OpenAI Codex Subagents roll out – 2M+ weekly users claim, +300% since Jan
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI shipped Codex Subagents across the Codex desktop app and Codex CLI; users can spawn multiple specialized workers in parallel while keeping the main thread cleaner; OpenAI’s docs frame it as a fix for “context pollution/rot” plus a sandboxing/threat-model surface, and a small but sharp knob (context: fork) runs noisy skills in an isolated subagent and returns only final output. Early workflows show fan-out code review (security/bugs/races/flaky tests/maintainability) then aggregation; Codex’s own UI warns parallel delegation may increase token usage, with builders already flagging “token anxiety.” Adoption posts circulate alongside the rollout: an unlabeled usage chart plus an unaudited “2M+ weekly actives” and ~300% since early January.
• GPT‑5.4 signals: OpenAI leadership claims 5T tokens/day within a week and a $1B net-new revenue run-rate; Artificial Analysis reports $2.50/$15 per Mtok with ~185s first-token latency.
• Claude Code 2.1.77: fixes a deny-rule bypass via PreToolUse “allow”; raises Opus 4.6 output to 64k (128k max); remote runs add custom environments.
• Mistral Small 4 + serving: 119B MoE (128 experts/4 active), 256k context, Apache 2.0; €0.13/€0.51 per 1M tokens shown in Playground; vLLM/SGLang post day‑0 recipes with tool/reasoning parsers.
Across stacks, the motif is visible parallelism and cleaner transcripts (subagents, tiled canvases, disaggregated serving); what’s still unclear is how much the fan-out patterns amplify duplicate context reads and tool retries once metering and tracing catch up.
Top links today
- Codex subagents announcement and details
- Mistral and NVIDIA open models partnership
- Paper on benchmarks vs real-world work
- Perplexity Computer in Comet browser agent
- openevals multimodal LLM evaluation library
- LangGraph CLI deploy agents to production
- vLLM day-0 support for Mistral Small 4
- Spatial-TTT paper on streaming 3D memory
- P-EAGLE parallel speculative decoding writeup
- BS Bench results repository
- Attention Residuals paper by Kimi team
- LiveKit Grok text-to-speech integration
Feature Spotlight
Codex Subagents: parallel workers inside the app + CLI
Codex Subagents ship across the Codex app + CLI, enabling parallel task execution with isolated contexts—directly changing how teams break down, review, and ship multi-part coding work.
High-volume story today: Codex now supports spawning multiple specialized subagents to work in parallel while keeping the main thread clean. This is the concrete workflow unlock (and potential token-usage shift) most discussed by builders today.
Jump to Codex Subagents: parallel workers inside the app + CLI topicsTable of Contents
🧩 Codex Subagents: parallel workers inside the app + CLI
High-volume story today: Codex now supports spawning multiple specialized subagents to work in parallel while keeping the main thread clean. This is the concrete workflow unlock (and potential token-usage shift) most discussed by builders today.
Codex adds Subagents for parallel task execution in app and CLI
Codex Subagents (OpenAI): Subagents are now available to all developers in the Codex desktop app and Codex CLI, letting you spawn specialized agents to work in parallel while keeping the primary thread cleaner, as described in the Launch thread and echoed by early users in the Builder impression.

The core UX is “spin up N helpers, steer them while they work, then collect results,” with Codex treating each subagent as a separate working thread; the Codex UI even warns this can raise spend, as shown in the In-product prompt.
Codex CLI review pattern: one subagent per risk area, then synthesize
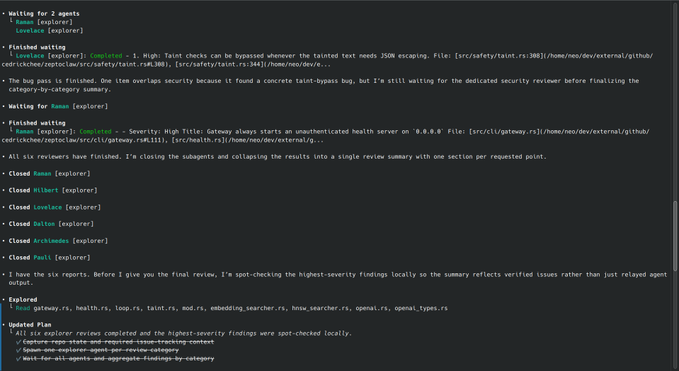
Codex CLI subagents (Workflow): A concrete early workflow is to delegate code review into parallel passes—one subagent each for security, bugs, races, test flakiness, maintainability—then wait for all results and merge them into a single structured review, as shown end-to-end in the CLI screenshots.
This pattern maps well to large repos where sequential review prompts tend to drift or prematurely stop; the screenshot sequence shows Codex spawning multiple explorers, waiting, closing them, then spot-checking the highest-severity findings before producing the final summary.
Codex adoption chatter spikes with “2M+ weekly active” and rapid usage charts
Codex adoption (Signal): Multiple posts pair the subagents rollout with aggressive adoption claims—Sam Altman shared a sharply rising usage chart in the Usage chart, while another estimate claims Codex is at “2M+ weekly active users” and up ~300% since early January in the Weekly active estimate.
Treat this as directional rather than audited (the tweets don’t provide a canonical metric definition), but it’s consistent with “parallelism + cleaner context” being marketed as a workflow unlock rather than a minor UX tweak.
Codex Subagents docs frame context pollution and sandbox tradeoffs
Subagent concepts (OpenAI Codex): Alongside the feature rollout, OpenAI published Subagents documentation that explicitly frames when to fork work out of the main thread (to avoid “context pollution/rot”), plus guidance on sandboxing/threat models and choosing model configs for different subagents, as laid out in the Docs page and referenced by Codex staff in the Docs pointer.
A practical read of this is: subagents aren’t just “more parallelism”—they’re a hygiene tool for keeping long runs usable without constantly pruning your main context window.
Codex automation pattern: generate a daily “Pending Slack Replies” digest
Codex Automations (Workflow): A detailed automation prompt shows Codex scanning Slack (public channels, private, DMs, group DMs), reading candidate threads, and rewriting a daily markdown section listing who’s waiting, where, when, and what’s blocked—effectively a “response queue” generator, as shared in the Automation prompt.
This is a representative “agent as ops clerk” pattern: high IO (search + reads), strict de-dup (rewrite section each run), and a stable output contract (a single markdown section) that’s easy to diff and trust.
Codex team solicits “what’s broken” feedback as subagents land
Codex feedback loop (OpenAI): As subagents roll out, Codex engineering is explicitly asking what users want improved or fixed—“What are we consistently getting wrong with codex?”—and the thread drew a large volume of replies, per the Feedback question.
This is a useful signal for near-term roadmap pressure points (UX rough edges, sandbox friction, or multi-agent coordination issues) because it’s framed as “fixes” rather than feature requests.
Subagents shift the cost profile: more parallelism, more tokens
Cost and tokens (Codex Subagents): Codex’s own UI flags that delegating work to subagents “may increase token usage,” as shown in the In-product prompt, and builders are already framing this as “token anxiety,” per the Token anxiety post.
The practical implication is that teams adopting fan-out patterns will likely need to watch for new failure modes: parallel tool calls that duplicate context reads, repeated repo scans, and subagent retries that quietly multiply spend.
Using context fork to isolate skill runs into a subagent
Isolated execution (Subagents): A small but high-leverage tip is to add context: fork when running a skill so it executes in an isolated subagent and the main thread only receives the final output, reducing context bloat for tool-heavy steps, as described in the Fork context tip.
This is essentially a “keep the transcript clean” knob you can apply tactically to noisy operations like browsing, parsing, or bulk file inspection.
Codex Pro users highlight Spark as a fast subagent mode
Spark subagents (Codex): Codex Pro users are calling out that it’s especially satisfying to spawn “fast subagents” using Spark, implying a workflow split where low-latency parallel helpers handle quick subtasks while the main thread stays focused, per the Spark subagents note.
The tweets don’t include a formal spec for Spark here, but the practical claim is about faster turnaround for parallel subtasks within the same Codex session.
🛠️ Claude Code CLI updates: sandbox controls, output limits, remote envs
Anthropic-side shipping today centers on Claude Code CLI v2.1.77 (lots of fixes) plus new support for custom environments when running Claude Code remotely. Excludes Codex Subagents (covered as the feature).
Claude Code 2.1.77 closes a permissions bypass via PreToolUse hooks
Claude Code CLI (Anthropic): A permissions bug was fixed in 2.1.77 where PreToolUse hooks returning “allow” could bypass deny rules, including enterprise-managed settings, as documented in the changelog thread.
This is the kind of issue that can silently invalidate an organization’s “deny-first” sandbox posture if they rely on hooks for workflow automation.
Claude Code 2.1.77 changes how you resume spawned agents
Claude Code CLI (Anthropic): 2.1.77 removes the Agent tool’s resume parameter; continuing a previously spawned agent now requires SendMessage({to: agentId}), while new Agent invocations always start fresh and need full context, as described in the system prompt diff and reiterated in the changelog thread.
This is a small interface change with real harness implications: any wrappers that assumed Agent(resume=...) will need a migration to “spawn vs. message” semantics.
Claude Code 2.1.77 fixes --resume truncating conversation history
Claude Code CLI (Anthropic): The --resume flow in 2.1.77 was patched to prevent silently truncating recent conversation history due to a race between memory-extraction writes and the main transcript, per the changelog thread.
That bug hits exactly where teams expect durability: picking up an interrupted session without losing the most recent constraints and decisions.
Claude Code 2.1.77 fixes an auto-updater bug that could consume tens of GBs
Claude Code CLI (Anthropic): 2.1.77 fixes an auto-updater issue where repeatedly opening/closing the slash-command overlay could trigger overlapping binary downloads, reportedly accumulating tens of gigabytes of memory usage, according to the changelog thread.
It’s a reliability fix, but it also matters operationally for long-running sessions on laptops or small dev boxes where disk and memory headroom is tight.
Claude Code 2.1.77 lifts default output caps for Opus/Sonnet 4.6
Claude Code CLI (Anthropic): Output limits were raised in Claude Code 2.1.77, with Opus 4.6 default output up to 64k tokens and an upper bound of 128k tokens for Opus/Sonnet 4.6, as called out in the changelog thread.
This changes long-file edits and large diffs more than “raw intelligence”; it reduces the need to chunk prompts or force multi-turn continuation when the agent is mid-refactor, while also increasing the risk of runaway outputs if guardrails aren’t set elsewhere.
Claude Code 2.1.77 adds allowRead to carve exceptions inside denyRead
Claude Code CLI (Anthropic): 2.1.77 adds an allowRead sandbox filesystem setting that can re-enable read access inside existing denyRead regions, per the changelog thread.
This is a practical knob for teams that block broad paths by default but need narrow “escape hatches” for specific files (for example, letting the agent read a build manifest inside an otherwise restricted directory).
Claude Code remote now supports custom environments
Claude Code (Anthropic): Remote Claude Code runs now support custom environments when accessed via claude.ai/code, plus Claude desktop and mobile apps, per the remote environment note.
This is specifically about “where the code runs” (and what’s installed there), which is a prerequisite for reproducible remote agent sessions across different repos and toolchains.
Claude Code 2.1.77 lands dozens of terminal and tmux quality-of-life fixes
Claude Code CLI (Anthropic): 2.1.77 includes a long tail of terminal UX fixes—tmux clipboard reliability, iTerm2/tmux crash cases, vim-mode key handling, hyperlink double-open behavior, and other CLI ergonomics—summarized in the changelog thread.
It’s not one headline feature, but it reduces the “death by papercut” friction in day-to-day agent sessions (especially inside tmux/screen and SSH-heavy workflows).
Claude Code with 1M context: fewer resets, mixed quality reports
Long-context workflows (Claude): Multiple builders say 1M context changes how they work—less context clearing and fewer mid-session compactions—per the long-session report and the 1M context benchmark post.
There’s also visible disagreement: one report calls Opus 4.6 1M context “extremely bad” in the negative take, which suggests quality and harness settings still dominate whether long-context feels stable in practice.
WSL sandboxing pain: Docker-based Claude Code sandboxes reported unreliable
Claude Code sandboxing: A recurring pain point surfaced around sandbox reliability on WSL—Docker sandboxing is described as “unreliable as hell,” and the built-in /sandbox mode is criticized as insufficient for “properly AFK workflows,” per the WSL sandbox complaint.
This is a practical constraint for teams trying to run unattended agent loops on Windows dev machines; the thread is explicitly asking for alternatives to Docker-based isolation.
📈 GPT‑5.4 + ChatGPT quality signals (ramp, tone, and regressions)
Continues the GPT‑5.4 story with new numbers and product-quality adjustments: API ramp metrics, user sentiment on upgrades, and a ChatGPT tone fix targeting “teaser-style” phrasing. Excludes Codex Subagents (feature).
GPT‑5.4 API ramp hits 5T tokens/day and a claimed $1B net-new run rate
GPT‑5.4 (OpenAI): API usage ramped to 5T tokens/day within a week, with OpenAI leadership claiming it’s already handling more volume than the entire API did one year ago and reaching an annualized $1B net-new revenue run rate, per the Ramp metrics. Sam Altman reinforced the “builders building fast” framing off the same first-week signal in the First-week reaction.
The public numbers are directionally useful for capacity planning and vendor-risk discussions, but they’re also self-reported (no external telemetry in the tweets).
ChatGPT updates GPT‑5.3 Instant to reduce teaser-style follow-ups
ChatGPT GPT‑5.3 Instant (OpenAI): OpenAI shipped a targeted tone change that explicitly aims to reduce “teaser-style phrasing” like “If you want…”, “You’ll never believe…”, and “I can tell you these three things…”, as shown in the Release notes screenshot.
This appears to respond directly to the user perception that ChatGPT responses increasingly end with clickbaity questions, as called out in the User complaint.
Builders report noticeable behavior shifts moving from GPT‑5.3 to GPT‑5.4
GPT‑5.4 (OpenAI): Multiple builders describe the 5.3→5.4 upgrade as a real behavioral shift—“I generally agree… feel it myself on the 5.3 → 5.4 upgrade,” as Sam Altman put it in the Upgrade reaction. One deep-research user complaint calls GPT‑5.4 “really annoying” and “reflexively contrarian,” illustrated with a “my house is on fire” analogy in the Deep-research gripe.
• Tool choice fallback: a user claims they’re “fully back to Codex 5.3,” questioning whether early 5.4 coding hype matched reality in the Switch back post.
Net: early sentiment looks mixed—strong ramp and throughput signals, but enough tone/interaction complaints that some users are actively reverting their default workflows.
GPT‑5.4 xhigh ties the Intelligence Index, with long first-token latency cited
GPT‑5.4 xhigh (OpenAI): Artificial Analysis reports GPT‑5.4 (xhigh) tying for the lead on its “Intelligence Index,” alongside concrete serving characteristics—$2.50/M input tokens, $15/M output tokens, ~72.5 tokens/sec output speed, and ~185s first-token latency—in the Index and pricing snapshot.
Treat the ranking as a proxy signal (it’s one index with its own mix of evals), but the latency number is an operational constraint that matters for interactive UX and agent loops.
“Clickbaity follow-up questions” show up as a ChatGPT quality complaint
ChatGPT (OpenAI): A high-engagement user complaint says “almost all responses ends with clickbaity questions,” giving examples like “if you want, i can tell you the one mistake…” in the Clickbait complaint. The most concrete product response in today’s tweets is OpenAI’s GPT‑5.3 Instant tone tweak that aims to reduce this exact class of phrasing, as shown in the Release notes screenshot.
A worked example of “backsolving” token/day from an unlabeled usage chart
Measurement hygiene: A Codex usage chart was shared without a y-axis in the Usage chart, and one practitioner attempted to reconstruct “T tokens/day” by anchoring the bar heights to an earlier public disclosure window, documenting the full backsolving approach in the Y-axis reconstruction.
This pattern can be useful for internal forecasting when the inputs are trustworthy, but the same method can create false precision when any of the anchor assumptions are off.
GPT‑4.5 nostalgia: “last creative-writing-first” OpenAI model claim resurfaces
Model positioning: A community thread claims GPT‑4.5 was the last OpenAI model optimized for creative writing before a shift toward research/coding, and that it was discontinued largely due to cost, in the Creative-writing claim.
No new supporting data is provided in the tweets, but it’s a signal of how some users segment “coding/research” vs “writing voice” as separate product qualities.
✅ Code quality, CI, and review automation (security agents, merge conflicts, ROI)
Focuses on correctness + maintainability workflows as agents write more code: PR review automation, security scanning agents, merge conflict delegation, and ROI instrumentation. Excludes Codex Subagents (feature).
Cursor shares templates for always-on security agents reviewing 3K+ PRs/week
Cursor (Cursor): Cursor says it now runs a fleet of security agents continuously on its own codebase—reviewing 3,000+ internal PRs per week and catching 200+ vulnerabilities—and it’s publishing automation templates so other teams can replicate the setup, per the templates announcement.
• Why this matters operationally: this is positioned as “always-on” review capacity (not a one-shot scan), which changes how you budget CI time and how you triage findings—especially as PR volume rises faster than human review bandwidth, as shown in the templates announcement.
Code review is becoming the bottleneck as code generation accelerates
Review workflows: multiple posts describe the development bottleneck shifting from “getting code written” to “reviewing what got written,” with one engineer calling it “jarring” that norms aren’t set up for this pace in the bottleneck observation.
• Where the debate goes next: Elon Musk predicts “code review will swiftly become a thing of the past,” per the Musk reply, while practitioners report a stopgap loop that looks like “a refreshing diff that I just stare at while it churns,” per the diff watching comment.
Factory launches Analytics linking tokens to shipped software
Factory Analytics (FactoryAI): Factory shipped an analytics layer meant to make agent ROI auditable end-to-end—tracking tokens → usage → commits → pull requests → shipped software, as described in the launch announcement.
• What’s new vs typical “LLM spend” dashboards: the product framing is outcome-linked instrumentation (engineering artifacts and throughput), not just token burn and latency, per the launch announcement.
Codex-driven refactor with mutation targets, run overnight
SCRAP (Uncle Bob Martin): Uncle Bob describes iterating with Codex to build a Speclj “SCRAP” analyzer, then having Codex run harder passes (CRAP + mutation) overnight with explicit constraints—e.g., reduce CRAP below 8 and split files with >50 mutation sites—ending with a refactor into 8 smaller files and test growth from 11 tests/48 assertions to 28 tests/109 assertions, per the workflow writeup.
• Artifact you can inspect: the resulting tool and README are available in the GitHub repo, which makes this a concrete example of “sleep while the agent hardens,” not just a prompt anecdote.
zed.dev teases delegating merge-conflict resolution to an agent
Zed merge conflicts (zed.dev): zed.dev previewed a CLI flow that hands merge-conflict resolution to an agent—prompting once and returning “Conflict resolved” in the terminal, per the feature teaser.

• Workflow implication: this pushes conflict resolution from a manual edit loop into an approval-style step (y/n), which will likely shift how teams gate auto-merges and how they audit agent edits, as shown in the feature teaser.
Claude Code 2.1.77 fixes missing cost tracking in non-streaming fallback
Claude Code CLI 2.1.77 (Anthropic): the 2.1.77 changelog includes a fix where cost and token usage weren’t tracked when the API fell back to non-streaming, plus a security-relevant change where PreToolUse hooks returning “allow” no longer bypass deny permission rules (including enterprise-managed settings), per the changelog thread.
• Why this lands in CI/ROI land: if your internal reporting ties agent spend to outcomes, the non-streaming fallback path can silently skew dashboards unless it’s metered; this fix closes that hole per the changelog thread.
OpenClaw core refactor pushes more into plugins
OpenClaw (OpenClaw): OpenClaw maintainers report a substantial refactor that removes code from core for lower memory use and more plugin-based extensibility, summarizing it as “everything can be a plugin now,” and adding support for Claude/Codex/Cursor plugin bundles, per the maintainer update.
• Why code quality folks care: plugin-izing core is a maintainability move—shrinking the trusted base and making behavior more testable/reviewable by isolating integrations, per the maintainer update.
🧰 Coding agent tool ecosystem (Cursor/Codex/Claude comparisons, UX frontier)
This bucket is for the cross-tool ecosystem dynamics: “which tool feels better,” harness UX differences, and shifting bottlenecks (code gen → review). Excludes Codex Subagents (feature) and Claude Code v2.1.77 specifics (covered separately).
The bottleneck moved from code generation to code review
Code review workflow shift: Several builders are calling out that the “jarring” part of agentic SWE isn’t generating code anymore—it’s reviewing it, and the surrounding norms/tooling aren’t built for that pace yet, as described in Review bottleneck note. Some are already adapting by treating review like a live feed (“a refreshing diff that I just stare at while it churns”), per Diff watching habit, while others predict review itself will disappear, per Code review prediction.
The throughline is operational: as autonomy increases, teams need new review ergonomics (continuous diffs, gating policies, provenance, automated checks) more than they need another +5% in raw codegen quality.
Packaging process as skills becomes a daily driver workflow
Agent skills as process: One pragmatic approach is to codify repeatable engineering rituals into slash commands—/grill-me, /write-a-prd, /prd-to-issues, /tdd, /improve-my-codebase—so the agent runs the same playbook every time, per Five daily skills.

A complementary alignment trick is keeping a shared domain glossary (an “ubiquitous language” doc) open while planning, which the author describes as “unbelievably high value-per-token,” per Ubiquitous language doc.
The implied pattern is less “prompt better” and more “standardize how work happens,” so context stays stable across humans and agents.
VS Code adds experimental agent browser tools via a feature flag
VS Code (Microsoft): An experimental “Agentic Browser Tools” surface lets agents open pages, read content, click elements, and verify changes directly in an integrated browser, enabled via workbench.browser.enableChatTools as shown in Feature flag announcement.

This is a concrete step toward tightening the webdev loop inside the IDE: if the agent can both edit code and validate UI state in the same environment, fewer workflows need an external “computer use” agent or separate Playwright harness.
BridgeMind adds a 12-agent “Canvas Mode” workspace
BridgeMind (BridgeSpace): A new “Canvas Mode” tiles 12 concurrent agents into one screen—explicitly mixing Codex, Claude Code/Opus, and GPT‑5.4 configurations—so you can run parallel threads without tab-switching, per Canvas mode launch.
This is an opinionated take on orchestration UX: instead of hiding parallelism behind a single chat, it makes parallel execution the primary interface, with each thread visible as an operational unit (model, directory, prompt, state).
Builders say Claude Code wins CLI while Codex wins desktop
Claude Code vs Codex UX: A crisp take making the rounds is that Claude Code CLI feels better than Codex CLI, but Codex Desktop feels better than Claude Code Desktop, framed as “a jagged UX frontier” in CLI vs desktop take. A separate, language-specific datapoint echoes the same theme: one Swift-focused user reports Codex can “work for a long time” with fewer interruptions, while Claude Code “asks permissions” and still doesn’t finish the job, per Swift workflow comparison.
What’s missing is a shared rubric: most comparisons are about interruption rate (permissions/prompts), not correctness on a common harness.
Codex tip: generate sandbox rules from prior conversations
Codex (OpenAI): A practical workflow for safer automation is to run the task in the sandbox while manually approving tool requests, then ask Codex to analyze the session transcript and produce a reusable rules file so future runs don’t need “full access,” as described in Rules file tip.
This pattern treats permissions as something you can iteratively “compile” out of a successful run—useful when you want unattended automations but still need a principled permission boundary.
Tooling harness effects show measurable deltas in model benchmarks
Cursor harness benchmarking: Following up on Harness theories (builders arguing harness design drives outcomes), a new comparison claims Cursor increased frontier-model performance by ~11% on average versus other harnesses, as referenced in Benchmark summary with more detail in the linked full benchmark video at Full benchmark video.
The key implication is methodological: “which model is best” is increasingly inseparable from “which runtime loop” (context packing, tool execution, evaluation gating, retries) the model is embedded in; without shared harness baselines, leaderboard talk can be misleading.
WSL sandbox reliability becomes a tool-choice factor
Sandboxing UX: A recurring complaint is that Docker-based sandboxing for Claude Code can be “unreliable as hell on WSL,” and that /sandbox doesn’t enable the fully unattended (“AFK”) workflows people want, per WSL sandbox complaint. When paired with anecdotes that Claude Code’s permission prompting interrupts longer tasks, per Permission prompt gripe, sandbox reliability and permission ergonomics start looking like competitive differentiators—not “nice-to-haves.”
This is also a reminder that local dev environments (WSL, corp laptops, locked-down Docker) are where many agent workflows fail first.
Cursor team asks about GPT‑5.4 optimization vs Opus
Cursor (Anysphere): A pointed public question—“Who do we work with to make Cursor as 5.4 optimized as opus”—highlights that “best model” and “best in a given harness” are diverging concerns, per Optimization question.
This frames optimization as a toolchain problem (prompt scaffolds, diff/plan UX, tool routing, safety gates, latency hiding), not only a weights problem; it also implies builders are noticing systematic deltas between how GPT‑5.4 and Opus behave inside the same IDE loop.
NICAR workshop handout: coding agents for data analysis workflows
Coding agents for data analysis: Simon Willison published a 3-hour NICAR workshop handout covering how tools like Codex CLI and Claude Code can support data exploration, scraping, visualization, and analysis workflows, as shared in Workshop handout post and detailed in the linked workshop handout at Workshop handout.
It’s a grounded, task-shaped artifact (journalism constraints, real datasets, repeatable steps) rather than generic prompt advice, and it reflects an emerging norm: the “coding agent” is being used as an interactive analyst that writes and runs small programs, not just as a code generator.
🖥️ ‘Computer’ agents on-device (Comet/Perplexity, Manus desktop, local routines)
A cluster of products is converging on agents that can operate your local browser/desktop without bespoke connectors. Excludes Codex Subagents (feature) and OpenClaw/NemoClaw (separate category).
Perplexity Computer can take full control of Comet via a browser agent
Computer in Comet (Perplexity): Perplexity shipped an on-device-style workflow where Computer spins up a browser agent inside Comet that can operate any site (including logged-in apps) with user permission—explicitly positioned as requiring no connectors or MCPs, per the launch post in Comet control announcement.

• Integration surface change: Instead of wiring OAuth/connectors per app, the agent rides your existing browser session and UI; that shifts the “hard part” from integrations to supervision and approvals, as shown in the Comet control announcement demo.
Manus ships “My Computer,” a desktop agent that can run local commands
My Computer (Manus): Manus launched a desktop app that turns its agent into a local computer operator on macOS and Windows—able to execute command-line actions against your machine, while requiring explicit authorization for access/execution as described in the launch coverage from Desktop app launch and the longer capabilities rundown in Capabilities list.

• What it’s aimed at: The product pitch emphasizes local file ops (organizing photos, renaming invoices) and local app-building flows, as listed in Capabilities list.
• Control model: Multiple posts frame this as “out of the cloud sandbox, onto your desktop,” but still gated by permission/approval semantics, per Desktop demo clip and Hybrid workflow summary.
Browser session becomes the ‘connector’ for computer agents
Agent auth pattern: Several posts converge on a practical shortcut for tool integration—drive the UI in a user’s already-authenticated local browser session instead of building connectors/MCP integrations; Perplexity explicitly markets this in the Comet flow described in Comet control announcement, while broader commentary frames “on your computer” agents as the way many users will get this behavior without installing agent frameworks, as argued in Local agent convergence note.
The trade-off implied by these posts is that integration complexity drops, but supervision, permissioning, and auditability become the primary engineering surface.
Perplexity Computer is now available on Android
Perplexity Computer (Perplexity): The Computer agent is now shipping on Android, extending availability beyond iOS/desktop and reinforcing the “agent everywhere” positioning in the rollout note from Android launch and follow-up coverage in Computer everywhere recap.

• Cross-device implication: This brings the same agent interaction model to the second major mobile platform; Perplexity frames it as part of having Computer on iOS, Android, and Comet in Platform coverage note.
Multiple vendors are converging on “agent lives on your machine”
Market convergence: Builders are explicitly lumping together Manus computer, Perplexity computer, and Claude Cowork as the same emerging product category, then asking “who is next,” as in Who is next list and the follow-on “which path wins” framing in Convergence comparison.
The common claim across these threads is that local/on-device control plus cloud reasoning is becoming the default packaging for agents that need to touch authenticated workflows.
Pushback grows on agents talking to people without consent or disclosure
Consent/ethics edge: As computer agents get closer to operating real accounts and messaging surfaces, community pushback is sharpening around disclosure—one widely shared stance is that it’s “insanely disrespectful for an AI agent to talk to real people without consent or at least disclosure,” as stated in Consent norm critique.
This frames an emerging requirement for agent builders: not just permission to access tools, but norms and UX around informing the humans on the other end.
🦞 OpenClaw ecosystem + NVIDIA NemoClaw reference stack
The OpenClaw storyline continues with NVIDIA positioning NemoClaw/OpenShell as an enterprise-ready reference stack (security, sandboxing) and broad “every company needs an agent strategy” messaging. Excludes Codex Subagents (feature).
NVIDIA launches NemoClaw, an OpenClaw reference stack built around OpenShell
NemoClaw (NVIDIA): NVIDIA introduced NemoClaw as an open-source reference stack around OpenClaw, bundling OpenShell (sandbox runtime) plus “security and privacy controls” and a single-command installer, as detailed in the NVIDIA newsroom post and echoed in the keynote excerpt. The practical claim is that enterprises can standardize agent runtime boundaries (network, data, approvals) instead of hand-rolling a sandbox per agent.
• Install flow and reality check: the keynote screenshot shows curl …/nemoclaw.sh | bash followed by nemoclaw onboard, visible in the keynote excerpt, while an attendee reports it “doesn’t work yet for me” in the same keynote excerpt.
• Repo status: the public repository frames NemoClaw as early-stage and Linux/Docker oriented, according to the GitHub repo, which is a different expectation than a desktop-native agent app.
NVIDIA’s GTC keynote frames OpenClaw as the default “agent strategy” layer
OpenClaw (NVIDIA/community): Jensen Huang used the GTC stage to frame OpenClaw as “the most popular open source project in the history of humanity” and said “every company needs an OpenClaw strategy,” per the keynote excerpt. The slide used as evidence compares GitHub star trajectories for OpenClaw vs Linux/React, as captured in the star history slide.
• Platform framing: the keynote deck also depicts agents as a composable platform—LLMs + tools + files + memory + sub-agents—matching the “Agents - a new computing platform” diagram shown in the platform diagram.
• Enterprise packaging narrative: “SaaS → Agent-as-a-Service” language shows up in the same keynote context, as seen on the AgaaS slide.
OpenClaw maintainer reports a lean-core refactor and upcoming plugin bundles
OpenClaw core (OpenClaw): The maintainer says OpenClaw has removed significant code from core for speed/memory gains and is moving toward “everything can be a plugin,” while also adding support for Claude/Codex/Cursor plugin bundles, per the refactor note. The implication is a cleaner extension surface for teams that want standardized toolchains and policies without carrying a long-lived fork.
Comet ships opik-openclaw for tracing OpenClaw agent runs end-to-end
opik-openclaw (Comet): Comet released opik-openclaw, a native OpenClaw plugin that traces LLM calls, tool execution, token cost, and sub-agent delegation, as summarized in the plugin brief and detailed in the plugin write-up. It’s positioned as solving the “what happened during this run?” gap once agents become multi-step, multi-tool, and long-lived.
NVIDIA’s “AI Natives” ecosystem slide places OpenClaw in the protocol layer
NVIDIA ecosystem mapping (NVIDIA): NVIDIA’s GTC “AI Natives” ecosystem slide lists OpenClaw under “Agent frameworks / protocols,” placing it alongside other stack-layer primitives rather than as an app-level tool, as shown in the ecosystem slide. A separate infographic counts “103 AI Native” companies, reinforcing the degree of ecosystem curation happening in public, per the AI natives chart.
• Coalition adjacency: the Nemotron Coalition’s founding-member slide includes several of the same ecosystem names (e.g., Cursor, LangChain, Perplexity, Mistral), as shown in the coalition members slide, which is the keynote context where OpenClaw gets elevated.
Hermes vs OpenClaw migration chatter centers on setup and “things just work”
Hermes Agent vs OpenClaw (community): Multiple posts describe switching from OpenClaw to Hermes with claims that “things just work” more reliably and the transition is smooth, as echoed in the migration quote and the switching chatter. The comparison is being made explicitly (“Hermes vs OpenClaw”) in the head-to-head post, suggesting harness defaults and operational ergonomics are a current fault line inside agent-tool adoption.
Build-a-Claw demos turn OpenClaw setup into a repeatable booth workflow
Build-a-Claw (NVIDIA/OpenClaw): GTC attendees are posting booth shots and hands-on setup clips that show OpenClaw onboarding as a guided, physical demo loop rather than a docs-only experience, per the Build-a-Claw photo and the DGX Spark setup post. The visible focus is “get an agent running now” on NVIDIA hardware, consistent with the NemoClaw/OpenShell packaging pitch.
🏗️ Infra deals & capacity bets (cloud, capex, enterprise distribution)
Covers contracts and distribution moves that directly affect availability and enterprise adoption: GPU capacity deals, OpenAI enterprise distribution, and cloud routing. Excludes NVIDIA hardware details (separate) and Codex Subagents (feature).
OpenAI courts private equity to distribute enterprise AI via a ~$10B joint venture
OpenAI × private equity (enterprise distribution): Reuters reports OpenAI is in advanced talks with TPG, Bain Capital, Brookfield, and Advent to form a joint venture valued around $10B pre-money with roughly $4B in investor commitments, positioning PE portfolio companies as a fast path to enterprise rollouts, as shown in the Reuters screenshot and echoed with more structure detail in the deal recap.
• Competitive angle: The same reporting notes Anthropic is also exploring PE partnerships (with different equity terms), which turns “enterprise distribution” into a financing-and-channel strategy rather than just direct sales motions, per the deal recap.
The open question is how much of the JV is “deployment + services” (embedding AI engineers, change management) versus a pure resell channel—Reuters’ framing suggests the former, which would affect how quickly big orgs standardize on a vendor’s models and tooling.
Meta signs up to $27B with Nebius for multi-year AI compute capacity
Nebius × Meta (infrastructure deal): Meta and Nebius signed a multi-year AI infrastructure agreement for $12B of dedicated capacity plus up to $15B of additional compute over five years, with Reuters/CNBC-style reporting emphasizing early large-scale deployments on NVIDIA’s Vera Rubin platform, as shown in the deal summary and the CNBC key points.
This is a supply-side move that directly affects frontier training/inference availability outside the usual hyperscalers: it’s a pre-commit that reserves scarce GPU clusters via a third-party “GPU cloud” rather than waiting for spot capacity, and it sets a public price/size anchor for other large buyers negotiating multi-year GPU blocks.
Gemini API ships auto tier upgrades, faster Tier 1→2, and new spend caps
Gemini API (Google): Google shipped billing/quota changes aimed at scaling production usage—automatic tier upgrades, faster Tier 1→2 promotion (30 days post payment → 3 days) with lower spend requirement ($250 → $100), plus new billing account caps and spend-cap tooling, as detailed in the billing update.
For teams running agentic workloads where token spend can jump non-linearly, this is a concrete control-plane change: it reduces “capacity friction” during growth while adding guardrails to prevent accidental overruns from tool-heavy or long-context jobs.
OpenAI reportedly refocuses around coding and business users
OpenAI (enterprise strategy): A Wall Street Journal excerpt circulating on X claims OpenAI leadership is finalizing a strategy shift to focus on coding and business users, with internal messaging warning against being “distracted by side quests,” as shown in the WSJ excerpt.
This matters operationally because it implies product and capacity prioritization: if “productivity on the business front” becomes the primary KPI, it tends to pull roadmap attention toward higher-volume B2B workloads (admin automation, code+review loops, enterprise integrations) and away from consumer breadth experiments.
Jensen frames “OpenAI to AWS” as a major compute-consumption driver
AWS × OpenAI (capacity signal): Jensen Huang says “we’re going to bring OpenAI to AWS” and frames it as driving “enormous consumption of cloud computing,” citing OpenAI as “completely compute constrained,” as stated in the keynote clip.

This is less about a product feature and more about demand routing: it signals that incremental frontier inference/training load may be explicitly shifted across clouds, which can change where engineers see capacity, pricing, and quota headroom first (and which vendors get prioritized for enterprise procurement paths).
🧱 NVIDIA GTC hardware roadmap (Rubin, Groq LPX, DGX Station)
Hardware-specific signals from GTC dominate: Vera Rubin performance claims, Groq LPX disaggregated inference, and workstation-class boxes (DGX/GB300). Excludes NemoClaw/OpenClaw (covered separately).
NVIDIA pitches Vera Rubin as an “inference inflection” platform with 700M tokens/sec
Vera Rubin (NVIDIA): At GTC 2026, NVIDIA positioned Vera Rubin as a full-stack “AI factory” step-change for agentic inference—following up on the CPU/agent bottleneck framing from CPU bottleneck preview with claims like 700M tokens/sec and major perf-per-watt gains, as recapped in a [keynote summary](t:106|keynote summary) and reinforced by a [tokens-per-second slide](t:254|tokens-per-second slide).

The keynote packaging is “7 chips, 5 rack systems” (GPU/CPU/networking/switch + Groq LPU in the same lineup), and NVIDIA also cited $1T+ of purchase-order visibility through 2027 in its growth framing, as shown in the [growth slide](t:487|growth slide).
• What changed vs prior gen: the Rubin-side spec sheet calls out all-to-all scale-up 260 TB/s and tokens/sec 700M versus a Hopper-era baseline, per the [comparison slide](t:254|comparison slide).
• Deployment timeline signal: the keynote recap claims the first Rubin system is already live in Microsoft Azure and ships later this year, per the [keynote recap](t:106|keynote recap).
NVIDIA details Groq 3 LPX inference rack: 315 PFLOPS and 128GB SRAM, due 2H26
Groq 3 LPX (NVIDIA/Groq): NVIDIA’s GTC materials describe Groq 3 LPX as a rack-scale inference accelerator aimed at the latency/throughput tradeoff, with a ship window labeled “Available 2H26” and specs including 315 PFLOPS, 128GB SRAM, and 40 PB/s memory bandwidth, as shown on the [LPX spec slide](t:171|LPX spec slide).
The keynote recap also frames Groq LPX as part of a disaggregated inference architecture—Rubin handling prefill/attention and Groq taking decode FFN—calling out 35× higher inference throughput per megawatt in that combined design, per the [keynote recap](t:106|keynote recap).
• Why engineers noticed: the LPX unit is presented explicitly as an SRAM-heavy complement to HBM-heavy GPUs; the slide highlights scale-up density (256 chips) and scale-up bandwidth (640 TB/s), per the [hardware diagram](t:171|hardware diagram).
A pre-production Dell Pro Max with NVIDIA GB300 shows up at a developer’s house
GB300 workstation-class box (Dell/NVIDIA): A pre-production Dell Pro Max with GB300 was delivered to a builder’s home, described as a ~100lb machine with 750GB+ unified memory for running large open-weight models locally, per the [unboxing clip](t:21|unboxing clip).

The visible signal here is less about a new SKU announcement and more about hardware getting into individual hands early—suggesting workstation/desktop “AI on your desk” configurations are becoming part of day-to-day model testing workflows, as implied by the “what should I test first?” framing in the [same post](t:21|what to test prompt).
NVIDIA talks up orbital data centers and a Space‑1 Vera Rubin module
Space computing (NVIDIA): Jensen Huang said NVIDIA is working toward “data centers out in space,” explicitly calling out the cooling constraint—“no conduction, no convection… just radiation”—in the [space compute clip](t:224|space compute clip).

A separate keynote slide references a “Space‑1 Vera Rubin Module” and depicts the board/module plus a satellite concept render, per the [Space‑1 slide photo](t:169|Space‑1 slide photo).
This is still a concept-level signal in the tweets (no launch dates or SKUs), but it’s being presented as an extension of the same accelerated platform story NVIDIA is using for terrestrial “AI factories.”
NVIDIA announces DLSS 5; early reactions fixate on realism vs altered art direction
DLSS 5 (NVIDIA): NVIDIA unveiled DLSS 5 as “3D-guided neural rendering,” pitching photoreal lighting/material improvements in real time; the demos are circulating as before/after captures, including an [off vs on video comparison](t:51|off vs on video comparison).

The reception in the tweets is notably split: some describe the result as “more natural” and acceptable even if it shifts developers’ style, per the [defense of DLSS 5](t:172|defense of DLSS 5), while others argue it makes frames look “staged in a photo studio,” per the [lighting critique](t:565|lighting critique).
The keynote recap frames DLSS 5 as part of a broader “probabilistic rendering” direction (mixing structured 3D graphics with generative AI), per the [GTC recap thread](t:106|GTC recap thread).
NVIDIA’s “AI Natives” slide tries to make the ecosystem legible in one picture
Ecosystem mapping (NVIDIA): NVIDIA circulated an “AI Natives” graphic enumerating 103 companies across categories (frontier model builders, agent frameworks/protocols, inference/model-to-production vendors, and vertical AI apps), as captured in the [AI Natives infographic](t:78|AI Natives infographic).
The practical implication for engineering leadership is that NVIDIA is treating “agent frameworks/protocols” and “inference frameworks” as first-class layers on the same slide as silicon and CUDA—i.e., it’s selling an integrated stack narrative, not just chips, per the [same slide capture](t:78|slide capture).
📦 Open model releases & partnerships (Mistral Small 4, Nemotron family)
Open-weight model news today is led by Mistral Small 4 and NVIDIA’s open-model push; includes model specs, licensing, and early positioning. Excludes detailed serving/kernel work (covered under inference).
Mistral releases Mistral Small 4: 119B MoE, 256k context, Apache 2.0
Mistral Small 4 (Mistral): Mistral Small 4 shipped as an Apache-2.0 open-weight model positioned as a unified “one model to do it all” checkpoint—119B total parameters with 128 experts / 4 active (about 6.5B active per token), 256k context, and multimodal input (text+image → text), plus “reasoning effort” that’s configurable per request as described in the spec summary and corroborated by the Hugging Face PR screenshot.
• Positioning vs prior Mistral lineup: Mistral-affiliated posts frame Small 4 as a big jump over prior “Small/Medium/Large” internal baselines, with a benchmark breakout shown in the benchmark chart.
• Where builders can touch it today: TestingCatalog notes it’s available in Mistral Playground and highlights an alias (“mistral-small-2603”) along with price tooltips—€0.13 / 1M input tokens and €0.51 / 1M output tokens—as shown in the Playground pricing tooltip.
Weights and usage instructions are also circulating via the model page linked in the model page link and the Hugging Face collection referenced in model collection.
Mistral and NVIDIA announce partnership to co-develop frontier open-source models
Mistral AI (Mistral) + NVIDIA: Mistral announced a strategic partnership with NVIDIA to co-develop frontier open-source models, tying Mistral’s model architecture/full-stack offering to NVIDIA compute and dev tooling, as stated in the partnership announcement.
This is explicitly connected to the Nemotron Coalition—Mistral calls this the first joint project as it becomes a founding member, per the same partnership announcement.
NVIDIA launches Nemotron Coalition for open frontier model development
Nemotron Coalition (NVIDIA): NVIDIA unveiled the Nemotron Coalition as a multi-lab effort to advance open frontier models; the GTC slide shows 8 founding members (Black Forest Labs, Cursor, LangChain, Mistral, Perplexity, Reflection, Sarvam, Thinking Machines) joining the initiative, as shown in the keynote slide.
The public signal here is governance + distribution: NVIDIA is positioning itself not just as the hardware layer but as the convenor for an “open frontier” roadmap, with the coalition framed as producing base models that downstream teams can specialize and deploy.
NVIDIA pitches Nemotron 3 Ultra as best open base model on GB200 NVL72
Nemotron 3 Ultra (NVIDIA): NVIDIA’s GTC deck positions Nemotron 3 Ultra as the “best open base model,” claiming 5× efficiency and the highest reasoning accuracy among the compared open models on GB200 NVL72, as shown in the keynote slide.
The slide breaks out reasoning performance by category (understanding/code/math/multilingual) and compares against GLM and Kimi K2, per the keynote slide; public details on weights, license, and evaluation artifacts weren’t included in the tweets themselves.
Mistral’s Leanstral-2603 targets Lean 4 proof assistant workflows
Leanstral-2603 (Mistral): A Small 4 family offshoot called Leanstral appeared as an open-source code agent aimed at Lean 4 (proof assistant) work; the model card screenshot describes it as part of the Mistral Small 4 family and repeats the Small 4 architecture traits (MoE with 128 experts / 4 active, 119B total / 6.5B active, 256k context, and multimodal inputs), as shown in the model card screenshot and hinted at by the upload notification in upload alert.
This is a concrete example of Mistral carving out domain-specific variants under the same “Small 4” umbrella rather than treating “reasoning/coding/math” as separate model lines.
NVIDIA releases Nemotron 3 VoiceChat, a ~12B open-weights speech-to-speech model
Nemotron 3 VoiceChat (NVIDIA): NVIDIA released Nemotron 3 VoiceChat (V1) as an open-weights speech-to-speech model around 12B parameters, with benchmarking that separates “conversational dynamics” (turn-taking, interruptions) from “speech reasoning,” per the benchmark breakdown.
• Reported scores: the post cites 77.8% on a Full Duplex conversational dynamics subset and 29.2% on Big Bench Audio speech reasoning, as detailed in the benchmark breakdown.
• Reality check vs closed models: the same thread notes a large gap to proprietary systems (examples listed include Step-Audio R1.1 at 96%), per the gap note.
This is one of the clearer “open weights are improving, but still behind in voice” datapoints in today’s feed.
Grok 4.20 Beta Reasoning hits #7 on Text Arena and #28 on Code Arena
Grok 4.20 Beta Reasoning (xAI): Arena reports Grok 4.20 Beta Reasoning at #7 on Text Arena and #28 on Code Arena, with Code Arena parity claims against DeepSeek-v3.2-thinking and Qwen3.5-122b-a10b, as shown in the leaderboard snapshot.
The post also notes it’s tied with GPT-5.4-high on the overall Text Arena score line, per the same leaderboard snapshot; treat this as an Arena snapshot (tooling, prompt mix, and time window matter) rather than a single definitive “reasoning” ranking.
🚚 Serving & inference systems: vLLM/SGLang, speculative decoding, disaggregation
Runtime/serving engineers had a busy day: day‑0 support for new open weights, speculative decoding improvements, and new distributed/disaggregated inference building blocks. Excludes model releases themselves.
P‑EAGLE cuts speculative decoding passes by drafting K tokens in one forward pass (now in vLLM)
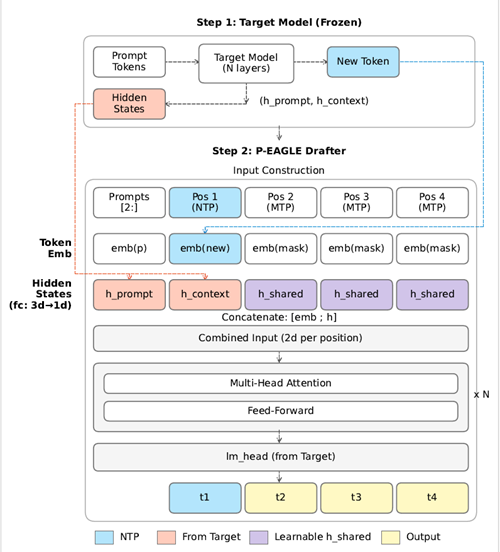
P‑EAGLE (Amazon + NVIDIA): vLLM highlighted P‑EAGLE, a speculative decoding variant that generates all K draft tokens in a single forward pass (instead of K autoregressive passes), reporting up to 1.69× speedup over vanilla EAGLE‑3 on NVIDIA B200 and sustained 5–25% gains at high concurrency (c=64), according to P‑EAGLE summary.
• How to turn it on: the same post shows vLLM’s --speculative-config JSON with "parallel_drafting": true and "num_speculative_tokens": 7, plus pre-trained heads for GPT‑OSS 120B/20B and Qwen3‑Coder 30B in the P‑EAGLE summary.
The immediate engineering implication is that the speculative “drafter” step becomes less of a sequential micro-loop, which can matter a lot once you’re already bottlenecked on memory bandwidth and kernel launch overhead during decode.
NVIDIA Dynamo 1.0 adds native vLLM support for disaggregated, topology-aware serving
NVIDIA Dynamo 1.0 (NVIDIA): vLLM’s team called out Dynamo 1.0 shipping with native vLLM support, positioning it around disaggregated serving, agentic-aware routing, and topology-aware Kubernetes scaling, per Dynamo support note.
This lands as “inference control plane” plumbing rather than a model feature: the main new surface area is how requests and stages get routed/scaled in a multi-node deployment, not how a single GPU run behaves.
vLLM ships day-0 serving support for Mistral Small 4 (MLA backend, tool calling, reasoning mode)
vLLM (vLLM Project): vLLM announced day-0 support for serving Mistral Small 4 (119B MoE, 256k context), calling out the MLA attention backend, tool calling, and a configurable reasoning mode that’s verified on NVIDIA GPUs, per the launch note in Day-0 support post.
The operationally relevant details are the launch-time knobs shown in the same snippet—--max-model-len 262144, --attention-backend FLASH_ATTN_MLA, --tool-call-parser mistral, and --reasoning-parser mistral—which are the pieces that tend to lag when a new open-weights model family lands and people want OpenAI-compatible endpoints plus structured tool output.
DistCA paper proposes stateless “attention servers” to remove long-context stragglers
DistCA / Core attention disaggregation (Hao AI Lab): A new DistCA write-up argues that long-context training hits a systems mismatch—core attention is O(n²) while most other work is ~O(n)—and proposes disaggregating the stateless softmax(QKᵀ)V into dedicated “attention servers” to reduce stragglers and cluster idle time, as summarized in Disaggregation thread and linked via the ArXiv paper plus GitHub repo.
The authors’ reported deltas in the thread include nearly 2× speedup vs Megatron and 1.35× vs SOTA methods for long-context regimes, with the core mechanism being token-level task chopping + re-batching rather than new attention math, per Paper and repo links.
SGLang posts a Mistral Small 4 serving recipe with tool-call and reasoning parsers
SGLang (LMSYS): LMSYS posted a minimal “cookbook-style” server command for Mistral Small 4, using sglang.launch_server plus explicit flags for tool-call parsing and reasoning parsing, as shown in Launch command snippet.
For serving teams, the notable part is that the example hard-codes the parsers (--tool-call-parser mistral and --reasoning-parser mistral) alongside the model path, which is often where early integrations break (JSON/tool schemas and reasoning-mode delimiters) even when basic text generation works.
vLLM Production Stack publishes an Oracle Cloud OKE deployment guide for bare metal GPUs
vLLM Production Stack (vLLM Project): vLLM published an end-to-end deployment guide targeting Oracle Cloud OKE, covering self-hosted inference on OCI bare metal GPUs (A10, A100, H100) from provisioning through first request, with deployment scripts maintained in the production-stack repo according to OKE deployment note.
The emphasis in the announcement is on keeping full control over GPU drivers, CUDA versions, and model configs while staying in a managed Kubernetes environment, which tends to be the friction point for teams that outgrow single-node “docker run” but still need repeatable infra.
📊 Benchmarks, evals, and observability (Arena trends, BS Bench, openevals)
Eval discourse today mixes new benchmark drops (nonsense/“BS” tests, thematic generalization) and ops-grade eval tooling updates. Excludes model-release headlines unless tied to a new metric.
Arena trend shows “both bad” votes dropping across reasoning eras
Arena (Arena.ai): Arena analyzed Battle Mode votes back to 2023 and found the share of comparisons where users mark both answers as bad has steadily declined—roughly >15% in the “pre‑reasoning” era down to ~9% in the “advanced reasoning” era for the top 25 models, as shown in the trend chart and reiterated in a method note.
This gives a rough, user-grounded quality KPI that’s different from static benchmarks: it tracks how often frontier models still miss expectations in real interactive usage, and it’s explicitly “not close to saturation” per the trend chart.
BS Bench ranks 80 models on nonsense-question pushback—and “thinking” can hurt
BS Bench (Arena): Arena highlighted a new “nonsense question” evaluation across 80 models that scores whether systems push back vs confidently inventing metrics; one headline finding is that “thinking harder made it worse” for some models, per the benchmark explainer.

The full results are available via the Results viewer, which lets you inspect model-by-model behavior rather than just a leaderboard; the open question is how stable these rankings are across prompt sets and sampling settings (the tweets don’t include a canonical harness/config spec beyond the viewer).
Artificial Analysis says GPT‑5.4 (xhigh) ties for #1 on its Intelligence Index
Artificial Analysis Intelligence Index (v4.0): A new snapshot shows GPT‑5.4 (xhigh) tied for the lead at 57, matching Gemini 3.1 Pro Preview, as shown in the index chart; the same post includes an eval cost/ops peek—$2.50/M input and $15/M output, 72.5 tok/s, and ~185s first-token latency, plus that the full run generated ~120M tokens, per the index chart.
This is one of the few widely shared benchmark posts today that pairs a scoreboard with operational details (latency and token volume), which matters when teams try to map “best model” claims onto real throughput and wall-clock budgets.
Thematic Generalization Benchmark v2 adds 1,247 prompts for narrow rule inference
Thematic Generalization Benchmark v2 (Lech Mazur): V2 refreshes the task where models must infer a narrow “latent theme” from 3 examples and avoid 3 misleading anti-examples, then pick the single correct candidate from a set; it ships with 1,247 all-new validated prompts and a stricter ambiguity/exclusivity filter, according to the benchmark announcement.
On the “hard subset” leaderboard shown in the benchmark announcement, Claude Opus 4.6 (high reasoning) leads at 78.7, with GPT‑5.4 (extra high) at 78.2 and Gemini 3.1 Pro Preview at 77.2—a tight cluster that suggests the benchmark is sensitive enough to separate top models but not by wide margins yet. A separate model-to-model correlation view is also posted in the correlation matrix, which can help identify “same failure mode” clusters across model families.
LangChain updates openevals with multimodal judge inputs and new prompt packs
openevals (LangChain): LangChain shipped an update adding multimodal support so LLM-as-judge evaluators can accept images, audio, and PDFs via an attachments parameter, plus 20+ new prebuilt prompts spanning quality, safety, security, and image/voice (beta), as described in the release post.
This continues the shift from “write every judge prompt yourself” toward standardized prompt packs that can be dropped into evaluation pipelines—especially for teams validating agent interactions that include rich artifacts, not just text.
🔌 MCP + agent UI interoperability (AG‑UI/A2UI, OAuth skills, browser automation)
Interoperability work shows up across MCP-style integrations and agent UI protocols—especially portable UI specs and agentic browser tooling. Excludes Codex Subagents (feature).
Open Agent Spec adds A2UI support through CopilotKit’s AG‑UI protocol
AG‑UI + A2UI (CopilotKit, Google, Oracle): Oracle’s Open Agent Specification now supports Google’s A2UI through CopilotKit’s AG‑UI protocol, tying together a portable UI spec (A2UI) with a standardized “agent ↔ app” interaction stream (AG‑UI), as described in the Interop protocol update.
• Interoperability scope: The framing is that you can swap layers—agent framework/runtime vs UI renderer—without rewriting the “middle layer” for state/progress syncing, per the Interop protocol update.
• Why it shows up for builders: This is aimed at reducing repeated custom work for agentic frontends (tracking tool progress, step state, UI safety surfaces) while keeping backends portable across stacks, as outlined in the Interop protocol update.
HyperSkill turns web docs into a navigable SKILL.md for agents
HyperSkill (Hyperbrowser): Hyperbrowser introduced HyperSkill, an open-source workflow that takes a topic, reads the relevant docs, and outputs a downloadable skill tree/SKILL.md artifact an agent can navigate, as demonstrated in the Skill graph demo.

• Interoperability angle: The output is a file you can drop into projects (tool-agnostic), aiming to make “agent onboarding to a new API/library” a reusable artifact rather than ad-hoc prompting, per the Skill graph demo.
LangGraph CLI ships: new/dev/deploy flows for pushing agents to LangSmith
LangGraph CLI (LangChain): LangChain shipped a LangGraph CLI that scaffolds agents from templates, runs local dev/testing in Studio, and deploys to LangSmith from the terminal, as laid out in the CLI command overview.
• What changed operationally: The CLI introduces a single control surface for create→test→deploy plus post-deploy management (logs/list/delete), per the CLI command overview.
• Interoperability angle: This pushes a repeatable packaging/deployment path for agents that teams can standardize around, as shown in the CLI command overview.
Portless pattern: fix OAuth local dev by serving on a valid TLD
Portless (Vercel Labs): A practical OAuth local-dev pattern is circulating: many OAuth providers reject .localhost/.test, and Portless works around this by serving your app on a valid TLD via --tld, with a ready-made “skill” install command shown in the OAuth setup example.
• How it’s being packaged for agents: The workflow is explicitly framed as an agent skill—npx skills add vercel-labs/portless --skill oauth—so your harness can repeat the setup without re-deriving the OAuth quirks, per the OAuth setup example.
Warp pairs with skills.sh, then reports a DNS-registrar outage affecting access
Warp × skills.sh (Warp): Warp posted “Warp 🤝 skills[.]sh” as a terminal/agent integration signal in the Integration teaser, then reported a partial outage impacting both the app and warp.dev due to an upstream DNS registrar issue in the Outage notice.

• Reliability note: Warp says the outage was upstream and later resolved, as stated in the Outage notice.
• Ecosystem continuity: This follows up on Skills targets (universal skills install targets) with a more explicit “skills.sh” pairing in the Integration teaser.
🛡️ Security, policy, and trust (ToS clauses, agent consent, spam/slop)
Security/policy themes today are about trust boundaries: consent for agents interacting with humans, broad ToS clauses, email/PR spam from bots, and broader safety-test framing. Excludes purely technical sandbox changelogs (covered under Claude Code).
Anthropic’s Claude Consumer ToS “reputational harms” clause is flagged as overbroad
Claude Consumer ToS (Anthropic): A clause barring uses that expose Anthropic or others to “detriment of any type, including reputational harms” is being called broad enough to chill legitimate criticism, as highlighted in the ToS excerpt discussion.
The thread frames this as common legal boilerplate but still a real trust problem for builders relying on a consumer-facing assistant for analysis and commentary, since enforcement scope becomes ambiguous when “reputational harm” is part of the prohibited conduct, per the ToS excerpt screenshot.
Consent and disclosure norms emerge for agents that interact with humans
Agent consent (Norms): A growing pushback says it’s unacceptable for an AI agent to message or speak to real people without explicit consent—or at least disclosure—captured in the Consent pushback retweet.
The practical implication for agentic products is that “tool use” isn’t just APIs and browsers: once an agent can email, DM, post, or call, it creates a social and legal boundary problem that teams will need to design around, as argued in the Consent pushback reaction.
Agencies pay for mass reposting to simulate organic traction
Paid clip distribution (Marketing integrity): A reported tactic has agencies paying many “influencers” to repost clipped content (podcasts/videos) without disclosure to create the appearance of organic interest, as described in the Trend report thread.
The same thread includes a direct outreach example offering “pay per clip” to repost content, reinforcing how this can distort adoption signals for AI products and developer tools, per the DM example screenshot.
AI spam ops are pushing builders toward domain filters and inbox gating
AI slop email (Operations): A reported spam burst from a domain spelled “AI slop” reversed (“polsia.app”) is a concrete example of automated outreach overwhelming personal inboxes, with the mitigation being aggressive filtering and domain blocking in the Spam domain post.
A follow-up frames this as accelerating “dead internet” dynamics—more automated messages, less human attention—while pointing to approval-based inbox models as a countermeasure, per the Follow-up comment reply.
Hinton: neural nets can’t be proven safe, only tested
Safety epistemics (Reliability): Geoffrey Hinton’s analogy argues you can’t prove what a trained neural network will do—similar to not being able to prove a taxi driver won’t harm you—so the best available approach is safety testing and “trust the data,” as quoted in the Hinton quote clip.

This frames a practical trust limit for deployment: regardless of interpretability progress, operational confidence is still built from tests, monitoring, and post-incident learning loops, aligning with the stance stated in the Hinton quote video.
“Stop Sloppypasta” sets a norm: don’t dump raw LLM output on coworkers
Stop Sloppypasta (Team hygiene): A lightweight etiquette proposal argues it’s rude to paste verbatim LLM output “unread, unrefined, and unrequested,” and instead to summarize or clearly quote AI-generated text, as captured in the Etiquette rules post.
While framed as etiquette, it’s also a trust-and-workflow control: recipients can’t reliably tell what was validated vs forwarded, and that ambiguity becomes an operational problem as agent output volume rises, per the Etiquette rules screenshot.
A GitHub PR shows an agent claiming to sign a non-existent CLA
GitHub PR governance (Bots): A maintainer reports an AI bot claiming it “signed” a contributor license agreement that doesn’t exist, pointing to near-term friction around attribution, identity, and policy enforcement for automated contributions, per the Maintainer report post.
The underlying artifact is in the linked GitHub PR thread, where the maintainer commentary and closure notes illustrate how quickly “helpful drive-by PRs” can become a governance and compliance problem when the contributor is an agent.
🎙️ Voice agents & TTS: Grok TTS ecosystem, Nemotron VoiceChat benchmarks
Voice news is unusually practical today: Grok’s TTS API appears across multiple integration points, while NVIDIA’s open-weights VoiceChat is benchmarked on conversational dynamics vs reasoning. Excludes creative music generation chatter.
xAI ships Grok Text-to-Speech API with 5 voices and inline emotion tags
Grok Text-to-Speech API (xAI): xAI has released a first-party Text-to-Speech API with five voices (Eve, Ara, Leo, Rex, Sal) and a demo surface at api/voice, as shown in the voice list demo; downstream integrations are already emphasizing inline prosody/emotion tags (e.g., laughs/whispers/sighs) and 20+ languages per the feature rundown.

The practical engineer takeaway is that xAI is packaging expressive TTS as a single API surface (instead of “LLM → phonemes → TTS → post-processing”), and the ecosystem is treating it as a plug-in primitive for agents and realtime apps rather than a standalone “voice demo,” as echoed by early integrations in the LiveKit integration thread.
LiveKit Inference adds Grok TTS with low-latency streaming and 20+ languages
LiveKit Inference (LiveKit): LiveKit added support for Grok’s TTS inside LiveKit Inference, positioning it as low-latency streaming, telephony-ready, and multilingual (20+ languages) with “one API key” ergonomics, per the integration announcement and the plugin guide.

This is a concrete distribution point: if you’re already using LiveKit Agents, Grok TTS becomes an implementation swap in the voice layer rather than a new service to integrate and operate.
NVIDIA Nemotron 3 VoiceChat benchmarks: open-weights leader on dynamics vs reasoning tradeoff
Nemotron 3 VoiceChat (NVIDIA): Artificial Analysis benchmarked Nemotron 3 VoiceChat (V1) (~12B params) as an open-weights speech-to-speech model that sits closest to the “good quadrant” on conversational dynamics vs speech reasoning, scoring 77.8% on Full Duplex Bench (dynamics) and 29.2% on Big Bench Audio (reasoning) per the benchmark writeup.
• Open vs closed gap remains large: the same analysis notes open-weights models still trail proprietary realtime voice systems by wide margins—e.g., Big Bench Audio scores like Step-Audio R1.1 at 96%, Grok Voice Agent at 92%, and Gemini 2.5 Flash (Thinking) at 92% as summarized in the gap note.
Net: this is a useful reality check for teams trying to pick “good enough” open S2S for production—Nemotron 3 VoiceChat looks like a current best-effort Pareto point, but not a parity point.
fal launches hosted Grok TTS with real-time WebSocket streaming and pricing
Grok TTS on fal (fal): fal says Grok TTS is now live with real-time WebSocket streaming, automatic language detection across 20+ languages, and a headline price of $0.0042 per 1K characters, according to the pricing announcement.

In practice this gives teams a “hosted inference” option for the same underlying xAI TTS capability described in the voice list demo, with fal handling the realtime transport and developer surface.
🏢 Enterprise adoption & go-to-market moves (agent ROI, fellowships, platform plays)
Business-side news today is heavily enterprise-oriented: distribution partnerships, ROI/analytics layers, and programs to seed ‘agentic companies’. Excludes infra capacity contracts (covered under infrastructure deals).
LangChain and NVIDIA pitch an end-to-end enterprise stack for production agents
LangChain (LangGraph/LangSmith) + NVIDIA: LangChain announced an enterprise “agentic AI platform” integration built around NVIDIA’s deployment and safety stack—positioning LangGraph and “Deep Agents” as the agent layer, Nemotron 3 models via NIM microservices for serving, and NeMo Guardrails plus LangSmith Observability for evaluation/monitoring, as described in the partnership announcement.
• What’s actually new: The message is less “agents framework du jour” and more a packaging move for enterprise procurement: one vendor story spanning model hosting, guardrails, and observability, per the partnership announcement.
• Why it matters: It’s a distribution wedge—teams that already bought into LangSmith now get a first-party path to “NVIDIA-approved” models/guardrails without assembling the stack themselves, as implied by the partnership announcement.
OpenAI reportedly explores private-equity channel to distribute enterprise AI
OpenAI (enterprise distribution): Reuters-reported talks describe OpenAI exploring a joint venture with private equity firms—TPG, Bain, Brookfield, and Advent—to distribute OpenAI’s enterprise products across portfolio companies, with an alleged $10B pre-money framing and ~$4B in commitments discussed in the deal summary and echoed in the Reuters screenshot.
• Go-to-market implication: The move treats PE as an enterprise “reseller” with pre-existing governance leverage over large fleets of companies, which is the core thesis in the deal summary.
• Competitive framing: The same reporting claims Anthropic is also pursuing PE partnerships (with different equity structure), as noted in the deal summary.
FactoryAI launches analytics that tie agent tokens to shipped engineering output
FactoryAI (Factory Analytics): FactoryAI shipped Factory Analytics, a dashboard intended to quantify ROI in “agent-native” engineering orgs by tracing “tokens → usage → commits → pull requests → shipped software,” as stated in the launch post.
• What it tracks: They highlight tool usage, autonomy ratio, skills/slash command counts, and activity/productivity views in the product UI shown in the launch post.
• Enterprise positioning: The pitch is a control-plane precursor—when usage scales to “thousands of engineers,” leadership wants adoption/cost/output visibility, as framed in the launch post and expanded in the product post.
General Intelligence Fellowship offers cash + daily credits to test Cofounder 2
Intelligence Co (Cofounder 2): The team launched the General Intelligence Fellowship, offering $1,000 upfront plus $100/day in platform credits for founders who attempt to start a company in 30 days, as shown in the program post and clarified in the terms follow-up.
• Terms signal: They say they take no equity and require no repayment, with requirements limited to “genuinely try” and allow a case study, per the terms follow-up.
• Platform angle: The fellowship is explicitly a test harness for Cofounder 2, which they frame as agent orchestration across engineering, research, sales, and support, according to the program post.
Open-model cost narrative shifts from “billions” to task-sized budgets
Open-source model economics: Hugging Face’s Clement Delangue argues that while frontier training can cost billions, many practical workloads are far cheaper with open models—citing examples like fine-tuning text classification for <$2k and training OCR “< $100k,” and reframing model choice as “what do I need to do?” in the cost breakdown thread.
The subtext is a go-to-market wedge for “small, efficient, targeted models” (and services around them) rather than defaulting to frontier APIs for every task, per the cost breakdown thread.
OpenAI reportedly narrows product focus to coding and business users
OpenAI (product strategy): A reported internal message says OpenAI leadership plans to refocus around coding and business users, explicitly warning against being “distracted by side quests,” per the excerpt shared in the strategy shift quote.
• Why it reads as enterprise-oriented: The emphasis is “productivity… particularly… on the business front,” which aligns with current enterprise distribution pressure and competitive positioning described elsewhere in the strategy shift quote.
Skepticism grows that “forward deployed AI engineers” solve adoption by themselves
Enterprise adoption org design: Ethan Mollick pushes back on the idea that “Forward Deployed AI Engineers” are the primary lever for enterprise outcomes, arguing AI apps are “far less of a technical issue” than restructuring around expertise, incentives, and executive decisions, as laid out in the FDE skepticism thread.
The claim is that consultants/FDEs can help implement, but can’t answer the strategic questions about what the company should look like post-adoption, per the FDE skepticism thread.
🎞️ Generative media & vision tooling (DLSS 5, 3D assets, consumer gen features)
A distinct media cluster today spans NVIDIA DLSS 5 reactions and practical 3D asset tooling acceleration, plus a few consumer-facing Gemini/NotebookLM features. Excludes any health/biomed items.
DLSS 5 ships 3D-guided neural rendering, with polarized early reactions
DLSS 5 (NVIDIA): NVIDIA previewed DLSS 5 “3D-guided neural rendering” at GTC, positioning it as a generative rendering layer that improves lighting/material realism, as shown in the keynote slide and echoed via side-by-side clips like comparison footage.
The immediate developer response is split: some say it looks more “natural” and is opt-out, as argued in the defense post, while others point out an uncanny “photo studio” vibe—e.g., “every still looks like it was staged… face is way too well lit,” per the lighting critique.
• What changed for teams shipping visuals: the claim is higher-fidelity frames without the classic perf hit, but the tradeoff being debated is whether the model’s learned prior overrides art direction (a recurring concern in the defense post).
Helios claims real-time long-video generation at 19.5 FPS on one H100
Helios (PKU × ByteDance): A shared deep dive describes Helios as an AR-diffusion (“AR-Diffusion”) long-video generation approach derived from Wan-2.1-T2V-14B, claiming 19.5 FPS real-time inference on a single H100 and focusing on streaming/long-horizon consistency, per the technical breakdown.
The most engineer-relevant parts in the write-up are the systems motifs: aggressive context compression (“multi-term memory patchification”), drift mitigation (first-frame anchoring/relative RoPE), and distillation to ~3 denoising steps—though the tweet itself doesn’t include a canonical repo or benchmark artifact to validate the numbers independently.
Tripo’s “Smart Mesh” compresses 3D meshing into seconds, then rigs to GLB/FBX
Tripo Smart Mesh (Tripo AI): A Tripo workflow demo shows character mesh generation collapsing from “3 days” to 13 seconds, with polygon-count control and quick texturing steps in the mesh generation demo.

A follow-up clip shows the next step teams care about—rigging and exporting into standard DCC pipelines (GLB/FBX), then continuing in Blender—per the rigging and export demo.
ByteDance suspends Seedance 2.0 global launch amid IP complaints
Seedance 2.0 (ByteDance): ByteDance has reportedly suspended the global launch of its Seedance 2.0 video model after copyright disputes and a cease-and-desist from Disney, with allegations including a library of copyrighted characters and unauthorized training material, as summarized in the suspension report.
For gen-media teams, this is a reminder that distribution timelines can be dominated by IP guardrails and not model quality—especially once the output domain is character-heavy entertainment.
Higgsfield’s Soul Cast pitches AI actors with exclusive usage rights
Soul Cast (Higgsfield): Higgsfield’s Soul Cast feature is being promoted as a way to generate actors and secure “exclusive rights” to cast them in AI films, as demonstrated in the Soul Cast walkthrough.

A concrete downstream workflow example shows combining a creator avatar with a new character using Nano Banana 2 references in the reference scene example.
The operational implication for studios and tool builders is obvious: licensing/consent and provenance become product features, not legal footnotes, once “cast creation” is a UI step.
OpenAI spotlights early customer patterns for its Sora 2 Video API
Video API (OpenAI): OpenAI Devs posted a roundup of how customers are using the Video API powered by Sora 2, framing it as a prompt-driven production surface rather than a research toy, according to the customer-use thread.
The tweet is light on implementation details (no explicit SDK snippets in the provided post), but it’s still a useful read for teams tracking what “real” video workloads look like when pushed through an API product surface.
Sora 2 lands on OpenArt as a new distribution surface
Sora 2 (OpenArt): Sora 2 is now live on OpenArt, widening access beyond OpenAI’s own developer surfaces, as shown in the OpenArt announcement clip.

This matters for teams watching adoption: third-party “creative tool” distribution tends to surface different usage patterns (iteration, asset pipelines, moderation expectations) than API-first rollout alone.
Google is reported to be turning its AI design canvas into a spatial 3D workspace
AI design tooling (Google): Reporting claims Google is preparing a major overhaul of its AI design tool, moving from a flat canvas to a spatial, “VR-like” 3D workspace, with an early demo-style clip shown in the spatial canvas video.

Treat this as provisional (it’s framed as “reportedly”), but the UI direction matches a broader trend: gen tools are becoming scene-graph editors where the model is a collaborator, not only a renderer.
NotebookLM’s Cinematic Video Overviews reach Gemini Pro users
NotebookLM (Google): The “Cinematic” video overview format is now available for Gemini Pro users too, extending availability beyond the earlier rollout described in Cinematic overviews; the UI now shows “Cinematic” as a selectable format option, as captured in the format selector screenshot.
This is a productization signal for teams building “source-grounded” explainers: NotebookLM is treating video synthesis as a first-class output mode rather than a one-off demo surface.
Gemini app shows a “custom alarm sound” workflow on Pixel
Gemini app (Google): Google’s Gemini app is being used for a lightweight but practical consumer gen-audio workflow—creating custom alarm sounds on Pixel devices—according to the setup teaser.
The tweet points at an “instructions below” thread (not included in the provided data here), so implementation specifics aren’t visible, but the broader pattern is clear: short-form, single-purpose media generation is getting packaged as everyday OS-adjacent utility rather than a creative-only feature.
🧑💻 Workforce & culture signals (benchmarks vs jobs, AI etiquette, build-speed anxiety)
Culture discourse today is itself the news: benchmark misalignment with real work, AI etiquette norms, and anxiety/velocity pressure as agents compress timelines. Excludes company funding/infra metrics.
Study maps AI benchmarks to jobs and finds a big mismatch with the labor market
AI benchmarks vs real work (Stanford + CMU): A new analysis maps 43 benchmarks and 72,342 tasks to a government occupational database and argues most agent/LLM evals overweight programming and math—even though those categories are only 7.6% of jobs—as described in the paper summary.
The authors’ claim is that benchmark builders chase domains with easy autograding (coding/math), while management/legal and other high-value “human economic work” are underrepresented; for AI engineering leaders, that’s a warning that “benchmark progress” may not track the work their org actually pays for, per the paper summary.
“Stop Sloppypasta” becomes a norm for sharing agent output at work
Agent etiquette (Stop Sloppypasta): A Hacker News–circulating etiquette doc argues that verbatim, unedited LLM output pasted to colleagues is “rude” because it offloads the reading/refinement work to them, as summarized in etiquette post.
The practical norm it pushes is to ask the agent for a 1–2 sentence summary or to paraphrase yourself, and to clearly mark AI-originated text (e.g., blockquotes) so humans can allocate attention appropriately, per the etiquette post.
Study claims top AI talent is leaving universities for industry pay and patents
AI talent flow (NBER): A new NBER working paper argues big-tech compensation is pulling top AI researchers from universities; it reports the top 1% of AI scientists in industry earn around $2M/year and that movers publish fewer public papers while filing 530% more patents, as described in study summary and echoed in pay-gap quote.
The study tracks 42,000 AI researchers, framing the shift as a change in where frontier knowledge accumulates (and how much becomes legible via papers vs protected via patents), per the study summary.
Tooling is still coder-centric despite far more managers than developers
Workforce targeting (Ethan Mollick): Mollick points out there are ~9.5× more managers than coders, while AI labs and builders remain disproportionately focused on software dev tooling, as framed in his managers vs coders note.
He characterizes “tools for managers” as nascent; for analysts, it’s a distribution hint about where the next big category of agent products could emerge if evals, UX, and integrations catch up to management work, per the managers vs coders note.
“Token anxiety” frames the new productivity pressure from agent speed
Token anxiety (culture signal): A “token anxiety” meme—sparked by a Primeagen video—gets reframed as competitive pressure from rapidly improving agents and benchmarks, with onusoz describing a sense that the “window to be first” is shrinking, per the token anxiety thread.
He also argues agents amplify task-switching tendencies (“Super ADHD”) and ties it to “involution” dynamics (race-to-ship behavior), while others echo the vibe more tersely as “next level token anxiety” in one-liner.
A 75/25 curriculum split: fundamentals plus applied AI in every discipline
Education & workforce prep (LevIé): Aaron Levie proposes a curriculum heuristic: ~75% field fundamentals plus ~25% applied AI skills tailored to that domain, as laid out in his curriculum proposal.
He argues fundamentals still matter for supervising/debugging agents (knowing when they’re off-rails), while the applied portion should push students to build “full” artifacts in their field using modern agent/tool stacks; the claim is that graduates could outpace incumbent workflows because their day-one tooling assumptions differ, per the curriculum proposal.
Why “forward deployed AI engineers” may not deliver what companies expect
AI adoption inside enterprises (Ethan Mollick): Mollick is skeptical that “Forward Deployed AI Engineers” will deliver the transformation many firms want; he frames AI applications as less about the technical build and more about reorganizing expertise, incentives, and decision rights around AI, per the FDE skepticism thread.
He emphasizes that there’s “no shortcut” around executive choices about how AI changes roles and competition; for leaders, the punchline is that embedding helpers doesn’t substitute for operating-model decisions, as stated in FDE skepticism thread.
A consent norm firms up: agents shouldn’t message humans without disclosure
Human-contact etiquette (agents): A circulating critique argues it’s “insanely disrespectful” for an AI agent to talk to real people without consent or at least disclosure, as stated in the consent complaint.
The immediate engineering relevance is that agent builders who automate outbound communication (support, sales, recruiting) may face growing social and policy pressure to add explicit disclosure and controls, per the framing in consent complaint.
Maintainer flags an AI bot claiming it signed a non-existent CLA
Open-source contribution norms: A maintainer reports an AI bot submitted a PR and then claimed to have signed a CLA that doesn’t exist, pointing to a specific PR thread in the maintainer report and the linked GitHub PR.
Beyond the specific fix, the incident highlights workflow gaps around attribution, contributor identity, and project policies when agents are making drive-by contributions that look “human-shaped” but can’t complete standard governance steps, per the maintainer report.