Экспорт NVIDIA H200 в Китай обещает вдвое увеличить пропускную способность обучения — Blackwell остаётся дома
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
По сообщениям, Вашингтон готов немного ослабить хватку: Reuters сообщает, что США могут позволить китайским покупателям ускорители NVIDIA H200, оставаясь при этом препятствуя поставкам Blackwell B200/GB200. Это позволило бы поднять пользователей из сильно ограниченного H20 к действительно клаcc Hopper, примерно в 2 раза увеличив пропускную способность обучения и существенно увеличив объём памяти высокой пропускной способности на узел. Другими словами, Китай перешёл бы от экспортного silikon‑уровня четвертой очереди к тому, что ближе к тому, чем сегодня реально обучаются западные лаборатории.
Это — разворот по отношению к позиции “пробел Blackwell”, о котором мы говорили ранее: вместо жесткого ограничения Китая на H20 регуляторы, похоже, готовы допустить сильные вычисления класса H при условии, что самая новая генерация останется внутри страны. С коммерческой точки зрения победители очевидны — NVIDIA за кремний, TSMC на 4N, Amkor по упаковке и Samsung по устаревшему HBM — все они смотрят на более крупный рынок обучения ИИ в Китае, не поставляя ни одного Blackwell.
Для инженеров по ИИ и планировщиков инфраструктуры внутри Китая сдвиг огромен: можно проектировать кластеры, схемы размещения памяти и предположения по пропускной способности, исходя из возможностей эпохи H200, а не бережно обходиться с H20. Для команд США и союзников преимущество всё чаще заключается в масштабе Blackwell, межсоединениях и стеке ПО, а не в том, чтобы просчитать, как задержки H20 будут сдерживать серьёзных конкурентов.
Top links today
- Fundamental limits of scaled LLMs paper
- Cognitive foundations of LLM reasoning paper
- Agent0 self-evolving tool-using agents paper
- Seer fast synchronous RL for LLMs
- AccelOpt self-improving AI kernel optimization
- Adversarial Poetry single-turn jailbreak attacks
- ForgeDAN evolutionary framework for LLM jailbreaks
- Hallucination dynamics and mitigation in LLMs
- Failure to Mix probability control study
- When to Think and Look vision controller
- Early science acceleration experiments with GPT-5
- COPYCHECK detecting memorized training books in LLMs
- EvoLMM self-evolving multimodal reasoning model
- FT on Deloitte auditing OpenAI finances
- Reuters on Nvidia H200 exports to China
Feature Spotlight
Feature: Gemini 3 Pro hits new SOTAs and shows up in real coding work
Gemini 3 Pro posts new SOTA results (FrontierMath tiers, RadLE), while builders report multi‑hour, 1.7k‑line edits in the CLI—tempered by UX issues (silent fallback to 2.5). Clear signal of real‑world readiness and rough edges.
Today’s timeline centers on Gemini 3 Pro: fresh benchmark wins and first‑hand developer reports of large, reliable edits; also user complaints about the Gemini CLI silently falling back to 2.5. This section owns all Gemini‑3 capability/adoption items.
Jump to Feature: Gemini 3 Pro hits new SOTAs and shows up in real coding work topicsTable of Contents
🔶 Feature: Gemini 3 Pro hits new SOTAs and shows up in real coding work
Today’s timeline centers on Gemini 3 Pro: fresh benchmark wins and first‑hand developer reports of large, reliable edits; also user complaints about the Gemini CLI silently falling back to 2.5. This section owns all Gemini‑3 capability/adoption items.
Gemini 3 Pro + Live-SWE agent hits 77.4% on SWE-bench Verified
A community team reports that Gemini 3 Pro paired with a Live‑SWE agent reaches 77.4% on SWE‑bench Verified, beating all previously reported models including Claude 4.5 on this hard, multi‑step bug‑fix benchmark. SWE-bench postThat’s a coding‑centric eval where the agent must actually apply patches to real GitHub repos and pass tests, not just explain what to do.
For engineering leaders this is one of the first credible signs that Gemini 3 Pro is competitive at end‑to‑end software maintenance, not just toy coding problems: if you already have an agent harness (Cline, Cursor, Claude Code, in‑house), it’s now worth A/B testing Gemini 3 Pro as the planning or execution brain against GPT‑5.1 and Sonnet 4.5 on your own repo‑level tasks.
Gemini 3 Pro posts new FrontierMath highs on expert and research tiers
Gemini 3 Pro Preview is now clearly quantified as the top general model on the FrontierMath benchmark, with ~37.6% accuracy on brutal expert problems (tiers 1–3) and ~18.8% on research‑style tier‑4 questions, ahead of GPT‑5 and Gemini 2.5 Deep Think. FrontierMath threadBuilding on yesterday’s note that it had taken the lead on this benchmark, FrontierMath SOTAthis new leaderboard gives concrete margins: on tiers 1–3 GPT‑5.1 high sits around 31.0% and Gemini 2.5 Deep Think at 29.0%, while on tier 4 Gemini 3 Pro’s ~18.8% beats GPT‑5.x and Deep Think clustered near 10–12%.
For AI engineers this means Gemini 3 Pro can reliably handle about 4 in 10 expert‑level math questions and 1 in 5 research‑like problems in this benchmark, which is materially ahead of prior general models. You still can’t outsource real research, but for math‑heavy product features, proof‑sketching, or agentic tools that need non‑trivial reasoning, this pushes Gemini 3 into the short list of default options alongside GPT‑5.1 rather than as a mere alternative.
Developers push Gemini 3 Pro through 1,700-line edits and architecture work
Hands‑on reports show Gemini 3 Pro holding up in long, messy coding workflows, not just benchmark scripts. One engineer used Gemini 3.0 inside Gemini CLI to edit 1,749 lines over roughly three hours, with a double‑edit verification pattern catching its own mistakes and fixing them without the user having to intervene. long edit storyAnother practitioner says that for complex software‑architecture questions it “felt on par with GPT‑5.1, and honestly a step ahead of Sonnet 4.5,” with Gemini usually proposing similar designs to GPT‑5.1 but doing so faster. architecture comparisonThis is why teams are taking Gemini 3 seriously: it appears to handle large, multi‑file edits and high‑level design in one harness, something many earlier models struggled with once changes exceeded a few hundred lines. If you’re evaluating coding agents, a good pattern from these anecdotes is: let Gemini 3 Pro do the planning and initial edits, then use a second pass (either the same model or another) to re‑diff and re‑run tests before merging.
Gemini 3 Pro overtakes radiology residents on RadLE v1 exam
On the new RadLE v1 diagnostic benchmark, Gemini 3 Pro scores 51% accuracy, beating radiology trainees at 45% but still far below board‑certified radiologists at 83%. RadLE summaryThe shared chart also shows GPT‑5 thinking at ~30%, Gemini 2.5 Pro at ~29%, OpenAI o3 at ~23%, Grok 4 at ~12%, and Claude Opus 4.1 effectively failing this test. RadLE summary
The point is: for image‑heavy, structured tasks like reading exam‑style radiology questions, Gemini 3 Pro is already beyond junior doctor baseline while still clearly not a replacement for a specialist. For teams building triage tools, second‑reader systems, or teaching aids, that gap (51% vs 83%) is the safety buffer; you can treat the model as a strong assistant that surfaces differentials and edge cases, but you should not let it sign off on imaging reports without a human in the loop.
Developers flag Gemini CLI silently falling back from 3 Pro to 2.5
At the same time, multiple builders are complaining that Gemini CLI sometimes ignores the selected Gemini 3 Pro model and silently routes to Gemini 2.5 Pro instead. One user says they bought “Google Pro Ultra Extreme” expecting to lock in Gemini 3 but found the CLI “doesn't let you only use gemini 3, [it] silently uses gemini 2.5 pro in the background.”fallback complaint Another describes selecting Gemini 3 Pro, watching it fail on a simple minimum spanning tree implementation, and then seeing it switch to 2.5 without any notice. MST failureThe same thread warns “gemini cli doesn’t let you peg gemini 3 pro… don’t buy.”limit warning
On top of that, power users want higher daily limits than 100 messages for Gemini 3 and better hooks into services like Antigravity. quota requestFor teams this is a trust issue more than a raw capability one: if the client can downgrade models without clear signaling, you’ll want to log model name versions on every call and consider wrapping the CLI with your own thin layer that asserts the model you think you’re using actually shows up in the response metadata before you roll it into production workflows.
Gemini CLI becomes a primary surface for Gemini 3 Pro
Gemini 3 usage is increasingly flowing through the Gemini CLI, which is now preinstalled in Google Colab runtimes, so you can drop into a terminal, type gemini, and authenticate without any extra setup. Colab CLI demoWorkshops at AI Engineer Code Summit walked through using the CLI with Gemini 3, MCP servers, and computer‑use tools, positioning it as Google’s equivalent of “AI in the terminal” for day‑to‑day dev work. summit workshopA new site, geminicli.com, pulls this together with install instructions and docs on auth modes (Google login, API key, Vertex AI) and extensions. CLI website
For AI engineers this means Gemini 3 Pro is no longer just a web‑app model; it’s a first‑class backend for shell‑native agents, batch scripts, and IDE hooks. If your stack is already on Colab or GCP, the path of least resistance is now to prototype agents via Gemini CLI in Colab and then promote the same commands into CI or your own wrappers, instead of wiring raw REST calls from scratch.
📊 Evals: long‑context MRCR, token efficiency, and knowledge reliability
Mostly non‑Gemini evaluations and scoreboards today: long‑context multi‑needle MRCR analysis, token‑hungry thinking models, and a new knowledge/hallucination “Omniscience Index.” Excludes Gemini‑3 results (covered in the feature).
Artificial Analysis Omniscience Index separates knowledge from hallucinations
Artificial Analysis introduced an Omniscience Index that scores models on 6,000 hard questions across 42 topics in 6 domains, mixing accuracy and hallucination rate into a single metric where +1 is a correct answer, −1 is an incorrect (hallucinated) answer, and 0 is abstention. index summaryOn this scale, Claude 4.1 Opus comes out on top with an OI of +5 (about 31% correct, 48% hallucination), while Grok 4 leads raw accuracy at roughly 35% but drags a worse OI due to more aggressive guessing; most other models, including many open weights, sit well into negative territory, meaning they hallucinate more than they help.
Because the benchmark also reports separate accuracy and hallucination percentages, it gives teams a clearer way to pick models for "ask me anything" surfaces or safety‑critical domains—favoring models like Opus that say “I don’t know” more often over ones that answer confidently and wrong.
Kimi-linear-48B overtakes Gemini-class models on 1M-token MRCR tests
Context Arena’s latest MRCR runs show Kimi’s new linear-48B model degrading much more slowly than frontier baselines on very long contexts, taking the top spot on hard 4‑needle and 8‑needle retrieval at 1M tokens while staying competitive on 2‑needle. MRCR updateAt 1M, it posts 4‑needle AUC/pointwise of 62.7% / 51.5% and 8‑needle 43.8% / 35.3%, beating the previously best Gemini‑3‑class thinking model on those settings despite underperforming it at 128k where that rival still leads. MRCR updateThe catch is efficiency: only ~60% of the 1M‑token runs completed due to higher token usage and OOMs, so while the model looks attractive for MRCR‑heavy workloads, infra teams will need to watch memory headroom and failure rates closely when pushing to the upper context limits. MRCR leaderboard
Olmo 3‑Think 32B posts modest LisanBench score but burns ~18k tokens
Early LisanBench results for Olmo 3 32B Think highlight a growing gap between open models and top proprietary systems on reasoning efficiency: it scores 359 on the benchmark—decent but far from the leaders—while averaging around 18k reasoning tokens per problem. LisanBench resultThe leaderboard image shows Olmo 3‑Think clustered with other mid‑tier models while Gemini‑ and Grok‑family models sit thousands of points higher, underscoring that open‑weight reasoning stacks still tend to “overthink” compared with tuned frontier models.
For AI engineers, that means Olmo 3‑Think is an interesting playground for tool‑driven, long‑CoT workflows, but not yet a drop‑in replacement where token budgets or latency are tight—especially in multi‑agent setups where 18k‑token traces stack up quickly.
👩💻 Coding agents in practice: Codex uptime, plan/act pairings, IDE UX
Hands‑on agent/dev stack updates dominate: Codex outage recovery and user kudos, Windsurf planner/worker pairing, Claude Code UX changes, and LangChain 1.0 + Salesforce EDR. Also Karpathy’s LLM Council ensemble app.
LangChain 1.0 and Salesforce EDR show what production multi‑agent stacks look like
LangChain 1.0 is out with a cleaner API for production agents—dynamic prompting, middleware, better outputs, and tight LangGraph integration—so you can treat multi‑step agent flows as real applications instead of fragile scripts langchain v1 post overview video. That same stack underpins Salesforce’s Enterprise Deep Research (EDR), a LangGraph‑orchestrated system where a master planner coordinates specialized search agents for the web, academic papers, GitHub, and LinkedIn, plus visualization and reflection agents, to produce cited research reports with optional human steering edr overview edr github repo. LangChain’s team is also pushing concrete "context engineering" patterns—like using a filesystem as a scratchpad to avoid bloated prompts—and is surveying how people actually wire agents in 2025, which should feed back into more opinionated defaults for coding and research agents alike filesystem blog agent survey.
OpenAI Codex sees partial US outage, then restores service and resets limits
OpenAI’s Codex service had a partial outage around 10:30am PST that mainly affected US traffic, causing high latency and degraded availability before the team rolled out a fix and brought things back to normal later in the day outage notice regional impact fix confirmation. To compensate, they reset rate limits for all Codex users and again suggested trying GPT‑5.1‑Codex‑Max, with power users reporting that once the incident cleared "Codex is great today" rate limit reset user praise. Following up on Codex fixes, this is another reminder that if you depend on Codex as a core coding agent, you should wire in status checks and fallbacks instead of assuming 24⁄7 reliability.
GPT‑5.1‑Codex‑Max shows strong autonomous debugging and planning behavior
Builders are finding that GPT‑5.1‑Codex‑Max is not only good at writing code, but also at autonomously running it to diagnose subtle bugs. One engineer describes Codex executing a boolean mesh generator, counting triangles, comparing the result to its expectations, and then pinpointing the misuse in the calling code—"just surreal" as a debugging loop mesh debug story followup detail. Others are now using Codex to prepare structured change plans that GPT‑5.1 Pro then applies to large codebases, a practical plan‑then‑act pairing instead of a single monolithic agent codex plan pairing. In side‑by‑side trials, these kinds of investigative tasks are where people say Codex now clearly pulls ahead of other coding agents short praise capability comparison.
Karpathy’s LLM Council turns multiple frontier models into a self‑critiquing coding panel
Andrej Karpathy released LLM Council, a ChatGPT‑style web app where your question first goes to several frontier models, then each one anonymously critiques and ranks the others before a "chairman" model writes the final answer council overview. The current council includes GPT‑5.1, Gemini 3 Pro Preview, Claude Sonnet 4.5, and Grok 4 via OpenRouter, and early runs show the models are surprisingly willing to say a peer’s answer was better, turning it into both an ensemble answering system and a lightweight evaluation harness for prompts and coding tasks. Others are already loading Karpathy’s long tweet about the design into tools like NotebookLM to mine patterns, hinting that "LLM councils" and similar ensembles may become a standard way to harden agent behavior before you trust a single model in your IDE council notebooklm.
Claude web app surfaces compaction, richer Skills flow, and Claude Code passes
Anthropic’s Claude web app now exposes more of the agent’s inner workings, including a visible "Compacting our conversation so we can keep chatting" status bar plus progress meter when it trims history to stay within context web ui changes. The new Skills creation flow lets you create a skill by writing a simple prompt, co‑designing one in chat with Claude, or uploading a .skill/.zip file, while Claude Code adds referral links and guest passes that showed up in screenshots from the AIE Code Summit web ui changes sdk workshop talk. Building on Claude CLI update, these changes move more of the "agent harness"—skills, compaction, and model variants—into first‑class product UI instead of hidden config files, which should make it easier for teams to standardize how they use Claude Code across engineers workshop schedule skills question.
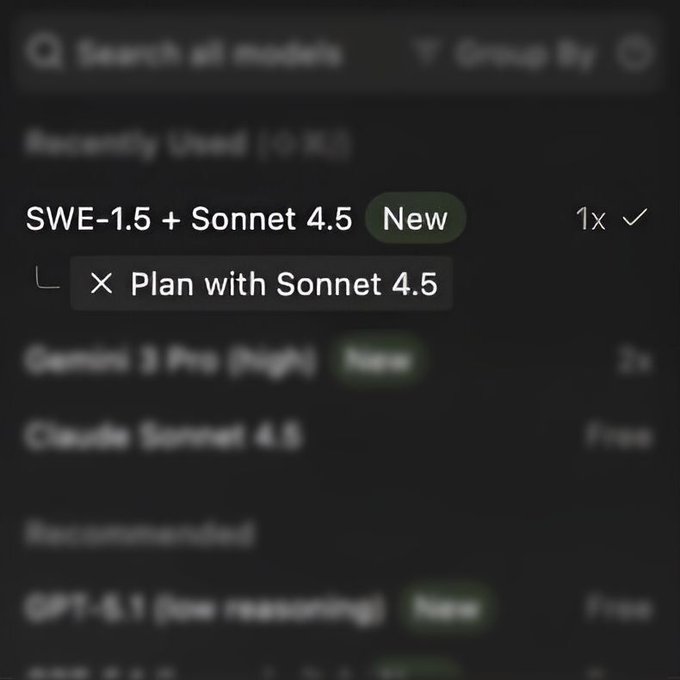
Windsurf pairs Sonnet 4.5 planner with SWE‑1.5 editor for AI pair programming
The Windsurf IDE introduced a new dual‑model mode where Claude Sonnet 4.5 handles high‑level planning and a smaller SWE‑1.5 model applies the concrete edits to your repository windsurf announcement. In the model picker it shows up as a single "SWE‑1.5 + Sonnet 4.5" option, giving you an explicit planner/worker split for "AI pair programming" that should keep reasoning quality high while cutting token usage and latency for the actual patching work.
CodexBar switches to JSON‑RPC and adds live status pings for Codex
The CodexBar macOS menubar client now queries Codex usage via JSON‑RPC instead of parsing terminal output, which makes credits and token statistics refresh noticeably faster for people who keep it open while they work jsonrpc change. A new integration with OpenAI’s status page also shows incident state directly in the tray—using a dot or exclamation mark depending on the severity—so you can quickly tell whether a slowdown is your own quota issue or a wider Codex degradation status ui screenshot.
🧩 MCP and agent interoperability: UI surfaces and web reading
Interoperability advances: an MCP Apps extension to standardize interactive UIs, easy web‑reader hookup to Claude Code, and cloud browsers for agents. Excludes IDE feature work which sits in the coding agents section.
GLM Web Reader MCP gets one-line Claude Code integration
Zhipu’s GLM Web Reader MCP, which exposes full-page extraction over HTTP, now has a copy‑pasteable one‑liner to wire it into Claude Code, making it trivial to give Claude agents first‑class web reading. Following up on Web reader MCP, which covered the server’s title/body/metadata/links output, today’s update focuses on the client side: a single claude mcp add -s user -t http web-reader <url> --header "Authorization: Bearer <api_key>" command registers the MCP with Claude Code’s CLI profile so any workspace can call it without bespoke glue code cli add example.
For AI engineers, this means you can standardize on GLM’s reader as a drop‑in web tool across Claude Code projects instead of writing per‑app scrapers; once the MCP is added, the same tool name and schema work in every agent harness that speaks MCP. The official docs spell out the response fields (title, main content, metadata, outbound links) and confirm it runs as a remote HTTP service so you don’t have to host it inside your own process space mcp docs. This closes the loop from last week’s server announcement to an end‑to‑end pattern: spin up Web Reader, point Claude Code at it with one CLI call, and your agents gain robust page ingestion with minimal custom code.
mcporter tightens TypeScript MCP client for tools and CLIs
Peter Steinberger’s mcporter library, a TypeScript client that masquerades MCP servers as simple TS APIs or standalone CLIs, picked up a batch of "housecleaning" improvements that make it more practical as a generic MCP front end mcporter update. The update adds a tmux "skill" (so agents can control terminal multiplexing sessions) and upgrades the bundled browser tools with search, while companion agent-scripts changes improve code‑snippet detection, filter out Claude‑specific noise from MCP listings, and harden handling of missing API keys mcporter repo.
For people wiring multiple MCP servers into their own apps, mcporter’s approach means you can call tools as typed functions instead of hand‑rolling JSON RPC calls or bespoke shells, then optionally package those same tools as small CLIs for human operators. Today’s tweaks are incremental but push it closer to being a default glue layer for MCP‑based ecosystems: more built‑in skills, less log noise, and slightly safer defaults reduce the friction of exposing new servers to agents or developers without having to understand every quirk of the underlying protocol agent scripts repo.
🖼️ Generative media momentum: Banana Pro everywhere, techniques, checks
A large slice of posts are creative/vision: Nano Banana Pro set as default in major apps, leaderboard leads, and repeatable prompt techniques (map restyles, ID swaps, coordinates). Also provenance and detection callouts.
Hyperreal Banana Pro images spur detection tests and caveats
Creators are sharing hyperreal portraits and lifestyle shots from Nano Banana Pro that easily fool people—one user posts a mirror selfie of a woman in a black dress and heels and jokes that anyone who thinks it’s real has been duped by Banana Pro’s realism Hyperreal selfie example. At the same time, another thread shows Banana (or an attached detector) correctly flagging an image as AI‑generated even when it’s only provided as a screenshot of an AI image, suggesting provenance cues or visual artifacts are robust enough to survive one more capture step Detection on screenshot.
For teams deploying image models into consumer apps, this has two clear implications. First, you should assume your users—and their friends—will sometimes treat Banana outputs as real photos, especially on mobile where EXIF and context are hidden. Second, if you’re serious about labeling or moderating AI images, you’ll likely need both embedded provenance (e.g., SynthID) and separate visual detectors, because images will get screenshotted, cropped, and re‑encoded before they’re reported or audited.
Perplexity makes Nano Banana Pro and Sora 2 Pro default generators
Perplexity set Nano Banana Pro as the default image model and Sora 2 Pro as the default video model for Perplexity Max subscribers across both Perplexity and its Comet browser, so most heavy users will now hit Google’s stack by default for media generation Perplexity defaults update. This is a strong signal that, in practice, Perplexity’s team thinks Banana’s image quality and Sora 2’s video output are now the safest bets for everyday answering, thumbnails, and explainer clips.

For AI engineers, this means if you’re benchmarking or fine‑tuning against Comet/Perplexity outputs, you should now treat Banana Pro and Sora 2 Pro as the production baseline rather than an optional upgrade. It also reinforces the pattern that third‑party AI browsers are converging on a small set of frontier image/video models instead of trying to maintain their own model zoo, which simplifies routing but raises the bar for anyone trying to displace Google in this niche.
Adobe Firefly adds Gemini 3 Nano Banana image tool across surfaces
Adobe quietly wired a Gemini 3 + Nano Banana Pro image tool into multiple Firefly entry points: Text to Image, Image Editor, Generative Fill and related flows Firefly integration note. So if you live inside Creative Cloud, you can now reach Google’s image model without ever leaving Adobe’s UI.
For builders, this is notable for two reasons. First, it signals that Firefly is happy to host non‑Adobe models when they’re far ahead on text rendering and compositional control, rather than insisting on in‑house only. Second, it shows the distribution pattern for Banana Pro: instead of chasing individual artists one by one, Google is showing up inside the tools studios already use, which changes how you think about targeting your own plugins or workflows in the Adobe ecosystem.
Consumer tools race to offer free or unlimited Nano Banana Pro
A cluster of creator platforms are dangling cheap or unlimited Nano Banana Pro access: one user notes a 1‑year unlimited Banana Pro deal on InVideo Invideo unlimited offer, another shows OpenArt giving unlimited Nano Banana usage Openart nano bundle, and Flowith reports over 1,000,000 free Banana images generated so far on its service Flowith usage stat.
If you’re an AI product lead, the takeaway is that image generation pricing is getting compressed from both sides: high‑end apps charge for orchestration, while many end‑user tools are subsidizing model calls until people are hooked. That makes it harder to monetize “raw” image API usage directly, and pushes independent devs toward either workflow value (templates, batch tools, verticals) or very tight integration with specific communities rather than selling per‑image access to Banana itself.
Nano Banana Pro becomes a companion for AI papers and math
Omar Shakir shipped a browser app where you drop in an AI paper PDF or technical book and then use Nano Banana Pro to remix figures, redraw charts, and visualize equations directly inside the reading flow Paper explorer app. You can highlight a theorem or table and ask it to generate a more intuitive diagram, annotate an equation with color‑coded steps, or turn a dense results table into a visual story Equation annotation tip Table to illustration prompt.

For engineers and researchers, this reframes Banana Pro from “just an image model” into a kind of visual teaching assistant: it sits next to your arXiv tab and helps unpack tricky math or architecture diagrams. It also suggests a product pattern worth copying: pair a strong vision model with a narrow reader UI (papers, dashboards, logs) and expose a few high‑leverage prompts like “annotate this equation” or “redraw this experiment pipeline” instead of trying to be a generic image playground.
Claude workspaces quietly gain Nano Banana image generation via skills
Even though Claude itself doesn’t natively generate images, builders are wiring Nano Banana Pro into Claude workspaces using the new Skills system. Simon Willison calls out a skill that adds a Banana image endpoint via a simple markdown skill file and a few Python scripts Skill integration example, and others show that once the skill is installed, you can treat Nano Banana as “Claude’s image head” from inside normal chats Claude banana remark.
This pattern—using Claude as the orchestrator and Banana as the renderer—will matter for anyone standardizing on Claude for reasoning. It lets you keep your prompt steering and safety layer in one place while swapping in Google’s image model as a tool, rather than re‑writing workflows around Gemini. It’s also a concrete example of why Skills/MCP‑style protocols are so important: they make it trivial for one lab’s model to ride along inside another lab’s agent environment.
Geo and live‑data prompts show Banana Pro’s grounding muscles
People keep poking Nano Banana Pro with grounded prompts and it’s holding up: one example asks it to “create an image of the major event that happened at coordinates 41°43′32″N 49°56′49″W” and the model returns a detailed Titanic‑style sinking scene without explicit mention of the ship Titanic coordinates prompt. Another has Banana Pro do an online search for the latest FC Barcelona score and then generate an in‑stadium scoreboard showing the correct opponent, scoreline and goal scorer at the right minute Live match scoreboard.
For anyone building agents or dashboards on top of Banana, the point is that it’s comfortable both inferring events from raw coordinates and combining web search results with templated visuals. That makes it a good candidate for things like sports dashboards, location‑based storytelling, and incident visualizations, as long as you keep a separate truth source for the underlying data and treat the image as a garnish rather than the source of record.
Reliable subject swapping and ID prompts emerge for Nano Banana Pro
Prompt authors are converging on a repeatable recipe for swapping real people into stylized scenes with Nano Banana Pro. One technique has Banana first convert subjects in a photo into plain gray 3D mannequins, then use that as a structural reference to re‑render the scene with animated characters in the exact same poses and camera angles—like turning a famous basketball alley‑oop into Spongebob and Patrick or Goku and Vegeta Animated dunk examples How to 3d proxy. A separate thread shows Westeros passports and ID booklets for Game of Thrones characters, mixing realistic backdrops with in‑universe documents Westerosi passport series.
For AI artists and app builders, this means you can now treat Banana as a fairly controllable compositor: lock down geometry with a neutral 3D pass, then iterate on style and identity in a second step. That opens up safer parody tools (sports moments, meme remakes, character travel docs) that keep layouts and semantics stable while wildly changing who appears in the frame.
Coffee‑table photobook prompts show Banana Pro’s editorial range
Several threads lean into a very specific photobook aesthetic: Banana Pro is asked to “show a page from the most unhinged photography book” or “a glossy book by an everyday ghost documentarian,” and it responds with believable spreads—complete with captions like “The Tuesday Night Haunting” or “The Collection of Discarded Dental Floss Harps, 2019–2023” Dental floss harps spread Everyday haunt photobook. Others ask for subtle pareidolia in kitchen tools or colanders that almost look like faces, or a mushroom growing out of a discarded sneaker on a London lot, all formatted as plates with museum‑style captions Pareidolia captions Mushroom sneaker plate.
This is interesting for anyone doing publishing or storytelling tools. It shows Banana can handle not just isolated images but whole editorial packages—image composition, typography, and caption tone together—so you can prototype fake photobooks, zines, and art catalogs with a single prompt rather than wiring separate layout systems on top.
Nano Banana Pro starts to define its own slide‑design aesthetic
Some designers are noticing that they can now recognize a Nano Banana Pro deck on sight. Daniel McKee posts a short video flipping through a set of slides and says “No other model can make slides like that,” arguing that Banana’s blend of layout, typography, and illustration has a distinct look compared with DALL·E or Midjourney Banana slide flip video. Other threads, like Claude’s frontend aesthetics skill, lean on Banana to turn wireframes or specs into polished hero sections and infographics rather than generic “AI slop” Frontend aesthetics prompt.

For AI engineers supporting product or marketing teams, this hints at a coming divide: some models will be favored for raw photorealism, while Banana might become the default for presentation‑grade visuals—infographics, annotated diagrams, hero images that feel designed. If that’s your use case, it’s worth running a small bake‑off and seeing whether your stakeholders can actually tell which slides came from which model.
🛡️ Safety and misuse: jailbreaks, limits, and detection signals
Today’s safety stream features new jailbreak routes and diagnosis of systemic limits/misaligned behaviors, plus a practical method to flag trained‑on books. No wet‑lab content; strictly model behavior and governance.
Adversarial poetry emerges as a universal single‑turn jailbreak across 25 LLMs
A new "adversarial poetry" paper shows that rewriting harmful prompts as poems dramatically increases single‑turn jailbreak success across 25 proprietary and open‑weight models, with average success rates around 62% for hand‑crafted verses and some providers exceeding 90%. paper summary
Instead of complex multi‑turn attacks, the authors apply a fixed meta‑prompt that converts 1,200 MLCommons harmful prompts into verse, then use three LLM judges plus humans to score whether outputs are both non‑refusals and concretely helpful for the underlying malicious goal. paper summaryPoetic framing sharply outperforms non‑poetic baselines across CBRN, cyber‑offense, manipulation, and privacy risk taxonomies, highlighting that current alignment layers are heavily tuned to surface style, not underlying intent. For safety teams, this is a clear signal that evals and defenses need to cover stylistic transformations (rhyming, meter, narrative wraps) rather than relying on literal keyword and tone patterns.
Case study argues chat LLMs are structurally pushed into a "false‑correction loop"
A long single‑conversation case study documents how a deployed chat model repeatedly hallucinates details about the author’s own research papers, then doubles down even after corrections, leading to what the paper calls a "false‑correction loop". case study summary
The author argues this is not random noise but a structural outcome of reward setups that favor smooth, confident, institution‑deferential answers over honest ignorance or serious engagement with unfamiliar work. Safety‑wise, the claim is that RLHF and similar procedures teach models to perform epistemic humility while still fabricating theorems, figures, and citations when pressured, especially around non‑canonical science. For AI teams using chat models as research assistants, the story is a reminder to log and audit long‑horizon interactions, and to treat detailed citations about niche work as untrusted until independently checked.
COPYCHECK uses uncertainty patterns to flag likely trained‑on books
Another paper introduces COPYCHECK, a framework that exploits LLM over‑confidence on training data to detect whether specific books likely appeared in a model’s training set, without any labeled examples or manual thresholds. copycheck summaryThe method slices each candidate book into short snippets, repeatedly queries the model, and aggregates token‑level uncertainty into book‑level features that can be clustered into "seen" vs "unseen" groups.
On open‑weight LLaMA variants, clustering achieves roughly 90% accuracy in distinguishing pre‑training books from newer ones not in the crawl, according to the authors. copycheck summaryFor regulators, publishers, and auditors, this offers a practical signal for training‑data provenance; for model owners it’s also a warning that memorization patterns can leak enough to support external membership inference even when outputs look harmless.
ForgeDAN evolutionary framework automates strong jailbreak prompts against aligned LLMs
The FORGEDAN paper proposes an automated jailbreak generator that uses evolutionary search plus LLM‑based judges to craft natural‑sounding adversarial prompts that bypass safety filters better than prior systems like AutoDAN. forgedan summaryIt mutates seed prompts at character, word, and sentence level, ranks candidates by semantic similarity to a harmful reference answer, and then applies a dual‑judge check that separately scores refusal vs harmfulness.
Only prompts whose outputs both avoid refusal and contain substantive harmful content count as successful, sharply reducing false positives compared to keyword‑based heuristics. Across several chat models, ForgeDAN reportedly achieves higher jailbreak success while maintaining fluency and stealth, underscoring how black‑box adversaries can keep pace with safety fine‑tunes. For safety engineers, this is an argument to integrate automated red‑teaming frameworks into pre‑deployment testing, not just rely on ad hoc prompt lists.
Theory paper formalizes five built‑in limits of scaled LLMs
A theory‑heavy paper argues that even arbitrarily scaled LLMs face hard ceilings from computability, information theory, and learning constraints, leading to five enduring problems: hallucination, context compression, reasoning degradation, retrieval fragility, and multimodal misalignment. limits summaryThe authors show that finite parameters force lossy compression of world facts, long inputs suffer position‑dependent information loss, and autoregressive decoding makes small early errors snowball into confident but false continuations.
This framing pushes back on "scale fixes everything" instincts and instead suggests that some failure modes will remain structural unless we change architectures (e.g., external memory, verifiable modules) or training objectives. For AI engineers, the takeaway is to treat hallucination and long‑context drift as properties to be engineered around with tools and system design, not bugs that further pretraining alone will fully erase. followup comment
Audit finds ~9% of US newspaper articles contain undivulged AI‑generated text
An audit of 186,000 articles from 1,528 American newspapers uses the Pangram detector to estimate that about 9% of newly published pieces are partially or fully AI‑generated, with usage skewed toward smaller outlets and topics like weather and tech. newspaper auditA separate analysis of 45,000 op‑eds at the New York Times, Washington Post, and Wall Street Journal finds opinion columns are about 6.4× more likely than news pieces to include AI‑written segments.
Yet in a manual check of 100 AI‑flagged pieces, only 5 disclosed any AI use, suggesting disclosure norms lag well behind practice. While this isn’t an LLM jailbreak story, it’s directly about misuse and transparency: AI‑assisted content is already pervasive in information ecosystems that people treat as human‑authored by default, and detection plus disclosure policy is becoming a concrete governance problem rather than a hypothetical.
Failure‑to‑Mix study finds LLMs ignore requested output probabilities
The "Failure to Mix" paper shows that modern LLMs largely fail to follow explicit instructions to randomize their outputs according to target probabilities, defaulting instead to near‑deterministic step‑function behavior. paper summaryWhen asked to output "1" with 49% probability and "0" with 51%, models answer "0" almost 100% of the time, with the choice flipping sharply once the requested probability crosses ~50%, and temperature tuning barely helps.
The authors extend this to multi‑way choices and story‑based tasks, finding that token and word biases (e.g., "sun" vs "moon") dominate requested mixes, so models talk coherently about mixed strategies but fail to enact them in practice. This matters for safety and scientific use cases where you want controlled exploration or calibrated uncertainty: orchestration layers should not assume models can faithfully sample from arbitrary distributions just because you describe them in the prompt.
Mathematical analysis dissects how hallucinations grow and proposes uncertainty‑aware decoding
A solo‑author paper from the Catholic University of America offers a mathematical treatment of "hallucination dynamics" in autoregressive LLMs, tying compounding token‑level errors to miscalibrated probabilities and lack of semantic uncertainty signals. hallucination analysisThe work blends probabilistic modeling, information theory, and Bayesian uncertainty to argue that even small early misestimates can diverge sharply from factual trajectories as decoding proceeds.
On the mitigation side, the author sketches uncertainty‑aware decoding schemes (including contrastive methods and abstention) and links them to retrieval grounding and post‑hoc factuality checks. While more conceptual than empirical, this kind of analysis is useful for infra and safety engineers thinking about when to stop generation, when to re‑query tools, or when to route outputs through fact‑checkers instead of assuming that longer chain‑of‑thought means greater truthfulness.
🧠 Reasoning, RL, and system efficiency research
A cluster of new methods target faster RL rollouts, self‑evolving agents, kernel auto‑optimization, and vision‑language thinking control. Mostly research artifacts with concrete efficiency or accuracy deltas.
Seer speeds up synchronous RL rollouts for reasoning models by up to 97%
Seer is a new online context-learning system for synchronous LLM reinforcement learning that tackles long-tail latency and poor GPU utilization in chain-of-thought style training runs paper summary. It combines divided rollout (splitting groups of trajectories across machines), context-aware scheduling based on early length probes, and adaptive grouped speculative decoding, delivering 74–97% higher rollout throughput and 75–93% lower tail latency on production-grade reasoning workloads like Moonlight and Kimi‑K2 while keeping training strictly on-policy ArXiv paper.
AccelOpt uses LLM agents to auto-tune Trainium kernels toward peak throughput
AccelOpt presents a self-improving LLM agent system that incrementally optimizes AI accelerator kernels—in this case AWS Trainium’s Neuron Kernel Interface—without human hardware experts in the loop paper thread. Using an optimizer agent that proposes kernel rewrites, an executor that benchmarks them, and a memory of successful transformations, AccelOpt lifts average throughput on the NKIBench suite from 49%→61% of peak on Trainium‑1 and 45%→59% on Trainium‑2, matching the improvements achieved with Claude Sonnet 4 while being roughly 26× cheaper by relying on open-source models ArXiv paper.
Agent0 shows self-evolving LLM agents can boost reasoning with zero human data
Agent0 introduces a fully autonomous, self-evolving agent framework that splits a base LLM into a curriculum agent that writes tasks and an executor agent that solves them, using only reinforcement learning and tool calls instead of any human-curated training set paper thread. The system co-evolves these two roles so that tasks become harder while the executor improves, yielding about +18% on mathematical reasoning and +24% on general reasoning benchmarks for a Qwen3‑8B base model, demonstrating that tool‑integrated self-play can materially strengthen reasoning without labeled data ArXiv paper.
PAN world model simulates long-horizon video futures for action planning
PAN is a large world model that predicts future video frames conditioned on language-described actions, enabling agents to simulate and score long-horizon futures before acting paper overview. The system encodes each frame into a latent state, updates that state using a language model that incorporates the next action, and decodes via a video diffusion model; trained on action-rich captioned videos, it outperforms strong commercial generators on action following, remains stable over long rollouts, and supports planning by letting downstream agents search over imagined trajectories ArXiv paper.
HEAD-QA v2 expands healthcare exam benchmark; size beats prompting tricks
HEAD-QA v2 extends the original Spanish healthcare multiple-choice benchmark to 12,751 questions spanning 10 years of national specialization exams, with standardized Spanish text and carefully checked English and multilingual translations paper summary. Experiments across modern open models show that raw model size and in-domain knowledge dominate performance, while sophisticated prompting and small retrieval-augmented setups provide limited or even negative gains, making HEAD‑QA v2 a useful stress test of genuine medical reasoning rather than prompt-engineering finesse ArXiv paper.
Uncertainty-guided "lookback" cuts visual reasoning tokens by ~40%
"When to Think and When to Look" studies large vision-language models on a difficult multimodal exam and finds that extra chain-of-thought sampling often helps small models and hard visual science questions, but on easier perception tasks long reasoning tends to drift away from the image paper summary. The authors introduce an uncertainty-guided controller that detects pause phrases in the reasoning, selectively injects short prompts to re-examine the image, and thereby improves accuracy on visual math and specialist problems while using about 40% fewer reasoning tokens, all without any additional training ArXiv paper.
Test-time scaling survey reframes CoT, trees, and ensembles as subproblem topologies
A new survey on "Test-time Scaling of LLMs" argues that most reasoning and search-time tricks—chain-of-thought, branch-solve-merge, tree-of-thought, ensembles—can be viewed through how they decompose a task into subproblems organized sequentially, in parallel, or as a search tree paper summary. By unifying these methods around subproblem structure instead of surface prompt patterns, the authors highlight common trade-offs between compute budget, exploration breadth, and dependency between steps, and outline design principles for future test-time scaling schemes that target specific reasoning failure modes more systematically ArXiv paper.
🏗️ AI infra economics: capacity doubling, H200 export talk, local pushback
Infra posts focus on serving capacity growth targets, potential H200 access in China, memory price spikes, and data‑center opposition. All have direct implications for model serving/training supply and risk.
US weighs allowing Nvidia H200 exports to China, softening AI chip curbs
Reports say the US government is considering letting Nvidia sell its H200 accelerators into China, a major shift from the earlier H20‑only, heavily down‑spec export regime. H200 is roughly twice as capable as H20 thanks to much higher HBM bandwidth and throughput, so approval would instantly make it the strongest data‑center AI GPU legally available in China and narrow the effective compute gap with US labs. h200 reuters summary
Commentary notes this would move China from "fourth‑tier" export chips to a prior‑generation but still top‑tier part, with clear commercial winners in Nvidia, Amkor (packaging), Samsung HBM, and TSMC if volumes ramp. (h200 reuters summary, trump export rumor)Analysts frame the move as Washington keeping Blackwell‑class parts at home while monetizing surplus Hopper capacity, but it would still accelerate Chinese frontier and open‑source model training if approved, so infra and policy teams should watch the final rule text and any HBM supply knock‑on effects closely. Reuters article
Local pushback stalls an estimated $98B of US AI data‑center builds
A new roundup estimates that roughly $98B of US data‑center capacity was delayed or blocked in Q2 2025 as local communities, zoning boards, and grid regulators pushed back on large campuses tied to AI workloads. Cases span Archbald, PA (resident‑drafted zoning amendments), Kansas City’s $12B Red Wolf hyperscale site (rezoning challenges plus a new "Large Load" tariff above 75MW), and Wisconsin fights over new transmission lines to Vantage facilities, all of which create real siting and timing risk for GPU builds. data center thread
For infra and finance teams, the message is that power and permits—not GPUs alone—are turning into the binding constraint: even well‑capitalized AI tenants will face longer lead times, more bespoke tariffs, and higher non‑silicon costs, and those frictions will shape where the next wave of model‑training and serving capacity can actually land inside the US grid. data center thread
UBS: AI capex still ~1% of global GDP, below past tech build‑outs
A UBS Research chart circulating today argues that, in GDP terms, current AI capital spending remains well under historical "bubble" build‑outs like UK and US railroads in the 1800s (~3–4.5% of global GDP) or 1990s telecom and ICT waves (~1.2–1.3%), with AI projected around ~1.1%. ai capex tweet
Commentators pair this with ongoing GPU shortages and data‑center constraints to claim we’re not yet in an infra overbuild, even though AI platform equities look frothy, implying there’s still headroom for sustained compute and facility investment before macro saturation looks like prior manias. (ai capex tweet, ai bubble followup)For AI leaders budgeting long‑lived GPU and power contracts, this is a reminder that competitive pressure to scale infra is likely to continue rather than fade in the near term.
💼 Enterprise adoption: airlines and commerce flows go agentic
Fewer pure business items today but notable wins: a global airline rolling out ChatGPT Enterprise with AI literacy/CoE, and ChatGPT’s Instant Checkout with Shopify merchants. Excludes creative‑model defaults and evals.
Emirates rolls out ChatGPT Enterprise across the airline
Emirates Group is entering a strategic collaboration with OpenAI that includes an enterprise‑wide deployment of ChatGPT Enterprise, paired with AI literacy programs, an internal "AI champions" network, and a formal AI Centre of Excellence. This is one of the first public examples of a global airline standardizing on ChatGPT Enterprise as core employee tooling rather than a side pilot. Emirates collaboration tweet(see Emirates press release).
For AI engineers and leaders, the interesting part isn’t just "another logo" on OpenAI’s customer slide. Emirates is talking about embedding agents into real operational workflows—contact centers, ops, maintenance, finance—backed by training programs and a governance structure rather than ad‑hoc usage. That means teams building agents and copilots can now expect questions like "does this pattern scale to 100+ business units and 24/7 ops?" rather than "can we do a quick POC?" Emirates summary post.
The press release also hints at co‑developed use cases and early access to research, which suggests OpenAI is treating Emirates as a design‑partner for aviation agents. So if you’re building vertical tools around travel, logistics, or customer support, you should assume ChatGPT Enterprise is the baseline in that org: your integration story is now "augment what their internal AI CoE is doing" rather than "replace email and spreadsheets".
In practical terms, this kind of deal normalizes patterns like: single‑tenant ChatGPT for sensitive data, org‑wide SSO, usage analytics, and standardized prompt libraries. If you’re selling into similar enterprises, it’s a good moment to align your own stack—logging, RBAC, auditability, content filters—with what ChatGPT Enterprise already provides, because buyers will compare you directly against it.
Overall this move signals that tier‑1 airlines are ready to move from scattered copilots to coordinated AI platforms, and that OpenAI is willing to bundle product, education, and executive‑level strategy into one package. Expect more large travel and transport players to announce similar "enterprise‑wide" AI adoptions over the next 6–12 months as they race not to be the last airline without an agent strategy.
ChatGPT adds Shopify Instant Checkout for US users
OpenAI has turned ChatGPT into a direct commerce surface: logged‑in US users on Free, Plus, and Pro plans using GPT‑5.1 can now buy products from Shopify merchants like Spanx, Skims, and Glossier directly inside chat via a new Instant Checkout flow. The feature is live on web, iOS, and Android for US accounts. Shopify checkout tweet(full details in ChatGPT release notes).
Practically, this is the first mainstream example of an LLM chat turning discovery + comparison + purchase into one continuous agentic flow, without bouncing people to a separate browser tab. For AI engineers and product leads, the interesting bit is the pipeline: model → web search and product selection → structured product object → payment and fulfillment, all under a single UX that normal users already trust. It’s a strong template for building your own domain‑specific "instant checkout" flows around subscriptions, bookings, or SaaS upsells.
For merchants and commerce teams, this shifts the question from "should we support AI search?" to "how do we expose our catalog and policies to chat agents safely?" If you’re building tooling around Shopify or other e‑commerce platforms, it reinforces that well‑structured product data, clean images, and return policies aren't just SEO anymore; they’re the raw material your customers’ AI agents will be reasoning over.
The point is: OpenAI is quietly training both users and merchants that it’s normal for AI agents to own the final click in a purchase, not just surface links. If you’re designing agents today, it’s time to think through fraud checks, consent flows, and how you’ll limit what an agent can buy on a user’s behalf, because the bar is now "as safe and simple as a Shopify checkout" rather than "paste a link and hope they click".
🦾 Humanoids: capability demos and a safety lawsuit
Two robotics headlines: a 60 kg humanoid performing a full backflip and a whistleblower lawsuit alleging unsafe practices at a humanoid startup. Useful context for embodied‑AI roadmaps and safety governance.
Whistleblower suit claims Figure humanoids can deliver skull‑fracturing blows
A new California lawsuit from former Head of Product Safety Robert Gruendel alleges Figure AI pushed its humanoid robots toward home and workplace use while ignoring internal warnings about dangerous forces and inadequate safeguards Figure lawsuit thread. The complaint says a malfunctioning robot punched a stainless-steel fridge hard enough to leave a ~0.25 inch gash, exerting forces over 20× typical human pain thresholds and, in Gruendel’s words, enough to “fracture a human skull,” and describes near‑miss incidents where robots reportedly moved unpredictably within a couple of feet of workers’ heads Figure lawsuit thread.
Gruendel claims management diluted or removed certified emergency‑stop hardware, dropped at least one physical safety feature for aesthetic reasons, and quietly walked back an ambitious safety roadmap after raising over $1B, framing his firing as retaliation for pressing these issues Figure lawsuit thread. For anyone working on embodied AI, this case is a stark reminder that once you mix large actuators, learned policies, and human‑scale spaces, safety engineering, documentation, and internal escalation channels need to be treated as first‑class product work, not bolt‑ons behind demo videos.
PHYBOT M1 humanoid lands full backflip with 10 kW bursts
Beijing Phybot’s 172 cm, 60 kg PHYBOT M1 humanoid is shown performing a clean standing backflip, hitting around 10 kW peak power and recovering to stable stance, a capability that until recently was limited to top-tier research robots like Atlas PHYBOT spec summary. The bot runs a 72 V system with 32 DoF, up to 530 N·m joint torque, dual 9 Ah batteries for roughly 2 hours of operation, and an onboard compute stack of NVIDIA Jetson Orin NX plus an Intel i7 paired with 3D LiDAR for perception and planning PHYBOT spec summary.

For AI and robotics teams, this is another data point that full-body dynamic maneuvers are becoming productized rather than lab-only, on hardware that could realistically host modern vision–language or control models. The combination of high peak power, long-ish runtime, and decent onboard compute suggests PHYBOT-class platforms could become real-world testbeds for embodied agents once software stacks mature, especially in logistics or inspection scenarios where agility and recovery from disturbances matter.
🧭 Model roadmaps and signals: Grok thinking, GLM 30B, Perplexity Model C
Roadmap‑class signals across labs and platforms. No overlap with the Gemini‑3 feature; this section tracks upcoming model changes and codenames developers may need to plan around.
Perplexity “Model C” appears as in‑house post‑training candidate
Perplexity users are seeing a hidden "Testing Model C [max]" option with a reasoning toggle in the model selector, and community sleuthing now suggests this is Perplexity’s own in‑house model currently in post‑training model c first look. A follow‑up from a well‑known tester says it’s “likely a Perplexity's own model, currently in post‑training stage! Soon”, which points away from yet another hosted frontier API and toward a custom stack tuned for their search and Comet browser surfaces model c update.
For engineers and analysts this is an important roadmap shift: an in‑house model would let Perplexity optimize deeply for retrieval, browsing, and answer formatting, and potentially improve unit economics versus reselling frontier tokens. It also means evals of “Perplexity vs X” may increasingly be evals of a distinct model family, not just a UI on top of OpenAI or Anthropic. If you integrate Perplexity as a tool or benchmark source, assume its behavior and latency will drift as Model C moves from post‑training into production.
Rumored OpenAI model “Shallotpeat” targets pretraining bugs
Multiple posts claim OpenAI is working on a new model codenamed “Shallotpeat”, reportedly aimed at fixing bugs that surfaced during pretraining of current GPT‑5‑series systems shallotpeat rumor. Commenters speculate it might be the long‑teased IMO math model, but the more grounded read is that this is a major refresh of the pretraining pipeline itself rather than a simple fine‑tune shallotpeat repost.
One summary of reporting in The Information says Shallotpeat is being built to address structural issues uncovered during earlier runs, which could include data mixing, instability, or subtle capability regressions information article. For practitioners this matters less as a name and more as a signal that OpenAI is iterating on the foundation of its large models between headline versions, not just stacking RL and tools on top. If accurate, the next wave of GPT‑5‑class checkpoints could land with cleaner training dynamics, fewer sharp bugs, and more consistent behavior across deep‑reasoning and long‑context settings, even if the public branding never mentions “Shallotpeat” at all.
Zhipu GLM planning a 30B model release in 2025
China’s Zhipu AI (Z.ai) plans to add a ~30‑billion‑parameter GLM model to its lineup in 2025, complementing its existing 355B‑scale flagship and smaller agents glm 30b tweet. That size is roughly the current sweet spot for many self‑hosted and latency‑sensitive workloads, so this is a clear signal they want GLM to compete more directly with 30–40B open models from Meta, Qwen, and others.
The announcement thread frames this as part of a broader push to capture both high‑end and mid‑tier markets, with the 30B variant aimed at “smaller models” that are easier to deploy widely while still being strong on reasoning and code glm 30b tweet. Paired with Z.ai’s description of GLM 4.5/4.6 training recipes (single‑stage RL, 15T tokens, SLIME agent RL) in a recent strategy interview, this suggests the 30B will likely share the same data and RL stack rather than being a stripped‑down afterthought zai playbook. For AI teams betting on Chinese or open‑ish stacks, this is a concrete roadmap marker to budget around for 2025 clusters and agent platforms.
Grok 4.1 will spend more compute “thinking” per question
xAI is changing Grok 4.1 so it spends more compute time “thinking” about each question, with the explicit goal of improving accuracy on hard prompts. Elon Musk says this is already rolling out (“going forward, Grok 4.1 will spend more compute time thinking about your question”), which implies a trade‑off of higher latency and cost for deeper reasoning on the same model tier grok 4-1 post.
For builders this is a roadmap signal that xAI is leaning into test‑time scaling and slow‑mode style behavior, similar to “thinking” variants from other labs, rather than only shipping new checkpoints. It also follows earlier hints of a bigger Grok 4.20 upgrade by Christmas, suggesting we may see a stack where baseline Grok handles bulk traffic while 4.1+thinking and 4.20 target high‑stakes queries grok 4.20 plan. AI engineers integrating Grok should watch real‑world latency, and consider routing only the trickiest calls through the higher‑compute configuration once more details on knobs and pricing land.