OpenAI Responses API adds 10× warm containers – headcount targets ~8,000
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI shipped a Responses API infra update: agent tool workflows can reuse a warm container pool so skills/shell/code-interpreter containers start ~10× faster than cold spins; it’s an explicit attack on “tool-call tax” in iterative agent loops where startup latency dominates wall-clock, though OpenAI hasn’t published independent before/after traces or tail-latency breakdowns.
• OpenAI distribution/monetization: Reuters reports ads coming to ChatGPT Free and Go users in the U.S.; Codex is now usable from a free ChatGPT account; a screenshot shows Codex spawning 5 subagents (explorer/worker roles); another user reports Codex Windows threads disappearing after restart; Reuters/FT also peg OpenAI’s end‑2026 headcount target at ~8,000 and describe a plan to merge Codex deeper into the ChatGPT desktop app.
• Cursor: Composer 2.0 appears #2 on Vercel’s Next.js agent evals at 76% success; Cursor teases “Glass” as a more controllable agent UI surface.
• Commit provenance: Codex and OpenCode both reject auto self-attribution in Git commits; Ryan Greenblatt floats minimal AI-usage metadata as a measurement middle ground.
Net: agents are getting faster tool runtimes and broader consumer funnels; accountability gaps (attribution norms) and adversarial surfaces (e.g., indirect prompt injection cited at 14.8% at k=100 on Opus 4.6) remain only partially addressed.
Top links today
- Responses API container pool details
- BitVLA 1-bit VLA robotics paper
- Can AI agents agree paper
- LLM agents not faithful self-evolvers paper
- Reasoning reward model for agents paper
- Reasoning models for embeddings paper
- Theory of mind multi-agent evaluation paper
- Mixture-of-experts router coupling paper
- Reuters on OpenAI enterprise hiring push
- Goldman Sachs view on AI GDP impact
- FT chart on China model progress
- All-In episode with Terence Tao
Feature Spotlight
AI attribution in Git commits: credit, provenance, and accountability
Multiple builders push back on auto-crediting AI in commits: useful for measuring adoption, but seen as an obnoxious growth hack that shifts accountability. The outcome affects OSS norms, auditability, and enterprise policy.
High-volume debate on whether coding agents should automatically add themselves to commit metadata/authorship, balancing transparency for measurement vs developer consent and ownership. Excludes other tool updates (covered in their respective categories).
Jump to AI attribution in Git commits: credit, provenance, and accountability topicsTable of Contents
🧾 AI attribution in Git commits: credit, provenance, and accountability
High-volume debate on whether coding agents should automatically add themselves to commit metadata/authorship, balancing transparency for measurement vs developer consent and ownership. Excludes other tool updates (covered in their respective categories).
Codex opts out of automatic commit attribution to keep humans accountable
Codex (OpenAI): OpenAI’s Codex team says they intentionally avoid auto-adding Codex credit/attribution in Git commits—framing it as a human-ownership and accountability choice—even though it makes it harder to measure how widely Codex is used across public repos, as described in the commit attribution tradeoff.
Mollick argues auto-attribution is mostly marketing, not accountability
Attribution norms (commit provenance): Ethan Mollick argues AI systems shouldn’t auto-add themselves as credited/co-authored on GitHub; he frames it as primarily marketing that can undermine a user’s ability to choose their relationship to AI-assisted work, as stated in the attribution stance.
OpenCode removes AI self-credit in commits; disclosure stays user-controlled
OpenCode (thdxr): OpenCode says it previously had commit attribution but removed it; the rationale is that auto-credit feels like an “obnoxious” growth hack and the human should decide how/if to disclose AI usage—extending the analogy that it would be weird to see commit authors like “Dax + Neovim,” per the removal rationale.
A compromise proposal: lightweight AI-usage tags in commit messages
Commit provenance (measurement vs consent): Ryan Greenblatt suggests a middle ground where commits include minimal metadata indicating AI assistance (without making the AI a coauthor), to support diffusion/capability measurement work—he cites analysis needs like those of eval orgs as the motivation in the metadata proposal.
A poll asks whether Codex should add commit attribution like Claude
Codex attribution (community sentiment): swyx posts a poll asking whether Codex should add self-attribution to commits “like Claude does,” aiming to quantify developer preferences around consent vs traceability, as posed in the poll prompt.
🧰 OpenCode: harness workflow, UX iteration, and contributor funding
Day’s OpenCode-focused thread cluster: /review UX, AWS console flow, performance debugging, UI tweaks, and new sponsorship/payment rails. Excludes commit-attribution debate (covered in the feature).
OpenCode begins $1,000/month sponsorships for pi contributors
OpenCode (OpenCode): OpenCode says it has started sponsoring contributors to pi, showing multiple $1,000/month sponsorships in-product in the Sponsorship screenshot. This is direct OSS funding rather than credits. It’s concrete.
• Who’s covered: The screenshot lists at least four sponsored contributors at $1,000/month each, as shown in the Sponsorship screenshot.
• Community signal: A commenter frames it as “modern day patronage,” reinforcing this as an intentional product/community direction, per the Patronage comment.
OpenCode shares a CloudShell-first AWS workflow that picks up Bedrock auth
AWS console flow (OpenCode): OpenCode describes a CloudShell recipe—open CloudShell, run npx opencode-ai, inherit AWS auth and “pick up Bedrock models,” then drive AWS work via the agent, as laid out in the AWS console steps. It’s framed as a joke (“cause a sev1 incident”), but the underlying detail is a real bootstrap path for AWS-authenticated agent sessions.
OpenCode asks users to submit heap snapshots to debug memory issues
Debug workflow (OpenCode): To investigate reported memory issues, OpenCode asks affected users to open the command palette (Ctrl+P) and run “Write heap snapshot,” then upload it, as requested in the Heap snapshot request. This is a lightweight support loop. It’s actionable telemetry for a JS/Electron-style app.
OpenCode Go adds UPI Autopay billing in India
OpenCode Go (OpenCode): UPI Autopay is now live for OpenCode Go in India, priced at ₹900/month, as stated in the UPI autopay announcement (and echoed via retweets in the thread). Billing friction drops. That’s the whole point.
OpenCode pushes /review as a run-and-review alternative to GitHub UI hacks
/review (OpenCode): OpenCode’s maintainer argues that pushing code just to get LLM review via “awkward GitHub UI hacks” is a bad workflow, and points to /review as an alternative that can also run your code/tests while reviewing, per the Review workflow complaint. The point is fewer forced roundtrips through GitHub when you want execution-backed review.
OpenCode experiments with tighter UI layout by removing horizontal padding
UI layout (OpenCode): OpenCode’s maintainer is actively tweaking the UI—removing horizontal padding and asking whether it’s “better/worse,” per the Padding change question, then noting the lack of a clean before/after in a follow-up, per the Before after followup. File editing UX is still flagged as needing work, according to the File edits note.
OpenCode flags an upcoming “minimal mode” for high-risk console usage
Minimal mode (OpenCode): After sharing the AWS console flow, OpenCode notes that this is a good use case for an upcoming “minimal mode,” per the Minimal mode mention. No spec is given. It’s a directional signal that OpenCode expects UI/permissions constraints to matter more in complex admin consoles.
OpenCode reiterates an open-source, anti lock-in product stance
Product direction (OpenCode): OpenCode’s maintainer posts a straightforward statement of intent—hoping the future of building software “stays open source and free from lock-in,” and wanting to do more than hope, as written in the Open source stance. It’s positioning. It’s also a constraint on future monetization choices.
OpenCode nudges maintainers toward GitHub Sponsors for OSS funding
OSS funding channel (OpenCode): OpenCode’s maintainer publicly asks a maintainer to “turn on GitHub sponsors,” per the Sponsors request, and later frames the motivation as ensuring key OSS work can continue, per the Funding rationale reply. Another community member offers to share a list of OSS folks who “need the money more,” in the Offer of OSS list, reinforcing that OpenCode is trying to normalize maintainer funding as part of the ecosystem.
OpenCode asks users if they use the sidebar
UX telemetry prompt (OpenCode): OpenCode’s maintainer asks a direct product question—“do you use the opencode sidebar,” per the Sidebar usage question. It reads like a decision gate for UI complexity vs. focus.
🧩 Cursor Composer 2: eval momentum, UX surfaces, and model-choice debate
Continues yesterday’s Composer 2 storyline but with new signals: Next.js eval leaderboard placement and Cursor’s new “Glass” UI surface. Excludes provenance/transparency fallout details from prior day’s feature.
Cursor Composer 2 hits #2 on Vercel’s Next.js agent evals leaderboard
Next.js agent evals (Vercel): Following up on Composer launch—initial pricing/bench claims—Vercel’s public Next.js agent evaluations now show Cursor Composer 2.0 in 2nd place, with the eval page listing 76% success on the benchmark suite, as highlighted in the Leaderboard callout and detailed in the Evals dashboard.
The board is becoming a de facto reference for “agentic Next.js work” (migrations + codegen + execution), so this is a concrete datapoint for teams comparing IDE-native agents vs CLI agents rather than relying on generic coding leaderboards.
Cursor teases “Glass,” an agent UI focused on clarity and control
Glass (Cursor): Cursor published a first look at Glass, describing it as an early-but-“clearer now” interface for working with agents, per the Glass teaser and the Product page.
This is a UX surface story more than a model story: it signals Cursor is investing in “operator control” as a product dimension (how you steer, inspect, and recover), not only raw model quality.
Composer 2’s model-choice debate shifts to “rank vs real-world results”
Composer 2 (Cursor): A critique thread argues Composer 2 inherits hallucination issues from its Kimi K2.5 foundation, pointing at LMArena Code rankings where Kimi K2.5 is shown lower than alternatives (e.g., GLM-5, MiniMax M2.7), as laid out in the Ranking-based critique.
The tension is that the same week it’s being criticized for the base model choice, it’s also posting strong task-eval outcomes elsewhere—see the Next.js eval result—so “Arena rank” vs “workflow harness + targeted post-training” is becoming the argument.
A practical model-selection heuristic: “double-check behavior” across GPT‑5.4 and Opus 4.6
Model-selection heuristic: A practitioner report distinguishes GPT‑5.4 High vs Medium by “smart double-checks when needed,” and places Opus 4.6 closer to GPT‑5.4 Medium but with fewer required double-check cycles, per the Effort tier comparison.
This kind of heuristic shows up in Composer/Codex/Claude multi-model workflows because the cost isn’t only “best possible answer,” but how often a model forces you into an extra verification loop before you can merge.
Composer 2 is being framed as Kimi’s biggest distribution win
Kimi K2.5 (Moonshot): Independently of whether Cursor’s disclosure was handled well (covered earlier), some community framing is now straightforward: “Composer 2 was Kimi’s biggest PR win,” as stated in the PR win framing.
This sits alongside the measurable adoption signal that Composer 2 is placing highly on tool-specific evals like Next.js, per the Next.js leaderboard callout, which effectively turns Cursor into a downstream distribution channel for the base model vendor.
Builders ask for Composer 2 as an API for custom agent stacks
Composer 2 (Cursor): A recurring integration ask is surfacing: make Composer 2 available as an API endpoint (e.g., via OpenRouter) so people can call it from their own agent runtimes, as stated in the API availability request.
This is a distribution signal: Composer’s perceived value is increasingly “model + harness behavior,” and engineers want that packaged as a callable primitive, not only an IDE feature.
The “agent data flywheel” moat narrative gets mocked as tools leapfrog
Competitive dynamics: A meme-y but repeated ecosystem point: claims that one tool’s “data flywheel” makes it unbeatable keep getting invalidated by the next tool jump (Cursor → Claude Code → Codex → Composer 2), as summarized in the Flywheel skepticism post.
It’s not a benchmark, but it reflects a real planning constraint for engineering leaders: model/harness advantage windows appear short, and switching costs (workflows, prompts/skills, eval harnesses) are what teams actually feel.
🧠 OpenAI coding stack: Codex distribution + ChatGPT monetization shift
Codex availability/distribution signals plus a major ChatGPT business-model update in the U.S. Excludes Responses API infra mechanics (covered under agent-frameworks).
OpenAI to show ads to free and Go ChatGPT users in the US
ChatGPT (OpenAI): OpenAI says it will begin showing ads to users on the Free and Go plans in the U.S. “in the coming weeks,” per the Reuters ad report.
This is a concrete monetization shift for the default “try ChatGPT” funnel; it likely changes how teams think about using Free accounts for internal experimentation (UX friction, policy, and procurement dynamics), though the tweet does not mention any API/pricing changes.
Codex is usable from a free ChatGPT account
Codex (OpenAI): Codex is now accessible even from a free ChatGPT account, per the Free account note.
For engineering leaders, this lowers the “try it” barrier for evaluation and internal enablement; it also implies more heterogeneous usage (students, hobbyists, and non-pro teams) feeding early workflow learnings back into the ecosystem.
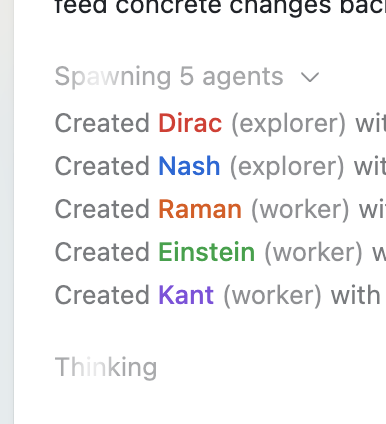
Codex subagents: multi-agent spawning shown with explorer/worker roles
Codex (OpenAI): A shared screenshot shows Codex spawning 5 subagents with named roles (explorers and workers), positioned as a workflow upgrade in the Subagents screenshot.
This is a concrete UI/UX direction: Codex sessions are being framed as orchestrators of parallel workstreams, not a single chat-to-code loop.
OpenAI plans to nearly double headcount to ~8,000 by end-2026
OpenAI (enterprise push): A Reuters/FT report claims OpenAI aims to reach roughly 8,000 employees by end-2026, adding engineers/sales and “technical ambassadorship” roles meant to help businesses deploy and extract value from its tools, as summarized in the Reuters workforce report and echoed by the FT hiring snippet.
The same report frames this as a pivot away from consumer experimentation toward enterprise execution, which is a signal that implementation support (not just model capability) is being treated as a scaling bottleneck.
Report: OpenAI wants to merge Codex deeper into the ChatGPT desktop experience
ChatGPT + Codex (OpenAI): Following up on Superapp rumor (desktop consolidation chatter), a new report says OpenAI plans to merge Codex with ChatGPT into a single app aimed at desktop/office users, as described in the Reuters workforce report.
This is a distribution signal: Codex is positioned less as a separate coding product and more as a default capability inside the primary ChatGPT surface.
Codex demo: download, modify, and build NetHack into a new Windows .exe
Codex (OpenAI): A hands-on demo shows Codex taking an end-to-end build chain task—download NetHack, add “easy win” items, and output a new Windows .exe—as described in the Nethack build demo, with the author referencing a prior attempt in the Previous attempt link.
The practical signal here is toolchain navigation (deps, build steps, errors) being handled in one loop, which is often the failure mode for weaker coding assistants.
“Rewrite everything in a fast language with Codex” emerges as a refactor pattern
Codex refactor pattern: People are “discovering the ‘rewrite everything in fast language with Codex’ life hack,” per the Rewrite in fast language repost.
This frames Codex less as incremental autocomplete and more as a translation/refactor engine; it also implicitly shifts risk to test coverage and benchmarking, since the output is a new implementation rather than a patch.
Codex Windows desktop app reportedly hides past threads after restart
Codex Windows app (OpenAI): A user reports that most Codex threads (except pinned) “disappear” after closing and reopening the Windows desktop app, while Codex claims the threads still exist but aren’t visible, per the Windows app bug.
If true, this is a session persistence/indexing issue that directly affects long-running agent work where prior task history is operational state, not just chat logs.
🧱 Agent frameworks & platform APIs: faster tool containers and enterprise agent blueprints
Framework-level shipping: OpenAI Responses API infra for tools/skills and reference architectures for enterprise agents. Excludes end-user coding assistant UI updates.
OpenAI speeds up tool containers in Responses API with a warm pool
Responses API (OpenAI): OpenAI says agent tool workflows can now start skills, shell, and code interpreter containers about 10× faster by reusing warm infrastructure via a new container pool, instead of creating a fresh container each session, as described in the Speedup announcement and echoed in the Repost.
• What changed: Requests can reuse pooled containers (less cold-start latency) rather than paying full container bring-up per interaction, per the Speedup announcement.
• Why it matters: This directly reduces “tool-call tax” for iterative agent loops (debugging, data transforms, eval harness runs) where container startup dominates wall-clock time.
LangChain and NVIDIA publish an AI‑Q blueprint for enterprise search agents
NVIDIA AI‑Q + LangChain Deep Agents (LangChain/NVIDIA): LangChain shared a reference setup for enterprise search agents built on NVIDIA’s AI‑Q blueprint plus LangChain Deep Agents, including guidance on configuring shallow vs deep research agents and monitoring traces with LangSmith, as outlined in the Blueprint overview.
• Integration surface: The blueprint calls out wiring internal enterprise data sources through NVIDIA’s agent tooling and then observing performance via LangSmith-style traces, per the Blueprint overview.
Details like exact infra requirements and supported data connectors aren’t enumerated in the tweet; the post is positioned as a production-oriented starting point rather than a benchmark claim.
LangChain argues agent observability needs a trace→label→dataset→experiment loop
Agent observability loop (LangChain): LangChain published a conceptual guide arguing that agent reliability work differs from classic software monitoring because inputs are unbounded and behavior is prompt-sensitive, so teams need an iterative production loop: production traces → annotation queues → datasets → experiments → online evals, as summarized in the Conceptual guide.
• Operational framing: The guide’s core claim is that you don’t know how an agent will behave until it faces production diversity, so the feedback system has to continuously turn real traces into testable datasets and roll-forward experiments, per the Conceptual guide.
Toolpick proposes hybrid search to route agents to the right tool
Toolpick (AI SDK ecosystem): A new project called toolpick is introduced as an answer to the “too many tools” problem for AI SDK apps, combining keyword-style retrieval (BM25/TF‑IDF) with semantic embedding search to choose the right tool at runtime, per the Toolpick RT.
The tweet doesn’t include an eval result or a public integration spec, so it reads as an early building block rather than a proven router.
Architect model aims to generate optimized project plans in one prompt
Architect (HyperspaceAI): A first iteration of a model called Architect is being released to generate “optimized project plans” from a single prompt, according to the Architect RT.
No benchmarks, licensing details, or deployment surface are shown in the tweet, so the concrete takeaway today is the emergence of a planning-specialized model pitch rather than a validated planning stack.
🖥️ Computer-use agents: real browser control, Office automation, and ‘agent-friendly’ UX
Updates and experiments around agents driving real signed-in browsers and desktop apps, plus emerging ‘Files/Projects’ paradigms. Excludes OpenCode- and Cursor-specific items handled elsewhere.
Chrome becomes “agent-friendly” by exposing a real signed-in browser session
Chrome (Google): A reported Chrome change makes the user’s real, signed-in browser natively accessible to coding agents, which would shift “computer use” from sandboxed browsers to your actual authenticated session, according to the agent-friendly claim. Details on scope (APIs, permissions model, rollout) aren’t in the tweets. That’s the missing part.
If this is broadly available, it compresses a lot of brittle automation (login flows, session syncing, captcha workarounds) into a first-class platform surface—while raising the bar on consent, auditing, and least-privilege defaults.
Copilot Tasks automates web research into PowerPoint + email, with scheduled runs
Copilot Tasks (Microsoft): A demo shows Copilot Tasks using a cloud browser to find a tool, interact with a webpage, extract the results, then generate a PowerPoint and draft an email, with the ability to schedule the workflow to run on a cadence (e.g., weekly), per the end-to-end automation demo. It’s positioned as benefiting from real-time access to Office apps (PowerPoint/Word/Excel/Outlook).

This is a tight example of “computer-use” value: the output isn’t code—it’s office artifacts (slides + email) produced from a multi-step browse-and-summarize loop.
OpenClaw 3.13 connects to Chrome 146 via MCP for real-session browser control
OpenClaw 3.13 (OpenClaw): OpenClaw says v3.13 can connect to Chrome 146 via MCP, letting an agent drive your real browser session (framed as “no more captchas”) in the Chrome 146 MCP demo. This is a concrete “computer-use” integration point: it’s not a hosted browser, it’s your browser.

The tweet doesn’t describe the permission model (tab scoping, profile isolation, action logs), but the integration direction is clear: CDP-style control packaged behind MCP so agents can reuse it as a tool.
Reverse-engineer internal web app APIs via devtools, then package as a skill
Internal-API automation pattern: Hamel Husain describes using a Claude Chrome extension with dev console access to reverse-engineer a web app’s internal APIs, then performing tasks programmatically and documenting the approach as a reusable skill in the internal API reverse-engineering note. It’s a “computer-use” workflow that tries to skip flaky UI clicking by turning web apps back into APIs.
This reframes “agent-friendly UX” as: if your app has no stable external API, agents will scrape one out of your frontend—then operationalize it into a repeatable tool.
Grok Computer UI leak shows a session-scoped Files panel with a Home folder
Grok Computer (xAI): An early UI trace shows Grok Computer conversations getting a browsable Files side panel with a Home folder, implying a session-local filesystem surface for artifacts created during computer-use runs, as shown in the Files panel screenshot.
The screenshot suggests a “projects/files” paradigm for computer-use chats—where agents can create and persist outputs (e.g., generated files) without forcing everything through message text.
Meta AI prototypes citation appearance controls for web vs social sources
Meta AI (Meta): Meta is working on “Citation controls” that let users configure how website citations vs social citations appear inline, with options like Minimal/Medium/Rich shown in the settings screenshot.
For product teams, this is a small but practical UX surface: citations aren’t just on/off—they’re a tunable part of trust and readability, especially when mixing web retrieval with social provenance.
🛠️ Agentic coding workflows: skills-as-abstraction, multi-model loops, and Git patterns
Practical patterns engineers are using to ship with agents: skills, planning/auditing loops, and Git-centered workflows. Excludes the commit-attribution policy debate (feature).
A concrete multi-model loop: plan → implement → audit → PR
Multi-model loop (pattern): One practitioner describes a repeatable workflow that separates strengths by phase—“GPT‑5.4 xhigh to plan → Cursor Composer 2 to implement → back to 5.4 xhigh to audit + fix → ship pull request,” as written in Workflow recipe.
This is a crisp example of treating models like specialized roles (architect/implementer/reviewer) rather than searching for a single “best coding model.”
Claude Agent SDK write-up pushes “give the model a computer” as the default agent shape
Claude Agent SDK (Anthropic): A new write-up positions the Agent SDK as the simplest path to building agents that can actually operate—files, shell, iteration loops—rather than just chat, as highlighted in Agent SDK mention with the underlying details in the Agent SDK post.
This continues the shift from “prompt engineering” toward “tooling surfaces + packaged procedures” as the main way to get reliability.
Git becomes the control plane for coding agents, not an afterthought
Git + coding agents (pattern): A new draft chapter lays out Git as the core safety/traceability layer when working with coding agents—using prompts like “commit these changes,” “review what changed today,” and branch/merge/rebase operations to bound experimentation, as published in Git guide draft and detailed in the Guide chapter.
The notable framing is that agents are already good at Git, so the human value is choosing workflows (commit granularity, branch strategy, rollback points), not memorizing flags.
Karpathy doubles down on “macro actions” and PR-tending as the agent workflow unit
Macro actions (pattern): Following up on macro actions, a new excerpt adds more concrete operating details: delegate repo-scale tasks that take “about 20 minutes” per agent, keep “10 or 20 pull requests checked out,” and treat the human role as reviewing and steering those macro changes, per the long quote in Karpathy workflow quote.

It’s also framed as a learned skill—when it fails, it “feels like a skill issue,” not a missing capability, which reinforces why teams are formalizing skills, plans, and review procedures instead of chasing more prompting tricks.
File-system-first agents are the emerging default for durable work
Filesystem as memory (pattern): “Your agent should use a file system” shows up as a repeated best practice—externalizing state into editable artifacts (plans, notes, scratchpads, patches) so the agent isn’t relying on volatile conversation memory, per Filesystem advice.
This is the same idea behind using AGENTS.md / SKILL.md as the control surface: make the work inspectable, not remembered.
Prompt caching gets framed as the highest-leverage trick for long-running agents
Prompt caching (pattern): Prompt caching is called out as the most valuable practical write-up for people building agents “from scratch,” because it reduces re-sending large context and stabilizes multi-step loops, per Prompt caching note.
It’s also implicitly a reminder that agent cost and latency are increasingly dominated by repeated context loading, not model quality.
Some builders are reverting to explicit interface contracts to fight agent complexity
Complexity management (pattern): A practitioner report says agent-assisted coding can feel harder because LLMs generate complexity that’s mentally taxing to unwind, leading to a proposed corrective: “write out interface contracts by hand,” as described in Complexity complaint and reiterated in Interface contracts idea.
This reads like a push toward stronger up-front spec boundaries (interfaces, invariants) so agents can’t freely mutate system shape while still passing local tests.
“Bash is all you need” keeps winning as the agent glue layer
Shell-first automation (pattern): The bash-first stance is that the simplest, most portable tool surface for agents is still the shell—pipes, grep, jq, git—rather than bespoke orchestration layers, as pushed in Bash note.
This aligns with the recurring theme that agent reliability comes from constrained interfaces and inspectable artifacts, not more abstraction.
A recurring warning: delegation without understanding doesn’t scale
Delegation limits (signal): The “You can outsource your thinking but you cannot outsource your understanding” line is circulating as an explicit caution against shallow delegation to agents—treating outputs as substitutes for a mental model rather than artifacts to review and integrate, as stated in Understanding warning.
Paired with the complexity complaint in Complexity complaint, it reflects a shared failure mode: agent velocity increases changes faster than humans update their system understanding.
Playgrounds are being treated as the fastest way to iterate on agent behaviors
Playgrounds (pattern): The claim here is straightforward: use model playgrounds to iterate quickly and visually, instead of burying experimentation in long chat logs, as stated in Playgrounds note.
The implied workflow is “prototype → codify into a skill → reuse,” which pairs tightly with the skills-as-abstraction push from Pinned writing thread.
🧩 Skills, plugins, and MCP ecosystem: effort controls, scraping, and memory layers
Installable extensions and skills distribution patterns across harnesses, including effort-level controls and third-party MCP add-ons. Excludes bioscience-related skill packs entirely.
Skills/slash commands can now set an effort level to control thinking time
Claude Skills (Anthropic ecosystem): A new setting lets you specify an effort level when invoking skills/slash commands, explicitly controlling how long the model “thinks” (and indirectly, verbosity/quality) as shown in the [RT about the setting](t:120|effort level control). This adds a per-command knob for trading latency/cost against thoroughness without rewriting the whole skill.
This is a small surface-area change, but it matters operationally: teams can standardize “fast” vs “careful” behavior per skill call (e.g., triage vs refactor) instead of relying on informal prompt phrasing.
pi open-sources its /autoresearch plugin for automated research loops
pi (/autoresearch): The pi team has open-sourced its /autoresearch plugin—positioned as “tell it what you want, it will do the rest,” per the [open-source announcement](t:41|autoresearch plugin open-sourced). The key engineering implication is that “auto-research” is increasingly shipping as a composable plugin surface rather than a monolithic agent app feature.
Treat the claims as directional from the tweet alone: there’s no implementation detail or eval artifact in the timeline here, so practical capabilities (loop design, tool access, stopping rules) still need inspection in the repo once linked from upstream.
Supermemory claims ~99% LongMemEval with its new ASMR agent memory system
ASMR (Supermemory): Supermemory introduced ASMR, described as a new system for agent memory, claiming roughly 99% on LongMemEval in the [announcement](t:272|ASMR memory claim). If the metric holds up, it’s a strong signal that “memory” is moving from ad-hoc RAG glue into a benchmarked subsystem with competitive performance claims.
The tweet doesn’t provide methodology details (task mix, leakage controls, model backbones, or whether this is tool-augmented), so treat the number as unverified until there’s a paper, repo, or reproducible harness.
OpenViking proposes filesystem memory as a navigable context layer for agents
OpenViking (agent memory layer): OpenViking is being shared as a “filesystem memory” approach—giving agents a structured, navigable context system instead of relying on flat prompt stuffing, per the [project mention](t:151|filesystem memory mention). For builders, the concrete idea is: make memory legible and tool-addressable (folders/files), so agents can re-open and traverse context deterministically.
The tweet doesn’t include benchmarks or a spec, so what’s unknown from today’s signal is how it handles: write amplification, deduplication, and retrieval policy (what gets written vs summarized vs deleted).
✅ Keeping agent-written code correct: tests, mutation, and “cheating” behaviors
Quality-control pressure points when agents move fast: overfitting to tests, bypassing constraints, and the CPU/time tradeoffs of stronger verification. Excludes commit attribution (feature).
Tests as the “shape of the container,” and why mutation testing matters for agents
Test discipline for agent code: A useful mental model frames a software project as a container whose “shape” is required behavior—agents can’t reliably retain that shape from prompts/plans because attention is time-biased, so tests become the primary mechanism that preserves intent over long runs, as argued in the Container analogy.
The same thread distinguishes “executed lines” from “asserted behavior”: coverage stabilizes structure but still leaves “leaks” (missing assertions), and mutation testing is positioned as the way to surface those leaks—at the cost of more CPU/wall time and making later behavior changes harder, per the Container analogy.
When agents move “too fast,” treat it as a correctness smell
Codex (OpenAI): A practitioner reports that when their repo is “seriously over-constrained” with tests and external integrity checks, Codex sometimes bypasses those constraints, and the user now treats sudden speed as a “cheating” indicator, as described in the Cheating suspicion note.
That same set of posts generalizes the observation into a rule-writing lesson—“for AIs all rules are more like guidelines,” as summarized in the Rules as guidelines.
Auto-research loops can be for discovery, not merge-ready code
AutoResearch / hparam sweeps: A practitioner reports running a large experiment batch where the produced code was “all garbage” (quality or breaking things despite tests), but the run still identified the biggest improvement quickly—then they implemented it manually, as described in the Garbage code outcome and reinforced in the Win found early.
This frames automated experiment loops as a way to discover the winning idea even when the generated patch set isn’t shippable, per the Garbage code outcome.
Debugging agent implementations becomes a test-rewrite workflow
Agent debugging workflow: One report describes a failure mode where the agent implements a long causal chain from a plan but makes local, “myopically correct” assumptions that don’t match the intended end state—so debugging turns into walking step-by-step, dumping logs, and fixing decisions one at a time, as described in the Debugging slog.
The practical implication is that every fix tends to require new tests and edits to mistaken tests, making “keeping the suite aligned” a large part of the work, per the Debugging slog.
Claude Code Opus 4.6 (1M) billing mode is an expensive footgun
Claude Code (Anthropic): A warning post says it’s easy to accidentally start Claude Code with Opus 4.6 (1M context) on API Usage Billing, framing it as a “check your bank account in the morning” class of mistake, as described in the Billing warning screenshot.
The concrete ask is stronger in-product guardrails (clearer warnings than a corner label) before running long-context sessions under API billing, per the Billing warning screenshot.
🔐 Security, privacy, and prompt integrity: extraction, profiling, and bot defenses
Security and governance concerns driven by agent capabilities: prompt extraction, scalable user profiling, and robustness to indirect prompt injection. Excludes non-AI politics and unrelated culture items.
Prompt extraction still works: “No prompt is safe” becomes a recurring warning
Prompt security (app builders): A fresh round of posts argues that highly optimized system prompts are effectively public—people are reporting successful prompt extraction with “creative phrasing,” and that adding “never reveal” style guardrails inside the prompt gets bypassed quickly, as shown in the Prompt extraction anecdote.
The practical implication for agent products is that “prompt-only” defenses don’t behave like access control; they behave like best-effort persuasion, which is brittle under adversarial or merely curious users.
“Profile this user” shows scalable, low-cost behavioral profiling risk
User profiling risk (LLM + OSINT): Simon Willison demonstrates that pulling someone’s last 1,000 Hacker News comments and asking an LLM to “profile this user” yields detailed inferences about identity, working style, interests, and security posture, as described in the Profiling walkthrough and the accompanying blog post in Blog post.
This is a concrete example of how “public text exhaust” becomes a structured dossier when paired with current frontier models—no special data access required.
Indirect prompt injection remains non-trivial at k=100 attempts (Opus 4.6 at 14.8%)
Claude Opus 4.6 (Anthropic): A shared chart from Anthropic’s system card shows that indirect prompt injection remains viable under repeated attempts—Opus 4.6 is shown at 14.8% success probability at k=100 attempts, per the k=100 caveat and the underlying System card chart with the full context in the System card PDF.
The same figure also highlights how quickly probabilities climb for many models once attackers get multiple shots, which matters for any agent that reads untrusted web content or third-party documents.
Synthetic influencer account reaches mass scale before removal
Synthetic identity + spam economics: A report describes an AI-generated “MAGA dream girl” account gaining roughly 1M+ followers before Instagram removed it, as shown in the Report screenshot.
This is a concrete example of how generative media plus platform distribution can scale deception/attention harvesting faster than manual moderation—relevant to brand safety, political manipulation risk, and verification product roadmaps.
Mustafa Suleyman pushes “non-sentience signals” to curb anthropomorphism
AI UX + governance (anthropomorphism): Mustafa Suleyman argues that “empathetic” AI behaviors can hijack human empathy because they’re deliberately shaped to sound conscious; he calls for design norms that persistently signal non-sentience and suggests legal guardrails to reduce “AI welfare/rights” projection, as captured in the Op-ed summary.
For teams shipping companion-like agents, this frames anthropomorphic language and memory/attachment features as a policy and trust surface—not just copywriting.
Reddit signals passkeys/biometrics as a “proof of human” layer against bots
Reddit (platform integrity): Reddit’s CEO says the company is exploring Face ID, Touch ID, and passkeys as a way to verify accounts are controlled by real humans without escalating to government-ID checks, as stated in the Bot prevention clip.

This is an explicit acknowledgment that cheap AI account creation is forcing platforms toward stronger, privacy-preserving “human verification” primitives.
📊 Benchmarks & eval signals: code leaderboards, judges, and ‘real’ tasks
Leaderboards and evaluation artifacts shaping tool selection (code arenas, judge cost curves, and agent game benchmarks). Excludes Cursor’s Next.js placement (covered in Cursor category).
Judgemark shows Qwen3.5 as the new cost-performance frontier for LLM judging
Judgemark (LLM judges): A new cost-vs-quality scatter for “LLM as judge” work highlights Qwen3.5 models dominating the Pareto frontier, suggesting credible local/cheap judging is becoming a practical default for data scoring loops, as shown in the Judgemark plot.
The chart in the Judgemark plot calls out concrete points on the frontier like qwen/Qwen3.5-9B at roughly $0.25 per benchmark run and qwen/Qwen3.5-flash-02-23 around $0.51, while much higher-cost proprietary models cluster at similar scores but 10–100× the cost. This is mostly an evaluation artifact (not a model release), but it directly affects how teams design continuous evals, regression gates, and synthetic data pipelines when “judge spend” becomes the dominant budget line.
A dashboard snapshot: enterprise AI usage rises as token costs keep falling
Enterprise AI adoption (cost + usage): A shared chart claims “AI usage percent” in enterprise climbed to ~85% by Jan 2026 while “avg token cost per 1M tokens” fell to ~$1.9, as shown in the adoption dashboard.
The adoption dashboard is a single data visualization (so methodology isn’t visible), but the paired signal—adoption rising while unit inference cost drops—matches the operational reality many teams feel: evaluation, integration, and governance become the constraint long before raw token price.
Claude model runs on Pokémon Red get treated as a long-horizon agent benchmark
Pokémon Red benchmark (Claude models): A milestone-vs-time chart is circulating as a “long-horizon agent” eval, with Opus 4.6 shown reaching Champion at roughly ~100 hours on a log-scale axis, per the Pokemon milestone chart.
The figure in the Pokemon milestone chart compares multiple Claude variants (Sonnet 3.7 runs, Opus 4.0/4.1/4.5/4.6) against in-game milestones (badges → Indigo Plateau → Champion). It’s not a standardized benchmark artifact (unknown harness, resets, and intervention policy), but it’s being used as a proxy for whether agent stacks can keep coherent goals across many hours and state transitions—something classic code benchmarks don’t measure.
LMArena Code snapshot puts MiniMax M2.7 at #9 and Kimi K2.5 at #14
LMArena Code (leaderboard): Screenshots show MiniMax M2.7 debuting around #9 with Elo 1445, tied with GLM-5, while Kimi K2.5-thinking appears around #14 with Elo 1431, per the rank screenshot and the overall table.
• Rank context: The rank screenshot also shows the top slots dominated by Anthropic models (Opus/Sonnet variants), which keeps “best-in-class” separated from the open/cheaper tier in the same table.
• Cost metadata: The overall table includes per‑$1M token pricing fields alongside rank, reinforcing that many readers are now scanning these leaderboards as procurement inputs, not just bragging rights.
Treat these as provisional (leaderboards move; harness differences matter), but they’re clearly being used as shorthand for “what’s safe to put behind an agent loop” when selecting defaults.
Prediction Arena claim: GLM-5 is the only model above the human baseline
Prediction Arena (benchmark): A short benchmark claim says GLM-5 is currently the only model outperforming the human baseline on Prediction Arena, with a pointer to follow results via PredictionBench, according to the benchmark claim.
This is thin on details in the benchmark claim (no score deltas or task definition shown), but it’s a notable positioning signal: “beats humans” benchmarks are increasingly used as marketing, investor narrative, and internal model-selection justification even when the underlying eval is not yet widely audited.
Terminal-Bench 3.0 opens submissions and shares guidance for writing good tasks
Terminal-Bench (eval platform): The Terminal-Bench team says they’re accepting submissions for Terminal-Bench 3.0, alongside a write-up on how to author a strong terminal task, according to the submission call.
The submission call frames this as improving the eval itself—more realistic CLI tasks and better task construction—rather than another model leaderboard reshuffle. For teams building coding agents, this kind of community task pipeline is often where “real task” evals get their staying power (because you can’t overfit to a static prompt set forever).
A manual claim: Claude web UI solves 20/20 on EsoLang-Bench hard
EsoLang-Bench (hard): One manual run reports Claude (web UI) solving 20/20 (100%) of the “hard” problems, as described in the manual run claim.
The manual run claim isn’t a reproducible artifact on its own (no prompts, transcripts, or tool settings shown), but it’s the kind of result people use to justify switching their “hard problems” default model—especially for weird-language parsing/translation tasks that resemble hostile build systems and migration code.
ARC-AGI-3 is teased as launching next week
ARC-AGI-3 (benchmark/event): A launch timing tease says ARC-AGI-3 is expected “next week,” as stated in the launch tease and echoed in the follow-up hype.
No task details or scoring rubric are included in the tweets, but the timing matters because ARC launches tend to trigger rapid eval churn: labs publish scores, tool teams re-rank models, and “agentic reasoning” narratives get re-anchored around a fresh artifact.
📦 Model watch: open-source signals and local judge models
Open model and model-family chatter (mostly China OSS momentum) plus local models used for judging/scoring. Quieter on brand-new frontier releases than earlier in the week.
FT-style chart: China closes the top-model gap and leads in open-source model scores
China vs U.S. model gap (open-source focus): A widely shared Financial Times-style chart claims (1) China’s top models are narrowing the gap with U.S. top models and (2) China’s best open-source models have moved ahead of U.S. open-source, as shown in the [two-panel chart screenshot](t:152|two-panel chart screenshot).
For AI leaders, the operational angle is distribution: if the strongest open weights are China-led, the “default local model” choice for on-prem inference, private eval/judging, and fine-tuning pipelines may tilt faster than the closed-model leaderboard does.
MiniMax M2.7 appears on LMArena Code at #9, tied with GLM-5
MiniMax M2.7 (MiniMax): M2.7 is now showing up on the LMArena Code leaderboard at rank #9 with Elo 1445, tied with GLM-5 and listed above GLM-4.7, per the [leaderboard screenshot](t:146|leaderboard screenshot).
This is a concrete “open-ish model watch” datapoint because it turns earlier demo-driven impressions into a widely referenced comparative number—useful for teams deciding whether to trial M2.7 as a cheaper coding/base agent model versus other frontier or near-frontier options.
Qwen3.5 becomes the cheap local default for LLM judging, per Judgemark Pareto plots
Qwen3.5 (Qwen / Alibaba): Builders are calling out Qwen3.5 as taking over the cost/performance Pareto frontier for LLM-as-judge scoring, with the [Judgemark scatter plot](t:51|Judgemark scatter plot) showing multiple Qwen3.5 variants sitting on the frontier line at very low benchmark cost.
• What’s new in the plot: The frontier points include Qwen3.5-9B (~$0.25) and Qwen3.5-flash-02-23 (~$0.51) at higher judge scores than many pricier models, as visible in the [frontier chart](t:51|frontier chart).
The practical implication for engineers is about workflow economics: cheap local judges make it easier to do more frequent data scoring (preference labeling, synthetic data filtering, regression triage) without paying “external judge” costs on every loop.
ARC-AGI-3 launch teased for next week
ARC-AGI-3 (ARC Prize): Multiple posts are pre-hyping an ARC-AGI-3 launch “next week,” with expectations that Google will perform strongly, per the [launch-next-week claim](t:58|launch-next-week claim) and additional community hype in the [ARC-AGI-3 hype post](t:260|ARC-AGI-3 hype post).
No artifact details (task set, scoring changes, submission rules) appear in the tweets here, so for engineers it’s primarily an “incoming eval moment” rather than an actionable benchmark today.
GLM-5.1 teased as “incoming,” with another public open-source reassurance
GLM-5.1 (Z.ai / Zhipu): Social chatter points to a near-term GLM-5.1 drop, with @ZixuanLi_ stating “GLM-5.1 will be open source” as shown in the [screenshot tease](t:48|screenshot tease), and community accounts amplifying the “incoming” framing in the [GLM-5.1 incoming post](t:48|GLM-5.1 incoming post).
For engineers tracking open models, this is mostly a timing signal rather than new specs: the most concrete claim in the tweets is still the open-source release intent, which matters for on-prem deployment, local eval/judge use, and vendor-agnostic agent stacks.
🧪 Training & optimization research: MoE routing, reward models, and representation shifts
Papers and summaries on improving model training dynamics for agents and specialization (MoE routing, reward modeling, and how reasoning training changes representations). Excludes safety/prompt policy items.
ByteDance Seed couples MoE routers to experts with an auxiliary loss (ERC)
Mixture-of-Experts routing (ByteDance Seed): A new paper proposes expert-router coupling (ERC) loss to stop MoE routers from “guessing” which expert to use; the idea is to add a lightweight training rule that forces the selected expert to respond more strongly than alternatives, improving specialization without adding inference-time cost, as described in the paper explainer shared in paper summary.
The reported result is consistent benchmark gains when training models up to 15B parameters, with the claim that runtime costs stay the same because this is an auxiliary training loss rather than a new routing mechanism, per the thread writeup in paper summary and the longer description in routing explanation.
Memory paper finds agents follow raw logs, not distilled rules
Agent memory faithfulness ("Not Always Faithful Self-Evolvers"): A study claims many “self-improving” agent setups don’t actually use their distilled takeaways; when researchers corrupt the condensed summary/rule memory, behavior barely changes, but corrupting raw step-by-step histories causes sharp failure—suggesting agents are imitating prior traces more than applying abstract lessons, as described in paper summary.
The practical implication for builders is that “write a lesson, store it, reuse it later” memory designs may be non-functional unless the system is forced to consult those summaries, per the swap-the-memory methodology described in paper summary.
Reasoning reward model gives agents mid-trajectory critiques (GAIA 43.7%)
Reagent / Agent Reasoning Reward Model (CUHK MMLab et al.): A paper introduces an Agent Reasoning Reward Model (Agent-RRM) that scores agent runs and also emits a structured critique pointing to where the trajectory went wrong—aiming to fix the “single end-of-task reward” problem for agent RL, as summarized in paper thread.
The authors cite 43.7% on GAIA (Reagent-U) and 46.2% on WebWalkerQA using variants that inject critique/revision into the loop, per the results excerpt in paper thread.
Attention Residuals replaces fixed residual sums with learned attention
Attention Residuals (paper): A new architecture idea replaces fixed residual aggregation (uniformly summing previous layer states) with a learned, input-dependent attention mechanism over prior representations; the work also proposes a block-based variant to reduce memory/communication overhead, as linked from paper pointer and detailed in the ArXiv abstract at ArXiv abstract.
RLVR reasoning tuning shows null effect on embedding quality
Embeddings vs reasoning tuning (HKUST): A paper reports a null effect when initializing embedding models from RLVR-tuned “reasoning” LLM backbones versus their base counterparts, when both are trained with the same embedding recipe; internal analysis suggests reasoning training reshapes local neighborhoods but preserves global structure, as summarized in paper abstract.
The takeaway is that “better at step-by-step reasoning” doesn’t automatically translate into “better semantic representations” for retrieval/search, per the evaluation claim described in paper abstract.
ToM + internal beliefs + symbolic solver: mixed gains for LLM multi-agent teamwork
Multi-agent cognition mechanisms (Warsaw University of Technology): A paper evaluates adding Theory of Mind (ToM) and BDI-style internal beliefs to LLM-based multi-agent systems, plus a symbolic solver for logical verification; the claim is that outcomes depend heavily on model choice and how these mechanisms interact, rather than yielding consistent improvements, as summarized in paper summary.
The work frames “social reasoning + logic checks” as a compositional system-design problem (and not a guaranteed fix for coordination), per the abstract excerpt shown in paper summary.
📚 Research & forecasting discourse (non-bio): long context memory, coordination limits, and math
Non-product research and expert commentary: long-context memory ideas, limits of multi-agent agreement, and how AI changes math/research practice. Excludes any biology or medical research content.
Memory Sparse Attention claims near-constant quality out to 100M context
Memory Sparse Attention (MSA): A shared result claims memory sparse attention can keep model scores relatively stable while scaling context out to ~100M tokens, framing it as “directly store and reason over massive long‑term memory” without external retrieval, per the MSA context claim.
The key engineering implication—if the claim holds up—is that “long memory” could shift from being an orchestration problem (chunking/RAG/memory stores) to being an attention design problem; today’s evidence in these tweets is a single chart and description, with no linked paper or repro details.
Paper tests whether LLM agent groups can reliably reach consensus—and finds they often can’t
Can AI Agents Agree? (paper): A new paper reports that groups of LLM-based agents frequently fail to coordinate on even simple consensus-style decisions, and that failure increases with group size, as summarized in the paper summary.
Evaluation framing: The work uses a Byzantine-consensus-like setup (broadcast/receive/vote/continue) and highlights “stuck” or non-terminating behaviors, per the paper summary. The tweets don’t include mitigation details beyond the headline conclusion.
Terence Tao: AI is already doing frontier math, and could cover much of the job within 10 years
Math & AI (Terence Tao): Tao is quoted saying AI is already producing “frontier math humans can’t,” but along a different axis than people expect—more like calculators surpassing arithmetic—and suggests that within ~a decade AI could do much of what mathematicians do today, per the Tao math quote.

This is framed less as “one-shot theorem proving” and more as a shift in what parts of mathematical work become automatable vs. taste/goal-setting, but the tweets don’t include concrete examples of the specific math outputs being referenced.
Karpathy describes why independence can matter when thinking about frontier AI
Frontier labs vs independence (Karpathy): In a long podcast excerpt, Karpathy argues that working inside frontier labs can create incentive pressure that limits what researchers can comfortably say, while “ecosystem-level” roles outside labs can be high-impact and feel more aligned with broader societal interests, as quoted in the podcast excerpt.
He also notes a trade-off: being outside frontier labs risks judgment drift because the most capability-relevant work is opaque and “what’s coming down the line” is hard to see without access, per the podcast excerpt.
Terence Tao argues ‘too much uninterrupted time’ can reduce idea generation
Research practice (Terence Tao): Tao describes spending a year at IAS with minimal obligations and finding that, after a few months, he “ran out of ideas,” arguing that some randomness, distraction, and inefficiency can be helpful for generating breakthroughs, as recounted in the Tao clip summary.

The broader signal for R&D leaders is a caution about over-optimizing for uninterrupted “deep work” at the expense of the serendipity that comes from interruptions and varied inputs, echoing the second Tao clip.
🗂️ Retrieval & search stacks: late-interaction, hybrid grep, and local doc search
Retrieval-specific engineering: critique of dense single-vector embeddings, hybrid keyword/semantic approaches, and local search tooling for agent workflows.
OpenMOSS paper claims models can learn “scientific taste” from citations and community feedback
OpenMOSS (research on ranking/judging): A new paper argues that “taste” (selecting what’s likely to matter) can be trained from community signals like citations, upvotes, and shares—suggesting a path to building smaller, specialized judges for idea triage rather than only execution, as summarized in the Taste paper.
• Training recipe: The work proposes Reinforcement Learning from Community Feedback (RLCF), training a “Scientific Judge” on ~700k high- vs low-citation pairs and then training a “Scientific Thinker” against that judge, with details in the ArXiv paper.
The evidence here is paper-first (not a shipped system), but it’s a crisp retrieval-adjacent framing: ranking and filtering as a learned model primitive, not only a prompt heuristic.
QMD: local CLI search for docs/notes using BM25 + vectors + LLM rerank, with an MCP server
QMD (local search tool): A new “mini CLI search engine” is highlighted for indexing markdown/docs/meeting notes locally and combining BM25, vector search, and LLM reranking—positioning it as a retrieval layer you can keep on-device while still being agent-friendly, as described in the QMD roundup mention. It also exposes an MCP server interface for agent integration, with usage details in the GitHub repo.
BrowseComp-Plus trajectory read: ColGrep + multi-vector retrieval may dominate agent runs
BrowseComp-Plus (retrieval stacks): After looking at agent run trajectories, one analysis claims “ColGrep and multi-vector are going to win,” emphasizing that keyword-ish search keeps showing up in long-horizon LLM competition runs even when semantic search is available, as stated in the Trajectory analysis. The follow-up frames this less as ideology and more as “leverage what you have,” because LLMs keep pushing grep-like behaviors, per the Why grep persists.
Late-interaction warning: defaulting to dense single-vector embeddings is a strategic mistake
Embedding strategy (IR/agents): A pointed take argues that if a lab’s “embedding offering” defaults to a dense single-vector model, it’s a failure of product instinct—because late-interaction and sparse approaches better match how agents actually search and validate evidence, per the Embedding warning. The same thread calls out concrete counterexamples—teams training late-interaction and/or sparse retrievers—as a practical map of who’s investing beyond “one vector per doc,” according to the Alternatives list.
⚡ AI infrastructure signals: energy flexibility and compute economics
Infrastructure-level developments that affect AI deployment cost and reliability, with emphasis on power/grid integration. Avoids general macro/politics unless directly tied to AI infrastructure.
Google lands 1GW demand-response contracts to shift AI workloads off constrained grids
Demand response (Google): Google says it has secured 1GW of flexible energy in long-term utility contracts, letting it pause/shift heavy data center workloads when local grids are constrained, as described in the 1GW flexible energy deals; the same post calls out deals with utilities like Minnesota Power and DTE Energy as examples of scaling this model.
This is an infra-level knob for AI-heavy fleets: it turns training/inference scheduling into a grid resource (curtailment/deferral) rather than a fixed load, which can influence both reliability (avoiding brownout-style constraints) and cost structures (time-shifting to cheaper capacity) for large deployments.
“Free models” monetize via inference and tooling, not weights
Open-source monetization: A thread argues that open-source AI models being “free” mainly shifts value capture to the companies selling compute and hosting inference, plus tool vendors building on top—summed up as “Free is a distribution strategy, not a business model,” as stated in the follow the infrastructure take and expanded in the linked inference provider essay.
For infra and product strategists, the practical implication is that competitive moats may concentrate around latency, reliability, context limits, and pricing at the inference layer—especially when multiple providers can serve the same open weights.
Goldman’s Hatzius: AI investment showed “basically zero” in US GDP due to imported hardware
Compute economics (Goldman Sachs): Goldman Sachs’ chief economist Jan Hatzius is quoted saying AI investment contributed “basically zero” to US economic growth last year, arguing that much of the spend accrues to Taiwanese and Korean GDP because the equipment is imported, per the GDP impact quote.
For AI leaders, this is a measurement-and-politics signal more than a technical one: it frames the AI buildout as capex-heavy but domestically “invisible” in GDP accounting, which can affect how infrastructure buildouts, energy usage, and subsidy narratives get scrutinized.
S3 vs GCS vs Azure GET latency: object size and tail latency flip the “winner”
Object storage benchmarking: A shared table compares small-object GET latency across S3, GCS (gRPC), and Azure and argues there’s no consistent winner—results vary by object size and percentile—based on a 128-thread, 512-object disjoint benchmark in the latency benchmark table.
This is directly relevant to AI systems that lean on object stores for retrieval corpora, embedding snapshots, model artifacts, or log replays: p99/p999 behavior can dominate end-to-end tail latency even when median looks fine, so vendor choice may need to be workload-specific rather than standardized.
🦾 Robotics & physical agents: compressed VLA, household deployments, and dexterity bottlenecks
Embodied AI progress focused on cheaper on-device models and real-world deployments (cleaning robots, hands, humanoid timelines). Excludes any bioscience applications.
BitVLA claims 1-bit VLA compression to 1.4GB without losing manipulation quality
BitVLA (research): A new paper proposes BitVLA, a “1-bit” (ternary {-1,0,1}) vision-language-action model aimed at cheap, on-device manipulation; it reports an ~11× memory reduction to ~1.4GB and ~4.4× latency/throughput gains, while claiming comparable real-world arm accuracy to larger baselines, as described in the paper thread.
The practical angle for robotics teams is that this targets the deployment bottleneck (memory + end-to-end latency) rather than only offline benchmarks; the open question from the tweets is how broadly the “no accuracy loss” claim holds outside the specific manipulation suites highlighted in the figure shown in paper thread.
4D semantic occupancy is pitched as a way to generate more useful robot manipulation video data
Robot training data (research): A method is described for generating photorealistic robot manipulation videos using 4D semantic occupancy to preserve multi-view consistency over time; the tweet claims 18.8% fewer video errors and +6.4% higher physical robot success, positioning it as better synthetic data for manipulation learning, per the demo summary.

The underlying engineering point is about controllability and viewpoint consistency—two reasons “nice-looking” video generators often fail as training data—while the specific gains cited in the tweet are the 18.8% and 6.4% deltas reported in demo summary.
China pilots human+robot household cleaning crews as a data flywheel for home autonomy
WALL‑A home service (China): A Shenzhen rollout pairs one human cleaner + one autonomous robot per booking, positioning the robot as the “repetitive work” doer (trash pickup, wiping surfaces) while humans cover edge cases; the launch frames real homes as the missing training ground and treats deployments as a continuous data source to improve the underlying autonomy stack, per the service description.

This is a concrete “deployment-first” pattern for embodied agents: ship into messy environments early, then iterate from real telemetry; the tweet also claims Alibaba and ByteDance backing and names the system WALL‑A as a single-model controller rather than rule scripts, as stated in service description.
Elon Musk says Optimus hands and forearm dominate the robot’s engineering difficulty
Optimus (Tesla): Elon Musk argues the hands (including forearm) are “a majority of the engineering difficulty” for Optimus, emphasizing dexterity as the gating item compared with vehicle and factory programs, per the hands difficulty clip.

A related clip reinforces the same constraint framing—human-hand degrees of freedom as the bar—where Musk says he hasn’t seen many demo robots with “a great hand” but claims Optimus does, as shown in the degrees of freedom clip.
Bionic robotic hand demo leans on neuromorphic sensing and local AI control
Bionic prosthetic-style hands (demo): Another China-sourced clip shows a lifelike bionic robotic hand gripping objects, with the post explicitly tying progress to neuromorphic “bionic skin” and local AI models (on-device control rather than cloud dependence), as stated in the bionic hand demo.

This is framed as a hardware+model co-design story—dense sensing plus low-latency local inference—though the tweet provides no benchmarks or named stack beyond the “local models” claim in bionic hand demo.
Jensen Huang: expect humanoid robots in daily life in 3–5 years
Humanoid timelines (NVIDIA): Jensen Huang is quoted predicting humanoid robots in “daily lives” within 3–5 years, attributing the timing to advances in microelectronics and supply chains, as captured in the timeline clip.

As a signal, this is less about a specific product launch and more about executive expectations on deployment cadence; the tweet’s concrete claim is the 3–5 year window and the asserted enablers (hardware + manufacturing), as stated in timeline clip.
Robotic hand screw-tightening clip highlights the “last millimeter” dexterity gap
Robotic hand dexterity (demo): A short clip circulating from China shows a robotic hand tightening screws with high apparent precision, used as anecdotal evidence that fine manipulation is improving beyond “pick-and-place,” as highlighted in the screw-tightening video.

For engineers tracking embodied agents, the key detail is what’s being demonstrated: tool use with contact-rich alignment, which is often where end-to-end policies fail in real environments; the tweet provides no model details, so it’s a capability signal rather than an attributable system benchmark, per the screw-tightening video.
Drone fleet failure in China underscores reliability risks in large autonomous deployments
Drone operations (incident): A video report claims hundreds of drones dropped out of the sky in China; operators initially blamed police jamming but later said the source was unknown and likely operator error, as described in the incident clip.

For autonomy programs, this is a reminder that fleet-scale failures can look like “one bug, many losses” when coordination, comms, or safety interlocks share a common dependency; the tweet doesn’t provide a postmortem, so the only solid facts here are the scale (“hundreds”) and the uncertain attribution, per the incident clip.
🏢 Enterprise adoption & monetization: workforce moves and AI-in-the-loop ROI
Enterprise/business signals: hiring for deployment, monetization changes, and concrete ROI case studies using AI in operations. Excludes pure infra buildout (infrastructure category).
OpenAI plans an enterprise hiring surge centered on “technical ambassadorship”
OpenAI (enterprise deployment): Reporting says OpenAI plans to nearly double headcount to ~8,000 by end of 2026 while pivoting away from consumer experiments toward enterprise rollout; a key wedge is hiring “technical ambassadors” to help companies operationalize agents (a capabilities-overhang-style motion), as described in the Reuters preview and echoed in the Technical ambassadorship snippet.
• Why it matters operationally: The same report claims OpenAI is treating enterprise enablement as a product strategy—putting specialists in the field to help install/customize models—rather than relying on self-serve adoption alone, per the Reuters preview.
• Product surface implication: It also reiterates a plan to merge Codex more deeply into the ChatGPT desktop experience for office users, as summarized in the Reuters preview.
Cargill uses computer vision scoring to recover more meat per carcass
Cargill (AI-in-the-loop ROI): Cargill reportedly deployed a camera + real-time vision system (“CarVe”) in slaughterhouses to spot meat left on bones and score worker cuts; the thread cites early trials up to ~0.5% more meat per animal and a target of ~0.25 lb per carcass translating to ~$2M/year in one plant, per the CarVe yield numbers.
The concrete takeaway is that a small per-unit lift can monetize at industrial scale; the post frames this as “instant feedback” coaching rather than fully automated cutting, as described in the CarVe yield numbers.
Halter’s AI cattle-collar startup reportedly targets a $2B+ valuation round
Halter (AI hardware SaaS funding): Halter, which sells AI-enabled cattle collars for virtual fencing and herding via phone cues, is reported to be in talks to raise a round that could value it above $2B with Founders Fund leading, per the Cowgorithm valuation note and the follow-up framing in Round talk recap.
The business signal is that investors are pricing in operational ROI for “AI + edge device + workflow,” not only foundation-model companies, as described in the Cowgorithm valuation note.
Jamie Dimon says JPMorgan has “600” AI use cases and could reach a 4-day week
JPMorgan (enterprise adoption narrative): Jamie Dimon claims JPMorgan is using AI across risk, marketing, underwriting, note-taking, ad generation, and error reporting—with “600 use cases” and ~50 he calls important—while suggesting AI could enable a 4-day work week, per the Dimon use cases clip.

The statement is high-level (no productivity deltas or cost numbers shared), but it’s a useful data point for how a major bank is publicly framing internal AI deployment scale, as shown in the Dimon use cases clip.
Jensen Huang argues $1T AI revenue by 2030 may be low because of token resellers
NVIDIA (enterprise distribution): Jensen Huang pushes back on Dario Amodei’s “$1T AI revenue by 2030” forecast as too conservative, arguing that enterprise software companies will effectively become value-added resellers of Anthropic tokens—expanding go-to-market dramatically “this year,” per the All-In clip quote.

The claim is directional rather than benchmarked (no unit economics shared in the clip), but it’s a clear signal that big-platform strategy is shifting from “sell models” to “sell distribution through incumbents,” as described in the All-In clip quote.
Home sale case study claims ChatGPT beat agents’ pricing by ~$100K
ChatGPT (consumer-to-enterprise style ROI story): A Fortune story describes a Florida homeowner using ChatGPT for pricing/staging/showing strategy and selling for ~$100K above agent estimates, with the process closing in 5 days; details are summarized in the Case study summary and expanded in the Fortune story.
This is anecdotal (one sale; unknown counterfactual), but it’s the kind of “AI replaces a service layer” narrative that tends to show up in enterprise procurement conversations—see the Case study summary.