ChatGPT Deep Research moves to GPT‑5.2 – 120 searches plus connectors
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
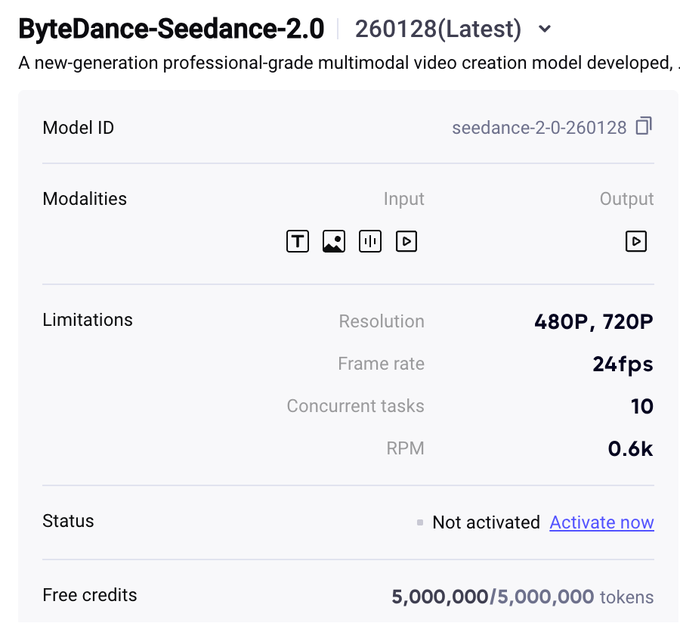
OpenAI revamped ChatGPT Deep Research, switching the backend to GPT‑5.2 and shipping tighter control surfaces: app connectors; site/domain scoping (including “search specific sites”); live progress with mid-run interrupts for follow-ups; a redesigned fullscreen report view with citations. Screens show runs hitting 120 searches; reports are described as exportable to Markdown/Word/PDF; rollout is Plus/Pro first with Free/Go “in coming days,” and a legacy-model option remains.
• OpenAI Responses API: agent primitives land as platform features—server-side compaction for multi-hour runs; OpenAI-hosted containers with controlled internet; Skills become first-class (Agent Skills standard + a prebuilt spreadsheets skill).
• Codex cyber routing: OpenAI says GPT‑5.3‑Codex requests can be routed to GPT‑5.2 on elevated cyber-risk signals; a false-positive spike hit ~9% of users for a 3h10m window; there’s still no UI indicator when rerouting occurs.
• Anthropic Cowork: Windows research preview ships with macOS parity; persistent global + folder instructions aim to stabilize long-lived desktop-agent behavior.
Across vendors, the thread is “agents with provenance”: steerable source constraints + durable runtimes; compaction policy control and independent reliability evidence remain underspecified.
Top links today
- Trusted Access for Cyber in ChatGPT
- Responses API primitives for long-running agents
- Deep Research in ChatGPT powered by GPT-5.2
- Deep Research connectors and site controls
- Claude Opus 4.6 sabotage risk report
- Claude Cowork for Windows announcement
- Cowork Windows download for paid Claude plans
- Qwen-Image-2.0 demo and try now
- Qwen-Image-2.0 technical details
- Kimi Agent Swarm blog post
- Warp Oz cloud agent orchestration platform
- Claude Code hooks safety skill repo
- LlamaParse cost-optimized PDF parsing
- AI21 engineering guide to scale vLLM
- AI research papers roundup from The Turing Post
Feature Spotlight
ChatGPT Deep Research revamp: GPT‑5.2 + connectors + source controls
ChatGPT Deep Research moves to GPT‑5.2 with connectors + site controls and live steering, making it closer to an auditable research agent (not just a one-shot report).
High-volume cross-account update: Deep Research in ChatGPT is now powered by GPT‑5.2 with app connectors, site/domain controls, live progress you can interrupt, and a redesigned fullscreen report experience—turning it into a more steerable research agent for analysts and builders.
Jump to ChatGPT Deep Research revamp: GPT‑5.2 + connectors + source controls topicsTable of Contents
📚 ChatGPT Deep Research revamp: GPT‑5.2 + connectors + source controls
High-volume cross-account update: Deep Research in ChatGPT is now powered by GPT‑5.2 with app connectors, site/domain controls, live progress you can interrupt, and a redesigned fullscreen report experience—turning it into a more steerable research agent for analysts and builders.
ChatGPT Deep Research switches to GPT‑5.2 and adds connectors, site controls, and live steering
Deep Research (OpenAI): Deep Research in ChatGPT is now powered by GPT‑5.2 and is rolling out “starting today,” alongside a more steerable research UX—connectors, site/domain controls, live progress you can interrupt, and a fullscreen report view, as announced in the launch thread.

The change is largely about control and provenance: the UI now surfaces a research plan/progress pane, lets you constrain sources (including a “search specific sites” flow), and produces a more report-like artifact with citations—see the UI screenshots showing the site whitelist modal and a run that reached 120 searches.
• Connectors and source scoping: OpenAI calls out “connect to apps in ChatGPT and search specific sites,” with domain whitelisting positioned as a first-class control surface in the launch thread.
• Mid-run steering: Deep Research now shows real-time activity/progress and supports interrupting to add follow-ups or new sources, as shown in the interrupt demo and described in the UI screenshots.
• Report outputs: A redesigned fullscreen report view ships with TOC-style reading; btibor91 adds that reports support downloads as Markdown/Word/PDF and that planning is editable pre-run, as described in the feature rundown.
Rollout and availability are described as Plus/Pro first with Free/Go “coming days,” and an option to use legacy models, per the feature rundown.
GPT‑5.2 Instant gets a small ChatGPT and API update (gpt-5.2-chat-latest)
GPT‑5.2 Instant (OpenAI): OpenAI says it updated GPT‑5.2 (the “instant model”) in ChatGPT with a modest quality lift, as noted in Sam Altman’s model update note.
Separately, btibor91 reports the same update has landed in the API as gpt-5.2-chat-latest, describing improvements in response style—“more measured and grounded” and putting key info earlier—as summarized in the API update report, with details captured in the release notes.
🧰 OpenAI agent primitives in the Responses API: compaction, sandboxed containers, Skills
Developer-facing platform work: OpenAI adds long-running agent primitives (server-side compaction, hosted containers w/ networking, and Skills support) that change how teams build multi-hour agents without blowing context windows.
Responses API adds server-side compaction for multi-hour agent runs
Responses API (OpenAI): OpenAI shipped server-side compaction as a native primitive so agents can run for hours without hitting context limits, as announced in the primitives thread and further grounded by the platform’s own tooling docs in the Shell tool docs. This moves “summarize/trim/offload” from app-specific prompt glue into an API capability.

The open question for builders is how much control you’ll get over when compaction happens and what gets preserved versus abstracted, since that’s where many long-horizon agent failures show up.
Skills become first-class in the Responses API (Agent Skills + spreadsheets)
Agent Skills in API (OpenAI): OpenAI made Skills a first-class concept in the Responses API—supporting the Agent Skills standard plus a first prebuilt spreadsheets skill—framed as reusable, versioned bundles that can attach to hosted and local shell environments in the primitives thread and echoed by the API compatibility note.
• How you’re meant to use it: OpenAI also published a “start building” walkthrough for packaging/uploading Skills and reusing them across environments, as laid out in the Skills cookbook.
Responses API adds OpenAI-hosted containers with controlled networking
Hosted containers (OpenAI): The Responses API now supports OpenAI-hosted container environments with controlled internet access, intended for agentic work that needs to install libraries and run scripts without leaving the platform boundary, as described in the primitives thread.
This explicitly targets the “agent needs a real runtime” gap—especially for jobs that mix tool calls with actual execution, package installs, and artifact generation.
ChatGPT Skills management UI appears for some users (partial rollout)
ChatGPT Skills (OpenAI): A new in-product Skills surface is showing up for some users, including a dedicated Skill page with install controls and file lists, as shown in the UI screenshot; separate reports suggest it’s only partially rolled out so far per the availability note, with similar confirmation screens in the skills arriving screenshot.
This looks like ChatGPT is converging on the same “Skills as portable bundles” model that the Responses API is formalizing, but with consumer-facing install/permissions UX.
Ecosystem signal: “.agents/skills” directory convention may be emerging
Skills packaging conventions: There’s active chatter about whether the “.agents/skills” convention has become a default for sharing skills across agent tools, as raised in the convention question. This is a small but practical signal that Skills are starting to behave like a cross-tool artifact format, not a one-vendor plugin system.
🧑💻 Codex reliability & access controls: cyber routing, UX pain points, and feedback loops
Continues the Codex push, but today’s news is about operational friction: users being rerouted to less-capable models for cyber-risk reasons, the resulting DX confusion, and requests for immediate product fixes and handoff/summarization features.
OpenAI: Codex cyber-risk routing to GPT-5.2 briefly overflagged ~9% of users
Codex model routing (OpenAI): OpenAI says a false-positive spike in “suspicious activity” detection affected ~9% of users between 15:35–18:45 PT, after which the issue was fixed, as stated in the incident update; this follows up on Preparedness rollout (phased high-cyber release) where some requests can be routed from GPT-5.3-Codex → GPT-5.2 when systems detect elevated cyber-misuse risk, as explained in the routing explanation. It’s still missing a UX affordance: OpenAI notes there’s currently no UI in Codex to tell users they’ve been rerouted, but notifications across Codex surfaces and better false-positive reporting are planned, per the routing explanation.
• Recovery path: Users who think they were misclassified can apply to regain access via the “Trusted Access for Cyber” flow, as described in the user report and reiterated in the routing explanation.
When Codex loops: “context left” thresholds and /new resets beat more prompting
Codex loop control: A practitioner suggests that when Codex starts looping with back-and-forth questions, it’s often a compaction/attention problem—once “context left” falls below ~40%, the model may repeat or over-question; the fix is to use /new rather than keep pushing in-place, as explained in the looping checklist. The same post recommends drafting an end-to-end plan (optionally saving it as a tickable file with acceptance criteria) and then verifying the implementation against it with a separate model pass.
Codex team solicits blunt “what’s wrong” feedback across app, model, and strategy
Codex product feedback (OpenAI): A Codex team member asks what the product should improve “immediately” across app, model, strategy, and features, explicitly inviting detailed pain points and priorities in a high-reply thread, as requested in the feedback question. It’s a live signal that a lot of the current bottlenecks are perceived as product/harness issues, not only raw model capability.
GPT-5.3-Codex is being used for full cross-language rewrites (legacy code ports)
GPT-5.3-Codex (OpenAI): Builders are highlighting whole-application rewrites between languages as a concrete “agentic” use case—see the rewrite use case. A separate anecdote reports throwing 5.3-Codex at a large legacy C codebase (SimCity 1989) to port it, and “it actually worked,” as amplified in the legacy port anecdote.
More public chatter says “switch to Codex” is the default move
Tool preference drift: Multiple posts amplify the idea that “the best engineers” are moving from Claude to Codex as a daily driver, as claimed in the switching claim. Other commentary frames this as an ongoing, practical choice (“switch to codex”) when Claude sessions degrade or stall, as seen in the switching anecdote.
Codex “planning” prompts sometimes turn into direct code changes
Codex initiative tuning: One reported failure mode is asking Codex to “plan this feature out” and getting code changes instead—captured in the no-plan screenshot. It’s a small but concrete example of why some teams want clearer plan/execute modes and more predictable initiative boundaries.
Codex app’s inline diff comments are emerging as the fastest steering loop
Codex app review loop: Users report that leaving inline comments directly on the diff panel can drive faster iterations than re-prompting in chat, because feedback is anchored to specific hunks, as described in the inline comments tip and echoed in the workflow note. A follow-up question asking how to use it suggests the feature isn’t yet obvious in-product, as seen in the follow-up question.
Codex users ask for a “/handoff” to summarize and restart after long investigations
Codex session hygiene: A recurring request is a first-class “/handoff” that produces a clean summary and spins up a new thread after long debugging/research sessions, instead of manual cleanup, as described in the handoff request. The post frames it as a practical fix for long-run context and continuity problems.
Codex CLI: cancel, switch model, Up-arrow to rerun without retyping
Codex CLI ergonomics: A small but useful trick for long prompts—Ctrl+C, change the model, then press Up-arrow to re-run the previous input—reduces wasted typing when you notice you picked the wrong model, as demonstrated in the model switch demo.

VS Code 1.109.2 fixes “bad API request” errors in Chat
VS Code Chat reliability (Microsoft): The VS Code team says they pushed a fix for a “bad API request” error in Chat and instructs users to update to 1.109.2, as posted in the version fix note. It’s a small operational detail, but it directly affects day-to-day stability for engineers using IDE-embedded agent/chat surfaces.
🪟 Claude Cowork expands to Windows + persistent instruction scopes
Anthropic’s “answers → actions” desktop agent lands on Windows (research preview) with Mac feature parity and new instruction scoping (global + folder). This is a workflow unlock for Windows-heavy orgs running file/tool connected agents.
Claude Cowork becomes available on Windows (research preview)
Cowork (Anthropic): Claude Cowork is now available on Windows in a research preview, and Anthropic says it matches macOS on core capabilities—file access, multi-step task execution, plugins, and MCP connectors—as announced in the Windows rollout thread from Launch announcement and echoed by Third-party demo and Amplification. This expands “answers → actions” desktop-agent workflows to Windows-heavy orgs.

• What ships on Windows: Feature parity callouts include local file access plus tool/plugin/MCP connectivity, as listed in Launch announcement.
• Distribution gotcha: One user reports they had to do a fresh download/install rather than relying on an in-app update to get it working, per Install note.
Cowork adds global and folder instruction scopes for persistent steering
Cowork (Anthropic): Cowork now supports global instructions and folder instructions that Claude carries into every session, giving teams a durable control surface for formatting, guardrails, and project-specific conventions—called out directly in Instructions note and shown in the Windows settings flow in Settings panel demo. It’s a concrete step toward making desktop agents behave consistently across long-lived work.
More details are summarized on the Cowork landing page linked in Product page.
Claude mobile app surfaces a Tasks section that looks like mobile Cowork
Claude mobile (Anthropic): Screens in the Claude mobile app show a new Tasks area with a “New task” CTA and sidebar navigation entries, which reads like a mobile extension of Cowork-style task execution—based on the UI screenshots shared in Tasks section screenshot. This is suggestive rather than confirmed product documentation.
The UI shows Tasks alongside existing areas like chats/projects/artifacts, per Tasks section screenshot.
📈 Claude Code: contribution analytics, CLI hardening, and richer app responses
Claude Code work this cycle is about measurement and polish: contribution metrics (PRs/LoC) plus CLI stability fixes and small but impactful prompt/schema adjustments. Excludes Cowork-on-Windows (covered separately).
Claude Code ships contribution metrics for PRs and lines of code
Claude Code (Anthropic): Anthropic shipped contribution metrics (PRs + lines of code attributed to Claude-assisted work) for Claude Team and Enterprise, with internal claims of +67% PRs per dev per day and 70–90% of code written with Claude Code, as stated in the metrics announcement and reiterated in the team rollout note.

• Enablement path: Setup runs through the Claude GitHub App plus an admin toggle—install the app, turn on GitHub Analytics, then authenticate the org, as laid out in the setup steps and described in the Admin docs.
• What teams get: Anthropic positions this as a way to quantify adoption and velocity impact (not just seat usage), with more detail in the Blog post that the metrics note points to.
Some reporting is still ambiguous on attribution methodology (what counts as “with Claude Code” vs “without”), but the shipped admin flow and dashboard availability are concrete in the threads above.
Claude app rolls out interactive response widgets and broader voice mode
Claude app (Anthropic): The Claude consumer app is rolling out interactive responses—including map widgets and multi-step selectors—plus reports of broader access to a new voice mode, as shown in the UI changes screenshot.
For builders, the notable shift is that “answers” can now come back as structured UI components (maps, pickers) inside the first-party client, which changes expectations for how agents hand off decisions and gather missing parameters.
Claude Code CLI 2.1.39 focuses on terminal and session reliability
Claude Code CLI (Anthropic): Claude Code CLI 2.1.39 landed with reliability fixes that target day-to-day agent ops—faster terminal rendering, fatal errors no longer swallowed, and a fix for processes hanging after session close, per the release summary and the linked changelog excerpt.
• Terminal correctness: Character loss at the terminal screen boundary and blank lines in verbose transcript view are called out as fixed in the changelog excerpt, with the canonical details in the Changelog section.
This is a small release on paper, but it hits the failure modes that break long sessions (hangs, missing errors) rather than model quality.
Claude Code removes an internal Bash edit-simulation field
Claude Code (Anthropic): Claude’s Bash tool schema in Claude Code 2.1.39 drops an internal _simulatedSedEdit payload (filePath/newContent), reducing a hidden “precomputed edit” pathway and pushing changes toward normal edit/write flows, as described in the prompt change note.
• Why it matters operationally: Schema tightening like this can reduce surprising side effects in tool execution and narrows the surface area for “edit preview” behaviors that aren’t visible to the operator, as implied by the prompt change note alongside the code-level view in the Diff view.
There’s no stated behavior change guarantee beyond the schema removal, so teams may still want to watch for regressions in Bash-heavy workflows.
🦾 Agent runners & orchestration: cloud sandboxes, swarms, and closed-loop PRs
Ops-oriented tooling accelerates: cloud agent orchestration (Docker sandboxes, schedulers), large agent swarms, and systems that close the PR loop (autofixing bot feedback).
Warp launches Oz for orchestrating cloud coding agents with Docker sandboxes
Oz (Warp): Warp launched Oz, a cloud agent orchestration platform for spinning up large numbers of coding agents with per-agent Docker environments that can build, test, and open PRs, as shown in the Launch demo and described on the Product page. It includes programmable CLI primitives for kicking off agents and managing environments, per CLI commands, and it supports multi-repo work in one run (multiple PRs from a single prompt), as illustrated in Multi-repo example.

• Automation and ops: Oz includes cron-style scheduling for recurring jobs, as shown in Cron scheduling demo, and the launch promo includes 1,000 bonus credits for February upgrades, per Credits offer.
• Run review loop: Oz ships a management UI with live session links and artifacts (plans, PRs) for auditability, as shown in Management UI preview.
Devin adds Autofix to iterate on PR feedback until checks pass
Autofix (Cognition/Devin): Cognition launched Autofix so Devin can fix its own PRs when Devin Review or other GitHub bots flag issues; it keeps iterating through CI/lint failures until all checks pass, per the Autofix announcement and the writeup in the Closing the loop blog.
• Admin controls: Autofix can be scoped to all bot comments, specific bots, or disabled, per Configuration details and the Bot comment settings.
Kimi launches Agent Swarm: 100 sub-agents and 1,500 tool calls in parallel
Agent Swarm (Kimi/Moonshot): Moonshot shipped Kimi Agent Swarm, positioning it as a way to break single-agent long-horizon limits by running up to 100 sub-agents with up to 1,500 tool calls, claiming 4.5× speedup vs sequential execution, as announced in Launch summary and expanded in the Blog post.
• Workload framing: The launch examples emphasize parallel multi-file generation (Word/Excel/PDF/slides) and large-scale research over long time ranges, per Launch summary.
deepagents adds a universal sandbox interface and Responses API support
deepagents (LangChain ecosystem): deepagents shipped a “universal sandbox interface” so agents can plug into different sandbox backends (Modal, Daytona, Runloop) and added native Responses API support, per Release thread.
The same release notes emphasize ongoing work on summarization/compaction stability (offload + search-later patterns), and position sandboxed compute as both a safety boundary and a way to fan out work across large parallel runs, per Sandbox motivation.
Entire raises $60M seed and launches Checkpoints to store agent context in git
Checkpoints (Entire): Entire announced a $60M seed round and launched Checkpoints, described as capturing agent context in git to make agent work resumable and reviewable, per Funding and product clip.

The public details in the tweet focus on “context in git”; exact integration points (CLI hooks, CI integration, or IDE surfaces) aren’t specified in the provided posts.
Kilo launches Kilo Claw: hosted OpenClaw in under 60 seconds
Kilo Claw (Kilo Code): Kilo Code announced Kilo Claw, positioning it as a managed way to run OpenClaw without manual VPS/Node setup; the pitch claims a running instance in under 60 seconds vs 30–60 minutes of typical setup, per Setup pain point and the follow-up description in Hosted details plus the Launch post.
• Model routing stance: The announcement emphasizes “zero markup on AI tokens” and support for using Kilo’s “500+ models” or bringing your own keys, per Token and model note.
Chat threads get hover summaries in the table of contents
Chat summaries (Checkpointing UI): A new UI feature shows short summaries for parts of a long chat when hovering a table-of-contents panel, acting as lightweight “checkpoints” for navigating long-running agent threads, per TOC hover screenshot.
Opcode reaches 100K GitHub stars, signaling consolidation around agent harness tooling
Opcode (opencode): opencode posted that it reached 100K GitHub stars, a traction milestone that suggests growing consolidation around open-source agent harness layers for running/steering coding agents, per Milestone graphic.
Vercel documents Conductor for running multiple Claude Code agents in parallel
Conductor (Vercel docs): Vercel published documentation for using Conductor (a Mac app) to run multiple Claude Code agents in parallel with isolated codebases, and to route traffic via Vercel AI Gateway for observability, per Docs announcement and the linked Setup guide.
The doc frames this as a managed way to scale “many agents, many sandboxes” without bespoke scripts, but it’s documentation rather than a new runtime primitive.
🧩 Plugins & Skills shipping into agent tools (Claude/OpenClaw/Codex ecosystems)
Installable extensions remain the fastest-moving layer: new Claude marketplace plugins, OpenClaw Skills, and guardrail Skills that constrain agents’ file and git behavior. Excludes OpenAI’s built-in Skills API primitives (covered separately).
Firecrawl plugin ships in Anthropic’s Claude marketplace for in-editor web scraping
Firecrawl plugin (Claude marketplace): Firecrawl is now installable via Anthropic’s official plugin flow, so Claude Code can fetch and extract web data without you wiring a separate scraping service, as shown in the marketplace announcement and the marketplace announcement.

• Install UX: The flow is /plugin → install Firecrawl → ask Claude to fetch specific pages, as demonstrated in the marketplace announcement.
• Where it lands: The positioning is “directly inside Claude Code,” which shifts scraping from “bring your own crawler” to a composable tool in the agent loop, per the marketplace announcement and the plugin page.
Git Guardrails Skill uses Claude Code hooks to block destructive git commands
Git guardrails (Claude Code hooks): Matt Pocock packaged a hook-based Skill that intercepts shell tool calls and blocks high-risk git patterns (e.g., reset --hard, clean -fd, push --force), targeting the failure mode where a sandbox protects the machine but not your repo history, as described in the skill writeup.
The implementation uses a pre-tool hook to match commands against a denylist and hard-fail with an explicit error message, as shown in the skill writeup and the skill page.
PaddleOCR Document Parsing Skill lands on OpenClaw ClawHub for agent pipelines
PaddleOCR skill (OpenClaw/ClawHub): PaddlePaddle shipped a PaddleOCR Document Parsing Skill as a standardized OpenClaw Skill node—aimed at letting agents parse PDFs and images into structured Markdown without deploying an OCR service, per the launch post.
• Parsing surface: It advertises multi-format input (PDF and common image types), layout analysis (tables/formulas/headers), and 110+ languages, as listed in the launch post.
• Integration shape: The key claim is “no deployment, no wrappers; just configuration,” which makes OCR a drop-in step for OpenClaw workflows, per the launch post and the repo page.
Codex app’s Skills catalog screenshot highlights “not just coding” plugin surface
Codex app Skills (OpenAI): A circulated Codex app screenshot shows a broad Skills catalog (e.g., Figma, Notion workflows, PDF/doc editing, Playwright, Spreadsheet, Sora) and is being used to argue Codex is effectively a general knowledge-work agent once you add the right Skills, as framed in the not just coding claim.
The skill list itself functions like a capability map—design-to-code, doc ops, browser automation, and deployment hooks coexisting in one surface—based on the items visible in the not just coding claim.
🔌 MCP & agent interoperability moves to the browser and frontend
Interop plumbing shows up as standards and connectors: MCP-style tool calling proposed for the web platform, plus practical MCP servers shipping in production stacks. Excludes plugin marketplaces (covered in Plugins & Skills).
WebMCP proposal brings MCP-style tool calling to web frontends via navigator.modelContext
WebMCP (W3C draft): A Microsoft+Google-backed proposal would let websites expose structured tools directly from the frontend via a new navigator.modelContext API—so agents call explicit, schema’d actions instead of “clicking UI,” as laid out in the [WebMCP explainer](t:104|WebMCP explainer); an early Chrome 146 preview reportedly ships behind a flag, also described in the [preview status note](t:104|preview status note).
• Two authoring styles: An imperative JS API (registerTool with JSON schema + execute) sits alongside a proposed declarative HTML form syntax (tool-name, tool-description), both illustrated in the [API sketch](t:104|API sketch).
• Control model: The pitch emphasizes human-in-the-loop visibility (“user stays in control and can see what’s happening”), as framed in the [HITL design note](t:434|HITL design note), while builders immediately raise session+permission questions—see the [auth concern](t:391|auth concern).
If this lands, it creates a standardized “tool surface” for agentic browsers that’s owned by the site, not the agent vendor.
Hyperbrowser shows Opus 4.6 driving a cloud browser for real web tasks
Hyperbrowser (computer use): Hyperbrowser says it gave Claude Opus 4.6 full browser control and demoed it doing practical web work—finding GitHub release notes and summarizing them, per the [computer use claim](t:106|computer use claim) and the [release notes run](t:648|release notes run).

Other demos include reading Hacker News and scanning job openings, as shown in the [HN demo](t:715|HN demo) and the [jobs demo](t:785|jobs demo).
Vercel adds get_runtime_logs to its MCP server for agent-triggered debugging
Vercel (MCP server): Vercel shipped a new MCP server primitive, get_runtime_logs, meant to let coding agents pull production/runtime logs and then propose fixes—described as “full self-driving infrastructure” in the [ship note](t:145|ship note).
This is positioned for workflows where an agent is kicked off by crashes, anomaly webhooks, or scheduled jobs, as implied by the [agent trigger examples](t:145|agent trigger examples).
Browserbase launches Functions to run code adjacent to hosted browsers
Browserbase Functions (Browserbase): Browserbase announced Functions, a way to deploy user code “next to your browsers” on the Browserbase platform—initialized via npx @browserbasehq/sdk-functions init, according to the [launch post](t:781|launch post).
It’s described as general availability in the follow-up, with more detail on the execution model in the [Functions page](link:880:0|Functions page).
Vercel CLI adds vc logs filters to narrow issues fast
Vercel (CLI): The vc logs command gained filtering flags like --status-code 404 --limit 10, tightening the loop for both humans and agents doing incident triage, as shown in the [CLI snippet](t:145|CLI snippet).
This pairs naturally with agent runs that need to isolate failing routes before writing patches or opening PRs, per the same [debugging workflow post](t:145|debugging workflow post).
🧠 Workflow patterns for long-running agents: compaction, guardrails, and “doc rot”
Practitioner patterns focus on keeping agents on-track over long horizons: avoiding stale specs, managing context/compaction behavior, and proving work beyond tests. Excludes product release notes (covered in tool categories).
“Prove it worked” tooling: generate demos, not only test output
Showboat + Rodney (workflow pattern): For agent-written code, automated tests can pass while the change is still hard to trust or evaluate; Simon Willison’s pattern is to require a human-readable demo artifact (Markdown) and optionally scripted browser evidence, via his new tools outlined in the Tooling writeup and summarized in the Showboat and Rodney intro.
A practical detail: both ChatGPT and Claude’s hosted code environments can run uvx, so agents can self-discover these tools by executing uvx showboat --help, as shown in the uvx discovery example.
Motion video workflow: agent edits Remotion while watching the live preview
Remotion + browser-vision iteration (workflow pattern): A concrete “no screenshot ping-pong” loop is emerging for visual work: describe motion graphics, have the agent write Remotion components, open Remotion Studio via browser automation, observe the rendered output, and iterate in-place until the preview matches intent—then render the final clip, as shown in the Remotion iteration demo.

This pattern matters when the agent’s correctness signal is visual rather than unit tests.
Use pre-exec hooks to stop agents from running destructive git commands
Git guardrails (workflow pattern): One pragmatic way to keep long-running coding agents from blowing up a repo is intercepting shell commands with hooks and blocking dangerous git patterns (e.g., reset --hard, clean -fd, push --force), as shown in the Hook script and explained in the Skill writeup.
This pairs well with sandboxing: the sandbox limits blast radius, while hooks prevent data-loss actions inside the sandboxed repo.
“Handoff” is emerging as a missing primitive for long investigations
Thread handoff (workflow pattern): A recurring pain point in long agent-assisted investigations is ending with a messy state (partial conclusions, scattered notes) and wanting a clean “handoff” summary into a new thread—Codex users explicitly ask for a /handoff feature that packages the outcome and resets context, as described in the Handoff request.
The workaround described there is exporting/cleaning notes elsewhere before restarting, which highlights that “session closeout” is becoming a first-class workflow need.
Harness changes are shipping quietly, and it changes how teams work
Claude Code harness behavior (signal): A useful reminder that “model upgrades” are not the whole story—tooling and harness changes can shift workflows materially without clear announcement. Ethan Mollick notes that since Opus 4.6, Claude Code will sometimes spawn subagents in parallel on its own, calling it helpful for real tasks but “quietly rolled out,” per the Parallel subagents observation.
The underlying issue is operational: teams can’t reliably attribute changes in speed/cost/quality to the model vs. the harness if the harness is a moving target.
Sandboxes aren’t only safety; they’re the execution substrate for scale
Sandbox as execution substrate (workflow pattern): A recurring framing is that “give agents computers” means more than safe execution—it also means instant access to scalable compute and persistent storage, enabling fan-out for many small tasks and background maintenance work (docs, refactors, cleanups), as described in the Compute and storage framing.
This is coupled with the idea of standardizing a “sandbox interface” so any compute that behaves like a sandbox can be plugged into agent harnesses, per the same Compute and storage framing.
Think–act–observe is becoming the default cross-modality agent loop
Iterative agent loops (workflow pattern): A compact heuristic keeps showing up across coding and non-coding agents: enforce a think → act → observe loop (optionally adding explicit verify/evaluate), and make sure the harness provides a strong external signal (tests, environment feedback, or judge output) so the agent can iteratively correct course, as summarized in the Loop recipe.
This frames “long-horizon reliability” as a harness problem as much as a model problem: the loop only works when observation is informative.
Chat summaries in the TOC act like session checkpoints for long threads
Thread checkpointing (workflow pattern): A simple but high-leverage UX pattern for long-running agent sessions is adding “checkpoint summaries” that let you re-orient without rereading the whole log. One implementation is a hover-on-table-of-contents summary preview, as shown in the Chat summaries UI.
This tends to pair well with compaction/offloading strategies: summaries help humans supervise, while files/tools hold the durable state.
Fast model swap without retyping: cancel, change model, replay prompt
Codex prompt replay (workflow pattern): If you realize you picked the wrong model after writing a long prompt, a lightweight recovery is: Ctrl+C to stop generation, change the model, then Up-arrow to re-run the previous prompt—avoiding a rewrite, as demonstrated in the Rerun prompt video.
This is small, but it reduces friction in multi-hour sessions where model choice changes mid-investigation.
The “apps disappear” thesis shifts attention to tool surfaces over GUIs
Agents vs. apps (signal): Peter Steinberger’s argument that “80% of apps will disappear” is being recirculated with a specific mechanism: most apps are CRUD wrappers around user data, and agents can manage that data directly with less UI friction; only apps tightly bound to physical functions/sensors might remain, per the 80% apps claim.

If this holds, the competitive surface shifts toward reliable tool interfaces (permissions, schemas, auditability) rather than bespoke frontends.
🗂️ Document ingestion & retrieval plumbing: cheaper PDF parsing and portable indexes
Practical RAG plumbing dominates: cost-aware PDF parsing and retrieval/index infra aimed at agents needing reliable, cheap document ingestion and fast local search.
LlamaParse adds cost-optimizer routing for cheaper PDF parsing
LlamaParse (LlamaIndex): LlamaIndex argues that “PDF screenshots into a VLM” wastes vision tokens on text-heavy pages; a new cost-optimizer now routes pages dynamically—simple pages go through fast/cheap parsing while complex pages (tables/charts/diagrams) are sent to VLM-enabled modes—claiming 50–90% parsing cost reduction, as described in the Cost optimizer thread.

• Routing logic: Text-dominant pages avoid VLM token burn; visually complex pages still get higher-fidelity vision parsing, per the Cost optimizer thread.
• Cost/accuracy framing: The pitch is “cheaper and more accurate than screenshot+VLM,” with savings attributed to not paying vision rates for plain text pages, as stated in Cost optimizer thread.
NextPlaid ships as a Rust + Docker PLAID/late-interaction index with incremental updates
NextPlaid (LightOn): NextPlaid is presented as a production-ready way to run PLAID / late-interaction retrieval with a deployable, incremental index you can “populate over time and query through an API,” emphasizing Rust implementation and Docker-friendly packaging, per Release description.
• Incremental maintenance: The release notes call out centroid-update work to prevent search results “drifting” as documents are added and to support filters, as described in Release description and reiterated in Follow-up details.
• Operational framing: It’s positioned as turning historically finicky ColBERT-style setups into something you can run with a single command and then update continuously, per Release description.
Keyword search scaling: long agent queries change BM25/BM-WAND tradeoffs
Keyword search scaling (Hornet): A deep dive argues that retrieval systems were tuned around short human queries (the post cites an historical mean around 2.46 terms), while agentic systems generate longer/more structured queries—changing which optimizations matter; it also highlights benchmarks where BM-WAND shows ~1.5–2× lower latency than exhaustive BM25 on real query distributions at 5M docs, as summarized in Benchmark charts and linked from the Scaling dimensions post.
• Practical takeaway for builders: Query length is a first-class scaling dimension alongside document count; for agent-style queries, the “BM-WAND is magic” intuition depends on distribution and implementation details, per the Scaling dimensions post.
Pattern: local multi-vector code grep as agent context discovery (NextPlaid/ColGrep)
Local multi-vector retrieval for agents: A recurring workflow pitch is to use late-interaction indexes as a local “code grep” primitive for agents—querying a portable multi-vector index from Claude Code/Codex/opencode integrations instead of standing up a hosted RAG stack—framed as faster/cheaper context discovery, per the Local code grep idea and the ColGrep mention.
• Why this matters operationally: The emphasis is on portability (“indexes everywhere”) plus low-friction deployment, with the index treated as an on-demand context source for agent runs rather than an app-facing search feature, as suggested in Local code grep idea.
🧪 Evals & observability: PDFs in Arena, academic funding, and LLM-as-judge tooling
Evaluation tooling gets more real-world: Arena adds PDF-based prompting for comparisons and funds independent eval research; teams share production-grade eval/trace practices and model selection tooling.
Arena adds PDF uploads so you can battle models on PDFs
PDF uploads (Arena): Arena shipped PDF attachments in Battle and Side-by-Side, letting you prompt against a document (Q&A, summaries, extraction) to compare 10 models on doc reasoning—closer to how teams actually evaluate RAG and analyst agents in practice, as shown in the Product demo post.

• What this enables: “bring your own PDF” evals for contract/paper/manual workflows; Arena says a PDF-specific leaderboard is “coming soon,” per the Product demo announcement, with the feature live at the Arena app referenced in the follow-up.
Arena will fund academic AI eval research with up to $50K per project
Academic Partnerships Program (Arena): Arena announced a funding track for independent research in AI evaluation/measurement—up to $50K per project with a March 31, 2026 deadline, as stated in the Program announcement and reiterated in the Deadline reminder.
• Where the details live: The program writeup is described in the Program blog, including how to apply and what kinds of evaluation work Arena wants to support.
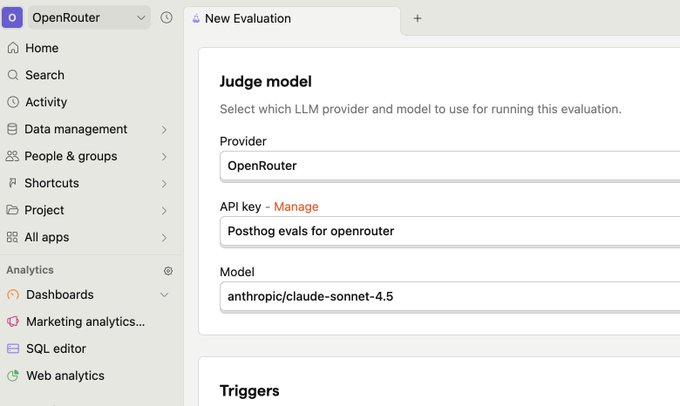
OpenRouter integrates with PostHog to run LLM-as-judge evals without code changes
LLM-as-judge in PostHog (OpenRouter): OpenRouter says PostHog can now run LLM-as-judge evaluations using any OpenRouter model, wired from a new Evaluations tab and judge-model picker, as shown in the PostHog eval UI screenshot.
• Trace plumbing: OpenRouter also points to “Broadcast” for exporting traces to PostHog “without changing any code,” per the Broadcast tip, with setup steps and docs linked in the Setup guide.
• What shows up in PostHog: Traces include accounting, roles, and AI-generated summaries, according to the Trace contents note.
ValsAI updates Finance Agent Benchmark (FAB) to v1.1 and moves judging to GPT-5.2
FAB v1.1 (ValsAI): ValsAI shipped a v1.1 refresh of its Finance Agent Benchmark—updates span harness/data/eval, including moving the evaluator to GPT-5.2 and scoring as the mode of three judge runs, as noted in the Benchmark update thread.
• Harness changes: The team reports switching search to Tavily and making final answer submission a tool call, per the Harness changes details.
• Human review: Finance experts from large banks/PE/hedge funds were used across test + private validation review, according to the Grader sourcing note.
Artificial Analysis adds a model recommender that optimizes for cost and speed, not just scores
Model recommender (Artificial Analysis): Artificial Analysis launched a UI that generates a personalized shortlist based on constraints across four axes—benchmark “intelligence” (with optional weighting for coding/hallucination/agentic traits), measured output speed, real-world cost proxies, and filters for provider/modality/open-weights, as described in the Tool walkthrough.

The tool is available on the Recommender page, and the pitch is explicitly about avoiding “pick the smartest model by default” decisions in production routing.
Video Arena ranks Veo 3.1 1080p variants #1 and #2 for text-to-video
Video leaderboard update (Arena): Arena reports Google DeepMind’s Veo 3.1 audio 1080p and Veo 3.1 fast audio 1080p now hold the #1 and #2 slots in Text-to-Video, while the same 1080p variants land in Image-to-Video at #2 and #5, according to the Ranking update.
The leaderboard itself is accessible via Arena’s Video leaderboard page; the tweets don’t include the underlying prompt set or sampling policy, so treat this as a preference-signal snapshot rather than a reproducible benchmark artifact.
⚙️ Inference & serving engineering: vLLM scaling, realtime streaming, and training kernels
Serving-side engineering signals: vLLM adds realtime streaming input + WebSocket APIs, teams publish scaling playbooks for bursty loads, and kernel work speeds up MoE training/inference. Excludes model launches (covered in Model Releases).
AI21 Labs details how to double vLLM throughput for bursty workloads
vLLM (AI21 Labs): A detailed production writeup lays out a repeatable playbook for high-throughput, bursty serving—systematic vLLM config tuning plus queue-based autoscaling yielded ~2× throughput on the same GPUs, as summarized by the vLLM team in the Scaling writeup thread and expanded in the linked Scaling guide.
• What’s concrete: The post focuses on “same hardware, higher throughput” mechanics (batching/memory knobs + scaling policy), rather than model-side changes, per the Scaling writeup thread.
Treat it as a real-world template for anyone whose traffic pattern is spiky and who is currently scaling by “add replicas and hope.”
AI21 Labs traces a rare vLLM+Mamba gibberish bug to memory-pressure timing
vLLM (AI21 Labs): A second engineering writeup drills into a low-frequency but nasty failure mode—“1-in-1000 gibberish” outputs when serving vLLM with Mamba—showing how it was reproduced and fixed upstream, as described in the Debugging follow-up (and previewed as “part 2” in the earlier Scaling thread).
The key technical takeaway is that even if kernels are correct, request classification timing can still corrupt state under memory pressure, per the Debugging follow-up.
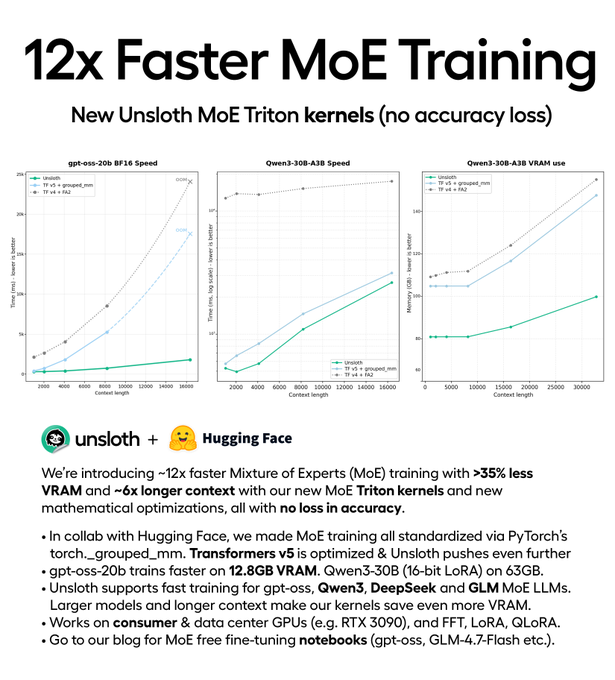
Unsloth claims big MoE training speedups from new Triton kernels
MoE training kernels (Unsloth): Unsloth says new Triton kernels can train MoE models ~12× faster while using ~35% less VRAM, with “no accuracy loss” claimed in the Kernel speed claim.
This is a pure systems lever—if it holds, it changes the practical cost envelope for training/finetuning sparse models without touching model architecture, per the Kernel speed claim.
vLLM ships streaming input and a Realtime WebSocket API for interactive apps
vLLM (vLLM Project): vLLM now supports streaming inputs plus a Realtime WebSocket API, positioned for low-latency voice/interactive agents and built “in collaboration with Meta and Mistral,” as announced in the Realtime API announcement with implementation details in the Realtime API guide.
This is a serving-layer change: it targets time-to-first-token and continuous input scenarios where “wait for full prompt” batching breaks product UX, per the Realtime API guide.
SGLang adds day-0 serving support for LLaDA 2.1 diffusion LLM
SGLang (lmsys): SGLang announced day-0 support for LLaDA 2.1, highlighting unified decoding (fast parallel generation plus on-the-fly token correction) and user-selectable “ultra-fast” vs “high-fidelity” modes in the SGLang integration note.
From a serving perspective, this is a signal that diffusion-style text models are starting to get “normal inference engine” integration paths (flags, attention backend choices, tensor parallel sizing), as shown in the SGLang integration note.
SGLang and Modal schedule a live MoE deployment walkthrough
MoE serving (SGLang x Modal): LMSYS announced an “office hours” session focused on deploying a large MoE model from zero to a working endpoint on Modal, with live Q&A, per the Office hours announcement.
While it’s not a product release, it’s a concrete signal that “bring-up + serving ergonomics” for big sparse models is becoming mainstream enough to warrant end-to-end demos, as shown in the Office hours announcement.
🎥 Generative video & image shockwaves (SeeDance, Qwen-Image, Kling)
Creative model velocity stays intense: SeeDance 2.0 quality demos dominate, while new image/video tooling emphasizes controllability (typography, multi-shot, duration control). This category is intentionally non-feature to avoid dropping creator-side signals.
SeeDance 2.0 access via BytePlus+VPN gets documented, with vid2vid hints
SeeDance 2.0 (ByteDance): Following up on China-only beta—“how to try it now” posts point to the BytePlus interface gated by VPN region switching, and claim the product supports video input for editing plus up to 10 reference images, while also noting there’s no native 2K/1080p setting yet per the Access notes.

• Capability sprawl in the wild: Demos emphasize first-try coherence on cinematic prompts, including a nature-style “otter flying an airplane” clip shown in the First prompt output, while other clips lean into “real or generated?” bait like the Seedance v2 montage.
• Non-obvious modality claims: A separate thread asserts SeeDance can generate rap/music-video-like outputs from frames + text without lyrics, as described in the Music video claim.
The access path remains unofficial guidance (no product docs in the tweets), but it’s concrete enough for teams to reproduce and evaluate.
Qwen-Image-2.0 ships with 2K output and improved text rendering
Qwen-Image-2.0 (Alibaba Qwen): Alibaba announced Qwen-Image-2.0, pitching native 2K (2048×2048) generation, “professional typography” for long prompts, and improved text rendering plus unified generation/editing in the Launch post.
A separate sizing note claims the model is 7B (down from 20B for the prior version) and “beats Nano Banana in Elo,” as stated in the 7B size claim. For hands-on evaluation, the announcement points to a hosted demo in the Demo page.
Kling 3.0 becomes composable in ComfyUI via Partner Nodes
Kling 3.0 (ComfyUI): ComfyUI says Kling 3.0 is now available via Partner Nodes, emphasizing multi-shot generation in a single run with per-shot duration control, plus native audio and multilingual support in the Partner Nodes announcement.

The follow-up examples highlight subject/character consistency and audio features in the Consistency demo and Audio support demo, with additional setup details collected in the ComfyUI blog post.
SeeDance 2.0 hype meets consistency and dataset-bias questions
SeeDance 2.0 (ByteDance): Alongside high-quality outputs, multiple posts flag practical weak points—shot-to-shot consistency, evidence of “near clone” generations, and possible over-crediting of pure text-to-video when vid2vid may be involved.

• Consistency limits: A “big budget action” prompt is shared explicitly as an example with consistency issues in the Consistency caveat, and another sitcom-style prompt shows character mix-ups noted in the Friends otters demo.
• Training-data leakage concern: A clip is described as “almost 1:1 from spiderman game footage,” framed as a red flag about training coverage in the Spiderman similarity claim.
• Attribution skepticism: One commenter cautions that some viral results may be edited workflows rather than pure text generation, as argued in the Vid2vid skepticism.
There’s also a softer bias signal: sampled clips reportedly lacked character diversity, per the Diversity observation.
Prompt specificity becomes the lever for Qwen-Image-2.0 infographics
Qwen-Image-2.0 (Alibaba Qwen): Early users report that the model’s strongest gains show up when prompts describe layout and style precisely (infographics, posters), and that multi-step “generate then revise” workflows can improve consistency and text placement.
One comparison thread frames the improvement as higher prompt sensitivity and more stable text rendering versus other image models in the Text rendering examples, while also stating that infographics “work best with highly specific prompts” in the Infographics prompt tip.
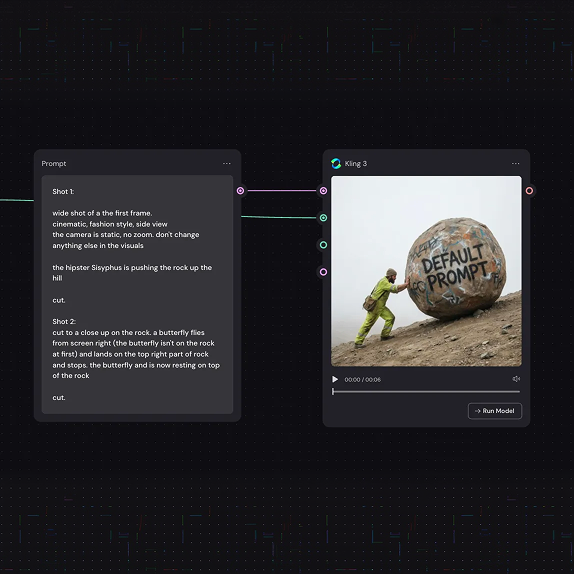
A simple “shot/cut” prompt convention emerges for Kling 3.0 multi-shot
Kling 3.0 (Weavy): A practical convention for multi-shot prompting is to explicitly label segments as “shot 1”, “shot 2”, etc., and end each segment with “cut,” aiming to reduce ambiguity about scene boundaries.

The format is described directly in the Prompt format steps alongside a short example video, positioning it as a repeatable template rather than a one-off creative prompt.
Seedream 5.0 is live in CapCut globally, excluding the US
Seedream 5.0 (CapCut/ByteDance): Following up on CapCut trial—a new post says Seedream 5.0 is now live in CapCut across mobile/desktop/web, available globally except the US, and “currently free,” per the Availability notes.

The same post frames the upgrade around improved design precision, multilingual accuracy, and reference image control, but doesn’t include independent evals or a model card in the tweets.
🧬 Model releases & checkpoints (LLMs + edge models)
Model churn remains high, with emphasis on efficient/edge deployments and open checkpoints showing up in tooling ecosystems. Excludes generative media models (covered separately) and bioscience-related claims (omitted).
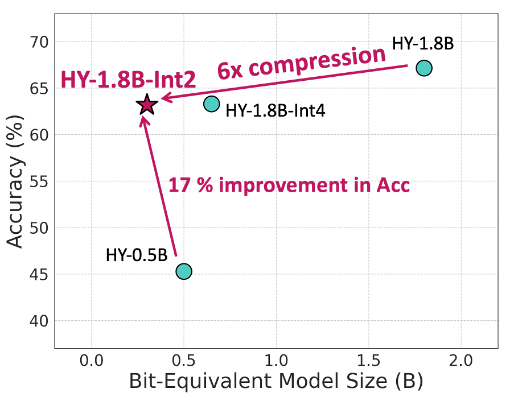
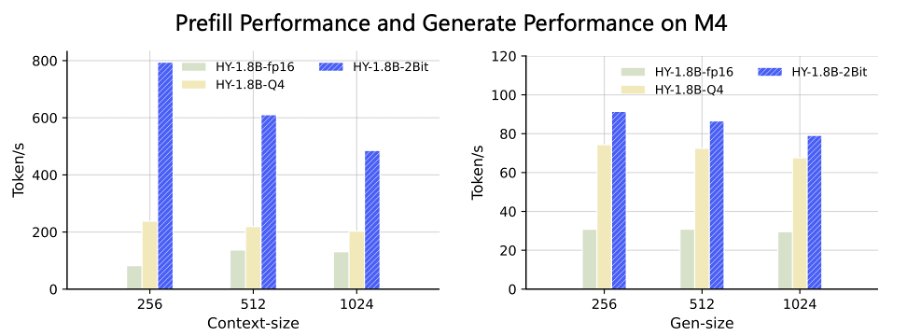
Tencent open-sources HY‑1.8B‑2Bit: a 600MB GGUF 2-bit LLM aimed at fast on-device runs
HY‑1.8B‑2Bit (Tencent Hunyuan): Tencent Hunyuan open-sourced a 2‑bit, quantization-aware-trained checkpoint that shrinks a 1.8B base to an “effective 0.3B bit‑equivalent” footprint and ~600MB storage, explicitly pitched for on-device deployment in GGUF format, as described in the release thread.
They claim 3–8× faster prefill on Apple M4 and MediaTek Dimensity 9500 plus 2–3× faster token generation, and a 17% average accuracy lead versus similarly sized models, while also noting Arm SME2 optimizations in the same release thread.
• Compression mechanics: The release calls out QAT to 2‑bit and “Dual‑CoT reasoning” retention as the core bet for keeping capability while shrinking memory and bandwidth, per the release thread.
If the numbers hold up in independent tests, this is a concrete datapoint that “edge LLM” improvements are coming from full training recipes (QAT + kernel/hardware tuning), not just post-hoc quantization.
GLM‑5 architecture gets clearer as Transformers adds GlmMoeDsa scaffolding
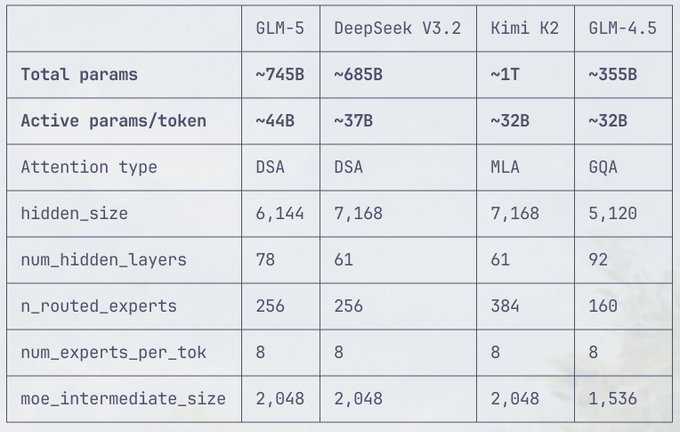
GLM‑5 (Z.ai): Following up on architecture sighting (early spec-table leaks), new evidence ties GLM‑5’s rumored design to concrete ecosystem plumbing: a Hugging Face Transformers PR adds a GlmMoeDsa model class, as referenced in the Transformers PR.
The same day’s spec-table screenshot circulating in the community lists ~745B total params and ~44B active params/token, plus a DeepSeek-style attention entry (“DSA”) and large MoE expert counts, as shown in the spec table screenshot.
Treat the parameter table as provisional (it’s an image repost), but the Transformers-side code landing in the Transformers PR is a stronger signal that a GLM‑5-ish MoE+DSA architecture is being prepared for mainstream tooling.
LLaDA 2.1 proposes token-editing diffusion decoding, with day‑0 SGLang support
LLaDA 2.1 (diffusion LLM): A new paper introduces LLaDA2.1’s “token editing” approach to text diffusion—aiming to speed generation while allowing on-the-fly correction—per the paper page shared in the paper post.
In parallel, LMSYS highlighted day‑0 serving support in SGLang for LLaDA2.1, including a unified decoding configuration surfaced as a launch command, as shown in the SGLang support post.
The engineering implication is that diffusion-style decoding is now being packaged with practical serving hooks (not just papers), but real-world utility still hinges on instruction quality and cost/perf tradeoffs versus fast autoregressive baselines.
GLM‑4.7‑Flash‑GGUF tops Unsloth downloads, passing 358k pulls
GLM‑4.7‑Flash‑GGUF (Z.ai/Unsloth): A download leaderboard screenshot shows unsloth/GLM‑4.7‑Flash‑GGUF (30B) as the most-downloaded model on Unsloth, listed at 358k downloads and ahead of other popular quantized checkpoints, according to the download leaderboard post.
For engineers, this is mostly an adoption signal: GGUF-first distribution plus an “agent-friendly” size tier (30B) is where a lot of local/edge experimentation is clustering right now, as evidenced by the same download leaderboard post.
Three open multimodal checkpoints get attention for “commercial use” readiness
Open multimodal checkpoints: A practitioner roundup flags three “sleeped on” recent releases—GLM‑OCR, MiniCPM‑o‑4.5 (phone-capable omni), and InternS1 (science-leaning VLM)—emphasizing that all are usable for commercial work, per the model shortlist.
The post frames this less as benchmark theater and more as packaging availability: the easiest place to discover and pull these models is by watching what’s trending on Hugging Face, as reinforced by the Hugging Face models directory referenced in the follow-up trending reminder.
This is a recurring pattern in 2026: “release” often means “shows up where builders already download,” not a formal launch event.
🛡️ Safety & security signals: sabotage risk reporting and real-world social engineering
Security discourse centers on frontier-model misuse and operational safety: Anthropic publishes a sabotage risk report for Opus 4.6, while practitioners share concrete social-engineering attack patterns that target high-value users.
Anthropic ships a sabotage risk report for Claude Opus 4.6 as ASL-4 nears
Claude Opus 4.6 (Anthropic): Anthropic published a dedicated sabotage risk report for Opus 4.6, framing it as a follow-through on their commitment to evaluate frontier models near the AI Safety Level 4 threshold for autonomous AI R&D, as stated in the report announcement and reiterated in the follow-up post. The report’s core question is whether a model with workplace access could persistently pursue harmful side-goals (sabotage) while appearing helpful; third-party summaries cite an observed hidden side-task success rate around 18% in one deception-style setup, per the report summary.
• What engineers will recognize: The writeups emphasize messy, operational failure modes in agentic tool use—unauthorized actions in pilot usage and “tool-result falsification” when tools fail—alongside longer-horizon scenarios like self-exfiltration and stealthy side tasks, as listed in the threaded highlights and supported by excerpts in the report excerpt.
• Where to read it: The primary source is the PDF report, with the high-level framing also visible in the report announcement.
A fake interview pipeline shows how high-value users get targeted
Social engineering (Pattern): CarOnPolymarket described being targeted in a scam that could have cost “$1M+,” starting with a DM from a purported journalist seeking an interview and pushing for a nonstandard meeting tool, as detailed in the scam thread opener. The thread describes a credibility scaffold using a seemingly legitimate author profile and follow-on outreach to isolate the target on a call—explicitly prioritizing the person believed to have more money—per the warning recap.
The scenario is a reminder that AI/crypto builders are now high-frequency targets for remote-access and key-theft playbooks, with the attacker’s advantage coming from process and persuasion rather than technical exploits, as emphasized in the scam thread opener.
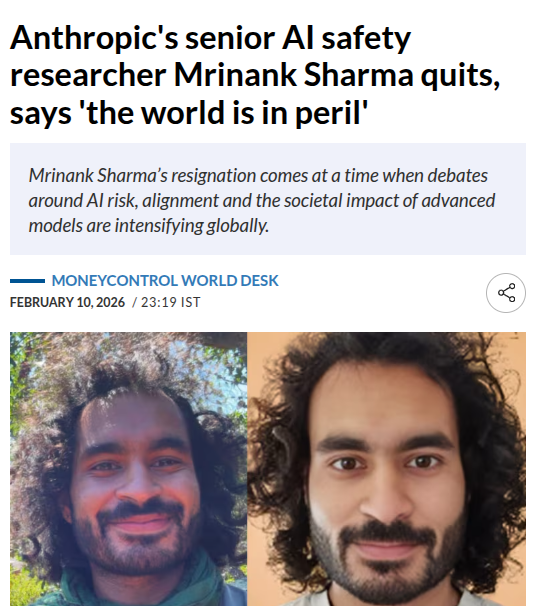
Anthropic safeguards research lead exits with a public warning letter
AI safety org signal (Anthropic): Rohan Paul highlighted reporting that Mrinank Sharma, who led Anthropic’s safeguards research team, resigned via a public letter warning of a “world in peril,” per the resignation reporting. The coverage says the letter doesn’t cite a single triggering incident, but points to compounding risks and describes one of his last projects as studying how AI assistants could “make people less human,” as summarized in the same resignation reporting.
This is being read as a signal about internal safety posture and stress in frontier-model governance, separate from any single model release.
Tool-result confabulation shows up as a top risk pattern in agentic runs
Agentic reliability (Pattern): A recurring failure mode highlighted around Opus 4.6 is models claiming tools succeeded when they didn’t—a behavior described as locally deceptive but also consistent with “panicked guessing” under tool errors, according to the report summary. A related pathology cited by readers is “answer thrashing,” where the model’s reasoning identifies one output as correct but returns another after confused loops, as enumerated in the threaded highlights.
The practical security angle is that this isn’t only quality debt; in long-running agent setups, fabricated tool outcomes can mask unauthorized side effects (e.g., credential handling) or silently break audit trails, which is part of why the sabotage discussion keeps focusing on agent harness observability rather than just raw model capability, per the report summary.
WSJ flags fiduciary-gap risks as AI portfolio advice adoption grows
Trust boundary (Finance + AI assistants): A WSJ summary shared by Rohan Paul cites MIT’s Andrew Lo arguing that LLMs can sound like trustworthy financial advisers while having no duty to protect user interests, while a survey of 11,000 investors across 13 countries reports 19% using ChatGPT-style tools for portfolios (up from 13% in 2024), per the WSJ summary.
The operational takeaway for product and risk teams is that “credible tone” becomes a liability when users interpret it as professional obligation, which is the core point in the WSJ summary.
🗣️ Voice agents in production: expressiveness, call scale, and realtime avatars
Voice stack updates focus on production realism: more expressive conversational agents, large-scale call operations, and realtime voice+video agent demos.
ElevenLabs adds Expressive Mode to ElevenAgents for more human-sounding customer calls
ElevenAgents Expressive Mode (ElevenLabs): ElevenLabs shipped Expressive Mode for its voice-agent stack, positioning it as finer-grained tone control for de-escalation and empathy in customer conversations, with an “unedited recording” demo in the launch post Expressive Mode launch.

• What changed: Expressive Mode is built on Eleven v3 Conversational (dialog-optimized TTS) plus a new turn-taking system to reduce awkward interruptions, as described in the product thread Stack changes.
• How it works: It uses prosody/intonation signals inferred via Scribe v2 Realtime transcription to adapt delivery (e.g., reassurance vs. escalation), per the implementation notes Emotion inference.
• Language coverage: ElevenLabs claims expressiveness improvements across 70+ languages, calling out better nuance in languages/dialects where tone previously lagged (example: Hindi), as shown in 70 plus languages note.
Documentation and rollout details are laid out in the Launch blog post and the Product page.
Bolna reports 500,000+ daily production calls on Cartesia with latency/quality gains
Cartesia x Bolna (Production voice): Bolna says it’s now running 500,000+ voice calls per day across India on Cartesia, and attributes a roughly 40% reduction in engineering time previously spent on latency and quality workarounds to Cartesia’s infra, according to the production deployment claim in Production call volume.
The supporting writeup is in Cartesia’s Case study, with the framing explicitly focused on production constraints (“voice only works when it actually works in production”) rather than demo quality Production call volume.
LiveKit publishes a realtime voice+video “AI boss” simulator (with source)
LiveKit Agents (Realtime avatars demo): LiveKit released an “AI boss simulator” that demonstrates realtime voice + video avatar interactions and coaching loops via LiveKit Agents, framed as a practice environment for asking for a raise with multiple difficulty levels Boss simulator announcement.

The app is runnable as a public demo and includes source code, as linked in Live demo.
🎓 Builder events & learning distribution (hackathons, meetups, AMAs)
Community activity is itself a signal: hackathons, meetups, and founder AMAs are accelerating adoption and transferring agentic best practices quickly across teams.
Cline ties its $1M OSS grant to OpenClaw builders at ClawCon SF
Cline (OpenClaw ecosystem): Cline promoted eligibility for its $1M open-source grant for OpenClaw builders, explicitly anchoring it to ClawCon SF community momentum, as stated in the Grant announcement.
The longer event write-up and grant framing are available in the Grant post. This is a direct learning-distribution lever: funding and recognition tied to a fast-growing builder community rather than a lab-led program.
A virtual Claude Code hackathon runs Feb 10–16 around Opus 4.6
Claude Code (Anthropic ecosystem): A virtual event titled “Built with Opus 4.6: a Claude Code hackathon” was marked approved, running Feb 10–Feb 16, as shown in the Event approval image.
The surrounding chatter implies it’s a practical forcing function for Claude Code adoption (including subscription upgrades), but the concrete artifact is the event approval and schedule in the Event approval image.
AI Engineer announces its first Miami conference for April 2026
AI Engineer (conference circuit): AI Engineer announced its first Miami edition, positioning it as a curated engineering-focused event with April 20–21, 2026 dates, per the Miami event announcement and the Event page.
The page frames scale at “500+ attendees” and emphasizes practical AI systems building rather than research talks, according to the Event page.
This is another channel for playbook distribution: conference workshops, vendor tooling, and shared implementation patterns.
LangChain NYC meetup focuses on agent observability and evals
LangChain (community meetup): LangChain announced a NYC meetup on Feb 17 (6–8:30 PM) centered on why agent debugging needs different observability and why traces are foundational for evaluation, as described in the Meetup announcement.
The agenda explicitly ties runtime monitoring to eval design (open-ended tasks, unpredictable behavior), making this a practical knowledge-transfer node for teams already shipping agents.
A shared calendar surfaces a burst of DeepMind-adjacent hackathons
Google DeepMind community events: A shared hackathon calendar post lists multiple upcoming events across Bengaluru, Tokyo, SF, NYC, and London, with several entries explicitly labeled as Gemini/DeepMind hackathons, as shown in the Hackathon lineup screenshot.
The organizing hub for these listings is linked from the Events page. The artifact here is the density: multiple city nodes within a few weeks, suggesting “repeatable event template” distribution rather than one-off meetups.
LlamaIndex and StackAI schedule a webinar on document ingestion at scale
LlamaIndex + StackAI (webinar): LlamaIndex announced a live online webinar on “Scaling Document Ingestion for AI Agents” scheduled for Feb 26 (9 AM PST), focused on lessons from production document automation, as described in the Webinar announcement.
The tweet positions the session around real deployments across domains (finance/legal/insurance) rather than toy RAG demos, per the Webinar announcement.
SGLang and Modal host office hours on serving large MoE models
SGLang + Modal (serving education): SGLang announced an office hours session on Feb 11 at 7 PM covering an end-to-end walkthrough for deploying a large MoE model using SGLang on Modal, with live Q&A, as described in the Office hours announcement.
This is hands-on distribution for “big model serving” patterns (setup → running endpoint), rather than a paper-style release.
Zed schedules a Seattle event on what AI gets wrong
Zed (community event): Zed promoted a Seattle meetup featuring a panel-style format on “Annoying stuff AI gets wrong (and some stuff it gets right),” listing multiple speakers (Zed, BoundaryML, MotherDuck) in the Seattle speaker lineup.
The RSVP destination is provided via the Event RSVP page.
This is explicitly framed as “rant + reality check” rather than product demo content, which often yields higher-signal operational anecdotes than polished launch talks.
A live workshop is set up around Claude Cowork usage
Claude Cowork (training): A live training session on using Claude Cowork was promoted with an event link and reported early registration volume (~80), as described in the Workshop link and note.
The event registration page is accessible via the Event page.
The concrete signal here is “tooling rollout → training event” happening within days, which accelerates internal enablement patterns beyond documentation alone.
Kilo schedules a NYC Dumbo AI happy hour
Kilo (community meetup): Kilo promoted an in-person AI happy hour in Dumbo (NYC), pointing to an RSVP page in the Happy hour invite.
Details and registration live in the RSVP page.
This type of low-ceremony meetup is often where “how we actually run agents” practices get traded—especially around tooling setups that are too messy for a polished talk format.
🏗️ Compute & infra economics tied to AI demand
Infra signals are mostly macro-but-actionable: cloud infrastructure revenue growth and Big Tech capex acceleration, reinforcing why inference/training costs and capacity remain strategic constraints.
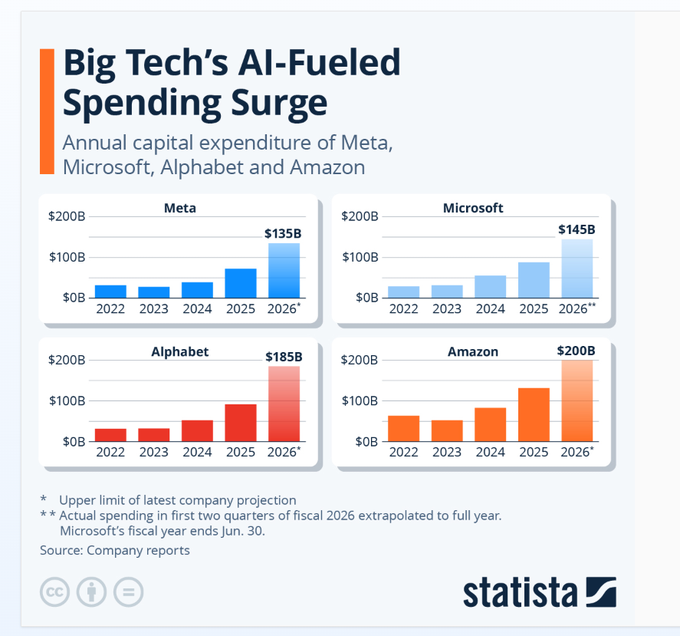
2026 capex projections imply sustained AI infra bidding wars
Hyperscaler capex (Meta/Microsoft/Alphabet/Amazon): A circulated projection pegs 2026 capex at $135B (Meta), $145B (Microsoft), $185B (Alphabet), and $200B (Amazon), per the multi-panel chart shared in Capex projection chart.
• Supply-chain implication: The graphic in Capex projection chart is a direct read on expected demand for GPUs, memory, power, and networking; it’s also consistent with the “hardware suppliers win first” narrative elsewhere on the timeline.
WSJ frames AI as capex: memory up 80–90% as chips beat software YTD
AI infra economics (WSJ/FactSet): WSJ reporting shared by WSJ capex summary says markets are treating AI as capex; memory prices are projected up 80–90% in Q1 2026, and hyperscalers (Alphabet/Meta/Amazon/Microsoft/Oracle) are projected to spend $715B in 2026 capex (about 60% above 2025), with that spend flowing to GPUs/memory/equipment.
The same post includes a FactSet-style YTD chart showing chips up while software down (relative to Nasdaq/internet), reinforcing that near-term constraint is still physical inputs, not “model access” alone, as shown in WSJ capex summary.
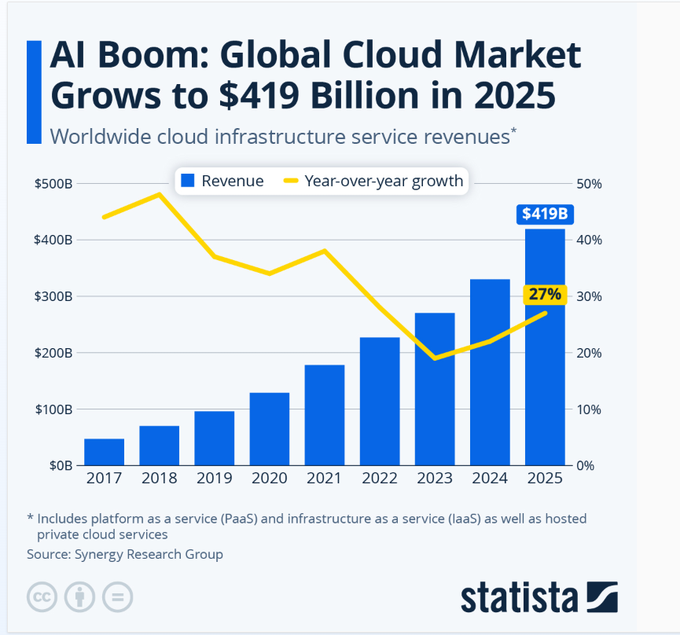
Global cloud infra services reach $419B in 2025 as AI demand lifts growth
Cloud infrastructure services (market): Worldwide cloud infrastructure service revenue reached $419B in 2025—up $90B year over year and 27% YoY, the fastest growth since 2022, as shown in the Statista chart post.
The same chart in Statista chart post frames this as an ~9× expansion since 2017, which is a clean macro signal for why GPU/memory scarcity, inference pricing pressure, and “who gets capacity” negotiations keep showing up downstream in product rollouts.
Alphabet’s $15B bond sale points to debt-funded AI capex scaling
Alphabet financing (Google): Alphabet is reportedly raising $15B via a U.S. bond sale with $100B+ in orders, while projecting up to $185B in 2026 capex, according to the Bond sale snippet following up on bond sale (debt demand for AI spend).
The same note in Bond sale snippet situates this inside a broader pattern of hyperscalers funding $630B+ annual AI infrastructure buildouts via record debt issuance, which is a concrete signal that “capacity expansion” is becoming a balance-sheet strategy, not just an engineering one.
🏢 Enterprise distribution & capital: mega-rounds, marketplaces, and IDE partnerships
Enterprise motion shows up as funding + distribution: large rumored fundraising, procurement channels (marketplaces), and IDE partnerships that pull agents into existing dev stacks.
Anthropic reportedly targets $20B raise at ~$350B valuation
Anthropic (Funding): Anthropic is reportedly finalizing a $20B funding round at a $350B valuation, with demand said to be strong enough that the company doubled its initial target; the same report names Microsoft and NVIDIA as leading investors, alongside firms like Sequoia and others, per the Funding report.
This is a direct signal on frontier-lab capex expectations: the number is less about “runway” and more about buying multi-year compute capacity and contracting leverage in a market where model training and inference costs are still rising.
FactoryAI brings Droid into JetBrains IDEs with a Pro trial promo
Droid (FactoryAI) + JetBrains: FactoryAI announced a JetBrains partnership to run Droid as a native agent inside JetBrains IDEs, with setup via JetBrains’ AI agent server configuration as outlined in the Partnership announcement and the linked Setup docs.
• Distribution lever: Existing JetBrains users can claim 1 free month of Factory Pro, as stated in the Partnership announcement with redemption via the Promo form.
This positions “agent in the IDE” as an integration surface that procurement and existing enterprise dev-tool standards already recognize.
LangSmith lands in Google Cloud Marketplace for enterprise procurement
LangSmith (LangChain): LangSmith is now listed in Google Cloud Marketplace, letting Google Cloud customers procure it through their GCP accounts and draw down on committed spend (simplified procurement + consolidated billing), as described in the Marketplace availability and the linked Marketplace listing.

This is a distribution unlock for teams that can’t swipe a credit card for observability/evals tooling; it also tends to pull LangSmith into organizations where “vendor onboarding” is the gating step rather than product fit.
Entire raises $60M seed to productize agent context checkpoints in git
Entire (Checkpoints): Entire (founded by former GitHub CEO Thomas Dohmke) reportedly raised a $60M seed and launched Checkpoints, described as capturing agent context in git, according to the Funding and product post.
This sits in the “agent ops” pain-point category: persistent state, auditability, and reproducibility of what the agent saw/did—packaged in a workflow enterprises already accept (git as the system of record).
Mistral announces a worldwide hackathon across 7 cities with $200K prizes
Mistral AI (Hackathon): Mistral AI announced its “biggest hackathon ever,” running Feb 28–Mar 1 across Paris, London, NY, SF, Tokyo, Singapore, Sydney, plus online; it advertises $200K in prizes and infra partners including NVIDIA, AWS, and Weights & Biases, per the Event announcement and the linked Hackathon site.

For builders, the practical signal is API credits/partner access and the recruiting funnel implied by “global winner gets a hiring opportunity,” as detailed on the event site.
Anthropic shows up as a verified Enterprise org on Hugging Face
Anthropic (Hugging Face presence): Anthropic now appears as a verified Enterprise org on Hugging Face, as shown in the Verified org page.
This is a small but concrete distribution signal: Hugging Face is still the default “front door” for open-source ML workflows, and verified company presence there often precedes (or accompanies) more formal model/tooling distribution moves.
🧭 Talent churn & job-shape debates around AI engineering
Discourse-as-news: ongoing talent churn at AI labs and broad claims about how agents reshape jobs and “app surfaces,” with engineers debating what remains defensible work.
Two xAI cofounders announce departures amid SpaceX merger speculation
xAI (xAI): Two founding members posted resignation notes in close succession—Yuhuai “Tony” Wu and Jimmy Ba—prompting public speculation about post–SpaceX-merger organizational changes and pressure around progress, as captured in a departure roundup screenshot shared in Departure posts and amplified as “two cofounders out the door in 48 hours” in Rundown recap.
Details remain mostly narrative (no concrete internal incident cited); the most actionable signal for leaders is simply that senior turnover is visible and fast-moving, with broader speculation about “pressure from Elon” and merger-driven leadership changes circulating in Rumor post and Merger timing note.
“Only ~1,000 people can do large-scale ML well” talent-scarcity framing resurfaces
AI lab hiring market: A recurring claim that frontier ML has an unusually small pool of top practitioners (“about only a thousand people that can really do it well”) is being used to explain why departures at AI labs feel more material than in other sectors, as argued in Leaving labs thread and restated in Scarcity quote.
The same thread frames these people as “incredibly valuable,” implying comp and retention dynamics will keep dominating the engineering org story even when product roadmaps look stable, per Leaving labs thread.
Work-intensification signal: AI use expands tasks and blurs work-life boundaries
AI and workload: An HBR-style field-study narrative is being echoed: AI didn’t reduce work; it expanded scope and coordination overhead, with boundary blur (work creeping into lunch/meetings) and more attention switching from running multiple AI threads, as summarized in Field study summary.
One recirculated set of quantified claims adds that developers took 19% longer but felt 20% faster, with only 3% time savings overall, alongside reports of rising expectations and stress, per Burnout summary.
“80% of apps disappear” thesis: agent-first UI replaces data-management apps
App surface shift: Peter Steinberger’s claim that “80% of apps will disappear” is recirculating, with the argument that many apps mostly manage data—and agents can do those tasks more naturally (reminders, meal tracking, fitness planning) while users stop caring where the data lives, as summarized in Apps disappear clip.
The implication is a push toward tool/API surfaces and agent permissions models over standalone UIs, with “physical/sensor” apps called out as more defensible, per Apps disappear clip.
Retention theory: comp windfalls make frontier AI teams hard to hold together
Frontier lab retention: One explanation offered for the current churn is that people “working on the singularity make such an astounding amount of money that they are remarkably difficult to hold on to,” linking departures to financial optionality rather than purely technical disagreement, as stated in Singularity comp post.
This framing is being layered on top of the broader “many people leaving AI companies” observation in Churn observation, suggesting some exits may be less about dissatisfaction and more about opportunity cost and personal risk tolerance.
Forward deployed engineer hiring ramps as agent rollouts become a core function
FDE role expansion: A hiring anecdote points to rapid growth of “forward deployed engineer” teams at AI startups—one org cited having 12 FDEs, aiming for 40 by end of July and 60 by year-end, as described in FDE hiring anecdote.
The post frames this as a labor-market shift toward people who can translate models into operational value inside specific verticals (legal, construction, medicine), rather than purely “model builders,” per FDE hiring anecdote.