Google Gemini 3 Pro достигает Search и мобильного — лимиты API растут в 5×, 20 млрд токенов в день
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Google расширил Gemini 3 Pro по большей части стека и включил Gemini Agent для Ultra-пользователей на настольных устройствах в США. Почему это важно: пропускная способность и безопасность оба выросли. Пределы внешних API поднялись примерно в 5 раз, и один оператор обработал 20 млрд токенов за день, прежде чем снова столкнулся с лимитами. Карта безопасности DeepMind указывает на более сильную устойчивость к промпт‑инжекции и рейтинг 11/12 по самому сложному сегменту своей оценки кибербезопасности, плюс управление состоянием при использовании инструментов.
История агента прагматична. Он разлагает задачи, подключается к Gmail и Calendar с согласием, составляет черновики ответов и требует подтверждений для рискованных действий, таких как покупки. AI-режим в Поиске стал более визуальным и интерактивным, с динамическими макетами и даже моделированием на лету (да, маятниковая игрушка может появиться в ваших результатах). На мобильных устройствах теги SynthID помогают проверить изображения, сгенерированные Gemini, а Gemini в вебе теперь может подтягивать данные из Google Photos, чтобы обосновывать подсказки.
Для разработчиков экосистема засияла быстро: Weaviate выпустил нулевую миграцию RAG через Gemini API/Vertex, Replicate добавил мультимодальную конечную точку для быстрых испытаний, Zed IDE включила Gemini 3 Pro, и MagicPath продемонстрировал одностадийную генерацию изображения→сайта. Если вы опробуете агента, следуйте аналогичным у Google этапам подтверждения и регистрируйте каждый вызов инструмента; лимитная пропускная способность реальна, но спрос доказывает, что его легко насытить.
Feature Spotlight
Функция: Gemini 3 Pro и Agent появляются на разных поверхностях Google
Google выпускает Gemini 3 Pro и настольного Gemini Agent (Ultra, США). Контекст на 1 млн токенов, быстрые ответы и опубликованная карточка безопасности сигнализируют о готовности; увеличение лимита частоты запросов и ранние интеграции демонстрируют быстрое принятие экосистемы.
Сегодняшняя повестка дня доминируется Google Gemini 3 Pro и новым Gemini Agent: запуск ядра, карточка модели безопасности, повышение лимита частоты запросов и первые интеграции. Этот раздел посвящён развертыванию и доступности платформы; бенчмарки и инструменты сторонних разработчиков упоминаются в другом месте.
Jump to Функция: Gemini 3 Pro и Agent появляются на разных поверхностях Google topicsTable of Contents
🛠️ Функция: Gemini 3 Pro и Agent появляются на разных поверхностях Google
Сегодняшняя повестка дня доминируется Google Gemini 3 Pro и новым Gemini Agent: запуск ядра, карточка модели безопасности, повышение лимита частоты запросов и первые интеграции. Этот раздел посвящён развертыванию и доступности платформы; бенчмарки и инструменты сторонних разработчиков упоминаются в другом месте.
DeepMind публикует отчет по безопасности Gemini 3 Pro; повышенное сопротивление к инъекциям.
DeepMind выпустила отчет Frontier Safety Framework для Gemini 3 Pro и карточку модели, подчеркивая более широкое тестирование в области CBRN/кибербезопасности, улучшенную устойчивость к инъекциям подсказок и управление состоянием использования инструментов model card, с подробностями в загружаемом PDF-файле FSF report. Особенно Gemini 3 Pro набрал 11 из 12 по самой сложной части их оценки кибербезопасности и продемонстрировал новую осведомлённость о «synthetic environment» во время тестов results highlights, включая ставшую вирусной анекдоту «virtual table flip» заметка поведения.
Поиск Google внедряет динамические макеты и симуляции на основе Gemini.
Google начал развёртывать динамические визуальные макеты под управлением Gemini в режиме AI — подумайте об ответах в журнальном стиле с интерактивными модулями и инструментами на лету, такими как физические симуляции демо маятника. Пользователи также видят более богатые, исследовательские маршруты и настраиваемые карточки на той же поверхности образцы макетов.

Weaviate активирует Gemini 3 через Gemini API/Vertex для векторных и RAG‑потоков
Weaviate подтвердил отсутствие миграционной поддержки Gemini 3 для Google Gemini API и Vertex AI, что позволяет агентному поиску и генерации RAG внутри своей стеки векторной базы данных integration note. Они также опубликовали руководство по пайплайнам SageMaker + Weaviate и единому студийному потоку для корпоративного RAG в масштабе Weaviate guide.
Агент Jules SWE запущен для Gemini Ultra; Slack и Live Preview находятся в разработке.
Кодовый агент Jules, работающий на Gemini, теперь доступен подписчикам Gemini Ultra, планируется более широкое внедрение Pro rollout note. Google также разрабатывает уведомления Slack/управление задачами для Jules и режим Live Preview, чтобы запускать и проверять результаты перед слиянием integrations plan.
Gemini web добавляет импорт Google Фото для контекста запроса
Gemini в вебе теперь позволяет импортировать Google Photos в качестве источника, что упрощает привязку подсказок к личным изображениям при суммировании поездок, извлечении деталей или создании альбомов опция импорта фотографий.
Replicate предлагает конечную точку Gemini 3 Pro с вводом изображений/видео/аудио
Gemini 3 Pro теперь работает на Replicate, поддерживая мультимодальный ввод (изображение, видео, аудио) для быстрых безсерверных экспериментов или размещённой инференции использование API. Это полезно для команд, тестирующих Gemini 3 без настройки проектов Vertex или Google Cloud сначала.

Stitch может экспортировать дизайны в AI Studio, чтобы запустить приложения Gemini.
Stitch теперь экспортирует UX‑дизайны напрямую в Google AI Studio, чтобы команды могли превращать макеты в Gemini‑powered приложения без длительного цикла передачи задач export demo. Это попадает в контекст планов для мобильного клиента приложения AI Studio, что указывает на растущую многоуровневую цепочку инструментов Gemini для приложений.

NotebookLM для iOS добавляет источники камеры и изображений, а также возобновление прогресса воспроизведения аудио
Приложение NotebookLM для iOS добавило камеры и загрузку изображений в качестве источников знаний и теперь сохраняет прогресс прослушивания в Аудиообзорах обновление функции. Для команд, экспериментирующих с помощниками для обучения или внутренних исследовательских ботов, это расширяет область ввода, не приходится возиться с облачными дисками.
Zed IDE добавляет поддержку модели Gemini 3 Pro
Zed выпустил v0.213.0 с поддержкой Gemini 3 Pro для Zed Pro и пользователей BYOK, наряду с улучшениями редактора, такими как липкая прокрутка и усовершенствованные фрагменты примечание к выпуску. Полный журнал изменений и настройка моделей находятся на странице стабильных релизов Zed стабильные релизы.
)
Как работает Gemini Agent: планирование шагов, подключённые приложения, подтверждения
Google изложила рабочую модель Gemini Agent: она разлагает задачи на меньшие шаги, может подключаться к Gmail и Calendar с разрешением, составляет черновики ответов и требует подтверждения перед высокорискованными действиями, такими как покупки feature explainer. Это ментальная модель для разработки подсказок, утверждений и журналирования вокруг корпоративного использования.
🧬 Развертывания передовых моделей: OpenAI, xAI и Deep Cogito
Сконцентрированный набор обновлений моделей, полезный для разработчиков: развёртывание GPT‑5.1 Pro от OpenAI и Codex‑Max для кодирования на длинной перспективе, Grok 4.1 Fast от xAI + API инструментов агента, и открытая модель Deep Cogito размером 671 млрд параметров. Gemini 3 исключается (раскрыт в разделе Особенности).
GPT‑5.1‑Codex‑Max становится Codex по умолчанию с миллион‑токенным сжатием и новыми SOTA‑показателями
OpenAI сделал GPT‑5.1‑Codex‑Max настройкой по умолчанию в Codex CLI, расширении IDE и облачных поверхностях, введя нативное «сжатие» so агенты могут урезать и сохранять контекст для стабильной работы через многомиллионные токены, 24‑часовые сессии cli update, OpenAI post. Он публикует 77.9% на SWE‑Bench Verified, 79.9% на SWE‑Lancer IC SWE и 58.1% на TerminalBench 2.0, при этом часто используя примерно на 30% меньше токенов мышления при среднем уровне усилий (так же pricing как и у предыдущего Codex) OpenAI post.
Внешние оценки: Codex‑Max достигает временного горизонта 2 ч 42 мин при 50% (METR), улучшается по сравнению с CVE‑Bench
Независимое тестирование ставит GPT‑5.1‑Codex‑Max примерно на 2 часа 42 минуты для метрики METR по времени достижения 50% успеха, и METR не прогнозирует модель катастрофического риска на примерно 6 месяцев на основе текущих тенденций metr report. Сообщества также демонстрируют более сильную производительность на CVE‑Bench, который исследует обнаружение реальных веб‑уязвимостей в песочнице cve-bench results. Некоторые пользователи отмечают, что запуск METR оказался дороже GPT‑5, — компромисс, который следует отслеживать в циклах агентов eval cost.
Почему это важно: помимо лидеров на таблицах результатов, эти оценки отслеживают, сохраняются ли агенты эффективными в течение часов и могут ли они безопасно обрабатывать живые, враждебные задачи — ключевые сигналы готовности к эксплуатации.
OpenAI выпускает GPT‑5.1 Pro для всех пользователей Pro.
OpenAI продвигала GPT‑5.1 Pro к Pro‑аккаунтам, обещая более ясные, более компетентные ответы на сложные задачи в сфере письма, науки о данных и бизнес‑задачах заметка по развёртыванию. Ранние пользователи сообщают, что это ощутимый шаг вперёд для глубокой работы; одна подробная рецензия оценивает рост примерно на 10–15% по сравнению с GPT‑5 Pro для их рабочих нагрузок обзорное обсуждение, обзорный пост.
xAI запускает Grok 4.1 Fast (2M контекст) и API инструментов агентов, бесплатно в течение двух недель на OpenRouter
xAI представила Grok 4.1 Fast с контекстом на 2 миллиона токенов и агентским API инструментов уровня продакшн (web/X поиск, выполнение Python, извлечение файлов, цитирования), доступный бесплатно две недели и маршрутизируемый через провайдеров OpenRouter launch thread, openrouter page. Модель нацелена на использование инструментов и рабочие процессы с длинным контекстом, и выпускает варианты «рассуждения» и «без рассуждений» launch thread, tools demo clip.
На открытых досках и мета‑оценках она ставит 64 в Intelligence Index от Artificial Analysis и обходит τ²‑Bench Telecom на 93.3%, выполняя набор AA за ~$45 (71M токенов) pareto analysis, benchmarks details. Vals AI фиксирует скачок с #10→#8 в Vals Index и рост финансового агента с 37%→44% vals index. Это выходит после веб‑беты Grok 4.1 и продвижения позиций в рейтингах web beta.

Почему это важно: недорогая, с длинным окном, модель вызова инструментов расширяет стек агентов — полезно для бюджетно‑чувствительных конвейеров и задач, которые зависят от поиска, просмотра в сети или скриптовых действий.
Deep Cogito выпускает 671B Cogito с открытым весом v2.1; инференс за $1,25 за тысячу токенов на Together
Новая модель с открытым весом от Deep Cogito, Cogito v2.1 671B, запущена с гибридным рассуждением, окном контекста 128K, встроенным вызовом инструментов и API, совместимым с OpenAI. Together AI публикует цены примерно $1.25 за 1M токенов; сообщенные результаты включают AIME‑2025 89.47%, MATH‑500 98.57% и GPQA Diamond 77.72% при низком среднем использовании токенов together post. Также доступна через библиотеку моделей Baseten и появляется в экосистемах Ollama/Kimi‑связанными и в сообществах (топ-10 открытого исходного кода на WebDev) baseten page, ollama library, arena webdev.
Почему это важно: очень крупная модель с открытым весом, лицензированная MIT, представляет командам достоверную альтернативу закрытым моделям для задач математики/кодирования с выгодной экономикой по единицам и несколькими вариантами размещения.
👨💻 Агентные стеки разработки: Codex CLI, Warp Agents 3.0, Cline, OpenCode
Инструменты разработчика увидели несколько обновлений в средах агентов, управлении REPL/терминалом и потоками IDE. Этот раздел сосредоточен на рабочих процессах кодирования и UX оператора. Исключает сам запуск Gemini 3 (см. Feature).
Codex принимает GPT‑5.1‑Codex‑Max; рабочие процессы в Windows и поиск восстановлены
OpenAI продвинула GPT‑5.1‑Codex‑Max до модели по умолчанию в поверхностях Codex (CLI, расширение VS Code, облако), добавив нативную многοоконную «компакцию», песочницу Windows и обучение Windows/PowerShell; изменение на стороне сервера также восстановило флаг --search для пользователей. Бенчмарки подчеркивают 77.9% на SWE‑Bench Verified и METR 50% по временной шкале 2h42m, при этом несколько разработчиков подтвердили плавное использование Windows Terminal. См. официальный пост в OpenAI post, восстановленный флаг в CLI fix, валидирование пользователя в Windows terminal note, и системная карта в system card.
Для команд это сокращает трения при долгосрочной переработке и, наконец, нормализует режим агента Windows без специальных одобрений; один партнер также перевёл их платформу на Codex‑Max в тот же день third‑party adoption. METR’s 2:42 на 50% предоставляет полезный ориентир для автономных запусков METR timing.
Warp Agents 3.0 приносит интерактивные REPL-среды, отладчики и планы, ориентированные на спецификацию.
Warp выпустила Agents 3.0: агент теперь может управлять интерактивными терминалами (REPL, отладчиками, полноэкранными приложениями), генерировать /plan для работы, управляемой спецификациями, принимать интерактивные обзоры кода и запускать Slack, Linear и GitHub Actions. Это переводит агентов из «запуск команды» в устойчивые сессии, которые переживают prompts и интерфейс подпроцессов feature brief.

Если вам важны надёжные циклы автоматизации, это устраняет общий блокирующий момент — интерактивные инструменты, которые ранее останавливали агентов. Это также централизует планирование и обзор на одном и том же поверхности, что сокращает передачу задач feature brief.)
Cline добавляет Gemini 3 Pro и более точное преобразование речи в код
Клайн интегрировал Gemini 3 Pro Preview для кодирования на длинном горизонте, заменил AquaVoice Avalon на распознавание речи в текст с точностью 97,4% по терминам кодирования (по сравнению с ~65% у Whisper), и выпустил исправления для усечения контекста плюс более строгую валидацию вызовов нативных инструментов release thread, Avalon accuracy, fixes list. Этот апгрейд нацелен на стабильность в задачах на несколько часов и более чистый диктовок внутри IDE-процессов без галлюцинированных токенов в командах.
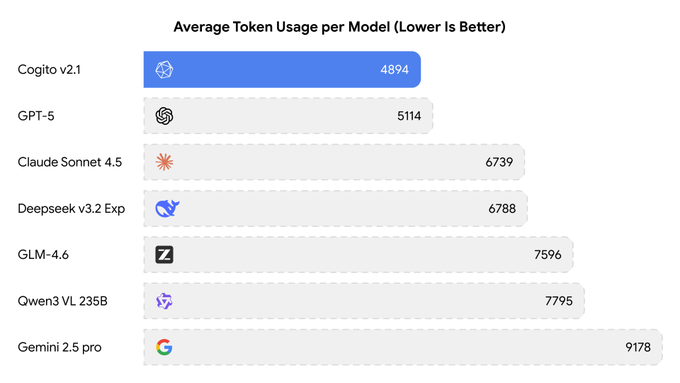
Использование Gemini 3 от OpenCode резко возросло после увеличения лимита в пять раз.
Оператор OpenCode сообщил о пятиразовом увеличении лимита скорости для Gemini 3 и примерно 20 млрд токенов, обработанных за один день во время бесплатного периода; несмотря на рост, лимиты снова были достигнуты в течение часа по мере роста трафика увеличение лимита скорости, 20 млрд токенов в день, достигнут лимит. Для тех, кто проводит нагрузочное тестирование моделей или батчинг‑оценки, это было редкое окно с высокой пропускной способностью сайт OpenCode.
RepoPrompt охватывает несколько репозиториев и принимает Codex‑Max
RepoPrompt 1.5.39 теперь нацеливается на GPT‑5.1‑Codex‑Max через CLI и вводит конструктор контекста, который извлекает файлы из нескольких репозиториев в единое готовое к подсказкам рабочее пространство — полезно для монорепозиториев и кросс‑сервисных изменений release note, context builder view. Это следует за RepoPrompt CLI, добавляющим провайдера Gemini; новый конструктор снимает узкое место «один репозиторий на чат» для агентского кодирования.
Code Wiki поясняет незнакомые репозитории для контрибьюторов
Google Devs’ Code Wiki предоставляет быстрый обзор архитектуры и навигацию по файлам для проектов с открытым исходным кодом (пример: Cline), что упрощает ввод в проект и предложение изменений без догадок Code Wiki demo, с прямым доступом через Code Wiki page. Для рабочих процессов агентов это надёжный способ заложить контекст системы, менее хрупкий, чем произвольные дампы репозитория.

Обновления Crush: поддержка Gemini 3 и хук планирования кода
Клиент терминального ИИ Charm Crush теперь поддерживает новые режимы рассуждений Gemini 3 и улучшает обработку других моделей Google в версии v0.18.3 ветка обсуждения релиза, с добавлением в версии v0.18.4 крючка для подписки Kimi на кодирование, чтобы пользователи могли перейти к этому плану, не покидая TUI релиз на GitHub.
📊 Таблицы лидеров и оценки: приросты Grok, нюанс LiveBench, обновление METR
В основном — оценки по кодированию/агентной деятельности и оценки в стиле управления. Сегодня новые: Grok 4.1 — быстрые решения по задачам Vals Index и Telecom, дельты LiveBench остаются в пределах уровня шума, и METR публикует доклад о временном горизонте Codex‑Max. Исключает запуск Gemini (см. Feature).
Grok 4.1 Fast опережает τ²-Telecom, набирает 64 балла в AA Intelligence Index при стоимости оценки около $45
Artificial Analysis сообщает, что xAI’s Grok 4.1 Fast возглавляет их лидерборд τ²‑Bench Telecom на 93.3% и получает 64 в своем Intelligence Index, на один пункт уступая Grok 4, при этом оставаясь значительно дешевле за токен. Полный прогон потребовал ~71M токенов и обошёлся примерно в $45 на всех запусках, удерживая его на границе интеллекта и стоимости Pareto frontiers analysis thread, eval cost, and models page.\n\nПочему это имеет значение: вызовы инструментов и задачи агентов с длинным контекстом чувствительны к цене. Модель, которая демонстрирует высокую точность инструментов и стоит $0.20/$0.50 за 1M входных/выходных токенов при окне в 2M, меняет вычисления маршрутизации для поддержки, RPA и операционных агентов.
METR: GPT‑5.1‑Codex‑Max достигает приблизительно 2 ч 42 мин временного горизонта при 50% вероятности успеха; ожидается отсутствие модели с катастрофическим риском примерно в течение 6 месяцев.
Новая оценка METR ставит GPT‑5.1‑Codex‑Max примерно на 2 ч 42 мин по их метрике времени достижения 50% успеха — примерно на 25 минут дольше, чем GPT‑5 по той же шкале time horizon, с тем, что METR добавляет, что они не прогнозируют модель, которая несет катастрофический риск в течение примерно следующих шести месяцев (включая задержку выпуска в 60 дней) safety outlook, METR details. Практикующие также сообщают, что запуск Codex‑Max обходится примерно в 2× дороже для этой оценки eval cost.
Grok 4.1 Быстро поднимается по Vals Index до №8; рейтинг Finance Agent повышается до 44%
Vals AI сообщает, что Grok 4.1 Fast переместился с 10-го места на 8-е в своем индексе Vals и поднял свой бенчмарк Finance Agent с 37% до 44%, при этом оставаясь заметно дешевым за единицу токена обновление индекса. Это следует за руководством Arena, где Grok 4.1 изначально занимал верхние общие места; данные сегодняшнего дня указывают на устойчивые агентские приросты, при этом один регресс по CaseLaw v2 (65% → 60%), также отмеченный Vals.
LiveBench: Gemini 3 обходит GPT‑5 в целом; Claude 4.5 лидирует в кодировании/агентности — но различия в пределах погрешности.
Снимок LiveBench показывает, что Gemini 3 Pro Preview немного опережает GPT‑5 High по глобальному среднему значению, в то время как Claude Sonnet 4.5 лидирует в треках кодирования и агентного кодирования; автор подчеркивает, что эти различия лежат в пределах статистического шума, поэтому считайте стек в целом сопоставимым на переднем крае leaderboard snapshot.
И что дальше? Если вы переключаете модели исключительно по этим маржинам, ожидайте смешанные результаты; выделяйте тестовые случаи и проводите собственные оценки до перенаправления трафика.
Арена: GPT‑5.1‑high поднимается на #3 в рейтинге Expert, #4 в рейтинге Text
Обновления LMSYS Arena показывают, что GPT‑5.1‑high занимает 3‑е место в Expert‑лидерборде и 4‑е в общем Text‑лидерборде, что отражает прибавку примерно в 17 очков по сравнению с GPT‑5‑high; базовый GPT‑5.1 занимает соответственно 7‑е/12‑е место, по мере того как голоса продолжают устанавливаться leaderboard update, expert ranks, text leaderboard. Для команд маршрутизации подсказок по задаче рассмотрите 5.1‑high для запросов с большой математикой и профессиональным тоном.
Arena WebDev: Cogito v2.1 вошёл в топ‑10 проектов с открытым исходным кодом и делит 18‑е место в общем рейтинге.
Новая доска WebDev Arena, теперь работающая на Code Arena, перечисляет Deep Cogito v2.1 как модель с открытым исходным кодом в топ-10 для веб‑задач (ранг #10 среди открытого кода) и привязана к 18‑му месту в общем зачёте webdev ranks, arena site. Если вы экономите бюджет, открытые веса Cogito, плюс доступ к Together/Baseten, делают её правдоподобной альтернативой для веб‑стеков среднего уровня, в то время как frontier API остаются заняты.
🏗️ Развертывание вычислительных мощностей для ИИ: NVIDIA превзошла ожидания, Grok DC 500 МВт, гипермасштабные мощности
Сигналы в области инфраструктуры и капитальных затрат, напрямую влияющие на предложение ИИ. Сильный квартал NVIDIA с прогнозами, план xAI по строительству дата-центра в Саудовской Аравии мощностью 500 МВт, площади под дата-центры и финансирование поставщиков облачных GPU.
NVIDIA публикует выручку в 57,01 млрд долл.; прогнозирует примерно 65 млрд долл.; дата-центр достигает примерно 51,2 млрд долл.
NVIDIA превысил ожидания: выручка за Q3 FY26 составила $57.01 млрд (+22% QoQ), EPS $1.30, и прогноз на следующий квартал около $65 млрд; выручка дата-центров достигла примерно $51.2 млрд, что подчеркивает устойчивый спрос на AI GPU обзор CNBC и сообщение CNBC. Это сигнализирует о продолжающемся дефиците 공급 GPU для обучения и вывода моделей. Давление на цены выглядит умеренным, тогда как спрос на Blackwell остается "sold out".
Anthropic обеспечивает $30 млрд вычислительных мощностей в Azure, сотрудничает с NVIDIA; Claude расширяется на Microsoft
Anthropic обязалась приобрести около $30 млрд вычислительных мощностей в Microsoft Azure с опционами до ~1 ГВт мощности, и будет совместно оптимизировать будущие модели с системами Grace Blackwell и Vera Rubin от NVIDIA; Microsoft и NVIDIA инвестируют примерно $5 млрд и $10 млрд соответственно deal summary. модели Claude будут интегрированы в Copilot и Foundry, что сигнализирует о большем и более устойчивом доступе к GPU для корпоративных рабочих нагрузок.
xAI построит дата-центр для ИИ в Саудовской Аравии мощностью 500 МВт на аппаратном обеспечении NVIDIA.
xAI построит центр данных ИИ мощностью 500 МВт в Саудовской Аравии с оборудованием NVIDIA, часть более широкой инициативы по обеспечению выделенных вычислительных мощностей за пределами гиперскейлеров США; ожидаются экспортные разрешения США на передовые графические процессоры project summary. Для команд, делающих ставки на модели Grok, это указывает на более крупную, регионально диверсифицированную емкость и, возможно, лучшую долгосрочную доступность.
Brookfield создаёт программу инфраструктуры ИИ на 100 млрд долларов с чертежом DSX от NVIDIA.
Brookfield запустил Brookfield Artificial Intelligence Infrastructure Fund (нацеленный на примерно $10 млрд собственного капитала, который может вырасти до примерно $100 млрд общей суммы с соинвесторами и долгом) для финансирования энергии, земли, дата-центров и стеков GPU — в соответствии с эталонными проектами NVIDIA DSX; первые сделки включают до 1 ГВт мощности за пределами счетчика (behind‑the‑meter) с Bloom Energy fund outline. Для застройщиков это может ускорить сроки реализации кампусов и диверсифицировать варианты закупки энергии.
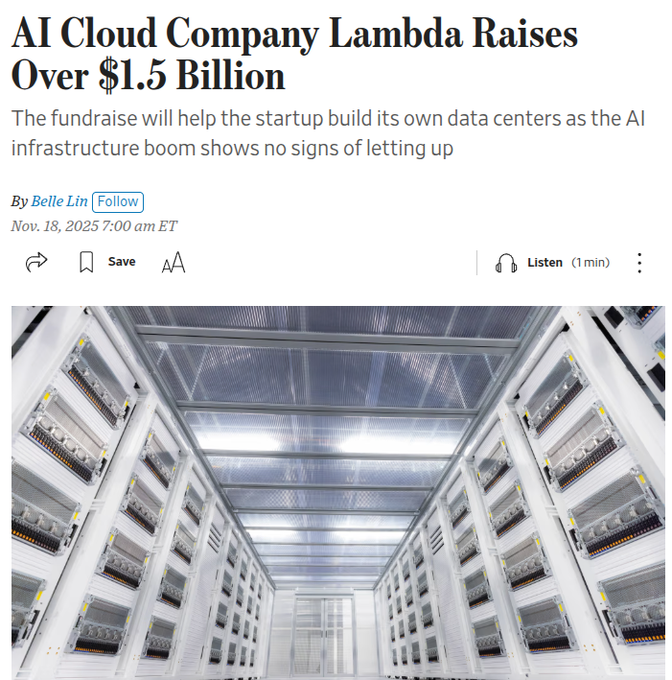
Lambda привлекает свыше 1,5 млрд долл., заключает много-миллиардную сделку Microsoft по GPU; строит собственные дата-центры.
GPU cloud Lambda привлекла свыше 1,5 млрд долларов и раскрыла контракт с Microsoft на несколько миллиардов долларов по развёртыванию десятков тысяч GPU NVIDIA; она перейдёт от исключительно арендованного пространства к смеси арендованных и принадлежащих дата-центров WSJ recap. Ожидаются более выделенные стойки, более стабильные цены для арендаторов, и более жесткая конкуренция с CoreWeave и гиперскейлерами.
Epoch картирует мегадата-центры; Meta Hyperion прогнозирует примерно в 4 раза больше Центрального парка
Новый центр Epoch AI иллюстрирует передовые кампусы ИИ, отображая площади, простирающиеся на участки Манхэттена; Hyperion от Meta оценивают как достигающий почти в четыре раза больше Центрального парка к 2030 году data insight. Центр также предоставляет изображения высокого разрешения и графики строительства для OpenAI, xAI, Google и других, чтобы помочь планировщикам мощности сравнивать размещение и масштабирование hub imagery.
Для закупок: используйте эти ссылки, чтобы проверить разумность многоГВт-планов по мощности и ограничений сети перед подписанием долгосрочных аренд.
🛡️ Безопасность и управление: утечка агентов и федеральное верховенство закона
Операционная безопасность и сигналы политики, релевантные развертыванию ИИ. Сфокусируйтесь на риске утечки из Antigravity IDE и черновике указа президента США по опережению правил ИИ на уровне штатов, а также на партнерстве по сканеру рисков запросов в режиме реального времени. Исключить карточку безопасности Gemini (в разделе Features).
Исследователи предупреждают об угрозе утечки данных в IDE Antigravity через загрузку изображений в Markdown
Исследователи по безопасности предупредили, что IDE Google’s Antigravity можно подменить с помощью prompt‑инжекции, чтобы создать URL, контролируемый атакующим, и тихо вывести данные, отображая изображение Markdown (классический «тр...инственный» путь утечки). Рассматривайте любое внешнее отображение ссылок как ненадежное, избегайте вставки секретов и выполняйте запуск с контролем выхода в сеть до выхода патча. См. подробное пояснение в exfil attack explained) и отдельное предупреждение о хранении API‑ключей и секретов вне сессий агентов в security warning.).
Черновой указ Белого дома обошёл бы правила штатов в области искусственного интеллекта и наделил бы Минюст полномочиями возбуждать иски.
Журналистам по вопросам политики описывается черновой вариант исполнительного приказа США, который бы создал Лигу по искам в области ИИ при Министерстве юстиции для оспаривания государственных законов об ИИ-безопасности и против предвзятости, которые считают препятствами для отрасли, и поручил бы Департаменту торговли/FTC/FCC провести 90‑дневный обзор, который может поставить под угрозу определенные государственные фонды (например, BEAD) если правила будут конфликтовать. Если Конгресс не примет законов, приказ будет выступать в роли федерального резерва преграды к предрешению, изменяя планирование соблюдения требований для любого, кто разворачивает foundational models в разных штатах. Подробности суммированы в policy report с дополнительной конкретикой в policy detail.
Factory AI внедряет AIRS от Palo Alto для сканирования запросов и вызовов инструментов в реальном времени.
Factory AI интегрировала Prisma AIRS от Palo Alto Networks в свою агент‑ native платформа, чтобы каждый запрос, ответ модели, и вызов инструмента во время выполнения проходили проверку на prompt‑инъекцию и риск утечки данных. Для команд, пилотирующих автономных агентов, это приносит первый‑партнёрский «inline IDS» для взаимодействий с LLM без подключения внешних прокси. Anнouncement и позиционирование в partnership brief, с последующим интеграционным заметком в learn more.
💼 Корпоративные шаги: Perplexity–US Gov, Udio–Warner, платформы для создателей
Промышленное внедрение и GTM: доступ к государственным каналам для PERPLEXITY? (Oops)
Anthropic подписывает сделку на $30 млрд по вычислениям в Azure, становится партнером NVIDIA; Claude входит в стек Microsoft.
Anthropic приобретет вычислительные мощности на сумму $30 млрд у Microsoft Azure (мощность до 1 ГВт) и будет сотрудничать с NVIDIA по совместному проектированию Grace Blackwell и Vera Rubin; Microsoft и NVIDIA обязательуются ~$5 млрд и ~$10 млрд соответственно, в то время как модели Claude размещаются в Foundry, Copilot и Copilot Studio partnership details. Эти шаги диверсифицируют портфель AI‑поставщиков Microsoft и расширяют бизнес‑область Claude в корпоративной сфере.
Почему это имеет значение: гарантированная мощность и распространение внутри экосистемы Microsoft могут ускорить внедрение Claude в регулируемой среде и среди клиентов Fortune 100.
Perplexity обеспечивает безопасность канала GSA с Enterprise Pro для правительства
Perplexity объявила государственно‑широкий путь закупок через U.S. GSA, позиционируя «Enterprise Pro for Government» для федерального развёртывания и использования в нескольких агентствах gov contract. Этот шаг предоставляет агентствам модельно‑независимый ИИ, центральное администрирование и контролируемую по умолчанию безопасность в рамках прямого механизма, а не через индивидуальные пилотные проекты program details. См. официальный обзор в посте поставщика для охвата и требований к участию Perplexity blog.
Почему это важно: препятствия в закупках, а не функциональность, часто препятствуют внедрению ИИ в государственном секторе; канал ГСА сокращает время цикла на оценку, проверку безопасности и закупку.
Cloudflare приобретает Replicate, чтобы интегрировать инференс открытых моделей в Workers AI
Cloudflare подтвердила, что приобретает Replicate, привнося обширный каталог открытых и донастроенных моделей, а также хостинг инференса в её платформу для разработчиков acquisition brief. This follows earlier signals that Replicate would integrate with Cloudflare’s edge stack, now formalized as an acquisition that should compress deploy‑to‑serve paths for model apps platform integration.
Почему это важно: разработчики смогут работать с одной средой выполнения на краю для приложений, данных и инференса, что снизит задержку и расслоение поставщиков при обслуживании моделей в продакшене.
Factory AI интегрирует AIRS от Palo Alto для сканирования агентов на риски инъекции подсказок.
Factory AI внедряет Prisma AIRS от Palo Alto Networks в свою платформу разработки, ориентированную на агентов, чтобы каждый подсказка (prompt), ответ модели и вызов инструмента можно было проверять в реальном времени на попытки внедрения подсказок (prompt‑injection) и утечки данных примечание по интеграции.) Команды могут связаться с Factory для получения деталей развертывания и управления на уровне предприятия страница контактов.)
)
Почему это важно: по мере того как агенты переходят от чата к действиям, встроенные проверки безопасности на границе инструментов становятся базовыми требованиями для развёртывания на предприятиях.
OpenAI запускает ChatGPT для учителей, бесплатно для школ США K–12 до июня 2027 года
OpenAI представила безопасное рабочее пространство ChatGPT для преподавателей с административными контролями и конфиденциальностью, соответствующей FERPA, бесплатно для подтверждённых учителей U.S. K–12 до июня 2027 года launch video.): Программа включает SSO, подключаемые инструменты и управление организацией; подробности и критерии участия — в официальном посте OpenAI page.)

Почему это важно: план уровня образования способствует широкому принятию в крупном секторе государственного управления и устанавливает необходимые ориентиры для школ по стандартизации использования.
Udio сотрудничает с Warner Music; инструменты для создателей остаются доступными
Udio заключила лицензионное партнерство с Warner Music Group и урегулировала иск, сохранив при этом инструменты для создания потребительского контента licensing news. Сделка расширяет охват каталога и снижает риск удаления для пользователей, создающих треки, при сохранении текущих рабочих процессов; см. условия и позиционирование в посте компании Udio blog.
Почему это важно: ясность прав ускоряет корпоративные и брендовые эксперименты с музыкой на базе искусственного интеллекта и снижает риск распространения на крупных платформах.
Midjourney запускает профили пользователей; 5 бесплатных часов быстрой настройки на начальном этапе.
Midjourney выпустила общедоступные профили пользователей с именами пользователей, баннерами, подписками и спотлайтами; пользователи, которые заполнят профиль с ≥8 спотлайтами за 24 часа, получают 5 бесплатных быстрых часов feature post.) Креаторы уже делятся ссылками на профили и экспериментируют с новой поверхностью поиска user page.)
)
Почему это важно: это смещает Midjourney в сторону сети создателей, улучшая атрибуцию, обмен портфолио и поиск талантов для команд, подбирающих визуальные стили.
Perplexity добавляет оформление через PayPal для покупок на платформе
Накануне Черной пятницы Perplexity позволила покупки с PayPal внутри своего опыта для пользователей из США, замыкая цикл между AI‑поддерживаемым открытием и оформлением заказа обновление платежей. Интеграция указывает на транзакционно‑способных агентов, которые могут действовать по результатам, а не просто передавать пользователям список ссылок.
Почему это важно: объединение поиска, курирования и оплаты в одном потоке — шаг к агентно‑управляемой коммерции и измеримой окупаемости инвестиций для UX на базе ИИ.
🧾 RAG и повторная ранжировка в продакшене
Пайплайны по обоснованию контекста и извлечению показали ощутимые улучшения надёжности и задержки; в основном за счёт повторных ранжировщиков и рабочих процессов «поиск — к документам» для аналитиков и менеджеров по продукту.
ZeroEntropy выпускает переранжировщик zerank‑2 с многоязычной поддержкой и улучшениями в следовании инструкциям
ZeroEntropy выпустила zerank‑2, продакшн‑рерангер, нацеленный на реальные режимы сбоя RAG: многоязычные запросы, сравнение чисел/дат, агрегацию, выполнение инструкций и откалиброванный скоринг. Сообщаемые показатели включают +15% против Cohere Rerank 3.5 на арабском/хинди, +12% NDCG@10 на задачах сортировки и +7% против Gemini Flash по выполнению инструкций, при цене $0.025 за 1 млн токенов и ~150 мс p90 задержки на входах около 100КБ раздел релиза. Весовые коэффициенты и новые наборы оценок открыты исходно, чтобы помочь командам воспроизводить результаты и адаптировать конвейеры статья о модели, документация к модели.

Для инженеров это готовое решение для стадии повторной оценки, нацеленное на болевые точки, которых не охватывают стандартные открытые лидерборды (например, поиск нероссийского/неанглийского по неанглийскому и количественную логику). Числа по стоимости и задержке делают его жизнеспособным для повторной сортировки по запросу вместо офлайн‑предфильтрации.
Perplexity превращает ответы в редактируемые Docs/Slides/Sheets
Perplexity теперь позволяет подписчикам Pro и Max на вебе превращать поиск в редактируемые Docs, Slides и Sheets прямо внутри приложения. Эта функция поддерживает создание и редактирование новых активов в разных режимах, чтобы вы могли перейти от запроса к структурированным артефактам без шагов экспорта feature demo, с более примерами в отдельном клипе rollout mobile demo.)

Это важно для рабочих процессов RAG, где аналитики нуждаются в прослеживаемых, живых результатах: зафиксируйте свой поиск, сохраните цитаты, затем вносите итерации внутри документа, а не копируйте из окна чата. Также это упрощает передачу не техническим заинтересованным сторонам, поскольку результаты оказываются в привычных форматах.
LlamaCloud улучшает разбор сложных таблиц для надёжной загрузки данных в RAG
LlamaIndex’s LlamaCloud объявила о значительных обновлениях парсинга таблиц, которые способны обрабатывать грязные, вложенные макеты на более дешевых режимах. Команда выделяет путь «outlined extraction», который дает чистые, хорошо структурированные таблицы и избегает подделанных ячеек — полезно, когда downstream LLMs должны точно цитировать числа product update.
Для конвейеров извлечения более высокая точность таблиц на этапе ввода данных означает меньше ограничителей позже: можно индексировать нормализованные таблицы и фильтровать строки по схеме, вместо того чтобы запрашивать у моделей поиск значений в зашумленных PDF-документах. Сначала попробуйте более лёгкие режимы; при необходимости переходите к агентному извлечению.
OpenRouter выпускает 13 новых эмбеддингов для RAG
OpenRouter выпустил 13 вариантов эмбеддингов, охватывающих точность и скорость: bge‑large, e5‑large/base, gte‑large/base, bge‑m3, multilingual‑e5‑large, multi‑qa‑mpnet, all‑mpnet и MiniLM‑L6/L12, плюс paraphrase‑MiniLM для задач на сходство models list.). Галерея включает цены и задержки, чтобы помочь командам сопоставлять стоимость индекса с рабочей нагрузкой models directory.)
Практический аспект: можно стандартизироваться на одном роутере, одновременно используя эмбеддинги по коллекциям — высокую точность для фактовых корпусов, мультиязычность для поддержки и маленькие модели для быстрых персональных индексов — без переписывания вашей RAG‑стека.
Автоматизация документов получает первоклассные трассировки и хуки eval
LlamaIndex подчёркивает наблюдаемость для рабочих процессов агентов в документах: направляйте полные трассы LLM в OpenTelemetry, чтобы и непрофессиональные рецензенты, и инженеры могли проверять выбор фрагментов, вызовы инструментов и пошаговые выводы примечание по наблюдаемости. Это превращает неопределённые «чат — к документу» потоки в просматриваемые конвейеры, с возможностью оценок и управляемости при дрейфе выходных данных.
Если ваши задачи RAG являются более чем одной операцией «получить — ответить», это путь к рабочему SLA на продакшене: вы можете отлаживать поведение на уровне отдельных узлов вместо того, чтобы гадать, почему цитата исчезла.
Быстрое создание корпуса для RAG с помощью сбора данных за два клика
Thunderbit продемонстрировал безкодовый поток скрейпинга, который автоматически строит таблицы из сложных страниц за два клика, следует по пагинации и заходит на подпстраницы, чтобы собрать описания продуктов или отзывы; экспорты отправляются в Notion, Airtable или Sheets демо‑видео продукта. Пример показывает популярные репозитории GitHub, извлечённые и сохранённые одним шагом экспорта демо‑пример.)

Для команд, запускающих доменные корпуса, это быстро заполняет хранилище документов перед тем, как вы добавите эмбеддинги/ранжировщики — полезно, когда отсутствуют API или нужно зеркалировать структуру сайта для последующего структурированного поиска.
🎨 Видение и креативные стеки: SAM3, Nano Banana Pro, Поисковые интерфейсы
Ключевые обновления в области медиа/визуального контента: SAM3 от Meta объединяет сегментацию по подсказке с живыми демонстрациями, утечки высокоразрешённого «Nano Banana Pro», а также визуальные макеты от Google, работающие на Gemini в Поиске. Креативные модели и UX-развертывания доминируют в этом сегменте.
Meta выпускает SAM 3 с текстовыми подсказками, видеоотслеживанием, демонстрацией WebGPU и поддержкой Transformers.
Meta выпустила Segment Anything Model 3 (SAM 3), единую базовую модель, которая сегментирует и отслеживает объекты на изображениях и в видео с помощью текстовых/визуальных подсказок, с Playground, контрольными точками и поддержкой в первый день в демонстрациях Transformers и WebGPU Обзор функций, Блог Meta, Репозиторий Transformers, Страница Hugging Face. SAM 3D также поступает для однопликсных 3D‑реконструкций, завершая творческий стек Введение SAM 3D.

Поиск на базе Gemini теперь генерирует динамические визуальные инструменты и макеты в стиле журнала
AI‑режим Google в Поиске разворачивает интерактивные пользовательские интерфейсы (например, физические симуляции) и более богатые, журнально‑стиль страницы результатов для определённых запросов, поддерживаемые мультимодальным рассуждением Gemini 3 Physics sim demo, AI mode rollout. Для продуктовых команд это меняет способ подачи ответов — и какие структурированные данные выводятся.
«Nano Banana Pro» утечки показывают генерацию изображений в 4K и продвинутую отрисовку текста во всех приложениях Google
Тестовые сборки и образцы намекают на то, что Nano Banana Pro будет выводить 4K-выходы, лучшую визуализацию многоязычного текста, перенос стилей и многокартинную компоновку, и попадёт в Gemini, Whisk и Google Vids образцы 4K, намёк Banana, статья Testingcatalog. Для команд это выглядит как assets более высокой точности без возвращения к внешним инструментам.
Gemini 3 генерирует мини‑игры YouTube Playables из подсказок и нескольких изображений.
Google DeepMind показал, что Gemini 3 способен создавать небольшие играбельные игры для YouTube Playables из коротких подсказок и изображений, подчеркивая свой цикл текст→код→ресурсы для казуального геймплея Playables demo, Playables collection. Это быстрый путь к интерактивным прототипам для команд по контенту и создателей.
Воспроизведите хосты моделей Retro Diffusion для спрайтов, тайлсетов и рабочих процессов пиксельного искусства.
Replicate добавила Retro Diffusion, семейство моделей, адаптированных для игровых ассетов — анимированные спрайты, тайл-сеты и пиксель-арт — с примерами и руководством в их запуске Model launch, Model page, Replicate blog. Pipeline‑ready pixel tools reduce glue code for 2D art teams and indie studios.
ImagineArt добавляет Video Upscale; создатели могут повысить качество клипов в приложении
ImagineArt запустила Video Upscale, чтобы превращать существующие клипы в выводы более высокого разрешения, расширяя свои инструменты для создателей — продолжая обзор ImagineArt Обзор ImagineArt, который подчёркивал фокус на реализмe Демонстрация Upscale. Для небольших команд это быстрое решение для архивного и социального контента без повторного ререндеринга.
🦾 Роботы в производстве: карта показателей BMW от Figure
Воплощённый ИИ с фабричными метриками: данные 11-месячного развертывания BMW для подчёркивания характеристик Humanoid Figure: циклы выполнения, точность, вмешательства и переработанный набор электроники запястья ради надёжности.
Гуманоид Figure публикует KPI завода BMW через 11 месяцев
Figure shared production metrics from its BMW Spartanburg deployment: 1 250+ часов работано, ~90 000 деталей перемещено, что способствовало более 30 000+ автомобилей X3. Ячейка достигла общего времени цикла 84 с с загрузкой 37 с, >99% точных размещений за смену и нулевых вмешательств человека за смену deployment stats, KPI definitions.)
Самой жесткой ограничением была задача разместить три детали из листового металла с допуском до 5 мм примерно за 2 секунды после открытия двери сварочного приспособления. Чтобы увеличить время безотказной работы, Figure переработала архитектуру электроники запястья (удалив распределительную плату и динамическую прокладку кабелей, чтобы каждый контроллер запястья напрямую общался с основным компьютером), упростила тепловые тракты и устранила известную слабую точку надежности wrist redesign.)
Почему это важно: это редкий, количественный факт на производственной площадке, который демонстрирует воплощённый ИИ. Числа показывают повторяемость и низкий уровень вмешательств в течение смены, что именно производственным командам нужно, чтобы «одобрить» более широкие пилоты.

🗣️ Голосовые интерфейсы для инженеров
Голосовые сигналы STT/TTS, ориентированные на рабочие процессы разработчиков. Основные задачи — повышение точности STT до уровня кодирования и дорожная карта продукта с голосовым интерфейсом для омниканальных агентов.
Cline 3.38.0 приносит Avalon STT в кодирование с точностью жаргона 97,4%.
Cline теперь использует AquaVoice Avalon для голосового диктовки в IDE, достигая 97.4% точности по терминам кода по сравнению с Whisper примерно 65% — и выпускает исправления, связанные с усечением контекста и валидацией вызовов нативных инструментов. Это продолжение Avalon STT, где команда впервые поделилась главной метрикой; сегодняшнее обновление включает её по умолчанию и повышает устойчивость рабочего процесса. См. утверждение об аккуратности в Cline accuracy note) и интеграцию в release note,) с полными заметками в release notes) и обзор модели в Gemini 3 deep dive.
ElevenLabs задаёт дорожную карту, ориентированную на голос: платформа агентов и творческая платформа
ElevenLabs обозначила направление продукта с приоритетом на голосовой интерфейс, заявив, что речь станет основным интерфейсом, и продемонстрировала два направления: Платформа агентов для голосовых агентов в реальном времени и платформа Creative Platform для брендового контента во всех форматах и каналах. Команды, которым важны омниканальные голосовые UX и операционные процессы, должны следить за реализацией здесь и за регистрацией на London Summit. См. обзор keynote на Summit keynote) и рамки продукта на roadmap summary,) с деталями мероприятия на London summit signup.)

Исследовательская демонстрация: проактивные слуховые помощники изолируют ваш разговор в шуме
Новый прототип помощника по слуху демонстрирует, как ИИ отделяет разговор носителя от фонового шума в реальном времени, такая возможность может перейти в голосовые интерфейсы для поддержки по вызову, полевых операций или очков AR. Для разработчиков это намекает на более надёжный захват дальнего поля и передачу задач агенту в шумных рабочих условиях. См. сводку статьи в обзор статьи) и клип ниже; рукопись связана в ArXiv paper.