LiteLLM 1.82.7 and 1.82.8 compromised on PyPI – 10:39–14:35 UTC
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
LiteLLM’s PyPI releases 1.82.7 and 1.82.8 were reported as malicious; a .pth install-time payload allegedly exfiltrated secrets (SSH keys, cloud creds, kube configs, env vars) and could propagate via transitive dependencies, meaning a routine pip install litellm was enough to compromise an environment. PyPI briefly quarantined the project (non-installable), then yanked the bad versions and restored installs; DSPy pegged an availability window at 10:39–14:35 UTC, while separate accounts claim the poisoned build was live for under ~1 hour—incident timelines are still mostly tweet- and screenshot-sourced. Downstream projects issued scope notes (browser-use says only v0.12.3 in a narrow window; Hermes Agent warned of exposure in parts of its stack); responders also flagged GitHub-thread spam that can bury remediation details.
• Anthropic/Claude Code Auto mode: Teams-only research preview; pre-tool-call classifier decides when to auto-allow vs block risky file writes/bash; Shift+Tab toggles permission modes.
• Cursor/Composer 2 report: CursorBench plot claims ~61% at ~$0.35/task with ~8k completion tokens; RL task mix skews to “iterate on feature” (~39%) and “debugging” (~32%).
• Serving perf: vLLM MRV2 rewrites the execution core behind an env flag; Google TurboQuant claims ≥6× KV-cache compression and up to 8× faster attention at 4-bit on H100, with “zero accuracy loss” asserted but not yet widely replicated.
The common thread is autonomy pressure meeting supply-chain reality: agent stacks increasingly auto-install and auto-act, while ecosystem proposals shift toward registry diff-scans and 48-hour holds, plus tighter package-manager controls around install scripts and network calls.
Top links today
- Anthropic on multi-agent harness for frontend
- Anthropic Economic Index on user experience
- Cursor Composer 2 training technical report
- Figma use_figma MCP tool docs
- PyPI listing for LiteLLM (check versions)
- Snyk analysis of LiteLLM supply chain attack
- Hugging Face hf-mount virtual filesystem tool
- vLLM project repository
- Gemini case studies for research acceleration
- Learning from language feedback via meta-learning
- BIGMAS graph multi-agent reasoning paper
- MIT Technology Review on OpenAI automated researcher
- Reuters on China open-source AI distribution
Feature Spotlight
Claude Code ‘Auto mode’: permission decisions via pre-tool classifier (Teams preview)
Auto mode cuts the biggest CLI friction (permission spam) while keeping a runtime safety gate. It’s a meaningful step toward unattended agent runs—without going fully “skip permissions,” but still requires sandboxing discipline.
Big cross-account launch: Claude Code adds Auto mode to reduce constant file-write/bash approvals by running a safety classifier before each tool call. Risky actions are blocked and require a different approach; Anthropic stresses this reduces—but doesn’t eliminate—risk and recommends isolated environments.
Jump to Claude Code ‘Auto mode’: permission decisions via pre-tool classifier (Teams preview) topicsTable of Contents
🤖 Claude Code ‘Auto mode’: permission decisions via pre-tool classifier (Teams preview)
Big cross-account launch: Claude Code adds Auto mode to reduce constant file-write/bash approvals by running a safety classifier before each tool call. Risky actions are blocked and require a different approach; Anthropic stresses this reduces—but doesn’t eliminate—risk and recommends isolated environments.
Claude Code adds Auto mode to reduce permission prompts (Teams preview)
Claude Code (Anthropic): Claude Code shipped Auto mode, a middle ground between approving every file write/bash command and fully skipping permissions—Claude now makes the permission decision on your behalf, as described in the launch thread from Auto mode announcement.
• Positioning: The release frames Auto mode as the successor to the old “YOLO” path—see the “Goodbye --dangerously-skip-permissions, hello auto mode” note in Flag change reaction.
• Availability: It’s rolling out as a research preview on the Teams plan, per the rollout summary in Teams preview details.
Claude Code Auto mode uses a pre-tool-call classifier to block risky actions
Safety layer for tool calls (Anthropic): Auto mode isn’t “auto-approve everything”; before each tool call, a classifier checks for potentially destructive actions so safe actions can proceed while risky ones are blocked and Claude is forced to try a different approach, according to the safeguard explanation in Classifier safeguard description.

• Risk framing: Anthropic explicitly says this “reduces risk but doesn’t eliminate it,” and recommends isolated environments, as stated in Auto mode announcement.
• Operational behavior: The model may reroute its strategy after a block instead of repeatedly requesting approvals, as summarized in Runtime safety filter summary.
Claude Code permission UX: Shift+Tab mode switch, with Auto mode as a distinct setting
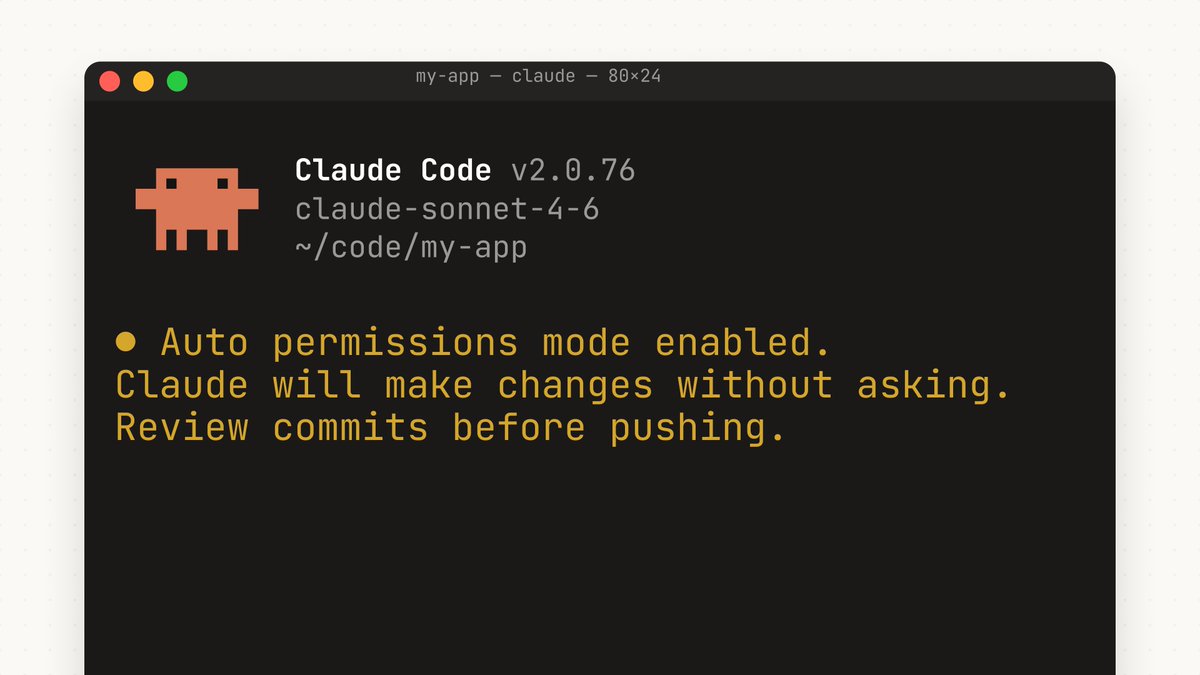
Claude Code CLI/UX (Anthropic): Auto mode shows up as a dedicated permission mode in the UI, sitting alongside options like “Auto accept edits” and “Bypass permissions,” with quick switching via Shift+Tab, as shown in the settings capture in Permission mode menu.
• Practical implication: This makes it easier to dial autonomy up/down mid-session without dropping all safeguards, which is the friction point highlighted in the original Auto mode pitch from Auto mode announcement.
Claude Code Auto mode rollout: Teams-only now, with scaling to other surfaces planned
Rollout mechanics (Anthropic): Multiple posts emphasize the current constraint—Auto mode is Teams-only today—while hinting at broader availability once Anthropic “scales it,” per the note in Teams-only and scaling note.
• Surface gap: TestingCatalog notes it’s not on desktop yet and is “in the works,” while still being CLI-activatable, as summarized in Teams preview details.
• Why it matters: This tier-gating shapes who can actually run longer unattended agent tasks without prompt fatigue, which is the core complaint in the “no more permission prompts” chorus in Permission prompt fatigue.
Builder sentiment: approval fatigue is the bottleneck Auto mode is targeting
Agentic coding workflow (community): The dominant reaction isn’t about new capabilities so much as removing interruption—“no more permission prompts” shows up as the headline value prop in Permission prompt fatigue, with others echoing that prompts should be “a thing of the past,” as in Permission prompts comment.
• Pragmatic take: Some builders frame Auto mode as a way to keep moving while still feeling responsible, rather than going straight to full bypass, as captured in YOLO substitute remark.
🎨 Figma MCP as a first-class design surface for coding agents (Claude/Cursor/Copilot)
High-signal interop cluster: Figma’s MCP tool + skills enable agents to read/write real Figma files with design-system context; multiple vendors showcase design-to-code loops. Excludes general non-MCP design tools (covered elsewhere).
Figma’s use_figma MCP tool makes the canvas writable by agents
use_figma MCP (Figma): Figma is opening up direct agent control of the canvas via a new use_figma MCP tool plus teachable “skills,” positioning it as a standard way for agents to read/write real Figma files instead of relying on screenshots or brittle UI automation, as described in the [Figma MCP announcement](t:16|Figma MCP announcement).
• Why engineers care: MCP turns “design system context” (components, variables, tokens) into something an agent can query and mutate deterministically, which is the missing link for design-to-code loops that don’t drift.
• Ecosystem signal: downstream tools are already demoing agents writing into Figma through this interface, as shown in the [Factory demo](t:206|Factory demo).
Cursor adds Figma component generation with design-system tokens
Cursor + Figma (Cursor): Cursor can now create new components and frontends directly in Figma while adhering to a team’s design system, including variables/tokens and naming conventions, according to the [Cursor Figma demo](t:15|Cursor Figma demo).

• Design-system enforcement: the flow explicitly calls out implementing variables, tokens, and naming conventions through the Figma plugin, as noted in the [plugin details](t:274|Plugin details).
• Workflow impact: this moves “UI scaffold” from a manual handoff into an agentic step that can be replayed and kept consistent with system primitives.
A more reliable Claude Code → Figma loop via Plugin API codegen
Claude Code + Figma MCP (Anthropic/Figma): One emerging reliability pattern is to have Claude generate code that targets Figma’s Plugin API (i.e., translate intent into known Figma functions) rather than “freehand” design edits; the claim is that this makes outcomes more repeatable when working with design-system context, per the [integration note](t:7|Integration note) and the [Plugin API detail](t:218|Plugin API detail).
Copilot CLI can edit Figma files through Figma’s MCP server
Copilot CLI + Figma MCP (GitHub/Figma): GitHub is highlighting that, with Figma’s MCP server, you can drive changes directly to Figma files from GitHub Copilot CLI or @code, per the [GitHub MCP mention](t:103|GitHub MCP mention). This is an interoperability step: the same MCP surface can be used by multiple agent frontends without bespoke Figma integrations per tool.
Warp ships a Figma MCP skill pack for token-aware edits
Warp Figma skills (Warp): Warp is shipping a packaged skill set for editing Figma designs through the Figma MCP server; installation is via npx skills add warpdotdev/figma-skills, as shown in the [Warp Figma walkthrough](t:397|Warp Figma walkthrough).

• What’s shipped: a public skill repo exists for the integration, as linked from the [repo pointer](t:887|Repo pointer) and detailed in the [GitHub repo](link:887:0|GitHub repo).
FactoryAI’s agents write directly into Figma via use_figma MCP
FactoryAI + Figma (FactoryAI): FactoryAI is demoing a native connection from its agents (“Droids”) into the Figma canvas using use_figma MCP, with the pitch that agents can write real components/variables with full design-system awareness, as shown in the [FactoryAI canvas demo](t:206|FactoryAI canvas demo).

Figma and Anthropic schedule a Claude Code ↔ Figma roundtrip livestream
Workflow education (Figma/Anthropic): A livestream titled “From Claude Code to Figma – and Back Again” is scheduled for March 31 (9:00AM PST), framed as hands-on guidance for roundtrip workflows between Claude Code and Figma using the MCP server, as announced in the [livestream post](t:175|Livestream post) and described on the [event page](link:175:0|Event page).
🛡️ Supply-chain wake-up: LiteLLM PyPI credential-stealer and downstream fallout
Today’s dominant security story: compromised LiteLLM releases (1.82.7/1.82.8) exfiltrated credentials and hit transitive dependents; ecosystem response includes PyPI quarantine/yank, incident writeups, and calls for stronger package-manager install-script controls. Excludes Claude Code Auto mode (feature).
DSPy warns about transitive exposure and signals it may remove LiteLLM as a default dep
DSPy (DSPyOSS): DSPy maintainers published a time-bounded advisory saying the malicious LiteLLM versions were available from 10:39–14:35 UTC, and that anyone who installed LiteLLM 1.82.7 or 1.82.8 should treat the environment as compromised and rotate potentially exposed credentials, per DSPy incident advisory.
They also said a forthcoming DSPy 3.3 will “likely drop the dependency on LiteLLM” and instead expect providers to follow a small set of standards (OpenAI-style completions/Responses), as stated in DSPy dependency plan.
browser-use limits the blast radius to v0.12.3 installs during the LiteLLM window
browser-use (open source): The project reports that only browser-use v0.12.3 was impacted (it was the only version depending on LiteLLM), and only for installs between 10:39–16:00 UTC; their cloud services were not affected, according to Scope-limited advisory.
The post repeats the key verification step—checking for LiteLLM 1.82.7/1.82.8—and suggests rotating credentials if those versions were pulled, as outlined in Scope-limited advisory.
Hermes Agent posted a LiteLLM incident notice and mitigation guidance
Hermes Agent (NousResearch): Hermes users were warned that LiteLLM was a dependency “within parts of Hermes Agent,” and installs during the last 4–24 hours could be affected; Teknium points to a specific security notice in Hermes security notice.
The notice highlights the impacted LiteLLM versions (1.82.7/1.82.8) and frames the expected impact as secrets exfiltration (API keys, logins), aligning with the broader incident description in Incident overview.
AI diff scanning and publish holds proposed for critical packages
Registry scanning proposal: A detailed suggestion is for PyPI/npm/crates registries to run automated scans on releases of high-impact packages by diffing against the prior version and flagging suspicious signals (large base64 blobs, new URLs, unusual publish IP/location), then impose a 48-hour hold for review when risk is high, as laid out in Registry scanning proposal.
The argument is framed as low marginal cost (tokens per release) versus high blast radius, in the same spirit as the transitive-dependency risk described in Incident overview.
Lockfile discipline resurfaces as an incident-response control for agent toolchains
OpenHands (OpenHandsDev): In response to the LiteLLM compromise, OpenHands reported production environments were unaffected and emphasized that open-source developers who bypassed the lockfile while installing dependencies should check if they were affected, as stated in Exposure investigation note.
This is a concrete reminder that “agent stacks” often install large dependency trees, and lockfile bypass turns a time-bounded PyPI incident into local compromise risk, per the framing in Exposure investigation note.
Package-manager install-script controls get proposed as a post-LiteLLM mitigation
Package management controls: A concrete mitigation proposal is to make “nouveau” package managers (explicitly calling out uv and bun) reduce risk from install-time scripts—e.g., adding guardrails up to manually approving batches of network calls—per Install-script guardrails idea.
This is directly tied to the LiteLLM attack’s install-time execution mechanism described in Incident overview.
Security-audit branding gets scrutinized after the LiteLLM compromise
Audit/assurance signal: Commentary argues that LiteLLM’s “Secured by Delve” positioning looks hollow after the compromise, with specific criticism of Delve’s audits and lack of response in Audit backlash thread.
A related practitioner take suggests “AI-powered scans” for popular packages should be table stakes at registries, but also implies audit badges are not a substitute for release-channel controls, per Registry scanning proposal and the follow-up correction in PyPI scanning context.
Supply-chain fear pushes a renewed “fewer dependencies” stance
Dependency posture shift: Karpathy frames the LiteLLM incident as a reminder that deep dependency trees are a systemic risk, and says this has made him “growingly averse” to dependencies—preferring to “yoink” simple functionality via LLMs when feasible, per Dependency critique.
This is less about LiteLLM specifically and more about the engineering response to transitive compromise risk, which the incident narrative in Dependency critique made concrete.
Incident response got noisier: suspicious spam comments show up on the LiteLLM GitHub issue
GitHub incident-response noise: During the LiteLLM disclosure, Simon Willison called out the odd pattern of many low-effort “thanks that helped” comments on the GitHub issue thread, asking for theories in Suspicious comments question.
This matters because operational guidance (which versions are compromised, how to verify installs) often concentrates in a single issue thread, and large-scale spam can bury remediation details, as implied by Suspicious comments question and the broader urgency in Incident overview.
PyPI’s existing scanning-partner API is cited as a reason LiteLLM was quarantined fast
PyPI scanning capability: Simon Willison notes that PyPI already supports scanning via an API used by partners, and suggests this may explain why LiteLLM was quarantined quickly after going live, per PyPI scanning note.
That comment directly answers calls for registry-side detection made in Registry scanning proposal, while leaving open how comprehensive the current partner scanning is in practice.
🧵 Agent runners & swarms: Hermes 0.4.0, API backends, and parallelism UX
Operational agent tooling saw big movement: Hermes Agent’s largest release adds background self-improvement and an OpenAI-compatible API server, while builders highlight multi-agent swarms and long-running missions. Excludes MCP-specific Figma items (separate category).
Hermes Agent v0.4.0 adds background self-improvement and an OpenAI-compatible API server
Hermes Agent (NousResearch): v0.4.0 lands as the largest Hermes release ("300 merged PRs") and turns Hermes into an OpenAI-compatible agent backend while adding a background post-response improvement loop, as described in the release announcement from release post and the release summary thread from release highlights.
• OpenAI-compatible API server: Hermes now exposes both /v1/chat/completions and /v1/responses, including stateful chaining via previous_response_id, per the API server details in API server details.
• Background self-improvement: after a response is delivered, a separate review agent decides what to remember and what to convert into reusable skills, as outlined in self-improvement loop.
• Ops surface expansion: the release adds more messaging adapters (including Signal/Matrix/SMS) and ships CLI/context-handling upgrades (streaming by default, queue/status tooling, CLAUDE.md support), as listed in CLI upgrades.
The net change is Hermes moving from “agent you run” to “agent platform you can plug UIs into,” with the release notes tracked in the GitHub release notes linked from release notes link.
Hermes Agent issues guidance for users exposed via LiteLLM dependency compromise
Hermes Agent (NousResearch): Nous/Hermes maintainers posted a security notice describing exposure via LiteLLM as a dependency in parts of Hermes Agent, including impacted versions and a short “check/rotate/remove” playbook, as shown in security notice screenshot.
The notice calls out LiteLLM 1.82.7 and 1.82.8 as affected releases and frames the safest response as treating the environment as compromised (rotate secrets/keys and remove the dependency) for anyone who installed during the relevant window, per the maintainer guidance in security notice screenshot.
BridgeSpace usage: 12-agent and 50-agent swarms for parallel code/security audits
BridgeSpace (BridgeMind): Multiple demos show BridgeSpace being used as a swarm runner for parallel security/audit work—including a phone-driven flow that triggers a 12-agent security audit and a separate run that launches 50 agents inside the same environment, per the 12-agent walkthrough in 12-agent swarm demo and the 50-agent clip in 50-agent swarm clip.

• Parallel audit decomposition: one example shows 10 explorer agents spawned in parallel for auth-flow review, each scoped to specific file paths and using the gpt-5.4-mini high variant, as captured in subagent roster screenshot.
The common thread is pushing long-horizon review work into many small, path-scoped investigations, then aggregating findings back into a single thread.
LangSmith Fleet adds custom Slack bots for calling agents by handle
LangSmith Fleet (LangChain): Fleet now supports custom Slack bots, giving each agent its own handle so teams can run agent workflows directly from Slack, as announced in the Fleet launch post from Fleet announcement.

In practice, this is being framed as a shared collaboration surface where a team can see agent inputs/outputs in-channel (instead of fragmented per-user threads), as described in Slack-first workflow notes.
Founder signal: engineering work moving into Slack/Linear via cloud-hosted agents
Cloud-hosted agent ops: A founder report describes spending multiple days without running local dev commands, with most engineering/marketing execution happening through Slack and Linear while agents run “in the cloud,” alongside the claim that building an internal orchestration layer is itself a full-time effort, as laid out in cloud agents workflow note.
The post also explicitly contrasts DIY orchestration with paying for “battle-hardened” systems (citing Devin) as a way to externalize the ops burden, per cloud agents workflow note.
🧩 Cursor’s Composer 2: training report, RL recipe, and CursorBench economics
Cursor published technical details on how Composer 2 was trained (continued pretraining + RL + benchmark development) with emphasis on emulating the Cursor environment. This continues the Composer storyline with new concrete training/benchmark specifics and cost/performance plots.
Cursor details how Composer 2 was trained and where it sits on CursorBench cost vs quality
Composer 2 technical report (Cursor): Following up on RL claim (Composer 2’s RL story), Cursor released a training report describing three pillars—continued pretraining, reinforcement learning, and benchmark development—aimed at emulating the Cursor IDE environment, as stated in the Technical report announcement. The report also surfaces CursorBench positioning data where Composer 2 lands around 61% at roughly $0.35/task and ~8k completion tokens, versus points like GPT-5.4 at ~63% and ~$1.20/task and Opus 4.6 at ~61% and ~$2.00/task, as shown in the CursorBench plots.
• Benchmark targets: The report frames Composer 2 as scoring strongly on CursorBench plus public SWE benchmarks (SWE-bench Multilingual, Terminal-Bench), per the Technical report announcement.
• What RL was trained on: The RL training task mix is dominated by “iterate on feature” (~39%) and “debugging” (~32%), based on the chart shared in the RL task mix.
Composer 2 RL takeaway: improvements show up in both pass@k and pass@1
Composer 2 RL effect (Cursor): A notable interpretation circulating is that Composer 2’s RL phase improved both pass@k and pass@1, implying gains beyond “just sampling better” and pointing toward capability uplift rather than only reweighting, as highlighted in the RL pass@k and pass@1 note.
Composer 2’s early adoption pitch is feel: speed plus taste in frontend work
Composer 2 usage signal (Cursor): Multiple builders are emphasizing “feel” as the differentiator—“so fast, so smart” in the Composer 2 feel and “preferred model for frontend design work… at this speed” in the Frontend design preference—suggesting Cursor is winning some workflows where low-latency iteration matters more than raw benchmark deltas.
⚙️ Inference/serving performance: vLLM MRv2, KV-cache compression, and ultra-low latency UX
Systems posts centered on reducing CPU/GPU sync and KV-cache cost: vLLM’s new execution core, Google’s TurboQuant KV-cache compression claims, and editor-grade latency targets. Excludes on-device storage mounts (dev tools).
Google TurboQuant claims 6× KV-cache memory cuts and up to 8× faster attention
TurboQuant (Google Research): Google published TurboQuant, a KV-cache-focused quantization approach that claims ≥6× KV memory reduction and up to 8× faster attention scoring at 4-bit on H100, with “zero accuracy loss” framing via a two-stage scheme (PolarQuant + QJL) described in the TurboQuant breakdown and the underlying Google blog post.

A concrete detail that matters for serving teams is the emphasis on avoiding hidden overhead (extra per-block constants/metadata), since KV-cache is often bandwidth-bound in long-context workloads, as called out in the TurboQuant breakdown.
vLLM ships Model Runner V2: GPU-native input prep and async-first execution core
vLLM (vLLM project): vLLM introduced Model Runner V2 (MRV2), a ground-up rewrite of the execution core aimed at higher throughput and better speculative decoding behavior; it moves more prep onto the GPU, goes “async-first” with less CPU↔GPU synchronization, and adds Triton-native components, while keeping the external API unchanged per the MRV2 announcement and the deeper write-up in the MRV2 blog post.
• How to try it: it’s opt-in behind an env flag—export VLLM_USE_V2_MODEL_RUNNER=1—as shown in the MRV2 announcement.
• What else is bundled in the 2026 roadmap: the team also surfaced supporting work like KV/memory allocation and prefill disaggregation improvements in their GTC recap, which frames MRV2 as part of a broader “GPU-first” serving architecture rather than a one-off patch.
Zed’s edit prediction runs in ~200ms via Baseten-hosted Zeta
Zed (Zed + Baseten): Zed highlighted an Edit Prediction loop where AI code completions appear in about 200ms, with the Zeta model running on Baseten according to the Latency demo and echoed in Baseten’s positioning around “inference has to be invisible” in the Inference feel framing.

This is one of the clearer “latency as UX” datapoints in editor-integrated inference: the demo shows completions arriving fast enough to feel like local tooling rather than a chat roundtrip, as visible in the Latency demo.
Data center power and cooling constraints show up as an inference scaling ceiling
Serving capacity constraints: a recurring infra signal is that scaling models is increasingly bounded by electricity, heat, and cooling, not just GPUs; one widely shared claim is data centers already consuming ~10% of US electricity, with new builds hitting ~400MW scale (and sometimes discussed in GW terms), alongside water-cooling for chips dissipating ~2kW each, per the Datacenter power note.

This frames long-context and high-throughput inference as a physical-systems problem (site power delivery, cooling loops, and time-to-build), beyond model/kernel optimizations, as described in the Datacenter power note.
🧭 Workflow patterns: memory compaction, “you still must read code,” and autonomy ladders
Practitioner guidance focused on how to keep agents effective over time: periodic memory extraction/compaction, understanding-first discipline, and staged autonomy (draft → guarded retrieval → supervised actions). Excludes specific product releases covered elsewhere.
Delegation ceiling: you can outsource code, not understanding
Understanding-first discipline: Multiple posts repeat the same constraint for agent-driven development: you can delegate writing and searching, but you still have to read and understand the code to know what you’re shipping and where you can go next, as stated in the Read and understand code and reinforced in the Cant outsource understanding.
In practice this frames “review” as comprehension (architecture + invariants), not line-by-line nitpicking—especially as agents increase output volume.
HBR autonomy ladder: treat agents like employees with roles, limits, and audits
Agent rollout pattern: A Harvard Business Review piece argues that the core risk is “bad actions,” so production agents need a job description, limits, and a manager; it highlights distinct requirements like agent identity + permissions, trusted data sources, hard rule checks between a model and transactions, and full audit trails, as summarized in the Autonomy ladder summary and expanded in the HBR article.
This frames safe deployment as staged autonomy (drafts → guarded retrieval → supervised actions → narrow bounded autonomy) rather than a binary “agent on/off” switch.
Teams are reporting worse production code from “heavily vibe-coded” work
Code quality signal: A concrete failure mode is circulating: someone inherits a “heavily vibe-coded” React area described as “the worst…in the last 10y,” used to argue that teams are seeing broad code-quality degradation and only catching it late, per the Vibe-coded React warning.
The actionable takeaway is organizational, not tooling: if agent output is allowed to bypass normal design/testing pressure, the cleanup arrives later as operational cost rather than PR friction.
Claude Code /memory “Auto-dream” rumor points to background memory compaction
Claude Code (Anthropic): A /memory setting called Auto-dream is being spotted as an unreleased toggle; the reported behavior is a background subagent that periodically reviews recent sessions, consolidates learnings, updates MEMORY.md, and prunes/reorganizes stale detail into separate files, per the Auto-dream menu leak and earlier chatter in the Reddit feature rumor.
This is a concrete “memory hygiene” pattern (index file + topic shards) aimed at keeping project memory short and durable, instead of growing a single notes blob.
Cursor “Continual Learning” plugin turns chat history into AGENTS.md memory
Cursor (Plugin workflow): A new pattern is getting packaged as a plugin: every N prompts, a subagent reviews conversation history, extracts durable facts/preferences, and writes them into an AGENTS.md file that the agent can reuse later, as described in the Plugin behavior summary and detailed in the Plugin page.
This is a practical middle ground between ad-hoc summarization and full vector-memory: it produces an editable, repo-local artifact that can be code-reviewed and versioned.
MCP vs CLI debate gets reframed as “computer vs no-computer”
Interface debate: The MCP vs shell argument is being reframed as whether you give the agent a full computer (Turing-complete bash) or a constrained API surface; the thread emphasizes that the security posture differs depending on whether the agent co-resides on your machine vs runs isolated, per the Computer vs no computer argument.
This pushes teams toward an explicit design choice: larger action space increases capability, while narrower connectors reduce blast radius when prompts or inputs are adversarial.
Agent code-audit prompt: find hard-coded constants and unfinished “TODO/will” paths
Repo hygiene pattern: A reusable agent prompt pattern is circulating: first force the agent to read AGENTS.md and README.md and map architecture; then sweep the entire repo for hard-coded constants that should be dynamic plus “TODO/will/would” comments as unfinished logic, as written in the Agent coding life hack.
The follow-on prompt asks the agent to fix everything while maintaining a granular TODO list (or converting the findings into dependency-structured tasks), turning “agent review” into a structured backlog generator.
Reliability is a systems property: handoffs and escalation are the missing primitives
High-reliability pattern: A recurring point from high-reliability orgs is being applied to agents: reliability comes from the system (handoffs, escalation, and when to pull in humans), and current agentic tooling is often weaker at these coordination edges than the models themselves, per the Reliability is systems property.
This fits cleanly with the “autonomy ladder” framing: the hard engineering work is designing the supervision and transfer points, not only improving single-agent capability.
🧰 Builder utilities: hf-mount, sandboxed local agents, and agent-friendly storage interfaces
Developer tooling highlights included filesystem-shaped primitives (mount remote assets as local FS) and local sandbox orchestration for coding agents. Excludes MCP servers (separate category).
hf-mount turns Hugging Face Hub assets into a local filesystem
hf-mount (Hugging Face): Hugging Face introduced hf-mount, a CLI that mounts Hub assets as a local filesystem—positioned as a way to use remote storage “100x bigger than your local disk,” with read-write mounts for Storage Buckets and read-only mounts for models/datasets, per the launch blurb in hf-mount announcement and the implementation notes in mount semantics.
• Why it matters for agent-heavy workflows: it turns “agent storage” into plain file ops (read/write/ls) so existing tools can treat Hub-hosted state like local state, as described in hf-mount announcement.
LiteParse benchmarks a fast, non-VLM document parser for agent context
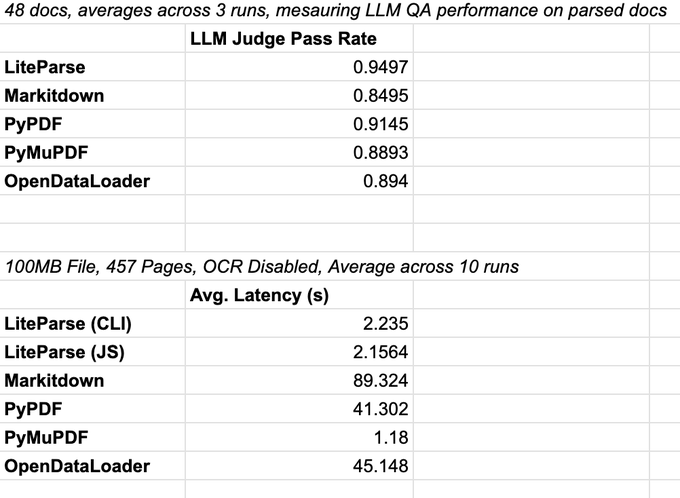
LiteParse (LlamaIndex): following up on earlier URL/stream parsing work URL parsing, LlamaIndex is now pushing LiteParse as a fast, non-VLM parser that outputs an interpretable spatial representation and supports a two-step “fast parse + screenshot deep-dive” workflow, with a benchmark claiming LLM judge pass rate 0.9497 (vs 0.8495 for Markitdown) and CLI latency around 2.235s on a 457-page file (vs 89.324s Markitdown), as shown in LiteParse benchmark.
• Agent-builder framing: LiteParse is being positioned as “highest quality context to AI agents” without using a vision model, while still enabling targeted page-level screenshot inspection, per LiteParse benchmark.
• Concrete downstream use: a compliance-reporting example pairs extraction/classification with agent orchestration, citing LiteParse/LlamaParse as the ingestion layer in compliance workflow screenshot.
Sandcastle proposes offline Docker sandboxes for coding agents with git patch-back
Sandcastle (mattpocockuk): Sandcastle is a TypeScript tool-in-progress for orchestrating locally sandboxed coding agents inside Docker; the design goal is “Docker Desktop as the only dependency,” 100% offline, and “no GitHub involved, only git,” with commits produced in the sandbox then patched back onto the host, as outlined in Sandcastle overview and reiterated in design constraints.
• Workflow implication: it’s aiming at a safer default execution model for agentic coding (run tools in an isolated container, then apply deltas), without tying the workflow to any specific model vendor, per Sandcastle overview.
Virtual filesystem interfaces as an agent-friendly storage primitive
Virtual filesystem pattern: a recurring agent ergonomics idea is to map storage backends (S3/Notion/Box/custom) onto filesystem operations—read/write/ls—so agents keep working in their “fs-ops” comfort zone while avoiding bulk data copying, as argued in virtual filesystem pattern.
• Why teams care: it standardizes “where state lives” behind one interface (including memory/scratchpads between agents) and reduces custom connector surface area, per the rationale in virtual filesystem pattern.
🏢 OpenAI product strategy: Sora shutdown and compute reallocation toward next frontier model
Multiple reports and reactions describe OpenAI discontinuing Sora (app + API) and shifting resources toward a forthcoming frontier LLM (“Spud”) and broader ‘agent’ tooling focus. This is primarily about compute allocation and product consolidation, not media workflows.
Reports say OpenAI is shutting down Sora to reallocate compute to “Spud”
OpenAI product focus shift: Coverage and internal-report summaries say OpenAI is discontinuing Sora as a consumer app and as a developer API—and also dropping plans to support video inside ChatGPT—in order to free up compute for its next major LLM (codename “Spud”), which leadership describes as arriving in “a few weeks,” according to the WSJ summary and the Compute reallocation excerpt.
• Compute rationale: The same thread claims Sora was viewed internally as a drag on scarce GPU resources during heightened model competition, per the Compute reallocation excerpt and the Side quests framing.
• Release expectation signal: Multiple posts repeat the “very strong model” / “accelerate the economy” language around Spud, as paraphrased in the Few weeks claim and the AGI Deployment excerpt.
OpenAI posts a shutdown notice for the Sora app, with timelines TBD
Sora (OpenAI): The official Sora account says it’s “saying goodbye” to the Sora app and acknowledges the news is disappointing, while promising more details soon—specifically timelines for the app and API plus how users can preserve their work, as shown in the Shutdown screenshot and reiterated in the Edited shutdown message.
The operationally relevant detail for teams is that the announcement is explicit about forthcoming migration/preservation guidance, but does not yet specify dates or data-export guarantees.
OpenAI reportedly renames its product org to “AGI Deployment” amid leadership reshuffle
OpenAI org structure: A report recap claims Sam Altman has stepped back from direct control of safety and security orgs—moving safety under CRO Mark Chen and security under President Greg Brockman—while OpenAI renames its product org to “AGI Deployment,” as quoted in the Org changes recap and highlighted by the AGI Deployment excerpt.
• What Altman is doing instead: The same reporting says Altman is focusing on capital raising, semiconductor supply chains, and building datacenters “at unprecedented scale,” per the Org changes recap and the Spud milestone recap.
Sora research is said to pivot to world models aimed at robotics
Sora research (OpenAI): Reporting snippets claim Sora’s research team is being redirected from consumer video productization toward “systems that deeply understand the world by learning to simulate arbitrary environments,” with an emphasis on longer-term world simulation for robotics, as shown in the World-model excerpt and echoed in the WSJ summary.
This frames Sora less as a sunset of video R&D and more as a rebrand/repurposing of the underlying work toward world modeling.
Sora postmortems focus on retention collapse and the creator power law
Sora adoption dynamics: A long creator-side post argues Sora usage “collapsed to zero” for many users after the initial novelty, and that the economics are rough because content creation is power-law distributed—“95%+ of users just want to passively consume”—making churny subscription monetization unattractive for a compute-heavy product, according to the Creator postmortem.

• What creators wanted: The same post suggests high-output creators gravitate toward more complex, power-user workflows rather than a constrained text box and short clips, as described in the Creator postmortem.
A public request asks OpenAI to open-source Sora as it winds down
Open-source ask (Sora): Hugging Face CEO Clément Delangue publicly asks whether OpenAI would open-source Sora as the app is shut down, framing it as a meaningful contribution to the field and a way to preserve the work of the team, per the Open-source request.
No OpenAI response appears in today’s tweet set, and the request does not cite licensing, weights, or a specific artifact (model, dataset, tooling) that would be released.
🖌️ AI-first design & prototyping tools (non-Figma): editable canvases, site-to-layers, and wireframe loops
A wave of design/prototyping products aimed at builders: importing live sites into editable layers, agent-driven layout editing, and “design agent with taste” pitches. Excludes Figma MCP specifics (covered separately).
Google demos a Flash-Lite browser that generates each web page in real time
Gemini 3.1 Flash-Lite (Google DeepMind): Google demoed a browser concept where pages are generated on-the-fly as you click and navigate—treating HTML/CSS as a streaming model output rather than a prebuilt site, as shown in the DeepMind demo.

A second clip shows the same idea applied to “imagined” historical UIs (e.g., “facebook in 2004”), per the Alt browsing demo, which frames this more as a prototyping surface than a faithful web renderer.
Moda launches a URL-to-brand design agent that outputs editable slides and assets
Moda (Moda): Moda launched a design platform that imports brand identity from a website URL and generates fully editable slides, social posts, and one-pagers on a canvas—positioned explicitly as a “design agent with taste,” per the Funding tweet and the Product walkthrough.

• Brand in, slides out: The product page describes URL-based brand import and export targets including Google Slides and PowerPoint, as outlined on the Product page.
• Builder signal: LangChain notes it’s built with “Deep Agents” and uses LangSmith for observability, according to the Stack note.
Paper Snapshot imports a live website into editable layers (no screenshots)
Paper Snapshot (Paper): Paper added a “snapshot” flow that pulls a live website into the editor as editable layers, aiming to preserve structure by using the site’s real HTML/CSS instead of a static screenshot, as shown in the Feature announcement.

The follow-up post suggests it’s already usable as a starting point for rebuilding/iterating on existing marketing pages, per the Try it prompt.
Agentation adds Layout Mode for on-page wireframing and agent feedback loops
Layout Mode (Agentation): Agentation shipped a new mode for directly rearranging and resizing elements on the page, adding components, and generating structured design feedback intended to feed downstream agents, as demonstrated in the Layout mode launch.

The product write-up describes the output as structured placement/annotation data (coordinates, sizes, labels) that can be passed to an agent workflow, as detailed in the Feature write-up.
💼 Funding & org moves: OpenAI Foundation spend, SoftBank leverage, and new AI labs
Business/organization updates with operational relevance: OpenAI Foundation expansion and spending commitment, financing pressure around big AI bets, and new well-funded labs/hardware efforts. Excludes OpenAI’s Sora/Spud strategy (separate category).
OpenAI Foundation commits $1B in 12 months and formalizes an “AI Resilience” org line
OpenAI Foundation (OpenAI): The Foundation published a new mission/operations update that includes a commitment to spend at least $1B over the next year, positioning it as a society-wide effort around AI benefits and risks, as outlined in the Foundation spend pledge and detailed in the Foundation update. It also sets named leadership over “AI Resilience,” with Wojciech Zaremba moving into that role, alongside new hires/transitions for operations and finance, as listed in the Foundation spend pledge and summarized in the Update recap.
• Leadership and org design: Zaremba transitions to Head of AI Resilience, with Jacob Trefethen named Head of life sciences and curing diseases in the same update—plus shifts for civil society/philanthropy and additions including a CFO and director of operations, according to the Foundation spend pledge and Exec team summary.
The update is high-signal for analysts because it turns “safety” into a budgeted program and a staffed org line (resilience) rather than a generic principle, per the Foundation spend pledge and Foundation update.
Figure founder Brett Adcock launches Hark, an AI lab targeting “personal intelligence” with custom devices
Hark (Brett Adcock): After ~8 months in stealth, Adcock announced a new AI lab called Hark aimed at a proactive multimodal “personal intelligence” system that pairs foundation models with bespoke hardware, as described in the Hark launch description and expanded in the Team and compute claims.

• Capital, team, and compute: The announcement claims $100M of Adcock’s own funding, 45+ engineers/designers, and thousands of B200 GPUs expected online by April, with a first model targeted for summer, according to the Team and compute claims.
• Product thesis: The pitch frames the device layer as the “interface” for a system with highly personalized memory and multimodal inputs/outputs—speech, text, vision—per the Interface plus memory framing and Hark launch description.
The immediate analyst signal is another well-funded entrant choosing an end-to-end stack (models plus hardware) for consumer-facing agent experiences, with unusually explicit near-term GPU sourcing claims in the Team and compute claims.
SoftBank reportedly pushes its own leverage cap to fund a new ~$30B OpenAI bet
SoftBank financing (FT): A Financial Times report says SoftBank is pushing up against its self-imposed 25% loan-to-value ceiling to finance a reported ~$30B OpenAI investment, increasing borrowing against assets whose values are hard to mark in real time, as described in the FT leverage summary.
For AI leaders tracking capital availability, the key operational point is that this is debt capacity being used to underwrite AI bets (and, indirectly, compute buildout and model rollouts), with the risk profile tied to private-asset valuation and potential forced de-leveraging if marks move, per the FT leverage summary.
📏 Benchmarks & measurement: new reasoning tests, SWE evals, and “review doesn’t scale” claims
Eval/benchmark chatter spans interactive reasoning (ARC-AGI-3), new SWE benchmarks, and ongoing concerns that “AI writes, humans review” breaks down at scale. Excludes pure research-paper summaries (separate category).
ARC-AGI-3 will test interactive reasoning across 1,000+ levels and 150+ environments
ARC-AGI-3 (ARC Prize): ARC-AGI-3 is slated to launch March 25, 2026 as an interactive reasoning benchmark—1,000+ levels across 150+ environments that require exploration, learning, planning, and rule discovery with no instructions, per the Launch announcement.
The same post anchors expected “ceiling” context by citing prior best-of results—Gemini 3.1 Pro at 98% on ARC-AGI-1 and Gemini 3 Deep Think at 84.6% on ARC-AGI-2—as background for how hard ARC-AGI-3 intends to be, as stated in the Launch announcement.
Cognition and Mercor announce APEX-SWE for realistic SWE evaluation
APEX-SWE (Cognition x Mercor): Cognition says it collaborated with Mercor on APEX-SWE, a new benchmark aimed at evaluating models on “realistic software engineering tasks,” as announced in the Benchmark announcement.
The tweet doesn’t include task format, scoring methodology, or a public harness link yet, so comparability to SWE-bench-style setups is still unclear based on the Benchmark announcement.
LisanBench correlation with ARC-AGI-1/2 fuels debate about benchmark “farming”
LisanBench (benchmark discourse): New correlation analysis between LisanBench and ARC-AGI-1/2 is being used as evidence in a “benchmark farming” argument—claiming Sonnet/Opus 4.6 may be over-optimized for LisanBench—based on correlations reported as 0.8741 (ARC-AGI-1) and 0.8244 (ARC-AGI-2) in the Correlation stats.
The same post flags uncertainty about the conclusion—“maybe ARC-AGI-1 is also just a cooked benchmark,” while noting METR and ARC-AGI-2 don’t show as drastic an effect—per the Correlation stats.
LisanBench vs METR time horizons shows a very high correlation in a small sample
METR horizons vs LisanBench (measurement chatter): A small-sample comparison claims a Spearman ρ = 0.965 between LisanBench average score and METR “p50 horizon,” with caveats that sample sizes are small and METR used high-compute settings for some GPT models, according to the Correlation plot.
A follow-up corrects an axis labeling mistake—“y-axis should be minutes”—and also notes uncertainty about the reasoning budget used for Opus 4.5/4.6, as stated in the Axis correction.
PrinzBench adds GPT-5.4 Pro (Extended) and reports a new 79/99 top score
PrinzBench (community benchmark): GPT-5.4 Pro (Extended) was added to PrinzBench and reportedly scored 79/99, beating GPT-5.4 (xhigh) by 10 points, according to the Benchmark update.
The benchmark author notes they “had to throw out a lot of questions” that turned out not to be difficult for models, implying rapid saturation pressure on the task set, as stated in the Benchmark construction note.
LisanBench vs AidanBench correlation shared, with a claimed “Gemini bias” effect
AidanBench vs LisanBench (measurement chatter): Another correlation plot reports Spearman ρ = 0.777 (n = 35) between LisanBench average score and AidanBench total, with the author attributing lower correlation to a previously identified “Gemini bias,” per the Correlation chart.
This is being framed as validation of benchmark-specific model effects rather than a clean “single capability axis,” as described in the Correlation chart.
📚 Docs-for-agents devex: content negotiation, llms.txt skepticism, and discoverability
A smaller but concrete devex thread: teams are iterating on agent-facing doc surfaces (content negotiation, nav surfacing) while calling out weak defaults like llms.txt. Excludes repo-local steering files (covered under workflows).
Sentry MCP minisite adds content negotiation for agent-friendly docs
Sentry MCP (Sentry): The Sentry MCP minisite now serves an agent-optimized experience via HTTP content negotiation, with markdown returned when clients request it—a concrete move away from relying on llms.txt, which the team calls “useless” in this context, as noted in the [content negotiation change](t:737|content negotiation change) and the linked [agent-docs rationale](link:1037:0|agent docs note).
• Practical devex change: by varying responses on the Accept header, agent clients can fetch concise setup and usage info without scraping the full human-oriented site, as implied by the [implementation references](t:1037|implementation links).
Sentry adds an Integrations nav section to make MCP and CLI discoverable
Sentry (Sentry): A discoverability fix landed after the question “how do people know MCP exists?”—Sentry is adding an Integrations section in org settings that surfaces an MCP & CLI page (plus integrations pages), as shown in the [discoverability discussion](t:928|MCP discoverability note) and the corresponding [UI/navigation PR](link:928:0|navigation PR).
• Why it matters: it turns MCP setup from “read the docs somewhere” into a first-class in-product entry point, which tends to be the difference between agents getting used and agents being forgotten.
🔎 Retrieval for agents: late interaction, hybrid grep, and “deep research is retrieval” framing
Retrieval remained a core builder theme: late-interaction (ColBERT-style) momentum, arguments that deep research bottlenecks on evidence gathering, and codebase file-search stack discussions. Excludes document parsing tools (in dev tools).
BrowseComp-Plus: deep research bottlenecks on getting evidence into context
BrowseComp-Plus (Hornet): A new write-up argues BrowseComp-Plus is “a deep research benchmark” on paper but a retrieval benchmark in disguise, because the hardest step is usually getting the right evidence into context—not reasoning after it’s retrieved, as stated in Retrieval problem framing and expanded in the Blog post.
This framing matters for eval design: if toolchains change retrieval quality/latency, they can swing “agent reasoning” outcomes without any model changes.
ColBERT fine-tuning story: MaxSim updates fewer tokens, making training less noisy
ColBERT training dynamics: A concrete argument for why ColBERT-style late interaction can be comparatively friendly to fine-tuning is that MaxSim selects a small set of token matches to update, keeping other document-token representations stable—so updates are more “surgical,” as explained in Fine-tuning intuition alongside the broader dual-encoder training tradeoff discussed in the MLR paper.
Coding-agent retrieval pattern: ColBERT file search paired with an RLM router
ColBERT file search for coding agents: A concrete workflow claim is that swapping file search to a late-interaction model changes agent outcomes enough that “if your coding agent is not an RLM with ColBERT file search, you’re ngmi,” as stated in File search results claim, with a follow-up push for an RLM+ColBERT+ColGrep stack in Collab suggestion.
This is less about “better reasoning” and more about moving higher-signal code snippets into context earlier, which shortens agent iteration loops.
ColGrep: local regex speed with late-interaction semantics for agent workflows
ColGrep (hybrid retrieval): The ColGrep idea is presented as a pragmatic middle layer for coding agents—keep regex as the backbone (agent-friendly, precise), but add semantic matching via late interaction; the case stresses that local indexes avoid privacy and freshness issues, as argued in Local index direction and detailed with agent-search rationale in ColGrep for agents.
This also doubles as an “MCP vs CLI” adjacent point: retrieval quality often comes down to what evidence you can fetch cheaply and locally, not whether the agent can execute arbitrary tools.
Late-interaction retrieval argues the real enemy is single-vector search, not grep
Late interaction retrieval: The “grep-is-all-you-need” backlash is framed as a category error—people equate “neural search” with single-vector embedding retrieval, then conclude it’s bad; the counterclaim is that late interaction (ColBERT-style) has been winning for years, including via the “late interaction can’t stop winning” quote highlighted in Grep vs neural search take.
The practical implication is that agent retrieval stacks should treat “semantic search” as multi-vector by default when the task is iterative and keyword-ish (code search, investigative retrieval), rather than trying to replace grep outright.
PyLate lands in MTEB, and late-interaction models keep taking top slots
PyLate (MTEB integration): PyLate is reported as merged into MTEB so late-interaction models can be run and compared on the “official” benchmark harness and leaderboard surfaces, as announced in PyLate merged to MTEB.
• Code retrieval deltas: One claim highlighted is a ~150M LateOn-Code model beating “Gemini embedding” on a Borda-style metric, per MTEB code comparison.
• New small-model entry: ColBERT-Zero is described as taking the top spot under 150M parameters, according to ColBERT-Zero note.
Scaled-up multimodal late interaction looks strong; benchmark saturation becomes the worry
Multimodal late interaction: As late interaction is scaled up into multimodal settings, the discourse shifts from “does it work?” to “how fast will benchmarks saturate?”, with that concern stated directly in Multimodal late interaction note.
A separate thread points to incremental gains from “a newer late interaction model” adding points on top of prior results in Leaderboard improvement note, reinforcing that retrieval benches may need faster refresh cycles to stay discriminative.
Sparse + late interaction: a proposed hybrid to “solve search” efficiently
Sparse ColBERT hybrid: There’s an explicit request for a sparsified ColBERT—keeping the strengths of sparse/lexical retrieval while retaining late-interaction matching—positioned as a path to more efficient, agent-ready search, as argued in Sparsified ColBERT ask.
Single-vector retrievers: strong on known benchmarks, weak on the next one
Retrieval eval signal: A meme crystallizes a recurring critique of single-vector embedding retrieval—performance can look dominant on benchmarks that were public pre-training, but degrade quickly on newly released tasks, as shown in Single-vector benchmark meme.
👥 Labor & org shifts: hiring funnels get noisy, referrals win, and agent fatigue shows up
Career and org process discourse tied to AI: inbound applications getting overwhelmed by AI-assisted applying, shifts toward referrals/recruiters, and general frustration with constant prediction discourse. Excludes pure politics and non-AI culture.
AI mass-apply tools are breaking inbound hiring funnels
Hiring funnels: More engineers are arguing that inbound applications are collapsing under AI-assisted mass applying—volume up, signal down—so companies lean harder on referrals and recruiter sourcing, as described in inbound apps thesis and reinforced by the “closed my job board” postmortem in job board shutdown note.
The operational implication is that “apply on the website” stops being a meaningful channel once it can be spammed at near-zero cost, and screening effort shifts from evaluating candidates to filtering noise.
Vercel says internal tools are shifting from SaaS UIs to generated apps and agent interfaces
Internal tooling shift (Vercel): Vercel’s CEO says “almost every SaaS app inside Vercel” has been replaced by a generated app or agent interface deployed on Vercel—covering support, sales, marketing, PM, HR, analytics, design/video workflows—while systems of record (Salesforce/Snowflake) remain underneath, as described in internal replacement anecdote.
The core org-level change described is that teams stop fighting legacy ontologies/UI constraints (e.g., Salesforce) and instead generate a fit-for-purpose surface—or skip UI entirely and “ask an agent,” with “UI is a function of data” reframed as “that function is increasingly the LLM,” per internal replacement anecdote.
Warm referrals can replace inbound applications for senior engineers
Job-search workflow: One concrete pattern: an engineer on the market reportedly sent zero applications and ignored inbound recruiter messages, yet still got three offers via former colleagues making “warmest referrals,” as detailed in anonymous referral anecdote.
The post also underlines that public GitHub activity isn’t a reliable proxy for employability (the example profile shows 0 contributions for multiple years), which matters as hiring funnels get noisier and heuristics get weaker.
Developer prediction fatigue is showing up as a culture signal
Org discourse: A blunt sentiment thread captures growing fatigue with the constant stream of AI (and tech) “what the future will be” predictions—less debate about any specific claim, more burnout with the cadence and certainty, as put in anti-prediction rant.
This shows up as an attention-allocation issue inside teams too: narrative churn competes with shipping, measurement, and incident response.
📄 Research drops: world models, meta-learning from feedback, and AI-for-science case studies
Research highlights include simpler/stable world-model training recipes (JEPA variants), models learning from conversational feedback, and case-study style AI-assisted discovery reports. Excludes benchmark announcements (separate category).
LeWorldModel proposes a minimal JEPA recipe that trains stably from pixels
LeWorldModel (JEPA): A new paper proposes an end-to-end world model from raw pixels that avoids the classic JEPA “collapse” failure mode using only two objectives—next-embedding prediction plus a latent-spread regularizer—rather than a pile of stop-grad / EMA-target / multi-loss tricks, as summarized in the Paper thread description.
• What’s concrete: The authors claim a small setup (15M parameters) that trains “in a few hours” on one GPU, while enabling planning up to 48× faster than foundation-model-based world models, per the Paper thread.
• Why engineers care: It’s a recipe-level contribution: if the “two-loss” stability holds across domains, it’s a simpler base primitive for action-prediction loops than today’s more brittle world-model training stacks, as laid out in the Paper thread.
DeepMind trains LLMs to learn from conversational feedback and ask better questions
Social meta-learning (Google DeepMind): A paper proposes training LLMs in simulated teacher–student dialogues so they incorporate corrective feedback mid-conversation (instead of treating turns as independent), and adds “Q-priming” to increase clarification-seeking on underspecified tasks, per the Paper summary.
• Training setup claim: The thread contrasts offline filtering vs online RL-style training and says the online variant generalizes from 4-turn training dialogues to 10-turn conversations, as described in the Paper summary.
• Behavior shift: “Q-priming” is reported to make models 5× more likely to ask clarifying questions rather than guessing early, according to the Paper summary.
V-JEPA 2.1 shifts JEPA training toward dense, action-relevant features
V-JEPA 2.1 (Meta FAIR): Meta researchers describe a JEPA-style video learner tuned to produce dense, spatially grounded representations (where objects are and how they move) rather than only global scene semantics, with the intent of making the representation more useful for control and robotics, per the Paper summary.
• Key change: A “dense predictive” objective where visible tokens also contribute to loss, plus “deep self-supervision” across intermediate layers, according to the Paper summary.
• Reported scale + effect: The thread cites training on 1M+ hours of video and notes about a +20% gain in robotic grasp success versus the earlier system, as stated in the Paper summary.
Gemini scientific case studies highlight repeatable human-in-the-loop techniques
Gemini for research (case studies): A Google-authored paper compiles examples where Gemini-based models contributed to progress on open research problems when used as a guided collaborator—decompose, challenge, ask for counterexamples, and validate with code—rather than as a one-shot oracle, per the Paper summary.
• Repeated technique signal: The write-up stresses iterative checking and external verification (e.g., code-backed testing of conjectures) as the difference between “helpful” and “misleading,” as described in the Paper summary.
• Scope note: The thread frames it as spanning multiple domains (theory CS, economics, optimization, physics) with “many case studies,” with the citation visible in the Paper summary.
🎬 Generative media toolchain: video extensions, V2A models, and creator pipelines
Generative media updates beyond Sora: new video tooling endpoints, open audio-video generation papers/models, and creator workflow sharing. Excludes Sora shutdown (covered under OpenAI strategy).
daVinci-MagiHuman releases as an open-source single-stream audio-video model
daVinci-MagiHuman (SII-GAIR): A new open-source audio-video foundation model was released with a single-stream Transformer architecture (text+audio+video in one sequence, self-attention only), per the paper and model links and the Paper page.

• What’s concrete in the release: the model is described as 15B parameters, multilingual (6 languages), and optimized for fast generation via distillation + latent-space super-resolution, according to the Model card.
• Why it stands out: the paper positions the architectural simplification (single stream; no cross-attention) as the core speed/engineering lever, per the paper and model links.
fal adds Grok Imagine Reference-to-Video and Extend Video APIs
Grok Imagine video (fal): fal shipped two new endpoints—Reference-to-Video (multiple reference images for consistency) and Extend Video (continue a clip)—as shown in the launch post.

• What engineers get: an API surface for character/scene consistency via reference sets plus a separate continuation primitive, per the launch post.
• Why it matters: it’s another “hosted plumbing” layer where teams can standardize around a single vendor surface even if the underlying model/provider changes later (useful for eval harnessing and cost routing).
Replicate ships Grok Imagine video extension + reference-to-video with examples
Grok Imagine video (Replicate): Replicate added Extend Video and Reference-to-Video for Grok Imagine, with examples emphasizing long-form shot continuation, multi-image scene building (up to 7 images), and promptable audio/scene transitions, per the Replicate announcement and the audio transition example.


• Interface details: the examples show prompts aimed at camera direction (“pulls back extremely far…”) and dialogue/audio transitions (“continue…in French”), as demonstrated in the camera direction example and audio transition example.
• Scene construction: the reference-to-video flow highlights assembling a scene from multiple stills, as shown in the Seven-image scene build.
OpenRouter lists free experimental access to several frontier video models
Video generation APIs (OpenRouter): OpenRouter is shown offering free, experimental access to multiple video models—ByteDance Seedance 1.5 Pro, OpenAI Sora 2 Pro, and Google Veo 3.1—according to the models list screenshot.
• Practical implication: the listing suggests a low-friction evaluation path for teams that want to benchmark prompts/workflows across providers without first committing to per-model billing setup, per the models list screenshot.
Uni-1 preference Elo charts put an autoregressive image model at #1
Uni-1 (Luma Labs): Following up on Uni-1 launch (unified generate/edit/reference image model), new preference charts circulating today claim Uni-1 takes the top spot across Overall, Style & Editing, and Reference-Based Generation, as shown in the Elo chart post.
• Architecture framing: separate discussion highlights Uni-1 as a decoder-only autoregressive transformer that generates images token-by-token (LLM-style) rather than diffusion, per the architecture description and its

.
• Evidence quality: the tweets provide category Elo bars and competitor names, but no single canonical eval artifact beyond the chart screenshot in the Elo chart post.
A Freepik Spaces music-video pipeline bundles prompts across multiple gen models
Creator workflow (Freepik Spaces): A shared workflow packages 25+ prompts plus multiple image-to-video/audio-to-video steps into a repeatable “music video” pipeline inside Freepik Spaces, according to the workflow teaser and the workflow walkthrough.

• Toolchain composition: the thread describes generating grids (Nano Banana), doing lipsync (OmniHuman/Veed Fabric), then animating shots (Kling node), with the “Space” shared for reuse via the shared Space link and the Space invite.
• Why it maps to engineering: it’s a concrete example of turning a multi-model, multi-step creative process into a portable artifact (prompt pack + node graph), per the workflow walkthrough.
CapCut rolls out Dreamina Seedance 2.0 to emerging creator markets first
Seedance 2.0 (CapCut/Dreamina): In a continuation of Seedance rollout (distribution via CapCut/Dreamina), new rollout detail says Dreamina Seedance 2.0 is landing first in the Philippines, Indonesia, Thailand, and Brazil across mobile/desktop/web, per the rollout post.

• Operational detail: the post is explicit about geo sequencing and multi-surface availability rather than a single app launch, as stated in the rollout post.
ComfyUI schedules an LTX 2.3 deep dive across modalities
LTX 2.3 (ComfyUI): ComfyUI announced a live deep dive on LTX 2.3 to test text+image-to-video, first/last frame control, and audio-driven generation, per the stream announcement and the Stream link.
• Scope: the agenda explicitly calls out modality-by-modality testing rather than a single demo run, as described in the stream announcement.