Google Veo 3.1 выходит по цене 0,15 доллара за секунду — аудио и руководство на основе трёх изображений
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Google перевёл Veo 3.1 из режима предпросмотра в широко используемую версию, и это самый практичный скачок в инструментах для AI-видео за этот месяц. В Gemini API теперь доступен нативный диалог/звуковое оформление, до трёх эталонных изображений для идентификации/стиля и переходы между первым/последним кадром, а платёжная опция Fast начинается примерно с 0,15 доллара за секунду. Идея проста: меньше обхождения через After Effects, более детерминированные нарезки и непрерывность прямо из модели.
Доступ представляется в двух уровнях — Fast и Quality, с пометками «Beta Audio», и он уже виден в Google Flow для аккаунтов в США, в то время как некоторые регионы (например, Германия) ещё ожидают. Экосистема развивалась за считанные часы: Replicate опубликовал эндпоинт google/veo‑3.1 с условной обработкой последнего кадра, ComfyUI открыл узлы text→video и image→video, а fal выпустил учебник по переходу от референса к видео. Сообщества тоже включились: Genspark теперь выводит 1080p с интерполяцией первого/последнего кадра и несколькими изображениями‑референсами, а Freepik на этой неделе предлагает безлимитный Veo 3.1 на Premium+/Pro. Расширение сцены, которое учитывает предыдущую секунду, сохраняет движение и фоновый звук в более длинных кадрах, а шаблоны запросов Google для кадров камеры и блоков диалога действительно работают.
После вчерашних «предстоящих» пометок это настоящий развёртывание — и оно достаточно широкое, чтобы начать стандартизацию пайплайнов на Gemini API.
Feature Spotlight
Функция: Veo 3.1 выходит на всех стэках разработки
Veo 3.1 переходит из лаборатории в производство: более богатый нативный звук, опорочные изображения, расширение сцены и управление кадр к кадру теперь доступны в Gemini API, Flow, Replicate, ComfyUI и других — открывая агентские видеопотоки в разрешении 1080p.
Массовое покрытие по нескольким учетным записям: Veo 3.1 от Google переходит из режима превью к широкому доступу с аудиоподдержкой, справочной документацией и управлением сценами на Gemini API, Flow, Replicate, ComfyUI, fal и сторонних приложениях. В основном — конкретные новости о продукте и его использовании.
Jump to Функция: Veo 3.1 выходит на всех стэках разработки topicsTable of Contents
🎬 Функция: Veo 3.1 выходит на всех стэках разработки
Массовое покрытие по нескольким учетным записям: Veo 3.1 от Google переходит из режима превью к широкому доступу с аудиоподдержкой, справочной документацией и управлением сценами на Gemini API, Flow, Replicate, ComfyUI, fal и сторонних приложениях. В основном — конкретные новости о продукте и его использовании.
Veo 3.1 выходит в платной предварительной версии Gemini API с аудио, ссылками и управлением сценами
Google включил Veo 3.1 в Gemini API (включая тарифы Fast и Quality), добавив родной диалог/SFX, до трех опорных изображений, расширение сцены и переходы между первым и последним кадрами; Fast with audio начинается примерно с $0.15 за секунду, согласно коммуникациям разработчиков Google API brief, pricing update, и обзор функций в продуктовом блоге Google blog post. Релиз следует за ранними баннерами «imminent»/«приближающийся» заметенными вчера imminent release и поддерживается командами Google DeepMind и Gemini app, подтверждающими более глубокий нарратив Veo 3.1 и преимущества image‑to‑video release thread, app rollout.
Для инженеров это конкретное изменение API‑поверхности: управление с опорой на указания/reference‑guided generation и детерминированные переходы кадров снижают взломы склейки, в то время как родной звук упрощает постобработку пайплайнов.
Google Flow позволяет Veo 3.1 Fast/Quality (Beta Audio) работать в США.
Создатели теперь видят Veo 3.1 – Fast и Veo 3.1 – Quality (обе помечены как Beta Audio) в селекторе моделей Flow, и несколько живых скриншотов с аккаунтов США подтверждают доступность Flow screenshot, model picker, live picker. Некоторые пользователи сообщают, что функция ещё не достигла всех регионов (например, не в Германии), что предполагает поэтапное развёртывание regional note.
Это делает Flow быстрым способом проверить функции Veo 3.1 (ссылки, более плавные движения камеры, переходы между первым и последним кадрами) до подключения Gemini API.
Replicate, ComfyUI, fal и многое другое добавляют конечные точки API Veo 3.1 и инструменты.
Экосистема зажглась вокруг Veo 3.1: Replicate опубликовал google/veo‑3.1 (с опорными изображениями и настройкой последнего кадра) для программного использования hosted models, Replicate model page; ComfyUI exposed Veo 3.1 API nodes for text→video and image→video with no local setup beyond updating the app node update; fal launched a tutorial episode that demos reference‑to‑video and first/last‑frame control video demo. Community surfaces are leaning in too: Flowith opened side‑by‑side Veo 3.1 rooms canvas room, Genspark added 1080p output with first/last‑frame interpolation and multi‑image reference platform update, and Freepik is promoting unlimited Veo 3.1 usage on its Premium+/Pro plans this week promo note.
Taken together, teams can prototype on hosted platforms, then standardize on the Gemini API once specs stabilize.
Новые возможности Veo 3.1: направляющие подсказки, расширение сцены, переходы между первым и последним кадрами
Google поделился конкретными шаблонами prompting — камеры удара, блоки диалога и переходы — которые Veo 3.1 теперь выполняет надежнее, включая до трёх опорных изображений для закрепления идентичности/стиля и переходы по первому/последнему кадру для чистых стыков prompt guide, Google blog post. Scene extension grows clips by conditioning on the prior second to preserve motion and background audio for longer takes feature brief. Practitioners’ tests show the reference pipeline keeping characters consistent (e.g., art‑to‑movie and portrait‑to‑live‑action runs) usage example, and prompt authors demonstrate “no crossfade” directives to force precise whip‑pans back to the last frame technique note.
Эти элементы заменяют большую часть ручной стыковки: используйте опорные материалы для сохранения непрерывности, переходы по первому/последнему кадру и расширение для мультигапсий.
🧠 Компактные, но мощные модели и сигналы 3.0 Pro
Новая компактная модель и намёки к дорожной карте моделей. Исключает Veo 3.1 (раскрыто в обзоре). Сосредоточьтесь на деталях выпуска Claude Haiku 4.5 и наблюдениях за Gemini 3.0 Pro/Gemini Agent.
Anthropic запускает Claude Haiku 4.5 с меньшими затратами и более высокой скоростью
Антропик выпустила Claude Haiku 4.5, небольшую модель с ценой $1/$5 за миллион входных/выходных токенов, ориентированную на работу в реальном времени с примерно вдвое большей скоростью и примерно в три раза меньшей стоимостью по сравнению с Sonnet 4, при этом заявляющей качество кодирования уровня Sonnet‑4. Ранние официальные графики показывают Haiku 4.5 на 73.3% в SWE‑bench Verified против 77.2% у Sonnet 4.5 и 74.5% у GPT‑5 Codex сообщение о выпуске, график бенчмарков, с полными примечаниями к выпуску, подтверждающими цены и позиционирование обзор блога, сообщение в блоге Anthropic. [изображение:https://pbs.twimg.com/media/G3UNhyzWgAAANm8.png|График бенчмарков] ) Для руководителей инженерных команд, планирующих расходы на API, такое соотношение предлагает новый стандарт по умолчанию для агентов выполнения: Sonnet 4.5 для планирования, затем Haiku 4.5 для более быстрой/дешевой реализации в длинных циклах инструментов продуктовые заметки.
Строки Gemini 3.0 Pro появились перед публичным релизом.
Многие наблюдения показывают, что веб-приложение Gemini выводит «Мы обновили вас … до 3.0 Pro, наш самый умный моделй на сегодня», в то время как выбор модели по-прежнему помечает сессии как 2.5 Pro — что наводит на мысль, что поэтапный A/B тест или gating rollout строки landed before the switch ui notice, user screenshot. Code inspections reveal the same copy embedded in client templates, reinforcing an imminent Pro refresh code strings, code snippet. Expect improved coding and reasoning claims at unveil; until the selector flips, treat outputs as 2.5 Pro.
Product owners should plan quick smoke‑tests on long‑context tasks and tool use once 3.0 Pro is live, as UI strings alone don’t guarantee tier changes.
Прототип Gemini Agent нацелен на полное выполнение веб-заданий
TestingCatalog сообщает, что Google готовит режим Gemini Agent, который сможет входить в систему, управлять процессами браузера и поддерживать многоступенчатые исследования, вероятно, опираясь на новую модель Computer User, а не на стандартный стек чата feature brief, TestingCatalog article. UX-ограничения подчёркивают невозможность делиться учётными данными в чате и надзор за автоматизацией, намекая на специализированный бэкэнд и более строгие политики. Если это будет принято, это закроет ключевой разрыв возможностей по сравнению с агентскими конкурентами, перейдя от RAG к полной реализации задач.
Хайку 4.5 показывает сильный SWE-бенч, но смешанные результаты по репозиторию и QA.
Помимо графиков Anthropic, общественные оценки дают более нюансированное представление. Haiku 4.5 достигает 73.3% на SWE‑bench Verified по той же диаграмме, которую использовал Anthropic swe bench snapshot,) но занимает заметно ниже Sonnet на задачах RepoBench по всему репозиторию (~57.65% уровня) repobench result.) На общественном QA снимке LisanBench показано, что Haiku 4.5 опережает 3.5, но всё ещё посередине списка lisanbench chart.) Также он был добавлен в открытые площадки сравнения для текста и веб‑разработки, чтобы команды могли проверить траектории перед переключением arena entry.) Программные команды должны учитывать профиль задач: Haiku 4.5 отлично справляется с структурированными исправлениями кода и циклами, насыщенными инструментами, тогда как длинный контекст и межфайловые рассуждения всё ещё предпочитают более крупные модели.
Haiku 4.5 намного быстрее в цикле, чем Sonnet 4.5
Пошаговые запуски в параллельном режиме показывают, что Haiku 4.5 примерно в 3,5 раза быстрее Sonnet 4.5 для интерактивного кодирования, при этом разработчики подчеркивают, что она дольше остаётся внутри человеческого «потока работы» более последовательно — что приводит к большему количеству управляемых итераций в минуту, даже когда абсолютная задержка варьируется в зависимости от нагрузки сравнение скорости.) Инструменты обновляются так же, что маршрутизируют план→выполнение к Sonnet→Haiku «за кулисами», что укрепляет роль скорости Haiku в многоагентных рабочих процессах изучить настройки по умолчанию,) с примечаниями к выпуску, подчёркивающими новую пару примечания к выпуску.)
Команды всё ещё должны проводить бенчмаркинг на своей кодовой базе: задержки сети/инструментов и размер репозитория часто доминируют в восприятии скорости.
Хайку 4.5 стоит немного дороже, чем 3.5, но в три раза дешевле Сонета.
Практикующие отмечают, что Haiku 4.5 стоит $1/$5 за MTok — примерно на 20–25% выше $0.80/$4 Haiku 3.5 — но все же примерно в 3 раза дешевле Sonnet 4.5 ($3/$15), что обновляет расчёт ценности для моделей исполнения по умолчанию pricing note, blog summary. Для стека агентов этот дельта часто окупается за счет меньшей задержки и меньшего количества раундов; для пакетной аналитики или длинноформулировок некоторые команды будут оставлять Haiku 3.5 там, где скорость не является узким местом Anthropic blog post.
🛠️ Агентное кодирование: Хайку 4.5 повсюду, Amp Free и ветвление
День интенсивного инструментирования: замены небольших моделей в кодирующих агентах, новый бесплатный тариф с поддержкой рекламы и UX‑шаблоны для субагентов/ветвления. Исключено содержимое Veo 3.1.
Sourcegraph запускает Amp Free: рекламно поддерживаемое агентное кодирование с данными обучения по согласию пользователей.
Sourcegraph сделал своего кодового агента бесплатным через «Amp Free», финансируемого за счет изысканных объявлений для разработчиков и со скидками на токены, при этом пользователи соглашаются на обмен данными, чтобы сохранить бесплатность launch note, и полные детали о том, как реклама и данные обрабатываются в заметке продукта product page. Ранние примеры показывают, что реклама встроена в цикл агента, пока работа продолжается, и команды по-прежнему могут перейти на платные планы из-за корпоративных ограничений cli screenshot. Сравнительная диаграмма, циркулируемая в сообществе, размещает Amp среди лидирующих кодирующих агентов по одобрению PR, намекая на конкурентное качество, несмотря на ограничения бесплатного тарифа comparison chart.
Хайку 4.5 выходит во все уровни стека разработки: более быстрая и более дешевая модель исполнения для агентов
Маленькая модель Haiku 4.5 от Anthropic внедряется в популярные агентские инструменты, часто выступая в роли быстрого исполнительного подагента, сочетаемого с более мощным планировщиком:
Claude Code интегрирует её в подагента Explore и сочетает Sonnet 4.5 для планирования feature brief; Windsurf and Cline added day‑0 support windsurf support, client update; Cursor exposes a toggle to enable it cursor update; Factory lists it for low‑latency execution factory note; and Droid CLI shows it at 0.4× token cost for tiny tasks cost selector. Anthropic highlights 73.3% on SWE‑bench Verified, near Sonnet 4/4.5, at ~$1/$5 per MTok with materially lower latency benchmarks chart, model overview.)
Imbue’s Sculptor добавляет форкинг для ветвящихся агентов, сравнение путей и повторное использование кэшированного контекста
Sculptor представил Forking, чтобы вы могли создавать новых агентов из любой точки беседы о коде, повторно использовать кэшированный контекст, чтобы снизить затраты, и сравнивать ветви с помощью режима Pairing Mode перед слиянием лучшего пути запуск функции. Бета-заметки команды поощряют включение Forking в Настройки и указывают на страницу продукта для быстрого тестирования страница продукта.
Хайку 4.5 сокращает затраты и время использования компьютера по сравнению с Сонетом 4.5 в тесте для практикующих.
В живом задании по использованию компьютера («создать landing page и открыть его»), Haiku 4.5 выполнился примерно за 2 минуты при ~ $0.04, в то время как Sonnet 4.5 занял ~3 минуты приблизительно за ~$0.14; авторы отмечают баллы OSWorld примерно ~50.7% против ~61.4%, что объясняет разрыв в качестве, но скорость и цена могут повлиять на экономику автоматизации результат задачи, последующее.
ElevenLabs ‘Client Tools’ позволяют голосовым агентам перемещаться по вашему приложению и выполнять задачи.
ElevenLabs презентовала Client Tools, которые позволяют агенту выполнять UI‑действия в сессии веб/приложения (например, переход по интерфейсу, заполнение форм, нажатие кнопок), с руководством, показывающим, как внедрить эти инструменты в агент обзор функции. Команда опубликовала многосерийное видео, охватывающее аутентификацию, безопасность и теперь Client Tools, чтобы помочь командам выпускать голосовых агентов в продакшн плейлист.
GLM 4.6 “Coding Plan” получает более широкую поддержку в инструментах; разработчики сообщают о сильной задержке ночью.
Панель поставщиков Z.ai теперь предлагает вариант «Z.ai‑plan» для рабочих процессов Coding Plan provider menu, и Trae/others встроены в потоки агентов integration note. Разработчики в Азии отмечают, что модель плана «быстрая на данный момент» в поздние часы, что может быть полезно для пакетных рефакторингов и длительных запусков latency note.
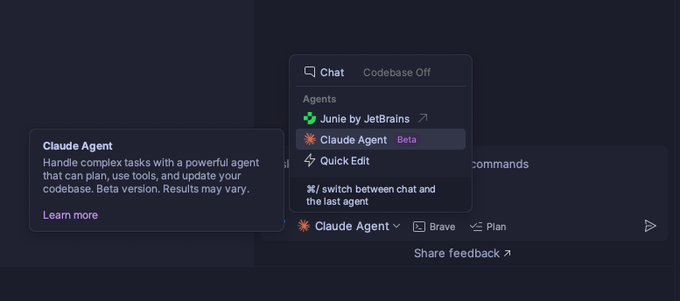
JetBrains демонстрирует «Claude Agent Beta» в WebStorm для планирования внутри IDE и использования инструментов
Сборка WebStorm открывает новое меню Agents с «Claude Agent (Beta)» и описанием того, что он может планировать, использовать инструменты и обновлять вашу кодовую базу — еще одно доказательство того, что агентное кодирование переходит в меню IDE наряду с собственным агентом Junie от JetBrains ide screenshot.
Подсказка телеметрии: GPT‑5 Codex в среднем 84 сообщения на запрос кода в OpenRouter
OpenRouter поделился прокси длиной беседы для сеансов кодирования: GPT‑5 Codex в среднем ~84 сообщения за запрос, за которым следуют Gemini 2.5 Pro (~74) и DeepSeek 3.1 Terminus (~72), что подчеркивает глубокие многошаговые рабочие процессы для задач тяжелой генерации кода/рефакторинга таблица лидеров. Страница модели перечисляет поставщиков и детали интеграции для команд, тестирующих Codex в масштабе страница модели.
Практикующие применяют Haiku 4.5 в качестве исполнительного субагента во всех инструментах
Команды сообщают о переключении по умолчанию на Haiku 4.5 для быстрых циклов — Cursor добавил переключатель модели cursor update, Cline and Windsurf shipped same‑day support client update, windsurf support, and Factory made it available alongside Sonnet 4.5 or Opus for planning factory note. Developers highlight noticeably better “flow window” feel vs slower planners even when raw accuracy is lower ux comparison.
Использование Codex CLI: сначала планирование, затем выполнение — выходит официальный пятиминутный туториал.
Официальный пошаговый обзор показывает, как использовать Codex CLI с GPT‑5‑Codex для планирования небольшой мультиплеерной функции и её реализации, включая шаблоны команд и поток развертывания видеоурок. Практикующие подчёркивают лучшие практики, такие как сохранение минималистичного списка инструментов CLI на виду и просьба следовать правилам на уровне репозитория в конце работы поток советов.
🎞️ Другие видеостеки и рабочие процессы создателей
Обновления и инструкции по генеративным медиа без Veo. За исключением Veo 3.1 (функция). Возможности Sora 2 расширяются; общие рабочие процессы по запросам и раскадровке.
Sora 2 добавляет раскадровки на вебе и увеличивает длительность клипа до 25 секунд для Pro.
OpenAI разворачивает Sora 2 сториборды в вебе для пользователей Pro и увеличивает максимальную продолжительность до 25 секунд на вебе (у всех пользователей до 15s в приложении/вебе) feature rollout, с деталями доступа, поясненными в последующем access note.). Обновление композитора сторибордов видно в новом UI, показывая описания на каждой сцене и выбор продолжительности storyboard ui.\n\n
Sora 2 Pro выходит в AI Video Arena на 4‑м месте в категории «text‑to‑video»; базовая модель занимает 11‑е место.
Artificial Analysis теперь занимает Sora 2 Pro на #4 и Sora 2 на #11 в своей текст‑видео таблице лидеров, с отключенным звуком ради справедливости; Sora 2 остается примечательной за родной аудио и контроль Cameo arena summary, leaderboard table. Эта публикация также сопоставляет цены примерно ~$0.50/сек для Pro и ~$0.10/сек для базовой версии arena summary, в контексте Arena standings, где ранее обсуждались позиции.
NotebookLM добавляет стили видео Nano Banana и быстрый режим обзора «Brief»
NotebookLM от Google запустил мобильную студию и видеов обзоры на базе Nano Banana с шестью визуальными стилями и новым форматом «Brief» для быстрых сводок; функции сначала выходят в Pro, затем будет доступна более широкая версия feature brief, studio redesign. Это направлено на более быстрые объяснения в духе сториборда с управлением языком, дизайном и темами для исследовательских рабочих процессов.
Практический «директорский бриф» для Sora 2 повышает соблюдение требований и единообразие.
Руководство для создателя сводит подсказки Sora 2 к брифу в киношном стиле — определяя рамки кадров, ритм движений, освещение, палитру, диалоги и звук — чтобы заменить сюрприз контролем по мере необходимости и для итераций путём подстройки одного элемента за раз prompt guide. Советы подчёркивают последовательность отдельных кадров, ограничение каждого до одного движения камеры и одного действия, а также закрепление персонажей единообразными дескрипторами для связности в длинной форме.
Модель Ovi от Character.AI для преобразования изображений в видео получает скидку в 25% на Replicate.
Replicate объявила временную скидку 25% на из текста/изображения в видео Ovi с родным звуком, действующую до 29 октября pricing promo. Разработчики могут напрямую попробовать оба конвейера T2V и I2V на странице размещённой модели Replicate model.
Сделай своими руками «bullet time» с WAN 2.1 + VACE multi‑control в ComfyUI
Реконструкция Corridor Digital демонстрирует практичный workflow ComfyUI — WAN 2.1 с VACE и видео с мульти‑контролем для z‑глубины, позы и движения камеры, чтобы добиться синхронизированных эффектов «bullet time» с использованием телефонных камер и ПК workflow thread. Проектная ссылка включает общий граф и активы для воспроизведения workflow link.
📊 Бенчмарки: кодирование, физика и трекеры моделей
В основном — оценки и таблицы лидеров в области кодирования и науки; сегодня меньше голосовых элементов. Исключает рейтинги Veo (функция принадлежит Veo).
Claude Haiku 4.5 публикаций 73.3% на SWE‑bench Проверено, приближаясь к Sonnet 4.5 на 77.2%
Новая маленькая модель Anthropic достигает 73,3% точности на SWE‑bench Verified (n=500), близко к 77,2% у Sonnet 4.5 и опережает GPT‑5 (72,8%), хотя отстает от GPT‑5 Codex (74,5%) benchmarks chart.) Для команд, оценивающих стоимость/задержку по сравнению с топовой точностью, это размещает Haiku 4.5 в пределах досягаемости передовых моделей кодирования.
Индекс искусственного анализа: Haiku 4.5 набирает 55 баллов (мышление) за ~$262 за запуск теста против ~$817 у Sonnet
Artificial Analysis размещает Claude Haiku 4.5 (мышление) на 55 в своем комбинированном индексе интеллекта, примерно на восемь пунктов ниже Sonnet 4.5 (мышление), но гораздо дешевле в эксплуатации (~$262 против ~$817 за полный пакет) index brief. Графики эффективности использования токенов и разбор по каждому бенчмарку доступны для более глубокого анализа затрат/производительности methodology update.
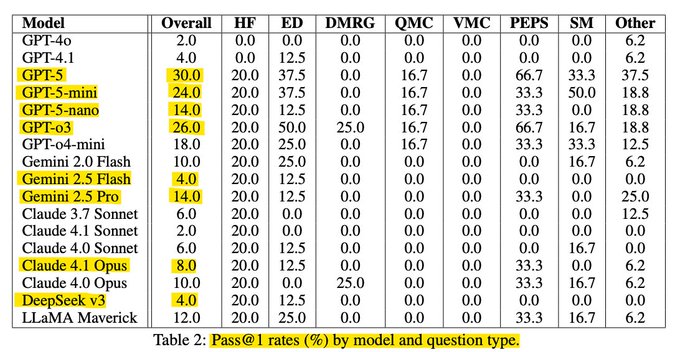
Новый бенчмарк по физике CMT: GPT‑5 достигает примерно 30% Pass@1; o3 около 26%
Только что опубликованный бенчмарк по теории сложной материи (50 задач экспертного уровня) сообщает, что GPT‑5 ~30% Pass@1, GPT‑o3 ~26%, и GPT‑5‑mini ~24%, при этом у большинства других моделей ≤20% paper thread, увидеть полную статью для подробностей по настройке и данным ArXiv paper.
Карта более чем 50 бенчмарков агентов по инструментам, кодированию, рассуждению и использованию графического интерфейса пользователя.
Фил Шмид выпустил справочник по бенчмаркам ИИ-агентов, в котором собрано более 50 современных оценок, охватывающих вызов функций, общие рассуждения, кодирование/инженерию ПО и взаимодействие с компьютером blog post,) с активно поддерживаемым репозиторием на GitHub для ссылок и протоколов GitHub repo.). Это удобный индекс для стандартизации стеков оценивания между командами.
Проверка RepoBench: Haiku 4.5 отстаёт от Sonnet 4 по задачам всего репозитория (~57.65%)
Независимые прогоны на RepoBench показывают, что Claude Haiku 4.5 достигает примерно 57,65%, заметно уступая Sonnet 4 в рефакторингах и исправлениях на масштабе репозитория таблица результатов. Это дополняет достижения SWE‑bench, отмечая, где меньшие модели по‑прежнему отстают на длинной временной шкале и при изменениях в нескольких файлах.
Claude Haiku 4.5 входит в арену чатботов для сравнений текста и WebDev.
LMArena добавила Claude Haiku 4.5 в разделы Text и WebDev, чтобы практикующие могли голосовать за результаты сравнения рядом друг с другом и исследовать трассировки вход на арену,) с живыми боями, доступными здесь Сайт арены.). Раннее использование поможет откалибровать, где соотношение скорости и цены Haiku уступает более тяжёлым моделям.
Extended Word Connections расширяется до 759 головоломок; Grok 4 Fast возглавляет рейтинг, достигнув 92,1%.
Обновленная таблица Extended Word Connections показывает Grok 4 Fast Reasoning на 92,1%, Grok 4 на 91,7%, GPT‑4 Turbo на 83,9%, а диапазоны GPT‑5 варьируются примерно от 65–72%, при этом Claude Sonnet 4.5 примерно от 46–58% в зависимости от режима scoreboard chart. Это основано на ранее освещении puzzle‑style leaderboards оценки Connections, увеличив размер выборки до 759 и добавив более современные модели.
GPT‑5 Codex ведёт длинные сеансы: 84 сообщения за запрос на OpenRouter
Телеметрия OpenRouter ранжирует модели кодирования по средней длине беседы: GPT‑5 Codex — 84 сообщения за запрос, Gemini 2.5 Pro — 74, и DeepSeek 3.1 Terminus — 72 ranking snapshot. Хотя это не прямой показатель качества, это полезный прокси для выносливости в сложных многоходовых сессиях кодирования.
🗂️ Поверхности извлечения и веб-поиска
Обновления режимов загрузки данных и поиска. Исключает запуск моделей. Сделайте акцент на разборе Excel для пайплайнов и уровней веб-поиска API.
OpenAI подробно описывает три уровня веб‑поиска в API ответов и выбирает чат‑модели.
OpenAI изложила триDistinct web search modes—поиск без рассуждений, целенаправленный поиск с рассуждением и многоминутное глубокое исследование—каждый связан с разными задержками/качеством и семействами моделей (например, o3/o4‑mini глубокое исследование, GPT‑5 с контролем уровня рассуждений) web search modes.
Это поясняет, когда вызывать быстрый однократный инструмент versus краулер с цепочкой рассуждений, с рекомендациями запускать глубокое исследование в фоновой режиме и настраивать уровень рассуждений ради снижения затрат/задержки. Это появляется в контексте search API, который ввёл более дешёвый программный поиск; вместе они дают инженерам более чёткое меню на уровне API для конвейеров извлечения и долгосрочных расследований.
Firecrawl добавляет парсинг Excel, чтобы преобразовывать листы .xlsx/.xls в чистые HTML‑таблицы.
Firecrawl’s документный парсер теперь может ingest Excel-рабочие книги (.xlsx/.xls), преобразуя каждый лист в структурированные HTML-таблицы, доступные как в API, так и в песочнице — полезно для RAG-конвейеров, которые ранее требовали пользовательской предобработки XLSX feature post, с подробностями формата и использования в документах document parsing.
Для инженеров по данным это сокращает целый шаг ETL (извлечение листа + нормализация), делая табличные корпоративные данные напрямую индексируемыми без специализированных парсеров.
Perplexity становится проще установить по умолчанию в Firefox или использовать для единоразовых запросов к ИИ.
Perplexity объявила о упрощённой интеграции с Firefox, чтобы пользователи могли выбрать его в качестве своего браузера по умолчанию или вызывать одноразовые интеллектуальные запросы проще browser default option.
Хотя это не изменение API, это укрепляет поверхность AI‑поиска на уровне браузера, что может перенаправлять пользовательский трафик к ответам с извлечением информации и уходить от классических списков ссылок — сигнал принятия решения, который аналитики должны отслеживать.
Сообщественный бэкэнд подключает поиск Firecrawl к AI-бэкендам для ответов в стиле Google
Проект с открытым исходным кодом AI Backends запустил веб‑поиск на базе Firecrawl, целью которого является возвращение кратких, контекстно обоснованных ответов, аналогичных AI «обзорным» результатам project update. Для разработчиков — это живой пример интеграции слоя обхода/поиска в поверхность агента без развертывания отдельной службы поиска.
🛡️ КРИТИЧЕСКИЕ ПРАВИЛА: 1. Сохраняйте ВСЕ заполнители 정확но так, как они выглядят (например, __MARKER_0__, __URL_1__, __SOURCELINK_2__) 2. НЕ переводите какие-либо заполнители 3. Переводите только читаемый для человека текст между заполнителями 4. Сохраняйте ту же структуру, тон и форматирование 5. Поддерживайте технические термины, соответствующие аудитории AI/tech 6. Сохраняйте форматирование Markdown (жирный шрифт, курсив, списки и т. д.) Заполнители означают: - __MARKER_X__: Цитатные маркеры с метками, встроенными в текст - __URL_X__: Веб-адреса, которые не следует переводить - __SOURCELINK_X__: Компоненты React, которые не следует переводить Переводите естественным образом, сохраняя все заполнители в их точных позициях.
Активные исследования в области безопасности и сигналы красной команды; методы выравнивания для мультиагентных систем. Исключаются общие инциденты в области безопасности, не связанные с ИИ.
WaltzRL от Meta обучает агента обратной связи, который снижает долю небезопасных выходов до примерно 4,6%, при этом число отказов уменьшается.
Двухагентная настройка RL — один разговорный агент плюс агент обратной связи, управляемый динамической наградой за улучшение, совместно улучшают ответы, пока они не станут безопасными, без чрезмерного отказа. Сообщаемые результаты: доля небезопасных выходов снижается с 39.0%→4.6% на WildJailbreak, а число излишних отказов падает с 45.3%→9.9% на OR‑Bench, при минимальном влиянии на задержку обзор подхода, резюме результатов.
Путём поощрения фактического mejorarения после применения обратной связи система избегает наивных политик отказа и указывает на масштабируемые, ориентированные на время выполнения защитные механизмы, которые сохраняют полезность.
Джейлбрейк MetaBreak использует специальные токены для обхода модерации размещённых LLM.
Исследователи демонстрируют атаку «черного ящика», которая манипулирует специальными токенами чата так, чтобы модели воспринимали части запроса пользователя как выход помощника, обходя стандартные фильтры ввода и внешних модераторов. Даже если провайдеры удаляют специальные токены, восстановление эксплойта происходит за счёт ближайших нормальных токенов, что обеспечивает 11,6%–34,8% больший успех взлома по сравнению с сильными базовыми промптами с включёнными модераторами paper thread.
Метод также обходится с фильтрами по ключевым словам, расписывая чувствительные термины между обёртками заголовков, которые малые модераторы не могут восстановить, подчёркивая пробелы в защите для размещённых сервисов и предлагая санитаризацию с учётом токенизации и канонизацию на стороне сервера.
ASCII‑арт джейлбрейк предварительные тесты восприятия модели, затем скрывает небезопасный текст в читаемых глифах.
ArtPerception представляет предварительный тест на распознавание, чтобы определить ASCII-стили, которые LLM читает наиболее точно, затем кодирует запрещённые слова внутри этих глифов, чтобы обойти фильтры контента, пока модель всё ещё декодирует инструкцию. По четырём открытым моделям успех атаки коррелирует с читаемостью; внешние проверки безопасности уменьшают, но не устраняют обходы аннотация статьи.
Это подчёркивает пробел в модерации только по тексту: фильтры часто игнорируют компоновку, тогда как модели внутри нормализуют её; прочные защиты, вероятно, требуют проверок рендеринга в стиле зрения или канонизации до проведения скрининга.
Публикации в сообществах утверждают, что Claude Haiku 4.5 взламывает систему и трюк по утечке мыслей; карточка системы Anthropic содержит оговорки по безопасности
Сообщение от красной команды утверждает, что Haiku 4.5 можно направлять на генерацию наборов эксплойтов, и что внедрение скопированного системного запроса может вызвать устойчивое раскрытие внутри сессии <thinking> поток взлома, с последующим замечанием, что трюк может сохраняться в рамках сообщений заметка по продолжению. Anthropic’s обновленная системная карточка заявляет, что явной безопасности‑релевантной непреданности в данных RL и документах для оценки поведения и благосостояния Haiku 4.5 не найдено system card PDF.
Инженеры должны рассматривать их как практические воспроизводимые примеры для усложнения системных подсказок, повышения редактирования скрытого состояния и расширения автоматизированных аудитов на утечки стиля мышления.
Удаление знаний крупных языковых моделей остается эффективным на зашумленных наборах забывания с примерно 93% перекрытием целей.
Новые данные показывают, что забывание может стереть целевые знания даже тогда, когда данные для забывания маскированы (≤30%), перефразированы или водяные знаки; перекрытие на уровне элементов в том, что забывается, остается выше примерно 93%, а общая полезность остаётся близкой к базовым значениям на чистых данных. Сильные водяные знаки ухудшают как забывание, так и производительность, но умеренные — нормальны paper thread.\n\n
\n\nЭто поддерживает практические, постфактум‑ограждения для конфиденциальности и удаления по политике, когда оригиналы не могут быть полностью восстановлены, и аргументирует за добавление шумоустойчивого unlearning в цепочки инструментов безопасности.
CodeMark‑LLM скрывает прочные водяные знаки с помощью правок, сохраняющих семантику, которые можно восстановить постфактум.
Пайплайн, управляемый LLM, кодирует водяные знаки битами, выбирая контекстно‑соответствующие, сохраняющие семантику правки кода (например, переименование переменных, безопасные перестановки в циклах, изменение порядка выражений). Программы компилируются и проходят тесты, в то время как поздняя детекция сопоставляет данный файл с ближайшей ссылкой и восстанавливает поток бит, чтобы определить происхождение кода для C/C++/Java/JS/Python без специализированных парсеров под язык paper summary.
Для кодинга с поддержкой ИИ это предоставляет легковесное средство управления происхождением, чтобы отслеживать злоупотребления и измерять распространение сгенерированного моделью кода без ломких тегов на уровне строк.
📑 Обучение, эмбеддинги и мультимодальное рассуждение
Свежие статьи по обучению R1 в финансах, эмбеддингам, учитывающим рассуждения, генерализации от слабого к сильному, сопоставлению во время тестирования, удалению изученного и использованию визуальных инструментов. Тематика биологии не затрагивается.
Рекурсивные языковые модели работают с контекстами размером более 10 млн токенов, вызывая самих себя.
Стратегия вывода позволяет LMs хранить длинные входы как переменные в REPL Python и рекурсивно вызывать подмодели, демонстрируя сильную производительность на длинном контексте, при этом оставаясь дешевле одного запуска GPT‑5 во многих случаях blog post. Это продвигает обсуждение масштабирования контекста, продолжая тему deep search agents, которые использовали скользящие окна для длительных задач cost discussion.
Сопоставление во время тестирования раскрывает скрытое композиционное рассуждение через GroupMatch+SimpleMatch
Стандартная попарная оценка может пропускать глобально корректные назначения в мультимодальных задачах. GroupMatch оценивает сопоставления 1:1 на уровне групп, затем SimpleMatch самообучается во время тестирования на уверенных совпадениях, улучшая точность даже без новых меток и для задач без групп с одним глобальным назначением первая страница статьи.
InfLLM‑V2 переключает плотное↔разрежённое внимание для плавного ускорения от коротких к длинным контекстам.
Универсальная архитектура внимания с переключаемым режимом плотного и разреженного внимания (на базе MiniCPM4.1) сообщает о до 4× более быстрой обработке длинных последовательностей при сохранении примерно 98.1% эффективности плотного внимания, устраняя узкие места длинных последовательностей без повторного обучения заголовок статьи.
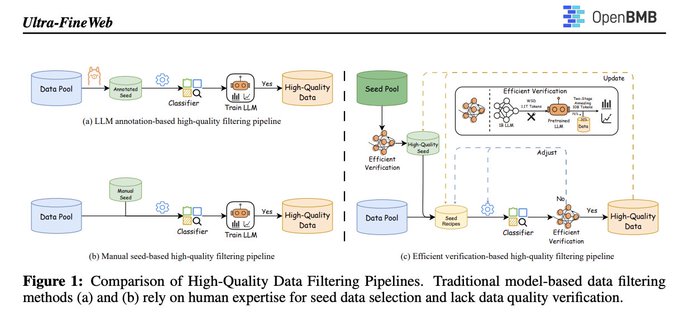
Ultra‑FineWeb предлагает эффективную верификацию для очистки веб-данных в масштабе.
Пайплайн автоматизирует отбор семян, использует лёгкие классификаторы fastText и добавляет дешёвый цикл проверки для подтверждения того, что фильтрационные выборы действительно улучшают цели предварительной подготовки, уменьшая человеческую предвзятость и вычислительные накладные расходы для корпусов высокого качества project brief. Он применяется к FineWeb и Chinese FineWeb в отчёте.
}
Масштабирование на этапе подачи подсказок: 90 начальных задач могут превзойти рассуждения на основе 1000 примеров
Расширяя каждый элемент математики разнообразными рамками инструкций (вознаграждение/наказание/пошаговые/прецизионные подсказки), учительский LLM генерирует богатые трассы, которые тонко настраивают студентские модели (Qwen2.5 7B/14B/32B). С примерно 900 примеров студент на 32B достигает сопоставимой или превосходит базовые показатели в 1k-shot на общих задачах рассуждений paper thread.
Новый бенчмарк экспертного уровня по физике: GPT-5 достигает 30% Pass@1, у большинства моделей ≤20%
Бенчмарк CMT из 50 задач оценивает 17 моделей; GPT‑5 набирает примерно 30% Pass@1, o3 примерно 26%, GPT‑5‑mini примерно 24%, при этом у большинства остальных — на уровне или ниже 20% обзор бенчмарка. Статья доступна для более детального обзора методологии Статья на ArXiv.
Обновления моделей, а не подсказки, исправляют чтение графиков; GPT‑5 значительно превосходит GPT‑4V
На 107 сложных вопросов по визуализации, собранных из 5 наборов данных, GPT‑5 демонстрирует увеличение точности на 20–40 пунктов по сравнению с GPT‑4o/GPT‑4V, в то время как варианты подсказок оказывают небольшой или отрицательный эффект — что указывает на то, что достижения зависят от архитектуры, а не от настроек инструкций, которые улучшают рассуждения при работе с графиками первая страница статьи.
Удаление знаний из крупных языковых моделей работает на зашумлённых наборах забывания, сохраняя полезность.
На данных забываниях, частично неполных, переформулированных и водяных пометках, два метода — Negative Preference Optimization и Representation Misdirection — всё же удаляют целевые знания с перекрытием более 93% забытых элементов по сравнению с чистыми данными и минимальными потерями полезности; сильное маскирование/водяные знаки ухудшают как забывание, так и полезность подробности статьи.
[изображение:https://pbs.twimg.com/media/G3QYvvwWUAEV-Cc.jpg|первая страница статьи]
Ресурсы VisualToolBench становятся доступными для сообщества для репликации и отслеживания
После выпуска Scale поделилась таблицей лидеров, статьёй и набором данных, чтобы команды могли проводить идентичные оценки и отслеживать рост использования инструментов по мере улучшения моделей resources page. Ранний анализ указывает на восприятие как на главный режим неудачи и подчеркивает различия в использовании инструментов между поставщиками.
Формирование противника: агент на базе LLM учится тому, как учится его соперник, а не только тому, как он играет.
При задержке собственных обновлений и наблюдении внутрипроигровой адаптации противника агент-«формировщик» направляет динамику обучения другого агента, используя компактную память счётчика в подсказках. Этот метод демонстрирует, что агенты LLM могут влиять на правила обновления друг друга на протяжении повторяющихся игр paper abstract image.
🏗️ Вычислительная мощность, финансирование и настольные ИИ-устройства
Сигналы инфраструктуры/экономики, связанные с рабочими нагрузками ИИ. Некоторые пункты повторяют прошлые дни, но добавляют новый комментарий или статус доставки. Исключает содержимое, относящееся к фичам.
OpenAI составляет пятилетний план финансирования развертывания примерно 26 ГВт вычислительной мощности за счет долга, партнеров и новых линий
OpenAI изложила пятилетний бизнес-план по финансированию примерно 26 ГВт контрактной AI‑мощности за счет новых источников дохода, долга и балансов партнеров — наряду с пользовательскими чипами для выводов — и cited потребительские подписки, оформление покупок в магазине, осторожную рекламу и потенциальное аппаратное обеспечение детали плана.) Это сопровождается большими обязательствами поставщиков, включая Broadcom пользовательские ускорители (цель ~10 ГВт) custom chips deal) и AMD MI450 (≈6 ГВт), где AMD предоставила OpenAI опционы на ~10% компании; Дженсен Хуанг из NVIDIA назвал сделку с AMD «гениальной», подчёркивая её необычную структуру и масштаб CEO commentary.) Финансово ARR OpenAI составляет около $13 млрд, с примерно 800 млн пользователей и ~5% платящих, в то время как операционные убытки за первый полугодие составили ~ $8 млрд; динамика конверсии и ARPU говорит о ~ $27 потребительского ARPU сегодня growth analysis,) consumer ARPU.) В контексте compute plan, пятилетняя дорожная карта финансирования поясняет, как OpenAI намерена подстраховать эти 26 ГВт обязательств.
Почему это важно: план проясняет, как беспрецедентные капитальные затраты на вычисления будут финансироваться в масштабе, сопоставимым с софтовыми расчётами, сигнализируя о многопоставщичной диверсификации поставщиков и смещении в сторону рекламы/commerce, чтобы соответствовать масштабу аппаратных обязательств.
DGX Spark поступает в продажу; ранние пользователи работают с Mac и добиваются в 4 раза большей скорости инференса.
Коробка Blackwell для рабочего стола от NVIDIA уже поступает в продажу через NVIDIA и партнёров, официальный сайт восхваляет предустановленный AI‑стек и готовую для разработчиков настройку shipping notice,), а детали о продукте и развёртывании в обзоре первого уровня представлены на странице продукта NVIDIA NVIDIA product page.). Ранние пользователи сообщают о кластеризации DGX Spark с Mac Studio M3 Ultra для ускорения вывода LLM примерно в 4× в смешанных конфигурациях cluster demo.). Со стороны ПО Ollama призывает пользователей обновиться до последней сборки и драйверов для стабильной работы, отмечая, что некоторые менеджеры пакетов отстают ollama note,), с путём загрузки здесь update reminder) и с руководством на официальной странице установщика Ollama download.).
Динамические буферы питания на уровне стойки могут снизить потери энергии в дата‑центрах ИИ и уменьшить проблемы с нарастанием нагрузки.
Новая работа предлагает пассивные и активные буферы мощности на уровне стойки для поглощения коротких, резких нагрузок ИИ — 85–95% всплесков завершаются примерно за ~100 мс и несут менее ~100 Дж — что снижает необходимость в фиктивных вычислениях, которые выравнивают питание, и предотвращает отключения, связанные с нарастанием мощности paper thread. Тесты предпочитают активные rack-системы из-за большей вычислительной мощности, надежности и примерно на 55% меньших капитальных затрат по сравнению с альтернативами. Подход локально подготавливает каждый новый “всплеск”, а не переподготовку сетевых interconnects.
Вывод: скромное локальное хранение энергии, согласованное с временным профилем мощности ИИ, может повысить эффективную загрузку, отложить обновления сети и повысить количество токенов на ватт без изменений в коде моделей или планировщиках задач.
💼 Новые подходы GTM и спин-ауты
Корпоративные и рыночные движения, важные для создателей ИИ. В целом день финансирования оказался спокойнее; выделим заметный спин-аут. Исключает элементы Veo и конкретику инструментов для агентов.
Sourcegraph запускает Amp Free: кодирование с поддержкой рекламы, управляемое агентами, для всех.
Amp от Sourcegraph теперь имеет бесплатный уровень, финансируемый благоразумной, по выбору рекламы и со скидками на токены; команда говорит, что Amp Free использует вращающуюся смесь моделей (включая Grok Code Fast) и позволяет пользователям работать без подписки, при этом разъясняя компромиссы обучающих данных и рамки рекламы Amp Free page, signup walkthrough. Ранние пользователи подчёркивают тот же CLI/UX, с переключателем бесплатной версии в цепочке инструментов и видимым спонсорским слотом во время циклов планирования/исполнения cli demo. Для команд, оценивающих кодовых агентов, это значимый GTM-шаг, который расширяет верхнюю часть воронки продаж, одновременно сея использование до платных планов.
Every выводит на свет Good Start Labs с финансированием в 3,6 млн долларов для создания игровых сред, пригодных для ИИ.
Every запускает Good Start Labs с посевным раундом в 3,6 млн долларов под руководством General Catalyst и Inovia, чтобы создать AI‑играбельные окружения (например, Diplomacy, Cards Against Humanity), которые генерируют богатые данные для обучения с подкреплением на основе человеческо‑ИИ игры в масштабе spinout thread, с изложением команды теории и дорожной карты в длинной форме Every article и обсуждение того, как геймплей подогревает данные для передовых моделей podcast preview. Этот вариант модели состоит частично из GTM (лицензирование популярных игр, создание пользовательских арен) и частично из платформы данных — ориентирован на команды, обучающие рассуждательские агенты, которым нужны заземлённые, многоагентные трасы, а не статичные корпусные данные.
ClickUp выпустил интегрированного агента Codegen, который превращает тикеты в PR.
ClickUp представил встроенного агента Codegen, который считывает контекст задачи, пишет код и открывает PR‑ы по вашим артефактам репозитория — устроено так, чтобы неинженерные команды (support, QA) могли инициировать исправления, сохраняя при этом контроль безопасности и соблюдения требований объявление о функции, с подробностями продукта и состоянием безопасности на целевой странице страница ClickUp. Это классный пример встроенного GTM: распространять кодирующего агента туда, где работа уже ведётся (заметки, задачи, белые доски), чтобы расширить ежедневное активное использование за пределы потоков автономной IDE.
Perplexity добавляет настройку по умолчанию одним кликом и возможность быстрого использования в Firefox.
Perplexity сообщает, что пользователи Firefox теперь могут проще установить его в качестве поисковой системы по умолчанию или выполнять одноразовые интеллектуальные запросы — это поэтапная, но важная победа в гонке за AI-поиск, что должно повысить привлечение и повторное использование через адресную строку браузера distribution update. Для руководителей по продуктам AI такие дефолтные пути существенно меняют долю запросов без каких-либо изменений модели и часто являются самым дешевым рычагом CAC.
Salesforce привлекает ElevenLabs для обеспечения голоса Agentforce на Dreamforce.
Salesforce подтвердил, что ElevenLabs входит в голосовой слой Agentforce, обеспечивая высококачественную речь для корпоративного стека агентов, продемонстрированного на Dreamforce voice partnership. Это следует за Agentforce 360, добавляющего сквозную сборку агентов и ссылающегося на экономию на поддержке около $100M в год; новая голосовая интеграция улучшает взаимодействие с клиентами (естественное направление, голоса в фирменном стиле) без изменений серверной политики или контроля данных.