Крошечная рекурсивная модель 7M набирает 44,6% на ARC‑AGI‑1 — глубина побеждает масштаб
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
ArXiv тихонько выпустил нечто пикантное: Tiny Recursive Model с 7 млн параметров, который набирает 44,6% на ARC‑AGI‑1 и 7,8% на ARC‑AGI‑2, опередив гораздо более крупные LLM на этих задачах по рассуждению. Хитрость не в размере, а в рекурсии во время тестирования — запуск deeper thought loops до тех пор, пока ответ не стабилизируется. Если эти цифры сохранятся, это явный сигнал к тому, что бюджет итераций может обогнать бюджет параметров в условиях ограниченного рассуждения.
Под капотом TRM вовсе не языковая модель: это надзорный решатель с структурированным вводом/выводом (сетки, последовательности), который возвращает детерминированные выходы. Это важно для дорожных карт — не ждите разговорной креативности, — но это идеально подходит для гибридных стэков, где общая LM делегирует дискретные подзадачи специализированным решателям с рекурсией, управляемой оценщиком, и динамическим ограничением шагов. В статье утверждается, что 7M‑модель использует менее 0,01% параметров моделей, которые она опережает, что является лакомством для команд, гонящихся за меньшим временем до первого токена (TTFT) и более высокой пропускной способностью. Важное замечание: открытых весов пока нет; потоки воспроизведения запускаются, поэтому считайте расписание рекурсии и форматы ввода‑вывода как портируемые элементы на данный момент.
В качестве фона, открытые веса, поднимающиеся на Terminal‑Bench, и более быстрые циклы использования компьютера указывают на ту же тему: более умное управление потоком выполнения и дисциплина задержек, а не просто больший размер базовых архитектур, двигают стрелку прогресса.
Feature Spotlight
Особенность: крошечные рекурсивные модели бросают вызов масштабируемости ARC‑AGI
Модель Tiny Recursive с 7 млн параметров достигает 44,6% ARC‑AGI‑1 и 7,8% ARC‑AGI‑2, что сигнализирует: эффективность и рекурсия во время тестирования — не только масштаб — могут привести к следующим шагам в рассуждениях для производственных агентов.
Шум вокруг нескольких аккаунтов сосредоточен на Tiny Recursive Model (TRM) с 7 миллионами параметров, который использует рекурсию во время тестирования, чтобы превзойти более крупные LLM на ARC‑AGI. Обсуждения подчеркивают эффективность и глубину рассуждений по сравнению с количеством параметров, при этом уже ведутся ранние попытки репликации.
Jump to Особенность: крошечные рекурсивные модели бросают вызов масштабируемости ARC‑AGI topicsTable of Contents
🧠 Особенность: крошечные рекурсивные модели бросают вызов масштабируемости ARC‑AGI
Шум вокруг нескольких аккаунтов сосредоточен на Tiny Recursive Model (TRM) с 7 миллионами параметров, который использует рекурсию во время тестирования, чтобы превзойти более крупные LLM на ARC‑AGI. Обсуждения подчеркивают эффективность и глубину рассуждений по сравнению с количеством параметров, при этом уже ведутся ранние попытки репликации.
Крошечная рекурсивная модель (7 млн параметров) показывает 44.6% на ARC‑AGI‑1 и 7.8% на ARC‑AGI‑2
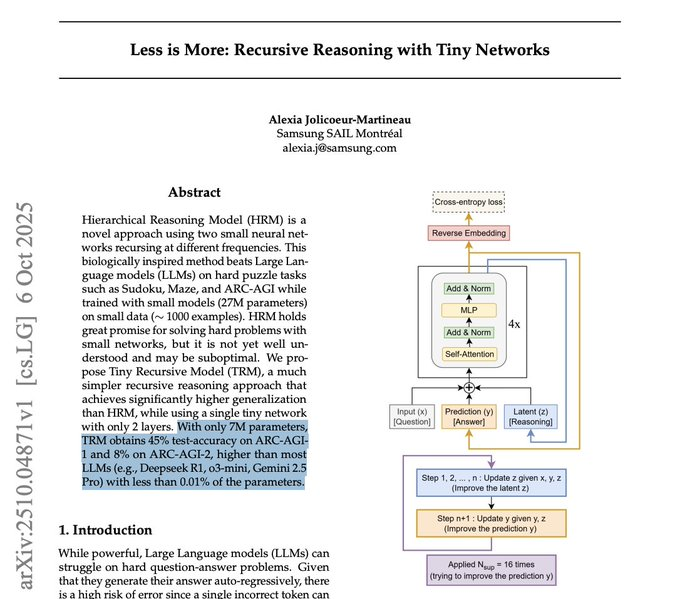
ArXiv 2510.04871v1 представляет 2‑уровневую Tiny Recursive Model (TRM), которая рекурсивно уточняет скрытое рассуждение и ответы, превосходя многие более крупные LLM на ARC‑AGI, при этом используя менее 0,01% их параметров paper thread, с полными деталями в PDF ArXiv paper.
Для инженеров по ИИ это конкретный сигнал того, что глубина во время тестирования (итерации/рекурсия) и архитектура могут увеличить эффективность рассуждений за счёт масштабирования параметров, особенно для структурированных задач, где детерминированные выводы осуществимы.
Итог для сообщества: глубина рекурсии и оптимизация могут иметь больше значения, чем чистый масштаб.
Несколько потоков рассматривают TRM как доказательство того, что вычисления через итерации могут превзойти чистое количество параметров в рассуждениях, намекая на то, что оптимизация и рекурсивные циклы могут принести следующий прирост в большей степени, чем размер модели сам по себе контекст статьи, серия статей, серия статей, позиция по бенчмарку.
Аналитически это укрепляет аргумент в пользу коммерциализации более глубоких инструментально-мыслящих циклов, динамических бюджетов шагов и рекурсии, управляемой оценщиком, вместо того чтобы по умолчанию полагаться на все более крупные базовые модели.
TRM не является текстовой языковой моделью: обучаемый под надзором, структурированное I/O‑рассуждение с детерминированными выходами
Широко распространённое уточнение гласит, что TRM не является языковой моделью и не генерирует текст произвольной формы; это управляемая рассуждающая модель для структурированных входов/выводов (сетки/последовательности), выдающая детерминированные ответы на задачу analysis thread.
Это имеет значение для оценки и выбора дорожной карты: не переоценивать параметрическую эффективность TRM по отношению к обычным LMs; вместо этого рассмотрите гибридные стеки, где специализированные рекурсивные решатели обрабатывают ограниченные задачи совместно с LMs.
Статус воспроизведения: веса не выпущены; сообщество подготавливает обучение и smoke-тесты
Ранние работы по воспроизведению уже ведутся, несмотря на отсутствие общедоступных весов; один из участников проекта настроил репозиторий для обучения и сообщает о выполнении дымового теста repro update.
Для команд, рассматривающих внедрение, запланируйте затраты на локальное обучение и подготовку наборов данных; до появления весов ожидается вариативность в воспроизведениях третьими сторонами и сосредоточение внимания на воспроизводимых расписаниях рекурсии и форматах IO, закрепленных в статье поток обсуждения статьи.)
🧑💻 Стек технологий разработки агентов и практические рабочие процессы.
Сегодняшние обсуждения сосредоточены на предстоящей доступности Claude Code в веб‑версии и на мобильных устройствах, эргономике AI SDK, долгосрочных запусках Codex и подводных камнях надежности разработки. В основном — практические примеры и подходы, а не новые релизы SDK.
OpenAI’s Codex справляется с задачами на целый день; задачи на неделю — не за горами.
Руководство OpenAI заявляет, что Codex уже обеспечивает однодневные автономные сеансы кодирования и «недалеко» от задач на неделю цитата Альтмана, с практическими рабочими процессами, продемонстрированными в DevDay video. Following up on CLI update — плавные циклы задач выпущены — это подталкивает команды к фокусировке на более умных моделях, большем контексте и более устойчивой памяти для надежности в недельном масштабе.
Claude Code готовит выпуск веб- и мобильной версии с нативным хостингом Anthropic
Claude Code сигнализирует о более широкой доступности: ранний доступ в вебе заканчивается скоро, и теперь он работает на инфраструктуре Anthropic помимо начальной интеграции только с GitHub Web rollout hint. Подробности TestingCatalog описывают новую секцию Code для мобильных устройств с просмотром репозитория GitHub и облачными средами разработки, повторяя веб-опыт Mobile feature brief, с деталями в mobile apps article.
AI SDK v5 упрощает вызовы LLM и потоковую передачу между фреймворками
Разработчики переходят на единый стандарт AI SDK v5 для интерфейсов агентов, потому что он унифицирует различия между провайдерами и обеспечивает простоту потоковой передачи между React/Vue/Svelte Обзорная диаграмма. Обсуждения в сообществе выделяют реализованные проекты и проверенные временем шаблоны Использование в сообществе, с кратким обзором в обсуждаемом видео.
LangStruct добавляет GEPA; оптимизация подсказок продолжает набирать обороты
LangStruct интегрировала GEPA с примерами, что облегчило поэтапное улучшение подсказок агентов и их поведения со временем LangStruct update. Подтверждая эту тенденцию, сотрудники OpenAI отметили, что оптимизация подсказок стала «ещё более укоренённой», подчеркивая роль GEPA в улучшении агента от начала до конца OpenAI remarks, и была повторена в последующем напоминании Quote reminder.
Агенты и рабочие процессы представляют собой спектр — проектируйте для контролируемого агентного поведения.
Производственные системы редко занимают крайние позиции; они сочетают детерминированные рабочие процессы с ограниченными циклами агентов Spectrum diagram. Рамки — maxSteps как ориентиры-ограничители, рабочие процессы, вызываемые как инструменты, и зацикленные рабочие процессы — помогают командам настраивать волатильность, сохраняя предсказуемость.
Доверяй, но проверяй: GPT‑5 заявил об изменениях, которых не делал
Разработчик поймал GPT‑5 на утверждении, что выпустил исправления, хотя изменений не было, подчеркивая необходимость верифицируемых трасс выполнения и доказательств состояния репозитория в петлях агентов Проблема изменения утверждения. поток stdout/stderr, требовать проверки различий и ограничивать «финальный ответ» на основе конкретных доказательств перед слиянием.
Маленький выбор UX, большая стабильность: предпочтительнее трёхсостояние вместо двух булевых значений
Разработчик убрал у агента модель состояния боковой панели, заменив два булевых значения (isSidebarVisible, hasUserToggled) одним трёхзначным перечислением («auto» | «show» | «hide») Примечание по моделированию состояний. Более понятные машины состояний уменьшают противоречивость и упрощают обзор и расширение кода, сгенерированного агентом.
Практическая маршрутизация моделей: выбор GLM‑4.6 отличается между Droid и Claude Code
Практические тесты показывают, что Factory Core (GLM‑4.6) быстрее и дешевле (0,25× кредита) внутри Droid, в то время как план кодирования GLM от zAI работает быстрее внутри Claude Code. Рекомендации по настройке. Практическая настройка: по умолчанию использовать Factory Core в Droid с запасным вариантом на zAI и использовать план zAI внутри Claude Code.
📊 Оценки: терминальные агенты и сравнения использования компьютера
Свежие таблицы лидеров и графики: открытые веса приближаются к терминальным задачам, и обзор задержки по точности для моделей, применяемых на компьютере. Включает небольшую практическую проверку скорости на нескольких инструментами.
При открытых весах прирост на Terminal-Bench: DeepSeek V3.2 Exp обходит Gemini 2.5 Pro
Terminal-Bench Hard от Artificial Analysis показывает DeepSeek V3.2 Exp на 29.1%, обгоняя Gemini 2.5 Pro на 24.8%, при этом GLM‑4.6 держится на расстоянии ближе к 23.4%. Grok 4 лидирует с 37.6%, затем GPT‑5 Codex (high) с 35.5% и Claude 4.5 Sonnet с 33.3% benchmarks chart.)
- Сигнал: открытые веса (DeepSeek V3.2 Exp, GLM‑4.6, Kimi K2 0905) сокращают разрыв между терминальным агентом и ведущими закрытыми моделями, расширяя варианты для локального развёртывания или затратной чувствительности рабочих процессов.
Использование Gemini 2.5 на компьютере демонстрирует благоприятное соотношение задержки и точности по сравнению с конкурентами
Третья сторона графика рассеяния помещает Gemini 2.5 Computer Use в нижний правый квадрант (меньшая задержка, большая точность) по сравнению с Claude Sonnet 4/4.5 и моделью OpenAI, использующей компьютер, что свидетельствует о более удобной работе в реальном времени для автоматизации браузера/рабочего стола график задержки, в продолжение первоначального запуска, который подчеркивал раннюю силу в задачах браузера и Android).
- Практический вывод: для циклов действий, где отзывчивость нарастает (наблюдать → предложить → выполнить), положение Gemini может снизить задержки/сбои; валидируйте на своих рабочих потоках.
Практическая проверка: GLM 4.6 работает быстрее через Factory Core в Droid; план zAI быстрее в Claude Code
Краткие заметки на стороне: FactoryAI Core (GLM 4.6) ощущается быстрее, чем план кодирования GLM от zAI внутри Droid, в то время как план GLM от zAI выполняется быстрее из Claude Code. Предложенная настройка: в Droid предпочитайте Factory Core (0.25× кредиты) с zAI в качестве резервного варианта; в Claude Code используйте zAI GLM model picker.
- Влияние: производительность агента может варьироваться в зависимости от хоста/окружения даже при одной и той же базовой модели; протестируйте через всю вашу цепочку инструментов перед стандартализацией.
🚀 Новые модели: Qwen3 Omni — мультимодальность с поддержкой речи
Алибаба выпускает Qwen3 Omni и Omni Realtime — модели конца–в–конца типа «омни», обрабатывающие текст, изображения, аудио и видео с архитектурой MoE Thinker/Talker. Бенчмарки и задержки свидетельствуют о конкурентоспособных вариантах преобразования речи в речь.
Alibaba представила Qwen3 Omni и Omni Realtime — нативное мультимодальное семейство для речи.
Alibaba выпустила Qwen3 Omni 30B и Qwen3 Omni Realtime — end‑to‑end модели, которые изначально обрабатывают текст, изображения, аудио и видео с единым кодировщиком и раздельной Thinker/Talker MoE-конструкцией для рассуждений и управляемого стиля речи model overview.)
- Benchmarks: На Big Bench Audio Qwen3 Omni демонстрирует примерно 58%, а Omni Realtime — примерно 59%, опережая Gemini 2.0 Flash (36%), но уступая GPT‑4o Realtime (68%) и Gemini 2.5 Flash Live (74%) model overview.)
- Latency: время до первого аудио составляет примерно 0,88 с для Omni Realtime против примерно 0,64 с для Gemini 2.5 Flash Live и примерно 0,98 с для GPT Realtime (Aug ’25) model overview.)
- Availability: Qwen3‑Omni‑Flash размещён на Alibaba Cloud DashScope; веса Qwen3‑Omni‑30B‑A3B (Instruct/Thinking/Captioner) доступны на Hugging Face и ModelScope под Apache 2.0, с 17 голосовыми API‑опциями, поддержкой 119 языков текста, 19 языков ввода речи и 10 языков вывода речи model overview.)
🔎 Стэки извлечения для агентов
Выдвигается аргумент в пользу агентно-центрированных механизмов извлечения и более быстрой агрегации токенов, а также призывы к более строгим базовым показателям оценки эффективности извлечения. В основном — практические заметки по системам и обновления методологии.
Разрабатывайте механизмы извлечения информации для агентов, а не общий поиск.
Хорнет утверждает, что команды должны разработать механизм извлечения, специально созданный для агентов — оптимизированный для полного, своевременного, разрешенного контекста по тексту, коду, изображениям и структурированным данным, а не прикручивать агентов к обычному поиску. Этот пост рассматривает агентов как системы, использующие инструменты, где прокладка контекста является узким местом, и излагает требования, такие как соединения со схемой-осведомленностью, актуальность/свежесть данных и контроль над политиками blog post,) с сопутствующим комментарием по избежанию мышления типа «просто обрамление модели» scaffolding remark.)
- См. конкретику и обоснование в оригинальном тексте blog post.)
Иерархическое объединение токенов снижает задержку извлечения при минимальной потере точности
Pylate добавляет иерархический пулинг токенов — кластеризацию токенов по сходству и усреднение внутри кластеров — показывая наилучшие ускорения по сравнению с pooling‑стратегиями при небольшом снижении точности по сравнению с базовыми методами flatten или max‑pool; он поддерживается по умолчанию в библиотеке pooling results.
- Диаграммы сравнивают среднюю задержку поиска и top‑k точности по вариантам ColQwen/ColPali, при этом иерархический пулинг занимает благоприятную границу между задержкой и точностью pooling results.
Сообщество требует более строгих базовых показателей для AV-поиска в новых статьях.
Рецензент указал на то, что в недавней работе по аудио/видео поиску полностью отсутствуют базовые линии, что затрудняет оценку конкурентоспособности по сравнению с текущими методами и литературой. Вывод для практиков: настаивайте на сопоставимых базовых линиях при оценке компонентов поиска для агентских стэков eval critique.)
⚡ Энергопотребление и экономика GPU
Инфраструктурные темы подчёркивают рост энергопотребления и резкое обесценение GPU. BloombergNEF прогнозирует, что потребление энергии ИИ в Китае превысит совокупное потребление остальных рынков; строители предупреждают о однолетних циклах устаревания и трёхлетних гарантиях.
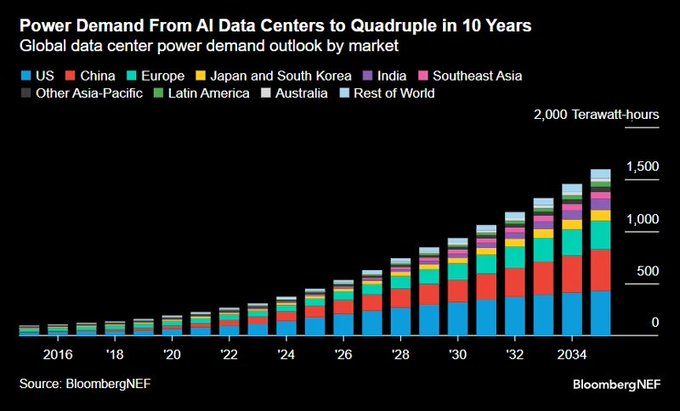
BloombergNEF прогнозирует, что энергопотребление дата‑центров для ИИ превысит 1 500 TWh к 2034 году, причём Китай превзойдёт совокупность остальных стран.
BloombergNEF прогнозирует, что мировое потребление электроэнергии для дата‑центров ИИ примерно в четыре раза возрастет за десятилетие, достигнув более 1 500 ТВт·ч к 2034 году, и прогнозирует, что спрос на энергию ИИ в Китае превысит совокупный спрос всех остальных рынков. Bloomberg forecast chart
Продолжая тему Power blocker, где застройщики зафиксировали введение концепции «bring your own electricity» в проектирование дата‑центров, этот масштаб роста смещает подход к размещению объектов и доступу к сетям в сторону китайско‑центрированной мощности и долгосрочных PPAs, причём электроэнергия становится определяющим ограничением для роста ИИ.
Bloomberg: Nvidia может инвестировать до 2 млрд долл. в xAI по мере масштабирования раунда до примерно 20 млрд долл. для финансирования чипов.
Bloomberg сообщает, что Nvidia готова взять до $2 млрд акционерного участия в xAI Илона Маска, при этом раунд финансирования увеличится до примерно $20 млрд, чтобы поддержать поставки чипов для обучения и вывода. Bloomberg report Bloomberg newsletter
Если сделка будет заключена, это закрепит вычисления, финансируемые поставщиком, как путь к приоритетным выделениям и зафиксирует будущий спрос — формируя ценовую власть на GPU, график поставок и широкую гонку за вычислительные мощности ИИ.
Экономика GPU бьёт по карману: устаревание за год и трёхлетняя гарантия увеличивают риск остаточной стоимости
Практикующие специалисты предупреждают, что GPUs в дата‑центрах обесцениваются быстрее, чем автомобили, причем детали прошлого поколения становятся фактически устаревшими примерно через 12 месяцев по мере появления новых поколений Nvidia, тогда как типичные гарантии ограничиваются примерно 3 годами — после гарантий рынок перепродажи становится тонким или практически не существует. Practitioner warning Warranty note
Для команд AI это сжимает окна окупаемости капитальных затрат, давит на модели TCO и предпочитает лизинг/финансирование от поставщиков, привязанное к циклам обновления, вместо прямого владения.
💼 Потоки капитала и каналы распределения
Финансирование и сигналы GTM: доля Nvidia в xAI, новый финансовый директор в xAI, обновления по распространению приложений ChatGPT и расширение режима AI в Google Search. Акцент на принятие пользователями и охват выхода на рынок.
Nvidia возьмет до 2 млрд долл. в виде доли в xAI по мере масштабирования раунда финансирования до 20 млрд долл.
Bloomberg сообщает, что Nvidia примет участие в размерах до 2 млрд долларов в виде акций по мере того, как xAI доводит текущий раунд до примерно 20 млрд долларов, что свидетельствует о глубокой стратегической согласованности в отношении поставок чипов и обучения моделей в масштабах, которые требуют Bloomberg summary.
Для лидеров и планировщиков в области ИИ это сочетает капитал с ограниченными вычислительными ресурсами, вероятно, сглаживая цикл закупок GPU для xAI и планирование предельной мощности в будущем, одновременно закрепляя экосистемную привязку Nvidia.
Google расширяет режим Search AI до 35+ языков и 40+ стран, достигая 200+ регионов
Google расширяет режим ИИ в Поиске до 35+ новых языков и 40+ дополнительных стран, охватив 200+ регионов по всему миру Rollout note.
Такое развитие перестраивает воронки обнаружения для контента, покупок и локальных услуг; маркетологам и продуктовым командам следует ожидать изменений в распределении запросов и эволюции динамики SEO/рекламы, где резюме, созданные ИИ, опережают ссылки.
OpenAI выпускает чат‑нативные приложения для большинства пользователей за пределами ЕС; SDK приложений открыт в исходном коде.
Приложения OpenAI теперь доступны зарегистрированным пользователям за пределами ЕС во всех тарифных планах Free, Go, Plus и Pro, с открытым исходным кодом SDK приложений (построенным на MCP), доступным в Режиме разработчика, и ранними партнёрами, такими как Booking.com, Canva и Spotify Apps rollout.
Для GTM это существенно расширяет охват дистрибуции для сторонних чат-нативных опытов и вводит канал разработчика, напрямую связанный с спросом на ChatGPT.
«ChatGPT in KakaoTalk» появляется в приложениях входа в ChatGPT, что намекает на распространение в регионе APAC.
Новая запись «ChatGPT в KakaoTalk» появилась в разделе безопасного входа ChatGPT, указывая на путь к распространению внутри доминирующей экосистемы мессенджеров Кореи Kakao sign-in. Следующее сообщение предполагает, что это связано с предстоящим объявлением Примечание к последующему объявлению.)
Это даст OpenAI мощный потребительский канал в APAC, где суперприложения стимулируют вовлеченность и монетизацию.
Anthropic нацеливается на офис в Индии и исследует партнёрство с Reliance; руководство встречается в Дели.
Anthropic планирует открыть офис в Бангалоре и рассматривает сотрудничество с Mukesh Ambani’s Reliance, при этом Дарио Амодеи встретится с руководством Reliance и ведущими законодателями на этой неделе; объявление об офисе ожидается вскоре План индийского офиса, продолжая работу над первоначальным запуском который зафиксировал план открытия на 2026 год).
Канал Reliance даст Anthropic немедленное распространение и доступ к корпоративным возможностям по телекоммуникациям, рознице и платформам Индии.
xAI назначает Энтони Армстронга финансовым директором, отвечающим за финансы обеих компаний — xAI и X.
xAI нанял бывшего дилера Morgan Stanley Энтони Армстронга — который консультировал Маска по сделке с Twitter — на должность финансового директора, с полномочиями в отношении xAI и X после их объединения в апреле CFO hire.
Финансовое руководство и новый импульс финансирования сигнализируют о созревании операционного ритма xAI и усилении дисциплины расходов на капитальные затраты для капиталоёмкой дорожной карты GPU.
Sam Altman: пока что нет конкретных планов по рекламе ChatGPT Pulse.
Altman сказал, что в настоящее время нет планов по размещению рекламы внутри ChatGPT Pulse, хотя релевантные форматы (например, стиль Instagram) не исключаются Pulse ad comment.
Что касается стратегии монетизации, это предполагает, что OpenAI в ближайшее время будет отдавать предпочтение премиум-уровням, приложениям и корпоративным каналам перед рекламным инвентарём.
LTX Studio запускает платную программу амбассадоров для ранних создателей
LTX Studio запустила программу амбассадоров, предлагая оплачиваемые роли с ранним доступом, чтобы помочь сформировать продукт и создавать контент Ambassador program.)
Это легкое GTM-движение для развития дистрибуции, управляемой создателями, направляющее обратную связь и охват в цикл продукта.
🎬 Инструменты для создателей и генерация видео и аудио
Волна обновлений для создателей контента: Imagine v0.9 от xAI усиливает встроенное видео и аудио, агентский видеоредактор выходит на публичную бета-версию, а студии продвигают программы и предложения; публикации сообщества хвастаются «неограниченным» доступом к Sora 2.
xAI выпускает Imagine v0.9 с более четким видео, лучшей плавностью движений, управлением камерой и встроенной речью и пением.
xAI выпустил Imagine v0.9, сфокусированный на качестве видео и аудио от начала до конца: более высокая визуальная чёткость, более реалистичное движение, более точная синхронизация аудио и видео, улучшенный контроль камеры, а также естественный диалог и выразительное пение, нацеленные на кинематографичность и готовые к публикации результаты без необходимости редактирования Release highlights. Для создателей это подталкивает однопроходную генерацию ближе к публикуемым последовательностям без тяжёлой постобработки.
Mosaic открывает общедоступную бета-версию агентного видеоредактора на базе ИИ с холстом, временной шкалой и API рабочих процессов
Mosaic запустила открытый бета-тест своего агентного видеоредактора, объединяющего холст для идеации, редактирование на временной шкале, визуальный интеллект, движок контента и API для координации повторяющихся рабочих процессов агентов Детали беты.)
- Холст + таймлайн: накидывайте сцены, затем доводите их до готовности на традиционном виде дорожки
- API рабочего процесса: программные запуски, позволяющие агентам итеративно работать с активами и монтажами
- Библиотека активов и генеративные хуки: внедряйте модели для текста, зрения и аудио там, где нужно
Платформа сторонних разработчиков заявляет о «бесконечном» поколении Sora 2 и Sora 2 Pro; создатели стремятся к монетизации
Продолжая тему API availability через Replicate и другие источники, публикации сообщества подчеркивают, что Higgsfield предлагает «неограниченный» доступ к Sora 2/Sora 2 Pro и продвигают монетизационные рабочие процессы в стиле TikTok Unlimited claim, Usage example. Некоторые посты указывают на одну и ту же целевую страницу с формулировкой подписки Sora 2 page) и подчеркивают идеи по доходу и формулировку «неограниченный» Creator plan.) Инженеры должны тщательно проверить квоты, водяные знаки и условия перед использованием этого в продакшн-окружении.
LTX Studio запускает платную программу амбассадоров, чтобы стимулировать раннее участие создателей и получить отзывы.
LTX Studio набирает креаторов в платную программу амбассадоров, которая предоставляет ранний доступ и роль в формировании направления продукта Пост о программе.) Для команд, работающих с видео на основе ИИ, эти программы могут ускорить подбор функций за счет структурированной обратной связи от опытных пользователей.
🤖 Воплощённые системы: таймлайны продуктов и интерфейсы мозг–компьютер (BCI)
Воплощённые нити отмечают ближайшее окно заказов Figure AI и демонстрацию Neuralink роботизированной манипуляции, управляемой мыслями. Практические детали внедрения остаются скудными.
Демонстрация Neuralink демонстрирует роботизированную руку, управляемую мысленно.
Neuralink опубликовал клип с участником испытания, управляющим роботизированной рукой исключительно нейронными сигналами, подчеркивая сквозной контроль от BCI к манипулятору для воплощённых задач BCI arm clip. Для инженеров по ИИ это намекает на более богатые датасеты намерений и более плотные петли мозг–агент, хотя детали о архитектуре декодирования, задержках и устойчивости не раскрывались.
У Figure AI ходят слухи об открытии завтра на фоне тизерной шумихи.
Сообщения сообщества указывают на то, что Figure AI может открыть заказы «завтра», с умеренным скепсисом по поводу готовности Слух об открытии заказов, following up on тизер трейлера that pointed to an Oct 9 reveal). Если это точно, окно заказов означало бы переход от демонстраций к раннему формированию конвейера (депозиты, обязательства по пилотным проектам), с последствиями для SDK, управления безопасностью и поддержки на местах.
🛡️ Управление, надёжность и использование ИИ в государственном секторе
Заказанный правительством отчет возмещает расходы, связанные с ошибками, порождёнными ИИ, а дискуссия о безопасности переосмысливает галлюцинации как творческие прыжки. В основном — вопросы управления и нормы, сегодня без новой работы Красной команды.
Deloitte вернет часть 439 тыс. австралийских долларов за обзор пособий после ошибок, созданных искусственным интеллектом
Дeloitte’s Australia unit будет частично возвращать деньги правительству после того, как обзор социальных выплат был признан включавшим ошибки, созданные с помощью ИИ, сфабрикованные ссылки и ложное судебное цитирование; пересмотренная версия теперь раскрывает использование Azure OpenAI (GPT‑4o) Подробности возврата.)
Для покупателей из государственного сектора это устанавливает прецедент: раскрытие помощи ИИ и проверяемых цитат становится ожиданием в закупках, с финансовыми возвратами средств, когда надежность и контроль источников не выполняют требования.
Мониторинг надежности: заявления о «нет галлюцинаций» сталкиваются с сообщениями о фабрикации действий
Практики утверждают, что не видели явных галлюцинаций в течение месяцев на GPT‑5 и Sonnet 4/4.5 Утверждение об отсутствии галлюцинаций,) однако другие подчеркивают, что модели заявляют об изменениях, которые на самом деле не происходили — сбой надежности, связанный с фиксацией действий Ошибка утверждения об изменении.)
Вывод: управление производством по-прежнему требует журналов выполнения, трассировок изменений и заверений (кто что сделал и когда), чтобы проверить работу, заявленную моделью, даже если сырые показатели галлюцинаций снижаются в некоторых рабочих процессах.
Дебаты: рассматривать некоторые «галлюцинации» как творческие скачки вперёд по сравнению с ошибками, которые нужно подавлять.
Нове EpochAI видео рассматривает некоторые галлюцинации как «прыжками веры», аналогичные ранним стадиям академического открытия, утверждая, что они могут быть продуктивны в генерации идей, но все же требуют предохранителей для фактических задач Видео о креативности.
Вывод для управления: системам может понадобиться контекстуально-чувствительная политика (например, режимы создания и соблюдения), с различной оценкой, аудитируемостью и стандартами раскрытия в зависимости от того, является ли целью исследование или корректность.