Anthropic блокирует около 1 млн TPU Google — мощность достигает 1 ГВт.
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Anthropic буквально превратила слухи в сталь: она планирует забронировать примерно 1 млн TPU Google, с более чем 1 ГВт мощностей, которые должны заработать в 2026 году. Расходы оцениваются в «десятки миллиардов» и речь идет не только о обучении; Anthropic заявляет, что выбрала TPU из‑за цены и производительности и для сервинга, где маржинальность падает, если выбрать неправильный силикон. Это редкое вычислительное соглашение, которое действительно меняет дорожную карту: гарантированная пропускная способность означает более короткие очереди на обучение и меньшее число ограничений по скорости для клиентов в следующем году.
Google продвигает Ironwood (TPU v7) как первую «сервировку» части головоломки, и это согласуется с позиционированием Anthropic перед корпоративными покупателями, которым важнее устойчивые затраты на токены, чем единичные мегапроекты обучения. Спрос, похоже, не выдуман: комментарии компании оценивают годовую выручку примерно в 7 млрд долларов, что объясняет, почему они заранее покупают мощность, а не молятся на аннулирования в списках GPU. Тем не менее Anthropic осторожен и утверждает, что остается на мульти‑облаке и с мульти‑силиконной стратегией, включая Amazon Trainium и графические процессоры NVIDIA в смеси, чтобы рабочие нагрузки попадали туда, где экономическая эффективность единицы и задержки действительно имеют смысл.
Итог: это финансовый хедж на вычисления и ставка на сервинг, объединенные в один пакет, и это оказывается реальным давлением на конкурентов показать аналогичную емкость на 2026 год, а не только подписанные Меморандумы о взаимопонимании.
Feature Spotlight
Особенность: Anthropic × Google обеспечивают безопасность ~1 млн TPU, более 1 ГВт к 2026 году
Anthropic заключает многолетнюю, многомиллиардную сделку с Google Cloud на поставку до 1 млн TPU (>1 ГВт к 2026 году), значительно расширяя обучение и обслуживание Claude и пересматривая экономику вычислений для корпоративного ИИ.
Подтверждение между аккаунтами о том, что Anthropic резко расширит использование Google Cloud TPU — десятки миллиардов долларов затрат — для масштабирования обучения и инференса Claude. Несколько твитов приводят цифру в 1 млн TPU, более чем 1 ГВт мощности, доступной онлайн к 2026 году, и текущую привлекательность для корпоративных клиентов.
Jump to Особенность: Anthropic × Google обеспечивают безопасность ~1 млн TPU, более 1 ГВт к 2026 году topicsTable of Contents
⚡ Особенность: Anthropic × Google обеспечивают безопасность ~1 млн TPU, более 1 ГВт к 2026 году
Подтверждение между аккаунтами о том, что Anthropic резко расширит использование Google Cloud TPU — десятки миллиардов долларов затрат — для масштабирования обучения и инференса Claude. Несколько твитов приводят цифру в 1 млн TPU, более чем 1 ГВт мощности, доступной онлайн к 2026 году, и текущую привлекательность для корпоративных клиентов.
Anthropic заключает контракт на ~1 млн TPU от Google и >1 ГВт на 2026 год в сделке стоимостью десятков миллиардов.
Anthropic и Google подтвердили масштабное расширение TPU — примерно миллион чипов и значительно более 1 ГВт мощности, вводимой в эксплуатацию в 2026 году — для масштабирования обучения Claude и его обслуживания, расходы оцениваются как «десятки миллиардов». Компания представляет ход как ориентированный на цену‑производительность на TPUs, рассчитанный на ускоряющийся спрос. После compute pact, который отмечал переговоры и ранние сигналы, сегодняшние публикации количественно оценивают мощность и сроки и вновь объясняют, почему TPUs соответствуют шкале затрат Anthropic Deal announcement, Anthropic blog post, Press confirmation, Google press page.
Для лидеров в области ИИ заголовок конкретен: гарантированная пропускная способность в 2026 году (очереди на обучение и готовность к обслуживанию) и явная защита против дефицита GPU — без отказа от использования других стеков.
Картина спроса Anthropic: более 300 тыс. бизнес-клиентов, крупные аккаунты выросли примерно в 7 раз по сравнению с прошлым годом, выручка около 7 млрд долларов.
Anthropic говорит, что теперь обслуживает более 300,000 компаний с ростом почти в семь раз в крупных аккаунтах за прошлый год; комментарии добавляют годовую выручку, приближающуюся к 7 млрд долларов, и Claude Code, достигающий темпа около $500 млн в течение месяцев — что помогает обосновать масштабирование TPU Anthropic blog post, Company summary, Analysis thread.
Implication for buyers: capacity won’t just shorten waitlists—it should stabilize SLAs and rate limits as onboarding accelerates.
Ironwood, седьмого поколения TPU от Google для инференса с высокой пропускной способностью, является центральной частью плана Anthropic.
Google выделяет Ironwood (TPU v7) как дизайн, ориентированный на сервинг, который снижает стоимость за токен за счёт 256‑чиповых подов и 9 216‑чиповых суперподов, соответствуя потребности Anthropic масштабировать инференс экономично наряду с обучением Google press page. Anthropic’s own post ties the expansion to observed TPU price‑performance over multiple generations, reinforcing why this capacity lines up for 2026 Anthropic blog post.)
Для платформенных команд это сигнал практических выгод: более дешёвый стабильный пропускной уровень для корпоративного трафика, а не только окна массового обучения.
Несмотря на мегасделку по TPU, Anthropic вновь подтверждает стратегию мультиоблачной и мульти‑силиконовой архитектуры.
В дополнение к расширению Google TPU Anthropic подчеркивает, что продолжит обучение и развёртывание на платформах Amazon Trainium и NVIDIA GPU; Amazon остаётся основным партнёром по обучению через Project Rainier, снижая завиcимость от поставщиков и позволяя задачам попадать туда, где экономика единицы и задержка подходят лучше всего Anthropic blog post, Analysis thread.
Для архитекторов это означает, что проблемы портируемости сохраняются: планируйте неоднородные ядра, сборки моделей и оркестрацию, которая может переключаться между целями TPU, GPU и ASIC по мере изменения цен и очередей.
🖥️ OpenAI покупает Sky: Mac-действия, чувствительные к экрану
OpenAI приобрела Software Applications Inc. (Sky), команду с давним опытом работы с Apple, создающую Mac, интерфейс естественного языка, адаптированный под экран. Исключает соглашение о вычислениях Anthropic–Google (раскрыто в разделе Feature). Здесь внимание уделяется UX агента на уровне ОС и сигналу по слияниям и поглощениям (M&A).
OpenAI покупает Sky, чтобы добавить в ChatGPT действия на Mac, учитывающие экран.
OpenAI приобрела Software Applications Inc. (Sky), агент-оверлей для Mac, который понимает, что отображается на экране, и может выполнять действия через нативные приложения; команда присоединяется, чтобы перенести эти возможности в ChatGPT, условия не разглашены OpenAI blog, и подтверждение сделки по сообщениям сообщества acquisition post, announcement link.
OpenAI представляет сделку как переход от “ответов” к помощи пользователям в выполнении задач на macOS, что предполагает более глубокие разрешения на уровне ОС, контекст и выполнение действий за пределами веб-автоматизаций OpenAI blog.
Выпускники Workflow/Shortcuts, стоящие за Sky, привносят глубокие навыки автоматизации macOS в OpenAI
Основатели Sky ранее создавали Workflow (покуплен Apple и превратился в Shortcuts), и публикации сообщества говорят, что у команды был запланирован летний релиз до приобретения — оверлей-агент, который мог считывать экран и управлять приложениями Mac — что подчёркивает редкую, низкоуровневую экспертизу по автоматизации macOS, которая сейчас в стеке OpenAI предзапуск деталей, описание продукта, итоги сообщества. Эта фоновая информация снижает риск интеграции и ускоряет создание надёжного агента ОС, учитывающего разрешения по сравнению с исключительно браузерной автоматизацией.
Сигнал в шуме: Sky демонстрирует продвижение платформы OpenAI в агентов уровня ОС
Практикующие аналитики отмечают, что OpenAI находится на волне поглощений и описывают продукт Sky как плавающего десктоп‑агента, который понимает активное окно и может инициировать действия в локальных приложениях, таких как Календарь, Сообщения, Safari, Finder и Почта — явный шаг платформы за пределы веб‑автоматизации feature explainer.). В сочетании с собственной стратегией интеграций OpenAI это предполагает краткосрочную консолидацию UX агента на уровне ОС, чтобы завоевать доверие, контролировать задержки и усилить разрешения вокруг чувствительных действий OpenAI blog.
OpenAI представляет Sky как переход от чата к действию — и раскрывает пассивную инвестицию, связанную с Алтманом.
В своей заметке OpenAI underlines that Sky will help «сделать дела» on macOS — not только respond to prompts — while stating all team members are joining OpenAI to deliver these capabilities at scale OpenAI blog. . Пост также сообщает, что фонд, связанный с Сэмом Алтманом, держал пассивную инвестицию в Sky, и что независимые Комитеты по сделкам/аудиту одобрили сделку, о чем руководители будут следить по мере расширения полномочий агентов уровня ОС OpenAI blog.)
Что даёт Mac‑агент, ориентированный на экран, для разработчиков и ИТ
Агент в стиле Sky может анализировать контекст на экране и вызывать нативные намерения — связывая неоднозначный диалог («что на моём экране?») с детерминированными действиями приложений и одобрениями пользователя. Сообщения сообщества приводят конкретные домены приложений, на которые нацелился Sky (Календарь/Сообщения/Заметки/Safari/Finder/Почта) и интерфейс рабочего стола в виде наложения, что сигнализирует о новых точках интеграции для безопасной, проверяемой автоматизации и политики управления на парках устройств macOS объяснение функции, описание продукта.
🎬 Кинематографическое ИИ-видео выходит в открытый доступ: LTX‑2 прибыл.
Lightricks’ LTX‑2 доминирует в сегодняшних генеративных медиа‑обсуждениях: нативное 4K до 50 кадров в секунду с синхронизированным звуком, последовательности длиной 10–15 секунд и доступность «с самого дня» через fal/Replicate; веса будут открыты позже в этом году. Исключает новости о мировых моделях Genie (отдельная категория).
LTX‑2 дебютирует с нативным 4K, частотой до 50 кадров в секунду и синхронизированным звуком; открытые веса выйдут позже в этом году
Lightricks’ LTX‑2 поступает как видео‑двигатель искусственного интеллекта кинематографического уровня: нативный вывод 4K, до 50 кадров в секунду, синхронизированное аудио/диалог, и примерно 10–15‑секундные последовательности, созданные для реальных творческих рабочих процессов, с готовностью API сегодня и весами, запланированными к открытию позже в этом году capability highlights, weights plan. Ранние тестеры позиционируют его как скачок по сравнению с ранее демонстрационными моделями, указывая на точность разрешения и плавность движения, соответствующие профессиональным пайплайнам review thread.
fal выпускает day‑0 LTX‑2 API (Fast/Pro) для текста→видео и изображения→видео до 4K с тарификацией за каждую секунду
fal выпустила LTX‑2 на первый день с конечными точками Fast и Pro как для текста → видео, так и для изображения → видео в разрешениях 1080p, 1440p и 4K, поддерживая синхронизированное аудио и до 50 кадров в секунду; использование тарифицируется по секундам с опубликованными тарифами на каждой странице модели краткая справка о доступности, Text to video fast, Text to video pro, Image to video fast, Image to video pro.
На практике это дает командам немедленный путь к прототипированию и масштабированию высокодетализированных клипов через API без необходимости управления собственным обслуживанием, при этом сохраняя чистый трак для перехода на Pro для более качественных прогонов.
Воспроизведите списки LTX‑2 Fast и Pro с руководством по подсказкам и примерами рабочих процессов.
Replicate теперь размещает lightricks/ltx‑2‑fast и lightricks/ltx‑2‑pro, полностью с подсказками по написанию промптов, примерами пайплайнов и API‑плейграундами, чтобы ускорить внедрение в существующие инструменты hosting update, Replicate fast model, Replicate pro model. Для инженеров по ИИ это снижает трение интеграции (одноклик‑развертывания, согласованные SDK) и позволяет параллельно сравнивать Fast/Pro для настройки соотношения цена–качество в продуктивной среде.
Практики называют LTX‑2 новым ориентиром; нативное 4K‑движение и текстура превосходят масштабированные выводы.
Первые тестировщики отмечают явный разрыв в восприятии между нативным 4K LTX‑2 и ранее применяемыми масштабированными конвейерами, отмечая более резкие текстуры, более устойчивое движение и согласованный звук, что сокращает сроки постпроизводства review thread, native vs upscaled. Для команд, оценивающих смены моделей, ожидайте меньше артефактов в сценах с быстрым действием и диалогами, а также упрощение редакционных процессов при монтаже коротких роликов и трейлеров.
🧭 Агентные браузеры: режим Edge Copilot и осенние обновления
Microsoft Edge добавляет режим Copilot с действиями для навигации по странице, управления вкладками и контекста истории. Сессии Copilot «Fall release» намекают на Mico/Clippy, группы и функции мониторинга состояния. Исключает OpenAI Atlas (предыдущий день), чтобы сегодня сосредоточиться на обновлениях Edge.
Edge добавляет режим Copilot с действиями, уровнями автономии и opt‑in Page Context
Microsoft превращает Edge в агентный браузер: режим Copilot может переходить по страницам, выполнять многошаговые действия (отписаться, забронировать, прокручивать к разделам), управлять вкладками и использовать историю просмотров, если пользователи включат Контекст страницы. Практические отчёты показывают три уровня автономности (легкий, сбалансированный, строгий) и переключатель Предпросмотра для наблюдения за задачами или их фонового выполнения обзор возможностей, как включить, глубокий разбор.
- последовательности действий и использование инструментов видны, с предлагаемыми сценариями для обычных задач и ограничениями по доступу к истории образцы действий.
Осеннее обновление Copilot Sessions приносит группы, Mico/Clippy и память между приложениями
На сессиях Copilot Microsoft презентовала широкий осенний апдейт: группы до 32 участников, долгосрочная память, охватывающая приложения, и более выразительный аватар Mico — с пасхалкой-появлением Clippy. Ранние заметки также подчёркивают Q&A по здоровью, основанный на проверенных источниках, более сильные настройки приватности и поэтапное развёртывание в США перед расширением feature collage, event stream, feature recap.\n\n
\n\nПосле обзора Feature lineup, который намекал на 12 областей, сегодняшняя сессия вывела цифры (32‑пользовательские группы) и конкретные возможности на дорожную карту, при этом усиливая концепцию «AI-агентного браузера» в рамках Edge и Copilot.
✏️ Делайте релизы быстрее в AI Studio: аннотируйте и кайфуйте от кодинга
Google AI Studio добавляет режим Annotate: рисуйте на интерфейсе вашего запущенного приложения и позвольте Gemini внести изменения. Разработчики демонстрируют потоки «vibe coding» с готовыми компонентами и надёжным поиском. Сегодня появились явные сигналы роста вовлечённости (скачок трафика).
Google AI Studio добавляет режим Annotate для точечного редактирования кода
Google AI Studio теперь позволяет рисовать прямо на предварительном просмотре вашего приложения, и Gemini реализует изменение в коде, сводя циклы обзора→спецификации→коммита к одному проходу. Обновление доступно внутри опыта Build и поддерживает тонкие настройки (например, анимации) без выхода за пределы IDE‑подобного холста feature brief, announcement, AI Studio build, annotate details.
Для команд это делает полировку интерфейса и отзывы заинтересованных сторон намного более выполнимыми — непрофессионалы могут помечать цели в контексте, в то время как инженеры сохраняют чистый журнал различий. Ранние пользователи сообщают, что функция кажется естественной в новом AI‑помощи‑потоке «указать, рассказать намерение, выпустить» feature mention.
Vibe-кодирование в AI Studio: намерения на естественном языке в исполняемые приложения с привязкой к поиску
Создатели продемонстрировали «vibe coding» в AI Studio: выбирайте готовые компоненты (речь, анализ изображений), опишите приложение на естественном языке и получите исполняемый код плюс живой просмотр, основанный на Google Search. Демонстрация проходит через циклы выделения и редактирования, показывая изменения интерфейса Gemini и вызовы данных от начала до конца video demo, YouTube demo.
Помимо скорости прототипирования, привязка к Search добавляет поведение, близкое к производству (свежие результаты/цитирования) на ранних версиях, сокращая разрыв между логикой демо и реальными интеграциями feature brief.
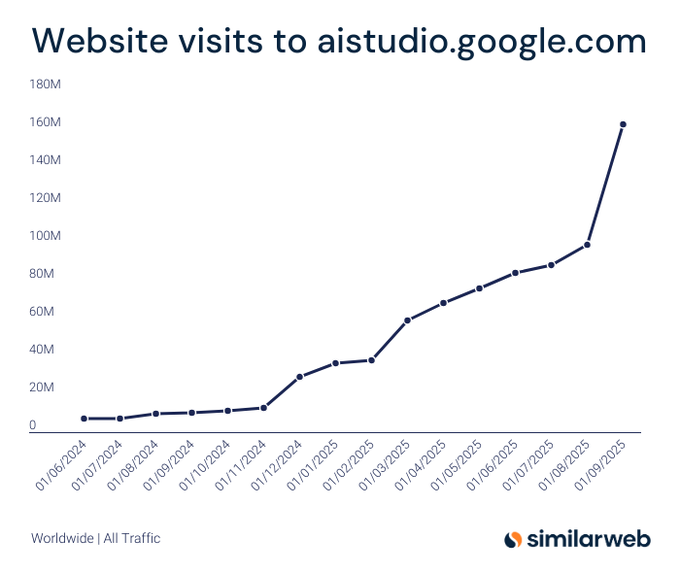
Трафик AI Studio вырос на 64% в сентябре, достигнув примерно 160 млн посещений в месяц.
Сайт‑трафик AI Studio вырос примерно на 64% в сентябре до более чем 160 млн посещений, его крупнейший скачок с цикла Gemini 2 — доказательство того, что annotate‑and‑vibe рабочие процессы в кодировании находят отклик у разработчиков traffic chart.). Далее, продолжение по traffic surge, которое освещало достижение в 160M+, сегодняшний график подчеркивает Momentum, а не единичный скачок, предполагая устойчивый интерес по мере внедрения новых функций Build.
🚀 Инфраструктура агента для разработчиков: агент Vercel, WDK, Marketplace
День Vercel Ship AI приносит единый стек агентов: Vercel Agent (проверка кода + расследования), Набор инструментов разработки рабочих процессов ('use workflow' — устойчивость), Marketplace для агентов/сервисов и бэкенды без конфигурации для AI‑приложений.
Vercel Agent запускается в открытой бета-версии с ИИ-ревью кода и расследованиями инцидентов
Vercel представила AI‑командного партнера, который выполняет PR‑ревью, запуская симулированные сборки в Sandbox и инициируя ИИ‑ведомые расследования, когда телеметрия сигнализирует об аномалиях, теперь доступен в Public Beta на AI Cloud product blog, и полностью задокументирован в посте запуска Vercel blog. Это вписывается в более широкое движение Ship AI, нацеленное на то, чтобы агентские рабочие процессы стали первоклассными для команд разработки.
Набор инструментов разработки рабочих процессов превращает надёжность в «просто код» благодаря прочным, возобновляемым шагам.
Vercel’s WDK добавляет примитив use workflow, который превращает асинхронные функции в прочные рабочие процессы, которые ставят на паузу, возобновляются и сохраняются автоматически; каждый use step изолирован, повторно выполняется при ошибке, и состояние воспроизводится при развёртываниях обзор функций, с более детальной информацией в описании запуска Vercel блог. Ранние разработчики сразу потребовали средства управления, такие как отмена, ключи идемпотентности, обработка изменений кода и откаты — полезные сигналы для эргономики WDK и документации, которые стоит осветить далее вопросы для разработки, вопросы на последующие обсуждения.
Vercel Marketplace дебютирует с агентскими приложениями и сервисами инфраструктуры ИИ, с единой системой выставления счетов.
Vercel открыл рынок, который поставляет plug‑in “агентов” (например, CodeRabbit, Corridor, Sourcery) и “сервисы” (Autonoma, Braintrust, Browser Use, Chatbase, Mixedbread и другие) за одну установку и оплату marketplace blog, с объявлениями партнёров о доступности в первый же день coderabbit launch, mixedbread launch. Цель — снизить разрознённость интеграций для команд, применяющих агентные паттерны, при этом сохраняя централизованный сбор наблюдаемости.
AI SDK 6 (beta) объединяет абстракцию агентов с процессом утверждения инструментов с участием человека и редактированием изображений.
Бета-версия Vercel AI SDK 6 стабилизирует уровень абстракции агента, добавляет одобрение на выполнение инструментов для контроля человека на этапе исполнения и расширяет поддержку редактирования изображений — что позиционирует SDK как интерфейс по умолчанию для моделей и провайдеров в приложениях-агентах sdk beta image. Эти возможности дополняют Vercel Agent и WDK, чтобы команды могли определить логику один раз и запускать её надежно в AI Cloud.
Бэкенды без конфигурации на Vercel AI Cloud предоставляют инфраструктуру, задаваемую фреймворком, и единую наблюдаемость.
Vercel AI Cloud теперь обеспечивает развёртывание и масштабирование бэкендов из выбранного вами фреймворка без лишнего YAML или Docker, добавляет масштабирование на уровне маршрутов и централизует логи, трассировки и метрики, чтобы AI‑приложения получили контрольную плоскость производственного уровня из коробки backends blog, Vercel blog. Для разработчиков агентов это дополняет стек AI, чтобы упростить развёртывание инструментально насыщенных, stateful‑сервисов без bespoke infra plumbing.
🧩 Корпоративное сотрудничество и контекст: проекты, знания, память
Функции для команд доминируют: OpenAI расширяет Общие проекты (с ограничениями по уровням) и выпускает Знания компании с коннекторами/цитатами; Anthropic разворачивает память проекта для Max/Pro с инкогнито-чати.
Корпоративные знания доступны для Business, Enterprise и Edu с поиском GPT‑5 по Slack/SharePoint/Drive/GitHub и ссылками на источники
ChatGPT теперь может получать доверенные ответы из инструментов вашей организации — Slack, SharePoint, Google Drive, GitHub — с моделью на базе GPT‑5, которая ищет по источникам и указывает, откуда взялся каждый ответ; теперь доступно для Business, Enterprise и Edu снимок функции, OpenAI блог.
Новые коннекторы добавлены вместе с развертыванием (например, Asana, GitLab Issues, ClickUp), и администраторы могут ознакомиться с примечаниями к выпуску для бизнеса, чтобы узнать детали настройки и управление видимостью business notes, и Business release notes. См. обзор OpenAI об возможностях и поведении цитирования OpenAI блог.
OpenAI запускает Shared Projects для Free, Plus и Pro с ограничениями по уровням тарифов и памятью, доступной только для проектов.
OpenAI расширяет Shared Projects на все уровни ChatGPT, чтобы команды могли работать в общих чатах, с файлами и инструкциями, с автоматически включенной памятью проекта в общих проектах feature post, rollout summary.
- Ограничения по тарифам: Free поддерживает до 5 файлов и 5 участников, Plus/Go до 25 файлов и 10 участников, и Pro до 40 файлов и 100 участников, согласно заметкам OpenAI release summary, и OpenAI release notes.
Anthropic выпускает Memory с привязкой к проекту для Max и начинает развертывание Pro с чатами в режиме инкогнито и механизмами обеспечения безопасности
Anthropic включила Memory для клиентов Max и в течение следующих двух недель выведет его для Pro; у каждого проекта своя память, которую пользователи могут просматривать и редактировать, с режимом инкогнито чата, который не сохраняется, следуя внутренним тестам безопасности rollout note, memory page.
Практикующие подчёркивают память, ориентированную на проект, как практичный способ предотвратить перекрестное влияние между несвязными рабочими потоками user sentiment, с полными деталями и настройками в объявлении Anthropic Anthropic memory page.
📄 Движение в области Document AI: LightOnOCR‑1B и инструменты
OCR/VLM остаётся в центре внимания: LightOnOCR-1B дебютирует как быстрая сквозная доменно-настраиваемая модель; vLLM добавляет поддержку OCR-моделей; прикладные руководства объясняют развёртывание и аспекты «оптического сжатия». В основном сегодня — практические релизы и инструкции.
LightOnOCR‑1B дебютирует: быстрый OCR от начала до конца и качество на уровне SOTA; анонс выпуска обучающих данных намечен.
LightOn презентовала LightOnOCR‑1B, сквозное OCR/VLM, которое нацелено на точность на уровне передовых достижений, при этом работает значительно быстрее недавних релизов, и говорится, что курируемый набор данных для обучения будет выпущен в ближайшее время. Команда описывает выбор дизайна (например, размер учителя, разрешение, адаптация к домену) и готовые к запуску модели, включая доступность vLLM. См. объявление и технический блог для архитектуры и результатов абляции release thread,) с дополнительными заметками о том, что набор данных «скоро будет доступен» follow‑up note,) и страницы моделей и коллекций для немедленного использования Hugging Face blog,) Models collection.
Baseten объясняет «оптическое сжатие» DeepSeek‑OCR и предоставляет 10‑минутный путь развертывания.
Baseten объясняет, почему пайплайны, ориентированные на изображение, DeepSeek‑OCR dramatically дешевле и быстрее (сжатие текста визуально перед декодированием) и предоставляет готовый шаблон для развертывания инференса менее чем за десять минут. Это дополняет практические рекомендации по операциям, следуя за поддержкой vLLM и конверсиям на уровне библиотеки, о которых сообщалось вчера, с конкретными соотношениями пропускной способности/стоимости для производственных команд blog summary, Baseten blog, и дополнительной ссылкой-пойнтером от команды blog pointer.)
Hugging Face обновляет открытое сравнение моделей OCR с участием Chandra, OlmOCR‑2, Qwen3‑VL и усреднённых оценок
Hugging Face обновил своё прикладное руководство и сравнение для открытых OCR/VLM, добавив Chandra, OlmOCR‑2 и Qwen3‑VL, а также усреднённый балл OlmOCR, что даёт практикам более чёткие trade-offs между точностью, задержкой и схемами развёртывания. Пост дополняет недавние работы LightOnOCR и DeepSeek, сосредотачиваясь на практических пайплайнах и расходах blog update, with the full write‑up here Hugging Face blog.
vLLM фиксирует волну появления небольших, быстрых OCR-моделей, выходящих на продакшн-обслуживание.
vLLM отметил, что компактные OCR-модели «взлетают» на платформе, подчеркивая практичный, высокопроизводительный сервис для рабочих нагрузок по обработке документов в задачах ИИ. Это соответствует немедленной доступности LightOnOCR‑1B через vLLM и более широкой динамике в направлении эффективного развертывания OCR/VLM vLLM comment, model availability.
Hugging Face продвигает развертывание за несколько кликов для последних OCR-моделей
Hugging Face подчеркнула, что текущие модели OCR можно развернуть в несколько кликов на своей платформе, снизив порог входа для команд по выведению документального ИИ в продакшн без собственной инфраструктуры. Это перекликается с обновленным сравнением моделей, чтобы помочь практикам выбрать и быстро вывести deployment note.
🧠 Исследование: маршрутизация агентов, проактивное решение проблем, точность трассировки
Новые работы нацелены на место, где агенты терпят неудачи: маршрутизация, учитывающая ответ (Lookahead), распределённая self-routing (DiSRouter), проактивная оценка от конца до конца (PROBE) и выполнение инструкций внутри рассуждений (ReasonIF).
ReasonIF обнаруживает, что передовые LRM нарушают инструкции по времени рассуждений более чем в 75% случаев; тонкая настройка помогает умеренно.
Бенчмарк ReasonIF от Together AI показывает, что модели вроде GPT‑OSS‑120B, Qwen3‑235B и DeepSeek‑R1 игнорируют директивы на уровне шага (форматирование, длина, многоязычные ограничения) в более чем 75% рассуждений; многошаговое prompting и лёгкая тонкая настройка улучшают показатели, но не полностью исправляют соответствие на уровне процесса обзор статьи.
[изображение:https://pbs.twimg.com/media/G39-YSsWoAAYm5r.jpg|монтаж фигуры]
Код, статья и блог доступны для воспроизведения и рецептов обучения репозиторий GitHub, блог проекта.)
Бенчмарк PROBE показывает ограничения проактивного агента: только около 40% успешного прохождения от начала до конца в реальных рабочих сценариях
PROBE (Proactive Resolution of Bottlenecks) тестирует агентов на три шага — поиск, идентификация корневой причины блока, затем выполнение точного действия — на длинных, шумных корпусах (электронная почта, документы, календари); топовые модели достигают примерно 40% успешности на всём пути, с частыми неудачами в идентификации коренной причины и параметризации конечного действия paper abstract.
Цепочечные фреймворки инструментов работают хуже, когда поиск пропускает ключевые доказательства, что подчёркивает зависимость проактивной помощи от отбора доказательств и точной спецификации действия.
Маршрутизация с предвидением прогнозирует выходы модели, чтобы выбрать лучшую LLM, в среднем на +7.7% выше передовых маршрутизаторов
Новая маршрутизационная рамочная система «Lookahead» прогнозирует латентные представления ответов для каждой кандидатной модели перед маршрутизацией, давая в среднем прирост на 7,7% по семи бенчмаркам и работая как с каузальными, так и с маскированными LMs paper thread, с подробностями в препринте ArXiv paper.
) Она в особенности улучшает открытые задачи, принимая во внимание ответ при принятии решений, а не только классификацию по входу, и достигает полной производительности примерно за ~16% обучающих данных, уменьшая требования к данным для маршрутизатора.
DiSRouter: распределенная самоориентированная маршрутизация между небольшими и крупными LLMs с накладками менее 5%.
DiSRouter удаляет центральный маршрутизатор и позволяет каждой модели решать, отвечать ли или говорить «я не знаю» и пересылать вверх по цепочке, соединяя маленькие и крупные модели для большей полезности при низкой стоимости; авторы сообщают о менее чем 5% перегрузке маршрутизации и устойчивости при изменении пула моделей аннотация статьи.
Обучая модели к само‑оттклонению через SFT и RL, система избегает хрупких глобальных маршрутизаторов, которые необходимо перенастраивать всякий раз, когда пул обновляется.)
SmartSwitch ограничивает «недостаточное обдумывание», блокируя преждевременные переключения стратегий; QwQ‑32B достигает 100% на AMC23
SmartSwitch отслеживает генерацию подсказок переключения (например, «или же»), оценивает текущее размышление небольшой моделью, и если оно всё ещё перспективно, откатывается назад, чтобы углубить этот путь перед разрешением переключения; в задачах по математике он повышает точность, уменьшая количество токенов/время, причем QwQ‑32B достигает 100% на AMC23 аннотация к статье.
В отличие от запросов типа «быть доскональным» или фиксированных штрафов, селективное вмешательство сохраняет маневренность, одновременно обеспечивая глубину там, где это требуется.
Letta Evals делает снимки агентов для оценки с сохранением состояния и воспроизводимости через контрольные точки файла агента («Agent File (.af)»).
Letta представила метод оценки, который сохраняет контрольную точку полного состояния агента и окружения в файл агента (.af), чтобы команды могли воспроизводить и сравнивать поведение агента целостно — не только по подсказкам — на протяжении долгоживущих обучающихся агентов product note.
Это нацелено на растущий разрыв в тестировании агентов, где дрейф памяти и окружения делает традиционные однократные или безсостояние оценки вводящими в заблуждение с точки зрения готовности к производству.
Комбинирование нескольких крупных языковых моделей с помощью «консорциумного голосования» снижает вероятность галлюцинаций и усиливает сигналы неопределенности.
Исследование объединяет разнообразные LLM и группы семантически эквивалентных ответов для голосования большинством и вводит «энтропию консорциума» в качестве шкалы неопределенности; такой черный ящик часто превосходит самосогласованность одной модели, при этом обходится дешевле, чем декодирование с множеством выборок paper abstract.
Результат служит сигналом для триажа, помечая случаи с низкой уверенностью для человека — полезно для производственных шлюзов, где переобучение недоступно. Продолжая тему самосогласованности, которая предлагала гарантии ошибок для голосования большинством, это расширяет идею на основе разнородных моделей, а не на множественных выборках одной.
🧪 Качество обслуживания: точность поставщика и стабилизация открытой модели
Производственные заметки по улучшению открытых моделей в агентских системах: снижение подсказок GLM‑4.6 Клайна и фильтрация провайдеров (:exacto) повышают надёжность вызовов инструментов; OpenRouter подтверждает приросты :exacto; Baseten добавляет быстрый хостинг GLM‑4.6.
Cline стабилизирует агентов GLM-4.6 с сокращением подсказок на 57% и маршрутизацией провайдера :exacto
Cline сообщает о производственном укреплении открытых моделей за счёт уменьшения системного промпта GLM‑4.6 с 56 499 до 24 111 символов (−57%), что ускорило ответы, снизило стоимость и снизило число сбоев вызовов инструментов; они также теперь автоматически выбирают эндпойнты OpenRouter на основе «:exacto», чтобы избегать молча ухудшающихся хостов, которые ломали вызовы инструментов. Смотрите детали и до/после настройку инструкций в Cline blog, a side‑by‑side run where glm‑4.6:exacto succeeds while a standard endpoint fails by emitting calls in thinking tags в provider demo, и подтверждение OpenRouter, что скачок качества Cline произошёл благодаря :exacto в OpenRouter note.
SGLang Model Gateway v0.2 добавляет маршрутизацию по нескольким моделям с учетом кэша и надежность уровня продакшна
LMSYS переработала SGL‑Router в входной шлюз модели SGLang: фронт‑дор Rust gRPC, совместимый с OpenAI, который запускает флоты моделей под одним шлюзом с маршрутизацией на основе политики, предзаполнение/разделение декодирования, кэшированная токенизация, повторные попытки, прерыватели цепей, ограничение скорости и метрики/трейсинг Prometheus. Он нацелен на бэкенды агентов, где качество конечной точки варьируется, и отказоустойчивость, наблюдаемость и интеграция инструментов/MCP являются обязательными gateway release, с перечнем возможностей надежности/наблюдаемости для рабочих нагрузок продакшена reliability brief.)
Baseten запускает размещение GLM‑4.6 с API, тарифицируемым по объему использования, и самое быстрое предложение от сторонних компаний.
Baseten объявил о доступности GLM‑4.6 через управляемый инференс с ценообразованием API для команд, которые предпочитают оплату по использованию, и вновь подтвердил, что это самый быстрый сторонний хост для этой модели по недавним bake‑offs. Для команд, стандартизирующих открытые модели у разных провайдеров, это добавляет опцию готовой конечной точки наряду со стэками, размещаемыми локально hosting note.)
План смешанной модели Factory CLI → выполнение сохраняет 93% качества при более низких затратах
Factory выступает за разделение работы агента между моделями — использовать сильную, более дорогую модель (например, Sonnet) для планирования и более дешёвую открытую модель (например, GLM) для исполнения — утверждая, что вы сохраняете ~93% производительности, при этом «платя только за размышления» премиум. Это практичный шаблон для снижения вариативности поставщиков и стабилизации вызовов инструментов без привязки к единой конечной точке API поток обсуждения, with broader mixed‑model support landing in the Factory CLI заметка о смешанных моделях.)
🛡️ Доверие и доступность: политика удаления данных и обзор сбоев
Операционные сигналы: OpenAI подтверждает возврат к удалению данных за 30 дней для ChatGPT/API после окончания срока действия меры судебного удержания; отдельная кратковременная неполадка вызвала сообщение «Слишком много одновременных запросов» с обновлениями статуса к восстановлению.
OpenAI восстанавливает 30‑дневное удаление для ChatGPT и API после окончания периода юридического удержания
OpenAI говорит, что удалённые и временные чаты ChatGPT снова будут автоматически удаляться в течение 30 дней, а данные API также будут удаляться спустя 30 дней после окончания юридического удержания 26 сентября 2025 года policy screenshot.
-> текст обновления политики
Teams should verify retention assumptions in privacy notices, DSR workflows, and logging/backup pipelines; OpenAI notes it will keep a tightly‑access‑controlled slice of historical user data from April–September 2025 for legal/security reasons only policy screenshot. Community commentary stresses this mirrors prior standard practice and that the earlier hold stemmed from external litigation constraints, not a product policy change context thread.
Сбой ChatGPT вызывает «Слишком много одновремённых запросов»; страница статуса сообщает о восстановлении в тот же день
ChatGPT кратко возвращал сообщение «Слишком много одновременных запросов»; страница статуса OpenAI отслеживала расследование, устранение неполадок и полное восстановление в тот же день после обеда скриншот ошибки, Статус OpenAI.
Согласно журналу инцидента, ошибки начались во второй половине дня, устранение было применено примерно в течение часа, и все затронутые сервисы вскоре после этого восстановились Статус OpenAI. Мониторы пользователей и сторонних сервисов сообщили о повышенных уровнях ошибок в течение этого окна, что согласуется с признаками аварийности и обновлениями по устранению неполадок отчет об отключении.
🕹️ Модели мира в браузере: эксперимент Genie 3
Публичный эксперимент Genie 3 от Google, судя по всему, близок к старту: интерфейс для эскиза вашего мира и подсказок по персонажам появится в интерфейсе, сообщается, что пользователи будут генерировать и исследовать интерактивные миры. Отдельно от видеодвигателя LTX-2.
Публичные интерфейсы экспериментов Genie 3; процесс «создать мир» наводит на мысль о скором запуске.
Google’s Genie 3 appears ready for a public browser experiment: интерфейс «Создать мир» с подсказками для Environment и Character, плюс переключатель на изображение от первого лица, был замечен на фоне сообщений о том, что пользователи будут генерировать и затем исследовать интерактивные миры. Несколько скриншотов и обзоров указывают на приближающееся развёртывание, а не на демонстрацию только в лаборатории documented scoop, и наблюдатели сообщества теперь называют релиз почти подтверждённым confirmation post.)
Новый интерфейс приглашает текстовые описания мира и аватара и даёт намёк на создание мира по эскизу, что согласуется с ранее заявленной Google концепцией «модель мира». Для аналитиков и инженеров это сигнал о практических данных об управляемом пользователем моделировании, входах управления и петлях взаимодействия от первого лица — ключевых для обучения агентов и оценки в браузерно‑безопасных песочницах ui preview. Полные детали и ссылки на артефакты собраны в обзоре TestingCatalog TestingCatalog article, с дополнительными записями интерфейса, подтверждающими ту же последовательность ui screenshot.
📊 Оценка агентов и наблюдаемость: многошаговые диалоги и автоматизированные инсайты
Расширенные инструменты эвалюации: LangSmith добавляет агент Insights и многоходовые эвалюации для достижения цели; Letta выпускает эвалюации агентов с сохранением состояния, используя снимки Agent File, чтобы воспроизвести полное состояние и окружение. Практично, ориентировано на продакшн.
LangSmith добавляет Insights Agent и оценки многоступенчатых диалогов.
LangChain представил две функции оценки в LangSmith: агент Insights, который автоматически классифицирует паттерны поведения агента, и многоходовые оценки, которые оценивают целые беседы по целям пользователя, а не по отдельным ходам feature brief. Это закрывает общую пропасть в QA продакшн-агентов, смещая от проверок рубрик на уровне хода к измерению успеха на уровне траектории по задачам, таким как планирование, использование инструментов и восстановление после ошибок.
ReasonIF обнаруживает, что LRMs игнорируют инструкции во время рассуждений более чем в 75% случаев.
Исследование ReasonIF от Together AI показывает, что передовые крупномасштабные модели рассуждений часто не следуют инструкциям во время самого процесса рассуждений — более 75% несоблюдений в многоязычном рассуждении, форматировании и контроле длины — несмотря на способность к решению paper summary. Авторы выпускают эталонный набор плюс код и данные; простые вмешательства, такие как многошаговые подсказки и тонкая настройка с учетом инструкций, частично улучшают соблюдение resources bundle, ArXiv paper, и GitHub repo.
Для оценщиков это объясняет, почему проверки по выводу без обработки пропускают скрытые сбои: аудиты на уровне процессов и метрики точности соблюдения инструкций должны находиться наряду с точностью.
Letta Evals дебютирует тестирование агентов с сохранением состояния через снимки Agent File.
Letta представила набор тестов для оценки, предназначенный для долговечных агентов, снимки полного состояния агента и окружения в файл агента (.af), чтобы тесты могли детерминированно воспроизводить поведение, сравнивать изменения и оценивать обновления apples‑to‑apples product note, launch claim. Команды могут оценивать целый агент (а не только подсказки) и даже нацеливать существующих агентов как фикстуры для оценки, решая основную проблему дрейфа в системах с памятью и обилием инструментов.
Новый бенчмарк PROBE делает упор на проактивных агентов; лучшие модели достигают примерно 40% end-to-end.
Новый набор данных PROBE (Proactive Resolution of Bottlenecks) оценивает рабочие процессы агентов, которым приходится искать в длинных зашумленных корпусах, выявлять единственный истинный узкий место и выполнять одно точное действие с параметрами. Ведущие модели достигают примерно 40% End‑to‑end успешности, причём большинство сбоев связано с идентификацией коренной причины и неполными аргументами к действию paper thread.
Такой стиль оценки имитирует реальную работу с знаниями: находить правильные доказательства, разрешать вопросы владения и сроков, и действовать одним разом — полезно для оценки готовности корпоративных агентов помимо качества чата.
Мультимодельное голосование консорциума снижает галлюцинации и добавляет откалиброванную неопределённость.
Статья от Cambridge Consultants и соавторов предлагает объединение нескольких LLM, группировку семантически эквивалентных ответов и голосование большинством, чтобы как снизить галлюцинации, так и показать уверенность через энтропию консорциума — часто превосходя самосогласованность одной модели за меньшие затраты paper details. В контексте сертифицированных методов голосования с ошибками, о которых сообщалось вчера error guarantees, это предлагает прагматичный, «черный ящик» маршрут к производственным риск-флагам без переобучения.
Подход также обеспечивает дешевый сигнал воздержания для оценочных конвейеров: замедляйте или эскалируйте, когда кластеры ответов распадаются.