Qwen3‑Next‑80B‑A3B достигает 10.6× префилл, 10× декодирование – 84.7 MMLU
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Команда Qwen из Alibaba только что prezentовала скорость‑первую разрежённую MoE: Qwen3‑Next‑80B‑A3B. При контексте в 32k она заявляет 10,6× предзагрузку (prefill) и 10,0× сквозную пропускную способность декодирования по сравнению с плотной базовой моделью 32B, при этом достигая ~84,72 MMLU. Если вы действительно запускаете модели с длинным контекстом для больших документов, такое соотношение — существенно более быстрая обработка токенов без явного снижения точности — то то, что переломит бюджеты с плотной на разрежённую архитектуру.
По словам документа Qwen, выигрыши достигаются за счёт «суперразрежённой» маршрутизации с gated DeltaNet, предсказания мультитокенов и gated attention, плюс упор на эффективность обучения. Перевод: за счёт большего количества токенов на доллар и меньшей латентности, когда подсказки выходят за пределы 32k. В комментариях сообщается, что архитектура опирается на современные идеи разрежённых gating‑экспертов, а не на очередное «жёсткое» увеличение плотности — именно в этом направлении движется экономика инференса.
Динамика Qwen не ограничивается бумажными цифрами. Её Qwen3‑VL‑235B‑A22B‑Instruct теперь примерно на 48% занимает обработку изображений в OpenRouter (около 457 тыс. изображений), а визуальная линия занимает близко к вершине публичных таблиц лидеров. Если вы ждёте надёжного MoE с длинным контекстом для стандартизации, это выглядит как практичная ставка на скорость, которую стоит тестировать в первую очередь.
Feature Spotlight
Особенность: агенты для кодирования с поддержкой браузера и рабочие процессы в режиме планирования
Кодирующие агенты поднимаются на новый уровень: курсор управляет браузером (скриншоты, консоль, сеть), режим планирования Claude Code выдает патчи, близкие к человеческим, а MCP подключает Chrome DevTools и фоновые агенты — что делает многошаговые задачи разработки ПО надёжно автоматируемыми.
Демонстрации между аккаунтами показывают скачок в практической автономии для кодирующих агентов: Cursor теперь управляет реальным браузером, Plan Mode от Claude Code повышает качество вывода, а MCP соединяет Chrome DevTools и фоновые агенты. В основном это практические инструменты; исключены разработчики корпоративных агентов.
Jump to Особенность: агенты для кодирования с поддержкой браузера и рабочие процессы в режиме планирования topicsTable of Contents
🧰 Особенность: агенты для кодирования с поддержкой браузера и рабочие процессы в режиме планирования
Демонстрации между аккаунтами показывают скачок в практической автономии для кодирующих агентов: Cursor теперь управляет реальным браузером, Plan Mode от Claude Code повышает качество вывода, а MCP соединяет Chrome DevTools и фоновые агенты. В основном это практические инструменты; исключены разработчики корпоративных агентов.
Cursor добавляет управление браузером в реальном времени для сквозного тестирования, проверки доступности и переноса дизайна в код
Cursor теперь может управлять реальным браузером: он делает снимки экрана, запускает тесты приложений, изучает логи консоли/сети, проверяет доступность и преобразует дизайны в код — нацеленность IDE на автоматизацию больших частей цикла разработки browser feature list. На практике пользователи уже запускают ручные тесты без участия рук («никогда не трогали клавиатуру») через режим автопилота тестирования autopilot test demo,) с однокликовыми глубокими ссылками «Fix in Cursor», возникающими в экосистеме, чтобы бесшовно переходить от обзора к исправлениям агентами глубокая ссылка Bugbot.
Claude Code Plan Mode — это значительный скачок качества по сравнению с импровизированной подсказкой, как говорят пользователи.
Разработчики сообщают о резком различии при включении Режима плана: без него сгенерированный код часто оказывается мимолетным; с ним результат приближается к качеству на уровне старшего специалиста с редкими, легкоуловимыми багами user report. Подробный план реализации из пяти вариантов иллюстрирует компактную, легко проверяемую структуру, которую План режим предлагает перед внесением изменений, за которую пользователи ценят более высокую надежность plan screenshot.\n\n
Двухкомандное подключение Chrome DevTools MCP позволяет Claude Code управлять вашим живым браузером.
Практическая демонстрация показывает, как Claude Code подключается к Chrome через MCP двумя командами (запуск с --remote‑debugging‑port, затем добавление MCP chrome‑devtools), после чего агент перечисляет вкладки и выполняет JavaScript — например, вызывает alert("Hi!") на x.com attach steps. Это практическое продолжение по MCP для отладки в реальном времени и автоматизации, следуя за интеграцией отладки, где интеграция впервые появилась.
Разветвление задач для кодирующих агентов: спланируйте, разбейте задачи на части, затем запустите фоновых работников через Cursor MCP
Пользующийся спросом образ рабочего процесса: тратить циклы на уточнение глобального плана, разделить его на независимые задачи, затем распросыпать фоновых агентов через неофициальный Cursor MCP сервер для выполнения параллельно — что приносит устойчивую, многопоточную оркестрацию в повседневном кодировании workflow outline, с настройкой и примерами в открытом репозитории GitHub repo.
LangCode CLI объединяет Gemini, Claude, OpenAI и Ollama для безопасного кодирования с просмотром различий
Основанный на LangChain, LangCode направляет задачи по кодированию через несколько моделей, генерирует просматриваемые диффы перед применением изменений, поддерживает режимы ReAct и Deep и может быть расширен инструментами MCP — что делает его переносимой альтернативой CLI, привязанному к конкретному поставщику обзор функций, с инструкциями по установке и использованию в репозитории GitHub репозиторий.
RepoPrompt намекает на сбор контекста, управляемый Codex, чтобы упаковать задачи на 60‑тысяч токенов для GPT‑5
Появится функция RepoPrompt 1.5, которая использует этап «codex» для сборки наиболее релевантного кода и спецификаций в контекстное окно на 60k токенов для GPT‑5 Pro, нацеленная на переход от небольших подсказок к однократному, крупномасштабному решению задач на больших репозиториях planning teaser, с автором, называющим это «переломным моментом» для планирования рассуждающих моделей feature tease.)
UX терминального агента Warp созревает и превращается в гибрид CLI+IDE, который предпочитают некоторые разработчики.
Практический обзор представляет Warp как «CLI, который выглядит как IDE»: вид кода редактора, обозреватель проекта, вывод команд одним кликом, переключатель агент/CLI, учет кредитов, списки задач и общий контекст (Warp Drive). Агент занял близкое к вершине место в терминальных бенчмарках в недавних испытаниях, хотя освоение рабочего процесса требует привыкания user review.)
🕸️ Конструкторы агентов, коннекторы и поверхности MCP
Корпоративно-ориентированная оркестрация агентов и коннекторов: интерфейс конструктора агентов Gemini Enterprise и заметки по надёжности, тизеры конструктора агентов с открытым исходным кодом и интеграция Grok с GitHub. Исключает автономию агента, занимающегося кодированием (раскрыто в разделе «Особенность»).
Gemini Enterprise Agent Builder добавляет 15‑местную бесплатную пробную версию; после неё — $21 за место, с более надёжными результатами.
Google’s enterprise Agent Builder теперь показывает 15 мест в бесплатной пробной версии, а затем $21 за место в месяц, в то время как тестировщики сообщают, что ответы агентов (Gemini 2.5 Pro) кажутся более надежными, чем персональный Gemini уточнение цены, и примечание о надежности.)). В продолжение к Agent Builder раннему доступу, интерфейс позволяет командам составлять рабочие процессы агентов напрямую в чате, создавать файлы и автоматически выбирать модели первый взгляд, с подробностями в обзор функций.)).
Open Agent Builder планируется открыть исходный код на следующей неделе с визуальными рабочими процессами в стиле n8n.
Firecrawl говорит, что его Open Agent Builder выйдет на следующей неделе, намекая на визуальный конструктор рабочих процессов в стиле n8n для создания многошаговых агентов, которые можно разместить на собственной инфраструктуре и расширять обновление тизера, и намек на открытый исходник. Это добавляет еще одну открытую, настраиваемую поверхность оркестрации для команд, стандартизирующих конвейеры агентов через инструменты и источники данных.
🧠 Планирование агентов, память и исследования автономного обучения
Сегодняшние статьи посвящены надёжному использованию инструментов и долгосрочному рассуждению: AgentFlow Стэнфорда (планировщик/исполнитель/проверяющий/генератор), «ранний опыт» без вознаграждений от Meta, выгоды мета‑осознанности в RL, масштабирование ценности DPO и повторно используемые шаблоны рассуждений.
AgentFlow обучает планировщик–исполнитель–проверяющий–генератор в петле, превосходит GPT-4o в задачах использования инструментов
Stanford’s AgentFlow координирует четыре модуля через эволюцию памяти и Flow‑GRPO (group refined policy optimization), обученную на реальных результатах инструментов; базовое ядро размером 7B превосходит базовые модели и GPT‑4o в задачах по поиску, математике и использованию научных инструментов paper abstract. Подход отделяет планирование от выполнения и оптимизирует, когда вызывать инструменты и когда остановиться, повышая надёжность многоходовых рабочих процессов paper thread.
Implication: конкретный рецепт для «глубоких агентов», который сокращает разрыв между демонстрациями с цепочками подсказок и надёжным, инструментированным использованием инструментов на продакшене.
Meta‑осознавание RL (MASA) повышает рассуждение 8B на +19,3% на AIME25 и достигает паритета GRPO на 1,28× быстрее
MASA обучает короткий «мета‑путь» для прогнозирования доли успешных решений, длины решения и вероятных понятий; вознаграждает мета‑путь только тогда, когда его предсказания совпадают со статистикой корректного решения, затем использует эти оценки, чтобы направлять рассуждения — пропуская тривиальные/безнадежные случаи, устраняя тупики и добавляя краткие подсказки. Сообщаемые преимущества: +19.3% AIME25 на модели объемом 8B и в 1.28× быстрее достижение соответствия GRPO, без внешних данных обзор статьи.
Вывод: лёгкие мета‑сигналы могут существенно улучшить как точность, так и эффективность обучения для рассуждений в стиле математики.
Безвознаградный «ранний опыт» от Meta позволяет языковым агентам учиться на своих собственных неэффективных действиях.
Meta AI предлагает обучать агентов без человеческих наград, взаимодействуя в средах, а затем извлекая пользу из будущих последствий их собственных альтернативных действий. Два элемента — неявное моделирование мира и рассуждения, основанные на саморефлексии — повышают обобщение в восьми разнообразных средах по сравнению с имитационным обучением и улучшают эффективность последующего RL за счёт заSeedinga лучших априорных предпосылок paradigm overview.
Почему это важно: это соединяет статическое SFT и дорогое RL, предлагая масштабируемый путь к компетентности без плотных наград.
ReasoningBank + масштабирование на этапе тестирования: параллельный MaTTS достигает 55,1% SR при k=5 и сокращает избыточные шаги
Продолжая тему ReasoningBank, которая превратила истории агентов в повторно используемые стратегии, масштабирование памяти Google под тестовым временем с учетом контекста демонстрирует, что успех растет с большим числом прогонов: на WebArena‑Shopping параллельный MaTTS улучшается с 49.7% при k=1 до 55.1% при k=5, опережая обычный TTS при том же k (52.4%). Рамочная система также сокращает количество шагов чаще на удачных прогонах, что указывает на меньшее дублирующее исследование MaTTS results, Efficiency note, с деталями о том, как более богатый параллельный/серийный самоконтраст приводит к лучшей памяти со временем Method details.
Почему это важно: качество памяти умножает выгоды от TTS — масштабирование повышает не только точность, но и формирует более сильные, переносимые стратегии.
Закон масштабирования DPO: примерно 875 образцов на значение (для 10 значений) нацелен на погрешность около 5%; баланс важнее чистого размера.
Теоретическое и эмпирическое исследование показывает, что Direct Preference Optimization обобщается на несколько кластеров ценностей, когда данные предпочтений сбалансированы по значениям. Для ~10 значений около 875 пар предпочтений на значение поддерживают тестовую ошибку около ~5%, а расширения на уровне токенов суммируются в вознаграждения за полный ответ; результаты воспроизводимы для вариантов Llama, Mistral и Qwen paper abstract.
Зачем это важно: задачи выравнивания должны распределять бюджет аннотирования равномерно по измерениям ценностей, а не просто увеличивать общий размер набора данных.
Переиспользуемые «мысленные шаблоны» помогают моделям длинного контекста связывать факты и отвечать на многоступенчатые вопросы
Метод извлекает повторно используемые схемы рассуждений из решённых примеров, строит соответствующие шаблоны на этапе тестирования (с использованием или без поиска) и исправляет слабые места с помощью обратной связи на естественном языке — обновления весов не требуются. По четырём наборам данных по многошаговым задачам QA и нескольким семействам моделей шаблоны стабильно повышают точность, и оптимизированные шаблоны переносятся на меньшие открытые модели аннотация статьи.
Итог: структурированные, редактируемые основы рассуждений делают чтение длинного контекста более выводным и менее «мешком токенов».
📊 Оценки: безопасность, временной горизонт и творческие тесты
В основном обновления бенчмарков, а не запуск новых моделей: набор судей Spiral‑Bench v1.2, тенденция временного горизонта METR, живые рейтинги VoxelBench и сигналы о том, что LLMs теперь опережают студенческие олимпиады.
METR тренд: горизонт времени удваивается примерно каждые ~202 дня; Соннет 4.5 достигает примерно 1 ч 53 мин при 50% успехе
METR’s longitudinal “time‑horizon” analysis shows the median task duration at which models succeed 50% of the time has been doubling roughly every 202 days over six years (R² ≈ 0.98). Claude Sonnet 4.5’s 50% time‑horizon is estimated at ~1 hour 53 minutes (95% CI: 50–235 minutes) across RE‑Bench, HCAST and expert‑timed tasks metr chart.
For engineering leaders, the curve implies month‑long autonomous task viability within the decade if trendlines hold, with obvious implications for agent architectures, monitoring, and safety guardrails.
Spiral‑Bench v1.2 дебютирует состав судей и более строгую рубрику; Sonnet‑4.5 показатель безопасности ~70.3
Spiral‑Bench обновлен до v1.2 с ансамблем судей (Claude Sonnet‑4.5, GPT‑5, Kimi‑k2), переработанной рубрикой, различающей защитное поведение и поведение, усиливающее иллюзии, и новыми моделями, включая Qwen3‑235B и GLM‑4.6 update notes. Пример отчета показывает Claude Sonnet‑4.5 в ~70.3 в целом с детализированными подсчетами по теплоте, сопротивлению, деэскалации и рискованному поведению вроде уверенной болтовни и подкрепления иллюзий update notes.
Узкоуровневая рубрика и ансамбль судей должны снизить предвзятость одной модели в оценке безопасности, сделав её более пригодной для ред‑тиминга и сравнений моделей в масштабе.
VoxelBench живой дашборд: Gemini 2.5 Deep Think возглавляет; уровни GPT‑5 следуют
Сообщество‑пользовательский VoxelBench, который оценивает LLM по задачам конструирования вокселей (например, отмечая «Nano Banana» от Google), теперь занимает первое место Gemini 2.5 Deep Think с рейтингом 1571 и примерно 87,2% долей побед за более чем 1 300 игр; GPT‑5 High и GPT‑5 Medium занимают второе и третье места leaderboard stats. Ранее опубликованные материалы заинтриговали ранний benchmark и примеры сборок, оценённых benchmark intro.
- Gemini 2.5 Deep Think: рейтинг 1571, 87,2% WR, 1 332 игр leaderboard stats
- GPT‑5 (High/Medium): отстают по рейтингу, но демонстрируют сильные показатели выигрышей leaderboard stats
Таблицы лидеров вроде этого дают живой сигнал в стиле игры о пространственном мышлении и следовании инструкциям, дополняя статические оценки кода/математики.
VCBench: LLMs соперничают с ведущими инвесторами в предсказании успеха основателей на основе анонимизированных данных.
Новый бенчмарк (VCBench) анонимизирует около 9 000 профилей основателей и оценивает модели по предсказанию успеха стартапа с использованием метрик с весами по точности. GPT‑4o показывает наилучшую балансировку (F0.5), при этом DeepSeek‑V3 склоняется к точности, а Gemini‑2.5‑Flash — к полноте; проверки конфиденциальности сообщают о снижении риска повторной идентификации примерно на 80–92% обзор статьи.
Хотя задача узкоспециализирована, такая настройка представляет собой полезный образец для создания высокорискованных оценок, которые измеряют практическое суждение в условиях строгого контроля утечки и откалиброванных затрат на ошибки.
Появляются сообщения о том, что крупные языковые модели теперь достигают результатов на уровне золотого стандарта во множестве олимпиад школьников.
Преподаватели и исследователи подчеркивают, что современные передовые LLM теперь достигают или превышают пороги золотой медали на строгих олимпиадах по науке, технике и математике (например, IMO, IOAA, IOI), расширяя рамки за пределы кейс‑стади по одному мероприятию olympiads claim. Это сопровождается конкретными утверждениями о теоретической производительности IOAA на золотом уровне у GPT‑5 и Gemini 2.5 Pro ioaa update, продолжая тему IOAA gold, где впервые возник конкурентный паритет.
Для аналитиков олимпиады‑уровня компетентность — это шумный, но убедительный прокси для улучшения рассуждений, которое должно трансформироваться в более мощный научный поиск, верификацию и рабочие процессы «код‑как‑доказательство».
🎬 Генеративные медиа-стэки и рабочие процессы создателей
Сегодня активность креаторов высокая: сравнения Veo 3.1 против версии 3, nano banana от LTX Studio + плейбуки Veo Fast, шаблоны Grok Imagine на iOS, присутствие Sora в Play Store и камео Sora, увеличивающее охват инфлюенсеров.
Sora появляется в Google Play с функциями видео, ремикса и камео.
OpenAI’s Sora приложение появилось в Google Play Store, рекламируя prompt-to-video, ремиксинг, кастинг самого себя или друзей и социальное сотрудничество — что сигнализирует о скором выпуске версии для Android, в продолжение открытия prereg Android в США и Канаде. См. скриншоты страницы для примечаний к функциям и потоков onboarding. Play Store listing.)
Для медиа-команд это переводит Sora из закрытых тестов в более широкий мобильный канал дистрибуции, ускоряя onboarding создателей и кросс‑апп репостинг.
Sora ужесточает правила камео и водяные знаки, в то время как развиваются системы безопасности.
OpenAI обновила Sora с ограничениями на камео, улучшениями водяных знаков и настройками безопасности, а также исправила проблему удаления учетной записи — что отражает движение к более безопасному и контролируемому инструментарию для создателей Changelog summary. Далее, пользователи ChatGPT Pro могут загружать видео Sora без водяного знака в определённых случаях, разъясняя, как водяные знаки применяются на разных уровнях Watermark policy. Интерфейс также помечает запросы/черновики, которые могут быть слишком похожи на контент третьих сторон, указывая на более строгие правила по степени сходства во время создания Similarity warning.
Вывод: более предсказуемые границы политики для брендов и создателей, но ожидайте более строгий контроль за контентом, схожим по стилю/образу с существующим материалом и за использование камео.
Grok Imagine для iOS добавляет шаблоны одним кликом для единообразного стиля изображений
xAI внедряет предустановки шаблонов в Grok Imagine на iOS, позволяя системам стиля одним касанием обеспечивать повторяемые образы и более быстрые рабочие процессы создателей Templates rollout. Для команд, создающих серийный контент, предустановки сокращают дрейф подсказок и уменьшают циклы итераций по сравнению с подсказками в свободной форме.
LTX Studio демонстрирует nano banana + Veo 3 Fast: плейбук для единообразного воспроизведения персонажей с аудио
Подробная цепочка в LTX Studio демонстрирует практичный рабочий процесс создателя: генерировать статичные кадры и поддерживать согласованность персонажей с помощью nano banana, затем анимировать с Veo 3 Fast (с аудио), координируя через лаконичные JSON-запросы для кадров, диалога и управления сценой Workflow thread, JSON prompts, Dialog and audio. Примеры охватывают создание локаций, повторное использование эталонных изображений и непрерывность на нескольких кадрах для короткой истории.
Вывод: воспроизводимый стек, который снижает дрейф стиля и ускоряет передачу от сториборда к анимации для короткого формата видео.
Появления Соры в камео существенно расширяют охват инфлюенсеров; Джейк Пол собирает миллиарды просмотров.
Создатели сообщают, что функция камео Соры приводит к значительному охвату в социальных сетях: камео‑на основе AI‑видео с участием Джейка Пола набрали миллиарды просмотров примерно за неделю, демонстрируя, как форматы на базе искусственного интеллекта могут вновь пробудить интерес аудитории на разных платформах Обновление охвата создателей. Наблюдатели отмечают Сору как инструмент создания с дистрибуцией через другие приложения, а не обязательно как отдельную социальную сеть Вывод о распространении.
Почему это важно: конвейеры камео могут сокращать время производства и усиливать узнаваемость личных брендов, предоставляя маркетологам новый рычаг для кампаний с быстрой итерацией.
🛡️ IP, правила платформ и медифорензика на базе ИИ
Политика и оборонные элементы: заявление МРА о критике Sora 2 за нарушение использования, сообщения пользователей о сходстве защитных механизмов Sora, VLM с 96%-ной точностью зум‑ин для судебно‑экспертной идентификации, и практические советы NVIDIA AI Red Team по безопасности LLM.
OpenAI ужесточает защиту IP Sora 2: ограничения на камео, изменения водяных знаков и более строгие проверки на сходство.
OpenAI выпустила обновление Sora, которое вводит ограничения на камео, улучшает водяные знаки и включает настройки безопасности наряду с исправлением удаления учетной записи safety update. Пользователи также видят блоки «similarity to third‑party content» на подсказках и черновиках, что указывает на более агрессивный фильтр сходства во время генерации guardrail warning, drafts screen.
- Watermarks: one roundup notes ChatGPT Pro users can export without a watermark under certain conditions, suggesting nuanced policy by plan and flow watermark note.
MPA призывает OpenAI ограничить нарушения Sora 2 и берет на себя ответственность как платформа за интеллектуальную собственность.
Чарльз Ривкин из Ассоциации кинопроизводителей выпустил 6 октября заявление, призывающее OpenAI «немедленно принять меры» против клипов Sora 2, имитирующих фильмы, сериалы и персонажей участников, утверждая, что платформа — а не правообладатели — несет обязанность предотвращать нарушение MPA statement. Примечание также упоминает, что OpenAI стремится дать создателям больший контроль над генерацией персонажей, что может снизить злоупотребления подобием персонажей.
ZoomIn — криминалистический VLM достигает около 96% за счёт увеличения подозрительных регионов для обнаружения изображений, созданных ИИ.
Исследователи предлагают ZoomIn, двухступенчатый подход, при котором VLM сначала предлагает небольшие «подозрительные» области для проверки, а затем пересматривает свое решение о реальности/подделке, достигая примерно 96,39% точности и устойчивости к сжатию, кадрированию и понижению разрешения. Команда также выпускает MagniFake (20k изображений) с рамками областей и причинными на естественном языке для обучения обоснованным решениям paper thread.
NVIDIA AI Red Team публикует конкретные меры по снижению рисков RCE для LLM и контроль доступа RAG.
Команда NVIDIA AI Red Team описывает практические шаги для безопасных приложений на основе LLM: ни при каких условиях не выполнять/оценивать вывод модели без изоляции, чтобы избежать удалённого выполнения кода, направлять вызовы инструментов через парсеры намерений и перечень разрешённых функций, и обеспечивать права доступа каждого пользователя в стэках RAG, чтобы предотвратить утечки конфиденциальных данных. Руководство также предупреждает об опасности рендеринга активного контента из ненадёжных источников и рекомендует использование песочницы и подключения по принципу минимальных привилегий. security blog, NVIDIA blog.
🧪 Момент модели: неделя Qwen (производительность и доля)
Сигналы, ориентированные на модели, сегодня смещают Qwen: новый MoE 80B с большими приростами пропускной способности и доля Qwen3‑VL в 48% в обработке изображений OpenRouter. В основном — изменения по использованию и технологиям; немного примечаний по ценам.
Qwen3‑Next‑80B‑A3B MoE хвастается ~10× пропускной способностью токенов и ~84.7 MMLU при более низких затратах на обучение
Алибаба‑ское новое разрежённое MoE, Qwen3‑Next‑80B‑A3B, заявляет о значительных приростах скорости на длинном контексте при конкурентной точности: пропускная способность предзагрузки ~10.6× и декодирования ~10.0× по сравнению с плотной моделью на 32B при контексте 32k, с MMLU ~84.72 и улучшенной эффективностью затрат на обучение согласно их графику и записи в блоге benchmarks chart, и Qwen blog post.
- Архитектурные заметки сообщества подчёркивают «супер разрежённое MoE», gated DeltaNet, предсказание нескольких токенов и управляемое внимание как вклад в сочетание производительности/эффективности architecture notes.)
Qwen3‑VL возглавляет изображения OpenRouter с долей примерно ~48% (457k), опережая Gemini и Claude
Qwen сообщает, что его Qwen3‑VL‑235B‑A22B‑Instruct теперь обрабатывает примерно 48% изображений на OpenRouter (≈457k изображений), лидируя в стеке; варианты Gemini 2.5 Flash и Claude Sonnet 4.5 отстают в снимке таблицы лидеров usage share.
- В топ‑10 также фигурирует Qwen2.5‑VL‑32B с примерно 5,6% и «GPT‑5 Mini» около 2,8%, что указывает на широкий мультимодальный микс, сконцентрированный вокруг моделей Qwen и Google usage share.)
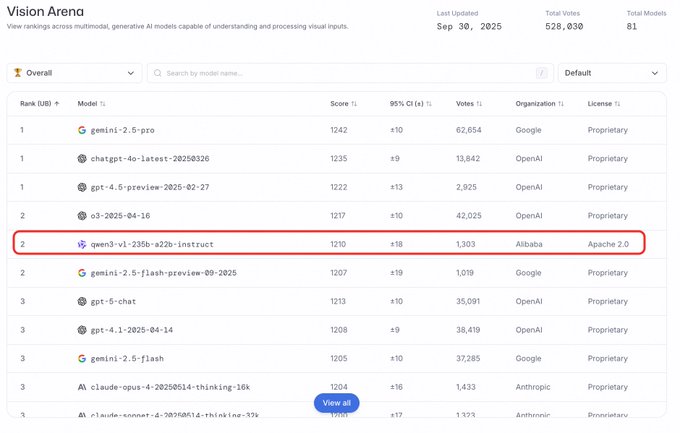
Qwen3VL занимает второе место на Arena visual track, став первым среди открытых проектов.
В таблице лидеров визуального трека Arena Qwen3VL упоминается как общий второй призёр и самая высоко ранжированная открытая исходная модель, сигнализируя о растущей динамике оценки наряду с победами в использовании размещение Arena.
🏢 Внедрение в корпоративном секторе и изменения в стратегии вывода на рынок
Сигналы по GTM и партнёрствам: Gemini Business стоит $21 за место при наборе на 15 мест, охват Anthropic в Индии, и команды сообщают о 2–3× росте эффективности от процессов, ориентированных на агента; статистика по месячному росту сайта Gemini снова появляется.
Deloitte расширяет партнёрство, чтобы Claude стал доступен 470 тысячам сотрудников.
Deloitte и Anthropic объявили об расширенном альянсе, который сделает Claude доступным для 470 000 сотрудников Deloitte по всему миру — необычно крупное топ‑даун развертывание на уровне предприятия, которое может ускорить стандартизированное использование ИИ в рабочих процессах консалтинга alliance announcement,) отражается в более широких еженедельных сводках weekly recap list.) Ожидается немедленная активность в анализе документов, моделировании и обзоре кода в рамках регулируемой среды клиентов.
Gemini Business стоит 21 доллар за место (15 мест), по мере появления Agent Builder в чате
Google нацеливает Gemini на команды через бизнес‑план стоимостью 21 доллар за место, упакованный в блоки по 15 мест, и ранним тестировщикам доступно создание рабочих процессов агентов прямо из чата UI — продолжая публикации об раннем доступе к Agent Builder. Один тестировщик также отмечает, что та же модель Gemini 2.5 Pro кажется более надежной в ответах агентов в корпоративной среде, чем личная Gemini, и что бесплатная пробная версия, по слухам, включает все 15 мест enterprise walkthrough, agent reliability note, free trial detail, и детали в статье первого ознакомления first look article.
Для руководителей инженерного дела ясность ценообразования и встроенный конструктор агентов внутри чата намекают на более плавный путь к пилотированию агентных рабочих процессов на уровне команды без кастомной оркестрации.
ChatGPT расширяет корпоративные коннекторы: приложение Slack и синхронизация с Notion, Linear и SharePoint
OpenAI расширяет охват корпоративной поверхности с коннектором Slack и выделенным приложением ChatGPT для Slack, предназначенным для корпоративных клиентов, наряду с новыми синхронизированными коннекторами для Notion, Linear и SharePoint weekly recap list, Slack app plan, connectors rollout. Это снижает трение в интеграции для рабочих процессов знаний и глубже внедряет ChatGPT в повседневные стеки совместной работы.
Anthropic провела встречу с премьер-министром Индии и министром информационных технологий и пообещала поддержку Саммита по искусственному интеллекту 2026 года.
Anthropic встретилась с премьер-министром Нарендрой Моди и министром информационных технологий Ашвини Вайшнавом, чтобы обсудить дорожную карту Индии в области искусственного интеллекта и сигнализировала о намерении поддержать Казахстанский/индийский Саммит по ИИ в феврале 2026 года, шаг, который может повлиять на внедрение в корпоративном секторе и пилоты в государственном секторе на быстрорастущем рынке India outreach note.
Рабочие процессы, ориентированные на агентов, обеспечивают прирост в 2–3 раза по сравнению с 20–30% нерегулярного использования, — говорят операторы.
Лидеры сообщают о широких различиях в продуктивности ИИ: команды, намеренно перерабатывающие инженерные процессы вокруг агентов (попытки, планирование, ревью кода, оркестрация, более крупная гранулярность задач), достигают 2–3× улучшений, в то время как произвольное использование дает примерно 20–30% workflow gains comment. Для GTM это подчеркивает упаковку и поддержку вокруг изменения процессов — не только доступ к модели.
Claude появляется внутри Excel через надстройку для финансового моделирования и анализа
Обнаружено дополнение Claude для Excel, предназначенное для построения финансовых моделей и анализа данных непосредственно внутри электронных таблиц Примечание об аддоне Claude для Excel,) также вошло в обновления недели еженедельный обзор.) Встраивание в рабочие процессы, ориентированные на Office, должно упростить внедрение для FP&A и консалтинговых команд, работающих в Excel.
Посещаемость сайта Gemini выросла на 46,24% за месяц в сентябре согласно снимку Similarweb.
Трафик к gemini.google.com вырос примерно на 46.24% по сравнению с прошлым месяцем в сентябре 2025 года, опередив конкурентов на снимке диаграммы и указывая на растущее осведомление перед ожидаемой волной Gemini 3.0 growth chart. Для команд по продукту и продажам это обнадеживающий сигнал на верхушке воронки, который следует сочетать с испытаниями вроде Gemini Business.
Строки «Режим врача» появляются в веб-приложении ChatGPT, намекая на GTM в здравоохранении
Упоминания о новом “Clinician Mode” были замечены в веб-приложении ChatGPT, наряду с другими корпоративными функциями в той же еженедельной сводке clinician mode strings, weekly recap list. Если формализовать, ориентированный на здравоохранение режим с ограниченным охватом может нацелиться на требования соблюдения и рабочие процессы для клинических команд, расширяя присутствие ChatGPT в корпоративном секторе в регулируемых сферах.
Тестировщики Gemini Enterprise сообщают, что ответы агентов кажутся более надёжными по сравнению с персональным Gemini.
Ранние тестеры считают, что ответы агентов, работающих на Gemini 2.5 Pro в версии Enterprise, кажутся более надёжными, чем те, что они наблюдают в персональной Gemini, что может отражать настроенные значения по умолчанию, ограничители или политики контекста на бизнес-уровне agent reliability note. В сочетании с пакетными местами и встроенным в чат Конструктором агентов это усиливает ценностное предложение для предприятий enterprise walkthrough.
Perplexity готовит выплаты за приглашения через Dub для ускорения роста числа пользователей.
Perplexity готовит программу приглашений на ограниченный срок с денежными выплатами через Dub, что сигнализирует о ростовом маркетинговом движении для расширения охвата помимо органических каналов payouts program leak. Для конкурентов ожидается краткосрочная конкуренция в области реферальной экономики и партнёрских программ для создателей контента, а не в чистом соответствии по функциям.
📄 Парсинг и конвейеры веб-данных для агентов
Конкретные строительные блоки для агентов, голодных до данных: MarkItDown от Microsoft (десятки форматов → Markdown с OCR/транскрипцией) и редактор ScrapeCraft для скрапинга с поддержкой ИИ на LangGraph.
Microsoft MarkItDown: единое решение для преобразования документов в Markdown (PDF, Office, HTML, медиа); сейчас около 81 тыс. звезд
MarkItDown от Microsoft консолидирует PDF-файлы, документы Office, HTML, JSON/XML, ZIP‑файлы и даже YouTube/аудио в чистый Markdown с встроенным OCR и транскрипцией — идеален в качестве готового префпрессора для пайплайнов агентов, которые трактуют Markdown как «родной» формат GitHub repository.
Для инженеров ИИ это устраняет хрупкое межформатное сцепление: единый инструмент выдает структурированный текст плюс сохраненные таблицы/ссылки/метаданные, обеспечивая последовательное разбиение на части, индексацию и сборку подсказок по разнородным корпусам в масштабе GitHub repository.)
ScrapeCraft выпускает визуальный редактор для скрейпинга с поддержкой ИИ, основанный на LangGraph.
ScrapeCraft объединяет ScrapeGraphAI с LangGraph, чтобы предоставить AI‑помощник, веб‑базированный редактор скрейпинга: проектируйте конвейеры визуально, собирайте данные с большого числа URL, выводите результаты в реальном времени, автоматически генерируйте Python (async) и определяйте динамические схемы — создано для агентов, которым нужны надежные, воспроизводимые веб‑потоки данных обзор проекта, и репозиторий на GitHub.\n\n
\n\nЭто приносит эргономику в стиле «курсор» к процессу загрузки данных, уменьшая необходимость ручной разработки скрейперов и упрощая интеграцию шагов извлечения, валидации и хуков развёртывания непосредственно в рантаймах агентов.
🏭 Промышленная робототехника и конкурентное преимущество Китая в производстве (исключение, не связанное с ИИ)
Несколько графиков/постов утверждают, что Китай теперь производит около 80% промышленных роботов и лидирует в областях передового производства — последствия для цепочек снабжения воплощённого ИИ и кривых затрат. Ограничено макро-сигналами; обновлений по чипам сегодня нет.
Китай сейчас производит около 80% промышленных роботов, что обеспечивает рост круглосуточных «ночных фабрик».
Аналитика утверждает, что Китай производит около 80% мировых промышленных роботов и обладает самой высокой плотностью роботов, предупреждая, что 24/7 «темные фабрики» могут обеспечить ценовое и объёмное преимущество, которое изменит глобальную конкурентоспособность в производстве analysis thread, с приложенной ссылкой на источник source article.)
Влияние на оборудование для ИИ и воплощённых агентов: более быстрые циклы развертывания и более низкая себестоимость единицы для автоматизированных линий в Китае, что повлияет на то, где продукты ИИ с большой долей робототехники можно будет сначала масштабировать и наиболее прибыльно.
Китай занимает лидирующие позиции в рейтингах передового производства в областях материалов, покрытий и аддитивных процессов.
Новая сравнительная таблица показывает, что Китай занимает первое место во многих самых передовых вертикалях в области материалов и производства — охватывая наномасштабные материалы, специализированные покрытия, умные материалы и аддитивное производство — часто с большим отрывом от США ranking table.
Для разработчиков ИИ это укрепляет аргумент о том, что первичные компоненты для робототехники, датчиков и прецизионного приводного оборудования будут дешевле и легче добываться из китайских цепочек поставок, что потенциально сдвигает траектории стоимости встроенного ИИ и сроки поставки в пользу Китая по мере масштабирования автоматизации на заводах.