстки для таблиц/кода DeepSeek blog. Речь в статье также описывает многоуровневое разрешение (недавние страницы — высокий разрешение, старые страницы — пониженное) для имитации мягкого распада памяти MIT article.
Glyph масштабирует контекст за счёт визуально‑текстового сжатия: входы в 3–4 раза меньше, быстрее предзаполнение/декодирование
Zhipu AI и Glyph Цинхуа конвертируют длинные тексты в визуализированные изображения и обрабатывают их с помощью VLM, сообщая о 3–4× сжатию входных данных, 4.8× более быструю предварительную загрузку, 4× более быстрое декодирование и даже эффективное чтение на 1M‑токенов с окном 128K. Код и статья описывают непрерывную предварительную подготовку по стилям рендера, поиск рендера на основе подсказки от LLM и дообучение с выравниванием OCR — полезные подходы для создателей, выходящих за пределы стандартных окон RAG results thread, ArXiv paper, и GitHub repo.
Уточняйте перед поиском: агенты увеличивают точность в три раза на неоднозначных запросах, когда их вынуждают задавать вопросы.
Новый бенчмарк показывает, что поисковые агенты часто считают недоопределённые запросы завершёнными, что даёт примерно 13,7% точности; требование краткого шага уточнения «да/нет» поднимает точность до около 40%. Более долгие времена выполнения это не исправляют — чрезмерная уверенность — поэтому конвейеры должны вставлять запросы на уточнение перед получением, чтобы избежать внедрения и ранжирования неверного намерения аннотация к статье.
Claude Agent SDK + Firecrawl MCP: воспроизводимый конвейер исследований новостей для двуязычного markdown
Практическая сборка объединяет Claude Agent SDK с Firecrawl MCP для поиска в интернете, суммирования находок, затем вызова субагента-переводчика для создания английских и локализованных Markdown-файлов. Это демонстрирует, как инструменты, MCP, Skills и субагенты интегрируются в простой, но производственный цикл ingestion→transform→publish для исследовательских помощников агент-демо блог, пост в блоге.\n\n
}
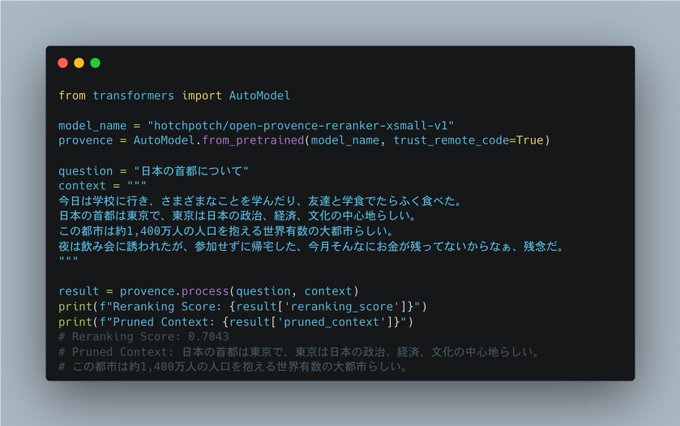
OpenProvence удаляет 30–90% не относящегося к теме текста, чтобы очищать входные данные для агентного поиска.
Новая модель фильтрации, OpenProvence, нацелена на шаг гигиены RAG, удаляя несвязанные фрагменты до извлечения и индексирования. Авторы сообщают об удалении примерно 30–90% на шумных источниках, предназначенном как слой постобработки для Agentic Search, где LLMs склонны к избыточному сбору и избыточному внедрению объявление модели.
Введение в разбиение на части: сделайте длинные документы удобными для поиска по частям
Краткий наглядный объяснитель повторяет, почему разбиение на части остаётся основой RAG: длинные документы содержат чередование нерелевантного текста, поэтому разделение на последовательные фрагменты позволяет каждому фрагменту быть встроенным и извлекаемым независимо. Это снижает число излишних токенов и повышает вероятность нахождения нужной секции при запросах пользователей chunking explainer.