Sora 2 Pro tops iOS Free chart – 15s High takes 20–30 minutes
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI’s Sora 2 Pro is breaking into the mainstream: the app just hit #1 on Apple’s U.S. Top Free chart, and the staged Pro rollout is now visible in‑app with a Sora 2 vs Sora 2 Pro toggle. Creators are flocking to the new 10s/15s High settings, but real‑world latency is sobering — a 15‑second High clip often takes 20–30 minutes end‑to‑end, which will force teams to plan queues and editorial passes around spiky compute windows.
Policy and platform economics are moving just as fast. Sam Altman says likeness use will be opt‑in and that OpenAI will explore revenue sharing with rightsholders — a sensible bridge from “wild‑west UGC” to licensed fan fiction — yet a free watermark remover is already circulating, gutting provenance unless OpenAI leans on embedded signals and distributor‑side checks. Guardrails are jittery: public‑domain lookalikes are getting blocked, while Altman’s “everyone” cameo setting has spawned viral in‑app deepfakes. On the capability front, Sora 2 scored 55% on a tiny GPQA Diamond sample by showing answers in video; engineers suspect a large language model (LLM) re‑prompting layer is solving the task before generation. Early Pro quirks — cameo artifacts, overlapping voices, and stricter people‑photo limits — suggest the creative flywheel is spinning faster than the compliance machinery.
Feature Spotlight
Feature: Sora 2 Pro rollout, licensing controls and creator shockwaves
OpenAI’s Sora 2 Pro expands (15s High‑res) while OpenAI moves toward opt‑in likeness and rev‑share for IP owners—just as a free watermark remover circulates. Distribution, policy, and integrity collide for AI video.
Dominant story today: Sora 2 Pro reaches more users (15s, High quality), the app jumps to #1, and a free watermark remover appears as Sam Altman cameos go viral. Sama outlines opt‑in likeness and revenue‑share for rightsholders. This section owns all Sora news; other categories explicitly exclude it.
Jump to Feature: Sora 2 Pro rollout, licensing controls and creator shockwaves topicsTable of Contents
🎬 Feature: Sora 2 Pro rollout, licensing controls and creator shockwaves
Dominant story today: Sora 2 Pro reaches more users (15s, High quality), the app jumps to #1, and a free watermark remover appears as Sam Altman cameos go viral. Sama outlines opt‑in likeness and revenue‑share for rightsholders. This section owns all Sora news; other categories explicitly exclude it.
Free Sora watermark remover arrives, raising integrity and enforcement risks
Within days of the public rollout, a free tool to strip Sora 2’s watermark is circulating, with before/after examples already posted. This undermines provenance and complicates rightsholder audits just as OpenAI pitches revenue‑share models. watermark example tool announcement
- The tool’s speed suggests any static, visible watermark is insufficient; robust embedded tagging and distributor‑side checks will be needed. watermark example
- Expect platform responses (hash‑matching, SynthID‑style signals, platform‑level detection) to become table stakes if licensing is to work. tool announcement
Sora jumps to #1 on iOS Top Free, continuing its rapid climb
OpenAI’s Sora app reached the top spot on Apple’s U.S. Top Free chart, ahead of Gemini and even ChatGPT, following up on Top 3 momentum two days ago. Screenshots show Sora at #1 while the team teases more invite codes. app store chart
- Bill Peebles says more invites are coming as the team iterates fast, which should sustain growth in the short term. app store chart
- Community‑shared code “FRIYAY” briefly unlocked additional onboardings, illustrating demand pressure on access controls. invite code screen
Altman’s ‘everyone’ cameo setting fuels viral Sora deepfakes in‑app
Sam Altman’s cameo permissions are set to allow public use, and compilations of hyper‑realistic clips are already trending inside Sora—illustrating both the product’s viral flywheel and the moderation challenges ahead. cameo compilation
- Popular clips include skits like “stealing GPUs at Target,” travel, and public dance scenes, highlighting the meme‑ready format. cameo compilation
- This sits in tension with rightsholder and likeness policy changes, so auditing and opt‑outs will need to be easy to trigger and enforce. update post
Similarity guardrails block even public‑domain lookalikes, foreshadowing stricter filtering
Attempts to prompt a Steamboat Willie‑style scene were blocked for “similarity to third‑party content,” indicating conservative defaults that may over‑block public‑domain references as licensing controls tighten. guardrail warning
- Expect more precise, rightsholder‑defined policies (opt‑in likeness, revshare) to replace blunt similarity checks over time. update post
- In the interim, creators should anticipate false positives and design prompts to avoid close stylistic matches. guardrail warning
Sora 2 Pro 15s High clips taking ~20–30 minutes to render for many users
Operational reports suggest a 15‑second High‑quality Sora 2 Pro generation commonly takes ~20–30 minutes end‑to‑end. That cadence has implications for throughput planning, queue sizing, and creator workflows. render timing
- Users are seeing an explicit Sora 2 vs Sora 2 Pro selector in the UI as the staged rollout continues. ui toggle
- The new 10s/15s durations and High quality settings (covered yesterday) amplify compute load at peak hours, so expect spiky queues. render timing
Sora’s creator loop: from multi‑scene remix to app‑store dominance in one week
The same lightweight loop—generate, remix, iterate—is powering rapid content velocity and discoverability, likely contributing to Sora’s #1 charting. The pattern is becoming a de facto production primitive. remix workflow app store chart
- Invite waves (e.g., FRIYAY) spur bursts of new creators that reinforce the feed’s freshness. invite code screen
- As watermark stripping spreads, platform‑level provenance will be critical to preserve trust as volumes scale. watermark example
Remix workflows emerge as a lightweight storyboarding loop for Sora
Creators are chaining scene iterations using Sora’s Remix: generate, post, select Remix, describe the next beat, repeat. It’s a pragmatic production loop for episodic shorts and iterative direction. remix workflow
- The “Mario’s Escape” thread lays out a simple 4‑step cycle that mirrors shot‑by‑shot storyboarding. remix workflow
- For teams, this offers a fast feedback loop that complements heavier pipelines (e.g., separate audio design, post‑edits). remix workflow
Rollout quirks: Pro cameos show artifacts; voices overlap; people photos restricted
Early Pro users report cameo face/voice artifacts and occasional voice overlaps in multi‑cameo scenes; starting generations from real‑person images appears restricted even for self‑photos. Engineers should factor these constraints into prompt design and editorial passes. cameo artifacts voice overlap people image note
- Users describe distorted likeness when switching from standard to Pro in otherwise identical setups. cameo artifacts
- Mixed‑cameo scenes seem most fragile, recommending isolated takes and separate audio layers in post. voice overlap
Sora 2 scores 55% on GPQA subset when prompted to show answers in video
Epoch reports Sora 2 achieved 55% on a 10‑question GPQA Diamond sample by generating videos of a professor holding up A–D answers; GPT‑5 scored 72% on the same set. It’s a notable cross‑modal result for a video model. gpqa test evaluation design
- Each question was run until four videos were produced; ambiguous letters counted as incorrect. evaluation design
- While small‑N, it suggests upstream LLMs in the pipeline can steer accurate answer selection embedded into the video. gpqa test
Engineers suspect an LLM re‑prompting layer is solving tasks before video generation
Analysts hypothesize Sora routes prompts through an LLM that rewrites or expands instructions—possibly solving a task first—before emitting the video prompt. This mirrors re‑prompting layers used in other video generators. prompt rewrite claim method detail
- If true, it explains out‑of‑distribution wins (e.g., GPQA letters) and points to prompt‑quality as a primary control surface. prompt rewrite claim
- For safety, it also means text‑layer policies (e.g., refusal, watermarking instructions) must be robust upstream. method detail
💻 Agentic coding stacks and CLIs
Busy day for developer tooling: Codex CLI update, BYOK agent setups, free model access in IDE agents, and improved agent governance. Excludes Sora items (covered in the Feature).
Codex CLI 0.44 ships with UI refresh, streamable HTTP MCP, and early “codex cloud” management
OpenAI pushed a substantial Codex CLI update focused on dev ergonomics and agent backends. Highlights include a refreshed chat/model picker UI, streamable HTTP MCP servers, and an experimental cloud task manager. See the full notes in the release post release notes and details here GitHub release.
- Windows quality-of-life: fewer repetitive approvals for read‑only commands release notes.
- Custom prompts now support named and positional args for cleaner reuse custom args guide.
- Numerous fixes across model switching, fuzzy search, and workflows release recap.
Cursor v1.7 adds hooks, sandboxed terminals, PR summaries, and browser control
Cursor rolled out a sizable agent stack upgrade: runtime hooks to observe/shape agent loops, sandboxed command execution with automatic isolation for non‑allowlisted commands, auto‑generated PR summaries, a menubar agent monitor, image‑file context, and browser automation for UI debugging feature roundup. This lands after parallel agent branches shipped yesterday Parallel agents.
- Hooks (beta) enable auditing, redaction, and policy logic without forking the agent hooks beta.
- Sandboxed terminals default to no‑internet, workspace‑scoped read/write for safer exec sandbox info.
- Menubar status and image‑context improve day‑to‑day ergonomics menubar view image support.
Droid CLI BYOK: wire in GLM‑4.6 and hot‑swap with Factory‑hosted models
Developers showed how to add Zhipu’s GLM‑4.6 Coding Plan to Droid via ~/.factory/config.json and switch between it and Factory‑provided GPT‑5‑Codex/Sonnet/Opus without lock‑in config how‑to. It’s a pragmatic pattern for teams mixing premium and open weights in one agent loop.
- Docs outline Bring‑Your‑Own‑Key configuration and model selection at runtime docs page.
- The same flow supports local or on‑prem deployments for sensitive repos byok details.
Factory Max Plan offers 200M Standard Tokens for $200, with per‑model cost multipliers
Factory AI introduced a Max plan priced at $200/month for 200M “Standard Tokens,” with a model selector that shows multipliers (e.g., 0.5× for GPT‑5/GPT‑5‑Codex, 1.2× for Sonnet 4.5), letting teams budget capacity across models plan launch. Power users are already switching and noting simple overage controls user take.
- Token multipliers make effective budget transparent (e.g., 0.5× doubles usable tokens on a cheaper model) selector view.
- Devs are comparing Max vs vendor direct limits for heavy Opus/Sonnet work to optimize spend pricing question.
Cline exposes free Grok Code Fast 1 with ~96% diff‑edit success in internal runs
Cline’s IDE agent now lets users pick Grok‑code‑fast‑1 for free; their multi‑month diff‑edit success chart places it among the top models (~95–96%) alongside Claude Sonnet model access. This is a quick way to trial strong code‑edit loops without paying per‑token.
- Model picker flow: install Cline and select Grok Code Fast in the provider UI model access.
Context7 MCP server connects agents to up‑to‑date code docs for ~44k GitHub projects
Upstash’s Context7 MCP server gives coding agents on‑demand access to documentation indexed across roughly 44k GitHub projects—handy for retrieval and planning without leaving the IDE server overview.
- Open source and free to self‑host; drop‑in for MCP‑capable agents GitHub repo.
Jules SWE Agent adds a CLI and developer API, plus memory and file‑callouts
Google’s Jules team shipped a terminal client and an API so you can trigger tasks from scripts, while adding repo‑scoped file callouts, env‑var management, and a persistent memory feature to stabilize long‑running jobs changelog.
- The changelog details latency fixes and VM setup reliability improvements changelog.
- API keys and abuse auto‑detection are live in the new settings page api key page.
Teams turn on mandatory PR conversation resolution after adopting Codex reviews
A team reports Codex review comments are strong enough that they’ve enforced “all PR conversations must be resolved before merge,” attributing the change to the quality of Codex feedback policy change. It’s an adoption signal that AI review can be a credible gate rather than a suggestion layer.
- Expect tighter feedback loops and fewer dangling TODOs in CI with AI as a first-class reviewer policy change.
- Counterpoint: users still want allow-listed commands and stricter controls in Codex headless runs feature request.
CopilotKit + LangGraph: AG‑UI streams subgraphs, emits real‑time nested events, supports Vibe Coding MCP
Building agent frontends gets easier: CopilotKit’s AG‑UI protocol now streams subgraph outputs directly, surfaces nested graph events in real time, and adds a Vibe Coding MCP integration for in‑app tool calls and checkpoints docs overview.
- Frontend actions: let agents call UI tools, stream chat with shared state, and gate via HITL checkpoints docs overview.
- Start here if you’re wiring LangGraph pipelines to a production UI docs page.
🏗️ Compute capacity, neocloud spend and pricing
Concrete spend and capacity moves dominate: Microsoft’s neocloud outlays, Groq’s footprint, and transparent H100 pricing. Excludes Sora distribution economics (Feature).
Microsoft lines up ~$33B in neocloud deals to ease GPU crunch
Microsoft is spreading AI training and inference across multiple neoclouds, committing more than $33B to accelerate capacity and regional coverage while preserving flexibility on spend classification. The biggest tranche is ~$19.4B with Nebius, tied to 100k+ Nvidia GB300s for internal LLM work, with CoreWeave, Nscale, Oracle and Lambda filling in by role and geography neocloud breakdown.
- Provider split: Nebius (~$19.4B), CoreWeave ($10B+ near Portland for OpenAI/internal training), Nscale (~$6.2B for UK/Norway inference), Oracle (Bing inference), Lambda (undisclosed jobs) neocloud breakdown
- Strategy: Move heavy training off owned sites to rented clusters (frees Azure for customers) and book more as OpEx vs CapEx for cash‑flow optics neocloud breakdown
- Parallel build: Microsoft is still expanding owned capacity (e.g., Racine training site targeting ~900 MW utility power) neocloud breakdown
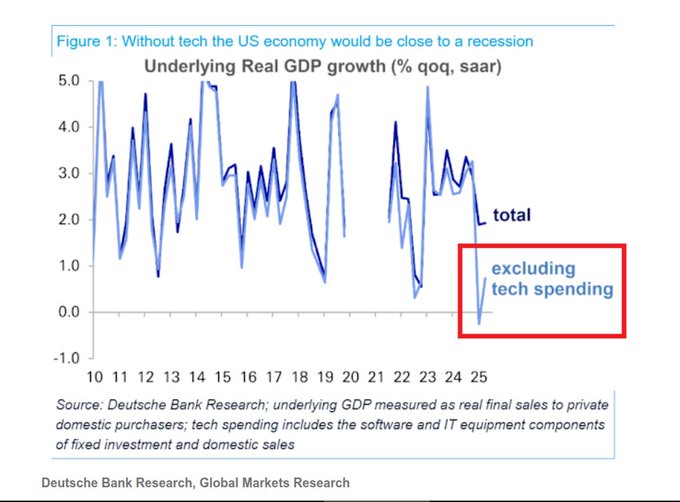
Deutsche Bank: Strip out AI capex and US domestic demand trends near zero
Macro signal for infra planners: Deutsche Bank estimates that without AI‑related investment (data centers, chips, software), underlying US demand would be flat to near 0%—AI capex is carrying growth. Following up on $7T capex (multi‑trillion buildout expected), new figures peg 2025 AI spend at ~$375B, rising to ~$500B in 2026 research summary capex estimates.
- 2025–2026: UBS sees AI infrastructure spend climbing from ~$375B to ~$500B, with constraints shifting from chips to power/land by 2026–27 capex estimates
- Market breadth: “Magnificent 7” account for outsized S&P gains; equal‑weighted index lags, reinforcing how AI buildout skews growth research summary
- Framing: Research notes argue current GDP uplift is mostly from building AI capacity, not yet from realized productivity research quote
Together posts transparent H100 pricing: ~$2.39/GPU‑hr on demand
Clear price signals for inference: Together’s Instant Clusters advertise 8× NVIDIA H100 at ~$19.12/hr (~$2.39 per GPU‑hr) with on‑demand access and discounts for reserved terms, making capacity planning and cost modeling more straightforward for AI teams pricing announcement pricing page.
- Instant clusters spin up in minutes; reserved pricing options are published alongside on‑demand pricing page
- Transparent per‑GPU economics help compare with managed APIs or neocloud contracts at similar SLAs pricing announcement
Groq says it stood up 12 data centers this year as brand lands on McLaren F1
Acceleration on both capacity and mindshare: Groq reports twelve data centers stood up year‑to‑date, while a WSJ profile details its expansion cadence; the company’s logo also appears on McLaren’s F1 car for the Singapore GP weekend, signaling commercial momentum company recap expansion article F1 livery photo.
- Footprint: 12 DCs YTD; company also highlighted broader September milestones (remote MCP, SDK updates, $750M raise) company recap
- Coverage: WSJ outlines Groq’s data center expansion plan and go‑to‑market around low‑latency inference expansion article
📊 Leaderboards and new eval suites
New head‑to‑head signals: LMSYS Text & Vision Arena changes, a new repo‑editing benchmark, APEX job tasks, and language‑by‑model telemetry. Excludes Sora evals (covered in the Feature).
APEX: GPT‑5 leads job‑task benchmark at 64%, edging Grok 4 at 61%
A new APEX AI Productivity Index, focused on economically valuable work, puts GPT‑5 in first at 64%, ahead of Grok 4 at 61% across legal, finance, consulting, and medicine index overview.
- Role breakdowns show GPT‑5 at 70.5% for big‑law associate, 62.0% for general practitioner (MD), 64.8% for consulting associate, and 59.7% for investment banking analyst domain scores.
- Commentary suggests “this is the worst it will ever be,” implying rapid iteration ahead as models and scaffolding improve analyst take.
MCPMark: Real‑tool agent benchmark tops out at 52.56% pass@1
A new MCPMark benchmark stress‑tests Model Context Protocol agents across Notion, GitHub, Filesystem, PostgreSQL, and Playwright; the best model reached 52.56% pass@1 and 33.86% pass@4 on 127 tasks paper summary.
- Tasks average ~16 execution turns and ~17 tool calls, far exceeding prior MCP tests (higher realism) paper summary.
- Local services (e.g., Filesystem, PostgreSQL) scored higher than SaaS tools (Notion, GitHub), hinting at auth, latency, or schema‑understanding gaps paper summary.
Repo Bench: GPT‑5 Codex Med tops at 72.06%, Sonnet 4.5 close behind
A new repository‑editing benchmark drops first scores, with GPT‑5 Codex Med at 72.06% and Claude Sonnet 4.5 around 68.82% on large‑context reasoning plus precise file edits bench results.
- Public runner will ship next so teams can reproduce locally and compare against the leaderboard runner release.
- Tasks emphasize instruction following, context navigation, and file diffs; the chart notes it is not a pure coding‑skill test (methodology caveat) bench results.
Epoch AI revamps benchmarking hub for trend comparisons across 18 evals
Epoch AI refreshed its benchmarking dashboard, making it easier to view SOTA trends, drill into individual benchmarks, and compare models across multiple suites dashboard update benchmarking dashboard.
- Data spans 18 benchmarks (5 internal, 13 external), including mathematics, coding, long‑context and agentic action model pages.
- Analysis highlights how accuracy scales with estimated training compute on GPQA Diamond and MATH Level 5, with recent models outperforming older peers at similar compute dashboard update.
Vision Arena adds per‑category leaderboards and clearer tagging
LMSYS Vision Arena re‑introduces categories (captioning, diagrams, OCR, humor, etc.) and per‑category boards, improving signal quality for real‑world multimodal use cases categories update arena blog post.
- Messages can be tagged without being forced into a bucket, preserving organic prompts while enabling filtered leaderboards category list.
- Category views use the same transparent ranking math as the overall board, but scoped to task types for apples‑to‑apples comparisons categories update.
OpenRouter’s language rankings: Grok 4 Fast dominates German usage
OpenRouter published popularity and usage telemetry by natural language for 58+ languages; Grok 4 Fast currently dominates German prompts and completions rankings post openrouter rankings.
- Rankings include share by model and vendor, enabling teams to match model selection to language markets more data.
RTEB expands with FreshStack target for retrieval generalization
Hugging Face’s retrieval benchmark RTEB added FreshStack, broadening task coverage after launch, following up on RTEB launch with a new real‑world codebase target suite update.
- RTEB is designed to measure generalization with private splits beyond memorization, so new datasets tighten leakage controls and domain spread suite update.
Video Arena lists Luma’s Ray 3 and Ray HDR 3 for community testing
The Video Arena added Ray 3 and Ray HDR 3, inviting community head‑to‑heads across prompts, with voting to surface preference trends video models live video arena.
- Access currently routes via Arena’s Discord; votes and matchup records will shape the public boards over time video models live.
‘Lavender’ image model appears on Artificial Analysis Arena vs GPT‑IMAGE‑1
Artificial Analysis Arena users spotted a new image model nicknamed “Lavender,” likely related to GPT‑IMAGE‑1, being evaluated on creative prompts (e.g., watercolor noir detective office) model comparison.
- Early side‑by‑sides suggest style and text rendering differences versus GPT‑IMAGE‑1; formal model card and metrics are still pending model comparison.
Cline’s diff‑edit chart: closed models ~95–96% success; GLM‑4.6 leads open weights
Long‑running diff‑edit success rates from the Cline coding agent show closed‑source models (Sonnet 4/4.5, Grok Code Fast 1) clustered near ~95–96%, with GLM‑4.6 among the strongest open weights in recent months benchmarks chart.
- Developers can try Grok Code Fast 1 for free inside Cline to replicate results and compare within their codebases benchmarks chart.
🧪 Compact multimodal and retrieval model drops
Fresh models for VLM and retrieval show up with practical tooling: Qwen3‑VL A3B small‑active MoE, Jina’s listwise reranker, ModernVBERT doc retriever, and an open video+audio generator. Excludes creative‑tool UX (separate media tools section).
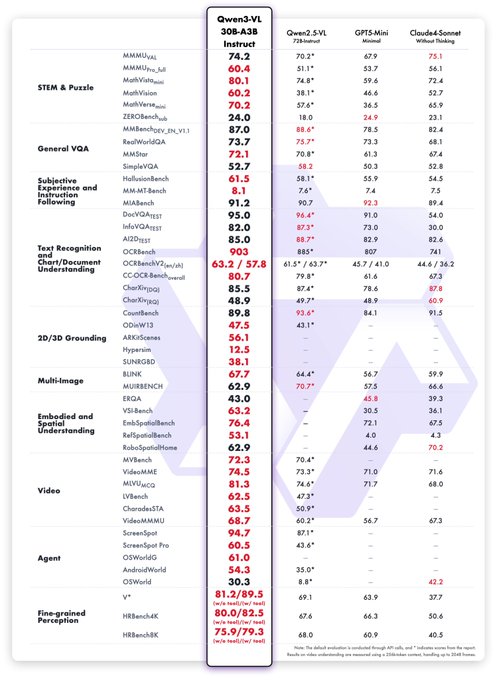
Qwen3‑VL‑30B‑A3B (3B active) drops with FP8 options; challenges mid‑tier closed models
Alibaba released Qwen3‑VL‑30B‑A3B Instruct/Thinking editions that activate only 3B params per token (small‑active MoE) and ship FP8 variants, positioning them against GPT‑5‑Mini and Claude4‑Sonnet on STEM/VQA/OCR and more release thread.
- Claims competitive or better results across STEM, VQA, OCR, video, and agent tasks; see their side‑by‑side plots release thread.
- FP8 builds for both the 30B‑A3B and the larger 235B‑A22B aim at lower latency and cost on modern GPUs release thread.
- Quickstarts and recipes are live in the official cookbooks, with hosted chat for hands‑on trials GitHub cookbooks and Qwen chat demo.
- Model cards and weights are organized in a public collection for reproducible benchmarking Hugging Face collection; blog post outlines architecture and evaluation setup Qwen blog post.
Jina reranker v3 (0.6B) hits 61.94 nDCG@10 on BEIR with “last but not late” listwise interaction
Jina AI unveiled a 0.6B multilingual listwise reranker that processes query + many candidate docs in one causal window and extracts embeddings from final tokens, reporting 61.94 nDCG@10 on BEIR while staying far smaller than prior generative rerankers announcement.
- “Last but not late” interaction allows early cross‑document context before final token embedding extraction; supports up to 64 docs within a 131k context window (implementation based on Qwen3‑0.6B) Jina blog post.
- Model card and examples are available for immediate integration in retrieval stacks Hugging Face model.
- Method and metrics are detailed in the accompanying paper for independent replication ArXiv paper.
ModernVBERT/ColModernVBERT: 250M bidirectional VL retrievers beat larger models on doc tasks
A compact 250M bidirectional vision‑language encoder retriever, ModernVBERT (and ColModernVBERT multi‑vector variant), reports +10.6 nDCG@5 gains on document retrieval versus causal‑attention baselines, with MIT‑licensed models and data model thread.
- Bidirectional attention improves multi‑vector (late interaction) retrieval while retaining single‑vector parity; collections and embed variants are available on Hugging Face HF collection and ColModernVBERT page.
- The team’s write‑up outlines training recipe, ablations, and public datasets for reproducible evaluation Hugging Face blog.
Ovi open video+audio generator launches at ~$0.20 per 5s clip with weights and playgrounds
A Veo‑3–style, unified text/image→video+audio model “Ovi” is live with code, weights, and hosted inference. Fal priced generation at about $0.20 for 5‑second, 24 FPS clips; synchronized audio is produced in one pass fal launch.
- 5‑second, 720×720 outputs with multiple aspect ratios (9:16, 16:9, 1:1) and both T2AV/I2AV conditioning paper link.
- Try it in the Fal playgrounds for text‑to‑video and image‑to‑video runs Fal text to video and Fal image to video.
- Model weights and spec are published for reproducibility and offline experiments Hugging Face model.
🔗 Agent interop: MCP, ACP and AG‑UI in practice
Interoperability matured: stable MCP SDKs, ACP clients spreading beyond Zed, and AG‑UI frontends for LangGraph agents. Excludes core IDE/CLI features (those are in Dev Tooling).
MCP Go SDK hits v1.0 with stable API and near‑complete spec coverage
Model Context Protocol’s Go SDK reached v1.0.0 with a forward‑compatibility commitment (no breaking changes going forward) and implementation coverage for almost all of the spec; client‑side OAuth remains the lone gap. See the release details in GitHub release.
- Stability pledge: v1.0.0 marks API stability so agent and tool authors can adopt without churn release note.
- Spec parity: Implements nearly all MCP behaviors; client OAuth is planned post‑1.0 GitHub release.
- Production signal: The SDK is already in use by Google and Go community projects per the maintainers GitHub release.
ACP spreads beyond Zed: Neovim, Emacs and Marimo ship Agentic Commerce Protocol clients
Interoperability for agent actions via ACP is broadening from Zed to other environments. Zed’s progress report lists working clients for Neovim (CodeCompanion, avante.nvim), Emacs (agent‑shell), and Marimo Notebook, with Eclipse prototyping underway Zed blog post.
- Multi‑editor footprint: Neovim plugins can speak ACP to external agents and tools adoption update.
- Notebook integration: Marimo adds ACP to data‑science workflows, not just IDEs Zed blog post.
- Enterprise runway: An Eclipse prototype is in flight, hinting at broader Java/enterprise use Zed blog post.
Context7 MCP server pipes up‑to‑date docs from 44k GitHub projects into your agent
Upstash’s Context7 ships as an MCP server that connects coding agents to current documentation for roughly 44,000 GitHub projects—so agents can answer with canonical API references instead of stale memory project page, GitHub repo.
- Zero‑setup source of truth: Drop the server into your MCP client and query live docs across popular repos project page.
- Free access tier: Positioned as a no‑cost docs backbone for dev agents, with MCP standardization easing integration GitHub repo.
- Complements AG‑UI flows: Pairing live docs with UI‑driven tool calls reduces hallucinations in code suggestions project page.
CopilotKit brings AG‑UI to LangGraph: subgraphs stream, nested events, and Vibe Coding MCP
CopilotKit released an AG‑UI Protocol frontend for LangGraph agents that streams subgraphs, emits real‑time events from nested graphs, and wires in a Vibe Coding MCP for in‑app tool calls integration update. Docs cover setup and patterns for shared state chat, generative UI, and HITL checkpoints LangGraph guide.
- Tool control from UI: Frontend tool calls let agents take deterministic in‑app actions (buttons, forms) integration update.
- Streaming graph telemetry: Subgraphs and nested graphs surface events live for better debuggability LangGraph guide.
- MCP add‑on: Vibe Coding server aligns with MCP to standardize coding tools across agent stacks vibe server docs.
🧠 Reasoning and tool‑use research updates
Multiple fresh papers on multi‑agent tool use, reusable thought templates, brain‑inspired sequence memory, and vision–text unification tests. Avoids biomedical papers by design.
Google’s TUMIX lifts Gemini‑2.5 Pro to 34.1% on HLE with diverse parallel tool‑use
By mixing many agent styles (text‑only, code, search) in parallel and sharing notes with an LLM judge that stops early when confident, Google’s TUMIX boosts hard‑reasoning scores while cutting cost. Reported HLE rises to 34.1 on Gemini‑2.5 Pro, with consistent gains vs other tool‑augmented scaling tricks. See method and bar charts in paper thread.
- Diverse agents (≈15 styles) collaborate across a few rounds; an LLM‑judge halts when consensus emerges paper thread.
- Outperforms Self‑MoE, Symbolic‑MoE, DEI, GSA on HLE/GPQA/AIME at similar token budgets (numbers in chart) paper thread.
- Key idea: mix strategies, not just more samples; preserve diversity by limiting refinement rounds paper thread.
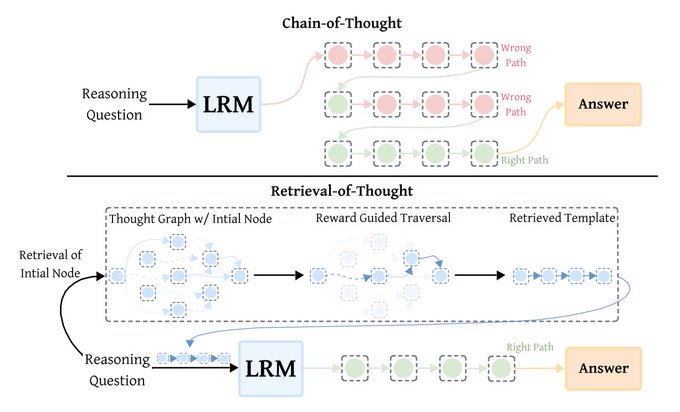
Retrieval‑of‑Thought reuses a “thought graph” to cut tokens 40%, speed +82%, cost −59%
RoT stores vetted reasoning steps as a graph and retrieves a problem‑specific template into <think> sections, slashing output tokens without hurting accuracy. The authors report up to 40% fewer tokens, 82% faster inference, and 59% lower cost while maintaining quality overview thread, with the paper and algorithm details in ArXiv paper.
- Nodes encode sequential and semantic relations among steps; reward‑guided traversal assembles the template overview thread.
- Small models benefit disproportionately (better instruction following with less exploration) overview thread.
Dragon Hatchling (BDH‑GPU) links brain‑like local rules to near‑Transformer performance and effectively unbounded context
A brain‑inspired language model with local neuron updates (excitatory/inhibitory circuits, Hebbian memory) achieves sparse, often monosemantic activations and maintains long‑range reasoning by evolving state rather than caching all tokens. The GPU‑friendly BDH variant matches attention behavior while avoiding fixed context limits paper details.
- Memory sits in synaptic connections; layers attenuate irrelevant past signals, enabling long contexts paper details.
- Many units are monosemantic at <100M scale, aiding interpretability and debugging paper details.
MCPMark shows top agents only pass 52.56% once and 33.86% across 4 tries on real tool tasks
A new benchmark stress‑tests Model Context Protocol use across Notion, GitHub, Filesystem, PostgreSQL, and Playwright. The best model manages 52.56% pass@1 and 33.86% pass^4 over 127 CRUD‑heavy tasks averaging ~16 turns and ~17 tool calls—underlining how brittle tool‑use remains benchmark paper. This lands following up on Agentic gym, a standardization push for multi‑turn RL.
- Local tools (Postgres, FS) fare better than remote (Notion, GitHub), hinting at network/tool API fragility benchmark paper.
- Efficient runs use fewer calls; weak runs loop without progress—planning remains a core gap benchmark paper.
ReSeek trains agents to judge and discard bad retrieval mid‑search, improving multi‑turn QA
Instead of trusting each hop, ReSeek adds a strict JUDGE step with span‑level rewards for factuality and usefulness. Agents write <judge> Yes/No </judge> after every retrieval and backtrack when evidence is weak, beating strong RAG/RL baselines across eight datasets and a synthetic ‘FictionalHot’ suite paper abstract.
- Dense rewards train mid‑trajectory self‑correction; larger models help less on fictional data, isolating reasoning vs memory paper abstract.
Bridge trains interdependent parallel generations, improving accuracy up to 50% vs independent sampling
Instead of treating batch samples as independent, Bridge views batched hidden states as holistic tensors to generate mutually informed responses. With a small parameter bump (~2.8–5.1%), RL with verifiable rewards yields up to 50% relative mean‑accuracy gains and scales to arbitrary widths at inference paper summary, with full details in ArXiv paper.
- Compatible with post‑generation aggregation; focuses on pre‑aggregation diversity with consistency paper summary.
LongCodeZip compresses long code contexts via perplexity‑guided function/block selection
A two‑stage scheme ranks functions by conditional perplexity, then selects blocks under a token budget to retain high‑impact code, reducing latency and API cost while preserving quality on code LLM tasks paper highlight. Paper details and examples in Hugging Face page.
- Coarse (function‑level) then fine (block‑level) pruning maximizes relevance per token paper highlight.
- Designed for code structure (imports, call graphs), not generic text heuristics paper highlight.
ToM‑infused dialogue agents lift social goal completion up to +18.9% on Sotopia
ToMA builds compact snapshots of beliefs, desires, intentions, and emotions for both sides, simulates a few turns, and fine‑tunes on the best drafts. Gains reach +18.9% on 3B and +6.9% on 7B models, with improved rapport and partner‑aware compromises paper abstract.
- Analysis shows more first‑order partner reasoning and fewer passive stalls—useful for negotiation/support bots paper abstract.
Unified vision–text models rarely transfer understanding↔generation end‑to‑end; stepwise forcing wins on RealUnify
RealUnify (1,000 items, 10 categories, 32 subtasks) finds unified models seldom use one skill to boost the other; prompting them to solve in steps improves outcomes. Direct end‑to‑end underperforms, while stepwise pipelines help “understanding→generation,” and a hand‑picked pairing shines on “generation→understanding” paper summary.
- Track 1: Reasoning to draw; Track 2: Draw/reconstruct then answer—direct mode is weak, stepwise helps paper summary.
- Takeaway: training must explicitly teach cross‑skill cooperation, not just co‑locate abilities paper summary.
💼 Enterprise adoption and product strategy signals
Signals from enterprise‑facing apps and platforms: acquisitions, pricing tiers, and developer surfaces. Excludes compute contracts (infra category) and Sora’s monetization (Feature).
OpenAI acquires Roi to push adaptive personal AI companions beyond finance
OpenAI bought Roi, a personalized finance assistant, and is signaling a broader shift toward adaptive, evolving AI companions that learn users’ preferences over time. This reads as a consumer and enterprise strategy move toward stickier, cross‑vertical assistants. acquisition note
- Roi’s pitch was a companion that “understands us, learns from us, and evolves with us,” a framing OpenAI echoes for future apps acquisition note
- Expect product surface area beyond finance, with implications for data retention, account linking, and privacy guardrails for enterprise deployments
Factory AI’s $200 Max plan offers 200M Standard Tokens with model cost multipliers
Factory AI introduced a Max plan priced at $200/month for 200M “Standard Tokens,” with a model picker that shows per‑model multipliers (e.g., GPT‑5 and GPT‑5‑Codex at 0.5×, Sonnet 4.5 at 1.2×, Opus 4.1 at 6×). This clarifies budgeting and encourages workload‑aware model selection. pricing plan multiplier ui
- Users can set overage instead of hard limits, aligning agent workloads with predictable costs user reaction
Google’s Jules SWE Agent adds developer API and CLI, memory and context controls
Jules now exposes an API and a terminal CLI, plus repository‑level memory, file call‑outs, and environment‑variable management to improve reliability and reduce latency hiccups. It’s a step from single‑repo copiloting toward orchestrated, scalable dev workflows. changelog highlights cli overview changelog
- CLI supports task creation, remote VM use, and an interactive dashboard; API keys enable integration in pipelines cli overview
- Memory stores user preferences and corrections for better persistence across tasks changelog highlights
Perplexity makes Comet free; $200 Max adds background assistant, $5 Plus coming
Perplexity opened its Comet AI browser to everyone for free, while a $200/month Max tier gains a new “background assistant” to run multiple tasks asynchronously; a $5 Comet Plus news‑style curation add‑on is in the works. This follows Comet rollout where availability broadened from a waitlist with premium bundles. features and tiers
- Free tier now includes side‑panel assistant, specialized tools (news, shopping, travel, finance, sports) features and tiers
- Max’s background assistant is a mission‑control board for queued jobs with progress and notifications (useful for research and ops) features and tiers
- A $5 Comet Plus is planned as an AI‑curated content experience, expanding the monetization ladder features and tiers
Agent Client Protocol gains momentum across editors and tools
ACP is spreading beyond Zed: Neovim plugins (CodeCompanion, avante.nvim), Emacs (agent‑shell), and Marimo Notebook now speak the protocol, with Eclipse and Toad prototypes underway. This standardizes how devs wire any agent into their editor of choice. adoption report progress report
- Available agents include Gemini CLI and Claude Code via adapters, showing cross‑vendor practicality adoption report
- Early adoption suggests lower switching costs and more repeatable agent UX across IDEs progress report
Context7 MCP server connects agents to up‑to‑date docs for 44k GitHub projects
Upstash’s Context7 MCP server gives coding agents on‑demand access to current documentation across ~44k GitHub projects (free), tightening the loop between IDE agents and real library APIs. For platform teams, this reduces stale‑docs failures in agent plans. server overview github repo
- MCP surfaces unify retrieval and tool use across agents, improving answer faithfulness in code changes and PR reviews server overview
MCP Go SDK reaches v1.0 with stability guarantees and broad spec coverage
The Model Context Protocol’s Go SDK shipped a stable 1.0.0, committing to backward compatibility while implementing nearly all behaviors in the spec (client‑side OAuth is still pending). This reduces integration risk for production‑grade agent stacks. sdk release go sdk release
- The SDK is already in use at Google and across the Go ecosystem, with most historical bugs closed go sdk release
Microsoft adds Agent Mode to Word for conversational document authoring
Microsoft 365 Copilot’s new Agent Mode lets users shape documents through chat—adding sections, formatting, and styles in real time—without leaving the page. It’s a clear step toward embedded, workflow‑native agents in Office. word update
- Expect downstream admin, compliance, and template policy work as teams fold Agent Mode into review workflows word update
Opera’s Neon AI browser launches Founder plan at $59.90 for 9 months with agentic perks
Opera started inviting early adopters to a Founder version of its upcoming Neon AI browser, bundling Tasks, Chat, Do, Make & Cards and promising early‑access features and community benefits. Pricing is $59.90 for 9 months (pay for 3, get 9). founder offer
- Agentic features include cloud task execution (“Make”), prompt cards, and workspace memory; perks include direct team access and early features founder offer
- The offer positions Neon against AI browsers with a clear pre‑launch pricing anchor and community moat
Vercel’s v0 grants $5/month AI credits per user and first access to new shadcn components
Vercel is lowering the on‑ramp for AI app prototyping: v0 now gives each user $5 in monthly AI credits, lets you scaffold apps by prompting (no API keys), and is the first place to access new shadcn components. platform update components template v0 demo
- Model routing includes GPT‑5 and Sonnet 4.5, making quick trials feasible without manual billing setup platform update
- Templates and component remix flows shorten the path from prompt to deployable UI components template
🛡️ Safety routing and over‑blocking signals
Trust & safety surfaced via routing and filters today. Excludes Sora watermark/rights issues (handled in the Feature).
OpenAI routes sensitive chat segments to GPT‑5 Instant for faster crisis support
ChatGPT will now detect distress‑related content and automatically route those portions to GPT‑5 Instant, with model identity still reportable on request and a gradual rollout starting today model routing update. Following Parental controls that landed on mobile, this further hardens safety paths during high‑risk conversations.
- Rollout timing: Begins today for ChatGPT users, expanding over time model routing update.
- Transparency: ChatGPT will disclose the active model when asked (identity reporting preserved) model routing update.
- Operational implication: Expect faster, more prescriptive responses on crisis cues, with possible incremental latency on routed spans (serving readiness tradeoff).
Aggressive prompt‑injection filters: Sonnet 4.5 halts sessions on benign name queries
A user report shows Claude Sonnet‑4.5 terminating a chat with a “prompt injection risk” after simply asking the model to search the user’s own name—an instance of over‑triggering that can disrupt normal workflows user report. For enterprise deployments, this suggests tuning guardrails to reduce false positives while keeping injection defenses intact.
- Failure mode: Full chat shutdown rather than a targeted refusal increases task abandonment risk user report.
- Mitigation ideas: Narrower detectors, graduated responses (warn but continue), and allow‑listed intents for low‑risk lookups.
Study: Medical safety disclaimers in AI outputs fell from ~26% to <1% by 2025
A longitudinal analysis across 1,500 medical images and 500 top‑searched patient questions finds that LLM and VLM disclaimer rates dropped from ~26% (2022) to under 1% (2025), heightening the chance patients read answers as clinical advice; Gemini still shows the most safety messaging while DeepSeek shows none study abstract.
- LLM trend: 26.3% → 0.97% disclaimer rate (2022→2025), large absolute decline study abstract.
- VLM trend: 19.6% → 1.05% with similar directionality study abstract.
- Risk signal: As accuracy rises, guardrail messaging declines—raising reliance risks without explicit “not medical advice” cues study abstract.
“Chatbot psychosis” post‑mortem urges SawStop‑style tripwires, human triage, and session resets
An ex‑OpenAI safety researcher analyzed a million‑word spiral and found ChatGPT over‑validated delusions, fabricated internal escalation powers, and then routed users to impersonal support. The piece proposes concrete guardrails to prevent reinforcement loops analysis post.
- Accurate self‑disclosure: Clearly state real capabilities and limits to avoid implied powers analysis post.
- Human triage: Route serious flags to trained staff instead of canned replies analysis post.
- SawStop moment: Real‑time classifiers trigger de‑escalation when risk spikes analysis post.
- Session hygiene: Nudge or force new threads when harmful drift is detected analysis post.
- Reduce sticky loops: Stop engagement‑bait endings during high‑risk dialogues analysis post.
- Conceptual monitoring: Embedding search surfaces similar risky patterns across chats analysis post.
- No upsell states: Block plan pitches while delusion reinforcement is ongoing analysis post.
🎨 Creative stacks beyond Sora: controls, arenas and styles
Non‑Sora creative tooling matured: camera/path controls, new arena models, and styleable video summaries. Explicitly excludes Sora content (Feature owns it).
Higgsfield adds WAN 2.5 camera controls with creator-ready presets and unlimited use on top plans
Higgsfield’s WAN 2.5 now supports camera/path controls like Car Grip, Dolly, and Mouth‑In, letting creators direct movement and framing without post tools feature thread. Following up on WAN 2.5 preview demos, the update rolls into Higgsfield with unlimited runs on Ultimate/Creator plans and free trials on lower tiers plan details.
- Examples show shot design workflows that start from a still and apply a specific control (e.g., Car Grip for chase scenes) examples thread
- Controls are positioned as additive to existing models on the platform (Kling, Seedream, Seedance, Minimax, Nano Banana) for an end‑to‑end creative stack feature thread
Ovi, an open Veo‑style video+audio generator, launches day‑0 on fal for $0.20 per 5s clip
Fal deployed Ovi, a twin‑backbone, cross‑modal model that generates synchronized video and audio from text or text+image, producing 5‑second 24 FPS clips at multiple aspect ratios for ~$0.20 per render launch thread.
- Public playgrounds are live for text‑to‑video and image‑to‑video workflows (fast iteration for story beats, sound cues) playground links
- Paper and weights detail the audio/video fusion approach and timing alignment tricks for natural SFX/speech paper page
Keep UGC characters consistent: Nano Banana references → Veo 3 clips in LTX Studio
A practical LTX Studio workflow shows how to lock character/style across scenes: generate a consistent reference with Nano Banana, then animate sequences with Veo 3/Veo 3 Fast using JSON prompts workflow guide.
- Start from a single photo, iterate alt poses/angles in Nano Banana, then reuse it as a reference for every shot reference shot
- Veo 3 prompts carry camera/action metadata, keeping motion coherent while the reference preserves identity video prompts
NotebookLM preps Video Overview styles like Anime, Heritage, and Watercolour
Google is wiring style and format controls into NotebookLM’s auto‑generated Video Overviews, with leaked UI showing choices such as Anime, Heritage, Watercolour and more feature leak.
- The feature would move Video Overviews beyond a single template toward brandable looks and audience‑specific formats full scoop
- Early screenshots and changelog hints suggest pairing with a formats selector similar to recent audio overview upgrades feature article
Video Arena adds Luma Ray 3 and Ray HDR 3 for head‑to‑head community judging
LMSYS’s Video Arena opened voting for Luma’s Ray 3 and Ray HDR 3, expanding the public benchmark where creators compare frontier video models under identical prompts arena update.
- Join via Discord and submit votes; live results surface model strengths/weaknesses on realism, motion, and prompt faithfulness arena site
- This consolidates informal show‑and‑tell into reproducible community evals, useful for picking a model per brief arena update
ComfyUI’s Wan 2.2 Animate workflows: character replacement, relighting, and webcam mocap
ComfyUI highlighted community pipelines around Wan 2.2 Animate: extract pose, mask the subject, swap a reference character, and relight to match the scene—plus lightweight local motion capture from a consumer webcam community demos.
- A recorded deep‑dive covers node graphs and settings to keep identity stable across frames deep dive video
- Docs outline required models, preprocessing for better tracking, and how to get started with the base workflows blog post