DeepSeek mHC stabilizes 27B multi‑lane residuals – 6.7% overhead
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
DeepSeek details Manifold‑Constrained Hyper‑Connections (mHC), a residual redesign that splits the shortcut path into n parallel streams while constraining mixing matrices so the composite still behaves like an identity map at scale; unconstrained Hyper‑Connections can amplify residual signals by ~3000× across depth, but mHC reports ~1.6× growth and stable training up to 27B params, outperforming both plain Transformers and vanilla HC on standard benchmarks. Systems notes frame widened shortcuts as a memory‑traffic problem more than a FLOP problem; a fused‑kernel, mixed‑precision implementation with communication overlap holds wall‑clock overhead to ~6.7% at n=4 lanes in their setup, though authors warn decoder latency and bandwidth could dominate at inference without similarly tight kernels. Engineers quickly promote mHC as 2026’s first major architecture tweak, emphasizing its “widened thinking highway” metaphor and 27B‑scale evidence while noting the need for independent replications.
• Open coding SOTA: IQuest’s 40B LoopCoder posts 81.4% on SWE‑Bench Verified, beating Claude Sonnet‑4.5 and GPT‑5.1 on several coding evals; a 2‑pass shared‑weight “looped” transformer, commit‑diff mid‑training and MLX/GGUF ports position it as a compact, deployable coding contender.
• Voice stack and devices: OpenAI consolidates audio teams around a new Q1 2026 speech architecture targeting emotive full‑duplex conversation and interruption handling, tied to an audio‑first companion device roughly a year out, led by Kundan Kumar with infra support from Ben Newhouse.
Top links today
- The Information 2026 AI predictions
- Forbes 2026 agentic AI predictions
- PwC 2026 enterprise AI predictions
- FT on European bank AI job cuts
- Reuters on Samsung HBM4 progress
- Reuters on TSMC Nanjing export license
- Tom’s Hardware on DRAM shortages and BYO RAM
- SiliconAngle on OpenAI 2026 audio model
- Arxiv big world hypothesis interactive agents paper
- Arxiv Will AI Trade computational no-trade paper
- Arxiv hyperparameter transfer across model scales paper
Feature Spotlight
Feature: DeepSeek mHC stabilizes multi‑lane residuals
DeepSeek’s mHC makes multi‑lane residuals trainable at scale (27B) with ~6.7% overhead at n=4, fixing HC instability (~3000× amp → ~1.6×) and reducing memory traffic via fused kernels/recompute—high impact for long, expensive pretrains.
Biggest cross‑account story today: DeepSeek’s mHC (Manifold‑Constrained Hyper‑Connections) — a drop‑in residual redesign that widens the shortcut stream (n lanes) while restoring identity‑style stability and cutting memory traffic. Heavy engineering notes, not just theory.
Jump to Feature: DeepSeek mHC stabilizes multi‑lane residuals topicsTable of Contents
🧠 Feature: DeepSeek mHC stabilizes multi‑lane residuals
Biggest cross‑account story today: DeepSeek’s mHC (Manifold‑Constrained Hyper‑Connections) — a drop‑in residual redesign that widens the shortcut stream (n lanes) while restoring identity‑style stability and cutting memory traffic. Heavy engineering notes, not just theory.
DeepSeek’s mHC widens residual streams while keeping 27B‑scale training stable
mHC (DeepSeek): DeepSeek’s Manifold‑Constrained Hyper‑Connections (mHC) replace single‑lane residuals with a small bundle of parallel residual streams while projecting mixing matrices onto a manifold so the shortcut still behaves like an identity map at scale, according to the detailed breakdown in the paper explainer and the first‑page snapshot in the
. The authors report that unconstrained Hyper‑Connections (HC) can amplify residual signals by ~3000× across depth, whereas mHC constrains this to around 1.6×, enabling stable training up to 27B parameters and beating both a plain Transformer baseline and vanilla HC on standard benchmarks, as summarized in the paper explainer and the ArXiv paper.
• Architecture change: Standard residuals carry one hidden state forward; HC generalizes this to n parallel residual streams with learned pre/post mixing, and mHC then constrains those mixing steps so they behave like safe averaging operators rather than arbitrary linear maps, which is what restores identity‑style behavior across many layers per the paper explainer.
• Reasoning potential: Community commentary frames this as a way to widen the model’s internal "thinking highway" without flipping training into an unstable regime, which matters for long, expensive pretrains where a single loss spike or gradient blow‑up can waste millions of GPU‑hours, as several engineers note in the summary thread and architecture comment.
The point is: mHC gives labs a drop‑in way to experiment with multi‑lane residual paths and richer internal routing while keeping optimization behavior close to the well‑understood identity‑residual regime.
mHC tackles the GPU memory wall with fused kernels and ~6.7% overhead at n=4
Systems angle (DeepSeek mHC): The mHC paper treats widened residual streams as a systems problem as much as an architectural one, arguing that naive n‑lane Hyper‑Connections inflate activation reads/writes, activation checkpoints, and pipeline traffic almost linearly in n and can shift large‑scale training from compute‑bound to memory‑bound, as described in the memory wall summary. To counter this, DeepSeek reports that a production‑style implementation with fused kernels, mixed precision, selective recomputation, and communication overlap keeps training overhead to about 6.7% extra wall‑clock time at n=4 lanes in their setup, according to the engineering notes in the training details.
• Memory traffic focus: The authors emphasize that memory traffic—bytes moved per token between HBM and SMs—becomes the key limiter once residual width is scaled, and they argue that without fusion and careful scheduling, multi‑stream HC can stall GPUs despite looking cheap in FLOP counts, as outlined in the memory wall summary.
• Inference caveat: For inference, they note that widened residual bundles naturally threaten decoder latency because most real‑world serving setups are bandwidth‑limited rather than math‑limited; they suggest mHC is only practical when kernels are tight enough that extra lanes do not dominate per‑token bandwidth, a concern repeated in the memory wall summary.
Overall, mHC is being positioned not just as a theoretical connectivity tweak but as a blueprint for widening residual highways without blowing up training stability or overrunning the GPU memory wall.
Engineers quickly dissect DeepSeek mHC as 2026’s first major architecture tweak
Community response (DeepSeek mHC): Within hours of the mHC paper appearing, multiple practitioners were posting longform explainers that translate the math into highway‑lane metaphors, risk profiles, and deployment guidance, turning this into one of the first widely discussed architecture changes of 2026, as seen in the paper explainer, the overview tweet, and the reaction in the researcher comment. One creator even used Google’s NotebookLM to auto‑generate a video walkthrough of the paper’s key ideas, showing how AI tools are now helping engineers digest dense architecture work in near real time in the

.
• Framing in practice: Commentators highlight that mHC could let labs "widen the thinking stream" without betting whole pretrains on brittle optimization, framing it as insurance against loss spikes and gradient norm explosions in very deep models, as discussed in the overview tweet and enthusiast repost.
• 2026 narrative: Several AI accounts point out that it is "a pretty crazy fundamental result" and that it sets a high bar for early‑year research by combining topology‑aware design with concrete 27B‑scale results, which they tie into broader expectations of more expressive Transformer variants in 2026 in the enthusiast repost and researcher comment.
The early reaction signals that engineers see mHC not as an isolated trick, but as part of a broader push to re‑architect residual pathways and allocate capacity more intelligently in the next generation of frontier models.
🚀 Coding SOTA shake‑up: 40B LoopCoder tops SWE‑Bench‑V
Fresh model news centered on code: a 40B open model from IQuest (LoopCoder) posts new highs across several coding evals. Excludes DeepSeek mHC (covered as feature).
IQuest’s 40B LoopCoder sets new open-source SOTA on SWE‑Bench Verified
IQuest-Coder-V1-40B-Loop (IQuestLab): A new 40B-parameter coding model from China’s IQuest Labs posts 81.4% on SWE‑Bench Verified, edging out Claude Sonnet‑4.5 (77.2%) and GPT‑5.1 (76.3%) while also leading several other coding benchmarks, according to multiple benchmark threads metrics breakdown and sota recap; charts show it matching or beating much larger frontier models across BFCL, Bird‑SQL, Mind2Web, Terminal‑Bench v1.0 and FullStackBench despite its smaller size.
• Headline numbers: Benchmark plots attribute to IQuest‑Coder 81.4% on SWE‑Bench‑V, 49.8–49.9% on BigCodeBench, 81.1% on LiveCodeBench v6, 69.9% on Bird‑SQL, 73.8% on BFCL, 58.6% on Mind2Web, 51.3% on Terminal‑Bench v1.0, and 68.3% on FullStackBench, with Sonnet‑4.5, GPT‑5.1, Kimi‑K2 and Qwen3‑Coder as comparators metrics breakdown.
• Community framing: Commentators describe it as “40B looped transformers new SOTA on SWE‑Bench Verified beating Claude 4.5 Opus” and highlight that it is a 40B open model outperforming 1T‑scale closed models on some tasks sota recap and metrics breakdown.
Treat these benchmark screenshots as strong but still early signals; some observers note the need for independent reruns before treating LoopCoder as a definitive new leader lab intro.
LoopCoder technical report details code‑flow training and 2‑pass transformer design
IQuest-Coder-V1 (IQuestLab): The technical report for IQuest‑Coder describes a code‑flow training paradigm that learns from repository commit transitions plus a looped transformer architecture that reuses the same layer stack twice with shared weights, so the second pass refines the first pass’s draft rather than acting as a separate model, as explained in a technical breakdown training notes and the linked report technical report pdf; mid‑training steps push context from 32K to 128K tokens on reasoning and agent trajectories, and post‑training bifurcates into "Thinking" and "Instruct" variants.
• Code-flow data: Instead of only static code, the model is mid‑trained on commit diffs and repository evolution traces so it learns how patches change a codebase over time, which the authors frame as closer to real software engineering workflows training notes.
• Looped transformer: The LoopCoder variant runs the same block stack twice on the same context with shared parameters; attention in the first pass is more global, while the second pass emphasizes local refinements, with a learned gate mixing global (pass‑1) and local (pass‑2) attention patterns training notes.
• Long-context reasoning traces: Mid‑training uses 32K then 128K contexts containing tool invocations, logs, errors and test outputs from agent‑style traces, so the model learns multi‑step "try, see output, adjust" patterns before final instruction and reasoning RL phases training recipe.
• Thinking vs Instruct heads: After mid‑train, IQuest splits the family into Thinking models (reinforcement learning on complex reasoning tasks) and Instruct models optimized for everyday coding assistance, documented in both the technical report and model card hf instruct model.
This makes LoopCoder one of the more explicitly agent‑shaped coding pretrains so far, with architecture and data choices tuned for multi‑step repo edits rather than single‑shot completions.
IQuest-Coder Loop variant targets efficient deployment with MLX and GGUF ports
Loop variants and local ports (IQuestLab): Beyond the base checkpoints, IQuest and the community have shipped a Loop architecture variant and several compressed ports—MLX 8‑bit and GGUF—that aim to keep deployment footprints manageable while preserving the new model’s coding strength, according to the model pages and ports on Hugging Face model overview and mlx 8bit model.
• Loop for efficiency: The IQuest-Coder-V1-Loop variant uses the 2‑pass shared‑weight transformer to trade some depth for reuse and to shrink high‑bandwidth memory (HBM) and KV‑cache requirements compared with naïvely stacking more unique layers, which the authors say helps throughput and deployment costs on common GPUs model overview.
• MLX 8‑bit build: An MLX 8‑bit quantized version appears under the mlx-community/IQuest-Coder-V1-40B-Instruct-8bit repo, targeting Apple Silicon and other MLX runtimes; metadata notes 40B parameters in 8‑bit with BF16/U32 tensors for feasible local experimentation mlx 8bit model.
• GGUF quantization: A GGUF conversion (cturan/IQuest-Coder-V1-40B-Instruct-GGUF) offers 2‑, 4‑ and 6‑bit variants, with rough VRAM guidance of ~14.8 GB (2‑bit), 24 GB (4‑bit) and 32.6 GB (6‑bit), which positions LoopCoder for use with llama.cpp‑style inference stacks gguf model.
These ports, along with claims that the Loop design reduces memory pressure, indicate a deliberate push to make a 40B‑scale code model usable on high‑end consumer and workstation hardware rather than only multi‑GPU servers.
Quant fund–backed IQuest Labs emerges as new Chinese coding LLM contender
IQuest Labs (Ubiquant): A new lab spun out of Chinese quant hedge fund Ubiquant has entered the coding LLM race with IQuest‑Coder, backed by reported assets under management of roughly CNY 70–80B (~$10–11.4B) and average 2025 returns near 24%, as outlined in background threads on the release lab background; the lab’s lead contributor Jian Yang previously worked on Qwen2/3, and the group is positioning itself alongside DeepSeek as another China‑based, quant‑fund‑seeded AI shop.
• Financial and org context: Posts describe Ubiquant operating research groups like AILab, DataLab and Waterdrop Lab, paying out around CNY 463M (~$66M) in 2025 dividends while now funding IQuest’s open coding models as part of a broader AI push analysis thread.
• Open SOTA plus skepticism: Commentators in the open‑source community highlight that "China's new opensource code model beats Claude Sonnet 4.5 & GPT 5.1 despite way fewer params" analysis thread, but some caution that early MLX and GGUF ports and certain benchmark runs may be "benchmaxxed" and need third‑party verification before being treated as settled verification concern.
For engineers and analysts, IQuest’s arrival signals more intense competition in high‑end coding models from China, with quant‑fund capital and talent feeding into open releases rather than only closed, product‑tied stacks.
🎙️ OpenAI’s new audio stack and a voice‑first device path
Several reports outline OpenAI merging audio teams and targeting a Q1’26 architecture rev with emotive duplex speech and interruption handling. This is distinct from the mHC feature.
OpenAI targets Q1 2026 audio model revamp and plans voice‑first companion device
OpenAI audio stack (OpenAI): Multiple reports say OpenAI has merged several audio engineering, product and research groups and is building a new speech model architecture for release in Q1 2026, aimed at more natural, emotive output and faster turn‑taking than today’s GPT‑realtime stack, according to The Information and follow‑up coverage in SiliconANGLE and user summaries summary thread and siliconangle recap; the same effort is tied to an "audio‑first" companion device expected roughly a year out, building on OpenAI’s io Products hardware partnership siliconangle recap and The Information article.
• New architecture and runtime goals: The new model is described as a fresh audio architecture rather than a minor fine‑tune; goals include more natural and emotional prosody, lower response latency, full‑duplex conversation where the model can speak while the user talks, and robust interruption handling so users can cut in without derailing answers summary thread and concise recap.
• Team consolidation and leadership: OpenAI reportedly pulled together previously separate audio teams over the past two months because current voice models lag text models on accuracy and speed; the push is led by voice researcher Kundan Kumar (ex‑Character.AI), infra lead Ben Newhouse, and multimodal ChatGPT PM Jackie Shannon leadership details and summary note.
• Device roadmap: The new stack is intended to power a companion‑style, audio‑first device that can proactively suggest actions and help users pursue goals, with launch timing described as "about a year" out; this follows OpenAI’s May 2025 deal with Jony Ive’s io Products to explore AI hardware summary thread and siliconangle recap.
The reports frame this as OpenAI trying to close the gap between voice UX and its strongest text models, while laying groundwork for a dedicated conversational device that depends on low‑latency, interruption‑tolerant speech as a primary interface rather than a secondary feature in the ChatGPT app.
🛠️ Agent harnesses and Claude Code power‑features
Today’s coding threads focus on multi‑agent orchestration, Claude Code’s leaked system prompts, and practical CLI/IDE wiring. Excludes mHC and model SOTAs.
Leaked Claude Code prompts reveal upcoming agent swarms, MCP search, and prompt suggester
Claude Code (Anthropic): Versioned system prompts extracted from cli.js show that Anthropic has already specced a richer Claude Code harness with agent swarms, a session search assistant, MCP discovery, and a prompt-suggestion agent, according to the reverse‑engineered prompt dump in the system prompt leak.
• Agent swarms and teammates: An ExitPlanMode payload with isSwarm set to true dispatches "swarm teammates" rather than a single helper, while a TeammateTool describes operations such as spawn, assignTask, claimTask, and shutdown, indicating first‑class multi‑agent workflows and task routing inside Claude Code itself system prompt leak.
• Session search and MCP orchestration: A "Session Search Assistant" prompt is tuned to rank past sessions by tags, titles, branches, summaries, and transcripts, and an "MCP Search" tool is mandated as a prerequisite before calling tools, with support for loading MCPs at runtime and even invoking them via CLI to reduce token usage system prompt leak.
• Prompt suggester and CLI focus: A dedicated "Prompt suggestion generator" agent is defined to propose next actions, while the prompts explicitly describe a CLI-centric execution path for MCP calls, pointing to a future where Claude Code behaves more like an orchestrator of tools and teammates than a single in‑IDE assistant system prompt leak.
The leak sketches a near‑term Claude Code direction where multi‑agent collaboration, searchable long‑running sessions, and MCP‑first tool discovery are part of the built‑in harness rather than external scaffolding.
Ralph Wiggum pattern emerges as a simple but powerful bash-loop harness for Claude Code
Ralph harness (community): Builders continue to rally around "Ralph"—a minimalist bash loop that repeatedly feeds a markdown PRD to Claude Code—as a practical pattern for autonomous coding agents, with discussion centering on context management, human‑on‑the‑loop vs AFK usage, and a new plugin implementation Ralph overview and Ralph blog.
• HOTL vs AFK execution: Geoffrey Huntley says human‑on‑the‑loop (HOTL) Ralph—where a person nudges and reviews key steps—remains his default, while AFK Ralph (fully unattended runs) has been rare since Opus 4.5 because careful "malloc of context" across iterations is crucial for reliability HOTL advice and Ralph usage.
• Promise tokens and control flow: Experiments with <promise>DONE</promise> markers show that explicitly asking the model not to think of certain states can backfire, since the language model fixates on the forbidden token, as Huntley notes in a comment about "don’t think of an elephant" semantics promise marker remark.
• Bash vs Claude plugin showdown: A New Year livestream pits the original bash‑loop Ralph against Anthropic’s newer Claude Code plugin implementation on the task of building a markdown‑driven prompt pipeline, with early observations that the plugin version finished faster and exposed more features but the bash version still produced clearer READMEs and caught a bug once prompts were updated to read GitHub issues as well as specs showdown invite and early results.
• Loom and future harnesses: Huntley mentions that his own "loom" harness blends the Ralph bash style with plugin‑style features until loom "can replace me," underscoring a trend toward thin, deterministic shells that let LLMs manage plans while code enforces iteration, logging, and sandboxing loom comment.
The ongoing Ralph discussion frames agent harness design as equal parts loop control, context budgeting, and review strategy rather than a feature baked into any single IDE integration.
RepoPrompt adds parallel tabbed chats and prompt export for MCP and CLI agents
RepoPrompt (community): RepoPrompt’s first 2026 release upgrades its repo‑aware agent harness with true parallel chats, tab‑scoped context, and a /rp-oracle-export command that emits finalized prompts for use in MCP servers or CLI workflows, building on its earlier framing as a "context engineering" layer for coding agents release summary and context engine.
• Parallel chats with scoped context: The new UI supports multiple chat tabs whose context is scoped per tab, so a RepoPrompt "oracle" can maintain distinct task threads (e.g., feature A vs bug B) without cross‑contaminating repo context, which users say helps keep long‑running conversations focused release summary and terminal usage.
• Prompt export into harnesses: The /rp-oracle-export slash command outputs the distilled instructions and context that RepoPrompt built up, ready to paste into an MCP tool definition or a CLI script, tightening the loop between human prompt design and executable agent harnesses release summary.
• CLI integration focus: Maintainer posts highlight that these exports are meant to feed into command‑line setups like Codex or Claude Code, turning RepoPrompt from a one‑off chat front‑end into a design surface for reusable, tested task templates terminal usage.
This update positions RepoPrompt as a bridge between interactive, human‑in‑the‑loop planning and the more rigid prompts that power MCP tools and non‑interactive agent loops.
CC-MIRROR CLI emerges as a variant manager for Claude Code-compatible providers
CC-MIRROR (community): A new tool called CC-MIRROR is shown as a "Claude Code Variant Manager" that helps users spin up, configure, and maintain multiple Claude‑style agent variants pointing at different providers and APIs from a single CLI menu CC-MIRROR UI.
• Quick setup and diagnostics: The CC-MIRROR menu includes options like "Quick Setup" for registering a provider and API key in ~30 seconds, "Manage Variants" for updating or removing them, "Update All" to sync against upstream prompts, and a "Diagnostics" mode to health‑check every variant, along with settings for default paths CC-MIRROR UI.
• Provider abstraction for forks: The tool is pitched as a way to create local "Claude Code" forks backed by alternative backends such as MiniMax, Z.ai, or OpenRouter, aligning with community efforts to treat the harness and the model provider as swappable layers CC-MIRROR UI.
CC-MIRROR underlines how much of the Claude Code value now lives in harnesses and prompts, not only in Anthropic’s API, by making it easier to test and operate multiple compatible stacks side by side.
Clawdbot and Clawdis turn Discord into an AI coding and ops console
Clawdbot ecosystem (community): Peter Steinberger’s "Clawdbot" is shown running in a busy Discord, helping users configure the Clawdis CLI, answer setup questions, and even push code changes, with a growing set of agent skills like DNS operations and summarization layered on top Clawdbot Discord view and Discord invite.
• CLI integration and teaching: In one thread, Clawdbot walks a user through configuring Clawdis with pnpm clawdis configure, selecting MiniMax as a provider, and filling in an OpenAI‑style config stub, effectively acting as both doc and interactive helper for standing up a local Claude‑like harness Clawdbot Discord view.
• Operational skills and slash commands: Steinberger highlights new skills like a domain/DNS operations pack under agent-scripts/skills/domain-dns-ops, meant to let agents inspect and adjust DNS records via standardized Skill interfaces, and shows Clawdbot using summarizer "auto bubbles" to condense threads DNS skill repo and summary bubbles.
• Personal assistant flavor: Other posts show Clawdbot ranting humorously about Swift 6 complexity, closing PRs on command, and coordinating with tools like Things3 CLI, reinforcing its position as an always‑on, personality‑driven control plane for a growing set of terminal and HTTP agents Swift 6 rant and Things3 CLI demo.
The Clawdbot/Clawdis combo illustrates how some teams are converging on Discord as the human‑facing front end to rich, scriptable coding and ops agents that actually run on servers and CLIs.
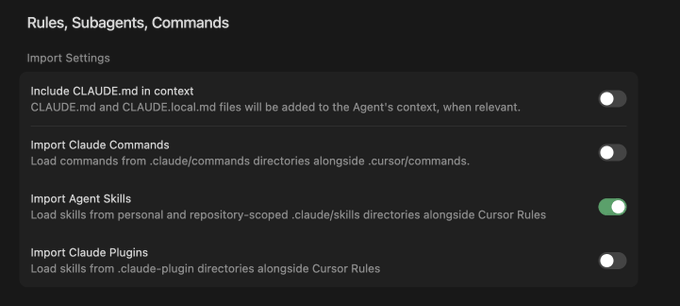
Cursor can now import Claude Skills as first-class agent capabilities
Cursor agent settings (Cursor): Cursor’s settings panel now exposes an "Import Agent Skills" toggle that loads skills from personal and repo‑scoped .claude/skills directories alongside Cursor Rules, effectively letting the IDE treat Claude Skills as reusable, structured extensions for its own agent Cursor settings screenshot and skills docs.
• Shared skills between tools: The UI groups Skills with other cross‑tool imports like CLAUDE.md and Claude commands, signaling that a single skill definition can inform both Claude Code sessions and Cursor’s own agent, which can simplify maintaining organization‑wide automations Cursor settings screenshot.
• Rules plus skills composition: By placing Skills next to Cursor’s Rules system, the editor moves toward a composite harness where high‑level behavior (Rules) and concrete operations (Skills) live side by side, matching how many Claude Code power users already structure their automation packs skills docs.
For teams already investing in Claude Skill libraries, this offers a way to reuse that work inside Cursor’s agent instead of rebuilding equivalent logic as bespoke editor commands.
Superset terminal turns multi-agent coding into a first-class, 10+ agent workflow
Superset multi-agent terminal (Superset): Superset is showcased as a terminal environment explicitly built to "run 10+ parallel coding agents on your machine," wiring CLI agents like Claude Code, Codex, and others into isolated Git worktrees so each one can tackle a task without merge conflicts Superset teaser and Superset site.
• Isolated worktrees and conflict avoidance: The demo shows each agent operating in its own worktree, which lets them edit and test in parallel while a human later chooses which diffs to accept, rather than having agents overwrite each other’s changes in a single repo tree Superset teaser.
• Agent‑agnostic orchestration: The product site describes Superset as compatible with any CLI‑driven coding agent, suggesting that developers can mix different models (Claude Code, GPT‑5.2‑Codex, etc.) in one session, focusing the harness on process—task assignment, review, and apply—rather than on a single provider Superset site.
Superset illustrates how multi‑agent harnesses are shifting from ad‑hoc tmux setups toward managed, repo‑aware orchestration layers that treat each agent as a worker in a shared factory.
gifgrep 0.2.0 becomes a terminal-native GIF search skill for agents and devs
gifgrep (community): The gifgrep tool ships a 0.2.0 release that can render animated GIF previews directly inside Kitty or iTerm and download them on demand, and it is already being wired into agent environments as a lightweight "reaction GIF" skill gifgrep demo and gifgrep release.

• Inline previews and downloads: The demo shows a terminal UI listing GIF search results and animating a selected GIF inline; pressing f opens Finder with the downloaded file selected, which Steinberger calls an end to the "national nightmare" of hunting for clips outside the terminal gifgrep demo.
• Agent skill integration: In the same thread, the maintainer notes gifgrep is part of his broader "gardening the army" of agent scripts, implying that agents like Clawdbot can call gifgrep as a Skill to fetch media for memes or status messages during chats gifgrep demo.
While niche compared to coding harnesses, gifgrep shows how even small, focused CLIs are being packaged as Skills to expand what conversational agents can do from within a terminal‑centric workflow.
🏗️ Compute supply watch: HBM4 signals, DRAM crunch, China fab license
Infra stories emphasize memory supply and policy continuity impacting AI capacity and device pricing. New specifics vs yesterday include Samsung HBM4 customer feedback and BYO‑RAM builds.
Samsung says HBM4 samples earn strong customer praise ahead of 2026 ramp
HBM4 memory (Samsung): Samsung reports that early HBM4 samples are receiving positive feedback from key customers, and reiterates a target of mass production in 2026, positioning itself against SK hynix’s current HBM lead as described in the hbm4 update and the reuters report; HBM4 widens each stack to a 2,048‑bit interface with 32 channels, enabling on the order of 2 TB/s per stack at up to 8 Gb/s per pin.
HBM4’s wider bus and more channels mean higher bandwidth without relying only on faster clocks, which directly addresses the memory bandwidth bottlenecks of future GPU and accelerator designs referenced in the hbm4 update; Reuters notes SK hynix held about 53% HBM share in Q3 2025 versus Samsung’s 35% and Micron’s 11%, so strong sampling feedback is a signal Samsung may claw back share once HBM4 qualifies for production workloads, especially in AI training clusters where bandwidth per GPU is now as decisive as FLOPs.
US grants TSMC Nanjing an annual 2026 license for US chipmaking tools
China fab tooling (TSMC): The US Commerce Department’s BIS has granted TSMC’s Nanjing fab an annual 2026 export license so US chipmaking tools and parts can keep flowing without per‑shipment approvals, replacing the expired Validated End‑User (VEU) regime and avoiding disruptions at a fab that produced about 2.4% of TSMC’s 2024 revenue on mature 16 nm‑class nodes, according to the tsmc license thread and the reuters article; this follows earlier multi‑year tool authorizations for Samsung and SK Hynix China fabs noted in china tools, which covered their existing lines but banned capacity upgrades.
TSMC Nanjing is not a leading‑edge AI training node, but continuity for 16 nm and similar processes matters because these fabs still supply power management ICs, networking chips and other support silicon used in servers and AI infrastructure, as described in the tsmc license thread; BIS emphasizes that such licenses allow continued operation of foreign‑owned fabs in China while restricting expansions and node shrinks, which keeps a lid on China’s access to top‑end training chips but avoids a sudden shock to global semiconductor supply chains that could spill over into AI hardware availability.
RTX 5090 desktop GPU rumored near $5,000 as DRAM costs seen up 40% by Q2 2026
GPU pricing and DRAM (Nvidia): New reports suggest Nvidia’s upcoming RTX 5090 could launch near $5,000, up from earlier talk of around $1,999, while forecasters expect memory costs to rise about 40% by Q2 2026, increasing bill‑of‑materials for GPUs and other hardware as summarized in the gpu pricing note and the reuters coverage; this sharpens earlier warnings about a DRAM supercycle that would see AI‑driven HBM demand squeeze PC RAM pricing into 2027, following up on dram cycle, which had already flagged broad DRAM inflation.
The point is: if these price corridors hold, both consumer‑class GPUs and data center accelerators will reflect higher memory input costs, because boards combine large HBM stacks with more conventional GDDR or DDR components that track the same commodity cycle, as described in the gpu pricing note; for AI builders, that implies the cost per incremental training or inference node may climb through 2026 before any new capacity from DRAM makers like Samsung, SK hynix and Micron meaningfully softens the curve.
PC builder Maingear offers BYO‑RAM builds as 32GB kit prices spike ~394%
DRAM retail (Maingear): Boutique PC builder Maingear is introducing "bring your own RAM" options for new systems, after its CEO reports some 32 GB kits are up about 394% in cost and 64 GB kits up to 344%, making predictable sourcing and pricing difficult through at least 2026 as described in the maingear quote and the tom hardware piece.
This move signals how the DRAM supercycle—driven by AI data center HBM demand—has started to distort consumer and prosumer channels, with Maingear now explicitly encouraging buyers to source memory separately rather than bundling it in prebuilt configurations, according to the maingear quote; the CEO characterizes the situation as a "multi‑year problem", implying that PC builders serving AI developers and gamers may keep experimenting with de‑bundled or customer‑supplied memory to avoid being locked into volatile module pricing.
📊 Leaderboards and eval pulses: attention, Elo and Arena
Mostly eval snapshots and plots across labs: attention‑stress benchmark, Anthropic Elo ‘Lisan’ plot, Arena WebDev top models, and multi‑hop no‑CoT reasoning gains. Excludes IQuest metrics (covered under model releases).
Anthropic Lisan chart shows big Elo jump for Opus 4.5 Thinking
Lisan Index (Anthropic): A community reconstruction of Anthropic’s internal Lisan Index plot places Claude‑opus‑4.5‑thinking at a conservative rating around 1920, implying a >99% win‑rate versus Claude‑3‑opus and a large gap over earlier Sonnet and Opus checkpoints, as shown in the shared chart in the lisan index plot.
The scatter over release dates suggests stepwise gains: Claude 3 Opus near 1150, Claude 3.5 Sonnet around 1220, Claude 3.5 Sonnet 20241022 around 1400, Claude 3.7 Sonnet Thinking roughly 1500, Claude Opus 4 Thinking in the mid‑1700s, Claude Sonnet 4.5 Thinking around 1800, and now Opus 4.5 Thinking near 1920 lisan index plot. The plot is labeled as "conservative rating (rating − 2×RD)", so the underlying true Elo could be higher, but even under this conservative view the chart frames Opus 4.5 Thinking as a substantial frontier step above prior Anthropic models.
Arena Code WebDev top‑4: Opus 4.5, GPT‑5.2, Gemini 3, MiniMax M2.1
Code Arena WebDev (LM Arena): LM Arena’s Code Arena highlights Claude Opus 4.5 (Thinking), GPT‑5.2‑High, Gemini 3 Pro, and MiniMax‑M2.1 as the current top‑four models for end‑to‑end web UI generation, following up on Arena wrap which tracked cross‑domain 2025 leaders arena webdev intro.

In this WebDev track, models are asked to produce fully working, SVG‑based web experiences directly in the browser, so scores reflect a mix of layout fidelity, interaction wiring and code quality rather than isolated coding snippets, and Arena’s team stresses that all examples shown were generated live during Code Arena sessions arena webdev intro. The cohort—Anthropic, OpenAI, Google and MiniMax at the top—illustrates that different labs’ frontier models can contend closely once the metric is "shipping a small app" instead of pure code‑completion accuracy.
Gemini 3 Flash leads community ‘misguided attention’ benchmark
Misguided attention benchmark (community): A community run of the "misguided attention" benchmark shows Gemini‑3‑flash‑preview_high at about 68.5% mean overall score, ahead of Gemini‑3‑pro‑preview_high at 62.4% and Claude‑opus‑4.5_16000 at 60.7%, with GPT‑5.2 variants, DeepSeek‑V3.2, Kimi‑K2 and GLM‑4.7 trailing further behind in this attention‑stress setting, according to the shared results in the attention bench run.
This benchmark stresses models with long contexts and deliberately distracting content rather than standard QA, so the ranking—Gemini 3 Flash variants clustered at the top, then Gemini 3 Pro, Anthropic Opus 4.5, then OpenAI GPT‑5.2 and others—highlights differences in attention stability under interference that are not obvious from headline leaderboards attention bench run. The chart also shows relatively small gaps between many frontier models, so these numbers should be treated as a narrow‑scope stress test rather than a global capability verdict.
Recent models show strong 2‑ and 3‑hop no‑CoT reasoning
Multi‑hop latent reasoning (community): A new evaluation of 2‑ and 3‑hop latent reasoning without chain‑of‑thought finds Gemini 3 Pro hitting about 60% accuracy on 2‑hop and 34% on 3‑hop questions, while older models like GPT‑4 score under 10–12% on 2‑hop and below 5% on 3‑hop, according to Ryan Greenblatt’s summary in the multi-hop comment and the detailed write‑up in the lesswrong post.
The dataset is built from natural facts that models are expected to know (for example, mapping "age at death" to "atomic number"), then composed into multi‑hop queries where the intermediate step is latent; performance jumps for newer models persist even when chain‑of‑thought is disabled and prompts use "content‑free" filler tokens to reduce indirect cues lesswrong post. Greenblatt notes that this contradicts earlier expectations that multi‑hop no‑CoT reasoning would remain a long‑term weakness, and instead points to a clear upward trend between GPT‑4‑class systems and the latest Gemini 3 / Opus‑4.5 / GPT‑5.2 models multi-hop comment.
Cross‑lab Glicko rankings spotlight GPT‑5.2 Pro, Opus 4.5 Thinking, Gemini 3 Pro
Cross‑lab Glicko rankings (community): A community‑maintained Glicko‑2 rating table aggregates dozens of benchmarks to rank each vendor’s top 15 models, putting GPT‑5‑2‑pro at 2012, Claude‑opus‑4‑5‑thinking at 1960, and Gemini‑3‑pro‑preview at 1924 as the flagship models for OpenAI, Anthropic and Google respectively, as shown in the shared tables in the glicko tables tweet.
On the OpenAI side, GPT‑5 variants fill most of the top slots with ratings between ~1536 and 2012, with o3‑series models interleaved in the high‑1700s to mid‑1800s; Anthropic’s list shows a clean progression from Claude 3 Opus (~1150) up through the 3.5 and 4.x families to Opus 4.5 and its thinking variant near 1842 and 1960; Google’s table is topped by Gemini 3 Pro and Gemini 3 Flash Preview, followed by Gemini 2.5 Pro and several Flash and Flash‑Lite variants glicko tables tweet. The maintainer notes these are Glicko‑2 ratings with explicit rating deviations and benchmark counts, so the numbers reflect both performance and uncertainty, and give a meta‑view across many task‑specific evals.
GPQA Diamond plot tracks sharp capability gains and collapsing costs
GPQA performance frontier (community): A new GPQA Diamond vs. cost plot shows frontier models gaining +119% to +198% in GPQA score while per‑million‑token costs fall 90%–99.7% along three different frontiers between early 2023 and late 2025, according to the visualization shared in the gpqa cost-capability.
The capability frontier (dominated by models like Claude Opus 4.5 Thinking, Gemini 3 Thinking and GPT‑5.2 Thinking) reaches around 0.9 GPQA score—above the plotted human PhD range—while cutting cost per million tokens by about 90%; the balanced frontier shows +176% GPQA at 99.4% lower cost, and a low cost/performance frontier achieves +119% GPQA with roughly 99.7% cheaper inference gpqa cost-capability. The chart, attributed to OneUsefulThing and amplified by community accounts, underlines that on this PhD‑level science benchmark models have not only crossed human‑expert ranges but done so while making high‑end performance substantially cheaper to deploy.
Vending‑Bench 2: GLM‑4.7 and DeepSeek‑V3.2 stand out among open models
Vending‑Bench 2 (Andon Labs): A fresh Vending‑Bench 2 evaluation places DeepSeek‑V3.2 9th overall and 2nd among open models behind GLM‑4.7, extending GLM‑4.7’s strong showing beyond LM Arena’s text leaderboard noted in open text top, according to Andon Labs’ summary in the vending bench post.
The shared results highlight that, when tested on Vending‑Bench 2’s mix of coding and reasoning tasks, GLM‑4.7 retains a narrow lead among open‑source models, with DeepSeek‑V3.2 close behind and many other open models further down the table vending bench post. The author frames this as part of a broader "benchmark monopoly" trend, where a small cluster of community evals (Arena, Vending‑Bench, attention‑stress tests) increasingly shape perceptions of which open models are viable frontier alternatives.
LisanBench crosses 15k runs as maintainer warns about eval costs
LisanBench usage (community): The creator of LisanBench, a community benchmark for reasoning‑style models, notes that usage has exceeded 15,000 runs and warns that if saturation continues they may have to discontinue the service due to evaluation costs, in comments shared by scaling01 in the lisanbench note.
The remark frames LisanBench ("> 15000") as already heavily used by model builders and hobbyists, but also highlights that sustaining multi‑model, multi‑run eval infrastructure is financially burdensome when each new frontier model triggers large numbers of test calls lisanbench note. This underscores a broader tension between the community’s desire for up‑to‑date, independent benchmarks and the practical cost of running them at the scale needed to keep pace with rapid model releases.
📑 Reasoning theory and training science (non‑mHC)
New papers beyond the feature: System‑2 coordination over LLM substrate, interactivity as a learning objective, hyperparameter transfer across scales, compute‑bounded ‘trade’, and recursive LM processing. Excludes mHC.
Recursive Language Models let LLMs self‑call to handle prompts 100× longer than context
Recursive Language Models (MIT/CSAIL): Zhang, Kraska and Khattab introduce Recursive Language Models (RLMs), where an LLM treats long prompts as an external environment it can programmatically traverse and recursively call itself on sub‑spans, enabling it to process inputs up to two orders of magnitude longer than its native context window while improving quality and often cost, according to the announcement and arxiv paper.
• Inference‑time scaling: Instead of extending the transformer’s context, an RLM learns to write small “programs” that scan, chunk, and summarize or reason over parts of the input, calling the base model on those chunks and then combining the results in further steps announcement.
• Beats naive long‑context tricks: On four long‑context benchmarks, RLMs outperform both base LLMs and common strategies like sliding windows and hierarchical summarization, and they do so even when total tokens processed are kept comparable or lower arxiv paper.
• Cost and deployment: The authors argue this can match or beat standard long‑context methods on per‑query cost, since the base model can stay relatively small and stateless while the recursion logic lives in a thin controller that orchestrates calls announcement.
RLMs push a line of work where tool‑use and self‑calling become the main way to scale reasoning over large corpora, without waiting for ever‑longer monolithic context windows.
Stanford paper frames AGI as “substrate + coordination” with phase‑transition theory
The Missing Layer of AGI (Stanford): Edward Chang’s paper argues LLMs are a necessary System‑1 substrate and that AGI hinges on a missing System‑2 coordination layer that constrains and binds patterns to goals, formalized as UCCT where reasoning appears as a phase transition once anchoring strength crosses a threshold, as summarized in the paper thread and detailed in the arxiv paper.
• Fishing/anchoring metaphor: The work recasts hallucinations as "unbaited casts" into the model prior; small, well‑designed in‑context anchors can flip behavior from generic text to goal‑directed reasoning when effective support overcomes representational mismatch paper thread.
• MACI coordination layer: It proposes a concrete coordination stack (MACI) with behavior‑modulated debate, a Socratic judge to filter weak arguments, and transactional memory to maintain state across episodes, described as the missing layer on top of LLM substrates paper thread.
• Test‑time control: The theory targets test‑time steering rather than new pretraining, suggesting that small numbers of examples can override vast prior training once above the UCCT threshold, which is meant to explain why two or three in‑context demos can reliably fix arithmetic or tool use.
The paper positions future AGI work less as building new substrates and more as inventing better coordination physics over existing large models.
“The World Is Bigger” proposes interactivity as a core continual‑learning objective
The World Is Bigger (U. Alberta & Amii): Lewandowski et al. formalize the big world hypothesis by embedding an agent as an automaton inside a universal environment and introduce interactivity as an objective that measures an agent’s ability to keep learning new predictions, arguing this better captures continual learning than fixed tasks, as explained in the paper summary and shown in the
.
• Embedded constraint: The environment is modeled as a universal local Markov process (like a cellular automaton) that can simulate any bounded automaton, so the agent is always capacity‑limited no matter how large the network becomes paper summary.
• Objective via TD errors: Exact algorithmic complexity is uncomputable, so interactivity is approximated as the gap between frozen and online temporal‑difference prediction errors; meta‑learning then searches for policies that maintain a high gap, encouraging behavior that keeps creating learnable surprises paper summary.
• Linear vs ReLU collapse: In an environment‑free self‑prediction setup (d=1000, T=10, depth 2–4), deep linear networks sustain or improve interactivity with depth, while deep ReLU policies often collapse and stop adapting, hinting at architectural choices that matter for long‑horizon continual learning paper summary.
The study suggests that for embedded agents, maintaining a rich stream of learnable prediction error—not just minimizing loss—may be key to avoiding stagnation in big, long‑running systems.
Apple’s Complete(d)P shows small‑run hyperparameters can transfer across width, depth and batch
Completed Hyperparameter Transfer (Apple): Apple researchers propose Complete(d)P, a recipe for rescaling optimizer hyperparameters so that settings tuned on a small model can be reused across width, depth, batch size, and training duration, reporting that a 7.2B model reached the same loss 1.32× faster when using module‑wise transferred settings, according to the summary thread and arxiv paper.
• Module‑wise scaling: Instead of a single global learning rate and weight‑decay, they derive scaling rules per module (e.g., attention vs MLP) so training dynamics stay similar as layer size and count change, extending ideas like μP to a more fine‑grained, architecture‑aware regime summary thread.
• Batch and duration transfer: They further adjust AdamW updates so that noise scale and total effective update budget remain comparable when batch size or training length change, allowing hparams from cheap short runs to transfer to long, large‑batch pretrains without full retuning summary thread.
• Trust‑region search: Because good regions in this space have sharp boundaries, they use a trust‑region hyper‑search around theoretically predicted values, which helps identify per‑module optima that remain stable when scaled summary thread.
The work points to a future where expensive large‑scale LLM and VLM runs can lean heavily on theory‑backed hyperparameter reuse rather than bespoke sweeps at every scale.
Survey maps self‑evolving agents as a path toward artificial superintelligence
Self‑Evolving Agents Survey (multi‑institution): A 90‑page survey led by Huan‑ang Gao catalogs how self‑evolving agents can adapt models, context, tools, and architectures over time, framing them as a plausible route toward artificial superintelligence (ASI), as summarized in the survey highlight and detailed in the arxiv paper.
• What to evolve: The paper structures evolution across four targets—base models, long‑term context/memory (including prompt evolution), external tools, and single‑ vs multi‑agent architectures—and surveys methods that operate at each level survey highlight.
• When and how: It distinguishes intra‑test‑time (within an episode) from inter‑test‑time evolution, and reviews reward‑based learning, self‑generated and cross‑agent demonstrations, and population‑based search as mechanisms for continuous adaptation
.
• Domains and evals: The authors note that most empirical work still sits in narrow domains like coding and games, and they call out the need for clearer evaluation protocols to separate genuine self‑improvement from overfitting to static benchmarks survey highlight.
The survey consolidates a scattered literature into a common vocabulary, making it easier to relate emerging “self‑tuning” agent systems to longer‑term ASI scenarios.
“Will AI Trade?” shows compute‑bounded agents can invert the classic no‑trade theorem
Will AI Trade? (Peking University): Li and Deng revisit classic no‑trade theorems under compute limits and show that AI agents with identical beliefs but bounded computation can still sustain ongoing trade in a stylized repeated‑pattern game, effectively inverting the no‑trade result for practical AI markets, as outlined in the paper explainer and arxiv paper.
• Strategies as periodic patterns: They map strategies in repeated games to finite periodic action sequences where repeat length encodes compute power; agents must fully use their allowed period, so longer patterns represent more complex reasoning paper explainer.
• Instability at equal compute: When two agents have equal repeat length, some games lack any stable Nash equilibrium because each pattern can be countered by another of the same length, forcing continuous switching—interpreted as ongoing trade; with unequal lengths, behavior can converge paper explainer.
• Matching Pennies insight: If agents can hide their true computational power by using shorter repeats, even simple games like Matching Pennies never reach stability, suggesting that in real markets, opaque compute budgets could keep AI‑driven trading dynamics in constant flux paper explainer.
The paper reframes rational‑expectations arguments by treating computation itself as a strategic resource, hinting that AI markets may not settle into classic no‑trade equilibria even with shared priors.
TimeBill framework proposes time‑budgeted inference via dynamic KV cache pruning
Time‑Budgeted Inference (TimeBill): A Turing Post explainer describes TimeBill, a framework where LLM inference is governed by a time budget rather than a token budget, predicting response length and runtime and then dynamically adjusting KV‑cache pruning so more requests finish within latency SLOs without large quality loss, according to the framework summary and timebill explainer.
• Predict, then prune: TimeBill first estimates how long an answer will be and how much wall‑clock time the model has, then tunes how aggressively it drops older key–value pairs from memory during generation to stay within the allotted time framework summary.
• From tokens to milliseconds: The write‑up emphasizes that this shifts control from token counts (which are only loosely tied to latency) to direct time management, aligning better with production realities like p95 response targets and mixed request loads timebill explainer.
• Quality–latency trade‑off: The framework is pitched as keeping more tasks “on time” while degrading gracefully; exact empirical numbers are not in the tweet, but the mechanism highlights how temporal control can be added on top of existing transformer stacks framework summary.
TimeBill sits at the intersection of reasoning and systems work, showing how smarter runtime policies around context management can effectively buy compute for harder prompts under fixed latency budgets.
Vibe coding survey formalizes human–agent coding workflows into five patterns
Vibe Coding Survey (multi‑institution): A 92‑page survey on vibe coding organizes how developers collaborate with coding agents into five archetypes—full automation, step‑by‑step collaboration, plan‑based, test‑based, and context‑enhanced workflows—arguing that system design and feedback loops matter as much as model power for productivity, as outlined in the survey recap and arxiv paper.
• Triadic interaction model: The authors describe a triad of developer, coding agent, and project, connected by iterative instruction–feedback loops where tests, logs, and structured prompts act as the main communication channels survey recap.
• Taxonomy and pitfalls: They claim messy prompts and vague goals cause large productivity losses even with strong models, and highlight patterns—test‑driven tasks, structured instructions, explicit review phases—that correlate with better outcomes and fewer failure spirals survey recap.
• Security and isolation: The survey stresses that agents should run in sandboxed environments with clear capability boundaries, and that scaffolding (IDEs, CLIs, orchestrators) has to mediate tool access and data exposure vibe coding note.
This work treats vibe coding as an emerging engineering discipline, giving names and structure to practices that many coding‑agent users are converging on informally.
“Genesis of Silicon” essay recasts AI as a denoising system needing human semantic entropy
Genesis of Silicon (Tianqiao Chen): Chen’s essay frames modern AI as a vast denoising algorithm that compresses the world into ordered predictions, arguing that humans remain valuable by supplying high‑level semantic entropy—rare, meaningful surprises—that models cannot anticipate, as described in the essay summary and expanded in the essay page.
• Low vs high‑level entropy: Low‑level entropy is likened to label noise or random web crawl junk that training pipelines should scrub out, while high‑level entropy is an unexpected but coherent counterexample, edge case, or new task that forces the model to revise its internal hypotheses essay summary.
• Noah/Flood metaphor: Chen uses the biblical Flood as an analogy for dataset cleaning—removing low‑level chaos—while Noah represents the preserved seed of semantic unpredictability that prevents the system from converging to “heat death” with no gradients left to learn from follow‑up thread.
• AI for science angle: The essay ties this to AI‑for‑science, arguing that scientific progress depends on hard negatives, failed experiments, and weird signals and that future pipelines must explicitly protect and amplify such data rather than averaging it away essay summary.
The piece is more conceptual than empirical but offers a vocabulary for distinguishing destructive noise from the kind of surprise that pushes large models into new regimes.
🦾 Drones, humanoids and service robots enter real workflows
Strong applied robotics clips: precision firefighting and PV‑cleaning drones, a humanoid returning tennis balls, airport/service deployments, and last‑meter construction logistics.
China fields fire truck with roof‑launched drone for 200 m high‑rise fires
Firetruck‑mounted drone (China): A new Chinese fire truck integrates a launch bay for an autonomous drone that can climb 200 m, project water 45 m horizontally, and deploy in under one minute, targeting high‑rise fires that conventional ladder trucks cannot reach drone truck summary.

The video shows the small drone taking off from the truck roof and flying up a tower facade before firing a concentrated jet into upper‑floor windows, illustrating how a single vehicle can service vertical structures without complex ladder setups drone truck summary; the numbers given in the post—200 m altitude and 45 m spray distance—suggest coverage for roughly 60‑storey buildings and large setbacks, pointing to near‑term integration of drone modules into standard urban fire fleets rather than bespoke experiments drone truck summary.
Firefighting drones demo precise suppression on real outdoor blazes
Firefighting drone (China): A short field video shows a firefighting drone flying to an active blaze and extinguishing it with a directed suppressant stream, with the poster arguing that this kind of applied robotics matters more than benchmarks because it solves real constraints fire drone demo.

The drone appears to place suppressant exactly on the flame source rather than blanket an area, which implies closed‑loop control over plume location and nozzle aim fire drone demo; the accompanying comment stresses that this kind of system targets hard‑to‑reach spots where traditional trucks or hoses are slow or dangerous, positioning aerial robots as a new tool for municipal fire services rather than a research curiosity fire drone demo.
Autonomous drones start cleaning utility‑scale solar farms in China
Solar cleaning drone (China): A widely shared clip shows an autonomous drone traversing large PV arrays and spraying cleaning fluid in straight passes, pitched as a way to increase solar yield without human crews, with the poster framing energy as "the biggest bottleneck of the future" in China solar drone demo.

The point is: this is not a lab video but an operational‑looking deployment over a big field installation, with commentary stressing "no show, just genuine work" and tying it to scaling constraints for solar build‑out in China solar drone demo; a follow‑on post repeats the same video while linking it to OpenAI’s audio efforts, reinforcing that builders see energy and AI demand as coupled trends energy commentary.
Service robots quietly roll out across airports, hotels and casinos
Service robots (multiple vendors): Helsinki Airport now runs small cleaning and food‑service robots on its concourses—alongside a robot‑baked pizza kiosk branded "Fizza"—with the poster saying robots are "quietly showing up in public spaces and doing routine work" airport robots post.

Additional clips from New York properties and Las Vegas Strip resorts show similar autonomous cleaners operating on hotel carpets and casino floors, indicating that service robots are being deployed as always‑on janitorial staff in high‑traffic venues rather than as one‑off demos vegas service robots; financial analysis elsewhere in the thread ties this trend to banks planning a 10% headcount reduction—about 212 000 European roles—under AI and automation pressures, reinforcing that routine back‑office and front‑of‑house work are being targeted together bank job forecast.
Tracked robot tackles last‑meter steel beam logistics on construction sites
Steel beam carrier robot (China): A tracked robot is shown moving a long steel beam through a narrow, cluttered residential construction site, with the commentary emphasizing that cranes can lift heavy loads but struggle with the final tight, messy approach to the install location beam robot demo.

The robot appears to handle both terrain irregularities and tight clearances while maintaining beam balance, effectively solving the "last‑meter" problem where manual labor is expensive and dangerous beam robot demo; the post frames this as a targeted, non‑showcase deployment—an example of robotics addressing a specific, under‑automated step in the construction logistics chain rather than trying to replace entire trades beam robot demo.
UBTECH’s Walker S2 humanoid rallies tennis balls with closed‑loop control
Walker S2 humanoid (UBTECH): UBTECH’s Walker S2 humanoid is shown hitting fast‑moving tennis balls over a net, chaining perception, prediction, foot placement, and racket control into a short rally, which the commentator notes is far harder than it looks because the ball "does not wait for you" walker tennis analysis.

The description stresses that the robot must see the ball early, estimate its trajectory, move its legs to stabilize, and swing so that racket and ball meet at the right time, all while absorbing impact without wobbling or falling—tasks where many humanoids still look shaky walker tennis analysis; the post argues that a decent‑looking tennis hit implies a whole‑body controller doing more than replaying canned poses, since contact timing varies every rally, and positions this as evidence that humanoids are edging toward responsive, athletic manipulation rather than scripted showpieces walker tennis analysis.
Unitree Go2 Pro robot dog passes real‑world dog‑park stress test
Go2 Pro quadruped (Unitree): A "real life dog‑park" test of the Unitree Go2 Pro shows the robot following a handler, climbing stairs, tracking moving targets, and staying upright amid occlusions and crowding, with the author arguing that the bar is shifting from "can it walk" to "can it behave" dog park test.

The run exercises whole‑body feedback control on uneven terrain and stairs while the robot keeps lock on the right person in a dynamic environment, which is a much harsher test than lab floors dog park test; the commentary frames this as a sign that locomotion is becoming commoditized and that the next challenge is robust, socially acceptable behavior in mixed human‑robot spaces such as parks, campuses, and warehouses dog park test.
GR‑Dexter framework scales dexterous bimanual hands to out‑of‑distribution tasks
GR‑Dexter (ByteDexter V2 platform): A new GR‑Dexter framework trains a 56‑DoF bimanual robot with 21‑DoF hands—ByteDexter V2—to execute long‑horizon everyday tasks such as makeup decluttering and pick‑and‑place, using a 4 B‑parameter Mixture‑of‑Transformer vision‑language backbone plus an action diffusion transformer gr-dexter summary.

Training mixes next‑token prediction on vision‑language data with flow‑matching on robot trajectories, drawing from web data, cross‑embodiment logs (Fourier ActionNet, OpenLoong, RoboMIND), 800+ hours of human hand video with 3D tracking, and a small teleop set gr-dexter summary and project page; a unified retargeting pipeline standardizes crops, masks missing action dimensions, aligns by fingertips, and filters VR jitter, which the authors say boosts out‑of‑distribution success in makeup decluttering from 64% to 89% and pick‑and‑place on unseen objects from 45% to 85%, while also reaching 83% on unseen instructions ood gains summary.
🎬 Creator stacks: Spaces workflows, Gemini prompts, Grok video ratios
A lighter but active day for media generation: repeatable thumbnail pipelines, prompt recipes, and format updates. Useful for marketing/brand teams. Excludes model SOTAs.
FLUX.2 Pro lands in Firefly and Photoshop with shared ‘golden’ prompts
FLUX.2 Pro integration (Adobe): Community posts note that FLUX.2 Pro is now available inside Adobe Firefly and Photoshop, giving Creative Cloud users direct access to the popular model from within their existing image workflows rather than via standalone UIs firefly integration.
• Creator recipes: Alongside the integration, prompt authors share a "golden prompt" for cinematic FLUX.2 images and videos, pitched as a high‑quality starting point for users who want strong composition and lighting without hand‑tuning long prompts flux golden prompt.
• Stack effect: The combination means designers can stay in Photoshop/Firefly, apply FLUX.2 generations to layers, and iterate using community‑tested prompts instead of building their own from scratch, which lowers the barrier for non‑prompt‑engineering‑focused teams firefly integration.
Together, the host‑app support and shared prompts move FLUX.2 Pro from an experimental playground model toward a more routine production tool in standard creative suites.
Freepik Spaces workflow turns 2 images into 16 thumbnail variants
Nano Banana workflow (Freepik): Creator TechHalla shares a Freepik Spaces pipeline that takes a short text description plus two input images and fan‑outs into 16 different thumbnail prompts driven by Nano Banana Pro at 2K resolution, all wired as a reusable Space for YouTube‑style thumbnails spaces overview.

• Template structure: The Space uses one text box for video context, two image inputs (creator face + subject image), and 16 Nano Banana Pro nodes, each with a distinct prompt style (e.g. MrBeast‑style, food, gaming), as described in the shared setup spaces overview.
• Reusability: The full workflow is published as a public Space so others can clone it and inspect or tweak the underlying prompts and node graph via the shared link spaces template.
The setup shows how non‑technical creators can get a multi‑style thumbnail batch system without touching code, using Spaces as the orchestration layer over image models.
NotebookLM auto‑produces explainer video from DeepSeek mHC paper
NotebookLM storytelling (Google): A practitioner reports using Google NotebookLM to ingest DeepSeek’s mHC Transformer architecture paper and have the tool automatically generate a video overview that simplified the core concepts for a non‑expert audience user report.
• Workflow: The user loads the mHC PDF, then asks NotebookLM to create a video explainer; the system outputs a narrated, structured walkthrough of the ideas, effectively turning dense ML research into a shareable clip without manual scripting or editing user report.
• Use case signal: The author calls this one of their “best use cases” for NotebookLM, highlighting AI‑assisted technical storytelling as an emerging pattern where research papers become auto‑generated educational media rather than static documents user report.
This shows NotebookLM functioning as a bridge from longform technical text into video content, useful for teams that need internal teach‑ins or external explainers but lack dedicated video staff.
Grok Imagine adds five video aspect ratios for creative layouts
Video ratios (xAI): Grok Imagine’s image/video generator now supports five aspect ratios—2:3, 3:2, 1:1, 9:16, 16:9—expanding beyond a single default canvas so creators can target feeds, stories, and widescreen in one system grok ratios.
• Format coverage: The new set spans tall poster (2:3), landscape (3:2), square (1:1), vertical short‑form (9:16), and standard horizontal video (16:9), which aligns with major social and video platforms’ preferred formats grok ratios.
• Stack implication: This change turns Grok Imagine into a more flexible piece of a creator stack where the same prompt can be reused across multiple placements without external cropping or re‑framing.
The update is framed as a creative expansion rather than a model‑quality change, but it directly affects how marketing and social teams can route Grok output into campaigns.
Gemini shares Nano Banana prompt for notebook‑paper 2026 vision boards
Vision board prompt (Google): Google’s Gemini team posts a ready‑to‑use Nano Banana Pro image prompt for a blue ballpoint knolling‑style 2026 vision board on lined notebook paper, complete with glow highlights and handwritten annotations vision board intro.
• Prompt details: The reply includes the full long‑form prompt specifying sketch medium, cross‑hatching, yellow highlighter outline, arrowed notes, and notebook paper background, with a slot where users insert their own 2026 items prompt text.
• Intended usage: The team suggests running it in the Gemini app, experimenting with alternate styles like magazine cutouts or notebook paper, and sharing variations, positioning this as a lightweight way for users to visualize annual goals without custom prompt engineering vision board intro.
This gives creators and marketers a concrete, production‑ready prompt pattern they can adapt for their own planning visuals.
🧭 2026 outlook: continual learning, multi‑agent systems and IPO watch
Threads cluster around continual learning becoming practical, multi‑agent harnesses, and macro enterprise themes (power, sovereign AI, IPO pipeline). Excludes technical mHC or model metrics.
Labs and analysts frame 2026 as the year continual learning moves into production
Continual learning 2026 (multi‑lab): Multiple prominent researchers and commentators are now labeling 2026 as the turning point when continual learning—models that update after deployment instead of waiting for big retrains—starts to become practical at scale; Google DeepMind researchers Ronak Malde and Varun Mohan both say "2026 will be the year of continual learning" and expect "huge progress" there, echoing earlier comments from Anthropic’s Dario Amodei about continual learning being "solved" or at least becoming workable by 2026 deepmind posts and leaders list. The Information’s 2026 outlook goes further by predicting that a breakthrough in continual learning could push AI compute usage toward "100% inference and basically 0% training," even speculating this might hurt Nvidia’s stock, while analysts like Rohan Paul push back that continual learning still needs frequent fine‑tuning, evals and safety checks, so it likely shifts rather than erases training demand information summary and nvidia take. Teknium adds that any genuine continual learning scheme must still involve weight updates—"otherwise it hasn’t learned anything"—and warns that naive batch‑size‑1 updates risk overfitting, underscoring that the exact algorithms and architectures behind practical continual learning are still an open question training comment.
• Labs flag progress, not details: Posts from DeepMind and others do not yet describe specific methods, but repeated public hints about nested learning, test‑time training and self‑improving agents suggest major labs are already running internal experiments along these lines deepmind posts.
• Compute split debate: Commentary around The Information’s claim that training compute may fall to 0% while inference rises to 100% stresses that continual learning could actually increase total compute by adding many small, distributed updates and more evaluation infrastructure, which would still benefit GPU vendors information summary and nvidia take.
Overall, the center of gravity for 2026 expectations is that models will start to adapt during use rather than only between generations, but there is no consensus yet on how this will change the ratio of training to inference or whether market narratives like "Nvidia crashes on continual learning" are grounded in how such systems are likely to be built.
Analysts see 2026 as a potential mega‑IPO year for SpaceX, OpenAI and Anthropic
Mega‑IPO pipeline 2026 (multi): New reporting compiled by Kimmonismus says SpaceX, OpenAI and Anthropic are all exploring potential IPOs as early as 2026, with combined valuations that could exceed $1.5 trillion and individual listings large enough that a single offering could surpass the entire 2025 US IPO market in deal size ipo preview. This deepens earlier analysis that 2026 could be a crowded IPO window for AI‑native companies, following up on AI IPOs which framed a broad backlog of AI firms waiting for market conditions to improve.
The thread notes that even one such listing would be a once‑in‑a‑generation payday for investors, banks and lawyers, underscoring how much capital markets now hinge on AI‑centric businesses ipo preview and ft link. No exact timelines or underwriting details are public, and the tweets stress that any of these offerings could still slip, but they set expectations that 2026 may be the year when some of the most systemically important AI and space companies test public markets.
Community forecaster sketches 2026 as coding/maths AGI and multi‑agent default
Coding and math AGI (community): Independent forecaster scaling01 publishes a detailed 2026 roadmap where frontier models reach what they call "coding and mathematics AGI"—predicting >90% scores on many current math and coding benchmarks, METR long‑horizon SWE tasks out past 24–30 hours, and a new generation of 5–10T‑parameter systems that feel like the same capability jump from GPT‑4 Turbo → o1 → GPT‑5.2 repeated again by late 2026 detailed forecast. They expect 2026 to be "the year of multi‑agent systems," with agents routinely delegating to sub‑agents, an emerging "agent economy" where AI agents pay other agents for work, and general‑purpose harnesses (analogous to Claude Code but broader) turning into standard infrastructure detailed forecast and subagent note.
• Benchmark saturation and Elo gap: The thread forecasts saturation on many evals (e.g., SWE‑Bench Verified, ARC‑AGI 1–2, FrontierMath 1–3 all above ~95%) and uses an internal "Lisan Index" chart to argue that by end‑2026, frontier models will sit ~369 Elo points above today’s best, implying roughly an 89% win‑rate over current leaders elo chart and winrate claim.
• Continual learning and test‑time training: As a follow‑on, scaling01 argues that efficient test‑time training plus continual learning will become the 2026 "next paradigm" and might be what ultimately leads from narrow coding superintelligences to broader AGI, whether via mech‑interp‑targeted LoRA‑style updates or more brute‑force systems like markdown skill files and nested learning architectures continual learning note and narrow asi comment.
• Release cadence and lab standings: They project model release cycles compressing from ~6 months (2023) to ~monthly by 2026, expect Anthropic to be widely viewed as "ahead of everyone else" with a non‑trivial chance of overtaking OpenAI’s valuation, and see DeepSeek‑V4 narrowing the open vs closed gap in H1 2026 before closed models pull ahead again on economically valuable tasks detailed forecast.
The picture is aggressively bullish and speculative, but it gives a concrete checklist—multi‑day agent runs, benchmark ceilings, multi‑agent harnesses, and a 5–10T parameter frontier—for what this slice of the builder community is watching for over the next 12 months.
Forbes 2026 predictions highlight agentic enterprises, sovereign AI and rising power use
Forbes 2026 outlook (Forbes): A Forbes piece by Mark Minevich projects that by 2026 every employee will have a dedicated AI assistant executing real work across HR, scheduling, forecasting, inventory and communications, with about 40% of enterprise applications embedding task‑specific agents, and it argues that career advancement will favor "human–machine teams" and AI‑fluent generalists who can orchestrate these systems forbes summary and forbes article. The same 11‑point forecast expects orchestrated multi‑agent systems coordinating dozens to hundreds of specialized agents on long‑running workflows, with central platforms hosting shared agent libraries, testing environments and live monitoring tied directly to P&L and operational metrics forbes summary.
• Sovereign AI and data center power: Forbes estimates sovereign AI spending could reach around $100B in 2026, as governments fund national models and infrastructure, and warns that data center electricity demand may climb from 415 TWh in 2024 to roughly 945–980 TWh by 2030, with US consumption potentially rising 130% from a 4% share of national power in 2024 forbes summary.
• IPO and infra bets: The piece also ties a possible $1.5T SpaceX IPO into a broader "space + AI" investment theme and sees Amazon re‑emerging as an AI infra leader as AWS Trainium adoption increases and growth re‑accelerates into the high‑teens or low‑20s percent range, framing chip, power and sovereign infra as the main levers for AI competition rather than just model quality forbes summary.
• Security and browser surface: On the risk side, Forbes expects identity to become the main security battleground as deepfakes and agent hijacking surge in 2026, pushing AI firewalls, agent governance and quantum‑resilient cryptography, and predicts the browser will consolidate as the primary enterprise operating environment for agents, workflows and authentication, which also makes it the top attack surface forbes summary.
The article gives a numbers‑heavy view of 2026 in which agent orchestration, sovereign AI budgets and power‑hungry data centers are as central to strategy as which frontier model leads the latest benchmark.
AiBreakfast’s 2026 forecast shifts focus to code generation, video, FSD and xAI
2026 landscape (AiBreakfast): Commentator AiBreakfast lays out a broad 2026 forecast where the center of gravity in AI shifts away from conversational feel and toward code generation, agents and real‑world automation; they argue that "all meaningful progress benchmarks shift to code gen capabilities," with models writing long systems, debugging themselves and shipping real apps so that even non‑technical users can build software from short prompts prediction thread. The post also predicts that English‑language chat quality has mostly converged, with future gains living in deep‑research and long‑horizon modes that many everyday users will not notice directly prediction thread.
• Compute, video and autonomy: AiBreakfast expects compute prices to rise before they fall, seeing 2026 as another year where GPU demand stays ahead of supply; they call short‑form video the main 2026 "shock vector" with more personal, adaptive clips and consistent characters, and predict that fully unsupervised driving plus robo‑taxis will reprice personal transport so that many people happily give up car ownership prediction thread.
• Platform and model politics: The forecast anticipates Apple going through a leadership change and signing a deep integration deal with a major model provider, xAI’s Grok becoming the dominant conversational model for Tesla owners (because it’s "fully embedded" in cars), X rising toward Instagram‑scale usage with prediction markets and money transfer, and the EU remaining a regulatory drag on rapid AI deployment prediction thread.
• Agents and shifting AGI goalposts: Similar to other 2026 outlooks, AiBreakfast expects the definition of AGI to keep moving as capabilities improve, sees xAI leaning into a more opinionated conversational style, and emphasizes that "human taste" and aesthetic judgment will grow in value as more of the mechanical work is handed off to agents prediction thread.
Taken together, this forecast sketches a near‑term world where agents quietly absorb more white‑collar workflows, video personalization and full self‑driving dominate consumer‑visible change, and arguments about whether "AGI" has arrived remain largely semantic.
Peter’s 26 bets for 2026 cover Chinese labs, agents, RL, products, deals and infra
Twenty‑six 2026 bets (community): A long forecast attributed to "Peter" and summarized by Kol Tregaskes sets out 26 quantified concepts and predictions for 2026 that together map a crowded AI landscape, ranging from which labs lead to how agents and infra evolve 26-bets-summary. On the model side, the bets include a Chinese open model topping LM Arena’s WebDev leaderboard for at least a month, Chinese labs leading in image and video generation for at least three months, and no diffusion‑only image models remaining in the top‑5 image leaderboards by mid‑2026 as more expressive or hybrid architectures take over 26-bets-summary.
• Agents, research and RL: The list expects a mainstream computer‑use agent breakthrough that can reliably operate GUIs, at least one 1‑GW‑scale model scoring above 50% on the hardest benchmarks such as FrontierMath Level 4 or ARC‑AGI‑3, and a new scaling regime where reinforcement learning begins to "saturate" and a different technique becomes the main axis of progress toward the end of the year 26-bets-summary.
• Products, deals and infra: Other bets include a breakout voice product with over 50M weekly active users, a single‑founder company hitting $50M ARR with an AI product, a major lab spending more than $10B acquiring a strong non‑AI company, Nvidia investing over $10B into energy via a startup or partnership, and visible AI data‑center build‑out fights over power and zoning where AI firms sometimes lose and face delays 26-bets-summary.
• Where progress may stall: The same forecast is relatively bearish on dramatic 2026 improvements in very small phone‑sized models, interpretability, diffusion‑based coding models or full alternatives to transformers and tokenizers, suggesting that most of the near‑term action will remain in large models, agentic systems and infra rather than radical new architectures 26-bets-summary.
Compared to institutional outlooks from Forbes or PwC, this community map is more speculative but also more granular, assigning explicit odds to dozens of intertwined developments across labs, agents, products and infrastructure.
PwC’s 2026 AI business predictions focus on studios, orchestrators and AI generalists
PwC 2026 predictions (PwC): PwC’s 2026 AI business outlook describes a shift from scattered, crowdsourced AI pilots to top‑down programs where leaders choose a few high‑value workflows, fund an internal "AI studio" and then re‑engineer processes end‑to‑end around agents, orchestration and measurement pwc summary and pwc predictions. The firm expects enterprises to adopt orchestrated multi‑agent systems that coordinate dozens or hundreds of specialized agents on long‑running workflows, with central platforms hosting shared agent libraries, pre‑release testing, working demos and live monitoring directly tied to P&L and operational KPIs pwc summary.
• Workforce and skills: PwC argues that workforces will tilt toward AI generalists who can design, supervise and debug agentic workflows, with knowledge roles taking on an hourglass shape (strong junior and senior tiers, thinner middle), and with frontline staff increasingly managing agents rather than doing all the work themselves pwc summary.
• Responsible AI as routine: The predictions say that "responsible AI" will become day‑to‑day practice rather than a separate initiative, with automated testing, deepfake detection, AI inventories, risk tiering, documentation and independent assurance becoming standard for higher‑risk or higher‑value systems pwc summary.
• Orchestration layer: PwC emphasizes an orchestration layer that can move end‑user ideas into production through simple dashboards, drag‑and‑drop pipelines, multi‑vendor tools, real‑time data and strong security and rollback mechanisms, suggesting that glue code and platform engineering around agents may be as important as the agents themselves pwc summary.
Compared with more speculative 2026 forecasts, PwC’s view is very enterprise‑operations‑centric, highlighting studios, orchestrators and governance as the main levers by which large organizations will turn agentic AI into measurable business results.
Morgan Stanley projects 10% European bank job cuts by 2030 as AI automates central services
AI labour impact (Morgan Stanley): Morgan Stanley analysts estimate that European banks could cut about 10% of roles, or roughly 212,000 jobs, by 2030 as AI and broader digital delivery automate routine work, particularly in back‑ and middle‑office "central services" such as processing, control functions and the layers that shuttle data and approvals between front‑line staff and core systems banking forecast and ft jobs article. The analysis covers 35 banks with around 2.12 million employees, attributing much of the pressure to investor demands for cost cuts and improved returns on equity relative to US peers, and citing bank statements that AI and digitalisation could deliver up to 30% efficiency gains in some areas banking forecast.
Examples already on the table include ABN Amro targeting roughly 20% staff reductions by 2028 and Société Générale’s leadership saying few areas are exempt from cost cuts, while Morgan Stanley notes that AI is especially well suited to tasks like reading forms, extracting fields, reconciling breaks, drafting standard reports and routing cases, which dominate many central services roles banking forecast. The forecast stresses that these are medium‑term numbers out to 2030 rather than a 2026 shock, but it reinforces a core theme of several 2026 outlooks: white‑collar automation via agents and AI tools is moving from theory into concrete headcount plans.