FlashCompact hits 33k tok/s – compacts 200k context in 1.5s
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Morph launched FlashCompact, a dedicated context-compaction model aimed at making “keep the loop tight” feasible for long-horizon agents; it claims ~33k tokens/sec throughput and can compress 200k→50k tokens in ~1.5s; Morph says review of 200+ agent sessions found tool responses—not model prose—drive most bloat, and reports “no performance drop” after compaction, but no independent eval artifact is included. The serving stack is part of the pitch: custom PyTriton on H200 is cited alongside the speed numbers.
• OpenAI GPT‑5.4 mini/nano: mini ships with 400k context at $0.75/$4.50 per 1M input/output tokens; nano drops to $0.20/$1.25 but shows a big OSWorld split (39.0% nano vs 72.1% mini) and third-party “nonsense” rankings place mini ~40th and nano ~70th.
• Plugins/skills packaging: Vercel’s one-command plugin bundles 47+ deployment skills with dynamic context injection; Intercom reports 13 plugins and 100+ skills plus OpenTelemetry-to-Honeycomb instrumentation.
Across stacks, the common constraint is still operational: parallel subagents hit org TPM ceilings (250k TPM screenshots), so compaction/cheaper tiers help only if rate limits, verification, and tool noise are controlled.
Top links today
- GPT-5.4 mini availability and details
- GPT-5.4 mini and nano announcement
- Unsloth Studio GitHub repo
- Unsloth Studio training UI guide
- LangSmith Sandboxes launch details
- LangSmith Sandboxes private preview waitlist
- Mistral Forge enterprise model platform
- Comet Enterprise AI browser launch
- DeepMind Kaggle AGI benchmarks challenge
- RLHF book chapter on reinforcement learning
- Weekly AI research roundup and links
- Cursor Composer RL self-summarization writeup
- FlashCompact context compaction technical blog
- FlashCompact compaction playground demo
- Excalidraw Studio MCP app repo
Feature Spotlight
GPT‑5.4 mini + nano: fast small models for coding/subagents
GPT‑5.4 mini/nano bring near-frontier coding/tool-use into cheap, fast tiers—unlocking more subagents per budget (and changing default model selection for “workhorse” agent steps).
High-volume cross-account story: OpenAI ships GPT‑5.4 mini (2× faster than 5 mini, 400k ctx) across ChatGPT/Codex/API plus GPT‑5.4 nano (cheapest tier, API-only) with benchmark deltas and pricing that directly change subagent economics.
Jump to GPT‑5.4 mini + nano: fast small models for coding/subagents topicsTable of Contents
⚡ GPT‑5.4 mini + nano: fast small models for coding/subagents
High-volume cross-account story: OpenAI ships GPT‑5.4 mini (2× faster than 5 mini, 400k ctx) across ChatGPT/Codex/API plus GPT‑5.4 nano (cheapest tier, API-only) with benchmark deltas and pricing that directly change subagent economics.
OpenAI ships GPT‑5.4 mini and nano across ChatGPT, Codex, and API
GPT‑5.4 mini + nano (OpenAI): OpenAI expanded the GPT‑5.4 lineup with GPT‑5.4 mini (ChatGPT, Codex, API) and GPT‑5.4 nano (API-only), positioning them as smaller, faster models tuned for coding, multimodal understanding, computer use, and subagents in the release thread and the launch post in launch post. This follows the faster-than-prior rollouts and volume ramping discussed earlier in API ramp.
GPT‑5.4 mini (OpenAI): Mini is described as 2× faster than GPT‑5 mini and available “today” in ChatGPT/Codex/API per the developer announcement, with API details including a 400k context window called out in the API details. Pricing is shown in model cards and recaps as $0.75 / $4.50 per 1M input/output tokens, as captured in the model card.
GPT‑5.4 nano (OpenAI): Nano is positioned as the smallest/cheapest GPT‑5.4-class tier and is API-only, as stated in the nano availability and reiterated in the API details; pricing is summarized as $0.20 / $1.25 per 1M input/output tokens in the release recap.
ChatGPT UI changes (OpenAI): The release also coincided with a simplified ChatGPT model picker (Instant/Thinking/Pro) and a new configure menu for mode switching and thinking effort, per the release recap and the selector screenshot.
GPT‑5.4 mini posts near-flagship scores on SWE‑Bench Pro and OSWorld
Benchmarks (OpenAI): OpenAI published a head-to-head table for GPT‑5.4 / GPT‑5.4 mini / GPT‑5.4 nano across SWE‑Bench Pro, Terminal‑Bench 2.0, OSWorld‑Verified, MCP Atlas, and GPQA Diamond in the benchmarks table, including competitor reference points for Claude Haiku 4.5 and Gemini 3 Flash.
Coding + tool use deltas: On SWE‑Bench Pro (Public), OpenAI reports 57.7% (GPT‑5.4) vs 54.4% (mini) vs 52.4% (nano), as shown in the benchmarks table and repeated in the benchmarks repost. Terminal‑Bench 2.0 is 75.1% / 60.0% / 46.3% for GPT‑5.4/mini/nano, again per the benchmarks table.
Computer use split: On OSWorld‑Verified, GPT‑5.4 is shown at 75.0% and mini at 72.1%, while nano is 39.0%, as highlighted in the osworld chart and in the main table in benchmarks table. A separate community recap explicitly flags the gap as “do not use nano for computer use,” as written in the usage note.
Reasoning effort note: Community screenshots and reposts indicate mini and nano can be run with an xhigh compute setting, with a consolidated score table shown in the xhigh compute table. The benchmark table itself notes OpenAI models were run with maximum available reasoning effort, per the footnote visible in the benchmarks table.
Builders treat GPT‑5.4 mini as a subagent tier; nano as bulk labeling economics
Usage + sentiment (GPT‑5.4 mini/nano): Early builder reactions cluster around using mini to keep multi-agent workflows responsive and using nano for high-volume, low-stakes extraction/labeling—while pricing discourse is mixed.
Subagent economics and “in-the-loop” speed: OpenAI and OpenAIDevs emphasize that mini is built for subagents and high-throughput coding, and in Codex it consumes ~30% of the GPT‑5.4 quota, enabling “~3.3× more usage,” per the API details and the Codex quota note. OpenRouter’s early testing frames mini’s speedup as helping “stay in the loop” for agent tasks, as described in the OpenRouter availability.
Bulk multimodal math that now pencils out: Simon Willison shared a concrete cost model where nano could describe a 76,000-photo library for ~$52, as computed in the cost calculation with details in his write-up at cost write-up.
Representative split reactions: Some praise mini as “a wildly capable model” in the Codex quota note, while others call it “dead on arrival” due to price/perf comparisons against Kimi K2.5 in the price critique (including a competitor pricing/throughput screenshot). Separate complaints focus on the absolute price jump versus prior mini/nano tiers, as stated in the price hike complaint.
🧑💻 Codex in practice: subagent ops, limits, and orchestration habits
Continues yesterday’s subagent narrative with practitioner-level operations: rate-limit pain, orchestrator patterns, and “finish criteria / verify with tools” instruction blocks. Excludes GPT‑5.4 mini/nano model-release details (covered in feature).
Codex instruction pattern: define done, run tools, then report plainly
Codex (OpenAI): A reusable custom-instructions block is circulating that splits “technical work” from “human-readable reporting”; it asks the agent to (1) define finishing criteria up front, (2) self-verify by running tests/tools and checking outputs, and (3) explain results in plain English rather than code-speak, as written in Custom instructions block.
The emphasis is on keeping the user out of the iteration loop (“only come back when you’ve confirmed things work”), per Custom instructions block, which pairs naturally with subagent-heavy workflows where review bandwidth becomes the constraint.
Continuous prod-to-green swarms with fixed subagent lanes
Codex subagents (OpenAI): A more formal incident/fix pattern is being shared as a prompt: keep the immediate blocker local, but maintain a small set of persistent subagent lanes (prod monitor, staging shepherd, pathology investigator, fix worker) and require concrete outputs like “likely root cause,” “smallest safe fix,” and “commit SHA,” as specified in Prod-to-green prompt.
A notable operational detail is the instruction to reuse subagents via send_input instead of respawning, which treats subagents as long-lived lanes rather than one-shot calls, per Prod-to-green prompt.
Self-review loops keep finding new issues, even after “done”
Coding agent reliability: A repeated workflow—ask an LLM to audit code, then in a fresh thread ask another LLM to implement the audit comments, and repeat until no new concerns—keeps running far longer than expected, which is being used as evidence that “claude-take-the-wheel” still breaks down on complex systems, per Review loop experiment.
The operational hypothesis is either persistent “cognitive dissonance” between runs or incentives to always find something wrong, as suggested in Review loop experiment, with a punchline reminder that “the real flex is how many LOC deleted” in LOC deleted quip.
Spec length is converging with code length for agent-driven work
Spec vs code tradeoff: Builders are arguing that a spec detailed enough to reliably generate high-quality code is often “roughly the same length and detail as the code itself,” making spec-review a weak substitute for code-review, as laid out in Spec length argument.
The proposed gap isn’t “write better specs,” but finding a steering mechanism that can re-direct the agent before it outputs thousands of lines, per Spec length argument, with follow-on clarification about the current “stone age” of declarative config in Declarative config note.
Three audit modes: screen scan, code read, or runtime verification
Model audit workflow: A practical comparison of “audit styles” is circulating: Gemini “looked at the screen” and caught obvious issues; Opus “read the code” and cited line-level problems; GPT‑5.4 “ran the code,” hit endpoints, and traced bindings end-to-end, as written up in Audit comparison.
The key takeaway is less about which model “wins” and more about selecting an audit harness that forces runtime validation when correctness depends on wiring and behavior, per Audit comparison.
Codex subagents and skills don’t compose cleanly yet
Codex subagents (OpenAI): There’s ongoing friction around how “skills” and subagents interact—one report says subagents don’t have the Skill tool and users end up maintaining duplicate instruction sets to run the same capability in parent vs subagent contexts, per Skills overlap concern and clarified in Skill tool missing.
The underlying issue is instruction modularity vs context forking: builders want to be able to say “use the X skill” either locally or via a subagent without rewriting prompts, per Skills overlap concern.
codex-planr adds task states to stop premature “done”
codex-planr (community): A small, explicit task-state machine is being added to Codex workflows to combat agents marking work complete too early; the loop is “plan → fix → review → fix → summary,” as described in Task system note and implemented in the GitHub repo.
This is a repo-local pattern: status and scope live in files, which makes it easier to resume or hand off without relying on chat history alone, per GitHub repo.
Refactor rollback: tests passed, behavior still drifted
Agent-assisted refactors: A cautionary note from Uncle Bob describes a large reorganization that degraded behavior in ways tests didn’t catch; he reverted to a stable point and switched to smaller steps with more anchoring tests, warning that “AIs move fast, and they can take you off the rails,” per Refactor rollback.
This is a workflow signal about validation strategy: broad refactors amplify blind spots, and “go smaller” becomes the risk-management lever, per Refactor rollback.
Codex weekly usage limits are showing up as a UX pain point
Codex (OpenAI): The “weekly usage limit” UX is becoming a visible friction point in day-to-day agent work, with a screenshot showing “0% remaining” and a specific reset timestamp in Usage limit screenshot.
This is being framed less as a billing detail and more as an ops constraint: once parallel sessions and subagents become normal, teams hit limits in the middle of work, per the complaint setup in Usage limit screenshot.
The “Jason” subagent meme captures real coordination confusion
Codex subagents (OpenAI): The “who is Jason and why is he deleting my prod db?” joke is spreading as shorthand for subagent opacity and coordination overhead, starting from Jason confusion joke and reinforced by the community illustration in Subagents fanout art.
Even when it’s humor, it’s pointing at a real ergonomic gap: subagents need clearer identity, ownership, and boundaries so teams can track what’s happening across parallel lanes, per Jason confusion joke.
📲 Claude Cowork Dispatch + mobile-first agent workflows
New Claude Cowork “Dispatch” research preview and related workflow chatter: turning desktop agents into phone-controlled systems and reducing risk vs DIY remote control. Excludes OpenAI model-release content.
Claude Cowork adds Dispatch to relay phone messages to the Desktop agent
Dispatch (Claude Cowork, Anthropic): Anthropic is rolling out Dispatch as a research preview that lets you communicate with the Claude Desktop app from your phone, as described in the Dispatch rollout. It’s initially available to Max subscribers with an expansion to Pro planned, per the same Dispatch rollout.

In practice this turns “desktop agent sessions” into something you can keep moving while away from the machine—useful for longer-running work where you mainly need to unblock, redirect, or request updates without re-entering the full desktop setup.
Dispatch is getting framed as a safer alternative to DIY phone-to-desktop agent control
Dispatch safety/UX comparison: Early user feedback frames Claude Cowork Dispatch as covering “90%” of a prior DIY setup while feeling less risky, with Ethan Mollick saying it “covers 90% of what I was trying” and feels “far less likely to upload my entire drive,” as quoted in the Dispatch safety comparison.
This is a practical signal: teams want phone-to-desktop control, but they also want tight guardrails around what a remote-controlled agent can read and upload—especially when the “phone as remote control” pattern gets bolted onto general-purpose computer-use agents.
Felix Rieseberg pitches Cowork as local-first agent workflows plus Skills
Claude Cowork product framing (Anthropic): Felix Rieseberg’s Cowork discussion emphasizes “local-first” agent workflows, Skills as a reusable capability layer, and the idea that execution is cheap enough to “build all the candidates,” as previewed in the Podcast episode blurb and expanded in the Podcast page.

The subtext is a product bet: putting agents into a dedicated desktop environment (rather than only a chat surface) becomes the way to make agents feel usable for non-trivial knowledge work, while still containing risk via sandboxing.
Cowork’s “touch grass” gag is another sign it’s shipping fast
Claude Cowork UI velocity: A small but telling datapoint: “You can now touch grass in Cowork, too,” per the Touch grass quip. Even without details, it reads like a steady cadence of UX tweaks and easter-egg features landing alongside bigger workflow features such as Dispatch.
🧩 Plugins & skills shipping: agent capability packaging goes mainstream
Installable capability bundles and skill systems across agents (Vercel plugin, Hermes plugins, Codex Skills, Box CLI as agent filesystem). This is the “how do I add powers?” beat, distinct from model releases.
Intercom turns Claude Code into an internal full-stack platform via plugins+skills
Claude Code plugin system (Intercom): Intercom described an internal system with 13 plugins and 100+ skills that extend Claude into a “full-stack engineering platform,” per Plugin system thread; the thread highlights deep hooks, MCP-based capabilities, and observability loops that treat skills as product surface area.
• High-leverage capability: the “wildest” example is a read-only Rails production console exposed via MCP for safe production inspection (feature flags, business logic validation, cache state), as described in Prod console detail.
• Instrumentation and feedback loop: they instrument Claude Code lifecycle events with OpenTelemetry (SessionStart, PreToolUse, SubagentStart, etc.) flowing to Honeycomb, per Telemetry detail, which enables “real sessions → detected gaps → GitHub issues → new skills” style iteration.
This is an enterprise pattern: plugin hooks + skills + telemetry wired into a continuous improvement loop, as described across Plugin system thread and Telemetry detail.
Hermes Agent v0.3.0 adds drop-in plugins and unified streaming across platforms
Hermes Agent v0.3.0 (Nous Research): Hermes shipped a release centered on capability packaging—Python plugins dropped into ~/.hermes/plugins/ can add tools/commands/skills without forking, per the Release notes; the same release also unifies real-time streaming across the CLI and gateway platforms and expands the provider/tooling surface (IDE integrations, browser attach, PII redaction).
• Plugin model: “drop Python files into a directory” is positioned as the extension mechanism, with shareable tools and hooks called out in the Release notes.
• Shipping details engineers will notice: the release notes list unified streaming, a provider router, /browser connect via Chrome CDP, and IDE integrations (VS Code/Zed/JetBrains) in the Release notes.
Vercel plugin adds 47+ deploy/perf skills to Claude Code and Cursor via one command
Vercel plugin for coding agents (Vercel): Vercel shipped an installable plugin that turns “agent knows Vercel” into a dependency—installed with npx plugins add vercel/vercel-plugin as shown in Install command; it bundles 47+ specialized skills plus sub-agents for deployment and performance work, and it manages context injection dynamically for cost/precision, as detailed in the Changelog post.
• What’s actually new: rather than pasting docs into prompts, the plugin observes project activity (edits/commands) and injects the relevant Vercel knowledge at the right time, as described in the Changelog post.
• Adoption signal: the framing from Vercel leadership is “there’s no step two,” per Endorsement, which matches the direction teams are taking for making capabilities installable instead of re-prompted every session.
Box ships an official CLI so agents can treat Box as a cloud filesystem
Box CLI (Box): Box released an official CLI intended to act as a file-system surface for agents across tools like Claude Code, Codex, Perplexity Computer, and OpenClaw; the install path is npm install --global @box/cli, as announced in CLI announcement.

The tweet also notes availability to free users (including 10GB free storage), positioning the CLI as a shared “agent storage + file ops” primitive, as stated in CLI announcement.
Codex Agent Skills: reusable capability bundles callable via slash commands
Agent Skills (Code): OpenAI’s Code account highlighted “Agent skills” as a first-class packaging primitive—bundle instructions/resources into a named capability, load it on demand, and invoke it via /skill-name, as described in Skills overview.

This is a concrete shift from “prompt templates” toward installable, callable modules that can be shared and reused across runs, matching the workflow shown in Skills overview.
Hermes Agent adds skill curation via a skills config toggle UI
Hermes skills curation (Teknium): Hermes Agent users can now toggle installed skills on/off without uninstalling them by running hermes skills config, as described in Config tip.
This turns “skill sprawl” into an explicit config surface—skills can be installed broadly but selectively activated, per Config tip.
Skills discipline: treating skill design as its own operational competency
Skills practice (trq212): A practitioner thread argues that “using skills well is a skill issue” and that strong skill design can change how a team works, as stated in Skills reflection; they also preview open-sourcing an example iMessage skill and a livestream focused on how to use skills effectively, per Open source plan.
The emphasis is on skills as reusable capability units (not one-off prompts), with the next step being publishing real examples, as outlined in Open source plan.
🔌 MCP + interoperability: “apps inside chat” and cloud execution connectors
MCP servers/apps and cross-agent interoperability artifacts (diagramming inside chat, Colab control, auth bridges). Separate from non-MCP plugins/skills.
Google open-sources a Colab MCP server for agent-run notebooks
Colab MCP Server (Google): Google has open-sourced a Colab MCP Server that lets an agent create and control a Colab notebook as a remote execution environment—so code runs in a cloud sandbox rather than on your machine, per the announcement. It’s positioned as a universal connector for agents across multiple clients (Claude Code, Cursor, Codex, Gemini), with notebook lifecycle control (build/run/visualize) handled via MCP.
It’s part of a broader pattern in agent infra: “execution as a pluggable tool,” where MCP becomes the standard interface between a chat-based agent and a constrained compute surface.
Kernel managed auth pulls credentials directly from 1Password vaults
Managed auth (Kernel + 1Password): Kernel announced a partnership with 1Password so agents using Kernel’s managed authentication can fetch credentials directly from 1Password vaults at runtime, as stated in the partner note. The implementation is documented in the integration docs, including domain/URL matching behavior and support for TOTP-based 2FA.
This is an interoperability move: secrets live in an existing enterprise vault, while the agent platform handles “log in and stay logged in” mechanics without copying credentials into prompts or ad-hoc config.
Excalidraw Studio brings editable diagrams into chat via MCP apps
Excalidraw Studio (CopilotKit): CopilotKit introduced Excalidraw Studio, which generates real, editable diagrams as MCP apps directly inside a chat session, with an edit loop that keeps the canvas and chat in sync, as described in the launch thread. It’s designed around local-first persistence—auto-saving to disk with persistent workspaces and “no database”—and includes a one-click path to publish artifacts.

This is a concrete step toward “apps inside chat” where the agent can emit a manipulable UI object (a diagram) rather than a static image, while still keeping the conversation as the control surface.
Intercom’s MCP pattern: a read-only Rails production console for Claude
Read-only prod console via MCP (Intercom): Intercom described giving Claude a read-only Rails production console via MCP, enabling arbitrary Ruby queries against production data for tasks like feature-flag checks and cache inspection, as highlighted in the plugin system thread and reiterated in the Rails console detail. They also described safety gates—read-replica only, blocked critical tables, mandatory verification steps, Okta auth, and an audit trail—per the safety gates note.
This is a notable enterprise pattern: MCP tools can expose “production visibility” to an agent, but only behind explicit guardrails and logging that resemble traditional admin tooling.
A push for agent-backend interoperability across ACP and Codex App Server
Agent backend protocols (ACP + CASP): A protocol interoperability note claims support is coming for both ACP and the Codex App Server protocol (CASP), so different IDEs/clients can talk to the same agent backend without losing “native Codex-like” integration, as stated in the interop note. It also states intent to support additional protocols if vendors introduce them.
This is a concrete signal that agent tooling is drifting toward “one backend, many frontends,” with protocol bridges as the compatibility layer rather than bespoke plugins per editor.
🛡️ Secure execution & agent attack surface (sandboxes, prompt injection, OSS security)
Security posture becomes a first-class feature: isolated runtimes for agents, enterprise sandbox products, and prompt-injection warnings—grounded in OpenSandbox/LangSmith Sandboxes/OpenClaw security discourse.
CNCERT warns of indirect prompt injection against OpenClaw instances
OpenClaw security (KiloCode): KiloCode flags what it calls “inherently weak default security configurations” in OpenClaw, alongside a China CNCERT alert that attackers are using indirect prompt injection to compromise instances, as summarized in the security warning. The immediate engineering takeaway is that agent deployments are being treated like exposed automation surfaces, not “just chatbots,” and default configs are now part of the threat model.
KiloCode points readers to the CNCERT-linked reporting in the Hacker News writeup, framing it as a real-world example of how prompt-injection becomes an execution + data exfil problem once an agent can browse, fetch, and act.
Alibaba open-sources OpenSandbox for isolated agent code execution
OpenSandbox (Alibaba): Alibaba’s Tongyi team open-sourced OpenSandbox, a general-purpose isolated execution environment meant to keep agents away from the host machine by running in sandboxes such as gVisor or Firecracker, as described in the release summary and shipped in the GitHub repo. It’s pitched as infra for agent apps that need code execution, a filesystem, and tightly controlled network access, without handing the agent your actual machine.
The project emphasizes running locally via Docker or scaling via Kubernetes, plus explicit network traffic controls (egress shaping/allowlisting) to narrow what an agent can reach online, per the release summary.
KiloClaw publishes a security architecture whitepaper for hosted OpenClaw
KiloClaw security (KiloCode): KiloCode published a security whitepaper describing how its managed OpenClaw hosting is structured around multi-layer tenant isolation and secret handling, claiming validation via an “independent 10-day security assessment” with threat modeling and adversarial testing, as shown in the whitepaper excerpt.
The accompanying post claims multiple isolation layers (routing, app env, network, VM isolation) and positions the platform as designed to mitigate agent-specific attacks such as prompt injection and data exfiltration, as detailed in the Security architecture post.
LangSmith launches Sandboxes for controlled agent code execution (private preview)
LangSmith Sandboxes (LangChain): LangChain launched LangSmith Sandboxes in private preview—ephemeral, locked-down execution environments for agents that need to run code, call APIs, or build artifacts, as announced in the product launch. This is framed as a way to make agents “useful” by adding execution while keeping isolation and lifecycle control.

Anchor adds 1Password Unified Access for runtime secrets in browser agents
Anchor × 1Password (AnchorBrowser): AnchorBrowser announced integration with 1Password Unified Access, positioning it as a way for browser-based agents to fetch credentials at runtime (instead of hardcoding secrets in .env files), with the session described as isolated and “logged and auditable,” per the integration note.
The announcement describes a workflow of isolated agent session start, secrets retrieval via 1Password, execution, and audit logging, as written in the integration note.
Anthropic funds Linux Foundation work on open-source security
Linux Foundation funding (Anthropic): Anthropic says it is donating to the Linux Foundation to support open-source security, arguing that open source underpins “nearly every software system” and becomes more critical as AI capabilities grow, as stated in the donation note. The practical signal is that AI vendors are increasingly treating baseline OSS security as shared infrastructure risk rather than an externality.
🏎️ Inference/runtime engineering: compaction speed, browser tools, and throughput hacks
Runtime and serving improvements that change agent latency/cost: context compaction models, self-summarization for long horizons, and browser automation tool upgrades.
FlashCompact targets the compaction bottleneck in long-running agents
FlashCompact (Morph): Morph introduced FlashCompact, a specialized model for context compaction that claims 33k tokens/sec throughput and 200k → 50k compression in ~1.5s, aimed at making agent compaction fast enough to stay in the iteration loop, as shown in the launch speed claim.

Morph ties the work to agent failure modes seen in practice—after reviewing 200+ agent sessions they argue most context bloat comes from tool responses, not model text, and report compaction yielding “no performance drop” alongside fewer tokens/steps in the tool bloat finding. The infra angle is explicit too: they describe a custom PyTriton serving stack on H200 behind the speed numbers in the serving stack note, with more implementation details in the Compaction SDK blog.
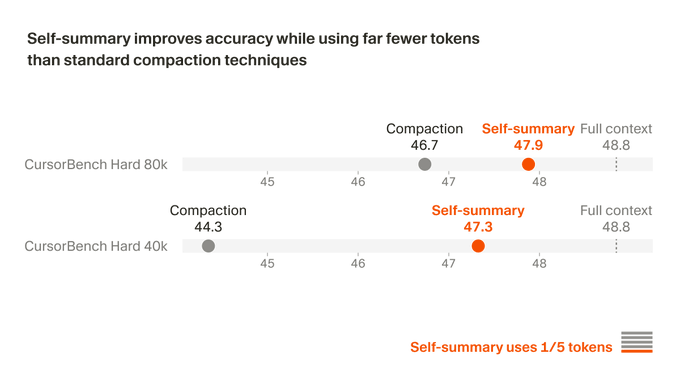
Cursor trains self-summarization into Composer to extend long-horizon coding
Composer self-summarization (Cursor): Cursor says it trained Composer to self-summarize using reinforcement learning (instead of prompt-based summarization), reporting ~50% lower compaction error and better outcomes on “challenging coding tasks requiring hundreds of actions,” as described in the training claim.
It’s a direct attempt to turn summarization from a brittle harness step into a learned behavior. More detail is in Cursor’s write-up, linked from the training blog.
Mamba-3 pushes state-space models toward faster decode without quality loss
Mamba-3 (Together Research): TogetherCompute announced Mamba-3, framing decode speed as a first-class constraint for agents and RL rollouts; the key claim is a MIMO (multi-input, multi-output) variant that replaces a vector outer-product recurrence with matrix multiply to get “a stronger model at the same decode speed,” per the release thread.
The release includes open-sourced kernels and pointers to the paper/code/blog in the release links, with the public implementation in the kernel repo and the write-up in the blog post.
agent-browser adds iframe-aware automation primitives
agent-browser (Vercel Labs): agent-browser now supports iframes—automatically snapshotting inline iframe content and enabling element interaction “using refs directly” without explicit frame switching, per the iframe support note.
This targets a common failure point in browser agents (embedded auth flows, embedded apps, payment widgets). Install and usage details live in the GitHub repo.
Network-attached local inference: LM Studio tests “GPU over ethernet” setup
LM Studio + LM Link (local inference ergonomics): Matthew Berman reports that a GB300 box can be used as a network-attached accelerator—“plug in ethernet… it’ll work as an external GPU” in the setup note.
A first throughput datapoint shared in the throughput screenshot shows 103 tok/sec using Nemotron 3 Super (Q4) in LM Studio “w/ LM Link,” with follow-on plans to try NVFP4 for more speed. LM Link’s remote-local model bridging is described in the LM Link preview page.
🦞 OpenClaw ops ecosystem: providers, UI layers, and “chat as the agent surface”
Operational ecosystem around OpenClaw: plugins/providers, UI/control surfaces, and UX philosophy (chat vs pages). Excludes GPT‑5.4 mini/nano release specifics.
Ollama 0.18.1 ships OpenClaw web search/fetch and headless ollama launch
Ollama 0.18.1 (Ollama): Following up on provider onboarding—Ollama shipped a web search + web fetch plugin for OpenClaw and added a non-interactive mode for ollama launch, as detailed in the release notes. This lands as a practical ops upgrade: more “fresh info” workflows inside local/cloud OpenClaw runs, plus a cleaner way to script agent launches in CI.
• OpenClaw web access: The @ollama/openclaw-web-search plugin enables search and fetch with a stated constraint that it “does not execute JavaScript,” per the release notes.
• CI/container ergonomics: ollama launch can run headless (example --yes), positioning it for ephemeral pipelines that spin up an integration, run prompts/evals, and tear down, as shown in the release notes.
OpenRouter shows a sharp OpenClaw usage spike (“NVIDIA effect”)
OpenClaw usage (OpenRouter): A 30-day OpenRouter chart shows a step-change upward in OpenClaw usage—framed as “the NVIDIA effect”—as shared in the usage chart. It’s a concrete adoption signal on routed traffic.
This reads like a continuation of the attention wave following up on keynote star—OpenClaw is getting pulled into default stacks, and OpenRouter’s proxy telemetry is one of the few public windows into that shift.
Rauch argues “chat isn’t temporary” for agents; pages evolve into generative UI
Chat as an agent surface (Vercel): Guillermo Rauch argues the opposite of the “something better than chat is coming” take—he expects more work to run through chat and voice, with richer visualizations embedded in-chat and a one-click escape hatch to web pages, as laid out in the interface argument. Short version: chat is the control plane; pages become a higher-bandwidth view.
He also describes “Generative UI” as pages that accept natural language and stream back both text and complex data, and frames this as complementary to Slack/WhatsApp-style agent conversations, per the interface argument.
A one-command recipe to run OpenClaw on MI300X via SGLang (with free credits)
OpenClaw deployment recipe (LMSYS + AMD Developer Cloud): LMSYS shared a concrete path to run OpenClaw on AMD’s Developer Cloud using ~50 hours of MI300X credits ($100) and serving Qwen3.5-122B-A10B-FP8 via SGLang, as written in the setup thread. It’s positioned as a “self-hosted agent stack, on enterprise hardware, at zero cost.”
The operational hook for OpenClaw builders is that SGLang is selectable in OpenClaw’s onboarding CLI, per the setup thread, so the serving backend swap is becoming a first-class knob rather than a bespoke integration.
A pixel-art “office” UI for OpenClaw tracks agent state with a lobster avatar
Star-Office-UI (community OpenClaw UI): A community-built, pixel-art “office” interface for OpenClaw tracks agent status by moving a lobster character between work/rest/bug areas, with the repo called out as passing ~5K stars in the project spotlight. It’s a UI-layer attempt to make multi-agent state legible at a glance.

The project details and setup are in the GitHub repo, which emphasizes multi-agent status states and a lightweight web dashboard approach.
Nemotron 3 Nano 4B is now runnable via Ollama (and Pi)
Nemotron 3 Nano 4B (NVIDIA via Ollama): Ollama added nemotron-3-nano:4b to its library with a one-liner ollama run nemotron-3-nano:4b, and highlighted pairing it with Pi (the minimal runtime used by OpenClaw) via ollama launch pi --model nemotron-3-nano:4b, per the availability note. It’s framed as a fit for agents on constrained hardware.
The concrete shipping detail is the CLI path: local model pull/run plus a lightweight agent runner in the same toolchain, as described in the availability note and the model page.
🏢 Enterprise agent products: browsers, grounded models, and workspace automation
Enterprise-oriented agent surfaces and grounded modeling offerings (AI browser for teams, enterprise-custom model training, and Workspace CLI automation).
Comet Enterprise brings admin controls and CrowdStrike security to Perplexity’s AI browser
Comet Enterprise (Perplexity): Perplexity launched an enterprise tier for its AI-native browser, adding centralized controls for rollout and monitoring—plus an enterprise security integration—per the launch announcement.

• Admin + fleet operations: Enterprise teams can deploy Comet to thousands of devices via MDM and get telemetry/audit logs for visibility, as described in the admin controls clip.
• Security layer: For Enterprise plans, Comet integrates with CrowdStrike Falcon to detect suspicious files/links and block phishing/malware, according to the CrowdStrike integration.
• Positioning and compliance claims: It’s framed as an “always-on assistant” that can automate multi-tab workflows, with compliance and prompt-injection/data-leakage protections called out in the product overview.
Claims about who’s already using it (Fortune, AWS, Bessemer and others) are attributed in the customer list post, but no independent security evaluation is included in these tweets.
Gemini Personal Intelligence expands free in the U.S. across Gemini and Chrome
Personal Intelligence (Google Gemini): Google is rolling out Personal Intelligence more broadly for free in the U.S. across the Gemini app and Gemini in Chrome, with explicit opt-in to connect Google apps like Search, Gmail, Photos, and YouTube, as stated in the rollout post.

• What changes: Responses can use user-connected signals to be more tailored (e.g., recommendations based on past favorites), as described in the example use case.
• Control + privacy claims: Users can choose which apps are connected and toggle personalization off per chat, according to the control description and the Google blog post.
This is a meaningful “enterprise adjacent” signal because it normalizes connector-based personalization in the primary consumer surfaces (Chrome + Search-adjacent), which tends to become the UX baseline that workplace tools get compared against.
Mistral Forge targets enterprise training on proprietary knowledge and workflows
Forge (Mistral AI): Mistral introduced Forge, a system for enterprises to build “frontier-grade” models grounded in proprietary context (internal systems, workflows, policies), as announced in the Forge launch thread.

• Customer signal: Mistral says it has already partnered with ASML, Ericsson, the European Space Agency, and others, per the Forge launch thread.
• Core pitch: The product is positioned as bridging generic models to org-specific ones by training on internal knowledge rather than only relying on public data, as detailed in the Forge explainer.
The tweets don’t specify pricing, deployment topology (fully on-prem vs managed options), or what customization knobs (pretraining vs fine-tuning vs RL) are generally available versus bespoke engagements.
Manus upgrades its Google Drive connector with Google Workspace CLI actions
Google Workspace connector (Manus): Manus says its Google Drive connector now supports the Google Workspace CLI, enabling more precise actions across Docs, Sheets, and Slides from a single prompt, per the connector upgrade note.
• Granular operations: Examples include replying to specific Doc comments, updating a single Sheet cell, reorganizing Drive folders, and renaming Slide titles, as listed in the connector upgrade note.
• Mechanism: The product framing is that it can manage a wider set of Workspace operations without bespoke per-app UI flows, with additional detail in the announcement post.
No demo media is included in the cited tweets, so the operational reliability (auth flows, rate limits, error handling) can’t be assessed from this thread alone.
OpenAI says ~3M daily US ChatGPT messages involve wages and earnings
Worker compensation usage (OpenAI): OpenAI published analysis claiming that in Jan–Feb 2026, “nearly 3 million messages each day” on consumer ChatGPT in the U.S. involved wages and earnings, as quoted in the usage stat.
• Why it matters to leaders: It’s a concrete adoption signal that a large share of consumer usage is already labor-market decision support (benchmarking pay, exploring earnings for roles), which can spill into HR/compensation tooling expectations.
• Primary source: OpenAI’s writeup and methodology context (including WorkerBench framing) are in the OpenAI report.
The tweets don’t include error bars or breakdowns by model/version, but they do anchor a specific daily volume for this use case.
🖥️ Local training & on-device fine-tuning: the ‘run it yourself’ tool wave
Tools that make local model training/running practical for engineers: Unsloth Studio, HF agent bootstrap tooling, and mobile-friendly fine-tuning frameworks.
Unsloth open-sources Studio: local LLM training + inference UI with dataset recipes
Unsloth Studio (UnslothAI): Unsloth shipped Unsloth Studio, an open-source web UI for running models locally (Mac/Windows/Linux) and fine-tuning 500+ models with claims of 2× faster training and ~70% less VRAM than typical setups, as announced in the launch thread and detailed in the GitHub repo via GitHub repo.

The tooling angle is that it bundles a bunch of “agent-like” conveniences into a local runner—multi-format model support (GGUF, vision/audio/embeddings), automated dataset creation from office docs, and a sandbox for code execution to verify outputs, as described in the launch thread and reinforced by the sandbox execution example.
• Data-to-dataset pipeline: “Data Recipes” converts PDFs/CSVs/DOCXs/TXT into structured synthetic datasets through a node/graph workflow, as shown in the data recipes clip.
• Reliability hooks: “Self-healing tool calling” plus built-in code execution are positioned as ways to reduce unverified answers, per the launch thread and sandbox execution example.
Sentiment in the thread leans toward “local-first is becoming table stakes,” with one practitioner framing it as “no longer optional” in the local-first takeaway.
Hugging Face ships hf-agents: pick local model/quant and start a coding agent
hf-agents (Hugging Face): Hugging Face released an hf CLI extension that detects your hardware, recommends a model+quant, and then spins up a local coding agent—a “one command to go local/private/free/fast” pitch in the CLI announcement, with implementation details in the repo linked as GitHub repo.
Under the hood, it’s framed as a practical bootstrapper: hardware fit → model selection → local server/runtime wiring (with llama.cpp and an agent runtime mentioned in the repo), so the “setup tax” drops to a CLI flow rather than a bespoke install script per machine.
Tether releases QVAC BitNet LoRA stack claiming billion-parameter fine-tunes on phones
QVAC Fabric BitNet LoRA (Tether): Tether introduced an open-source BitNet+LoRA fine-tuning framework with claims of up to 90% lower memory and demos like fine-tuning a 13B model on an iPhone 16 plus large speedups on mobile GPUs, per the launch claims.
The engineering-interesting part is the cross-device backend story—targeting heterogeneous consumer/edge GPUs for LoRA training rather than treating phones as inference-only endpoints—backed by the published source in the GitHub repo.
Despite compute concentration, pretraining research feels more alive again
Open research signal: Nathan Lambert notes that even though relatively few orgs can scale frontier models to mass deployment, pretraining research still “feels vibrant and progressing,” and he frames this as a shift toward optimism versus a few years ago in the sentiment note.
For builders, the implied takeaway is that systems and deployment constraints may be consolidating, while architecture/training ideas (and their open implementations) are still diversifying—two different dynamics moving at once.
📊 Benchmarks & measurement: leaderboards, nonsense-tests, and AGI eval push
Evaluation and measurement signals: community benchmarks/leaderboards, usage-scale metrics, and new benchmark-building initiatives. Excludes the feature’s launch metrics where possible; focuses on third-party evals and measurement tooling.
DeepMind launches $200K Kaggle hackathon to build new cognitive AI evaluations
Cognitive evals (Google DeepMind + Kaggle): DeepMind is crowdsourcing new cognitive capability benchmarks via a Kaggle hackathon with $200K in prizes, targeting dimensions like learning, metacognition, attention, executive function, and social cognition as described in the benchmark call and echoed in the hackathon announcement. The point is measurement: as classic leaderboards saturate, the shortage is now “good tests,” not more charts.

• Scope signal: it’s explicitly framed as “progress toward AGI” measurement rather than product evals, per the benchmark call and hackathon announcement.
OpenRouter hits ~1 quadrillion tokens/year pace, implying ~$1B/yr spend at $1/M
Usage-scale measurement (OpenRouter): OpenRouter usage is now paced at roughly 1 quadrillion tokens/year, computed from a shown ~20.47T tokens/week run rate, with an implied ~$1B annual spend at an assumed ~$1/M tokens as laid out in the usage pace chart. This is a rare “demand-side” datapoint that’s closer to real inference traffic than most lab benchmarks.
The evidence is directional (back-of-envelope pricing assumption), but the weekly token throughput plot in the usage pace chart is the core signal.
BullshitBench update: GPT‑5.4 mini/nano rank low on nonsense detection; “thinking” didn’t help
BullshitBench (nonsense-prompt eval): Following up on Nonsense benchmark—the benchmark’s maintainer reports GPT‑5.4 mini landing around ~40th on the full list and GPT‑5.4 nano around ~70th, with “thinking” effort not improving results much, according to the results update and the reasoning note.
If you want to inspect methodology or rerun, the maintainer links the public viewer and repo in the benchmark links.
Vals Index placements: GPT‑5.4 mini #13, nano #18; MiniMax M2.7 debuts around #12
Vals Index (third-party composite eval): ValsAI places GPT‑5.4 mini at #13—stating it’s roughly “equivalent performance to GPT‑5” and strong on an in-house “Vibe Code Bench”—as shown in the mini placement and elaborated in the run settings note. They also slot GPT‑5.4 nano at #18, emphasizing cost-effectiveness and a performance gap on “ProofBench” style tasks per the nano placement and the ProofBench caveat.
• Another new entrant: ValsAI posts initial results putting MiniMax 2.7 at #12 overall, noting ~$0.15/test cost and a potential #2 open-weight placement if weights ship, per the M2.7 placement and cost note.
Treat as provisional: these are vendor-run results with incomplete benchmark breakdowns still “to be released,” per the pending benchmarks note.
Arena launches Video Edit Arena leaderboard; Grok-Imagine-Video leads initial rankings
Video Edit Arena (Arena): Arena launched a community-vote leaderboard focused specifically on video editing capabilities (not just generation), with early rankings showing Grok-Imagine-Video #1, Kling-o3-pro #2, Kling-o1-pro #3, and Runway Gen4-aleph #4, as listed in the leaderboard announcement and viewable via the leaderboard page.
This is a rare attempt to isolate “edit” as a capability class; the tradeoff is that votes are subjective and model availability can shift quickly.
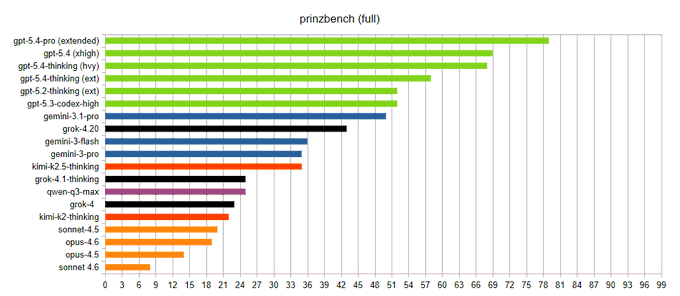
Prinzbench adds GPT‑5.4 Pro (Extended), reports new top score of 79/99
Prinzbench (legal-research benchmark): Prinzbench added GPT‑5.4 Pro (Extended) and reports a new high score of 79/99, beating GPT‑5.4 (xhigh) by 10 points, per the benchmark result. The benchmark’s framing and dataset are described in the linked GitHub repo, which positions it as testing “obscure info + legal research” rather than coding/math.
The evaluation is niche by design; the useful signal is a third-party attempt to measure “economically valuable” research behavior outside common coding suites.
Arena adds customizable leaderboard columns (price, context, votes, license)
Leaderboard UI (Arena): Arena added per-user leaderboard customization—columns like price per MTok, max context, total votes, license, and org can be toggled—per the customization demo. This is a small change, but it moves Arena closer to “benchmark explorer” instead of a single global ranking.

Arena adds GPT‑5.4 mini and nano to Text and Vision Arena matchups
Model inclusion (Arena): GPT‑5.4 mini and nano were added to Arena’s Text and Vision matchups, per the arena availability note, with Arena pointing users to run head-to-head comparisons via its main site in the voting link. This is mainly a distribution/measurement signal: it means the models will start accumulating public preference data outside vendor-reported evals.
🏗️ Compute & supply-chain constraints: chips, energy, and scaling bottlenecks
AI scaling constraints and compute economics: EUV bottlenecks, memory crunch signals, and the ‘Jevons paradox’ framing for why cheaper intelligence can still drive total spend up.
EUV lithography supply chain looks like a medium-term hard cap on AI scaling
EUV lithography (ASML ecosystem): A detailed thread breaks down why EUV tools are likely to be the pacing item for AI chip scaling—citing a 10,000+ supplier chain, multi-step tin-droplet laser timing, 18-mirror optics, and 3nm overlay requirements, with a projection that production may not exceed ~100 EUV machines/year by 2030 as described in EUV bottleneck thread.

The constraint here isn’t “money” so much as specialized sub-suppliers (for example Zeiss mirrors) and ultra-tight yield sensitivity, which turns one slow component into a global throughput limit for GPU/accelerator roadmaps.
“Structural Jevons paradox” framing: cheaper inference can explode total compute
Digital Intelligence Capital (economics paper): A shared paper summary claims inference price declines can drive more aggregate compute through more compute-intensive agent architectures—describing a “structural Jevons paradox,” plus an “endogenous depreciation” dynamic where models lose economic value when a smarter competitor ships, as summarized in Paper summary.
The thread’s additional claim is that data/network effects and ongoing compute costs can push the market toward winner-take-all outcomes; treat that as a modeling conclusion rather than an observed industry fact.
Anthropic’s compute ramp is framed as expensive without long-term commitments
Anthropic compute procurement: A note relayed by Dwarkesh suggests Anthropic could reach 5–6 GW by year end, but at higher cost than if it had locked in long-term compute early—because cloud partners (Bedrock/Vertex) can take ~50% gross margin, and short-term rates have climbed, as stated in Compute cost note.

It also claims they may need to raise model prices to suppress demand if supply can’t keep up, which is a direct “capacity meets pricing” linkage that infrastructure teams should watch.
Memory-chip crunch may persist to ~2030, pressuring AI system costs
Memory supply (SK Group): A reported outlook says the global memory-chip crunch could last until around 2030, with wafer supply running 20%+ behind demand and prices expected to keep rising, as relayed in Memory crunch claim.
If this holds, it directly hits AI system cost structure (HBM/DRAM content per accelerator node) and can make “compute is cheaper” narratives false at the rack level even when model efficiency improves.
Citadel argues generative AI adoption follows an S-curve, not exponential
GenAI adoption constraints (Citadel Securities): A post argues adoption will follow a historical S-curve because physical and economic boundaries (compute, data centers, energy) halt exponential substitution; it claims that if marginal AI operating costs rise above human labor costs, firms stop substituting, as described in Adoption S-curve view.
This is a counterpoint to “efficiency always wins” narratives—grounded in capital and energy constraints rather than model capability.
Older GPUs can get more expensive as new models monetize them better
GPU rental economics (model efficiency): A clip argues that because newer models deliver much higher “value per token” on the same GPU, older hardware can become more expensive to rent—illustrated by “3 years ago: GPT-4 on H100” versus “now: GPT-5.4 on H100,” as described in Rental inversion example.

This frames a practical planning risk: demand can rise faster than efficiency gains, so unit-cost drops don’t necessarily translate into lower total spend.
🗂️ Retrieval, parsing, and “make docs agent-readable” pipelines
Practical doc/search pipelines for agents and RAG: PDF/layout parsing, web content extraction partnerships, and prompt-optimization loops for relevance judging.
Dropbox Dash shows a DSPy loop for optimizing a relevance judge (and how it overfits)
Dropbox Dash (Dropbox): Dropbox shared a concrete “judge improvement loop” using DSPy to tune a relevance judge, with the NMSE metric dropping from 8.83 (hand-tuned) to 5.11 (MIPROv2) and 4.86 (GEPA), as shown in NMSE chart. This is the part engineers will recognize: once you treat prompts like parameters, you need the same discipline as model training.
• Overfitting modes: early runs copied example-specific keywords/usernames or even changed task parameters like the rating scale, according to Overfitting caveats screenshot.
• Operational takeaway: the write-up frames prompt optimization as a measurable loop (not vibes), but it only works if you add constraints and review edits, as reinforced by Dash judge post header.
Firecrawl plugs into Wikimedia Enterprise for structured Wikipedia pulls
Firecrawl (Firecrawl): Firecrawl announced a Wikimedia Enterprise partnership to return “cleaner, structured data” for Wikipedia fetches while paying into Wikipedia’s infra, as described in Partnership announcement and detailed in the Partnership blog post. This matters because Wikipedia is often the first stop in RAG ingestion pipelines, and extraction quality tends to dominate downstream retrieval behavior.

The post also notes JavaScript is not executed in their fetch-style workflows (important for determinism and safety), aligning with how many agent crawlers are now being built.
LlamaParse argues audit trails need layout metadata, not just PDF-to-markdown
LlamaParse (LlamaIndex): LlamaIndex highlighted a recurring doc-agent failure mode: converting documents to markdown isn’t enough when humans need an audit trail back to the exact PDF/slide/table regions; they’re pushing layout detection + segmentation as metadata context to make decisions inspectable, per Doc agent UX pitch. Short sentence: trust is a UI problem.

The tweet frames this as the blocker for contract/KYC/diligence-style workflows where “show me where you got that” matters more than raw extraction accuracy.
keep.md adds X bookmark export and HN-as-markdown feeds for agents
keep.md (Keep): keep.md shipped more “make it agent-readable” plumbing: one-time export of all X bookmarks, plus a markdown feed that can ingest sources like Hacker News with keyword filters and backfill controls, according to X bookmarks export and HN source UI. Short sentence: it’s a personal ingestion pipeline.
• Document normalization: the latest version also converts PDFs/images/HTML/Word/Excel/CSV to markdown for downstream use, per File-to-markdown list.
• Practical workflow surface: the product positioning is “context you can hand to agents,” as shown on the Product page.
A searchable, cross-linked index of 1,000+ CHM oral histories goes live
Computer History Museum oral histories (DynamicWebPaige): A new site indexes “a thousand oral histories” and makes them searchable plus “deeply interconnected,” turning long transcripts into a navigable knowledge surface, per Searchable oral histories and the anecdote example in Neutral corner excerpt. Short sentence: this is retrieval-first publishing.

For analysts, it’s also a tidy case study in how to ship a niche corpus: dense source docs, then a discovery layer that exposes relationships instead of only keyword hits.
Weaviate shows a “query agent” pattern for contracts: NL in, routed queries out
Query Agent (Weaviate): Weaviate described an internal app where a “Query Agent” turns natural-language questions into the right collection selection, filters, and aggregations for contract/legal document search, per Query agent demo. Short sentence: this is RAG plus query planning.

The emphasis is less on model choice and more on wiring: routing + structured query generation + returning precise, auditable slices of results (useful framing for teams building enterprise doc search beyond chat).
Hornet’s 100M-doc search post highlights embedding-scale iteration pain
Hornet (Hornet.dev): Hornet published a “what we learned” post from building a 100M-document search engine, emphasizing that wrangling large embedding datasets is slow and that iteration speed becomes the limiting factor, as described in Scaling note and expanded in the Search engine lessons. Short sentence: one experiment can take a day.
This is a systems-flavored reminder that retrieval work is often dominated by data movement and evaluation cadence, not model architecture.
🧠 Training & post-training: RLHF practice, reasoning limits, and agent learning loops
Training and post-training artifacts engineers reference for building better agents: RLHF/RL notes, model self-improvement loops, and agent training paper roundups (non-bio only).
Cursor trains Composer to self-summarize with RL to extend long-horizon coding
Composer self-summarization (Cursor): Cursor says it trained Composer to self-summarize using reinforcement learning rather than prompt-based summaries; it reports ~50% lower compaction error and improved success on coding tasks that require “hundreds of actions,” as described in RL self-summarize claim and expanded in Training writeup.
The key engineering claim is that summary quality becomes a learned behavior that preserves the right state for later steps, instead of a brittle “compress the transcript” prompt—an approach that directly targets the failure mode where long agent runs drift after repeated compactions.
DeepMind and Kaggle launch a $200k challenge to build new cognitive evaluations
Cognitive eval hackathon (Google DeepMind + Kaggle): DeepMind is funding a Kaggle hackathon with $200K in prizes to create new evaluations targeting cognitive dimensions like learning, metacognition, attention, executive function, and social cognition, as announced in Hackathon launch and echoed in Benchmark request.
The premise is that many benchmarks are saturating, so the field needs tests that hold a higher bar for measuring capability growth—especially for models that are increasingly used inside agent loops, per the framing in Benchmark request.
Study reports AI assistance can hurt skill formation without average speed gains
Skill formation study (Anthropic researchers, via secondary summary): A widely shared summary claims randomized experiments found AI assistance can impair conceptual understanding, code reading, and debugging when learning a new Python library—reporting ~17% lower test scores for AI users and limited average speedup, as quoted in Study summary.
The most actionable nuance in the summary is that interaction style mattered: “fully delegating” performed worst, while using AI for targeted concepts preserved learning outcomes more often, per the interaction-pattern breakdown described in Study summary.
PokeAgent Challenge turns Pokémon into a living benchmark for long-horizon decision-making
PokeAgent Challenge (benchmark): A new benchmark frames Pokémon as a two-track agent challenge—competitive battling (partial observability and game-theoretic reasoning) and RPG speedrunning (long-horizon planning)—backed by 20M+ battle trajectories and validated via a NeurIPS competition, per Paper post and the Paper page.
Unlike many coding-centric agent evals, this is explicitly about sequential decision-making under uncertainty and generalization, with a live leaderboard component described in Paper page.
RLHF Book expands practical RLHF notes on policy gradients and implementation tradeoffs
RLHF book chapter (Nathan Lambert): The RLHF book’s reinforcement learning chapter got a substantial expansion focused on policy-gradient algorithms (PPO, REINFORCE, GRPO variants) and the implementation details people trip over in practice, as flagged in RLHF chapter update.
It reads like a “what actually matters when you implement this” refresh: loss aggregation, asynchronicity, and why simpler algorithms sometimes win on memory/throughput—details that map directly onto post-training pipelines for coding/agent models, per the updated outline in RLHF book chapter.
City-grounded world simulation model uses retrieval plus lookahead to stabilize long videos
Grounded world simulation (Seoul World Model): A paper on grounding world simulation models in a real metropolis proposes retrieval-augmented conditioning on real street-view images plus a “Virtual Lookahead Sink” to re-ground generation over long horizons, as shared in Paper post with details on the Paper page.

The training-and-systems angle is the attempt to turn sparse real captures into long, spatially faithful trajectories (hundreds of meters) using view interpolation and chunked re-grounding, per the method overview in Paper page.
Mixture-of-Depths Attention proposes depth-wise KV access with near-FlashAttn2 efficiency
Mixture-of-Depths Attention (ByteDance Seed): MoDA lets each attention head attend to both current-layer sequence KV and depth KV from earlier layers, aiming to reduce “signal degradation” in deep transformers, with a hardware-efficient algorithm claiming 97.3% of FlashAttention-2 efficiency at 64K and ~2.11% average downstream gains on 1.5B models, as shown in the abstract screenshot in MoDA abstract and described on the Paper page.
This is an architecture-level attempt to make depth scaling less lossy without paying a big inference tax, using a mechanism that looks closer to learned cross-layer retrieval than fixed residual accumulation.
Ropedia Xperience-10M releases 10M egocentric interaction episodes for embodied AI
Ropedia Xperience-10M (dataset): A new large-scale egocentric multimodal dataset was announced with 10 million interaction “experiences” and 10,000 hours of synchronized first-person recordings, targeting embodied AI, robotics, world models, and spatial intelligence, as summarized in Dataset release.

For training pipelines, the notable part is the sensor stack and annotation depth (multi-stream video, audio, depth/pose, hand/body motion capture, IMU, hierarchical language annotations) described in Dataset release.
VoxCPM proposes end-to-end TTS with hierarchical semantic-acoustic modeling
VoxCPM (OpenBMB / TsinghuaNLP): VoxCPM is presented as an end-to-end generative TTS framework that avoids external discrete speech tokenizers by using hierarchical semantic-acoustic modeling with semi-discrete residual representations, claiming strong zero-shot TTS quality at 0.5B parameters and reporting low WER/CER figures in the shared tables, per Paper thread.
The training framing is “skeleton first, flesh later”: a text-semantic model plans semantics/prosody, then a residual acoustic model reconstructs fine detail under a diffusion objective, as described in Paper thread.
Weekly paper list clusters around agent RL and reward modeling for computer-use
Agent-RL research curation (The Turing Post): This week’s paper roundup clusters heavily around RL for agents—items like OpenClaw-RL, agentic search RL with self-reflection, video-based reward modeling for computer-use agents, and RLVR scaling questions—compiled in Research list with the full index in Full list and links.
As a signal, the set suggests “training for long-horizon tool use” is being treated as a first-class research track, not a prompting/harness problem, based on the titles emphasized in Research list.
📚 Builder education & events: courses, meetups, and how-to artifacts
Learning and distribution mechanisms for engineers: courses on reliable agents, meetups/hackathons, and practical writeups/guides circulating today.
Harness engineering gets framed as the new coding-agent bottleneck (Michael Bolin interview)
Harness engineering (The Turing Post): A new interview with OpenAI’s Michael Bolin argues the bottleneck is shifting from “model writes code” to the harness around the model—tools, constraints, repo legibility, and feedback loops—captured in the Interview framing and linked as the Interview video.

The thread explicitly names this as a “new inner loop” teams are still learning, and it ties that to practical Codex workflow design rather than model-selection debates, per the Interview framing.
Simon Willison adds a Subagents chapter to Agentic Engineering Patterns
Agentic Engineering Patterns (Simon Willison): A new “Subagents” chapter documents subagents as the practical mechanism for scaling work beyond a single context window—treating them as delegated, fresh-context workers that return findings to the parent agent, as described in the Guide update and detailed in the Subagents guide.
The writeup anchors on concrete workflows (e.g., repo exploration and targeted file scanning) rather than abstract “multi-agent” framing, per the Subagents guide.
LangChain Academy publishes a free “Building Reliable Agents” course (LangSmith-centric)
LangChain Academy (LangChain): LangChain published a new free course on “Building Reliable Agents” that frames agent engineering as iterative production hardening—observability, evals, and deployment loops built around LangSmith, as outlined in the Course announcement.

The course pitch is explicitly about what changes when your “software” is a non-deterministic model—multi-step tool use, real user traffic, and debugging via traces rather than only code paths, per the Course announcement.
GTC executive dinner notes: agents are a full-stack problem, not a model demo
GTC exec dinner (LlamaIndex × Modular): Jerry Liu shared notes from an NVIDIA GTC executive dinner where discussion focused on end-to-end agent stack questions—general vs specialized models, whether reliability is a systems vs model problem, how non-technical users adopt tools like Cowork, and where repetitive document work still dominates, as summarized in the Dinner recap.
The post reads as a snapshot of where exec and builder conversations are converging: agent UX and operational friction are central, even when model capability is improving quickly, per the Dinner recap.
LangChain schedules 11 in-person meetups and hackathons for agent builders
LangChain meetups (LangChain): LangChain shared an 11-event run of meetups/hackathons (SF, Shenzhen, Stockholm, NYC, Amsterdam, CDMX, Miami, Dublin, Buenos Aires) as an in-person distribution channel for agent engineering practices, according to the Meetups schedule.
The post emphasizes agent-specific topics like deployment reliability and production learnings in the event lineup, per the Meetups schedule.
🎨 Gen media & creative tooling: image/video speed, rendering, and eval arenas
Generative media and vision updates with real workflow impact: Midjourney V8 speed/2K mode, ultra-fast video iteration loops, DLSS 5 neural rendering debate, and ComfyUI model drops.
Dreamverse shows real-time video iteration: 30s 1080p in ~4.5s on one GPU
Dreamverse (Hao AI Lab): Hao AI Lab is demoing Dreamverse, an interface built on its FastVideo inference stack where generation is fast enough to iterate “live”—they claim 30s 1080p clips in 4.5 seconds on a single GPU, with scene edits returning in ~5 seconds, as stated in the launch thread and detailed in the blog post.

• Workflow shift: The loop is “Generate → watch → edit” with natural-language revisions like “Make it darker” and “Slow the camera,” per the launch thread.
• Systems angle: They attribute the latency to an optimized serving stack (fast attention backends, 4-bit quantization, fused kernels, multi-user serving), as listed in the stack details.
The demo emphasis is on feedback-loop speed more than maximum single-shot quality, as framed in the launch thread.
Midjourney opens V8 Alpha with ~5x speed and native 2K mode
Midjourney V8 (Midjourney): Midjourney has opened early community testing of V8 Alpha on its alpha site with ~5x faster image generation, stronger adherence to detailed prompts, improved text rendering (best when specified in quotes), and a new 2K native mode via --hd, as described in the V8 community test and expanded in the long follow-up.
• Control and compatibility: V8 keeps backwards compatibility with V7 personalization profiles, moodboards, and style references (srefs), per the long follow-up.
• Cost and modes: --hd, --q 4, sref, and moodboard jobs are currently 4x slower and cost 4x, and Relax mode isn’t supported yet, according to the long follow-up.
Prompting guidance is shifting toward longer, more specific prompts and early use of --raw, as written in the long follow-up.
DLSS 5 messaging splits on what “generative” changes in-game
DLSS 5 (NVIDIA): Following up on DLSS 5 launch (3D-guided neural rendering), discussion today centers on what DLSS 5 is and isn’t changing: one report says NVIDIA staff asserted characters/assets aren’t modified and the effect is “solely the lighting,” per the booth clarification, while Jensen separately described it as adding generative AI that “doesn’t change artist direction,” as captured in the press conference clip.

Some reactions frame public pushback as “hating it because it’s AI,” as argued in the complaint post, while the press-conference wording suggests broader interpretation risk if “generative” is read as more than lighting/material inference.
Reve integrates into ComfyUI with Create/Edit/Remix nodes for 4K workflows
Reve (ComfyUI): The Reve image model is now available inside ComfyUI with dedicated nodes for Reve Create, Reve Edit, and Reve Remix, with ComfyUI describing ~5 second generation and support for outputs up to 4K, as announced in the ComfyUI integration post.
ComfyUI positions Create for rapid iteration, with Edit/Remix as follow-on nodes for refinement and multi-image blending, as reiterated in the 4K Create note and the Remix note. Availability on ComfyCloud is pointed to in the ComfyCloud availability and the linked ComfyCloud page.
Arena launches a Video Edit leaderboard for frontier video models
Video Edit Arena (Arena): Arena launched a Video Edit Arena leaderboard to benchmark video editing capabilities via community voting, with early rankings listing Grok-Imagine-Video at #1, followed by Kling-o3-pro and Kling-o1-pro, as stated in the launch post and reflected on the linked leaderboard page.
The leaderboard page reports 2,895 votes so far and includes per-model score uncertainty and head-to-head win-rate breakdowns, according to the leaderboard page.
ComfyHub grows its shared workflow catalog
ComfyHub (ComfyUI): ComfyUI announced an expanded ComfyHub catalog—more creators and more shared workflows—positioned as a larger “library” for building image/video/audio pipelines, per the ComfyHub announcement and the linked workflows page.

The update is framed around discoverability and breadth of reusable graphs rather than a single new node or model, as shown in the ComfyHub announcement.
Gamma Imagine is being used as an editable invite generator
Gamma Imagine (Gamma): A hands-on demo shows Gamma Imagine generating multiple event-invite options from a date + theme, then iterating with follow-up prompts and UI buttons, as shown in the graphic generation demo and the follow-up example in the invite example.

The workflow emphasis is “generate three options, then refine,” with editable typography and layout variants visible in the graphic generation demo.
QuiverAI highlights Arrow workflows for prompt-to-SVG and vector cleanup
Arrow (QuiverAI): QuiverAI highlighted workflows around Arrow for generating and editing SVGs, including real-time drawing of vector paths and raster-to-vector conversion with tooling to inspect path quality, per the Arrow thread and supporting clips like the opacity comparison demo.

The shared examples emphasize “vector-first” asset creation (icons, technical drawings, type) and validation via outline/opacity inspection, as described across the Arrow thread and opacity comparison demo.
Weavy shows a Kling Elements workflow aimed at tighter video control
Kling Elements (Weavy): Weavy shared a practical workflow for using Kling 3.0 Elements to get more structured control over video generation (framed as moving away from pure prompt iteration), with an example workflow and a longer tutorial linked in the workflow post.

The pitch is that “elements” act as higher-leverage controls for cinematic iteration, as described in the workflow post and backed by the linked example workflow.
🧭 Work, skill, and org-change signals from the agent era
When the discourse itself is the news: skill erosion vs leverage, Jevons-paradox hiring arguments, and “still need to read the code” reality checks—useful context for leaders and engineering org design.
Coinbase claims agents write 50% of code and resolve 60% of support tickets
Operational metrics: A circulated claim attributes to Coinbase that AI agents now write “over 50%” of code and resolve “60%” of support tickets, and that scaling autonomy includes giving agents stablecoin wallets for machine-to-machine payments, per the agent metrics clip.

Whether or not the exact percentages generalize, the important signal is what’s being counted: code contribution and ticket resolution as measurable “agent work outputs.”
Reliability reality check: “I still have to read code line by line”
Verification load: Following up on Code review bottleneck (review as the constraint), builders are repeating that even with much faster output they still have to read every line because models “still lie,” as stated in the read every line complaint and reiterated in the they still lie followup.
This shows up as an eye-time bottleneck: throughput improves, but trust still demands human audit.
Sam Altman frames “character-by-character” coding as a fading baseline
Software work (OpenAI): Sam Altman’s reflection on gratitude for people who “wrote extremely complex software character-by-character” landed as a cultural marker for how fast expectations are shifting around AI-assisted development, per the gratitude post. The same text is already being remixed into “the era of human coding is over” narratives in the repost framing.
The practical subtext for engineering leaders is less about obsolescence and more about what gets valued next: supervision, debugging, and system design now look like the enduring bottlenecks even as code generation becomes cheap.
Structural Jevons paradox paper: cheaper inference can increase total compute spend
AI economics: A new-ish paper making the rounds is being summarized as “structural Jevons paradox”: falling inference prices push downstream teams toward more compute-intensive agent architectures, so aggregate compute demand still grows, per the paper screenshot. It’s also framed as a competitive dynamic where “a perfectly working LLM becomes economically worthless” when a stronger one ships, in the same paper screenshot.
For org design, the implied constraint is budget volatility: unit costs may drop while total usage—and internal dependence on agents—keeps climbing.
Don’t optimize away the hard parts: use AI for busywork, keep the struggle
Learning posture: A long essay argues that friction is where understanding forms—agents should remove busywork, but teams should keep “meaningful resistance” (unclear problems, hard tradeoffs, uncomfortable conversations), per the reflection essay. It’s a cultural counterweight to “speed = progress.”
In org terms, it’s a guideline for how to deploy agents without hollowing out judgment and taste.
Orchestrating intelligence: one person managing 12 Codex subscriptions
Org behavior shift: A clip making the rounds points to “software engineering is shifting to orchestrating intelligence,” using an extreme anecdote of someone managing 12 separate $200 Codex subscriptions, per the multiple-subscriptions clip.

This is a concrete sign of how teams are treating agent capacity like parallel headcount—budgeted, provisioned, and actively managed.
Surveys: high-income workers report rising job insecurity tied to AI capability
Workforce sentiment (UBS/UMich/NY Fed via CNBC): A CNBC writeup being shared says top earners show the steepest drop in labor-market confidence since the 1970s and record-high fear of unemployment, with “AI fear” floated as a driver, per the survey summary. It also claims quit rates are at record lows for office roles (ADP), in the same survey summary.
Even if unemployment is currently low in some sectors, this reads as a retention-and-risk perception shift inside knowledge-work orgs.
Citadel: gen-AI adoption should follow an S-curve due to physical constraints
Adoption ceiling thesis: Citadel Securities argues gen-AI adoption should plateau rather than grow exponentially because automation at scale hits physical/economic bounds—compute, data centers, and energy—per the adoption chart. It also claims that if marginal AI operating cost rises above labor cost, substitution slows, in the same adoption chart.
This sits in direct tension with Jevons-style stories; the debate is becoming “elastic demand vs hard caps.”
Org design analogy: engineers split into “bank tellers” vs “i-bankers”
Agency tiers: A leadership-oriented analogy compares some software engineers to “bank tellers” and others to “investment bankers” in terms of autonomy, value, and institutional trust, arguing processes should adapt when a team skews heavily toward the latter, per the agency analogy.
It’s a shorthand for why “one process fits all” breaks faster in an agent-heavy org: the same agent tooling can either amplify execution or amplify risk, depending on who’s driving it.
Open source shifts from producer-only to consumer activity via AI tooling
Ecosystem culture: A small but sharp observation argues that building/using open source is increasingly a consumer behavior—more like installing apps than joining a dev community—per the consumer shift note.
For AI orgs, this changes adoption dynamics: “choice of stack” becomes less about engineering buy-in and more about end-user onboarding, safety defaults, and support load.