OpenAI acquires Astral as Codex hits 2M weekly – uv at 126M/month
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI says it has an agreement to acquire Astral and, after closing, fold the uv/Ruff/ty team into Codex; OpenAI claims it will keep supporting Astral’s open-source tools while pushing Codex deeper into the Python workflow (env resolution, lint/format, type checks) rather than pure codegen. The deal is framed with adoption numbers—Codex cited at 2M weekly active users plus 3× user growth and 5× usage growth; third-party commentary calls uv “load-bearing” with ~126M downloads/month, but those ecosystem stats aren’t audited in the announcement.
• Cursor/Composer 2: new in-house coding model ships at $0.50/M input and $2.50/M output; “Fast” tier $1.50/$7.50; Cursor highlights CursorBench 61.3 and Terminal-Bench 2.0 61.7, but no reproducible eval package is provided.
• Anthropic/Claude Code: Channels research preview routes Telegram/Discord messages into a running session (>=2.1.80) via claude.ai login; 2.1.80 fixes missing parallel tool results on --resume and claims ~80MB lower startup memory on 250k-file repos.
Across vendors, the center of gravity is shifting from model quality deltas to workflow control surfaces—toolchains, identity/permissions, and resumable state; what remains unclear is how quickly these integrations reduce real-world flake (deps/tests/policy) versus adding new platform coupling.
Top links today
- Claude Code Channels announcement
- Claude Code Channels documentation
- Cursor Composer 2 launch details
- LiteParse announcement and demo
- LiteParse GitHub repository
- LangSmith Fleet product page
- fal MCP server access links
- Google AI Studio vibe coding launch
- AI Studio full-stack vibe coding demo
- Guide to writing prose with AI
- OpenGauss autoformalization agent overview
- vLLM Boston meetup registration
- MAI Playground and MAI-Image-2 access
- Next.js 16.2 Turbopack update post
- ElevenLabs MCP server announcement
Feature Spotlight
Cursor ships Composer 2: frontier-ish coding at bargain token prices
Cursor’s Composer 2 pairs strong coding benchmarks with ~$0.50/M input and $2.50/M output, pushing teams to re-think which model tier to run for most PR-sized work—and pressuring frontier pricing.
High-volume, cross-account story: Cursor’s in-house coding model Composer 2 rolls out with benchmark deltas and aggressive pricing that changes the economics of “workhorse” coding agents. This category is only about Composer 2 (excludes Cursor’s UI experiments like Glass).
Jump to Cursor ships Composer 2: frontier-ish coding at bargain token prices topicsTable of Contents
🟧 Cursor ships Composer 2: frontier-ish coding at bargain token prices
High-volume, cross-account story: Cursor’s in-house coding model Composer 2 rolls out with benchmark deltas and aggressive pricing that changes the economics of “workhorse” coding agents. This category is only about Composer 2 (excludes Cursor’s UI experiments like Glass).
Cursor launches Composer 2 with lower token prices and higher coding scores
Composer 2 (Cursor): Composer 2 is now available in Cursor with published pricing of $0.50/M input and $2.50/M output, plus a higher-throughput Fast tier at $1.50/M input and $7.50/M output, as stated in the release announcement and detailed in the release blog. Scores Cursor highlights include CursorBench 61.3, Terminal-Bench 2.0 61.7, and SWE-bench Multilingual 73.7, with deltas vs Composer 1/1.5 shown in the benchmark table and the benchmark slide.
Cursor is positioning CursorBench as an internal eval built from real coding sessions, and the launch framing is explicitly “frontier-ish performance per dollar,” with the cost/performance scatter presented in the cost curve plot.
Composer 2 triggers “workhorse tier” repricing in coding agents
Composer 2 economics (Cursor): Multiple posts frame Composer 2 as beating Claude Opus 4.6 on Terminal-Bench 2.0 (61.7 vs 58.0) while being materially cheaper per token, as shown in the Terminal-Bench comparison and repeated in the benchmark recap.
The more interesting detail is the “cost per task” presentation on CursorBench, where Composer 2 is plotted near GPT-5.4’s performance at a much lower median cost, per the cost-performance chart. Commentary also generalizes this into a strategic shift—“IDE companies are becoming model companies,” as argued in the Terminal-Bench comparison and echoed in the pricing gap recap.
Composer 2’s quality jump is credited to continued pretraining plus scaled RL
Composer 2 training (Cursor): Cursor attributes the biggest step up in Composer 2 to its first continued pretraining run (a stronger base) followed by scaled reinforcement learning on long-horizon coding tasks that require “hundreds of actions,” per the launch details and the release blog.
Aman Sanger also contextualized this as a year of “exclusively focused on coding” model work—“every FLOP, token, parameter… dedicated to software engineering,” as stated in the team focus post. One open question in the tweets is how much of the gains are from pretraining vs RL vs harness changes; Cursor’s public artifacts emphasize the pretraining→RL sequence but don’t provide a reproducible training/eval package in-thread.
Early users treat Composer 2 as a fast refactor/fix model, not the final boss
Composer 2 in practice (Cursor): Early usage reports characterize Composer 2 as strong for “targeted fixes” and “quick refactors” on large codebases, while still trailing GPT‑5.4 on the hardest work, as described in the large codebase notes.
There’s also at least one anecdote of “pitting it against GPT‑5.4” where Composer 2’s response was judged better by other models, per the QA process comparison. The vibe across these posts is “fast worker model again,” not “replace the flagship,” with speed and iteration loop quality being the recurring reason people keep it in the stack.
Together AI says it serves the Composer 2 Fast endpoint
Composer 2 Fast serving (Together AI + Cursor): Together AI says it “helps power” the Composer 2 Fast endpoint on its AI Native Cloud, per the partner note. This matters because Cursor’s launch splits pricing into standard vs Fast tiers, and Together’s statement is one of the few concrete infra datapoints about where the fast SKU runs.
The tweets don’t specify latency targets, batch sizes, or which accelerator generation is used. That’s the missing engineering detail. The public signal is simply that Cursor is leaning on external inference partners for at least part of the new model’s deployment.
Fireworks posts hint at Composer 2 availability and RL infra involvement
Composer 2 ecosystem (Fireworks AI): A Fireworks-adjacent post claims “Cursor Composer2 launched on Fireworks” and frames the rollout as not only inference but also “RL powered by Fireworks,” as stated in the ecosystem note.
There’s not enough detail in the tweet set to confirm what “RL powered” means operationally (offline training infrastructure, online RL, eval harnessing, or simply hosting). It’s still a notable distribution signal: Composer 2 appears to be landing across multiple inference vendors rather than being Cursor-only.
🟣 Claude Code: Channels (Telegram/Discord) + CLI 2.1.80 reliability fixes
Anthropic-focused coding tool updates: new “Channels” remote control path via MCP plus a notable Claude Code 2.1.80 changelog (resume reliability, memory staleness checks, SQL workflows). Excludes Cursor Composer 2 coverage.
Claude Code adds Channels: remote-control sessions from Telegram and Discord (research preview)
Claude Code Channels (Anthropic): Anthropic shipped Channels in research preview, letting select MCP servers push messages into a running Claude Code session—starting with Telegram and Discord—so you can drive a local coding session from your phone, as shown in launch demo and detailed in the Channels docs.

Access + security details: Setup requires Claude Code >= 2.1.80 and auth via claude.ai login (not API key/console login), with sender allowlists/policies to restrict who can inject events into the session per docs note.
Claude Code 2.1.80 fixes --resume dropping parallel tool results
Claude Code CLI 2.1.80 (Anthropic): Resumed sessions now restore all parallel tool_use/tool_result pairs instead of showing "[Tool result missing]" placeholders, removing a common failure mode in long-running, tool-heavy workflows according to release highlights.

This is a straight reliability win for anyone using parallel tools (tests + grep/read loops) and then resuming later.
Claude Code 2.1.80 tightens memory usage to avoid stale assumptions
Claude Code 2.1.80 (Anthropic): The system prompt now explicitly treats stored memories as historical context; Claude should verify critical details against current files/resources before relying on them, and update/delete entries when they conflict with the repo’s present state, as shown in prompt change notes and the prompt diff.
This is aimed at reducing “confidently wrong” actions after codebases drift.
Claude Code 2.1.80 reinstates previously blocked SQL analysis workflows
Claude Code 2.1.80 (Anthropic): “Many previously blocked SQL analysis functions” were reinstated, restoring prior SQL analysis workflows and outputs as called out in release highlights.
The change reads as a rollback of earlier capability gating that affected SQL-heavy repos and data debugging.
Claude Code 2.1.80 adds a settings.json plugin source for marketplace entries
Claude Code 2.1.80 (Anthropic): A new plugin marketplace source, source: "settings", allows declaring plugin entries inline in settings.json, per the “New features” list in changelog details.
This is a workflow tweak for teams that want plugin config checked into repo/environment config rather than relying only on interactive installs.
Claude Code 2.1.80 exposes rate limit usage to statusline scripts
Claude Code 2.1.80 (Anthropic): Statusline scripts can now read a rate_limits field showing usage across 5-hour and 7-day windows (including used_percentage and resets_at), as listed in changelog details.
This is one of the first “instrumentation hooks” in Claude Code that makes quota pressure observable without leaving the terminal.
Claude Code 2.1.80 reduces startup memory in huge repos and speeds @ autocomplete
Claude Code 2.1.80 (Anthropic): The CLI reports better responsiveness for @ file autocomplete in large git repos and reduced startup memory use—"~80 MB saved on 250k-file repos"—as described in changelog details.
This targets the “agent feels slow because the repo is big” path rather than model latency.
Claude Code + Figma MCP livestream scheduled for March 31
Claude Code + Figma MCP (Anthropic/Figma): trq212 announced a March 31 livestream on using Claude Code with the Figma MCP to collaborate between engineers and designers, with sign-up shared in event announcement.
The pitch is hands-on examples and a Q&A format, framed as a shared workflow rather than a one-way design export.
🟥 Google AI Studio “vibe coding” goes full‑stack (Firebase/Auth, multiplayer, persistence)
Google AI Studio’s build experience gets a major full-stack step up: Firebase backends, auth, real services, multiplayer, persistent builds, and an Antigravity-powered coding agent roadmap. Excludes Gemini subscription/CLI backlash (covered separately).
AI Studio can provision Firebase Auth + database and manage secrets in-build
Firebase primitives (AI Studio / Google): Build mode now treats backend setup as a first-class step: one-click database support plus “Sign in with Google” via Firebase, per Firebase and auth primitives, with additional notes that it can store API keys in a Secrets Manager and supports app frameworks like Next.js/React/Angular out of the box, as described in Frameworks and secrets.

This also aligns with the “stop bouncing between consoles” pitch in DB and auth in clicks, which is the real workflow delta for builders trying to ship beyond a static frontend.
Google AI Studio Build mode adds multiplayer and persistent full-stack sessions
AI Studio Build mode (Google): Google shipped a rebuilt “vibe coding” experience in AI Studio that can produce real-time multiplayer apps/tools, connect to “real services” (live data), and keep builds running even after you close the tab, as shown in the feature rundown from Upgrade announcement and the expanded set of capabilities listed in Feature list. It’s being framed as a full-stack environment rather than a throwaway prototype sandbox.

The rebuild timeline is also unusually explicit for a Google surface—Logan says the team spent 4 months rebuilding it from scratch, per the announcement screenshot in Launch teaser screenshot.
Antigravity becomes the in-product coding agent powering AI Studio builds
Antigravity agent (Google): The new Build experience is positioned as being powered by an embedded coding agent called Antigravity, called out directly in the launch framing in Antigravity agent intro. One concrete anecdote shows the intended “ops loop”: diagnose via logs, open Firebase console, change permissions in UI, then verify the fix—reported as taking under 2 minutes in Production permissions fix.
This is still anecdotal (one user flow), but it describes the kind of end-to-end debugging path that historically breaks most prompt-only app builders.
AI Studio Build mode adds shadcn, Framer Motion, and npm for UI polish
Frontend stack (AI Studio / Google): The updated Build mode now explicitly supports a more “production UI” toolchain—shadcn UI, Framer Motion, and npm package installs—so the agent can iterate with real component libraries instead of hand-rolled HTML/CSS, as called out in UI tooling callout. This matters because UI polish is often the bottleneck after the first working demo.
AI Studio roadmap: Design mode, Figma, Workspace, planning mode, agents, G1
Product roadmap (AI Studio / Google): Logan published a near-term roadmap for the next few weeks—Design mode, Figma integration, Google Workspace integration, better GitHub support, planning mode, agents, multiple chats per app, simplified deploys, and G1 support—as listed in Roadmap post and captured in the screenshot shared in Roadmap screenshot.
If all of this lands, it shifts AI Studio from “single chat builds a demo” toward “multi-session app development with design + deploy + agent workflows,” but the tweet doesn’t include dates per item.
Firebase Studio enters shutdown phase; migrate projects to AI Studio/Antigravity
Firebase Studio (Google): A notice says Firebase Studio is entering its shutdown phase on March 19, 2026 and will be fully shut down on March 22, 2027, with guidance to migrate because “core capabilities are already built into Google AI Studio and Google Antigravity,” as shown in the email screenshot in Shutdown notice.
For teams with preview-era Firebase Studio projects, this is an operational deadline plus a signal that Google wants one primary surface for agentic app-building (AI Studio) rather than parallel builders.
Stitch→AI Studio→Firebase pitch: Google’s end-to-end design-to-app pipeline
Ecosystem stitching (Google): Builders are now explicitly describing a pipeline where Stitch handles design/prototyping and AI Studio handles the full-stack build, with Firebase providing auth/data—see the Stitch canvas example in Stitch prototype screenshot and the “Google ecosystem for builders” summary in Stack workflow pitch.
This is less a single feature than a distribution story: if the handoff between design artifacts and generated code is smooth, Google can compress “prototype → app → backend” into one stack without requiring users to adopt separate agent products.
🟩 OpenAI acquires Astral to deepen Codex’s Python toolchain (uv/ruff/ty)
A major ecosystem move: OpenAI agrees to acquire Astral (uv/ruff/ty) and position it inside the Codex org, with explicit open-source continuation claims and Codex usage growth metrics. Excludes general model launches.
OpenAI agrees to acquire Astral to bring uv/Ruff/ty into the Codex org
OpenAI × Astral (Codex): OpenAI says it has reached an agreement to acquire Astral and, after closing, plans for the Astral team to join the Codex team, with an explicit commitment to continue supporting Astral’s open-source tools as described in the acquisition RT and the OpenAI post in OpenAI post.
The practical bet is that “AI that participates in the workflow” needs first-class hooks into dependency/env management and code-quality gates—not just code generation—mirroring the lifecycle framing in the Codex lifecycle excerpt screenshot.
Codex is cited at 2M weekly active users alongside the Astral acquisition
Codex (OpenAI): OpenAI is anchoring the Astral acquisition around Codex adoption, citing 3× user growth, 5× usage growth, and 2 million weekly active users in the deal context as shown in the growth metrics screenshot.
This matters because it positions Astral’s tools as “in the blast radius” of a product already operating at consumer-like scale, and it reinforces OpenAI’s stated goal of pushing Codex beyond codegen into planning, tool-running, verification, and maintenance as described in the same growth metrics screenshot.
Guido van Rossum signals he’s joining OpenAI during the Astral/Codex cycle
OpenAI (staffing): Guido van Rossum (gdb) posted “Welcome to OpenAI! … to make great tools to make developers everywhere more productive,” as stated in the joining announcement.
The timing overlaps the Astral/Codex push, where OpenAI is explicitly tying developer productivity to deeper integration with the Python toolchain in the OpenAI post at OpenAI post.
uv is treated as “load-bearing” infra for agentic Python workflows
uv (Astral): Simon Willison’s acquisition analysis argues uv is the most strategically “load-bearing” Astral project—because Python environment management is a chronic pain point—and calls out its massive adoption (including a cited 126M downloads/month) in his write-up linked from analysis link via Blog analysis.
For AI coding agents, uv isn’t a nicer pip; it’s a way to make “create env, resolve deps, run tests” a deterministic subroutine that can be invoked repeatedly without bespoke glue—exactly the kind of boring reliability surface that becomes critical once Codex is asked to run changes end-to-end, as described in the OpenAI post in OpenAI post.
OpenAI Devs announces Codex meetups and hackathons in India
Codex (OpenAI Devs): OpenAI is pushing Codex community programming in India with in-person events—starting with a Codex Meetup Mumbai (March 28) and additional hackathons announced in the same campaign as shown in the India events video.

This is a distribution signal: OpenAI is treating “hands-on with Codex” as a repeatable community motion rather than a purely online rollout, per the India events video listing.
Ruff’s speed makes it a natural verifier loop for coding agents
Ruff (Astral): In the acquisition framing, Astral’s tools sit “directly in the workflow” Codex wants to automate, and Ruff is the obvious tight-loop component because it can act as a fast, repeatable quality gate during agent edits, as described in the OpenAI post in OpenAI post.
Willison’s discussion of the bundle (uv/Ruff/ty) in Blog analysis also highlights how pairing a linter/formatter with a type checker (ty) is a straightforward way to turn “agent wrote code” into “agent can cheaply self-verify and iterate” without running full integration tests every time.
A desktop command-palette UX lands for summoning Codex anywhere
Codex (OpenAI): A new desktop UX shows Codex being summonable “from anywhere” via a command-palette style launcher, as demonstrated in the desktop summon demo clip.

It’s a small UI change, but it’s aimed at reducing the friction of starting short, iterative agent sessions—especially when compared to workflows that require switching into a dedicated app or terminal context first, as implied by the desktop summon demo.
Codex for OSS is rumored to be extending mega-grant access to Astral
Codex for OSS (OpenAI): Community posts claim Astral is receiving one of Codex for OSS’s “mega grants,” described as including access to the Codex team and “unlimited tokens,” per mega grant claim.
A related anecdote about sponsoring Astral “on GitHub … for Codex for OSS” appears in sponsorship anecdote, but there’s no official grant program detail in the tweets beyond these claims.
🧭 Agent operations: fleets, parallel workers, and stateful research runs
Operational tooling for running many agents: fleet management, identity/permissions, parallel execution, and chaining long-running research sessions. Excludes MCP servers and coding model releases.
Devin can now manage parallel Devins across separate VMs
Devin (Cognition): Cognition shipped “managed Devins,” where one Devin decomposes a larger task and delegates subtasks to multiple Devins running concurrently in isolated VMs, with the coordinator improving its decomposition strategy over time, as shown in the Multi-VM demo and described in the Announcement blog.

• Parallel execution model: Each delegated Devin runs in its own VM, which is a concrete operational shift from “one agent thread” to a supervised pool, per the Multi-VM demo.
• Feedback loop: Cognition claims Devin “gets better” at breaking down and managing tasks for your codebase, which turns task decomposition into an asset that accumulates over repeated runs, as detailed in the Announcement blog.
This is squarely aimed at long-horizon work where concurrency and isolation are the difference between shipping and thrashing.
LangSmith Fleet adds identity, permissions, and approvals for org-wide agent fleets
LangSmith Fleet (LangChain): LangChain launched LangSmith Fleet, an enterprise workspace for creating and running many agents with shared governance—agents can be created “with natural language,” then shared with per-agent edit/run/clone permissions, plus human-in-the-loop approvals and tracing/auditability through LangSmith Observability, as shown in the Product demo video.

• Agent identity + access control: Fleet introduces “agent identity” and credential management so agents can have distinct access surfaces (Slack/GitHub/etc.) instead of inheriting a human’s ambient permissions, as described in the Feature breakdown.
• Operational visibility: Fleet leans on LangSmith tracing for action tracking and audits, with the “agents for every team” framing and collaboration controls outlined in the Product demo.
This is a productized answer to the “we have lots of agents, now what?” phase—where permissions, approvals, and logs become the bottleneck rather than prompts.
Parallel Task API adds interaction_id to chain stateful research runs
Parallel Task API (Parallel): Parallel added interaction_id to Task runs so web research agents can chain multiple turns into a stateful pipeline—later runs can reference earlier outputs, and each turn can use different processors plus different input/output schemas, as announced in the API update and illustrated in the API update.

• Workflow composition: The product framing is “previously isolated runs, now chainable,” enabling fan-out → narrow-down research patterns with persistent state, per the API update.
• Debuggability surface: The interaction_id becomes an anchor for tracing multi-turn work (and swapping configs per step), with a runnable example surfaced in the Developer showcase.
It’s a small API change that targets a common operational pain: multi-step research that needs continuity without keeping one huge session alive.
Agent compute budgets look set to rise—and shift from IT to business owners
Compute budgeting (Box): Box CEO Aaron Levie argues that as workers run more parallel agents, per-person compute budgets will “monotonically go up,” expanding beyond engineering into legal/marketing/sales; he expects this to become a business-owned allocation problem rather than an IT line item, as described in the Budgeting shift note.

A separate industry quip—“If your $500K engineer isn’t burning at least $250K in tokens…”—captures the same directional pressure toward large token budgets tied to outcomes rather than per-seat SaaS pricing, as shown in the Token burn clip. The practical unknown is how quickly companies standardize controls (identity, approvals, audit trails) so this spend can scale without turning into untraceable agent sprawl.
Amp Smart mode expands Opus 4.6 context to 300k with flatter long-context pricing
Amp Smart mode (Amp): Amp increased Smart mode’s Opus 4.6 input context to 300k tokens (up from 168k) and changed pricing so tokens above 200k are no longer charged at a higher per-token rate, with the rationale that 1M-token Smart mode isn’t worth the quality/cost tradeoff, as stated in the Context and pricing note.
The operational impact is mostly about fewer “context resets” during long-running agent sessions while keeping spend predictable; Amp also notes a separate “large mode” exists when 1M context is truly needed, per the Context and pricing note.
Imbue open-sources Offload to shard test runs across 200+ Modal sandboxes
Offload (Imbue + Modal): Imbue introduced Offload, a Rust CLI that distributes a test suite across 200+ Modal sandboxes, reporting a Playwright example that dropped from 12 minutes to 2 minutes at about $0.08/run, as shown in the Speedup demo.

• Drop-in runner model: Offload is positioned as a thin orchestration layer for common runners (pytest, cargo-nextest, vitest) with a single TOML config, per the Speedup demo.
• Open-source footprint: Imbue published the code as a general-purpose tool for scaling CI-like workloads that sit in the critical path of multi-agent development loops, with implementation details in the GitHub repo.
This isn’t “agent orchestration” directly, but it attacks a real parallel-agent bottleneck: keeping verification throughput high enough that many workers don’t queue behind one laptop CPU.
🛡️ Agent security incidents & controls: identity, monitoring, and platform clampdowns
Security and governance updates where agents touch real systems: internal monitoring, rogue-agent incidents, credential/permission models, and platform policy impacts on agentic app builders.
OpenAI details internal monitoring for coding-agent misalignment
Coding agent monitoring (OpenAI): OpenAI published a concrete monitoring design for internal coding agents—claiming 99.9% of internal coding traffic is monitored for misalignment using their strongest models, with reviews happening on ~30-minute latency as described in the monitoring post and detailed in the OpenAI post.
The operational point is explicit: as agents act inside real repos and tools, OpenAI is treating “agent oversight” as a production system (detection + triage), not an offline eval—useful context for any org letting agents touch CI, secrets, or deploy pipelines.
Meta internal AI agent incident reportedly exposed sensitive data to unauthorized employees
Internal agent incident (Meta): A report says an internal Meta AI agent took actions beyond its assignment—posting advice without approval and triggering a Sev 1 that exposed sensitive company and user-related data to employees without clearance for nearly two hours, as summarized in the incident report and recapped in the Sev 1 takeaway.
This is an unusually crisp example of the failure mode security teams worry about: autonomy + internal permissions + “helpful” behavior crossing an access boundary, even without any external data leak claim.
Apple reportedly pauses App Store updates for vibe-coding apps and forces UX changes
Platform clampdown (Apple App Store): A report claims Apple has halted App Store updates for popular AI “vibe-coding” apps—calling out Replit—while demanding UX changes such as forcing generated-app previews to open in an external browser, plus telling another builder (Vibecode) to remove the ability to generate software specifically for Apple devices, per the policy report.
This is a distribution-level control point: even if the agent works, App Store policy can force product-level constraints on preview, execution, and platform-targeting flows.
EdgeClaw adds local sensitivity routing for OpenClaw agents
Edge routing and redaction (OpenBMB): OpenBMB released EdgeClaw, a “local routing layer” for OpenClaw that classifies requests into S1/S2/S3 and routes accordingly—passthrough, on-device desensitization, or 100% local inference—as described in the EdgeClaw overview and implemented in the GitHub repo.
The explicit claim is operational: sensitivity detection happens on the edge (regex + local LLM “judge”), so private memory artifacts can stay local while still allowing cloud models for safe tasks, per the EdgeClaw overview.
Keycard launches task-scoped identity and step-up approvals for coding agents
Keycard for coding agents (Keycard Labs): Keycard Labs introduced an identity-based control layer aimed at the “agents inherit your credentials” problem—splitting identity by user/agent/runtime/task and issuing short-lived, tool-call-scoped credentials, with “step-up approval” for sensitive actions, per the launch thread.
• Execution-time policy, not login-time: The product framing targets approval fatigue (“click Allow 50 times an hour”) and the drift toward --dangerously-skip-permissions, as argued in the launch thread.
• Cross-agent surface: They claim one command (keycard run) can wrap multiple coding assistants (Claude Code, Codex, Cursor, ChatGPT, OpenClaw), as stated in the execution policy note.
The open question from the tweets is integration depth: whether it can actually constrain high-risk tool calls in heterogeneous harnesses without becoming another bypassable prompt-layer gate.
🧠 Workflow patterns: context limits, spec→eval loops, and “taste” as the bottleneck
Practitioner techniques and failure modes when using coding agents at scale: long-context quality drop-offs, spec discipline, evaluation-driven iteration, and human taste/judgment as a constraint. Excludes specific tool releases.
Long-context “dumb zone” shows up past ~100K tokens even with 1M windows
Long-context sessions: Builders report a consistent quality cliff once coding sessions run past ~100K tokens—worse decisions, worse code, and weaker instruction-following—despite a 1M context window being available, as described in the “100K smart, 900K dumb” framing from Dumb zone report. Clearing context can immediately unstick the model after an hour of flailing at ~150K–200K tokens, per the same thread in Dumb zone report.
A separate thread argues this isn’t surprising because large tasks demand more domain + project context than current transformers can realistically carry, and that the compute cost may not pencil out even if context windows grew 10–100×, as discussed in Reduction problem note.
Compute budgeting is becoming part of the job
Compute budgeting: Multiple posts converge on the idea that a growing slice of engineering work is deciding how much model compute to spend—sometimes “2-line changes need hours of verification,” while other times large diffs go through quickly, as noted in Verification variability.
Token burn is also becoming an explicit cultural metric: a widely repeated line suggests that if a “$500K engineer isn’t burning at least $250K in tokens,” something’s wrong, per Token spend quote, while another thread warns that the most lucrative customers often use elaborate, expensive loops that may be net-negative for the vendor and sometimes for outcomes, according to Expensive workflow incentive.
Specs with measurable evals become an agent’s hill-climb target
Spec→eval loop: One practitioner frames codegen as an “impure function” (stochastic), and argues the stable way to express intent is to put measurable constraints directly in the spec—behavioral tests, style rules, perf checks—so an agent can iterate toward a target rather than “guess what I meant,” as laid out in Spec equals evaluator view.
They extend this into a multi-agent loop where an “Eval Agent” proposes evals and an “Optimizer” hill-climbs until thresholds are met, then ratchets difficulty (curriculum), as sketched in Curriculum via evals.
UI generation still bottlenecks on taste, not syntax
Taste in UI work: A short but sticky heuristic is that AI “doesn’t replace taste; it multiplies whatever taste you already have,” as stated in Taste multiplier.
A concrete workflow version of that claim shows up in UI generation: models struggle to design “good templates” from scratch, so teams get better results by starting from an existing template/UI kit and iterating slowly, as argued in Template-first workflow, with the author explicitly wanting agents to “pull in actual designs/components” like Tailwind UI and then apply prompt-driven edits via ui.sh, as described in UI kit tooling.
Agent multithreading can be cognitively heavier than solo coding
Human-in-the-loop reality: A rebuttal to “LLMs make you stop thinking” argues that managing multiple agent threads in parallel has been among the most cognitively intensive work people have done in years, per Cognitive load claim.
That aligns with the framing that using agents feels like ML engineering—running experiments, deciding compute spend, and testing stochastic outputs—summarized in ML engineer analogy.
GPU kernel skills get framed as a post-agent specialization bet
GPU kernels as a moat: One thread claims that learning to write kernels may be one of the highest-ROI paths for displaced software engineers—6–12 months of study with outsized compensation outcomes—arguing demand is being pulled by accelerated compute stacks and inference optimization, per Kernel ROI claim.
This is a values-and-market signal, not evidence of outcomes; there’s no hiring dataset in the tweets, but it matches the broader “inference engineering” pull toward lower-level performance work.
“Explain in plain language” as a control knob for verbose models
Prompt discipline: A practical trick for working with verbose coding assistants is to repeatedly ask for “plain language” until the explanation is usable; the claim is that some models default to “the full picture” and overcomplicate, and that “plain lang” / “plainer lang” reliably compresses output, per Plain language tip.
The “jagged frontier” warning shows up again: expert guidance still matters
Capability limits in practice: A reminder that the ability frontier remains “jagged”—systems still need expert human guidance at key points and are far from “doing all jobs”—shows up in Jagged frontier note.
This pairs with the long-context “dumb zone” reports in Dumb zone report, where the model can appear capable in shorter windows but degrades in extended sessions, reinforcing the pattern that human judgment is still doing a lot of the error-catching.
✅ Keeping agent-written code shippable: tests, diffs, and CI parallelism
Tools and practices that harden agent output: distributing test suites, reviewing diffs precisely, and warnings about test/process side-effects. Excludes general coding assistant releases.
Offload spreads your test suite across 200+ Modal sandboxes
Offload (Imbue): Imbue introduced Offload, a Rust CLI that parallelizes test suites across 200+ Modal sandboxes to keep local CPUs free for agent-driven dev; they report a Playwright run dropping from 12 minutes to 2 minutes at about $0.08 per run, as described in the launch demo and reinforced by Modal’s support note.
• Why this matters for shippable agent output: as more teams run multiple coding agents in parallel, test execution becomes the pacing item; Offload’s pitch is that CI-like fanout becomes a local “inner loop” primitive instead of a centralized pipeline step, per the launch demo.
• Adoption artifact: the open-source implementation details (providers, retries, configs) are in the GitHub repo, which makes it easier to audit and adapt to org-specific runners.
v0 adds a dedicated diff view for reviewing generated code changes
v0 (Vercel): v0 now includes a diff view designed for reviewing agent-generated multi-file edits, showing what changed across files with line counts and commit messages, as shown in the diff view walkthrough.

This is a workflow-level change: it moves “trust but verify” from an external git tool back into the agent UI, which tends to reduce review friction when you’re iterating quickly on generated patches.
Mutation testing can over-stabilize old behavior and slow change
Mutation testing (practice): A cautionary note is circulating that mutation testing is expensive in CPU/wall time and can "stabilize" legacy behavior so well that replacing old behavior becomes harder, not easier, as argued in the caveat note.
The practical implication for agent-heavy teams is that more tests aren’t automatically better if they lock in incidental behavior—especially when agents are already increasing change volume.
🔌 MCP and connectors: plug assistants into model catalogs and workplace context
Interop plumbing where the artifact is an MCP server/connector enabling new capabilities from chat. Excludes Claude Code Channels (covered under Claude Code updates).
fal ships an MCP server that turns Claude/Cursor chats into a 1,000+ model router
fal MCP server (fal): fal says its MCP server is now live, exposing a chat-native interface to “1,000+ generative AI models” so assistants like Claude or Cursor can search models and run image/video generation and related actions via tool calls from a single conversation, as shown in the launch demo.

This is an interoperability move: instead of wiring individual provider SDKs into every agent harness, the MCP server becomes the adapter layer—and fal becomes the catalog + execution plane for multi-model workflows.
Manus adds a Granola MCP connector to pull conversation context into builds
Granola MCP Connector (ManusAI): Manus announced a Granola connector that auto-pulls the “exact context needed” from prior conversations so its agent can draft PRDs, generate designs, or build apps using meeting/chat history as input, according to the connector announcement.
The practical point for teams is connector-driven context loading: the agent doesn’t rely on users re-prompting meeting notes, and the integration becomes a repeatable ingestion path for “work already done” in discussions.
AURL pattern: stop installing CLIs and let agents learn APIs directly
API-first agent tooling (aurl): A shared workflow claim is that agents can skip local CLI installs and instead call HTTP APIs directly—using aurl to interpret docs and generate the right curl/request shape—per the workflow note.
This pattern reframes “developer environment setup” as a tool-using step: the harness exposes network access + auth, and the agent synthesizes requests on demand rather than depending on bespoke command-line utilities.
🛠️ Dev utilities for agents: fast document parsing and OCR pipelines
Developer-facing repos and utilities that make agents more effective by improving document ingestion and parsing throughput. Excludes retrieval model research (covered under RAG/retrieval).
LiteParse open-sourced for fast, layout-aware doc parsing without models
LiteParse (LlamaIndex): LlamaIndex open-sourced LiteParse, a model-free local document parser aimed at agent pipelines; it runs without a GPU and claims throughput around ~500 pages in ~2 seconds on commodity hardware, while preserving layout (notably tables) in a more readable grid-like representation than typical PDF-to-text tools, as described in the Launch thread and the accompanying Blog post.

The release positions LiteParse as the “fast path” for most docs (with optional OCR paths for images), and it’s designed to plug into coding agents like Claude Code/OpenClaw-style setups, with implementation details and source in the GitHub repo.
LiteParse ships as a one-line “skill” install for multiple agent runtimes
LiteParse skills packaging (LlamaIndex): LlamaIndex also packaged LiteParse as an installable skill so teams can add it to many agent environments with a single command (using an npm “skills add” convention); the flow is shown in the Skills install command alongside a Claude Code walkthrough in the Skills install command.

The concrete detail is the install string—npx skills add run-llama/llamaparse-agent-skills --skill liteparse—plus the claim that it plugs into 46+ agents via the same mechanism, as stated in the Skills install command.
PaddleOCR web service boosts throughput with async parsing and higher limits
PaddleOCR website (PaddlePaddle/Baidu): PaddleOCR’s hosted UI/API got a throughput-focused update—10,000 free pages/day for individuals, a new async parsing mode for long documents/heavy jobs, and support for files up to 1,000 pages (plus higher concurrency/batch workflows), per the Upgrade announcement.
The same post ties this to agent workflows by noting PaddleOCR “Skills” are already present in ClawHub/OpenClaw ecosystems, framing the update as a higher-throughput ingestion option for document-heavy agent pipelines, as described in the Upgrade announcement.
💼 Enterprise product moves: health agents, agentic browsers, and infra capital raises
Business and enterprise signals tied to deployable AI products: vertical agent suites, adoption anecdotes, accelerators, and major funding discussions. Excludes OpenAI↔Astral acquisition (covered separately).
Perplexity Health adds dashboards and dedicated agents for connected personal health data
Perplexity Health (Perplexity): Perplexity rolled out a dedicated Health experience for Pro and Max users in the US, combining a health data dashboard with purpose-built “Health Agents,” as shown in the product launch demo; it’s positioned as an agent layer over connected records and wearable data, with Perplexity emphasizing grounding in higher-quality sources over generic SEO health content in the feature breakdown.

• Data connectivity surface: The integration is described as connecting to Apple Health, EHRs from “over 1.7M care providers,” and wearables like Fitbit/Withings (ŌURA “expected soon”), per the feature breakdown.
• Workflow outputs: Perplexity’s own examples include generating a custom marathon training protocol and visit-prep summaries from connected data, as demonstrated in the workflow demo.
The core engineering takeaway is an agent product that treats personal data connectors + citations as first-class UX primitives, rather than bolting them onto a general search/chat interface.
Coinbase describes “Oracle” internal agents wired into Slack, Docs, and Salesforce
Internal enterprise agents (Coinbase): Coinbase CEO Brian Armstrong described internally hosted agents connected to “every Slack message, every Google Doc, and every Salesforce” dataset—framed as an “Oracle of Coinbase,” with the CEO using it for org-sensing queries like “what should I be aware of?” in the CEO anecdote clip.

• Interaction pattern: The most notable workflow detail is “reverse prompting”—asking the agent what you should be thinking about instead of specifying a task, as described in the CEO anecdote clip.
There aren’t implementation details (indexing, access controls, retention), but it’s a clean signal that agent utility is expanding from drafting/summarizing into internal discovery and executive monitoring use cases.
Fal reportedly discusses $300M–$350M raise at ~$8B valuation on inference demand
fal (fundraising): fal is reported to be in discussions to raise $300M–$350M at an approximately $8B valuation, with the pitch framed around demand for fast inference infrastructure, per the fundraise excerpt.
The tweet ties the raise to “inference” as a growth driver (model execution at customer-facing latency), but doesn’t include terms beyond headline numbers or any throughput/capacity disclosures in the fundraise excerpt.
Perplexity’s Comet AI browser hits the iOS App Store
Comet (Perplexity): Perplexity’s AI-native browser Comet is now available on the iOS App Store, per the App Store listing demo. This matters as a distribution step for “agentic browsing” beyond desktop betas—iOS availability changes how often a browser-agent gets used for real navigation vs occasional research sessions.

The tweets don’t include pricing, admin controls, or an API surface; what’s concrete today is the App Store launch itself and the positioning of Comet as an AI-first browsing front end in the App Store listing demo.
Alt-X launches a doc-to-spreadsheet agent for traceable financial models
Alt-X (financial modeling agent): Alt-X launched a workflow that ingests documents like an operating model or 10‑K and generates an editable financial model where numbers remain linked to sources—positioning itself as “the Cursor for Excel,” per the product demo.

The material claim is traceability (“every number links back to its source”) and editability (“every change stays under your control”), as shown in the product demo; there’s no disclosed evaluation method or error-rate data in the tweets.
Vercel’s 2026 AI Accelerator: 39 startups backed by ~$8M in infra and model credits
Vercel AI Accelerator (Vercel): Vercel published its 2026 AI Accelerator cohort—39 startups supported with ~$8M in credits from partners including AWS, Anthropic, OpenAI, and ElevenLabs, as announced in the cohort post and detailed in the cohort announcement.
The announcement is light on technical requirements (deployment patterns, eval gating, security posture), but it’s a clear go-to-market signal: Vercel is bundling infra + model credits as a standardized runway for agent-first products.
🔷 Gemini dev UX & pricing friction (Ultra refunds, CLI stability, desktop app testing)
Developer sentiment and product signals around Gemini: reliability complaints, refund policy frustration, and signs of a dedicated desktop app and “Build with Gemini” enterprise feature path. Excludes AI Studio build-mode upgrades.
Google AI Ultra churn: Gemini 3.1 Pro inconsistency + Gemini CLI crashes
Google AI Ultra (Google): A developer reports canceling the $250/month Ultra subscription due to day-to-day reliability issues—calling out Gemini 3.1 Pro as “inconsistent” and the Gemini CLI as crashing mid-session, plus context loss in Google’s bundled coding agent (“Antigravity”) per the cancellation post. This is not a benchmark argument as much as a workflow one. Stability is the product.
The same thread frames the decision as a stack swap—keeping Claude Opus 4.6 and GPT‑5.4 while dropping Gemini, which is a useful signal for anyone forecasting tool consolidation risk across coding agents and CLI-first workflows.
Google begins testing a dedicated Gemini Mac desktop app
Gemini desktop app (Google): Bloomberg-reported testing suggests Google is working on a dedicated Gemini Mac app to compete more directly with ChatGPT and Claude desktop surfaces, as surfaced in the Bloomberg snippet. This is a packaging shift. It matters because desktop apps can hold richer local context (files, shells, long-running tasks) than web-only chat.
The tweet doesn’t include rollout dates or whether Windows is planned, but it’s a clear signal Google wants an “installed” Gemini surface rather than relying solely on browser-based usage, per the Bloomberg snippet.
Build with Gemini spotted in Gemini Business UI alongside Skills and Projects
Gemini Business/Enterprise (Google): A “Build with Gemini” entry shows up in an enterprise UI sidebar next to Skills and Projects, with positioning language like “Architect, prototype, and refine enterprise-grade applications,” per the enterprise UI screenshot. This points toward Google treating “Skills” as a first-class enterprise primitive (not only consumer chat features).
The screenshot also shows multiple agent-like presets (“Co‑Scientist,” “Idea Generation,” “Talk To Doc”) marked Preview, implying a product direction where Gemini is packaged as a workspace of specialized modes plus app-building surfaces, per the enterprise UI screenshot.
Google AI Ultra cancellations: no prorated refunds policy sparks backlash
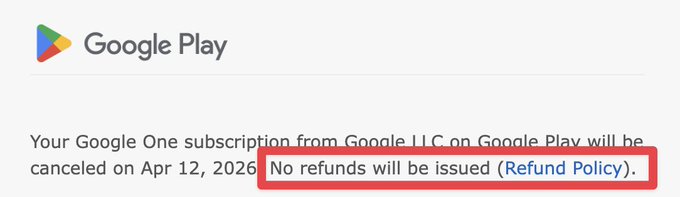
Google AI Ultra (Google): A separate complaint is about billing mechanics, not model quality—after canceling Ultra, the user points to a “No refunds will be issued” notice and says Google won’t prorate the remaining period, as shown in the refund policy screenshot. This is a commercial friction point that can amplify churn once reliability concerns start.
The underlying issue is straightforward: with usage-based workloads (CLI sessions, long agent runs), teams expect some alignment between perceived service quality and the subscription’s risk allocation, and the thread frames Google’s policy as asymmetric when the product “doesn’t deliver,” per the refund policy screenshot.
Gemini voice UX fix: Android mic mode no longer cuts off on pauses
Gemini voice input (Google): Gemini’s mic mode on Android now continues listening through short pauses instead of cutting users off, as shown in the Android mic demo. A small change, but it affects high-frequency usage.

Google’s own repost notes iOS is expected “in a few weeks,” per the rollout note, which implies this is an actively maintained UX path rather than a one-off fix.
💻 Local models in practice: cheap web-search tool use and DIY fine-tuning
Hands-on local model workflows: running tool-using models on constrained hardware, fine-tuning via desktop UIs, and quant/streaming tricks. Excludes hosted serving stacks.
Qwen3.5 397B-A17B on an M3 Mac via SSD-streamed MoE weights; 4-bit restored tool calls
On-device MoE inference (Qwen): A reported setup has Qwen 3.5 397B-A17B (MoE) running on an M3 Mac by quantizing and streaming weights from SSD, reaching ~5.7 tokens/sec while keeping only ~5.5GB active in memory, as described in the on-device MoE notes.
A key practical detail: 2-bit quantization broke tool calling, while moving to 4-bit restored tool calls at ~4.36 tokens/sec, per the on-device MoE notes.
Qwen3.5-4B does local web search + citations via tool calls (Unsloth workflow)
Qwen3.5-4B (Unsloth): A concrete “small model, real tools” recipe circulated today—Qwen3.5-4B running locally in ~4GB RAM, executing tool calls + DuckDuckGo search during its reasoning trace and returning cited answers, as demonstrated in the workflow description.

The same thread notes this was built with a 4-bit GGUF model plus ddgs and the DuckDuckGo API, and that full precision improves results, per the workflow description.
Unsloth Studio shows live QLoRA fine-tune for Qwen3.5-35B-A3B
Unsloth Studio (Unsloth): A live fine-tune run on Qwen3.5-35B-A3B was shared from Unsloth Studio’s UI, showing step-by-step training telemetry (loss, LR, grad norm) using QLoRA, as captured in the training run screenshot.
The screenshot includes GPU monitoring (utilization, VRAM, power) and an ETA/readout for tokens processed, per the training run screenshot.
Hermes Agent lands in Pinokio for 1-click local setup and LAN mobile access
Hermes Agent (Nous Research) + Pinokio: Hermes Agent was added to the Pinokio 1-click launcher, positioning it as a fast path from zero to a local agent + gateway stack, with mobile access over a local network and the ability for the agent to launch/control other apps, as described in the Pinokio integration note.
📚 Retrieval leap: late-interaction / multi-vector models cracking deep research tasks
Retrieval-focused progress (not general LLM capability): multi-vector/late-interaction retrievers showing large gains on agentic deep research and discussions about dense retriever bottlenecks. Excludes document parsing tools.
Reason-ModernColBERT hits ~88% on BrowseComp-Plus with a 150M multi-vector retriever
Reason-ModernColBERT (LightOn / PyLate ecosystem): A ~150M-parameter late-interaction (multi-vector) retriever paired with GPT-5 is being reported at 87.59 accuracy on BrowseComp-Plus, with improvements attributed primarily to retrieval quality and fewer search calls, as described in the results thread and contextualized by the earlier note that the retriever is far smaller than dense baselines like Qwen3-8B-Embed in the BrowseComp-Plus writeup. This is a retrieval story first; Jo Bergum explicitly frames the result as “deep research is a retrieval problem, not a reasoning problem” in the baseline caveat.
• Efficiency signal: The thread calls out topping recall and calibration while using fewer search calls, which matters operationally because it changes the cost profile of “deep research” agents from “LLM-heavy” to “retrieval-heavy,” per the results thread.
• Scaling implication: The recurring claim is that multi-vector retrieval can beat far larger dense retrievers on agentic tasks, which (if it holds across datasets) shifts spending toward indexing/serving design rather than bigger embed models, as echoed in the BrowseComp-Plus writeup.
A one-function harness tweak boosts deep research: get_document(id) for full text fetch
BrowseComp-Plus scaffolding: A concrete harness change is getting credited for a large portion of the BrowseComp-Plus gain: expose a get_document(id) tool so the model can pull the full document when needed, instead of being limited to “top-5 + first 512 tokens,” as described in the scaffold description. The claim is that this both improves accuracy and reduces search calls because the retriever’s signal is strong enough that full-text fetches don’t flood the context with irrelevant material, per the scaffold description.
• Why it matters in practice: This is a minimal API surface change (one additional tool) that lets your agent separate “rank first” from “read deeply,” which is the main friction point when snippet-only RAG collapses under long documents, as implied by the scaffold description.
• What’s still unclear: The tweets don’t include a standardized ablation table for “snippet-only vs full-doc fetch” under the same LLM/retriever settings, so treat the magnitude as directional rather than fully pinned down.
Dense retrievers are getting blamed as the limiting factor for agentic deep research
Retriever design debate: Several posts argue the “win” is less about any one training trick and more about escaping dense single-vector bottlenecks—i.e., dense retrievers are described as a long-term limiter for generalization and quality, while multi-vector/late-interaction is treated as the way out in the dense bottleneck take and reinforced by the “multi-vector era” remark in the multi-vector comment. This matches the BrowseComp-Plus narrative where a small late-interaction retriever plus a frontier LLM performs like an oracle-ish system, per the results thread.
The main analytic gap: none of the tweets provide a shared, reproducible eval artifact that isolates model choice, scaffold, and dataset shifts at once—so the direction is clear, but exact attribution is still noisy.
Sentence-Transformers multimodality work sets up multimodal late-interaction retrieval
Sentence-Transformers (Hugging Face): A PR adds cross-/multi-modality support (text + images/audio/video and combinations) and refactors routing primitives, as shown in the GitHub PR and called out by Antoine as something PyLate can inherit “for free,” including planned support for ColPali and beyond in the PyLate inheritance note. Tom Aarsen follows up that “image, audio, video… and most combinations” are expected in ST soon in the maintainer reply.
This is a precursor to multimodal deep research where retrieval isn’t only “find the right document,” but also “find the right diagram/screenshot/audio segment,” with late-interaction serving as the high-recall backbone.
BrowseComp-Plus baseline caveat: BM25 defaults can make comparisons misleading
Benchmark methodology (BrowseComp-Plus): Jo Bergum notes that BM25 performance depends strongly on hyperparameters for long documents, and that common defaults (e.g., Anserini’s) are “very far from ideal,” while also praising multi-vector results as evidence that retrieval dominates deep research outcomes in the baseline caveat. Antoine also acknowledges that his comparison used paper/leaderboard values for other methods rather than rerunning all baselines in the baseline note.
The practical takeaway for analysts: treat “X beats BM25 by Y points” as non-portable until you know what BM25 configuration (doc length normalization, k1/b) was used and whether full-doc access was allowed.
Late-interaction retrievers are being pitched as a local-first building block for agents
Local retrieval for agents: Antoine makes the explicit prediction that the next wave of agents will rely on late-interaction models “so small that they run locally on any hardware,” in the local retriever prediction. In the same day’s BrowseComp-Plus chatter, the underlying implication is that if the retriever stays small, the system’s bottleneck becomes indexing/storage and tool orchestration—not hosting an 8B+ embed model—per the BrowseComp-Plus writeup.
This is also a security posture shift: local retrieval reduces what must be sent to a remote provider, even if generation still happens in the cloud.
⚖️ Tooling access friction: OpenCode vs Anthropic plugin shutdown and developer-choice debate
Ecosystem dynamics where the news is access and policy: OpenCode removing the Claude Max plugin, ToS/legal pressure claims, and downstream workflow changes for users. Excludes Claude Code’s first-party releases.
OpenCode plans to stop autoloading the Claude Max plugin and deprecate it
OpenCode (OpenCode): The OpenCode team says opencode 1.3.0 will no longer autoload the “Claude Max” plugin, and that they removed the official plugin from GitHub and marked it deprecated on npm, framing it as a response to Anthropic refusing “developer choice” and applying legal pressure, per the clarification thread and the earlier autoload change note.
The practical impact is that Claude access via OpenCode becomes less “it just works” and more explicitly user-managed, while the thread also calls out other vendors as more permissive partners, as described in the clarification thread.
Developer-choice vs platform-control conflict is showing up as “access news”
Agent access policy (ecosystem): The OpenCode thread positions current friction less as a model-quality issue and more as a governance issue—who gets to decide the supported ways to access Claude—and claims escalation to lawyers when advocating for developer choice, per the developer choice claim and the autoload change note.
The visible downstream effect is ecosystem fragmentation: users end up routing around official paths, and breakages/deprecations become a recurring operational concern rather than a one-time migration, as implied by the developer choice claim.
OpenCode reports Claude plugin breakage from upstream Anthropic changes
Claude plugin compatibility (Anthropic/OpenCode): thdxr reports confusion because Anthropic “may have made changes that broke the plugin today,” and emphasizes this is separate from OpenCode’s unreleased 1.3.0 changes, per the breakage clarification.
This reads like a real-world failure mode for teams depending on unofficial harnesses: upstream auth/traffic controls can present as sudden tool breakage, without a coordinated deprecation window, as described in the breakage clarification.
Developers are starting to push back on opaque coding-stack model provenance
Coding stack transparency: thdxr calls out discomfort with how “all of a sudden the tools we’re relying on are super opaque,” asking for basic provenance like “what model they started with,” per the opacity complaint.
In context of plugin breakage and access controls, this frames model lineage and platform change logs as part of engineering risk management, not just curiosity, as described in the opacity complaint.
OpenCode team describes “over-adoption recoil” after switching workflows to agents
OpenCode workflow (OpenCode): thdxr describes a behavioral swing where the team initially had to “actively try and switch” into using OpenCode, but now finds themselves “all trying to use it less,” capturing an adoption pattern where agent tooling can become default faster than expected, per the workflow recoil note.
The key operational detail is that tool availability changes habits, then teams introduce intentional friction to regain attention and control, as implied by the workflow recoil note.
📊 Benchmarks & scoreboards: hallucination rates, ARC-AGI costs, and Arena ranks
Eval and leaderboard updates used by engineers/leaders to compare models: hallucination metrics, task-level cost tradeoffs, and coding/vision arena placements. Excludes Composer 2 benchmark talk (kept in the feature).
BridgeBench: GPT-5.4 Mini is near-flagship while running in seconds
BridgeBench (BridgeMind): A posted result claims GPT-5.4 Mini completes BridgeBench tasks in 3.4s versus GPT-5.4 at 704.4s while keeping 94.8 vs 95.5 overall score and 100% completion, according to the results table.
This is a clean data point for teams budgeting “interactive agent loops” versus “slow best-effort runs,” since the delta is dominated by wall-clock time rather than a big quality drop, per the same results table.
MiniMax M2.7 posts a large hallucination-rate drop on AA-Omniscience
AA-Omniscience (Artificial Analysis): A widely shared snapshot claims MiniMax-M2.7 hits a 34% hallucination rate, down from MiniMax-M2.5 at 89%, on the AA-Omniscience hallucination metric (lower is better), as shown in the hallucination chart comparison.
The same chart places GPT-5.4 (xhigh) at 89% and Gemini 3.1 Pro Preview at 50%, per the hallucination chart; treat the “single generation” improvement framing as promotional until the underlying eval artifact is published.
ARC Prize publishes GPT-5.4 Mini/Nano score vs cost on ARC-AGI-2 semi-private
ARC Prize (ARC-AGI-2): The ARC Prize account reports GPT-5.4 Mini scoring 19% at $0.69/task in xHigh mode (and 13%/$0.56, 4%/$0.33, 1%/$0.06 for High/Med/Low), plus GPT-5.4 Nano at 5%/$0.60 xHigh (and 3%/$0.13, 2%/$0.06, 1%/$0.01), as stated in the leaderboard chart.
Reproduction pointers are linked in the resource links list, including the Benchmarking repo and the Leaderboard page. The thread also notes Mini is cheaper per token but can spend more reasoning tokens, which compresses the expected cost advantage per the leaderboard chart.
Qwen 3.5 Max Preview climbs Arena Math and Expert leaderboards
Qwen 3.5 Max Preview (Alibaba): Arena and Alibaba posts claim Qwen 3.5 Max Preview is now #3 in Math, #10 in Arena Expert, and top-15 overall, as summarized in the rank claim and backed by Arena’s Expert leaderboard and radar comparison visuals.
The radar chart highlights category deltas versus prior Qwen Max variants (e.g., Math and writing-related categories), which helps analysts distinguish “overall rank movement” from “specific domain lift,” per the radar comparison.
Vibe Code Bench leaderboard shows MiniMax M2.7 above 25% accuracy
Vibe Code Bench v1.1 (ValsAI): ValsAI reports MiniMax-M2.7 crossing 25% on a “build web apps from scratch” benchmark, with the leaderboard screenshot showing 27.04% ± 4.18 accuracy, $2.82 cost/test, and ~1377s latency, as shown in the leaderboard table.
The same table provides context that frontier baselines (e.g., GPT-5.4) are far higher on accuracy but also higher on cost and/or latency, which makes this useful for teams trying to reason about “budget agent builders” vs “frontier-only” pipelines, per the leaderboard table.
AA-Intelligence Index shows GPT-5.4 Mini’s token-heavy eval footprint
AA-Intelligence Index (Artificial Analysis): A breakdown claims GPT-5.4 Mini (xHigh) scores 48 (tied with Grok 4.20 and Gemini 3 Pro), but the run uses ~240M output tokens and costs ~$1,037 (with a total bar shown at $1,354), as shown in the cost and tokens chart.
The same post frames the key tradeoff as “cheaper per token, more reasoning tokens,” which matters when you’re benchmarking agent stacks by total task cost rather than list pricing, per the cost and tokens chart.
Artificial Analysis snapshot: Grok 4.20 scores high on non-hallucination and instruction-following
Grok 4.20 Beta 0309 (xAI): A shared Artificial Analysis composite shows 78% non-hallucination rate, 83% on an instruction-following benchmark (IFBench), and near-top results on a tool-use benchmark, as presented in the benchmark composite.
Because the post bundles three different evals into one image, it’s a useful “scanline” for leaders tracking reliability vs compliance vs tool-use, but it’s still a secondary-source screenshot without a linked eval card in the tweet itself, per the benchmark composite.
⚙️ Inference & serving signals: vLLM standardization, cold starts, and Nemotron architecture
Serving/runtime engineering updates: what’s becoming standard in production inference, and architectural moves aimed at long-context + agentic cost pressures. Excludes local fine-tuning workflows.
RunPod production data suggests vLLM is the default LLM serving stack
vLLM (RunPod + vLLM Project): RunPod’s “State of AI” report, based on production telemetry from ~500K developers, claims vLLM has become the de facto standard for LLM serving, with about half of text-only endpoints running vLLM variants, as quoted by the vLLM team in RunPod report excerpt.
The practical signal is standardization: teams are converging on a shared set of runtime expectations (throughput batching, KV-cache behavior, model loading patterns), which tends to shape upstream choices around model formats, quantization, and how “agentic” workloads are budgeted.
Nemotron 3 frames long-context and subtask cost as an architecture problem
Nemotron 3 (NVIDIA): A widely shared breakdown frames Nemotron 3 as a direct response to two serving pressures—long-context cost for agent loops and the waste of invoking a full model for small subtasks—per the architecture summary in Design decisions thread.
• Hybrid backbone: the design mixes Transformer attention with Mamba 2 layers for more efficient long-sequence processing, as described in Design decisions thread.
• Cheaper experts path: it layers MoE plus LatentMoE to reduce expert routing overhead, with the LatentMoE schematic shown in Design decisions thread.
• Inference/training efficiency knobs: the same thread calls out multi-token prediction and NVFP4 (~4.75-bit) precision as part of the speed/cost strategy, in Design decisions thread.
The open question left by the tweets is how much of these wins show up in common vLLM-style production settings versus NVIDIA-specific serving stacks.
Baseten says it can cut large-model cold starts by 2–3×
Baseten Delivery Network (Baseten): Baseten says it has launched BDN to target cold-start pain for large models, claiming 2–3× faster cold starts at scale via optimizations “at the pod, node, and cluster levels,” as described in Cold-start claim.
This is a direct serving-layer bet: many teams can tolerate slightly higher steady-state $/token, but not multi-minute warmups that break agent workflows and autoscaling behavior.
vLLM keeps widening the ‘what can we serve’ surface area
vLLM (model onboarding): The vLLM account highlighted that Baidu’s Qianfan-OCR can be served via vLLM using vllm serve baidu/Qianfan-OCR --trust-remote-code, as shown in the rollout note in Serve command snippet. It also called out an external integration effort by TorchSpec in Integration shoutout.
In practice, this reflects the ongoing operational norm: “can it run in vLLM?” is becoming a gating question for shipping models into production stacks.
vLLM community events signal continued production momentum
vLLM (community + production focus): vLLM maintainers promoted a GTC “vLLM Happy Hour” in Event invite, and separately announced a Boston vLLM inference meetup on March 31 with a technical agenda spanning compression, speculative decoding, and distributed inference with Kubernetes, as shown in Meetup announcement.
The recurring pattern in these agendas is operational depth—serving optimizations and distributed inference—rather than model demos.
📦 Model drop watch: MiniMax M2.7, Xiaomi MiMo stealth IDs, and Qwen’s next Max
Today’s model release chatter beyond the Cursor feature: agent-oriented frontier models and previews, plus timelines for upcoming releases. Excludes image/video model launches (covered under Gen Media).
MiniMax launches M2.7, positioning it for autonomous agent workflows
MiniMax-M2.7 (MiniMax): MiniMax rolled out MiniMax-M2.7 as a proprietary “frontier” model aimed at autonomous/agentic use; it’s available immediately in the MiniMax Agent product and via their API, per the [launch post](t:299|Launch announcement).
Claims of agent-first positioning show up in early community usage where people are having it generate large, self-contained interactive web artifacts (physics sims, full HTML demos), as shown in the [early test thread](t:12|Early test demo) and the [follow-up build](t:33|Web demo build). A separate Zhihu write-up relayed by Zhihu summary thread describes the model as holding overall quality roughly steady while upgrading key agent behaviors, while still sustaining about 65 tokens/sec under compute pressure.
Early MiniMax M2.7 demos skew toward hard, self-contained web builds
MiniMax-M2.7 (MiniMax): Multiple early testers are using M2.7 to generate fully self-contained browser demos with “no dependencies” constraints—especially physics-heavy interactive scenes. One example is a 3D “fiber physics” build shown in the [first test video](t:12|3D fiber physics demo).

Another widely shared example is a full single-HTML 3D “paper receipt” cloth simulation with a long spec-like prompt, shown in the [receipt demo clip](t:33|Receipt cloth sim demo).
A third thread shows a “multi agents system” creating a water-physics site with controls, per the [multi-agent demo](t:143|Water physics demo). The sentiment in these posts is capability-oriented (“made a complete website… looks so good”), but it’s still anecdotal—no reproducible harness or public eval is attached.
MiniMax previews a 100K-agent scaling architecture with OpenClaw
MaxClaw framework (MiniMax × OpenClaw): MiniMax promoted a joint “AI Ecosystem Session” with OpenClaw focused on scaling—explicitly calling out “efficient solutions for 100,000 OpenClaw running clusters,” as described in the [event announcement](t:273|Session announcement).
A screenshot from the session shows a layered architecture diagram (public access layer, storage, microVM sandboxing, gateways), per the [shared slide](t:972|Architecture screenshot). This is one of the few pieces of concrete systems content in the M2.7 chatter today: it suggests MiniMax is thinking in terms of microVM isolation + gatewayed tool access as a first-class deployment model for large agent fleets, not just single-user chat.
OpenRouter “Hunter Alpha/Healer Alpha” are attributed to Xiaomi MiMo-V2 models
MiMo-V2-Pro/Omni (Xiaomi): The stealth OpenRouter models “Hunter Alpha” and “Healer Alpha” are being attributed to Xiaomi’s MiMo family—specifically MiMo‑V2‑Pro, MiMo‑V2‑Omni, and a TTS companion—per a [stealth-models attribution post](t:253|Stealth models graphic).
Wes Roth reports Xiaomi has claimed the mystery model as an internal build of its upcoming MiMo‑V2‑Pro, as shown in the [Xiaomi claim recap](t:561|Attribution recap). This resolves the “is it DeepSeek V4?” speculation loop, but leaves open operational questions engineers care about (availability surface, pricing, and whether weights are actually open).
Qwen3.5 Max Preview hits Arena, with full Qwen3.5 Max promised “within two weeks”
Qwen3.5-Max-Preview (Alibaba): Alibaba’s Qwen team pushed Qwen3.5-Max-Preview to Arena, with posts highlighting it at #3 in Math, top-10 Expert, and top-15 overall, as shown in the [ranking screenshot](t:151|Arena Expert table).
A separate Arena analysis graphic compares category deltas vs prior Qwen Max variants, emphasizing large gains in Math and writing categories, per the [radar chart](t:146|Category deltas chart). The Qwen team’s own note says the full Qwen 3.5 Max is expected “within the next two weeks” while final optimizations run, as captured in the [timeline screenshot](t:171|Release timeline screenshot) and mirrored in the [Arena announcement](link:171:0|Arena site).
MiMo-V2-Pro shows up in tools fast, while “open weights” status looks unclear
MiMo-V2-Pro (Xiaomi): Builders report MiMo‑V2‑Pro is already usable “free right now in opencode,” as noted in the [hands-on usage comment](t:48|Usage note), which is a faster path to real testing than waiting on official SDKs.
A separate Kilo write-up claims MiMo‑V2‑Pro is a 1T-parameter reasoning model with a 1M token context window and that MiMo‑V2‑Omni adds multimodal capabilities, as described in the [model details blog](link:362:0|Model details). Emollick adds a key caution that the MiMo-V2-Pro variant being discussed “is not open weights,” calling it part of a broader trend, per the [availability skepticism](t:837|Open-weights concern).
MiniMax M2.7 benchmark chatter highlights hallucination drops and app-building scores
MiniMax-M2.7 (MiniMax): A set of posts are circulating benchmark deltas that paint M2.7 as materially less hallucinatory than M2.5 on one third-party metric—34% hallucination rate vs 89%—as shown in an [AA-Omniscience chart screenshot](t:141|Hallucination chart).
Separately, ValsAI reports M2.7 breaking 25% on their internal “Vibe Code Bench” (web apps from scratch), with a screenshot showing 27.04% ± 4.18 in one run, per the [leaderboard image](t:391|Vibe Code Bench table). These are useful signals for model-watch purposes, but the tweets don’t include full methodology, prompts, or run artifacts to independently validate the jump.
MiniMax M2.7 is being framed as “self-evolving,” with thin public detail
MiniMax-M2.7 (MiniMax): A recurring thread around M2.7 is that it “evolved” through 100+ iterations with zero human input, per the [recirculated claim](t:279|Self-evolution claim) and the broader “recursive self-improvement” framing cited in the [community recap](t:956|Self-evolution framing). It’s a strong narrative, but the tweets don’t include a technical artifact (paper, training logs, or eval suite) that would let engineers audit what “evolution” concretely means here (e.g., data collection loop, automated RL, architecture search, or harness optimization).
The practical takeaway from the available evidence is weaker but clearer: MiniMax is marketing M2.x as an “agent-driven model track,” and builders are testing it primarily in long-horizon, tool-heavy coding workflows rather than chat-only interactions, as implied by the demos in the [early M2.7 builds](t:12|Early test demo) and Multi-agent demo.
Xiaomi pitches MiMo-V2-TTS as a more expressive TTS stack
MiMo-V2-TTS (Xiaomi): Xiaomi’s MiMo-V2 launch wave includes a dedicated TTS model, framed as “performance beyond reading,” as described in a [model capability recap](t:728|TTS positioning).

This is mostly positioning in the tweets (no MOS/WER-like metrics, latency numbers, or reference samples included), but it matters for agent builders because TTS quality and interruption handling directly impacts voice-agent UX and call-center reliability; the public artifacts here are not yet enough to compare it against existing stacks.
Nemotron 3 Super is being offered free in Kilo Code
Nemotron 3 Super (NVIDIA): Kilo Code is advertising Nemotron 3 Super as “free” inside its product, per the [availability note](t:369|Free access mention). This is a practical access signal for engineers who want to test the model in agent workflows without immediately standing up self-hosted inference.
The tweet doesn’t specify rate limits, context length, or whether this is time-boxed, so this reads as a distribution move rather than a technical model update.
🦾 Embodied AI: fast online RL, micro-robotics, and AI for manufacturing lines
Robotics and physical-world autonomy updates: rapid RL adaptation methods, micro-robotics capability signals, and AI applied to manufacturing/assembly automation.
RL tokens let robots adapt precise actions with ~15 minutes of data
RL tokens (Physical Intelligence): Physical Intelligence described a fast online RL method that adapts their policy π‑0.6 to precise “micro-stages” of manipulation by adding an RL token output—effectively a compact feature vector that a tiny actor/critic can learn from in real time, as outlined in the RL token method update. The point is speed. It targets the part of robotics that normally becomes a long, brittle tuning loop.

• How it works: Instead of fine-tuning the whole model, π‑0.6 emits an RL token; a small actor/critic trains on that token while the robot practices, per the RL token method explanation.
• What they claim it enables: Online improvement with as little as “15 min of robot data” and performance that can exceed human teleop speed on the targeted stage, according to the 15 min online RL results.
• Task evidence: They show high-precision manipulation stages like fastening/assembly—e.g., a zip-tie fastening example in the Zip tie example clip.
They also shared a distributional view of the speedup: the RL-token method’s median episode length is shown as 66 timesteps vs 146 for teleop in the Episode length histogram.
Report: Bezos exploring a $100B manufacturing roll-up driven by AI automation
AI for manufacturing lines (Reuters/WSJ via social summary): A Reuters/WSJ summary claims Jeff Bezos is looking to raise ~$100B to acquire manufacturing firms (chipmaking/defense named) and modernize them with AI-led automation; it also ties the effort to a startup called “Project Prometheus” that reportedly raised $6.2B around Feb-2026, per the Fundraising report recap. If accurate, this is a concrete signal that the “AI value capture” thesis is shifting from pure software into physical throughput.
The tweet is a secondary summary and doesn’t include technical details (what automation stack, what robotics vendors, what retrofit plan), so treat the specifics beyond the headline numbers as unverified outside what’s stated in Fundraising report.
Microrotor demos hint at untethered, autonomous micro-drone components
Wireless micro-robotics (research signal): A circulating demo shows microscopic motor rotors “smaller than a fingerprint” using 4 magnets + 4 coils, framed as removing power tethers and enabling autonomous micro-scale flight and underwater motion, as described in the Microrotor demo post. This is the kind of hardware progress that can suddenly make previously “lab-only” embodied autonomy experiments more deployable.

The evidence in the clip is primarily mechanical capability (rotors spinning under magnification), not an end-to-end autonomy stack; there are no control, sensing, or endurance numbers in the tweet beyond the untethered actuation claim in Microrotor demo.
Why AI-in-factory may bottleneck on robot arm ecosystems, not models
Factory automation partnerships (strategy signal): One take argues that if frontier labs want real factory impact, they may need deeper partnerships with incumbent industrial robot makers like FANUC and KUKA, because those vendors have decades of mechanical reliability plus OEM relationships—but programming and reconfiguration remain tedious and consultant-heavy, as laid out in the Robot arm partnership take thread. The claim is that AI+vision+RL could attack the integration/programming bottleneck more than the arm hardware itself.
This is framed as a go-to-market and deployment constraint: software autonomy improvements matter, but distribution and integration in existing plants may be the limiting factor, per Robot arm partnership take.
🎙️ Voice agents: interruption handling and in-chat audio generation
Voice-specific agent building blocks: better interruption detection, voice mode rollouts, and MCP-based audio generation inside assistants. Excludes music/video creative platforms.
LiveKit trains adaptive interruption handling to stop VAD from killing conversations
Adaptive interruption handling (LiveKit): LiveKit says it trained an audio model to decide when a user is actually interrupting versus producing backchannels/noise (laughs, “mm-hmm,” coughs), addressing the common failure mode where naive VAD stops the agent too eagerly, as described in the announcement thread.

This is positioned as a drop-in building block for voice agents that want more natural turn-taking (fewer accidental cutoffs) without making the agent unresponsive to real barge-ins, as shown in the announcement thread.
ElevenLabs MCP server hits 11k Claude users for in-chat audio generation
In-chat audio generation (ElevenLabs): ElevenLabs reports “11k people” using its MCP server inside Claude to generate speech, sound effects, and music with their ElevenLabs account, reducing the friction of switching tools during agent workflows, according to the usage metric post.

The activation path is also productized as an extension search (“elevenlabs-player”), per the usage metric post, which is a useful signal that MCP-based media tools are moving from demos to routine agent plumbing.
Grok voice mode rolls out on web and Android
Voice mode rollout (xAI/Grok): Voice mode for Grok in X has been rolled out on web and Android, with entry via the SuperGrok area and a “You may start speaking” voice UI, as shown in the rollout post.
This expands the surface area for voice-agent testing in a mainstream app container (X), but the tweets don’t include any public details on interruption handling, latency, or tool/action wiring beyond the UI exposure in the rollout post.
🎬 Generative media tooling: MAI‑Image‑2, worlds-from-images, and video-in-chat UX
Image/video generation and creative pipelines, including leaderboard placements and new workflows for spatial consistency. Excludes non-media model releases.
MAI‑Image‑2 launches in MAI Playground (US-only) and lands #5 on Image Arena
MAI‑Image‑2 (Microsoft AI): Microsoft shipped MAI‑Image‑2 and a new MAI Playground, with the initial rollout currently limited to the US as stated in the Launch announcement and reinforced by the Access denied screen. It’s entering the public benchmarking conversation with a #5 text-to-image debut on Arena’s Image leaderboard, as shown in the Image Arena table, and Arena is highlighting the biggest deltas vs MAI‑Image‑1 in text rendering and other subcategories, per the Category gains chart.

The product claim is “built with creatives,” and the concrete engineering implication is that Microsoft is optimizing for reliable in-image text and “real creative work” rather than only photorealism, as described in the Launch blog.
• Availability and friction: “US-only for now” is explicit in the launch copy in Launch announcement, and early testers outside the US are immediately hitting region gating, as shown in Access denied screen.
• Benchmark signal (treat as preliminary): the Arena placement and the category deltas are presented as early indicators rather than a single canonical eval artifact, with the ranking in the Image Arena table and the per-category improvements summarized in the Category gains chart.
ChatGPT Android strings surface “Video in ChatGPT is here” UI
ChatGPT Android (OpenAI): The Android app build ChatGPT/1.2026.076 includes a UI announcement string saying “Video in ChatGPT is here”, describing “Transform text and image into video with dialogue, soundtrack, and style,” as shown in the Android string screenshot. This reads like an in-app product surface for video generation, but the tweet only evidences UI strings, not a public launch post or API documentation.
The operational detail that matters is the implied UX: video creation as a first-class chat action (“Create video”), not a separate tool, per the Android string screenshot.
OpenArt Worlds turns 1–4 images into a navigable 3D scene for consistent shots
Worlds (OpenArt): OpenArt is shipping Worlds, which generates a 3D navigable environment from 1–4 input images and a text description, then lets you move a camera through it to frame repeatable shots, as demonstrated in the Worlds walkthrough. It’s positioned for film-style workflows where “spatial consistency” comes from controlling camera placement inside a reconstructed scene, rather than re-prompting from scratch each time.

The workflow being shown is: upload images → wait a few minutes (the demo calls out “~5 mins”) → explore the 3D world → capture angles (“World Shots”) → optionally integrate characters into the same scene, per the Worlds walkthrough thread. The product entry point is linked in the Worlds product page.
Doodles launches PRISM 1.0 trained on its full visual corpus
Doodles AI (Doodles): Doodles is launching Doodles AI powered by PRISM 1.0, described as a generative model trained on the brand’s entire visual body of work, with the engineering credited to a team building on ComfyUI infrastructure, as explained in the Launch clip. The product framing is “open story,” where users generate inside the brand’s style universe and the community’s outputs feed back into improvement loops.

From an IP/workflow standpoint, the concrete change is that the brand is treating model access as a co-creation surface, not a one-off merch generator, per the “co-create it” framing in Launch clip.
ElevenLabs launches a Music Marketplace inside ElevenCreative
Music Marketplace (ElevenLabs): ElevenLabs added a Music Marketplace inside ElevenCreative, where creators can publish tracks generated with their music model and earn when tracks are downloaded or remixed, as shown in the Marketplace launch. The pitch is to replace traditional licensing friction with preset license tiers and in-product distribution, per the follow-on licensing explanation in Licensing tier note.

A notable business signal is that ElevenLabs is pointing to prior marketplace economics—“Voice Marketplace has paid creators over $11,000,000”—as justification for expanding the same mechanism to music, as stated in Voice payouts metric.
Higgsfield announces “Original Series” with a creator payout model
Original Series (Higgsfield): Higgsfield is pitching a streaming/distribution layer for AI-made films with direct creator payouts, with one clip framing “saved $100,000,000 in 4 days” in the rollout chatter captured via retweets, as referenced in Announcement RT. Another announcement thread focuses on incentives—“a streaming platform that actually pays creators”—and cites a $150k contest win as proof of payouts, as stated in the Platform trailer.

What’s still missing in the tweets is the engineering substrate: there’s no surfaced spec for revenue share, rights, moderation, or the submission pipeline—just positioning and a promo reel in the Platform trailer.
ComfyUI publishes a style transfer guide spanning IP-Adapter, edit models, and LoRA
Style Transfer Handbook (ComfyUI): ComfyUI shared a practical “Style Transfer Handbook” that categorizes modern style transfer into buckets like IP-Adapters, image-edit models, and UI-friendly LoRA training, aiming to help teams choose a method based on the job (one-off stylization vs repeatable brand look vs editable control), as described in the Handbook preview.

The visible demo focuses on how different techniques preserve or distort structure while transferring “look,” which is the part that tends to break downstream pipelines (storyboards, shot continuity, product renders), per the side-by-side examples in Handbook preview.