Kosmos AI Scientist достигает 79,4% точности, на 1 500 статьях — Google тестирует Co‑Scientist
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Эдисон Сайентифик запустила Kosmos, автономного «ИИ‑ученого», который превращает исследования на основе длинной горизонтовой литературы в воспроизводимые запуски, привязанные к коду и источникам. Он обеспечивает 79,4% проверяемой точности выводов — тот уровень пропускной способности, который превращает вычисления в публикационную работу.
Бета‑пользователи говорят, что 20‑шаговый прогон заменил месяцы труда экспертов, линейно масштабируясь с глубиной. И Google продвигает тот же шаблон: Gemini Enterprise тестирует «Со‑ученого», который турнир‑ранжирует ~100 идей за ~40 минут по явной рубрике, тогда как новый Deep Research NotebookLM просматривает сотни страниц и составляет цитируемый отчет.
Своевременный 94‑страничный обзор аргументирует необходимость агентов с замкнутым циклом, которые планируют эксперименты, вызывают инструменты и оценивают свои собственные шаги. Если вы занимаетеесь этой волной, установите бюджетные рамки и фиксируйте каждый шаг.
Feature Spotlight
Особенность: ИИ‑ускоренные агенты для науки и исследований
ИИ-исследовательские агенты появляются: Kosmos утверждает синтез за один запуск примерно 1,5 тыс. статей и 42 тыс. LOC с проверяемыми выводами, в то время как Google тестирует 40‑минутного многоагентного Co‑Scientist, который за один прогон ранжирует около 100 идей; NotebookLM добавляет отчеты Deep Research.
Рост межаккаунтной активности в области автономных исследований: Kosmos “AI Scientist,” Gemini Enterprise Co‑Scientist от Google и Deep Research от NotebookLM. Инженерам важно это, потому что эти системы реализуют долгосрочные рабочие процессы с аудируемыми следами и отбором идей в формате турнира.
Jump to Особенность: ИИ‑ускоренные агенты для науки и исследований topicsTable of Contents
🔬 Особенность: ИИ‑ускоренные агенты для науки и исследований
Рост межаккаунтной активности в области автономных исследований: Kosmos “AI Scientist,” Gemini Enterprise Co‑Scientist от Google и Deep Research от NotebookLM. Инженерам важно это, потому что эти системы реализуют долгосрочные рабочие процессы с аудируемыми следами и отбором идей в формате турнира.
Kosmos «ИИ‑учёный» дебютирует с проверяемыми результатами и пропускной способностью уровня эксперта
Edison Scientific представила Kosmos, автономную исследовательскую систему, способную синтезировать около 1 500 статей и писать около 42 000 строк аналитического кода за один запуск, с точностью выводов 79,4% и полной прослеживаемостью к коду и цитированиям Altman endorsement, Launch article. Команда выделяет семь примеров открытий и структурированный подход к глобальной модели, который позволяет агенту оставаться на цели на протяжении миллионов токенов.
- Бета‑пользователи сообщили, что один 20‑шаговый запуск заменил примерно 6,14 месяцев экспертной работы, при этом восприятие масштаба работы линейно зависит от глубины выполнения scaling chart.
Почему это важно: Kosmos упаковывает долгосрочные исследования в повторяемые, поддающиеся аудиту рабочие процессы. Это тот самый элемент, который руководители лабораторий и руководители НИОКТ должны обосновывать расходованием вычислительных ресурсов и соблюдением требований одновременно.
Gemini Enterprise «Co‑Scientist» запускает турнирные рейтинги для уточнения исследовательских идей
Внутренние строки и демонстрации показывают, что Google тестирует два потока с несколькими агентами внутри Gemini Enterprise: Генерация идей и Со‑учёный, который за один запуск тратит примерно 40 минут на генерацию и турнирную ранговку примерно 100 идей по критериям, заданным пользователем утечка функционала, Краткое описание функции. Трёхшаговый цикл использует исследовательскую цель + данные, запускает специализированных агентов для исследования, затем оценивает и ранжирует на основе явного рубрикователя.

Почему это важно: Команды получают воспроизводимый интерфейс для целенаправленного формирования идей с встроенной оценкой, что является узким местом при масштабировании отбора литературы и проверки гипотез по организациям.
NotebookLM “Deep Research” превращает широкие веб-обзоры в структурированные, цитируемые отчеты
Google анонсировала режим Deep Research в NotebookLM, который может автономно просматривать сотни страниц, синтезировать выводы в структурированный отчет и прикреплять аннотированный список источников; он также расширяет поддерживаемые типы источников (например, Drive URL-адреса, Sheets, изображения) для наборов исследований с мультимедийным контентом демонстрация возможностей, сообщение в блоге Google. Ранние тесты пользователей называют его «выдающимся инструментом для обучения», отмечая интегрированные майндмапы, флеш-карты и викторины для последующего изучения заметки из практики.

Почему это важно: Это готовый к применению исследовательский помощник с длительным режимом извлечения информации и поддающимися аудиту выводами — полезен для обзоров продуктов, сканирования политик и бэкграундов, которые ранее занимали дни.
Обзор каталогизирует научные языковые модели большого масштаба (LLMs) и аргументирует в пользу петлей агентов, привязанных к реальным доказательствам.
Комплексный обзор научных LLMs объединяет 270 наборов данных и 190 бенчмарков, предлагает таксономию, охватывающую переход от сырых наблюдений к теории, и отслеживает смещение от одношаговых викторин к оценке по процессу: этапы, инструменты и промежуточные результаты поток статьи, ArXiv paper. Авторы выступают за замкнутые контуры агентов, которые планируют эксперименты, вызывают симуляторы или лаборатории, валидируют результаты и обновляют общие знания — формируя подход к обучению и оценке систем за пределами статических корпусов.
Почему это важно: Это дорожная карта для инженеров, которые соединяют модели, инструменты и оценщиков в надёжные конвейеры для научной работы, с бенчмарками, которые поощряют процесс — а не только итоговый ответ.
🏭 ИИ-фабрики, дата-центры и победы в операциях
Инфраструктура остаётся горячей: Дженсен Хуанг из NVIDIA расставил акценты в пользу кастомных ASIC против «AI-фабрик», Groq открыл площадку в Сиднее мощностью 4,5 МВт, а OpenAI вернула примерно 30 тысяч CPU-ядер благодаря настройке журналирования. Также опубликовано: ценовые тренды на H200/B200 и дефицит DRAM/VRAM. Исключаются запуски исследовательских агентов (освещаются как функция).
Дженсен Хуанг из NVIDIA отвергает кастомные ASIC как «научные проекты», хвалит фабрики ИИ
На UBS Q&A во время GTC Дженсен Хуанг заявил, что пользовательские ASIC не смогут повторить полный стек «AI‑фабрики» NVIDIA, ссылаясь на внутреннюю дорожную карту, утверждающую примерно до ~40× впереди Hopper и возможность размещать POs масштаба $100 млрд с полностью интегрированными системами и уверенностью в цепочке поставок transcript highlights. Для инфраструктурных лидеров сообщение ясно: покупатели будут подведены к времени выхода на выручку, а не к спискам чипов.

Это формирует закупки вокруг уверенности в платформе и рисков выполнения. Если вы моделируете долгосрочные ставки на дата‑центры, создавайте сценарии, в которых варианты ASIC не существенно снижают TCO после учета программного обеспечения, сетевых решений, энергопотребления и сроков поставки.
OpenAI освобождает примерно 30 000 ядер процессора, отключив дорогостоящий путь Fluent Bit.
Команда наблюдаемости OpenAI профилировала узловой Fluent Bit и обнаружила вызовы fstatat64 (запускаемые inotify), которые занимали примерно 35% CPU; отключение этого пути вернуло примерно 30 000 CPU-ядер Kubernetes кластерам, обрабатывающим почти 10 PB логов в сутки talk recap, with methodology and impact shared in the KubeCon session KubeCon talk. Это большой операционный выигрыш: та же нагрузка, половина CPU.
Если вы используете Fluent Bit, воспроизводите трассировку perf, протестируйте поведение inotify под сильной нагрузкой аппендеров и разверните выпуск за фич-флагах. Экономия масштаба может сразу увеличить мощность для инференса.
Groq открывает площадку в Сиднее мощностью 4,5 МВт для обслуживания региона APAC с локальным выводом.
Groq запустила дата-центр мощностью 4,5 МВт в Сиднее в партнёрстве с Equinix Fabric, обеспечив обслуживание токенов с низкой задержкой для Австралии и более широкого региона APAC launch note, с деталями в пресс‑релизе компании press post. Для команд в Австралии это сокращает межокеанальную задержку и может снизить стоимость за запрос при маршрутизации к ближайшим узлам.
Ожидайте, что региональные политики маршрутизации и резервирование мощности будут иметь значение. Если вы проводите пилотирование Groq, протестируйте разницу задержки между Сиднеем и регионами США/ЕС и соответствующим образом скорректируйте управление трафиком.
Цены на H200 и B200 достигают пиков на запуске, затем снижаются, но остаются на повышенном уровне.
Morgan Stanley демонстрирует циркулирующие сегодня данные о цене аренды для 8× H200 и ранних B200 узлах, резко растущие при запуске, затем снижаются по мере наращивания предложения — но не возвращаются к прежним базовым уровням chart thread. Вывод для планировщиков мощности: дефицитные надбавки смягчаются, но структурный спрос поддерживает минимальные цены выше, чем у прошлой генерации.
Разрабатывайте бюджеты моделей с учетом поэтапного снижения цен, а не полного возвращения. Зафиксируйте короткие сроки для пикового окна; пересмотрите условия по мере поступления дополнительной мощности.
По сообщениям, цены на RAM/VRAM утроились за считанные месяцы на фоне спроса на серверы для искусственного интеллекта.
Широков распространённый разбор Gamers Nexus сообщает, что цены на DRAM выросли примерно в 3 раза за последние месяцы, что повлекло за собой последствия для NAND и VRAM GPU по мере того, как AI-серверы занимают доступное предложение; предыдущие меры по снижению перепроизводства и возможная координация производителей приводятся в качестве драйверов video note, , озвученные сообществом, указывающим на привязку к лабораторной инфраструктуре market note. . Это затрагивает как сборку серверов, так и планы по локальному краю AI.
Бюджетные резервы на память следует увеличить. При спецификации кластеров или локальных узлов инференса следите за сроками поставки и рассматривайте предварительные закупки DIMM/VRAM‑heavy SKU до следующего повышения лимита выделений.
🛠️ Агентные инструменты разработки и процессы кодирования
Новые публикации, посвящённые созданию/эксплуатации агентов: паттерны Deep Agents в LangGraph, Claude Code на Windows, руководство NVIDIA по Bash‑агенту для использования на компьютере, архитектура OpenCode и эргономика CLI. Исключает исследовательскую автоматизацию (см. характеристику).
Claude Code получает однострочный установщик для Windows (без WSL)
CLI для кодирования Anthropic работает в Windows одной командой, приведен пример установки Claude Code v2.0.35 без WSL: curl -fsSL https://claude.ai/install.cmd -o install.cmd && install.cmd && del install.cmd Windows install. Это снижает трение при настройке корпоративных ноутбуков и лабораторных машин; возьмите скрипт напрямую, если вам нужно сначала проверить его установочный скрипт.
LangChain формализует «Deep Agents» с планированием, субагентами и памятью
LangChain изложил паттерны агентов 2.0 («Глубокие агенты»), которые превращают хрупких агентов с одним циклом в оркестрованные системы с явным планированием, специализированными субагентами и устойчивой памятью, построенной на LangGraph объяснение фреймворка.). Команды получают более явный контроль над состоянием, восстановляемость и передачу инструментов для длинных многошаговых задач.
)
Amp CLI добавляет параметр --mode, чтобы управлять тем, как агент выполняется.
Sourcegraph’s Amp теперь поддерживает amp -m <mode> (например, rush, free), чтобы вы могли контролировать стиль выполнения из командной строки для повторяемых CI и локальных запусков cli update. Это следует после context management, где Amp поделился конкретными паттернами для сохранения контекста агента стабильным при редактировании; флаг помогает закрепить поведение для воспроизводимых дифов.
mcporter компилирует удалённый MCP-сервер в готовый к запуску CLI
С одной командой npx mcporter generate-cli --compile вы можете превратить удалённый MCP-сервер (например, deepwiki) в подписанный, запускающийся CLI, который объединяет инструменты и флаги для офлайн- или скриптового использования cli example.)\nХорошо подходит для фиксации версий, изоляции доступа и передачи товарищам по команде бинарника с нулевой настройкой MCP docs.)\n\n
)
NVIDIA демонстрирует Bash‑агента для использования компьютера, созданного с помощью LangGraph.
Руководство NVIDIA демонстрирует создание агента на естественном языке → Bash с использованием LangGraph’s create_react_agent(), с мерами безопасности и готовым к продакшену путём за менее чем час обзор руководства. Это яркий пример координации использования инструментов для автоматизации оболочки и операционных инструкций.
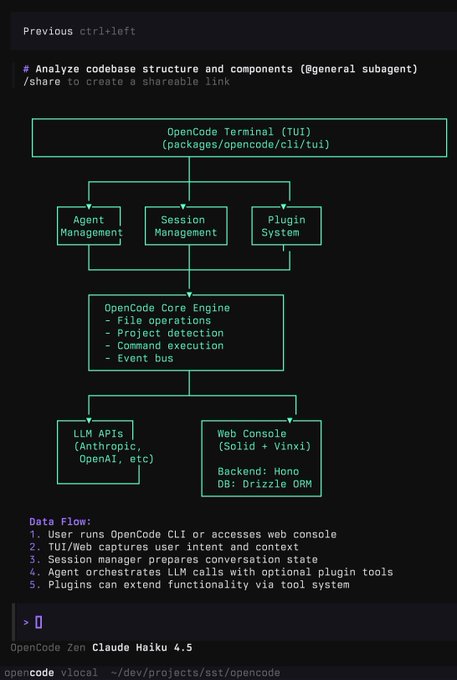
OpenCode демонстрирует полнофункциональный TUI агента с плагинами и веб-консолью.
Ранний взгляд на OpenCode показывает терминальный интерфейс и веб-консоль, наложенные на движок с управлением агентами/сессиями, системой плагинов, операциями с файлами, обнаружением проектов и выполнением команд, подключенные к API Anthropic/OpenAI; бэкенд использует Hono и Drizzle ORM architecture diagram. Это нацелено на команды, стандартизирующие рабочие процессы разработки вокруг запусков агентов и трассируемости.
LangGraph «Swarm» демонстрирует многоагентный инструмент Article Explainer
Сообщественный Article Explainer использует архитектуру Swarm от LangGraph для координации специалистов, которые разбирают PDF-файлы, создают объяснения и аналогии, извлекают код и запускают проверки по безопасности в одном чат‑интерфейсе project page. Это практический план по многоагентному распределению труда на технических документах.
🔭 Часы Gemini 3: сигналы и строки предварительной версии
Свежая волна обсуждений Gemini 3 и строк в приложении; сегодняшние пункты добавляют текст пользовательского интерфейса, связывающий создание изображения «3 Pro» с более новым Nano Banana, ежедневные обновления gemini‑cli и анекдоты тестировщиков. Исключено Co‑Scientist/Deep Research (рассматривается как функция).
Строки приложения связывают создание изображений Gemini 3 Pro с Nano Banana 2.
Новый текст интерфейса говорит: «Попробуйте 3 Pro, чтобы создавать изображения на более новой версии Nano Banana», и сопроводительная строка утверждает, что 3 Pro и Nano Banana 2 будут выпущены вместе скриншот строк. Это ужесточает ожидание того, что Gemini 3 Pro будет поставляться вместе с обновлённым стеком изображений, продолжая историю Vids leak, которая показала надпись “powered by Gemini 3 Pro” внутри Google Vids.
Сигналы сходятся к Gemini 3 на следующей неделе; gemini‑cli обновляется ежедневно
Несколько трекеров теперь ожидают запуск Gemini 3 на следующей неделе, и ходят слухи, что Nano‑Banana 2 и возможно Veo 4 могут появиться вместе с ним; разработчики также отмечают, что gemini‑cli претерпел заметные обновления почти ежедневно по мере подготовки Google к выпуску timing thread, release rumor. Один тестировщик даже сообщает о скрытном появлении на мобильной через функцию Canvas, намекая на поэтапную активность развертывания mobile sighting.
Ранний тестировщик: Gemini 3 связывает «идеальный» YouTube Short с ответом на запрос.
Аннотация раннего доступа говорит, что Gemini 3 может отвечать, прикрепляя точный YouTube Short, который отвечает на вопрос, что указывает на более тесную выборку/инструментарий по видеоконтенту по сравнению с предыдущими моделями примечание тестировщика. Для команд по продукту это означает более богатые, основанные на источнике ответы в потребительской помощи, обучении и потоках поддержки.
Сообщество спрашивает, чем объясняется хайп вокруг Gemini 3 по сравнению с GPT‑5 Pro
Инженеры задаются вопросом, почему сообщество так уверено, что Gemini 3 обгонит нынешних лидеров, и требуют конкретной поддержки помимо тизерной шумихи и анекдотов comparison question. Некоторые тестеры остаются оптимистами, называя слухи о модели потенциальным «бэнгером», но детали об оценщиках, использовании инструментов и ценообразовании пока не известны anticipation post.
📊 Эталонные показатели и как измерять работу агента
Одно конкретное обновление лидерборда плюс метаобсуждение оценок: Design Arena теперь возглавляют варианты GPT‑5.1, в то время как несколько тем призывают переходить от точности ответов к хрупкости агента, порочным петлям и ошибкам планирования.
Количество обращений к бенчмаркингу агентов растёт для оценки хрупкости, пессимистичных петель и использования инструментов
Множество потоков считают, что сегодняшние баллы не отражают экономическую ценность, потому что они измеряют однократные ответы, а не то, умеют ли агенты планировать, восстанавливаться и эффективно использовать инструменты — это следует за тем, как ML/HPC leaderboard показал, что агенты медленнее опытных людей. Этан Моллик критикует тесты типа «фиктивный торговый автомат» и настаивает на диагностике, которая выявляет ошибки восприятия, повторяющиеся петли неудач и промпт‑намерения benchmark critique, eval gap thread, why failures, brittleness call. Его метод “job interview” предлагает предметно‑ориентированные, практические испытания, чтобы увидеть, обобщается ли модель за пределы заготовленных стендов interview article, с деталями в связаном руководстве article.
Идея в том, чтобы создавать оценки, которые оценивают процесс, а не только финальные ответы. Включайте логирование шагов, трассировку вызовов инструментов и решения по рубрикам, чтобы можно было увидеть, где планирование ломается, а не только то, правильно ли последний токен выглядел agentic measures thread.)
Варианты GPT‑5.1 свергли Claude на Design Arena
Сообщественный рейтинг Design Arena теперь возглавляет GPT‑5.1 (High) с Elo ~1374, опережая другие варианты GPT‑5.1 и выталкивая Claude 4.5/Opus с вершины benchmarks chart. Для команд, которые полагаются на Design Arena как прокси для UI/UX и качества структурированного инструкирования, это новый сигнал к повторной проверке подсказок и инструментов против уровней GPT‑5.1.
Два быстрых теста окупятся: сравните GPT‑5.1 High и Medium по вашим подсказкам для агентов и убедитесь, что ваши постобработчики справляются с его более развёрнутыми обоснованиями, которые чаще всего поощряются в оценке.
Практический рецепт оценки: критерии, применение и автоматизация для проверяемости
Шрея Р. предлагает прагматичный стек оценки: (1) определить четкий критерий успеха, (2) указать, как применять его последовательно, и (3) автоматизировать его на масштабе — рассматривать «верифируемость» как проблему дизайна оценивателя, а не как свойство самой задачи evals framework thread. Что хорошо сочетается с взглядом Karpathy’s Software 2.0, согласно которому прогресс ускоряется там, где результаты легко проверить (код, математика), поэтому ваш каркас важен не меньше, чем ваш набор данных verifiability argument.
🔋 Локальная эффективность инференса: интеллект на ватт
Исследование Stanford×Together предлагает IPW как единую метрику и анализирует 1 млн запросов на 8 ускорителях. Результаты показывают увеличение IPW в 5,3 раза с 2023 года и значительную экономию за счёт гибридной локальной и облачной маршрутизации.
Исследование IPW: локальные LLM покрывают 88,7% запросов; увеличение эффективности в 5,3 раза, гибрид экономит ~60%
Стэнфорд и Together предлагают показатель Интеллект на ватт (IPW = точность ÷ мощность) и профилируют 1 млн реальных запросов по 8 акселераторам; локальные модели решили 88,7% одноступенчатых подсказок, и IPW улучшился примерно в 5,3× с 2023 года (≈3,1× прирост моделей, 1,7× аппаратное) обзорная ветка, детали эффективности. Гибридная маршрутизация — удерживая примерно 80% трафика локально — сокращает энергопотребление/вычисления/стоимость ≈60% (≈45% при маршрутизации в 60%), при этом Apple’s M4 Max упоминается как способный эффективно запускать локальную модель размером 120B результаты маршрутизации, объем исследования, и полные методы в статье ArXiv paper.
🗂️ Извлечение и конвейеры обработки документов в ИИ
Практические достижения в области поиска и извлечения: документация Gemini File Search циркулирует с путями к коду, в то время как публикации разбираются в наградах за модульные тесты RLVR OlmOCR2 и обновлённом руководстве по модели OCR от HF. Исключает NotebookLM Deep Research (функция).
OlmOCR‑2 использует детерминированные модульные тесты (RLVR) для оценки результатов парсинга в масштабе
Рассуждение на выходных разборчиво объясняет, как OlmOCR‑2 автоматизирует вознаграждения: используйте сильную модель (Sonnet) для скелетирования HTML и генерации модульных тестов для каждого документа, затем обучайте парсер с RLVR, используя доли прохождения как вознаграждения — человеческие метки не требуются Paper notes. The figure shows page‑level rewards as the fraction of tests passed, a practical recipe teams can replicate for invoices, tables, and forms Paper notes.
- Применяйте цикл scaffold→tests→reward для запуска доменных парсеров; начинайте с детерминированных проверок (селекторы, итоги).
Документация по Gemini File Search появилась вместе с кодом для хранилищ, загрузок и обоснованных ответов.
Файловый поиск Gemini от Google теперь имеет понятное руководство по API, охватывающее создание хранилища, прямые загрузки файлов vs импорты через Files API, асинхронную проверку статуса и привязку ответов модели к индексированному контенту API docs,) с примерами от первого лица в документации Gemini file search.) После запуска по бесплатному тарифу, который рекламировался как “RAG in a box,” сотрудник Google также продемонстрировал помощника поддержки, построенного на File Search плюс Google Cloud Search, что сигнализирует реальные рабочие процессы за пределами примеров Docs bot demo.)
- Протестируйте оба пути загрузки (прямой загрузки и через Files API) и проверьте статус импорта перед промптингом; в документации показаны точные формы запроса/ответа API docs.)
- Начинайте с малого: по одному хранилищу на домен и добавляйте привязку Search только там, где это нужно, чтобы стоимость оставалась предсказуемой Gemini file search.)
Агентный RAG TeaRAG сохраняет точность, сокращая количество токенов примерно на 60%.
Новый агентно‑ориентированный RAG‑фреймворк TeaRAG сокращает извлечение информации до фактовых троек и графа знаний, затем обрезает контекст с помощью Personalized PageRank; на 6 бенчмарках он сокращает выходные токены на 61% и 59%, при этом повышая точное соответствие на 4% и 2% Paper summary. Он также обучается с учётом процессов, ориентированных на оптимизацию предпочтений, чтобы предпочитать доказательственные, более короткие рассуждения.
- Направляйте длинные форматы QA через графы троек, чтобы уменьшить контекст модели; в цикле измеряйте EM и количество токенов на ответ.
Руководство HF по OCR добавляет новые модели и рекомендации по тому, когда проводить тонкую настройку для документного ИИ.
Hugging Face обновил свой практический путеводитель по OCR — теперь охватывает модели вроде Chandra и OlmOCR‑2, когда запускать из коробки vs донастройку, открытые наборы данных и советы по локальному vs удалённому развёртыванию Blog update, с полным обзором здесь Hugging Face blog. Для команд, создающих RAG поверх PDF, это краткая карта решений для повышения точности транскрипции, осведомлённости о верстке и QA документов.
💼 Внедрение на предприятиях, ценообразование и ROI
Сигналы об ИИ в организациях: Meta формализует «влияние на основе ИИ» в обзорах на 2026 год, лидеры считают, что ценообразование на агентов должно отслеживать рост производительности, а более умное расписание Gmail приводится как ROI с низким уровнем трения.
OpenAI освободила примерно 30 000 ядер процессора, отключив горячий путь Fluent Bit.
Команда по наблюдаемости OpenAI изучила логирование на уровне узла и обнаружила, что вызовы fstatat64 (запускаемые через inotify) доминируют на CPU в Fluent Bit. Отключение этого снизило загрузку CPU для той же работы с логами в два раза, возвращая около 30 000 ядер кластерам Kubernetes, которые обрабатывают примерно ~10 PB/сутки логов обзор доклада, с пошаговым руководством, размещённым в открытом доступе YouTube talk. Урок: профилируйте перед масштабированием; один параметр по умолчанию может быть очень дорогим.)
)
Локально‑облачная маршрутизация обеспечивает экономию затрат на вычисления до ~74% и экономию энергии до ~80%.
Стэнфорд и Together представили «Intelligence per Watt» и обнаружили, что гибридная маршрутизация, сохраняющая локальными простые запросы, может снизить расход энергии на до 80,4% и стоимость вычислений на до 73,8%, при этом экономия составляет около 60% даже при 80%-й точности маршрутизации обзор метрик. Эта статья охватывает 1 млн реальных запросов по 20+ локальным моделям и 8 ускорителям; IPW улучшилось примерно в 5,3 раза в период 2023–2025 гг., а охват творческих задач на локальном оборудовании превышает 90% ArXiv paper.
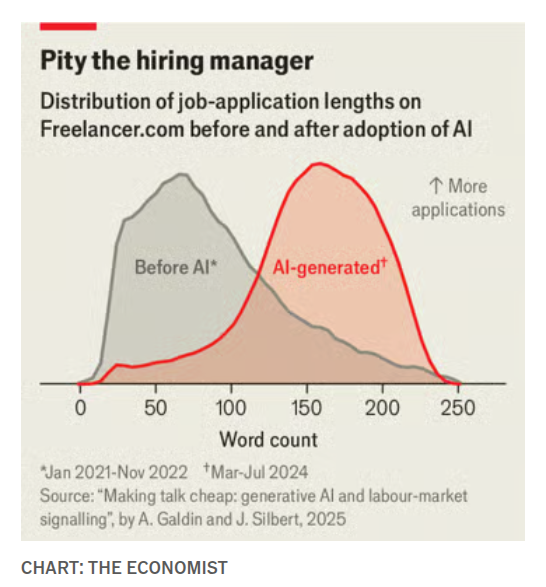
Исследование: предложения, созданные ИИ, размывают сигналы; заработная плата подрядчиков падает примерно на 5%
На Freelancer.com инструменты LLM сделали поданные заявки длиннее (медиана ~79→~104 слов), размывая сигналы о затратах усилий, которые ранее коррелировали с качеством; исследование оценивает примерно 5%-ное снижение заработной платы и ~1,5%-ное снижение найма по сравнению с контрфактом без AI study summary. Для команд это предупреждает, что «cheap talk» может ухудшать фильтры отбора, если вы не скорректируете рубрики и тесты.
Обращения растут к оценке агентной работы, а не к одностадийным ответам.
Этан Моллик и другие утверждают, что мы переоцениваем однократные тесты и недоизмеряем то, что делает экономическую ценность: использование инструментов, планирование, восстановление после ошибок и хрупкость при изменении agent eval gap. Критики отмечают, что демонстрационные задачи вроде «автоматов-торговцев» не показывают, почему агентов терпят неудачи (видение, ловушки безвыходности, застрявшие повторные попытки) vending bench critique, и требуют диагностику причин отказов WHY наряду с точностью failure reasons. Для практических рекомендаций по оценке соответствия модели см. предложенный подход «интервью при устройстве на работу» для ИИ evaluation essay.
Ценообразование на основе ИИ-агентов должно учитывать ROI, а не лимиты на количество пользователей в SaaS.
Box’s Aaron Levie утверждает, что ценообразование агентов должно быть привязано к приросту производительности (например, платить примерно 10% компенсации инженера, если выпуск удваивается), а не к устаревшему потолку SaaS за $10–$50 за пользователя pricing argument. Суть в том, что когда агенты обеспечивают измеримый рост производительности, бюджеты следуют за результатами, а не по нормам на одного пользователя.
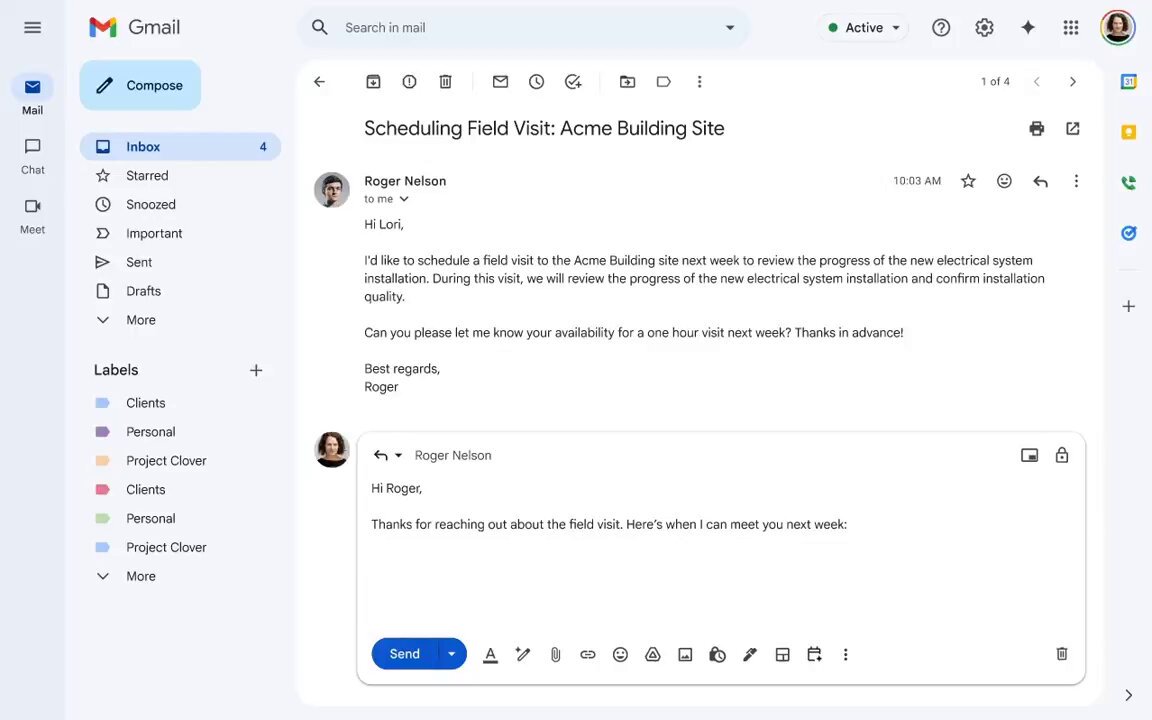
Gmail добавляет контекстно‑ориентированное планирование, которое предлагает варианты времени и автоматически бронирует.
Новый поток планирования в Gmail анализирует контекст письма, чтобы предлагать подходящие времена и автоматически создаёт событие в календаре, как только получатель выбирает слот, устраняя классическую цепочку запросов и ответов feature demo. A follow‑up shows it avoids blind free‑time dumps and handles the event creation step end‑to‑end feature details.
🧠 Динамика рассуждений и проверяемость
Концептуальные и эмпирические материалы: рамка Karpathy’s “verify > specify” возвращается; одна статья разбирает коллапс энтропии в обучении с подкреплением (RL) для рассуждений, и длинная цепочка формализует проверяемость через рубрику→применение→автоматизация.
RL для рассуждений: энтропия схлопывается; 600 подобранных задач могут сопоставлять примерно 17 тыс.
Новое исследование в области обучения с подкреплением с проверяемыми вознаграждениями показывает, что энтропия модели падает, когда тренировка чрезмерно подталкивает к нескольким путям с высокой наградой; обновления вне политики и пороги отсечения ухудшают это, что вредит обобщению. При тщательной курации около 600 хороших задач могут сопоставлять обучение на около 17k, а адаптивные регуляризаторы энтропии плюс повторное взвешивание токенов с положительным преимуществом стабилизируют обучение обзор статьи.
Карпатхи: Программное обеспечение 2.0 автоматизирует то, что можно проверить, а не то, что можно задать.
Андрей Карпатхи утверждает, что самой сильной моделью для экономического влияния ИИ является проверяемость: задачи с перезапускаемыми, вознаграждаемыми и эффективно повторяемыми циклами практики (математика, код, формальные головоломки) будут расти, в то время как неверифицируемая творческая/стратегическая работа отстает Karpathy thread. Для руководителей инженерных команд это означает, что дорожные карты должны отдавать предпочтение задачам, для которых можно построить автоматизированный оцениватель и позволить системам "практиковаться" в масштабе.
OlmOCR2 превращает разбор в RLVR, используя модульные тесты, сгенерированные LLM, в качестве вознаграждений
OlmOCR2 очерчивает паттерн, чтобы полуп Structed задачи можно было верифицировать в масштабе: использовать мощную модель для скелетирования HTML и автоматически генерировать детерминированные модульные тесты для каждого документа, затем оптимизировать парсер с RLVR по этим тестам — человеческих меток не требуется paper notes. Этот цикл «LLM‑как‑оценщик» переносим на счета, формы и другие задачи QA с документами, где окружение можно сбросить.
TeaRAG сокращает примерно 60% токенов, подталкивая EM вверх через факт‑граф и процесс DPO
TeaRAG представляет токен‑эффективный агентский RAG: создавайте компактные триплеты фактов, ранжируйте их на графе знаний и обучайте с использованием процессо‑осознанного DPO, чтобы рассуждения оставались чёткими. Сообщаемые преимущества: точное совпадение увеличивается на до 4% при примерно 61% и 59% меньшем числе сгенерированных токенов на двух бенчмарках paper summary. Следуя за DeReC runtime (95% сокращение времени выполнения для фактчекинга), это демонстрирует, что можно повысить достоверность и вместе уменьшить бюджет мышления.
)
Практическая рамка: проверяемость = критерии оценки, применение, автоматизация
Шрея Шанкар переопределяет проверяемость как инженерный артефакт, а не как свойство задачи: определить критерий успеха, реализовать надёжный и полный оцениватель, затем автоматизировать его в масштабе framework thread.); утверждение: большинство задач становятся проверяемыми, как только вы верно закодируете корректность — поэтому узкое место в создании хороших оценщиков, а не в ожидании более умных моделей.
Разрыв в оценке агента: призыв к диагностике причин неудачи WHY за пределами баллов за один ответ.
Итан Моллик и другие утверждают, что текущие лидерборды не отражают то, что экономически важно: использование инструментов, восстановление после ошибок, обобщение и хрупкость. Они указывают на «фиктивные демонстрации с торговым автоматом» и призывают проводить оценки, которые тестируют намерение подсказки, диагностируют ошибки восприятия и обнаруживают «порочные циклы», когда агенты повторяют неудачи agent eval point, vending‑bench remark, and job interview post. Вывод: создавайте obвязки, которые объясняют, почему агенты терпят неудачи, а не только оценивают, ответили ли они однажды.
Опрос: масштабирование агентов за счет увеличения объема задач, инструментов и проверяющих в одной петле G‑E‑F
Обзор сред окружения агентов формализует цикл Генерация‑Исполнение‑Обратная связь: среды должны одновременно создавать разнообразные задачи и проверять результаты, обеспечивая плотные, устойчивые к взлому вознаграждения. Он подчеркивает разделение между генератором и верификатором и акцентирует точные проверки для кода/математики по сравнению с рубрикой или моделями вознаграждений для открытого текста survey summary. Для строителей задача — масштабировать задачи, доступ к инструментам и оценщиков вместе.
🎨 Креативные медиа: перенастройка освещения, стилизованные LoRA и демо
Набор обновлений для создателей: LoRA для Qwen‑Edit с освещением под несколькими углами, LoRA ChronoEdit от NVIDIA, образцы ImagineArt v1.5, демо по направлению игрового искусства на базе ИИ и короткий клип Grok Imagine.
LoRA ChronoEdit‑14B «Paint‑Brush» от NVIDIA выходит с быстрыми кинематографическими рестайлами.
NVIDIA выпустила ChronoEdit‑14B Diffusers Paint‑Brush LoRA на Hugging Face, демонстрируя почти мгновенные изменения внешнего вида/градаций на одном и том же кадре демо релиза модель Hugging Face. Редакторы могут просматривать диапазоны цветовых градаций и паттернов тона, не повторяя генерацию полных кадров.

Для творческих руководителей это позволяет свести итерации градации к prompts, сохраняя направление точным, пока вы исследуете несколько вариантов обработки на основе одного базового кадра.
Qwen‑Edit Multi‑Angle Lighting LoRA выпускает управляемые предустановки повторного освещения
Qwen‑Edit‑2509 Multi‑Angle Lighting появился с направленным повторным освещением по картам яркости (например, фронтальное, фронто‑левое, сверху), позволяя создателям изменять освещение на одной неподвижной съемке без многовидовой съемки release note.). Автор называет это ранним прототипом и просит более крупные наборы данных по освещению, с рабочим Space для практических испытаний Hugging Face page и Hugging Face Space.)

Почему это важно: быстрое, параметризованное повторное освещение — отсутствующий регулятор для товарных снимков, ключевого арта и непрерывности кадров — эта LoRA дает командам дешевый регулятор, который можно попробовать уже сегодня.
Выпуск ImagineArt версии 1.5 получил похвалу за более чётких и более реалистичных людей.
Создатели сообщают, что ImagineArt 1.5 уже вышла, отмечая заметно более резкие рендеры и более естественные, правдоподобные лица и кожу user report, с другим постом, называющим выпуск 1.5 «поистине впечатляющим» в плане реализма release note. Если вы проводите сравнения моделей изображений, добавьте 1.5 в ваши A/B‑тесты — это, похоже, улучшение качества, которое может вытеснить стэк по умолчанию.
Демонстрация игры с поддержкой ИИ: одна мировая модель управляет ассетами, освещением и камерой.
Играбельная демонстрация показывает рабочий процесс, ориентированный на ИИ, в котором одна сжатая модель мира управляет активами, освещением и камерой — позволяя одному человеку за вечер изучить около 50 направлений искусства game demo. The clip flips styles live, hinting at pipelines where style becomes a parameter, not a rebuild.

Команды, создающие прототипы или вертикальные срезы, могут опробовать это для быстрого согласования художественного направления перед вложениями в активы на заказ.
Grok Imagine микро‑клип демонстрирует высокую точность макро‑деталей на опаловом пауке
Продолжая тему демо‑материалов от создателей, которые освещали реалистичные микро‑клипы, новый 6‑секундный образец «opal spider» демонстрирует чёткие радужные ноги и плавное градиентное освещение — достаточно хорош для быстрых промо‑роликов или сокращённых версий для соцсетей short clip. Это подтверждает силу Grok Imagine в коротких, ярких визуальных элементах.

Если вам нужен захватывающий B‑roll, этот вывод выглядит готовым к тестированию в календарях контента.
🛡️ Сигналы безопасности, идентичности и управления
Слухи об идентичности и управлении: Кими предупреждает о подменах личности, Фей-Фей Ли скромнее рассматривает AGI как научный термин, а по сообщениям Ян ЛеКун планирует уйти из Meta, при этом выступая за мировые модели вместо LLM.
Сообщение: Ян ЛеКю́н уйдёт из Meta; называет LLMs тупиком, поддерживает мировые модели
Сообщается, что Ян Лекун планирует уйти из Meta, критикуя LLM как «мертвый тупик» и продвигая причинно‑мировые модели, которые планируют и действуют иерархически с измеримыми целями. Если это подтвердится, это сигнализирует о громком движении в сторону альтернативных архитектур. report summary Gizmodo report
Moonshot AI предупреждает о подделках под именем Кими; подтверждает официальные аккаунты
Moonshot AI заявляет, что только @Kimi_Moonshot и Kimi.com являются официальными, и предупреждает, что аккаунты-двойники вроде “Kimi CLI” или “Kimi_Official” — мошенники. Команды должны проверить подлинность перед взаимодействием или установкой инструментов, претендующих на бренд Kimi. предупреждение бренда Официальный сайт
Фэй-Фэй Ли говорит, что AGI — больше маркетинг, чем наука; части существуют, целого — нет.
Фэй‑Фэй Ли утверждает, что «AGI» — это маркетинговая метка, отмечая, что мы достигли отдельных элементов, таких как разговорный ИИ, но не всей научной цели. Это напоминание сосредоточиться на конкретных возможностях и оценке, а не на ярлыках.

🤖 Воплощённый ИИ: дебаты о манёвренности двуногих и подлинности
Бипед TRON 1 от LimX Dynamics вызывает интерес своей подвижностью и возможностью голосового ввода/вывода; отдельная ветка оспаривает клип UBTech гуманоид как CGI и требует доказательства. В основном демонстрации, сегодня ограниченная информация о стеке.
Гуманоид UBTech: клип «складская армия» назван критиками CGI; сообщество требует доказательств.
Вирусное видео с складом, в котором выстроились ряды гуманоидов UBTech, вызвало немедленный отклик: видные основатели называют это CGI, а другие просят у UBTech первичные доказательства сцены authenticity thread. Это вспыхнуло всего через несколько дней после factory rollout (развертывание Walker S2, нацелено 500 единиц), повышая давление на наличие проверяемых кадров, демонстраций на месте или съёмок в непрерывном режиме.
И что с того? Надёжные доказательства влияют на доверие покупателей, анализ безопасности и найм. Если это действительно так, это сигнализирует о значимом объёме производства и калибровки. Если нет — клиенты потребуют отдельные тесты на месте перед пилотами. В любом случае инженерам следует планировать протоколы оценки, которые проверяют непрерывную работу, бесповреждённые запуски и безопасность с участием человека в замыкании процесса.
LimX TRON 1-бипед демонстрирует ловкую подвижность; сообщество просит голосовой ввод/вывод и ассистента
Свежий клип TRON 1 демонстрирует уверенную бипедальную походку и быструю адаптацию, побуждая к добавлению голосового управления и управления в стиле ассистента для бытового использования demo thread. LimX bills TRON 1 as a research‑ready platform with modular foot ends and SDK hooks, which makes voice I/O and higher‑level autonomy a practical next step for labs and startups Product page.)