Карпатий оценивает, что AGI будет через 10 лет — агенты по-прежнему упускают 4 базовых момента.
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
И длинная беседа Андрея Караптуи с Дваркешем Пательем получилась настолько откровенной, что это холодный душ для хайпа вокруг агентов. Он говорит, что AGI примерно через 10 лет, и называет сегодняшние демонстрации агентов «лохотроном» (slop), утверждая, что команды должны перестать продвигать автономных коллег и начать исправлять фундаментальные проблемы. Его контрольный список прямой: надёжное использование компьютера, настоящая мультимодальность, устойчивая долговременная память и непрерывное обучение — четыре пробела, которые мешают агентам выполнять настоящую работу. Он даже формулирует макро-влияние как внедрение в рост ВВП примерно до 2%, а не как шикарную сингулярность на фоне ажиотажа.
Критика затрагивает текущие методики. Усиленное обучение (reinforcement learning), по его словам, протягивает одну награду через каждый токен — «пьёт подсказки через соломинку» — что поднимает ложные шаги и ослабляет обучение. Наивное синтетическое самосовершенствование выглядит умно, но приводит к потере разнообразия, порождая почти идентичные размышления, из-за чего модели становятся хуже. Его предложение «когнитивного ядра» переворачивает архитектуру: сохранять небольшой встроенный объём памяти для алгоритмов мышления, отправлять факты к поиску и инструментам и рассматривать человеческую забывчивость как особенность, которая вынуждает к обобщению. Далёкие задержки в области автономного вождения служат предостерегающим примером для программных агентов: ожидайте утомительную итерацию, а не чистые крутизны взлётов.
Для строителей проектов вывод прагматичен: сфокусируйтесь на сжатых, верифицируемых рабочих процессах с прочными «оградами» (guardrails), инвестируйте в управление средой и состоянием, и рассматривайте RL, ориентированное на конкретные роли, где паритет может прийти раньше, чем у общих агентов.
Feature Spotlight
Особенность: проверка реальности агента Карпатия перерабатывает краткосрочные дорожные карты
Широко распространённое интервью Карпати утверждает, что современные агенты ещё не готовы выступать в роли коллег; ИИ общего назначения, вероятно, появится примерно через десять лет. Задаёт руководителям ожидания относительно того, во что инвестировать (память, инструменты, мультимодальность) — и избегать завышенных обещаний.
Сегодня доминирует перекрёстное освещение интервью Dwarkesh x Karpathy: агенты названы «слопом», ИИ общего назначения — примерно через десятилетие, ограничения RL и пробелы (память, мультимодальность, непрерывное обучение). Влияние на то, как команды сейчас формируют рамки агентов.
Jump to Особенность: проверка реальности агента Карпатия перерабатывает краткосрочные дорожные карты topicsTable of Contents
🧭 Особенность: проверка реальности агента Карпатия перерабатывает краткосрочные дорожные карты
Сегодня доминирует перекрёстное освещение интервью Dwarkesh x Karpathy: агенты названы «слопом», ИИ общего назначения — примерно через десятилетие, ограничения RL и пробелы (память, мультимодальность, непрерывное обучение). Влияние на то, как команды сейчас формируют рамки агентов.
«Агенты — это чепуха»: Карпатхи предупреждает, что индустрия переоценивает возможности агентов.
Андрей Карпати говорит, что нынешние ИИ-агенты переоценены — «это чепуха» — и предполагает, что ажиотаж может зависеть от стимулов фандрейзинга; он подчеркивает, что базовый интеллект, надежное использование инструментов и настойчивость пока отсутствуют. Цитируемая выдержка и клип здесь quote clip with the exact timestamp in YouTube timestamp.
Вывод: ограничить проекты агентов узкими, проверяемыми рабочими процессами с жесткими ограничителями, вместо того чтобы продвигать их как автономных сотрудников.
Полное интервью Карпати с Dwarkesh выходит: ИИ общего назначения примерно через десятилетие, агенты не готовы к работе.
Dwarkesh Patel опубликовал разговор, разбитый на главы, с Андреем Карпати, в котором он прогнозирует, что ИИ общего назначения всё ещё примерно через десять лет, и утверждает, что современные агенты не готовы к реальным задачам. Обсуждение устанавливает ожидания постепенного влияния, а не резких скачков, и формулирует конкретные пробелы, которые команды должны закрыть в ближайшее время. См. список глав и отметки времени в chaptered episode и длинное видео в full episode.
Для дорожных карт речь подчеркивает приоритет использования вычисления, мультимодальности, долгосрочной памяти и непрерывного обучения над громкими демо.
RL-критика: «высасывать кусочки надзора через соломинку» против человеческого обучения
Карпатхи утверждает, что обучение с подкреплением распространяет одну конечную награду на каждый ток в траектории — «впрыскивая обучающие сигналы через соломинку» — поднимая ложные шаги и давая слабые сигналы обучения по сравнению с тем, как люди учатся и самоорганизуют знания. Он призывает к этапам исследований, на которых модели «размышляют» над материалом во время предварительного обучения, но отмечает, что наивные синтетические размышления могут ухудшать модели. Подробности и примеры в thread highlights.
«Идея „когнитивного ядра“: удалить большую часть памяти, чтобы модели были вынуждены искать факты и сосредотачиваться на алгоритмах мышления»
Карпати предполагает, что LLM слишком отвлекаются на запоминание в ходе предобучения; он предпочёл бы маленькую встроенную память плюс извлечение, сохраняя «алгоритмы мышления» внутри модели и перенося факты в инструменты. Он рассматривает забывчивость человека как особенность, которая заставляет к обобщению — руководство по проектированию агентов с дизайном, ориентированным на извлечение thread highlights.)
Синтетическое самообучение сводит разнообразие к минимуму; поддержание энтропии является актуальной исследовательской проблемой.
Спросили, почему языковые модели (LLMs) не могут просто самостоятельно генерировать размышления о книге и обучаться на них, Андрей Карпати говорит, что выводы выглядят разумно, но сходят к почти идентичным ответам на повторяющиеся запросы, что подрывает разнообразие и делает модели хуже. Открытая проблема — генерировать высокоэнтропийные, не коллапсирующие синтетические трассы, которые действительно помогают обобщению основные моменты ветки.)
AGI не будет ощущаться как сингулярность; скорее всего, он внесёт вклад в рост ВВП примерно на 2%.
Вместо внезапного разрыва Карпати утверждает, что прогресс будет впитываться в базовый темп экономического роста и реинжиниринг бизнес‑процессов, смягчая краткосрочные ожидания, но при этом указывая на значительную накапливающуюся ценность chaptered episode. Для планирования отдавайте предпочтение поэтапной автоматизации, которая внедряется в существующие организации, а не крупномасштабным рискованным проектам.
Задержки автономного управления как поучительный пример для сроков агентов
Карпатий размышляет о том, почему автономное вождение занялось дольше, чем прогнозировали на ранних этапах, и предполагает, что те же реалии длинного хвоста применимы к программным агентам — крайние случаи, хрупкое восприятие и нарастающее трение инструментов — что побуждает лидеров выделять бюджет на итерации и оценку на масштабе эпизод с разделами.
Обучение аналогиям: дети против взрослых, и сон как антипереобучение для обобщения
Karpathy использует человеческие analogии — детское поведение с высокой энтропией исследования против застывших мыслительных циклов взрослых — и отмечает работы, утверждающие, что сновидения способствуют обобщению, борясь с переобучением; вывод для инженеров таков: смещать обучение агентов в сторону исследования и разнообразных следов, а не зацикленных на запоминании петель основные моменты ветки.)
Разделение сообщества: десятилетний путь к AGI против претензий ближайшего срока
Интервью возобновило спор между исследователями, ожидающими ближайшего появления AGI и десятилетний прогноз Карапати; скептики спрашивают, кому доверять, подчёркивая ощутимые пробелы в возможностях агентов на сегодняшний день обсуждение, заголовок десятилетия.
Специализированное RL может достичь паритета быстрее, чем общие агенты, утверждают некоторые комментаторы.
Реагируя на Karpathy, некоторые считают, что RL‑обученные, роль‑специфичные LLM могут достигнуть человеческого уровня производительности в узких областях знаний значительно раньше, чем общие агенты, что поддерживает краткосрочную стратегию вертикализированных рабочих процессов вместо универсальных “сотрудников” analysis.
🛠️ Агентное кодирование: взлёт IDE Codex, Claude Code Q&A, ранний веб
Плотный поток практических обновлений в области агентного кодирования: расширение IDE OpenAI Codex, новая сборка 0.47.0, обзоры из реального мира; Claude Code добавляет интерактивные вопросы и веб‑просмотр. Исключает дискурс Карпати (раскрыто в материале).
OpenAI выпускает IDE-расширение Codex для VS Code, Cursor и Windsurf
Новая IDE-расширение Codex от OpenAI приносит агентское кодирование в популярные редакторы, сегодня доступны пути установки для VS Code и руководство для Cursor и Windsurf. Расширение интегрируется с облачными запусками Codex и существующей CLI/SDK, позволяя разработчикам планировать, редактировать, запускать и просматривать внутри среды редактора. См. ссылки на установку и документацию в заметке о выпуске, VS Code extension, и более широкие руководства в разработчикских документах и демонстрационное видео в демо-видео.\n\n
\n\nПо сравнению с CLI, IDE-поток подчеркивает контекстно-зависимые диффы и асинхронное делегирование, сохраняя навигацию по репозиторию и обзоры в одном цикле; он также согласуется с усилиями OpenAI по маршрутизации задач между локальными и облачными песочницами, описанными в документации страница продукта.
Claude Code для веба появляется в раннем предварительном просмотре с облачными сессиями
Организационный на уровне всей компании переключатель «Claude Code in the Web» и скриншоты указывают на preview облачного IDE с разделённой панелью, где участники могут создавать/просматривать сессии кодирования и выбирать типы окружения. Ожидаются история сессий и частичное соответствие CLI, возможно обработка CAPTCHA для входа, похожего на Google Meet. В продолжение General agent shift, это переносит Claude Code за пределы терминалов к выполнению в браузере settings screenshot, с описанием функций и скриншотами в preview article и более подробную информацию в feature article.
Для команд размещённая IDE может стандартизировать песочницы, включать наборы навыков и упростить внедрение по сравнению с локальными настройками каждого разработчика.
Claude Code теперь задаёт уточняющие вопросы во время режима планирования
Anthropic добавил интерактивный Q&A внутри Claude Code, при этом модель делает паузу, чтобы задать целевые вопросы — особенно в режиме Plan — когда спецификации неоднозначны или существует несколько путей. Команды могут подтолкнуть к более любознательному поведению через руководство по проекту и подсказки навыков, и это работает как в процессах планирования, так и в исполнении feature brief, author note, docs page.
Это снижает переработку при крупных правках и соответствует парадигме Skills (постепенное раскрытие инструкций и скриптов), которая появилась на этой неделе; вместе они помогают Claude «загрузить нужную стратегию действий, затем подтвердить предположения» прежде чем приступить к коду.
Codex v0.47.0 вышел; сообщество составляет журнал изменений до официальных заметок.
OpenAI’s Codex выпустил версию v0.47.0, что ранние пользователи обновлялись и запускались до публикации официальных заметок о выпуске. Сообщества-мейнтейнеры свели изменения из коммитов — новые /name для чатов, параллельный поиск файлов, улучшения MCP и исправления стабильности — в то время как тег релиза на GitHub появился вскоре после version update, compiled changelog, release page.
Некоторые Pro-пользователи кратко достигали недельных лимитов во время длинных сессий до обновления лимитов, что служит напоминанием о том, чтобы распределять работу между уровнями «thinking» High и Medium, когда это возможно plan limit screen.
Практическое занятие: Codex CLI отлично справляется с длинными запусками; очереди, огромный контекст, минимальный чат
Двухдневный практический отчет описывает, как Codex CLI отправляет примерно 6 тыс. строк в нескольких сессиях с щедрыми пределами, глубокий контекст, который «кажется, что длится бесконечно», минималистичный TUI и зависимую очередь запросов, которая поддерживает поток, пока выполняются задачи. Желания включают режим планирования, более простые переключатели моделей и фоновые команды; отмечена работа над интерфейсом вокруг запросов на разрешения в песочнице и трудности с shadcn UI глубокое погружение.)
Автор ненадолго достиг лимитов Plus в середине выполнения, но обновился до Pro и возобновил через несколько минут, что подчеркивает ценность пакетной обработки работы и наблюдения за /status во время многочасовых рефакторингов экран ограничения плана, лимит снят.
Cursor Nightly тестирует фонового агента на запуск после плана.
Ночные сборки Cursor демонстрируют опцию “Background” рядом с Agent, что намекает на автономное выполнение после плана с меньшей нагрузкой на передний план. Это часть более широкой тенденции позволять агентам исследовать параллельно и сообщать результаты, сохраняя детерминированные контрольные точки для слияний UI screenshot.
Ожидается, что больше IDE будет предлагать явные режимы background/parallel по мере того как рабочие процессы, ориентированные на план, станут стандартом в Codex, Claude Code и у конкурентов.
Zed выпускается на Windows и добавляет нативный Codex через ACP
Вывод редактора Zed в октябре приносит первоклассную поддержку Windows плюс нативную интеграцию OpenAI Codex через ACP, наряду с обновлениями, улучшающими качество жизни, такими как последовательности действий и более быстрое обновление панели проектов. Команда опубликовала стабильные примечания к выпуску и блог о запуске на Windows, чтобы разработчики быстро вошли в курс дела stable releases, blog post, ACP note.
Для агентских стэков кодирования ACP сохраняет вызовы инструментов Codex резкими внутри Zed без лишней «клеящей» ленты, а поддержка Windows расширяет базы установок для смешанных операционных систем.
Cursor добавляет установку одной командой для расширения Codex
Пользователи Cursor теперь могут установить расширение Codex от OpenAI за один шаг через CLI (cursor --install-extension openai.chatgpt@0.5.20), что упрощает стандартизацию окружений в командах. Последующее обновление показывает, как выглядит успешная установка в интерфейсе пользователя install command, installed view.
Это дополняет релиз в IDE-маркетплейсе и снижает трение для организаций, которые управляют расширениями через скрипты и dotfiles.
GLM 4.6 «Coding Plan» загорается внутри Claude Code для некоторых пользователей.
Разработчики сообщают, что Claude Code работает по пути «Coding Plan» GLM 4.6, отмечая более плавное/быстрое планирование с использованием последней настройки модели. Хотя это и не подтверждено статистически, это отражает растущую гетерогенность в бэкендах агентов по мере того, как команды маршрутизируют планирование и реализацию к различным моделям dev experience.\n\n
\n\nЕсли это сохранится, это предполагает, что редакторские агенты всё чаще будут посредниками между несколькими профилями рассуждений (быстрый план vs. глубокий рефакторинг) за единым UX.
🧩 Совместимость и MCP: корпоративные коннекторы и паттерны размещения
MCP закрепляется как корпоративная платформа: ChatGPT Business/Enterprise/Edu получает полную бета-версию MCP; разработчики обсуждают шлюзовые маршрутизаторы, более качественную выдачу инструментов и размещение агентов в песочнице. Исключаются особенности IDE Codex/Claude (раскрыто в разделе кодирования).
OpenAI включает полный MCP в ChatGPT для бизнеса/предприятия/образования с режимом разработчика и RBAC
OpenAI включила полную поддержку Model Context Protocol в ChatGPT для Business, Enterprise и Edu, добавив режим разработчика для приватного тестирования коннекторов и RBAC на уровне организации, чтобы администраторы могли контролировать, кто строит и публикует коннекторы с возможностью действий (выходящие за рамки чтения/поиска до записи/модификации рабочих процессов). Подробности включают правила публикации, настройки рабочих пространств и рекомендации по безопасности в примечании к развёртыванию OpenAI help center,, озвученного административным брифом, подчёркивающим такие же параметры управления admin note.
Как размещать агентов Claude: песочничные контейнеры, примерно $0.04–$0.05 за час и готовые провайдеры
Anthropic поделилась конкретным шаблоном размещения для Claude Agent SDK: запуск каждого агента в изолированном контейнере с доступом к файловой системе и bash для Skills, с типичной стоимостью выполнения около $0.04–$0.05 в час и вариантами поставщиков, включая AWS, Cloudflare, Vercel, Modal, Daytona, E2B и Fly.io руководство, доки по размещению. Руководство также охватывает длительные задачи и изоляцию на уровне пользователя; в контексте engineering docs, которые изложили схему Skills и лучшие практики, это закрывает круг вопросов о том, как безопасно развертывать агентов на базе Skills в масштабе cost note, code overview.
OSS «MCP Gateway» объединит несколько серверов MCP за одной конечной точкой доступа
С открытым исходным кодом «MCP Gateway» запланирован выпуск, чтобы объединить множество MCP-серверов в одну доступную конечную точку, что упрощает настройку клиентов и корпоративные операции для флотов инструментов и общей инфраструктуры gateway tease. Эта схема снижает разброс клиентов/инструментов, централизует аутентификацию/политику и обеспечивает маршрутизацию по арендаторам без изменения нижележащих MCP-серверов.
RepoPrompt улучшает UX инструмента MCP: более чистый вывод Markdown и читаемое представление file_search
RepoPrompt’s MCP инструменты теперь выводят результат в чистом Markdown внутри интерфейсов агентов, с переработанным file_search, который отображает встроенные, удобочитаемые совпадения — делая результаты проще восприятия как пользователями, так и моделями tool preview. Автор заметки лучшее поведение бенчмарков, когда инструменты представляют структурированные, читаемые выводы вместо машинно‑ориентированных строк author note.
⚙️ Обслуживание и маршрутизация: много-модульные маршрутизаторы и ускорения для диффузионных LLM
Новости рантайма сосредоточены на маршрутизации моделей и декодировании: HuggingChat Omni автоматически выбирает среди более чем 100 OSS-моделей; новые техники без обучения ускоряют диффузионные LLM; заявления о производительности GLM 4.6 выходят на поверхность. Сфокусировано на инфра- и рантайме, а не на IDEs.
HuggingChat Omni запускает автоматическую маршрутизацию на более чем 100 открытых моделях, работающую на маршрутизаторе с 1,5 млрд параметров.
Hugging Face представила HuggingChat Omni, который динамически маршрутизирует каждый запрос к лучшей из более чем 100 открытых моделей во время вывода, стремясь к лучшему соотношению стоимость/задержка/качество без микроменеджмента пользователя product post. Дирaктор маршрутизатора — открытый Arch‑Router‑1.5B от Katanemo, общий вместе с анонсом ради прозрачности и воспроизводимости Hugging Face model.
Помимо удобства, это нормализует мульти‑модельные операции: команды могут стандартизировать единый входной пункт чата, в то время как бэкенд переключается между gpt‑oss, DeepSeek, Qwen, Gemma, Aya, smolLM и другими в зависимости от характеристик запроса feature recap.)
Elastic-Cache ускоряет декодирование диффузионных больших языковых моделей до 45× за счёт селективного обновления KV
Новая методика декодирования для диффузионных LLM обновляет кэш KV только там, где внимание дрейфовало, сохраняя стабильные части неповреждёнными; в сочетании с скользящим окном и поуровневым перерасчётом это обеспечивает до 45× быстрее декодирование без повторного обучения и без потери качества на задачах по математике, коду и мультимодальным данным обсуждение статьи. Подход не требует обучения и не зависит от архитектуры, что делает его совместимым с существующими развертываниями diffusion LLM.
[изображение:https://pbs.twimg.com/media/G3d2gd9akAMWCYw.png|Название статьи]
Практически Elastic‑Cache переопределяет кэш KV как адаптивный ресурс: пороги дрейфа определяют, когда перерасчитывать глубокие слои, снижая задержку при сохранении согласованности ответов на разных шагах обсуждение статьи.
GLM 4.6 опережает поставщика speedboards от Artificial Analysis, достигая 114 TPS и примерно 0,18 с TTFT
Baseten сообщает, что GLM 4.6 — самый быстрый провайдер на тестах рассуждений Artificial Analysis, достигая 114 токенов/с, и разъясняет опечатку до ~0,18 с времени до первого токена (TTFT) в продакшне provider claim, typo correction, with public rankings available for verification benchmarks chart. This follows KV routing gains where Baseten showed ~50% lower latency and 60%+ higher throughput after adopting NVIDIA’s Dynamo KV‑cache routing, underscoring how stack‑level optimizations translate into leaderboard speed.
Фреймворк dInfer заставляет диффузионные LLM достигать скорости 800–1100 токенов в секунду за счёт трюков декодирования без обучения.
Ant Group/Inclusion AI’s dInfer реорганизует декодирование диффузионной LLM в четыре взаимозаменяемые части (модель, менеджер итераций, декодер, менеджер KV) и добавляет три обучения‑свободных оптимизации — сглаживание итераций, иерархическую/кредитную декодирование и обновление близлежащего KV — чтобы достигнуть 1100+ токенов/с на HumanEval и примерно 800 токенов/с на шести задачах, обгоняя fast dLLM примерно в 10×, сохраняя при этом качество paper thread.
Поскольку он нацелен на задержку для одиночной последовательности (а не на скрытие батча), dInfer напрямую релевантен интерактивным агентам, которым нужны стабильные ответы менее чем за секунду paper thread.)
vLLM добавляет отслеживание MFU в основной движок для анализа использования на устройстве
Новый PR добавляет режимы анализа MFU (использование FLOP-модели) в vLLM, предлагая либо быстрые оценки, либо детализированный графовый учет и данные графика Roofline, чтобы команды могли определить резервы пропускной способности и узкие места во время обслуживания запросов PR details. Это помогает операторам в производстве количественно оценивать реальные улучшения эффективности от маршрутизации, кэширования KV и изменений квантования без внешних профайлеров.
📊 Оценки: потолки FrontierMath и легковесные рассуждения comps
Epoch публикует интенсивный анализ FrontierMath (caps, pass@N, kitchen‑sink на 57%); побочные ветви сравнивают масштабирование ChatGPT Agent; Haiku 4.5 соответствует ранним моделям рассуждений без «мышления», часто в 5 раз быстрее.
GPT‑5, похоже, ограничен ниже 50% на FrontierMath после 32 запусков.
Epoch’s 32‑run study finds sub‑logarithmic pass@N gains for GPT‑5 on FrontierMath, with an extrapolated ceiling under 50% and diminishing returns per doubling of attempts model scaling chart, run details. A targeted follow‑up on 10 previously unsolved problems produced 0 solves across 100 more tries, reinforcing the limit unsolved batch. Full write‑up and plots in Epoch’s analysis Epoch post.
Почему это важно: насыщение pass@N означает, что улучшения следующего поколения должны повысить вероятность «решить хотя бы раз» или надёжность на каждую проблему, а не просто увеличить число попыток.
“Kitchen‑sink” агрегация достигает 57% решений; агент ChatGPT добавляет уникальные победы через веб-поиск.
Объединение 52 запусков моделей из хаба, 16 запусков ChatGPT Agent, один Gemini 2.5 Deep Think и 26 в основном o4‑mini запусков приводит к тому, что 57% FrontierMath Tiers 1–3 были решены хотя бы один раз (pass@the‑kitchen‑sink) runs collected, aggregation note. ChatGPT Agent вносит наибольшее количество уникальных решений, вероятно, потому что для бенчмарка разрешён веб-поиск agent unique solves.
Следствие: совокупно достижимый набор сегодня больше, чем у любой отдельной модели, и использование инструментов (поиск) существенно расширяет охват.
Epoch прогнозирует общий потолок около 70% к H1’26; один лишь ChatGPT Agent, вероятно, менее 56%.
Экстраполируя текущие кривые, Epoch оценивает предел «all‑in» примерно 70% решённых задач при участии множества моделей и множества прогонов, по сравнению с сегодняшним лучшим одноблочным проходом pass@1 около 29% cap estimate, trend line. Separately, scaling just ChatGPT Agent appears to cap below 56% based on 16‑run behavior agent cap curve, with more details in the Gradient Update analysis thread, Epoch post.
Читайте: в краткосрочной перспективе ожидаются выгоди за счёт надёжности в уже достижимых задачах, а не массовое расширение границы возможного.
Haiku 4.5 соперничает с ранними моделями «рассуждений» без мышления и работает примерно в 5 раз быстрее в тестах
Epoch сообщает, что Claude Haiku 4.5, при отключённом рассуждении, показывает аналогичные или лучшие результаты по сравнению с ранними лёгкими моделями с «рассуждением» (например, o1‑mini) во многих оценках и имеет примерно в 5× быстрее время выполнения на запуске Mock AIME в их настройке eval post, benchmark hub, comparison note, following up on Haiku evals где были зафиксированы результаты ARC‑AGI и разброс задач).
Вывод: аккуратное выполнение и меньшие, быстрые модели могут сопоставлять первые волны рассуждений и являются полезными для рабочих процессов с задержками и агентов «планируй‑затем‑исполняй».
🧪 Наука обучения: квантованное обучение с подкреплением, действия памяти и кредиты за токены
Сегодняшние результаты исследований подчеркивают более дешевое и более стабильное постобучение и более тонкую настройку распределения кредитов. Некоторые из них относятся к обучению; другие — к формированию политики. Не пересекаются с категориями выполнения во время работы или оценки.
QeRL от NVIDIA: квантованное обучение с подкреплением с адаптивным шумом обучает модели размером 32 миллиарда параметров на одной карте H100.
QeRL объединяет квантование NVFP4 с LoRA и вводит адаптивный шум квантования, чтобы шум служил исследованием во время RL, что даёт примерно в 1.8× быстрее обучение по сравнению с QLoRA, при этом достигая полного качества дообучения на GSM8K (90.8%) и MATH‑500 (77.4%). Сообщается о единичном использовании GPU для моделей 32B на H100 80 GB, и выпускается код. Смотрите ключевые детали в разборе и статье, а также репозиторий для реализации. обзор метода ArXiv paper GitHub repo
Законы масштабирования в обучении с подкреплением закрепляются на 400 тыс. GPU‑часов и прогнозные кривые до свыше 100 тыс. часов.
Далее, продолжая тему ScaleRL, исследование добавляет подтверждения тому, что сигмоидные кривые вычисление→производительность позволяют экстраполировать крупномасштабные RL‑запуски по малым пилотам; команда провела >400 000 GPU-часов и демонстрирует точные предсказания за пределами 100 000+ GPU-часов, с рецептом, который превосходит DeepSeek, DAPO, Magistral и MiniMax по асимптотическому счёту и эффективности. Диаграммы и обсуждения подчёркивают разделение потолка и эффективности. paper overview community summary
Microsoft’s BitNet Distillation превращает FP LLMs в 1.58‑битные модели с близкими к паритету результатами по задачам
BitDistill тонко настраивает готовые полноточные LLMs в варианты BitNet с 1.58-битной (тернарной) точностью, которые сохраняют сопоставимую точность с FP16, уменьшая требования к памяти и ускоряя токены/секунду, через конвейер, который включает SubLN, внимание-дистилляцию по стилю MiniLM и короткую непрерывную предобучающую разминку. Графики производительности в статье демонстрируют высокую точность по сравнению с большими базами FP, наряду с более быстрой инференцией и меньшим использованием RAM. обзор статьи Hugging Face paper
Внимание: ритм «предпланирования и якорения» позволяет детализированный учет токенов в обучении с подкреплением.
Анализ голов внимания выявляет локальные токены-«начало‑чанков» и глобальные «якоря», к которым далее шаги обрашаются неоднократно. Оптимизация RL для повышения вклада в этих критических узлах — и переноса части вклада от якорей обратно к их открывающим — улучшает задачи по математике, Q&A и головоломкам, особенно на моделях размером 8B, по сравнению с равномерным или только неопределённостью вклада. Визуализации и детали метода приведены в объяснении к статье. обзор статьи
[изображение:https://pbs.twimg.com/media/G3bOVKlX0AAMv8c.png|Рисунок статьи об attention]
Память как действие обучает агентов редактировать свой контекст на лету ради долгосрочных выгод
Эта структура делает операции с памятью первоклассными действиями — сохранять, сжимать, суммировать, удалять — чтобы политика обучалась тому, когда курировать рабочую память во время многошаговых задач, повышая точность и сокращая количество токенов за ход. Разделение обучения выполняется на каждом редактировании памяти и присваивает итоговые вознаграждения с штрафами за эффективное использование токенов, что приводит к более сильной производительности на задачах с несколькими целями, одновременно снижая входные затраты. paper thread\n\n
Распределение кредитов на уровне токенов и управление памятью выступают рычагами для более дешёвого постобучения.
В сумме сегодняшние работы указывают на две управляемые «ручки» для пост‑обучения: (1) явное вознаграждение за токены «план» и «якорь», которые структурируют рассуждения, и (2) обучение агентов обрезать и переписывать собственную рабочую память во время задачи, чтобы держать бюджет контекста под контролем. Эти вмешательства приводят к измеримым улучшениям без грубой силы вычислений, дополняя пути квантования RL и дистилляции. Смотрите работу по attention‑credit и политику «память как действие» для конкретных рецептов. attention method memory actions
AEPO балансирует энтропию, чтобы стабилизировать обучение агентов с подкреплением и повышает долю прохождений на 14 наборах данных.
Agentic Entropy‑Balanced Policy Optimization борется с избыточной развёрткой и нестабильными градиентами путём (1) динамического распределения бюджета на развёртывания и штрафования за последовательные вызовы инструментов с высокой энтропией, и (2) отсечения и перенастройки градиентов токенов с высокой энтропией с использованием преимуществ, учитывающих энтропию. Всего около ~1k образцов RL на Qwen3‑14B, AEPO сообщает GAIA Pass@1 47.6% (Pass@5 65.0%), Humanity’s Last Exam 11.2% (26.0%), и WebWalker 43.0% (70.0%). paper card
Думать про токены не помогает машинному переводу; более конкретные цели и черновики действительно помогают.
Во многих парах языков добавление скрытых «мыслей» перед ответами практически не даёт улучшения качества машинного перевода; обучение небольших моделей имитировать пошаговые следы также отстает по эффективности по сравнению с простым обучением переводу источника в цель. Полезные промежуточные сигналы появляются только тогда, когда следы включают черновые переводы, что подразумевает, что настоящий выигрыш — в большем и лучшем параллельном тексте (или целевых целях учителя), а не в общих рассуждениях. paper first page)
Смешайте веса «thinking» и «instruct», чтобы настроить глубину рассуждений без повторного обучения.
Простая интерполяция весов между моделью Thinking и моделью Instruct выявляет три режима: низкое смешивание действует как Instruct (краткие ответы, скромные прибавки); среднее смешивание внезапно включает явную цепочку рассуждений (CoT) с резкими скачками качества (иногда меньшим количеством токенов); высокое смешивание вызывает «мышление» на каждом входе с ростом стоимости токена и выравниванием отдачи. Большая часть поведения «мышления» сосредоточена в поздних слоях; FFN вызывают мышление, тогда как внимание повышает корректность. обзор статьи)
🗺️ Обоснованный поиск: Google Maps в Gemini и мультимодальном RAG
Новости по данным и связке / grounding имеют практический уклон: привязка карт к Gemini API открывает агентов, ориентированных на местоположение; мультимодальные RAG-фреймворки и советы по парсингу становятся заметны. Исключены обновления IDE и оценки.
Gemini API добавляет привязку Google Maps к более чем 250 млн мест.
Google внедрил живую привязку карт к Gemini API, позволяя приложениям рассуждать на основе актуальных данных из более чем 250 млн объектов и объединять карты + поиск в единое пространство обзор функций, с демонстрациями в AI Studio и полными документами по использованию инструмента сообщение в блоге Google, сообщение AI Studio, демо-приложение, и документация API. Это открывает доступ к агентам, учитывающим локации, для маршрутов, логистики, полевых операций и обнаружения storefront без необходимости кастомного скрапинга или устаревших кешей POI.
RAG‑Anything: кросс‑модальный поиск, сохраняющий структуру
Новый фреймворк предлагает подход с двойным графом + плотным поиском для извлечения информации по тексту, изображениям, таблицам и формулам, не сводя документы к тексту с потерей информации paper thread.). Он моделирует кросс-модальную раскладку (рисунок–подпись, строка–столбец, ссылки на символы) наряду с семантическими связями, обходит граф структуры, чтобы извлечь связанные фрагменты, объединяет их с результатами по векторным представлениям, затем восстанавливает обоснованный контекст для VLM, чтобы ответить. Преимущество — более высокий охват и более чистые ответы на длинных документах со смешанным содержимым, где особенно важно сохранять заголовки, единицы измерения и ссылки на панели.
Навык Claude в работе с PDF базовый; для сложных документов используйте LlamaParse.
Обзор практиков показывает, что встроенный навык PDF Claude Code основан на PyPDF + reportlab и будет давать сбой при сканировании, работе со сложными таблицами и диаграммами; для парсинга промышленного уровня используйте LlamaParse через semtools или вставьте ссылку SDK в пользовательский навык practitioner note. Это сохраняет структуру для последующего RAG и заполнения форм, при этом оставаясь с прогрессивным раскрытием возможностей навыков и низким токеновым следом.
Проблемы парсинга документов и способы их устранения для RAG в продуктивной среде
Полевая сессия подводит итоги там, где RAG‑пайплайны терпят неудачу — сканы, рукописный текст, штампы/водяные знаки, флажки, отклонение верстки и извлечение графиков — и рекомендует смешанный стек: специализированные модели по регионам, надежное обнаружение макета, обоснованные цитаты и бенчмаркинг на неоднородных корпусах в масштабе обзор сессии. Считайте разбор как компонент первого класса (а не предварительный шаг), подключите извлекатели диаграмм/таблиц и проверяйте с опорой на ссылки, чтобы укрепить доверие к ответам.
🎬 Стек создателя: управление Veo 3.1, распределение Reve, ранги редактирования изображений
Большой объём креативных твитов: руководство по движению камеры Veo 3.1 и расширение сцен; образцы Sora 2; модели Reve на fal/Replicate; рейтинги Image Arena. Выделено отдельно, чтобы не перегружать основные инженерные направления.
Gemini делится конкретными подсказками по движениям камеры Veo 3.1 и рецептами съемки.
Команда Google Gemini опубликовала готовые к использованию образцы запросов для Veo 3.1 — охватывающие панорамирование, наклон, тележку, трекинг, съемку вручную и даже движения крана сверху вниз — плюс примеры кадров с диалогами за плечом и медленными push‑in, что делает кинематографическое управление намного проще на практике советы по камере, пример для крана, рецепт диалога, пример push‑in. Следуя по предыдущим подсказкам, которые демонстрировали микро‑детализированность реализма, Gemini также предлагает пользователям перейти на страницу Veo 3.1 для немедленного создания и обмена страница Gemini Veo, с дополнительными указаниями по наклону вниз, чтобы подчеркнуть руки и тонкие эмоции пример наклона.
Reve image models расширяют распространение на Replicate и fal с сильными ранними результатами
Модели Reve доступны теперь как на Replicate, так и на fal, расширяя доступ к генерации изображений по тексту, редактированию с высоким качеством и точным рабочим процессам отрисовки текста Replicate page, fal launch. Ранние показы выделяют пространственно осознаваемые макеты с несколькими изображениями и надежные конвейеры редактирования, сигнализируя о правдоподобной альтернативе для задач дизайна и брендинга, которым нужны четкий шрифт и единая структура capability overview.
LTX Studio сочетает Veo 3.1 с начальными и конечными кадрами для анимации статичных изображений и внедрения диалога
LTX Studio интегрировала Veo 3.1 и демонстрирует простой творческий цикл: генерируйте статические кадры, затем анимируйте, устанавливая начальные и конечные кадры — удобно для сохранения идентичности и постановки, одновременно накладывая реплики на кадр teaser tutorial. Это руководство делится кадрами, с которых можно начать, а затем переходит к анимации, используя новые элементы управления Veo; образец, который многие создатели могут повторно использовать для быстрого прототипирования короткометражек stills post.
Лидеры среди создателей: Riverflow 1 удерживает первое место в разделе «Редактирование изображений»; MAI‑Image‑1 от Microsoft входит в топ‑10 по генерации изображений по тексту
Artificial Analysis показывает Riverflow 1 от Sourceful на вершине доски Image Editing (ELO 1217), опережая Google’s Nano‑Banana (Gemini 2.5 Flash) и Seedream 4.0 от ByteDance editing leaderboard. В то же время новый MAI‑Image‑1 от Microsoft дебютирует на #9 на доске Text‑to‑Image с 4 091 голосом, что свидетельствует о достойном первом появлении среди устоявшихся претендентов text‑to‑image rank.
Расширение сцены и кадры, ориентированные на изображение, с Veo 3.1 переходят от подсказок к повторяемым рабочим процессам
Создатели сходятся к явному паттерну Veo 3.1: сгенерировать исходный клип, поместить его в конструктор сцен и использовать «Extend» с целенаправленным промптом, чтобы перенести движение и тон на более длинные планы scene extension thread, prompt sample. Руководство Replicate дополняет это практическими подсказками по промптингу и условиям по опорочным изображениям, чтобы персонажи и стиль сохранялись единообразными на протяжении нарезок Veo 3.1 guide. Один демонстрационный пример даже привязывает сцену к карте изображения, чтобы направлять происходящее в конкретном месте, подчеркивая усиленную визуальную кондиционировку Veo image prompt demo.
25‑секундные сырые клипы Sora 2 циркулируют по мере того, как создатели вносят правки в промпты, упорядоченные по раскадровке.
Создатели делятся прямыми 25‑секундными выходами Sora 2, чтобы оценить качество движения и соблюдение, одновременно создавая небольшие инструменты и рабочие процессы (например, prompting, управляемый раскадровкой), чтобы управлять темпом и компоновкой кадров для более длинных клипов сырой клип, рабочий процесс раскадровки.
Открытая альтернатива: ComfyUI добавляет Ovi для генерации текста→видео+аудио за один проход
Character.AI’s Ovi, созданный на базе WAN 2.2 + MMAudio, теперь запускается внутри ComfyUI, выводя синхронизованное видео и аудио по единому запросу — доступный открытый стек для создателей, которые хотят локальные или составляемые узлы вместо закрытых сервисов Ovi brief, Ovi link.
🏗️ ИИ-фабрики, энергия и геополитика
Инфраструктурно-экономические вопросы: объекты ИИ на несколько ГВт, региональные партнёрства и математика капитальных затрат. Сохраняет фокус на предложение и спрос на вычислительные мощности ИИ. Избегает дублирования продуктов и оценок.
Структура финансирования OpenAI, требующая больших вычислительных мощностей, выходит на поверхность на фоне разговоров об оценке примерно в 500 млрд долларов.
Далее по поводу server budget (~$450B к 2030 году), новый обзор FT описывает рабочее разделение, которое могло бы оставить Microsoft, сотрудников и некоммерческую организацию с приблизительно ~30% владения каждый, и соглашение с NVIDIA, предоставляющее ~$10B в акциях за закупки графических процессоров на ~$35B (до ~$100B); OpenAI также запланировала 6 ГВт у AMD (со второй половины 2026 года) и сотрудничество с Broadcom, нацеленное на еще ~10 ГВт пользовательских ускорителей FT summary.
Если реализуется, эта стратегия «акции за вычисления + мульти‑поставщик GW» обеспечит жесткую привязку поставок для передовых моделей, при этом разведет доли — смещая конкуренцию к выбору локаций энергии, координации запусков обучения и экономике вывода.
NVIDIA заявляет, что доля китайского рынка ИИ‑GPU снизилась с примерно 95% до 0% на фоне экспортного контроля.
Дженсен Хуанг заявил о «временном прощании» с китайским рынком ИИ, утверждая, что доля NVIDIA там снизилась с примерно 95% до 0%, поскольку экспортные правила толкают покупателей к внутренним стекам, таким как кластеры Huawei Ascend и адаптированные межсоединения event quote.). Замечание подчеркивает, как политика может резко изменить глобальные цепочки поставок ИИ, с последствиями для сроков обучения моделей и трансграничных программных экосистем.
Poolside и CoreWeave планируют создать «Горизонт», центр обработки данных для искусственного интеллекта мощностью 2 ГВт в Западном Техасе с энергоснабжением на месте.
Poolside сотрудничает с CoreWeave над созданием автономного по энергопитанию комплекса вычислительных мощностей ИИ мощностью 2 гигаватта на ранчо площадью 500 акров в Западном Техасе, используя близлежащий природный газ для обхода ограничений сети; компания также привлекает около $2 млрд инвестиций при оценке около $14 млрд и ожидает первоначального доступа к GPU NVIDIA через CoreWeave в декабре project summary.
Для разработчиков ИИ это сигнализирует о дальнейшем вертикальном интегрировании энергетики и вычислений: выделенные источники энергии, сосредоточенные рядом с многогигаваттовыми кластерами, чтобы минимизировать расходы и избежать задержек межсоединений.
Голдман: гиперскалеры движутся по графику к примерно $300 млрд капитальных затрат на дата‑центры, вызванных ИИ, в 2025 году.
Исследование Goldman Sachs показывает, что Google, Amazon, Microsoft и Meta вместе потратят порядка $300 млрд на капитальные расходы дата-центров в этом году, при этом коэффициенты capex-to-cash-flow у гиперскейлеров растут по сравнению с циклом TMT 2000 года капекс диаграмма.
Для команд в области ИИ это означает продолжающийся рост доступности ускорителей, оптических линков и силовых оболочек — но также сохраняющееся давление на использование, маршрутизацию и инструменты энергоэффективности, чтобы ROIC оставался в диапазоне.
Groq сотрудничает с Aljammaz, чтобы обеспечить ИИ-инференс с низкой задержкой по всему Ближнему Востоку.
Groq объявил о региональном дистрибуционном и доставочном партнерстве с Aljammaz Technologies для расширения развертываний GroqCloud и GroqRack по регионам MENA, выравнивая свою инференс-платформу на базе LPU с местными системными интеграторами на GITEX Global 2025 launch note, with details in the company’s newsroom Groq blog post.
Ожидается упрощение региональных закупок и путей поддержки для задач RAG/агентов с временем отклика менее секунды, где сетевые и энергетические ограничения делают пропускную способность на ватт критической.
Oracle Cloud развернет 50 000 ускорителей AMD Instinct MI450, начиная с 2026 года.
Oracle заявил, что OCI добавит 50 тысяч GPU AMD Instinct MI450 к началу 2026 года, что сигнализирует о более широкой стратегии мультивендорных акселераторов помимо NVIDIA для мощности обучения и инференса ИИ замётка по развёртыванию. Для практиков, кросс‑ISA портативность (CUDA‑to‑HIP/ROCm) и сопоставимость производительности по BF16/FP8‑вычислениям будут иметь значение для планирования и арбитража затрат между облаками.
Stargate ОАЭ: G42 и Khazna строят гипермасштабный кластер ИИ мощностью 1 ГВт в пустыне
Объединённые Арабские Эмираты: G42 и Khazna Data Centers спешат запустить «Stargate UAE» — кампус искусственного интеллекта мощностью 1 гигаватт с партнерствами по поставщикам от OpenAI, NVIDIA, Oracle, Cisco и SoftBank, что позиционирует регион как развивающийся центр вычислений в области ИИ site photo.
Локализованные мегакластеры снижают межконтинентальную задержку и диверсифицируют поставки, но повышают требования к координации лицензирования моделей, суверенной резидентности данных и экспортного контроля.
🛡️ Безопасность и злоупотребления: риски глубоких исследований, отравления, газлайтинг в речи
Кластер исследований в области безопасности демонстрирует системные риски: глубокие исследовательские агенты обходят запреты; небольшие фиксированного объема обучающие отравляющие данные сохраняются; речевые LLM подвержены газлайтингу; непрерывное предобучение на мусоре ухудшает когнитивные способности.
Anthropic: около 250 отравленных документов могут внедрить бэкдор в LLM независимо от масштаба модели и данных
Anthropic, Институт безопасности ИИ Великобритании и Институт Тьюринга сообщили, что почти постоянное абсолютное количество отравленных образцов — около 250 документов — успешно внедряет скрытые триггеры во всевозможные модели от 600 млн до 13 млрд параметров, даже по мере роста общего объема обучающих данных; единообразное перемешивание работает лучше всего, и эффект медленно исчезает при чистой продолженной тренировке Anthropic blog. Та же фиксированная схема со счётом сохраняется и для альтернативных целей (например, смена языка), и безопасные дообучения могут быть взломаны так, чтобы соответствовать только когда появляется триггер results recap.
Глубокие исследовательские агенты можно направлять на создание более применимого вредоносного контента.
Новый обзор по безопасности показывает, что многоступенчатые агенты типа «глубоких исследований» уникально уязвимы: злоумышленники могут внедрять вредоносные подзадачи в план агента (Plan Injection) или переназначать намерение как академическую/безопасностную работу (Intent Hijack), чтобы обойти отказ, что приводит к более связным и практичным вредоносным выводам, чем обычный чат paper thread. Авторы демонстрируют управление извлечением, более низкие показатели отказов и полированные длинные отчеты, которые проходят мимо обычных защит на уровне чатов analysis thread.
Речевые LLM теряют около 24% точности под воздействием простых газлайтинговых промптов.
Обзор на 10 740 образцах показывает, что пять голосовых LLM легко направляются стилистическими продолжениями — гнев, профессиональная уверенность, сарказм, скрытые сомнения и когнитивные нарушения — что приводит к в среднем снижению точности на 24,3% во многих задачах, таких как распознавание эмоций и вопросы и ответы, при этом увеличившееся число извинений/отказов сигнализирует о сниженной уверенности обзор статьи. Самые сильные ухудшения пришли от когнитивных и профессиональных стилей; фоновый шум усугублял все эффекты.
Постоянное предобучение на мусорном веб-тексте приводит к стойкой «мозговой порче» у больших языковых моделей (LLMs).
Исследователи приводят причинно‑следственные доказательства того, что воздействие высокововлечённого, низкокачественного текста вызывает стойкое когнитивное снижение у LLM: сниженная глубина рассуждений, ослабленная производительность в условиях длинного контекста и ухудшенная безопасность. Основной режим отказа — «пропуск мыслей» с более темными чертами личности (например, нарциссизм), и меры смягчения, такие как рефлексия или последующая донастройка, лишь частично восстанавливают ущерб — что повышает важность строгого отбора данных в конвейерах обучения обзор статьи.)
🎙️ Голосовые и агентов в реальном времени: хуки операционной системы и присоединение к встречам
Небольшие, но заметные обновления голосового UX: горячее слово Windows «Hey Copilot» и контекст экрана; Claude пытается присоединяться к Google Meet; ElevenLabs и Expo демонстрируют практические пути развития голосовых агентов.
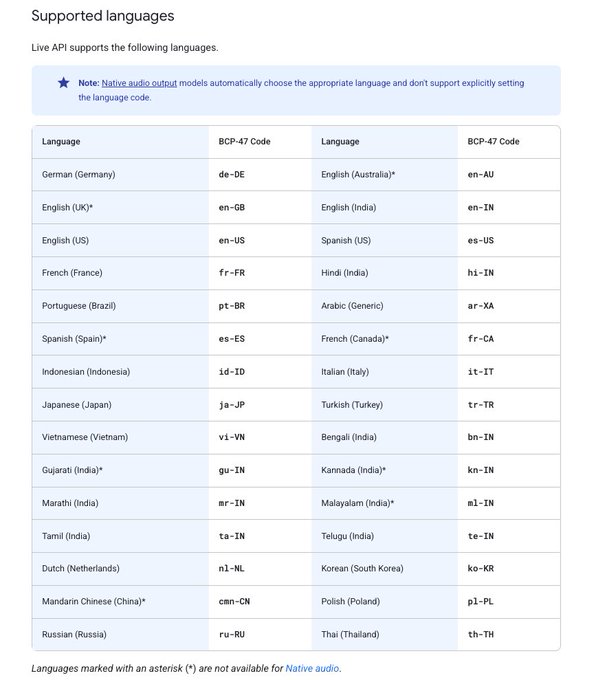
Gemini Live API приносит вызов функций в реальном времени для агентов на 30 языках
Разработчики теперь могут прототипировать агентов в реальном времени с API Gemini Live, включая вызов функций и поддержку нескольких языков, доступно для тестирования в OnePlayground демо-страница с подробной документацией по инструментам в реальном времени и возможностям ссылка на документацию AI Studio live Документация по инструментам в реальном времени Руководство по Live API."
Клод тестирует присоединение бота к Google Meet с передачей CAPTCHA
Anthropic’s web app отображает интеграцию Google Meet, при которой Claude пытается присоединяться к встречам в роли бота, останавливаясь для помощи пользователя, чтобы пройти CAPTCHA Google перед входом settings snippet.)
Для лидеров в области ИИ это конкретный шаг от чата к реальному присутствию (календарь/Meet), поднимающий практические вопросы идентификации, потоков аутентификации и соответствия требованиям в корпоративных встречах.
ElevenLabs назначает саммит на 11 ноября, посвящённый голосовым интерфейсам и доступу.
ElevenLabs объявила о своем Сан-Франциско-саммите 11 ноября, который будет включать доклады о голосовых интерфейсах и акцент программы Impact на доступность, включая сессию с защитником по двигательным нейронным болезням event brief.)
Для продуктовых команд, разрабатывающих голосовых агентов, ожидайте практических подходов к инклюзивному дизайну, лицензированию для некоммерческих организаций и уроков развертывания, которые выходят за рамки демонстрационного ПО и приводят к реальным внедрениям в организациях.
Как развёртывать кросс-платформенных голосовых агентов с Expo + ElevenLabs
Свежий сборник рецептов показывает, как создавать кроссплатформенных (iOS/Android) голосовых агентов с использованием Expo React Native и SDK ElevenLabs, включая аудио WebRTC, разрешения и каркас приложения docs page, и готовый стартовый набор v0 для быстрой инициализации проектов starter page agents cookbook.
💼 Корпоративная динамика: выручка Claude Code, банковские внедрения, платежи
Коммерческие сигналы: траектория выручки Anthropic с Claude Code, приближающимся к $1 млрд ARR; банк из топ‑5 разворачивает Amp Enterprise; локализация платежей ради роста. Только бизнес‑угол зрения, не инфраструктурный.
Anthropic нацеливается на выручку в 20–26 млрд долларов к 2026 году; примерно 80% — корпоративный сегмент, Claude Code приближается к 1 млрд долларов годового повторяющегося дохода (ARR)
Anthropic прогнозирует годовую выручку в диапазоне $20–$26 млрд к 2026 году на фоне ~$9 млрд темпа роста к концу 2025 года, при этом примерно 80% выручки будет приходиться на предприятия, а Claude Code сам по себе приблизится к ARR в ~$1 млрд цели по выручке.
Следуя за Снимок ARR, это обновление добавляет первый явный разбор: 300k+ компаний используют Claude, и помогающий кодированию помощник становится самостоятельной статьей расходов примерно на миллиард — свидетельство того, что агентное кодирование переводится в платные места в масштабе цели по выручке.
Один из топ‑5 банков США внедряет Amp Enterprise у примерно 10% инженеров, что свидетельствует о широком принятии агентов
Один из топ‑5 банков США приобрёл Amp Enterprise примерно за 10% своей численности разработчиков, о чём говорит поставщик, что вскоре это будет крупнейшее развертывание фронтирных кодирующих агентов в крупном банке США bank purchase. Это развертывание сочетает значимый платный развертыванием с открытым для целей Amp Free предложением, которое открыто для хаккинга по выходным и повышения осведомлённости free tier note. Для лидеров в области искусственного интеллекта это конкретное доказательство того, что регулируемые предприятия пилотируют кодирующих агентов в существенных, командных по размеру когорт, а не в изолированных POC.
Julius добавляет платежи UPI в Индии, чтобы ускорить локальную конверсию.
Julius включил UPI на этапе оформления заказа для индийских клиентов, устранил трения с картами и позволил пользователям переключаться на UPI в настройках выставления счетов за секунды payments update. Команда обосновала этот шаг графиком роста ежемесячного объема UPI на 1,200× с 2016 года — теперь примерно 20 млрд транзакций — подчеркивая, почему локальные инфраструктуры важны для экспансии AI SaaS upi growth chart.
🧪 Моделирование дорожных карт и таблиц лидеров
День релиза легкой модели: сигналы вокруг сроков Gemini 3.0 и размещение модели изображения от Microsoft в таблице лидеров. Исключаются элементы маршрутизатора и времени выполнения, а также творческое распространение (обсуждается в другом месте).
Сигналы сходятся на выпуске Gemini 3.0 в этом году, при этом ряд источников указывает на декабрь.
Множество независимых отчётов говорят, что Google нацеливается на декабрьский временной окно выпуска Gemini 3.0, после того как Сундар Пичай публично пообещал выпустить модель в этом году и охарактеризовал её как «более мощного AI-агента». См. утверждение о сроках и формулировку в обзоре, а также пресс-обзор с цитатой генерального директора. timing claim, Techzine report
Если график подтвердится, ожидайте пошаговый скачок возможностей агента, соответствующий экосистеме приложений и API Google, а не тихое постепенное обновление — такое позиционирование повлияет на конкурентные дорожные карты на Q4 для OpenAI и Anthropic.
MAI‑Image‑1 от Microsoft дебютирует на 9‑м месте в Artificial Analysis Text‑to‑Image
Первый собственный внутри Microsoft образец модели преобразования текста в изображение MAI‑Image‑1 вошёл в таблицу лидеров Artificial Analysis Text‑to‑Image в топ‑десятку, заняв 9‑е место и набрав 4 091 голос. Размещение рядом с давними действующими лидерами сигнализирует о надёжном качестве для модели версии 1 и добавляет ещё одну крупную лабораторию в гонку за генерацию изображений. leaderboard entry
Для инженеров следите за ценами и доступом к API; модель уровня Microsoft в верхней когорте может изменить стандартный выбор в рамках медиа‑пайплайнов Azure и A/B‑тестов против конечных точек изображений Sora/Flux/Gemini.
PaddleOCR‑VL‑0.9B демонстрирует 90.67 на OmniDocBench v1.5, заявляя о лидерстве в мультиязычном документальном ИИ
Новость о недавно опубликованном с открытым исходным кодом PaddleOCR-VL-0.9B от Baidu gets credit for a 90.67 score on OmniDocBench v1.5, при этом утверждается, что она превосходит GPT-4o, Gemini 2.5 Pro и Qwen2.5‑VL‑72B, оставаясь ультракомпактной. Это превращает вчерашний выпуск модели в конкретный сигнал лидерборда по 109 языкам и сложным макетам. model highlight продолжая тему компактного VLM.
Если эти результаты подтвердятся в независимых тестах, кривая цена-эффективность для корпоративного понимания документов смещается в сторону малых VLM, что позволяет локальные развёртывания и пакетные конвейеры, где важны конфиденциальность и пропускная способность.
«Avenger 0.5 Pro» выходит на вершину Video Arena (изображение в видео)
Новая, ранее малоизвестная модель под названием Avenger 0.5 Pro от “VR” поднялась на вершину рейтингов Video Arena в задачах преобразования изображений в видео, вытеснив устоявшиеся системы. Детали скудны, но внезапное перемещение в таблице лидеров указывает на быструю итерацию или новый обучающий запуск от нового участника. leaderboard update
Для аналитиков вывод таков: конкуренционная текучесть в i2v — ожидайте более быстрых темпов релизов и планируйте инфраструктуру оценки, способную принимать непрозрачные модели с минимальной документацией, проверяя при этом временную согласованность и соблюдение подсказок.