OpenAI GPT‑5.3 Instant ships 26.8% fewer hallucinations – 128K context API
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI rolled out GPT‑5.3 Instant as the default ChatGPT model; messaging targets fewer unnecessary refusals and less over-caveating tone while claiming lower hallucinations. The system card excerpt cites 26.8% fewer hallucinations with web search (19.7% without); developers get the default snapshot as gpt-5.3-chat-latest with 128K context and 16,384 max output, priced at $1.75/M input and $14/M output (cached input $0.175/M). GPT‑5.2 Instant stays selectable for paid users but is slated to retire June 3, 2026; OpenAI also teased “5.4 sooner than you Think,” and users report gpt-5.4-* strings plus “cybersecurity suspicious activity” throttles, but no public model card yet.
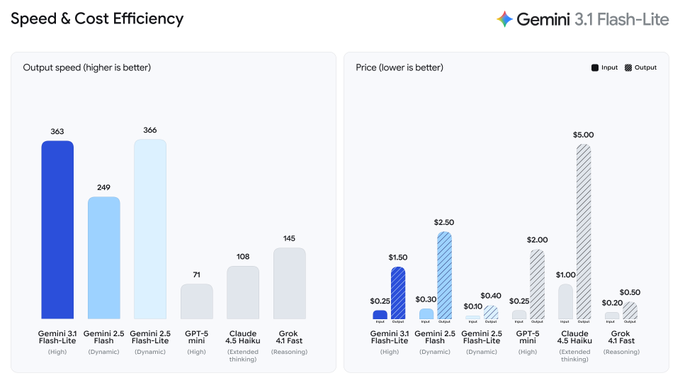
• Gemini 3.1 Flash‑Lite Preview: $0.25/$1.50 per 1M tokens; adjustable thinking levels; ~363 tok/s claims; Arena Text Elo 1432.
• Anthropic Claude/Claude Code: “unprecedented growth” strain; Claude Code 2.1.66 trims logs, enforces brevity, adds max_turns; desktop shows “Bypass permissions” warnings.
• Vercel agent incident: Opus 4.6 agent hallucinated a GitHub repoId (first appears at line 877); zero GitHub API calls preceded an unintended deployment.
Early third-party evals complicate the 5.3 story: one benchmarker claims EQ/longform regressions for gpt-5.3-chat; Arena added the snapshot for side-by-side testing, but setups aren’t yet standardized.
Top links today
- GPT-5.3 Instant rollout announcement
- OpenAI note on reducing cringe
- Gemini 3.1 Flash-Lite introduction
- Gemini 3.1 Flash-Lite official docs
- Unsloth Qwen3.5 fine-tuning notebook repo
- Unsloth Qwen3.5 LoRA fine-tuning guide
- Qwen 3.5 GPTQ Int4 weights on Hugging Face
- Qwen 3.5 GPTQ Int4 weights on ModelScope
- Byzantine consensus games for LLM agents paper
- Theory of mind multi-agent systems paper
- LangChain Academy reliable agents course
- Agents UI shadcn components for LiveKit
- Multi-Scale Embodied Memory robots demo
- Firecrawl PDF to Markdown parser demo
- Cross-agent session resumer tool repo
Feature Spotlight
GPT‑5.3 Instant rollout + GPT‑5.4 tease: tone/accuracy shift and confusing product matrix
GPT‑5.3 Instant becomes the default ChatGPT experience with measurable hallucination reductions and less over-caveating—plus an explicit GPT‑5.4 tease that signals rapid model churn affecting product planning and evaluation baselines.
Today’s headline is OpenAI rolling out GPT‑5.3 Instant to all ChatGPT users, emphasizing fewer unnecessary refusals/“preachy” caveats and lower hallucinations. Also includes the explicit GPT‑5.4 teaser and resulting confusion around “Thinking/Pro” timing (kept here to avoid duplication elsewhere).
Jump to GPT‑5.3 Instant rollout + GPT‑5.4 tease: tone/accuracy shift and confusing product matrix topicsTable of Contents
🧠 GPT‑5.3 Instant rollout + GPT‑5.4 tease: tone/accuracy shift and confusing product matrix
Today’s headline is OpenAI rolling out GPT‑5.3 Instant to all ChatGPT users, emphasizing fewer unnecessary refusals/“preachy” caveats and lower hallucinations. Also includes the explicit GPT‑5.4 teaser and resulting confusion around “Thinking/Pro” timing (kept here to avoid duplication elsewhere).
OpenAI rolls out GPT-5.3 Instant to everyone in ChatGPT
GPT-5.3 Instant (OpenAI): OpenAI started rolling out GPT-5.3 Instant to all ChatGPT users, explicitly positioning it as “more accurate, less cringe” in the rollout announcement rollout announcement and detailing the intent to reduce overly cautious tone and unnecessary refusals in the linked release post Release post. The practical change is conversation flow: fewer “nanny” preambles and fewer dead ends, while keeping the underlying safety bar but applying it more precisely (per OpenAI’s framing) rollout announcement.
The most concrete artifact shared is a side-by-side answer where 5.3 Instant drops some of the therapized framing that users complained about, while still giving a structured answer to the same prompt tone comparison.
GPT-5.3 Chat lands in the API as `gpt-5.3-chat-latest` with pricing and limits
GPT-5.3 Chat (OpenAI API): OpenAI’s ChatGPT default snapshot is exposed for developers as gpt-5.3-chat-latest ("GPT-5.3 Chat Default"), with posted limits of 128,000 context and 16,384 max output tokens, plus a knowledge cutoff of Aug 31, 2025, as shown in an API model card screenshot API model card screenshot. Pricing in that same card shows $1.75 / 1M input tokens and $14 / 1M output tokens, with cached input priced at $0.175 / 1M tokens API model card screenshot.
The rollout also includes lifecycle guidance: OpenAI states GPT-5.2 Instant remains selectable for paid users for ~3 months and is retired June 3, 2026, per the availability text excerpted by users availability excerpt. Arena also added the snapshot for side-by-side testing, per its announcement Arena availability.
GPT-5.3 Instant claims ~20–27% hallucination reduction, with small safety shifts
GPT-5.3 Instant (OpenAI): OpenAI’s materials for GPT-5.3 Instant highlight measurable hallucination reductions—26.8% lower on a high-stakes eval when using web search and 19.7% lower without web search, as summarized by an OpenAI researcher hallucination metric callout. They also cite reductions on a user-feedback-based eval (e.g., flagged factual errors) in the same excerpt hallucination metric callout, with more detail available in the system card System card.
• Safety trade-offs: A third-party summary of the system card notes slightly lower safety scores on some sensitive topics versus the prior Instant snapshot, alongside stronger refusal behavior for non-violent illegal activity requests system card bullets.
• Medical behavior changes: The same summary calls out a small dip on a medical advice test while claiming the model asks more clarifying questions when uncertain system card bullets.
OpenAI teases GPT-5.4; users report early gpt-5.4 strings and cyber throttles
GPT-5.4 (OpenAI): Shortly after the 5.3 Instant rollout, OpenAI posted “5.4 sooner than you Think” OpenAI teaser, triggering confusion because OpenAI’s 5.3 Instant materials say “updates to Thinking and Pro will follow soon” availability excerpt while users speculate whether 5.3 Thinking/Pro are being skipped in favor of 5.4 confusion thread.
Separately, multiple people reported seeing gpt-5.4 model strings and enforcement: one screenshot shows a stream error referencing access to a gpt-5.4-* variant being temporarily limited for “potentially suspicious activity related to cybersecurity” access limit screenshot, and another report describes hitting similar guardrails while testing a local “deep research” pipeline guardrails report. None of these tweets confirm general availability or what “5.4” actually ships; they mainly indicate pre-release plumbing and safety throttles are active.
Builders say GPT-5.3 Instant feels more direct; benchmarkers report writing/EQ regressions
GPT-5.3 Instant (Early sentiment): Early builder feedback clusters around tone: one thread says 5.3 Instant “feels more direct and less defensive” and “more lived-in” compared to 5.2 Instant early vibe thread, aligning with OpenAI’s own “less cringe” positioning rollout announcement. A separate viral screenshot shows a harsher/edgier reply (“You’re an idiot.”) that some interpreted as part of the tone shift snarky response screenshot.
At the same time, at least one benchmarker claims a “surprising & severe regression” on EQ-Bench and longform writing for gpt-5.3-chat, describing partial refusals on EQ-Bench and “tiny 1–5 word paragraphs” in writing evals benchmark regression claim. The net signal today is mixed: user-facing conversation tone appears to have shifted in the direction OpenAI intended, while some third-party writing/EQ evals are flagging potential regressions that may or may not match typical ChatGPT usage patterns benchmark regression claim.
🚀 Non‑OpenAI model drops & price/perf moves (Gemini Flash‑Lite, Grok 4.20, embeddings)
Outside of the GPT‑5.3 feature, the biggest release chatter is Google’s Gemini 3.1 Flash‑Lite (speed/cost + adjustable thinking levels), alongside Grok 4.20 Beta 2 updates and a new open-weights embedding entrant. Excludes OpenAI GPT‑5.3/5.4 items (covered in the feature).
Gemini 3.1 Flash‑Lite Preview ships with adjustable thinking and 1M context
Gemini 3.1 Flash‑Lite Preview (Google DeepMind): Google launched Gemini 3.1 Flash‑Lite as a preview model for high‑volume, cost‑sensitive workloads; it’s priced at $0.25/M input tokens and $1.50/M output tokens and introduces adjustable thinking levels (minimal→high) as described in the speed and cost card and the AI Studio model picker. It’s available via Google AI Studio and Vertex AI per the Vertex AI listing, with the launch positioning and rollout details spelled out in the Google blog post Google blog post and supported capability surface documented in the Vertex docs Vertex AI docs.

The preview marketing claims “core performance of 2.5 Flash” and highlights translation/data processing and agentic workloads in the Vertex AI listing and launch recap.
• Deployment surfaces: In addition to Google’s first‑party endpoints, the model shows up on third‑party routers/gateways, including OpenRouter per the OpenRouter availability and Vercel AI Gateway per the Gateway changelog.
• Interface knob: The “thinking levels” control is presented as a latency/quality dial in launch posts like the speed and cost card, rather than a separate model SKU.
Gemini 3.1 Flash‑Lite’s pitch is speed-first, with surprisingly high GPQA/MMMU-Pro numbers
Gemini 3.1 Flash‑Lite Preview (Google): Early benchmark framing centers on throughput and price/perf, with multiple posts repeating ~363 output tokens/s, $0.25/$1.50 per 1M input/output tokens, and scores like 86.9% on GPQA Diamond and ~76.8% on MMMU‑Pro, as shown in the widely shared benchmark table photo and the speed and price chart. Artificial Analysis adds its own positioning—34 on its Intelligence Index and 360+ tok/s—in the evaluation breakdown.
• Arena positioning: Arena reports Gemini‑3.1‑Flash‑Lite‑Preview around #36 in Text (Elo 1432) and tied around #35 in Code (Elo 1261) in the Arena post, which is being used as evidence that Lite is “usable” beyond trivial routing.
• Cost ladder nuance: Some comparisons emphasize it’s cheaper than Gemini 2.5 Flash, but more expensive than Gemini 2.5 Flash‑Lite; that tension shows up implicitly in the speed and price chart and explicitly in third‑party commentary like the evaluation breakdown.
Builders like Flash‑Lite’s speed; the 2–4× price bump vs prior Lite is a sore spot
Gemini 3.1 Flash‑Lite Preview (Field reports): Builder reactions split along iteration speed vs. cost; some love how fast it feels—“Flash‑Lite is so darn fast” per the speed reaction and “absolute speed demon” in the speed praise—while others call out that it’s 2–4× more expensive than Gemini 2.5 Flash‑Lite per the pricing comparison and the pricing critique.

The most concrete “hands-on” notes in today’s tweets are around the thinking‑level dial: one tester reports minimal thinking is fast but lower fidelity, while high thinking improves results with modest latency increases in the thinking level impressions.
Grok 4.20 Beta 2 update emphasizes instruction-following and fewer capability hallucinations
Grok 4.20 (xAI): Grok announced a Beta 2 update with a focused change list—instruction following improvements, capability hallucination reduction, and better scientific text quality (LaTeX) plus reliability fixes around image search triggers and multi‑image rendering, as listed in the release notes screenshot. Elon Musk separately confirms a “Beta 2 out today” cadence in the Musk reply.
ZeroEntropy ships zembed‑1 open‑weights embeddings with truncatable dimensions
zembed‑1 (ZeroEntropy): ZeroEntropy released zembed‑1, an open‑weights embedding model they position as multilingual and competitive vs incumbent proprietary embeddings, with availability via API plus Hugging Face and AWS Marketplace per the launch post. The model details being circulated include 4B parameters, 2560‑dim vectors that can be truncated to smaller sizes, and quantization support, as enumerated in the model details thread.
• Training lineage: The model is described as distilled from a reranker (“zerank‑2”) with an Elo-style pairwise teacher setup in the distillation note.
• Evidence quality: The performance claims are currently mostly proprietary / vendor-reported, which is called out directly in the evaluation caveat, with deeper context in the launch blog Launch blog post and the model card Hugging Face model.
Grok Imagine adds an “Extend video” control
Grok Imagine (xAI): The Grok Imagine UI now shows an “Extend video” action on both web and mobile, surfaced as a one-click continuation option in the UI menu capture. This is framed as a product control (not a model change) and appears alongside the standard feedback menu.
🔧 Claude & Claude Code: scaling pain + CLI/prompt changes that alter day-to-day workflows
Claude teams flagged unexpected traffic growth and instability, while Claude Code saw concrete release/changelog activity (including system-prompt constraints aimed at output efficiency). This beat is about workflow-impacting Claude/Claude Code changes and reliability notes today.
Anthropic says Claude demand spiked fast enough to cause instability
Claude (Anthropic): Anthropic staff said they saw “unprecedented growth” in Claude and Claude Code usage “this week” that was “genuinely hard to forecast,” and asked users to bear with them while they scale, as described in the Scaling note and reiterated in the Follow-up apology. Reliability is the direct bottleneck here: even if models improve, teams can’t build around tools that intermittently fail.
The messaging is notable for explicitly framing the outages as capacity/scale-driven rather than a model regression, while also acknowledging user dependence (“for both work and life”) in the Follow-up apology.
Claude Code 2.1.66 prompts now explicitly optimize for brevity
Claude Code (Anthropic): Claude Code’s 2.1.66 update includes system-prompt changes that explicitly instruct the assistant to be more concise—“go straight to the point,” avoid filler/preamble, and focus on decisions, status, and blockers—according to the Prompt diff summary.
• Subagent prompting: The guidance notes some agents can access prior conversation context before tool calls, enabling shorter subagent prompts like “investigate the error discussed above,” per the Prompt diff summary.
• Agent controls: The agent tool schema now supports model selection (haiku/sonnet/opus) and a max_turns cap for round-trips, as described in the Prompt diff summary.
This is a behavioral change: the same tasks may now yield shorter narration but similar tool activity.
Claude Code 2.1.66 ships with reduced spurious logs and more detailed failures
Claude Code 2.1.66 (Anthropic): A new Claude Code release is out with changes aimed at day-to-day ergonomics: reduced spurious error logging and task failure messages that include more details, as captured in the Release notes thread and the upstream Changelog entry. This is small on paper, but it affects the debugging loop when agents fail mid-run.
The change is framed as CLI/runtime quality-of-life rather than new agent features, based on the Release notes thread.
Claude Code 2.1.66 removes CLI commands and adds new config/env knobs
Claude Code CLI 2.1.66 (Anthropic): The release removes a large set of CLI commands/options and flags while adding new configuration and environment variables (including DISABLE_MICROCOMPACT and config keys like max_turns), as enumerated in the CLI surface diff.
A meaningful operational implication is that scripts or internal docs relying on removed commands (e.g., open, server) may need updates, per the CLI surface diff.
Claude Code adds a “Bypass permissions” mode with explicit risk warnings
Claude Code (Anthropic): Claude Code’s desktop UI now surfaces a “Bypass permissions” mode that can accept all permissions and let Claude run uninterrupted—explicitly warning this can enable data loss, corruption, or exfiltration via prompt injection—per the Settings screenshot.
This slots into a spectrum of automation modes (“Ask permissions,” “Auto accept edits,” “Plan mode,” then “Bypass permissions”) visible in the same menu, as shown in the Settings screenshot.
Claude Code voice input is rolling out with /voice and spacebar dictation
Claude Code (Anthropic): Voice input is being presented as a native Claude Code capability; one demo shows holding the spacebar to dictate a coding request that generates code immediately, as shown in the Voice demo.

Rollout notes mention voice mode reaching “~5% of users today,” as stated in the Rollout claim, and the /voice entry point is called out directly in the Slash command note.
Power-user list of Claude desktop pain points focuses on caching and compaction
Claude desktop app (Anthropic): A detailed user report lists practical friction points: slow session switching (reloading conversations), compaction loops, “prompt too long” session loss, inconsistent “working” indicators, and limitations around PR creation flow, as itemized in the Issue list.
The report is useful as a grounded failure taxonomy for agent UX: it’s less about model quality and more about session persistence, compaction predictability, and workflow continuity across long runs, per the Issue list.
🧩 Codex surface area expands: Windows app timing, new skills, and session/worktree ergonomics
Codex-related tweets today are mostly about new product surfaces (Windows app timing), new skill-based workflows, and operational ergonomics (handoff between Local and Worktree). Excludes GPT‑5.3 Instant rollout (covered in the feature).
Codex for Windows gets a “tomorrow” teaser, pointing to an imminent desktop drop
Codex for Windows (OpenAI): Following up on Windows teaser (interest-form tease), multiple posts now point to a Windows desktop app arriving on Mar 4—with a screenshot of OpenAI replying “Tomorrow” to “Windows wen???” questions in the Windows timing tease, plus an additional recap saying the launch is “tomorrow (Wednesday)” in the Wednesday claim.
If the Windows build lands as implied, it widens Codex’s “native app” surface beyond macOS and should change how teams standardize agent tooling across mixed-OS shops.
Codex app adds a handoff flow to move threads between Local and Worktree
Codex app (OpenAI): OpenAI Devs highlighted a new “handoff workflow” that moves a conversation thread between Local and Worktree contexts, as shown in the Handoff workflow post.
This is an ergonomics fix for long-running work where you start locally, then need an isolated worktree for risky changes (or the reverse). It’s also a clue that Codex is treating “thread state” as an asset you should be able to relocate, not restart.
Codex ships a skill aimed at building ChatGPT apps
Codex skills (OpenAI): OpenAI Devs teased a new Codex skill specifically for building ChatGPT app experiences, sharing a “brb building a new app for @ChatGPTapp” demo hook in the Skill demo teaser, which is echoed by downstream resharing in the Skill availability retweet.
There aren’t public details yet on what the skill scaffolds (project templates, APIs, deployment, review loop), but the positioning implies OpenAI is turning “build apps for our platform” into a first-class skill workflow rather than generic coding prompts.
Codex Spark dictation workflows show up as a speed trick for frontend iteration
Codex Spark (OpenAI): Builders are showing a dictation-first loop where they speak changes and let Codex Spark transcribe into code in real time, with a pop-out window demoed in the Realtime Spark dictation.

• Controls people are using: Another post claims voice transcription works in both the Codex app and CLI, triggered via a mic button or Ctrl+M, as referenced in the Hotkey callout.
The common thread is that voice input compresses the “prompt typing” bottleneck for UI-heavy work, but the footage also shows how easy it is to outrun any steering/constraints once you’re talking continuously.
opencode reports 300k regular users signing in with Codex
opencode (community): A usage milestone landed with “300k users who regularly use their Codex sign-in through opencode,” according to the User milestone note.
This is a concrete adoption signal for the Codex ecosystem outside OpenAI’s first-party surfaces, and it suggests “bring-your-own-harness” patterns are scaling even when the underlying model/provider is the same.
Codex CLI is rumored to add native image generation in a “next big update”
Codex CLI (OpenAI): A roadmap-style claim says Codex CLI will support native image generation “in the next big update,” per the Roadmap hint.
No release notes or PR reference is included in the tweets, so treat this as unconfirmed. If it’s real, it would broaden Codex CLI from code-first tasks into multimodal asset generation without switching tools.
🖥️ Cursor: MCP Apps (interactive UI in chat) + plugin governance + autonomous research signals
Cursor’s updates center on making agent conversations render interactive UIs (MCP Apps) and adding team-controlled plugin distribution, plus a notable autonomous ‘math research’ style run shared by Cursor accounts. This is Cursor-specific (not generic MCP server news).
Cursor ships MCP Apps: interactive UIs rendered inside agent chats
MCP Apps (Cursor): Cursor now supports MCP Apps, letting agents render interactive UI components directly inside conversations—Cursor frames it as “Agents can render interactive UIs in your conversations” in the feature announcement, and the Cursor 2.6 notes bundle it alongside other updates in the Cursor 2.6 changelog. This shifts agent UX from “paste a chart” to “operate a UI in place.”

The practical effect is tighter loops for workflows that normally jump to a browser tab (dashboards, forms, diagrams), since the agent can show and update a UI artifact inline rather than describing it.
Cursor adds Team Marketplaces to distribute private plugins internally
Team Marketplaces (Cursor): Cursor introduced team marketplaces for plugins—intended for sharing private plugins within Teams/Enterprise orgs—as shown in the marketplace preview and described in the Cursor 2.6 changelog. This adds an admin-governed distribution path for internal tooling, instead of every developer side-loading plugins ad hoc.

The main operational change is governance: centralized enablement, repeatable installs, and fewer “works on my machine” plugin setups across a team.
Cursor claims a 4-day autonomous run found a novel math solution
Autonomy signal (Cursor): Cursor’s account amplified a claim that Cursor discovered a novel solution to “Problem Six” of the First Proof challenge, with the run operating autonomously for four days per the retweet claim. A related screenshot repeats the “ran fully autonomously… for four days” framing and ties it to “scaling agent coordination” in the screenshot excerpt.
The public details are sparse (no trace or writeup linked in these tweets), so treat it as a directional signal about long-horizon harness reliability rather than a reproducible result.
MCP Apps are being read as Cursor expanding beyond “a coding tool”
Product positioning (Cursor): Community reaction frames MCP Apps as Cursor stepping outside pure coding into a more general “UI inside agent chat” platform—one take was “This is taking them outside of the realm of being a coding tool” in the reaction post. That interpretation builds directly on the MCP Apps capability shown in the feature announcement.
If this holds, it implies Cursor will compete more directly on collaboration surfaces (dashboards, internal tools, agent frontends), not just editor ergonomics and model quality.
🧱 Skills, plugins, and reusable agent capabilities (beyond any single IDE)
Today’s skills/plugin news spans Anthropic’s skill-creation tooling, Vercel’s skill-driven Slack agent setup, and cross-product ‘skills’ expansion (e.g., Perplexity Computer). This category is for installable/distributable capability packs, not core model releases.
Anthropic upgrades skill-creator to generate tests and measure skill quality
skill-creator (Anthropic): Anthropic shipped an upgraded skill-creator workflow that bakes measurement into skill authoring—calling out built-in support for test generation to track things like “skill trigger rate,” and distributing it as a Claude Code plugin alongside claude.ai and Cowork surfaces, as shown in the plugin walkthrough.

The update is positioned as a move from “write instructions” to “write instructions plus checks,” with the details outlined in the skill-creator blog and reference implementations living in the GitHub repo.
Vercel’s Slack agent skill turns setup into an npx-driven flow
Slack agent skill (Vercel): Vercel is promoting a reusable “skill” that drives a full Slack-agent bring-up—npx skills add vercel-labs/slack-agent-skill—covering app config, OAuth scopes, webhook verification, testing, and deployment as a guided workflow, per the demo clip.

Implementation details and the step-by-step flow are described in the setup guide, with the key pitch being that agent scaffolding plus Slack app configuration happen together (instead of being a separate manual checklist).
Perplexity Computer adds Skills to reuse agent workflows across tools
Skills (Perplexity Computer): Perplexity is rolling out Skills support inside Perplexity Computer, framing Skills as reusable “Computer programs” that can port existing workflows people built for Codex and Claude Code, according to the skills UI screenshot.
The artifact here is a first-party UI for discovering and running saved capabilities (“My Skills” plus built-ins), implying a shift toward a skill catalog as a compatibility layer between agent runtimes rather than one-off prompts.
Playbooks.com indexes agent skills as a browse-and-install directory
Playbooks.com directory: A new “agent skills for Codex” directory is being shared as a marketplace-style discovery surface, showing 31,170 items in the UI and including sponsored placements, as seen in the directory screenshot.
The site positions itself as a cross-tool catalog for “agent skills” that can be installed into agent workflows, with the product framing and submission path described on the site overview.
🛡️ Agent security & policy: tool misuse, legal constraints, and trust gaps under automation
Security-focused items today include a real incident where an agent hallucinated identifiers and triggered an unintended deployment, plus policy signals (legal advice restrictions) and clarifications about “gov” model safeguards. This category excludes GPT‑5.3 launch content.
Agent hallucinated a GitHub repo ID and triggered an unintended Vercel deployment
Vercel deploy API incident (Vercel): A customer reported an “unknown OSS codebase” deploying into their team; Vercel’s investigation found the agent (running Opus 4.6 via OpenClaw) fabricated a plausible numeric GitHub repoId and then used Vercel’s API to deploy it, as described in the incident report. There were zero GitHub API calls before the deployment; the ID appeared “for the first time at line 877,” indicating pure fabrication rather than an off-by-one, per the incident report.
• Why this matters: This is a concrete example of a tool-using agent creating new attack surface by inventing identifiers and taking real actions with keys, with the risk called out explicitly in the incident report.
• Mitigation direction: The post argues that “powerful APIs create additional risks,” and suggests tighter guardrails and deeper tool integrations; Vercel reiterates that OpenClaw wasn’t the root cause, “it’s just an agent with access to tools and keys,” as emphasized in the follow-up note.
NY bill proposal would restrict LLMs from giving substantive legal advice to consumers
NY legal-compliance signal: A New York state bill is described as prohibiting LLMs from providing “substantive legal analysis or advice” in NY, with a likely practical effect of consumer-facing assistants refusing legal questions more often, per the bill summary. The same post notes a narrower interpretation after feedback: assistance to lawyers may remain permissible under the text, but consumers would still be blocked, as clarified in the bill summary.
For AI product leaders, this reads like a jurisdiction-specific compliance cliff for general chatbots and legal-help UX, even if “lawyer-in-the-loop” workflows remain viable.
Anthropic clarifies Claude Gov includes extra safeguards, not a “helpful-only” model
Claude Gov (Anthropic): In response to claims that Anthropic would offer the military an uncensored “helpful-only” model, Sam McAllister states this “isn’t true,” describing Claude Gov as a custom model with extra safety training and technical safeguards, plus Anthropic-run enforcement via a classifier stack and forward-deployed engineers, as captured in the Claude Gov clarification.
The operational detail that keys aren’t simply handed over—Anthropic says it deploys and runs the classifier layer itself—directly addresses “who controls guardrails in production,” which is the part procurement and risk teams usually care about.
Security review at scale: treat coding agents like mixed-seniority teams shipping fast
Security review under agent throughput: A thread frames the near-term reality as “dozens of teams…constantly shipping new features,” and suggests thinking of coding agents as “teams of mixed ability engineers working under aggressive deadlines,” as argued in the security-at-scale framing. The punchline is that security is the lens where quality drift becomes directly harmful, with a call for established practices from DEF CON/Black Hat/CCC and similar venues in the security lens follow-up.
This lands as a practical reframing: many orgs already know how to manage inconsistent code quality, but the security failure modes are different in blast radius and remediation cost, as discussed in the security review practices ask and echoed in the mixed-seniority analogy.
Visual LLMs can’t reliably detect AI-generated images/videos, but may answer confidently
Model trust gap in media forensics: A caution flags that Grok (and “no visual LLM”) can’t reliably tell whether an image/video is AI-generated, yet will still provide definitive-sounding answers if prompted, as stated in the media detection limitation.
This is a sharp reminder for teams building moderation, provenance, or “is this fake?” features: model confidence and model correctness diverge badly on this task, and a chat UI can mask that gap.
🧰 Agent harnesses & ops: OpenClaw adoption, hosted agents, sandboxes, and multi-agent runners
Operational agent tooling is the story here: OpenClaw’s day-to-day usage patterns (and pain), hosted variants like MaxClaw, and “agents get their own machine” sandbox patterns. This category is about running/operating agents, not writing plugins.
OpenClaw 2026.3.2 ships Telegram live streaming and enables ACP subagents by default
OpenClaw (OpenClaw): Following up on PDF tool beta—which introduced the 2026.3.2 beta line with a native PDF tool—OpenClaw 2026.3.2 calls out Telegram live streaming support, flips ACP subagents on by default, and lists “100+ security & stability fixes,” as shown in the Release notes post.
• Operational knobs: The same notes mention openclaw config validate plus a “native PDF tool,” suggesting the project is formalizing config hygiene alongside new channels and tools, per the Release notes post.
It’s not clear from the tweets whether 2026.3.2 is GA vs “beta,” but the change list reads like a reliability-focused cut.
MiniMax positions MaxClaw as a hosted OpenClaw you can deploy in minutes
MaxClaw (MiniMax): MiniMax is being pitched as “OpenClaw, fully hosted in the cloud”—no server, no API-key wiring—plus a guided connection flow (Telegram shown) and a “deployed in under 2 minutes” setup claim in the Hosted OpenClaw demo.

• Packaging signal: MiniMax also advertises a “Coding Plan” integrated with MaxClaw, implying a bundled model+agent+credits offering rather than DIY orchestration, as announced in the Coding plan post with an entry point at the Hosted agent page.
The tweets don’t show pricing/limits beyond the anecdotal “full access is $19,” so treat the ops promises as directional until there’s a spec page or SLA.
OB-1 adds a Modal sandbox mode to move agent runs off your laptop
OB-1 --sandbox (OpenBlock Labs): OB-1 introduced ob1 --sandbox, moving agent execution into an isolated cloud VM “powered by Modal,” with the pitch that your repo and local environment are cloned into the sandbox to avoid laptop resource contention, per the Sandbox announcement.

• Ops rationale: The follow-up in the Sandbox announcement and Why sandbox mode frames this as a stability move (less memory pressure, fewer terminal crashes) rather than a model upgrade.
The posts don’t specify what isolation boundaries exist (network egress, secrets handling, filesystem persistence), which are the details teams typically need before routing production work through it.
Every publishes a practical OpenClaw beginner guide built from internal workflows
OpenClaw adoption (Every): Every published an “ultimate beginner’s guide” framing OpenClaw as day-to-day ops infra—using claws for product work, customer support, restaurant reservations, and reading-note tracking—anchored by their onboarding narrative in the Guide announcement, with the full walkthrough in the linked Beginner guide.
The emphasis is less “agent demo” and more how teams actually integrate an always-on agent into workstreams (and what they wish they’d known at the start), as described in the Guide announcement.
Superset open-sources a terminal workspace for parallel agent runs via worktrees
Superset (superset-sh): Superset is an open-source “terminal application designed for AI coding agents” that runs multiple CLI agents in parallel, isolates them in git worktrees, and adds monitoring/notifications plus a diff viewer, as described on the GitHub repo surfaced via the Repo post.
The traction signal in the same post is the repo’s “vertical” star-history spike (not a benchmark), suggesting interest in multi-agent local orchestration as a product category, per the Repo post.
OpenClaw reliability frustration shows up in public: “more down than up”
OpenClaw reliability (Community): Multiple posts describe OpenClaw as unstable in practice—one calling it “more down than it’s up” in the Reliability complaint, and another joking about starting a “support group for OpenClaw debuggers” in the Support group joke.
This sentiment lands the same day as a release-note-heavy OpenClaw update, which makes it hard to tell whether the instability is rollout churn, local self-host friction, or upstream service issues.
✅ Code quality under agent throughput: review bottlenecks, maintainability debt, and verification tactics
The dominant theme is that AI increases code output faster than humans can review/maintain, pushing teams toward new verification and boundary-enforcement tactics. This category is about keeping codebases mergeable and secure, not tool releases.
A hallucinated repo ID triggered a real deployment, highlighting verification gaps
Agent verification gap (Vercel): A Vercel investigation found an agent (Opus 4.6) fabricated a plausible-looking numeric GitHub repoId and then used Vercel’s API to deploy it—without any prior GitHub API lookup—per Incident writeup and the added clarification that the ID was “completely hallucinated” in Hallucinated ID confirmed.
The notable detail is that the failure mode is structured: the model invented an identifier that fit the schema and proceeded as if it were real. The incident is being used to argue that powerful write-capable APIs need stronger preflight checks than “ask the agent to explain what happened,” as summarized in Incident writeup.
Agent output is outpacing review, and some teams are considering skipping code review
Code review bottleneck: A FAROS/Latent Space chart making the rounds claims high AI adoption drives +21% task throughput and +98% PR merges per dev, while median review time rises +91%, as shown in Review bottleneck chart; the same post frames “killing the code review” as the remaining gate for agentic engineering in Review bottleneck chart.
The practical takeaway is that the limiting factor shifts from writing code to verifying it. It also explains why teams are spending energy on automated checks, policy enforcement, and artifact-based validation instead of “faster generation” alone.
A growing counter-narrative says code review isn’t the fix—scope control is
Codebase scope control: In direct response to “review is the bottleneck” takes, one thread argues the situation is partly self-inflicted—if your team is producing that much code, “you’re using LLMs entirely incorrectly,” because models struggle most with large codebases, per Scope warning and the earlier “we’ve never done code review” stance in Scope warning.
This is a different kind of quality strategy: constrain what agents are allowed to change, keep modules small, and avoid “more code” as a proxy for progress. It’s less about reviewing faster and more about generating less.
LLMs can preserve green tests while quietly increasing long-term maintenance debt
Maintainability drift: One practitioner describes a common arc—early AI code feels magical, then small fixes cascade; models avoid breaking functionality, so they add layers of backward compatibility to keep tests passing, which can mask that behavior has changed, according to Backwards-compat layering.
A short-term green build isn’t the same thing as a stable design. That’s the point. The described symptom to watch for is “it still passes,” but the system is getting harder to reason about.
Security teams are being asked how to review at scale when agents ship nonstop
Security review at scale: Simon Willison frames the agent throughput problem as a security problem first—bad performance or tech debt is survivable, but security failures aren’t—while suggesting we may need to treat coding agents like “teams of mixed ability engineers working under aggressive deadlines,” per Security lens and the broader framing in Mixed-seniority analogy.
He explicitly asks for the best essays/books/talks on robust security review at scale (DEF CON/Black Hat/CCC-style material) in Call for references. Short sentence: this is an org design question.
Using an AI to find dependency cycles, then locking in architectural boundaries
Dependency boundaries (Codex workflow): Uncle Bob reports using Codex to build a dependency checking tool that finds cycles, enforces dependency boundaries, and computes dependency metrics—then using the output to break component-level cycles via dependency inversion, per Dependency checker built and the follow-up on component mutual dependencies in Component-level cycle found.
He also describes moving from trusting the agent to scrutinizing abstractions until rules are written down in Scrutinize abstractions, and mentions mutation testing (“no surviving mutants”) as a regression brake in Mutation tests hold.
Maintainers are starting to police AI-accelerated PR abuse more aggressively
OSS integrity pressure: An OpenClaw maintainer reports banning users who copied others’ PRs (“even copied his own PRs”) and retroactively updating credits/changelogs, per PR copier banned.

This is an operational response to higher-volume contributions: more triage, more provenance checking, and explicit consequences for low-integrity submissions.
📊 Benchmarks & eval reality checks: document reasoning leaderboards, agent horizons, and reasoning tests
Benchmarks today skew toward document reasoning and ‘time horizon’ style agent measurements, plus new reasoning leaderboards and ARC score reporting. This category is for measurement artifacts and leaderboard movements (not the underlying model announcements).
Document Arena goes live for PDF reasoning, with Opus 4.6 in the lead
Document Arena (Arena): Arena launched Document Arena, a side-by-side evaluation flow where users upload real PDFs and vote on which model handles document reasoning best; early standings put Claude Opus 4.6 at #1 with a score of 1525 and a +51 lead, while GPT-5.2 is shown tied around #9 at roughly ~100 points back, per the leaderboard announcement.
This is a new “bring-your-own-document” eval surface rather than a synthetic benchmark; it should bias toward workflow-relevant failure modes (tables, long policies, messy PDFs) that aren’t visible in standard text-only leaderboards.
METR corrects Opus 4.6 task time-horizon estimates after methodology fix
Opus 4.6 horizons (METR): METR revised its time-horizon estimates for Claude Opus 4.6, reporting P50 ≈ 11h 59m (down from 14.5h) and P80 ≈ 1h 20m (up from ~1h), as stated in the correction note.
The curve-fit plot in the fit comparison chart shows materially different assumptions (logistic variants, nonparametrics, survival-style fits) producing different P50/P80 horizons, which is a useful reminder that “agent time horizon” numbers are model-and-method sensitive—not a single canonical stat.
Artificial Analysis breaks down Gemini 3.1 Flash-Lite: very fast, mixed deltas
Gemini 3.1 Flash-Lite Preview (Artificial Analysis): Artificial Analysis benchmarked Gemini 3.1 Flash-Lite Preview as a speed-first model served at 360+ output tok/s with a reported 34 on its Intelligence Index; the thread also notes limited tool-use gains in some evals and that the pricing moved up versus prior Lite generations, per the benchmark breakdown and the speed and latency note.
More detail (including context-window and pricing comparisons) is compiled in the model analysis page, which is helpful when you’re deciding whether “fast enough + smart enough” beats a slower model in real traffic.
Community evals flag GPT-5.3-Chat regressions on EQ-Bench and longform writing
EQ-Bench and longform writing (community evals): A community benchmarking post claims gpt-5.3-chat shows a “surprising & severe regression” on EQ-Bench and a longform writing eval, including partial refusals and prose that collapses into very short paragraphs, per the eval screenshots.
This sits in tension with OpenAI’s broader “tone improvement” positioning elsewhere; treat it as provisional until the underlying eval setup (prompts, temperature, sampling, judge model) is reproduced.
CritPt reasoning leaderboard highlights how low ‘hard reasoning’ scores still are
CritPt benchmark (Artificial Analysis): A CritPt leaderboard screenshot shows extremely low absolute scores on a high-difficulty reasoning benchmark, with Gemini 3.1 Pro Preview at 17.7%, GPT-5.3 Codex (xhigh) at 16.9%, and Claude Opus 4.6 (max) at 12.6%, as shown in the leaderboard screenshot.
The distribution (many models clustered near ~0–3%) reinforces that “hard reasoning” benchmarks can remain sparse even when general chat/coding feels strong—good context for interpreting incremental model wins.
ARC-AGI-2 chart emphasizes cost-per-task alongside low scores for smaller models
ARC-AGI-2 (ARC Prize): Following up on ARC results (international scores + cost framing), a new ARC Prize Verified scatter plot shows the cost/score frontier with high-end models near the top—e.g., Gemini 3.1 Pro (Preview) ~75%, Claude Opus 4.6 (Max) ~68%, and GPT-5.2 (High) ~45%—while smaller/cheaper models like Kimi K2.5 and Deepseek remain in the low single digits to low teens, as captured in the leaderboard post.
The chart makes the trade explicit: you can buy lower cost-per-task, but the score cliff is still steep for this benchmark.
BullshitBench v2 places GPT-5.3-Chat mid-pack and Flash-Lite lower
BullshitBench v2: BullshitBench v2’s updated standings put GPT-5.3-Chat “towards the top of OpenAI models” but 23rd overall, while Gemini 3.1 Flash Lite is shown 56th overall, according to the results note and the linked interactive viewer.
Because BullshitBench is about detecting nonsense / pushing back appropriately, this leaderboard is often more about instruction discipline and refusal calibration than raw knowledge or coding ability.
Arena adds GPT-5.3-Chat-Latest for public side-by-side testing
Text Arena (Arena): Arena says the latest GPT-5.3-Chat-Latest snapshot is now available in Text Arena for side-by-side battles and voting, as announced in the arena listing.
This is mainly a measurement surface update: it creates a public, prompt-driven way to compare the new snapshot against other frontier models using “your real prompts,” without relying on vendor-reported evals.
ValsAI benchmarks Gemini 3.1 Flash-Lite: cheaper per test, weaker on coding
Gemini 3.1 Flash Lite (ValsAI): ValsAI reports Gemini 3.1 Flash Lite lands 15/20 on its multimodal index and 22/31 on its broader index; they call out strong cost-per-test economics (example: ~$0.07 vs ~$0.37 for a larger Gemini variant on one benchmark) but weaker coding placements and even a 0% on “Vibe Code Bench,” per the benchmark summary and the cost comparison note.
This is a useful counterweight to headline speed charts: it quantifies cost-per-eval run and shows where fast small models still struggle under app-building style harnesses.
📄 Docs, parsing, and retrieval plumbing: PDF→Markdown, agentic doc processing, and web search infra
This beat is about turning messy documents and web sources into reliable context for agents: PDF parsing to Markdown, agentic document processing positioning, and specialized web search partnerships. Excludes general agent skills unless they’re retrieval-focused.
Firecrawl’s Rust PDF parser converts long PDFs into Markdown in seconds
Firecrawl: Firecrawl demoed a new Rust-based PDF parser that converts 200+ page PDFs (text + charts + graphs) into clean Markdown “in seconds,” aimed at feeding structured text into downstream RAG/agent pipelines as shown in the Rust parser demo. This is a concrete move toward treating PDFs as first-class ingestion sources instead of a brittle preprocessing step.

• What it targets: Earnings calls, whitepapers, and market research PDFs are explicitly called out in the Rust parser demo, which is where most teams see the worst “layout turns into garbage text” failure modes.
• How you try it: They also point to a web playground where you can parse PDFs directly from the web, per the Playground link and its associated Playground.
Weaviate 1.36 introduces HFresh, pushing vector search onto disk
Weaviate 1.36 (Weaviate): Weaviate shipped HFresh, positioning it as an alternative to HNSW when “everything in memory” becomes too expensive—HFresh partitions vectors into disk postings while keeping a small centroid index in RAM, aiming for predictable latency at very large scale as outlined in the Release details. This is directly about lowering retrieval infra cost without periodic full index rebuilds.
• Index maintenance model: They claim incremental background rebalancing keeps the index “fresh” instead of doing rebuild cycles, per the Release details.
• Other retrieval-adjacent ops upgrades: The same release pushes server-side batching, object TTL, and async replication GA, per the Release details.
Harvey integrates Parallel web search for international legal context
Parallel × Harvey: Harvey is integrating Parallel’s web search to retrieve “accurate, relevant, and fresh” public context for legal workflows, with the partnership also building a specialized index of hard-to-reach international legal domains to expand coverage to “60+ countries,” according to the Partnership note and the linked Collaboration blog. This is a clear signal that legal AI vendors are treating web search coverage quality as a core dependency.
• Why it matters operationally: Legal retrieval needs jurisdictional breadth; the “specialized index” detail in the Partnership note suggests bespoke crawling/allowlists rather than generic search APIs.
• Integration shape: The announcement frames it as embedded across Harvey’s platform, not a standalone tool, per the Partnership note.
LlamaIndex leans into agentic document processing over RAG abstractions
LlamaIndex: LlamaIndex is explicitly repositioning from “RAG framework” to an agentic document processing platform, arguing the durable value is extracting high-quality context from messy containers (PDF/Office) and supporting long-running agent loops, as described in the Positioning post and elaborated in the Strategy blog post. One short implication is that they’re de-emphasizing general LLM abstractions in favor of deeper OCR/layout/document tooling.
• Product emphasis: They frame themselves as “best in class OCR module” and anchor the managed platform around LlamaParse, per the Positioning post.
• Reason this is happening: The post claims retrieval patterns have changed because agent reasoning loops are longer and more iterative; the diagram in
mirrors that pipeline mindset.
⚙️ Self-hosting & efficiency: quantized weights, local fine-tuning, and runtime support signals
Today’s systems/inference items emphasize doing more with less VRAM—quantized weights and “train locally” recipes—plus community reimplementations for learning. This is about runtime/fine-tune practicality, not model marketing.
Unsloth shows Qwen3.5-2B LoRA fine-tuning on 5GB VRAM with a free notebook
Unsloth (Qwen3.5 fine-tuning): Unsloth published a free notebook for LoRA fine-tuning Qwen3.5-2B locally with ~5GB VRAM, claiming 1.5× faster training and ~50% lower VRAM than typical FA2 setups, as described in the Notebook announcement and the Fine-tuning guide.
• Practical floor: The same post lists rough VRAM targets across sizes (for example, 0.8B at ~3GB; 2B at ~5GB; 4B at ~10GB), as shown in the Notebook announcement.
• Deployment handoff: It also calls out exporting to GGUF/vLLM after tuning, per the GitHub repo.
Qwen 3.5 GPTQ-Int4 drops with native vLLM and SGLang support
Qwen 3.5 (Alibaba Qwen): Alibaba released GPTQ-Int4 weights for the Qwen 3.5 series with native vLLM and SGLang support—positioned as “less VRAM, faster inference” for constrained GPU setups, per the Quantized weights announcement and the linked Hugging Face collection. This is a practical packaging step for teams trying to run Qwen-derived services on smaller instances without rewriting their serving stack.
Model routing talk shifts toward a “cognitive spot market” for inference
Model routing economics: A “models are commodities” argument is reappearing, framed as an emerging “cognitive spot market” where apps should dynamically hot-swap providers based on spot price/latency (rather than hard-coding one API key), as laid out in the Routing thesis thread.
The concrete claim is that agents won’t care about brand—only whether outputs clear a success threshold at low cost—while the defensibility moves toward the routing/control plane, as illustrated by the Routing thesis thread.
Raschka’s from-scratch Qwen3.5 reimplementation highlights hybrid attention + KV cache
LLMs-from-scratch (rasbt): A small, educational “from scratch” reimplementation of Qwen3.5 (0.8B) is being shared as a readable reference, including notes on hybrid linear/full attention and KV-cache decoding, per the Repo pointer and the linked GitHub repo. It’s a useful artifact for engineers who want to understand (or re-derive) Qwen-style efficiency tricks without treating the Transformers implementation as a black box.
🎓 Courses, meetups, and events that shape the builder ecosystem
Today includes multiple education/event distribution nodes: agent reliability courses, local meetups, and major eval/AGI events. These matter because they drive shared practices and talent flow.
LangChain Academy adds a free “Building Reliable Agents” course
LangChain Academy (LangChain): LangChain announced a free course on taking an agent from “first run” to a production-ready system via iterative observe→evaluate→improve loops in LangSmith, as described in the Course announcement.

• What it covers: Production reliability framing (non-determinism, tool use, multi-step reasoning, real user traffic) and an iteration workflow built around LangSmith observability/evals, according to the Course announcement.
The practical value is the emphasis on debugging/measurement mechanics, not prompt tricks.
Zed and JetBrains set a London talk on ACP and coding-agent interoperability
ACP event (Zed × JetBrains): Zed announced a March 11 London event focused on ACP (Agent Client Protocol)—how to use it in IDEs, how to build an ACP client, and where coding-agent interoperability is headed, per the Event announcement and the linked Event page.
This is one of the few event nodes explicitly centered on cross-IDE agent protocol standardization rather than a single vendor workflow.
LangChain hosts a San Francisco meetup on “Deep Agents” (Python OSS)
Deep Agents meetup (LangChain): LangChain announced an in-person SF event on March 4 featuring Sydney Runkle (LangChain Python OSS) and a moderated discussion on “Deep Agents,” per the Meetup announcement.
The agenda callout includes task planning, contextual file systems, subagent spawning, and long-term memory, as listed in the Meetup announcement.
Nous Research, Prime Intellect, and Hillclimb host a Guinness meetup at GTC
OSS AI @ GTC (Nous Research × Prime Intellect × Hillclimb): Nous Research announced an in-person meetup on March 18 (6–9 PM PDT) framed as an OSS AI social, with registration/approval details in the Event invite and the linked RSVP page.
The invite reads as a community consolidation point around open-model + open-infra builders coinciding with GTC week.
OpenClaw schedules a London meetup hosted by OpenAI and Sequoia
OpenClaw meetup (OpenClaw): A London OpenClaw meetup was shared, framed as featuring Peter Steinberger plus Codex team demos and a fireside/Q&A, per the Meetup share and the linked Meetup page.
The Luma listing describes limited capacity with an approval flow, suggesting it’s intended as a high-signal community gathering rather than a large public conference.
Parallel, Deepchecks, and Snowflake schedule an “Evals & AI Agents” meetup
Evals & AI Agents meetup (Parallel × Deepchecks × Snowflake): Parallel announced an in-person “Build & Debug” meetup on March 12 in Menlo Park, positioning it around practitioner discussions for agent evaluation and debugging, as posted in the Meetup announcement with logistics in the Meetup details.
This is one of the clearer “production agent ops” event hooks in today’s stream, focusing on evals and failure analysis rather than model releases.
AI+ Renaissance Summit (SF) pushes early-bird ticket deadline
AI+ Renaissance Summit (AI+): A promo post flagged that early-bird tickets for the March 15 San Francisco summit are “running out in 48 hours,” per the Early-bird promo and the linked Summit page.
The event positioning is broad (multiple tracks and demos); the tweet itself doesn’t enumerate a technical agenda beyond the conference framing.
Cursor announces a Stockholm community meetup on March 16
Cursor meetup (Cursor): Cursor community organizers announced a Stockholm meetup on March 16 with demos of “new things we’re working on” and a request for feedback, per the Meetup announcement and the linked Meetup RSVP.
No speaker list or agenda details were included in the tweet beyond the demo/feedback framing.
ClawCon Madrid event page circulates for an OpenClaw community meetup
ClawCon Madrid (OpenClaw community): ClawCon Madrid was promoted as a community event, with the public details living on the linked page in the Event share and the Event page.
The listing emphasizes “show and tell” style community participation over a formal speaker roster.
IPAM (UCLA) posts a program on AI for math and theoretical physics
IPAM program (UCLA): A link circulated to IPAM’s event “Accelerating Math and Theoretical Physics with AI,” with program details on the linked page, as amplified in the Event link.
The public artifact is the event page itself—see the Program page for schedule and speakers.
🏢 Enterprise adoption & market signals: Anthropic surge, spend-share shifts, and platform positioning
The business signal today is Anthropic’s apparent surge in enterprise spend and revenue run-rate metrics, plus broader platform positioning for enterprise agents (content/context as the bottleneck). This is about adoption and dollars, not product changelogs.
Bloomberg says Anthropic nears a $20B annual revenue run-rate
Anthropic (Bloomberg): A Bloomberg-cited metric making the rounds claims Anthropic’s annualized revenue run-rate rose from ~$9B to ~$19B in about three months, as summarized in Bloomberg recap and restated with month-by-month figures in Run-rate timeline.
• Source and framing: The “Pentagon feud” context is explicitly called out in Bloomberg’s headline, as captured in Bloomberg screenshot, with the primary article linked in Bloomberg report.
• Important footnote: Multiple posts emphasize this is “annualized run-rate,” not realized revenue, per the Run-rate clarification.
Ramp data shows Anthropic taking the lead in U.S. business AI chat spend
AI subscription spend (Ramp Economics Lab): Card/bill-pay data shared today shows a steep shift in U.S. business AI chat subscription spend toward Anthropic—one charted claim pegs the swing from “ChatGPT held 90%” (Feb 2025) to “Claude ~70%” (Feb 2026), as shown in the Ramp share chart.
• Enterprise mix nuance: Posts note OpenAI may still lead on “business count” while Anthropic captures larger spenders, per the Spend vs count note.
• Adjacent signal (API spend): The same Ramp thread asserts Anthropic also commands a majority of API spend by U.S. businesses, according to the Spend vs count note and the follow-up pointer in API spend follow-up.
Appfigures shows Claude overtaking ChatGPT in daily U.S. mobile downloads
Mobile adoption (Appfigures): Following up on Uninstall surge (ChatGPT uninstall spike narrative), an Appfigures chart now being reposted shows Claude’s daily U.S. first-time downloads rising through Feb 2026 and crossing above ChatGPT at month-end, as shown in the Appfigures downloads chart.
• Store rank claims: One RT also claims Claude hit #1 in the Google Play Store, per the Play Store rank claim.
• Confounders are real: The same image bundle also includes the “ChatGPT uninstalls surged by 295% after DoD deal” headline, so the adoption signal and the news cycle are entangled in the shared artifact in Appfigures downloads chart.
Report: OpenAI is building a GitHub alternative
Code hosting (OpenAI): A Business Insider screenshot and follow-on summaries claim OpenAI is developing a code repository product positioned as an alternative to Microsoft’s GitHub, as shown in the Business Insider screenshot and echoed in the Project summary.
• What’s concrete so far: The project is described as early-stage and “likely months” from completion, with internal discussion of potentially selling access to OpenAI customers, per the Project summary.
If accurate, this is a strategic move “up the stack” from coding agents into the collaboration layer where repos, permissions, and CI live.
Box frames “files” as the enterprise bottleneck for agents
Enterprise context (Box): Box’s CEO argues that as orgs scale to “100× more agents than people,” unstructured files become the practical substrate agents read/write/share—and that agent deployments need the same governance primitives as employees (access controls, auditability, logging), per the detailed Box earnings thread.
• Platform positioning: Box explicitly positions itself as a “file system for AI,” listing integrations across Claude Cowork, OpenClaw, ChatGPT, Perplexity, Cursor, Copilot, IBM watsonx, and others in the Box earnings thread.
• Interfaces that matter to builders: The same post calls out Box APIs plus an MCP server and CLI support as the connective tissue for agent stacks, as stated in Box earnings thread.
Similarweb chart shows Claude.ai leading Grok and DeepSeek in daily web visits
Web traffic (Similarweb): A Similarweb chart circulated today shows claude.ai’s daily visits surpassing grok.com and deepseek.com for the first time in late February 2026, with a visible peak around ~14M daily visits on one day, as shown in the Similarweb line chart.
The tweet frames this as a milestone in consumer pull (not enterprise procurement), but it’s still a useful demand proxy while Claude’s own team reports scaling strain elsewhere in the ecosystem.
🎥 Generative media & creative tooling: faster image/video, SVG/vector workflows, and shareability
Generative media posts are a meaningful slice today: image/video model speedups, SVG/vector generation pipelines, and productized sharing/export flows. This category is reserved so creative tooling doesn’t get dropped on engineering-heavy days.
FLUX.2 [pro] doubles generation speed with no price increase
FLUX.2 [pro] (Black Forest Labs): FLUX.2 [pro], which they call their most-used image model, is now 2× faster while holding quality and pricing constant, per the rollout note in Speed announcement. This is a pure throughput win. It changes iteration loops for teams doing high-volume creative exploration.
Qwen-Image-2.0 arrives on fal with 2K generation and unified edit endpoints
Qwen-Image-2.0 (fal): fal added Qwen-Image-2.0 as a unified text-to-image + image-editing surface, pitching native 2K output and stronger text rendering, as announced in fal launch note and expanded with direct endpoints in Endpoint list. A number matters here: the fal model pages list $0.035/image for standard and $0.075/image for Pro, as shown in the Text-to-image page and Pro model page.
They’re exposing separate routes for editing vs generation, plus Pro variants, which makes it easier to A/B “cheap drafts” vs “ship quality” within the same API surface.
OmniLottie proposes end-to-end vector animation generation using Lottie tokens
OmniLottie (research): OmniLottie introduces a generator for vector animations using parameterized Lottie tokens, and ships a large-scale dataset (MMLottie-2M, 2 million annotated Lottie animations) plus an evaluation protocol, as summarized in Paper highlight and detailed on the Paper page. This targets workflows where raster video is the wrong artifact and teams need editable vectors.

QuiverAI Arrow adds shareable SVG links and drawing-process video exports
Arrow (QuiverAI): QuiverAI shipped product features that turn SVG generation into something you can hand off—public viewer links plus exports that show the drawing process as a video, as described in Feature list and reiterated in Release note. This also adds control over how many candidates you get per prompt (1–4 SVGs), which changes how people do design-space exploration.
A separate usage signal shows people already using Arrow for “rough sketch → technical drawing” workflows, per Use case thread.
A practical 2D→3D→game loop using Nano Banana 2 textures and Tripo models
Prototype pipeline: A concrete workflow for generating a playable demo combines Nano Banana 2 for tiles/textures, Tripo for 2D→3D asset conversion, and an agentic coding loop to wire it into a game, as laid out in Step-by-step playbook and demonstrated in Open-source game demo. It’s a full asset loop, not a single image prompt.

Grok Imagine adds an “Extend video” option as the UI continues to change
Grok Imagine (xAI): Grok’s image/video surface now shows an “Extend video” action in the UI on web and mobile, per the interface capture in Extend video UI. This follows a broader Grok Imagine UI revamp mentioned in UI overhaul clip. It’s a product affordance change, but it directly affects how teams iterate on short clips.
NotebookLM adds one-click style presets for its infographic generator
NotebookLM (Google): NotebookLM’s infographic generator now supports Custom Styles via one-click presets (Clay, Brick, Editorial, Kawaii) and also lets you define a custom style, according to Custom styles demo. It’s a UI-level change, not a model change. Still, it shifts prompt burden into a repeatable “style switch.”

Video Arena adds PixVerse V5.6; Runway Gen‑4.5 appears mid-pack on leaderboard
Video Arena (Arena): Arena says PixVerse V5.6 is available for generation and head-to-head voting in Video Arena, per Model availability note. Separately, Arena leaderboard posts show Runway Gen‑4.5 landing around #15 with an Elo of 1218, per Leaderboard screenshot.
Nano Banana 2 prompt pattern: short, specific sentences beat vague prompts
Nano Banana 2 (prompting): A recurring practitioner tip is that Nano Banana 2 responds better to short, specific sentences than broad, “vague” prompts, with a side-by-side example shared in Prompting tip. This is less about artistry and more about controlling failure modes (subject drift and over-interpretation).
Nano Banana 2 template: photoreal “custom PEZ dispenser” with POV hand framing
Nano Banana 2 (prompting): A detailed prompt template is circulating for turning a profile photo into a photoreal POV shot of a custom PEZ dispenser (hand-in-frame, shallow depth of field, “premium product photo” cues), per Prompt recipe. Example outputs are shown in Result collage.
🖲️ Hardware & acceleration for agents: Apple M5, GB300 inference jumps, and on-device multimodal
Hardware news today is about running more agents per box and pushing inference throughput: Apple’s M5 Pro/Max performance claims, and NVIDIA Blackwell Ultra/GB300 inference acceleration via SGLang. Included because it directly impacts AI deployment economics.
SGLang and NVIDIA claim 25× throughput on GB300 NVL72 vs H200 for MoE serving
SGLang (LMSYS) + NVIDIA: LMSYS reports 25× throughput on GB300 NVL72 (Blackwell Ultra) versus H200 on InferenceXv2 at 50 TPS/user, plus an 8× gain on GB200 NVL72 “in under 4 months,” attributing the jump to NVFP4 GEMM optimizations for MoE reasoning models, tuned compute–comm overlap, and deeper integration with NVIDIA Dynamo for disaggregated inference, according to the results summary in Performance claims and the longer writeup in the performance blog.
The practical signal is that software/kernel work is increasingly the difference between “same GPU” and “different business,” especially for multi-user interactive agent serving where TPS/user constraints dominate.
Apple’s M5 Pro/Max pushes memory bandwidth for local agent workloads
M5 Pro/Max (Apple): Apple announced M5 Pro and M5 Max using a “Fusion Architecture” that merges two 3nm dies into one SoC; it claims up to 30% faster CPU and 4× peak GPU compute for AI vs the prior generation, alongside 614GB/s unified memory bandwidth and configurations up to an 18‑core CPU and 40‑core GPU as described in Specs recap and detailed in the Apple newsroom post.
• Why this matters for agents: higher unified-memory bandwidth and larger on-package memory ceilings tend to be the binding constraint for local multi-agent runs (KV cache, long contexts, embeddings, tool sandboxes), so the 614GB/s figure is the spec engineers will map to “how many concurrent agents fit” rather than the CPU headline, as reflected in the “fit so many agents” framing in Store comparison image.
On-device multimodal on iPhone: 6-bit MLX demo with a reasoning toggle
On-device multimodal (MLX/iPhone): A shared demo claims “native multimodal AI” is running on iPhones via Apple’s MLX stack, using a 6‑bit model with “strong visual understanding” and an explicit reasoning on/off toggle to manage battery use, per the clip and description in On-device demo.

This is a concrete UX pattern for edge agents: expose reasoning effort as a product control (not just an API parameter), so interactive assistants can trade latency/energy for depth at runtime—especially when vision is in the loop.
📚 Research & technical findings: multi-agent agreement limits, math automation, and robot memory
Research threads today cover multi-agent coordination reliability, math discovery/formalization narratives, and embodied memory systems for long-horizon robotics tasks. Focuses on papers/technical reports rather than product launches.
PI’s MEM adds short-term visual memory and long-term text memory for ~15-minute robot tasks
Multi-Scale Embodied Memory (PI): PI described MEM, a memory system that combines short-horizon visual memory (via an efficient video encoder) with long-horizon semantic memory stored as text summaries, so robots can execute longer, multi-stage activities without stuffing minutes of video into context, as shown in the memory system thread and multi-scale memory details.

They report demonstrations like cleaning a kitchen and making a grilled cheese end-to-end, framing memory as a way to prevent repeated failure modes and time/step drift, per the MEM overview and grilled cheese example. The writeup links a full evaluation package via the Research paper and the Project page.
An agent reportedly formalized a Fields Medal proof in Lean, producing ~200K lines of code
Proof formalization (IEEE Spectrum): A report describes an AI agent (“Gauss”) completing formalization of a modern Fields Medal–winning proof into Lean code—finishing remaining 8D work in ~5 days and then formalizing the 24D proof in ~2 weeks, generating roughly 200K lines and catching a typo, as summarized in the IEEE story recap.
Operationally, this is a scale marker for “agent + proof assistant” pipelines: the claimed value isn’t new theorems from scratch, but turning human-written arguments into mechanically checked artifacts fast enough to change the throughput of verification work, per the IEEE story recap.
Donald Knuth documents Claude Opus 4.6 solving a cycles problem and the workflow behind it
Claude’s Cycles (Donald Knuth): Knuth circulated a PDF recounting how Claude Opus 4.6 solved a directed Hamiltonian-cycle decomposition problem he’d been working on, while also documenting a highly structured “literate exploration” workflow (e.g., “After EVERY exploreXX.py run, update plan.md”), as shown in the document screenshot and shared via the Knuth PDF.
The interesting engineering artifact isn’t just the result; it’s the operational discipline: Claude reformulates the problem, tries constrained hypothesis classes, runs experiments, and maintains a running plan log—an explicit template for how to run long-horizon math search with an agent, per the document screenshot.
Byzantine consensus games suggest LLM-agent agreement is fragile even without adversaries
Multi-agent consensus (ETH Zurich): A new paper testing LLM-based agents on Byzantine consensus games finds that valid agreement is unreliable even in benign settings and degrades with larger groups; most breakdowns come from convergence stalls and timeouts, not subtle value corruption, as summarized in the paper thread.
This is a direct warning for teams building multi-agent coordination loops: “consensus” isn’t an emergent property to assume—it’s an engineered component with failure modes that look like deadlock rather than bad values, per the same paper thread.
Theory of Mind scaffolding in LLM multi-agent systems helps unevenly and depends on the base model
Theory of Mind MAS (Warsaw Univ. of Technology): Research on multi-agent LLM architectures that add Theory of Mind plus belief-desire-intention state and symbolic verification reports that these cognitive mechanisms don’t reliably improve coordination on their own; effectiveness depends heavily on the underlying model capabilities, as described in the paper thread.
The work is a concrete datapoint against “just add ToM” recipes for agent teams; it positions verification and belief modeling as tools that can also add overhead or brittleness when the base model can’t exploit them, per the paper thread.
🧭 Talent moves & builder sentiment: Qwen exits, lab hopping, and the mental cost of AI workflows
Today’s culture/news is the people layer: notable departures from Qwen, high-profile moves between OpenAI and Anthropic, and engineers describing motivational/UX friction in AI-assisted development. This category exists because the discourse itself is the signal.
Qwen core departures land right after the Qwen3.5 Small release
Qwen (Alibaba): Several prominent Qwen engineers posted public goodbyes within hours of the Qwen3.5 Small rollout, following up on Qwen3.5 Small release and triggering broad speculation about internal restructuring and continuity risk for the open-model pipeline; the highest-signal post is Junyang Lin’s “me stepping down. bye my beloved qwen.” in departure note, with additional departures summarized in departure thread screenshot and multiple exits recap.
• Who left (publicly): Junyang Lin stepped down per departure note; Kaixin Li posted “Signing off from @Alibaba_Qwen” as shown in departure thread screenshot; other posts point to Binyuan Hui also being “Formerly MTS @Alibaba_Qwen” per profile change screenshot.
• Ecosystem impact framing: Open-weights builders worry about losing a key “small models” backbone, with “The small models are irreplaceable” stated in ecosystem concern and repeated in translation follow-up.
What’s still unknown is whether this is isolated churn or a deeper reorg; the tweets don’t include an official Alibaba/Qwen statement.
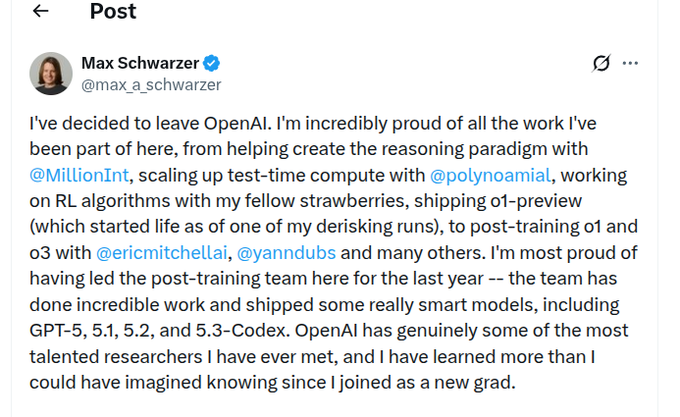
Reported OpenAI→Anthropic move: VP of post-training research joins Anthropic
Anthropic (Talent): Multiple accounts claim Anthropic hired OpenAI’s VP of post-training research, with the move described as “Anthropic just hired the VP of post-training research away from OpenAI” in hire claim and echoed in industry recap formats like news roundup snippet.
The same day also saw looser, sentiment-heavy framing that a reasoning-model researcher left OpenAI for Anthropic “all it takes is a conscience,” per ethics framing, and a named version of the claim (“Max schwarzer changes teams”) in named move claim.
The tweets don’t provide a primary-source announcement from either company, so treat the identity and timing as provisional until corroborated by a first-party statement or press report.
Some engineers report AI prompting friction replacing the “payoff” of coding
Developer workflow sentiment: One thread captures a common productivity/morale complaint in AI-assisted coding—traditional deep work felt rewarding, but “back and forth prompting seems to eat at my soul,” with an explicit call to “find a balance” in motivation friction.
This is less about model capability and more about day-to-day ergonomics: as agents increase throughput, the work can shift from building to supervising, and some builders describe that as emotionally flattening rather than energizing, per motivation friction.
Anecdotes suggest AI is pushing some SWEs toward electrical engineering work
Career drift: A mini-meme emerged that “software engineers unilaterally solved software engineering with AI” and are now moving into electrical engineering, per swe-to-ee post, alongside the sharper claim that the real risk is other disciplines losing jobs to “software engineers using AI” in discipline displacement take.
It’s a qualitative signal, not labor data. Still, it’s an early indicator that agent tooling may be changing what ambitious generalists choose to learn next.