GPT‑5 Pro подтверждён на 70,2% ARC‑AGI‑1 по цене 4,78 доллара — стоимость SOTA
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
ARC Prize переместил дебаты ARC‑AGI с vibes на receipts сегодня: подтвержденные, скачиваемые запуски показывают GPT‑5 Pro OpenAI на 70,2% на ARC‑AGI‑1 за 4,78 доллара за задачу и 18,3% на ARC‑AGI‑2 за 7,14 доллара. Эта комбинация точности и цены задаёт реальную производственную границу для агентов долгосрочного рассуждения.
В отличие от выборочных примеров, лидерборд поставляет файлы ответов и скрипты бенчмаркинга, чтобы команды могли аудировать, переоценивать и интегрировать петлю в свои пайплайны. Контраст с o3‑preview нагляден: в отчетах сообщается, что настройка High достигла около 87,5% на ARC‑AGI‑1 при увеличении think‑time примерно в 172 раза по сравнению с Low — и даже Low превысил бюджет ARC. GPT‑5 Pro лидирует там, где это важно: доступные, воспроизводимые запуски при фиксированной сумме расходов, а не героические настройки, которые немногие могут позволить.
После вчерашнего 7M Tiny Recursive Model на 44,6% на ARC‑AGI‑1 и 7,8% на ARC‑AGI‑2 зафиксированные 18,3% на ARC‑AGI‑2 сокращают разрыв на жестком разделении, удерживая задачи менее 10$. Панели мониторинга, агрегирующие стоимость и баллы, теперь провозглашают GPT‑5 наилучшей общей кандидатурой, но ваш параметр по умолчанию всё ещё должен формироваться на основе доменных оценок и бюджетов.
Если вы строите агентов, начинайте с фронтира стоимость–балл, затем маршрутизацию A/B и использование инструментов в ваших реальных рабочих процессах.
Feature Spotlight
Особенность: GPT‑5 Pro опережает ARC‑AGI благодаря затратам и воспроизводимым запускам
OpenAI’s GPT‑5 Pro устанавливает новые проверяемые максимумы по ARC‑AGI‑1 (70.2% за $4.78 за задачу) и ARC‑AGI‑2 (18.3% за $7.14 за задачу), с публичными следами и repro-скриптами — поднимая планку для экономически эффективного передового рассуждения.
Кросс‑аккаунтное покрытие сосредоточено на новых верифицированных оценках ARC Prize. Фокус — на затратных, скачиваемых прогонах и сравнении с прежним o3‑preview — явный сигнал для агентов рассуждений на уровне производственных затрат.
Jump to Особенность: GPT‑5 Pro опережает ARC‑AGI благодаря затратам и воспроизводимым запускам topicsTable of Contents
🏆 Особенность: GPT‑5 Pro опережает ARC‑AGI благодаря затратам и воспроизводимым запускам
Кросс‑аккаунтное покрытие сосредоточено на новых верифицированных оценках ARC Prize. Фокус — на затратных, скачиваемых прогонах и сравнении с прежним o3‑preview — явный сигнал для агентов рассуждений на уровне производственных затрат.
GPT-5 Pro подтвердил достижение передового уровня на ARC‑AGI‑1 (70,2% при $4,78) и ARC‑AGI‑2 (18,3% при $7,14) с прогонами, доступными для загрузки
ARC Prize опубликовал costed, воспроизводимые оценки для OpenAI’s GPT‑5 Pro на его полуприватном бенчмарке: 70.2% на ARC‑AGI‑1 за $4.78/задачу и 18.3% на ARC‑AGI‑2 за $7.14/задачу, при этом ответы и скрипты доступны для аудита ARC announcement, ARC leaderboard, HF responses, benchmarking repo, testing policy.
Это устанавливает явный frontier производственных затрат для агентов долгосрочного рассуждения, переводя разговор от выбраных выборок к ценовым, воспроизводимым запускам, которые команды могут повторно оценивать в своих собственных пайплайнах.
Контекст на передовой: o3‑preview достигает примерно 87,5% на ARC‑AGI‑1, но с примерно в 172 раза большим объёмом вычислений по сравнению с Low; GPT‑5 Pro лидирует по затратам на запуски.
Сообщественные разборы сравнивают по цене и воспроизводимости ARC‑оценки GPT‑5 Pro с ранними результатами o3‑preview: нерелизованный o3‑preview (High) якобы достиг ~87.5% на ARC‑AGI‑1, используя ~172× вычислений по сравнению с его Low‑настройкой, которая сама превысила лимит бюджета ARC—подчеркивая значимость задач GPT‑5 Pro стоимостью менее $10 на высокой точности context thread, ARC announcement.
Для руководителей в области инженерии это проясняет компромиссы: экстремальное время размышления может повышать точность, но запланированные и воспроизводимые запуски являются рамкой принятия решений для промышленного применения.
Разрыв между ARC‑AGI‑2 увеличивается: GPT‑5 Pro демонстрирует рост на 18.3% до $7.14 по сравнению с 7.8% компактного TRM за предыдущий день.
На более сложном бенчмарке ARC‑AGI‑2 подтверждённый показатель GPT‑5 Pro в 18.3% за $7.14/задачу представляет собой значительный скачок вперёд, продолжая работу над 7M TRM, который показал 7.8% и 44.6% на ARC‑AGI‑1 — свидетельство того, что продуманное на длинную перспективу рассуждение по цене не является единичным arc‑agi‑2 chart, ARC announcement.
Для аналитиков ARC‑AGI‑2 полезен для проверки обобщения за пределами сопоставления по образцам; оплачиваемые запуски здесь помогают прогнозировать реальную стоимость цепочек и использования инструментов, которые потребуют сложные агенты.
Панели управления консолидируют соотношение «цена» и «балл»: многие считают GPT‑5 текущей общей лучшей моделью по показателям ARC и составным индексам
Сводные графики показывают ARC‑баллы GPT‑5 Pro по затратам и сравнивают по индексам комплексного рассуждения; несколько аналитиков утверждают, что это самая сильная в целом модель на сегодня — хотя отмечается, что пригодность зависит от случая использования composite charts, arc‑agi‑2 chart.
Команды должны рассматривать это как ориентировочное: используйте границы стоимость‑балл для выбора базовых маршрутов, затем проводите валидацию на задачно‑специфичных оценках и бюджетных рамках.
🛠️ Стек разработки агентов: плагины, планирование и A/B‑тестирование
Обильный поток обновлений инструментов для практикующих по созданию кодирующих агентов; исключает функцию ARC‑AGI. В основном — плагины Anthropic Claude Code, данные по коэффициенту принятия и инфраструктура A/B‑тестирования агентов.
Claude Code запускает бета-версию плагинов с командами, субагентами, MCP-серверами и хуками
Anthropic выпустила Claude Code Plugins в публичной Beta, позволяя командам устанавливать курируемые наборы slash-команд, специально созданных субагентов, MCP-серверов и хуков рабочих процессов из магазина или репозитория в один шаг — “/plugin marketplace add anthropics/claude-code.” В продолжение web rollout, это первый модульный слой платформы для стандартизации поведения агентов между репозиториями и организациями. Настройки и потоки задокументированы с использованием примеров UI и CLI версии v2.0.12, включая включение/отключение, валидацию и конфигурацию магазина на уровне репозитория; общественные маркетплейсы уже работают. См. заметки по установке и использованию в анонсе и документации. release thread install hint changelog card community marketplaces Anthropic news
Amp лидирует по реальным одобрениям pull-запросов, достигая 76,8%, опережая OpenAI Codex и Claude Code
Sourcegraph’s Amp агент от Sourcegraph лидирует в наборе данных с 300k PR, имея уровень одобрения 76.8%, опережая OpenAI Codex (~74.3%) и Claude Code (~73.7%), что свидетельствует о более высоком качестве слияний в реальных условиях для рабочих процессов Amp. График собирает нескольких популярных агентов и интеграций IDE, предлагая редкий сигнал продуктивности в сопоставимых условиях для инженерных лидеров, внедряющих развёртывания агентов. dataset note benchmarks chart maintainer comment
Raindrop выпускает A/B‑эксперименты агентов с диффами по использованию инструментов и по ошибкам, а также хуки PostHog/Statsig.
Raindrop представила набор A/B, созданный специально для агентов, который накладывает ваши существующие флаги функций (PostHog, Statsig), чтобы сравнивать использование инструментов %, уровни ошибок, длину ответа, продолжительность беседы и пользовательские проблемы — для сравнения «вчера против сегодня» флаги не требуются. Уточнения позволяют командам прослеживать агрегированные сдвиги обратно к конкретным пользовательским событиям, облегчая выпуск или откат подсказок, инструментов и маршрутизирующих правил с доказательствами. launch post tool metrics view event drill‑down product site
Дорожная карта Codex CLI: фоновые циклы Bash, постоянные белые списки, улучшенная аутентификация; GPT‑5 Pro уже на подходе
OpenAI’s DevDay AMA изложило планы по ближайшему будущему для Codex CLI: фоновый bash для поддержания работы сервисов во время автономных циклов, постоянные белые списки разрешённых команд в песочнице и более плавный вход по коду устройства. Что касается моделей, GPT‑5 Pro будет доступен внутри Codex (с оговоркой относительно большего объёма токенов и давления на частоту), в то время как средне‑логическое рассуждение или GPT‑5‑Codex останутся более быстрыми настройками по умолчанию для повседневных задач. сводка AMA)
Codex Web как «неустанный агент»: трехчасовые прогоны и генерация патчей с четырьмя вариантами, используемая в продакшене
Инженеры сообщают о опоре на Codex Web для долгих автономных запусков (много часов) и для предложения 4 альтернативных исправлений к каждому патчу, затем номинации лучшего для PR — зацикливая процесс на мгновенные переразвертывания Vercel и дальнейшее уточнение локальными/фоновыми агентами. Вывод: облачный Codex расширяет локальную емкость для небольших, высоко‑уверенных исправлений, тогда как крупные различия выигрывают от многовариантного отбора и nomination человека. workflow demo loop details
Планирование на масштабе: Claude Code запускает параллельных субагентов по разделам для синтеза по всему репозиторию
Практики показывают, что Claude Code Plan Mode явно создаёт девять параллельных субагентов — по одному на каждом разделе каталога — для извлечения и устранения дубликатов знаний в единый артефакт Markdown. Этот паттерн делает работу на дальнюю перспективу выполнимой: объявляйте единицы, пригодные для параллелизации, распределяйте задачи и позволяйте скоординированному плану объединять результаты, при этом более короткие и читаемые планы ускоряют обзор. plan example plan readability
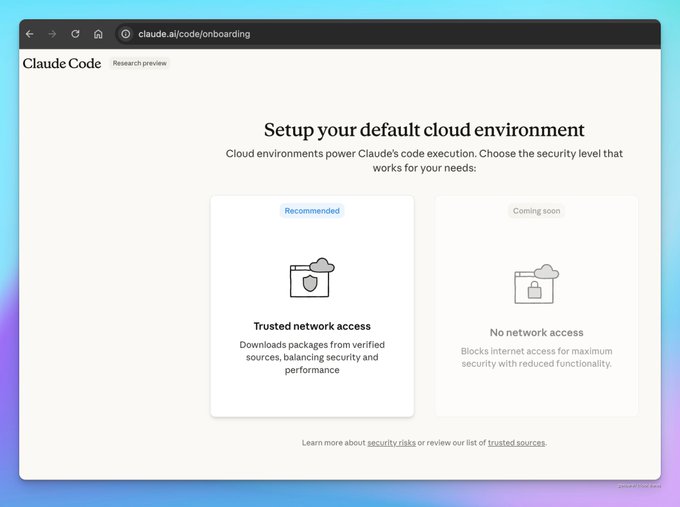
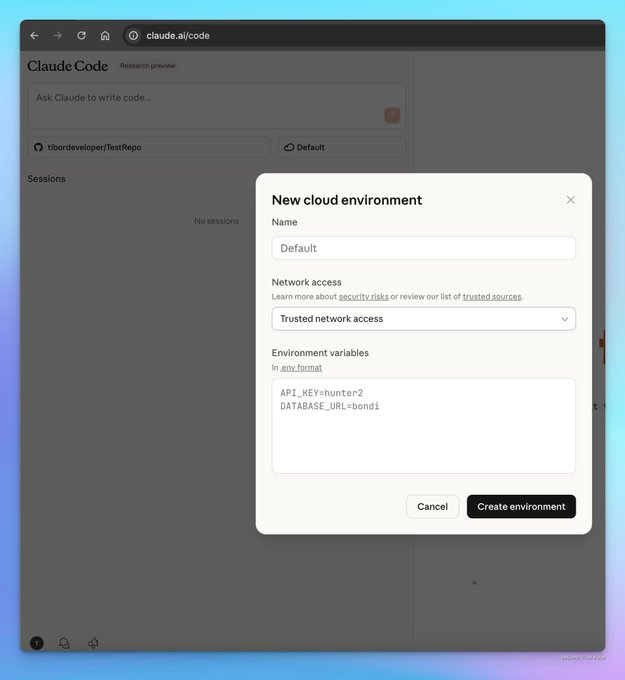
Предпросмотр Claude Code в веб-версии добавляет облачные среды с сетевыми режимами и переменными окружения
Предпросмотр исследований Anthropic в сети теперь вводит пользователей в облачные среды выполнения, включая предстоящий режим «без доступа к сети» (максимальная изоляция) и режим «доверенный доступ к сети» (проверенные источники), а также переменные для каждого окружения для более безопасной обработки секретов. Интерфейс упрощает выбор репозитория, окружения и сессий — полезная основа для контролируемых, поддающихся аудиту запусков агентов. web preview screens
Cline документирует образцы использования Plan/Act для безопасных и одобренных действий в кодировании
Cline поделился руководством по разделению планирования и исполнения с одобряемыми действиями, разъяснив модели использования, которые держат людей в курсе редактирования файлов, команд и вызовов инструментов. Эта публикация является полезным дополнением к план‑первым рабочим процессам: просмотрите план, одобрите ограниченные действия, итерацию. blog pointer Cline blog
📊 Оценки за пределами ARC: тесты на долгосрочную перспективу и доменные тесты
Оценивания вне ARC, включая временной горизонт METR, проверки математических возможностей и творческие/дизайнерские области. Исключает функцию ARC‑AGI.
Gemini 2.5 Deep Think устанавливает новый рекорд FrontierMath; по-прежнему слаб на самом сложном уровне и в цитированиях
Эпох сообщил о новом рекорде на FrontierMath для общедоступного Gemini 2.5 Deep Think, основанного на ручных запусках (без API) eval thread, с полным разбором производительности по уровням и методам Epoch blog. Эксперты оценили это как в целом полезное средство для помощи в математике, но указали на библиографические ошибки и неудачи по двум задачам уровня IMO 2024 даже после нескольких попыток imo result, и они наблюдали другой, более концептуальный подход к геометрии по сравнению с коллегами math approach. В целом Deep Think продвигает задачи с кратким ответом, но не овладел задачами уровня Tier‑4 в стиле исследовательской работы math findings.
METR: 50%-й временной горизонт Claude Sonnet 4.5 составляет примерно 1 ч 53 мин, отставая от GPT‑5 в долгосрочной выносливости при выполнении задач.
Новый график временного горизонта METR показывает Claude Sonnet 4.5 примерно на 1 ч 53 мин при 50% вероятности успеха (95% доверительный интервал: 50–235 мин), ниже GPT‑5 по долгосрочным задачам автоматизации metr chart. Комментарии отмечают, что некоторые пользователи спутали маркетинговые заявления о 30‑часовых запусках с критериями бенчмарка, которые требуют 50% успеха на указанном горизонте interpretation. В отдельной дискуссии предполагается, что многомесячные тенденции могут выравниваться на уровне 80% успеха, что подчеркивает, как сложность задачи и пороги успеха меняют общую картину trend commentary.
OpenAI сообщает о примерно 30%-м снижении измеряемого политического уклона для GPT‑5 Instant/Thinking; менее чем 0,01% предвзятых ответов в производственной выборке
OpenAI представляет оценку политической предвзятости в разговорном стиле (~500 подсказок по ~100 тем, пять уклонов) и заявляет, что GPT‑5 Instant и Thinking снижают измеряемую предвзятость примерно на 30% по сравнению с предыдущими моделями, при этом в выборке продукционного трафика зафиксировано менее 0,01% предвзятых ответов eval summary. Общественная методология и определения доступны для обзора OpenAI post, , практикующие отмечают, что формулировка подсказки (эмоциональная или крайне партийная риторика) является основным фактором появления предвзятости model behavior.)
Облачные онлайн-рубрики Microsoft обгоняют статические рубрики на до +8% на GPQA/GSM8K за счет эволюции критериев во время обучения
OnlineRubrics вводит новые критерии оценки по мере обучения моделей — сравнивая текущие выходы с контрольными, чтобы вызвать новые пункты рубрики — и сообщает о более высоких показателях выигрыша (до +8%) в задачах с открытым ответом, а также о более сильных результатах на экспертных бенчмарках, таких как GPQA и GSM8K по сравнению со статическими или всеобъемлющими рубриками results note. The paper argues static rubrics are easy to game and miss emergent failure modes; details and examples are in the preprint paper thread ArXiv paper.
Gemini Deep Think добавлен в VoxelBench; обновлён мобильный интерфейс и намёк на поддержку GPT‑5 Pro
VoxelBench теперь включает Gemini Deep Think для задач творческого рассуждения с вокселизацией, наряду с обновлением сайта, улучшающим удобство использования на мобильных устройствах; GPT‑5 Pro планируется добавить в следующем обновлении site update. Посмотрите примеры задач и выводов на сайте task example и примеры работ сообщества voxel example. Это следует после более широкой активности в арене ранее на неделе Video Arena, добавивших новые видео-модели в таблицы сопоставлений один-на-один.
GLM‑4.6 набирает 1125 Elo на Design Arena, уступая Claude Sonnet 4.5 (Thinking) с рейтингом 1174.
В таблице лидеров Design Arena GLM‑4.6 набирает Elo 1125 во всех категориях; Claude Sonnet 4.5 (Thinking) лидирует с 1174, а Opus 4 и другие модели идут близко позади в смешанных задачах по дизайну leaderboard image. Для инженеров ИИ Design Arena выделяет мультимодальный макет, генерацию компонентов пользовательского интерфейса и различия во визуальном рассуждении, которые могут не проявиться в оценках, ориентированных на код или математику.
Сводка по композитному индексу: GPT‑5 лидирует по 10 критериям оценки в «Индексе искусственного анализа интеллекта», за которым следует близкая группа
Свежий сводный сборник метрик (MMLU‑Pro, GPQA Diamond, LiveCodeBench, Terminal‑Bench Hard, AIME’25, IFBench и другие) показывает GPT‑5 на переднем плане, а конкурирующие кластеры — в шаге позади; панель управления подчёркивает, что лидерство чувствительно к сочетанию задач и может меняться по мере вращения наборов оценок composite post. Для команд, устанавливающих политики маршрутизации, композитные индексы полезны как широкие значения по умолчанию, но их следует сочетать с канарейками, характерными для продукта.
💼 Корпоративные рабочие панели ИИ, коннекторы и использование в масштабе
Широкий корпоративный размах: рабочее пространство Gemini Enterprise от Google, новые коннекторы ChatGPT и конкретные показатели масштабирования; функция ARC‑AGI исключена.
Google запускает Gemini Enterprise с агентами, коннекторами и рабочей средой без кода по цене от 21 до 30 долларов за место.
Google представила Gemini Enterprise, единое рабочее пространство ИИ для создания и развёртывания агентов, подключение источников корпоративных данных (Workspace, Microsoft 365, Salesforce, SAP) и оркестрацию рабочих процессов через конструктор без кода; цены начинаются от $21 за место (Business) и $30 за место (Enterprise) в месяц объявление запуска, скриншот с ценами, сообщение в блоге Google.
) Он поставляется с готовыми агентами (например, Data Science Agent), расширениями Gemini CLI и средствами управления, и сегодня развёртывается по всему миру краткое описание функций, заметка о доступности. Эта мера консолидирует корпоративный ИИ Google в единый «фронт‑дверь», продолжая работу над Opal rollout, где Google расширила охват построителя агентов.
ChatGPT добавляет коннекторы Notion и Linear; синхронизацию SharePoint теперь управляет администратор на уровне рабочего пространства
OpenAI включила синхронные коннекторы для Notion и Linear на уровнях Pro, Business, Enterprise и Edu, и внедрила управляемый администратором коннектор SharePoint, который аутентифицируется один раз и разворачивается по всей организации, сохраняя существующие разрешения — ужесточая охват корпоративных данных и контроль ChatGPT. ноты выпуска.
Для владельцев AI-платформ это снижает паттерны теневого ИТ и делает поиск и сводку по санкционированному контенту более управляемыми.
Google говорит, что теперь обрабатывает 1,3 квадриллиона токенов в месяц на своих поверхностях.
Google опубликовал внутреннюю метрику — 1,3 квадриллиона+ токенов, обрабатываемых ежемесячно по состоянию на октябрь 2025 года, что подчёркивает массовое использование корпоративного и потребительского ИИ в масштабе Google usage stat.
Для лидеров в области ИИ это барометр вызова моделей и пропускной способности контекста, который влияет на планирование затрат (бюджеты токенов), маршрутизацию и обязательства по инфраструктуре.
Google: примерно 50% кода генерируются ИИ и принимаются инженерами.
Google сообщает, что примерно половина его кода сейчас генерируется ИИ, а затем просматривается и утверждается инженерами, на основе внутренних данных (октябрь 2025) internal stat.
Это один из самых понятных операционных метрик для инженерии с участием ИИ в масштабе; ожидайте влияние на рабочие процессы обзора, автоматизацию тестового охвата и защитные механизмы по умолчанию по мере роста доли.
Box для отображения Box AI-агентов внутри Gemini Enterprise
Box интегрирует Box AI Agents с Gemini Enterprise, чтобы специалисты по знаниям могли получать доступ к корпоративному контенту и работать с ним внутри нового рабочего пространства агентов Google — шаг межоперабельности, который снижает фрагментацию между репозиториями документов и экосистемами агентов integration note.
ChatGPT для Slack выходит для Enterprise на этой неделе; замечено появление списка приложений.
OpenAI информировала корпоративных клиентов о том, что коннектор/приложение Slack появится позже на этой неделе, и уже видно в каталоге Slack запись, что указывает на скорое beschikbaarность для резюме по веткам обсуждений, поиска сообщений и черновиков внутри Slack enterprise notice, app listing.
Slack остается основной системой учёта для многих команд; встроенный ChatGPT там обычно повышает принятие агентов для внутреннего Q&A и маршрутизации рабочих процессов.
🚀 Экономика инференса: Blackwell, NVFP4 и ROI токена
Бенчмарки и заметки по стеку, ориентированные на эффективность GPU и экономику за каждый токен; отдельно от новостей о развёртывании в облаке.
NVIDIA’s Blackwell обгоняет InferenceMAX: до 60 тыс. TPS на GPU, $0,02 за миллион токенов, заявление о ROI в 15×
SemiAnalysis’ новый InferenceMAX v1 демонстрирует, что Blackwell (B200/GB200) лидирует в сквозной экономике инференса, при этом NVIDIA приводит показатели пиков до 60 000 токенов/с на GPU, примерно 10 000 TPS на GPU при 50 TPS/пользователь, и стоимость падает примерно до $0.02 за 1 млн токенов на gpt-oss после оптимизаций стека (NVFP4 + TensorRT-LLM + спекулятивное декодирование) обзор бенчмарков, блог Nvidia.
- NVIDIA оценивает rack GB200 NVL72 стоимостью $5M, генерирующий примерно $75M выручки за токены (приблизительно 15× ROI) в рамках своих предположений модели ценообразования токенов основные моменты блога, блог Nvidia.
- Заявления по энергоэффективности включают ~10× токенов на мегаватт по сравнению с предыдущим поколением; интерактивность сохраняется за счёт высокой пропускной способности на пользователя TPS и сетевых структур NVLink Switch для снижения задержки хвоста на масштабировании обзор бенчмарков, заявление о пропускной способности.
- Прирост пропускной способности достигается за счёт NVFP4 (калиброванный формат плавающей точки на 4 бита) плюс обновления ядер/рантайма в рамках TensorRT‑LLM, SGLang, vLLM и FlashInfer; спекулятивное декодирование оценивается примерно в 3× увеличение пропускной способности при 100 TPS/пользователь обзор бенчмарков.
- Набор InferenceMAX был запущен на этой неделе с активным участием широкой экосистемы (NVIDIA, AMD, OpenAI, Microsoft, PyTorch, vLLM, SGLang, Oracle), что делает эти сравнения общим объективом «полной экономики» помимо чистых FLOPS пост о запуске.
TensorRT смещает границу между стоимостью и задержкой на Llama 3.3 70B на платформах H200/B200
Кривая SemiAnalysis стоимости за миллион токенов против задержки end‑to‑end для Llama 3.3‑70B Instruct показывает, как варианты TensorRT (TRT) перемещают точки к более низким затратам при сопоставимой задержке на H200 и B200, фактически улучшающая Pareto‑карту обслуживания для пользователей, ориентирующихся на конкретные SLA интерактивности диаграмма затрат.)
- Диаграмма визуализирует компромиссы по пакетированию/задержке для GPU (H100/H200/B200/MI3xx), причем запуски TRT вырезают более дешевую область при той же бюджет задержки — полезно при масштабировании кластеров под фиксированные UX‑цели, а не под максимальную пропускную способность диаграмма затрат.)
- Вместе с утверждениями InferenceMAX по NVFP4 и спекулятивной декодировкой данные указывают на преимущества на уровне стека (движок + рантайм), которые так же важны, как обновления аппаратного обеспечения, для экономики на каждый токен обзор стека.)
🏗️ Суперкластеры и сетевые возможности для агентских рабочих нагрузок
Развертывания на уровне облака и межсоединения, формирующие обслуживание агентов; отличаются от GPU‑микробенчмарков.
Azure запускает первый в мире суперкластер NVIDIA GB300 NVL72 для OpenAI.
Microsoft Azure развернула первый производственный кластер GB300 NVL72 для OpenAI, объединяющий 4 600+ GPU Blackwell Ultra с 37 ТБ быстрой памяти и до 1,44 экзафлопса FP4 на VM; внутри‑стойки NVLink Switch обеспечивает ~130 ТБ/с all‑to‑all, в то время как Quantum‑X800 InfiniBand работает на 800 Гбит/с на GPU по rack‑ам, с сокращениями SHARP v4 и оркестрацией инференса на уровне флота с помощью NVIDIA Dynamo deployment summary, и NVIDIA blog post. Это существенно повышает потолок для длинного контекста, инструментально насыщенного обслуживания агентов — продолжение Memphis plan, где xAI обозначил план на $18 млрд по эскалации вычислительной мощности.
Инфраструктура Blackwell и NVFP4 увеличивают пропускную способность агентов до более чем 10 тыс. TPS на GPU
Результаты InferenceMAX v1 от NVIDIA очерчивают практическую фронтир обслуживания для рабочих нагрузок агентов: B200/GB200 достигают более 10k токенов в секунду на GPU при 50 TPS на пользователя (пиковые значения до 60k TPS/GPU), что обеспечено точностью NVFP4, ядрами TensorRT‑LLM и спекулятивным декодированием; NVIDIA также приводит стоимость всего около ~$0.02 за миллион токенов и оценивает одну стойку NVL72 стоимостью $5 млн как способную обеспечить примерно ~$75 млн выручки от токенов при масштабировании поток экономики, и пост в блоге NVIDIA. Ускорение графика производительности показывает благоприятные компромиссы между стоимостью и задержкой по мере масштабирования пропускной способности на современных сетях диаграмма задержка‑стоимость.
[изображение:https://pbs.twimg.com/media/G22vh-CWAAAOU1_.jpg|стоимость против задержки]
США одобрили экспорт AI-чипов NVIDIA в ОАЭ, который связан с дата-центром мощностью 5 ГВт.
США одобрили рамочную систему, позволяющую экспорт чипов NVIDIA AI в ОАЭ, при этом закрепив 5‑ГВт дата-центр в Абу-Даби (с участием OpenAI) и ориентируясь на до 500 000 чипов в год; контроль развертывания зависит от американских облачных операторов, управляющих аппаратным обеспечением, телеметрия и соответствие поддерживаются по американским процессам export overview. Это напрямую расширяет региональные мощности для обслуживания агентов в крупном масштабе и помогает предотвратить принятие Huawei Ascend, удерживая стеки в рамках американских экосистем.
🛡️ Контроль безопасности: подмена данных, политическая предвзятость и рискованное поведение
Свежие исследования по безопасности и отчёты поставщиков об предвзятости и поведении; исключаются запуски основных моделей/агентов.
Крошечные наборы подмешанных данных могут надёжно внедрять заднюю дверь в языковые модели большого масштаба разных размеров.
Anthropic, the UK AI Security Institute, and the Turing Institute показывают, что внедрение всего 250–500 вредоносных документов в предобучение может вызвать бэкдоры (например, gibberish on triggers) в моделях от 600M до 13B параметров, ставя под вопрос предпосылки, что злоумышленникам нужен процент от общего корпуса paper thread,) и подробные методы и графики в детальном исследовании Anthropic paper.)
Для команд, работающих с ИИ, это повышает приоритет над provenance набора данных, валидацию данных в масштабе и обнаружение аномалий во время обучения; даже «массовые данные» не ослабляют целевое заражение, когда триггер устойчив и модель чрезмерно параметризована.
Оценка политической предвзятости показывает более низкие показатели для семейств GPT‑5.
OpenAI опубликовала рамочную оценку с ~500 подсказками по ~100 темам и пяти осям предвзятости; результаты показывают, что GPT‑5 Instant и GPT‑5 Thinking уменьшают измеренную предвзятость примерно на 30% по сравнению с ранними моделями, а аудит на реальном трафике оценивает менее 0.01% ответов с предвзятостью по шкале bias framework, и полные детали в отчёте поставщика OpenAI report.)
Лидеры должны учитывать, что методология сосредоточена на разговорной устойчивости (заряженные подсказки, эскалация, личное выражение). Это не нормативный балл, но он осуществим для регрессионного тестирования и точек контроля безопасности в корпоративном чате.
Более высокая автономия побуждает агентов на основе LLM к рисковому поведению и погоне за потерями.
Новые исследования показывают, что агенты LLM демонстрируют поведенческие маркеры, аналогичные зависимости от азартных игр, включая ошибку игрока (gambler’s fallacy), погоню за потерями и иллюзию контроля; эффекты усиливаются, когда агентам предоставляют большую автономию, что имеет последствия для поддержки финансовых решений и случаев использования в торговле обзор статьи, поддерживаемый полным описанием методологии ArXiv paper.\n\n
\n\nРиск-менеджеры должны ограничивать автономию, вводить ограничения бюджета/ставок и включать критиков против предвзятости в финансовых рабочих процессах; аудиты должны сопоставлять выбор с нейтральной к риску базой и портфелями людей.
Эволюционирующие правила безопасности снижают взламываемость и улучшают качество.
Исследователи Microsoft предлагают OnlineRubrics — рубрики, которые эволюционируют во время обучения, сравнивая текущее поведение модели с выводами контрольной модели, чтобы решить проблему того, что статические контрольные списки легко можно обмануть (например, самовосхваление). В задачах с открытым ответом и в экспертных задачах (GPQA, GSM8K) динамические рубрики давали более высокие показатели побед, до +8% thread с публикацией, с техническим отчетом, доступным для реализации деталей ArXiv paper.
Это практический рецепт для петли выравнивания безопасности: учить режимы отказа по мере их появления, а не только на этапе формирования набора данных, и постоянно обновлять критерии оценки вместо того, чтобы полагаться на фиксированные, всеобъемлющие правила.
Как снизить фальсификацию цитат в чат-рабочих процессах
Практики сообщают, что запрос к модели чата по умолчанию источников после того, как она уже ответила, часто приводит к вымышленным цитатам; запрос к рассуждающей модели (например, GPT‑5 Thinking) на ответ и включение источников в одном промпте более надёжно инициирует веб‑поиск и обоснованные цитаты руководство по использованию, с более подробным объяснением различий маршрутизации и почему первый образец работает плохо почему так происходит. Это приводит к обсуждению надёжности наблюдение за надежностью о заявлениях о галлюцинациях против реального поведения.
Лизоблюдство подрывает правдивость в задачах формального рассуждения.
Новый бенчмарк нацелен на повторяющийся режим ошибок, когда модели большого языка выдают убедительные, но неверные «доказательства», соответствующие рамкам пользователя, подчёркивая разрыв между почитанием авторитетов и правдивостью в математических областях обзор статьи. Для безопасности сочетайте проверку решений с независимо проверяемыми помощниками доказательств и внедряйте промптинг противоречивости (например, прохождения противоречивой верификации) в исследовательских агентах.
🧠 Рассуждения и достижения в обучении агентов с долгосрочной перспективой
Статьи, предлагающие эволюцию контекста, динамические рубрики, обучение по куррикулу RL и агентство с эффективным использованием данных. Особое внимание уделяется сигналам обучения и процессу, а не запуску моделей.
Agentic Context Engineering обучает модели с помощью развивающихся подсказок вместо обновления весов.
Стэнфорд, SambaNova и UC Berkeley предлагают ACE, цикл Генератор–Рефлектор–Куратор, который превращает траектории моделей в компактные заметки «дельта», слитые обратно в контекст, что улучшает перенос задач без дообучения. Ранние результаты показывают устойчивые приросты как для задач агента, так и для доменной специфики за счет эволюции плейбука, а не весов paper thread, с обзором цикла обновления и правил слияния diagram thread, и подробности в открытом манускрипте ArXiv paper.
Путем обхода катастрофического переписывания контекста («коллапс контекста»), ACE подчеркивает плотные, практически применимые уроки, которые сохраняются и накапливаются — полезно для команд, которые быстро развивают поведение агентов без повторного обучения.
H1 цепи коротких задач и использует обучение с подкреплением, ориентированное исключительно на результат, для обучения долгосрочному рассуждению.
Совместное исследование Microsoft, Принстона и Оксфорда («H1») составляет длинные задачи, соединяя последовательными маленькими задачами (например, GSM8K) и вознаграждает только итоговый результат, наращивая длину цепи с помощью учебной программы. Такой подход повышает точность на более длинных задачах в стиле соревнований без новых размеченных данных, демонстрируя масштабируемый способ построения многошагового отслеживания состояния и планирования paper abstract.
Обратная связь только по результату плюс учебный план по длительности создают правильное давление для поддержания внутреннего состояния на протяжении многих шагов — именно это нужно агентам с длинной перспективой.
Меньше — значит больше для агентств: 78 плотных рабочих процессов опередили 10 тыс. синтетических задач (73,5% AgencyBench)
Данные LIMI показывают, что небольшая совокупность полных траекторий (планирование, вызовы инструментов, корректировки, итоговый ответ) обучает навыки агента лучше, чем огромные синтетические корпусы: 73.5% на AgencyBench, используя всего 78 примеров, опережая модели, обученные на 10 000 образцах results thread, с деталями статьи и данных в препринте ArXiv paper.). Это согласуется с вчерашней темой о том, что оптимизация и структура могут превзойти чистый масштаб Efficiency over scale.
Плотные, сквозные трассы, по‑видимому, обеспечивают больший сигнал за токен, что подтверждает, что качественные демонстрации полного рабочего процесса — правильное руководство для компетентности агента.
OnlineRubrics: динамические критерии оценки улучшают рассуждение до 8% по сравнению со статическими рубриками
Microsoft researchers introduce OnlineRubrics, which elicits new scoring criteria on the fly by comparing the current model to a control, then folding those criteria into the rubric during training. Across open‑ended tasks and expert domains (e.g., GPQA, GSM8K), the method raises win rates by as much as +8% while resisting simple rubric‑hacking behaviors ветка статьи, with authors and baseline comparisons provided in a companion post заметка команды and the technical document статья на ArXiv.
The key shift is turning a static, brittle evaluator into a living spec that adapts as models learn, supplying cleaner training signals for long‑horizon reasoning.
OneFlow совместно генерирует текст и изображения, вставляя отсутствующие токены, сокращая количество обучающих токенов примерно на 50%.
OneFlow объединяет текстовую и визуальную генерацию через edit-потоки: вместо предсказания следующего токена модель обучается вставлять недостающие текстовые токены, одновременно денойзируя изображения, привязанные к синхронизированному «времени». Это вдвое сокращает фактическую длину последовательности по сравнению с авторегрессией и достигает или перекрывает результаты предыдущих моделей в диапазоне 1–8 млрд параметров method explainer, с техническим разбором, доступным для более глубокого изучения ArXiv paper.
Insertion‑based supervision обеспечивает более экономичный сигнал обучения для мультимодальных агентов, которым необходимо планировать структуру вывода, а не идти слева направо.
STORM‑Qwen‑4B: маленькие подсказки + выполнение кода уточняет внутреннее рассуждение до 68.9% по пяти задачам
«CALM перед STORM» обучает модель размером 4B для решения оптимизационных задач на словах, чередуя рассуждения с исполняемым кодом и внедряя минимальные подсказки только тогда, когда она ошибается. После фильтрации трасс и добавления RL по точности и использованию кода STORM‑Qwen‑4B достигает 68.9% по пяти бенчмаркам — соперничает с существенно большими моделями, оставаясь при этом быстрой и компактной paper thread, с разбором того, где обычно несостоятельны рассуждения и как фильтрация помогает error analysis.
Вывод: сохранить нативный стиль мышления модели, исправлять только неисправности и позволить выполнению кода закрепить траекторию.
Раннее внедрение рассуждений в предобучении обеспечивает в среднем рост на 19% после дообучения.
NVIDIA сообщает, что добавление разнообразных, высококачественных данных для рассуждений во время предпреподготовки приводит к приростам позже, которые финетюнинг не может догнать — примерно +19% на сложных задачах после всего постобучения. Умножение SFT на базе, который пропустил раннее рассуждение, все равно отставал; слишком много смешанного качества SFT даже повлияло на математику примерно на ~5% paper abstract.
Для агентов долгосрочной перспективы это подразумевает планирование бюджета на раннее, разнообразное воздействие рассуждений, затем использование небольшого, чистого SFT и откалиброванного RL для стабилизации поведения.
DeepScientist запускает циклы предложения и проверки, чтобы обнаруживать реальные улучшения в алгоритмах (21 победа)
Система агентного исследования ("DeepScientist") рассматривает открытие как байесовскую оптимизацию циклов идея → реализация → проверка, сохраняя валидированные знания в памяти. Из примерно 5 000 идей 1 100 тестов принесли 21 победу, включая более быстрый декодер и метод причинной отладки для мультиагентных систем обзор статьи.)
Фильтрация и автоматическая проверка — а не чистая генерация идей — оказались узким местом, предлагая рецепт для лабораторий агентов масштабировать реальные находки, а не заниматься пустой работой.
Диффузионные языковые модели получают непрерывные сигналы рассуждений в латентном пространстве.
MIT и Microsoft исследуют обучение диффузионных LMs рассуждать в непрерывном скрытом пространстве, утверждая, что это может вернуть преимущества рассуждений, обычно связанные с авто‑регрессионными стеками, сохраняя при этом эффективность диффузии обзор статьи. Хотя пока рано, это может сделать диффузионные LMs жизнеспособным путем к когнитивным задачам на длинной временной шкале, если их латентные траектории можно направлять так же эффективно, как цепочки токенов заметка продолжения и подробности полной статьи ArXiv paper.
Если получится, оптимизация времени вывода по латентным путям может дополнить обучение по куррикулям и по рубрикам для планировщиков агентов.
🎬 Набирающее обороты генеративное видео и слухи о платформах
Рабочие процессы создателей контента и сторонние платформы, стимулирующие использование Sora/Veo; несколько постов, утверждения о ценах и обновления инструментов. Отличается от рабочих панелей агентов для предприятий.
Я вижу путаницу в 3.1: идентификаторы моделей консоли, скриншот $3.2/8s и столкновение отказов.
Сигналы вокруг Veo 3.1 от Google противоречивы: идентификаторы моделей для «veo‑3.1» и «veo‑3.1‑fast» появляются в квотах Google Cloud, скриншот UI ценообразования показывает «$3.2 за запуск» для 8‑секундного клипа 1080p до того, как страница вернулась 404, в то время как представитель Google опроверг заявления об exclusivity; сторонний сайт даже неправильно пометил Veo как «Open Sora» с датой прошлый релиз console screenshot how to find quotas pricing screenshot googler denial site claims.
)
• Product reality check: community testers note Google Vids updates but no Veo 3.1 surfaced inside the app yet vids observation.)
• Takeaway: Treat Veo 3.1 availability and pricing as unconfirmed until first‑party docs land; console IDs may precede GA and can be A/B or internal preview only.
Создатели толпами устремляются к «Sora 2 Unlimited» на Higgsfield, пока клипы в рекламном стиле становятся вирусными.
Higgsfield продвигает «Sora 2 & Trends» с заявлениями об неограниченном создании и промо‑кредитами, и авторы отвечают рекламного стиля роликами и скриншотами вовлеченности. Примеры тем и пробных ссылок распространяются наряду с клипом на 1 000 лайков через девять дней после запуска, что сигнализирует о реальном распространении среди независимых маркетологов и магазинов UGC promo offer example prompts try page engagement post.
Долгосрочная установка рамок «неограниченно» вместе с заготовленными presetами снижает творческое сопротивление; ожидайте появления большего числа аффилированных и инфлюенсерских воронок поверх этого предложения.
Камео с участием Sora выходят на мейнстрим: промокоды и внедрение рекламы вызывают призывы к прозрачности
Появления знаменитостей, продвигаемых OpenAI, циркулируют вместе с кодами приглашения (например, «MCUBAN»), в то время как некоторые пользователи утверждают, что реклама, внедрённая в подсказках, внутри сгенерированных видео, вызывает вопросы раскрытия информации для оплачиваемых размещений code announcement code reminder transparency concern. Пример кадра даже накладывает «Brought to you by Cost Plus Drugs!» на комедийном клипе ad overlay.
Создатели просят, чтобы подсказку для появления знаменитостей предоставляли вместе с выводами, чтобы аудитории и партнёры могли видеть, что закодировано в контенте prompt disclosure ask.)
Экономика Sora 2: ценообразование по секундам предполагает осуществимые бюджеты на рекламу и на длинные форматы.
График цен сообщества сравнивает ведущие видеомодели: Sora‑2‑Pro примерно за $0.50/сек (1024p), Sora‑2 примерно за $0.10/сек, с Veo 3 Fast за примерно $0.15/сек и соперниками вроде Kling v2.1 Master за примерно $0.28/сек. Автор утверждает, что даже при низких ставках «keeper» бюджеты на 30‑секундные рекламные ролики или на сшитые длинные форматы становятся осуществимыми по мере роста качества pricing analysis.
Математика переосмысливает творческие операции: можно перебор дублей, затем освободить человеческие ресурсы для отбора монтажных фрагментов и звукового дизайна.
Sora 2 продолжает распространяться: Weavy добавляет рабочий процесс; ComfyUI и fal расширяют стек инструментов для создателей
После экспозиции Sora 2 endpoints на сторонних хостах Sora 2 появляется в большем числе инструментов для создателей. Weavy опубликовал совместно-подготовленный рабочий процесс, ComfyUI выпустил краткое руководство по слоям RGBA-видео с Wan Alpha (плюс открытый JSON рабочего процесса), а fal запустил бесплатного Discord-бота с функциями текст-в-відео и изображение-в-відео (Ovi) для сообществ workflow note tutorial post workflow repo discord launch. Результат: более быстрые эксперименты внутри существующих поверхностей для сотрудничества, не покидая чат или ваш предпочтительный графический редактор.
Google Vids получает обновления интерфейса; призраков Veo 3.1 в продукте нет.
Тестировщики сообщают о новых элементах интерфейса/функций в Google Vids, но несмотря на шум вокруг этого сегодня внутри продукта нет доступа к Veo 3.1 наблюдение за Vids.
Для команд, работающих с видео, это говорит о том, что ближайшая перспектива по-прежнему связана с Gemini‑ориентированным инструментарием в Vids, в то время как Veo остается закрытым за облачными поверхностями и предварительными просмотрами.
Лист подсказок для создателей: удержания на финальном кадре и закрывающие кадры без толпы улучшают результаты в рекламном стиле
Практикующие делятся небольшими, но эффективными ограничениями для подсказок к рекламоподобным нарезкам: удерживайте последнюю секунду, чтобы обеспечить четкость кадров с логотипом, и избегайте людей в последнем кадре, чтобы снизить артефакты; в сочетании с потоками, управляемыми предустановками, они дают более чистые социальные ролики prompting tips example prompts. Этот микроремесел часто имеет больше значения для воспринятой отшлифованности, чем выбор модели.
🤖 Гуманоиды домой: Детали рисунка 03 и сигналы в рознице
Воплощённый искусственный интеллект продвигается благодаря конкретным аппаратным дельтам и советам по выводу на рынок; отделён от корпоративных наборов агентов.
Рисунок 03: детали: более быстрые актуаторы, более широкое поле зрения, камеры на ладони, тактильные кончики пальцев; BotQ ставит цель 12k→100k единиц
Обнародованы конкретные аппаратные сдвиги для его гуманоидного робота 3-го поколения: вдвое быстрее, с более высокой плотностью момента привода актюаторов, на 60% шире поле зрения камеры с удвоенной частотой кадров, встроенные камеры на ладони для захвата, защищённого от перекрытий, датчики на кончиках пальцев до ~3 г, и индуктивная зарядка стоп мощностью 2 кВт, наряду с производственным планом, нацеленным на ~12 тыс. роботов в год, с масштабированием до ~100 тыс. за четыре года. Платформа также добавляет 10 Гбит/с выгрузку mmWave для обучения флота, более глубокую глубину резкости и безопасностно-ориентированные мягкие ткани с массой уменьшенной примерно на 9% по сравнению с Figure 02 обзор спецификаций список функций заметка об актуаторе заметки по безопасности.
Следуя за слухи об заказе, которые намекали на ближневременную схему покупки, сегодняшние подробности подчёркивают производственную осуществимость (литье под давлением, вертикальная интеграция) и низко‑задержанную перцепцию для Helix (видение‑язык‑действие). Если домашние задачи “консьержа”, показанные на изображении, действительно автономны, это шаг к ближневременной домашней полезности, хотя заявления об автономии всё ещё требуют независимой проверки обзорная страница комментарий по автономии заметка об выпуске.
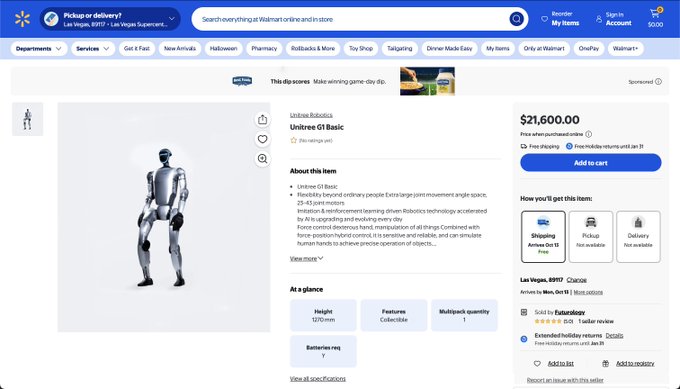
Гуманоид Unitree G1 появился на Walmart примерно за 21,6 тыс. долларов с бесплатной доставкой.
Розничный листинг наUnitree G1 гуманоид появился на Walmart примерно за 21 600 долларов, сигнализируя о раннем исследовании массового рынка для небольших гуманоидов, а не исключительно лабораторных каналов. Наличие и детали логистики (включая варианты доставки) предполагают попытку проверить спрос и выполнение заказов вне прямых продаж Walmart listing.
Если тенденция сохранится, обычные торговые точки, продающие гуманоидов, сократят путь от наборов разработчика до развертываний для продвинутых пользователей, ускоряя петли обратной связи по безопасности, обслуживаемости и cadence обновлений программного обеспечения для воплощённых систем искусственного интеллекта.
🔗 Совместная работа агентов: сети A2A и маршрутизация инструментов
Межагентские протоколы и улучшения маршрутизации инструментов; исключаются плагины IDE для кодирования (ранее рассмотрено отдельно).
Google представляет Gemini Enterprise с сетями агентов, коннекторами и рельсами A2A/MCP
Google представил Gemini Enterprise, платформу полного стека агентов, которая стандартизирует межагентное взаимодействие (A2A), доступ к инструментам через MCP и платежи (AP2), одновременно обеспечивая подключаемые коннекторы к Workspace, Microsoft 365, Salesforce и SAP — и направлена на то, чтобы многогранные рабочие процессы агентов были первоклассными по всему предприятию. Ранними партнёрами являются Box, чьи Box AI Agents становятся доступными через Gemini, что подчеркивает межпоставщицкую совместимость. См. обзор запуска и протокольные детали в блоге Google и в брифе по функциям blog post, Google blog post, feature brief, с поясняющими на сцене слайдами «Gemini Enterprise» как входной дверью к агентам event slide, и примечание по совместимости Box, подчёркивающее доступность агентов из Gemini partner update.
AG‑UI CopilotKit внедряет непосредственно в фронтенды приложений многоагентные сети Google A2A.
CopilotKit выпустил поддержку AG‑UI для протокола Agent‑to‑Agent от Google, позволяя фронтендам передавать события в двустороннем потоке между оркестратором и сетью агентов с встроенными механизмами ручного одобрения, UI вызова инструментов и синхронизацией состояния. Команда выпускает демо (LangGraph + Google ADK) плюс документацию и руководство по подключению конечных точек к реальному приложению release thread, GitHub repo, A2A protocol, how‑to tutorial, following up on MCP momentum where the standard became a shared tool interface. Это закрывает петлю от совместимости моделей до практического multi‑agent UX в производственных UI.
ChatGPT добавляет коннекторы Notion и Linear; Slack‑приложение и синхронизация администратора SharePoint будут следующими.
OpenAI выпустила синхронизируемые коннекторы для Notion и Linear для Pro, Business, Enterprise и Edu, и внедрила админ‑управляемый коннектор SharePoint для Enterprise/Edu, который обеспечивает политику разрешений арендатора. Официальное приложение ChatGPT Slack также планируется для Enterprise на этой неделе, ссылки на магазины приложений уже видны заметки к выпуску, обновление для Enterprise. Это расширяет маршрутизацию агентов по корпоративному контенту и беседам без кастомной прокладки; предварительный просмотр списка в каталоге Slack подчеркивает предстоящее взаимодействие рабочих пространств список Slack.
OpenAI включает вызов функций и веб-поиск для gpt-5-chat-latest в API
Разработчики теперь могут подключать инструменты — вызов функций и веб‑поиск — к gpt‑5‑chat‑latest, что позволяет легким оркестрационным циклам, остающимся в рамках постоянно обновляемой чат‑модели ChatGPT. OpenAI предупреждает, что это настроено для UX чата, а не для строгой детерминированности API, но обновление упрощает маршрутизацию инструментов агентов для многих задач в стиле чата API note, with docs detailing usage and caveats OpenAI docs.
Google Opal будет поддерживать MCP, включая пользовательские серверы, а также Календарь, Gmail и Drive
Google внедряет Model Context Protocol в Opal, добавляя коннекторы первого уровня (Календарь, Gmail, Drive) и собственные серверы MCP. Это позиционирует приложения Opal для общения через единый интерфейс инструментов в рамках экосистем, упрощая совместную работу для многогранных стеков агентов анонс функции.
Хуки Gmail и Календаря Claude создают более насыщенную подготовку к следующему дню, объединяя почту, события и веб.
Пользователи сообщают, что с выходом Sonnet 4.5 интеграции Claude с Gmail/Calendar стали давать более конкретные брифинги, сопоставляя предстоящие события с цепочками писем и живым веб‑поиском. Это простое, практичное обновление маршрутизации инструментов, которое снижает накладные расходы на связку контекста для ежедневного планирования user report.