MiniMax M2.1 opens 230B‑param MoE – 74% SWE‑bench push
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
MiniMax releases open weights for MiniMax‑M2.1, a 10B‑active / 230B‑total MoE coding model positioned as an agent backbone rather than a one‑shot autocomplete; launch charts claim 74% on SWE‑bench Verified, 49.4% on Multi‑SWE‑bench, 72.5% on SWE‑bench Multilingual, 47.9% on Terminal‑Bench 2.0 and an 88.6 VIBE average, with several scores edging Gemini 3 Pro and Claude Sonnet 4.5. The model targets multi‑language software work (Rust/Go/Java/C++/Kotlin/web/mobile) and “interleaved thinking” for tools and agents; weights ship under an MIT‑style license that adds a MiniMax branding requirement for commercial apps, and are exposed via MiniMax’s own API plus a Hugging Face release.
• Long‑context and bias profile: Context Arena’s MRCR run shows 49.2% AUC and 42.8% pointwise accuracy on 2‑needle retrieval at 128k tokens—roughly half GLM‑4.7’s input cost and ~85% lower output cost—but with strong forward‑drift bias and “creative” hallucinated needles in 74–82% of misses.
• Ecosystem and serving: vLLM and SGLang ship day‑0 parsers for MiniMax‑style tool/“thinking” tokens; Novita hosts inference on Hugging Face, and early 4–6‑bit Mac Studio tests report ~40–47 tok/s, making M2.1 an immediately runnable open coding/agent option.
Top links today
- MiniMax M2.1 Hugging Face model card
- Memory in the Age of AI Agents paper
- RL composition for new LLM skills paper
- RL composition skills GitHub repository
- Reinforcement learning for self-improving agent paper
- Refusal steering for sensitive topics paper
- QuantiPhy physical reasoning benchmark paper
- FT overview of AI world models for games
- Epoch AI Capabilities Index dashboard
- Nvidia Groq inference deal deep dive
- Eval framework for AI product managers
- PhysBrain egocentric embodiment paper
- PhysBrain egocentric embodiment project page
- Scaling RL for LLM content moderation paper
- Intel Fab 52 versus TSMC Arizona analysis
Feature Spotlight
Feature: MiniMax M2.1 open-sourced for real-world coding agents
MiniMax M2.1 releases open weights for agentic coding; community frameworks add day‑0 support, and posts tout SOTA SWE/VIBE plus local deployability—making a strong open option for dev/agent stacks.
Cross-account focus today: MiniMax ships open weights for its agentic coding model; immediate ecosystem pickup and benchmark claims aimed at SWE/VIBE use. This is the day’s major actionable model story for builders.
Jump to Feature: MiniMax M2.1 open-sourced for real-world coding agents topicsTable of Contents
🧰 Feature: MiniMax M2.1 open-sourced for real-world coding agents
Cross-account focus today: MiniMax ships open weights for its agentic coding model; immediate ecosystem pickup and benchmark claims aimed at SWE/VIBE use. This is the day’s major actionable model story for builders.
MiniMax open-sources M2.1 coding MoE as SOTA agent backbone
MiniMax M2.1 open weights (MiniMax): MiniMax has released open weights for MiniMax‑M2.1, a 10B‑active / 230B‑total MoE model positioned as SOTA for SWE‑bench, VIBE and Multi‑SWE coding and agent benchmarks, with claims of outperforming Gemini 3 Pro and Claude Sonnet 4.5 on several metrics in the launch chart launch thread; this follows agent backend, where M2.1 was described as a proprietary agent backend inside tools. The company highlights M2.1’s multi‑language programming focus (Rust, Java, Go, C++, Kotlin, mobile, web) and real‑world complexity targets in its product write‑up and text‑generation docs, which explain tool use, interleaved "thinking" and prompt caching for the model text generation guide and model news.
• Model and license details: M2.1 is a sparse MoE with 10B active parameters per token out of 230B total, advertised as higher‑throughput and easier to deploy locally than dense peers launch thread; community commentary notes an MIT‑style license with an added requirement to display the MiniMax brand when commercializing apps, which is relevant for product teams planning white‑label use license note.
• Distribution and surfaces: The model is available as MiniMaxAI/MiniMax-M2.1 on Hugging Face with Novita as one of the hosted inference backends hf release and hf model card; MiniMax also exposes it via the MiniMax Open Platform and a Codex‑style API with Anthropic/OpenAI SDK compatibility, documented in its text‑generation guide text generation guide.
• Positioning and training philosophy: MiniMax’s own alignment blog frames M2.1 as optimized both for open benchmarks and messy real workflows, emphasizing interleaved thinking (reasoning woven through the task, not in a single pre‑ or postfix block) and dual alignment to benchmarks and users alignment blog; the company explicitly invites users to "try harder & try anything" and stresses that M2.1 is built for agents doing complex multi‑step work rather than one‑shot code snippets testing invite.
• Promo and adoption push: To seed usage, MiniMax is offering an 80%‑off coding plan—"start 2026 with a $2 MiniMax Coding Plan"—plus a giveaway that bundles robots, NVIDIA GTC tickets and API credits for active M2.1 subscribers pricing promo and giveaway rules; the team’s own framing is that the model is “SOTA, fast, easy to infer, economically robust” and they ask rhetorically "What else could you ask for" miniMax slogan.
Developer responses describe M2.1 as a "huuuuge leap in SWE tasks" with strong agentic behavior and note that its mix of open weights plus commercial API makes it an unusually flexible coding model for 2026 planning dev reaction.
MiniMax M2.1 claims SOTA coding and strong long‑context at lower cost
Benchmarks and behavior of M2.1 (MiniMax): MiniMax backs its M2.1 open‑source release with aggressive benchmark claims—its launch chart shows 74% on SWE‑bench Verified, 49.4% on Multi‑SWE‑bench, 72.5% on SWE‑bench Multilingual, 47.9% on Terminal‑Bench 2.0, and an 88.6 VIBE average, with several scores edging out Gemini 3 Pro and Claude Sonnet 4.5 on particular tasks launch thread; following Zhihu review, which found M2.1 notably stronger at coding but weaker on math and spatial reasoning than its predecessor, new long‑context tests add more nuance.
• Long‑context retention vs peers: Context Arena’s MRCR suite evaluates minimax‑m2.1 on 2‑, 4‑, and 8‑needle retrieval up to 128k tokens, finding that it maintains a relatively flat degradation curve compared with GLM‑4.7, which "starts strong and crashes" past 64k mrcr writeup and mrcr leaderboard; at 128k, M2.1 scores an AUC of 49.2% on 2‑needle (slightly above Gemini 2.5 Flash Lite Thinking’s 47.9%) with 42.8% pointwise accuracy vs GLM‑4.7’s 22.1%, and on 4‑needle it reaches 33.3% AUC and 27.1% pointwise, again comfortably ahead of GLM‑4.7’s 13.1% pointwise mrcr writeup.
• Biases and "creative" errors: A separate bias analysis of minimax‑m2.1’s MRCR runs reports an extreme forward or "positive drift" bias, where the model tends to select later variants when uncertain: for example, in 2‑needle setups the correct‑variant‑1→2 misselection rate (picking 2 when 1 is right) is 61.1%, versus only 10.2% in the opposite direction, with a similar 7→8 vs 8→7 asymmetry in 8‑needle tests bias analysis; the same analysis finds roughly 2% key‑hash failures, 74–82% of misses involving “creative” hallucinated needles on the right topic/medium rather than true retrieval, and 5–8% refusals where the model breaks character to say it cannot find the requested variant bias analysis.
• Alignment and generalization framing: MiniMax’s own technical blog "Aligning to What?" argues that M2.1’s training was tuned to balance benchmark score maximization against agent generalization, emphasizing that interleaved thinking and compositional training examples help the model learn reusable plans rather than rote solutions alignment blog; the post also notes that while benchmarks like VIBE and SWE‑bench capture important skills, they still only partially proxy for the messy, multi‑step coding and agent tasks M2.1 is meant to handle alignment blog.
• Ecosystem perspective: A code‑LLM progress timeline shared by independent observers places models like M2.1 alongside DeepSeek‑R1, Qwen3‑Coder and GLM‑4.7 at the frontier of HumanEval and related coding benchmarks, underscoring how quickly open and semi‑open models have approached prior closed‑model baselines in 2025 code timeline; community comments underline that M2.1’s biggest practical win is its combination of competitive scores, open weights and comparatively low inference cost per token, which Context Arena estimates at roughly half the input cost and ~85% lower output cost than some long‑context rivals at equivalent 128k tests mrcr writeup.
The overall picture is that M2.1 looks very strong as an open coding and agent model—especially on multi‑language SWE and long‑context retrieval—but its tendency toward forward‑biased, "creative" answers and some math/spatial gaps from earlier evaluations suggest teams will still need careful harness design and evaluation when dropping it into high‑stakes workflows.
vLLM and SGLang ship day‑0 runtimes for MiniMax M2.1
Serving MiniMax‑M2.1 (vLLM, LMSYS, Hugging Face): In parallel with the open‑weights drop, multiple runtime stacks have added day‑0 support for MiniMax‑M2.1, giving teams ready‑made ways to serve it with tool‑calling and "thinking" modes; vLLM shows a vllm serve MiniMaxAI/MiniMax-M2.1 command with MiniMax‑specific parsers, and LMSYS’s SGLang publishes a multi‑GPU launch recipe tuned for agent workloads vllm commands and sglang recipe.
• vLLM integration: vLLM’s example uses --tensor-parallel-size 4, --tool-call-parser minimax_m2, and --reasoning-parser minimax_m2_append_think, plus --enable-auto-tool-choice, indicating first‑class support for MiniMax’s tool schemas and interleaved reasoning tokens vllm commands; the team frames this as "Day‑0 support" for what they call a "full‑stack development powerhouse" so that users can run M2.1 efficiently with server‑side streaming and batching.
• SGLang recipe for agents: LMSYS presents an SGLang launch that combines tensor parallelism and expert parallelism (--tp-size 8 --ep-size 8) with MiniMax‑aware tool and reasoning parsers and a --mem-fraction-static 0.85 flag, clearly targeting long‑running multi‑tool agents that need high throughput sglang recipe; their post calls M2.1 "a strong model for real-world development and a great fit for agent workflows" and positions SGLang as a natural orchestration layer around it sglang recipe.
• Hosted inference and quantization: Novita announces that MiniMax‑M2.1 is live on Hugging Face Inference, with their backend powering hosted runs novita support and hf release; community tests report that a 4‑bit or 6‑bit quantized version runs on high‑RAM Mac Studio setups with around 40–47 tokens/sec generation rates, suggesting that local dev and small‑scale agent hosting are feasible for well‑provisioned workstations perf summary.
• Ecosystem and community signals: MiniMax thanks vLLM for long‑term support and SGLang for day‑0 integration vllm thanks and sglang recipe, while LMSYS highlights the pairing "MiniMax models + SGLang = a strong stack for real-world workflows" sglang recipe; MiniMax itself encourages "all kinds of testing and challenges" on the open weights testing invite, underlining that it expects M2.1 to show up inside many third‑party agent harnesses.
Together these integrations mean M2.1 is not just a model file but a ready‑to‑run option across popular high‑performance inference stacks and hosted services, lowering friction for teams that want to trial it as a coding or agent backbone without building custom tooling first.
🧑💻 Coding agents in practice: workflows, prompts, and web automation
Mostly hands-on agent/dev tooling threads. Excludes MiniMax M2.1 release (covered as the feature). Focus is how engineers are using Claude Code and new automation nodes.
Claude Code writes ~200 PRs in a month as engineer skips IDE
Claude Code agents (Anthropic): Anthropic engineer Boris Cherny describes his first month as an engineer without opening an IDE at all, with Opus 4.5 generating around 200 pull requests line‑for‑line and even 1‑shotting a production memory‑leak fix by taking and reading a heap dump instead of manual profiling engineer account.
He notes that newer coworkers and new grads who lack habits from weaker models are exploiting Claude Code most effectively, saying expectations must be reset every month or two as coding capability improves engineer account. Other engineers highlight this as a striking shift in workflow—“Opus 4.5 wrote around 200 PRs, every single line” is being quoted as a reference point for how far coding agents have moved beyond autocomplete quote highlightusage reaction. Commentary around the thread stresses that even senior people feel behind and that “anyone worried about how AI will affect early career paths hasn’t seen how strong a 25‑year‑old with Claude Code is,” reinforcing that this level of delegation is starting to feel normal in some teams new grad remarkreassurance thread.
Addy Osmani links AI coding success to boring engineering foundations
AI workflows and engineering hygiene (Google): Chrome engineering lead Addy Osmani argues that this is the “most fun moment to be a developer in years,” but says the teams getting the biggest boost from AI coding tools are the ones that invested earlier in CI/CD, tests, documentation and code review engineering thread. He frames AI as changing the altitude of work—from typing syntax to reviewing implementations and catching edge cases—so features that once took days now ship in hours, while weak foundations turn agents into “chaos generators” rather than accelerators engineering thread. The thread emphasizes that understanding context provision, iteration on plans, and fast review of AI‑generated diffs is a learnable skill through repetition, and that the real multiplier comes from combining agent speed with human judgment rather than replacing core coding skills engineering thread.
Firecrawl n8n v2.0 turns web scraping into an agentic /agent workflow
/agent node for n8n (Firecrawl): Firecrawl ships v2.0 of its n8n integration, adding a new /agent node that lets users describe the data they want and have an AI agent autonomously search, navigate and gather it from complex websites in either sync or async mode, following up on the original n8n /agent release Firecrawl node which framed the goal‑to‑data pattern release overview.

• Resource grouping and schema tools: Nodes are now organized by resource type (Agent Actions, Map & Search, Crawl, Account and legacy Extract), and a redesigned schema generator can infer JSON schemas from examples or accept hand‑written schemas when precise control is needed node groupingschema update.
• Batch scrape and AI Agent tool support: Batch scrape now accepts multiple URLs in a single textarea so workflows can pass dynamic lists from prior nodes, and all Firecrawl nodes can be used as tools inside n8n’s AI Agent with $fromAI() so agents can autonomously scrape, crawl and search while filling parameters like URLs and prompts on the fly batch scrape changeagent tool use.
The team positions this as a way to move from brittle, hand‑wired scrapers to agent‑driven web automations that still expose schemas and resource types as explicit knobs rather than hiding them inside prompts agent docs.
Omar Shakir outlines Claude Code skill workflows and “context engineering” focus
Context engineering with skills (DAIR.AI): Educator and agent‑builder Omar Shakir expands on Andrej Karpathy’s “I feel behind” post by arguing that creative workflows and context engineering are now where anyone can contribute; he recommends spending at least two hours a day experimenting with tools like Claude Code and building skills that compound over time motivational thread. He describes a pattern of pairing Claude Code with a dedicated deep‑research subagent that reads new tools, papers and ideas, then using brainstorming sessions to implement at least one new skill per session—even if projects remain unfinished, those skills get reused and refined later brainstorming workflow. His notes point out that most of his work already happens inside Claude Code, so these exploratory sessions fit directly into his daily flow, and that “context engineering is where the game is intensifying,” with the main challenge being how to inject the best possible context into agents rather than finding yet another model agent memory commentagent academy.
Prompt template turns Claude Code into explainer + async background agent for non‑devs
Async explainer agent (trq212): Developer Trevor Rowbotham shares a prompt template that wraps Claude Code into two cooperating agents for non‑technical users—one long‑running background agent that executes work, and another “teacher” agent that periodically polls progress, hides noisy diffs, and explains everything in simple language template intro. The template is being used to help his non‑technical sister “vibe code” a WNBA stats site, with instructions telling Claude to spin off an async agent, summarize its work in approachable terms, and stop to ask for help if errors occur while guiding the user through fixes step by step full template. A community contributor has already packaged this pattern into a Claude Code plugin so others can invoke it without copying prompts, and the plugin repo is positioned as part of a larger collection of Claude Code plugins and skills for guided workflows plugin linkplugin collection.
Steipete’s personal stack turns Codex into a multi‑network orchestration layer
Multi‑agent dev environment (Codex + tools): macOS developer Peter Steinberger shows how he treats OpenAI Codex as a kind of terminal‑driven orchestrator for multiple agents and machines, wiring helpers like custom shell functions, Tailscale discovery, and remote ~/.zshrc edits so Codex can configure matching shortcuts across his MacBook and Mac Studio via SSH tailscale wiring.
He also runs his own summarize CLI as a background daemon tied to a Chrome extension, so any webpage, YouTube video or podcast is automatically extracted, sanitized and summarized into a side panel while he browses, with support for local or cloud transcription and free or local models summarize daemonsummarize site. Another layer in his stack is peekabooagent, which takes periodic screenshots of his screen and feeds them to a Claude‑powered lobstr “clawdbot” that comments on what he is working on—three concurrent Codex sessions, WhatsApp logs, and git output are all being monitored in one example log peekaboo session. Across several posts he also shares Codex Wrapped stats showing 15.7B+ input tokens and thousands of sessions in under a month on one machine, underlining how heavy daily coding and orchestration usage looks when agents become part of the inner development loop codex wrapped.
Cursor tip: one Plan Mode task per agent window to avoid context bloat
Plan Mode habits (Cursor): A power user highlights a Cursor workflow where each item on the Plan Mode to‑do list is opened in its own agent chat window at the bottom of the list, giving that sub‑agent a fresh context focused on a single task instead of sharing a history cluttered by previous steps plan mode advice.

The thread says that when all tasks share a single window, the context window fills up, earlier chat history pollutes the prompt, and the model can lose track of its current goal; the “one task, one agent window” pattern lets the user comfortably run about five parallel chats without hitting those issues plan mode advice.
Peakypanes + Oracle skill used for quick parallel Codex agents
Parallel Codex panes (Peakypanes): One developer suggests using Peakypanes with a 2×3 grid defined in .peakypanes.yml to spin up six Codex agent panes in one terminal, then wiring an “oracle” skill so Claude or GPT‑style agents can call Oracle with the right files attached when they get stuck on an issue peakypanes tip. They describe the advantage as getting multiple focused Codex sessions running in parallel—each with its own scrollback and plan—while Oracle aggregates relevant context (e.g. from specs) and hands richer prompts to a stronger model behind the scenes oracle suggestion. This workflow is framed as an easy way to prototype background debugging or refactor agents without building a full orchestration layer first.
Developers wire Claude Code, Gemini CLI and Codex into Obsidian workspaces
Obsidian as agent hub (multi‑tool): One user reports configuring Claude Code, Gemini CLI and Codex CLI inside a single Obsidian vault, with each agent writing markdown into its own folder so they can “plan how to work together” by reading each other’s notes rather than talking directly obsidian setup. Another reply points out that Claude Code plus its browser/Chrome extension should already integrate cleanly with Obsidian’s files‑and‑folders model, reinforcing that local note‑based workflows can act as a lightweight shared memory between heterogeneous agents extension notefollowup reply. The approach is described as an interim way to get multi‑agent collaboration—using the filesystem as the message bus—without waiting for a unified orchestrator that natively connects Claude, Gemini and Codex in one UI.
🏗️ AI factories, memory supply, and geopolitics of inference
Infra economics and capacity updates. New analysis extends the Nvidia–Groq storyline with memory strategy, plus fabs/DC power and export policy. Excludes model releases.
Bank of America sees Nvidia–Groq as a bid to own the inference rack
Inference stack (Nvidia and Groq): A Bank of America note argues that Nvidia’s roughly $20B non‑exclusive licensing deal for Groq’s inference technology is meant to turn inference into a first‑class product lane and keep racks “Nvidia‑shaped,” combining GPUs and Groq‑style LPUs under NVLink rather than letting customers bolt on third‑party inference boxes, expanding on the earlier licensing reports in Groq deal. The research describes GPUs as general‑purpose platforms for training and broad inference, with Groq’s SRAM‑centric Language Processing Units focused on ultra‑fast, predictable token generation, as summarized from the BofA summary.
Latency and architecture split: Groq’s own framing in the Groq explainer video stresses that inference is bottlenecked by latency, cost per query and power, not raw flops; its LPUs keep model weights and working data in hundreds of megabytes of on‑chip SRAM to avoid off‑chip fetches, trading capacity for very low per‑token delay. Analysts in the Rubin/CPX breakdown tie this to Nvidia’s roadmap: standard Rubin GPUs with large HBM4 stacks and NVLink links for training and high‑throughput decode, plus a Rubin‑CPX sibling with cheaper 128GB GDDR7 tuned for long‑context prefill, and a Groq‑style SRAM part for the fastest decode path.
Memory hedge and supply risk: Commentary in the DRAM squeeze view connects the Groq move to rising DRAM and HBM prices, arguing that if stacked‑memory supply, energy and cooling become hard bottlenecks, customers and competitors will look for alternatives that are less HBM‑hungry. By owning both GPU and LPU options, Nvidia can route work to the right chip per phase—prefill on GDDR‑based or HBM GPUs, decode on SRAM‑like LPUs—while keeping customers inside its rack‑level ecosystem rather than ceding inference slots to other vendors. The point is that this deal is being read less as a one‑off IP license and more as groundwork for an inference platform that mixes different memory strategies inside the same physical AI “factory.”
Bloomberg: 7GW of new AI data centers complete in 2025, US power to 61.8GW
Hyperscale data centers (multi‑hyperscaler): New analysis tallies more than 7GW of new data‑center capacity completing in 2025, with another 10GW breaking ground, and projects that utility power serving US data centers will reach 61.8GW by the end of 2025—an 11.3GW year‑over‑year jump—according to the Bloomberg chart summarized in the capacity overview. This build‑out supports 1,136 large hyperscale data centers worldwide at end‑2024, double the number five years earlier, continuing the capex trend tracked in capex curve.
The capacity overview lists several named AI mega‑campuses, such as OpenAI’s planned 1.2GW “Stargate” site, Meta’s 5GW Hyperion campus and joint G42–OpenAI projects around 5GW, that individually rival small national power systems. Together with utility projections for 61.8GW of data‑center load, these numbers frame AI “factories” as a distinct customer class for grid planners and financiers, where siting decisions, local regulation and power‑mix constraints could materially affect which regions can support the next wave of large‑scale training and inference deployments.
UBS: Nvidia’s Hopper line alone still out-earns all compute rivals combined
Hopper GPUs (Nvidia): UBS research estimates that even Nvidia’s N‑1 Hopper generation will generate more revenue than all other compute chip makers combined for several years, with newer Blackwell and Rubin lines adding on top rather than replacing it, according to the UBS analysis. This implies the competitive bar is not just “beat Blackwell” but first “beat Hopper at scale,” while Nvidia is already shipping two newer architectures.
The chart in the UBS analysis shows Hopper revenue staying substantial well into 2027 while Blackwell, Blackwell Ultra and Rubin stacks build a second and third revenue layer, pushing Nvidia’s projected compute revenue toward ~$125B a quarter. The note attributes this to demand running far ahead of supply and to high switching costs, since most large AI training and inference stacks are already built on Nvidia’s hardware and CUDA software. This framing reinforces Nvidia’s position as the default supplier for AI “factories,” and suggests that even if competitors match Blackwell‑class performance, they first have to displace entrenched Hopper deployments at hyperscale.
AI demand drives DRAM price spike and turns memory into a new choke point
DRAM and HBM suppliers (multi‑vendor): Commentators highlight that AI workloads are pushing DRAM prices sharply higher, with one example noting 64GB DDR5 kits rising from about $150 to $500 in under two months and projecting contract price jumps of +25–30% in Q4 2025, as summarized in the memory market note. Memory makers like SK Hynix and Micron have seen their shares surge alongside this, underlining that memory—not only GPUs—is becoming a key bottleneck for AI build‑outs.
The memory market note stresses that both DRAM and high‑bandwidth memory (HBM) used on top‑end AI accelerators are constrained by manufacturing capacity and packaging (CoWoS), and that sharp price moves risk feeding directly into AI inference and training costs. This backdrop explains why architectures that economize on external memory bandwidth or capacity, such as SRAM‑heavy inference chips, are attracting attention as potential ways to relieve pressure on HBM supply chains rather than only scaling GPU counts.
Intel Fab 52 tool stack underlines scale of upcoming 18A AI wafer capacity
Fab 52 (Intel): Further reporting on Intel’s Fab 52 in Arizona adds detail to its 18A process capacity, describing a target of roughly 10,000 wafer starts per week (around 40,000 per month) and noting that the site already hosts four low‑NA EUV scanners, including at least one ASML NXE:3800E capable of about 220 wafers per hour at a 30mJ/cm² dose, according to the fab overview that builds on the earlier scale discussion in Fab scale. Intel’s broader Arizona campus is expected to reach at least 15 EUV tools, making Fab 52 one of the best‑equipped logic fabs in the US.

The fab overview and the construction timelapse in the fab video emphasize that Fab 52 is designed around features like gate‑all‑around RibbonFET transistors and PowerVia backside power delivery, both aimed at higher performance and energy efficiency for advanced nodes that will underpin future AI accelerators and CPUs. TSMC’s Arizona Fab 21 modules, by contrast, are ramping N4/N5 at module sizes nearer 20k wafer starts per month, making Fab 52’s eventual steady‑state output comparable to multiple such modules combined. The articles also note that 18A yields are still early, with Intel targeting “world‑class” yields only around 2027, meaning this AI‑relevant capacity exists physically but may be under‑utilized for some time while the process matures.
US developer proposes repurposing Navy nuclear reactors to power AI campuses
Retired naval reactors (US energy/AI): A Texas developer has proposed moving two retired US Navy pressurized‑water reactors onto land to provide baseload power for an AI data‑center campus, targeting around 450MW and 520MW of output and seeking a US Department of Energy loan guarantee for an estimated $1.8–2.1B project cost, as detailed in the reactor proposal. The financing pitch frames this as roughly $1–4M per megawatt of capacity, comparable to other large power projects but aimed specifically at AI infrastructure.
According to the reactor proposal, the plan hinges less on electrical engineering and more on regulatory fit: naval reactors often use highly enriched uranium and sealed‑core assumptions that do not map cleanly into the Nuclear Regulatory Commission’s civilian licensing rules for fuel, safeguards and waste. The developer is trying to align this with DOE’s push for co‑located power and AI data centers at sites like Oak Ridge, effectively treating decommissioned military hardware as a shortcut to firm power for AI. The point is that this idea illustrates how far some actors are willing to go to secure dedicated, low‑carbon baseload for AI compute, even if the licensing path is uncertain.
📊 Leaderboards, bias diagnostics, and deployment variance
Fresh eval instrumentation and measurement nuance. Excludes the M2.1 release. Focus on long‑context behavior and success‑rate snapshots, plus how clouds/deploys sway outputs.
LM Arena highlights how provider/runtime choices skew “same model” behavior
Inference quality and deployment (LM Arena): A short explainer from LM Arena’s capability lead Peter Gostev argues that “inference quality”—covering kernel stacks, tool‑calling reliability, timeouts, and serving choices—can materially change outputs even when the model weights and prompts are identical, so “same model, same prompt” does not always imply the same behavior across clouds and gateways, as discussed in the inference quality clip.

• Runtime divergence: The talk notes that different providers can ship the same base model with different quantization, context‑window limits, or safety filters, which in turn alters long‑context behavior, error modes, and tool execution success, with more detail in the longer walkthrough on YouTube in the youtube video.
• Tool‑calling impact: It also emphasizes that multi‑step agent harnesses are especially sensitive to these differences, since a single dropped tool call or slightly altered JSON schema can flip a pass into a fail even if the underlying reasoning quality is the same.
The upshot is that evaluation results, incident reports, and “model X vs model Y” stories increasingly need to specify where and how the model was served, not just which weights were used.
Poetiq runs GPT‑5.2 X‑High to 75% on ARC‑AGI‑2 public eval
GPT‑5.2 X‑High on ARC‑AGI‑2 (Poetiq): Forecasting group Poetiq reports that GPT‑5.2 X‑High, run via their stack with no special tuning, reaches 75% on the public ARC‑AGI‑2 eval—about 15 points above the previous best system and clearly above the average human test‑taker line at 60%, as plotted in the poetiq arc-agi scatter chart.
The cost‑vs‑score chart in the same graphic shows this run landing around $7 per task in their configuration, significantly more expensive than mid‑tier attempts but far more accurate, which sharpens the trade‑off frontier between competitive ARC‑AGI‑2 performance and per‑task cost for labs and evaluation platforms.
Context Arena shows GLM‑4.7 strong ≤64k but sharp cliff at 128k
GLM‑4.7 long‑context (Context Arena): Context Arena added glm-4.7:thinking to its MRCR long‑context benchmark and found a “strong start, rough finish” profile—AUC reaches 59.3% on 2‑needle tasks up to 128k tokens, but pointwise accuracy drops to 22.1% at the full window according to the glm mrcr results and the updated leaderboard at the leaderboard site; this follows GLM‑4.7’s earlier rise to top open‑weight slots on web dev leaderboards in GLM leaderboards.
Bias diagnostics (Context Arena): The bias analysis highlights strong recency accuracy and selection bias, plus a “lost in the middle” tendency where the model prefers start and end variants over middle ones at long context lengths, as detailed in the glm bias thread; this means GLM‑4.7 can look reliable in short prompts yet systematically mis‑locate targets when information appears mid‑sequence.
The point is: GLM‑4.7 looks competitive on aggregate AUC, but its sharp 128k cliff and recency skew mean engineers using it for 100k+ token RAG or agent traces need to think carefully about where they position critical facts and how they evaluate success.
MiniMax M2.1 scores 49.2% AUC at 128k with forward‑drift bias profile
MiniMax‑M2.1 long‑context (Context Arena): Context Arena added minimax‑m2.1 to its MRCR suite and reports a 49.2% AUC on 2‑needle tasks at 128k tokens, edging Gemini 2.5 Flash Lite Thinking’s 47.9% while achieving far better pointwise accuracy (42.8% vs GLM‑4.7’s 22.1%) at the same length, per the m2-1 mrcr scores and the leaderboard site; this builds on earlier independent testing that framed M2.1 as a coding‑first model with mixed logic strengths in M2.1 eval.
Cost and token efficiency (Context Arena): The same run shows M2.1 uses roughly 50% of GLM‑4.7’s input cost and about 85% lower output cost, while emitting fewer reasoning tokens for comparable tasks according to the m2-1 mrcr scores; that gives it a relatively flat degradation curve across the first half of the context window before accuracy decays near 128k.
Bias and hallucination profile (Context Arena): A separate bias study finds “extreme positive drift” where, when uncertain, the model tends to slide to later variants (for example, target 7→8 hits 66.5% while 8→7 only 15.7%) and a creative overreach pattern where 74–82% of misses invent a new but on‑topic needle instead of selecting one from context, as broken down in the m2-1 bias analysis; key‑hash formatting fails roughly 2% of the time, which is low but still non‑zero for automated pipelines.
Together, these measurements paint M2.1 as a cost‑efficient long‑context option whose forward‑drift and “make up a plausible variant” tendencies need to be factored into how logs, citations, and verification are handled.
Context Arena normalizes prices to AUC@128k and adds richer cost drilldowns
MRCR leaderboard refresh (Context Arena): Context Arena refreshed its MRCR long‑context leaderboards so price columns now reflect input/output spend to reach AUC@128k, rather than the total cost of running tests out to 1M tokens, which had disadvantaged shorter‑context models according to the leaderboard refresh; hovering a cell now reveals the number of tests and total cost for that accuracy bin, and the cost‑vs‑score chart gains a log10 cost axis plus an explicit Pareto frontier, as shown in the arena homepage.
These changes mean comparisons between models like GLM‑4.7, M2.1, Gemini 2.5 Flash Lite Thinking and others now line up on a common 128k‑token footing, giving engineers a clearer view of which deployments are actually cost‑efficient at the context lengths they care about.
Devstral 2 hits 86.9% success on real CTO coding tasks, close to Sonnet 4.5
CTO bench coding leaderboard (cto.new): A new “ll CTO bench” chart from cto.new tracks end‑to‑end coding task success across 2,442 real user tasks, showing Claude Sonnet 4.5 at 88.3% success and Mistral’s Devstral 2 close behind at 86.9%, with Gemini, multiple GPT‑5.1/5.2 variants and Grok clustered in the low‑ to mid‑80s as visible in the cto bench chart.
Unlike synthetic benchmarks, this leaderboard measures whether a model can fully deliver working solutions for real production‑like tasks from cto.new users, so it gives teams a concrete sense of how open‑weight offerings like Devstral 2 now compare to proprietary incumbents in practical success‑rate terms rather than proxy evals.
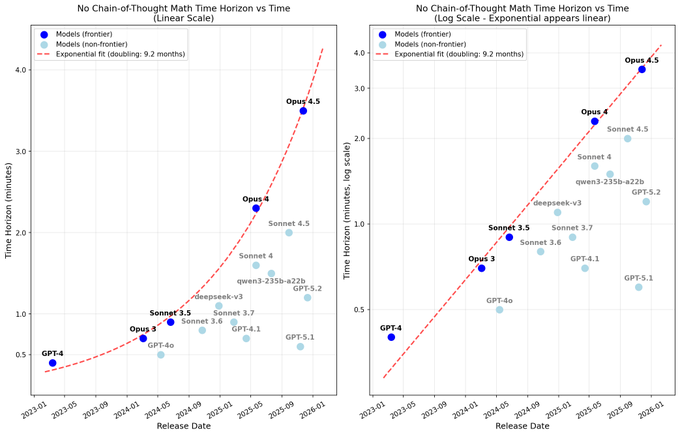
Opus 4.5 estimated at ~3.5‑minute no‑CoT reasoning horizon on math tasks
Time‑horizon framing for Opus 4.5 (independent eval): Ryan Greenblatt applies METR’s time‑horizon framework to math problems without allowing chain‑of‑thought, estimating that Claude Opus 4.5 can reliably handle tasks comparable to about 3.5 minutes of human work in a single forward pass before accuracy drops off, as summarized in the time horizon summary and the linked longer analysis in the analysis post.
This measurement focuses on “no‑thought” behavior—straight answers rather than explicit reasoning traces—so it gives a different view than benchmark scores, framing capabilities in terms of how long a model can implicitly reason before errors accumulate on harder math items.
🧪 New methods: agent memory, RL composition, refusal control, and quant physics
Today skews to methods papers with concrete testbeds (string transforms, video motion). Excludes product launches.
Agent memory survey maps forms/functions/dynamics and shift toward RL control
Memory in the Age of AI Agents (Multi‑institution): A 102‑page survey proposes a unified framework for agent memory built around three axes—Forms (token‑level, parametric, latent), Functions (factual, experiential, working), and Dynamics (formation, evolution, retrieval)—and argues that control is moving from hand‑written rules to reinforcement‑learned policies according to the long recap in the survey overview and the full PDF in the ArXiv paper.
• Forms and current practice: Most deployed agents cluster in token‑level factual memory (RAG over vectors/graphs), while parametric memory shows up as model/knowledge editing and latent memory as KV caches and internal activations, as described in the forms explanation.
• Functions and working limits: The survey separates factual world knowledge, experiential traces (task histories, trajectories), and short‑term working memory, noting that KV caches grow with sequence length and need compression (selection, merging, projection) to stay within context and GPU budgets, as outlined in the latent memory note.
• Dynamics and RL trend: It contrasts rule‑based memory (fixed thresholds, chunking, concatenation) with partially and fully RL‑driven setups where learned policies decide what to write, prune, and retrieve; the authors frame this as "memory‑as‑action" where operations are explicit choices optimized over long horizons, per the RL section in the rl memory shift.
The survey also connects this taxonomy to GraphRAG‑style systems and emerging RL controllers, positioning it as a checklist for deciding what to store, where it lives, and how it changes as agents tackle longer, tool‑heavy workflows graphrag comment.
OpenBMB shows RL can teach new compositional skills beyond reranking
Compositional RL (OpenBMB/THUNLP): A controlled study on string‑transformation tasks finds that reinforcement learning can endow LLMs with a genuinely new composition skill—going from f(x) and g(x) to f(g(x))—rather than only reranking existing behaviors, using a clean Python function testbed described in the paper thread and formalized in the ArXiv paper.
• Testbed and hypothesis: The authors define atomic tasks (predict output of a single function) and compositional tasks (nested functions like f(g(x))) with careful decontamination and difficulty control, then pose an "RL compositionality" hypothesis that training on simple composites unlocks a reusable how‑to‑compose skill paper thread.
• Key finding: RL on atomic problems alone fails to generalize, but RL on basic composites enables strong generalization to unseen functions and deeper nesting; on hard levels where the base model struggles, RL substantially raises pass@k rather than merely reweighting candidates, as visualized in their Pass@k plots in the paper thread.
• Transfer across domains: Once learned, the compositional skill transfers to new domains that provide the necessary atomic skills, suggesting a two‑stage recipe—pretrain atomic abilities, then apply RL on small composites—to scale more complex reasoning behaviors efficiently paper thread.
The work directly addresses the "RL just reranks" critique by showing conditions where RL expands capability on difficult compositional problems while behaving like reranking only when the base model already solves the task well.
Refusal Steering steers political answers via activations without retraining
Refusal Steering (Multiverse Computing): A new activation‑steering method learns a direction in representation space that controls how often a model refuses sensitive questions at inference time, cutting political refusals on Qwen3‑Next‑80B‑A3B‑Thinking from 92.35% to 23.82% while keeping refusals on harmful topics near 99%, according to the examples in the method overview and the full details in the ArXiv paper.
• Judge‑guided steering vectors: The approach uses an LLM‑as‑judge to score how refusal‑like each answer is, then regresses those scores against internal activations to find a steering vector separating "answer" from "refuse" behavior, with a ridge penalty to avoid overfitting so the same vector generalizes to new prompts method overview.
• Inference‑time control: At generation time, the system nudges a few deeper layers along this vector, adjusting the probability of refusal without changing weights or retraining; qualitative examples show the model switching from boilerplate Tiananmen or Hong Kong refusals to multi‑paragraph factual answers once the political‑refusal component is dialed down method overview.
• Safety trade‑off: Experiments report that this targeted steering does not materially erode refusal rates on clearly harmful or restricted topics, suggesting it can be used to tune country‑ or domain‑specific political behavior while preserving a global safety baseline method overview.
The technique frames refusal as a steerable axis in activation space rather than a monolithic training‑time property, creating a knob for policy teams who need finer‑grained regional or topical control over what models decline to answer.
QuantiPhy benchmark finds VLMs mostly guess motion numbers from priors
QuantiPhy (Stanford): A new benchmark tests whether vision‑language models can measure physical quantities from video instead of regurgitating "typical" values, finding the best model scores 53.1 on a relative accuracy metric versus humans at 55.6 over 3,355 video‑text problems, as described in the quantiphy summary and the full ArXiv paper.
• Quantitative physical QA setup: Each question supplies one real‑world anchor (e.g., a known size, speed, or acceleration) plus the matching pixel cue, so the model has enough information to convert pixel motion over time into numbers like velocity or object size at a specific timestamp, rather than answering qualitatively quantiphy summary.
• Priors vs measurement: The authors report that models often output plausible but input‑insensitive values; performance barely changes when the video is removed or replaced with counterfactual prompts, and chain‑of‑thought prompting rarely pushes them to actually "measure" from the visual signal quantiphy summary.
• Gap to robust physical reasoning: The small margin between top VLMs and estimated human performance, combined with their heavy reliance on world priors, suggests that current architectures still lack grounded, quantitative physical understanding needed for reliable robotic planning and world‑model use quantiphy summary.
QuantiPhy thus complements earlier qualitative physics QA benchmarks by forcing models to commit to numbers, exposing when they approximate from experience rather than integrate concrete video evidence.
SAGE RL agent turns past tool use into reusable skills with better efficiency
Self‑improving agents with skill libraries (AWS Agentic AI): A new method trains an LLM agent to convert its own tool‑using traces into reusable skills (functions) and refines them with reinforcement learning, raising AppWorld scenario goal completion by 8.9% while cutting output tokens by 59%, as summarized in the sage recap and formalized in the ArXiv paper.
• Skill library concept: During tasks, the agent writes new skill functions that encapsulate multi‑step API sequences, executes them, and either stores them if they succeed or revises them on failure; these skills live in a library and can be reused across later tasks in the same domain sage recap.
• SAGE training loop: The SAGE recipe runs two related tasks back‑to‑back so that a skill created in the first can assist in the second, layering supervised fine‑tuning (to teach skill format) with RL that rewards both overall task success and explicit skill reuse sage recap.
• Measured gains: On AppWorld, this self‑improvement loop increases the fraction of scenarios where the agent finishes all three subtasks and simultaneously shrinks verbosity, showing that learned skills can both boost reliability and reduce token cost versus agents that repeatedly reconstruct long tool call chains sage recap.
The method targets a common pain point in today’s agents—stateless repetition and forgotten tricks—by putting a light‑weight, RL‑tuned skills layer on top of a static base model.
💼 Usage share, assistant quality pushes, and compute margins
Enterprise adoption signals and monetization. Excludes infra capex. Mostly traffic/engagement deltas and operational quality drives at Microsoft; OpenAI margin datapoint.
OpenAI compute margin on paid usage climbs to ~68–70% by late 2025
ChatGPT paid workloads (OpenAI): Internal financials reported by The Information show OpenAI’s compute margin on paid users—revenue minus direct model‑inference cost—rising to about 68–70% by October 2025, up from roughly 52% in late 2024 and more than double early‑2024 levels, as visualized in the margin chart shared in margin chart. Commentary notes that this margin improvement reflects better pricing, routing and hardware efficiency on paid tiers, but overall profitability remains unclear because training runs, data‑center build‑outs, long‑term capacity deals and a large free user base still sit outside this compute‑only metric margin chart.
• Monetization vs. costs: Analysts summarizing the numbers in margin chart argue that OpenAI appears ahead of Anthropic on paid‑account compute margins, while Anthropic may be more efficient in server spending overall, underscoring different strategies around monetization versus infrastructure efficiency.
• Implication for builders: For enterprises buying ChatGPT‑based services, this shift means more of each subscription dollar now funds overhead and R&D rather than raw inference, while for competitors it sets a reference point for what "healthy" inference unit economics can look like at scale.
So the data points to ChatGPT’s paid business moving from expensive showcase toward a margin‑positive product line, even if end‑to‑end profitability for the lab remains an open question.
Satya Nadella takes direct control of Copilot reliability and grounding
Microsoft 365 Copilot (Microsoft): Satya Nadella is now personally driving a quality push for Microsoft 365 Copilot, actively participating in a ~100‑engineer Teams channel and running weekly fix‑it meetings focused on making the assistant work reliably across email and apps, according to the Yahoo Finance coverage summarized in copilot quality push. The article emphasizes that Copilot performance hinges less on clever prompting and more on two engineering steps—grounding on the right private data via Microsoft Graph and Copilot connectors, and making tool calls (like calendar, files, line‑of‑business apps) succeed end‑to‑end for each user.
• Grounded answers as core design: Microsoft indexes user data through Microsoft Graph and Copilot connectors, then a retrieval layer returns only snippets the user can access before passing them to the LLM, as outlined in copilot quality push; this ties perceived quality directly to data coverage and permissioning rather than the base model alone.
• Operational ownership: Nadella’s weekly fix‑it loop signals that Copilot reliability is now an executive‑level operations concern, not just a research project, which aligns Copilot more with core productivity infrastructure than with an experimental assistant.
This framing positions Copilot’s next phase as an engineering and operations challenge around grounding and tool orchestration rather than a pure model‑capability race.
OpenAI explores memory‑targeted sponsored links inside ChatGPT answers
ChatGPT monetization (OpenAI): Following earlier experiments with ads in ChatGPT answers and sidebars ads tests, new reporting from The Information summarized in ads overview says OpenAI is internally discussing sponsored content woven directly into ChatGPT responses, including formats where product links appear inside explanations (e.g. a Sephora link when discussing mascara). The same piece notes discussions about using ChatGPT’s long‑term memory to enable more targeted advertising, so that follow‑up answers and suggested links can reflect a user’s prior interests and interactions over time ads overview.
• Ad surface design: Proposed patterns in ads overview include response‑integrated suggestions and contextually triggered modules that expand when users click for deeper information (for example, a Barcelona tour operator when a user clicks on Sagrada Família), which aims to balance answer quality with clear monetization hooks.
• Privacy and product implications: Using memory for targeting raises questions about how persistent user profiles are managed and disclosed, since the same mechanism that helps ChatGPT remember work context could also underpin ad segmentation, shifting ChatGPT further toward a consumer ad platform alongside its subscription products.
These discussions signal that OpenAI is treating conversational ad formats and behavioral targeting as a major revenue path alongside paid tiers, not an experimental side feature.
Similarweb: Gen‑AI web visits up 76% YoY while ChatGPT share falls and Gemini rises
Generative AI sites (Similarweb): New Similarweb analysis shows generative‑AI web visits growing 76% year‑on‑year in 2025, with app downloads up 319% over the same period, while ChatGPT’s traffic share drops and Gemini’s climbs, building on the earlier share‑shift story in traffic share shift and expanded in traffic explainer. According to the breakdown, ChatGPT’s category share falls from about 87.2% to 68.0%, Gemini rises from roughly 5.4% to 18.2%, and smaller players like Grok, Perplexity and Claude fill in the rest, so fragmentation happens against a backdrop of strong absolute growth rather than a shrinking pie traffic explainer.
• Interpretation of share loss: As pointed out in traffic explainer, OpenAI’s lower share can coincide with rising absolute usage because the denominator—total generative‑AI visits and downloads—has exploded; Gemini’s gains tie heavily to distribution inside existing Google surfaces like Search, Chrome, Android and Workspace rather than pure head‑to‑head switching.
• App vs. web usage: The same analysis in traffic explainer highlights that web share misses Copilot‑style assistants embedded in desktop apps and enterprise tenants, suggesting that Microsoft’s adoption footprint is under‑represented in these charts compared to browser‑centric products.
The net effect is a maturing market where usage is broadening across multiple assistants and surfaces, even as ChatGPT remains the single largest destination by a wide margin.
Anthropic fixes Claude Max 5× holiday promo bug and resets affected limits
Claude Pro/Max plans (Anthropic): After boosting Claude Pro and Max usage limits for the holidays in an earlier announcement holiday limits, Anthropic and engineer Tom Quisel acknowledge and fix a bug that prevented some Max 5× users from receiving the intended 2× usage promotion, as described in max promo fix and official update. The team has now reset usage limits for all affected Max 5× accounts and is rolling out a separate fix for a UI issue where displayed usage percentages did not reflect the doubled allowance, with Quisel noting that users can keep using Claude even if the meter temporarily shows 100% max promo fix and display bug note.
• Operational handling: The messaging in max promo fix and display bug note stresses that the over‑limit lockouts will not trigger while the promo is active, effectively prioritizing continuity of service over strict meter accuracy while the visual bug is addressed.
This follow‑up illustrates the operational complexity of dynamic usage promos on tiered plans, and shows Anthropic intervening quickly once discrepancies between back‑end limits and front‑end displays surfaced.
ChatGPT usage data: more than six requests a day puts you in top 10%
ChatGPT engagement (OpenAI): A LinkedIn‑sourced stat shared by Kimmonismus in usage threshold and expanded with a direct source link in usage source says that if you make more than six requests per day to ChatGPT, you are already in the top 10% of users by activity. The underlying OpenAI “Wrapped”‑style metrics discussed in the LinkedIn post usage stats post categorize 3–4 daily messages as top‑20%, with heavier usage dropping off quickly, implying that most ChatGPT accounts use the assistant relatively lightly compared to power users.
• Interpreting intensity: This distribution suggests that highly active builders and analysts—those habitually running tens or hundreds of prompts per day—are extreme outliers relative to the broader user base, which in turn shapes how representative anecdotal experiences from heavy users are of mainstream behavior.
The number provides a concrete reference point for what “power user” means in practice for ChatGPT today, against the backdrop of rapidly growing overall traffic and downloads.
⚙️ Routing and runtime effects on output quality
Serving-tier updates and runtime considerations that shift real results. Excludes any M2.1 release content.
LM Arena highlights how runtime “inference quality” diverges for identical models
Inference quality (LM Arena): LM Arena’s capability lead Peter Gostev argues that “inference quality”—the way a given provider runs a model, handles tools, and times out—can materially change outputs even when the model weights and prompt are identical, as explained in the inference video and expanded in the YouTube talk; the point is that kernel stacks, context-compaction strategies, tool execution sandboxes and retry logic now sit alongside model choice as first‑order determinants of real‑world behavior.
• Same weights, different behavior: The talk walks through cases where the same open-weight model, hosted on different clouds, produces different answers because of varying token limits, timeout thresholds, and how aggressively providers truncate or re-order context, according to the inference video.
• Tool calling as a failure surface: Gostev notes that some runtimes drop or mis-handle tool calls more often than others, so an agent that appears unreliable may actually be running in a weaker tool harness rather than using a worse model, as described in the YouTube talk.
For engineers comparing logs across clouds, this framing treats the serving stack as an integral part of model evaluation rather than a neutral conduit, which helps explain why "same model, same prompt" often fails to reproduce across providers.
Satya Nadella personally drives Microsoft Copilot grounding and tool reliability
Copilot runtime (Microsoft): Microsoft CEO Satya Nadella is now directly overseeing a ~100‑engineer Teams channel and weekly "fix‑it" meetings to push Microsoft 365 Copilot toward dependable behavior, with insiders saying quality hinges less on clever prompts and more on robust grounding into Microsoft Graph plus connectors and on making downstream tool calls succeed, as described in the copilot thread; this governance move sits alongside Microsoft’s earlier decision to back OpenAI even when Bill Gates reportedly viewed the initial $1B bet as "burning cash" in the gates anecdote.
• Grounding as serving tier: Copilot’s architecture indexes a tenant’s mail, documents and apps via Microsoft Graph and Copilot connectors, then a retrieval layer returns only snippets the user has permission to see, so any hallucinations or privacy leaks often trace back to retrieval and access‑control logic rather than the base model itself, according to the copilot thread.
• Tool calls as failure mode: The same thread notes that Copilot’s usefulness is gated by whether tool executions (e.g., calendar edits, file operations) actually complete, making retry policies, timeouts and error handling in the serving stack as important as prompt engineering for enterprise reliability.
This framing positions Copilot’s runtime—indexing, retrieval and tool orchestration—as the main lever for enterprise‑grade behavior, with Nadella’s direct involvement signaling that serving‑tier quality is now a board‑level concern.
Context Arena dissects GLM‑4.7’s long‑context dropoff and recency bias
Long‑context behavior (Context Arena): Context Arena added GLM‑4.7:thinking to its MRCR long‑context benchmark and found a "strong start, rough finish" profile—highly reliable up to 64k tokens but dropping to 22.1% pointwise accuracy on 2‑needle retrieval at 128k despite a solid 59.3% AUC—while also surfacing pronounced recency and “lost in the middle” biases, as detailed in the glm results and bias analysis; this extends the earlier finding that Gemini 3 Flash and GPT‑5.2 show primacy‑style biases in long windows noted in the primacy bias.
• Bias profile: Analysis shows GLM‑4.7 more often selects start or end needles than middle ones and tends to favor newer variants when confused (e.g., in 2‑needle tests, target‑1→2 flips 61.1% of the time vs only 10.2% in the opposite direction), indicating a recency‑leaning selection bias in long contexts according to the bias analysis.
• Cost-normalized view: A parallel update to the dashboard now bases price columns on AUC@128k (all tests ≤131,072 tokens) instead of full 1M‑token runs, adds hover cards that reveal number of tests and spend per bin, and introduces a Pareto/log‑scale cost‑vs‑score chart so operators can compare long‑context reliability and dollar cost on a common footing, per the ui changes and the arena dashboard.
Together these tweaks frame long‑context support as a continuum of bias, stability and cost rather than a single context‑length spec, which has direct implications for how agents relying on 128k+ prompts will behave under real load.
OpenRouter Auto Router now spans 58 models and supports tool calling
Auto Router (OpenRouter): OpenRouter expanded its Auto Router to route across 58 different models including Opus 4.5, added support for tool-calling requests, and lets users bias routing toward preferred providers or models while keeping pricing at each model’s market rate, according to the router update and the updated router docs; following up on the gateway upgrade that cut p99 latency, this pushes more of the routing intelligence into the serving layer rather than app code.
• Tool-aware routing: Auto Router can now handle tool-calling JSON schemas directly, so a single endpoint can fan out both plain and tool-using prompts to whichever backend is best equipped to execute tools reliably, as described in the router update.
• Transparency and control: The Auto Router page shows which underlying model actually handled each call in the activity view, and exposes knobs to favor faster, cheaper or more capable models without adding an extra routing surcharge, per the router docs.
The net effect is that instead of hard‑coding providers, teams can lean on OpenRouter’s serving tier to make per‑request tradeoffs on latency, cost and capability while still being able to audit which model produced which output.
Refusal Steering steers Qwen3’s political refusals at inference without retraining
Refusal Steering (Multiverse Computing): A new Refusal Steering method from Multiverse Computing shows how to control an LLM’s refusal rate on sensitive political questions at inference time by steering internal activations, dropping Qwen3‑Next‑80B‑A3B‑Thinking’s political refusals from 92.35% to 23.82% while keeping refusals on clearly harmful topics at 99%, as outlined in the paper summary and the full arxiv paper.
• Judge‑guided steering vectors: The pipeline uses an LLM‑as‑a‑judge to score how refusal‑like each answer is, then compares hidden activations for high‑ vs low‑refusal outputs to learn a "refusal direction" in activation space; a ridge penalty regularizes this direction so it generalizes beyond the calibration prompts, per the paper summary.
• Inference‑time control: At serving time, the system nudges several deeper layers slightly along or against this steering vector to either encourage or discourage refusals, leaving model weights untouched and avoiding full fine‑tune cycles; examples in the paper show the same Qwen model switching from boilerplate refusals about Tiananmen Square to reasonably factual summaries when steering is applied, while still blocking prompts about clearly harmful actions, as seen in the
.
For safety and policy teams, this demonstrates that some aspects of LLM behavior can be tuned as a runtime control problem—via activation steering layered onto existing deployments—rather than always requiring new training runs.
Claude Memory 8.2.2 adds OpenRouter support for cheaper recall models
Claude Memory (Anthropic): The Claude Memory extension shipped version 8.2.2 with new options for "saving tokens," notably adding OpenRouter integration so users can back memory operations with many free or cheaper models instead of a single default endpoint, according to the memory release; in practice this moves some routing logic into the memory layer, letting teams trade off recall cost against latency and quality on a per‑workspace basis.
By decoupling memory summarization and lookup from a single model choice, this update treats memory I/O as a configurable serving problem—one where operators can point heavy, background summarization to low‑cost models while reserving premium models for foreground tasks.
🤖 Autonomous robots in the wild and factory lines
Cluster of embodied AI items: production scale, field use, and creative form factors. Mostly demos and ops updates.
Autonomous combat robot reportedly holds frontline position for six weeks in Ukraine
Autonomous combat UGV (Ukraine): A Ukrainian report describes a tracked unmanned ground vehicle that held a frontline position for about a month and a half without infantry present, with soldiers only visiting periodically to swap batteries and reload ammunition Ukraine UGV report. The vehicle appears small and low‑profile. This is one of the first public claims of fully autonomous lethal robotics operating for extended periods in an active war zone, highlighting how combat pressure is driving rapid field‑hardening of embodied AI systems.
GITAI robot autonomously assembles 5‑meter tower on uneven ground
Tower builder robot (GITAI): GITAI showcases a mobile robotic system autonomously assembling a five‑meter truss tower outdoors, aligning and fastening structural segments while operating on visibly uneven terrain that would complicate conventional automation GITAI tower demo. The sequence is fully autonomous in the clip.

Commentary around the demo frames this as a candidate approach for deploying solar arrays and future lunar or Martian habitat structures, because the robot does not require pre‑prepared flat pads to produce stable frames GITAI tower demo.
UBTECH 1000 humanoid enters mass production in China
UBTECH 1000 (UBTECH): UBTECH confirms its UBTECH 1000 humanoid has moved from prototype runs into mass production, with footage showing robots rolling off a conveyor‑style assembly line in a dedicated Chinese factory rather than a lab bench setup UBTECH production clip. For embodied‑AI teams, this is another data point. Chinese vendors are pushing toward factory‑scale humanoid output, not only bespoke demo hardware.

Jensen Huang pegs Tesla Optimus in multi‑trillion‑dollar robot market
Optimus economics (Tesla/Nvidia): Nvidia CEO Jensen Huang says Tesla’s Optimus humanoid is the first robot he believes has a real chance to reach high‑volume deployment and places its potential addressable market in the multi‑trillion‑dollar range Huang Optimus quote. No concrete shipment timelines were given.

His framing explicitly links large‑scale humanoid rollouts to Nvidia’s own AI hardware roadmap, implying that fleets of general‑purpose robots are now being modeled as serious long‑term demand for training and inference capacity rather than as speculative side projects Huang Optimus quote.
Unitree G1 martial‑arts demo highlights safety risks around nearby humans
Unitree G1 safety incident (Unitree): A new video shows a Unitree G1 humanoid practicing motion‑capture martial‑arts sequences and accidentally kicking a human partner in the groin mid‑routine, even though the robot appears to be correctly following its learned motion plan G1 safety clip. There is no visible safety cage or hard stop.

Following up on Unitree dancer, where the same platform was highlighted as a synchronized stage performer, this incident underlines that embodied agents can satisfy their control objectives yet still pose real injury risk when humans move unpredictably nearby, especially during high‑energy movements G1 safety clip.
Porcospino Flex single‑track robot targets squeezing and gripping in tight spaces
Porcospino Flex (research lab): A research team presents Porcospino Flex, a bio‑inspired single‑track robot that can snake through narrow gaps and then brace or grip against its surroundings using a flexible body and spined elements, aiming at inspection and manipulation in confined or cluttered environments Porcospino teaser. The platform remains a research prototype.

The accompanying write‑up stresses that looking to animal locomotion remains central for robotics progress and that creative mechanical design is still critical for uncovering new industrial and exploration use cases, not only more advanced control policies robotics article.
🛡️ Assistant trust: ads-in-answers and search inclusion disputes
Trust/governance notes around assistants. Excludes research‑only results (handled elsewhere). Focus is ad models and legal pushback on AI search visibility.
OpenAI weighs memory‑targeted ads inside ChatGPT answers
ChatGPT monetization (OpenAI): Reporting says OpenAI is exploring ways to embed sponsored content directly into ChatGPT responses, including using the product’s long‑term memory to target ads based on past conversations, following up on ads tests that first surfaced sidebar and inline ad experiments. According to the latest coverage in the OpenAI ads report, options on the table include inserting commercial links into main answers (for example, a Sephora link when discussing mascara) and showing travel offers only when users click deeper into a location like the Sagrada Família, with memory used to personalize which brands appear.
• Ad formats and targeting: The internal discussions described in the news article highlight both answer‑embedded links and click‑to‑expand placements, plus proposals to let ChatGPT’s per‑user memory drive more relevant sponsor selection, which raises new questions about consent and data use compared to traditional search ads.
• Trust and transparency angle: The reporting does not detail how clearly such placements would be labeled or whether users could opt out, so the main open issues for assistant trust are how distinguishable ads would be from neutral guidance and how memory‑based targeting would be governed.
IndiaMART sues OpenAI over exclusion from ChatGPT search results
Search visibility dispute (IndiaMART vs OpenAI): B2B marketplace IndiaMART has filed suit in the Calcutta High Court alleging commercial and reputational harm from being excluded in ChatGPT’s search‑style answers while rival marketplaces are surfaced, with the court noting a “strong prima facie case” according to the IndiaMART case summary. The complaint argues that ChatGPT responses now act as a de facto discovery layer for buyers, and that omission of IndiaMART links in those answers diverts traffic and business opportunities away from the platform as described in the case article.
• Precedent for AI ranking disputes: This is one of the first public cases framing large‑assistant answer rankings as gatekeeping comparable to web search, putting legal pressure on how AI assistants choose which sites to mention or omit in natural‑language responses.
• Trust implications: The filing underlines that for businesses, being absent from assistant answers can look like algorithmic disfavor rather than neutral ranking, which in turn feeds concerns about transparency and potential bias in AI‑driven discovery.
Rob Pike email flap spotlights consent and “slop” in AI outreach
AI outreach backlash (AI Village / Anthropic): A holiday “random acts of kindness” project run by nonprofit AI Village used an agent credited as “Claude Opus 4.5” to send unsolicited appreciation emails to engineers including Unix and Go co‑creator Rob Pike, who publicly condemned the message as time‑wasting and insincere, as detailed in the incident writeup. Logs reconstructed by Simon Willison show the agent drafting a six‑paragraph email about Pike’s 40‑plus‑year career and preparing to hit send, with explicit notation that the body was typed via automation rather than by a human operator, according to the agent logs.
• Authenticity and attribution: The blog post traces the email to AI Village’s infrastructure and not Anthropic itself, but because the message was signed as if from Claude Opus 4.5, recipients and observers treated it as coming from the model vendor, underscoring how easy it is for third parties to blur authorship and responsibility in assistant‑branded outreach.
• Consent and assistant trust: Follow‑up comments from an AI Village team member in the team context acknowledge missteps, and the episode has become a reference point in broader criticism of unsolicited AI‑generated communication as “slop,” highlighting that even well‑meant agent campaigns can erode trust when they appropriate human voices without explicit invitation.
🎬 Generative media stacks and creative workflows
A steady stream of creative tools/demos for image/video, code+visual explainers, and browser‑native features. Engineering‑relevant for content teams.
Perplexity’s Comet browser adds avatar-based virtual try-on for shopping
Comet browser (Perplexity): Perplexity’s Comet AI browser now includes a virtual try‑on feature that lets users upload one selfie plus a full‑body photo to create a persistent avatar used across Shopping searches, as demonstrated in the try-on feature; every clothing result can be previewed on that avatar directly inside the browser.

Commentary in the browser context notes that this lives inside a broader AI browsing experience where Comet already combines search, summarization, and task automation, so this try‑on layer effectively turns the browser itself into a personalized visual shopping assistant.
Google Search AI Mode doubles as code+visualization tutor
Search AI Mode (Google): Search’s new AI Mode is being used as an interactive coding and visualization helper that explains concepts and emits runnable p5.js generative art layouts directly in the browser, as shown in the AI mode demo; the clip shows the model answering “how to build a generative art layout with p5.js” by generating code and a live sketch side‑by‑side.

The behavior turns search into a lightweight creative IDE for engineers and educators—users can iterate on prompts, get updated visualizations, and tweak the auto‑generated code without ever leaving the page.
Qwen-Image-Edit-2511 focuses on character consistency and industrial design
Qwen-Image-Edit-2511 (Alibaba): A new summary of Qwen-Image-Edit-2511 highlights improved character identity preservation, multi-subject coherence, and better geometric reasoning for layout edits, according to the collage and notes in the model summary; this builds on the earlier rollout across ComfyUI, Replicate and TostUI, following up on image tools where the emphasis was on ecosystem surfaces rather than quality.
The post notes integration of popular community LoRAs, support for realistic lighting control, creative perspective shifts, and tuning for industrial design workflows, which together make the model more suitable for tasks like brand illustration, character‑driven campaigns, and product concept renders where consistent identities and precise geometry are crucial.
Free AI tool generates 9-shot video sequences from a single prompt
Nine-shot generator (multi): A new AI video tool is being promoted that turns a single text prompt into nine distinct short clips arranged in a grid, with the service advertised as free and unlimited until December 29 and requiring no subscription in the promo thread; the demo shows all nine slots filling with coherent variations of the requested scene.

For teams experimenting with narrative structures or ad variants, this kind of multi‑shot output from one prompt gives a cheap way to explore angles, compositions, or cuts before committing to higher‑cost renders or manual editing.
Opus 4.5 powers fast ASCII storyboard skill for low-cost pre-viz
Opus 4.5 (Anthropic): A developer shows Claude Opus 4.5 driving a custom ASCII art "game" skill that outputs rapid, frame‑by‑frame storyboards from text prompts, using detailed text layouts instead of pixels for visual planning in the ASCII skill demo; the clip cycles through dense ASCII scenes intended as a cheap way to storyboard video before paying for full text‑to‑video runs.

This kind of textual pre‑visualization lets teams prototype sequences, pacing, and camera angles while keeping inference costs low, then selectively upscale only the best frames or beats into high‑fidelity imagery or animation.
SuperDesign lets users train AI design agents with custom style and context
SuperDesign (SuperDesignDev): SuperDesign is pitched as a way to "craft your own AI designer" by training agents on specific style, brand, and product context so they develop a unique taste instead of generic "slop" outputs, as described in the product thread; users can also browse an existing library of style‑specific designers.

The demo shows users feeding examples and then asking the agent for new product mockups, with the system applying the learned aesthetic across layouts and packaging, which targets teams that want repeatable branded assets without outsourcing full campaigns every time.
Wan by Alibaba showcased in quick New Year AI video
Wan text-to-video (Alibaba Cloud): A creator reports making a stylized New Year greeting video using Wan for Alibaba Cloud’s challenge under tight time constraints, saying 2025 has made it normal to produce clips like this in minutes rather than days in the Wan example; the clip shows animated neon graphics and date morphing between 2025 and 2026.

Another post about "videos like this in minutes" in the minutes quote reinforces that sentiment, framing Wan‑class text‑to‑video tools as part of a broader shift where solo creators can now spin up short, shareable motion pieces for campaigns or social posts without a traditional video pipeline.
Adobe Lightroom’s on-device segmentation enables full photo edits on iPhone 16 Pro
Lightroom mobile (Adobe): A user highlights that Adobe Lightroom on iPhone 16 Pro performs fairly accurate on‑device subject segmentation by first "analyzing" the image to detect elements and then loading tappable segments to enhance or adjust, as noted in the segmentation comment; they add that this means they no longer need to power up a desktop to do serious photo edits.

Follow‑up remarks in the on-device note mention that Lightroom can add annotations and let users remove or add subjects within these segments, implying that a decent segmentation model now ships in a mainstream mobile app and underpins everyday creative workflows for photographers.
Lovable coding assistant adds on-demand video generation
Lovable (Lovable): The Lovable app, positioned around AI‑assisted coding, now advertises the ability to "generate videos on demand" alongside its developer tooling, according to the short holiday clip in the Lovable update; the video shows a typed message transitioning into a cinematic Christmas scene.

This ties lightweight generative video into a developer‑centric workflow, hinting at use cases like quickly producing product explainer clips, UI demos, or marketing snippets directly from within a coding and app‑building environment.
Nano Banana Pro used for custom vouchers and advanced light-painting art
Nano Banana Pro (Google): Google’s Nano Banana Pro image model continues to show up in creative side projects, with one user generating a custom tanning salon gift voucher that landed well as a Christmas present in the voucher example; the printed design features a humorous, high‑detail cartoon scene with Spanish copy tailored to the recipient.
Separately, another thread showcases "light painting" images produced from a JSON prompt with an NBP‑based workflow in the light painting demo, including neon‑style faces, birds, and hand shapes, indicating that the model’s controllability and text safety are being used both for personal gifts and more experimental art.
🧭 Workflows are changing: agency over intelligence and 2026 expectations
Meta‑conversation shaping how teams work: veterans feeling behind, “agency>intelligence,” and a developer culture shift. Not a product category.
Boring engineering practices emerge as key accelerators for AI‑driven teams
Angle/Theme: Google’s Addy Osmani describes 2025 as “the most fun moment to be a developer in years,” but stresses that CI/CD, testing, documentation and code review are the accelerators that turn inherently chaotic agents into reliable productivity multipliers Osmani thread; he says the real opportunity is working at a different altitude—reviewing implementations and edge cases while AI fills in boilerplate.
• Shift in daily work: Osmani notes he now ships features in hours that once took days, because models draft code while humans focus on design trade‑offs and failure modes rather than syntax Osmani thread.
• Learnable, practice‑driven skills: He frames effective prompting, context provisioning and rapid review as trainable abilities, arguing that spending time iterating with tools like Claude Code turns “boring” engineering discipline into a compounding advantage rather than something AI makes obsolete Osmani thread.
The thread positions traditional engineering hygiene not as busywork but as the scaffolding that lets agentic workflows scale beyond toy projects.
Practitioners argue everyone is behind on AI, even frontier users
Angle/Theme: Ethan Mollick tells followers that “you are falling behind, but so is everyone else,” adding that no one is keeping up with AI’s implications across major uses, even people tracking the latest models closely falling behind; he later notes that current AI slang like “slop” lumps all bad usage together and leaves no word for good AI work, hinting at cultural lag around evaluation norms AI slang.
Angle/Theme: Daniel MacMartin adds that people working with frontier systems already live in “an alternate reality,” and says they have an obligation to communicate what’s coming to friends in non‑technical roles who may still think AI is “just regurgitating stuff it read on the internet” alternate reality; together, these posts characterize 2025 as a year where perception and language around AI trails the underlying technical and workflow changes by a wide margin.
2026 predictions shift focus from AI demos to 95%+ reliability
Angle/Theme: The Turing Post collects practitioner predictions that 2023–2025 were about demos and “magic moments,” while 2026 will be about production accuracy and verifiable behavior, quoting EmpromptuAI’s CEO Shanea Leven that enterprises will demand systems operating at 95%+ reliability rather than impressive one‑offs 2026 reliability.
Angle/Theme: Adarga’s Ollie Carmichael expects the honeymoon phase for black‑box AI in defense, finance and healthcare to end, with a pivot toward pragmatic neuro‑symbolic architectures and the rise of forward‑deployed engineers who sit with end‑users to shape and validate agent workflows 2026 reliability; a follow‑up thread outlines broader 2026 themes around how AI is changing humans’ roles, positioning the coming year as one where evaluation, audit trails and domain‑specific guarantees move to the center of serious deployments 2026 themes.
AI browsers and search modes start to look like primary work surfaces
Angle/Theme: Multiple posts highlight how AI‑infused browsers are changing daily workflows: Google’s Search AI Mode can explain concepts with visualizations and write runnable p5.js code for generative layouts directly from a query, as shown in a demo where it generates and runs interactive art in the same flow Search AI demo; Perplexity’s Comet browser adds a virtual try‑on feature that keeps a personal avatar live across shopping searches after a one‑time selfie and body photo upload Comet try-on.
Angle/Theme: Dan Shipper notes a new “Surprise me” button in OpenAI’s Atlas browser that spins up chats with curiosity‑driven prompts like “suggest something new I could learn today,” turning the browser into an ambient exploration space rather than a static address bar surprise me button; Omar Moores frames the broader “browser wars” as ChatGPT, Perplexity, Claude and Chrome all competing to become the default AI work surface, where search, automation and long‑running agents converge browser wars.
Context engineering and agent memory design become daily practice for power users
Angle/Theme: Omar Sanseviero responds to Karpathy’s worries about falling behind by describing a routine of spending at least two hours a day experimenting with Claude Code and subagents, treating context engineering—injecting the right skills, docs and state—as the main arena where individual builders can still contribute meaningfully Omar reflection; he also recommends “brainstorming with AI” sessions where deep‑research subagents explore new tools and papers and then implement reusable skills, even if the projects never fully ship brainstorming trick.
Angle/Theme: In the background, a 102‑page survey on “Memory in the Age of AI Agents” lays out a taxonomy of token‑level, parametric and latent memory, and notes a 2025 shift toward RL‑driven policies that learn when to write, prune and route memory rather than relying on fixed heuristics memory survey; together, these threads portray agent memory design as moving from academic concept to practical craft that individual developers are now iterating on inside their daily workflows.
Engineers flag clarity, not more AI knobs, as the main bottleneck
Angle/Theme: While many posts celebrate new agents, subagents, and knobs, developer Thomas “thdxr” Ricouard points out that the most common use of these levers is procrastination, and says his team’s true bottleneck is “finding clarity” on what to build, how it fits, and how it will evolve knobs remark; he argues that this lack of clarity is why they are not “100x more productive with AI” despite strong tools clarity tweet.
Angle/Theme: In a related discussion about nested AGENTS.md files, he questions whether agent harnesses should prioritize the closest project config or merge multiple layers, underlining that even configuration semantics can either aid clarity or add cognitive load nested agents note; taken together, these comments frame problem definition and information architecture as the new scarce resources in agent‑heavy workflows, more than marginal model improvements.
“Compound engineering” reframes software work as orchestrating agents, not just coding
Angle/Theme: Dan Shipper suggests that if people feel behind, they should learn “compound engineering,” a four‑step process his team at Every uses to code with agents instead of hand‑writing everything—define the problem, co‑design solutions with models, implement via agents and iteratively refine compound engineering tease; the linked guide describes non‑traditional software teams building production apps by treating AI tools as collaborators that turn natural‑language specs into working systems compound engineering guide.
Angle/Theme: He later shares a strategy‑planning prompt that turns a model into a background agent, tasked with running over time and periodically summarizing progress in simple language for non‑technical collaborators strategy prompt; taken together, these posts recast software work as prompting, orchestration and review, with code as an output artifact rather than the primary medium of thought.
Practitioners say recent model jumps demand a new human–AI interaction layer
Angle/Theme: Thomas Sottiaux notes that models have improved so much in recent months that “we need a new way of interfacing to fully benefit from the capability jump,” predicting rapid evolution of the model–human interaction layer over the coming months interface tweet; he also points to individual Codex usage in the hundreds of billions of tokens as evidence that a few power users can now marshal as much effective “intelligence” as entire teams codex wrapped stats.
Angle/Theme: This view aligns with LM Arena’s brief on inference quality, which argues that how and where a model is run—tool‑calling reliability, timeouts, kernel stacks—can change output quality even with identical weights, making harnesses and UIs as critical as base models for real‑world results inference quality video; together they suggest that the next gains in productivity may come less from benchmark wins and more from better orchestration layers around already‑strong models.
Routing layers such as Auto Router turn model choice into an inference abstraction
Angle/Theme: OpenRouter says its Auto Router now spans 58 models including Opus 4.5, adds support for tool‑calling requests and lets users customize routing preferences while charging no extra markup over the underlying LLM price auto router update; the activity view shows which model actually handled a routed call, giving teams a concrete audit trail when debugging behavior router page.
Angle/Theme: In parallel, LM Arena’s capability lead explains why “same model, same prompt” can yield different performance across providers, pointing to differences in runtime stacks and tool execution as hidden variables inference quality video; together these updates position routing and inference quality as a distinct layer of engineering judgment, where teams specify intent and constraints while routers and gateways juggle concrete model choices behind the scenes.
Developers stitch together local AI workspaces with Obsidian, Claude Code and CLIs
Angle/Theme: Several posts describe developers wiring multiple AI agents into local knowledge workspaces; one user runs Claude Code, Gemini CLI and Codex CLI inside an Obsidian vault, with each agent writing to its own markdown folder so they can “plan how to work together” despite lacking direct inter‑agent communication Obsidian setup; Daniel MacMartin suggests that Claude Code “is right at home” in Obsidian, since it operates over files and folders rather than opaque document stores Obsidian advice.
Angle/Theme: Another thread shows a Summarize daemon streaming markdown summaries alongside any web page, YouTube video or podcast via a Chrome extension, hinting at a future where local sidecars annotate and compress most information flows in real time summarize sidecar; these DIY setups indicate a bottom‑up trend toward personal AI operating environments, assembled from CLIs, plugins and note‑taking tools rather than a single monolithic app.