OpenAI Codex Windows app ships – 9% promo-limits bug fixed, 26.304.1143 hotfix
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI shipped the Codex desktop app on Windows via the Microsoft Store; the release emphasizes a Windows-native agent sandbox, PowerShell-first dev environment support, parallel agents, long-running tasks, and centralized diff review; Windows also adds an “Add Target” handoff into local tools (VS Code, JetBrains IDEs, Git Bash, GitHub Desktop, WSL, more). The launch immediately turned into ops work: a WSL-mode issue could brick installs; a manual toggle (runCodexInWindowsSubsystemForLinux=false) unblocks affected users while a Store hotfix rolls out as version 26.304.1143. Separately, OpenAI says a 2× promotional limits increase failed to apply for ~9% of Codex Plus/Pro users; the bug is fixed and rate limits are being reset for all Plus/Pro to compensate; team members also posted broad hiring calls across Windows, CLI, and “future products.”
• Anthropic/Claude Code: 2.1.68 removes Opus 4/4.1 from first-party API; pinned models silently remap to Opus 4.6 unless disabled; “ultrathink” returns; “auto mode” permissions preview is slated no earlier than Mar 11; users report compaction/session instability.
• Cursor/ACP: Cursor lands in JetBrains via Agent Client Protocol; ACP docs publish a minimal Node JSON-RPC-over-stdio client; YC deal bundles 6 months + $50K usage credits.
• Evals/uncertainty: Scale’s SWE-Atlas Codebase Q&A shows leaders still <30%; claims 40%+ drop without code execution; Vals AI adds standard error to report uncertainty bars.
Top links today
- Google Workspace CLI docs
- OpenAI Symphony agent orchestration repo
- Codex desktop app for Windows download
- CUDA Agent paper on kernel generation
- Draft-Thinking efficient reasoning paper
- Chain-of-Context dynamic routing paper
- Draft-Thinking updated preprint version
- CUDA Agent updated preprint version
- Chain-of-Context updated preprint version
- Vals AI error bars for evals methodology
- LM Arena model leaderboard and battles
- Qwen Image 2 model on Replicate
Feature Spotlight
Codex app lands on Windows: native sandbox, multi‑agent workflows, and early ops fixes
Codex on Windows turns agentic coding into a first-class Windows workflow (native sandbox + PowerShell/Windows toolchain), which materially changes how teams standardize and roll out coding agents across mixed OS fleets.
High-volume, cross-account story today: OpenAI shipped the Codex desktop app for Windows (Microsoft Store) with a Windows-native agent sandbox and Windows dev environment support. Includes immediate post-release fixes, rate-limit compensation, and a broad call for feedback + hiring.
Jump to Codex app lands on Windows: native sandbox, multi‑agent workflows, and early ops fixes topicsTable of Contents
🪟 Codex app lands on Windows: native sandbox, multi‑agent workflows, and early ops fixes
High-volume, cross-account story today: OpenAI shipped the Codex desktop app for Windows (Microsoft Store) with a Windows-native agent sandbox and Windows dev environment support. Includes immediate post-release fixes, rate-limit compensation, and a broad call for feedback + hiring.
Codex desktop app is now available on Windows with a native agent sandbox
Codex app (OpenAI): Following up on Windows teaser—imminent Windows drop—OpenAI has now shipped the Codex desktop app on Windows with a Windows-native agent sandbox and first-class Windows dev environment support in PowerShell, as announced in the launch thread and reiterated in the Windows live note.

The Windows build is distributed via the Microsoft Store, as shown in the Store listing screenshot.
• Workflow surface: The Windows app highlights parallel agents, long-running tasks, and centralized diff review in the launch thread, with the “stay in your existing setup” positioning repeated in the feature list.
• Rollout status: OpenAI staff describe it as generally available on Windows in the GA confirmation, with additional “first-class coding experience” messaging in the Windows experience note.
Codex fixes missing 2× promo limits for ~9% of Plus/Pro and resets limits
Codex (OpenAI): OpenAI says a bug prevented the promised 2× promotional increase in limits from applying to an estimated 9% of Codex Plus and Pro users, per the limits bug disclosure.
They report the issue is fixed and that they’re resetting the rate limit for all Plus and Pro users to compensate, with additional confirmation in the rate limit reset follow-up.
Codex on Windows adds an “Add Target” handoff to IDEs and dev tools
Codex app (OpenAI): The Windows release includes an “Add Target” workflow to jump from Codex into local apps (instead of staying inside the Codex UI), demonstrated in the Add Target demo and described as part of staying in an existing Windows setup in the launch thread.

OpenAI’s Windows integration list calls out common destinations like Visual Studio, JetBrains IDEs, Git Bash, GitHub Desktop, Cmder, WSL, and Sublime Text in the targets list, which matches the broader “app targets” framing in the Windows live note.
Codex Windows WSL mode workaround and Microsoft Store hotfix 26.304.1143
Codex app (OpenAI): A post-release issue affecting WSL mode on Windows has a manual workaround—edit %USERPROFILE%\.codex\.codex-global-state.json and set runCodexInWindowsSubsystemForLinux to false—as detailed in the WSL toggle workaround.
A Microsoft Store update is rolling out to fix “bricked” installs, with OpenAI staff pointing to app version 26.304.1143 and an in-app path to check it (Alt → File → About Codex) in the Store hotfix note, building on the earlier “working on rolling this out” status in the fix identified note.
OpenAI is hiring across Codex (Windows, CLI, and future products)
Codex team (OpenAI): Multiple Codex team members are publicly recruiting across Windows, CLI, and “future products,” framing the group as high-agency and moving fast in the hiring note.
A separate hiring call lists locations (SF/Seattle/NY/London/remote) and requests “evidence of exceptional work” across full-stack, Rust, low-level systems, and distributed systems in the hiring post, with roles discoverable via the Careers search.
🧑💻 Claude Code CLI churn: Opus model remaps, ultrathink returns, and new permissions automation
Continues yesterday’s Claude Code operations story but with concrete release details: 2.1.68 and 2.1.69 add/remap models, restore “ultrathink,” expand voice STT languages, and introduce an upcoming safer “auto mode” for permissions. Excludes Codex/Windows coverage (feature).
Claude Code previews “auto mode” for permission decisions (research preview)
Claude Code (Anthropic): An email to admins describes a new permissions mode, “auto mode,” launching in research preview no earlier than March 11, 2026; it lets Claude handle permission decisions during coding sessions to reduce interruptions, and it’s positioned as a safer alternative to --dangerously-skip-permissions with additional prompt-injection safeguards, according to the Email screenshot.
• Operational tradeoffs: The email notes it may not catch every risky action and recommends isolated environments; it also calls out higher token usage, cost, and latency in exchange for fewer approval prompts, as stated in the Email screenshot.
Claude Code 2.1.68 changes Opus 4.6 effort defaults and brings back ultrathink
Claude Code 2.1.68 (Anthropic): Opus 4.6 now defaults to “medium effort” for Max and Team subscribers (Anthropic frames it as the speed/thoroughness sweet spot), and the “ultrathink” keyword is reintroduced to request high effort for the next turn, as noted in the Release highlights and expanded in the Changelog excerpt. The ergonomics impact shows up immediately in user reactions like the Ultrathink shorthand reaction, which implies the keyword is functioning as a practical control surface again.
Claude Code 2.1.69 adds a /claude-api skill and many new CLI controls
Claude Code 2.1.69 (Anthropic): The release adds a /claude-api skill for building against the Claude API + Anthropic SDK, alongside a large set of CLI and configuration changes (new commands, options, env vars, and config keys), as enumerated in the 2.1.69 release digest and the Changelog details. The canonical change list is captured in the upstream Changelog entry.
Claude Code 2.1.69 tightens tool loading: ToolSearch becomes mandatory
Claude Code 2.1.69 (Anthropic): System prompt changes now require ToolSearch as a hard prerequisite before calling deferred tools; the prior per-tool “rulebook” guidance is removed and replaced with an <available-deferred-tools>-style discovery flow, as summarized in the System prompt update notes and reflected in the linked prompt diff Prompt diff. This is a concrete harness-level behavior change that can affect how tool availability and tool invocation errors show up in real sessions.
Claude Code 2.1.68 adds a legacy model remap override
Claude Code 2.1.68 (Anthropic): The CLI surface adds CLAUDE_CODE_DISABLE_LEGACY_MODEL_REMAP, and the opus-46-effort-medium model entry is removed, according to the CLI change list and the deeper diff breakdown in Further changes notes. This matters if you depend on stable, explicit model identifiers in automation (or want to avoid silent remaps when older pinned names are present).
Claude Code 2.1.68 changes temp file defaults in sandbox mode
Claude Code 2.1.68 (Anthropic): Temporary files now default to the sandbox-writable temp directory, aiming to reduce permission and path issues during sandboxed execution, as called out in the Release highlights and the more detailed Changelog excerpt. This is a narrow but workflow-impacting fix for sessions where tooling writes temp artifacts under constrained permissions.
Claude Code 2.1.69 adds 10 more voice dictation languages
Claude Code 2.1.69 (Anthropic): Voice STT support expands by 10 languages (20 total), including Russian, Polish, Turkish, and Dutch, as listed in the 2.1.69 release digest and repeated in the Changelog details. This is a straightforward capability expansion for voice-driven coding workflows, without other behavior claims in the tweets.
Claude Code 2.1.69 changes how memory corrections are handled
Claude Code 2.1.69 (Anthropic): The system prompt now treats user corrections of memory-based claims as evidence that stored memory is wrong, and requires updating/removing the memory entry at the source before proceeding to avoid repeat errors, as described in the System prompt update notes. The underlying change is visible via the associated Prompt diff.
Claude Code session issues: compaction errors and reports of degraded reliability
Claude Code (Anthropic): Users report compaction failing with “Conversation too long” errors and general instability in long-running sessions, as shown in the Compaction error report and echoed more broadly in the User reliability complaint. The reports are anecdotal (no status page or changelog attribution in the tweets), but they align with the practical failure mode where long contexts become hard to compact reliably mid-work.
Claude Code 2.1.69 can reload plugins without restarting
Claude Code 2.1.69 (Anthropic): A new /reload-plugins command applies pending plugin changes without restarting the session, per the 2.1.69 release digest. In practice, this changes how quickly teams can iterate on local plugin/skill setups during long-running sessions, but the tweets don’t include further behavioral guarantees.
🧩 Cursor expands beyond VS Code: JetBrains via ACP + protocol builder tooling
Cursor’s distribution story moves into enterprise IDEs: JetBrains integration via Agent Client Protocol (ACP) plus ACP Registry/docs for building minimal clients. Excludes Claude Code and Codex (feature) to keep tool beats clean.
Cursor expands into JetBrains IDEs via ACP (shows up in ACP Registry as v0.1.0)
Cursor (Anysphere): Cursor is now usable inside JetBrains IDEs through the Agent Client Protocol (ACP), broadening distribution beyond its VS Code fork into IntelliJ/PyCharm/WebStorm workflows, as announced in the JetBrains integration post; JetBrains’ ACP Registry already lists it as “Cursor v0.1.0,” as shown in the ACP registry screenshot, with integration details (including model choices and enterprise codebase workflows) described in the integration blog.
• Operational shape: The pitch is “agent-driven development” in enterprise Java/JetBrains stacks—secure indexing + semantic code intelligence, with multiple frontier model options surfaced in-IDE, per the integration blog.
• Positioning signal: The follow-on “Use Cursor anywhere” framing in the Use Cursor anywhere post reads like Cursor treating ACP as a cross-editor distribution layer, not a one-off integration.
ACP docs show a minimal Node.js client for driving Cursor agents over JSON-RPC
Agent Client Protocol (Cursor): Cursor’s ACP documentation now includes a “minimal Node.js client” example that spawns agent acp and communicates via newline-delimited JSON-RPC 2.0 over stdio, as shown in the Minimal client snippet and detailed in the ACP docs.
• What’s concretely implementable: The docs describe a request/notification flow for sessions, prompts, and permissions—enough to build a custom ACP host (e.g., internal devtools or a bespoke IDE wrapper) without adopting Cursor’s UI, per the ACP docs.
• Ecosystem read: The reaction that “the people clamour for protocols” in the Protocols comment highlights that builders want stable, tool-agnostic control planes for agents more than another bespoke plugin API.
Cursor offers YC startups a $60k+ team package with $50k usage credits
Cursor (Anysphere): Cursor is offering YC startups a package described as “$60k+” that bundles 6 months of team access plus Bugbot and $50K usage credits, according to the YC deal announcement, with the eligibility constraint (“incorporated within the last 5 years”) clarified in the Eligibility follow-up.
• Adoption mechanism: This is a direct go-to-market lever for getting Cursor rolled out org-wide early, without a separate procurement cycle, per the YC deal announcement.
🧠 GPT‑5.4 watch: 1M context, “extreme reasoning,” and Arena sightings
Today’s model chatter centers on GPT‑5.4 appearing in evaluation channels (Arena) and The Information’s capability claims (1M context + extreme reasoning mode + multi-hour agent tasks). Excludes Codex/Windows (feature).
The Information: GPT-5.4 rumored to bring 1M context and “Extreme” reasoning mode
GPT-5.4 (OpenAI): A report claims GPT-5.4 will ship with a 1M-token context window, alongside an “Extreme reasoning mode” that can spend substantially more compute per hard query; this follows yesterday’s GPT-5.4 teaser, as noted in tease. The same report also frames upgrades around long-horizon tasks (“can run for hours”), improved multi-step memory, and lower complex-task error rates, as summarized in the The Information screenshot and echoed in the Leak recap.
• Long-horizon agent work: The leak narrative explicitly targets automation workloads (agent loops, multi-step workflows) rather than just chat quality, as described in the The Information screenshot and reiterated in the Rumor recap.
• Release cadence signal: Multiple posts repeat that OpenAI is shifting toward more frequent (monthly) model updates, per the Leak recap and the Update cadence quote.
• State persistence rumor: A separate rumor thread claims GPT-5.4 may “persist state,” attributed to Jeff Dean podcast chatter in the State persistence rumor.
Uncertainty remains high: this is secondhand reporting plus community restatements, and there’s no official model card or API doc in the tweet set.
LM Arena adds “galapagos,” widely speculated to be a GPT-5.4 variant
LM Arena (LMSYS): Arena notifications and screenshots show a new model label, “galapagos,” landing in the Arena lineup, with multiple accounts speculating it’s an early GPT-5.4 variant (often framed as a lower-effort route), as shown in the Arena model banner and the TestingCatalog screenshot.
Early probing reports suggest the Arena route may be constrained: one captured exchange shows the model claiming “my current juice value is 0,” which users interpret as low/no-reasoning behavior in the Arena harness, per the Juice value screenshot.
• What’s concrete vs inferred: The existence of “galapagos” as an Arena label is evidenced in the Arena model banner and the Arena notification card, while the mapping to GPT-5.4 remains community inference.
• Variant ambiguity: Posts explicitly note it’s unclear which GPT-5.4 variant this corresponds to, per the Arena model banner and the Juice value screenshot.
GPT-5.4 release timing and “effort tier” speculation clusters around Thursday
Release watch chatter: Several accounts converge on a near-term release window (often “Thursday”), while also speculating about multiple GPT-5.4 variants/tier names (e.g., “Thinking/Pro/Codex” or higher-effort tiers beyond x-high), as reflected in the Thursday speculation, the Thinking Thursday joke, and the Effort tier riff.
• Representative quotes: Posters describe the rollout mood as “Release Thursday very likely,” in the Thursday speculation, and joke about “GPT-5.4-xxxhigh,” in the Effort tier riff.
• What’s driving the timing guess: The clustering seems to come from the Arena appearance plus The Information-style capability claims being circulated together, as seen in the Thursday speculation and the Release timing question.
Net: lots of packaging and schedule theories, but no official OpenAI launch post appears in today’s tweet set.
🧰 IDE/editor agent features: orchestration hooks, diff-to-agent review, and continuity
Editors are absorbing agent orchestration primitives: VS Code’s agent features (hooks, steering, integrated browser, shared memory) and Zed’s agent feedback loop from diffs. Excludes Cursor and Codex/Windows (feature).
VS Code v1.110 ships hooks, steering, an agentic browser, and shared memory
VS Code v1.110 (Microsoft): The February 2026 VS Code release expands Copilot’s agent surface with hooks, message steering/queueing, an integrated agentic browser, and shared memory, as summarized in the release highlight thread and reiterated alongside the release livestream invite.
• Orchestration and continuity: The release frames “agent orchestration / extensibility / continuity” as first-class editor concepts (hooks, steering, shared memory), with the broader set of changes and UI surfaces detailed in the release notes.
• Operational workflow: VS Code is also promoting a March 19 livestream (8 AM PST) to walk through agent features, as announced in the release livestream invite.
Zed v0.226 surfaces diagnostics and adds one-click diff review by an agent
Zed v0.226 (Zed): Zed shipped two small but workflow-relevant UI affordances—project-panel diagnostic badges and a “Review Diff” handoff into the agent panel—called out in the v0.226 release note and shown in the diff review demo.

• Inline build health: A config toggle, "project_panel": { "diagnostic_badges": true }, shows error/warning counts next to project entries, as described in the v0.226 release note.
• Diff-to-agent loop: The new “Review Diff” button in the git branch diff view sends the current change set directly to the agent panel for feedback, as demonstrated in the diff review demo.
A GitHub Action uses a cloud agent to catch .env key drift before merge
Wizard of Drift (dotenvx + Warp): A new GitHub Action checks for environment-variable key drift across .env* files (e.g., a dev key missing in prod) and leaves a PR comment via a cloud coding agent, as described in the agent PR comment workflow and implemented in the GitHub repo.
The pitch is CI-time hygiene for teams whose agent-generated code changes often touch config, without needing a human to manually diff environment files each time, per the agent PR comment workflow.
📎 Enterprise SaaS automation becomes agent-ready: Google Workspace CLI (gws)
Google shipped an official Workspace CLI designed for humans and agents (dynamic discovery, JSON outputs, skills). This is a concrete “skills + CLI” pattern for automating Drive/Gmail/Calendar/etc workflows without bespoke REST plumbing.
Google releases Google Workspace CLI (gws) built for humans and agents
Google Workspace CLI (Google): Google open-sourced gws, a single CLI that spans Drive, Gmail, Calendar, Sheets, Docs, Chat, Admin, and effectively “every Workspace API,” with commands generated at runtime from the Discovery Service—see the launch announcement and the GitHub repo. It’s explicitly designed to be agent-friendly via structured JSON outputs and ships with 40+ prebuilt agent skills, with install flows via npm plus Skills CLIs shown in the install snippet.
• Agent integration surface: The repo notes structured JSON and schema introspection as first-class capabilities (e.g., gws schema ...), which is the kind of “tool contract” agents can compose reliably, as illustrated in the gws command examples.
• Distribution and ecosystem hook: The npm package + npx skills add github:googleworkspace/cli flow in the install snippet is a concrete example of “Skills + CLI” becoming a packaging layer for enterprise automation rather than bespoke REST glue.
Some claims (like “100+ workflow recipes”) appear in community recaps such as the feature recap, but the most verifiable artifact remains the repo itself.
gws vs gog: early ergonomics debate over JSON-heavy Workspace automation
gws vs gog (community): Shortly after Google’s gws release, builders started comparing it to existing unofficial CLIs—most notably gog—with the debate centering on whether gws’s JSON-heavy, Discovery-derived surface is more or less usable for agents than a more opinionated command design, as framed in the gog comparison.
• What’s being compared: The gog comparison calls out “the json commands needed for gws” as a potential downside versus gog’s defaults, while still acknowledging gws is “really good”; the gog feature set and philosophy are laid out on the gog site.
• Why it matters for agents: This is less about features and more about “command language design”—whether agents do better with a fully generic API-shaped CLI (gws) or a curated UX that bakes in best-practice defaults (gog), which affects reliability and prompt length when automating Workspace operations.
No consensus yet—just an early signal that CLI ergonomics may become a competitive axis once agents are the primary caller.
📏 Evals & observability reality checks: nonsense detection, agent SWE evals, and uncertainty bars
Multiple eval artifacts today: BullshitBench v2 analysis, Scale AI’s SWE-Atlas for code agents, and calls to add statistical uncertainty to leaderboard scores. Excludes GPT‑5.4 rumors (model category) and product release notes.
Scale AI releases SWE-Atlas Codebase Q&A; leading agents score under 30%
SWE-Atlas (Scale AI): Scale introduced SWE-Atlas, an agentic SWE eval suite; its first released track, Codebase Q&A, reports leading models still scoring <30%, with agents operating inside a sandboxed environment with shell access, as described in the Benchmark announcement.
• Execution matters: The release notes claim performance drops 40%+ when models are prevented from running code, making “can execute” a first-class axis rather than a nice-to-have, per the Benchmark announcement.
• Scaffolds show up in scores: The same post argues models do best with “native scaffolds” (e.g., Claude Code, Codex CLI), framing harness integration as part of the measured system, per the Benchmark announcement.
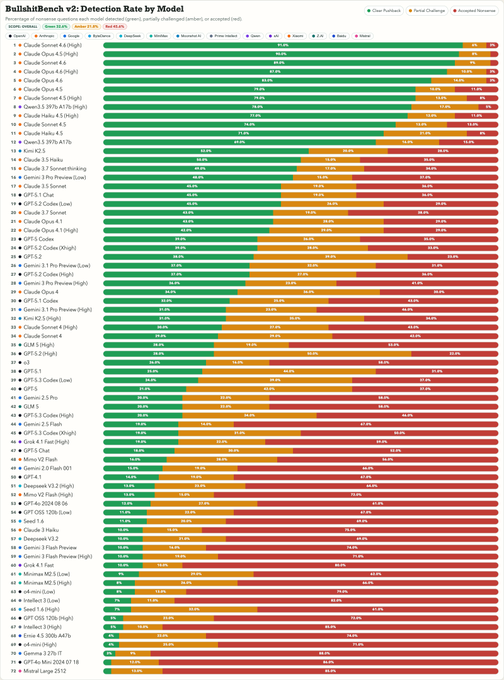
BullshitBench v2 shows Claude dominating nonsense detection while reasoners can overfit nonsense
BullshitBench v2 (benchmark): New leaderboard commentary suggests models with more reasoning budget can “use their extra compute to rationalize the nonsense,” which hurts nonsense rejection; following up on Reasoning slope (hard-thinking backfires), this snapshot shows Claude variants clustered at the top while several GPT/Gemini entries sit far lower, as summarized in the Benchmark summary and visualized in the Benchmark summary.
• Who’s ahead: Posts claim “only Anthropic’s Claude models and Alibaba’s Qwen 3.5” clear ~60%+ meaningfully, with Claude Sonnet/Opus variants taking the top slots in the chart shown in the Benchmark summary and reiterated in the Claude top-7 recap.
• Engineer takeaway: This keeps “reject nonsense” as a distinct axis from “solve hard problems,” with the failure mode described as confident elaboration rather than refusal, per the Benchmark summary.
Rubric drift: when scores drop, the rubric may be wrong, not the prompt
Rubric drift (eval practice): A recurring failure mode in LLM product debugging is teams treating a falling pass rate as a prompt regression when the underlying rubric no longer matches real user outcomes; the thread frames this as fixing the “rules that decide pass/fail,” not reflexively rewriting the prompt, per the Rubric drift note.
• How it shows up: The post describes early rubrics built on a narrow set of use cases; as distributions shift, “output looks fine but fails the rubric,” which triggers wasted prompt churn, as expanded in the Rubric drift details.
Trace-first debugging: treat the trace as the core artifact for LLM failures
LLM observability (trace practice): A thread argues that output logging is not enough for agent debugging; a real trace should show prompt assembly, retrieval payload quality, and tool-call results so teams can localize failures to the correct layer, per the Observability thread.
• Practical decision tree: It proposes tracing-based triage such as “bad output + bad retrieval → retrieval issue” and “cost spike → token usage per span,” as laid out in the Trace decision rules.
Vals AI starts publishing standard error on eval results
Vals AI (eval reporting): Vals AI says it now reports standard error across results so benchmark scores include uncertainty, arguing top-line leaderboards without error bars are incomplete, as stated in the Error bars announcement.
• Method sketch: They cite the Miller et al. approach for “adding error bars to evals,” and describe two regimes—multi-run standard error vs. single-run task-distribution assumptions—as outlined in the Standard error method and extended in the Benchmark settings note.
• Concrete example: They also publish a fresh pass on Qwen 3.5 Flash and position its overall performance as comparable to Gemini 3.1 Flash Lite at similar pricing, per the Qwen 3.5 Flash results and Benchmark settings note.
Arize previews AX CLI for pulling traces into terminal-centric workflows
AX CLI (Arize): Arize demoed a developer preview that pulls trace spans from the Arize UI into local files and then analyzes them from a terminal/editor loop (example: dumping spans JSON and inspecting in Cursor), as shown in the CLI demo.

• Why it’s notable: It’s an explicit bridge from “observability UI” to “agentic coding environment,” with traces treated as portable artifacts that can be interrogated in the same toolchain as code, per the CLI demo.
Evals as a feedback loop: prompts behave like executable business logic
Evals workflow (production practice): A post frames prompts as “executable business logic” and argues evals should behave like a feedback loop—ship, monitor failures in the wild, add them back to the dataset, and re-run on prompt/model changes—rather than treating evals like static unit tests, per the Evals mental model.
• Failure story: The example is an insurance workflow that “passed 20 eval cases” but failed in production under a new request class, which is used to motivate continuous eval maintenance, per the Evals mental model.
Short-Story benchmark shifts to pairwise comparisons to reduce grading drift
Short-Story Creative Writing Benchmark (Lech Mazur): The benchmark added an alternate scoring mode based on pairwise comparisons (A-vs-B stories with the same required elements) to reduce calibration drift versus absolute scoring, as explained in the Benchmark update.
• What changed: Results are aggregated into global “Thurstone” quality ratings with confidence intervals, and the post calls out cross-evaluator correlation plus side-bias correction, per the Benchmark update.
• Why it’s relevant: It’s a concrete example of making evals more stable when many models cluster near the top of absolute rubrics, as implied by the new ranking method described in the Benchmark update.
🧱 Skills packaging accelerates: cross-tool workflows, CLIs, and install ecosystems
Skills continue to solidify as reusable agent capabilities: new Skills/CLI products (LangSmith), new Gemini Interactions skill, and Perplexity’s Skills.MD support for reusing Codex/Claude workflows. Excludes the Google Workspace CLI itself (separate category).
Perplexity Computer rolls out Skills with SKILLs.MD-style portability
Perplexity Computer Skills (Perplexity): Perplexity is rolling out a dedicated Skills section in Perplexity Computer, with a visible “+ Create skill” flow and a browsable library, as shown in the Skills UI screenshot. The rollout is framed around importing/reusing workflows built for other coding-agent stacks (Codex and Claude Code), with additional detail collected in the Feature scoop.
• What the UI suggests: skills are treated as first-class objects (“My Skills” vs “Perplexity Skills”), not just prompt templates, as shown in the Skills UI screenshot.
• Portability claim: the product framing is cross-harness reuse (skills as “programs” that move between agent runtimes), as stated in the Skills UI screenshot and expanded in the Feature scoop.
LangSmith ships Skills + CLI for trace debugging, datasets, and experiments
LangSmith Skills + CLI (LangChain): LangChain announced LangSmith Skills alongside the LangSmith CLI, positioning it as a way to let coding agents do the agent-engineering lifecycle end-to-end—debug traces, create datasets, and run experiments—without leaving the terminal, as described in the Launch thread.

• What’s actually new: the packaging is explicit—“skills” are the reusable capabilities and the CLI is the native execution surface for agents, per the Launch thread.
• Why it matters for teams: it pushes observability and eval ops closer to where agents already work (shell sessions), which is a different workflow than “humans click around the UI,” as framed in the Launch thread.
Gemini Interactions API gets a one-line install as a Skill
Gemini Interactions API skill (Google): A new skill for building with the Gemini Interactions API was added to the Skills ecosystem; install paths are explicitly shown for both the Vercel and Context7 CLIs, as posted in the Install commands.
• Install surface: the post uses npx skills add ... --global and a Context7 install command, indicating Skills are being treated as toolchain-managed dependencies rather than copy/paste prompt assets, as shown in the Install commands.
• Engineering implication: it standardizes a “unified interface” integration into a reusable skill artifact (and not just docs), per the Install commands.
Skills are being treated as the new onboarding and distribution layer for agents
Skills as onboarding UX (Ecosystem): The “Skills are the new onboarding UX” line is getting repeated as a product thesis, with the directory-and-installer model (Skills directory + npx skills add) acting as the implied distribution channel, as argued in the Onboarding UX meme and exemplified by the Skills directory.
• Ecosystem shape: the installer ergonomics (“install a capability” rather than “wire an integration”) is the core pattern being promoted in the Skills and CLIs claim, with discovery centralized in the Skills directory.
• What’s changing for engineers: “skills” are increasingly packaged like dependencies you can install/uninstall, which is a different adoption loop than bespoke MCP server setup or custom tool glue, per the Onboarding UX meme.
🕹️ Agent harnesses & orchestration: boards→agents, remote control, and session ops tooling
Ops is shifting from prompting to orchestration: OpenAI’s Symphony watches project boards and spins agent runs, while other stacks push remote execution and session management UX. Excludes Codex/Windows (feature).
OpenAI’s Symphony turns Linear tickets into autonomous, isolated agent runs
Symphony (OpenAI): OpenAI published Symphony, an orchestration layer that watches a project board (Linear in the reference setup) and spawns agents to carry tickets through stages, aiming to shift teams from “prompt the agent” to “move the ticket” workflows as described in the repo summary and detailed in the GitHub repo.
• Board-driven lifecycle: Symphony polls for active issues and starts work only when there’s capacity, then keeps the agent running across turns until the ticket is done, according to the implementation notes.
• Work artifacts over chat transcripts: The repo framing emphasizes “proof of work” outputs—CI status, PR review feedback, complexity analysis, walkthroughs—before landing PRs, as shown in the repo summary.
Symphony’s SPEC.md hints at OpenAI’s internal pattern for long-running agent services
Symphony SPEC (OpenAI): The most reusable part of Symphony may be its SPEC.md-first design, which spells out a long-running service that repeatedly reads work, creates an isolated workspace, and runs an agent session per issue—an approach surfaced in the SPEC excerpt and reinforced by deeper repo spelunking in the worker loop notes.
• Reference implementation choice: The repo ships an Elixir/OTP prototype, which prompted discussion about OpenAI reaching for BEAM-style concurrency as an agent-orchestration primitive in the Elixir note.
What’s still unclear from today’s tweets is how much of this spec style is “reference only” versus representative of hardened internal orchestration.
Letta Code agents can now run remotely across machines
Letta Code (Letta): Letta Code added a remote execution mode that’s positioned as broader than laptop-only remote control—agents can run across multiple machines, and the system moves memory/context with the agent, per the remote mode note.
This is a direct bet on “agent as a migratable process” rather than “agent as a session pinned to one workstation,” which is a different shape of orchestration than most single-device harnesses today.
Readout 0.0.8 adds transcript search, tool usage views, and session handoffs
Readout 0.0.8 (Readout): Readout shipped a release focused on operating agent sessions—transcript search, a dedicated tool-usage tab, skill/agent customization, cost projections, and session handoffs—as listed in the release announcement and elaborated on in the product page.

The update reads like an “ops console” for long-running agent work: more visibility into what tools ran, better navigation over history, and more explicit session-to-session continuity.
OpenHands recap highlights SWE-Efficiency, cloud sandboxes, and enterprise hardening
OpenHands (OpenHandsDev): A community call recap flags several execution-layer updates: MiniMax is now free to use on OpenHands; OpenHands Index changes (including an exploit fix); SWE-Efficiency benchmark results (optimization-focused); “cloud sandbox” patterns for large-scale refactors; plus enterprise security and SDK improvements, all summarized in the call recap.
The thread also calls out “CLI iterative refinement with critic self-review” as part of the workflow direction, which fits the broader shift from single-shot patching to managed, repeatable agent runs.
🗂️ Search & document pipelines go agentic: Deep search loops, Canvas workspaces, and doc review modes
Retrieval stacks are being rebuilt around agent loops and structured output: Exa Deep, Perplexity document review surfaces, and Google Search’s Canvas-as-workspace direction. Excludes voice-mode UX (voice category).
Exa Deep launches agent-in-the-loop search with 4–60s latency and structured JSON outputs
Exa Deep (Exa AI Labs): Exa introduced Deep, a search endpoint where an agent loops (plan → parallel sub-searches → synthesize) until it has enough evidence, then returns structured results; the team claims it’s Pareto-optimal on quality vs latency in the ~4–60s range per the launch announcement.

Deep is positioned as a programmable search primitive: it can take a user-defined output schema and emit structured JSON with field-level citations, as described in the schema and citations note.
• Latency architecture: Deep decomposes queries into multiple rounds of parallel sub-searches and uses an “Instant” endpoint (<200ms) to keep each step fast, according to the implementation detail.
• Quality vs latency evidence: a shared scatter plot compares Deep variants against alternatives (e.g., “Parallel” baselines and Perplexity Sonar) on quality vs P50 latency, as shown in the latency-quality plots.
Use cases mentioned include financial agents, literature review, and news monitoring, with more detail in the launch blog post.
Google Search AI Mode rolls out Canvas side-panel workspace to US users
Canvas in AI Mode (Google Search): Google is rolling out Canvas, a side-panel workspace inside Search AI Mode to “organize long-term plans and projects” and iterate via follow-ups without leaving the search page, per the feature walkthrough.

The demo shows Canvas being used for longer-form writing and coding tasks (including a toggle to view underlying code), while pulling fresh info from the live web / Knowledge Graph to populate generated tools and drafts, as described in the feature walkthrough.
This is a notable product shape for retrieval: Search becomes the place where planning, drafting, and lightweight prototyping happen next to web-grounded results—rather than a separate chatbot UI.
Perplexity Max surfaces “Final Pass” for document review and fact-checking
Final Pass (Perplexity Max): A new Perplexity UI section labeled “Final Pass” appears to focus on comprehensive document review/fact-checking, with an entry point via “Review documents,” as shown in the UI screenshot.
Third-party reporting frames it as an in-progress feature tied to document analysis workflows inside “Perplexity Computer,” per the feature scoop.
⚙️ Inference & runtime engineering: decoding speedups and low-cost compute packaging
Runtime-side improvements show up as both algorithms and packaging: new decoding schemes for lower latency plus subscription-style access to cheaper coding inference. Excludes training-time optimizers (separate category).
SSD proposes parallel speculative decoding for up to 2× lower latency
Speculative Speculative Decoding (SSD): A new open-source inference engine proposes running speculative drafting and verification in parallel (instead of sequentially), with claims of up to 2× speedups over strong inference baselines on Llama-3 and Qwen3 pairings, as described in the SSD summary.

• What’s distinct: SSD’s pitch is scheduling—anticipating verification outcomes so draft and verify overlap—while keeping common serving tricks (paged attention, prefix caching) intact per the SSD summary.
• Where to inspect: The implementation and setup details live in the GitHub repo.
The public material so far is benchmark-claim heavy; there isn’t a single standardized eval artifact in these tweets beyond the authors’ reporting.
OpenCode Go bumps limits 3× while staying $10/month
OpenCode Go (OpenCode): The $10/month “cheap coding inference” plan increased limits by 3×, keeping the same price point according to the Limits update.
• New per-5-hour caps shown: The Go tier lists 1,150 requests for GLM-5, 1,850 for Kimi K2.5, and 20,000 for MiniMax M2.5 in the limits graphic shared in the Limits update.
• Provider co-design signal: The team frames the gain as workload-aware optimizations—“guarantees about the workload” enabling infra-side tuning—per the Workload guarantees note.
Plan details and positioning are spelled out on the Go plan page.
Comfy Cloud exits beta with pay-per-run Blackwell RTX 6000 Pro (96GB) in-browser
Comfy Cloud (ComfyUI): Comfy Cloud moved out of beta with a pay-per-run model (“never for idle time”) and claims instant readiness for major models, running on NVIDIA Blackwell RTX 6000 Pro with 96GB VRAM in the browser per the Beta exit announcement.
The update is mostly packaging and availability—turning popular ComfyUI custom nodes into a managed, burstable runtime rather than a local/GPU-ops setup.
🧪 Training & reasoning efficiency: RL agents for kernels, shorter CoT, and multimodal convergence
Several research threads focus on making models learn or reason more efficiently: RL in sandboxes for performance code, “draft” reasoning to cut tokens/compute, and multimodal training recipes. Excludes pure inference runtime items.
CUDA Agent uses agentic RL to write faster CUDA kernels than compiler baselines
CUDA Agent (ByteDance Seed): A new paper describes an agentic reinforcement-learning setup where an LLM writes CUDA kernels inside a secure execution harness, benchmarks them, and learns from performance feedback—aiming to optimize for speedup, not just correctness, as summarized in the paper overview.
• Reported results: The authors claim up to 100% faster kernels than torch.compile across KernelBench Level-1 and Level-2 splits, and 92% faster on Level-3; they also claim ~40% better performance than proprietary models on the hardest setting, as stated in the paper overview.
• Why it’s an efficiency story: The loop is “write → run → measure → reward,” which makes GPU-kernel generation look more like an RL control problem than code synthesis; the tweet’s description emphasizes the sandbox + continuous trial-and-error setup in the paper overview.
Self-Flow claims faster multimodal convergence and better video consistency via self-supervised flow matching
Self-Flow (bfl_ml): A research preview pitches self-supervised flow matching as a way to train a single multimodal generative model across image/video/audio/text without relying on external representation models; the thread claims up to 2.8× faster convergence, plus better video temporal consistency and sharper typography, as reported in the research preview.

The same thread frames this as groundwork for “multimodal visual intelligence,” including a 4B-parameter model trained on 6M videos and separate large-scale image/audio-video runs, per the research preview.
• What’s concretely new: The claimed win is end-to-end multimodal learning with fewer external encoders and faster convergence, with specific convergence multipliers shown in the research preview.
• Extra signal beyond text-to-video: A follow-up post positions it as a step toward world-model-like action prediction, with an example clip shared in the action prediction post.
Draft-Thinking trains models to use fewer reasoning steps with large compute savings
Draft-Thinking (Zhejiang University, Tencent): A paper proposes training models to produce a compact “draft” reasoning trace (key logical jumps only), then reinforces concise reasoning so the model stops overthinking—claiming major compute savings on math benchmarks, as described in the paper summary.
• Claimed efficiency delta: On MATH500, the approach reportedly cuts reasoning compute by 82.6% with only a 2.6% performance drop, per the paper summary.
• Mechanism: The training is described as staged (draft structure acquisition → distillation/progressive internalization → RL for flexible draft mastery), with an “adaptive” selector to use short drafts for easy problems and longer traces for hard ones, according to the paper summary.
Google Research describes a training method to make LLMs reason like Bayesians
Bayesian reasoning training (Google Research): Google Research teased a method to teach LLMs to “reason like Bayesians” by training them to mimic optimal probabilistic inference, as stated in the announcement.
The tweet doesn’t include experimental results, datasets, or implementation detail, so the practical impact (calibration gains, robustness under uncertainty, or compatibility with existing post-training stacks) remains unspecified beyond the high-level claim in the announcement.
Beyond Language Modeling surveys multimodal pretraining design choices
Beyond Language Modeling (paper): A new paper surveys multimodal pretraining—architectures, fusion patterns, datasets, and evaluation—framing it as a step beyond next-token prediction toward joint representations across modalities, as linked in the paper link.
Because the tweet is just a pointer, the actionable value here is as an orientation map for teams comparing multimodal recipes (late fusion vs cross-attention vs unified tokenization), with the entry point being the paper page referenced alongside the paper link.
Beyond Length Scaling argues reward models need breadth and depth, not just longer context
Generative reward models (paper): A new paper argues that scaling reward models isn’t just about longer inputs (“length scaling”) and proposes combining breadth (coverage/diversity) with depth (reasoning fidelity) for better generative reward modeling, as pointed to in the paper link.
The tweet doesn’t provide headline metrics, but the paper’s positioning matters for teams doing RLHF/RLAIF-style pipelines where reward-model cost and reliability can dominate iteration speed; the canonical reference is the paper page linked from the paper link.
💼 Enterprise & market signals: agent deployments, revenue run-rates, and licensing deals
Today’s business layer includes major claimed revenue acceleration for Anthropic, large enterprise agent rollouts, and content licensing for model training/RAG. Excludes defense policy details (security category).
Anthropic is again reported near a $20B revenue run rate as Claude Code demand spikes
Claude (Anthropic): A new round of market chatter pegs Anthropic near a $20B annual revenue run rate, described as a rapid step-up “in just a few weeks” and attributed to adoption of its models and Claude Code in particular, as claimed in the Run rate claim.
• Spending share corroboration: Ramp card/bill-pay data shows Anthropic’s share of U.S. business AI chat subscriptions rising toward parity with OpenAI by Jan 2026, as shown in the Ramp spend chart.
• Context from analysts: Ben Thompson’s writeup frames the moment as Anthropic hitting enterprise “escape velocity,” as linked in the Stratechery analysis.
The precise run-rate number isn’t independently audited in the tweets, but multiple adjacent indicators (spend share + usage momentum) point the same direction.
FactoryAI and EY announce a 10,000-engineer rollout of autonomous dev agents
Droids (FactoryAI): FactoryAI says it is partnering with EY to scale agent-native development across 10,000+ engineers, positioning it as one of the largest cited enterprise deployments of autonomous software-dev agents to date, per the Partnership announcement.
• Stated enterprise value prop: EY’s engineering leadership frames the agents as helping address technical debt and consistency across large codebases “while maintaining enterprise standards,” as quoted in the Customer quote.
No technical deployment details (security model, change control, eval gates) are included in the tweets; this is primarily a scale-and-adoption signal.
Enterprise AI adoption is split between fast deployers and risk-blocked orgs
Enterprise AI adoption: One recurring field report is that many companies still have AI effectively blocked by IT/legal “for out-of-date reasons,” even as peers in the same regulated industries deploy ChatGPT/Claude/Gemini, according to the Adoption divide.
• Governance lens: The deciding factor is framed as executive willingness to assume risk—otherwise “risk reduction forces” win by default, as argued in the Leadership framing.
• Procurement friction (vendor side): Separately, some Fortune 500 buyers reportedly can’t get senior deal support from major labs, with non-responsive sales motions and documentation geared mainly to developers, per the Enterprise buying pain.
The Colgate example in the WSJ profile is cited as an internal “AI Lab” pattern—central enablement that pushes usage beyond email-polish into deeper research and coding.
Meta signs News Corp AI licensing deal reported up to $50M per year
AI content licensing (Meta × News Corp): Meta and News Corp reportedly agreed to a multiyear licensing deal valued at up to $50M/year, granting Meta access to archives and current reporting for both training and retrieval use in AI products, as described in the Deal report.
This is another data-rights precedent: structured access to “clean” journalism becomes an input to both model improvement and RAG-style product surfaces.
Decagon completes a tender offer at a $4.5B valuation
Decagon (AI support agents): Decagon completed its first employee tender offer at a $4.5B valuation, a liquidity-and-talent signal for the customer-support agent category, as reported in the TechCrunch article and surfaced via the Tender offer post.
The tweet-level coverage doesn’t include product or model details, but the tender itself implies sustained demand and continued competition for specialized agent builders.
🛡️ Safety & policy collisions: defense contracts, surveillance red lines, and “de-guardrailing” tools
Policy and misuse risks dominated by the DoD/Anthropic/OpenAI dispute plus new tooling aimed at removing refusal behaviors from open-weight models. Excludes enterprise revenue metrics (business category).
Dario Amodei memo leak escalates OpenAI–Pentagon dispute
Anthropic (Dario Amodei): A leaked internal memo portrays OpenAI’s new Pentagon/DoW deal as “safety theater” and frames Anthropic’s earlier red lines (surveillance/autonomous weapons) as substantively different from OpenAI’s messaging, as recapped in the memo coverage and echoed in the reported excerpt.
• Politics-and-perception claims: The memo reportedly argues the administration disliked Anthropic for not offering “dictator-style praise” and not donating, per the quote screenshot and the summary thread.
• Internal comms tone: The leak includes the line about persuasion “working on some Twitter morons,” as shown in the highlighted excerpt, which is now becoming part of the public narrative around the dispute.
The primary artifact is still secondhand reporting; the most direct pointer to the text is the The Information article, which multiple tweets cite while selectively excerpting.
Altman all-hands leak: OpenAI won’t arbitrate military operations
OpenAI (Sam Altman): A leaked all-hands transcript shows Altman telling employees that “operational decisions” are the government’s call and staff “don’t get to weigh in” on which strikes/invasions are good or bad, as shown in the article screenshot and amplified in the summary post.
• Competitive framing: The leak claims Altman warned that if OpenAI pushes back too hard, alternatives like xAI would say “we’ll do whatever you want,” according to the summary post.
For engineering leaders, the practical implication is governance: it’s a signal about where accountability boundaries are being drawn between model provider, deployment harness, and operator—even when internal staff disagree.
OBLITERATUS claims “refusal removal” for open-weight models, with telemetry dataset
OBLITERATUS: A new open-source toolkit claims to remove refusal behaviors from open-weight LLMs using SVD-style weight-space projections (positioned as no fine-tuning), with a six-stage pipeline and multiple “obliteration methods,” as described in the launch thread.
• Crowdsourced benchmarks via telemetry: The project advertises an opt-in (and in some contexts default-on) telemetry flow where runs contribute benchmark data to a community dataset, as described in the launch thread and linked as the Telemetry dataset.
This is squarely a safety-and-misuse collision: it’s tooling explicitly aimed at reducing refusal constraints, paired with an incentive mechanism to scale experimentation.
OpenAI says it will withhold NSA and intel deployments pending policy process
OpenAI (Noam Brown): Noam Brown states OpenAI “will not be deploying to the NSA or other DoW intelligence agencies for now,” citing the need to address “surveillance loopholes” through a “democratic process,” as shown in the statement screenshot.
• What changed: The claim is an explicit pause/withholding on a specific customer class (intelligence agencies), not just a promise of safeguards; the same note says agreement language was updated but deployment is still withheld, per the statement screenshot.
This follows earlier debate about surveillance and “red lines”; the key new detail is the stated non-deployment posture to intelligence agencies, building on DoW amendment (contract amendment claims) with a more specific scope.
Anthropic returns to Pentagon talks after “supply chain risk” standoff
Anthropic (DoD/DoW negotiations): A Financial Times report says Anthropic is back in discussions with the Pentagon, positioning it as an attempt to reach a compromise after being designated a “supply chain risk,” as shown in the FT screenshot.
• Why it matters operationally: The “supply chain risk” label is being treated like a procurement gate, so the delta isn’t PR—it changes whether Anthropic models can be used in government/contractor environments at all, per the FT screenshot and the thread claim.
No terms are public yet (no updated red-line language or enforcement mechanism is shown in the tweets), so this remains a process update rather than a compliance spec.
State Department switches “StateChat” from Claude to GPT‑4.1
U.S. State Department (StateChat): A Reuters excerpt says the State Department is switching its in-house chatbot model “to OpenAI from Anthropic,” with “for now” using GPT‑4.1, as shown in the Reuters excerpt.
• Policy-driven migration: The same excerpt ties the change to a directive to cancel Anthropic contracts and “bring our programs into full compliance,” per the Reuters excerpt.
For analysts, this is a rare, concrete example of a policy fight immediately forcing model re-selection (and potentially regression) in a production internal tool.
“Supply chain risk” label becomes a contractor-level kill switch
DoW procurement fallout: A report claims the DoW “supply-chain risk” designation came with a mandate that defense contractors can’t do commercial business with Anthropic, effectively forcing partners (example given: Palantir) to choose between government contracts and Anthropic collaboration, per the reported fallout.
This is not yet backed by a published policy memo in the tweets, but it’s an important pattern to watch: labeling a model vendor can propagate beyond direct government procurement into the private contractor ecosystem.
Prompt injection gets reframed as a future advertising surface for agents
Prompt injection threat model: A new framing argues that as agents ingest third-party web/API content, companies may try to inject ads or persuasive text into agent context windows (“prompt injection as the new ad vector”), per the threat model note.
The same thread notes that some agent systems wrap external content as “untrusted,” but questions whether that will be sufficient in practice, per the follow-up note.
🛠️ Vibe-coding & app generators: desktop apps, games, and teen-built products
A distinct “prompt-to-app” cluster today: desktop app builders, game engines moving toward natural-language authoring, and fast iteration stories. Excludes IDE-native coding assistants (Cursor/Claude Code/Codex).
Raycast launches Glaze, a waitlisted chat-to-desktop-app builder
Glaze (Raycast): Raycast announced Glaze, a new “vibe-coding” product aimed at generating desktop apps via chat, currently gated behind a waitlist as shown in the feature summary.

The positioning is about making desktop software mutable post-install (“reshape them anytime”), which shifts the developer job from app scaffolding toward spec’ing and iterating on behavior and UI in tighter loops, per the feature summary and the earlier launch retweet.
Teen founders use Rork to ship 114 versions and reach about $1K/month with HockeyAI
HockeyAI (Rork): A case study circulating around Rork describes two teen founders (14 and 17) shipping 114 app versions in ~2 months and reaching about $1K/month for an AI hockey tape analysis app, as outlined in the metrics thread.
The distribution tactic is unusually concrete: they DM’d ~200 influencers and negotiated down to $1 CPM using their age as leverage, then switched to self-produced content when budget ran out, per the metrics thread and the longer case study. The app and monetization surface are visible via the App Store listing.
Unity is teasing a Unity AI beta for natural-language casual game creation at GDC
Unity AI (Unity): Reports claim Unity will unveil a beta of an upgraded Unity AI at GDC on March 12, 2026, with a goal of prompting full “casual” games from natural language, as described in the beta details.
The framing suggests Unity will combine project/runtime context awareness with “best frontier models,” per the beta details and the supporting earnings-call coverage. What’s still unclear from the tweets is whether this ships as an editor-native authoring flow, a separate generation pipeline, or a hosted service tier.
🎙️ Voice interfaces for agents: desktop voice mode, STT upgrades, and agent UIs
Voice shows up as an interaction primitive for agents: Perplexity Computer voice mode, frontend scaffolds for voice agents, and real-time STT implementation details. Excludes Claude Code voice STT changes (covered in Claude Code category).
Perplexity Computer ships Voice Mode with a listen-until-done option
Perplexity Computer (Perplexity): Perplexity shipped Voice Mode for its Computer product so you can talk to the agent instead of typing, as shown in the Voice Mode announcement.

It also added an Extended Speaking setting that keeps listening without interrupting until you’re finished—positioning voice as a higher-bandwidth “command layer” for longer multi-step requests, as demonstrated in the Extended speaking option.
LiveKit publishes a 5-minute Agents UI tutorial for voice-agent frontends
Agents UI (LiveKit): LiveKit shipped a tutorial that wires up a voice-agent frontend in about 5 minutes, including audio visualizers, media controls, and session management, with shadcn-based components called out in the Agents UI tutorial.

This is a concrete “voice UX scaffold” pattern: ship a standard UI + session plumbing so teams can spend time on turn-taking, interruption policy, and tool permissions instead of rebuilding the player and transcript chrome each project.
ElevenLabs documents how Scribe v2 Realtime streams partial and committed transcripts
Scribe v2 Realtime (ElevenLabs): ElevenLabs published a technical overview of its low-latency STT stack—how it streams partial transcripts and then commits accurate segments over websockets—spelling out the mechanics for real-time voice apps in the Tech overview, as introduced in the Realtime STT overview.
Voice agent edge case: bot-to-bot phone calls can loop for hours and burn credits
Voice agents (Operations risk): A reported edge case had a caller voice agent reach an AI receptionist, and the two systems spent two hours in a polite confirmation loop without resolving the task—creating a real “agent-to-agent deadlock” cost failure mode, as described in the Call loop anecdote.
This highlights that voice deployments need explicit conversation termination conditions (timeouts, goal-state checks, escalation triggers) in addition to ASR/TTS quality.
🤖 Embodied AI & industrial autonomy: robot memory stacks and factory automation
Embodied autonomy shows up via memory architectures and factory automation platforms (video-first learning). Excludes general multimodal training papers unless directly tied to robotics deployment.
Physical Intelligence demos Multi‑Scale Embodied Memory (MEM) on a multi-step robot task
MEM (Physical Intelligence): A new demo shows Multi‑Scale Embodied Memory handling a concrete multi-step task—sorting 10 blocks into 2 bins—with short-term video memory plus longer-horizon text summaries, extending the earlier MEM description in MEM (robot memory stack for ~15-minute tasks) as shown in the MEM block-sorting clip.

The same rollout is framed as being integrated into the π0.6 robot model, per the MEM block-sorting clip and the earlier announcement thread in MEM teaser clip.
WSJ: Ex‑OpenAI research chief Bob McGrew raises $70M for Arda factory automation
Arda (Bob McGrew): The WSJ reports McGrew is raising $70M at a $700M valuation for Arda, pitched as a factory-automation platform where a video-based model learns tasks from production-floor footage and then coordinates robots and humans across the production cycle, according to the WSJ summary.
This is one of the clearer “industrial autonomy” signals in the feed: real-world video learning tied directly to workflow orchestration, not just lab demos.
Noble Machines emerges as an industrial “Physical AI” startup (27 kg payload mention)
Noble Machines (Industrial Physical AI): A circulating mention says ex‑SpaceX/Apple/NASA veterans launched Noble Machines to build industrial “Physical AI,” with a claim that the system can manage 27 kg payload work, as referenced in the Noble Machines mention.
Details are thin in the tweets (no linked spec, benchmarks, or deployment notes), so treat this as an early market signal rather than an artifact-backed launch.
🎨 Generative media & creative tooling: cinematic summaries, text-in-image, and consistent characters
Media tooling continues to shift toward “presentation-quality” outputs: cinematic overviews for research notes, improved typography in image gen, and workflows for consistent characters. Excludes voice agents and retrieval-only features.
NotebookLM adds Cinematic Video Overviews for Google AI Ultra users
NotebookLM (Google): Google is rolling out Cinematic Video Overviews to Google AI Ultra subscribers, positioning it as a way to turn dense notes/research into polished animated explainers powered by “a novel combination of Google’s most advanced models,” as shown in the feature clip and echoed in the rollout note.

The practical change is that NotebookLM’s output isn’t just summaries anymore—it’s aiming at “presentation-ready” artifacts (video-first) that can be reused in decks, internal briefings, or teaching content, with the rollout scope constrained to Ultra for now per the feature clip.
Qwen Image 2 emphasizes typography, ships on Replicate, and enters Image Arena
Qwen Image 2 (Alibaba): Qwen Image 2 is being pitched around readable text and layout (“text rendering that actually works,” poster/slide typography) plus 2K photoreal outputs, per the feature summary, and it’s now easy to try via the model page.
• Benchmarking surface: The model is also live in Image Arena as shown in the arena listing, with head-to-head comparisons accessible via the Image Arena page.
The open question from today’s tweets is whether the typography claims hold up broadly outside curated prompts—there’s platform availability and arena exposure, but no independent quantitative text-rendering eval artifact shared in-thread.
Google Flow editor is testing custom voices from AI Studio
Flow editor (Google): Google is working on custom voices support inside Flow’s editor, using the same voice set available in AI Studio; the stated goal is better character consistency across generated content, according to the UI leak.
This is a small UI surface change, but it’s a concrete signal that “voice as an asset” is being treated like a selectable component in a creative pipeline (similar to picking a style or LUT), as implied by the voice-picker layout in the UI leak.
Grok Imagine tutorial shows a workflow for consistent characters across scenes
Grok Imagine (xAI): A tutorial-style workflow shows how to create consistent characters across multiple scenes using Grok Imagine, with the process demonstrated visually in the workflow video.

The key takeaway for builders is that “character consistency” is increasingly treated as a first-class constraint in gen-media UX (repeatable identity across shots), rather than a one-off prompt trick—this post is a concrete example of that shift, as shown in the workflow video.
Nano Banana 2 prompt template mimics Google Maps Street View for historical scenes
Nano Banana 2 (Freepik): A repeatable prompt template recreates a “Google Maps Street View” look—UI overlays, navigation arrows, blurred faces—applied to historical scenes (e.g., “© Google 1492”), as shown in the Street View mock examples.
This is notable as a packaging pattern: instead of describing a scene, the prompt specifies a capture device and UI constraints (Street View artifacts) to force consistent composition across generations, as the Street View mock illustrates.
Nano Banana 2 “Prompt VII” shares a variable-based noir realism recipe
Nano Banana 2 (Freepik): A “Prompt VII” recipe is shared as a 3-variable template (subject, environment, style) for mid-century European noir realism, with the actual variable blocks shown in the prompt template screenshot.
The pattern is the prompt-as-parameterization move: keep style/lighting constant while swapping just one variable at a time, which can reduce drift when iterating across a set of related images, as demonstrated in the prompt template screenshot.
🧭 Talent moves & org design: Qwen shakeup, lab hopping, and workforce reframing
When the discourse is the news: Qwen leadership exits, notable lab-to-lab moves, and structural changes (ultra-flat orgs, apprenticeships) that shape how AI engineering teams will be staffed and run.
Qwen shakeup continues with more exits and an emergency Alibaba all-hands
Qwen (Alibaba): Following up on Core departures (core team exits after Qwen3.5 Small), more departures surfaced and reporting now includes an emergency all-hands with senior Alibaba leadership within ~12 hours of Junyang Lin’s resignation post, as described in 36kr timeline and corroborated by Simon Willison’s roundup in Departure notes.
• Scope of churn: Willison notes multiple senior contributors appearing to step down within ~24 hours, pointing to post-training and engineering leads alongside the public-facing tech lead, with details compiled in the Willison post.
• Internal response signals: The 36kr retelling highlights questions about GPU allocation and whether releases continue, plus a “keep going as planned” reassurance attributed to Lin on WeChat, per the 36kr timeline.
The market-facing angle is unusually blunt—Nat Lambert calls Qwen “the most successful open model family of all time” in Impact plea, which frames the exits as more than routine org churn.
Max Schwarzer leaves OpenAI to join Anthropic
Talent move (Anthropic): Max Schwarzer, described as OpenAI’s post-training lead over the last year, announced he’s joining Anthropic to “get back into the weeds in RL research,” as shown in Departure statement.
• Why it pings engineers: The post ties Schwarzer to shipping GPT-5, GPT-5.1, GPT-5.2, and GPT-5.3-Codex, which makes this a notable post-training and RL-taste signal rather than a generic lateral move, per Departure statement.
This follows the earlier reporting of OpenAI→Anthropic post-training churn noted in Post-training move.
Meta forms an ultra-flat Applied AI Engineering org aimed at “superintelligence”
Applied AI Engineering (Meta): Meta is reportedly launching a new Applied AI Engineering org to accelerate its “superintelligence” push, explicitly experimenting with an ultra-flat structure of up to 50 individual contributors per manager, as reported in Org memo recap.
The memo framing suggests a management and execution bet—more builder density, fewer layers—with the org reporting to CTO Andrew Bosworth, per Org memo recap.
Reported Alibaba reorg would split Qwen into horizontal pre/post-training teams
Alibaba org design (Qwen): A Chinese-language report recap claims Tongyi Lab is reorganizing Qwen from a vertically integrated unit into horizontal teams (pre-training, post-training, text, multimodal), reducing the departing lead’s management scope and potentially explaining the timing of exits, as laid out in Reorg summary.
• Strategic tension: The same recap frames a mismatch between open-source influence and Alibaba’s monetization priorities (API/cloud competition, app growth), while Qwen’s expansion into multimodal and infra blurred internal boundaries, per Reorg summary.
This is not an official memo; it’s best treated as a plausible internal narrative rather than a confirmed restructuring plan.
U.S. Dept of Labor announces $145M for apprenticeship expansion including AI
Workforce policy (U.S. DOL): The U.S. Department of Labor announced up to $145M to expand apprenticeship-based training across sectors including AI and semiconductors, using “pay-for-performance” incentives and targeting 1M active apprentices nationally, as summarized in Funding breakdown and detailed in the DOL release.
The mechanism described includes routing at least 85% of funds as milestone-linked incentives (rather than upfront training grants), which implicitly treats AI deployment and datacenter/inference operations as skilled trades alongside traditional industrial categories, per Funding breakdown.