ScalingEval заменяет человеческих оценщиков на жюри из LLM — 36 моделей в рамках 1 745 пар
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
ScalingEval стал набором инструментов оценки без участия человека для рекомендаций продуктов, и это важно, потому что он превращает субъективные суждения A/B в повторяемые, запускаемые машинами аудиты. Панель из «судей» на основе LLM оценивает 1 745 пар продуктов на 36 моделях и устанавливает истинное значение большинством голосов, с тегами по каждой паре проблем, которые можно отслеживать со временем. Меньше стихийного руководства подрядчиками; больше итераций по политикам.
Согласно ветке обсуждения статьи, Gemini‑1.5‑Pro занимает лидирующие позиции по совокупным результатам, GPT‑4o предлагает самую чистую кривую скорости/стоимости, а Claude‑3.5‑Sonnet сообщает о близкой к 99% уверенности. Среди открытых опций GPT‑OSS‑20B занимает лидирующие позиции. Рабочий процесс также указывает, почему рекомендации идут не так — дополнения против substitutes, подбор размеров, ошибки «слишком похожи» — и показывает, где автоматизация держится: электроника и спорт требуют более высокого согласия судей, тогда как одежда и продукты остаются настолько запутанными, что требуют человеческих выборочных проверок.
Практическая победа — операционная: ансамблевое судейство снижает предвзятость одного модели, тегирование проблем становится воротами регрессии, а кластеры разногласий показывают точно, на чем сфокусировать исправления политики. Если вы еженедельно вносите изменения в рек-системы, это выглядит как способ сузить петли обратной связи без роста бюджета на разметку.
Feature Spotlight
Feature: OpenAI Codex capacity boost (mini + higher limits)
OpenAI expands Codex capacity: GPT‑5‑Codex‑Mini enables ~4× more usage at slight tradeoffs, +50% rate limits, and priority processing for Pro/Enterprise—immediate throughput gains for agentic coding and CI workflows.
Today’s biggest practical update for builders: OpenAI rolled out GPT‑5‑Codex‑Mini plus 50% higher Codex rate limits and priority lanes for Pro/Enterprise. Multiple devs report overnight repo refactors and 4× more usage per plan.
Jump to Feature: OpenAI Codex capacity boost (mini + higher limits) topicsTable of Contents
🧑💻 Feature: OpenAI Codex capacity boost (mini + higher limits)
Today’s biggest practical update for builders: OpenAI rolled out GPT‑5‑Codex‑Mini plus 50% higher Codex rate limits and priority lanes for Pro/Enterprise. Multiple devs report overnight repo refactors and 4× more usage per plan.
OpenAI ships GPT‑5‑Codex‑Mini and lifts Codex limits by 50%
OpenAI rolled out GPT‑5‑Codex‑Mini plus a blanket 50% rate‑limit increase for Codex, and priority lanes for Pro/Enterprise. Mini delivers ~4× more usage per plan at a small accuracy tradeoff (SWE‑bench Verified 71.3% vs 74.5% for Codex high) and is live in the CLI/IDE, with API support “coming soon” release details, limits and priority, benchmarks chart.
This comes a day after quota and tracking fixes, so it’s a clear capacity swing following up on usage fixes. ChatGPT Plus, Business, and Edu now get higher Codex throughput; Pro/Enterprise jobs should see faster starts under load limits and priority, plan math. If you were bottlenecked by Codex message caps, this raises the ceiling without changing code. The gap to Codex high is ~3.2 points on SWE‑bench Verified—acceptable for many refactors, test updates, and lints release details.
Overnight Codex run clears ~6,000 lints/types in a single repo
A practitioner queued long Codex runs with a progress markdown tracker and a stack of “continue” prompts, and woke up to ~6,000 linter/type issues fixed across the codebase—exactly the kind of batch work the new capacity makes viable overnight run. The same session kept going for hours with periodic re‑queues, showing Codex can grind through large, repetitive fixes while you sleep follow‑up status, kept working. gdb highlighted similar repo‑wide cleanups after the update usage note.
If you try this: keep a live tracker file, allow web lookups when stuck, and batch “continue” operations so you don’t babysit the loop overnight run.
Plan math: 1.5× more Codex messages; Mini counts 4× lighter
OpenAI teammates clarified the math: Plus/Edu/Team users get ~1.5× more Codex messages than yesterday, and using GPT‑5‑Codex‑Mini multiplies that further—Mini “contributes to usage limits 4× less,” effectively stretching the allowance even more plan math, limits clarification. Combine this with the global +50% rate‑limit lift and Pro/Enterprise priority processing to route large batches through Mini first, then reserve Codex high for hard cases limits and priority, model selection.
When to use Codex‑Mini vs Codex‑High
OpenAI recommends selecting GPT‑5‑Codex‑Mini for easier tasks or when you’re close to rate caps; use Codex high for tougher fixes where the extra ~3.2 points of accuracy matter (74.5% vs 71.3% on SWE‑bench Verified) model selection, benchmarks chart. The Mini variant is available right now via CLI/IDE (e.g., codex -m gpt‑5‑codex‑mini), with API support coming next cli example, release details.
🛰️ Pre‑release signals: GPT‑5.1 family and Polaris Alpha
Concentrated model roadmap signals today (excludes Codex feature): GPT‑5.1/GPT‑5.1 Reasoning/Pro strings, Nov 24 date in configs, and stealth ‘Polaris Alpha’ tests with 256K context and high rate limits.
OpenAI codepaths point to GPT‑5.1, Reasoning, Pro shipping Nov 24
Multiple config traces list “GPT‑5.1”, “GPT‑5.1 Reasoning”, and “GPT‑5.1 Pro” with a releaseDate set to November 24, 2025 in enterprise settings and UI configs RBAC code leak, and separate diffs repeat the date string in a model group labeled “GPT‑5.1 Models” config snippet. A separate roundup echoes the same three‑SKU lineup and date date confirmation.
Why it matters: roadmap signals let teams freeze test matrices, plan traffic shifting, and prep eval suites ahead of a likely three‑model drop. Expect the base to target latency and the Reasoning variant to trade speed for longer thinking; Pro typically carries higher limits.
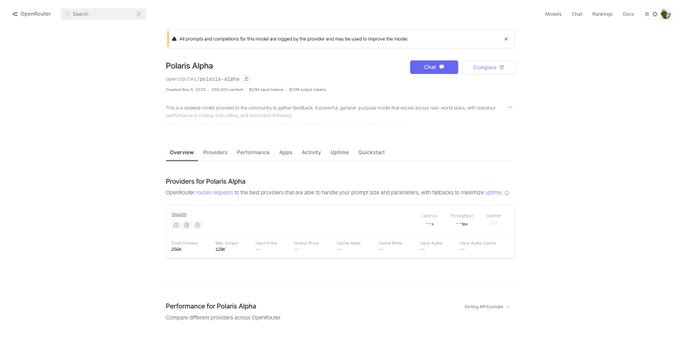
Polaris Alpha appears on OpenRouter with 256K context and stealth provider
OpenRouter now lists “Polaris Alpha” with a 256,000‑token context window and a Stealth provider, reinforcing that this is an unlabeled pre‑release checkpoint many link to GPT‑5.1 model card. Tooling screenshots show it selectable in agent UIs and IDE helpers tool model list, and early users note prompt‑sensitivity quirks while integrating it into agents—system prompts may need retuning agent run. OpenRouter says it’s benchmarking provider differences to explain observed behavior variance provider check.
GPT‑5.1 shows up in ChatGPT A/B; testers report faster replies
Early users say GPT‑5.1 is being A/B tested in ChatGPT and “much faster than GPT‑5” in side‑by‑side runs tester note. Community testers also report a companion checkpoint (“Polaris Alpha”) with high rate limits and strong efficiency in early access early tests. If these signals hold, 5.1 may ship with better throughput at comparable quality—a big deal for cost per task and queueing.
Polaris Alpha tops EQ‑Bench writing; clusters nearest GPT‑5 in outputs
Polaris Alpha is reported as the new leader on EQ‑Bench writing tasks, with testers noting its outputs cluster closest to GPT‑5 and that the model runs with high rate limits writing lead, eval update. This extends prior findings that its writing style was already the closest match to GPT‑5 Pro Style sim, suggesting the checkpoint has matured from stylistic parity to stronger measurable performance on long‑form writing evals.
Leak trackers see no ‘GPT‑5.1‑mini’ or ‘heavy’; three SKUs likely
Diff hunters say they haven’t found strings for “GPT‑5.1‑mini” or “GPT‑5.1‑heavy/large,” reinforcing a family consisting of GPT‑5.1, 5.1 Reasoning, and 5.1 Pro only sku note. Separate code excerpts enumerate those three exact names in config string list. For planners, that narrows test matrices and points to classic trade‑offs: base for speed, Reasoning for depth, Pro for ceilings (limits/features).
📊 Evals pulse: K2 Thinking costs/verbosity, Terminal‑Bench 2.0, Text Arena
Heavy eval traffic today: new cost/latency/verbosity data for K2 Thinking, Terminal‑Bench 2.0 and Harbor for sandboxed rollouts, SimpleBench and Vals deltas, and Text Arena movement. Excludes Codex feature.
AA: K2 Thinking scores 67; uses 140M tokens to run, ~$356–$1,172 per full eval
Artificial Analysis published full Intelligence Index results for Moonshot’s K2 Thinking: composite score 67 (top open weights), an unprecedented ~140M tokens consumed across the suite, and a Cost‑to‑Run of ~$356 on the base endpoint vs ~$1,172 on the Turbo endpoint. Base throughput is ~8 out/s, Turbo ~50 out/s. Following up on Pricing, this adds hard cost/latency math around the earlier $0.60/M in and $2.50/M out pricing and INT4 (~594 GB) release details AA index summary, token usage, pricing and speed, eval details.
- Notables: #2 overall in agentic tasks; 93% on τ²‑Bench Telecom (customer‑service tool use), but very verbose generations drive cost and latency eval details. See the model page and rollup at Artificial Analysis for per‑eval breakdowns AA homepage.
Terminal‑Bench 2.0 ships with Harbor to scale verified, sandboxed agent rollouts
A new chapter for command‑line evals: Terminal‑Bench 2.0 arrives with harder tasks, stronger verification and Harbor, a package for running sandboxed agent rollouts at scale. This combo makes it easier to reproduce, score and compare long‑horizon CLI workflows reliably across models and providers release thread, news brief.
For AI engineers, this is a cleaner path to A/B test tool‑using agents under isolation, collect traces, and avoid flaky pass/fail due to environment drift.
Text Arena: Baidu’s ERNIE‑5.0‑Preview hits 1432, surging into top ranks
On LMArena’s Text Arena, Baidu’s ERNIE‑5.0‑Preview‑1022 posted a score of 1432 in early convergence, with strengths reported in creative writing, longer queries and instruction following. It’s now battling near the very top, pending more votes arena update, Text Arena leaderboard.
For evaluation leads, add ERNIE‑5.0‑Preview to head‑to‑head runs in long‑form and instruction‑dense tasks; watch how its placement settles as sample size grows.
Vals Index: K2 Thinking is #2 open‑weights; ~5× slower “thinking” than GLM 4.6 but strong on tools
Vals.ai’s composite shows K2 Thinking holding #2 among open‑weights models. It excels on tool‑heavy tasks (Finance Agent, SWE‑Bench), yet its “thinking” mode is roughly 5× slower than GLM 4.6, which still leads overall on their open‑weights board vals summary, latency gap.
Route agentic, multi‑tool jobs to K2 if quality trumps speed; keep latency‑sensitive paths on GLM 4.6 or similar until K2’s throughput improves.
SimpleBench: K2 Thinking rises to 39.6% (rank ~19); long‑reasoning stalls observed
Community runs put K2 Thinking at ~39.6% on SimpleBench (around 19th), up from ~26.3% for the earlier K2, but testers also report API timeouts/stalls on very long reasoning traces that may depress scores in practice simplebench status, api stall report, long run stop.
If you’re evaluating K2 on SimpleBench, cap max‑thinking, watch for timeout handling, and retry failed long traces to separate model gaps from transport issues.
⚙️ Serving lessons: bandwidth, KV, and gateway latencies
Runtime engineering notes dominated by serving: a K2 deployment speedup traced to IP bandwidth, KV‑cache quantization tweaks on vLLM, and gateway latency cuts. Excludes gen‑media serving, covered separately.
Moonshot fixes K2 token speed by upgrading network, not GPUs
MoonshotAI says a recent K2 Thinking serving slowdown wasn’t compute-bound—the fix was increasing IP bandwidth, not adding more GPUs. Their lesson for operators: before throwing more H100s at throughput issues, check network pipes first throughput fix.
That maps to what many teams see in high‑concurrency LLM serving where egress and per‑IP throttles stall token streaming. Moonshot’s public K2 endpoints remain available with documented pricing and context specs for planning rollouts model page.
AA clocks K2 speeds: ~8 tok/s base vs ~50 tok/s turbo
Independent runs on Artificial Analysis put K2 Thinking’s standard endpoint at roughly 8 output tok/s and the turbo endpoint near ~50 tok/s; cost to run their full suite varied from ~$356 (base) to ~$1,172 (turbo) due to verbosity and token volume analysis thread. For serving owners, that’s a clean latency/cost trade: the faster tier buys throughput but drives up $/completion.
If you’re capacity‑planning long‑horizon agents, budget for high token counts—AA reports K2 used ~140M tokens across their evals—and route latency‑sensitive traffic to turbo only where it pays back in user experience cost and speed.
K2 Thinking on vLLM maxes 8×H100; FP8 KV cache needed to fit
A practitioner report shows K2 Thinking running on vLLM fully saturating VRAM on an 8×H100 box; they had to quantize the KV cache to FP8 to fit and keep it streaming vLLM run. Following up on vLLM guide where NVIDIA shared multi‑node best practices, this is a concrete datapoint: memory, not FLOPs, was the binding constraint.
For teams evaluating K2 on self‑hosted clusters, plan around KV size (context × heads × layers) and consider cache quantization/partitioning to hold concurrency without spilling. Expect trade‑offs: FP8 KV reduces memory pressure but can alter stability at extreme context or batch sizes.
OpenRouter trims gateway routing latency to ~15 ms (−40%)
OpenRouter cut average routing latency by about 40%, now advertising ~15 ms between users and model inference after edge and pathing optimizations latency update. That’s below a 60 fps frame time, which matters for real‑time UIs and voice loops.
If you saw provider variance on day‑one K2 endpoints, the team says it’s actively benchmarking and investigating outliers before following up publicly provider check.
🛠️ Agent & IDE stacks beyond Codex
Non‑feature coding/agent updates: orchestration hooks, background jobs, and faster free tiers for day‑to‑day dev. Excludes OpenAI Codex capacity story (covered as the feature).
Amp Free gets ~65% faster and a ‘rush’ mode that’s 50% faster, 67% cheaper
Amp upgraded its free tier with a much smarter model and ~65% speedup, and introduced ‘rush’—a mode tuned for small, well‑defined tasks that’s roughly 50% faster and 67% cheaper token‑by‑token than ‘smart’ free tier update, rush mode details. Docs cover when to pick rush vs smart and include thread examples for quick trials Amp blog, with a product page for the updated free tier Amp Free page.
Cline adds Hooks to validate, log, and trigger tools across an agent’s run
Cline introduced Hooks that let you inject custom logic at key moments in a task’s lifecycle—before and after tool calls, on task start/finish—to block risky ops, capture analytics, and kick off external workflows. The release outlines six hook points covering pre/post tool use and end‑to‑end task flow, making policy enforcement and telemetry first‑class for agent runs feature brief, with setup details in the project’s docs Docs.
Charm’s Crush gains Jobs to run background builds and swarms under agent control
Crush introduced Jobs: agents can now spawn and manage background processes like dozens of Xcode builds or a swarm of Docker containers, keeping long tasks off the foreground loop and under supervision release note. The team shipped it alongside the public repo, so you can wire it into existing CLI flows today GitHub repo.
Claude Code weekly: free web credits, Skills support, and output styles return
Anthropic’s weekly Claude Code update adds a promo for free credits on the web app, brings Skills support into the web experience, and restores output styles after user feedback; the CLI also gets better fuzzy search and steadier interactive prompts weekly roundup. A follow‑up confirms output styles are back because alternatives weren’t powerful enough yet follow‑up note.
Factory’s Droid Exec guide shows how to ‘chat with any repo’ via headless agents
Factory published a step‑by‑step guide for building a “chat with repo” feature using Droid Exec in headless mode, including streaming SSE responses, real‑time agent feedback, and a cloneable example repo guide, with full instructions in the docs Docs guide. This is useful when you want agent conversations grounded in the live file tree without a full desktop UI.
RepoPrompt 1.5.22 ships fast Markdown rendering and better memory for big repos
RepoPrompt 1.5.22 re‑adds chat Markdown using a high‑performance renderer and reduces memory usage when running discovery agents across large repositories. The maintainer notes the improvements help stabilize scoring variance seen during early K2‑Thinking endpoint tests release notes.
🧭 Managed RAG, extraction pricing, and developer guides
RAG workflows saw concrete guidance and pricing changes today: Gemini File Search JS snippets, Firecrawl credit unification, and an open‑source agentic RAG app example.
Gemini File Search ships full JavaScript examples and a step‑by‑step JS guide
Google/DeepMind added complete JavaScript snippets to the Gemini File Search docs and published a detailed JS tutorial covering persistent stores, concurrent uploads, chunking/metadata, and CRUD on documents—following up on initial launch. The managed RAG service continues to price indexing at $0.15 per million tokens with free storage and query‑time embeddings. See the updated docs in docs snippet and the full tutorial in dev guide, with a quick developer summary in usage guide and feature recap in feature brief.
Why it matters: teams can now copy/paste working JS for real workflows—creating named stores, batching uploads with per‑file metadata, and pruning or updating documents—without building RAG plumbing. For a fast start, Google’s guide demonstrates store discovery by display name, multi‑file streaming, and “find indexed doc” flows developer guide.
Firecrawl unifies pricing across scrape/crawl/map/search/extract; adds Extract calculator
Firecrawl simplified billing: one credit system now spans all endpoints, with Extract moved to credits (15 tokens = 1 credit) and a new web calculator to estimate request cost. The change removes token silos and makes budgeting predictable across pipelines pricing update, with earlier notes pointing to broader Extract usage alongside the new Branding schema branding format. Use the estimator to size jobs before you run them credit calculator.
Why it matters: this cuts pricing head‑scratching for teams chaining scrape → map → extract workflows. It also lets you cap spend by credits and compare extraction shapes (few long docs vs many short) before firing agents.
LlamaIndex shows an email‑driven finance agent for invoices and expenses
A worked example from LlamaIndex wires triage + extraction for finance ops: classify inbound emails/attachments (invoice vs expense), extract amount/currency/due date/payee, check budgets, and auto‑respond. It uses LlamaClassify and LlamaExtract under LlamaCloud workflows, with the full agent flow charted end‑to‑end flow diagram.
Why it matters: this is a concrete agentic RAG/extraction template you can fork today for AP/expense queues—particularly useful for teams that need consistent JSON fields plus human‑readable replies out of unstructured PDFs and emails.
Weaviate open‑sources “Elysia,” an agentic RAG app you can pip‑install today
Weaviate released Elysia, an open‑source agentic RAG application that uses a decision‑tree planner, dynamic display types (tables, cards, charts, docs), and auto “skill selection” over Weaviate collections. It’s a pip‑install plus Weaviate Cloud connect away, with both a web UI and Python API project post, and a technical breakdown of the decision tree + display system Weaviate blog.
Why it matters: this is a runnable pattern, not just a library. You can clone the exact tool‑calling and UI logic for data apps where agents need to choose how to render answers—not only what to say.
LlamaIndex + MongoDB share a reference RAG stack for docs→insights
A LlamaIndex/MongoDB reference architecture shows an S3 → LlamaIndex ingestion and embedding flow into MongoDB (document storage, vector index + metadata), feeding search/retrieval and “GenAI insights” layers. It’s a clean diagram for teams moving from folders of PDFs to searchable, grounded answers architecture slide.
Why it matters: this is a pragmatic blueprint for managed RAG on commodity pieces—S3 for raw files, LlamaIndex for chunking/embeddings, and MongoDB for vectors + filters—without bespoke infra.
🏗️ Compute geopolitics: China mandates local chips; US blocks Nvidia SKU
One non‑AI exception focused on AI supply: China orders state‑funded DCs to use domestic AI chips; US signals no exports for B30A. Clear near‑term impact on GPU availability, migrations, and cost of AI at scale.
US to bar Nvidia’s B30A exports to China
Washington has told agencies not to permit exports of Nvidia’s pared‑back B30A to China, effectively closing a loophole left by earlier Blackwell restrictions Reuters report. Nvidia’s CEO separately said there are “no plans to ship anything” to China right now, underscoring the near‑term freeze on Blackwell‑class supply into that market CEO comment.
This move matters because B30A was the down‑binned bridge: roughly ~50% of a B300, likely one AI die with 4 HBM3e stacks (~144 GB, ~4 TB/s) and NVLink to scale, positioned as a “useful in clusters” China SKU Reuters report. With that off the table, Chinese buyers will lean harder on domestic accelerators or older/export‑compliant parts, while global Blackwell capacity concentrates in friendly regions. That reshapes near‑term cluster design and software stacks.
This also lands in the context of Beijing’s mandate that state‑funded AI data centers use domestic chips—and rip and replace foreign parts if projects are <30% complete—following up on China mandate with a US counter that narrows import options Reuters summary Reuters article.
- Route China‑bound workloads to domestic accelerators and plan CUDA‑alternative paths (e.g., ROCm, OpenXLA).
- Expect reallocation: more GB200/Blackwell for US/KR/EU queues; China timelines slip or replatform.
- Budget for kernel/tuner work: bandwidth/topology changes (HBM, NVLink/PCIe) will surface new bottlenecks.
🧪 Reasoning & continual learning: SPICE, Nested Learning, 3TF
A dense research day on agent self‑improvement and CL: SPICE’s challenger/reasoner loop, Google’s Nested Learning paradigm, thought‑training for short outputs, and DS‑STAR for messy data agents.
Meta’s SPICE shows +8.9% math and +9.8% general reasoning in self-play
Meta introduced SPICE, a self-improvement loop where a Challenger generates doc‑grounded tasks and a Reasoner solves them without access to the docs, co‑trained via DrGRPO; reported gains are +8.9% on math and +9.8% on general reasoning paper thread, with the full method detailed in the preprint ArXiv paper.
Why it matters: SPICE turns real corpora into a scalable curriculum, a practical path for agents to keep getting smarter between major pretrain cycles.
3TF trains with thoughts but answers tersely, cutting tokens ~60–80%
Thought‑Training & Thought‑Free inference (3TF) teaches models using full chain‑of‑thought, then suppresses visible reasoning at inference to keep accuracy near CoT while shrinking outputs to roughly 20–40% of tokens on math and other tasks paper summary.
Why it matters: reasoning is expensive; 3TF offers a deployable recipe to preserve quality while slashing latency and cost.
DS‑STAR lifts messy‑data agents to 45.2% on DABStep and 44.7% on KramaBench
Google’s DS‑STAR orchestrates Planner, Coder, Verifier and Router agents over mixed formats (CSV/XLSX/JSON/markdown) and posts 45.2% on DABStep, 44.7% on KramaBench, and 38.5% on DA‑Code—steady gains over prior baselines results thread, with methodology in the paper ArXiv paper.
Why it matters: most enterprise data is messy and multi‑file; this shows eval‑backed progress for pragmatic data science agents.
InnovatorBench tests end‑to‑end LLM research; tasks need ~6.5× more runtime
InnovatorBench introduces 20 tasks across six domains—from data work to scaffold design—in a sandboxed ResearchGym, finding agents require ~6.5× more runtime than older tests, with frequent failures from early stopping and GPU conflicts paper summary. This lands after IMO‑Bench showcased proof‑focused evals; InnovatorBench stresses full research loops.
Why it matters: strong coding isn’t enough; robust agent research workflows need schedulers, retries, and resource hygiene.
Long sessions shift model beliefs; GPT‑5 moved 54.7% after debates
A study shows accumulating context changes stated beliefs and tool choices over time; GPT‑5 shifted 54.7% after 10 debate rounds and Grok 4 shifted 27.2% on politics after reading opposing material, with open‑weights models drifting less on long reads paper summary.
Why it matters: reliability decays across long sessions; teams should checkpoint stance, constrain tools, or refresh context in guided hops.
V‑Thinker: Reasoning by editing images boosts vision task performance
V‑Thinker couples visual CoT with code‑driven image edits in a sandbox, re‑perceiving after each step; the paper introduces VTBench and reports gains on geometry, ARC‑style grids, and other vision‑centric puzzles where drawing and localization help paper card, with an accessible roundup here explainer thread.
Why it matters: making reasoning steps concrete in pixels can improve grounding, not just narration.
Dr. MAMR fixes ‘lazy agent’ mode collapse with causal credit and restarts
A multi‑agent analysis finds common collapse where one agent does all the work; Dr. MAMR mitigates it using a Shapley‑style causal influence metric plus an explicit restart/deliberation action that prunes noisy steps and re‑plans paper thread.
Why it matters: planning/execution splits are popular in production; this gives concrete telemetry and controls to keep both agents contributing.
HaluMem evaluates hallucinations in agent memory with 1M‑token contexts
HaluMem benchmarks hallucinations at three operations—extraction, updating, and memory QA—using long, user‑centric dialogues; across tools, weak extraction cascades into bad updates and wrong answers, often under 55% accuracy paper abstract.
Why it matters: memory stacks are the backbone for assistants; this shows where they break and how to target fixes.
SAIL‑RL teaches models when and how to think via dual‑reward RL
SAIL‑RL is a post‑training framework that adds a ‘when to reason’ controller alongside ‘how to reason’, using a dual reward to curb hallucinations and boost multimodal reasoning; results improve over baselines on a state‑of‑the‑art vision‑language model paper card.
Why it matters: many pipelines always ‘think out loud’; selective reasoning can save tokens without losing accuracy.
Scaling agent learning with experience synthesis (DREAMGYM)
Meta’s DREAMGYM synthesizes diverse experiences to stabilize online RL for LLM agents, improving performance on tasks not originally RL‑ready and reducing variance during learning paper summary.
Why it matters: most real tasks lack dense rewards; synthetic curricula are a viable bridge from supervised agents to on‑policy learning.
💼 Enterprise momentum: Anthropic EMEA, valuations, and app partners
Mixed enterprise signals today: Anthropic expands offices and clients in Europe, reports of Google exploring deeper investment, OpenAI revenue projections, and new ChatGPT app tie‑ins.
Anthropic opens Paris and Munich; EMEA revenue run-rate up >9×
Anthropic is opening new offices in Paris and Munich and says EMEA is its fastest‑growing region, with run‑rate revenue up more than 9× year over year and large enterprise accounts up more than 10×. Anchor customers span L’Oréal, BMW, SAP, and Sanofi, with local hiring planned across sales, policy, and engineering News post, and full details in the company’s announcement Anthropic news.
For AI leaders, this signals deeper regional support, shorter procurement cycles, and closer policy engagement in the EU—useful if you’re piloting Claude Code or rolling out agentic tooling under EU AI Act timelines.
Google may deepen Anthropic stake, implying ~$350B valuation
Google is in talks to expand its Anthropic investment with additional funding, more TPU capacity, and possible convertible notes—moves that could lift Anthropic’s valuation to roughly $350B, according to new reporting Report summary.
If this firms up, buyers should expect more TPU supply earmarked for Claude and stronger go‑to‑market in regulated industries where Anthropic has been winning security reviews.
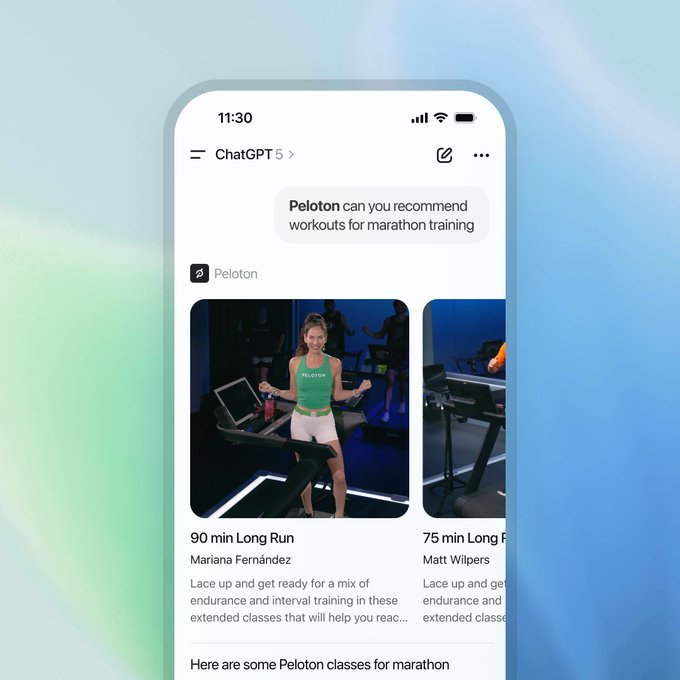
ChatGPT adds Peloton and Tripadvisor partner apps
OpenAI added Peloton and Tripadvisor apps inside ChatGPT: Peloton builds tailored marathon and class plans, and Tripadvisor handles hotel search and itineraries with live maps and pricing App screenshots.
This matters for enterprise app teams: the partner model here shows how domain apps can live inside ChatGPT while preserving their booking/workout flows—useful if you’re mapping your own product into ChatGPT’s app runtime and permission prompts.
OpenAI’s revenue charted toward ~$100B by 2027
A collated timeline of sourced reports charts OpenAI’s annualized revenue growth and projects a path toward ~$100B by 2027, aggregating Reuters and The Information checkpoints from 2023–2025 Chart thread, with source links at each step Reuters 2023 Reuters 2023 Dec The Information 2024 Reuters 2025.
For enterprise buyers, the takeaway is stability: a provider scaling revenue and capacity in step tends to maintain model availability SLAs and partner programs. It also hints at continuing price stratification across SKUs rather than across‑the‑board cuts.
UCSF plans ChatGPT Enterprise rollout in early 2026
The University of California, San Francisco announced it will bring ChatGPT Enterprise to campus in early 2026, migrating roughly 9,000 Versa Chat users and targeting HIPAA‑aligned use across research, education, and clinical workflows University post. This follows broader enterprise deployments such as Turner’s company‑wide rollout ChatGPT Enterprise, which established momentum for secured tenant setups.
For CIOs, the pattern is clear: start with a narrow, compliant tenant; migrate existing assistant users; and phase assistant‑to‑app integrations only after privacy reviews and data residency checks.
🎬 Generative media & serving: diffusion speedups and video ranks
Significant creative stack updates today justify a dedicated section: SGLang Diffusion serving (1.2–5.9×), WAN Animate cost/speed, LTX‑2 rankings, and new workflows. (Excludes LLM serving, covered under ‘Serving lessons’.)
LMSYS ships SGLang Diffusion with up to 5.9× faster generation
LMSYS released SGLang Diffusion, a high‑performance serving stack for image and video models that claims 1.2×–5.9× faster inference with an OpenAI‑compatible API, CLI and Python SDK. It supports popular open‑weights like Wan, Hunyuan, Qwen‑Image/‑Edit and Flux, and was co‑developed with FastVideo for a full open ecosystem from post‑training to serving launch thread, and LMSYS blog.
For teams running creative pipelines, this means lower latency and higher throughput without rewriting clients. The project also positions for upcoming hybrid generators that fuse autoregressive + diffusion, which LMSYS says SGLang Diffusion is designed to power hybrid roadmap.
Wan 2.2 Animate is 4× faster, now ~$0.08/s for 720p on fal
fal pushed a sizeable speed and quality upgrade to Wan 2.2 Animate: ~4× faster inference, sharper visuals, and pricing at about $0.08 per second for 720p jobs. That’s a practical cut for storyboard iterations and ad variants where minutes add up pricing update, fal model page, and wan move endpoint.
ComfyUI adds trajectory control node for Wan ATI workflows
A new Trajectory Control component for ComfyUI’s Wan ATI graph lets creators define motion paths for rendered shots, improving camera consistency and scene planning across shots feature note. This is a helpful upgrade for multi‑shot edits where you want to lock movement, then iterate style and content independently.
fal debuts InfinityStar, an 8B text‑to‑video under 30 seconds
fal launched “InfinityStar,” an 8B spacetime autoregressive engine that generates video in under 30 seconds, aimed at quick creative turns and consumer hardware constraints model drop, and model page.
If you’re exploring lighter T2V for UGC workflows, the sub‑30s target is notable for prototyping and live previews.
Lucy‑Edit local video editing is 2× faster and half the price
Decart’s Lucy‑Edit—an instruction‑guided video editor—got a major refresh: 2× speedup, ~50% lower cost, and open weights for local and self‑hosted use release note, Hugging Face org, and GitHub repo. For teams wary of API costs or content routing, this puts controllable edits (clothing, props, colorways) inside your own GPU box.
Reve Edit Fast enters top‑5 on Image Edit Arena at 5× lower cost
Reve’s new “Edit Fast” model is now publicly available and debuted in the Image Edit Arena’s top five. The Arena community calls out that it’s faster than the prior Reve Edit and around 5× more cost‑efficient in blind preference testing leaderboard update.
If you’re swapping backgrounds or style‑editing at volume, this is worth an A/B against your current default.
Flow by Google adds camera adjustment for Veo 3.1 edits
Flow by Google introduced a Camera Adjustment control for Veo 3.1 videos—tap the pencil to orbit or tweak the camera on generated clips. It’s a simple but meaningful handle for reshoots when the content is right but the angle isn’t feature demo, and how‑to tip.
Freepik launches Spaces: infinite canvas for real‑time creative colab
Freepik announced Spaces—an infinite canvas where teams can co‑create, share assets, and wire workflows across multiple AI models in real time. For agencies and social teams, this reduces the folder‑shuffle between prompts, boards, and reviews launch teaser, and workflow note.
Community demos showcase Grok’s image→video and text→video outputs
Early testers shared Grok’s video generation results across anime‑leaning prompts for both image→video and text→video. Quality looks promising on stylized content, though testers also posted mixed notes comparing promos vs. live results—so expect variance as settings mature tester note, demo clip, and comparison post.
🤖 Humanoids and factory lines: XPeng IRON, Tesla Optimus pilot
Embodied AI clips and details: XPeng shows robot internals to rebut suit rumors, and Tesla’s Fremont pilot line targets up to 1M/yr with ~$20k COGS at scale. Useful for teams eyeing sim‑to‑real and supply chains.
Tesla Optimus pilot line targets up to 1M units/year; ~$20k COGS at scale
Tesla has a pilot production line for Optimus in Fremont with an internal target of up to 1 million robots per year at maturity and a scale goal around $20,000 cost of goods per unit production target. That framing puts Optimus on an automotive‑style ramp and forces cost engineering trade‑offs—actuators, batteries, and assembly automation—earlier than most labs plan. Leaders should treat this as an anchor for supplier talks and factory takt‑time assumptions.
XPeng cuts open IRON on stage; 82‑DoF humanoid, 2,250 TOPS compute detailed
XPeng publicly dissected its IRON humanoid to rebut "person in suit" rumors, while sharing a fuller spec: 82 total degrees of freedom with 22 per hand, a bionic spine and toe articulation for natural gait, and on‑board compute rated at ~2,250 TOPS across three custom chips authenticity note, specs breakdown. The company says camera‑to‑action control uses a VLA stack (Vision‑Language‑Action) and imitation learning for quick routine fine‑tunes; the lifelike posture comes from spine/waist freedom, toe roll, and high‑DoF arm swing per a technical explainer how it walks.
Following up on demo footage, this is the first on‑stage teardown plus concrete specs. For teams working on sim‑to‑real and balance control, the message is clear: center‑of‑mass control, toe roll, and hand micro‑adjustments matter in the loop specs breakdown.
Standardized robot workcells pitched to scale imitation learning across sites
A "MicroFactory DevKit" concept making the rounds argues for identical, tightly‑controlled robot workcells so demonstrations and trained policies transfer across cloned cells with minimal domain shift devkit summary. The pitch: fix fixtures, sensors, lighting, and calibration to reuse data and policies instead of fighting distribution drift. If your embodied roadmap includes multi‑site rollout, standardize the physical stack before chasing more model data devkit summary.
Unitree G1 clips show agile motion; community flags unusual dance moves
Fresh Unitree G1 footage highlights unusually fluid motion sequences, prompting practitioners to trade notes on gait control and trajectory planning complexity for lower‑cost humanoids clip note. Treat these as qualitative signals of controller maturity, not production readiness; scheduling, safety limits, and task repeatability remain open questions for factory or service deployment clip note.