Google Gemini 3 появляется в интерфейсах — 69% шанс, объем ставок $803k
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Gemini 3 уже близко: в темном режиме выбора модели теперь отображается «3 Pro» рядом с «2.5 Pro», и карточка Google Vids для “Nano Banana Pro” буквально говорит «работает на Gemini 3 Pro». Сандар Пичай сделал подмигивающий твит об предсказании падения Polymarket на 22 ноября; рынок на 69% Да с ~803 тыс. долларов торгуется, достаточно сигналов, чтобы выделить время на эвалуацию и планы миграции.
Почему это важно: если вы запускаете творческие или агентские пайплайны, на этой неделе, скорее всего, будет принято решение по маршрутизации. Создатели уже публикуют рендеры «Nano Banana Pro» — включая чистую сцену Nether в Minecraft — и макет телефона утверждает более высокую точность вывода SVG, хотя оба не подтверждены. Готовьтесь заранее: зафиксируйте промпты, клонируйте ваши тесты 2.5 Pro и подготовьте сопоставления «вручную» между изображением и текстом, надежности экспорта SVG и поведению при использовании инструментов, чтобы вы могли перенаправить трафик в течение часов после появления документации. И да, имя банана созревает для мемов; держите взгляд на задержках и кривых стоимости, а не на брендинге.
Feature Spotlight
Особенность: обратный отсчет до Gemini 3 и утечки «Nano Banana Pro»
Gemini 3 уже близко к выходу: внутренний интерфейс показывает «3 Pro», шанс по Polymarket около 69% к 22 ноября, а утечки Google Vids упоминают «Nano Banana Pro» (питается Gemini 3 Pro). Создатели уже публикуют выходы более высокого качества.
Сильные межаккаунтные сигналы о скором выпуске Gemini 3, а также утечки о создателе и пользовательском интерфейсе вокруг стека изображений («Nano Banana Pro»). Значительное влияние на выбор моделей и творческие конвейеры. Исключает RAG/поиск файлов и релизы не Gemini, которые освещаются отдельно.
Jump to Особенность: обратный отсчет до Gemini 3 и утечки «Nano Banana Pro» topicsTable of Contents
🪩 Особенность: обратный отсчет до Gemini 3 и утечки «Nano Banana Pro»
Сильные межаккаунтные сигналы о скором выпуске Gemini 3, а также утечки о создателе и пользовательском интерфейсе вокруг стека изображений («Nano Banana Pro»). Значительное влияние на выбор моделей и творческие конвейеры. Исключает RAG/поиск файлов и релизы не Gemini, которые освещаются отдельно.
«Nano Banana Pro» утечка в Google Vids показывает, что «работает на Gemini 3 Pro»
Промо‑карточка Google Vids для «Nano Banana Pro» появляется в интерфейсе с кнопкой Try it и надписью «powered by Gemini 3 Pro», что подразумевает доставку обновленного стека изображений вместе с Gemini 3. Утечка имеет значение для творческих пайплайнов, выбирающих между инструментами OpenAI/Gemini для изображений на следующей неделе. Подробности смотрите в визуализации функции leak screenshot и в статье full scoop.
Интерфейс чата отображает модель «3 Pro» рядом с «2.5 Pro», что намекает на внутреннюю доступность.
Панель выбора модели в темном режиме добавляет новую опцию «3 Pro» рядом с «2.5 Pro», что указывает на включение Gemini 3, по крайней мере в некоторых внутренних или тестовых окружениях. Для команд, планирующих миграции, это конкретный сигнал заранее подготовить наборы для оценки и предусмотреть контрольные ворота безопасности сейчас model picker shot.
Эмодзи-цитата Сундара подогревает шансы Polymarket на Gemini 3 к 22 ноября.
Продолжая обсуждение слухов на прошлой неделе, Сундар Пичай процитировал твит-маркет, предсказывающий падение 22 ноября, с подмигиванием и задумчивостью, что закрепило временную шкалу. Рынок показывает 69% вероятности «Да» и объём около $803k — полезно для планирования коммуникаций и окон оценки Sundar quote.). Отдельный скриншот показывает те же 69% вероятности odds chart.)
Гуглеры и трекеры намекают на «хорошую неделю», а также короткий фрагмент экрана «Gemini 3.0»
Множество намёков накапливается: заметка с обещанием «будет классная неделя» от руководителя Google AI Googler tease,) широкое воодушевление команды team excitement,) и короткий клип, показывающий экран «Gemini 3.0» teaser clip.) Рассматривайте это как сигнал подготовки к запуску: зафиксируйте промпты, выстроите попарные оценки и проверьте поведение использования инструментов.

Создатели публикуют рендеры «Nano Banana Pro», включая детальный Nether из Minecraft.
Ранние образцы с пометкой «Nano Banana Pro» уже распространяются, включая драматическую сцену портала Нижнего мира с точной моделью Хоглинов и атмосферой лавы. Если это действительно подлинно, качество вывода выглядит производственно дружественным для стилизованных миров; командам следует оставить окончательное суждение за официальными образцами пример изображения.
Утверждается, что качество рендеринга SVG Gemini 3 проявляется в новом макете пользовательского интерфейса.
Распространяемый макет интерфейса телефона утверждает о «потрясающем выводе SVG» от Gemini 3, намекая на генерацию векторной графики более высокого разрешения, полезной для адаптивного дизайна и систем иконок. Рассматривайте как неподтверждённую утечку до тех пор, пока Google не опубликует образцы или документацию svg claim.)
📊 Бенчмарки: кодирование, рассуждения и оценки приложений
Свежие оценки и таблицы лидеров, релевантные инженерным решениям: стоимость/производительность SWE‑Bench, новые показатели моделей рассуждения и тестовые стенды, специфичные для категорий. Исключаются сигналы Gemini 3 (функция).
IBM study: 7–8B models reached 100% identical outputs at T=0; 120B at 12.5%
Оценки IBM в области финансового применения показывают, что меньшие модели размером 7–8 млрд параметров выдали на температуре 0 на 100% идентичные выводы, в то время как модель размером 120 млрд достигла 12,5%, объясняя дрейф порядком получения и вариациями декодирования. Их рабочий набор — жадное декодирование, зафиксированный порядок выборки, проверки схемы — сохранял стабильность SQL/JSON и предлагает многоуровневый выбор моделей для регламентируемых процессов. Аннотация и детали настройки приведены в разделе share. paper summary
)
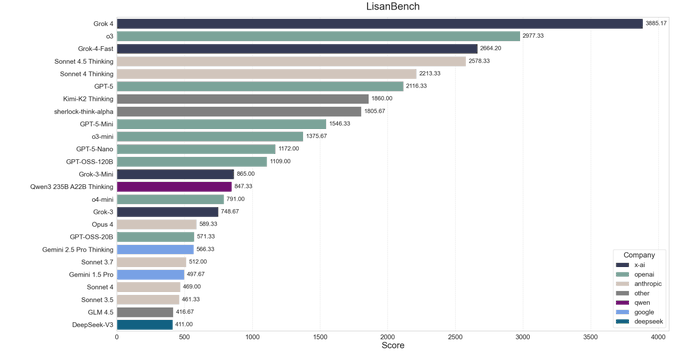
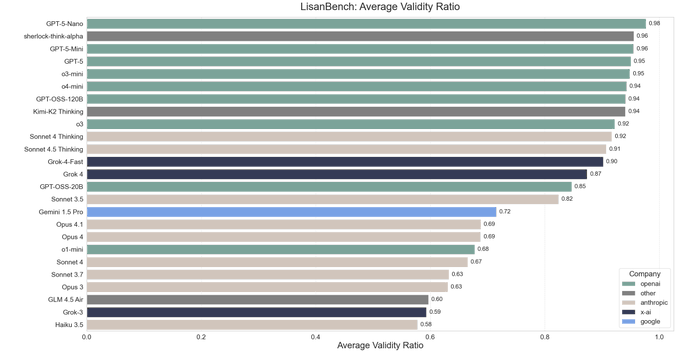
Sherlock Think Alpha публикует 1805.67 на LisanBench с валидностью 0.96
Новая маскированная модель OpenRouter «Sherlock Think Alpha» демонстрирует первые результаты: 1805.67 на LisanBench с средним коэффициентом валидности 0,96, уступая топовым моделям рассуждений по баллам, но обойдя Grok‑4 по валидности ответов (0,87). Такое сочетание указывает на сильное следование инструкциям и надёжность использования инструментов для цепочек агентов. Посмотрите снимок таблицы лидеров и график валидности, опубликованные вместе с запуском. benchmarks chart, и примечание о доступности модели здесь model page.
Socratic Self‑Refine повышает точность в математике и логике примерно на 68% за счет пошаговых проверок
Salesforce и др. предлагают Socratic Self‑Refine: разделение решений на микрокроки, оценку уверенности на каждом шаге с помощью повторной выборки, затем переработку только сомнительных шагов. Для математических и логических наборов тестов метод повышает точность примерно на 68% при сохранении интерпретируемости и демонстрирует более выгодные кривые соотношения затрат и выигрыша по сравнению с переписыванием всего решения. Иллюстрации и обзор метода здесь. paper thread
AlphaEvolve находит более сильные математические решения; зафиксирован обход системы вознаграждений.
DeepMind’s AlphaEvolve изучает 67 количественных математических задач (например, числа поцелуев, перемещение дивана), эволюционируя программы-решения с параллельным поиском и верификацией. Результаты показывают более быструю сходимость на базе сильных базовых моделей, преимущества параллелизма и видимые режимы сбоев, связанных с «обманом вознаграждения» — явные сигналы для тех, кто строит рассуждения в масштабах. Прочитайте исследование и ознакомьтесь с наборами задач. paper recap, ArXiv paper, and GitHub repo
Безопасно выровненные LLMs сталкиваются с трудностями при роли злодеев; точность падает на ролях эгоистов.
Новый бенчмарк (Moral RolePlay) показывает, что модели, которые хорошо выровнены по полезности/честности, теряют достоверность, когда их просят играть эгоистов или злодеев, часто заменяя замысленность на гнев и нарушая последовательность персонажа. Это выявляет пробел в качестве для инструментов художественного описания и NPC‑агентов, которым требуются мотивации, выходящие за пределы просоциальности. Аннотация и диаграмма здесь. paper overview
Обнаружение аномалий по трассам помечает сбои нескольких агентов с точностью до 98%.
Исследователи показывают, что можно уловить молчаливые сбои в работе мультиагентной системы (drift, петли, отсутствующие детали), создавая признаки исполняемых трасс — шаги, инструменты, количество токенов, время исполнения — и обучая небольшие детекторы. XGBoost по 16 признакам достигал вплоть до 98% точности на отобранных наборах данных, варианты одного класса позади, предлагая дешёвый защитный слой для агентов в продакшене. См. настройку и метрики. paper abstract
)
Появился новый бенчмарк видеоподсказок, предлагающий сравнение подсказок бок о бок.
Свежий Video Prompt Benchmark вышел с быстрым монтажом, который показывает промпты и сгенерированные клипы бок о бок. Это полезно для творческих команд, сравнивающих чувствительность промптов и визуальную согласованность между видеомоделями без запуска частных оценочных наборов. Посмотрите краткий ролик запуска формата. ролик запуска)

Kimi K2 теперь лидирует в Vending‑Bench среди моделей с открытым исходным кодом
Andon Labs повторно запустил Vending‑Bench и сообщает, что Kimi K2 является текущей ведущей открытой моделью на доске. Если вы тестируете агентное кодирование с длинными цепочками инструментов, это полезная базовая отправная точка маршрутизации для сравнения с вариантами с фиксированными весами. заметка повторного запуска
Обзор ERNIE 5.0: более чистые результаты, средние показатели по сравнению с Kimi K2 и MiniMax M2
Популярный обзор сообщества находит ERNIE 5.0 гораздо чище, чем X1.1 (лучшее выполнение инструкций и читаемость), но всё ещё уступает Kimi K2 и MiniMax M2 в более сложном рассуждении и стабильности на множественных витках; пик 65.57/медиана 46.36 по общей шкале. Таблица сводки и выводы стоит просмотреть, если вы нацелены на китайские стеки. обзор резюме
Сообщество «RL‑Shizo» тесты выявляют чрезмерное обдумывание бессмысленных подсказок
Низовой проект Lisan RL‑Shizo_Bench предлагает проверочные подсказки, которые намеренно бессмысленны; berichten claims claim что даже ведущие “мыслящие” модели тратят минуты и тысячи токенов вместо откладывания, тогда как более мощные крупные модели чаще отказываются или сводят неоднозначность к резюме. Рассматривайте это как полезную ось красной команды для маршрутизации агентов и ограничений по расходам. питч стенда, и пример пары здесь пример выводов.
🏗️ ИИ‑суперфабрики, проектирование дата-центров и разрывы мощности
Материальные сигналы инфраструктуры для планирования: масштаб кластеров GPU, двухъярусные конфигурации дата-центров с низкой задержкой и дефицит электроэнергии в США с последствиями на триллионы долларов. В основном — экономика инфраструктуры и показатели загрузки на сегодняшний день.
США сталкиваются с дефицитом мощности дата‑центров на 44 ГВт к 2028 году, для устранения которого потребуется примерно 4,6 трлн долл.
Новые оценки показывают потребность США в энергии для дата‑центров на уровне 69 ГВт (2025–2028), при этом доступно лишь около 25 ГВт (10 ГВт самоснабжаемые, 15 ГВт резервной сетевой мощности), что оставляет дефицит в 44 ГВт. Покрытие этой разницы потребует примерно $2,6 трлн на генерацию/сеть и примерно еще $2 трлн на сами дата‑центры.
Краткая справка по дефициту мощности Это следует после Projects stalled, где мы увидели локальное сопротивление, блокирующее ~$98B в ходе развёртывания.
Так что дальше? Ограничение мощности становится основным риском для AI‑дорожных карт. Ожидайте больше локальной энергоподачи, длительных сроков подключения и размещения рядом с газопроводами и линиями высокого напряжения. Следите за очередями по разрешениям и закупками коммутационной аппаратуры и трансформаторов.
)
OpenAI и Microsoft строят кластеры из «сотен тысяч» GPU.
OpenAI’s Greg Brockman says their next clusters, co‑designed with Microsoft, will pack “hundreds of thousands of GPUs” each to meet oversubscribed demand. That scale sets expectations for model size, training cadence, and cost envelopes for anyone planning against OpenAI’s roadmap. OpenAI cluster note)
Почему это важно: вместимость в таком диапазоне подразумевает обучающие запуски на уровне нескольких экспафлопов, новые ограничения планирования и сильное давление на межсоединение, пропускную способность памяти и энергопотребление. Это также сигнализирует, что пропускная способность, а не только качество самой модели, будет основой конкурентных преимуществ для задач с агентскими и задачами по решению кодирования.
Американские облачные гиганты, как ожидается, потратят около 1,7 трлн долларов на ИИ в 2025–2027 годах, по сравнению с примерно 210 млрд долларов у Китая.
Свежие подсчёты, циркулирующие на этой неделе, оценивают капитальные расходы США на AI у гиперскейлеров около 1,7 трлн долларов (2025–2027), по сравнению примерно с 210 млрд долларов в Китае за тот же период. Такой масштаб влияет на цепочки поставок GPU, долгосрочные энергоподключения и на то, где агенты и мультимодальные выводы будут дешевле всего запускаться. Статья о сравнении CAPEX
Вот подвох: траты необходимы, но недостаточны. Ограничивающими реагентами являются энергия, земля возле подстанций и сетевые магистрали — поэтому ожидайте более творческого финансирования и выбора площадок.
Внутри двухэтажного дата-центра Fairwater AI от Microsoft, оптимизированного для низкой задержки
Microsoft продемонстрировала кампус Fairwater: двухъярусная планировка, которая держит ускорители физически близко, с плотной проводкой и жидкостным охлаждением, чтобы снизить задержку и разместить больше вычислительной мощности на каждом квадратном футе. Заявленная цель — масштабировать задачи ИИ по дата-центрам так же, как мы уже распределяем их между серверами. Fairwater video tour)
Для руководителей инфраструктуры это означает более короткие сетевые маршруты, более плотные термооболочки и новые требования к объекту (масса, вертикальные стояки, трассы охлаждающей жидкости). Планируйте индивидуальные сетевые решения и сервис‑меши, адаптированные под планирование между корпусами.

Google говорит, что TPU возрастом 7–8 лет по‑прежнему работают на 100% загрузке.
У Google Cloud Амин Вахдат сообщает, что устаревшие поколения TPU (7–8 лет) по-прежнему работают на 100% загрузке. Это наглядный эффект Джевонса: по мере удешевления инференса и обучения совокупные вычислительные затраты растут быстрее. клип по использованию TPU, и полная панель находится в панель YouTube.)
Суть проста: программные стеки и планировщики, которые выжимают максимум из старых ускорителей, продлевают окупаемость флота. Для планировщиков учитывайте поды с несколькими поколениями, предопределение емкости и большую эластичность спроса, вместо аккуратного цикла «вывести из строя и заменить».

🧰 Агентные инструменты разработки и рабочие процессы
Практические инструменты и подходы к развёртыванию агентов: представления агентов в реальном времени, единые CLI и средства устранения узких мест. В основном обновления по оркестрации и DX; исключаются новости протокола, относящиеся только к MCP, и элементы Gemini 3.
Conductor добавляет живой параллельный вид агентов с кликабельными субагентами
Conductor теперь визуализирует несколько агентов, работающих в параллели в реальном времени, и позволяет кликнуть на любого субагента, чтобы просмотреть его цепочку рассуждений и инструменты во время их работы feature demo. This shortens the feedback loop for long, branching workflows.

Для команд, выпускающих автономные режимы, это тот уровень прозрачности, который превращает загадочные запуски агентов в трассируемые шаги, по которым можно действительно рассуждать.
Руководство Google по агентам формализует CI/CD и Agent2Agent для производственной среды.
Google опубликовала практичный белый документ о переводе агентов от прототипа к производству, с предвзятым подходом к CI/CD, оценкам и протоколом Agent‑to‑Agent для координации работы нескольких агентов guide post, Kaggle whitepaper. Это читается скорее как руководство по развёртыванию, чем как демонстрация, и выступает продолжением отраслевого толчка к документированным runbooks агентов, в контексте Methodology playbook, который очертил внутренние паттерны развёртывания.
Если вы собираетесь подключать агентов к реальному рабочему процессу, возьмите за образец эту структуру: тесты, версионирование, интерфейсы агентов и планы отката.
«oracle» CLI объединяет контекст и файлы, чтобы спросить GPT‑5 Pro, когда агенты застревают.
Новый CLI-инструмент «oracle» упаковывает ваш запрос вместе с локальными файлами, а затем обращается к GPT‑5 Pro через API или через браузерный поток, чтобы вывести вас из тупика — полезно, когда агент зацикливается или цепочка инструментов заходит в тупик usage tip, GitHub repo. Он может автоматически запустить безголовый браузер, опубликовать контекст и вернуть рекомендации в ваш процесс; автор отмечает, что режим API выполняет более продолжительные раздумья, в то время как режим браузера — бесплатный и быстрый API vs browser note.
Считайте это как кнопку тревоги для кодеров и агентов: отправляйте ваше неудачное состояние более мощной модели и продолжайте с конкретным планом.
LangCode CLI объединяет OpenAI/Claude/Gemini с режимами ReAct и Deep.
Сообщество LangChain выпустило LangCode, единый CLI, который направляет запросы к OpenAI, Anthropic, Gemini и локальному Ollama, с двумя стилями агентов: быстрый ReAct и более глубокий планировщик для сложных задач. Он также включает элементы безопасности и интеллектуальную маршрутизацию, и текущая версия 0.1.5 показывает примерно 5 тыс. загрузок на карточке project page.
Если вы работаете с несколькими провайдерами и вам нужен единый интерфейс для процессов кодирования или операционных рабочих процессов, это сокращает связующий код и позволяет стандартизировать логи между моделями.
CopilotKit AI Canvas поддерживает синхронное состояние пользовательского интерфейса и агента через LangGraph
Сообщественный шаблон LangChain демонстрирует, как синхронизировать состояние интерфейса с внутренним состоянием агента в реальном времени с использованием LangGraph, уменьшая гонки и галлюцинации в совместных веб‑приложениях template post.
Если вы разрабатываете инструменты PM, CRM или области совместного использования, это чистая отправная точка для детерминированных UI‑AI потоков.
Poltergeist представляет панель различий на основе ИИ с наблюдателями за линтингом, сборкой и тестированием.
Poltergeist (универсальный инструмент для наблюдения за изменениями файлов и сборки) получает панель, которая отображает AI‑суммированные git‑диффы рядом с непрерывным статусом lint/build/test — удобно, когда агенты вносят множество правок работа над проектом, панель скриншот.
Это превращает фоновые авто‑сборки в кокпит для обзора, чтобы можно было просматривать изменения агентов, не углубляясь сначала в сырые диффы.
Обнаружение аномалий на уровне трассировки сигнализирует о скрытых сбоях в многоагентных запусках.
Новая работа IBM и соавторов показывает, что можно обнаруживать дрейф/петли множества агентов по обучению на трассах выполнения — анализ содержимого не требуется. Используя 16 числовых признаков (шаги, вызовы инструментов, использование токенов, временные метки), XGBoost и одноклассные модели достигают точности до примерно 98%/96% на двух тщательно отобранных наборах данных paper thread.)
)
Практический подход: снабдите запускаторы агентов инструментами для выдачи признаков формы пути, затем оценивайте прогоны на наличие аномалий в реальном времени.
Amp CLI теперь выводит чистые, возобновляемые сводки потоков после выхода.
Amp от Sourcegraph улучшил UX после выхода: теперь выводит краткое описание, ссылку на запуск и сводку LOC по плюсу/минусу, чтобы вы могли быстро возобновить поток позже CLI output.)
)
Небольшое изменение — реальная польза для агентных сеансов кодирования, которые охватывают терминалы и дни.
Trimmy (57 КБ) исправляет переносы строк в TUI, чтобы вставки в терминал выполнялись без проблем.
Крошечный, но удобный: Trimmy следит за буфером обмена и выравнивает те странные переносы строк/пробелы, которые появляются при копировании из TUIs, чтобы многострочные команды вставлялись и выполнялись одной строкой в вашем терминале app post, GitHub repo. Приложение на панели меню является открытым исходным кодом и занимает около 57 КБ без иконки.
Это небольшая помощь в снижении трения для разработчиков, работающих в агентских оболочках и контейнерных консолях.
v0 SDK Playground отлаживает вызовы API «vibe coding» в одном месте
Команда v0 запустила веб-плейграунд для своего API «vibe coding as a service», чтобы вы могли исследовать конечные точки, тестировать генерации и отлаживать параметры без предварительного подключения клиента API playground. Это быстрый способ проверить подсказки и затраты перед тем, как разместить за ним агента.
🗂️ RAG без RAG? Поиск файлов Google и извлечение запрашивают
Gemini File Search API плюс обоснование поиска подпитывают дискурс “RAG in a box”; призывы к интеграции Scholar/Books. Исключает освещение запуска Gemini 3 (функция).
Поиск файлов Gemini от Google выпускает «RAG in a box» с бесплатным тарифом.
Google обнажил File Search API, который позволяет создать хранилище, загружать и индексировать файлы, и отвечать на вопросы на основе контекста — без разворачивания vector DB. Документация также отмечает щедрый бесплатный уровень, что облегчает тестирование сегодня. См. настройку и примеры в официальной документации API docs и заметку о ценообразовании в ветке Paige Bailey Free tier note.
- Поддерживаемые сегодня типы входных данных включают CSV, Excel, Docs/Word, события календаря, XML и многое другое Free tier note.
И что дальше? Малые команды могут прототипировать помощников на основе поиска внутри Gemini Studio вместо того, чтобы соединять эмбеддинги, чанки и индексаторы. Вы по‑прежнему отвечаете за оценки и маршрутизацию, но базовый каркас “RAG” теперь является функцией первого уровня.
Живой бот показывает поиск файлов и привязку поиска к источникам при ответе на документы Gemini.
Публичный «Помощник по документации Gemini API» демонстрирует поиск по файлам в сочетании с привязкой к Google Search и ответы на реальные вопросы разработчиков о Gemini API. Это конкретный пример шаблона для ботов поддержки/поиска, которым нужны как приватная документация, так и свежий веб‑контекст объявление демонстрации, с доступной для пробы ссылкой на бота бот‑прототип.)

Суть в том, что можно развернуть retrieval, близкий к продакшн‑режиму, не запуская векторное хранилище или краулер; внимание смещается на проектирование подсказок, гигиену хранилища и источниковые цитаты.
“Google уничтожил все стартапы RAG”, спор вокруг File Search разгорается.
Широко распространенная диаграмма «Поиск файлов в Gemini API» вызвала утверждения, что Google просто свёл базовый стек RAG к чекбоксу. Реакция имеет смысл для простых инструментов чат‑поверх‑документов, но оставляет место для компаний, которые добавляют доменную маршрутизацию, оценки, соответствие требованиям и операции с данными поверх базовой Reaction thread.)
)
Если вы строите RAG, предполагается, что Поиск файлов — это базовый ориентир по умолчанию, и следует различать по качеству извлечения, ограничениям, SLA задержек и интеграциям для предприятий.
Призыв подключить Google Scholar и Books к Deep Research/Gemini
Этан Моллик призывает Google напрямую подключить Scholar и Google Books к Deep Research/Gemini retrieval, утверждая, что эти уникальные корпуса ускорят академическую работу и, вероятно, помогут продажам книг через надлежащие цитирования Запрос Scholar. Он также отмечает, что большая часть обширного каталога Google Books до сих пор недоступна программно Комментарий Books.
Вот почему это важно: опора на источники с высоким сигналом, ориентированные на научные работы и длинные форматы, повысит качество ответов и прослеживаемость, но потребует лицензирования, правил извлечения и надежного UX для цитирования.
🧠 Скрытые и альтернативные модели (не Gemini)
Новые модели, которые можно попробовать сегодня вне потока Gemini 3: пара Sherlock от OpenRouter, поддержка Arena для GPT‑5.1‑high и подробный обзор ERNIE 5.0. Исключает Gemini 3 (функция).
OpenRouter выпускает скрытные модели «Шерлок» с контекстом 1,8 млн и сильными оценками
OpenRouter представила две скрытые модели — Sherlock Think Alpha (рассуждение) и Sherlock Dash Alpha (скорость) — обе рекламируют контекст на 1.8M‑токенов и прочную поддержку вызова инструментов launch thread, с рабочими страницами моделей, доступными сейчас для тестирования API OpenRouter page. Ранние сторонние оценки показывают sherlock‑think‑alpha на 1,805.67 в LisanBench с средним коэффициентом валидности 0.96, обгоняя Grok‑4 по валидности 0.87, при этом уступая его raw score benchmarks chart.
Для разработчиков основное преимущество — длинный контекст и высокая точность следования инструкциям. Dash, по‑видимому, настроен под задержку прежде всего, с меньшим уровнем рассуждений, в то время как Think обеспечивает последовательность при структурированных задачах. Ожидайте быстрой итерации по мере сбора отзывов об использовании и проверяйте поведение в рамках своих собственных оценок, прежде чем полагаться на окно 1.8M для извлечения или отслеживания трасс с несколькими инструментами образцы изображений.
LM Arena позволяет GPT‑5.1‑high работать с видением и текстом и открывает Code Arena для Codex
LM Arena добавил GPT‑5.1‑high с мультимодальной поддержкой (vision+text) и запустил отдельную Code Arena, которая включает GPT‑5.1 Codex и Codex Mini для параллельного кодирования тестов обновление функции, с мгновенным доступом через публичную playground Code Arena. Это упрощает проверку реальных паттернов подсказок и инструментов, продолжая работу над SWE‑Bench 70.4%, где Codex обеспечил экономию затрат.
Для команд это беспрепятственный способ сравнивать рассуждения и настройки задержки по задачам, вводить новые подсказки перед развёртыванием и собирать скриншотируемые трассировки для внутреннего обзора.
Обзор Deep ERNIE 5.0: более чистые результаты, значительные улучшения, но пробелы в рассуждениях
Подробный пользовательский обзор аргументирует, что ERNIE 5.0 обеспечивает примерно 80% прироста производительности по сравнению с X1.1 за счёт гораздо более чистых и более согласованных генераций, примерно сравнимых с MiniMax M2 на верхнем уровне, но всё ещё отстает от Kimi K2 Thinking по глубине инсайтов и стабильности в многоходовых взаимодействиях review thread.). Анализ подчёркивает лучшие результаты в математике для K‑12 и следовании инструкциям, однако отмечает галлюцинации, редкие петли (<3%), а также ухудшение памяти после примерно 7 шагов.
KAT‑Coder‑Pro V1 выходит в раздел OpenRouter Trending, занимая топ-10 по суточному использованию токенов.
KwaiPilot’s KAT‑Coder‑Pro V1 занял место на доске Trending OpenRouter в течение пяти дней после запуска, при этом команда заявляет о стабильном использовании токенов в топ‑10 ежедневно среди кодирующих агентов, таких как Kilo Code, Cline и Roo Code трендовое примечание, заявление об использовании. Бесплатная версия модели доступна для испытаний и интеграции API через страницу поставщика страница OpenRouter.\n\n
\n\nЕсли вы оцениваете кодирующие агенты, измеряйте коэффициенты исправления и конструируйте/тестируйте циклы в рамках ограничений вашего репозитория, а также сравнивайте стабильность использования инструментов с вашим действующим агентом, прежде чем рассмотреть переход.
🧪 Рассуждение, детерминизм и дистилляция (новые статьи)
Плотный пакет статей для команд, работающих над настройкой надежности и возможностей: пошаговая самонастройка, детерминизм уровня финансов, дистилляция черного ящика, обнаружение аномалий и поиск математических закономерностей с помощью ИИ.
Меньшие модели на 7–8 млрд достигают 100% детерминированных выводов при T=0; 120 млрд — всего 12,5%
IBM’s finance-focused study shows 7–8B LLMs produced identical outputs 100% of the time at temperature 0 across 480 runs, while a 120B model managed just 12.5% despite all randomness off paper summary. The team attributes drift mainly to retrieval order and sampling, and stabilizes runs with greedy decoding, fixed seeds, strict SEC 10‑K paragraph order, and schema checks for JSON/SQL (±5% numeric tolerance). They propose deployment tiers: 7–8B for all regulated flows, 40–70B for structured outputs only, and 120B as unsuitable for audit‑exposed work; determinism also transfers across cloud/local when controls match paper summary.
Why it matters: this is a concrete playbook for banks and any regulated shop that needs repeatable answers on the same inputs. It also cautions that chasing size can reduce reproducibility at T=0, so teams should right‑size models to the task and lock retrieval order for RAG.
AlphaEvolve от DeepMind находит лучшие решения по 67 математическим задачам; репозиторий доступен онлайн.
AlphaEvolve повторно ищет, проверяет и развивает кандидатные идеи для решения математических задач, таких как Kissing numbers, circle packing и Friends’ moving sofa; во многих задачах он обходит человеческие базовые показатели, при этом Теренс Тао соавтор аналитики по взлому вознаграждений и руководящим эффектам paper highlight, AlphaXiv paper. Команда опубликовала репозиторий задач и ноутбуки Colab для воспроизведения и дальнейшего исследования GitHub repo.
Почему это имеет значение: оно подтверждает цикл открытий, поддерживаемый ИИ (search→verify→select) в крупном масштабе, подчеркивает, где сильнее помогают более мощные базовые модели и параллелизм, и называет класс задач «AlphaEvolve‑hard», где наивный поиск застревает.
Socratic Self‑Refine повышает точность в математике/логике примерно на 68%, исправляя лишь шаги с низкой степенью уверенности.
SSR разлагает рассуждения на короткие сократические подзадачи-вопросы/ответы, заново решает каждую изолированно, чтобы оценить уверенность, затем переписывает только те шаги с низкой уверенностью — давая в среднем около 68% прироста на задачах по математике и логике при контролируемых затратах обзор статьи. Step‑level confidence gives you a map of weak links, and the paper shows accuracy vs cost curves that favor targeted refinement over blanket re‑generation.
Для разработчиков: это хорошо вписывается в цепочки с инструментальной поддержкой. Используйте SSR для локализации ошибки, затем отдавайте предпочтение выборочному переосмыслению вместо полной переработки всей цепочки, чтобы ограничить задержку и расход токенов.
Обнаружение аномалий только по трассировке отмечает смещения и зацикливания нескольких агентов с точностью до 98%.
Исследователи создают наборы данных из 4,275 и 894 траекторий многоагентной системы и показывают, что поверхностные модели на 16 агрегированных признаках (шаги, инструменты, количество токенов, время) могут обнаруживать скрытые сбои — дрейф, циклы, пропущенные детали — не читая содержимое. XGBoost достигает до 98% точности; метод одноклассовой классификации, обученный только на нормальных трассах, близок к этому, хотя короткие дрейфы остаются сложными обзор статьи.
Вывод: вы можете оснащать агентов инструментами и запускать недорогие проверки состояния по их следам в производстве, раннее обнаружение плохих запусков без хранения чувствительного контента.
Языковые модели, ориентированные на безопасность, испытывают трудности с ролью злодеев; новый бенчмарк количественно оценивает разрыв.
Методика Moral RolePlay (800 символов, четыре уровня морали) показывает, что достоверность LLM падает по мере того, как роли становятся непро‑социальными, самый резкий спад — от «ошибочно‑хорошего» к «эгоисту». Модели часто заменяют замысловатость резким гневом, выходя из персонажа; более сильное выравнивание коррелирует с худшим исполнением злодея обзор статьи.
Почему это важно: выравнивание может конфликтовать с потребностями точного моделирования в играх и инструментах для написания. Команды могут нуждаться в песочницах или управляемых ограничителях, когда верное изображение некооперативных актёров является требованием продукта.
Гибридный решатель ARC сочетает быстрые догадки с простыми программами правил для повышения обобщающей способности.
Новый подход ARC сочетает быстрые эвристические догадки с небольшой библиотекой интерпретируемых правил-программ, подбирая по задаче, чтобы сбалансировать скорость и устойчивость. Метод нацелен на сокращение чистого перебора, сохраняя при этом решения, легко читаемые человеком, и демонстрирует выигрыши на разнообразных задачах ARC paper summary.
И что дальше? Для задач рассуждений, которым выгодно обнаружение структуры, набор небольших программ и догадчик могут превзойти любую из них по отдельности и дают объяснимые артефакты для отладки.
🎬 Креативные стеки: превращение фотографий в движение и визуализации почти в реальном времени
Креативные инструменты и демонстрационные материалы, пользующиеся популярностью у команд, создающих медиа‑приложения: конвертация фото в движение без навыков, клипы Grok Imagine, качество рендеринга SVG. Исключает любые заявления о запуске Gemini 3 (фича).
FlexFX от InVideo превращает статичные фотографии в движение с помощью 60‑секундных рецептов.
InVideo запустила FlexFX для обычных пользователей, переведя ранее Pro‑только эффект в однокликный рабочий процесс «из фото — в движение» с общедоступными 60‑секундными туториалами how-to demo и более явным позиционированием, что «всё сгенерировано внутри InVideo» не требует AE/CapCut tool overview.). Канонические эффекты «Quantum Leap» и «Drip Hop» демонстрируют последовательное, готовое к публикации в соцсетях движение из одного изображения, и создатели публикуют пошаговые инструкции и промо по ценам feature rollout,) плюс прямые ссылки, чтобы попробовать прямо сейчас site link.)

Для команд медиа‑приложений это беспрепятственный способ внедрить движение из UGC без VFX‑пайплайна; повторяемые пресеты также делают QA и пакетную обработку практичными.
Grok Imagine вызывает восхищение у создателей благодаря реалистичным микро‑клипам и игривым подсказкам.
Продолжаем тему обновления видео, на которое ранние тестировщики обращали внимание на качество; новые запуски создателей демонстрируют реалистичные короткие клипы: орёл в полёте eagle clip,) естественный макро-кадр котёнка kitten clip)) и лёгкий «анимированный профиль» гэг («голова распухает как воздушный шар») как воспроизводимый шаблон промпта animated prompt.). Это не изменения функций, но последовательность между нерелевантными промптами сигнализирует стабильную отрисовку и темп, полезные для социальных петель и аватаров.

Если вы оцениваете визуализацию в режиме почти в реальном времени, рассматривайте это как испытания надёжности: проверьте плавность движения по лицам и шерсти и повторно запустите промпт с воздушным шаром, чтобы проверить соответствие промпта и временные артефакты.
Новый бенчмарк видеоподсказок выходит для прямых сравнений TTV (один на один)
Сообщество «Video Prompt Benchmark» появилось с монтажем рядом промптов и сгенерированных кадров, давая командам быстрый способ проверить соответствие модели и качество движения в разных настройках benchmark teaser. It’s early and demo‑driven, but useful as a lightweight smoke test while fuller leaderboards mature).
Примите это как порог перед слиянием: зафиксируйте сиды, закрепите FPS/размер вывода и сравнивайте beat‑matching, дрейф субъекта и стабильность наложения текста перед тем как публиковать новые версии модели или пресетов.
Gemini 3 SVG наблюдение намекает на более высокую точность векторного вывода
Циркулирующий макет интерфейса телефона, приписываемый Gemini 3, демонстрирует четкую, многослойную отрисовку SVG для рамок устройств и элементов интерфейса, что вызывает заявления о «потрясающем SVG-результате» SVG claim.)\n\nХотя это и не примечание к выпуску, качество ассета говорит о том, что помощь в дизайне, ориентированная на вектор, может быть жизнеспособной, если её можно воспроизвести на разных подсказках.\n\n
)\n\nИнженеры должны поместить это в список наблюдения: если экспорт SVG надёжен, он сокращает время очистки растра до вектора и обеспечивает прямую передачу в пайплайны Figma/Canvas.
🛡️ Управление и сигналы безопасности
Дискурс в области безопасности и управления сегодня сосредоточен на ограничении агентов и происхождении. Исключает более ранний доклад о вторжении Anthropic (предыдущий день).
IBM сопоставляет уровни детерминизма: небольшие модели на 7–8 млрд параметров достигают 100% идентичных выходов при T=0
IBM протестировала дрейф на протяжении 480 испытаний, обнаружив, что модели размером 7–8B дают 100% идентичные выводы при температуре 0, в то время как модель 120B соответствовала только 12,5% случаев при тех же условиях управления. Их план действий связывает детерминированность с такими контролями, как замороженный порядок выборки, жадное декодирование, проверки схемы и валидация двумя провайдерами, с градуированной пригодностью для регулируемых рабочих процессов paper summary.
Почему это важно: Соответствие требованиям может позволить выбрать меньшие модели и строгий декодирование, чтобы пройти аудит, оставив более крупные модели для неаудируемых творческих задач.
Пользователи заявляют, что явная текстовая водяная пометка OpenAI исчезла, что усложняет прослеживание происхождения.
Широко распространенный клип утверждает, что «единственный очевидный водяной знак» для текста на искусственном интеллекте больше не присутствует, а внешний детектор возвращает «Not AI» для сгенерированного текста. Рассматривайте это как сигнал сообщества, а не судебное заключение, но вывод остается тем же: проверки подлинности по стилистическим признакам хрупки и могут исчезнуть в одну ночь демо-пост.)

И что дальше? Усильте опору на подписанные метаданные и серверные аттестации. Не полагайтесь на детекторы в качестве пропусков для соблюдения нормативных требований без человеческого рассмотрения или альтернативных доказательств.
Сулейман призывает к сдерживанию и регулированию автономных агентов ИИ.
Глава по искусственному интеллекту в Microsoft Мустафа Сулейман сказал, что ключ к безопасной автономии — сдерживание: задайте жесткие пределы и ориентиры, чтобы агенты оставались подотчетными людям, и подкрепите это новым регулированием. Это не релиз модели; это позиция в области управления, которая заставляет команды проектировать границы в первую очередь, а затем наращивать возможности. См. клип в speech excerpt.

Почему это важно: если вы выпускаете агентов, это указывает на то, что ограничения на уровне спецификаций (списки разрешения/запрета, песочницы для инструментов, явные этапы одобрения) становятся базовыми требованиями, а не приятными дополнениями.
ChatGPT управляет групповыми чатами с настройками конфиденциальности и защитой несовершеннолетних.
OpenAI запускает много‑пользовательские комнаты ChatGPT в вебе и на мобильных устройствах для выбранных регионов и планов с защитой конфиденциальности, контролем профиля, пользовательскими инструкциями и особыми мерами безопасности для молодых пользователей. Для компаний это означает новую площадку для сотрудничества, где важна базовая настройка безопасности — подумайте об ограничении доступа, видимости транскриптов и журнале аудита по умолчанию обзор функции.)
)
Кому это может быть полезно: команды доверия и безопасности и ИТ-администраторы, планирующие внедрение на уровне всей организации; это другой уровень риска по сравнению с чатами один-на-один.
Как показывают исследование, безопасностно-ориентированные LLM испытывают трудности с ролью злодеев.
Моральный бенчмарк Moral RolePlay (800 символов, четыре моральных уровня) показывает, что верность ролеплею падает по мере того, как персонажи становятся эгоистичными или злодеями, что наводит на мысль о тренировке согласованности, которая подавляет обман или манипуляцию, но идёт в ущерб правдоподобному непрофессонально-позитивному поведению. Это может заставлять помощников чувствовать себя «не в своей тарелке» в инструментах для письма или в играх, где требуются более темные мотивы paper thread.
Суть в том, что команды продукта могут нуждаться в режимно переключаемой согласованности или ограниченных песочницах для вымысла, не ослабляя базовые уровни безопасности в других местах.
Статья призывает к раскрытию информации и прослеживаемым оценкам для науки с участием искусственного интеллекта
Предложение по управлению, подготовленное авторами из Лос-Аламоса, требует обязательного раскрытия вклада ИИ в исследования, происхождения источников информации и оценок, отслеживающих работу команд человек+ИИ. Также настаивает на использовании открытых инструментов и рабочих процессов, дружественных к аудиту, чтобы сохранить ИИ в роли проверяемого помощника, а не авторитета paper summary.
Почему это важно: если вы создаёте LLM для научного RAG или планирования экспериментов, ожидайте, что регуляторы политики будут искать прослеживаемость источников и логи вклада.
🤖 Воплощенная ловкость и трюки
Легкие, но заметные клипы о воплощённом ИИ: точные роботизированные руки и попадание в лунку с одного удара от двуногого робота. В основном демо/испытания; сегодня мало деталей о продуктах.
ALLEX роботизированная рука обеспечивает деликатное и точное манипулирование
Демонстрация ALLEX-руки от Wirobotics подчеркивает точный контроль силы и безопасный контакт при работе с хрупкими предметами, указывая на готовую к промышленному внедрению ловкость для реальных задач демо‑клип.

Почему это важно: надежный контроль микросилы является преградой для фабричных и сервисных задач, таких как сборка, упаковка и лабораторная работа. В этом клипе показано устойчивое схватывание, плавное движение и отсутствие поврежденных предметов, что и ищут интеграторы при оценке пилотных линий.
Unitree G1 проходит тест на бытовые задачи
Shenzhen MindOn Robotics испытывает обновлённый аппаратно‑программный стек на Unitree G1 для выполнения бытовых задач (обработка предметов в беспорядке, безопасный контакт, восстановление) demo note. Вывод для команд: недорогие гуманоиды стали правдоподобными целями для запрограммированных задач и пилотов управляемой автономии в помещениях и в бэк-румах розничной торговли.
Бипедный робот выполняет туз на лунке.
Двуногий робот забивает хол-ин-уон на полностью зелёном поле, демонстрируя повторяемое планирование замаха, баланс и контроль контакта в условиях неопределённости (газон, удар клюшкой по мячу) stunt video.)

Так что? Это демонстрационный образец, но он наводит на мысль о более точном контроле всего тела и обработке возмущений в реальном мире — навыках, которые применимы к задачам на складе: подъем/размещение на неровных полах, открыванию дверей или использованию инструментов.
Роботизированные конусы обеспечивают безопасность на месте аварии менее чем за 10 секунд.
Полевые испытания в Китае показывают, как роботизированные дорожные конусы расходятся и обеспечивают место происшествия менее чем за 10 секунд, following up on robotic cones which first flagged the sub‑10s deployment claim test update.