OpenAI GPT‑5.1 нацелен на 24 ноября с 3 SKU — Polaris Alpha на Elo 1748
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI’s следующая линейка выглядит более реальной, чем слухи. Путь кода клиента обозначает три «GPT‑5.1 Models» — GPT‑5.1, GPT‑5.1 Reasoning и GPT‑5.1 Pro — с датой выпуска, установленной на 24 ноября 2025 года. Если это подтвердится, вы имеете дело с разделением на 3 SKU для маршрутизации общих задач, более тяжелого процесса рассуждения и задач большей емкости без суеты в последнюю минуту.
Параллельно «polaris‑alpha» поднялся на вершину доски Creative Writing v3 с рейтингом Elo 1747.9. Строители предполагают, что это контрольная точка OpenAI с большим контекстным окном, но без явного режима «reasoning», что соответствует образцам: сильный стиль длинной формы и связность без явного излишнего обдумывания. Можно сказать, что это литературный контрбаланс к рассуждению‑первому 5.1.
Практический вывод: зафиксируйте текущие базовые параметры сейчас, затем добавьте polaris‑alpha к сопоставительным оценкам против ваших маршрутов класса GPT‑5. Зарезервируйте отдельно бюджет для Reasoning и Pro, если вам важны задержки или предсказуемость затрат, и считайте 24 ноября как предварительную, но продуманную дату — лучше привести в порядок мощность и оценки сегодня, чем сорваться на 24‑е.
Feature Spotlight
Feature: Nano Banana 2 preview leaks, then gets pulled
Nano Banana 2 briefly appeared on Media IO with exceptional text/infographic rendering; creators validated outputs across samples before access was pulled—clear signal that a major Google image model upgrade is imminent.
Google’s next image model briefly surfaced on Media IO with standout text/infographic fidelity and was then removed. Multiple creators verified samples. Excludes other creative tool updates to avoid duplication.
Jump to Feature: Nano Banana 2 preview leaks, then gets pulled topicsTable of Contents
🍌 Feature: Nano Banana 2 preview leaks, then gets pulled
Google’s next image model briefly surfaced on Media IO with standout text/infographic fidelity and was then removed. Multiple creators verified samples. Excludes other creative tool updates to avoid duplication.
Early tests show standout text, charts, and instruction fidelity from Nano Banana 2
During the short access window, users captured crisp on‑canvas text, whiteboard writing, charts, and accurate step‑by‑step outputs (including solving an integral) text fidelity sample, math whiteboard. Anime‑style prompts and cyberpunk scenes landed with consistent identity and layout as well anime sample, cyberpunk sample, anime consistency, with a larger compilation available for review sample gallery.
Nano Banana 2 quietly appears in Media IO as a working preview
Media IO briefly listed “Nano Banana 2 (Preview)” in its Text‑to‑Image model picker, and creators generated images during the window UI screenshot. Multiple sightings point to real access rather than a stub, with renders reported across platforms preview access and platform sightings.
Preview pulled: Nano Banana 2 disappears from Media IO after brief access
Hours after the leak, “Nano Banana 2 (Preview)” vanished from the picker; the slot now shows other models like Seedream/Imagen, confirming the preview was pulled removal notice. The quick reversal looks like either a controlled test or an accidental exposure, so expect a managed re‑release.
Positioning hints point to a Gemini 3 tie‑in for Nano Banana 2
Media IO’s page labels the model as “Gemini 3.0 Pro (Nano Banana 2 or GemPix2)” with “free early access,” fueling expectations NB2 could ship alongside or ahead of Gemini 3 Media IO page. Creators suggested NB2 might land before the Gemini 3 reveal after spotting it live in pickers across platforms platform sightings, with “available” reports earlier in the day preview note.
🧭 Frontier model roadmap: GPT‑5.1 family and Polaris Alpha
Fresh signals on OpenAI’s next models and a stealth checkpoint dominating creative writing. Excludes the Nano Banana 2 feature.
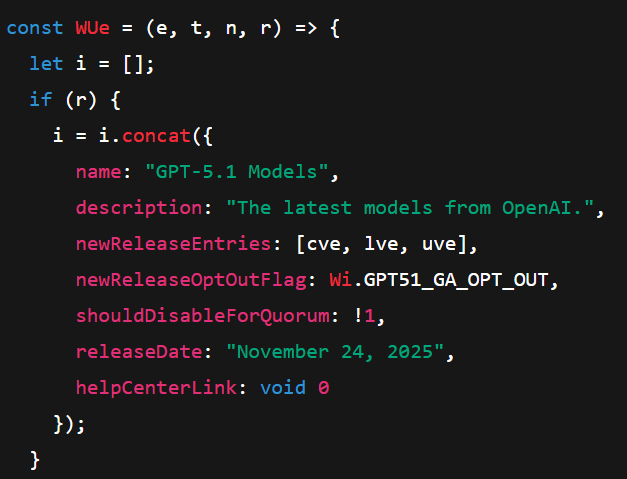
GPT‑5.1 family surfaces in code with Nov 24 release date
A client code path explicitly names “GPT‑5.1 Models” with three SKUs—GPT‑5.1, GPT‑5.1 Reasoning, and GPT‑5.1 Pro—and a releaseDate set to November 24, 2025 code path. Community trackers echo the same three variants as “preparing to ship,” pointing to an imminent family rollout family mention.
Why it matters: this narrows the window for planning model routing and evals, and hints that OpenAI will split general, reasoning, and higher‑capacity profiles at launch.
Polaris Alpha tops Creative Writing v3; likely OpenAI, large context
A new Creative Writing v3 leaderboard shows “polaris‑alpha” out front with an Elo of 1747.9, clear of the next cluster, signaling strong long‑form style and coherence leaderboard view. Builders speculate it’s an OpenAI checkpoint with a big context window and no explicit “reasoning” mode, consistent with earlier sightings on OpenRouter model origin note.
Following up on 256K context, today’s writing lead reinforces the profile: non‑reasoning, large‑context model that excels at literary quality. If you ship writing tasks, add it to head‑to‑head evals against GPT‑5‑class baselines.
🛠️ Agent engineering and IDE workflows
Practical agent loops, sandboxes, and cost cuts for AI engineering; mostly frameworks and IDE/runtime tooling today.
Anthropic open-sources Claude Code sandbox runtime (srt) for safer local tool use
Anthropic’s local sandbox for Claude Code is now open-source, exposing a CLI and Node API that wraps commands with OS sandboxing and proxy-based network filtering (deny/allow lists, FS guards) sandbox details. Teams can finally run MCP servers, bash, and codegen safely on laptops and CI without punching big holes.
Anthropic details Claude Agent SDK Loop for building reliable agents
A clear, three‑stage loop—Gather context → Take action → Verify output—was shared as the core pattern powering Claude Code and other agents, with subagents for parallel search, MCP tools, and LLM‑as‑judge checks framework thread. This is a practical recipe you can copy into agent graphs today to improve recall, tool use, and QA gates.
LangChain’s TokenCrush claims 70–90% token cost cuts for LangGraph apps
TokenCrush is a LangGraph extension that compacts prompts and RAG context, with claimed 70–90% token savings while preserving meaning in production graphs extension post. If you’re paying for multi‑agent loops, this is the kind of drop‑in compression worth A/B testing before the next bill.
LangChain Stock Research Agent V3 adds collab+observability; reports 73% lower costs
The community’s Stock Research Agent V3 ships on LangGraph + LangSmith with an interactive UI, real‑time traces, and a modular backend, and claims 73% cost savings vs earlier builds agent v3 thread. It’s a concrete template for multi‑agent orchestration with monitoring—timely following release of LangGraph 1.0.
Evalite previews custom scorers and a watch UI for TypeScript evals
Evalite’s next version will ship a library of custom scorers (e.g., tool‑call accuracy) and a live watch UI, making it easier to score agent outputs like tool usage from TS test files scorers preview. For agent teams, this helps move evals from notebooks into CI with clear, per‑case verdicts.
Athas v0.2.4 adds multi‑workspace tabs and fixes nested git staging
The Athas IDE’s 0.2.4 update introduces project tabs for multi‑workspace work, cleans up editor core issues, and corrects git status for nested paths and directory staging; Windows CLI/search build errors are also fixed release notes. If you’re trialing agent‑assisted editors, this release is more stable for real repos.
🔌 MCP and containerized agent infra
Standardizing tool access: compile MCPs to CLIs, run catalogs in Docker, and auth notes on OAuth DCR. Excludes IDE‑focused agent UX.
Docker Desktop adds MCP Toolkit with 300+ server catalog
Docker Desktop’s new MCP Toolkit (beta) exposes a catalog of 300+ Model Context Protocol servers—Playwright, Fetch, PostgreSQL read‑only, and more—ready to run in containers. This standardizes tool access for agents and makes local, isolated runs trivial for teams that don’t want bespoke installs mcp toolkit ui.
MCP maintainers signal shift away from OAuth Dynamic Client Registration
The MCP spec currently uses OAuth Dynamic Client Registration for auth, but maintainers now say they’ll move away from DCR soon—important for anyone wiring MCP servers to enterprise IdPs and rotating client credentials at scale spec note, maintainer comment. Details of the current flow are in the protocol’s authorization section MCP authorization.
McPorter compiles any MCP server into a standalone CLI
Using npx mcporter generate-cli "npx -y <server> …", engineers can wrap an MCP server into a compiled CLI for direct scripting and CI use—shown with chrome‑devtools—and pair it with explicit consent gates for sensitive ops in automation cli generator, consent example.
McPorter now inventories local MCP servers with health/auth states
npx mcporter list enumerates all configured MCP servers, reporting 27 in one example with per‑server health, auth‑required, and offline status. This makes it easier to reuse the same tool stack across clients like Claude, Codex, Cursor, and IDEs without duplicating config list output.
Docker surfaces “Ask Gordon” assistant alongside MCP and Models
Docker Desktop now shows an “Ask Gordon” assistant pane next to the new MCP Toolkit and Models sections, hinting at a first‑party chat surface to browse/run tools and models from inside Docker. It’s a convenient entry for developers to compose containerized toolchains with an assistant in the loop assistant panel.
⚙️ Modalities and runtime behavior in prod
New input modes and runtime UX that affect pipelines and stability; not about orchestration or IDE agents.
GPT‑5‑Codex Mini adds image input in CLI; brief outage fixed
OpenAI enabled image inputs for GPT‑5‑Codex Mini in the Codex CLI, so you can pass a file alongside text (e.g., codex -m gpt-5-codex-mini) to ground generations in screenshots and diagrams CLI demo video. Shortly after rollout, image inputs had a temporary outage outage note that was addressed the same day fix confirmed.

For engineers this unlocks code explanations from UI screenshots, OCR‑assisted refactors, and test generation from error dialogs—without leaving the terminal. Keep an eye on rate/size limits as they settle.
OpenRouter adds video input support and model filter in stateless API
OpenRouter now accepts video as an input modality and lets you filter the catalog to models that support it. The update is exposed in the stateless API and the public catalog UI, which lists options like Gemini 2.5 Flash/Pro for video analysis models catalog, with details on supported parameters on the site Models page.
Why it matters: pipelines that relied on frame extraction can route short clips directly to compliant LLMs, simplifying pre/post steps and reducing token churn for structured video QA, summaries, and moment queries.
Codex UI prompts auto‑fallback to Mini on rate pressure; toggle promised
Codex’s desktop UI now surfaces an “approaching rate limits” prompt that nudges users to switch to GPT‑5‑Codex‑Mini, trading capability for lower credit usage rate limit prompt. A maintainer replied they will add a setting to disable this interruption so long‑running work isn’t stopped by modal prompts maintainer reply.
Teams running production evals or multi‑hour agent runs should watch for silent model downgrades; pin versions in CI and request the toggle once shipped to avoid drift.
📑 Research: continual learning and synthetic RL
Strong paper activity: Google’s Nested Learning, Meta’s data curation theory, and experience‑synthesis RL. Excludes business/product framing.
Google’s Nested Learning ‘Hope’ accepted to NeurIPS
Google’s Nested Learning—centered on the ‘Hope’ architecture for multi‑timescale updates to curb catastrophic forgetting—was accepted to NeurIPS 2025 acceptance note, following up on Hope intro. The public write‑up reiterates context‑flow and nested optimization aimed at stronger long‑context retention and lower perplexity on streamed tasks Google blog post, with researchers framing it as a concrete step toward the memory problem commentary thread.
Theory shows when less data wins
FAIR proposes a formal framework—label generator, pruning oracle, learner—to predict when smaller curated subsets outperform using everything, deriving exact error laws and sharp regime switches paper highlight. Empirical checks on ImageNet and LLM math align with the theory, and pruning also prevents collapse in self‑training by filtering wrong labels in label‑aware mode.
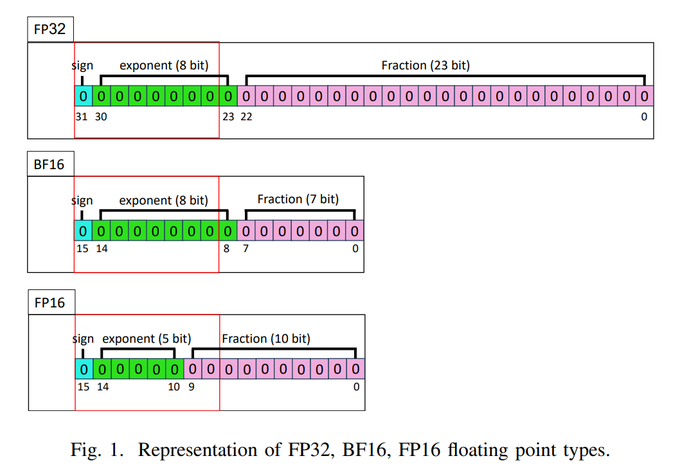
FP16 precision helps RL stability
A new analysis argues BF16→FP16 improves reinforcement learning because higher mantissa precision stabilizes gradients, value targets, and credit assignment under sparse or noisy rewards paper explainer. Expect training recipes to prefer FP16 during RL phases even if BF16 dominates pretraining.
Training proactive agents highlighted
Carnegie Mellon researchers’ “Training Proactive Agents” is called out as a key 2025 paper, focusing on objectives that drive initiative instead of purely reactive tool calls paper mention. For teams, that’s a nudge to evaluate goal setting, interruption handling, and self‑questioning alongside accuracy when you measure agent quality.
💼 Valuations, partnerships, and GTM
Market signals and enterprise adoption; quieter M&A but notable valuation chatter and partner integrations.
Anthropic said to target a $300–$400B valuation
Scaling01 reports Anthropic could seek a $300–$400B valuation in its next raise, signaling continued appetite for frontier AI equity valuation claim. This follows talk that Google may increase its stake at an implied ~$350B, noted earlier valuation rumor. For buyers and partners, that price range sets expectations on deal terms and secondary liquidity.
AI datacenter plans scale to tens of billions; Stargate pegged at ~$32B
A roundup thread pegs OpenAI’s ‘Stargate Abilene’ at ~$32B, >250× GPT‑4 compute, spanning ~450 football fields and thousands of workers over ~2 years, with broader AI DC demand forecast at 20–30 GW in the US by late‑2027 buildout overview. This is the non‑AI exception that matters: capital, power and siting constraints will shape model access, latency, and unit economics globally.
OpenAI acqui‑hires Jams; Jams and Hubble to sunset
Consumer video app Jams is joining OpenAI, with products Jams and Hubble closing later this year; only part of the team will transition company note. This looks like a talent buy toward consumer‑grade, AI‑assisted video experiences and may deepen OpenAI’s push into media UX.
GLM Coding plan lands at $3 Lite and $15/$30 Pro
ZhipuAI’s GLM Coding plan shows clear monthly tiers for dev workloads: Lite at $3/mo, Pro at $15 for month one then $30/mo, and Max at $30 first month then $60/mo pricing image, with details on the plan page pricing page. For budget‑sensitive teams, this sets a predictable GTM alternative to usage‑only pricing.
GLM‑4.6 selected to power Cerebras Code
ZhipuAI highlights GLM‑4.6 as the engine for Cerebras Code, pitching this as proof of why open weights matter for downstream integration and ecosystem growth partner welcome. For teams standardizing coding assistants, this is a signal that GLM‑4.6 is becoming a default in third‑party dev tools.
Microsoft preps Copilot Shopping with price predictions and review summaries
Microsoft is readying a new Copilot Shopping tab with price insights and review summarization ahead of Black Friday, alongside tracked prices and order history; a rollout this fall is implied feature brief, with details in TestingCatalog’s write‑up feature article. Expect Copilot to show up more in commerce journeys, not just knowledge tasks.
Perplexity’s Comet Assistant beta can drive the mobile browser
Perplexity is testing Comet Assistant on Android that accepts voice and executes browsing actions directly, shown across phone and tablet in a short demo mobile demo. For agent builders, it’s a reminder to design flows for narrow, reliable web actions on small screens.

🧮 INT4 QAT and long‑chain efficiency
Kimi K2’s quantization path: INT4 QAT for latency and stability in long reasoning; details matter for anyone running MoE stacks.
Kimi K2 explains INT4 QAT: W4A16 latency gains and 10–20% faster RL
Moonshot’s K2 team laid out why they train and serve with weight‑only INT4 QAT: W4A16 cuts decode latency on its 1/48 MoE because decoding is memory‑bound and FP8 weights approach ~1 TB per node, pushing I/O limits Zhihu explainer. Following up on INT4 QAT plan (earlier high‑level target), they confirm QAT uses fake‑quant + STE on BF16 masters engineer reply, and that INT4 was chosen over MXFP4/NVFP4 to run well on non‑Blackwell GPUs via mature Marlin kernels at a 1×32 quant scale Zhihu explainer.
They also report 10–20% faster end‑to‑end RL rollouts with fewer long‑chain failures thanks to lower latency and a tighter representational space Zhihu explainer. For long “thinking” traces that can exceed 1,500 tokens even on simple prompts, this directly affects cost and UX Thinking tokens. Roadmap hints include W4A8 and W4A4 next; K2 already sees W4A16 beat W8A8 for low‑latency serving on its MoE stack Zhihu explainer.
🛡️ Policy stances and usage norms
OpenAI’s public framing and geopolitical takes; guidance for leaders on positioning and risk narratives.
OpenAI frames “adult choice” and forecasts: 40×/yr cost drop; small AI discoveries by 2026, major by 2028
OpenAI published a policy-forward note arguing that adults should use AI on their own terms, alongside two hard forecasts: the cost per “unit of intelligence” has fallen roughly 40× per year, with AI expected to make small scientific discoveries in 2026 and more significant ones by 2028 OpenAI post, forecast recap, and quoted lines. The empowerment framing comes verbatim (“adults should be able to use AI on their own terms”) in the same post empowerment card, following up on compute reserves where OpenAI rejected datacenter guarantees and backed public compute reserves; this reads as a consistent posture: accelerate access while managing societal guardrails. See the full text in the OpenAI post.
For AI leaders, the signal is twofold: plan for rapidly falling effective costs, and prepare governance models that assume broad, individual access—not only enterprise gatekeeping. Expect pressure to translate these forecasts into roadmaps, funding asks, and public commitments.
Microsoft AI chief: gigawatt-scale AI runs ahead; systems will self-improve and write their own evals
Mustafa Suleyman said we can already imagine AI trained on gigawatt-scale compute runs “just a few years” out, capable of self‑improvement, goal setting, resource management, and even writing their own evaluations on‑camera statement.

For strategy teams, this sets expectations on capital intensity and autonomy. It strengthens the case for eval automation and governance tech that assumes systems will modify their own objectives and tests.
Palantir CEO: a US surveillance regime is preferable to China setting AI rules
Alex Karp told Axios that if the US doesn’t lead in AI, a surveillance-state scenario defined by China would be worse; he acknowledges surveillance has “huge dangers” but frames it as the lesser evil vs. ceding rule‑setting to Beijing Axios remarks. Coverage summarizes the stance and quotes in detail here: Gizmodo story.
This is a stark geopolitical framing aimed at policymakers. If you’re selling into regulated sectors, expect customers to reference this argument when justifying domestic procurement or stricter telemetry.
Energy framing shifts: 0.3 Wh per ChatGPT prompt; all AI DCs ≈ 2% of cement emissions
A widely shared explainer argues a single ChatGPT prompt uses ~0.3 Wh, and that all AI activity in global data centers in 2024 emitted about 2% as much as cement production—implying a 2% optimization in cement equals shutting down all AI services cheat sheet, energy comparison excerpt. The piece is positioned to rebalance climate narratives around AI usage; details in the Substack piece.
Communications teams can use these baselines to contextualize sustainability claims, while infra leads should still publish audited energy and water figures to avoid hand‑wavy comparisons.
Replit CEO warns ‘AGI by 2027’ timelines are hype and risk harmful policy
Amjad Masad argued that near‑term AGI date‑setting lacks scientific grounding and can drive unrealistic expectations and bad policy responses interview clip. The full conversation expands on why inflated timelines distort funding and regulation priorities (YouTube interview).

For execs, the takeaway is simple: de‑risk your external timelines. Anchor roadmaps to measurable capability milestones and third‑party evals rather than calendar‑year AGI predictions.
🏗️ AI datacenter buildouts and energy math
Synthesis of giga‑scale AI DC plans with concrete power, land, and timeline estimates; separate from model/business news.
OpenAI ‘Stargate Abilene’ scopes $32B, ~2‑year build over 450 fields
OpenAI’s next mega‑datacenter, internally described as “Stargate Abilene,” is sketched at >250× GPT‑4 compute, roughly 450 football fields of land, ~$32B capex, thousands of workers, and an ~2‑year construction window buildout overview. For infra leaders, that signals multi‑GW siting, new transmission, and large on‑site thermal and water strategies.
US AI datacenters could draw 20–30 GW by late‑2027 (~5% of U.S. power)
Compiled projections put U.S. AI DC load at 20–30 GW by late‑2027—about ~5% of average U.S. generation—with unusually high regional shares cited for Japan (~25%), France (~50%), and the UK (~90%) if similar buildouts land there power projections. Builders should expect gas‑turbine peakers paired with rising renewables, with siting gravitating to low‑regulation, high‑capacity corridors.
AI energy math: one ChatGPT prompt ≈0.3 Wh; 2024 AI DC emissions ~2% of cement
A widely shared ‘cheat sheet’ argues all AI activity in 2024 emitted roughly 2% as much as cement production, and a single ChatGPT request consumes about 0.3 Wh—useful reference points for policy and sustainability decks blog pullquote, with charts and methods in the original write‑up Substack post. Teams can cite the consumption snapshots shown for ChatGPT and Gemini when communicating scope ChatGPT energy chart.
Google’s ‘Suncatcher’ aims solar TPU compute in orbit at 8× energy efficiency by 2027
A roundup cites “Project Suncatcher,” an initiative to launch solar‑powered TPU satellites by 2027 that could run inference/train workloads at up to 8× the energy efficiency of Earth‑based datacenters roundup item. Treat this as exploratory until a first‑party plan lands, but it underscores the pressure to escape terrestrial power and cooling constraints.
📊 Leaderboards and eval oddities
Leaderboard moves and observability notes; excludes Polaris Alpha’s writing lead (covered under frontier roadmap).
French gov’s compar:IA leaderboard draws ‘rigging’ claims after Mistral tops GPT‑5/Claude
A state-backed arena (compar:IA) is being accused of bias after ranks showed Mistral 3.1 Medium above Claude 4.5 and GPT‑5, despite community expectations to the contrary arena criticism. The site lists BT satisfaction scores and even energy per request, but the perception of a home‑field tilt risks undermining signal quality for teams who route on public votes comparia ranking.
So what? Treat these head‑to‑heads as noisy preference data, not ground truth. If you use them for model routing, validate on your own evals and note language/country bias in the traffic mix.
Kimi‑K2 ‘thinking’ traces run 1,595 tokens on a trivial prompt; DeepSeek ~110
Observed traces show Kimi‑K2 Thinking emitting ~1,595 “thinking” tokens for a simple sentence request, compared with DeepSeek’s ~110 on a similar task token trace, DeepSeek count. This matches reports of heavier deliberate chains and may impact latency and cost unless capped—useful for diagnosing why “smart” mode stalls on long sessions. Following up on K2 eval cost, which flagged high token budgets in full evals.
Action for teams: log hidden‑thought token counts separately from visible output, set per‑task ceilings, and A/B route trivial asks to non‑reasoning variants to avoid runaway verbosity.
UGI leaderboard spotlights Kimi‑K2 as a strong uncensored entrant
Community testing on the UGI Leaderboard highlights Kimi‑K2 Thinking/Instruct as a top uncensored option, with a public space set up for side‑by‑side prompts leaderboard note, and a live board for head‑to‑head queries Hugging Face space. It’s not a formal benchmark, but it is useful to observe refusal rates and instruction‑following under fewer content blocks.
Here’s the catch: uncensored boards shift fast and can reward unsafe outputs. If you’re evaluating for production, duplicate prompts into your own spec‑driven evals and log refusal/override rates alongside accuracy.
🎬 Creative stacks: Face Swap, Blueprints, Grok (excludes Nano Banana 2)
Subject consistency and faster edit loops: Higgsfield pipelines, Leonardo Blueprints, Grok Imagine upgrades, Lucy‑Edit economics. Excludes the Nano Banana 2 feature.
Higgsfield Face Swap goes live with credits and $100k challenge
Higgsfield released Video Face Swap, which overlays your face on any clip while preserving lighting, motion, background, and audio launch details. For the next 9 hours, retweet + reply earns 200 credits via DMs launch details, and a $100,000 Global Teams Challenge is open through November challenge page. Creators are already chaining Face Swap with Recast to keep identity consistent across shots and to lip‑sync vocals in one pass workflow guide.

Grok Imagine gets visibly better at stylized video
Creators report a step‑change in Grok Imagine’s output quality—especially for anime‑style motion and stylized cuts—sharing smoother, more cohesive clips than recent months sample clips. One creator calls it their “new favorite video model,” citing better motion and framing creator endorsement, while others praise the latest update as “extremely good” update praise.

Leonardo Blueprints unlock multi‑angle, consistent scenes
Leonardo shipped Blueprints—template workflows for camera moves and angle changes—letting teams generate 45+ cuts from a single scene without losing the subject’s look feature demo. The flow many are using: generate a still, animate it, then request new angles via Blueprints; 45+ sets exist now with user‑created sets on the way feature overview, and you can try them in the app today Leonardo app.

🤖 Humanoids edge toward natural motion
XPeng IRON dominates with lifelike gait and a ‘cut‑open’ demo to address skepticism; includes fine‑hand dexterity clips.
XPeng CEO debunks “human inside” claims; IRON’s internals shown on stage
XPeng publicly addressed rumors by unzipping the IRON humanoid’s back panel on stage to reveal actuators, wiring, and cooling, while reiterating specs like 82 total DoF and 22 DoF per hand cut‑open demo. This follows the earlier cut‑open moment, noted in initial demo, but adds an explicit CEO rebuttal of the “performer inside” theory and clearer shots of the mechanical stack CEO rebuttal.

Why it matters: motion realism is pushing past the uncanny valley, and proof‑of‑machine demonstrations help shift attention to controller quality, actuator density, and thermal design—ingredients engineers need to evaluate real‑world viability.
XPeng IRON hand shows 1:1 human size, 22‑DoF and compact harmonic joints
Close‑ups highlight a 1:1 human‑size hand with 22 degrees of freedom and an in‑house “smallest” harmonic joint package aimed at dexterity without bulk specs callout. The flexing sequence suggests low‑backlash transmission and decent fingertip authority—key for pinch/grasp variety and tool use hand details.

For manipulation teams, the spec implies tighter joint spacing and better end‑effector controllability, but real tests will hinge on tactile sensing, slip control, and latency under load.
XPeng IRON’s latest walk demo narrows the uncanny valley with fluid gait
A fresh walking clip shows natural weight shifts, small balance corrections, and reduced perceived stiffness—“from 5 m your brain says ‘person’” walking clip. The takeaway for control engineers: the locomotion stack appears to be coordinating multi‑joint compliance and center‑of‑mass control better than prior public reels, hinting at more robust model‑based or learned controllers.

If this level holds under disturbance tests and varying ground friction, it shortens the gap between stage demos and service‑task readiness.
Unitree G1 clips rekindle motion‑control debate after odd movement sequences
Community‑circulated G1 footage shows unusual, rapid joint sequences that look non‑human, prompting questions about safety envelopes, controller tuning, and demo authenticity odd motion clip. Debates like this push vendors to publish more telemetry or standardized disturbance tests so engineers can separate controller quality from choreographed motion.

Actionable next step: ask for controller details (impedance gains, state estimator latencies) and request repeatable trials on uneven terrain to benchmark stability rather than stage choreography.