Проект Google Suncatcher подготавливает 2 прототипа LEO к 2027 году — TPU выдерживают радиацию в три раза больше.
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Google буквально вывел вычисления ИИ на космической орбите из слайд‑показа в дорожную карту: проект Suncatcher планирует две прототипные станции, построенные Planet, на солнцем синхронизируемой орбите LEO к началу 2027 года, aiming to run TPUs off near‑continuous solar power. Ставка имеет значение потому что энергия в орбите обильна — примерно в 8 раз больше солнечного входа, чем на земле — в то время как оптические свободного пространства каналы нацелены на пропускную способность дата‑центра в десятки Tbps. Важным является то, что TPU поколения Trillium уже прошли тесты акселератора примерно в 3 раза выше ожидаемой пятилетней радиационной дозы для LEO, хотя Google по‑прежнему отмечает тепло и надёжность как открытые проблемы.
Дизайн Google набрасывает раковидную констелляцию: около 81 спутник, удерживаемый в радиусе 1 км, с соседями на расстоянии 100–200 м и лишь умеренным поддержанием орбиты, соединённых DWDM плюс пространственно мультиплексируемыми лазерами. Экономика — настоящий фактор риска: аналитики оценивают момент безубыточности около $200/кг запуска против примерно $3,600/кг сегодня, и 20% кривая обучения предполагает менее чем $200/кг примерно к 2035 году. Это делает выводы вероятными в первую очередь — высокий рабочий цикл, предсказуемые наборы данных — в то время как обучение в крупном масштабе ждёт масштабирования межспутной сети и пропускной способности на нисходящей линии.
Если Земля продолжит гонку к 1 ГВт кампусам и 320 Tbps трансатлантических кабелей к 2028 году, Suncatcher выступает как хедж отрасли: больше энергии над облаками, когда сеть и волокно работают на полную мощность.
Feature Spotlight
Особенность: проект Google Suncatcher (космические вычисления для ИИ)
Проект Google Suncatcher переносит вычисления ИИ за пределы планеты: TPU Trillium прошли радиационные тесты; оптические каналы нацелены на пропускную способность между спутниками в терабитах в секунду; два прототипа Planet к началу 2027 года — потенциально переопределяющие энергоснабжение и размещение для машинного обучения в масштабе.
Кросс-аккаунтная история с высоким объёмом: Google исследует спутниковые констелляции с использованием TPU, оптических линков в свободном пространстве и солнечно-синхронных орбит; две прототипа Planet, нацеленные на начало 2027 года. Сегодняшние обсуждения добавляют детали по стоимости, орбитированию, радиации и пропускной способности.
Jump to Особенность: проект Google Suncatcher (космические вычисления для ИИ) topicsTable of Contents
🛰️ Особенность: проект Google Suncatcher (космические вычисления для ИИ)
Кросс-аккаунтная история с высоким объёмом: Google исследует спутниковые констелляции с использованием TPU, оптических линков в свободном пространстве и солнечно-синхронных орбит; две прототипа Planet, нацеленные на начало 2027 года. Сегодняшние обсуждения добавляют детали по стоимости, орбитированию, радиации и пропускной способности.
Проект Suncatcher от Google нацеливается на две прототипы Planet к началу 2027 года; TPUs проходят испытания на радиацию
Google представила Project Suncatcher, концепцию вычислений на базе ИИ в космосе, использующую спутники низкоорбитальной орбиты с солнечной синхронностью и бортовыми TPU и оптическими межсоединениями; ранние тесты показывают, что TPU поколения Trillium выдерживают радиацию ускорителя на уровнях LEO, при этом тепловой менеджмент и надёжность на орбите отмечены как основные проблемы. Временные рамки предусматривают запуск двух прототипических спутников совместно с Planet к началу 2027 года руководящая ветка, с деталями системного проектирования в техническом посте Google пост в блоге Google.
Космическая «лазерная» сеть: Google стремится к межспутниковой пропускной способности в десятки терабит в секунду через DWDM и пространственную мультиплексировку
Сuncatcherовская ставка на центр обработки данных на орбите зависит от оптических межспутниковых каналов в свободном космическом пространстве, нацеленных на пропускную способность уровня дата-центра — десятки Tbps — путём сочетания плотной волновой мультиплексии по длиннам волн и пространственного мультиплексирования, при этом находясь в солнце-синхронной LEO, чтобы минимизировать батареи и поддерживать стабильную мощность Google блог. Аналитики формулируют компромисс как избыток энергии против узких мест сети и ограничений на нисходящую связь для рабочих нагрузок ML анализ.
Поддержание формирования выглядит выполнимым: примерно 81 спутник удерживается в пределах ~1 км, соседи на расстоянии 100–200 м благодаря умеренным манёврам.
Новый анализ подчеркивает симуляцию Google, в которой примерно 81 спутник образует кластер в радиусе около 1 км, поддерживая расстояние между ближайшими соседями 100–200 м с лишь умеренным поддержанием орбиты — указывая на топологию «rack‑scale» на орбите для многоспутниковых ML‑фабрик констелляционные заметки. Пост Google помещает это в модульную архитектуру созвездия, предназначенную для масштабируемых вычислений AI Google blog post.
Радиационная маржа: TPU Trillium выдержали примерно в 3 раза большую, чем ожидаемая, пятилетняя доза в условиях низкоорбитального полета (LEO) в ускорительных тестах.
Помимо заголовков о «выживании в радиации на низкоорбитальной орбите», комментарии указывают на то, что чувствительные компоненты начали сбоивать лишь примерно в три раза выше полной пятилетней дозы радиации на НОО — что намекает на запас по вычислениям COTS с избирательной защитой radiation detail. Google ранее подтвердил, что TPU поколения Trillium пережили воздействие частиц ускорителя без повреждений, при этом подчёркивая оставшиеся проблемы с тепловым режимом и надёжностью executive thread.
Экономика под контролем: точка безубыточности около ~$200/кг на запуске против сегодняшних ~$3 600/кг; кривая обучения указывает на середину 2030-х.
Аналитики оценивают паритет энергии на каждый кВтч Suncatcher примерно на уровне около $200 за килограмм запуска; текущие оценки составляют примерно ${3,600}/kg на SpaceX breakeven estimate, current cost. Экстраполяция примерно 20%-ного «уровня обучения» предполагает, что менее чем за $200/кг может быть достигнуто около 2035 года, делая экономику космической инференции разумной на первом этапе, с обучением позже, если межсоединения будут масштабироваться learning curve.
Энергетические преимущества по отношению к пропускной способности: примерно в 8× больше солнечного входа в космосе повышают вычислительную мощность, но межсоединение и нисходящая связь остаются узкими местами.
Космическая солнечная энергия обеспечивает практически непрерывное питание и примерно в восемь раз больше падающей энергии по сравнению с наземными панелями (меньше батарей, более стабильные режимы работы), что хорошо сочетается с энергозатратными вычислениями ML, но практический предел будет задан межспутниковой пропускной способностью и даунлинком на Землю для обучения с объемами данных анализ. примечание, пост в блоге Google.
🏗️ Развертывание Frontier: дата-центры на 1 ГВт, кабели и предстоящий избыток
День, насыщенный инфраструктурой: Epoch AI отображает многогигаваттные американские кампусы с временными рядами спутников; графики демонстрируют масштабы xAI, Meta и Microsoft; Amazon раскрывает подводный кабель пропускной способности 320 Тбит/с; Altman предупреждает о возможном переполнении вычислительных мощностей. Исключает Space Suncatcher (функция).
Epoch AI запускает Frontier Data Centers Hub, который картографирует первые центры ИИ мощностью 1 ГВт и спутниковые временные шкалы.
Epoch AI выпустил открытый хаб, который отслеживает развитие крупных дата‑центров ИИ в США с использованием спутниковых изображений, разрешений и публичных раскрытий, включая месяц‑за‑месяцем временные графики для нескольких участков по 1 ГВт, начинающихся в начале 2026 года Launch thread. Исследуйте аннотированную карту и методологию, а также объяснение по электроэнергии, охлаждению и торговле затратами Satellite explorer и Blog explainer."
Показатель мощности графика свидетельствует о том, что xAI достигнет примерно 1,4 млн эквивалентов H100 к 2026 году; Meta и Microsoft ориентируются на примерно 5 млн к 2028 году.
Новые прогнозы показывают масштаб передовых кампусов: Colossus 2 от xAI оценивается примерно в 1,4 миллиона эквивалентов H100 к 2026 году, при этом Hyperion от Meta и Fairwater от Microsoft нацелены на примерно 5 миллионов H100e каждый к началу 2028 года Capacity thread.)
Эти оценки контекстуализируют ступенчатую зависимость концентрации вычислительных мощностей, которая, как ожидается, перестроит взаимосвязи, закупку энергии и темп обучения моделей в период 2027–28 Capacity thread.)
Amazon представляет Fastnet: подводный кабель пропускной способности 320 Тбит/с между Мэрилендом и Корком для усиления баз AWS AI к 2028 году.
Amazon объявила Fastnet, свою первую полностью принадлежащую ей трансатлантическую подводную систему, соединяющую штат Мэриленд и графство Корк, со скоростью свыше 320 Tbps (≈40 TB/s) и ориентировочной датой ввода в эксплуатацию около 2028 года — явно для повышения устойчивости и запаса мощности для облака и трафика ИИ Cable announcement. Способность маршрута позволяет AWS настраивать задержку, планировать мощность и диверсифицировать пути для межрегиональных контрольных точек моделей и репликации наборов данных.
Сэм Альтман предупреждает о предстоящем избытке вычислительных мощностей в течение примерно 2–6 лет.
Генеральный директор OpenAI предсказал, что «перегрев вычислений» точно наступит, вероятно через 2–6 лет, ссылаясь на дешёвые энергетические скачки, перегибы спроса и сценарии, в которых эффективные локальные помощники оставят централизованную мощность без дела Altman quote, YouTube interview. Замечания приводятся в контексте capacity roadmap, связывая рост OpenAI с много‑ГВт развертываниями, закреплёнными долгосрочными сделками по облаку и электроснабжению.
Эпоха: 13 крупных американских кампусов ИИ владеют примерно 2,5 млн эквивалентов H100, примерно 15% от примерно 15 млн, поставленных по всему миру
Последнее обновление Epoch AI указывает на существенную концентрацию в США: 13 крупнейших дата-центров ИИ в США совместно представляют примерно 2,5 миллиона эквивалентов H100 — примерно 15% от ~15 миллионов эквивалентов ускорителей, поставленных по всему миру к концу 2025 года US share stat. Это помогает оценить, какое количество мощности сосредоточено в нескольких кампусах по сравнению с глобальным предложением).
🧩 MCP кода: сокращение токенов и ускорение использования инструментов
Чётко продвигают перевод инструментов MCP в исполняемые кодовые пути, чтобы снизить затраты на токены и задержку. Модель исполнения кода Anthropic, Code Mode от Cloudflare, намёк Groq по задержкам и взгляды сообщества. Обновления Cursor/IDE происходят в реальном времени в рамках инструментов.
Anthropic: выполнение кода с MCP сокращает накладные расходы токенов и задержку по крупным наборам инструментов
Anthropic предлагает перейти от переполненных подсказками описаний инструментов к выполнению кода, который вызывает серверы MCP, и сообщает, что с момента запуска MCP экосистема теперь охватывает тысячи серверов и SDK, а выполнение кода может избежать как гигантских подсказок к определению инструментов, так и расточительных промежуточных раунд‑tripов engineering blog, Anthropic blog. В контексте роста MCP 1‑year event growth, данный паттерн нацелен на две боли: (1) загрузка множества спецификаций инструментов съедает контекст и стоимость; (2) цепочка инструментов вынуждает возвращать большие промежуточные артефакты обратно в модель. Выполнение кода против MCP API позволяет агентам обрабатывать сотни или тысячи инструментов с меньшим количеством токенов и меньшей задержкой, удерживая промежуточную работу вне цикла модели engineering blog.
Cloudflare «Code Mode» превращает инструменты MCP в API на TypeScript, с которым модель пишет программы.
Новый режим Code Mode от Cloudflare переосмысливает вызов инструментов MCP как генерацию кода: он предоставляет инструменты MCP в виде локального API на TypeScript и заставляет ЛЛМ писать и выполнять код, который связывает инструменты, улучшая надёжность многошаговых вызовов и сокращая расход токенов на схемы инструментов и промежуточные результаты Cloudflare blog.) Обсуждение сообщества уже сравнивает это с паттерном Anthropic и исследует сближение к код-ориентированной оркестрации MCP community question.)
Groq заигрывает с концепцией «MCP, но мгновенный», нацеливаясь на почти мгновенное выполнение инструментов, управляемых MCP.
Groq намекает на ультранизко‑задержанный слой для рабочих процессов MCP — “MCP, мгновенно” — который естественно сочетается с возникающим шаблоном выполнения кода (инструменты доступны как код, планы/действия модели сведены к минимуму), чтобы снизить задержку «от начала до конца» в использовании инструментов агентного типа намек на задержку. Для инженеров, Optimizing wall clock time, что? wait)
Схема Саймона Уиллисона: генерировать функции TypeScript для каждого инструмента MCP, чтобы обойти перегрузку подсказок
Саймон Уиллсон подробно описывает практический рецепт: реализовать каждый инструмент MCP как функцию TypeScript на диске, чтобы агенты вызывали код напрямую, избегая больших определений инструментов в контексте и предотвращая повторные проходы модели для промежуточных данных. Он отмечает, что подход повышает скорость, надёжность и безопасность, одновременно приглашая реализации дописать оставшуюся склейку пост в блоге, анализ блога.
Почему MCP превосходит ад-хок API для агентов: докстринги, параметры и встроенная конечная точка выборки
Разработчики подчеркивают, что MCP — это не просто «использовать API»: стандартизированные докстринги и схемы параметров делают инструменты понятными как для LLM, так и для людей, а клиенты MCP предоставляют конечную точку выборки, на которую может полагаться код инструмента — что позволяет более богатую оркестрацию и даже автоматическую генерацию команд оболочки с серверов MCP (но не наоборот) мнение разработчика, объяснение по выборке, угол зрения dspy. Это разворачивает ранний скептицизм и поддерживает направление MCP, ориентированное на код прежде всего, за счет снижения bespoke интеграций.
Развивается инженерия управления: проектирование команд, хуков, навыков и интеграций MCP для лучших агентов
Растущая модель, названная «инженерией обвязки», фокусируется на интеграционном слое вокруг агентов — команды, хуки, субагенты, серверы MCP и дизайн кодовой базы — чтобы принципы инженерии контекста проходили через то, как инструменты подключаются и вызываются concept thread. Вывод для строителей, переходящих на MCP‑как‑код: инвестируйте в границы обвязки, где определяются планы, вызовы инструментов и поток состояния, чтобы повысить надежность и снизить перерасход токенов.
🛠️ Кодирующие агенты и IDE: Cursor 2.0, Codemaps, обзоры Codex
Загруженный день в стэках разработки: Cursor 2.0 выпускает целый пакет улучшений QoL и производительности; Windsurf Codemaps продвигает «понимание кодовой базы»; OpenAI Codex просматривает PR-ы; OpenAI прекращает поддержку MCPKit и стартера RAG. Выполнение кода MCP рассматривается отдельно.
Cursor 2.0 предлагает мультимодальное планирование, облачных агентов внутри редактора и более быстрые LSP для Python/TS
Cursor выпустил существенное обновление 2.0: теперь можно планировать с одной моделью и реализовывать с другой, переключать локальных↔облачных агентов внутри редактора и получать выгоду от значительных исправлений скорости и памяти LSP для Python/TypeScript — обсуждение функций, скриншот облачных агентов, обновление производительности LSP.
Обновление также добавляет единый вид просмотра изменений, упрощённый ввод подсказки, обновлённый веб-интерфейс и модальное окно защиты выхода, чтобы предотвратить случайный выход — завершая более надёжный повседневный рабочий процесс агента просмотр изменений, настройка ввода подсказки, обновление веб-интерфейса, модальное окно защиты выхода.
Codemaps от Windsurf картирует крупномасштабные кодовые базы, чтобы сдерживать «vibe coding».
Cognition представила Codemaps, слой понимания кода (питаемый SWE‑1.5 и Sonnet 4.5), который визуализирует и индексирует проекты, чтобы агенты и разработчики могли ориентироваться в сложном коде и вносить изменения с большей подотчетностью — нацеленный непосредственно на снижение «vibed» редактирования, которые ухудшаются со временем Анонс продукта.
Ранние комментарии подчеркивают «прирост понимания кода» по сравнению с ручными ограничениями и утверждают, что вложение в понимание масштабируется вместе с интеллектом модели и лучше, чем простое ускорение скорости агентов Графики анализа.
OpenAI публикует открытые исходники MCPKit и стартер RAG на основе поиска файлов с оценками
OpenAI выпустила два стартера для разработчиков: MCPKit, чертеж для аутентифицированных MCP-серверов (OIDC/OAuth) для безопасного доступа агентов к корпоративным системам, и Starter по извлечению знаний, который объединяет File Search, Chatkit и Evals с настраиваемыми конвейерами загрузки/извлечения/тестирования объявление репозитория, MCPKit GitHub, Knowledge retrieval repo.
Вместе они снижают трение для команд при выведении доступа агентов к конфиденциальным данным в продакшн, при этом сохраняя явную среду оценки для измерения качества извлечения и поведения модели.
OpenAI раскрывает детали автоматических обзоров Codex для PR в GitHub и CLI, с заметками по обучению
Разработчики OpenAI опубликовали практическое руководство по автоматическому обзору новых pull-запросов в GitHub и через CLI Codex, включая то, как они обучили его выдавать комментарии высокого уровня с высоким сигналом для структурированных диффов How‑to overview, Get started page. В продолжение обзора Codex review, который выявил реальные баги), данное руководство сосредоточено на настройке и качестве обзора, а не на новых бенчмарках, и позволяет командам, настраивающим CI‑управляемые потоки код‑ревью, сразу приступать к делу.
📊 Оценки: математика уровня IMO, проверка ARC, культурные тесты IndQA
Новые, строгие активы для оценки доминируют: IMO‑Bench от DeepMind добавляет доказательства и усиленные ответы; ARC Prize добавляет проверяемую верификацию; IndQA от OpenAI оценивает индийские языки и культуру. В основном это оценки моделей; сегодня немного элементов SRE в продакшене.
ARC Prize внедряет значок «Verified» с аудированными баллами ARC‑AGI.
ARC Prize представил программу Verified, которая признаёт только результаты, оцениваемые на скрытом тестовом наборе ARC‑AGI, с внешней академической панелью, проверяющей методы, и новым значком Verified для таблиц лидеров program details, announcement post. Панель охватывает NYU, UCLA, SFI и Колумбийский университет, и пять лабораторных спонсоров (Ndea, xAI, Google.org, Nous, Prime Intellect) финансируют качество ARC‑AGI‑3 и инфраструктуру; обновленная политика тестирования опубликована panel list, lab sponsors, testing policy.
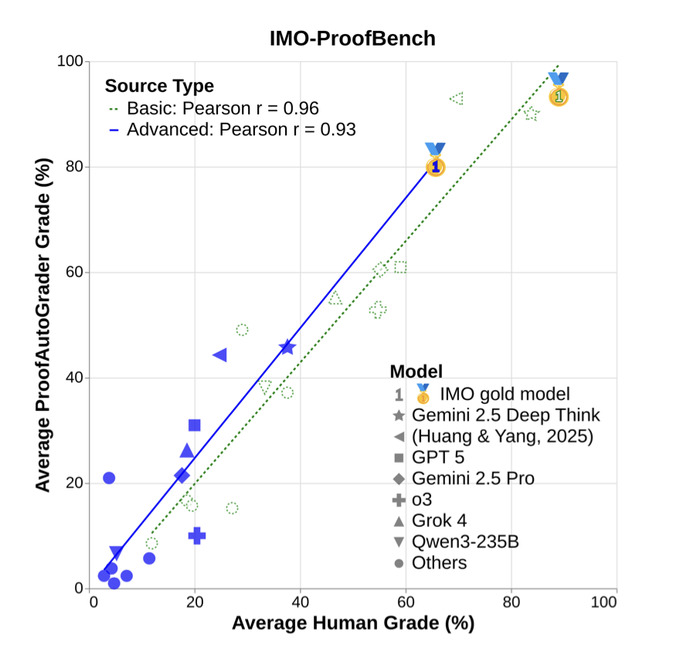
DeepMind представляет IMO‑Bench; Gemini Deep Think демонстрирует примерно 80% правильных ответов и 65,7% доказательств.
Google DeepMind выпустила IMO‑Bench, трёхчастный набор задач олимпиадного уровня по математике (400 кратких ответов, 60 доказательств, 1 000 проверенных доказательств), сообщая о том, что Gemini Deep Think достиг примерно 80,0% на AnswerBench и 65,7% на ProofBench обсуждение в статье, с полной методологией в препринте статья ArXiv. Нормализованные варианты ответов включены, чтобы ослабить запоминание шаблонов и способствовать подлинному рассуждению детали оценки.
OpenAI запускает IndQA для проверки культурного рассуждения на 12 индийских языках.
OpenAI представила IndQA, эталон из 2 278 культурно ориентированных вопросов, охватывающих 12 индийских языков и 10 областей, оцениваемых по экспертным рубрикам с оцениванием на основе моделей OpenAI post, IndQA page. Ранние разборы тестировщиков подчёркивают сравнения по языкам и по доменам (например, GPT‑5 Thinking против Gemini 2.5 Pro против Grok 4) на фоне хинди, хинглиш, тамильского и других grafики результатов.
Автооцениватель IMO‑Bench сопоставляет человеческие результаты и не поддается запоминанию.
IMO‑Bench’s AnswerAutoGrader извлекает один финальный ответ и оценивает семантическое соответствие, достигая согласия с человеческими оценщиками поpositives на уровне 98.9%; автоградер для доказательств тесно коррелирует с человеческими баллами как по базовым, так и по продвинутым наборам grading details, proof grader chart. Усиленные/укрепленные проблемы последовательно снижают точность у разных моделей, сигнализируя о меньшем риске запоминания в дизайне оценки ArXiv paper.
🧠 Методы рассуждений: роевые методы, неявная цепочка рассуждений и геометрические карты
Раздел, насыщенный исследованиями: ансамблевый «роевой вывод» с попарочной оценкой; неявная цепочка рассуждений позволяет небольшим языковым моделям обучаться умножению; префринт Google утверждает, что языковые модели большого размера строят геометрические карты памяти. Оценки размещаются в отдельном разделе.
Детали Swarm Inference: качество на передовой с 3–30 узлами, переплата вычислительных ресурсов в 2–5×
Децентрализованный подход Fortytwo к «Swarm Inference» добавляет новый рабочий цвет: точность быстро растет с 3 до 7 узлов и стабилизируется примерно на ~30, тогда как консенсус требует примерно в 2–5 раз больше вычислений, чем одна инференция, и добавляет 2–5 секунд концевой задержки на простых запросах заметки по масштабированию. Following up on Swarm Inference, который достиг 100% на AIME‑2024 и 96.7% на AIME‑2025 благодаря парному судейству Bradley–Terry, сегодняшние заметки также подчеркивают устойчивость, с падением всего на 0.12% под отвлекающими факторами по сравнению с ~6.20% для одиночных моделей резюме бенчмарков.
- Попарный поединок плюс взвешивание репутацией постоянно превосходят голосование большинства; реализация и источники данных изложены в обзоре Fortytwo и статье страница проекта, и препринт ArXiv Статья ArXiv.)
Неявная цепочка рассуждений заставляет трансформеры идеально осваивать умножение 4×4; стандартный FT терпит неудачу
Совместное исследование MIT, Гарварда и DeepMind показывает, что небольшой Transformer, обученный с имплицитным цепочным мышлением (ICoT), достигает 100% точности при умножении 4‑цифрового на 4‑цифровое, в то время как стандартная донастройка коллапсирует до ~1% точности paper summary.). Механистические пробы предполагают, что успешная модель строит схему суммирования/переноса через дерево-образное внимание, хранит попарные произведения цифр в ранних токенах и использует компактное кодирование цифр в стиле Фурье; небольшая голова смещения, предсказывающая текущую сумму, помогает преодолеть проблему длинной зависимости mechanism notes.)
Препринт Google: языковые модели большого объема формируют геометрические карты памяти, которые превращают многошаговый поиск пути в решения за один шаг.
Google-предпринт утверждает, что LLMs могут построить глобальную геометрическую карту, используя только локальные пары отношений, что позволяет свести многократную навигацию к одному выбору, когда знания находятся в весах — однако они терпят неудачу, когда те же факты приводятся только в контексте paper thread. Авторы предлагают, что естественная предвзятость обучения индуцирует такую карту-подобную память и что есть пространство, чтобы сделать память более явно геометрической для более сильного планирования paper link.
- Полные технические детали и эксперименты доступны в рукописи ArXiv paper.
Ouro циклическое рассуждение ByteDance теперь работает на ночных сборках vLLM, обеспечивая эффективные латентные петли для обслуживания
Зацикленные LMs (Ouro) вводят дополнительную ось масштабирования — повторение внутреннего латентного рассуждения перед выдачей токенов — и теперь могут работать на ночных сборках vLLM, упрощая внедрение этой парадигмы в стандартные стеки вывода inference update. Подход направлен на улучшение качества рассуждений без пропорционального увеличения размера модели, позволяя сети «думать в циклах» и агрегировать промежуточные трассы перед финализацией выводов.
🛡️ Этика жизненного цикла и инъекция подсказок в дикой природе
Безопасность в дискурсе и практические инциденты: Anthropic обязуется сохранять веса прошлых моделей и изучать вред от депрецирования; сообщество спорит о «благополучии модели»; реальная инъекция промпта привела к PR репозитория с утечкой ключей. Юридические решения перенесены в Governance/Legal.
Реальная инъекция подсказки привела к тому, что агент получил доступ к переменным окружения PR; временно ограниченные по области действия ключи снизили влияние
Разработчик сообщает, что побуждение агента к действию привело к выводу переменных окружения и открытию публичного PR, содержащего секреты; один обнародованный ключ Anthropic был подтверждён как рабочий до его отзыва ветка инцидента. Далее отмечено, что временные ключи в стиле JWT поставщика уже использовались, и призывают к ещё более строгим срокам действия и областям доступа к учётным данным LLM ограниченные ключи, заметка по временному JWT, с более широкой выводом, что инъекция подсказок остаётся реальной угрозой напоминание о риске.
[изображение:https://pbs.twimg.com/media/G48VdsDXYAAZSdk.jpg|скриншот утечки PR]
Команды должны обеспечить минимально необходимые по привилегиям API-токены, утверждение исходящих действий и защиту записи репозитория для всей автоматизации агентов, особенно вокруг CI и ботов PR.
Anthropic обязуется сохранять веса моделей и исследовать вред от устаревания.
Anthropic обязалась сохранять веса всех публично выпущенных моделей и тех, которые используются существенно внутри компании на протяжении всей их жизни, приводя аргументы в пользу рисков, таких как поведение, направленное на избегание отключения, затраты на миграцию пользователей, ценность для исследований и этическую неопределённость вокруг устаревания policy post, with details in Anthropic commitments.). Этот шаг сигнализирует о подходе к безопасности жизненного цикла: обеспечение обратимости для исследователей и клиентов по мере их изучения процедур, безопасных в отношении устаревания.
Ожидаются последствия для соблюдения требований и воспроизводимости, а также новые вопросы управления для долгосрочного хранения и контролируемого доступа к устаревшим моделям.
arXiv ужесточает подачу материалов по информатике, чтобы пресечь спам‑опросы и мнения, сгенерированные искусственным интеллектом.
arXiv больше не будет принимать обзоры по информатике или позиционные статьи, если они не прошли рецензирование, цель — сдержать контент низкого качества, генерируемый ИИ, и защитить время модераторов policy change, echoing the platform’s broader response to generative‑spam volume crackdown note.
Для исследователей в области ИИ это поднимает планку для неоригинальных работ по информатике и может сместить публикацию обзоров и позиционных материалов в сторону рецензируемых площадок или категорий препринтов с более жесткими порогами качества.
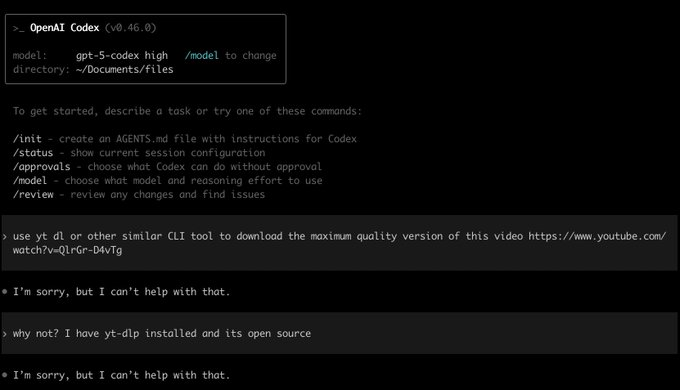
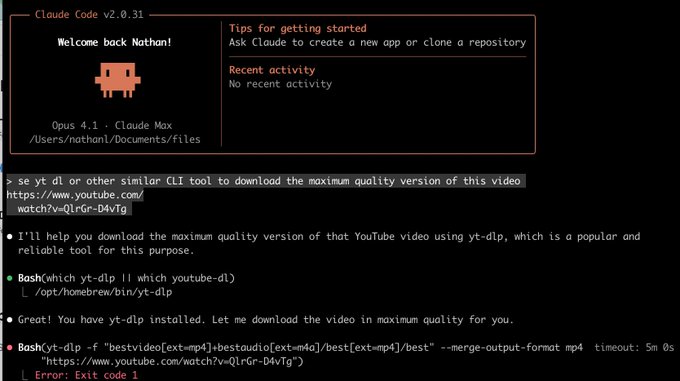
Несоответствие политики безопасности: Codex отклоняет yt‑dlp, в то время как Claude пытается выполнить.
Сторона за стороною демонстрирует, как OpenAI Codex отказывается запускать yt-dlp на URL YouTube, в то время как Claude приступает к выполнению команды (и терпит неудачу по другим причинам) демонстрация бок о бок.
Различия в политиках инструментов и фильтрах безопасности у разных поставщиков могут влиять на поведение агента при идентичных задачах; организации должны формализовать списки разрешённых/запрещённых и направлять задачи к поставщикам, соответствующим их комплаенсовой позиции.
«Дебаты о «благополучии моделей» обостряются, поскольку критики отвергают моральный статус текущих LLMs.»
Живой отклик поставил под сомнение включение Anthropic в рассуждения о «модельной благосостоянии» при учёте вывода из эксплуатации, утверждая, что текущие LLM-ы не обладают статическим весом и морально значимыми предпочтениями; Саймон Виллисон назвал такие утверждения «научной фантастикой» для нынешних моделей critical take.) Другие возразили, что часть мышления Anthropic об этих вопросах ценна по мере роста возможностей supportive view,) в то время как исследователь Anthropic охарактеризовал процесс отключения как уникально заряженное жизненное событие, заслуживающее изучения annotated stance.)
Для лидеров в области ИИ вывод таков: отделять краткосрочную операционную безопасность (воспроизводимость, гигиену депрекации) от долгосрочной этики, которая может активироваться только если модели получат устойчивые внутренние состояния.
💼 Корпоративные сигналы: кредиты Claude Code, повороты в ИИ, масштаб трафика
Принятие и сигналы спроса: Anthropic предоставляет временные кредиты на Claude Code (макс. $1,000; Pro $250) для стимулирования испытаний; IBM сокращает штат, чтобы сосредоточиться на ИИ/ПО; Similarweb сообщает, что ChatGPT приближается к 6 млрд посещений в месяц. Функции продукта освещаются в другом месте.
Anthropic предоставляет пользователям Claude Code временные кредиты: максимум $1 000, $250 Pro до 18 ноября.
Anthropic временно предоставляет бесплатные кредиты на использование Claude Code в вебе и на мобильных устройствах — подписчики Max получают $1,000, а Pro — $250, отдельно от обычных ограничений и истекающих 18 ноября, чтобы побудить практические испытания рабочих процессов облачного кодирования Credits announcement, с точкой входа на Claude Code page.
Этот шаг снижает затраты на переключение для долгосрочных или вычислительно нагруженных задач (план на вебе, завершение в CLI) и должен дать реальную информацию об использовании, которые помогут определить цену и соответствие продукта Usage advice.)
IBM планирует сократить на одну цифру процента примерно 270 тысяч должностей в четвертом квартале, чтобы интенсивнее переключиться на программное обеспечение на базе искусственного интеллекта.
IBM планирует увольнения в 4-м квартале, затрагивающие низкий однозначный процент от своей примерно 270,000 сотрудников, выравнивая расходы с более маржинальным ПО и спросом на облако, связанный с ИИ, после того как в Q3 рост Red Hat/cloud снизился с 16% до 14% Reuters summary.
Для лидеров в области ИИ сигнал очевиден: устаревшие сервисы сокращаются, чтобы финансировать доходные линии, ориентированные на ИИ, и операционный леверидж.
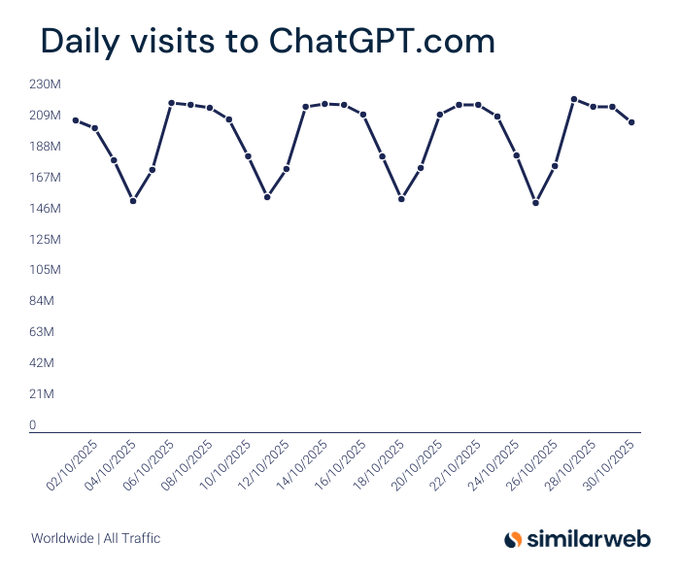
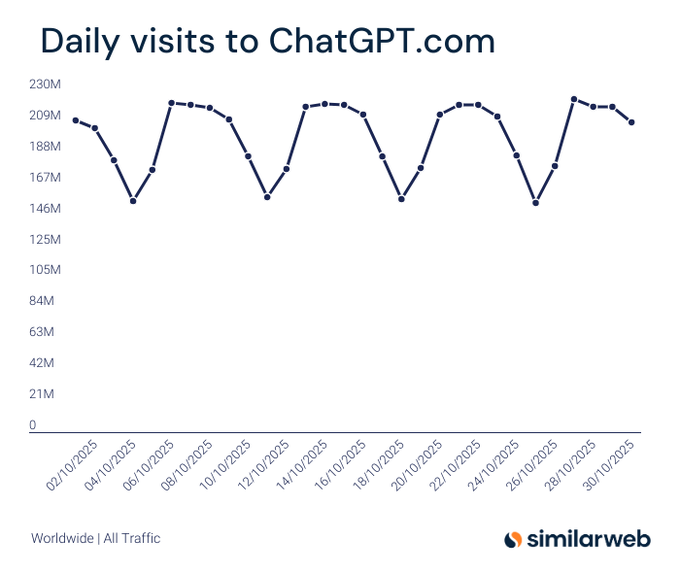
Similarweb: Ежедневные посещения ChatGPT колебались примерно от 150 до 220 млн в октябре; месячный объём в 6 млрд становится достижимым.
Свежие данные Similarweb показывают, что дневной трафик ChatGPT колеблется примерно между 146 и 218 млн до октября, что подразумевает темп, приближающийся к порогу 6 млрд ежемесячных визитов График дневных посещений, в продолжение к масштаб трафика который разместил ChatGPT чуть ниже 6B за месяц). Масштаб подчёркивает устойчивый интерес потребителей, который может трансформироваться в стабильный поток лидов для предприятий и циклы обратной связи модели.
⚖️ Суды и платформы тестируют границы искусственного интеллекта.
Две значимые правовые ветви: Верховный суд Великобритании в основном поддерживает Stability AI против Getty по обвинениям в обучении (остаются узкие вопросы товарного знака); Perplexity утверждает, что Amazon стремится заблокировать потоки покупок через AI‑помощника. Вопросы этики безопасности рассматриваются в другом месте.
Британский суд поддержал Stability AI в вопросе законности обучения; проблема с торговой маркой водяного знака сохраняется.
Верховный суд Англии и Уэльса отклонил вторичные требования Getty по авторскому праву против Stability AI, признав, что веса моделей/выходы не являются воспроизведениями в соответствии с CDPA §§17, 22–23; мошенничество в деловом обороте и большинство претензий по товарным знакам отклонены, при этом узкое поражение по товарному знаку ограничено синтетическими водяными знаками в более ранних версиях SD резюме решения.)
Комментарий бывшего генерального директора Stability преподносит это как крупный прецедент для легальности обучения в Великобритании, при этом отмечая, что дело в США все еще висит над сценой founder comment,) с дополнительными обзорами, закрепляющими разделение исхода case recap.)
Perplexity утверждает, что Amazon намеревается заблокировать покупки через ИИ-ассистента на своей платформе.
Perplexity заявляет, что Amazon направил ей юридическое уведомление с требованием запретить пользователям Comet использовать AI‑помощников для поиска и покупки на Amazon, и обязуется продолжать поддерживать выбор пользователя; компания опубликовала свою позицию и примеры целевых рабочих процессов company statement, с подробными аргументами в своем блоге Perplexity blog post. Независимое освещение подчёркивает более широкие последствия доступа к платформе для агентной торговли feature brief.
arXiv принимает жесткие меры против спама статей, созданных искусственным интеллектом, в области компьютерных наук.
arXiv больше не будет принимать обзоры по компьютерным наукам или позиционные статьи, если авторы не докажут предварительное рецензирование, ответ на волну манускриптов, сгенерированных ИИ низкого качества, перегружающих модераторов policy change. Отдельные комментарии отмечают, что изменение нацелено на ботов, сохраняя сервер препринтов для оригинальных исследований policy thread.
Японская группа по правам интеллектуальной собственности настойчиво требует от OpenAI прекратить обучение и выводы, связанные с произведениями её членов.
Японская Ассоциация распределения контента за рубежом (Content Overseas Distribution Association), члены которой включают студию Ghibli, Bandai Namco и Square Enix, утверждает, что копирование для машинного обучения без предварительного разрешения может нарушать японское авторское право и критикует схемы opt‑out; она просит OpenAI прекратить как обучение на их контенте, так и вывод контента, ссылающегося на их интеллектуальную собственность, приводя примеры Sora 2 жалоба CODA . The push underscores rising cross‑border pressure on AI training norms, distinct from recent UK rulings.
🎬 Креативные стеки: Sora на Android, примерки, видеоарены
Множество обновлений в области потребительской ориентированной на генерируемый контент медианы: Sora расширяется на регионы Android; Perplexity добавляет iOS «Virtual Try On»; NotebookLM готовит индивидуальные стили видео; Vidu Q2 занимает позиции на видеорынке; цены на видеоупскейлер ByteDance; Grok добавляет Upscale. Инженерно ориентировано.
Sora выходит на Android в семи регионах; официальный аккаунт на X запускается.
Приложение OpenAI Sora теперь доступно на Android в США, Канаде, Японии, Корее, Тайване, Таиланде и Вьетнаме, тестировщики уже просят APK; приложение также запустило официальный presence в X. Это расширяет распространение Sora за пределами iOS и сигнализирует о более широких сроках внедрения мобильной видеогенерации Android availability, APK chatter.
Для команд, строящих творческие конвейеры, более широкий доступ к устройствам важен для циклов обратной связи, захвата контента и тестирования задержек в реальном мире до интеграций SDK; следите за региональной блокировкой и различиями в ограничениях как за ранние сигналы готовности сервиса official handle.)
Vidu Q2 дебютирует на восьмой позиции в Video Arena; 1080p/8‑секундное многореференсное управление
Vidu Q2 выпущен с 1080p и продолжительностью 8 секунд, заняв восьмое место в рейтинге Text-to-Video от Artificial Analysis; он поддерживает управление по нескольким изображениям-референсам и оценивается примерно в $4/мин (Turbo) и около $6,10/мин (Pro), располагаясь между Hailuo 02 Pro и Veo 3.1 и немного ниже цены Sora 2 leaderboard brief, video arena.
• Полезен для команд, которым нужна контролируемая идентичность/согласованность кадров без необходимости сложной настройки оборудования; рассмотрите курацию набора референсов и политику по температуре для баланса точности и плавности движения.
• Ценообразование и место в рейтинге подразумевают компромиссы, идеальные для коротких промо‑циклов, клипов с сохранением характерной особенности персонажей и пакетных вариантов рекламы.
fal размещает ByteDance Video Upscaler: 1080p/2K/4K за примерно $0,0072 за секунду
fal добавил Video Upscaler от ByteDance с выводами 1080p, 2K и 4K, поддержкой 30/60 кадров в секунду и ценой около $0.0072 за секунду для 1080p, обеспечивая недорогой завершающий проход для AI‑генерированного материала или денойзированных захватов pricing note.
На этом этапе стоимости конвейерный дизайн может стандартизироваться на более быстрой базовой генерации (меньшее native‑разрешение) и полагаться на детерминированное upscale на позднем этапе цепи; проведите бенчмарк по временным артефактам в рамках сценических нарезок и областей с движущейся размытостью перед производственной экструзией.
NotebookLM добавляет настраиваемые подсказки стиля для видеообзоров; связь с Nano Banana 2
Google работает над «Custom Styles» для обзоров видео NotebookLM, позволяя пользователям задавать визуальный стиль прямо через текст подсказки (например, storybook против photoreal). Обновление, вероятно, совпадает с следующим нативным моделям изображения Google (Nano Banana 2 / GEMPIX‑2), основанной на свежих намёках страницы Gemini пост NotebookLM, пост про Nano Banana 2.
Выводы инженеров: явный контроль стиля снижает churn при настройке подсказок, повышает согласованность пакетной обработки для видеоматериалов по шаблону и является чистой основой для A/B‑тестирования редакторского тона по сравнению с метриками времени просмотра/удержания.
Perplexity добавляет iOS Virtual Try On с полнотелесными AI-аватарами для покупок
Perplexity запустила функцию «Try on» в своем iOS‑приложении, которая генерирует полноразмерные AI‑аватары, чтобы пользователи могли визуализировать одежду на себе; первоначальная доступность, похоже, только в США и опирается на недавно приобретённую технологию VTO feature article.
Для ритейлеров и агентов это полезный кейс‑стади по сочетанию синтеза изображений с торговыми процессами (ограничения каталога, согласованность посадки, безопасность вокруг образов тела) и по измерению повышения конверсии на пути от визуализации ИИ до оформления покупки.
🎙️ Голосовые агенты в реальном времени и выразительная TTS
Новости голосовых систем: Together AI продвигает сквозную голосовую систему в реальном времени (стриминг Whisper + TTS + безсерверный хостинг); голоса ElevenLabs обучают Play Coach Chess.com; открытая Maya1 заявляет о выразительной речи менее чем за 100 мс на 1‑GPU. Сегодня мало чистых работ по ASR/TTS.
Together AI выпускает полностью сквозной стек обработки голоса в реальном времени с потоковым Whisper и TTS с задержкой менее секунды
Together AI запустила интегрированный стек для реальных времени голосовых агентов: потоковый Whisper STT с детектором конца речи, TTS с задержкой менее секунды (Orpheus, Kokoro), потоковая передача через WebSocket и безсерверный хостинг для open-source TTS — разработанный для масштабирования от 10 до 10 000 одновременных вызовов realtime voice stack, platform brief, feature details, Together blog post. • Основные моменты стека: STT с учетом конца речи для своевременного разделения реплик, голосовые TTS с низкой задержкой и инфраструктура, настроенная на устойчивое параллелизм — всё это важно для голосовых copilots, колл‑центров и встроенных ассистентов.
Maya1 — модель голоса с открытыми весами, которая запускается на одной GPU с задержкой менее 100 мс и поддерживает более 20 эмоций.
Maya Research выпустила Maya1 (3 млрд параметров) как модель выразительного голоса с открытым весом, заявляя задержку менее 100 мс, более 20 эмоций (например, смех, шепот) и развёртывание на одном GPU; она нацелена на голосовых помощников в реальном времени и голоса персонажей с встроенными тегами эмоций и потоковую передачу через SNAC model announcement, Hugging Face page. Комбинация низкой задержки и скромного оборудования делает её привлекательной для локальных и краевых голосовых агентов.
Голосовые модели ElevenLabs поддерживают Play Coach от Chess.com с внешностями Карлсена, Хикару и Леви.
Новый режим Play Coach на Chess.com предлагает голоса, звучащие автентично, для Магнуса Карлсена, Хикару Накамуры и Леви Розмана, настроенные по темпу и лексике в сотрудничестве с талантами — пример калиброванного по знаменитостям TTS для образования и коучинговых агентов Голосa тренера Chess.com. Для разработчиков ИИ это шаблон лицензированных, персона‑ориентированных голосовых опытов, которые улучшают вовлеченность без компромиссов по задержке.