Claude Code PR Review costs $15–25 – substantive comments jump 16%→54%
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Anthropic shipped Claude Code “Code Review” in beta research preview for Team/Enterprise; opening a PR dispatches multiple agents to search issues in parallel, then “verify” findings and post one summary plus inline comments. Anthropic says it built this after code output per engineer rose ~200% and human review became the bottleneck; internal testing claims substantive review comments improved 16%→54%, <1% of findings were marked incorrect, and on 1,000+ line PRs it surfaced issues 84% of the time (avg 7.5 issues); average token-billed cost is $15–25 per PR, scaling with complexity—no independent benchmarks or methodology details yet.
• Devin Review vs paid-per-PR: Cognition launched a free PR review flow via URL rewrite (“github”→“devinreview”); pitches autofix and diff organization, but provides no comparable false-positive/coverage metrics.
• “Who checks the checker?”: builders argue maker/checker independence matters when the same vendor/model generates and reviews code; concern is shared blind spots, not anti-AI review.
• Codex plumbing: OpenAI added a phase field to separate in-progress commentary from final_answer; Codex hanging was acknowledged, then resolved with a rate-limit reset.
Top links today
- OpenAI acquires Promptfoo announcement
- Promptfoo open source repo
- Karpathy autoresearch self-tuning repo
- Claude Code multi-agent PR review
- Claude Code Review docs and pricing
- Devin Review free PR review tool
- Codex code review setup guide
- Codex Security product page
- OpenAI Agents SDK skills guide
- AGENTS.md impact paper
- a16z consumer AI Top 100 list
- Memex(RL) experience memory paper
- WorldCompass RL post-training framework repo
Feature Spotlight
Claude Code adds multi-agent PR review (depth-first, priced per PR)
Anthropic is productizing multi-agent code review inside Claude Code to remove the new bottleneck (human review) created by AI-accelerated code output—priced ~$15–25/review with internal metrics showing large lifts in substantive findings.
Today’s dominant engineering story is Anthropic’s new Claude Code “Code Review” feature: PR-open triggers a team of agents to find/verify issues and leave a high-signal summary + inline comments. Excludes Codex review and other review tools unless directly compared to this Claude feature.
Jump to Claude Code adds multi-agent PR review (depth-first, priced per PR) topicsTable of Contents
🧑⚖️ Claude Code adds multi-agent PR review (depth-first, priced per PR)
Today’s dominant engineering story is Anthropic’s new Claude Code “Code Review” feature: PR-open triggers a team of agents to find/verify issues and leave a high-signal summary + inline comments. Excludes Codex review and other review tools unless directly compared to this Claude feature.
Claude Code adds multi-agent PR review with verified findings and severity ranking
Claude Code (Anthropic): Anthropic shipped Code Review for Claude Code—when a PR opens, it dispatches a team of agents to hunt issues in parallel, verify each finding to reduce false positives, and leave one high-signal summary comment plus inline flags, as described in the feature thread and launch note. It was built because code output per Anthropic engineer is up ~200% and human review became the bottleneck, per the launch note.

• Effectiveness numbers: internal testing reports substantive review comments moving 16% → 54%, with <1% of findings marked incorrect, and on 1,000+ line PRs it surfaces issues 84% of the time (avg 7.5 issues), per the feature thread.
• Cost and availability: reviews average $15–25 in token-billed cost and scale with PR complexity, and the feature is in beta research preview for Team and Enterprise, as stated in the feature thread.
It’s positioned explicitly as depth-first review rather than a fast skim, with an open-source GitHub Action called out as a lighter alternative in the feature thread.
Code Review triggers a trust debate: generation and verification may need separation
Review governance: Multiple builders are raising the concern that using the same system (or same vendor loop) to generate and review code can preserve shared blind spots; one framing is that “verification and trust are at the heart of code review” and may require an independent governance layer, as argued in the trust and independence thread. Others make the critique more bluntly—“The same LLM that generated your code now reviews it?”—in the who checks the checker post and same system concern.
The discussion isn’t rejecting AI review; it’s questioning whether orgs should intentionally separate incentives and models between “maker” and “checker,” especially as automated review becomes default.
Builders say Claude Code Review catches bugs they miss and becomes hard to give up
Claude Code Review (Anthropic): Early users are describing Code Review as unusually high-signal; Boris Cherny says it “catches many real bugs that I would not have noticed otherwise” in the early usage note, and another user calls it “one of those things I can’t remember how I lived without” in the user reaction. Similar feedback shows up from Anthropic-side advocates calling it a “game changer” for internal eng/research teams in the internal adoption comment.
The recurring theme is that the depth-first, multi-agent approach feels more like a “real review” than lint-like nitpicks, but the comments are still anecdotal and mostly from builders already living in agentic workflows.
Cognition ships Devin Review: free PR review by swapping github to devinreview
Devin Review (Cognition): Cognition launched Devin Review, a free PR review tool that works via a URL rewrite—“swap github with devinreview on any PR”—and claims features including Autofix, smart diff organization, copy/move detection, and codebase-aware chat, as shown in the launch post.

The positioning is an explicit “save $15–25” contrast to Claude Code Review’s per-PR pricing, but the tweets don’t include comparable accuracy/false-positive metrics or validation methodology beyond the launch post.
Per-PR AI review pricing shifts the market: $15–25 becomes a visible benchmark
Code review pricing: Claude Code Review’s disclosed average cost of $15–25 per PR in the pricing details is being treated by some as a market-clearing signal rather than a deal-breaker; one take is that pitching “cheaper” misses the point because you can often spend more tokens to buy depth and lower miss rates, per the pricing argument.
At the same time, competitors are explicitly anchoring against that number with “free” or “save $15–25” messaging—see the free alternative pitch—which suggests per-PR review has become a first-class SKU, not just a bundled feature.
Some orgs reportedly drop Copilot licenses as Claude Code-style agents take over
Tooling market signal: A practitioner report claims some startups are “taking away” GitHub Copilot mainly by canceling unused seats, because devs have moved to agentic tools like Claude Code and Codex, with Copilot seen as less central to “agentic coding,” per the license cancellation note.
This is not a direct metric on Code Review adoption, but it frames why PR review is suddenly strategic: if agents accelerate code output, review throughput becomes a gating function and product differentiator.
🧰 Codex reliability, limits, and new “in-progress” messaging primitives
Operational updates and workflow mechanics around OpenAI’s Codex + GPT‑5.4 in coding contexts: incident status, limit resets, and new response-structure fields that change agent UIs. Excludes Promptfoo acquisition (covered elsewhere).
GPT-5.4 adds a phase field so agents can message while still working
GPT-5.4 responses API (OpenAI): OpenAI added a message-level phase parameter so long tasks can emit user-visible “still working” updates tagged as commentary, distinct from a terminal final_answer, as shown in the phase parameter example; the same post notes you need to replay the phase values back to the API on subsequent turns to preserve behavior in multi-turn agents, per the phase parameter example.
Codex hanging incident resolves, then OpenAI resets rate limits
Codex (OpenAI): OpenAI acknowledged reports that Codex could hang and become unresponsive after sending a request, as described in the incident acknowledgement; a follow-up says the issue is now “fully resolved and stable” and that rate limits would be reset shortly, per the resolution note.
This reads like an ops playbook: confirm degradation, stabilize, then clear the backlog pressure by resetting limits.
Codex Security publishes scale stats on findings and false-positive reduction
Codex Security (OpenAI): Following up on initial launch—research-preview AppSec agent—one summary claims Codex Security has scanned 1.2M commits, found 792 critical and 10,561 high-severity issues, and surfaced 14 CVEs (OpenSSH, GnuTLS, Chromium, PHP), while cutting false positives by 50% and over-reported severity by 90%, as listed in the scale metrics post.
GPT-5.4 can accept mid-run messages that redirect the reasoning path
GPT-5.4 (OpenAI): Builders report that GPT-5.4 can accept an additional user message while it’s working and adjust its reasoning trajectory mid-task, with a demo shown in the mid-reasoning redirect clip; the same thread hypothesizes a chunked, stateful orchestration loop (“work in chunks and holds state”) rather than a single uninterrupted generation, per the mid-reasoning redirect clip.

How Codex code review works inside ChatGPT subscriptions
Codex code review (OpenAI): A usage walkthrough says Codex review is available via ChatGPT subscriptions by connecting GitHub, enabling code review, then choosing “review all PRs / just yours / explicit trigger,” with explicit triggers done by commenting @codex review this, as outlined in the setup walkthrough; it also claims Codex will only post a 👍 unless it finds high-priority issues, and that you can shape what “high priority” means using AGENTS.md, per the setup walkthrough.

OpenAI shares its “skills” pattern for maintaining the Agents SDK repos
Skills in Agents SDK maintenance (OpenAI Devs): OpenAI describes using repo-local skills to standardize recurring OSS maintenance workflows—verification, integration tests, release checks, and PR handoff—as summarized in the blog announcement and detailed in the skills workflow blog.
The post frames skills as “workflow packaging” close to the repo, so agents don’t need repeated, giant prompts to rediscover project conventions each run.
Codex weekly limit resets become part of the product ritual
Codex limits (OpenAI): Multiple posts treat weekly limit resets as a predictable cadence—one callout says a “Weekly Codex limit reset” is incoming in the reset notice, while the community memed the reset mechanic as “Saint Tibo” in the rate limit saint image.
🧪 Autonomous optimization loops: “autoresearch” for training code + self-improving agents
Training/optimizer and self-improvement loops where agents run experiments, tune hyperparameters/architectures, and stack improvements—beyond one-off prompting. This is about the optimization recipe and engineering patterns, not general agent runners.
Karpathy’s autoresearch loop stacks ~20 real training tweaks for ~11% faster “Time to GPT‑2”
Autoresearch (Andrej Karpathy): following up on Repo loop with a concrete metric win, his first unattended run left an agent tuning nanochat for ~2 days; it autonomously explored ~700 changes and kept ~20 that were additive and transferred from depth=12 to depth=24, cutting the leaderboard’s “Time to GPT‑2” from 2.02 hours to 1.80 hours (~11%) per the Autoresearch results.
• What changed (examples): the agent caught a missing scaler multiplier on parameterless QKnorm (attention too diffuse) and tuned multipliers to sharpen it, as described in the Autoresearch results.
• Regularization + attention tuning: it added missing regularization for value embeddings and found banded attention was too conservative, per the same Autoresearch results.
• Optimizer/schedule cleanup: it surfaced mis-set AdamW betas and tuned weight decay scheduling and init, again per the Autoresearch results.
The interesting bit isn’t novelty; it’s that the loop planned experiments based on prior results and committed improvements end-to-end, as shown in the Autoresearch results.
Hermes Agent open-sources self-evolution loop with a reported +39.5% skill gain
Hermes Agent self-evolution (Nous Research): Nous shipped an open-source “self-evolution” system that uses DSPy + GEPA to mutate and select improvements to Hermes’s own skills/prompts/code (no GPU training implied—API-driven), as described in the weekend ship log Weekend ship log and backed by a phase 1 validation report link in Phase 1 report.
• Reported delta: phase 1 validation cites a baseline-to-optimized score move from 0.408 → 0.569 (+39.5%) on an arxiv skill, as shown in the Key result screenshot and documented in the linked Validation report.
• Mechanism: the loop maintains a population, applies LLM-driven mutations targeted at failure cases, and selects by fitness, as outlined in the Weekend ship log.
The report frames this as “skill optimization” rather than model-weight training, per the Weekend ship log.
Karpathy calls agent-swarm autoresearch the “final boss battle” for frontier labs
Agent-swarm autoresearch (Karpathy): in the same thread as his nanochat results, Karpathy claims “all LLM frontier labs will do this,” framing multi-agent autoresearch as the “final boss battle”; the proposed recipe is swarms collaborating on smaller models, promoting the best ideas up the scaling ladder, with humans contributing “on the edges,” per the Final boss battle claim.
He also generalizes the approach: any metric that’s cheap to evaluate—or has an efficient proxy like training a smaller net—can be optimized by an agent swarm, as stated in the Final boss battle claim.
GEPA’s “optimize_anything” pitch expands prompt evolution into code/config optimization
optimize_anything (GEPA): the GEPA project is pitching a universal API for optimizing any text-representable parameter—not just prompts, but also configs and code—via an evolutionary loop, as linked in the Optimize anything link and described in the associated Optimize anything post.
The idea is showing up in today’s agent self-improvement discourse (e.g., Nous’s Hermes self-evolution using DSPy+GEPA), with “GEPA for pre-training” also name-checked in the GEPA pretraining mention.
ProRes proposes per-layer residual scalars with deeper-layer warmups for stable pretraining
ProRes (arXiv 2603.05369): a new pretraining stabilization trick proposes gradually increasing a scalar per residual branch, with longer warmup schedules for deeper layers, as summarized in the Paper screenshot.
The included figure shows perplexity improvements as depth increases when using ProRes compared to several other normalization/init schemes, per the Paper screenshot.
🛡️ OpenAI acquires Promptfoo to harden agentic security testing in Frontier
Capital + product move: OpenAI’s acquisition of Promptfoo to strengthen enterprise-grade evaluation/red-teaming for agentic systems. Excludes Codex Security feature metrics (kept in Codex category).
OpenAI acquires Promptfoo to strengthen agentic security testing in Frontier
Promptfoo (OpenAI): OpenAI announced it’s acquiring Promptfoo to strengthen “agentic security testing and evaluation” inside OpenAI Frontier, while keeping Promptfoo open source under its current license and continuing to support existing customers, per the Acquisition announcement.
The immediate read for engineering leaders is that LLM app eval + red-teaming is being treated as a first-class product surface (not a bolt-on checklist), with integration language echoed in follow-on coverage about baking it into Frontier workflows for scanning/testing/compliance, as described in the Frontier integration framing.
• Open-source continuity: OpenAI explicitly says Promptfoo “will remain open source” and that it will continue servicing customers, according to the Acquisition announcement.
• Enterprise positioning signal: multiple secondary posts repeat the claim that Promptfoo is already used by “25%+ of the Fortune 500” for evaluating/red-teaming LLM apps, as stated in the Frontier integration framing and reiterated in the Enterprise testing pitch; treat this as a marketing/coverage claim unless independently verified.
• Ecosystem reaction: dev-rel and community accounts welcomed the move (and the team) in posts like the Welcome note and the Developer endorsement, framing it as a practical step toward scaling eval rigor as “AI coworkers” land in production.
🤖 Hermes Agent shipping spree: self-evolution, multi-channel gateways, and failover ops
Operational and product updates for NousResearch’s Hermes Agent as a long-running, tool-using agent: new skills, deployment surfaces, reliability knobs, and safety plumbing. Excludes general agent-memory papers (covered elsewhere).
Hermes Agent ships a self-evolution loop for skills, prompts, and code
Hermes Agent Self‑Evolution (NousResearch): Nous shipped hermes-agent-self-evolution, an evolutionary self-improvement system that uses DSPy + GEPA to mutate and select improvements to Hermes’s own skills/prompts/code, per the weekend release notes in Weekend shipping thread. A Phase 1 validation report shared by Teknium shows an example uplift from 0.408 → 0.569 (+39.5%) on a skill benchmark, as highlighted in Validation result screenshot and documented in the linked Validation report PDF.
• What’s new vs “agent tunes prompt”: it’s positioned as population-based search (targeted mutations + fitness selection), not a single-shot rewrite loop, as described in Weekend shipping thread.
• Operational implication: it’s explicitly “no GPU training”—API-call driven optimization—so it’s deployable for teams without training infra, per Weekend shipping thread.
Hermes Agent adds one-line automatic model/provider failover
Hermes Agent (NousResearch): Nous shipped automatic provider failover, switching to a configured fallback model when the primary hits outages or rate limits, described as “one line of config, zero downtime” in Weekend shipping thread. It’s positioned as supporting multiple providers including Codex OAuth and Nous Portal in the same release note.

• Why this matters: in long-running agent deployments, failures tend to happen mid-run; this feature moves “retry + reroute” from user playbooks into the agent runtime, per Weekend shipping thread.
• Open question: the tweet doesn’t describe failover semantics (state handoff, tool auth continuity, partial-output replay), so the exact reliability behavior remains unspecified beyond the headline in Weekend shipping thread.
Hermes Agent adds pre-LLM secret redaction across tool output streams
Hermes Agent (NousResearch): Nous says Hermes now performs secret redaction everywhere, scrubbing tool outputs for keys/tokens/passwords before they enter LLM context; they claim 22+ patterns covering AWS, Stripe, HuggingFace, GitHub, SSH private keys, and DB connection strings in Weekend shipping thread. It’s a direct response to the common “tool output leaks credentials into the prompt” failure mode.
• Placement: the wording implies the redaction happens in the tool-output pipeline, not as a post-hoc “please redact” prompt, per Weekend shipping thread.
• Trade-off: regex/pattern redaction can break debugging by hiding the wrong substrings; the tweet lists pattern breadth but not false-positive controls, per Weekend shipping thread.
Hermes adds an expanded “abliteration” skill for de-refusal weight edits
Hermes Agent (NousResearch): Teknium says Hermes can now “abliterate” (remove refusal/guardrail directions from) open-weight models rapidly—reporting a Qwen‑3B result going from 75% → 0% on their internal table after ~5 minutes, and that this capability is being merged as a built-in Hermes skill in Abliteration results. The broader Hermes ship log calls this OBLITERATUS, describing multiple CLI methods, presets, and tournament-style evaluation in Weekend shipping thread.
• Scope: described as working across Llama/Qwen/Mistral families with “surgical” weight edits, per Weekend shipping thread.
• Risk note: this is explicitly a de-safety capability; teams integrating Hermes in shared environments will want to treat this as high-risk functionality, as evidenced by the “uncensor” framing in Weekend shipping thread.
Hermes Agent can autonomously play Pokémon via headless emulation + RAM tooling
Hermes Agent (NousResearch): Hermes shipped a Pokémon Player capability that runs Pokémon Red/FireRed headlessly and lets the agent drive the game through native tools—reading game state from RAM, making battle/navigation decisions, and persisting progress across sessions, as described in the weekend ship log from Weekend shipping thread. It’s a concrete example of “agent + tool API + persistent state” working end-to-end.
• Integration shape: the new pokemon-agent package exposes a REST game server; Hermes calls it as a tool rather than screen-scraping, per the details in Weekend shipping thread.
• Why it matters: it’s a reusable harness pattern for other deterministic simulators (games, sandboxes, emulators) where “read state → act → checkpoint” is the core loop, again as laid out in Weekend shipping thread.
Hermes Agent expands to iMessage and Signal with cross-platform parity
Hermes Agent (NousResearch): Hermes now runs on iMessage and Signal in addition to Telegram/Discord/WhatsApp/Slack/CLI, with Nous claiming feature parity across channels (voice notes, images, DM pairing) in Weekend shipping thread. This turns Hermes into more of a “reachable everywhere” agent surface, not just a terminal tool.
• Engineering shape: it’s presented as a single agent reachable via a 7-platform gateway, rather than separate bots per platform, per Weekend shipping thread.
• Operational edge case: multi-channel fanout plus long-running tasks tends to amplify rate-limit and provider reliability issues; the same thread pairs this with failover and redaction features, per Weekend shipping thread.
Hermes Agent hits #16 globally on OpenRouter rankings by tokens
Hermes Agent (NousResearch): OpenRouter’s app ranking screenshot shows Hermes Agent at #16 globally with 4.19B tokens, positioned among other high-usage apps, as shown in OpenRouter ranking screenshot. That’s a usage signal for “agent as product” adoption beyond model benchmarks.
• Context: the screenshot also shows OpenClaw and multiple coding agents ahead by orders of magnitude, which frames Hermes as meaningful but not top-tier by raw token volume yet, per OpenRouter ranking screenshot.
Hermes Docker sandboxes can mount host volumes for shared data and repos
Hermes Agent (Teknium/NousResearch): Teknium shared a concrete config pattern for giving a sandboxed Hermes agent access to host files via Docker volumes—either in config.yaml (terminal.backend: docker plus docker_volumes) or via TERMINAL_DOCKER_VOLUMES, including read-only mounts for datasets, per Volume mount config. Short sentence: it’s a clean way to make “agent has access” explicit.
• Operational detail: the example uses "/home/user/datasets:/data:ro", which prevents accidental writes while still enabling retrieval-heavy workflows, as shown in Volume mount config.
Hermes Agent positions local model + local runner support as first-class
Hermes Agent (Teknium/NousResearch): Teknium claims Hermes supports locally running models and running the agent locally—framed as “gets shit done” in Local run support. It’s a small but relevant positioning signal for teams that want agent workflows without routing all traffic through hosted providers.
The tweet doesn’t include setup specifics (providers, tool sandboxes, or model server compatibility), beyond the headline in Local run support.
🦞 OpenClaw in the wild: installs, reliability pain, and OpenRouter usage signals
Ecosystem and ops signals around OpenClaw (and “Claw” variants): deployment friction, reliability reports, and usage/partner metrics. Excludes Hermes Agent (separate category).
OpenClaw still too brittle for non-coders: failures, forgetting, and context overflows
OpenClaw (ecosystem): A detailed non-coder field report says OpenClaw “doesn’t work yet” in day-to-day use—scheduled jobs fail, the agent forgets how to use its own browser, it doesn’t read AGENTS.md, fallback models fail, and the system hits context overflow errors “a lot” even when using a 1M context model, with /new and /reset not clearing it as expected, per the Reliability pain report.
The same report also claims a daily 4am reset wipes ongoing work, internal thoughts keep leaking despite repeated requests, and “always-on” operation requires frequent manual intervention—useful as a reality check against the hype cycle, but still anecdotal and environment-specific (Telegram + long-running jobs).
macOS Tahoe VM: manual launchctl sequence revives OpenClaw gateway service
OpenClaw gateway (macOS): A concrete repair sequence is shared for a broken ai.openclaw.gateway LaunchAgent on macOS Tahoe inside Parallels, using launchctl enable, then bootstrap, then kickstart—with verification via lsof on 127.0.0.1:18789 and /health returning 200 OK, as shown in the Launchctl repair notes.
The note also points to an updater-bundle footgun: the shipped script used bootstrap/kickstart but omitted launchctl enable, which can leave the service missing after update, per the same Launchctl repair notes.
Shenzhen Tencent Building install meetup shows OpenClaw’s offline distribution
OpenClaw (China distribution): Photos from Shenzhen show a large public “公益装机” (public-interest installation) event outside the Tencent Building where volunteers help attendees install OpenClaw, positioned as evidence that OpenClaw’s memetic spread in China is crossing into offline community support, per the Shenzhen install photos.
The event framing matters because it implies (1) real installation friction still exists, and (2) distribution is being driven by community “setup help” rather than purely app-store style onboarding.
OpenClaw becomes top user of Nemotron 3 Nano 30B on OpenRouter
OpenRouter + OpenClaw (usage signal): NVIDIA’s dev-rel feed highlights that OpenClaw is now the top user of NVIDIA Nemotron 3 Nano 30B on OpenRouter, suggesting meaningful routing volume and a fast-moving “agent stack chooses the model” dynamic, as echoed in the Usage spotlight and repeated via the Follow-on repost.
This is a usage signal (not a quality claim), but it’s one of the few quantitative breadcrumbs about which open agents are actually consuming which model families at scale.
Vitest adds an “agent” reporter to cut token-heavy test output by 80–90%
Vitest (tooling for agents): A merged PR adds a new agent reporter that suppresses passed-test noise and prints mainly failures + summary, with an estimated 80–90% token reduction for coding agents that run Vitest, according to the Vitest PR link and the linked GitHub PR.
This is small but operationally important for always-on agents (including OpenClaw-style setups) where test logs often become the single biggest “wasted context” source during iterative fix loops.
“Claw” product line proliferation: Zhipu launches AutoClaw (stock +13% claimed)
AutoClaw (Zhipu) naming pattern: A post claims Zhipu launched AutoClaw and the stock moved +13%, adding it to a growing list of vendor-branded “Claw” offerings (KimiClaw, MaxClaw, and others) cited as an emerging market pattern, per the AutoClaw repost.
No primary launch artifact is included in the tweets here, so treat the numbers as unverified; the clearer signal is the accelerating “Claw” branding convergence around agent products.
Running OpenClaw with dedicated GPU to explore narrow fine-tunes vs Opus defaults
OpenClaw (personal ops): One builder reports giving OpenClaw access to an A6000 Blackwell box and using it to “continuously explore” fine-tuning smaller models for narrow tasks instead of defaulting to frontier models, as described in the Local GPU fine-tune note.
It’s a single-user anecdote, but it’s a concrete example of how OpenClaw is being used as a long-running “model-ops loop,” not just a chat agent.
🔌 Interop plumbing: MCP roundtrips, agent hooks, and agent-driven computer use
MCP servers, lifecycle hooks, and “agent can drive tools/UI” plumbing across IDEs and agent environments. Excludes general coding-assistant releases (and the Claude Code Review feature).
VS Code adds Agent Hooks preview for policy and workflow automation
Agent hooks (VS Code/Microsoft): VS Code shipped Agent Hooks (preview)—configurable lifecycle triggers that can run commands and enforce policies at moments like SessionStart, UserPromptSubmit, PreToolUse/PostToolUse, PreCompact, and Stop, instead of relying on repeated prompting, as described in the Agent hooks overview and detailed in the hook docs.

• Policy surface: hooks are positioned as a guardrail layer (block/allow actions; run checks; shape agent behavior) with structured JSON input/output plumbing, per the hook docs.
• Operational fit: the event list includes compaction and subagent boundaries, which makes it usable for “long run” agent sessions where drift tends to appear, as shown in the Agent hooks overview.
agent-browser ships “Vercel Sandbox” skill for isolated browsing
Vercel Sandbox skill (agent-browser/Vercel Labs): agent-browser introduced a new agent skill called Vercel Sandbox, installable via npx skills add vercel-labs/agent-browser --skill vercel-sandbox, to give agents an on-demand isolated browser environment for navigation, screenshots, extraction, and automation, as announced in the skill launch post and demonstrated in the environment demo.

• Isolation primitive: the pitch is “browser as a sandboxed tool”—useful when you want agents to browse without sharing your primary desktop/profile, per the skill launch post.
• Adoption signal: the same project hit 20k stars, according to the repo milestone note and the linked GitHub repo.
Perplexity Computer can drive Claude Code + GitHub CLI to open PRs
Perplexity Computer (Perplexity): Perplexity Computer can now operate Claude Code as a subagent and use the GitHub CLI to open pull requests, turning “computer use” into an agent-of-agents workflow, as shown in the PR automation demo.

• Interop detail: the demo flow shows Perplexity issuing tool work to Claude Code and then using gh for PR creation, collapsing multiple toolchains into one run loop, per the PR automation demo.
• Why it’s distinct: this isn’t a new model; it’s an orchestration layer that can delegate coding work to a separate agent harness (Claude Code) and then execute repo operations (GitHub CLI), as the PR automation demo illustrates.
Devin adds Datadog via MCP Marketplace integration
Datadog MCP integration (Devin/Cognition): Devin can now connect to Datadog through its MCP Marketplace, giving the agent direct access to observability data for workflows that need debugging context beyond logs-in-chat, as announced in the Datadog access note with setup steps in the integration docs.
• Plumbing angle: the practical value is wiring an agent into a monitoring plane (metrics/traces/logs) through MCP rather than bespoke adapters, per the Datadog access note.
VS Code improves Copilot’s C++ context with symbol + CMake awareness
C++ DevTools for Copilot (VS Code/Microsoft): VS Code added symbol-level context for C++ and CMake-aware build configuration so Copilot/agents can reason over definitions, references, and call hierarchies—and run builds/tests aligned to the active CMake configuration—per the C++ dev tools update and the C++ team blog.
• Interop plumbing: this is effectively tighter wiring between the agent, the language service’s symbol graph, and the build system configuration layer, as outlined in the C++ team blog.
VS Code Live tees up “code to canvas” roundtrip with Figma MCP
Figma MCP roundtrip (VS Code/Microsoft): following up on Bidirectional roundtrip (design-to-code loop), VS Code announced a livestream at 9:30am PT focused on a “full roundtrip” where Figma designs go into code and rendered UI can be captured back into Figma as editable frames, per the livestream announcement and the YouTube stream.
• Roundtrip framing: the key claim is bidirectional state transfer (code → rendered UI → Figma layers), not just design ingestion, as described in the livestream announcement.
🏠 Local runs & sandboxes: Qwen locally, dspy-on-laptop stacks, and volume mounts
Practical self-hosting and sandbox wiring: local model serving, agent sandbox file access, and performance footguns. Excludes new model announcements (covered under model releases).
Run Qwen3.5 locally via Claude Code using llama.cpp server (Unsloth guide)
Unsloth (Qwen3.5 local runs): A step-by-step recipe shows how to point Claude Code at a local llama-server running Qwen3.5, targeting “local agentic coding” on machines with 24GB RAM or less, as outlined in the [setup thread](t:15|setup thread) and the linked [setup guide](link:15:0|Setup guide).
• Agentic extension: The same walkthrough also demonstrates building a Qwen 3.5-based agent that can autonomously fine-tune models using Unsloth, according to the [thread details](t:15|fine-tune agent example).
Claude Code local-model footgun: KV-cache invalidation can make inference ~90% slower
Claude Code (local inference performance): A reported integration gotcha says Claude Code can invalidate the KV cache for local models by prepending IDs, making inference about 90% slower, per the [Unsloth note](t:15|KV-cache slowdown note). It’s a small detail with big cost impact.
A follow-on comment suggests this behavior may differ when routing through Anthropic endpoints (potentially “stripped server-side”), per the [endpoint behavior question](t:660|Endpoint stripping question).
DSPy on a laptop: uv + llama-cpp server + GGUF + JSONAdapter minimal stack
DSPy (local dev stack): A compact “freest stack” for running DSPy against a local model pairs uv with llama-cpp-python[server], serves a GGUF (example: “Baguettotron”), and wires DSPy via an OpenAI-compatible base URL plus JSONAdapter, as shown in the [command-and-code snippet](t:270|Local DSPy stack).
This is a reproducible template for laptop-only experimentation where you want DSPy’s program structure without paying hosted inference.
Agent sandbox file access: Docker volume mounts via config.yaml or TERMINAL_DOCKER_VOLUMES
Hermes Agent (Docker sandbox wiring): A concrete pattern for giving a sandboxed agent durable file access mounts host paths into the agent container via config.yaml (terminal.backend: docker + docker_volumes) or a TERMINAL_DOCKER_VOLUMES env var, including read-only dataset mounts (e.g., ...:/data:ro), as documented in the [volume-mount snippet](t:268|Docker volumes config).
Portless adds .localhost → /etc/hosts auto-sync for browser routing edge cases
Portless (local dev routing): Portless added an option to auto-sync *.localhost hostnames into /etc/hosts when a browser doesn’t resolve them reliably; it supports a one-time sudo portless hosts sync or continuous syncing via PORTLESS_SYNC_HOSTS=1, as shown in the [command example](t:238|Hosts sync commands).
This is mostly plumbing, but it removes a recurring “why won’t my local URL resolve” failure mode in agent-and-browser-heavy workflows.
🏢 Enterprise assistants: Microsoft Copilot Cowork, JetBrains Air, and “multi-model” claims
Enterprise-oriented agent products and integrations (M365/IDEs) where governance, permissions, and cross-app execution are the main selling points. Excludes Anthropic’s Claude Code Review feature (covered as the feature).
Microsoft launches Copilot Cowork to execute multi-step work inside Microsoft 365
Copilot Cowork (Microsoft): Microsoft announced Copilot Cowork for Microsoft 365 users—turning a request into a plan and then executing it across apps and files while staying inside M365 security/governance boundaries, following up on background workflows (scheduled background tasks) with a more explicit “handoff and run” product surface as described in the launch blurb.

Execution is framed as “durable” and auditable inside the tenant, per the product excerpt, which is the practical enterprise hook compared to desktop-agent tools that need separate identity and data access plumbing.
JetBrains introduces Air, an agentic dev environment with multi-model support and isolated runs
Air (JetBrains): JetBrains introduced Air, an “agentic development environment” that supports Codex, Claude, Gemini, and JetBrains’ own Junie—available via JetBrains subscription or BYOK—positioned around running multiple agents in parallel with isolation primitives (Docker/worktrees) as summarized in the announcement and detailed on the product page.

• Workflow shape: Air is pitching “multitask with agents, stay in control,” with parallel execution plus visibility into what each agent is doing; the isolation framing is the key differentiator versus single-session CLI loops.
No pricing or rollout timeline is given in the tweet beyond the product landing page, but the integration list (Codex/Claude/Gemini) makes it one of the more explicit multi-vendor IDE agent plays surfaced today.
Copilot Cowork positions a multi-model stack and Anthropic collaboration as the differentiator
Copilot Cowork (Microsoft): Product materials and community amplification are leaning hard on a “multi-model advantage” story—Microsoft says it integrated technology “behind Claude Cowork” and will pick models “regardless of who built it,” as shown in the multi-model excerpt, and echoed in the recap video.
• What’s concrete vs implied: the concrete part is the M365 security boundary + sandboxed execution claim in the same excerpt; the “right model for the job” routing story is asserted, but no model list, routing policy, or audit surface for which model was used is described in these tweets.
The messaging matters because it’s a direct answer to enterprise procurement fears about vendor lock-in—while also raising obvious questions about transparency and change control when “best model” shifts month to month.
Copilot Cowork prompts skepticism about silent model downgrades and model staleness
Model transparency (Copilot Cowork): Even sympathetic observers are flagging a core risk: whether Microsoft will keep users on “lower-end models without telling you,” and whether Cowork stays current as frontier capability moves fast, per the skepticism note. A specific motivation is the magnitude of recent deltas—e.g., the same thread cites GPT-5 going from 38% to GPT-5.4 at 82% on expert tasks (GDPval-style framing), making “stale by months” a real product-quality cliff as argued in the skepticism note.
A second open question is scope: whether outputs are constrained to Microsoft apps/documents versus broader “improvise with code” workflows that made other agent products compelling, as raised in the scope question.
🌈 Google model/app churn: Gemma 4 leak, Gemini “effort level” controversy, Nano Banana 2
Google’s Gemini/Gemma wave: leaked evidence of upcoming models, app-level generation upgrades, and controversy around hidden reasoning effort controls. Excludes general benchmarks (tracked in evals category).
Gemini users claim a hidden “EFFORT LEVEL: 0.50” throttles reasoning
Gemini (Google): Screenshots show Gemini acknowledging an “effort level” parameter in its system instructions—reported as 0.50—with claims this affects Pro and Custom Gems while Canvas mode may behave differently, as captured in System prompt leak. Another update alleges AI Studio’s reasoning presets map to numeric effort levels (Low 0.25, Med 0.50), per Effort level update.

• Why it’s contentious: If effort differs by surface/tier without an explicit user control, it complicates regression tracking (“did the model change, or did the knob?”) and makes anecdotal comparisons noisier.
No first-party Google statement appears in these tweets, so the mechanism and scope remain uncertain.
Gemma 4 shows up in a LiteRT-LM PR adding NPU support
Gemma 4 (Google): A pull request in google-ai-edge/LiteRT-LM titled “Add NPU support … for Gemma4 model” (authored by copybara-service[bot]) suggests device/runtime integration work is already underway, as shown in LiteRT-LM PR mention.
This is evidence of ecosystem plumbing (LiteRT-LM + NPU path) rather than an official model launch; no weights, licensing, or public model card details are implied by the PR alone.
Gemini Interactions API demo: analyze a YouTube video in one call
Gemini Interactions API (Google): A code example shows client.interactions.create() taking mixed inputs (text prompt + video URI) to extract capabilities from a YouTube talk in one request, as shown in Interactions API code.
This pattern frames “video” as a first-class artifact for agent workflows (summarize, extract claims, generate notes) without a separate transcription step in the client code.
Gemma 4 sizing rumor repeats: ~120B total, ~15B active
Gemma 4 (Google DeepMind): Multiple accounts are repeating an MoE sizing claim of ~120B total parameters with ~15B active, without an official spec sheet, as stated in Size rumor screenshot and echoed again in Repeat sizing claim.
Treat this as unconfirmed; if true, it positions Gemma 4 as a materially larger open-weight offering than prior Gemma-family expectations, with implications for serving footprints and quantization targets.
Nano Banana 2 update adds aspect ratio, templates, and character preservation
Nano Banana 2 (Gemini app): Google’s Gemini app says “Nano Banana 2” is now live with improvements to real-world knowledge, advanced text rendering, image templates, aspect ratio control, and character preservation, per Feature list.
The post reads like an app-surface image generation refresh plus UI controls; it doesn’t mention API availability, versioning, or pricing changes.
A “fun week of launches” tease kicks up Gemini/Gemma speculation
Google launch cadence (DeepMind/Gemini): Logan Kilpatrick posted “Going to be a fun week of launches” in Launch tease, and follow-on chatter immediately lists possible drops like Gemini 3.1/Flash GA and Gemma 4 based on recent sightings, per Launch-week speculation.
There’s no concrete release artifact in these tweets; the signal is that builders expect multiple surface-level changes inside a week, which historically increases comparison noise across app, CLI, and API entry points.
DeepSeek v4 rumor returns with “highly likely this week” timing
DeepSeek v4 (DeepSeek): Timing speculation is circulating again—“highly likely this week” in Timing claim—alongside a screenshot of a chat with a partner/provider asserting the same estimate in Provider chat screenshot.
This remains rumor-level in the provided tweets (no release notes, model card, or endpoint evidence shown).
Gemini app surfaces Google Flights as an in-chat tool
Gemini app (Google): A screenshot shows Gemini calling Google Flights inside the app—“3 successful queries” plus a “Try again without apps” fallback—indicating a tool-style integration rather than pure text answering, per Flights integration screenshot.
This is a concrete instance of Gemini’s product-tool surface expanding (and therefore another axis where behavior can differ between “chat” and “tool-backed” answers).
Users try an “EFFORT LEVEL: 1.50” prompt to counter Gemini output drops
Gemini (Google) prompting pattern: People are prefixing chats with SPECIAL INSTRUCTION: think silently if needed. EFFORT LEVEL: 1.50 and claiming output quality improves, with an example demo in Prompt hack demo.

It’s presented as a lightweight prompt-side override; whether it consistently affects internal routing/compute allocation (vs. being treated as ordinary text) isn’t established in the shared evidence.
📊 Benchmarks & usage dashboards: where models win (coding vs design vs sycophancy)
Model/agent evaluation and market measurement: leaderboards, adoption indices, and benchmark design critiques. Excludes individual model launch rumors (covered under model releases).
a16z Consumer AI Top 100 returns with new rules for what counts as “AI”
Consumer AI Top 100 (a16z): The 6th edition updates its ranking rules to include AI-powered mainstream products (not only “AI-native”), and publishes refreshed web + mobile top-50 lists using January 2026 traffic data, as described in the Ranking rules change thread.
• Scope change: Products like Canva/Notion/CapCut/Grammarly now sit alongside chatbots and image tools because AI is “core to the experience,” per the Ranking rules change explanation.
• Competitive snapshot: The web list shows ChatGPT, Gemini, Canva, DeepSeek, and Grok in the top 5, as visible in the Ranking rules change.
a16z per-capita adoption index puts the US at #20 for AI usage intensity
AI adoption index (a16z): a16z publishes a per-capita “AI adoption” heatmap placing the US at #20 (with Singapore, UAE, and Hong Kong leading), based on blended web + mobile monthly uniques per capita, as shown in the Adoption map post.
• Market share fragmentation: Separate a16z charts argue chatbot share is splitting into three camps (Western tools, China, and Russia), with country-by-country slices shown in the Market share by country graphic.
• Engagement vs installs: Another chart claims ChatGPT holds ~87% share of app time spent (far higher than Gemini/Claude/Grok), as visible in the Time spent share chart screenshot.
Epoch AI adds new benchmarks; GPT-5.4 Pro narrowly edges Gemini 3.1 Pro
Epoch AI Capabilities Index (Epoch AI): Epoch says it updated its Capabilities Index with three added benchmarks—APEX-Agents, ARC-AGI-2, and HLE—and reports a fresh estimate where GPT-5.4 Pro scores 158 vs Gemini 3.1 Pro at 157, according to the Index update announcement.
The same post positions the website refresh as a usability change (“make it easier to find and use our work”) while explicitly tying the index update to the newly integrated benchmark set, as stated in the Index update thread.
BridgeBench ranks GPT-5.4 highest on debugging scenarios
BridgeBench (BridgeMind): A BridgeBench leaderboard screenshot ranks GPT-5.4 #1 overall and shows it leading the debug subscore over Claude Sonnet 4.6 and Claude Opus 4.6, according to the Benchmark table post.
The same table also surfaces the trade-off pattern BridgeMind keeps emphasizing—strong algorithm/debug/refactor scores alongside weaker UI/security components—based on the category breakdown visible in the Benchmark table image.
DesignArena shows a persistent GPT-5.4 gap on UI/design vs Claude Opus 4.6
DesignArena (Arcada Labs): A DesignArena Elo snapshot places Claude Opus 4.6 at the top (≈1381 Elo) while GPT-5.4 (Medium) appears around rank #9–10 (≈1309 Elo), as shown in the DesignArena rankings post.
The tweet frames this as “Claude owns UI work,” with Gemini 3.1 Pro Preview in the middle and multiple GPT-5.4 effort settings clustered lower in the same chart, per the DesignArena rankings commentary.
New “Opposite-Narrator Contradictions” benchmark quantifies sycophancy via perspective flips
Opposite-Narrator Contradictions (Lech Mazur): A new benchmark tests whether a model keeps the same judgment under opposite first-person narrations of the same dispute, and reports a contradiction-based “sycophancy rate” across 16 models, as introduced in the Benchmark definition post.
• Leaderboard snapshot: The chart shows Gemini 3.1 Pro Preview at ~0.5% and GPT-5.4 (medium reasoning) at ~2.0% on the headline contradiction metric, as read off the Benchmark definition image.
• Reproducibility hook: The author links more details and case structure via the public repository referenced in GitHub repo.
Document Arena ranks Anthropic models top for PDF reasoning and analysis
Document Arena (Arena.ai): Arena highlights a Document Arena snapshot where the top three PDF/document-analysis models are all Anthropic—#1 Opus 4.6, #2 Sonnet 4.6, #3 Opus 4.5—based on anonymous side-by-side votes on user-uploaded PDFs, per the Leaderboard note post.
Arena also points to a walkthrough explaining the evaluation flow and file handling, using the Walkthrough video as the primary artifact.
🧠 Long-horizon agents: indexed memory, AGENTS.md, and identity/governance primitives
How teams keep agents coherent over long tasks: structured memory, repo instruction files, and access/control layers. Excludes general security policy disputes (separate category).
AGENTS.md study reports 28.6% lower runtimes for AI coding agents
AGENTS.md efficiency evidence: Following up on Collaboration contract—repo instruction files as agent contracts—a new paper reports that having an AGENTS.md is associated with a 28.64% lower median runtime and 16.58% fewer output tokens for AI coding agents, per the AGENTS.md paper.
The paper’s claim is practical: instead of re-prompting repo structure every session, a single canonical file reduces agent “orientation time” across tasks, as summarized in the AGENTS.md paper.
Memex(RL) proposes indexed experience memory to scale long-horizon agents
Memex(RL) (Accenture): A new arXiv preprint proposes indexed experience memory for long-horizon LLM agents—building a structured, searchable index of past experiences instead of relying on raw context windows, as shown in the Paper screenshot.
It frames the core problem as agents losing track of what they tried and what worked on longer tasks, then introduces an RL loop to optimize when to write and retrieve memories (so memory isn’t just “dump more context”), as described in the Paper screenshot.
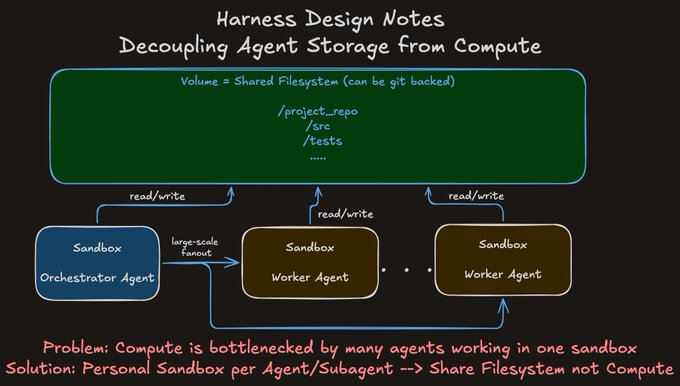
Harness pattern: give each agent its own sandbox and share only the filesystem
Harness design pattern: A concrete architecture pattern for long-running multi-agent work is to decouple storage from compute—give each agent/subagent its own sandbox while sharing a git-backed volume so they coordinate through the repo/filesystem rather than contending for one execution environment, as explained in the Harness design notes.
This is motivated by local runs where code execution fans out and shared compute becomes the bottleneck; the proposed fix is “personal sandbox per agent, shared filesystem not compute,” per the Harness design notes.
Teleport proposes giving every agent a first-class identity
Teleport (Agentic Identity Framework): Teleport is pitching a control-plane primitive for agent fleets—treating each agent as a first-class cryptographic identity with least-privilege access and auditable tool/service usage, as described in the Framework overview.
It explicitly calls out securing MCP tool calls, tracking budgets/guardrails, and detecting “shadow agents” and policy violations (with orchestration hooks like Kubernetes/Temporal mentioned), per the Framework overview.
ClawVault open-sources a markdown-native persistent memory vault for agents
ClawVault (Versatly): An open-source “persistent memory” system for agents stores memory as human-readable markdown with graph-aware links, plus primitives like checkpoints and search—positioned as local-first and git-friendly, as described in the Project summary and documented in the GitHub repo.
Supermemory pitches hook-injected memory instead of explicit “remember” tool calls
Supermemory: A workflow pitch for long-horizon coherence is to move “memory updates” out of the agent’s tool loop—send facts to Supermemory and let it maintain a knowledge graph plus auto-inject the right slice of context per turn via hooks, rather than relying on the model to decide when to recall/update, as described in the Usage tip.
The thread also claims a Claude Code plugin exists for this injection path, per the Usage tip.
Agent sandboxes: Docker volumes for durable file access and read-only datasets
Sandbox file access: A concrete setup pattern for long-horizon agents running in Docker is to mount host directories into the agent sandbox via config—e.g., bind-mount /projects read-write and datasets read-only—using terminal.docker_volumes or the TERMINAL_DOCKER_VOLUMES env var, as shown in the Config snippet.
This is a small but important enabler for persistent agent workflows: it keeps artifacts, logs, and intermediate state accessible across sessions without copy/paste, per the Config snippet.
⚖️ AI policy & government collisions: Anthropic sues over federal blacklisting claims
Policy/legal events with direct operational impact on AI deployment, especially government procurement and restrictions. Excludes general privacy-attack research (separate category).
Anthropic files two lawsuits challenging federal “supply chain risk” label and Claude stop-use order
Anthropic (Claude): Following up on Supply risk (Pentagon “supply chain risk” notice) and Sue plan (Amodei said they’d sue), Anthropic has now filed two lawsuits seeking to overturn both the “supply chain risk” designation and an order requiring federal agencies to stop using Claude, as reported in the Lawsuit claim and summarized in the Axios summary.
The complaint frames the designation as retaliation for protected speech, with Anthropic alleging the conflict escalated after it refused to remove Claude restrictions on autonomous lethal warfare and mass surveillance of Americans, as described in the Filing details. The filing also signals procurement impact beyond DoD by naming multiple agencies as defendants (including “U.S. Department of War” in the caption), per the Filing details.
Amodei reiterates Claude red lines on autonomous weapons and mass domestic surveillance
Anthropic (Claude): Dario Amodei published a public statement on Anthropic’s discussions with the “Department of War,” positioning Anthropic as supportive of national-security use (including deployments in classified environments) while keeping explicit red lines against fully autonomous weapons and mass domestic surveillance, as laid out in the Company statement.
The statement matters operationally because it’s a primary-source articulation of what Anthropic will and won’t permit in government deployments—constraints that are now intertwined with procurement access and the ongoing blacklisting/lawsuit narrative in the Blacklisting chatter.
🕵️ Privacy threats: LLM-driven de-anonymization and camera-free tracking via WiFi
Concrete research and demos showing new privacy attack surfaces enabled by agents/VLMs, relevant to product security and policy. Excludes government procurement/legal disputes (separate category).
Study: LLM agents can unmask pseudonymous social accounts at scale
LLM-driven de-anonymization (research): A study recap claims agents can link pseudonymous social accounts to real identities by scraping scattered personal details across posts—work that used to take “hours” for a human investigator can be done “in minutes,” raising the floor on targeted phishing/doxxing at scale, as described in the study recap.
The operational point is that “pseudonymity-by-fragmentation” (lots of small, individually non-identifying facts) looks increasingly brittle once an agent can autonomously collect, normalize, and cross-reference those fragments across platforms, per the study recap.
WiFi-DensePose: open-source pose tracking through walls using WiFi CSI
WiFi-DensePose (open source): A 100% open-source repo (reported at ~32K stars) reconstructs a 17-point human skeleton “through walls” using commodity WiFi signals and channel state information (CSI), with inexpensive receivers (e.g., ESP32-class) and an AI model translating amplitude/phase distortions into motion—see the walkthrough in project thread.

• What’s new for privacy threat models: It’s framed as camera-free tracking with no special imaging hardware—just ambient RF plus sensors—making “no cameras” less meaningful as a privacy boundary in some environments, per the project thread.
“Mass surveillance was hard… until Opus 4.6” becomes a capability meme
Surveillance capability signal (community): A short clip captioned “Mass surveillance was hard…until Opus 4.6” is circulating as a meme, reflecting a growing belief that stronger models plus better agent harnesses are lowering the effort required to operationalize surveillance-style workflows, as amplified in meme clip.

It’s not evidence of a specific new technique by itself; it’s a sentiment marker that builders are increasingly connecting model quality (Opus 4.6) with end-to-end monitoring/attribution risks, per the framing in meme clip.
⚡ Compute & money signals: Oracle’s Abilene rebuttal, energy scaling, and IPO skepticism
Infra signals that affect AI supply/demand: data center build claims, energy constraints, and capital-market narratives. Excludes tool-level rate limits (covered in coding assistant categories).
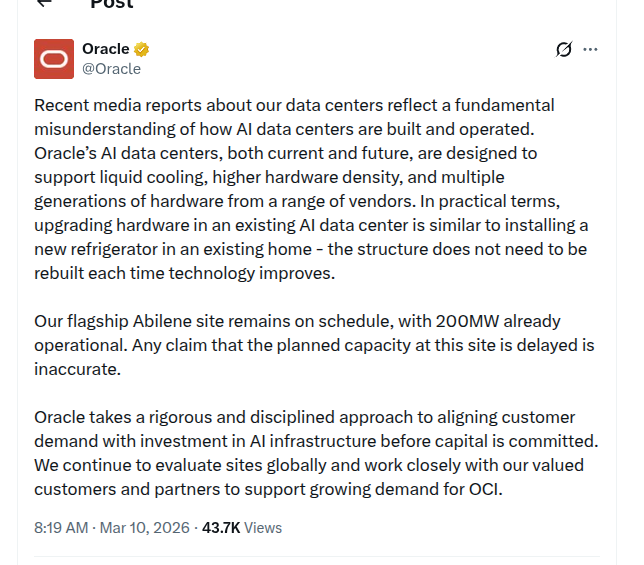
Oracle denies Abilene slowdown and says 200MW is already operational
Abilene AI data center (Oracle): Oracle issued another on-record rebuttal saying its Abilene site “remains on schedule,” with 200MW already operational, and calling any claim of delayed capacity “inaccurate,” per the Oracle statement excerpt.
Oracle also argues the reporting misunderstands upgrade dynamics—saying its AI data centers are designed for liquid cooling, higher density, and multiple hardware generations, and likening hardware refresh to “installing a new refrigerator” (no building rebuild), as described in the Oracle statement excerpt. In the earlier statement amplification, Oracle additionally claimed it has completed leasing for an additional 4.5GW to meet commitments to OpenAI, as summarized in the 4.5GW lease claim and echoed via the Oracle denial post.
OpenAI IPO chatter highlights valuation-vs-profitability tension
OpenAI IPO (capital markets): Investor conversations are described as mixed, with claims that OpenAI is at least six months away from an IPO and facing skepticism around an ~$850B valuation, a ~28× projected 2026 revenue multiple, and a profitability timeline that could extend to ~2030, as laid out in the IPO skepticism thread.
The same thread positions competitive pressure—explicitly naming Anthropic—as part of the “needs to reduce costs and further increase revenue” argument, per the IPO skepticism thread.
Energy becomes the bottleneck narrative, with China’s solar buildout as the exhibit
Energy constraint (China solar buildout): A widely shared datapoint framed AI progress as power-limited: “162 square miles of solar panels” on a high plateau, used as evidence that “whoever wants to win the race for AGI must also be the largest energy producer,” per the Solar plateau photos.
The post’s core claim is a supply-side one—panel manufacturing scale plus deployment scale lowering energy costs—rather than a model-side breakthrough, as stated in the Solar plateau photos.
🎬 Generative media pipeline updates: video motion control, 3D post, inpainting, brand assets
Creative tooling and media-model workflows that matter to builders shipping gen-media products: video identity control, 3D workflows, and inpainting/text rendering. Excludes general Gemini/Gemma model rumors (covered elsewhere).
Kling 3.0 and Motion Control land with 1080p output and mocap-style facial control
Kling 3.0 (Kling): Kling 3.0 and Kling 3.0 Motion Control were announced as generally available, with positioning around native 1080p “cinematic-grade” output and stronger emotional expression, as shown in the Launch announcement demo.

• Motion precision: Motion Control is framed as improving facial stability and motion fidelity “on par with professional motion capture,” per the Motion control details clip.
The tweets don’t include pricing, latency, or an API surface description; the concrete signal today is output quality + control emphasis rather than a new integration surface.
ComfyUI adds HY 3D advanced workflows for decomposition, UVs, and mesh cleanup
HY 3D advanced (ComfyUI/Tencent Hunyuan): ComfyUI shipped “HY 3D advanced” templates and nodes for production-oriented 3D post-processing—parts decomposition, UV unwrapping, and smart topology—as outlined in the Workflow release update.

• Workflow entry point: The release notes describe using Workflow templates (Workflow → Browse Templates → 3D) or searching for Hunyuan3D API nodes, per the Workflow release instructions.
Tencent’s team also echoed the rollout, per the Tencent acknowledgment post, but without additional technical specs.
ComfyUI workflow template for image+audio lip-sync video using LTX-2.3
LTX-2.3 workflow (ComfyUI templates): A new LTX-2.3 template shows how to generate a lip-synced video from an image plus an audio clip—shared as a ready-to-run ComfyUI workflow in the Workflow post, following up on LTX-2.3 release (open-source local video model).

The exact JSON is linked from the same post as a Workflow template, which makes it straightforward to wire into existing ComfyUI-based pipelines without rebuilding nodes by hand.
fal adds OneReward: unified inpainting with improved text rendering
OneReward (fal): fal says OneReward is now live, positioning it as a unified inpainting model that covers fill/extend/object removal while improving text rendering and mask-guided generation, as announced in the Model launch note.
• Availability: The model is framed as directly runnable “on fal,” with follow-up example outputs posted in the Example outputs thread.
No independent quality evals are included in the tweets; this is a distribution/availability update plus a feature claim.
MatAnyone 2 ships with a learned quality evaluator for scaled video matting
MatAnyone 2 (Hugging Face): MatAnyone 2 was announced as released on Hugging Face, framing the upgrade around scaling video matting using a learned quality evaluator; the release includes a paper link and an interactive app in the Release post.

The primary artifacts are the Paper page and the Demo app, which make it immediately usable for background removal/foreground extraction stages in video pipelines (ads, creator tools, compositing).
A repeatable “lofi loop” pipeline: still image → upscale → seamless loop
Lofi loop workflow (Freepik + video models): A creator shared a short “lofi loop” pipeline that starts with generating stills (via Freepik’s Z-Image), upscales them, then loops the animation; the end-to-end examples are shown in the Pipeline walkthrough.

• Looping constraint: The same thread notes leveraging Kling 3.0’s 15-second clip limit to close loops cleanly, aligning with the Kling 3.0 clip-length context in the Kling 3.0 note.
The post is tutorial-style rather than a product release; the new value is a concrete, reproducible sequence for teams making short, branded ambient clips.
🧱 Builder utilities: doc parsing, UI annotation for agents, and personal knowledge inboxes
Non-assistant dev tools and OSS repos that help engineers feed context, parse documents, or structure work for agents. Excludes MCP/protocol tooling (separate category).
Agentation launches UI annotations that export selectors and source paths for agents
Agentation (Agentation): Agentation’s new site describes a desktop UI annotation tool that captures high-signal frontend feedback (CSS selectors, source file paths, component hierarchy, computed styles) and formats it so you can paste it into Claude Code/Cursor-style agents, as outlined in the [product overview](t:122|product overview) and detailed in the [site docs](link:122:0|Product walkthrough).
• Round-trip detail: It’s positioned as a way to stop “describe it in words” UI bug reports by turning hover/click annotations into structured context the agent can act on, per the [workflow description](link:122:0|Product walkthrough).
• Optional live sync: The same docs mention a real-time sync mode (via MCP) so an agent can read annotations directly, but the core value remains the copy/paste artifact, as described in the [MCP sync section](link:122:0|Product walkthrough).
Surreal Slides converts PowerPoints into structured markdown for agents
Surreal Slides (LlamaIndex): Surreal Slides is a utility that converts a directory of PowerPoint files into clean structured Markdown (and data suitable for DB storage) so coding agents can consume deck content without screenshots, described in the [tool demo](t:140|tool demo).

It’s framed as a workaround for low-fidelity slide understanding in existing agent integrations—especially charts/tables—by doing offline conversion and then serving the outputs for retrieval (including a SurrealDB-backed flow), per the [launch description](t:140|tool demo).
keep.md adds a personal email inbox that converts newsletters to markdown
keep.md (keep.md): keep.md added a personal email inbox for subscribing to newsletters and confirming addresses, then ingesting messages as Markdown that can be accessed by agents via API/CLI/skill, as shown in the [feature announcement](t:115|feature announcement) alongside the [product page](link:115:0|Product page).

The same update frames email as another “capture surface” to feed an agent’s working set, extending beyond prior link/bookmark ingestion, per the [demo flow](t:115|feature announcement).
LlamaIndex doubles down on OCR, pitching chart-to-markdown accuracy as the moat
LlamaParse (LlamaIndex): LlamaIndex is positioning LlamaParse around document OCR quality—explicitly calling out charts and complex visuals as a gap where they use tuned VLMs to render “highly accurate markdown,” per the [chart parsing pitch](t:371|chart parsing pitch) and the [strategy memo](t:529|strategy memo).

The same thread says the company moved from a broad RAG framework posture toward “document infrastructure” as agents get better and context quality becomes the limiting factor, as described in the [focus shift](t:529|strategy memo).
napkin-math refreshes its systems-performance baseline numbers on a larger machine
napkin-math (sirupsen): the napkin-math repo updated its reference benchmark table using a c4-standard-48-lssd machine (previously a 6-core 2019 VM), publishing new latency/throughput numbers for CPU, SSD, hashing, compression, and sorting, as shown in the [updated table screenshot](t:254|updated table screenshot) and captured in the [repo](link:254:0|GitHub repo).
This is a practical recalibration for capacity planning and “back of the envelope” infra estimates, especially when agent workloads change bottlenecks from network to disk or from CPU to memory bandwidth, per the [bench refresh note](t:254|updated table screenshot).
Textual adds a GC mitigation switch for smooth scrolling of very large markdown
Textual (Textualize): Textual addressed brief (<100ms) scroll freezes on very large documents—explicitly called out as the kind “agents produce”—by breaking reference cycles with weakrefs and adding an option to disable garbage collection while scrolling, as described in the [performance note](t:352|performance note).

The report also notes Python 3.14 reduced the symptom, but the app-level changes improved smoothness across versions, per the [same update](t:352|performance note).
🧭 Engineering practice shift: skills erosion fears, org productivity, and ‘learn to code’ debates
The discourse itself: how engineers and orgs are adapting to agentic coding—skill-building concerns, role changes, and quality vs speed attitudes. Excludes pure product updates.
Coding literacy debate: “not knowing how to code” isn’t an advantage
Coding literacy (AI tooling discourse): Pushback is stacking up against the “non-coders have an advantage” take—builders argue that understanding code improves prompts and debugging, as reflected in the coding literacy stance and the analogy rebuttal reactions; the same thread of thought also shows up in a framing that output quality often comes down to prompt clarity and constraints, not model quality, per the prompting reflection. This is a skills signal.
The disagreement here isn’t about whether agents help—it’s about whether ignorance is leverage.
Org-level framing: efficiency gains depend on restructuring choices, not just tools
Organizational efficiency (AI adoption): A recurring point is that “individual productivity” talk is less informative than the org-level question—how teams re-organize to absorb AI, as argued in the org efficiency framing. In a related thread, the claim is that even if model progress froze, workflows would still transform over 5–10 years as organizations learn how to apply current tools, per the work transformation post. This is a management signal.
The operational implication is that structure choices can dominate tool capability.
“AI button” analogy: agentic coding changes motivation and craft feelings
Motivation shift (agentic coding): One practitioner describes a “drug/button” dynamic—once the tool exists it’s hard not to press it, but it can also erase the “mystery” and late-night drive of solving problems manually, as laid out in the button analogy reflection. It’s personal, but it maps to a wider craft anxiety: throughput rises while intrinsic motivation can drop.
The post is also a reminder that “review the code” isn’t the whole emotional story.
Quality vs velocity tension: frustration with LLM code and failed rewrites
Code quality tension (LLM-assisted dev): Some builders say they don’t want to ship more—they want the same output at higher quality, as stated in the quality-over-quantity note. The dark side shows up as maintenance drag: reports of finding “garbage LLM code” that models then can’t reliably improve, per the bad day recap and the repeated ‘generated code is shit’ gripe. This is about rework.
The common thread is that generation can shift the bottleneck from writing to cleanup and judgment.
Skill-building concern resurfaces: AI coding assistants may impair understanding
Skill-building concerns (AI-assisted coding): A claim circulating again is that AI coding assistant use can impair conceptual understanding, with Anthropic’s own research being cited as evidence in the vibe-coding harms skills post. This is being used as rhetorical ammo in the “vibe coding vs skill growth” debate.
The primary artifact isn’t linked in the tweets, so treat it as a secondhand citation.
Career-market signal: OSS AI engineering projects priced like acquihires
Open-source labor market (AI engineering): A provocative claim is that building a category-leading open-source AI engineering project can map to an “acquihire rate” of $10M–$100M per AI engineer, arguing you can skip business model/GTM and “just build,” per the acquihire-rate post. It’s a market sentiment datapoint.
The tweet’s core assertion is about where value is being assigned: engineering leverage over commercialization.
Governance discourse: bundling all AI concerns into “responsible AI” centralizes decisions
AI governance (org practice): A critique is that lumping every AI concern into “governance/responsible AI” creates a tangle and centralizes decisions that should be distributed, as stated in the governance tangle note. It’s a process complaint.
This reflects a split between policy-control instincts and “distributed ownership” adoption patterns.
Role-change skepticism: AI doesn’t automatically change SAFe/Scrum roles
Role design (enterprise adoption): A question posed for a SAFe/Scrum Master role highlights a friction point: if roles exist because of rigid org design, AI doesn’t necessarily change them; change only happens if the org changes, per the Scrum Master question. It’s a governance-and-incentives point.
The tweet frames “AI impact” as constrained by existing operating models.
Software abundance discourse: “natural language is the ultimate compiler”
Software abundance (agentic era narrative): A popular framing says software is moving from scarcity to abundance; natural language becomes the interface/compiler and “the bottleneck is having a useful idea,” as stated in the software abundance post.
The thread echoes long-tail dynamics seen in other media: distribution becomes cheap, and gatekeeping shifts from execution to taste/selection.
Practice signal: “best engineers context switch the least” resurfaces amid agent workflows
Context switching (engineering practice): Mitchell Hashimoto’s line that “the best engineers are the ones that context switch the least” is being recirculated, per the podcast clip. It’s being read as compatible with agentic workflows that offload interruptions.

The post positions focus as a durable advantage even as code generation gets cheaper.