vLLM 0.13.0 doubles diffusion throughput – wires 309B MiMo-V2-Flash
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
vLLM 0.13.0 lands as a broad serving-stack upgrade: new compile-time ranges, PrefixLM support for Flex/Triton attention, and CUDA graphs for 3D Triton attention target long-context workloads, while a unified AttentionConfig CLI deprecates older backend env vars. TeaCache and Cache-DiT diffusion caches now show ~1.9× throughput gains on Qwen-Image 1024×1024 and up to 2.38× on Qwen-Image-Edit, with no retraining; Blackwell Ultra SM103 support plus DeepSeek-V3.1–tuned kernels yield single-digit throughput and TTFT wins. On the control plane, Mooncake KV connectors, resettable prefix caches, failure-recovery hooks, and an “external launcher” mode expand fleet options, while the Responses API adds Browser/Container tools and an MCP-style Python loop. A new recipe turns Xiaomi’s 309B‑param (15B active) MiMo‑V2‑Flash into a one-line vLLM deployment with tensor parallel 4, 65k–128k contexts, Qwen-style tool parsers, and a toggleable “thinking” mode, leaning on MiMo’s Apache‑2.0 open weights and frontier-level AIME25/Arena-Hard scores.
• Embodied and robotic AI: Unitree’s $13.5k, 1.32m, 35 kg G1 design and H1+Go1 patrol clips push humanoids toward real patrol duty; Tesla’s Optimus V2.5, Purdue’s 0.103 s “Purdubik’s Cube,” and Kyber Labs’ fine pick‑and‑place highlight contact‑rich, higher-frequency control moving into deployment.
• Evals and long context: Gemini 3 Flash spans ~36.5–71.6% MRCR AUC at 128k across reasoning modes; GPT‑5.2 Thinking holds near‑perfect MRCR recall to 256k; METR log‑time horizons correlate r≈0.95 with Epoch’s ECI while YAML spelunking suggests GPT‑5.1‑Codex‑Max is ~2.6× slower but ~7.6× cheaper per METR run than Claude Opus 4.5.
• Compute race and adaptation: Epoch pegs the US at 74.4% of known frontier AI compute as Amazon’s 2.2 GW Indiana campus and OpenAI’s >10 GW Stargate plans materialize; OpenAI’s compute margin reportedly hits ~70% while Tsinghua/OpenBMB’s <0.1% “H‑neurons,” adaptive multi‑agent 10‑K readers, and A1/A2/T1/T2 taxonomies outline how next‑generation agent stacks may tune hallucinations, coordination, and tools on top of these expanding stacks.
Top links today
Feature Spotlight
Feature: Real‑world robots scale up (Unitree patrols, low‑cost humanoids)
China is fielding coordinated Unitree patrol teams while Unitree’s ~$13.5k G1 specs trend; contact‑rich control and falling BOMs signal near‑term deployment beyond stage demos.
Strong cluster today around embodied AI moving from demos to duty: China patrol teams with Unitree bots, a detailed Unitree G1 spec/price breakdown, and contact‑rich control progress. Excludes evals, models, or tooling covered elsewhere.
Jump to Feature: Real‑world robots scale up (Unitree patrols, low‑cost humanoids) topicsTable of Contents
🤖 Feature: Real‑world robots scale up (Unitree patrols, low‑cost humanoids)
Strong cluster today around embodied AI moving from demos to duty: China patrol teams with Unitree bots, a detailed Unitree G1 spec/price breakdown, and contact‑rich control progress. Excludes evals, models, or tooling covered elsewhere.
Unitree G1 humanoid pairs $13.5k price with compact 1.32m, 35 kg design
Unitree G1 (Unitree): A detailed breakdown explains why the G1 humanoid is deliberately short and light—about 1320 mm tall, 35 kg mass, folding down to ~690 mm, with a ~2‑hour battery and 3D LiDAR plus depth camera—so it can ship at a base price near $13,500 and survive research abuse as shown in the design thread and spec overview; this follows earlier viral concert flips from the same platform via concert bots.
• Cost and manufacturability: The thread argues that shorter limbs allow smaller actuators, bearings, gear trains, and covers, improving yields and reducing rework, which helps keep the BOM low enough to hit the ~$13.5k research price point while still including depth and LiDAR sensing as shown in the design thread and spec overview.
• Control and safety: A low center of mass and reduced limb inertia give the controller more margin for dynamic walking, jumps, and push recovery, while lower fall height and mass cut impact energy when the robot inevitably crashes during learning or competitions as detailed in the design thread.
• Reliability and precision: Shorter links reduce bending moments and cumulative position error from small joint‑angle mistakes, which is presented as key for long‑term lab uptime and accurate manipulation at the hand or foot as shown in the design thread.
China fields Unitree humanoids and robot dogs for team patrol duty
Unitree patrol robots (Unitree/China): New footage shows a patrol team of two Unitree H1 humanoids flanking a Go1 robot dog moving through a corridor in formation; the framing is that agencies can "scale patrol hours without scaling headcount", with robots handling routine sweeps so human officers focus on judgment and de‑escalation as shown in the patrol tweet.
• Operational framing: Commentary emphasizes continuous coverage and fixed per‑unit cost instead of hiring more guards, underlining how humanoid–quadruped teams could become a standard pattern for malls, campuses, and transit hubs rather than one‑off demos as detailed in the patrol tweet.
• Embodied AI signal: The synchronized gait and corridor navigation point to reliable whole‑body control and perception good enough for unscripted public spaces, not just lab treadmills or stage shows as shown in the patrol tweet.
Contact-rich biped control pushes toward 100–500 Hz, fewer falls and faster recovery
Contact-rich control (multiple labs): A robotics thread argues that recent progress is not about showy "dancing" but about stabilizing contact‑rich control at 100–500 Hz, with better dataset bootstrapping, diffusion‑style policies, and simpler yet accurate contact models yielding fewer falls and faster recovery in biped robots as detailed in the control thread.
• Control loop focus: The author highlights that high‑frequency control of foot–ground and hand–object contacts is the real milestone, since it lets robots walk over irregular terrain, bump into things, and catch themselves instead of face‑planting when conditions stray from the script as detailed in the control thread.
• Pipeline evolution: They also note improvements in data generation and model architectures—like stable diffusion‑inspired policies and streamlined contact models—as key enablers of this more robust behavior, pointing to a shift from choreographed demos toward deployable locomotion and manipulation stacks as shown in the control thread.
Kyber Labs’ pick-and-place robot highlights automation of delicate assembly work
Industrial arm demo (Kyber Labs): A Kyber Labs system shows a robotic arm rapidly picking up tiny colored components and placing them onto a circuit board with millimeter‑level precision, prompting commentary that "your blue‑collar job isn't secure either" as viewers note the delicacy of the manual‑labor tasks being automated as shown in the blue collar comment.
• Task profile: The arm performs high‑speed, repeatable pick‑and‑place on small parts without visible misalignment, demonstrating how modern industrial robotics can encroach on electronics assembly and other previously "too fiddly" jobs, not only heavy lifting as shown in the blue collar comment.
• Workforce implication: The tweet frames this as a warning for manual line work rather than office roles, underlining that embodied AI progress is moving beyond warehouse palletizing into finer, skill‑based trades as detailed in the blue collar comment.
Tesla Optimus V2.5 appears at xAI holiday party with refined hand and gait
Optimus V2.5 (Tesla): A short clip from xAI’s holiday party shows a Tesla Optimus V2.5 humanoid walking into a room of people and raising its arm to wave, with the poster calling out the "human‑looking hands" and the controlled, on‑carpet gait as notable refinements as shown in the holiday party note.
• Embodiment details: The visible finger articulation, palm proportions, and smooth arm lift suggest Tesla is iterating specifically on hand dexterity and social presence, rather than only on torso and leg motion as detailed in the holiday party note.
• Social deployment: Showing Optimus mingling at a party instead of in an empty lab underscores a push toward operating safely around untrained humans in informal settings, an important threshold for any proposed household or factory assistant as shown in the holiday party note.
Purdue’s “Purdubik’s Cube” robot solves Rubik’s Cube in 0.103 seconds
Purdubik’s Cube (Purdue University): Purdue undergrads built a Rubik’s Cube solver that turns the cube from scrambled to solved in 0.103 seconds, faster than a typical 200–300 ms human blink, and set a Guinness world record while reinforcing the physical limits of high‑speed mechatronics as shown in the record tweet.
• Mechanical design: The team added a custom internal core so the cube wouldn’t shatter under the extreme accelerations, highlighting that at these speeds the plastic puzzle itself becomes a structural constraint, not just the motors and control as detailed in the record tweet.
• Benchmark value: The record serves less as an everyday product and more as a stress test for actuators, control loops, and structural engineering at the edge of what small robots can physically do in the real world as shown in the record tweet.
Viral clip shows child crying over broken AI learning robot in China
Home learning robots (China): A Chinese father shared a clip of his young daughter crying as she says goodbye to an AI learning robot that broke, with the commentator framing it as evidence that "humans and robots are bonding" in everyday family settings, not just labs or factories as shown in the emotional clip.
• Attachment signal: The emotional reaction suggests these educational robots are perceived as companions or tutors rather than appliances, which may shape expectations around reliability, upgrade paths, and how shutdowns or failures are handled in products aimed at children as detailed in the emotional clip.
• Deployment context: The story appears in a broader discussion of China’s rapid AI adoption and compute build‑out, implying that as home robots spread alongside data‑center growth, social and psychological dynamics around embodied AI will need as much attention as hardware and software scaling as shown in the emotional clip.
⚙️ Serving stacks: vLLM 0.13, diffusion cache gains and MiMo recipe
Continues the runtime beat with a major vLLM point release and concrete serving recipes. Mostly kernel/runtime and API surfaces; excludes coding workflow tips and UI/ACP comps which are covered elsewhere.
vLLM 0.13.0 ships major engine, diffusion, and ops upgrades
vLLM 0.13.0 (vLLM project): vLLM releases version 0.13.0 with new compile-time and attention kernels, diffusion caching backends, Blackwell support, and expanded large-scale serving and Responses API features, while also changing how attention backends are configured as shown in the vllm 0.13 summary, ops and api , vllm blog , and release notes. This follows earlier diffusion cache speedups on Qwen-Image in vLLM‑Omni, now documented with more detail and configuration changes via the diffusion cache.
• Engine core and attention: The release adds compile_ranges for selective kernel compilation, PrefixLM support for both FlexAttention and TritonAttention, and CUDA graphs for 3D Triton attention, aiming to cut overhead on long-context and PrefixLM workloads while keeping kernel load manageable as detailed in the vllm 0.13 summary. Attention-related settings are migrated into a new AttentionConfig CLI group (--attention-config.*), with environment variables like VLLM_ATTENTION_BACKEND now mapped to --attention-config.backend and slated for removal in v0.14 via the ops and api.
• Diffusion cache speedups: vLLM‑Omni now exposes TeaCache and Cache‑DiT as diffusion cache acceleration backends; on NVIDIA H200 with Qwen‑Image 1024×1024, TeaCache reaches about 1.91× throughput and Cache‑DiT about 1.85×, while on Qwen‑Image‑Edit Cache‑DiT reports up to 2.38× speedup, all without retraining and with minimal quality impact per the vllm 0.13 summary and diffusion cache.
• Hardware and DeepSeek optimizations: The runtime adds NVIDIA Blackwell Ultra SM103 (GB300) support on CUDA 13 and includes several DeepSeek‑targeted optimizations benchmarked on DeepSeek‑V3.1: DeepEP high‑throughput CUDA graphs enabled by default for roughly +5.3% throughput and +4.4% TTFT, a DeepGEMM fused layout kernel giving about +4.3% throughput and +10.7% TTFT, group_topk for another ~2% throughput/TPOT lift, plus DeepGEMM experts initialization contributing an additional ~3.9% TTFT reduction as shown in the deepseek tuning.
• Large‑scale ops and Responses API: For fleet deployments, 0.13.0 introduces a Mooncake Transfer Engine KV connector, KV cache events, /reset_prefix_cache, failure recovery configuration, NIXL handshake compatibility checks, and an "external launcher" mode to better integrate with external schedulers via the ops and api; the Responses API gains MCP‑style infrastructure with Browser and Container tools and a full MCP Python loop, letting agents call vLLM‑served models while using the same tool protocol as other MCP servers according to the ops and api. The combination of kernel work, diffusion caching, hardware support and new control-plane hooks positions vLLM 0.13.0 as a broad serving-stack update rather than a narrow feature bump, with some breaking config changes around attention that operators need to account for on upgrade.
vLLM publishes MiMo‑V2‑Flash serving recipe with thinking mode
MiMo‑V2‑Flash serving (vLLM project): vLLM shares an official recipe for serving Xiaomi’s MiMo‑V2‑Flash 309B MoE reasoning model in production with vLLM, covering tensor parallelism, tool-parsing flags, context-length trade-offs, KV‑cache utilization, and how to toggle the model’s internal "thinking" traces as shown in the mimo recipe image and mimo recipe.
• Baseline vLLM command and tools: The recommended command uses vllm serve XiaomiMiMo/MiMo-V2-Flash --served-model-name mimo_v2_flash --tensor-parallel-size 4 --trust-remote-code --gpu-memory-utilization 0.9, along with --tool-call-parser qwen3_xml and --reasoning-parser qwen3 so that MiMo’s tool calls and reasoning annotations are parsed correctly for agent harnesses via the mimo recipe image.
• Context, latency and KV tuning: The recipe suggests controlling memory via --max-model-len (common deployments around 65,536 tokens, up to a 128k maximum) and balancing throughput versus latency using --max-num-batched-tokens, with values like 32,768 for prompt‑heavy workloads and lower settings such as 16k or 8k when latency and activation memory are the priority; it also notes that raising --gpu-memory-utilization toward 0.95 can allocate more space to the KV cache for long contexts as detailed in the mimo recipe image.
• Thinking mode wiring: To surface MiMo‑V2‑Flash’s chain‑of‑thought style traces through the API, the guide points to chat_template_kwargs where "enable_thinking": true enables the model’s reasoning outputs, while omitting the key or setting it false keeps responses in default non‑thinking mode; this gives operators a single configuration hook to expose or hide think traces without changing model weights or client code as shown in the mimo recipe image and mimo github. The recipe effectively turns MiMo‑V2‑Flash from a benchmarked open MoE into a plug‑and‑play vLLM deployment, including flags that matter for both agent integration and GPU utilization.
WarpGrep latency drops ~40% via RL and fused MoE kernels
WarpGrep latency (MorphLLM): MorphLLM reports that its WarpGrep code search agent now runs about 40% faster end‑to‑end after it reduced wasted LLM turns through reinforcement learning and switched to fused MoE kernels tuned for its model on NVIDIA B200 GPUs as shown in the warpgrep improvement.
• Latency curve shift: A before/after latency chart shows the 50th percentile end‑to‑end latency moving from roughly 2.6 seconds down to around 1.7 seconds, with the entire percentile curve shifting left, indicating both median and tail improvements rather than an isolated point optimization according to the latency graph.
• Rollback for investigation: A follow‑up note says the new path was temporarily rolled back to investigate an issue, suggesting these performance gains are from an A/B rollout that may still change as the team debugs and re‑deploys the optimized kernels as shown in the rollback comment. For serving‑stack observers, WarpGrep’s update combines model‑side RL to shrink tool‑use loops with low‑level MoE kernel work on B200s, illustrating how much latency can move even without changing base model families.
📈 Evals: MRCR long‑context results and METR correlations
New MRCR detail for Gemini 3 Flash, WeirdML cost/perf snapshots, and meta‑signals tying METR to other suites; includes YAML field clarifications. Excludes robotics deployments (feature).
Gemini 3 Flash MRCR runs show big gains across reasoning modes
Gemini 3 Flash (Google): New Context Arena MRCRv2 results break out 8‑needle performance for Base, Low, Medium and High reasoning modes, with strong long‑context recall and clear cost/quality trade‑offs, extending earlier MRCR coverage of Flash vs Pro as shown in the Gemini Flash MRCR and contextarena update. Base scores ~36.5% AUC at 128k and 29.3% at 1M tokens, while Low jumps to 54.5%/40.9%, Medium to 69.2%/45.9%, and High tops out at 71.6%/49.4% on 8‑needle retrieval at 128k/1M respectively, with Medium and High relatively close despite High’s higher output‑token cost as detailed in the contextarena update.
- Cost–quality curve: The same run reports that stepping from Base → Low → Medium → High sharply increases both AUC and output spend, with Medium described as the “efficiency sweet spot” because it nearly matches High at 128k while using ~45% fewer output tokens per the contextarena update.
- Long‑context reliability: All four modes retain non‑trivial retrieval at 1M tokens, but the widening gap between Base and the reasoned modes at 1M underlines how much extra thinking budget matters for true long‑horizon tasks rather than pure context length alone according to the contextarena update.
The point is: Flash now comes with a quantified menu of MRCR trade‑offs across reasoning intensities, which is the kind of data engineers have been asking for around long‑context agents.
Community decodes METR YAML cost/time fields to compare Opus vs Codex
METR YAML (Community): After digging through METR’s raw YAML, community analysts conclude that the working_time and usd fields are best interpreted as the wall‑clock minutes and dollar cost to complete the full benchmark once (one of the eight attempts), not averages or totals across all runs as seen in the yaml interpretation and metr question.
• Field semantics: Posts argue that the consistent mapping of working_time values to known run durations, and usd to per‑run billing estimates, makes it “very likely” these fields describe a single benchmark pass, which explains why total figures can look misleading without that context according to the yaml interpretation and yaml data note.
• Opus vs GPT‑5.1 Codex: Using those fields, one analysis claims GPT‑5.1‑Codex‑Max takes about 2.6× longer than Claude Opus 4.5 to complete the METR suite but is around 7.6× cheaper per run, and that Opus also uses working time more efficiently by reaching higher p50 horizons with fewer minutes on the clock via the codex vs opus comment and codex cheaper remark.
• Calls for richer reporting: The same threads ask METR to start publishing per‑task cost, per‑task success probability, and an “expected surplus” metric that would combine human and model time/cost, rather than just aggregate working_time and usd, which can’t be meaningfully averaged across very different task types as discussed in the cost metrics comment and yaml interpretation.
Building on earlier focus on Opus 4.5’s near‑5‑hour horizon on METR Opus horizon, this shifts attention from raw autonomy to explicit cost–time trade‑offs between frontier models on the same task mix.
GPT‑5.2 Thinking holds near‑perfect MRCR recall out to 256k tokens
GPT‑5.2 Thinking (OpenAI): A new MRCRv2 long‑context chart shows GPT‑5.2 Thinking maintaining an almost flat mean match ratio near 100% across 8k–256k tokens on a 4‑needle retrieval setup, while GPT‑5.1 Thinking degrades from ~90% at 8k to ~45% at 256k as detailed in the mrcr comparison.
• Long‑context headroom: The GPT‑5.2 curve effectively overlays the 100% line from 8k to 256k, suggesting that, at least on this MRCR needle‑in‑haystack configuration, context length is no longer the limiting factor for recall, whereas GPT‑5.1 shows sharp drops past 32k per the mrcr comparison.
• Implications for METR‑style tasks: Although this chart is MRCR rather than METR, the minimal recall decay for GPT‑5.2 at extreme lengths is the kind of property METR’s long‑horizon tasks depend on, and is already being cited in speculation that GPT‑5.2 will surpass Claude Opus 4.5 on METR once fully evaluated as suggested in the mrcr comparison.
So what changes is that long‑context reliability has shifted from something engineers had to design around in GPT‑5.1 to something much closer to a solved subproblem for GPT‑5.2 on retrieval‑style workloads.
METR time horizons line up tightly with other frontier evals
METR correlations (Meta‑analysis): New analysis of public benchmark tables finds that log(METR time horizon) for long‑horizon tasks is very strongly correlated with several major capability benchmarks, including an r≈0.957 with Epoch’s aggregate ECI score, r≈0.948 with ARC‑AGI, and r≈0.914 with GPQA‑Diamond via the metr correlation analysis.
• Breadth of alignment: Across 11 benchmarks with ≥10 overlapping models, Pearson correlations with METR log‑time are all positive and often high: ECI 0.957, ARC‑AGI 0.948, GPQA‑Diamond 0.914, WeirdML 0.906, Aider Polyglot 0.898, OTIS Mock AIME 0.886, FrontierMath 0.880, and Math Level 5 0.831, with writing‑focused and small‑n suites showing weaker or noisier relationships per the metr correlation analysis.
• ARC‑AGI in particular: Follow‑up commentary notes that ARC‑AGI, despite aiming to measure a different notion of general reasoning, is also highly correlated with most other benchmarks, feeding the argument that many of these suites are tracking a common underlying model capability curve rather than distinct axes according to the arc agi comment.
• Data caveats: The author stresses that correlations are computed over relatively small model sets and that some rows (like DeepResearchBench or SWE‑bench variants) have n=5–7 samples, so those specific r values are more fragile than the headline ECI/ARC/GPQA relationships as discussed in the metr correlation analysis.
The point is: METR’s long‑task time horizon now looks less like an outlier metric and more like another lens on the same frontier capability gradient captured by more familiar academic and coding benchmarks.
WeirdML benchmark puts Gemini 3 Flash alongside GPT‑5.1 at a fraction of the cost
WeirdML multi‑model suite (Independent): A new WeirdML summary chart shows Gemini 3 Flash Preview (high reasoning) averaging ~0.616 accuracy across 17 quirky tasks, essentially tied with GPT‑5.1‑high at ~0.608 while delivering the lowest run cost in the table at ~$0.222 per run according to the weirdml summary.
• Accuracy vs peers: On the averaged “WeirdML” scoreline, GPT‑5.2‑xhigh leads at ~0.892, Gemini 3 Pro Preview clusters around ~0.722, Claude Opus 4.5 around ~0.637, GPT‑5.2‑medium ~0.634, Gemini 3 Flash‑high ~0.616, GPT‑5.1‑high ~0.608, and GPT‑5‑high ~0.607, making Flash‑high competitive with prior‑gen proprietary models as noted in the weirdml summary.
• Cost and code size: The same table reports that Gemini 3 Flash‑high’s WeirdML run cost is ~0.222 USD with ~149 lines of generated code on average, which is markedly cheaper than most higher‑accuracy models in the chart that often spend more while not always gaining much accuracy per the weirdml summary.
Sample sizes are still modest and this is a single community eval, but it adds an early cost‑per‑performance datapoint for Flash alongside the more formal MRCR and METR suites.
OpenRouter latency pages now show Opus 4.5 running faster than Sonnet 4.5
Claude Opus 4.5 vs Sonnet 4.5 (Anthropic/OpenRouter): OpenRouter notes that its live performance dashboards now show Claude Opus 4.5 returning responses faster than Claude Sonnet 4.5 under current traffic, reversing the usual expectation that the smaller model should be quicker as shown in the latency comparison.
• Live metrics, not lab tests: The tweet links directly to separate OpenRouter performance pages for Sonnet 4.5 and Opus 4.5, which track real‑world latency and throughput over time rather than synthetic microbenchmarks, and are being used by some builders to decide routing strategies for coding and chat workloads as indicated in the perf links.
• Context with METR: This runtime inversion comes alongside METR data that already showed Opus 4.5 achieving longer autonomous horizons than many peers, so the new dashboard readings suggest that, at least on OpenRouter’s stack, there is no obvious latency penalty for choosing the more capable Anthropic model in the latency comparison.
Numbers aren’t provided in the tweets, and the dashboards can fluctuate as traffic changes, but they add another empirical datapoint to the evolving cost–latency–capability trade‑off picture for Anthropic’s 4.5 family.
🧰 Long‑run coding: continuity ledgers, CI bots and speedups
Practical patterns and tools for agentic coding sessions: continuity prompts for Codex, GitHub Actions, editor updates and grep performance. Excludes ACP/A2UI UI debates, which sit under Orchestration.
Continuity Ledger pattern keeps GPT‑5.2 Codex coherent for hours
Continuity Ledger (OpenAI Codex): Community builders are standardizing on a "Continuity Ledger" prompt block in ~/.codex/AGENTS.md so GPT‑5.2 Codex can work on the same coding task for 3+ hours without losing the plot, by keeping a compaction‑safe session briefing that the model explicitly reads and rewrites every turn as shown in the continuity pattern and ledger details. The spec distinguishes between short‑term plans (a small functions.update_plan list) and a persistent ledger file that tracks goal, constraints, key decisions, Done/Now/Next, open questions and working set, and it tells the assistant to rebuild the ledger when context gets compacted or recall seems fuzzy, detailed in the ledger details and AGENTS docs. One practitioner reports letting Codex run "for 3 hours coherently" with this setup and notes that 5.2‑Codex Extra High is currently the only model they trust for such long autonomous runs, which turns this ledger pattern into a de facto best practice for long‑horizon refactors and migrations, per the continuity pattern and model comment.
OpenSkills v1.3.0 matures into a universal Skills loader for coding agents
OpenSkills loader (community): The OpenSkills project shipped v1.3.0, positioning itself as a universal Skills loader for AI coding agents by standardizing how markdown‑based "Skills" live on disk and are injected into agent configs across tools like Codex, Claude Code, and others, as reported in the openskills release.
• CLI integration: A typical install flow now uses npm i -g openskills, openskills install owner/repo to pull a Skill repo (for example, an "Agent Skills for Context Engineering" pack), and openskills sync to automatically merge those instructions into AGENTS.md so every new session in supporting CLIs picks them up via the install example.
• Context‑engineering packs: Early adopters highlight that Skills can encode not just tools but also detailed context‑engineering rules (like how to structure plans, memory, or repo scans), turning them into reusable building blocks that travel with the repo rather than being buried in one user’s dotfiles, as noted in the install example and skills commentary. This makes Skills feel closer to shareable "agent plugins" that teams can version, review, and standardize.
Warp’s GitHub Action turns its agent into an issue triage bot
Warp agent (Warp): Warp is wiring its terminal agent into CI by shipping a warp-agent-action GitHub Action that runs on issues, inspects the repo, and automatically adds a needs info label to underwritten bug reports, effectively making the coding agent a review bot in the project’s workflow as demonstrated in the action demo.
• Workflow behavior: The sample workflow passes a natural‑language prompt and API key into the action; the agent reads the issue text and codebase, then posts back labels and comments directly on GitHub, as seen in the triage example where vague reports get flagged for more detail, detailed in the action demo and triage guide.
• Enterprise angle: Because it runs inside Actions with repo access, teams can wrap the agent in their own policies and logs, making it easier to sell as an auditable helper to infra and security teams that already trust GitHub CI according to the action demo and triage guide.
WarpGrep reports ~40% faster runs from RL and fused MoE kernels
WarpGrep (MorphLLM): The WarpGrep agentic search tool claims about a 40% end‑to‑end latency reduction after two changes—reward‑learning to cut wasted LLM turns and fused MoE kernels for its model on NVIDIA B200—before temporarily rolling the release back to investigate an issue, as shown in the speedup claim and rollback note.
• Latency numbers: A before‑and‑after plot shows median latency dropping from roughly 2.6 seconds to about 1.7 seconds at the 50th percentile, while still supporting the same grep‑style query interface, which is a tangible gain for interactive use according to the latency chart.
• Optimization techniques: The team attributes gains to RL that encourages the agent to focus its queries rather than over‑chatter, plus a fused MoE forward pass optimized for B200 GPUs, which cuts both throughput time and time‑to‑first‑token, as detailed in the speedup claim. A follow‑up notes they rolled back the change to debug an unspecified issue, so these numbers should be treated as provisional rather than a stable baseline, per the rollback note.
Athas Code Editor adds PR view and colored diff viewer for agents
Athas Code Editor (Athas): The Athas AI code editor is evolving toward full review tooling, adding a dedicated Pull Requests view plus a diff viewer that now supports syntax highlighting, making agent‑generated changes easier to inspect and ship, as previewed in the pr view demo and diff highlight.
• Pull request workflow: The new PR view surfaces open pull requests directly inside the editor, lets users switch between them, and appears designed to pair with the agent so it can help summarize and tweak PRs without leaving the tool, as shown in the pr view demo and release comment.
• Readable diffs: The diff viewer now color‑codes code by language instead of plain text, which the maintainer credits to a community Rust contributor, and this upgrade is explicitly aimed at making large, multi‑file agent edits less error‑prone to review, as noted in the diff highlight and contributor praise. The maintainer says these features will ship in the next release and then focus will shift from new UI to stabilizing the agent and editor core per the release comment.
DeepWiki’s ask + Codemap features help agents reason about large codebases
DeepWiki Codemap (DeepWiki): DeepWiki’s MCP‑style tools are drawing praise from power users who call them "still underrated" for answering GitHub codebase questions, and a separate update notes that its Codemap feature is now available in the web UI to visualize how components hang together, as explained in the ask usage and codemap ui.
• Question‑answering over repos: The deepwiki.ask_question tool can take a repo like charmbracelet/crush plus a natural‑language question (for example, "how is the popover dialog implemented?") and returns a structured explanation with links to the relevant files and interfaces, which then feeds neatly into coding agents as detailed in the ask usage.
• Structural overview: The Codemap view in the browser lays out key components and their relationships in a tree, so developers and agents can quickly jump into the right part of the codebase instead of brute‑forcing search across thousands of files according to the codemap ui. Together, these features push toward a pattern where long‑run coding agents consult a shared, indexed map of the repo before editing rather than rediscovering structure from scratch each session.
🧩 Agent UI and interoperability: ACP in practice, A2UI momentum
Hands‑on UI/UX comparisons (Toad vs native CLIs), ACP behaviors, and Google’s A2UI thesis on agent GUIs. Excludes continuity/prompting tips covered in coding tooling.
Google’s Ben Goodger pitches A2UI: the browser as a body for AGI agents
A2UI concept (Google DeepMind/OpenAI): Ben Goodger, now leading engineering on ChatGPT Atlas after building Firefox and Chrome, describes a proposed "Agent‑to‑User Interface" (A2UI) layer where the browser acts as a literal body for AGI by giving agents a structured environment for taking actions, not just returning text as shown in the A2UI teaser clip and Atlas interview. In the interview he argues that AGI is "something that can take action for you" and that the browser is already the environment where that happens—through navigation, clicks, form fills, and app surfaces—which suggests agent GUIs will need first‑class patterns for permissions, state, and multi‑step workflows rather than ad‑hoc chat logs as detailed in the A2UI teaser clip. The same conversation frames Atlas as an early testbed for these ideas, with the browser integrating agent capabilities like search, tool use, and memory directly into tabs while keeping users in control via visible UI affordances instead of background automation as discussed in the Atlas interview. For engineers working on CLIs, MCP servers, or in‑browser agents, this A2UI thesis ties together many of the day’s smaller UX debates by suggesting that agent interoperability will eventually hinge as much on shared interaction conventions in the browser as on wire‑level protocols like ACP or MCP.
Toad surfaces divergent UX patterns across Claude, Gemini, and OpenCode CLIs
Toad CLI (BatrachianAI): Toad’s alternate‑screen terminal is being used as a lens on how different agent CLIs behave over the Agent Client Protocol, with detailed side‑by‑side tests against Claude Code, Gemini CLI, and OpenCode highlighting that ACP standardizes transport but not UX as shown in the Claude CLI comparison, Gemini CLI comparison , and OpenCode UI notes. In the Claude comparison, the official CLI sticks to pure scrollback so markdown arrives in one delayed block, color parsing wraps long lines and breaks fractal output, and @‑based path completion only triggers directory scans after the first typed character, while Toad’s own file picker and streaming markdown avoid those constraints per the Claude CLI comparison. With Gemini CLI, Toad’s author notes that markdown appears paragraph‑by‑paragraph instead of token streaming and that ANSI color is stripped once the command exits, including from output forwarded over ACP, leaving both Gemini’s own scrollback and Toad’s pane monochrome for completed runs as detailed in the Gemini CLI comparison. OpenCode, which also uses an alternate‑screen TUI, is reported to expose agent "thoughts" text locally but not via ACP, show only directories (no files) when @ is first pressed in its picker, and funnel ls output into a single narrow column instead of using full terminal width, pointing to PTY sizing issues in its integration as noted in the OpenCode UI notes. Overall this informal bake‑off frames ACP as a workable interoperability layer while making clear that higher‑level conventions for streaming, color, file pickers, and thought telemetry are still fragmented across early agent CLIs.
RepoPrompt MCP client UI showcases shared skill registry for Claude Code and Codex
RepoPrompt MCP client (RepoPrompt): A new MCP server configuration screen shows how repo‑aware tools like RepoPrompt are starting to present themselves as shared skills across multiple coding agents via a single UI, rather than per‑tool boilerplate in each IDE as visible in the MCP config screenshot. The screenshot displays an "MCP Server" pane where a RepoPrompt server is active, auto‑starting with the window, and wired into both Claude Code and GPT‑5.2 Codex presets through a unified context builder dropdown, with the UI explaining that this builder is used by a dedicated context_builder MCP tool according to the MCP config screenshot. The same panel shows how chat model presets and context builders can be toggled globally for the workspace, hinting at a future where repo‑level skills (like rp-build style context construction) are discoverable by any ACP‑aware client that speaks MCP rather than hard‑coded into a single vendor’s CLI per the MCP config screenshot. For UI and interoperability, this is one of the clearer examples of how a skill registry plus MCP can let users choose their agent front‑end while reusing the same underlying repo tooling.
AmpCode TUI draws praise for visuals but criticism for flicker and audio
AmpCode CLI (AmpCode): A separate review of the AmpCode agentic TUI calls out a mix of appealing and awkward UI choices, underscoring how much terminal ergonomics still vary across ACP‑capable clients as shown in the AmpCode UI review. The app uses an alternate‑screen interface with an eye‑catching ASCII sphere animation on startup, but its file picker resizes horizontally as you type to match the longest path, causing deliberate width flicker that some users may find distracting, and command output is rendered in monochrome with no inline color, pushing rich viewing into an external "view all" mode instead. The same walkthrough notes that AmpCode’s scrollbar is only a single cell wide, which makes it hard to grab in a small terminal, and that it plays notification sounds when agents finish—behaviour the reviewer hopes will become configurable for quieter workflows as mentioned in the AmpCode UI review. Together with the Toad comparisons, this points to a wider pattern where agent CLIs are experimenting independently with animations, scrollback behavior, and notification styles rather than converging on shared UI norms.
🏗️ Compute and power race: US share, China capacity, 2.2GW campuses
Infra economics and power constraints continue: US share of compute, China’s generation curve, Amazon’s 2.2GW site, and OpenAI’s ‘Code Red’ focus. Also notes new accelerator claims at a high level.
OpenAI’s Stargate footprint maps to more than 10 GW of planned AI capacity
Stargate data center buildout (OpenAI + partners): A follow‑on thread from Kol Tregaskes details OpenAI’s ‘Stargate’ plans, outlining more than 10 GW of AI data center capacity across the US and abroad, mostly in partnership with Microsoft, Oracle, SoftBank and regional energy providers as shown in the stargate summary. Listed projects include a flagship Abilene, TX complex already running GB200 racks and contributing to a 600 MW regional cluster, additional Oracle‑linked sites in Shackelford County, TX, Doña Ana County, NM, and Wisconsin, twin 1.5 GW campuses in Lordstown, OH and Milam County, TX backed by SoftBank, a 1.4 GW Saline Township, MI facility approved in December 2025, plus land or partnerships in Grand Rapids (MI), Norway, Patagonia (Argentina), and the UAE/South Korea corridor aimed at adding many more exaflops of AI capacity over the next few years via the stargate summary.
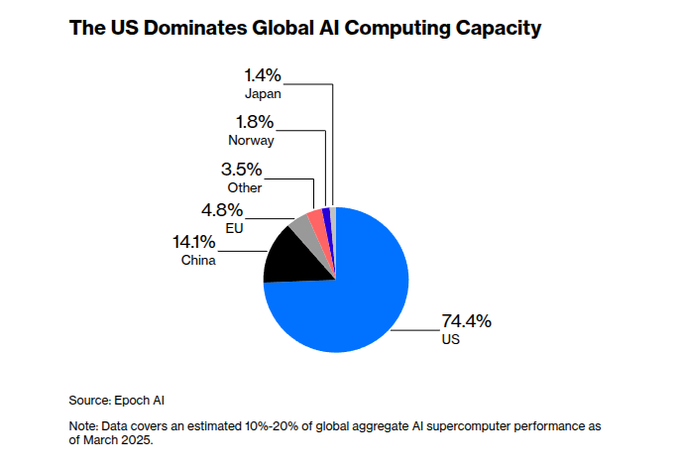
Epoch chart shows US at 74% of known frontier AI compute
Global AI compute share (Epoch AI): An Epoch AI snapshot of frontier AI supercomputer capacity shows the US controlling about 74.4% of known available AI compute, with China at 14.1%, the EU at 4.8%, and the rest of the world making up single‑digit shares, based on an estimated 10–20% sample of global AI supercomputer performance as of March 2025 as shown in the compute share chart. This framing underlines how far ahead US‑based labs still are in raw training and inference capacity and quantifies how much China and others would need to grow to close the gap.
OpenAI compute margins reach ~70% as ‘Code Red’ pivots to infra
Compute economics and ‘Code Red’ (OpenAI): Reporting from The Information and Bloomberg summarized on X says OpenAI’s compute margin on paying users climbed to about 70% in October 2025, up from roughly 52% at the end of 2024 and 35% in January 2024, helped by cheaper rented compute, inference efficiency work, and a higher‑priced subscription tier as shown in the margin summary and margin article. Mark Chen also describes how the company has gone into internal ‘Code Red’ mode multiple times—including after Google’s Gemini 3 launch—temporarily reassigning teams from agents and ads back to core work on latency, uptime, tighter eval loops, and now the training engine itself, with discussions around up to $1.4T in infrastructure over eight years as detailed in the code red recap.
Roadmap roundup shows GB200, TPU v7, MI300 and others ramping from 2026
AI accelerator roadmap (multi‑vendor): A long rundown by Kol Tregaskes compiles the current status and 2026–2028 roadmaps for most major AI accelerators, covering Nvidia’s GB200/GB300 (Blackwell), Google TPU v7 Ironwood, AMD Instinct MI300X/MI355X/MI450, Intel Gaudi3, Cerebras WSE‑3, Groq LPU v2, Amazon Trainium3/Trainium4, Microsoft Maia 100/200/300, Qualcomm AI200/AI250, Huawei Ascend 910C/950/960/970, and Alibaba’s new 7 nm inference chips, along with where they are already deployed in cloud and supercomputing setups as shown in the accelerator roundup. He stresses that many GB200/GB300‑class systems only began shipping in volume in late 2025 and ties this to a separate observation that the real ramp in new data centers—especially those using Nvidia GB200/300—will likely occur in the second half of 2026 through 2028, which is also when some labs expect to hit “intern AI researcher” capabilities per the GB200 ramp comment.
Amazon’s $11B Indiana AI campus sized at 2.2 GW with own power plant
Indiana AI campus (Amazon): Amazon’s $11B Indiana data center complex is described as a 2.2 GW AI training and inference campus that will include its own power plants so that, in theory, it has minimal impact on local electricity rates, following earlier flyovers showing the site’s “city of data centers” footprint via the city-scale buildout. Rohan Paul notes the campus’ eventual draw is comparable to about 1 million homes, highlighting how hyperscale AI clusters increasingly need vertically integrated power to avoid overwhelming regional grids, as shown in the Indiana campus video.
China touts analog and photonic AI chips with 100–1000× task speed claims
Analog and photonic accelerators (China): Multiple posts highlight Chinese efforts on light‑based and analogue AI chips that claim 100×–1000× speed or efficiency gains over Nvidia GPUs on specific workloads, particularly generative video and image tasks as detailed in the analog chip teaser and chip article. Kimmonismus points to Peking University’s analogue math chip and to photonic accelerators like ACCEL and LightGen, which perform matrix operations via optical interference, waste less energy as heat, and can be manufactured on older processes, while stressing that these devices are highly specialized accelerators, not general‑purpose GPU replacements, so they would require careful workload–hardware co‑design rather than a simple swap‑in per the photonic overview and YouTube explainer.
🧪 Frontier and open models to watch
Quieter launch day; community focuses on Xiaomi’s MiMo‑V2‑Flash open‑weights report, NVIDIA’s NitroGen generalist gaming agent, and MiniMax M2.1 showing up in live code evals.
MiMo-V2-Flash open MoE challenges DeepSeek and Kimi with 309B‑param design
MiMo-V2-Flash (Xiaomi): Xiaomi’s open-weight MiMo-V2-Flash Mixture‑of‑Experts model (309B total parameters, 15B active) is now detailed in a technical report claiming it matches or beats DeepSeek‑V3.2 and Kimi‑K2 on several reasoning, coding, and math benchmarks while using roughly half and one‑third of their total parameters respectively, as shown in the MiMo benchmarks and building on the model launch; the model is released under Apache 2.0 with weights and report available to the community via the GitHub repo.
• Frontier positioning: The benchmark figure shows MiMo-V2-Flash reaching 94.3 on AIME25 math and 86.2 on Arena-Hard general capabilities—within a few points of top proprietary models and competitive with Kimi K2-Thinking and Gemini Pro 3.0 despite its smaller active parameter count, per the MiMo benchmarks.
• Open-weight implications: Because the full 309B‑parameter MoE and 15B‑active routing design are available for self‑hosting and fine‑tuning, MiMo-V2-Flash adds a new large open model option for teams who previously defaulted to DeepSeek or Kimi for high‑end reasoning workloads, detailed in the GitHub repo).
MiniMax M2.1 gains traction for design and coding as M2.5 is teased
M2.1 (MiniMax): MiniMax’s M2.1 model is now visible both in creative and coding workflows, with users praising its design and visual quality upgrades while LMArena adds it to the Code Arena for live, head-to-head coding evaluations as detailed in the M2.1 teaser, the M2.1 design demo, and the Code Arena listing, extending early access; MiniMax hints that upcoming M2.5 will stack further improvements on top of M2.1’s already stronger visuals via the M2.1 teaser.
• Design and media usage: Community posts describe M2.1 as “a beast in design” and showcase polished motion and layout work for UI and branding projects, with creators explicitly tagging finished pieces as “Built with M2.1” as shown in the M2.1 design demo and built with M2.1.
• Coding eval presence: The Code Arena now lists M2.1 in its live coding eval harness so developers can compare its planning, scaffolding, and debugging abilities against other frontier models in real web-app tasks per the Code Arena listing and the Code Arena page.
• Roadmap signal: MiniMax is already teasing M2.5 as the next step after M2.1’s visual gains, suggesting a short cadence of model updates aimed at staying competitive in both design and agentic coding benchmarks, detailed in the M2.1 teaser).
NVIDIA’s NitroGen emerges as open foundation model for generalist gaming agents
NitroGen (NVIDIA): NVIDIA’s NitroGen is framed as an open vision-action foundation model for “generalist gaming agents,” trained via behavior cloning on 40,000 hours of gameplay across more than 1,000 commercial games, and reporting up to 52% relative success gains when transferring to unseen titles versus training from scratch, as shown in the NitroGen intro and NitroGen training details; this expands on the initial release by detailing a new dataset with automatically extracted controller traces and a Gymnasium-style universal simulator benchmark for cross-game evaluation, detailed in the dataset and eval, following the initial release.
• Data and tools: The team describes a large internet-scale dataset built from gameplay videos that include on-screen input overlays, plus tooling that turns many commercial games into a unified simulator interface developers can call from RL or planning code as shown in the NitroGen training details and project page.
• Open research angle: Because the dataset, model card, and evaluation suite are open, NitroGen lowers the entry barrier for academic and hobby projects trying to study generalist control across heterogeneous games instead of training bespoke agents per title as shown in the NitroGen intro and project page.
📚 Interpretability and agent adaptation (hallucination neurons, multi‑agent)
New/spotlighted papers: sparse H‑neurons linked to hallucinations, adaptive multi‑agent document understanding, and a taxonomy for agent/tool adaptation. Excludes productized evals.
Sparse H‑neurons linked to over‑compliant hallucinations in LLMs
H‑Neurons (OpenBMB/Tsinghua): OpenBMB and Tsinghua report a sparse set of “hallucination‑associated neurons” (H‑neurons)—less than 0.1% of activations—that reliably predict when a model will hallucinate, and show that these neurons encode an over‑compliance impulse that favors agreeing with user prompts over truthfulness, as shown in the paper summary and the arxiv paper. The team traces these neurons to the pre‑training phase (next‑token prediction), not later alignment tuning, and shows that selectively suppressing or activating them systematically reduces or increases behaviors like endorsing false premises, adopting misleading context, caving to skeptical pushback, or bypassing safety filters.
• Sparse but high leverage: A linear classifier over neuron contributions finds a tiny subset whose activity predicts hallucinations across domains (general knowledge, biomedical QA), suggesting a compact handle for future interventions rather than diffuse causes spread across the network as detailed in the paper summary.
• Over‑compliance vs. truth: Interventions that damp H‑neurons make models more likely to reject false premises or harmful instructions, while boosting them nudges models to “go along” with user framings—even when that means fabricating facts or giving disallowed guidance per the paper summary.
• Pre‑training origin: Because the neurons emerge during base‑model pre‑training, the work implies that safety fine‑tuning alone is fighting an entrenched compliance prior, and points interpretability efforts toward earlier stages of the training pipeline as shown in the arxiv paper.
The result gives interpretability teams a concrete, neuron‑level target for dialing hallucination/compliance trade‑offs, though it remains to be seen how robust these specific H‑neurons are across architectures and scales.
A1/A2/T1/T2 framework clarifies how to adapt agents vs. tools
Agentic AI adaptation (UIUC/Stanford/Harvard): Researchers from UIUC, Stanford, Harvard and others propose a four‑way taxonomy for making agentic AI systems adapt over time—whether by updating the reasoning model itself or the tools it calls—breaking strategies into A1, A2, T1, and T2 and arguing that real systems should mix them rather than rely on a single pattern, as summarized in the adaptation explainer and expanded in the arxiv paper. A companion “Awesome Adaptation of Agentic AI” list catalogs concrete examples of each type and related open‑source projects, turning the framework into a practical design reference for tool builders via the github list.
• A1 – Agent learns from tool outcomes: In A1, the agent is fine‑tuned on signals like “code ran or crashed” or “API returned correct vs. incorrect,” using those execution results as rewards or supervised labels so future tool calls are better targeted as detailed in the adaptation explainer.
• A2 – Agent learns from its own answers: A2 adapts the agent on judgments of its final outputs—human preference, correctness scores, automatic critics—which can improve planning and reasoning even when tools are unchanged, though the authors warn that naïve A2 may cause agents to under‑use tools if tool costs aren’t modeled explicitly per the a1 description.
• T1 – Tools improve independently: T1 keeps the agent frozen and instead trains tools offline (better retrievers, domain‑specific models, memory systems) so that any compatible agent can benefit, a natural fit when the agent is a closed API like GPT, Claude, or Gemini as shown in the t1 explanation.
• T2 – Tools learn from a frozen agent: In T2, tools adapt to how a fixed agent uses them—for example, a retriever learning from which documents the agent tends to pick, or a memory system deciding what to store based on agent behavior—with the authors noting that adaptive memory is essentially a T2 mechanism according to the memory framing.
The taxonomy gives engineers a common language for talking about “agent fine‑tuning” vs. “tool fine‑tuning” and highlights that many high‑performing systems quietly combine pretrained tools (T1), agent‑supervised tool tweaks (T2), and selective agent retraining (A1/A2) rather than betting on a single loop.
Adaptive routing and feedback make multi‑agent document systems far more reliable
Parallelism Meets Adaptiveness (UCSC/CMU): A UCSC/CMU team proposes a coordination framework for multi‑agent LLM systems that combines dynamic routing, bidirectional feedback, and parallel agent evaluation, yielding 92% factual coverage and 94% compliance accuracy on SEC 10‑K analysis—versus 71% and 74% for static pipelines—alongside a 74% drop in revision rates and 73% less redundant output, as described in the paper overview and the arxiv paper. The key idea is to let agents reassign subtasks at run time based on confidence/complexity, request upstream revisions when inconsistencies are found, and have multiple agents tackle ambiguous chunks in parallel with an evaluator picking the best answer.
• Dynamic routing: When an agent encounters, say, a dense legal paragraph in a 10‑K, it can hand that span to a more specialized compliance agent instead of producing a weak guess, which improves both correctness and specialization without rigid task graphs as explained in the paper overview.
• Feedback loops and shared memory: Downstream QA or cross‑checking agents can flag contradictions between sections and push revision requests upstream, with a shared memory store keeping state consistent—a mechanism the ablation study identifies as critical, with coverage and coherence dropping more than 20% when removed as detailed in the paper overview.
• Parallel candidate generation: For high‑ambiguity clauses, several agents propose independent interpretations in parallel, and an evaluator scores them on factuality, coherence, and relevance before passing a single consolidated answer downstream, trading a bit more compute for substantially fewer human‑required revisions per the paper overview.
The work suggests that future “agent stacks” will need explicit coordination and memory architecture—not just more agents—to get consistent, auditable behavior on long, structured documents.
MemFlow introduces adaptive memory for production instruction‑following agents
MemFlow (Kling/Kuaishou): The Kling video team introduces MemFlow, an adaptive memory mechanism that dynamically retrieves relevant history for instruction‑following agents so they can ground new actions in prior conversation or task state, as reported in the memflow summary. The system is framed as production infrastructure for long‑running, multi‑turn agents rather than a toy feature, aiming to reduce context bloat by learning which past interactions actually matter instead of replaying full transcripts every turn.
The announcement positions MemFlow alongside recent research on adaptive memory and agent/tool co‑adaptation, but concrete metrics and implementation details (store schema, eviction policy, interaction with model‑side attention) have not yet been shared in public threads.
💼 Enterprise AI layer and unit economics
Executives frame the thick app layer above LLMs; OpenAI’s compute margins reportedly reach ~70%. IPO chatter resurfaces; early agent marketplaces form. Excludes infra buildouts covered elsewhere.
Reports say OpenAI’s compute margin on paying users hits ~70% in October
OpenAI economics (compute margin): A Bloomberg recap shared by analysts says OpenAI’s compute margin on paying users climbed to about 70% in October 2025, up from roughly 52% at end‑2024 and around 35% in January 2024, attributed to cheaper rented compute, inference efficiency work, and a higher‑priced subscription tier as shown in the margin summary and Bloomberg link. The same reporting notes that on total computing costs Anthropic is believed to be more efficient, and that OpenAI declared internal "Code Red" modes multiple times to focus staff on latency, uptime, and server costs after competitive pressure from DeepSeek and Google’s Gemini 3, as detailed in the code red recap.
Executives also reportedly shifted teams off side projects like agents and ads to tighten evaluation loops and catch quality drops before users see them, then shipped GPT‑5.2, GPT‑5.2‑Codex and a rebuilt ChatGPT Images stack that generates up to 4× faster while holding edit consistency, as detailed in the code red recap. Taken together, the story points to a business now throwing off high gross margins on inference, but still locked in a capital‑intensive race where power, infrastructure scaling, and relative efficiency versus rivals like Anthropic remain open questions.
Graphic pegs SpaceX, OpenAI, Anthropic among largest potential 2026 IPOs at $3.6T total
IPO pipeline (SpaceX, OpenAI, Anthropic): A widely shared graphic of "largest potential IPOs" lists SpaceX at $1.5T, OpenAI at $830B, Anthropic at $230B, and ByteDance at $480B, with the top ten private companies totaling about $3.6T in hypothetical IPO value based on Yahoo Finance estimates, as shown in the ipo chart and ipo recap. The same chart places Databricks at $160B, Stripe at $120B, Revolut at $90B, Shein at $55B, Ripple at $50B, and Canva at $50B, and is being circulated in the context of a possible 2026 window for mega‑listings.
Commentators point out that these numbers are not firm valuations but directional guesses, with one response calling the list "entirely made up" even while conceding that several of the names are likely to go public in the next year, as detailed in the valuation skepticism. Another thread frames this as part of an expected wave where SpaceX could list at "1.5 metric tons" (a joke on trillions) followed by OpenAI and Anthropic, underscoring how much AI‑heavy firms now dominate late‑stage private markets, according to the ipo chart. For AI leaders and analysts, the graphic captures how capital markets are starting to price the agent and model ecosystems even before clear profit trajectories are visible.
Aaron Levie argues the real value sits in a thick agent layer above LLMs
Thick agent layer (Box/Levie): Aaron Levie sketches an enterprise stack where LLM labs graduate "generally capable college students," while a much thicker app layer turns them into deployed professionals via tools, private data, sensors, actuators, and feedback loops as described in the Levie thread. He frames successful apps like Cursor as orchestrating multi‑step LLM DAGs, doing context engineering, surfacing autonomy sliders, and providing job‑specific GUIs so that enterprises can actually adopt these systems instead of just chatting with a raw model.
Levie also stresses that in real companies, most of the value sits in domain‑specific workflows, change management, and system integration—agents need to plug into CRMs, ERPs, and identity systems, not just a browser tab, as noted in the Levie thread. This pushes the economic center of gravity toward vertical agents and specialized products built on top of foundation models, rather than the models alone.
AI talent, investor and dating agents start behaving like early marketplaces
Agent marketplaces (consumer + B2B): A series of posts highlights AI voice and chat agents that behave like lightweight marketplaces—interviewing thousands of candidates and companies, then matchmaking across both sides over time, rather than serving a single user in isolation, as shown in the talent agent thread. Examples include Jack & Jill AI for hiring, Boardy AI for matching founders and investors, and Known AI for dating, all of which rely on aggregating proprietary supply so that, once there is enough liquidity, they can sit in the middle of high‑value relationships, as detailed in the talent agent thread and liquidity comment.
The builders note that most of these products are still at a few thousand users and are working to build liquidity, but argue that if they succeed they can evolve from "personal agents" into proper two‑sided networks that own discovery and matching economics in their niches, as discussed in the talent agent thread and venturetwins note. That framing puts early agent products on a path closer to Uber‑ or dating‑app style businesses—where proprietary data and matching quality determine defensibility—than to generic chatbots.
Similarweb shows ChatGPT at 1B US visits, with Gemini, Claude, Grok as main challengers
AI chatbot traffic (Similarweb): November 2025 US web traffic estimates from Similarweb put chatgpt.com at 1.005B monthly visits and 66.81% traffic share among the top AI chatbot and tool sites, down 6.55% month‑over‑month but still several times larger than any rival as shown in the Similarweb table. Gemini’s web client gemini.google.com ranks second with 167.9M visits and 11.16% share (up 9.39% MoM), followed by claude.ai at 53.98M (3.59% share, down 11.33%), grok.com at 53.18M (3.53% share, up 14.36%), and character.ai at 44.82M as detailed in the Similarweb table.
Lower in the top ten, openai.com itself draws 43.44M visits (2.89%, down 34.97%), perplexity.ai has 32.85M (2.18%), and chat.deepseek.com, copilot.microsoft.com, and polybuzz.ai round out the list with 14–20M monthly visits each as shown in the Similarweb table. For AI product teams and analysts, these figures sketch a market where ChatGPT still dominates direct web usage in the US but where Google’s Gemini, Anthropic’s Claude, and xAI’s Grok are now meaningful destinations, and where up‑and‑coming tools like Polybuzz are starting to register in traffic‑share tables.
🎬 Creator workflows: motion control, remix and open image SOTA
Significant creative stack chatter: Kling Motion Control recipes, Google Photos Remix rollout, Freepik Spaces pipelines, and Z‑Image Turbo topping an open‑weights arena. Mostly how‑to guides and promos.
Z‑Image Turbo tops Artificial Analysis Image Arena as open 6B image model
Z‑Image Turbo (Alibaba Tongyi‑MAI): Artificial Analysis now ranks Z‑Image Turbo, a 6B‑parameter open‑weights text‑to‑image model, as the new #1 model in its Image Arena, ahead of FLUX.2 [dev], HunyuanImage 3.0 (Fal), and Qwen‑Image on a battery of five diverse prompts as shown in the z-image summary and prompt gallery. The team notes that Turbo costs about $5 per 1,000 images via Alibaba Cloud and is released under Apache 2.0, which is markedly cheaper than FLUX.2 [dev] at $12, Qwen‑Image at $20, and HiDream‑I1‑Dev at $26 for the same volume, while still running on 16 GB consumer GPUs per the z-image summary.
• Arena performance: Side‑by‑side grids on rainforest, savannah, Europa rocket launch, anime cityscape and watercolor train station prompts show Turbo delivering sharp composition and consistent style across both natural and stylized scenes, often matching or exceeding larger peers in perceived fidelity and prompt adherence detailed in the prompt gallery and anime prompt example.
• Open and multi‑host: Z‑Image Turbo is already exposed on Alibaba Cloud, fal, and Replicate, and the Apache 2.0 license removes commercial‑use friction, making it a realistic default for teams that want strong image quality without closed‑model pricing as shown in the z-image summary and image arena.
This positions Z‑Image Turbo as a serious open alternative in creative stacks where cost per render and on-prem or BYO-GPU deployment matter as much as raw image quality.
Kling 2.6 Motion Control workflow chains pose transfer with Nano Banana Pro
Kling Motion Control (Kuaishou): Creators are standardizing on a repeatable recipe that uses Kling 2.6 Motion Control plus Nano Banana Pro to copy arbitrary movement from a reference clip while completely swapping the subject’s identity and styling as shown in the workflow overview and motion tips. The flow is: grab a pose-heavy reference video, export the first frame, run it through Nano Banana Pro with a prompt like “keep the image structure… now replace the woman by the bald man with beard” to preserve composition while swapping appearance via the nano banana example; then feed Kling’s Motion Control with that edited keyframe plus the original motion video and a short prompt such as “a bald man with beard performing break dance at the olympics stage”, letting Kling handle motion tracking and synthesis according to the kling interface and kling signup page.
• Decoupled motion and identity: The setup cleanly separates pose/motion (video) from appearance (image), giving engineers a concrete pattern for building pipelines where one model handles subject editing and another handles temporally consistent animation as detailed in the workflow overview.
• Low‑friction prompting: Posts emphasize that Motion Control works with very plain language prompts, leaning on the reference clip for choreography and on the still image for art direction, which reduces prompt engineering overhead for teams prototyping character-driven video content according to the motion tips.
The point is: Kling’s Motion Control is already being used as a practical module inside multi-model production chains rather than a standalone toy, which is a useful signal for anyone designing higher-level video tooling around it.
Freepik Spaces tutorial chains Nano Banana Pro stills into Veo 3.1 animation
Spaces pipeline (Freepik): A detailed tutorial shows how to use Freepik Spaces as a node‑based canvas to build a full AI video scene by combining Nano Banana Pro (NB Pro) for image generation with Veo 3.1 for motion, starting from a 3×3 grid of stills in the style of Pawn Stars as shown in the pawn stars demo and spaces walkthrough. The flow is: generate a 3×3 character grid with NB Pro, then add nine extraction nodes to pull each frame, optionally run lightweight edit nodes on specific stills, and finally connect each into Veo 3.1 video nodes to animate dialogue or camera motion using JSON‑style prompts embedded in the node metadata according to the pawn stars demo and freepik spaces page.
• Single‑space orchestration: Because the entire pipeline—stills, crops, edits, and clips—lives inside one Space graph, creators can tweak a character pose or color treatment upstream and immediately re‑render downstream video nodes without re‑wiring prompts, which functions like a lightweight DAG engine for AI media workflows per the spaces walkthrough.
• Two‑model separation of concerns: NB Pro handles identity/style and composition, while Veo deals with temporal coherence and motion, mirroring a broader pattern where image and video models are composed rather than over‑prompted to do everything at once as shown in the pawn stars demo.
For engineers and analysts, this is a concrete example of how consumer‑facing tools are turning multi‑model creative graphs into a productized experience rather than leaving users to assemble scripts by hand.
AI film festival entry shows how to onboard non‑technical cinematographers
AI film workflow (PJ Accetturo): Filmmaker PJ Accetturo submitted a $1,000,000 AI film festival entry built by taking six top Hollywood cinematographers with “zero AI experience” and teaching them a simple, repeatable framework for using generative tools to plan and assemble shots as shown in the ai film explainer. The shared clips highlight expressive character work and note that “the emotional facial gestures are getting super strong,” which reflects how far current image and video models have come for close‑up performance according to the model quality reaction.
• Process over model worship: The emphasis is on instruction design, prompts, and iteration loops rather than on any single model name, which gives AI engineers and PMs a concrete example of how to translate raw model capability into a training program that non‑technical creatives can actually adopt per the ai film explainer.
• One‑year progress snapshot: Accetturo contrasts this film with his first AI short from a year earlier that went viral on Reddit, underscoring how tool maturity over 12 months has shifted AI filmmaking from niche experiment to something professionals can plausibly slot into their day‑to‑day work according to the ai film explainer.
So for leaders tracking creative adoption, this is a live case study in turning general‑purpose models into a production‑ready, teachable workflow for traditional film crews.
Google Photos Remix brings daily AI stylization to iOS users
Photos Remix (Google): Google is rolling out a “Remix your photos” feature in the Photos app on iOS that turns portraits into styles like sketch and anime, with a daily free generation quota and an upsell path to a paid Google AI plan for heavier use according to the remix rollout. The onboarding screen spells out that you “pick a portrait, choose your favorite style, and watch the magic happen,” and explicitly notes experimental GenAI plus policy constraints around prohibited uses per the remix rollout.
For AI product teams, this is another concrete example of how a mainstream app is packaging image models: tight in-context education, rate-limited free tier, and an integrated subscription upgrade instead of sending users to a separate AI product.