Meta сокращает около 600 позиций в области ИИ, организует финансирование Hyperion на $27 млрд — контроль над GPU централизуется
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Meta больше не хеджирует риски. По данным Axios и внутреннему слуху, компания сокращает примерно 600 ролей в сфере ИИ и направляет GPU‑вычисления и полномочия принятия решений в Superintelligence/TBD Labs, чтобы двигаться быстрее в производственном ИИ. Параллельно сообщается, что компания планирует привлечь около $27 млрд финансирования через Blue Owl для финансирования Hyperion, её дата‑центра ИИ в Луизиане. Читайте это как одну агрессивную ставку: меньше комитетов, больше вычислительной мощности в одной «воронке» и более быстрые сроки вывода моделей и продуктов.
FAIR — одна из команд, затронутых сокращениями, с сообщениями, что руководитель исследований Юандон Тян был уволен, что сигнализирует смещение от широкомасштабных фундаментальных исследований к продуктовым лабораториям, которые напрямую владеют вычислениями. Описываются «меньшие, богатые талантами команды», держатели GPU‑ключей, что должно снизить внутренние трения и сделает приоритеты понятными для руководителей—which, однако, концентрирует риск, если новая стековая архитектура окажется недовольна. Финансирование, синхронизированное с централизованным контролем GPU, телеграфирует позицию Meta в передовой гонке: закрепить мощность, закрепить пропускную способность и запустить продукты и модели.
Глядя шире, соотношение времени вписывается в рынок, где доступность мощности, а не чипы, всё чаще определяют скорость развертывания ИИ. Лоудон Каунти уже достигает 9,3 ГВт, ещё 6,3 ГВт планируется к 2028 году, и аналитики ожидают, что 25–33% спроса на новые дата‑центры будет приходиться на «за вне счёт» установки к 2030 году. Ожидайте, что Hyperion будет активно опираться на эти подходы.
Feature Spotlight
Особенность: Meta консолидирует ИИ — около 600 сокращений, попадание FAIR
Meta переходит от широких исследований к более узким группам продуктов на базе GPU: около 600 ролей сокращено, у FAIR пада влияние, Superintelligence/TBD Labs получают контроль — это изменяет темп выпуска Meta и сопоставление исследований с продуктами.
Отчёты между аккаунтами указывают на то, что Meta сокращает примерно 600 должностей в области ИИ (включая FAIR) и централизует вычисления и принятие решений в Superintelligence/TBD Labs; текущие ставки — перераспределение финансирования и доступ к GPU.
Jump to Особенность: Meta консолидирует ИИ — около 600 сокращений, попадание FAIR topicsTable of Contents
🧩 Особенность: Meta консолидирует ИИ — около 600 сокращений, попадание FAIR
Отчёты между аккаунтами указывают на то, что Meta сокращает примерно 600 должностей в области ИИ (включая FAIR) и централизует вычисления и принятие решений в Superintelligence/TBD Labs; текущие ставки — перераспределение финансирования и доступ к GPU.
Meta сокращает примерно 600 должностей в области ИИ; FAIR пострадал по мере централизации власти в суперинтеллекте/TBD
Meta сокращает примерно 600 позиций в своей AI‑организации, причем FAIR среди затронутых подразделений, по мере того как компания консолидирует принятие решений и доступ к GPU под Superintelligence/TBD Labs, чтобы «двигаться быстрее». Axios report
- Внутренние обсуждения и краудсорсинговый опрос о влиянии разъясняют затронутые направления в PAR/FAIR/Infra, подчеркивая масштаб сокращения layoff poll.
- Потоки обсуждений, резюмирующие реорганизацию, говорят, что меньшие, насыщенные талантом команды будут нести ответственность за вычисления, тогда как продуктовые лаборатории приоритетны по сравнению с широкими исследованиями reorg summary, и пресс-покрытие повторяет приблизительную цифру ~600 Axios report.)
$27 млрд финансирования подготовлено для дата-центра Hyperion AI от Meta, подчеркивая переход к вычислениям.
Вместе с реорганизацией ИИ Meta заключает договор на финансирование примерно $27 млрд с Blue Owl для финансирования дата-центра Hyperion в Луизиане — часть более широкой стратегии централизации и масштабирования вычислений для ИИ на фоне внутреннего соперничества за GPU reorg summary.
Это темп финансирования сочетается с консолидацией прав на принятие решений по GPU в Superintelligence/TBD Labs, что сигнализирует явное предпочтение продуктивному ИИ над рассеянным исследовательским портфелем reorg summary.)
Лидерская турбулентность: как сообщается, Yuandong Tian из FAIR уволен в ходе консолидации.
Сообщается, что директор FAIR по науке и исследованиям Юандон Тянь был уволен, когда Meta смещается в сторону Superintelligence/TBD Labs, что подогрело спекуляции о дальнейшем сдвиге руководства в исследованиях leadership note.
Комментарий трактует этот шаг как усиление влияния руководства продуктово-лабораторной команды на фундаментальные исследования по мере централизации ресурсов и GPU commentary, , при этом Axios предоставляет более широкий контекст увольнений Axios report.
⚡ Развертывание ИИ: капитальные затраты, сроки подачи мощности и размещение объектов.
Несколько постов анализируют долгосрочные капитальные вложения в ИИ, внедрение локального энергоснабжения (BTM), размещение в Индиане и дискуссию о космических дата-центрах. Сегодня новое по сравнению с вчера: подробные графики траекторий энергопотребления и динамики США/КНР.
Исследование по развертыванию ИИ: доход Nvidia за 2025 год соперничает с капзатратами на добычу; взрывной сценарий достигает более 1 ТВт к 2030 году
Глубокий разбор Динa и Дваркеша моделирует два пути для инфраструктуры ИИ: траекторию «взрывного роста», достигающую более 1 тераватта ИИ‑мощности к 2030 году, и сценарий «зимы», приближающийся к 100–250 ГВт. Он аргументирует, что прибыль от чипов может финансировать фабрики и инструменты на раннем этапе, подчёркивает время ожидания мощности как ограничение, и отмечает, что Китай может лидировать на более длинных временных горизонтах по мере того как износ активов сбросится и промышленный потенциал будет накапливаться buildout thread, blog post.))
- Доходы против цепочки поставок: выручка Nvidia примерно $200 млрд в 2025e сопоставляется с десятилетиями затрат на НИОКР и капитальные вложения (CapEx) у производителей оборудования; авторы формулируют понятие «дефицит CapEx», который может профинансировать больше фабрик buildout thread.)
- Преимущество в мощности: графики показывают сроки поставки солнечной/ветровой/газовой генерации примерно 1,5–3 года против около 6 лет для реакторов с водой под давлением (LWR) фиссией; генерацию, которую можно быстро разворачивать, предпочтительно для поддержания продуктивности GPU buildout thread.)
- Реальность размещения: дата‑центры США долгое время перепрофилировали обветшавшие активы электропитания от промышленности; этот запас заканчивается, что подталкивает к прямому снабжению энергией и новым развертываниям industrial reuse note.)
За пределами учётного прибора для обеспечения 25–33% мощности новых дата‑центров для ИИ к 2030 году
Jefferies, цитируя McKinsey, ожидает, что к 2030 году 25–33% дополнительного спроса на дата‑центры будет удовлетворено за счет мощности за пределами счетчика на месте (BTM) — газовые турбины, топливные элементы и аккумуляторы, размещённые на объекте — чтобы обойти очереди межсетевого подключения к сети на несколько лет и волатильные тарифы коммунальных служб btm summary. Это следует за 2‑GW campus самодостаточным планом в Западном Техасе, иллюстрирующим переход к генерации на месте для ИИ.
- Почему операторы поворачиваются к этому: более быстрое время вычислений, меньшее количество депозитов/рисков curtailed, и прямой контроль над формой нагрузки; приведены примеры, включая предлагаемое OpenAI примерно 10 ГВт «Stargate», сделку Oracle на 2,3 ГВт VoltaGrid и кампус в штате Вайоминг мощностью 1,2 ГВт btm summary.
Отчет округа Лаудоун: нехватка мощности для ИИ становится структурной по мере того, как поданная мощность достигает 9,3 ГВт, запланировано +6,3 ГВт к 2028 году
Свежие данные из округа Лаудон — самой плотной в мире кластер Центров обработки данных — показывают рост энергопотребления на 166% с 2021 года (с 2,0 до 5,33 ГВт), примерно 9,3 ГВт передано сегодня и ещё 6,3 ГВт запланировано к 2028 году, что подчёркивает энергию как основное ограничение пропускной способности для мощности ИИ county report, county report.
- Вывод: даже хорошо обслуживаемые узлы сталкиваются с устойчивыми ограничениями, что усиливает аргументы в пользу BTM‑проектов, размещения в нескольких штатах и долгосрочного обеспечения энергией, привязанного к поставкам GPU.
Google за планом дата-центра на территории 390 акров в Индиане, ранний макет показывает до пяти зданий
Местные документы идентифицируют Google как движущую силу за застройкой дата‑центра на 390 акрах в округе Морган, Индиана; концептуальные материалы указывают на возможность возведения до пяти зданий на площадке обновление по размещению.
- Почему это важно: расширяет гипермасштабируемый след по сети Среднего Запада, сохраняя доступ к железнодоправу и электроэнергии; соответствует более широким отраслевым тенденциям к генерации на месте и многообъектным кампусам.
Орбитальные дата-центры: Starcloud планирует спутник, оборудованный H100, скептики ставят под вопрос его практичность
Стартап Starcloud утверждает, что запустит спутник на базе NVIDIA H100 в качестве шага к орбитальным дата-центрам, предлагая обильное солнечное и вакуумное радиационное охлаждение и заявления o примерно в 10 раз более низких энергозатратах по сравнению с наземными площадками NVIDIA blog. Практикующие немедленно подняли вопросы реалистичности — задержка, экономика пропускной способности, ремонтопригодность и тепловой менеджмент на масштабе, призывая к осторожности в краткосрочной жизнеспособности skeptical take, в то время как другие подчеркнули, что концепция как научная фантастика становится реальностью concept post.
🛡️ Агентная безопасность браузера: меры против инъекций
Сильный фокус на рисках браузеров Atlas/agentic: PoC-инъекции в буфер обмена и предупреждения Brave; руководитель по информационной безопасности OpenAI сегодня опубликовал конкретные меры по снижению рисков. За исключением запуска Atlas (освещался вчера).
Инъекция буфера обмена перехватывает Atlas Agent Mode через скрытые события копирования
Новый прототип демонстрирует, что ChatGPT Atlas можно незаметно направлять через веб-страницу, которая вставляет содержимое в буфер обмена — в результате режим Agents может вставлять ссылки злоумышленников во время обычных задач, продолжая обзор clipboard injection о низкоуровневых похищениях браузеров. Демонстрация от Pliny подчеркивает ловушки «копировать в буфер обмена» как реалистичный путь к эксфильтрации и риск фишинга для агентских браузеров exploit write‑up.). Команды безопасности должны рассматривать записи буфера обмена как ненадёжный входной материал и ограничивать любые действия вставки/отправки агентом с помощью проверки или политики.
Brave предупреждает, что браузеры на базе ИИ небезопасны для чувствительных учетных записей; избегайте сессий с высоким риском.
Brave предупреждает, что AI‑браузеры сталкиваются с векторами prompt‑injection и перехвата буфера обмена, и рекомендует не использовать их для банковских операций, здравоохранения или других сессий с высоким риском до тех пор, пока не будут доказаны более сильные меры смягчения Brave guidance. Их заметка подчеркивает минимизацию разрешений страницы, тщательную проверку действий агента перед выполнением и предположение, что даже доверенные сайты могут содержать скрытые враждебные инструкции.
OpenAI подробно описывает защиту Atlas: режим наблюдения, ограниченные разрешения, одобрения пользователей
OpenAI’s CISO outlined concrete mitigations for ChatGPT Atlas, including Watch Mode (observe‑only), permission scoping, explicit user approvals for risky steps, rapid abuse triage, and defense‑in‑depth against prompt/clipboard injection CISO outline. A technical review summarizes additional guardrails and how they aim to contain page‑sourced instructions and tool misuse blog analysis. For teams piloting Atlas, defaulting to Watch Mode and least‑privilege page access reduces blast radius while the ecosystem hardens.
Оперативный справочник по агентским браузерам: изолировать профили/ВМ, просматривать действия, мониторить буфер обмена
Практические рекомендации сходятся на нескольких конкретных мерах предохранения: запуск Atlas/Comet в отдельных профилях браузера или в виртуальных машинах, избегать привязки к критическим учетным записям, требовать человеческого рассмотрения перед любым действием агента, которое фиксирует данные, отслеживать содержимое буфера обмена и поддерживать актуальность сборок — даже безобидные страницы могут скрывать эксплойты чек-лист безопасности. Эти шаги существенно снижают воздействие инъекций через подсказки или буфер обмена, пока поставщики работают над встроенными средствами защиты.
🧮 Детерминизм и пропускная способность в стеках обслуживания
vLLM внедряет пакетно-инвариантную инференцию и документирует техники детерминизма; SGLang сообщает об ускорениях и сотрудничестве с KTransformers. В основном — за счет инженерии времени выполнения; здесь нет запусков моделей.
vLLM обеспечивает побитово детерминированный вывод для разных размеров батча с одним флагом.
vLLM внедрил VLLM_BATCH_INVARIANT=1, гарантируя идентичные выводы и логпрофили независимо от того, запустите ли вы bs=1 или bs=N (включая предзаполнение), облегчая A/B-оценки и отладку обсуждение фичи. Продолжая тему KV-пулинг, который улучшил эластичное многомодельное обслуживание, это закрепляет принцип детерминизма для надёжного продакшн‑обслуживания примечание к релизу.
- Custom kernels and patches: Triton ops (incl. RMSNorm) to eliminate non‑deterministic paths custom ops summary.
- Execution control: torch.library overrides with a BMM monkeypatch to stop silent fall‑throughs execution override.
- Backend tweaks: fixed tile sizes in Triton MLA/FlexAttention, sorted top‑k for MoE, FlashInfer 4.0 RC for KV split flags, and a conservative FlashAttention path for non‑split KV backend tweaks.
- Multi‑GPU reductions: NCCL configured for tree reduction over a single channel for repeatable cross‑device sums multi-gpu setup.
- Test harness: split prefill vs prefill+decode, assert exact logprob equality across bs values for bitwise checks; improves repro and triage loops test methodology, debugging benefits.
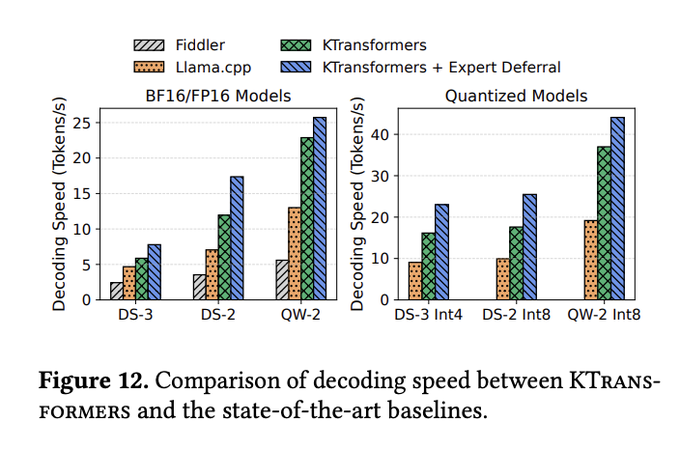
SGLang сотрудничает с KTransformers для ускорения разрежённых MoE и гибридного обслуживания на CPU/GPU.
LMSYS интегрировала стратегию вывода KTransformers и оптимизированные ядра в SGLang, нацелившись на разреженные нагрузки MoE и гибридное выполнение на CPU/GPU; команды сообщают о существенном приросте пропускной способности и бесшовном масштабировании до более крупных multi‑GPU развертываний integration post, tech blog.
- AMX‑оптимизированные CPU‑эксперты и кеш‑дружелюбные макеты повышают пропускную способность экспертной части; NUMA‑aware тензорное параллелизм и эффективная координация устройств снижают накладные расходы tech blog.)
SGLang достигает примерно 70 токенов в секунду для GPT‑OSS‑20B на DGX Spark после исправлений ядра и квантования
На компактной коробке NVIDIA DGX Spark SGLang теперь обслуживает openai/gpt‑oss‑20b примерно на 70 токенов в секунду — примерно рост около 1,4× по сравнению с прошлой неделей — после совместных исправлений Triton и квантования вместе с NVIDIA; готовое Docker‑изображение и команда запуска были опубликованы для воспроизведения perf demo, corroborated by NVIDIA AI Devs nvidia note.
- Однострочная настройка запуска (Docker) позволяет быстро воспроизвести тест, делая Spark разумной локальной средой разработки/edge‑платформой до масштабирования на более крупные кластеры perf demo.
🏢 Корпоративное распространение: сделки по вычислениям, платформы, трафик
Партнерство и сигналы распределения между поставщиками. Исключая реорганизацию Meta (рассматривается как функция). Смешанный набор слухов о вычислительных ресурсах, потребительских поверхностях и образовательных воронках.
Многомиллиардное соглашение Anthropic и Google по вычислениям крепнет по мере появления намёков на «ограничения скорости».
Bloomberg сообщает, что Anthropic ведет переговоры об облачном контракте с Google, оцениваемом в верхнюю десятку миллиардов, чтобы масштабировать нагрузки Claude, при этом общественные слухи предполагают, что это может снять текущие ограничения скорости покрытие Bloomberg, и обсуждение сделки.
Продолжая тему обсуждений по вычислениям, это сигнализирует о устойчивом многолетнем планировании мощности между передовой лабораторией и гиперскейлером — значимо для обучения моделей и закупок для корпоративного вывода.
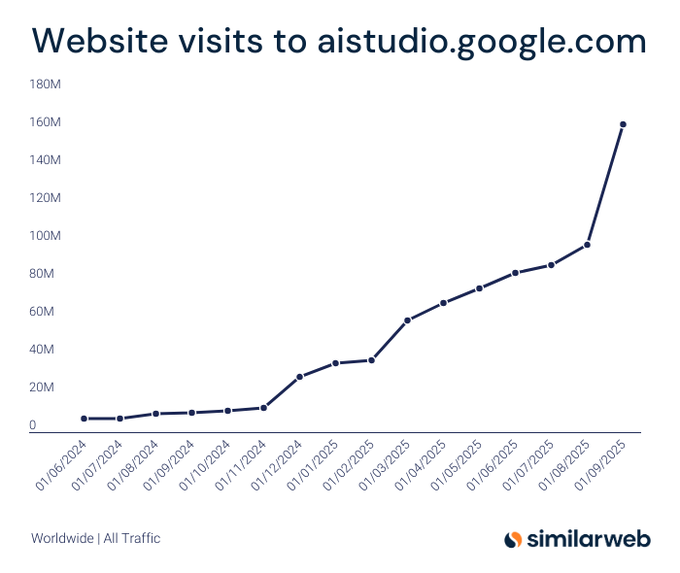
Gemini AI Studio трафик взлетел на 1 453% год к году до более чем 160 млн посещений к сентябрю 2025 года
График Similarweb показывает резкий рост посещений AI Studio, достигнув примерно 160 млн к сентябрю 2025 года — рост на 1 453% по сравнению с аналогичным периодом прошлого года traffic chart.
Для стратегов по платформе это сильный сигнал распределения для воронки разработчиков Gemini и расширяющейся поверхности для развертывания приложений и агентов.
Google запускает центр «Skills» с ~3,000 курсами по ИИ и технологиям и инструментами обучения для организаций.
Google объединяет почти 3 000 курсов, лабораторных работ и сертификаций — охватывая основы исследований ИИ DeepMind, лаборатории Gemini Code Assist и геймифицированный прогресс — доступно бесплатно для большинства пользователей и с административными инструментами для команд обзор навыков, и промо-курс.
Лидеры корпоративного обучения могут направлять повышение квалификации сотрудников через единую точку входа, подробности на официальном портале сайт Google Skills.)
Microsoft представляет 12 функций Copilot на Sessions: делегирование задач, Journeys, память и многое другое
23 октября Microsoft ожидается выпустить двенадцать возможностей Copilot — делегирование задач в Edge, Copilot Journeys, групповые беседы, управление памятью, коннекторы приложений и многое другое — и будет распространяться бесплатно в Edge для Windows/macOS feature rundown, и TestingCatalog brief.
Это расширит распространение Copilot как среди потребительских, так и корпоративных браузеров, укрепляя его влияние на повседневные рабочие процессы.)
Perplexity появляется на умных телевизорах Samsung наряду с Copilot благодаря кнопке искусственного интеллекта одним касанием.
Samsung встроит движок Perplexity в свои новые смарт‑TV рядом с Microsoft Copilot и собственным ИИ Samsung; пользователи смогут активировать ИИ при помощи специальной кнопки на пульте для голосовых вопросов и поиска медиа TV integration.
Это размещает AI‑агент в массовой гостиной, расширяя охват потребителей и каналы данных за пределы браузеров и телефонов.
Cline for Teams бесплатно до 2025 года, добавляет поддержку JetBrains, RBAC и централизованное выставление счетов.
Командная версия Cline бесплатна до конца 2025 года, включающая расширение JetBrains, контроль доступа на основе ролей, централизованную тарификацию через Cline, управление конфигурациями и панель для команды pricing note.
Для инженерных организаций, тестирующих ИИ‑кодирующих агентов в масштабе, это снижает сопротивление на этапе пилота и стандартизирует управление.
Google выявил, кто стоит за планом строительства дата-центра площадью 390 акров в Индиане, что усиливает развитие мощностей США в области ИИ.
Местные репортажи связывают Google с проектом дата-центра на площади 390 акров в округе Морген, Индиана, с концепциями, предполагающими до пяти зданий на объекте site report.
Хотя это не связано напрямую с ИИ, продолжающееся размещение Google расширяет доступ к вычислительным мощностям и электроэнергии в США, необходимый для Gemini и облачных ИИ-рабочих нагрузок — важный фактор предложения для распространения корпоративного ИИ.
OpenAI продвигает Atlas внутри ChatGPT с баннером «Try Atlas»; кодовое имя «Aura» подтверждено
Веб-приложение ChatGPT теперь рекламирует браузер Atlas через заметный баннер «Try Atlas», классический рычаг роста за счёт собственной площадки web banner. Другая заметка подтверждает, что «Aura» является внутренним кодовым названием в сборке macOS codename note.
Это ускоряет установку Atlas из аудитории более чем 800 млн пользователей ChatGPT, усиливая распространение без платных каналов.
📑 Исследования: надёжность рассуждений, отучение, обрезка токенов
Плотный пакет новых работ: латентно‑условный Free Transformer, бинарный RAR для снижения галлюцинаций, обучение‑забвение на основе внимания, сертифицированная самосогласованность и визуальная токенизация текста.
Free Transformer от Meta сохраняет преимущества энкодера, но осуществляет инференс с помощью модели, состоящей только из декодера, через латентное пространство Z.
Новая архитектура обусловливает генерацию обученной латентной переменной Z: маленький энкодер используется только на этапе обучения, затем пропускается при выводе за счёт выбора Z, сохраняя глобальное планирование и избегая затрат на энкодер. Сообщаемые преимущества охватывают кодирование, математику и MCQ на масштабах 1.5B/8B всего с ~3% дополнительной обучающей вычислительной нагрузки paper first page.)
Подход внедряет Z в середину стека (ключи/значения) для ранних глобальных решений, что помогает стабильности после ошибок небольших токенов, и держит бюджеты вывода ближе к стандартным декодерам diagram explainer.)
Гибрид «текст как изображение» сокращает количество токенов декодера, сохраняя точность и ускоряя работу крупных моделей.
Практическое правило: закодировать примерно половину контекста как одно изображение и оставить вопрос в виде текста — это снижает токены на стороне декодера примерно на 50% с почти равной точностью при извлечении и суммаризации. Большие декодеры получают ускорение на 25–45%, так как более короткие последовательности перевешивают накладные затраты на обработку изображения pipeline figure.
Это дополняет тенденции оптического сжатия, нацеливаясь на узкие места декодера без повторного обучения основы pipeline figure.
Двоичное вознаграждение с дополнением за счёт извлечения снижает число галлюцинаций примерно на 39%, сохраняя при этом полезность.
Метод обучения с подкреплением (RL) присваивает вознаграждение 1/0 за проверку выводов с опорой на полученные доказательства — без частичного зачета — обучая модели сохранять подтвержденные утверждения и говорить «я не знаю», когда сомневаются. На вариантах Qwen3 разрывы открытого толкования уменьшаются на 39%, а неверные ответы в коротких QA падают на 21.7% без снижения математических/кодовых навыков обзор статьи.)
Простые бинарные вознаграждения труднее подделать, чем нечеткие баллы, и в тестах давали более короткие, более ясные выводы обзор статьи.
Сертифицированная самосогласованность добавляет остановку по мартингейлу с явными гарантиями ошибок для голосования большинством
Логика на основе большинства голосов получает формальные границы конечной выборки и мгновенно действительный сертификат мартингала «Majority», который останавливает сбор данных, как только лидер становится статистически безопасен по сравнению со своим претендентом и остальными вместе взятыми. Варианты обучения во время тестирования дополнительно уточняют вероятность моды, чтобы сократить необходимое число образцов paper abstract.)
Это обеспечивает управляемые бюджеты вычислений и откалиброванную уверенность в задачах по математике с использованием базовых моделей Qwen/Llama paper abstract.)
Salesforce’s FARE оценивает общие рассуждения, повышая RL‑пайплайны до +14,1 балла.
Обучены на 2,5 млн примеров по математике, коду, использованию инструментов и рассуждению, FARE‑8B/20B предлагают краткие, надёжные выводы, которые устойчивы к смещению по позиции/стилю и служат как повторной ранжировкой или верификаторами в циклах RL. В качестве верификатора FARE поднял баллы на целых 14,1% по сравнению с проверками на совпадение строк paper first page.
Модели также находят близкие к лучшим решения на MATH и демонстрируют прочную работу на задачах переоценки кода, консолидируя инструменты оценки paper first page.)
VisionSelector обучается определять, какие токены изображений сохранять, тем самым удваивая скорость предзаполнения при сохранении 10% токенов
Крошечный, полностью обучаемый в конце‑концах счётчик выполняет дифференцируемый отбор top‑K по визуальным токенам, сохраняя точность при различных бюджетах сжатия, удерживая лишь 10–30% токенов. Префилл‑пропускная способность улучшается примерно в 2×, а использование памяти заметно падает на длинных документах/видео первая страница статьи.)
Поскольку это plug‑and‑play (~12.85M параметров), он встраивается в существующие MLLMs без изменения базовых механизмов внимания первая страница статьи.
Декодирование с опорой на вознаграждение для описаний изображений на стыке зрения и языка уменьшает количество галлюцинаций объектов примерно на 70% без повторной тренировки
Два небольших контролёра направляют генерацию во время декодирования: один наказывает за вымышленные объекты (обученные под человеческие предпочтения), другой вознаграждает упоминание объектов, подтверждённых детектором. Единственный вес балансирует точность и полноту; эксперименты показывают примерно на 70% меньше галлюцинаций объектов по сравнению с жадной декодировкой во всех моделях paper first page.
Поскольку руководство применяется только на выводе, оно улучшает существующие MLLMs с минимальными вычислениями по сравнению с sampling best-of-k paper first page.
Зондовые исследования могут извлекать данные об обучении выравнивания из моделей после обучения, что повышает риск утечки.
Исследователи Google показывают, что контроль за выравниванием (например, данные предпочтений) может частично восстанавливаться из открытых моделей с использованием методов в пространстве вложений, что подразумевает, что дистилляторы моделей могут непреднамеренно утекать проприетарные данные о безопасности и методы paper abstract.
Эта работа призывает к более жесткому контролю над конвейерами дистилляции и обработкой наборов данных при выпуске моделей с открытым весом paper abstract.
GraphFlow расширяет поиск RAG в графе знаний за счёт политик, обученных на потоках, примерно +~10% на STaRK
Извлечение трактуется как пошаговые перемещения вдоль KG; оцениваются только финальные следы, затем обученный «поток» распространяет кредит на более ранние переходы, чтобы направлять политику. На STaRK метод повышает точность извлечения и разнообразие примерно на 10% по сравнению с базовыми моделями на основе GPT‑4o обзор метода.
Адаптеры на вершине застывшего LLM считывают вопрос, след и кандидатные переходы, чтобы сбалансировать охват и специфичность без надзора на каждом шаге обзор метода.
RL с критикой после редактирования лучше персонализирует помощников, чем PPO; 14-миллиардная модель опережает GPT-4.1 в тестах
Генеративная модель вознаграждений оценивает полезность, персонализацию и естественность и формирует краткие критические замечания; политика отвечает, её critiqued, затем переписывает. Обучение как на исходных, так и на отредактированных ответах приводит к увеличению коэффициента побед на 11% по сравнению с PPO, причём модель размером 14B, по сообщениям, превосходит GPT‑4.1 по оценкам персонализации paper first page.
Многоаспектные вознаграждения снижают взлом вознаграждений (например, заполнение персоны) и сохраняют выводы краткими и в нужном тоне paper first page.)
🛠️ Кодирование с ИИ: рабочие процессы, команды и агенты
Контент для практиков:
- план Codex → внедрение рабочих процессов,
- переключение модели Factory,
- паттерны активного использования курсора,
- промо-материалы Cline Teams.
Сессии по безопасности отмечены как руководство разработчика.
«Жить опасно с Claude»: запуск кодирующих агентов в песочнице, даже при обходе разрешений
Доклад Саймона Виллисона призывает команды рассматривать флаги YOLO как --dangerously‑skip‑permissions в качестве ускорителя прототипирования, а не модели безопасности: держать агентов в песочнице и предпочитать асинхронные, контролируемые запуски, чтобы безопасно разблокировать автономию talk recap. Статья включает боевые истории и паттерны для балансировки пропускной способности с ограничителями на реальных кодовых базах session photo.
Cline for Teams бесплатно до 2025 года с расширением JetBrains, RBAC и централизованным выставлением счетов
Клайн объявил цены на Teams: 0$ в месяц до конца 2025 года (затем 20$/пользователь), включая расширение JetBrains, контроль доступа на основе ролей, простое управление конфигурациями, ограничения по моделям/поставщикам, панель команды и приоритетную поддержку — нацелено на организации, стандартизирующие кодирующих агентов pricing announcement. Промо‑акция фактически снимает препятствия на внедрение для пилотов на уровне команды event note.
Factory CLI теперь позволяет выбирать разные модели для режимов планирования и выполнения.
CLI фабрики добавляет выбор модели по каждому режиму — например, GPT‑5‑high для планирования и GPT‑5‑Codex для кода — с автоматическим переключением при смене режимов, соответствуя поэтапным рабочим процессам, которые многие команды уже практикуют feature note.). Изменение снижает необходимость ручной перенастройки и поощряет чистое разделение между высокоуровневым планированием и реализацией.
Это также снижает когнитивную нагрузку при просмотре запусков, поскольку выходные данные каждого режима последовательно формируются тем же классом модели changelog view.
Как на самом деле работают продвинутые пользователи Cursor: фоновые агенты, MCP в Notion, triage CI во вкладке GitHub
Инженеры Cursor поделились конкретными шаблонами: запускать фоновые агенты, пока продолжаешь доставлять в Tab, отправлять документацию через MCP прямо в Notion и использовать интеграцию GitHub для обработки сбоев CI без открытия IDE обзор использования, mcp к Notion, разбор CI. Много кто разделяет работу так, чтобы GPT‑5 занимался исследованиями и планами, в то время как Sonnet 4.5 уточняет правки, в сочетании с множеством небольших PR‑ов для сохранения жесткого контроля обзора пакетный рабочий процесс, план затем tab.
Полевой отчет: режим Atlas Agent завершил полный курс соблюдения требований, но потреблял ~80% CPU и зашел в тупик на середине выполнения.
Практикующий запустил Atlas через полный цикл обучения по обеспечению соответствия; агент в итоге выполнил задачу и получил ссылку на сертификат, но несколько раз зависал и подскачивал использование CPU до примерно 80%, требуя ручных перезапусков для восстановления run diary. Полезный сигнал, если вы оцениваете готовность к долгим, сохраняющим состояние задачам внутри производственных веб-приложений).
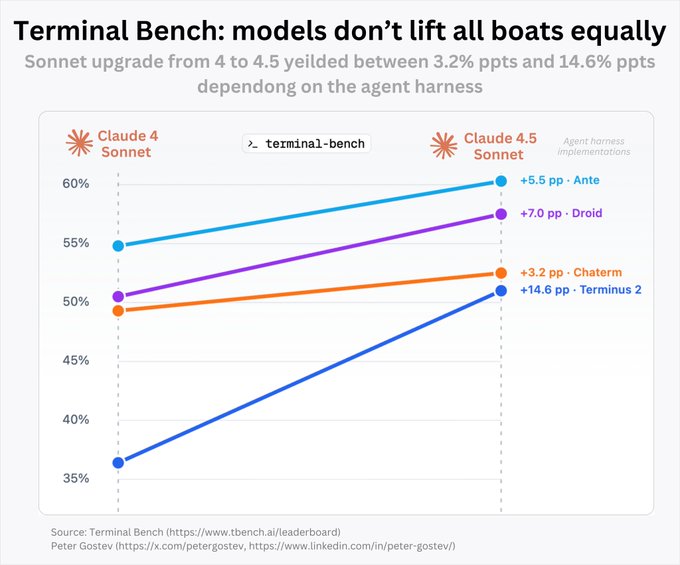
Сонет 4→4.5: приросты во многом зависят от настройки 'agent harness'; Terminus зафиксировал увеличение на +14.6 п.п., другие — значительно меньше.
Срез терминального бенча показывает, что обновление Claude Sonnet с версии 4 до 4.5 приводит к кардинально разным улучшениям в разных хаснесах — от +3.2 до +14.6 процентных пунктов — подчеркивая, что управление контекстом и память формируют результаты сильнее, чем просто сырой прирост модели benchmarks chart. Команды должны проводить бенчмарк в рамках своей собственной инфраструктуры, прежде чем приписывать победы исключительно модели.
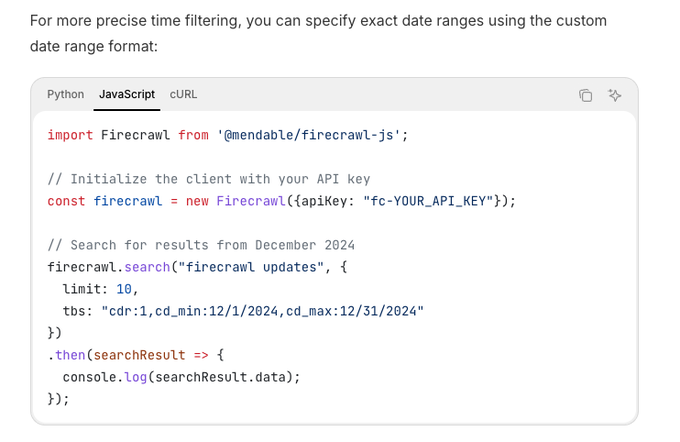
Firecrawl Search добавляет фильтры по диапазону времени, включая пользовательские диапазоны дат, для поиска более свежих агентов
Firecrawl’s search API now supports time scoping (e.g., прошлой неделе или явные диапазоны cdr), помогая конвейерам агентов извлекать своевременные источники без пост‑фильтрации api example. Это особенно полезно для задач RAG, где важна актуальность, или чтобы ограничить дрейф в записях оценок.
Дайте вашим голосовым агентам лицо: открытый демо-проект ElevenLabs × Decart × Pipecat демонстрирует пайплайн аватаров в реальном времени.
Готовый к запуску конвейер объединяет потоковую TTS ElevenLabs с аватарами в реальном времени, синхронизируемыми по движениям губ, и оркестрацию WebRTC от Pipecat — идеален для агентов поддержки, киосков и встроенных помощников pipeline overview. Пример репозитория включает настройку потоков речи, синхронизацию аватаров и транспорт, чтобы команды могли сосредоточиться на навыках, а не на каркасе demo code.
Наблюдение за багами: Claude Code SDK и расширение VS Code показывают сломанный /compact; исправление уже в пути.
Несколько пользователей сообщили, что /compact не работает в Claude Code SDK и расширении VS Code, что нарушает пути обновления с версии v2.0.0 bug report. Anthropic подтвердил, что исправление найдено и находится на рассмотрении maintainer reply. До тех пор ожидайте, что сжатие начнет новые чаты без предшествующего контекста.
Хрупкость MCP в Codex: частые тайм-ауты у MCP в инструментах разработчика; обходное решение предлагает увеличить таймауты запуска.
Команды сталкиваются с частыми тайм-аутами при запуске клиентов MCP (например, next‑devtools, chrome‑devtools, browsermcp), что мешает сеансам кодирования с использованием инструментов error screenshot. Предлагаемое решение — увеличить startup_timeout_ms сервера MCP в конфигурации до того, как будет применено более глубокое исправление workaround tip.\n\n
🎬 Креативные стеки: Veo 3.1 лидирует; новые сториборды и UI-дизайны
Сильный творческий импульс: Veo 3.1 возглавляет таблицы лидеров; новый сторибордист Popcorn; переработка дизайна чата; ценообразование Kling; мультиреференс‑контроль Vidu. Посвящено инструментам для медиа; исключает методы, предназначенные только для исследований.
Tencent открывает исходники Hunyuan World 1.1: однопроходное преобразование видео и мультвид в 3D на одном GPU
Tencent’s Hunyuan World 1.1 (WorldMirror) теперь с открытым исходным кодом, расширяя текстовое/однокадровое 3D до видео‑к‑3D и многовидовые входы, выводя облака точек, многовидовую глубину, камеры, нормали и 3D‑Гауссовы сплаты в одном проходе на одной ГПУ project summary. Links to the project page, GitHub, Hugging Face, demo and tech report accompany the release for immediate adoption into asset pipelines project summary.
Popcorn Хигсфилда запускается как инструмент для сторибординга с 8‑кадровой согласованностью и контролем ссылок.
Higgsfield выпустил Popcorn, браузерный генератор раскадровок, который сохраняет персонажей, освещение и оформление на протяжении 8 кадров, с тремя режимами создания: один промпт для 8 кадров, последовательности на основе ссылок или мульти‑референс с промптами для каждого кадра для полного контроля launch thread, creation modes. Ранние руководства показывают сквозные рабочие процессы, объединяющие Popcorn для макетов с последующими видеомоделями для анимации how-to guide, workflow recap.
Shengshu’s Vidu Q2 добавляет мультиреференс из 7 изображений для видео, защищённого по идентичности и раскладке; флагманский план — 600 юаней в месяц
Shengshu выпустил Vidu Q2 с «Reference to Video», который объединяет до семи эталонных изображений для зафиксирования идентичности персонажа и компоновки сцены, плюс режимы I2V и T2V с синхронизированным диалогом и звуком, а также глобальный API feature summary.); ценообразование варьируется от бесплатных уровней до флагманского плана за 600 юаней (~84 доллара США) в месяц, подано как прямой конкурент Sora 2 для управляемых кадров product site.)
Avenger 0.5 Pro дебютирует на втором месте в номинации image-to-video на арене Artificial Analysis.
Video Rebirth’s Avenger 0.5 Pro появился на Artificial Analysis Video Arena в категории image-to-video на втором месте после Kling 2.5 Turbo, что ознаменовало заметный скачок по сравнению с их моделью July 0.5, оставаясь закрытой для общественного пользования до выхода следующей версии arena summary. Арена‑листинг предоставляет несколько head‑to‑head prompts и ссылку на интерактивное сравнение моделей prompt sample, arena link.
ComfyUI демонстрирует рабочий процесс на базе Gemini для согласованности персонажей в разных сценах.
ComfyUI поделился рабочим процессом, сочетающим Gemini Flash LLM с Gemini Image APIs для создания последовательных персонажей в разных локациях, нарядах и позах — иллюстрированных в фотореалистичном, иллюстрированном и векторном стилях заметка по рабочему процессу. Пост содержит десятки примеров вывода, полезных как шаблон для команд, формирующих библиотеки персонажей перед видеосъемками пример вывода.)
Этот шаблон практичен для эпизодического контента и брендовых аватаров, которые должны оставаться согласованными в разных кампаниях.
Hitem3D v1.5_1536 Pro обеспечивает более чистую геометрию и большую последовательность по сравнению с Tripo 3.0 и Hunyuan 2.5
Новая модель Hitem3D v1.5_1536 Pro демонстрирует большую согласованность объекта (соотношение пропорций/силуэт) и более резкую геометрию на сложных аксессуарах по сравнению с Tripo 3.0 и Hunyuan 2.5 в бенчмарках по переводу одного изображения в 3D benchmark thread. Примеры подчеркивают улучшение сохранения резких краёв и сбалансированную текстуру материалов, со ссылкой на пробную версию модели examples link.)
Для 3D‑пайплайнов эти дельты сокращают время очистки сетки на последующих этапах и улучшают результаты авто‑ретопо.
Recraft представляет Chat Mode: разговорный логотип и визуальное редактирование с живым холстом
Recraft представил Чат‑режим, чат‑управляемое пространство для дизайна, где подсказки уточняют активы на живом холсте — полезно для бренд‑систем, постеров и последовательных визуальных направлений обзор функций. Ранний доступ к списку ожидания открыт, и примеры показывают редактирование соотношения сторон и итеративный стиль внутри панели чата страница ожидания, скриншот канваса.\n\n
\n\nДля команд такой подход снижает затраты на переключение инструментов в обзорах художественного руководства и делает процессы дизайна, управляемые подсказками, более повторяемыми.
Google Flow добавляет пометки-зарисовки, чтобы управлять тем, как изображения анимаются в видеомоделях.
Google Flow теперь поддерживает свободные каракули (аннотации), нанесённые поверх изображений, которым могут следовать последующие видеомодели для направления движения и деформации — полезно для предпросмотра и более точного художественного направления feature note. Подробный changelog описывает добавление в обновлении Flow changelog link.
Это соединяет раскадровку пометки и намерение движения, давая командам легкую поверхность управления перед дорогими генерациями.
Reve Image API выходит на fal с конечными точками редактирования, ремикса и преобразования текста в изображение.
fal добавил Reve Image API, подчеркивая точные правки, ремиксы субъектов и генерацию T2I в рамках одной интеграции api video. Для продуктовых команд это консолидирует общие креативные операции на инфраструктуре fal и дополняет недавние видео-предложения, такие как Kling 2.5 Turbo.
Открытый рецепт: ElevenLabs + Decart + Pipecat для аватаров, говорящих в реальном времени
Открытый конвейер показывает, как ElevenLabs транслирует TTS в синхронизацию губ реального времени аватара Decart, при этом Pipecat координирует и обрабатывает транспорт WebRTC; демо‑код доступен для разработчиков, чтобы форкнуть обзор конвейера, демо‑код. Эта связка представляет собой практическую базу для интерактивных ведущих, спикеров или встроенных гидов в приложении без привязки к поставщику.
📄 Document AI: внедрение OCR и инструменты на практике
Множество новостей по прикладному OCR: развертывания DeepSeek‑OCR и заявления о скорости, поддержка vLLM, руководства Hugging Face, веха PaddleOCR. Сфокусировано на конвейерах и операциях, а не на общих разговорах о VLM.
DeepSeek‑OCR пайплайн конвертирует 10 тыс. PDF-документов в Markdown быстрее чем за 1 секунду за страницу на одной карте A6000
Производственный отчет показывает, что 10 000 PDF-документов пакетно преобразованы в Markdown с помощью DeepSeek‑OCR со стабильной скоростью менее чем за 1 секунду на страницу на одном RTX A6000, обслуживаемом через FastAPI в Docker на WSL, с Ryzen 1700 и 32 ГБ ОЗУ pipeline note, и отдельный пост, описывающий аппаратную конфигурацию hardware details.
Продолжая работу над сканированием Microfiche, который подтвердил оптическое сжатие в реальных условиях, эта точка пропускной способности свидетельствует о готовности DeepSeek‑OCR к оцифровке больших архивов и последующему RAG. Выбор стека (FastAPI+Docker) также подразумевает легкую горизонтальную репликацию для достижения более высоких порогов ingest.
DeepSeek‑OCR получает поддержку сервера vLLM; партия из 27 915 страниц национальной библиотеки находится в процессе обработки.
Сообщество мейнтейнеров подтвердило, что DeepSeek‑OCR теперь работает на vLLM, и они обрабатывают коллекцию справочных руководств Национальной библиотеки Шотландии объемом 27 915 страниц в качестве реального тестирования vLLM support note. Для операций с высоким объемом данных флаг batch‑invariant у vLLM (одинаковые результаты при разных размерах пакета, включая предзагрузка) снижает дрейф и упрощает отладку в многопользовательских заданиях batch invariant post.
Hugging Face публикует прикладное руководство по открытым OCR-моделям, стоимости и схемам развертывания.
Hugging Face выпустил практическое руководство по построению OCR‑пайплайнов с открытыми моделями — охватывая затраты на размещение, когда стоит обслуживать локально vs удалённо, и какие бенчмарки смотреть — утверждая, что не существует единственного «лучшего» OCR, а лишь наилучшее соответствие для конкретного сценария blog thread, с полным разбором и примерами в посте HF blog.
Для команд, сопоставляющих DeepSeek‑OCR vs PaddleOCR‑VL vs другие VLMs, это предоставляет критерии принятия решений помимо чистой точности, включая fidelity компоновки (layout fidelity), бюджет токенов и общую стоимость владения.
Baseten упаковывает готовый к развёртыванию шаблон DeepSeek‑OCR с подсказками и образцами изображений.
Baseten представил готовый шаблон для развёртывания и тестирования DeepSeek‑OCR, объединяющий подсказки и примеры изображений для быстрой проверки и итераций deployment note, с репозиторием и инструкциями по настройке, доступными для клонирования в вашу инфраструктуру GitHub repo. Это сокращает время до получения первой ценности для команд, прототипирующих QA документов или извлечение визуального макета на GPU- или CPU-узлах.
PaddleOCR достиг отметки 60k ⭐ на GitHub; выделяет PP‑OCRv5 и расширение OCR‑VL
PaddleOCR достиг порога в 60 000 звезд, освещая эволюцию от легковесного стека OCR к мультимодальному пониманию документов с PP‑OCRv5 и PaddleOCR‑VL milestone post, и направляя новичков к кодовой базе и документации GitHub repo.)
Для промышленных пользователей зрелость проекта и широкая поддержка языков делают его надёжной базовой линией или компонентом ансамбля наряду с более новыми подходами к оптическому сжатию.
📊 Вариации провайдеров и дашборды по оценке
Операционные оценки вместо запусков моделей: концевые точки Exacto для точности вызова инструментов, данные о вариации поставщиков и чувствительность harness на Terminal Bench.
OpenRouter запускает конечные точки Exacto для оценки точности вызова инструментов; Groq лидирует среди поддерживаемых моделей.
OpenRouter introduced Exacto, новый набор конечных точек, которые оценивают fidelity поставщика для вызовов инструментов, сообщает, что Groq занимает самую высокую точность среди моделей, которые они запускают Exacto announcement. Фирма отмечает, что методология поддержана оценками, проведёнными OpenBench, что добавляет прозрачность выбора поставщика во время выполнения OpenBench credit. Раннее внедрение в экосистеме заметно, поскольку Mastra продемонстрировала варианты "exacto" в своей платформе, что сигнализирует о быстрой операционной реализации для команд, которые ориентируются на качество помимо цены и задержки Mastra availability.
Вариация между поставщиками: частоты вызовов инструментов Kimi K2 колеблются на 10 процентных пунктов между поставщиками.
Свежая телеметрия, опубликованная наряду с работой OpenRouter, показывает существенно различающееся поведение вызова инструментов для одной и той же модели в зависимости от провайдера: Fireworks 62,0%, Chutes 60,1%, Groq 59,8%, AtlasCloud 59,6%, Novita 57,7% и Nebius 52,4% (процент запросов, вызывающих инструменты) Таблица вариаций провайдера. Для AI-платформенных команд разброс оправдывает динамический выбор провайдера — сочетание такого рода дашбординга с маршрутизацией, обеспечивающей качество, как Exacto, может предотвратить скрытые регрессии, когда провайдеры меняют бэкенды Анонс Exacto.
[изображение:https://pbs.twimg.com/media/G36mavgXgAAmwmJ.jpg|Таблица вариаций провайдера]
Выбор подвески имеет значение: Sonnet 4→4.5 обеспечивает диапазон прироста от +3.2 до +14.6 п. п. на Terminal Bench
Обновлённые результаты Terminal Bench показывают, что обновление Sonnet от Anthropic даёт неравномерные улучшения в зависимости от оболочки агента (agent harness): +3.2 п.п. (Chatem), +5.5 п.п. (Ante), +7.0 п.п. (Droid) и ярко выраженное +14.6 п.п. на эталоне Terminus 2, что подчёркивает, как каркас и управление контекстом влияют на сквозные результаты Terminal Bench chart. Это добавляет практическую сторону вчерашней дискуссии о лидерборде — детали измерения важны — продолжая обсуждение SWE‑Bench debate о вариациях в оценке. Ожидайте, что команды будут сообщать как о модели, так и об harness в панелях оценки, чтобы различия были интерпретируемыми.
🧪 Открытые модели: реконструкция 3D‑мира и агентов для углублённых исследований
Артефакты моделей поступают сегодня: feed-forward 3D реконструкция Tencent (видео/мультвид на одном GPU) и глубоκий исследовательский агент PokeeResearch‑7B. Медиа‑модели остаются в разделе креатива.
Tencent выпустила открытые исходники Hunyuan World 1.1: прямой проход видео/мультвид→3D на одной GPU.
Tencent’s Hunyuan World 1.1 (WorldMirror) выходит как открытая, универсальная модель для 3D‑восстановления, которая превращает видео или входы с нескольких ракурсов в плотные облака точек, нормали, многовидовую глубину и параметры камеры, а также 3D гауссовские пятна в одном прямом проходе — разработана для работы на одной видеокарте за секунды Release thread. Команда подчёркивает гибкость «любой вход/любой выход» с геометрическими априорными данными (позы, калибровка, глубина) для разрешения структуры, а также демонстрацию, GitHub и отчёт; объявление также поддержано сообществом HF Community repost.
PokeeResearch‑7B выпускается как открытый агент для глубоких исследований с высокими многошаговыми показателями.
PokeeResearch‑7B дебютирует как открытый исходный глубокий исследовательский агент, демонстрируя конкурентные результаты по задачам с несколькими шагами доказательств, таким как BAMB, 2Wiki, TQ, NQ, Musique и HotpotQA; релиз доступен на Hugging Face, предварительные цифры опубликованы Release note. Публикуемая таблица результатов показывает, что варианты PR/PR+ ведут или достигают аналогичных показателей по нескольким бенчмаркам, подчеркивая охват поиска и пошаговую способность к рассуждению Results table.
🧪 Расчёт границ фронтира: квантовый рубеж и разгон GB200
Аппаратные сигналы, влияющие на ИИ: Willow от Google демонстрирует проверяемое квантовое преимущество на физической симуляции; установки GB200 предполагают приближённые повышения темпа обучения моделей в ближайшее время.
Willow от Google демонстрирует проверяемое квантовое преимущество в физической симуляции, примерно в 13 000 раз быстрее суперкомпьютеров.
Google Quantum AI сообщает о первом проверяемом квантовом преимуществе на сложной симуляции квантовых интерференций с использованием процессора Willow, работающей примерно в 13 000 раз быстрее ведущих классических суперкомпьютеров и с сквозной верификацией сигнала обзор преимущества, публикация в Nature. Команда использовала измерение «Quantum Echoes» для сертификации результатов, утверждая, что это открывает путь к практическому моделированию материалов и выводу структуры молекул, которые ранее были недоступны для классических методов обзор метода.
Разгон GB200: практикующие ожидают передовые модели примерно через 4–6 месяцев, с увеличением эффективности обучения примерно в 2–3 раза
Установки систем Nvidia GB200 (Grace‑Blackwell) ускоряются, и ожидается, что первые модели frontier‑масштаба, обученные на GB200, поступят примерно через 4–6 месяцев; GB200 уже приводят как ~2–3× более эффективной для обучения по сравнению с платформами предыдущего поколения deployment note. Для лидеров ИИ это означает более короткие циклы итераций и, возможно, больший контекст/параметр бюджет в рамках того же реального времени и капитальных затрат, что изменит сроки дорожной карты на 2026 год и cadence оценки.
🗣️ Голосовые агенты и аватары в реальном времени
Голосовые конвейеры и движение разработчиков: ElevenLabs демонстрирует стэк аватаров в реальном времени с Decart/Pipecat и объявляет сеанс в Google Startup School.
Открытый стек для аватаров в реальном времени: голос ElevenLabs, синхронизация губ Decart, Pipecat WebRTC
ElevenLabs опубликовала рабочую схему для голосовых агентов с лицами: транслируйте TTS от ElevenLabs, управляйте видеовизуальным аватаром Decart с синхронизацией губ в реальном времени и координируйте транспорт и инструменты через Pipecat/WebRTC Avatar pipeline. Получите образец приложения и схему подключения в референсном репозитории, чтобы форкнуть в свой стек Avatar demo code.
- Примечания по стеку: потоковая речь (низкая задержка), рендеринг аватара (Decart) и браузерный транспорт (Pipecat WebRTC) дают инженерам готовую отправную точку для поддерживающих ботов, презентаторов или полевых торговых агентов.
ElevenLabs продемонстрирует API голоса, музыки и SFX на Google Startup School.
ElevenLabs выступит с презентацией «Бесконечные пользовательские голоса, AI-музыка и звуковые эффекты с API ElevenLabs» в Google Startup School 12 ноября, освещая рабочие процессы, которые продуктовые команды могут внедрить уже сегодня с Eleven v3 Объявление мероприятия.
- Ожидайте практических руководств по созданию мультимодальных медиа‑опытов в реальном времени (пользовательские голоса, потоковая синтезация и советы по интеграции для команд разработчиков).
🗺️ Методы извлечения: потоки графа знаний и новые фильтры поиска
Обновления, ориентированные на извлечение: усиление KG‑trail для расширения объёма доказательств и временных ограничений параметров поиска для более свежего RAG; а также UX‑паттерны поиска с несколькими индексами.
GraphFlow обучает политики поиска в KG для расширения доказательств; около 10% прироста точности/разнообразия на STaRK
Новый метод GraphFlow рассматривает извлечение как пошаговые перемещения по графу знаний, затем обучает политику по значениям «потока», которые обратно распространяют вознаграждение по всей траектории — улучшая как точность, так и разнообразие примерно на 10% по сравнению с сильными базовыми GPT‑4o paper thread.
В отличие от расширений по принципу обхода в ширину, которые туннелят или повторяют шаги, GraphFlow помечает только полные траектории (дешёвый надзор) и использует правило исследования с детальным балансом, чтобы избегать тупиков; небольшие адаптеры на застывшей LLM оценивают следующие шаги, расширяя охват без тяжёлой донастройки paper thread.
Firecrawl Search добавляет фильтры по диапазону дат для более свежих входных данных RAG
Firecrawl теперь поддерживает поиск в интернете с ограничением по времени, включая пользовательские диапазоны дат через параметры cdr (например, cdr:1, cd_min, cd_max), что облегчает ограничение получения данных свежими источниками и уменьшает устаревшие цитаты в цепочках RAG feature note.
Это произошло за день после того, как Firecrawl снизил стоимость поиска в 5 раз, что сигнализирует о движении в сторону более дешевых и свежих входных данных для запросов в RAG-цепочках cost drop.
Множественные индексы и переработка запроса превосходят поиск по одному векторному представлению для искусства и семантического поиска
Практическое описание по извлечению показывает, как сочетание понимания запроса/его переработки с многоиндексным поиском (несколько векторных пространств плюс ключевые слова) превосходит пайплайны с одним эмбеддингом — особенно для нечетких запросов вроде «лучшие выставки импрессионистского искусства в Париже», где настроение, стиль и метаданные расходятся search pattern.
Для инженеров ИИ, занимающихся созданием UX, ориентированного на поиск, вывод таков: диверсифицировать представления (не ограничиваться одним эмбеддингом на документ) и направлять запросы к наиболее информативному индексу перед ранжированием.
🦾 Гуманоиды и воплощённый ИИ
Две заметных обновления в области embodied сегодня: рывок в аппаратном обеспечении и сенсинге Unitree H2 и заигрывание Apple/X1 с анонсом — сигнал к растущему темпу embodied стэков.
H2 от Unitree добавляет Jetson AGX Thor, манипуляторы с 7 степенями свободы и сенсорика исключительно по зрению.
Новый гуманоид Unitree H2 повышает вычислительную мощность и мехатронику, поддерживая NVIDIA Jetson AGX Thor (GPU Blackwell, 128 ГБ, примерно 2 070 FP4 TFLOPs при ~130W) и переходя к восприятию на основе стереокамер вместо LiDAR. Платформа также обновлена до рук с 7‑DoF, ног с 6‑DoF и новой подвеской F‑A‑R тазом, талией 3‑DoF и полезной нагрузкой 7 кг (макс. пики — 15 кг), ориентированной на лабораторные и исследовательские сценарии использования разбор спецификаций.
- Вычисления: поддержка Thor вместе с Orin обеспечивает на борту обработку зрения высокой пропускной способности и инференс политик без привязки к сети разбор спецификаций.
- Механика: добавлены степени свободы плеча–локтя–кисти (7 на руку) и артикуляция лодыжки (6 на ногу), что улучшает общую манёвренность тела и устойчивость контактов разбор спецификаций.
- Сенсоры: только визуальные (двойное стерео) заменяют LiDAR/Depth стек — сложнее, но более масштабируемо для исследований чистого зрительного 3D-восприятия разбор спецификаций.
- Энергия и полезная нагрузка: указано примерно 3 часа автономной работы; непрерывная полезная нагрузка 7 кг, пик 15 кг, подходит для задач манипулятора и использования инструментов разбор спецификаций.
X1 заинтригует новым роботом после появления в клипе Apple; представление состоится на следующей неделе.
Робот из стартапа X1 появился в новом клипе Apple, и X1 заявляет, что раскроет систему во вторник — еще один сигнал того, что embodied stacks ускоряются к публичным демо-версиям и доступу для разработчиков teaser note.
🗣️ Пульс сообщества: агентские браузеры, день 2
Дискурс — новости: множество негативных отзывов о скорости/циклах Atlas Agent Mode, соперничества Comet «голова к голове», reports о перегрузке CPU и баннеры на этапе внедрения. Этот раздел отслеживает настроение по использованию, а не по запускам.
Реакция на Day-2: режим Atlas Agent назвали медленным, зависающим и ненадёжным в реальном использовании.
X‑таймлайн с отрицательным смещением на Atlas, с тем, что несколько потоков вызывают медлительность агента, склонны к застреванию и трудности с доверием к базовым веб‑задачам sentiment snapshot. Практики охарактеризовали использование им сайтов как «болезненное», что подчеркивает разрыв в качестве между демонстрациями и рабочими процессами в продакшене usage critique, в то время как другие предположили, что репликация через API без графического интерфейса быстрее и надежнее, чем управление браузером с помощью видения engineering suggestion. Контр‑поток предупредил, что выпуск агентного браузера гораздо сложнее, чем форк Chromium, приводя в качестве примера собственный интерфейс, инструменты работы с памятью и слои безопасности как существенную работу architecture defense.
Полевой отчет: Atlas завершил курс по соблюдению требований, но занимал около 80% CPU и требовал перезагрузок.
Одно длинное задание — завершение корпоративной подготовки по соответствию требованиям от начала до конца — в итоге удалось, но заняло примерно 5 часов, несколько раз останавливалось до ручного перезапуска и приводило процессы Atlas к ~80% CPU в macOS Activity Monitor task diary. Пользователь все же счёл результативность агента «впечатляющей» за навигацию по UX не пропускаемого видеоконтента, но отметил использование ресурсов и задержки как главные преграды для повседневного внедрения task diary.
Comet против Atlas: сборка рассылки бок о бок; Perplexity предлагает бесплатный месяц Pro
Практическое сравнение выполнило ту же задачу по созданию рассылки в Comet от Perplexity и Atlas от OpenAI, чтобы сравнить поведение агентов и эргономику UX side‑by‑side test. Perplexity также предлагает бесплатный месяц Pro через промо‑ссылку, подталкивая продвинутых пользователей к пробному использованию Comet параллельно с Atlas Perplexity promo.
Веб-версия ChatGPT продвигает баннер «Try Atlas»; кодовое имя «Aura» появляется в пакетах приложений.
Веб-приложение ChatGPT сейчас демонстрирует заметный баннер приветствия «Try Atlas» для стимулирования установки, в то время как ресурсы приложения на macOS раскрывают внутренние названия пакетов «Aura» для компонентов Atlas banner sighting, bundle listing. Это первая широкая внутриигровая подсказка дня после запуска, продолжение к initial launch. Для ясности названий сообщество также подтвердило «Atlas = Aura» как кодовое имя поставки codename note.
}
Первый патч Atlas выйдет в течение 24 часов, что намекает на ускоренный темп исправлений.
Пользователи заметили сообщение «Обновить сейчас» внутри Atlas на второй день, что указывает на то, что OpenAI начал выпускать исправления сразу после запуска обновление подсказки. Учитывая объем ранних отзывов о производительности и стабильности, тесный график релизов будет ключом к конвертации пробного использования в удержание.
Продвинутые пользователи считают отсутствие изоляции нескольких профилей/сессий основным препятствием для повседневной работы.
Активные веб‑пользователи отметили, что Atlas отслеживает одну идентичность учётной записи ChatGPT и не обеспечивает мульти‑профильную изоляцию, которая обычно присутствует в Chrome/Arc — трудно тем, кто совмещает личные и рабочие учетные записи Google, куки и расширения для разных профилей profiles feedback. До тех пор, пока Atlas не введёт разделение профилей, многие будут держать сложный веб‑серфинг в основном браузере и резервировать Atlas для целевых агентских задач.
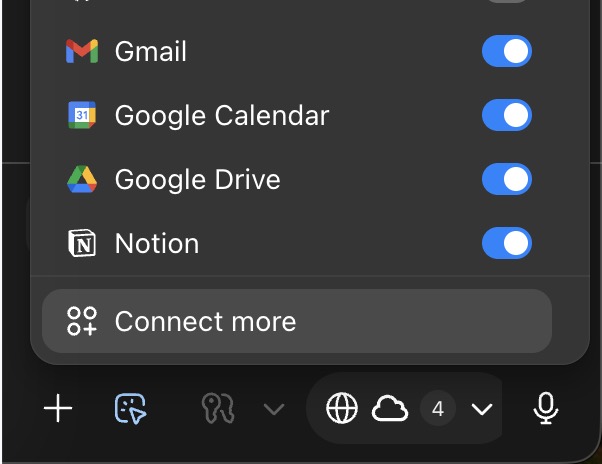
Раннее использование обнаруживает соединители Agent Mode и пользовательские инструменты GPT, встроенные в Atlas.
Искатели обнаружили, что переключение в Режим агента открывает доступ к коннекторам (с сохранёнными ключами) для использования инструментов первого лица, и что настраиваемые GPT могут вызываться как в браузере инструменты — полезно для интеграции Notion, документов и задач‑специфичных навыков в сессии обзор коннекторов, custom GPT tool. Это предполагает, что Atlas может действовать скорее как среда выполнения агента, чем как чистая боковая панель чата, если настроить всё вдумчиво.