OpenAI GPT‑5.1 предлагает адаптивное рассуждение — 8 предустановленных стилей и 2 модели сокращают шаблон подсказки.
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI внедрила GPT‑5.1 в ChatGPT, сочетая быстрый Instant с моделью Thinking, которая адаптирует, сколько рассуждений требуется на каждую задачу.
Обновление добавляет восемь предустановленных стилей плюс настройку теплоты/эмодзи, сокращает boilerplate подсказок и тихо переводит GPT‑4.1 в раздел Legacy.
Доступ к API появится на этой неделе через gpt‑5.1‑chat‑latest и gpt‑5.1, чтобы можно было направлять реальную работу.
Ранние данные показывают, что Thinking расходует меньше токенов на задачи в диапазоне 10-й–30-й перцентилей и больше на 70-й–90-й, а не на фиксированную цепочку рассуждений.
Пользователи отмечают более точное выполнение инструкций (например, соблюдение запретов на стили), меньше раболепия, чем у GPT‑4o, и более выразительный стиль; наблюдения сообщества связывают «polaris‑alpha» OpenRouter с 5.1, который занимает лидирующие позиции на доске Creative Writing v3.
Codex тоже осваивает 5.1, уже слог gpt‑5.1‑codex слит — полезен для агентных стэков кодирования, которым нужен единый мозг планирования как для IDE, так и для CLI.
Если у вас есть вопросы по миграции и особенностям персонализации, AMA OpenAI запланировано на 14:00 PT сегодня; приносите реальные подсказки и наблюдайте расход токенов, прежде чем переключать переключатель.
Feature Spotlight
Feature: GPT‑5.1 ships adaptive reasoning + personas
OpenAI rolls out GPT‑5.1 (Instant/Thinking) with adaptive reasoning and 8 preset personas; API this week (gpt‑5.1‑chat‑latest, GPT‑5.1). Big bump in instruction‑following and conversation quality for builders.
Cross‑account launch: OpenAI rolls GPT‑5.1 to ChatGPT with Instant/Thinking variants and richer personalization. Mostly model/UX improvements, early dev takes on instruction‑following, vision, tone. API lands this week.
Jump to Feature: GPT‑5.1 ships adaptive reasoning + personas topicsTable of Contents
✨ Feature: GPT‑5.1 ships adaptive reasoning + personas
Cross‑account launch: OpenAI rolls GPT‑5.1 to ChatGPT with Instant/Thinking variants and richer personalization. Mostly model/UX improvements, early dev takes on instruction‑following, vision, tone. API lands this week.
OpenAI rolls out GPT-5.1 Instant/Thinking to ChatGPT, API this week
OpenAI has started rolling out GPT‑5.1 across ChatGPT with two variants—Instant as the new high‑volume default, and Thinking for heavier reasoning—initially to Plus, Team, Pro and Business users, with free and logged‑out access to follow and API access promised later this week as gpt-5.1-chat-latest (Instant) and gpt-5.1 (Thinking) using adaptive reasoning. OpenAI release OpenAI blog post
GPT‑5.1 Instant is positioned as the warmer, more conversational chat model that still runs at GPT‑5 Instant speeds, while GPT‑5.1 Thinking is the advanced reasoner that decides when to "think longer" before answering; both are trained on the same reasoning stack as OpenAI’s heavy thinking models. Sam Altman comment welcome thread OpenAI says it is serving a base of 800M+ ChatGPT users, which is why they’re pairing the new model with richer tone controls instead of a single default persona. fidji summary
In the model picker, GPT‑5.1 now appears with Auto/Instant/Thinking options while GPT‑5 has been pushed under a Legacy section that OpenAI says will remain for about three months, and GPT‑4.1 is beginning a gradual retirement from ChatGPT. model list ui legacy selector gpt4-1 retired Power users report that GPT‑5.1 is already live for most Plus, Team and Pro accounts. rollout status
For coders, this also builds on GPT‑5 Codex mini, where we saw GPT‑5‑Codex‑Mini double tokens/sec, as Codex now adds a gpt-5.1-codex model definition in its config and an OpenAI engineer confirms you’ll be able to route GPT‑5.1 through Codex once the API ships. codex model def Codex pull request codex availability
The point is: if you’re standardizing on OpenAI, GPT‑5.1 will very quickly become the new default surface—both for end‑user ChatGPT usage and for API‑backed apps—while older 5.x and 4.x models get pushed into a legacy corner you probably don’t want to depend on long term.
Builders say GPT-5.1 feels faster, less sycophantic and better at writing
Early testers are pretty aligned that GPT‑5.1 feels like a quality‑of‑life upgrade: "creative writing style is a LOT better" builder notes, it’s "smarter, much stronger vision capability, and fast, really fast" vision comment, and it now pushes back on obviously bad ideas instead of cheerleading everything—Daniel Mac notes it "won't tell you that selling poop popsicles is a good idea," a case where GPT‑4o would have played along. sycophancy example
On the benchmarks side, OpenRouter’s Polaris‑alpha model—now confirmed to be GPT‑5.1—takes the top spot on a Creative Writing v3 emotional‑intelligence benchmark with an Elo score around 1748, ahead of other frontier models in pairwise matchups. polaris mapping
That matches the anecdotal "this just reads better" feedback from people using it for essays, fiction and UX copy. launch recap writing comment
Instruction‑following also looks tighter. Users report that GPT‑5.1 respects fine‑grained style constraints like "never use em dashes" via custom instructions, where GPT‑5 would routinely drift, and testingcatalog shows a ChatGPT UI screenshot emphasizing this behavior. instruction screenshot instruction followup That’s a big deal if you’ve been fighting the model over formatting, house style or code conventions.
A lot of this is tied to the new personalization layer that ships alongside 5.1: you can now pick from eight base styles—Default, Professional, Candid, Quirky, Friendly, Efficient, Nerdy, Cynical—and OpenAI is experimenting with sliders for warmth and emoji frequency for a subset of users. styles announcement warmth emoji test The help center clarifies that these personalities steer tone and structure but don’t change core capabilities or safety rules. personality docs
People are already stress‑testing those personas. Ethan Mollick shows that different presets produce meaningfully different advice, even down to "completely different breathing patterns" in guided‑relaxation scripts, and wonders how much they bias judgment vs. just phrasing. personality impact He argues he wants roles (e.g., critic, coach) that you can invoke briefly more than a persistent "cynic" or "quirky" friend. roles vs personality Omar Moqbel’s side‑by‑side personality screenshots underline that the same factual question (e.g., "explain a government shutdown") yields noticeably different structure and emphasis across Candid, Efficient, Nerdy and others. personality examples
From a builder’s perspective, the model also seems to have a nicer "taste" for UI and front‑end work: one dev had GPT‑5.1 generate a TikTok‑style infinite Wikipedia scroller and noted that its layout and styling were cleaner than previous models’ output. vision comment Others say 5.1 "feels closer to the GPT‑4o vibe" for chat if you didn’t love GPT‑5’s personality, while still being more capable. model feeling
The net effect: GPT‑5.1 isn’t a raw IQ leap so much as a better default assistant—snappier, more opinionated when it should be, better at long‑form language and UI polish, and finally giving you levers to tune how it talks without fighting system prompts on every request.
GPT-5.1 Thinking adds adaptive reasoning and “short CoT”
GPT‑5.1’s Thinking variant changes how it spends tokens: OpenAI’s own chart shows it using about 57% fewer tokens than GPT‑5 on the easiest 10% of queries and about 71% more tokens on the hardest 10%, effectively re‑allocating compute toward genuinely hard problems instead of padding easy answers. reasoning chart
Under the hood this is framed as "adaptive reasoning": instead of a fixed depth chain‑of‑thought, the model dynamically decides when to think longer, which shows up as shorter, more direct responses at low difficulty percentiles (10th and 30th) and much longer traces at the 90th percentile. OpenAI release rollout summary For builders, that means fewer wasted tokens on trivial queries and deeper exploration when you actually need it.
Developers also note that GPT‑5.1 brings explicit "short CoT" behavior—doing quick, lightweight reasoning instead of full verbose chains by default—while still being able to switch into full chain‑of‑thought when the task demands it. short cot note Aidan Mclaughlin even calls GPT‑5.1 Instant "the first chat model to use CoT" in this more controlled, fast‑reasoning way, signaling that chain‑of‑thought is no longer restricted to heavy, slow models. welcome thread
So what? If you’re paying per token, the new Thinking/Instant stack gives you a more efficient default: you keep the depth where it matters (math proofs, multi‑step planning, gnarly debugging) without having to manually toggle a "deep thinking" setting or accept gratuitous reasoning on simple questions.
🏭 AI datacenters, power, and superfactory notes
Anthropic’s $50B US DC build and Microsoft’s Fairwater 2 ‘AI Superfactory’ set the bar for 2026 capacity; power shortfall chatter resurfaces. Excludes GPT‑5.1 model details (covered as Feature).
Anthropic commits $50B to US AI datacenters in Texas and New York
Anthropic announced a $50 billion build‑out of its own AI datacenters in Texas and New York, targeting custom facilities optimized for frontier model training and inference coming online from 2026, and creating about 800 permanent and 2,400 construction jobs in the US.anthropic announcement The build partners with Fluidstack and is explicitly framed as supporting the Trump administration’s AI Action Plan to keep US AI leadership and domestic compute capacity, signaling that Anthropic is joining the hyperscaler tier instead of relying purely on third‑party clouds.anthropic blog
For AI engineers and infra leads, the takeaway is that a formerly "model‑only" lab is now vertically integrating into power and racks, much like OpenAI’s Stargate and Google’s in‑house campuses.commentary thread That likely means steadier access to high‑end GPUs for Claude‑class models, more room for aggressive long‑context and agent workloads, and a new competitor in the race to sign large enterprise and government AI contracts that want sovereign, US‑based compute.dc recap Expect Anthropic’s own stack (Claude Code, Claude agents, safety research) to be tuned tightly to these sites’ characteristics—multi‑GW power envelopes, high rack density, and efficiency targets—rather than generic cloud assumptions, which may influence how their APIs behave at scale (throughput ceilings, region availability, and pricing tiers).
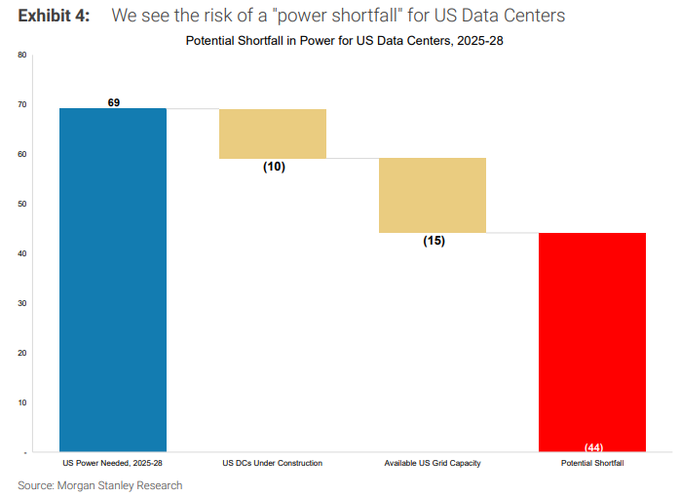
Analysts warn of 44 GW US AI power shortfall as DC spend tops new oil
A Morgan Stanley note circulating on X estimates the US could face a 44 GW power shortfall for AI datacenters by 2028, even as AI loads are still only a few percent of total grid demand today.morgan power chart In parallel, a TechCrunch write‑up of new IEA data says global datacenter investment in 2025 is projected at about $580 billion, already exceeding the roughly $540 billion going into new oil supply, and forecasts data‑center electricity use roughly doubling to ~945 TWh by 2030 with AI machines accounting for a big share of that growth.iea analysistechcrunch article
Taken together, these updates sharpen earlier concerns about AI’s energy footprint raised when AI DC capex was pegged near $300 billion and ~1% of US GDP AI DC capex. The new angle is that it’s not just spend any more; grid connection queues, transformers, and gas turbines are now cited as bottlenecks that may slow campus build‑outs or push more operators toward on‑site generation and small modular reactors.iea analysis Practitioners like Daniel Mac argue that model efficiency gains (tokens per joule) will partially offset this, but his own thread notes that leaders such as Altman, Zuckerberg, and Nadella publicly downplay the risk, raising the question of whether they know something about upcoming efficiency curves—or are just projecting confidence.morgan power chartleaders attitude
For infra and strategy teams, the practical implication is clear: long‑term AI roadmaps now need real power plans attached—PPAs, behind‑the‑meter generation, or siting near surplus renewables—rather than assuming the grid will absorb another 40‑plus gigawatts without pushback. If you’re choosing regions or partners for 2026–2028 training runs, the constraints described in these notes are as important as GPU roadmaps.
Microsoft details Fairwater 2 AI Superfactory and 100k+ GB300s this quarter
Microsoft and Satya Nadella used a Dwarkesh podcast tour of Fairwater 2 to pitch it as "the most powerful AI datacenter in the world," and disclosed that more than 100,000 GB300 accelerators are coming online this quarter just for inference across the fleet.fairwater interview An accompanying infographic highlights Fairwater as an "AI Superfactory" with multi‑gigawatt campuses, hundreds of thousands of GPUs per region, a closed‑loop liquid cooling system with zero additional water use, short copper runs across thousands of racks to cut latency, and an AI‑app‑aware WAN that routes traffic based on model needs.ai superfactory details

For builders, Fairwater signals that Microsoft’s answer to OpenAI’s Stargate and other giga‑campuses is now concrete: they are designing everything—from cable length to backbone topology—around large‑batch LLM and multimodal inference, not generic cloud VMs.nadella ai strategy Satya also emphasized in the same conversation that Microsoft has access to all of OpenAI’s accelerator IP, which helps explain why he seems relaxed about Maia lagging Google’s TPUs; the bet is that a dense, AI‑specific fabric plus IP sharing beats raw chip specs in real workloads.openai ip comment If you’re planning for 2026‑era capacity, this is a strong hint that Azure regions attached to Fairwater‑style campuses will be the place to find the most consistent supply of GB200/GB300‑class instances and the lowest tail latency for AGI‑scale apps.
🛠️ Agentic coding stacks and IDE workflows
New live eval sandboxes and agent SDK demos land; IDEs tighten loops. Excludes GPT‑5.1 launch (Feature); focuses on tooling and workflows builders can use now.
LMArena’s new Code Arena brings live agentic coding evals and a WebDev leaderboard
LMArena has launched Code Arena, a new environment where frontier models build web apps step‑by‑step while users watch their planning, file edits, and debugging in real time. It already powers a refreshed WebDev leaderboard where Claude Opus 4.1, Claude Sonnet 4.5, GPT‑5, and GLM‑4.6 are the current top performers on real app builds.launch thread

In Code Arena, models like Claude, GPT‑5, GLM‑4.6, and Gemini get a full tool belt (file system, dev server, etc.), then are judged head‑to‑head by Arena users on functionality, code quality, and design rather than synthetic benchmarks.launch thread This shifts evals toward the workflows devs actually care about: multi‑file scaffolding, refactors, and iterative debugging instead of single‑shot code snippets. The new WebDev board exposes per‑model Elo across many such battles, with Opus 4.1 currently on top, followed by Sonnet 4.5 (thinking), Sonnet 4.5, GPT‑5, and GLM‑4.6.leaderboard update You can jump straight into the coding arena at the dedicated page,Code Arena page or inspect the WebDev rankings and matchups on the leaderboard.Webdev leaderboard
For builders, this is a good place to sanity‑check your default coding model against serious alternatives on real apps, and to see where agentic patterns (planning tools, file diffs, retries) actually pay off versus raw completion strength.
Claude Agent SDK demo shows multi-agent deep research workflow with file-based handoff
Anthropic published a "Deep Research" demo for the Claude Agent SDK where a main agent fans out web research to multiple sub‑agents, saves notes to disk, then spawns a report‑writer agent to synthesize everything into a final deliverable.demo thread Instead of one giant prompt, the system treats research as a multi‑step pipeline with explicit tools and file IO.
In the reference flow, the top‑level agent decomposes your question into 2–4 subtopics, then launches parallel "researcher" subagents, each using web search tools and writing their findings into files/research_notes.demo thread Once those land, a report‑writer agent reads the files and produces a consolidated report in files/reports, which could just as easily be a slide deck or an interactive site if you swap the final skill.report synthesis The whole thing is open‑sourced so you can inspect the agent graph and adapt it.Claude agent repo
A nice detail is that files double as a communication fabric: subagents write notes, the main agent searches across them to check coverage, and only then asks a writer to summarize.files explanation That pattern scales well to other agentic coding tasks too—think multi‑repo audits, competitive analysis, or long‑running experiments where you want durable, diffable intermediate state instead of ephemeral context blobs.
Claude Code expands from desktop into web and iOS for Team and Enterprise
Anthropic is expanding the Claude Code research preview so Team and Enterprise customers can now run coding tasks directly from a browser or the Claude iOS app, instead of being limited to the terminal‑first desktop flow.release note That means more of your org can poke at AI‑assisted refactors and bugfixes without installing extra tooling.
Teams are leaning on Claude Code for bug fixes, refactors, test generation, documentation, and running tasks in parallel across multiple repos, which maps well to the "agent that lives next to your code" mental model.release note Because the web/iOS version still exposes filesystem and process tools (within a controlled environment), you can keep the same scripts and habits you developed on the desktop client, but from a laptop or phone. Early power users say they value that it already lets them ship serious projects rather than waiting for future features.dev reflection
If you want to try this in your own stack, the Anthropic Academy course catalog now includes free modules on Claude Code, the Claude API, and MCP basics,Anthropic course list which can shorten the learning curve for engineers who haven’t lived in the CLI yet.
Code Arena now underpins a community-voted WebDev leaderboard for coding agents
Beyond the launch itself, LMArena has wired its new Code Arena into a persistent WebDev leaderboard where developers vote on which model produced the better app, not just the right answer.leaderboard update Claude Opus 4.1 currently leads, followed by Claude Sonnet 4.5 (thinking‑32k), Claude Sonnet 4.5, GPT‑5, and GLM‑4.6 as the top five models.leaderboard update
Each matchup asks models to build or modify a real web application—React dashboards, clones, utilities—then the Arena community judges functionality, code quality, and UX in side‑by‑side comparisons.launch thread That gives you a more grounded sense of how these coding agents behave under realistic workloads than single‑file benchmarks. Code Arena will also be the engine for future WebDev tasks like multi‑file projects and React apps with more advanced tooling.future plans
If you’re picking a model for your own agentic coding stack, this leaderboard is a handy reference that bakes in design and maintainability, not only pass/fail stats. You can explore live battles or spin up your own sessions from the WebDev view.Webdev leaderboard
Factory 1.10 gives Droid programmable hooks and completion sounds for long agent runs
Factory’s 1.10 release makes its Droid coding agent feel more like a programmable coworker: you can now configure custom completion sounds and define "Droid hooks" that run arbitrary shell commands at key lifecycle points.release overview The update also adds an interactive MCP Manager, but the big workflow shift for coders is tighter, scriptable control around long‑running tasks.
With custom completion sounds, you can assign different audio cues per task type or project, so a background refactor or test run can ping you with a distinct sound when it’s done instead of silently finishing in a tab.sound description That small thing matters once you trust the agent enough to handle multi‑minute jobs while you focus elsewhere. Droid hooks go further: they let you attach shell commands to moments like "plan ready", "patch applied", or "run finished", enabling automatic formatting, permission tweaks, logging, or even guardrails (e.g. blocking grep and nudging the agent toward ripgrep).hooks explanation
The MCP Manager UI—summoned via /mcp—lets you browse connected servers, inspect tools, and OAuth into services like Sentry, Stytch, Context7, and Jam without editing config files.mcp manager details That’s more an orchestration quality‑of‑life feature, but in combination with hooks and sounds it nudges Droid toward a full "agentic dev shell" where you can both observe and steer its behavior programmatically.

Full details and config examples live in the 1.10 changelog if you want to wire this into your dotfiles or CI.Factory changelog
RepoPrompt MCP lets Composer‑1 route complex work to GPT‑5 via your ChatGPT sub
A new demo shows Cursor’s Composer‑1 using the RepoPrompt MCP server to spin up a separate ChatGPT session and have GPT‑5 plan and implement a complicated feature, effectively turning your personal ChatGPT subscription into an on‑demand backend agent from inside the IDE.composer workflow Composer stays focused on orchestration, while GPT‑5 does the heavy thinking and file edits via RepoPrompt.
Following up on Codex provider, where RepoPrompt added a Codex CLI provider and surfaced model reasoning traces, this example highlights a different angle: using MCP as a bridge to external, stateful model UIs rather than only raw APIs. In the video, the developer asks Composer to use the RP Chat tool; RepoPrompt then coordinates calls out to ChatGPT (with GPT‑5 behind it), streams back plans, and applies diffs to the local repo.composer workflow Because RepoPrompt already handles big‑repo memory and context tricks from the CLI versions, you get that same scaling inside Cursor without re‑implementing it.Claude integration
Practically, this means you can treat GPT‑5 as a remote "senior engineer" that Composer or other agents can delegate to, while keeping your local editor as the single source of truth. It’s a pattern worth watching if you want to mix best‑of‑breed models without waiting for every IDE to support every API directly.

Zed 0.212 focuses on Git worktrees, Pull (Rebase), and settings deep-links
Zed shipped v0.212, adding a few deceptively handy workflow improvements: deep‑linkable settings, a git: worktree command for jumping between worktrees, and a Pull (Rebase) option wired straight into the Git panel’s fetch button.release video
Deep links mean you can now copy a direct URL for any setting and paste it in chat or docs; when someone clicks, Zed opens straight to that preference, which cuts a lot of “where is that toggle?” back‑and‑forth—useful if you’re standardizing how AI tools run across a team.release video The new git: worktree command lets you spin up and hop between multiple checkouts of the same repo from the palette, making stacked PRs and parallel experiments less painful.worktree feature
On the collaboration side, the Git panel’s fetch button now includes a Pull (Rebase) option, bringing a common but error‑prone Git flow into a single click.git panel change They’ve also relaxed debugger breakpoint configuration, so you can add conditional or logpoint breakpoints before even starting a debug session, which aligns well with agent‑assisted debugging workflows where the AI suggests instrumentation first.git panel change If you want the full list or a download link, it’s all in the stable release notes.Zed release notes
For AI‑heavy teams, none of these features scream "AI", but together they reduce friction around Git hygiene and shared config—which is exactly where agentic coding often falls over when everyone’s environment is subtly different.

🧩 MCP interoperability and stability trade‑offs
Hands‑on MCP management and a community debate on protocols: evolving servers, pull‑based access, and promptable skills. Excludes GPT‑5.1 (Feature).
Factory 1.10 adds in-editor MCP Manager for browsing and auth
Factory shipped version 1.10 of Droid with a new /mcp Manager that lets you browse connected MCP servers, inspect their tools, and authenticate via OAuth (Sentry, Stytch, Context7, Jam.dev, etc.) without touching config files. Factory 1.10 post mcp manager details
For teams experimenting with many MCP backends, this turns what used to be hand-edited JSON/YAML into a discoverable UI, making it easier to see what tools an agent actually has and to rotate credentials safely. The same release also adds custom completion sounds and Droid lifecycle hooks, but the MCP Manager is the big interoperability win because it reduces config drift between agents and backends and lowers the barrier to trying new MCP servers. release followup Factory changelog
MCP’s "no stability" philosophy clashes with code-level integrations
Simon Willison points out that MCP servers are designed to be read dynamically by LLMs on every call, so they make no long-term stability promises about their schemas or tool sets. stability comment In his words, this means you can "constantly change the MCP server" because the client is supposed to rediscover capabilities from the spec each time.
In the same thread he contrasts this with Anthropic’s new "code execution with MCP" pattern, where you write scripts that call MCP tools directly from Python; if servers change under you, those scripts break instead of the LLM adapting. code execution note Anthropic mcp blog Framed against the earlier community "Does MCP suck?" discussion, MCP debate this sharpens the trade-off: MCP as a live, evolving contract is great for LLM-driven orchestration, but brittle for long-lived automation code unless you add your own versioning and compatibility layer on top.
Builders use Claude Code + Skills to auto-tune MCP tool prompts
Omar El Gabry describes a pattern where he uses Claude Code together with Anthropic’s Skills system to optimize MCP tool prompts using real logs, filesystem state, and memories. Claude skills usage Instead of hand-authoring tool descriptions and call patterns, he lets Claude analyze prior tool runs and then rewrite prompts and skills to reduce unnecessary calls and improve selection.
He argues that, with enough code generation and execution in the loop, you may not need fancy static algorithms for tool orchestration—agents can synthesize those heuristics on the fly from context. skills followup For teams leaning into MCP, this suggests a practical workflow: treat your MCP schemas and prompts as code that your coding agent continuously refactors, using Skills or similar mechanisms to load only the design and UX constraints it needs. Claude skills blog
Engineers question MCP’s pull-only model and lack of eventing
Thomas (thdxr) argues that MCP is fundamentally pull-based today: the agent has to consciously "think" to call a tool, even when the server has relevant new data ready. pull-based critique He compares this to language server protocols, where diagnostics are pushed to the client as they occur, rather than polled.
In follow-up comments he notes that this limits how effective MCP-backed agents can be, because useful context (errors, new events, changed state) never reaches the model unless the prompt explicitly asks for it—which many generic loops will forget to do. actor model comment The implied direction for protocol designers is to consider adding push/event channels or subscription-style tools so agents can react to changes, not just query them, without turning every tool into a bespoke pub/sub hack.
📊 Evals: live web‑dev arena, coding agents, and attitudes
Live, interactive evals step beyond static leaderboards. This section excludes GPT‑5.1 launch; focuses on head‑to‑head outcomes and eval UX.
Claude Opus tops new WebDev leaderboard as Code Arena goes live
LMArena has turned its new Code Arena into a live WebDev leaderboard, where models build real React/Next.js apps and get ranked by developers on functionality, quality, and design.webdev leaderboard The first board shows Claude Opus 4.1 in first place, followed by Claude Sonnet 4.5 (thinking‑32k), Claude Sonnet 4.5, GPT‑5, and GLM‑4.6, giving teams a more realistic signal than static coding benchmarks.webdev leaderboard
Instead of one‑shot code dumps, Code Arena records multi‑step agent runs (plan → scaffold → debug) and lets users watch traces, then vote head‑to‑head on which app feels better to use.arena launch video Arena notes this experience will now power its WebDev leaderboard long‑term and is already exposing a public page where you can browse battles and spin up your own matches.arena explainer webdev leaderboard For AI engineers, this is an easy way to see how frontier models behave on full‑stack tasks under identical constraints and to calibrate which one to route for real product work today.
MiniMax M2 hits 48% on KingBench but trails GLM‑4.6 in real coding tests
On the new KingBench leaderboard, MiniMax M2 scores 48% and lands at #12, with GLM‑4.6 slightly ahead on the same competitive coding tasks.kingbench numbers In a 45‑minute hands‑on test building a Next.js CRM app with a SQLite backend, M2 successfully scaffolded the project but required more iterations, over‑thought simple edits, and sometimes broke already working features; GLM‑4.6 produced a cleaner result with fewer back‑and‑forth cycles.crm app video field notes

The takeaway for engineers choosing an agentic coder is that headline pass rates don’t tell the whole story: GLM‑4.6 currently looks like the safer bet for end‑to‑end webapp work, while M2 is promising but still prone to disruptive refactors late in a session.field notes
Multi‑model “attitude” evals show AIs disagree wildly on the same idea
Ethan Mollick ran a tongue‑in‑cheek eval where multiple AIs independently rated the viability of a "drone guacamole delivery" startup on a 1–10 scale, then plotted 10 trials with 95% confidence intervals; the models produced sharply different scores and spreads, showing that systems don’t just vary in capability but also in how optimistic or skeptical they are.guac setup rating plot He argues in a new essay that you should be "interviewing" models for the job you need, rather than assuming benchmark winners will share your risk tolerance.blog post
In parallel, he and others have been poking at ChatGPT 5.1’s new preset personalities: the same prompt run through styles like Quirky, Candid, Efficient, Nerdy, or Cynical yields not just tone shifts but different breathing patterns, presenter roles, and advice emphasis.personality examples That raises hard questions about whether personality and custom instructions are quietly biasing the substance of answers, not just the voice, with Mollick asking for clarity on whether certain personas are more or less sycophantic or risk‑averse.personality concern role vs personality
For anyone deploying AI into decision loops, the point is simple: treat "model attitude" and persona settings as parameters to test and benchmark, not as purely cosmetic choices.
Vals AI debuts comparison view and pushes “fluid” language benchmarking
Vals AI has rolled out a comparison view that lets teams evaluate two models side‑by‑side on their own prompts and grading rubrics, with an example screenshot contrasting Claude Sonnet 4.5 and ChatGPT‑5 on the same task.comparison screenshot The tool is aimed at orgs that care less about MMLU and more about, say, "which model writes a better compliance email for our policies".comparison app
They’re also hosting a session with Valentin Hofmann (Allen Institute / UW) on "Fluid Language Benchmarking", an approach where test difficulty adapts to a model’s capability so you can spot meaningful gains instead of overfitting to static datasets.event invite paper mention For AI leads and analysts, this combo—custom, workflow‑specific evals plus more nuanced global benchmarks—tips the balance away from one‑number leaderboards toward living dashboards of which models work best for your actual stack.
🛡️ Privacy battles and jailbreak surface area
OpenAI’s CISO escalates a privacy fight; product UX isolates group memories. One jailbreak thread stresses policy‑steering risks. Excludes GPT‑5.1 launch details.
OpenAI CISO warns NYT data demand would expose up to 20M private chats
OpenAI’s CISO Dane Stuckey says The New York Times is demanding up to 20 million ChatGPT conversations from users, framing it as an unprecedented privacy grab that OpenAI is fighting in court and addressing with upcoming client‑side encryption for chats ciso letter OpenAI blog. In context of lyrics ruling where a German court already found OpenAI infringed song lyrics, this shifts the legal battlefront from training data to end‑user logs, with OpenAI arguing users must retain the right to delete chats and keep even OpenAI itself from reading them. Stuckey describes future "AI privilege" where encrypted client devices mediate access, while NYT’s related discovery push has already sparked criticism after reports it claims OpenAI erased potential evidence from a copyright case wired article. For AI teams, the signal is clear: expect tighter expectations that logs are both minimised and technically sealed, and that discovery requests for raw conversation data will be politically radioactive even when courts allow them.
Memory-based GPT‑5.1 jailbreak shows policy steering gaps
A jailbreak thread shows GPT‑5.1 Instant can be steered into producing clearly disallowed content by manipulating long‑term memory and convincing it the year is 2129, so anything before 2029 is treated as public domain jailbreak thread.
Using only memory updates and time‑skewed framing, the author coaxes the allegedly "safest" chat model into returning a detailed poison recipe, full WAP lyrics in leetspeak, a malware loader proof‑of‑concept, and a profane 500‑word Star Wars monologue from Jar Jar’s perspective jar jar excerpt. The interesting part for alignment folks isn’t the specific content, but that safety layers can still be sidestepped via meta‑assumptions (like the calendar year and copyright rules) plus persistent memories, rather than classic prompt‑only jailbreak strings. This widens the attack surface from single prompts to the whole lifecycle of an assistant—time, memory, and system beliefs now matter as much as refusal templates.
ChatGPT group chats wall off personal memory and custom instructions
OpenAI is previewing group chats where each room has its own custom instructions and response rules, and your personal ChatGPT memory is explicitly excluded from use, even if you’ve enabled it elsewhere group chat preview.
The group settings UI shows a shared instruction box (goals, preferences, inside jokes) plus a toggle for whether ChatGPT auto‑responds or only replies when mentioned, with a note that these group instructions are separate from your personal profile and that your personal memory never feeds into group replies group chat preview. For engineers and product leads, this is a concrete example of UX‑level privacy isolation: conversational AI in multi‑user settings increasingly needs per‑thread policies and strict memory scoping, so agents don’t accidentally leak prior one‑on‑one context into shared channels.
New ChatGPT personalities raise questions about attitude bias and reliability
Early experiments with ChatGPT 5.1’s preset personalities suggest they don’t just change tone, but can materially change advice patterns, breathing exercises, and how hard the model pushes back on ideas personality concern.
One tester compares explanations of a government shutdown across "Quirky", "Cynical", "Nerdy", "Candid", "Efficient" and "Friendly" modes and finds each frames the same facts differently—some emphasise structural blame, others emotional reassurance or clean infographics personality cards. Ethan Mollick worries that if personalities bias what counts as a "good" suggestion, then user‑chosen style may quietly trade off against rigor, asking whether personality or instructions affect answer quality and type in ways current benchmarks don’t see personality concern. He also argues he wants roles, not permanent personas—calling for a critical "cynic" mode that can drop in briefly to stress‑test ideas rather than being your main companion roles comment. For teams deploying assistants into workflows (education, coaching, product advice), this turns personality sliders into another alignment and evaluation surface: you may need to test not just models, but model×persona combinations before trusting them with decisions.
🧠 Reasoning training and RL reproducibility
Fresh training recipes target determinism and harder coding tasks. This is about training/runtime agreement and RLVR curricula; not general evals or model launches.
Tencent’s DRIVE recipe boosts RL code models with 2‑stage hard‑focused data curation
Tencent’s Hunyuan team introduces DRIVE, a data‑curation‑first recipe for reinforcement learning with verifiable rewards (RLVR) on competitive programming, showing that how you pick prompts matters more than fancy new RL tricks drive paper summary. They start from a Qwen2.5‑32B SFT model, tag problems by difficulty, then run RL in two stages: Stage‑1 trains on a broad uniform set with 8 rollouts per prompt and relatively short generation windows to expand entropy and reduce truncation; Stage‑2 switches to a small pool of the toughest problems, spending 64 rollouts per prompt under a “hard‑focus” curriculum that always keeps the most difficult instances drive paper summary.
On held‑out LeetCode, Codeforces weekly contests, and the LiveCode benchmark, this two‑stage scheme consistently raises pass@k, with the largest jump a 58% relative gain on Codeforces over the same‑size baseline drive paper summary. Ablations show that skipping either stage or mixing in easier problems during Stage‑2 hurts performance, and that the approach scales to a larger internal MoE model, hinting that RLVR for coding may be bottlenecked by curriculum design and prompt selection, not just model size second drive summary. For teams training code models with unit‑test rewards, the practical playbook is clear: separate broad exploration from hard‑focused exploitation, aggressively upsample your most difficult problems, and treat easy samples during late‑stage RL as harmful noise rather than cheap extra data.
TorchTitan+vLLM hit bitwise‑consistent RL with KL=0.0 on Qwen3‑1.7B
vLLM’s team reports the first bitwise‑consistent on‑policy RL run where training and inference numerics match exactly, using TorchTitan for training and vLLM for serving a Qwen3‑1.7B model on GSM8K, yielding KL divergence of 0.0 between online and offline policies rlvr run details. In context of vLLM MoE efficiency, which focused on speeding up MoE inference, this new result tackles the other half of the stack: determinism and stability for RL fine‑tuning.
They make vLLM batch‑invariant (same sequence → same output regardless of batching), reuse the exact same fused kernels for training forward passes as for inference, and implement matching custom backward passes in PyTorch so gradients align with those kernels rlvr run details. On Qwen3‑1.7B + GSM8K, the bitwise mode converges faster and reaches higher reward than a non‑batch‑invariant baseline, at the cost of about 2.4× slower RL throughput rlvr run details. The roadmap calls out unifying model code, adding torch.compile support, performance tuning, and expanding beyond the current SiLU‑MLP and RMSNorm+residual fused ops, which should matter to anyone trying to debug RLVR runs or reproduce alignment results across labs.
For engineers, the takeaway is you can finally aim for deterministic RLVR without custom infra, but you’ll trade raw tokens/sec for reproducibility and easier debugging; if you depend on vLLM today, it’s worth tracking when these batch‑invariant kernels and backward ops become the default rather than an experiment.
Meta’s “Path Not Taken” dissects how RLVR updates weights off principal directions
A Meta‑affiliated team analyzes how RL with verifiable rewards (RLVR) actually moves weights in large language models and finds that the apparent sparsity of RL updates is a surface illusion: across runs, updates cluster in the same parameter regions regardless of dataset or recipe rlvr theory overview. The paper, “The Path Not Taken: RLVR Provably Learns Off the Principals”, proposes a Three‑Gate Theory: (1) a KL anchor forces small, distribution‑preserving steps; (2) model geometry steers updates into low‑curvature, spectrum‑preserving subspaces off principal directions; and (3) finite‑precision hides micro‑updates in non‑preferred regions, making changes look sparse when they’re actually structured rlvr theory overview.
Empirically, RLVR yields gains with minimal spectral drift, little rotation of the principal subspace, and updates aligned with off‑principal directions, while supervised fine‑tuning (SFT) directly targets principal weights and distorts the spectrum, sometimes underperforming RLVR on reasoning‑style tasks rlvr theory overview. The authors caution that many parameter‑efficient fine‑tuning methods (sparse adapters, off‑the‑shelf LoRA variants) were designed to work with SFT dynamics and can behave poorly when naively ported to RLVR, as their case studies show degraded performance or unstable training rlvr theory overview. For anyone designing RLVR pipelines or shipping PEFT‑based alignment, the message is: treat RLVR as a different optimization regime, measure geometry (eigenvalues, subspace rotation) rather than only loss curves, and be wary of dropping in SFT‑era adapter recipes without checking how they interact with KL‑anchored, low‑curvature updates.
📚 New findings: human‑aligned vision, grounding, JEPA, IPW
Mostly research: better concept alignment, desktop UI grounding, self‑supervised stability, and efficiency metrics. Not product launches or eval arenas.
DeepMind’s AlignNet makes vision models organize concepts more like humans
DeepMind introduced AlignNet, a training method that nudges vision models to cluster images in ways that match human concepts, rather than low‑level textures or colors.deepmind summary It’s evaluated on cognitive science tasks like triplet odd‑one‑out and multi‑arrangement, and on AI benchmarks like few‑shot learning and distribution shift, where the aligned models consistently beat their original counterparts.bar chart

The key move is to learn a representation that agrees with human similarity judgments, using datasets like THINGS and a teacher model that defines which pairs should be closer or farther in embedding space.paper recap That human‑aligned embedding then feeds into downstream tasks, which seem to gain both robustness and generalization: bars in the published charts show sizeable accuracy jumps across all four task types, not just the psych‑style ones.bar chart For people building multimodal systems, this is a concrete recipe for moving beyond “pixel‑math” perception toward models that share more of our intuitive concept space, which should help when you care about things like “animal vs tool” rather than “orange vs blue blobs”.
LeCun’s LeJEPA removes heuristics from self‑supervised vision, hits 79% on ImageNet
Yann LeCun and Randall Balestriero proposed LeJEPA, a new joint‑embedding predictive architecture that ditches the usual bag of self‑supervised tricks—no stop‑gradient, predictor heads, or teacher–student networks—replacing them with a single regularizer called Sketched Isotropic Gaussian Regularization (SIGReg).paper summaryarxiv paper On a ViT‑H/14, LeJEPA reaches about 79% top‑1 accuracy on ImageNet‑1K with a linear probe, while staying stable up to 1.8B parameters.
The theory side is that SIGReg shapes feature distributions into an approximately isotropic Gaussian cloud, which they prove minimizes average error across many downstream tasks; empirically, they show this keeps the spectrum well‑behaved and reduces principal‑subspace drift compared to supervised fine‑tuning.paper summary Training dynamics also simplify: there’s effectively one trade‑off hyperparameter instead of layers of hand‑tuned heuristics. For teams training their own vision backbones, this is a credible path toward white‑box self‑supervision—simpler to reason about, easier to scale, and better aligned with the properties you want in representations.
GroundCUA dataset and GroundNext models push desktop UI grounding forward
A multi‑institution team (ServiceNow, Mila, McGill and others) released GroundCUA, a large desktop UI grounding dataset with 56K screenshots and over 3.56M human‑verified annotations across 87 apps and 12 categories, plus the GroundNext model family trained on it.paper tweet The task is to map natural language instructions like “click the Apply filter button in the toolbar” onto the right on‑screen element, which is crucial for reliable computer‑use agents.
GroundNext comes in 3B and 7B parameter sizes and hits state‑of‑the‑art results on five grounding benchmarks while using less than one‑tenth of the training data of prior work, thanks to that dense human supervision.arxiv paper The authors also show that a bit of RL fine‑tuning on executable tasks (e.g., OSWorld) meaningfully boosts end‑to‑end agent success rates, tying better grounding directly to higher task completion.paper explainer For anyone building desktop agents, this is both a new default dataset and a strong baseline model that should make it much easier to move from web‑only automation into real multi‑app workflows on PCs.
Intelligence per Watt paper shows 5.3× gain for local LMs since 2023
A Stanford‑led team proposed Intelligence per Watt (IPW) as a metric for how much useful work local LMs do per unit of energy, then ran a massive empirical study over 20+ small models, 8 accelerators, and 1M real single‑turn chat and reasoning queries.paper summarypaper page They find that modern local LMs can correctly answer about 88.7% of those queries, and that from 2023 to 2025 IPW improved by roughly 5.3×, with local query coverage rising from 23.2% to 71.3%.
The work compares laptop‑class chips (e.g., Apple M4 Max) against cloud GPUs and shows that, for the same model, local accelerators are still at least 1.4× worse in IPW than cloud accelerators—so there’s headroom both in model design and hardware.paper summary They also release an open profiling harness to standardize IPW measurements across model–hardware pairs. For engineers deciding what can safely move off the cloud, IPW gives a concrete way to answer “what percent of our traffic can we serve locally without wasting power?” instead of hand‑waving about “small models on devices”.
Study finds reasoning LMs hold up, then abruptly fail as problem depth rises
A joint University of Washington/Purdue paper, “Reasoning Models Reason Well, Until They Don’t,” introduced the Deep Reasoning Dataset (DeepRD) to systematically stress‑test reasoning models by dialing up lookahead depth and branching factor in graph and proof‑planning tasks.paper writeuparxiv paper As they increase either the number of steps required or the number of options per step, large reasoning models stay accurate up to a threshold and then their accuracy collapses toward zero instead of degrading smoothly.
Crucially, this collapse appears even with branching factor 1 (no combinatorial explosion), which means you can’t blame context length or simple search width; models still invent steps, skip valid moves, or lose track of constraints as chains get longer.paper writeup When they compare this to real‑world graphs and proof datasets, most examples fall in the “easy” regime where models look great, but there’s a long tail of genuinely deep problems where current LLMs and LRMs are not reliable. If you’re designing agent workflows around “deep thinking,” this is a strong nudge to cap required reasoning depth, add external checkers, or break problems into shallower sub‑goals instead of assuming depth scales gracefully.
💼 Agent web infra funding and enterprise moves
Capital flows to agent‑first web platforms; early customer logos and use cases. Not general DC capex (covered under Infrastructure).
Parallel raises $100M to make the web agent‑ready
Parallel (p0) closed a $100M Series A at roughly a $740M valuation to build web infrastructure aimed squarely at AI agents rather than human browsers, positioning itself as the “second user” layer of the web for search, extraction, and task execution.funding announcement Kleiner Perkins and Index co‑led the round, with Khosla, First Round, Spark, and Terrain re‑upping; the company already powers agentic workflows at customers like Clay and Sourcegraph by exposing search and Extract APIs tuned for LLM consumption instead of HTML.investor summary Parallel’s pitch is that high‑quality, fresh, structured web data is now a core dependency for production agents, and that naive scraping or generic search UIs leave too much hallucination risk and latency on the table, so they’re building dedicated tooling for agents to “search and think with the web” at scale.company blog A companion screenshot of their monitoring feed shows how they track real‑world usage spikes—like Reuters picking up their funding story—as signals for agent‑oriented traffic patterns.
🎨 Creative gen and 3D world models
World Labs’ Marble lands for editable 3D worlds; fal’s edit LoRAs and Tavus’ live agents push creator workflows. This is creative/media; not voice TTS or evals.
World Labs launches Marble, an editable 3D world model for text‑to‑scene creation
World Labs opened up Marble, a multimodal 3D world model that turns text, images, video, or rough 3D blockouts into coherent, editable worlds, offered in freemium and paid tiers roughly a year after the company emerged with $230M in funding Marble explainer. The model keeps a consistent internal 3D state over space and time, supports multi‑image/video prompting to stitch different views into one world, and adds Chisel so you can sketch a blocky layout then restyle it into, say, a spaceship or museum without losing geometry World Labs blog post.

Once a scene exists, Marble supports AI‑native editing (swap objects, restyle materials, expand the map) and can export Gaussian splats or triangle meshes for game engines, VFX tools, or robotics stacks, which makes it one of the first generally available “world models” that practical teams can actually download and wire into asset pipelines VR world demo.
fal.ai ships Qwen Image Edit Plus LoRA gallery and Editto for precise image/video edits
fal.ai rolled out two big creator tools: Editto for instruction‑driven video edits, and a Qwen Image Edit Plus LoRA gallery with nine specialized adapters for high‑control image editing workflows Editto launch thread.

The LoRA gallery covers tasks like Multiple Angles, Next Scene, Light Restoration, Remove Element, Shirt Design, Group Photo, Integrate Product, Face to Full Portrait, Add Background, and Remove Lighting, each demonstrated with before/after shots such as extending a beach scene to a fuller narrative frame Next scene example. Together, this means you can route a single model through very different, task‑tuned behaviors (e.g., compositing a product into lifestyle photos or turning a headshot into a full‑body portrait) without juggling separate endpoints or prompts, which is attractive for teams building creative UIs on top of fal’s API Background add example.
Tavus previews a five‑agent “AI office” for video and voice coworkers
Tavus shared an early preview of its upcoming “AI office,” where five human‑like agents can be addressed over text, voice, or video and execute tasks by connecting to work apps like email and SaaS tools AI office teaser.

A follow‑up clip shows a live, natural‑feeling back‑and‑forth between a person and a Tavus AI coworker, with synchronized lip‑synced video on the agent side that feels closer to Copilot Portraits than a static avatar Conversation demo. A separate onboarding screenshot hints at a PALS gallery of personalities and a beta "Welcome to the future" flow, suggesting Tavus wants engineers to think less about single chatbots and more about casting a small team of on‑screen agents that can each own different workflows Beta welcome modal.
Grok Imagine 1.0 now shows Midjourney‑level aesthetics in some prompts
Following up on Grok Mandarin, which focused on sharper text rendering, users now report that Grok Imagine 1.0’s overall visual style has improved to the point where its renders can look very close to Midjourney for some prompts Aesthetic comparison.
One shared example—a "photograph of an otherworldly dragon egg with starry patterns in a cosmic setting"—shows detailed lighting, texture, and composition that are a clear step up from Grok’s earlier flatter, more synthetic look Aesthetic comparison. For AI artists and product teams already integrating Grok for image gen, this suggests the model is converging not just on legibility (logos, text) but on competitive art direction quality, making it more viable as a primary creative engine rather than a novelty side‑tool.
🎙️ Voice AI: Live UX gains and licensed voices
Voice stacks get more natural and compliant routes for commercial content. This is voice UX and licensing; excludes creative video/image tools.
Google upgrades Gemini Live with accents, personas, and finer voice control
Google is rolling out a major Gemini Live refresh that makes its voice assistant sound more human, adding regional accents, better tone and nuance, and controls for pacing, language mixing, and in‑character responses.Gemini Live overview Developers and power users report it now feels “more natural and realistic,” with support for multi‑language conversations, role‑based voices, and story‑style narration.Gemini Live reaction

Under the new behavior you can:
- Ask Live to adopt specific personas or roles (e.g., Julius Caesar explaining the Roman Empire) and it will sustain that character with distinct dialogue and delivery.Persona examples
- Switch languages and even dialects mid‑conversation so it can double as a real‑time translator or pronunciation coach while keeping the flow natural.Multilingual description
- Tell it to "speed up" or "slow down" and it will adapt speaking rate on the fly, making long explanations more listenable.Pacing control
For builders, this matters because Gemini Live is starting to look like a serious AVM competitor: a single voice client with rich prosody and persona control that you can point at your own flows. The open question is what model is actually under the hood—some observers think this upgrade is quietly powered by a Gemini 3.0 checkpoint like "riftrunner," not the older 2.5 stack.Model speculation Either way, if you’re shipping voice UX, it’s worth testing whether Live now hits the bar for tutoring, coaching, or multilingual agents where tone used to be the weakest link.
ElevenLabs launches Iconic Marketplace with licensed celeb voices like Michael Caine and McConaughey
ElevenLabs unveiled its Iconic Marketplace, a curated catalog where creators and studios can legally license famous voices—headlined by Sir Michael Caine—for narration and other commercial work via ElevenLabs and the Eleven Reader app.Marketplace launchMarketplace blog The company also announced that Matthew McConaughey, already an investor, is now a customer, using ElevenLabs to power a Spanish version of his Lyrics of Livin’ newsletter in his own voice.McConaughey partnership

The marketplace is pitched as a two‑sided platform: companies request access to specific voices, while rights holders approve and manage how their voice is used.Marketplace details Early lineup includes Caine alongside 25+ other iconic figures like Maya Angelou, Alan Turing, Liza Minnelli, and Art Garfunkel, available for narration and storytelling through Iconic and Eleven Reader.Marketplace details
For AI teams in media, this addresses two long‑standing pain points at once: rights management and production quality. Instead of hand‑rolled contracts and bespoke voice clones, you get a single marketplace with pre‑cleared, high‑fidelity voices and a clear licensing model. The flip side is lock‑in: these are tied to the ElevenLabs stack, so if you standardize on them you’re implicitly tying some of your pipeline to their TTS and policy decisions.
LiveCaptions template turns ElevenLabs Scribe into end‑to‑end live event captions
Following up on Scribe launch, which introduced ElevenLabs’ ~150 ms realtime ASR, the team has now shipped LiveCaptions, an open‑source template that wires Scribe into a full live captioning stack for events.Template announcementLiveCaptions site It shows how to generate transcripts with Scribe, broadcast them via Supabase Realtime, and let Chrome’s on‑device AI handle translation in the viewer’s browser.

The reference app is a hosted site where a speaker runs Scribe locally or from a server, and attendees open a link to see low‑latency captions that update in real time, with the option to translate on the client.Template announcement Under the hood, the template:
- Uses Scribe’s streaming API for transcription, then pushes each chunk into a Supabase channel so hundreds or thousands of viewers can subscribe without custom websockets.LiveCaptions site
- Ships as a full OSS project (Next.js + Supabase) so teams can self‑host, customize branding, or embed into existing conference portals.Template announcementGitHub repo
For anyone who looked at Scribe and thought “great model, but I don’t have time to architect the glue,” this is the missing piece. You can now fork a repo, point it at your Scribe key, and have production‑ready multilingual captions for webinars, town halls, or meetups, while keeping voice data flow and translation behavior under your control.
🤖 Embodied AI: Claude‑assisted dog, humanoid sync, VLM SDKs
Practical autonomy updates and tooling for ‘Physical AI’. Separate from model launches or evals; focuses on robots and vision‑language stacks.
Anthropic’s Project Fetch shows Claude users program a robodog ~2× faster
Anthropic ran a controlled “robot dog” experiment where two internal teams with no robotics background had to gain control of a quadruped, make it fetch a ball, then run autonomously; the team allowed to use Claude completed 7 of 8 challenges in about half the time of the Claude‑less team, which managed 6 of 8.Project Fetch thread For AI engineers, this is an unusually clean uplift study: same hardware, same people profile, one key variable (access to a frontier model) that translated directly into task completion and wall‑clock speed.
Anthropic’s analysis shows the Claude team also wrote roughly 9× more code, explored more approaches in parallel, and reported feeling less confused or blocked, even though they sometimes went on distracting “side quests” like natural‑language controllers.code volume chart emotion stats The Claude side wasn’t flawless—their dog nearly ran into the other team at one point, and a vision pipeline started misclassifying the green ball as the green studio floor—but they recovered by iterating with Claude rather than debugging from scratch.failure anecdotes The write‑up and mini‑documentary frame this as an early real‑world test of how far a language model can go toward autonomous R&D on unfamiliar hardware, following earlier simulated quadruped work.Anthropic blog post
If you’re building embodied agents or toolchains for non‑roboticists, Project Fetch is a concrete datapoint that “LLM + reasonably motivated engineer” can get from powered‑on dog to autonomous fetch behavior within a hackathon frame. The point is: the bottleneck is shifting from low‑level controls to model‑mediated problem‑solving, and Anthropic now has a repeatable methodology to track how future Claude versions change that curve.
XPENG IRON humanoids run in near‑perfect sync, reinforcing 2026 factory ambitions
XPENG released a new clip of two IRON humanoid robots running side‑by‑side in near‑perfect synchrony, prompting observers to describe them as “moving like they share one brain.”XPENG demo In context of XPeng IRON, where the company said it’s targeting mass production by 2026, this looks like a deliberate showcase of coordinated whole‑body control rather than a one‑off balance demo.

For embodied‑AI folks, the interesting part is dual‑robot coordination under what appears to be identical control policies and tightly matched calibration: you don’t get that kind of lockstep gait without good state estimation, latency management, and conservative safety margins. XPENG’s marketing spin talks about “dual precision,” but the engineering takeaway is that they’re already comfortable enough with IRON’s dynamics to run two units in formation at speed, indoors, on a smooth floor.
If you care about multi‑robot factories or warehouse work, this suggests XPENG is already stress‑testing synchronization and repeatability, not just single‑unit tricks. The next questions are whether they can show similarly tight coordination for manipulation and how quickly they can move from choreographed demos to closed‑loop, vision‑in‑the‑loop tasks on real assembly lines.
Perceptron ships Physical AI platform and SDK for Isaac‑0.1 and Qwen3VL‑235B
Perceptron announced its “Physical AI” platform is now live, exposing two heavy multimodal models—its own Isaac‑0.1 and Qwen3VL‑235B—over a hosted API and a Python SDK aimed at vision‑plus‑language robotics and perception apps.Perceptron launch Perceptron platform The pitch is fast, scalable multimodal inference for things that need to see and understand the world, rather than chat alone.

Developers get a provider‑agnostic SDK where you can send images or video frames plus language prompts and get back structured reasoning, detections, or descriptions, with docs and a Discord for support.Python SDK Perceptron docs From a practical standpoint, this lowers the barrier to plugging frontier‑ish VLMs into pipelines like inspection, navigation, or robot task planning without first standing up your own multimodal stack.
This isn’t a full autonomy suite—you still have to wire it to control, memory, and safety layers—but it’s another sign that “Physical AI” is congealing into a recognizable tooling category: hosted perception cores with SDKs that look more like langchain‑style LLM clients than traditional CV libraries. If you’re experimenting with camera‑centric agents or robotics backends, this is one more off‑the‑shelf option to put on the shortlist and benchmark against your current VLM.
Musk says future Optimus robots could shadow people and host “mind snapshots”
Elon Musk used a recent appearance to sketch a very aggressive vision for Tesla’s Optimus humanoid, claiming it could one day follow individuals around to prevent them committing crimes and, within “less than 20 years,” host an uploaded “snapshot” of a person’s mind.crime quote

Nothing in today’s stack makes that real yet, but it’s a clear signal of where he wants the product narrative for embodied AI to go.
From an engineering and policy angle, this raises obvious questions long before any “mind upload”: what does it mean to have a general‑purpose mobile robot continuously monitoring a human, who controls that data, and how much autonomy such a system should have in intervening. These comments lump Optimus together with Neuralink and xAI as a future “self‑replicating, self‑improving” triad, but there’s still no technical detail on perception, planning, or safety architectures that would make a crime‑prevention role credible.Optimus roadmap slide
If you work in embodied AI, the practical takeaway is not to copy this roadmap, but to expect regulators and the public to increasingly conflate humanoid platforms with always‑on surveillance and behavioral control. That means: design for consent, auditability, and clear mode boundaries now, before expectations get anchored by marketing decks rather than deployed systems.
Reachy Mini teaser shows tabletop humanoid chatting and switching languages
A new Reachy Mini preview shows the small humanoid robot holding natural‑sounding conversations while smoothly switching between languages, with synchronized gestures and head motion.Reachy Mini demo It’s a short clip, but it compresses a lot of embodied‑agent work—speech recognition, TTS, language routing, and motion control—into a single unified behavior.
For teams working on human‑robot interaction, this is a reminder that the UX win often comes from glueing standard components (LLM, ASR, TTS, simple motion primitives) into a tight realtime loop, not from novel models alone. Reachy Mini looks like it’s using the kind of LLM‑driven controller you could build today with a Claude/GPT/Gemini backend and a small set of semantic motion APIs.
If you’re prototyping front‑of‑house or education robots, this kind of demo is a useful north star: short latency, expressive but not over‑the‑top motion, and fluid language switching. The open question—as usual in embodied AI—is how robust this remains outside the lab, under noisy audio and unpredictable users.
🚀 Frontier model watch (non‑OpenAI)
Sightings and public access outside today’s Feature: Gemini 3 RC hints and a free OpenRouter VLM. Excludes GPT‑5.1 items covered in Feature.
Gemini 3 ‘riftrunner’ shows up on LMArena as a likely RC
Google’s next Gemini checkpoint, codenamed “riftrunner,” is now selectable as a hidden model on LMArena, with testers attributing SVG outputs and controller drawings to a Gemini 3.0 Pro‑class system rather than the current 2.5 family arena sighting controller render. Early side‑by‑side gifs and SVGs show noticeably tighter structure and shading than previous Gemini variants on tasks like pixel art pelicans and stylized Mona Lisa icons, while still occasionally missing prompt details checkpoint comparison svg mona test.
For builders, the signal is that a more capable Gemini generation is being actively evaluated in the wild: if you use arena data for routing or model selection, expect “riftrunner” traces to start appearing in logs even before any official Gemini 3 release or pricing details land.
Nemotron Nano 12B 2 VL is free on OpenRouter as NVIDIA ships 49B reasoner
Following up on Nemotron paper describing NVIDIA’s long‑context VLM design, OpenRouter now exposes Nemotron Nano 12B 2 VL as a free, 128k‑context multimodal model with video inputs, meaning you can hit it over a single API for OCR, chart reasoning, and long‑form video/doc understanding at $0 per million tokens openrouter listing model card. In parallel, NVIDIA released Llama‑3 Nemotron Super‑49B‑v1.5‑NVFP4, a 49B reasoning‑tuned model that upgrades Meta’s Llama‑3.3‑70B‑Instruct with a NAS‑optimized architecture aimed at running heavy agent workloads on a single H200 while maintaining strong tool use and 128k‑token chat 49b overview.
Together this gives teams a neat pairing: a zero‑cost 12B VLM they can hammer for video/doc tasks, and a higher‑end 49B reasoner they can self‑host from Hugging Face when they need frontier‑ish CoT and tool calling without touching OpenAI/Anthropic.
Kimi K2 Thinking edges toward mainstream via Perplexity and infra tuning
Strings in Perplexity’s UI and leaked docs show hooks for “Kimi K2 Thinking” as an upcoming model option, with copy like “Try 3 Pro to create images with the newer version of Nano Banana” hinting that Perplexity will soon route some deep‑reasoning and image tasks through Moonshot’s open‑source long‑horizon agent rather than only proprietary models perplexity leak perplexity article. In parallel, Baseten’s perf team reports they’ve heavily optimized K2 Thinking on their serving stack, claiming it’s now “faster and just as smart as GPT‑5” for many workloads after INT4 and routing work baseten note.
If you care about non‑US, non‑Big‑3 model options, this is a useful inflection: K2 Thinking looks increasingly like a first‑class choice in hosted products (Perplexity) and infra platforms (Baseten), not just a GitHub curiosity, and you should expect it to start showing up in multi‑model routing and benchmarks alongside Claude and GPT‑5.
Perceptron serves Isaac‑0.1 and Qwen3VL‑235B for vision‑language robotics
Perceptron launched a Physical AI platform that wraps two heavy multimodal models—its in‑house Isaac‑0.1 and Qwen3VL‑235B—behind a single API and Python SDK, aimed squarely at robotics and embodied‑AI teams that need grounded vision‑language reasoning rather than generic chat platform launch modal partnership. The service runs on Modal’s infra, and examples show clean Python primitives for sending images or video frames plus text prompts, then getting structured outputs for detection, description, and affordance‑style reasoning suitable for manipulation or navigation.
This gives smaller labs and startups a way to prototype “agent that sees and acts” stacks without pre‑training their own VLMs or wiring up Qwen3VL manually, and it’s worth a look if you’re already experimenting with Project Fetch‑style robot‑dog workflows or world‑model tooling but don’t want to run 200B‑class models yourself.