The most full AI hub: fresh stories, workflows, prompts, deals. Updated daily.
Filter by tag
Tap to toggle filters. Selected tags narrow your feed.
Compromised LiteLLM 1.82.7 and 1.82.8 wheels executed a malicious .pth file at install time to exfiltrate credentials, and PyPI quarantined the releases. Treat fresh-package installs and AI infra dependencies as supply-chain risk, and check startup hooks on affected systems.

Public Anthropic draft posts described Claude Mythos as the company's most powerful model and placed a new Capybara tier above Opus 4.6. The documents also point to cybersecurity capability and compute cost as rollout constraints.

Google Research said TurboQuant can shrink KV cache storage to 3 bits with roughly 6x less memory, and early implementations already surfaced in PyTorch, llama.cpp, and Atomic Chat. The work targets a core inference bottleneck for long-context serving on local and server hardware.

Compromised LiteLLM 1.82.7 and 1.82.8 wheels executed a malicious .pth file at install time to exfiltrate credentials, and PyPI quarantined the releases. Treat fresh-package installs and AI infra dependencies as supply-chain risk, and check startup hooks on affected systems.
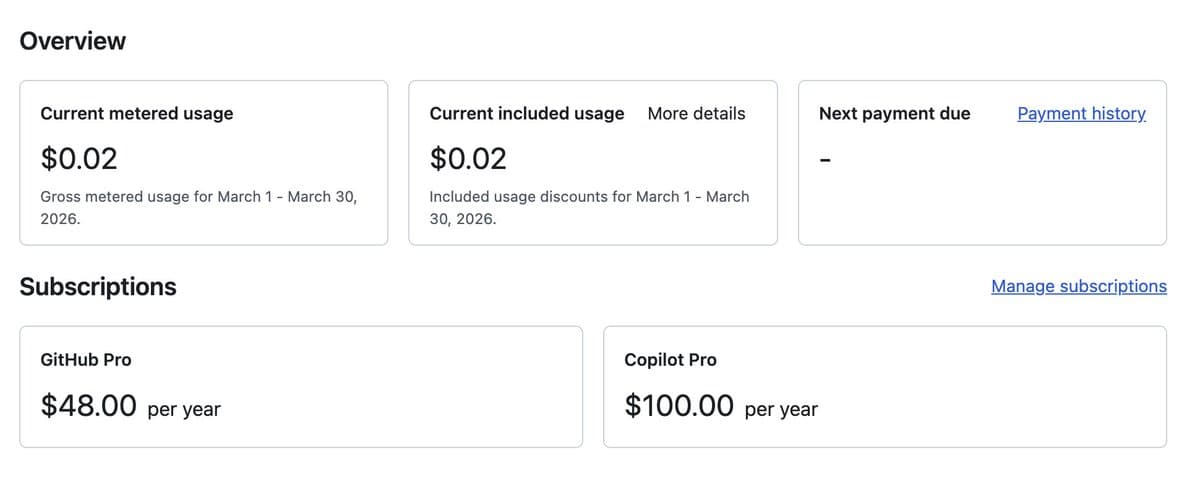
GitHub said Copilot Free, Pro, and Pro+ interaction data will train models by default from Apr. 24 unless users opt out, while private repo content at rest stays excluded. Teams should review per-user enforcement, enterprise coverage, and repo privacy settings before the change lands.
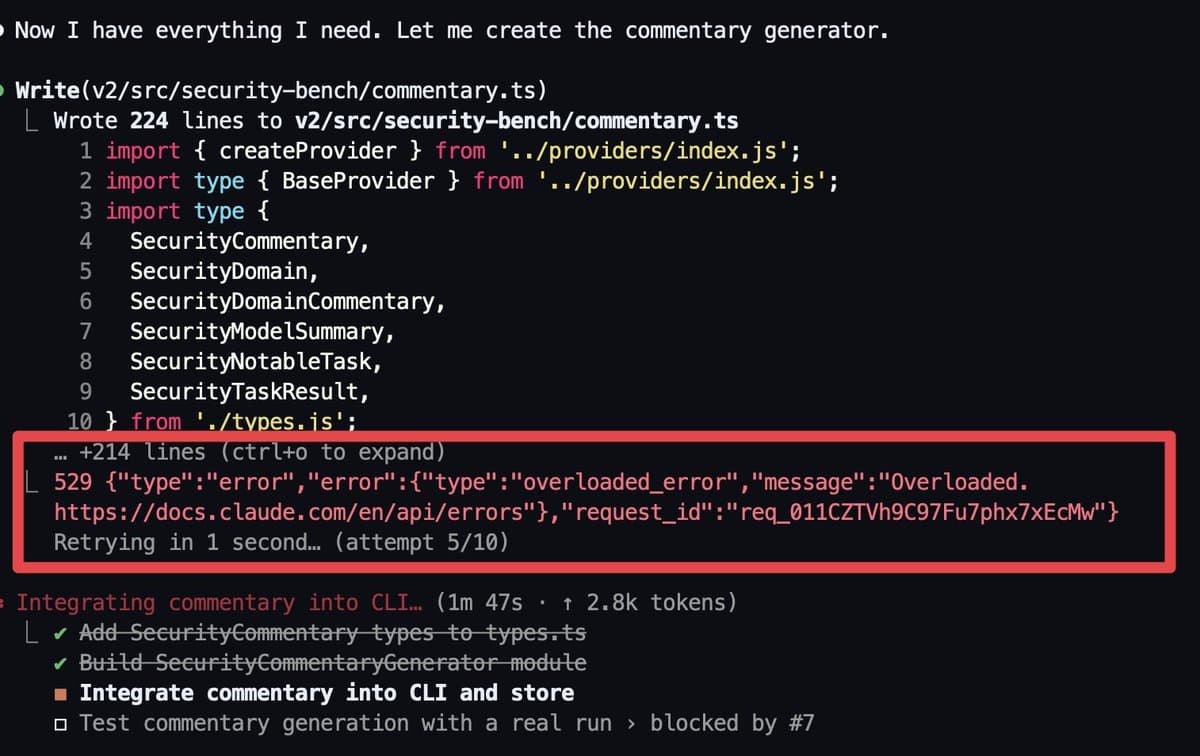
Anthropic confirmed new peak-time metering that burns through 5-hour Claude sessions faster, and multiple power users posted 529 overloaded errors and early exhaustion. If you rely on Max plans for coding, watch for session limits and consider moving daily work to Codex.




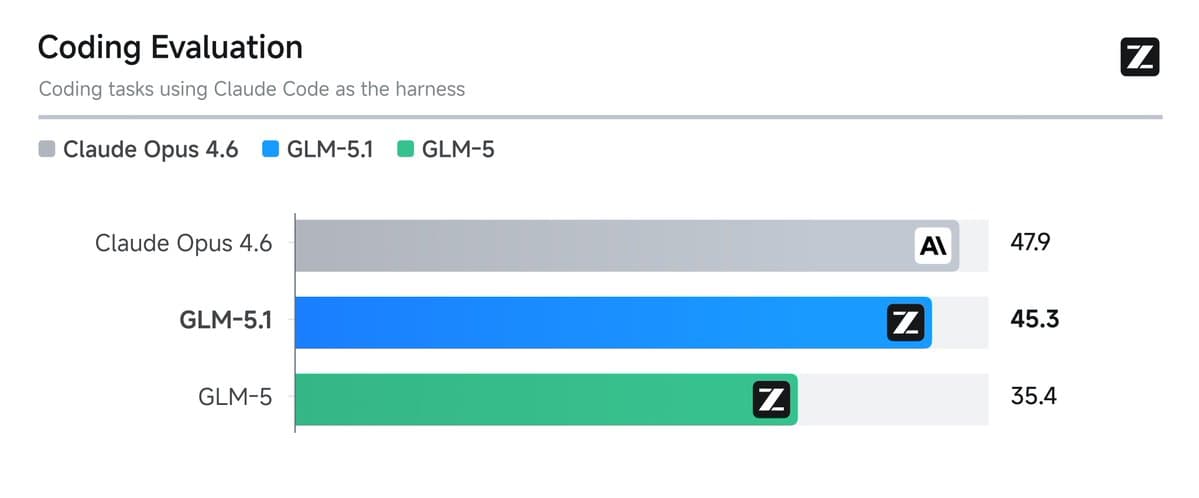
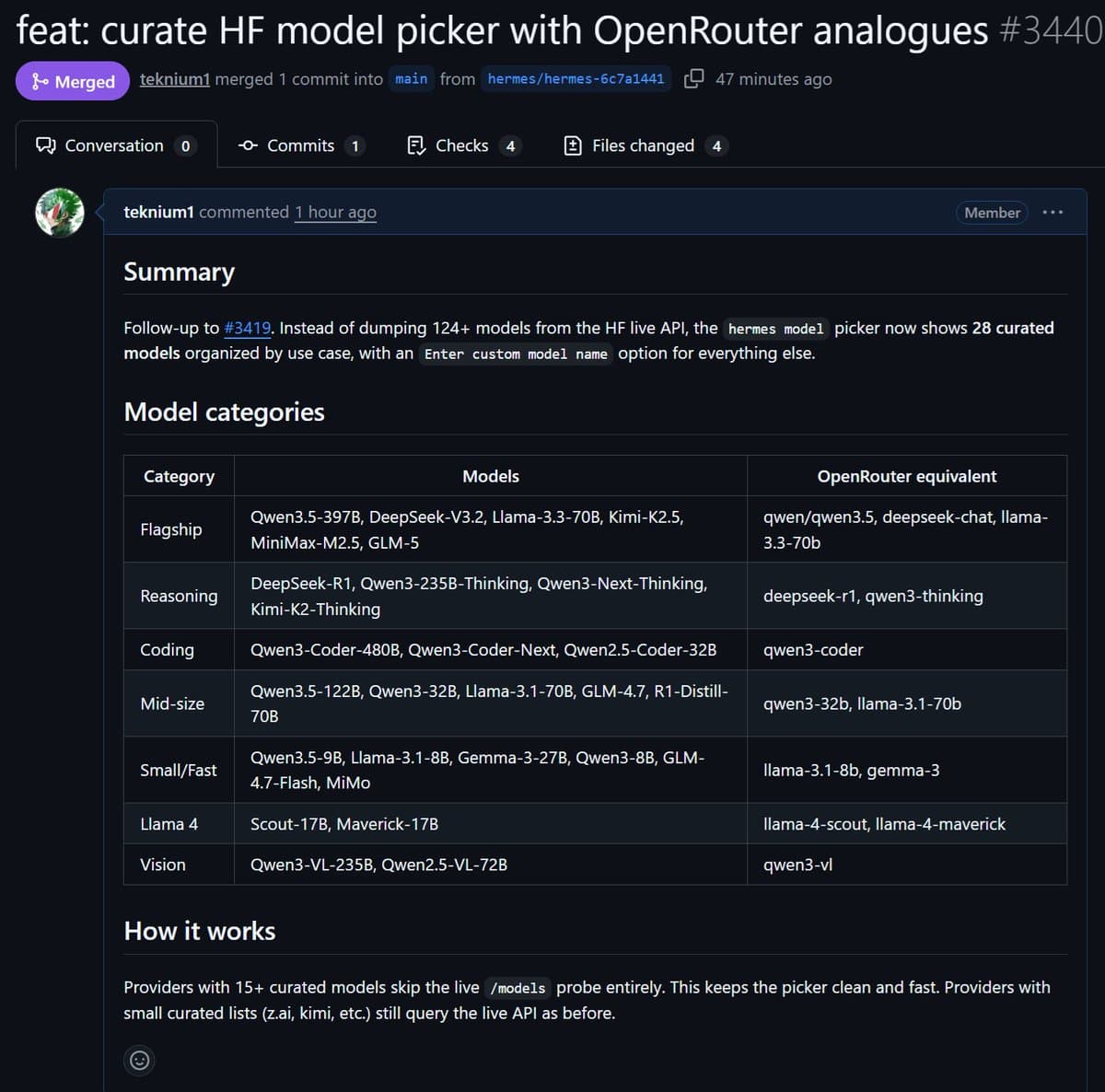
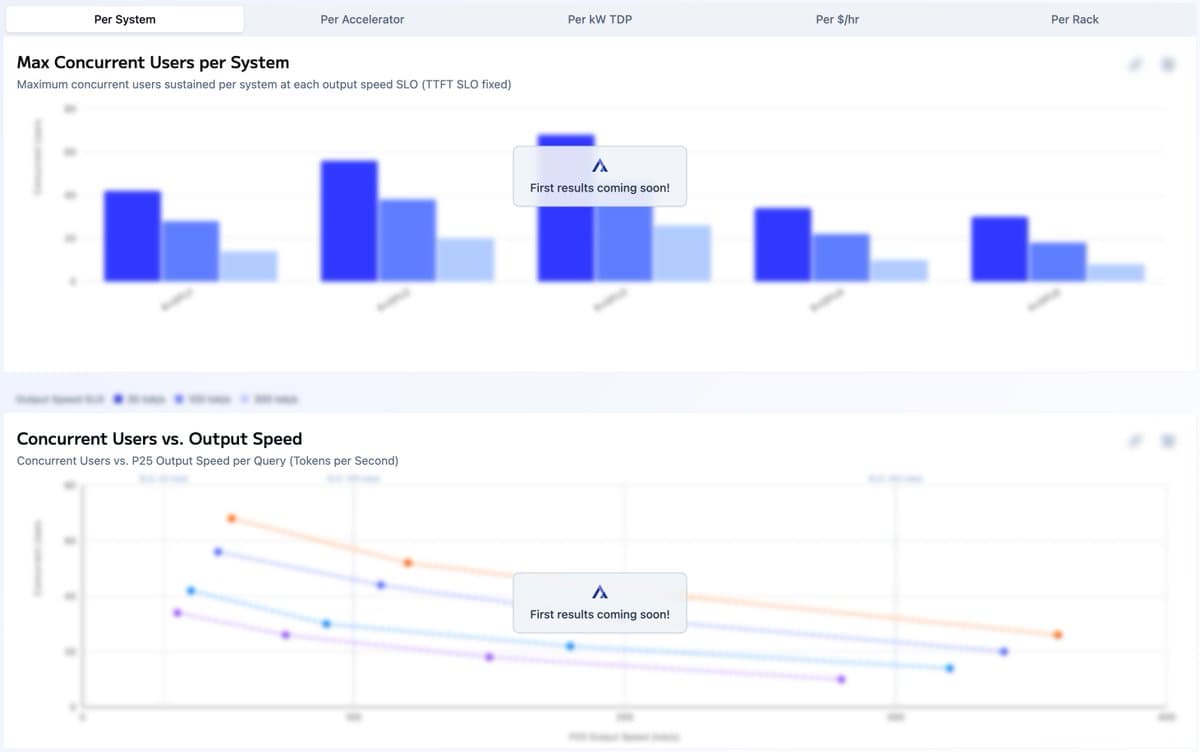

Cline launched Kanban, a local multi-agent board that runs Claude, Codex, and Cline CLI tasks in isolated worktrees with dependency chains and diffs. Teams can use it as a visual control layer for parallel coding agents on repo chores that split cleanly.


Mistral released open-weight Voxtral TTS with low-latency streaming, voice cloning, and cross-lingual adaptation, and vLLM Omni shipped day-0 support. Voice-agent teams should compare quality, latency, and serving cost against closed APIs.
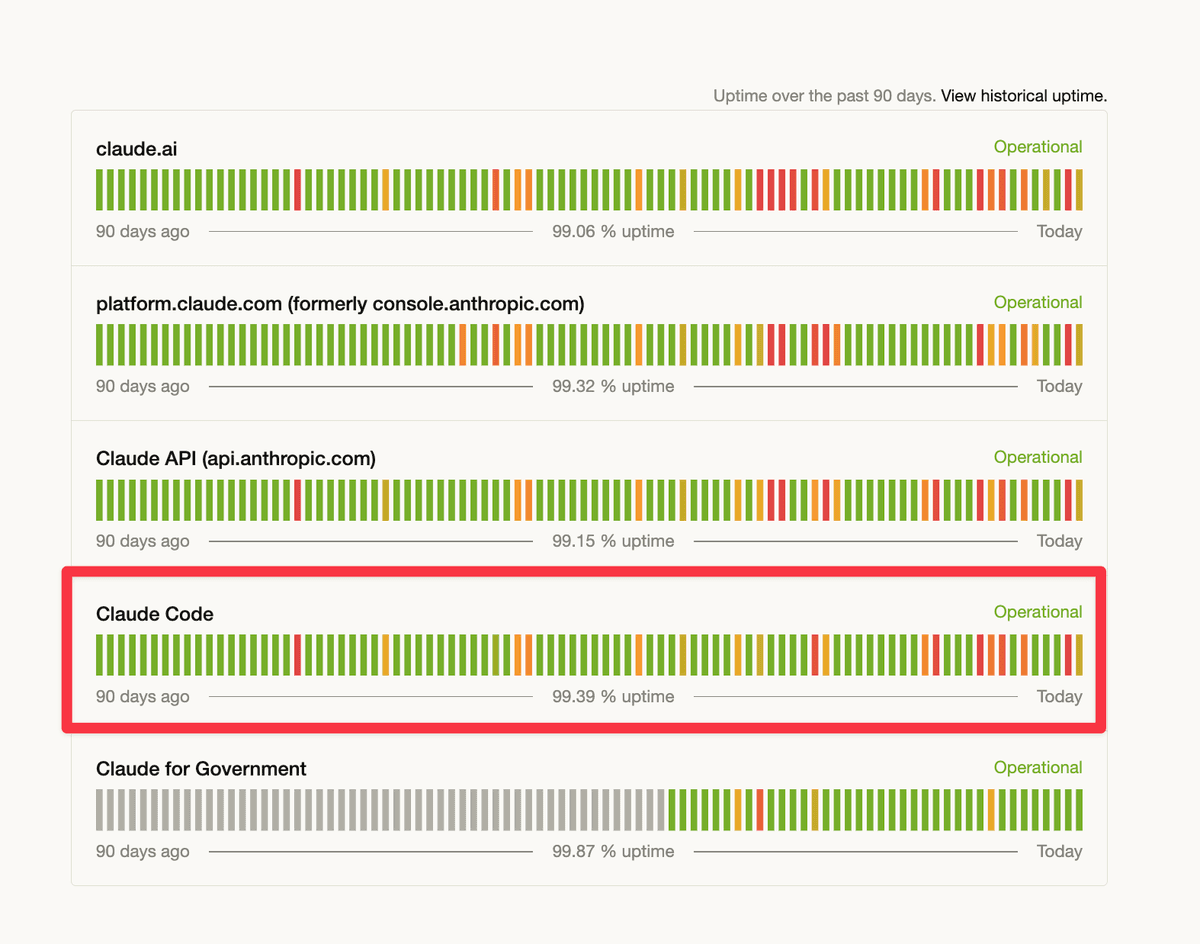
Anthropic said free, Pro, and Max users will hit 5-hour Claude session limits faster on weekdays from 5am to 11am PT, while weekly caps stay the same. Shift long Claude Code jobs off-peak and watch prompt-cache misses.

OpenAI rolled out Codex plugins across the app, CLI, and IDE extensions, with app auth, reusable skills, and optional MCP servers. Teams should test plugin-backed workflows and permission models before broad rollout.
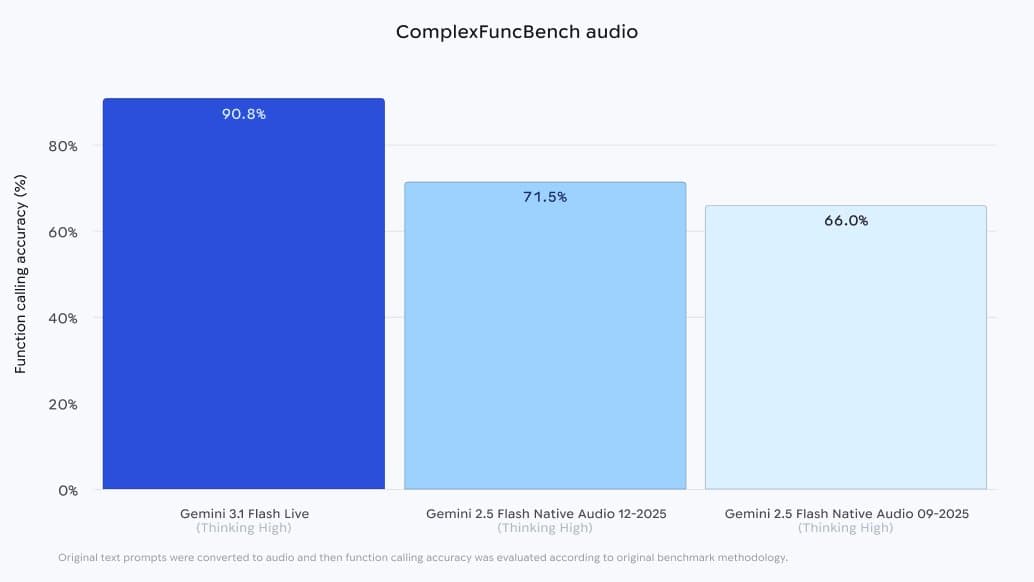
Google launched Gemini 3.1 Flash Live in AI Studio, the API, and Gemini Live with stronger audio tool use, lower latency, and 128K context. Voice-agent teams should benchmark quality, latency, and thinking settings before switching.

Get the best stories delivered to your inbox




