Kling Avatars 2.0 powers 5‑minute 1080p takes – Leonardo, Picsart go audio‑native
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Kling’s week-old “talking pictures” update grows up fast. Video 2.6’s native audio now pairs with Avatars 2.0, a single-photo talking-head model that carries expressive, lip-synced 1080p performances for up to 5 minutes, so explainers, songs, and ads can run as one continuous take. Day‑0 integrations at Leonardo, Picsart, Glif, Higgsfield, and fal mean that same one‑pass video+voice+SFX pipeline now lives inside tools you already use, not a walled-off playground.
The creative tests are the tell. Kling is showcasing a five‑moods, one‑line demo where tone, ambience, and timing all stem from the model, while shorts like “Zero Stars Delivery” and NEOVIA’s “Cyber Love” run fully on 2.6 audio. Avatars 2.0 is already singing in Chinese, fronting a Suno‑backed “Elf on da Shelf” video, and holding lip‑sync even on stylized characters. Leonardo lets you feed Lucid Realism stills as start frames for narrated shots, Picsart Flow treats Kling as its audio‑native engine, and Glif wraps 2.6 into agents that script and render shorts automatically. TheoMediaAI’s long review is the counterweight, charting where motion, audio, and multilingual delivery still wobble.
If your inner director has been stuck in prompt jail, this is the week where “describe the performance” starts to behave more like actual blocking than a lottery ticket.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught
Top links today
- Higgsfield Kling 2.6 unlimited native audio video
- Fal Kling Avatar 2.0 launch page
- Krea Nano Banana Context generation tool
- Runway Gen-4.5 video model overview
- Freepik Seedream 4.5 AI image model
- BytePlus ModelArk Seedream 4.5 video tools
- Vidu Q2 image-to-video generator
- PosterCopilot graphic design layout paper
- Light-X generative 4D video research paper
- BulletTime controllable time and camera paper
- Live Avatar real-time streaming avatars paper
- APOB AI Ultra 4K Seedream 4.5 mode
- Glif Nano Pro thumbnail designer agent
- Pictory AI Studio multimodal creative update
- Gemini 3 Deep Think reasoning mode overview
Feature Spotlight
Kling 2.6 + Avatars 2.0 go fully audio‑native
Kling 2.6’s native audio and Avatars 2.0 (5‑min inputs) hit major creator platforms, collapsing idea→final cut for ads, explainers, and character clips with one‑pass video+voice+SFX and stronger lipsync.
Today’s cross‑platform wave is about creation speed: one‑pass video+voice+SFX with tighter lipsync, plus Avatars 2.0 for 5‑min performances. New: Picsart/Leonardo/Glif day‑0s, creator tests, and promo credits.
Jump to Kling 2.6 + Avatars 2.0 go fully audio‑native topicsTable of Contents
🎬 Kling 2.6 + Avatars 2.0 go fully audio‑native
Today’s cross‑platform wave is about creation speed: one‑pass video+voice+SFX with tighter lipsync, plus Avatars 2.0 for 5‑min performances. New: Picsart/Leonardo/Glif day‑0s, creator tests, and promo credits.
Kling 2.6 shows emotionally synced native audio in full scenes
Following up on native audio launch, Kling is now emphasizing Video 2.6’s emotional range with an official demo where the same actress delivers one line across five distinct moods, with every voice, ambience, and sound effect generated by the model itself See the Sound thread.

A companion “See the Sound, Hear the Visual” spot underlines that both visuals and audio in the ad are pure Kling 2.6 output, reinforcing its pitch as a one‑pass storytelling engine rather than a silent clip generator

.
Creators are already shipping narrative shorts like the chaotic “Zero Stars Delivery” skit and the neon idol MV “Cyber Love,” each explicitly credited as end‑to‑end Kling 2.6 (Audio) productions Zero Stars short Virtual idol launch.
The mood from builders is that it feels closer to on‑set directing than classic prompting—one reviewer says Kling 2.6 “understands the prompt emotionally” and nails realistic timing Creator reaction clip, while another highlights how well native audio and lip‑sync hold up even on stylized animated characters Animated character test.
Kling Avatar 2.0 brings 5‑minute expressive talking heads
Kling rolled out Avatar 2.0, a single‑photo talking‑head model that can drive up to 5‑minute, 1080p performances with much richer facial expressions, gestures, and lip‑sync, aimed at explainers, ads, songs, and story content Avatar launch thread.

Partners are picking it up at day‑0: Higgsfield is marketing “Kling Avatars 2.0” with 5‑minute audio uploads as part of its Cyber Week toolkit Higgsfield avatar promo, while fal exposes Avatar 2.0 as a standard tiered endpoint with better emotion capture and longer inputs Fal day0 support.

Early use cases already include a music‑driven Chinese singing avatar demo Chinese singing test and a playful “Elf on da Shelf” music video that chains Avatar 2.0 with Suno for full song‑plus‑performance clips Elf music video, signaling that creators can now prototype full character performances without separate dubbing or animators.
Leonardo, Picsart, and Glif ship one‑pass Kling 2.6 audio video
Leonardo AI, Picsart, and Glif all added Kling Video 2.6 with native audio, giving creators one‑pass video+voice+SFX inside familiar tools and extending the broader rollout covered in creator tooling rollout.

Leonardo now lets you feed Lucid Realism stills as start frames and generate Kling 2.6 shots with built‑in voice and lip‑sync—pzf_ai calls the combo “Quiet words,” praising the cinematic feel and how little extra setup it requires Leonardo integration.
Picsart Flow positions Kling 2.6 (alongside Kling O1 and LTXV 2) as the audio‑native engine in its end‑to‑end production stack, so a text or image prompt yields a fully mixed clip with narration, ambience, and sound effects rather than silent footage Picsart Flow overview.
Glif’s update removes the need for a separate sound pipeline entirely—its Kling 2.6 Pro glif can take a single prompt and output dialogue, room tone, and effects in one render, and is already being wired into agents that script and render shorts automatically Glif audio launch Glif Kling workflow.
Creator deep‑dive reviews Kling 2.6 strengths, flaws, and language quirks
TheoMediaAI released a long‑form Kling 2.6 breakdown that digs into where its native audio and motion work well, where they break, and how the model behaves across languages, building on earlier community prompt guides for dialogue dialogue workflows.

His thread shares back‑to‑back tests of the same scripted exchange in Mandarin and English, asking native Chinese speakers whether the Avatar 2.0 delivery sounds natural before posting an English rendition of the scene for comparison Language check request

.
The review video, framed as “The Kling 2.6 Review/Roundup – The Good, The Bad, and the Audio,” also contrasts Kling’s one‑pass sound with workflows that pair other video models with Seedream 4.5 and Nano Banana Pro, giving filmmakers a practical sense of when to lean on Kling as the primary engine versus one component in a larger pipeline Review announcement YouTube deep dive.
🎥 Directable video beyond Kling: control, relights, shareable apps
Shot control and multi‑shot workflows progressed via Runway (Gen‑4.5 coherence; workflows→apps) and model comparisons. Excludes Kling 2.6/Avatars (covered in the feature).
Runway Gen‑4.5 reel highlights coherent multi‑aesthetic storytelling
Runway put out a new Gen‑4.5 reel showing it can keep a consistent visual language while switching between photoreal, cinematic, anime, 3D animation and even puppet‑like styles in a single sequence, tagged with the line “ALL YOUR WORLDS. ALL YOUR STORIES.” Gen-4.5 aesthetics This follows earlier demos of the model’s lighting and realism intuitive lighting, and matters if you’re trying to mix aesthetics in one film without characters or environments drifting.

For directors and motion designers, this suggests Gen‑4.5 can handle projects where, for example, a character moves from live‑action into anime and back while still feeling like the same world. It also hints that prompt design for Gen‑4.5 is less about fighting mode collapse and more about clearly describing each segment’s style and letting the model handle transitions, which is valuable when you’re planning longer, multi‑scene pieces rather than isolated shots.
Runway turns Workflows into shareable Apps for all plans
Runway is rolling out a feature that lets you convert any Workflow graph into an App you can share with your workspace, moving node‑based pipelines a step closer to productized tools. Workflows rollout For creatives, that means you can wrap a complex multi‑shot or multi‑model pipeline in a simple interface for producers, editors, or clients.

The teaser shows an abstract "Workflow" structure collapsing into a clean app icon with “Build / Share / Grow” on screen, signalling that parameters can be exposed in a way non‑technical teammates can safely use. For film teams or agencies, this can standardize things like “client preview generator”, “storyboard→animatic”, or “UGC cleanup+brand pass” into repeatable buttons instead of everyone hand‑editing graphs. It also positions Runway more like a small internal platform where lead artists ship tools, not just one‑off generations.
Sync Labs previews React‑1 for post‑hoc directing of AI performances
Sync Labs’ React‑1 model is pitched as a performance‑level editor for AI video: instead of regenerating a clip, you can adjust emotion, timing, head direction and lip‑sync after the fact, avoiding the classic “dubbed” feel. React-1 explainer It uses the audio track to rebuild the entire on‑screen performance, not only the mouth motion.

For filmmakers, that sounds closer to directing an actor than rerolling a model: you can re‑aim eye lines, sharpen or soften reactions, and tweak micro‑expressions to better hit beats without throwing away a good take. It should also reduce the number of full re‑renders needed when a client asks for “a bit more energy here” or “less smile on this line,” which is usually a pain with today’s video models. React‑1 isn’t widely available yet, but if the preview holds up, it could slot into post like a new kind of performance tool between generation and final compositing.
Vidu Q2’s “Static to Story” turns one image plus script into a short
Vidu is promoting an Image‑to‑Video workflow where you upload a single image, add a short script, and get a complete animated clip with synchronized audio and messaging—pitched as going from “Static to Story in one click.” Vidu image-to-video The demo shows a silhouetted figure turning into a moving shot as the "Static to Story" banner appears.

For designers, marketers, and storytellers, this bridges the gap between polished key art and motion: you can take a campaign visual or IP character illustration and quickly spin up a video version for ads, event teasers, or social posts without re‑staging everything. The fact that audio comes baked in also means you can prototype narrative beats or product explainer flows before committing to full sound design or VO sessions.
LTX Model compares three video models on the same dragon prompt
LTX Model shared a side‑by‑side video where the same dragon prompt is run through three different AI video models, producing noticeably different looks and motion behaviors from identical text. Three model dragon The clip highlights how physics, style, and detail choices vary by model even when the prompt is held constant.

This kind of comparative demo is useful if you’re picking a stack for a show or campaign: one model might give cleaner silhouettes but flatter lighting, another might feel more painterly but less stable, and a third might handle camera moves better. Treating models as creative “lenses” rather than interchangeable engines helps teams route the right shot to the right system—action scenes to one, stylized lore sequences to another—while keeping prompts maintainable across an entire project.
🖼️ Seedream 4.5 for production‑ready stills & consistency
Teams lean on 4.5 for sharper faces, text, and identity stability across looks. New today: Freepik launch reel, BytePlus consistency demo, Glif 4K support, and creator tests.
Freepik adds Seedream 4.5 for detailed, consistent portraits and products
Freepik is now hosting Seedream 4.5 for AI Partners and Pro users, promising sharper faces, consistent characters, realistic lighting, improved color depth, and natural proportions inside its own creation tools. Freepik intro

Follow‑up reels highlight how it behaves in practice: highly detailed portrait close‑ups, portrait examples product shots with integrated branding, product examples surreal but grounded character scenes, and varied lighting tests that keep skin tone and identity stable across looks. lighting examples Creators are already testing it in the wild, like a cinematic snowy Arc de Triomphe night scene generated on Freepik’s interface, which shows strong depth, atmosphere, and clean structure. creator test For illustrators and marketers already using Freepik’s library, this effectively turns it into a higher‑end portrait and campaign image generator rather than just a stock destination.
BytePlus shows Seedream 4.5 keeping one subject stable across many looks
BytePlusGlobal published a "one subject, many styles" demo where Seedream 4.5 maintains a woman’s identity while her outfits, hairstyles, gestures, and motion change shot to shot, all running on BytePlus ModelArk. BytePlus demo

For fashion, influencer and story‑driven work, this matters: you can swap wardrobe, camera angle, or action without your lead quietly morphing into a different person half‑way through. The clip underscores what 4.5 is optimizing for: stable facial structure and expressions plus coherent background, so creators can focus prompts on direction (pose, vibe, styling) instead of fighting identity drift frame by frame.
Glif integrates Seedream 4.5 with native 4K, better text, and ref uploads
Glif now offers Seedream 4.5 as a first‑class image model, adding native 4K generation, improved text rendering, and multi‑image uploads in a single workflow. Glif announcement

The short UI demo shows a creator cycling through highly detailed portraits and environments while sticking to one model, which simplifies pipelines where people previously bounced between separate “hi‑res” and “good text” models. Multi‑image upload means you can feed in brand references, character angles, or mood boards and let 4.5 infer style and identity, which pairs well with Glif’s existing Kling 2.6 video agents for teams wanting a stills‑to‑video path without leaving the tool.
Apob leans on Seedream 4.5 Ultra 4K for stable influencer faces
Apob AI expanded on how it’s using Seedream 4.5, saying the model now powers its Ultra 4K mode with sharper detail and "massive improvements" in character consistency for influencer, fashion, and brand videos, Apob reel building on the earlier 60% off yearly promo around this stack. Apob 4K deal

The promo reel cycles through the same persona across outfits and scenarios without the usual face wobble, which is exactly what social teams need when they’re betting a channel on a synthetic creator or recurring spokesmodel. The pitch here is that 4.5 gives Apob predictable, sponsor‑ready faces at 4K, so campaigns don’t fall apart when you change the angle, scene, or emotional beat mid‑video.
🛠️ Sketch‑to‑edit and context‑driven pipelines
Faster iteration tools for art direction: draw‑over edits, avatar day‑0s, and context refs that steer style/elements without long prompts. Excludes Kling core news (see feature).
Krea ships “Context” for Nano Banana Pro to steer generations from reference images
Krea introduced a new Context tool for Nano Banana Pro that lets you upload reference images and treat them like a system prompt, telling the model which style or elements to copy instead of writing long text prompts. Creators can, for example, ask Nano Banana to shoot cinematic fashion portraits of model B wearing the clothes from image A using this context layer rather than hand‑crafting every detail in prose. (Context launch thread, Clothing swap example)

The team frames Context as a way to guide results with high‑level art direction: you can specify whether to pull style, composition, or specific objects from your refs, and the same tool still exposes all of Nano Banana Pro’s usual powers like internet search and chat history memory. Feature capabilities For AI designers and filmmakers, this means faster iteration on branded looks, character continuity, and wardrobe/layout variations without rewriting prompts every time. You can try it directly inside Krea’s Nano Banana workspace, which now exposes the Context pane alongside standard settings. feature blog model page
Glif’s Nano Pro Thumbnail Designer agent turns a couple of refs into a YouTube‑ready cover
Glif rolled out a Nano Pro Thumbnail Designer agent that takes two reference images plus a short brief and spits out a polished YouTube thumbnail in under a minute. The agent runs on Nano Banana Pro, iterating through fewer than five prompt revisions to land on a final layout, so creators don’t have to design thumbnails from scratch every upload. (Thumbnail agent demo, Agent description)

In the demo, the creator feeds it two existing thumbnails as style and composition guides, then lets the agent propose new variants until one matches the desired framing and text balance, effectively treating the refs as visual context rather than writing massive art‑direction prompts. Thumbnail agent demo Glif is pitching this alongside its Kling 2.6 native‑audio workflows, so the same project can go from script to video to thumbnail inside one environment, with the thumbnail agent wired up as a reusable tool you can hit from a shared link. Kling workflow context You can spin it up directly from the published Glif, which exposes the inputs (two refs + title/hook) and shows the prompt template it uses under the hood. (Start creating link, agent page)
🎨 Reusable looks: MJ V7 srefs + claymorphic packs
Creators share portable style kits for fast art direction—new Midjourney V7 style refs and a claymorphic 3D prompt pack with ATL examples.
Claymorphic 3D prompt pack becomes a shared pastel toybox style
Azed_ai shared a reusable claymorphic 3D prompt that turns any [object] into soft, bouncy, pastel toys with chunky shadows and gradient backdrops, and people immediately started remixing it across subjects. prompt pack The ATL examples (cupcake, teacup, Pikachu, rocket) show how consistent the look is, which makes it feel more like a portable style preset than a one‑off prompt.
Creators are already using the same text to generate a snowman, snowman remix a chibi Captain America figurine, captain america remix and more, proving it holds up for characters, props, and food alike. For you as a designer or filmmaker, this is an easy “drop‑in” art direction for kid brands, UX icons, thumbnails, or lighthearted motion tests: swap [object] for your product or character and you get a cohesive, merch‑ready look without touching settings.
Dark 90s OVA anime look arrives as MJ sref 1665323633
Artedeingenio published a Midjourney V7 style ref --sref 1665323633 tuned for dark, mature late‑90s/early‑2000s OVA anime—think Vampire Hunter D: Bloodlust, Hellsing, Berserk (1997). dark anime style The samples include a jewel‑choker femme fatale, a guns‑drawn antihero, and windswept bandana wearers against dramatic skies, all with heavy shading and cinematic framing.
If you’re storyboarding gothic fantasy, horror, or serious action, this sref gives you a moody baseline that’s very different from the bright, flat modern anime defaults. You can prompt full scenes or single characters and reliably get that "VHS‑era OVA" depth of shadow and attitude, which is perfect for key art, teaser posters, or look‑dev passes before you commit to animation.
Midjourney V7 sref 6347653575 nails grainy 3D character dioramas
A new Midjourney V7 style reference --sref 6347653575 from azed_ai leans into grainy, pebble‑textured 3D characters on black backgrounds, with bold shapes and limited palettes. style launch The examples span a seated pastel character, a mustachioed boxer, a warrior with shield and spear, and more, all sharing the same tactile, almost felt‑like surface.
People are calling out how strong the texture and forms feel, saying things like it has “so cool… love the texture on these”. creator reaction If you’re doing mascots, album art, motion stings, or card art, this sref gives you a ready‑made visual language where any new character or prop you add looks like it belongs to the same physical toy line.
Idea‑factory sref 3748053327 unifies bold graphic worlds in MJ V7
Bri_guy_ai shared Midjourney V7 style ref --sref 3748053327, showing how it keeps a tight graphic identity across architecture, portrait, and wildlife landscapes. idea factory style In one set you get a Memphis‑meets‑Miami building facade, a patterned portrait with intricate clothing, and a surreal zebra valley under a yellow sky—all clearly part of the same visual system.
It leans on flat, bright planes of color, crisp linework, and slightly surreal compositions, so it’s strong for editorial spreads, brand worlds, or concept frames where you want different scenes that still feel like pages from one idea book. For creative directors, this is a handy way to lock in a "house look" for an entire campaign from a single sref instead of juggling prompt spaghetti.
MJ V7 collage sref 4137525063 delivers bold red/blue story panels
Azed_ai also dropped a Midjourney V7 style ref --sref 4137525063 that creates cohesive panel collages: deep blues, hot reds, white suns, and Japanese‑inspired silhouettes stitched into poster‑like layouts. collage style One grid shows landscapes, samurai profiles, and a city street portrait all framed as if they’re pages from the same graphic novel.
For comics, title cards, or pitch decks, this is an instant "director’s board" look. You can throw wildly different scene prompts at it—characters, vistas, architecture—and still end up with a consistent red/blue visual system that feels curated rather than random screenshots.
🏆 Showcases & awards: films, reels, and winners
A pulse of finished work and honors for inspiration. New today: OpenArt Music Video Awards winners, Luma Ray3 BTS “Star Seeker,” and a hybrid AE/VFX ad edit thread. Excludes Kling feature coverage.
James Harden’s MyPrize ad shows full AI–VFX hybrid workflow in the wild
Director Billy Woodward broke down the MyPrize commercial where James Harden never set foot on set, using Nano Banana Pro, Seedream, Midjourney and Photoshop for consistent start frames, Kling for realistic shots, and Seedance+Grok for animated sequences. (workflow thread, image gen details) The team then finished with classic After Effects work—swish pans, logo reveal, pacing, and sound design—to make the spot feel like a big-budget, broadcast-ready piece. after effects notes

Harden reportedly called it “the best commercial I've ever been in,”workflow thread which should encourage creatives who are blending AI character work with traditional editing and VFX rather than trying to replace the whole pipeline.
Busan International AI Film Festival honors “The Afterlife of Aphrodite”
Busan International AI Film Festival (BIAIF) awarded The Afterlife of Aphrodite an Official Selection prize, with director Gabriela Cardona sharing photos of the acrylic trophy, on‑stage moments, and a $1,000 certificate. award recap This puts the film on the map as a festival‑validated AI work rather than a social‑only experiment.
If you’re aiming at festival circuits, this is a signal that dedicated AI festivals are emerging with real juries, cash awards, and theatrical screenings, not just online showcases.
OpenArt Music Video Awards spotlight four standout AI-driven music videos
OpenArt revealed the winners of its Music Video Awards, highlighting four AI-heavy projects across Best Visuals, Best Character Design, Best Storytelling, and Best Use of AI. winners thread Shudu’s "world’s first digital supermodel" project took Best Visuals, BlueWaveAILabs won Best Character Design, StudioKanela’s If a robot had a heart… could it feel love too? earned Best Storytelling, storytelling winner and themeetingtent’s dark Little Red Riding Hood piece captured Best Use of AI. best use winner

For music video directors, animators, and character designers this is a clean reference point for where juries currently draw the line between clever AI experiments and fully realized, emotionally coherent work.
“The Digital Republic” enters 1Billion Followers Summit as a Gemini-powered AI short
Creator Isaac Horror released The Digital Republic, a seven‑minute AI short submitted to the 1Billion Followers Summit competition, built around the theme "Rewrite tomorrow."film overview The film follows a woman in a fractured future who enters a simulation to seek counsel from an AI reconstruction of Plato, with Nano Banana and Gemini used to generate the visuals and narrative beats.

For sci‑fi storytellers and essay‑film fans, it’s a concrete example of using current tools to stage philosophical dialogue and worldbuilding rather than only music videos or ads.
Claude 4.5 Sonnet and Glif agent auto-generate a complete short film
Fabian Stelzer’s team shared a short film that was "completely & autonomously generated" by Claude 4.5 Sonnet on Glif, driven by an agent that iteratively prompts, selects, and assembles shots without human shot‑by‑shot direction. autonomous film note The clip shows coherent narrative beats, cuts, and pacing rather than a loose montage, hinting at agent‑directed filmmaking workflows.
For filmmakers and tool builders, this is an early look at what happens when you give an LLM control over both script and visual generation, and ask it to deliver a finished short instead of isolated scenes.
Luma shares BTS reel for BTS “Star Seeker” Ray3 image-to-video piece
Luma posted a behind-the-scenes reel for BTS: Star Seeker, a polished image-to-video short built with its Ray3 model inside Dream Machine. bts announcement The piece follows the band through a stylized cosmic environment, showing how static hero images were turned into smooth, cinematic motion and transitions.

For music and entertainment teams, it’s a useful example of how far you can push fan-facing, label-ready visuals using image-to-video alone, and how much motion, lighting, and compositing polish you still need to add around the model.
Virtual idol group NEOVIA debuts “Cyber Love” music video built with Kling
ZOOI and Kling premiered <Cyber Love>, the debut music video for virtual idol group NEOVIA, described as a neon‑lit story of love crossing digital and real worlds. virtual idol debut The clip features an anime‑styled pink‑haired singer against dense cityscapes, with all visuals and audio credited to Kling 2.6’s video+audio pipeline.

For music producers and VTuber teams, it’s a template for launching entirely synthetic acts with cohesive visual identity and an original track, not just looping clips over stock beats.
“Elf on da Shelf” shows DIY holiday music video built from Kling Avatars + Suno
Creator Blizaine stitched together a playful Elf on da Shelf music video by pairing the newly released Kling Avatar 2.0 with Suno for the song, calling the combo a “Christmas Miracle.”creator comment The result is a character‑driven, lip‑synced holiday short that feels more like a quirky TV bumper than a raw model test.

This is a good reference for solo creatives who want to turn custom audio tracks into lighthearted seasonal content without a full live shoot.
“Zero Stars Delivery” returns Johnny and Mog in a fully AI-generated episode
Kling and creative partner ZOOI dropped a new episode of Zero Stars Delivery, a chaotic short where Johnny and Mog crash through glass doors with a pizza box before the “ZERO STARS” title card slams on. episode description The team notes the entire video was created with Kling Video 2.6 (including audio), positioning the series as an ongoing AI‑native cartoon property rather than a one‑off demo.

For animators and serial storytellers, it’s a live case of building recurring characters and slapstick tone on top of video models, then packaging them like a web series.
Producer AI shares weekly staff picks playlist featuring AI-native artists
Producer highlighted a new "Staff Picks" playlist, led by the track Wave of Devotion by C.H.A.R.I.S.M.O, spanning deep chill house, reggae‑tinged DnB, and psychedelic pop rock. playlist announcement The curation sits alongside AI Planet Magazine’s feature on Producer artists, positioning these tracks as part of an emerging AI‑first music scene rather than isolated demos.

If you score your own visuals or direct music videos, this kind of curated playlist is a handy source of AI‑adjacent audio that already has some narrative and aesthetic framing behind it.
🎙️ Interactive voice, music, and live fan activations
Voice and audio workflows for creators: ElevenLabs’ live activations and panels, synced SFX/VO tooling, and curated music picks for mood boards.
SyncLabs’ React-1 promises post-hoc emotional control of AI video performances
SyncLabs introduced React-1, a model that takes existing AI video and re-sculpts the performance using the audio track—controlling timing, emotion, micro-expressions, head direction, and lip sync after the fact rather than re-rendering from scratch react-1 explainer. Instead of a simple mouth-sync, it "rebuilds the whole performance" so avatars stop looking like dubbed characters and act as if they meant every word.
For filmmakers and avatar creators, this is a big workflow shift: you can treat the initial video as a rough take, then iterate on delivery in post the way you might direct an actor across multiple reads. The obvious uses are fixing stiff talking heads, localizing dialogue without dead eyes, and smoothing over script changes without re-running long, expensive generations. The open question is how well it handles fast motion and profile shots, which will matter if you’re aiming beyond straight-to-camera explainers.
Toyota and ElevenLabs launch live Brock Purdy AI fan activation
Toyota’s Northern California dealers and agency HL Advertising teamed with ElevenLabs to ship a live conversational experience where fans talk to an AI-powered version of NFL quarterback Brock Purdy, answer 49ers trivia, and win VIP rewards activation overview. Built on the ElevenLabs Agents Platform, the experience is averaging about 2 minutes of engagement per session across thousands of conversations, which is strong for a branded utility bot.
For marketers and fan-experience teams, this shows what “AI voice + agents” looks like in production: a character with a clear persona, real-time dialogue, and a tight game loop (trivia plus prizes) rather than a generic FAQ bot. If you’re designing similar activations, this is a live benchmark for session length and a concrete example you can point to when selling interactive AI hosts to sports or entertainment partners.
PixVerse pushes tightly synced SFX, music, and VO for short-form video
PixVerse is promoting its ability to auto-sync sound effects, background music, and voiceovers to video cuts, framing it as a way to "elevate your clips" with perfectly timed audio pixverse teaser. The demo shows a phone timeline where sound layers are added and locked to on-screen actions, then previewed as a cohesive short

.
For TikTok/Reels editors or YouTube Shorts creators, the promise is clear: instead of hand-placing whooshes and beats under every cut, you can lean on the tool to generate and align audio layers, then spend your energy on pacing and story. It’s worth checking whether the timing is accurate enough for hard rhythm edits and whether you can export stems for fine-tuning in a DAW.
ElevenLabs Summit panel puts AI co-creation in front of mainstream music execs
ElevenLabs hosted a summit session where will.i.am and Larry Jackson joined CEO Daniel Runcie to talk about how generative tools and real-time AI collaboration are reshaping the creative process for artists and producers summit session. The panel is less a feature launch and more a signal that high-profile music figures are treating AI voices and agents as core parts of future workflows rather than side experiments, which matters if you’re pitching or building tools in this space.
For working creatives, the takeaway is that major-label decision makers are already thinking about how to use AI to expand access and speed up collaboration, not to fully automate artists. That framing will influence which AI-native projects get budget and support over the next year.
Pictory AI’s text-to-speech feature targets quick, polished voiceovers
Pictory is spotlighting its built-in text-to-speech engine for generating "professional quality" voiceovers from scripts, promising natural narration that syncs tightly with video visuals pictory tts overview. Their Academy guide explains how you pick from multiple AI voices, generate line reads from a script, and have them auto-aligned to scenes, with room to adjust scene duration and audio levels afterward tts how-to.
For solo YouTubers and course creators, the appeal is obvious: you can draft a script, test different tones and accents, and get an edit-ready VO track without booking talent or recording your own mic pass. The trade-off is emotional nuance; these voices are clean and clear, but you’ll still want to spot-check emphasis and pacing before publishing.
Producer AI shares multi-genre staff picks playlist for creative mood-boarding
Producer AI highlighted a new Staff Picks playlist headlined by "Wave of Devotion" by C.H.A.R.I.S.M.O, spanning deep chill house, reggae-influenced drum & bass, psychedelic pop rock, and more, with a link to hear the full list staff picks playlist. The thread also notes that AI Planet Magazine’s latest issue features several Producer artists, framing the platform as both a tool and an emerging label-like ecosystem.
If you cut trailers, social spots, or concept films, this kind of curated AI-native playlist is useful as a quick mood board: you get a feel for what contemporary AI-assisted production actually sounds like across genres, and you can mine it for structure and mix ideas even if you’re not using the same tools.
🧪 Long‑form video, 4D rendering, and live avatars
Research teasers for next‑gen video: 4D rendering with camera/light control, decoupled time/camera, streaming avatars, and phase‑preserving diffusion. Mostly model/algorithm previews with demo reels.
Live Avatar aims for real-time, infinite-length audio-driven talking heads
Live Avatar is a streaming avatar model that turns live or pre-recorded audio into an animated talking head, and it’s built to run in real time with effectively infinite duration. Live Avatar reel

The demo shows a 3D-ish head with evolving texture and consistent motion responding fluidly to speech, branded as "Streaming Real-time Audio-Driven Avatar Generation with Infinite Length". For VTubers, educators, and live hosts, the key promise is that you don’t have to pre-bake clips anymore: feed continuous audio and the avatar keeps going without obvious segment boundaries or resets. Under the hood, the paper leans on a streaming architecture that keeps temporal state without drifting facial identity over long runs, which is exactly the pain point for creators trying to stitch short avatar clips into hour-long shows today. If this holds up in open code, it’s a big building block for live AI characters that can stay on-screen as long as your stream does. ArXiv paper
Stable Video Infinity open sources workflows for drift-free, potentially infinite clips
Stable Video Infinity (SVI) is being highlighted as a way to generate 8–10 minute and potentially infinite videos without the usual slow drift and quality collapse that plagues long autoregressive outputs. SVI long demo

The model uses Error Recycling Fine Tuning so it learns from its own mistakes over long horizons, plus a hybrid design: causal between clips and bidirectional within each clip, which better matches how human directors think in shots and sequences. It’s fully open source—code, datasets, training scripts, and benchmarks are all available—and you can customize it with LoRA adapters on relatively small datasets for your own style or IP. Official ComfyUI workflows ship alongside, with separate prompts per clip and padding settings tuned to avoid story drift, making it practical for artists who live inside Comfy graphs. SVI explainer For filmmakers, animators, and storytellers, this is one of the first serious attempts to make multi-minute, multi-scene AI shorts a repeatable workflow rather than a lucky one-off experiment.
BulletTime proposes decoupled control of time and camera for generated video
BulletTime is a research model that explicitly separates time evolution from camera motion, so you can decide how fast the action plays out independently from how the camera orbits or moves. BulletTime demo

The demo shows a detailed city scene where the camera sweeps around while temporal dynamics (like traffic and lighting) can be slowed, frozen, or advanced separately, echoing the “bullet time” effect you’d normally need a multi-camera rig for. For AI directors, that means you could keep a performance’s timing intact but explore totally different camera paths in post, or do the reverse—retime an action beat while holding a camera move you like. The paper, "BulletTime: Decoupled Control of Time and Camera Pose for Video Generation", describes a factorized representation of pose vs. dynamics, which should reduce the usual jitter and mismatched motion you get when you try to prompt a model into a complex move. ArXiv paper
Light-X teases 4D video rendering with explicit camera and lighting control
Light-X is introduced as a generative 4D video system that lets you move a virtual camera around a subject and relight the scene from different angles, all from the same underlying representation. Light X reel

For filmmakers and character artists, this looks a lot closer to working in a DCC or game engine than in a traditional text-to-video model: you get control over camera pose and illumination rather than hoping a prompt change lands the right angle. The short demo shows a human avatar smoothly rotating while light direction and intensity change realistically, hinting at uses like turntables, product spins, and 4D performances where you can pick shots in post instead of re-generating. The linked paper promises "Generative 4D Video Rendering with Camera and Illumination Control", which suggests it’s modeling geometry and reflectance, not just 2D frames, making it especially relevant if you care about continuity between shots and art-directed lighting across a scene. ArXiv paper
NeuralRemaster keeps structure while re-rendering images and video with phase-preserving diffusion
NeuralRemaster introduces phase-preserving diffusion (φ‑PD), a way to remaster or restyle images and videos while keeping their spatial structure almost perfectly intact, instead of blasting them with Gaussian noise and hoping alignment survives. NeuralRemaster mention The core trick, described in the paper "NeuralRemaster: Phase-Preserving Diffusion for Structure-Aligned Generation", is to randomize magnitude in the frequency domain while keeping phase, which encodes geometry. They also add frequency-selective structured noise (FSS) with a single cutoff knob to trade off rigidity vs. freedom. ArXiv paper For creatives, this reads like a more principled version of “keep the layout, change the look”: think re-rendering old footage in a new style, turning rough previs into polished frames, or replacing materials in a shot without losing camera moves or blocking. Because φ‑PD is model-agnostic and doesn’t add inference cost, it’s something you could imagine flowing into existing video pipelines as a higher-fidelity alternative to current img2img and vid2vid hacks when you need precise alignment across frames or cuts.
✍️ Authoring LLMs: reasoning modes for writers & agents
Reasoning‑first LLM updates that impact scripting, beats, and production agents. New: Gemini 3 Deep Think availability, Anthropic Interviewer pilot, DeepSeek V3.2 results, Nova 2.0 agentic metrics, and a Mistral coding board lead.
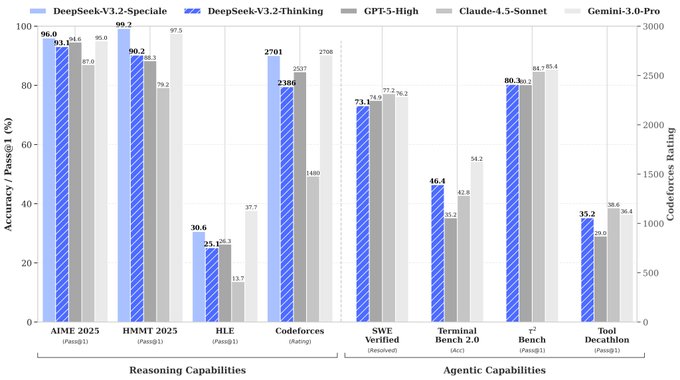
DeepSeek V3.2-Speciale matches or beats GPT‑5 on hard reasoning tasks
DeepSeek has detailed V3.2 and V3.2‑Speciale, claiming the Speciale variant reaches or exceeds GPT‑5 on several elite reasoning benchmarks, including 96.0% Pass@1 on AIME 2025 and 99.2% on HMMT 2025, plus a 2701 Codeforces rating DeepSeek benchmark thread.
On the "agentic" side, the same chart shows competitive scores on SWE Verified, Terminal Bench 2.0, τ²‑Bench and Tool Decathlon, with DeepSeek stressing its "Thinking in Tool‑Use" training on 1,800+ environments and 85,000+ complex instructions. That matters if you’re wiring agents to handle multi-step creative work—say, taking a brief, outlining a video series, then calling separate tools for style boards, scripts, budgets and calendars. V3.2‑Speciale looks like a top-tier brain for those orchestration tasks, especially if you’re comfortable juggling open-source weights and more experimental serving setups.
Amazon’s Nova 2.0 family emphasizes tool use and lower reasoning costs
Amazon has introduced the Nova 2.0 series—Pro, Lite, and Omni—framing them as reasoning- and agent-focused models with strong tool-calling scores and aggressive pricing Nova summary.
Independent Artificial Analysis scores put Nova 2.0 Pro at 62 on their composite Intelligence Index (vs 70 for GPT‑5.1 high and 70 for Claude 4.5 Opus), with standout agentic metrics like 93% on τ²‑Bench Telecom for tool use and 80% on IFBench for step-by-step reasoning
. Pricing is quoted at $1.25 / $10 per million input/output tokens for Pro, and $0.30 / $2.50 for both Lite and the multimodal Omni, which handles text, image, video and speech inputs with text+image outputs. For teams building writing agents, research bots or production pipelines, Nova is interesting not because it’s the absolute smartest model, but because it offers solid tool skills at a lower token bill, which can matter a lot once your agents run all day.
Gemini 3 Deep Think rolls out to Google AI Ultra users
Google has switched on Gemini 3 Deep Think for Gemini Advanced "AI Ultra" subscribers, adding a reasoning-focused mode you can pick directly from the app’s model selector for tougher math, logic and coding prompts. Deep Think runs iterative, parallel chains of thought and, in Google’s own reels, beats Gemini 3 Pro on benchmarks like Humanity’s Last Exam and ARC-AGI-2 while drawing on variants that hit gold medal performance at contests like the IMO and ICPC World Finals Deep Think launch.

For writers and production agents, this is the mode you’d route long puzzle plots, structural script problems, or multi-step story bibles through, while keeping faster, cheaper models for everyday chat. The early demo shows Deep Think explicitly labeled in the model picker, with Google suggesting it when you ask for "solve this logic puzzle" or other complex tasks Deep Think demo. There are already reports of some users getting stuck on the loading spinner, so if you rely on it for critical work it’s worth testing latency and stability before wiring it deeply into your pipelines.
Anthropic tests Interviewer, an AI co-moderator for user research
Anthropic is piloting Anthropic Interviewer, a Claude-powered research assistant that can draft interview guides, ask questions itself, and then summarize and analyze responses under human supervision Interviewer preview.
The UI screenshot shows a friendly onboarding message explaining that the bot will run a 10–15 minute conversation about "how people envision AI fitting into their lives," while explicitly warning participants not to share sensitive personal data. For creatives and product teams, this is basically an AI co-moderator for qualitative interviews: you can let it run consistent, scripted talks with users, then have it cluster themes and pain points for you after. The key is human-in-the-loop: you still design the research goals and interpret the findings, but the low-level asking and transcribing work gets offloaded.
Google Workspace Studio lets teams build internal AI agents
Google has launched Workspace Studio, a builder for custom AI agents that automate multi-step workflows inside Gmail, Docs, Sheets and Drive for Business and Enterprise customers Workspace Studio explainer.

The tool lets non-engineers define logic and actions—reading docs, summarizing, updating files, sending emails, generating reports—then deploy agents that respect existing Workspace permissions and don’t feed customer data back into external training. It’s distinct from Google Flow (scene creation) and AI Studio (app backends); this one is squarely about internal work automation. For creative orgs, that might look like an "episode coordinator" agent that ingests briefs, spins up script docs from templates, tracks feedback in Sheets, and emails status updates, all without you wiring up bespoke APIs. Tutorials are already live on YouTube and in Workspace Help Center, so if your team is on an eligible plan, you can start prototyping agents now.
GPT‑5 credited with core idea in nonlinear quantum mechanics paper
A new physics paper on when nonlinear quantum mechanics breaks relativistic covariance credits GPT‑5 with originating its key idea: applying the Tomonaga–Schwinger formalism to show that certain nonlinear evolutions can’t stay foliation-independent Physics chat screenshot.
According to the summary, the authors used a Generate–Verifier protocol with separate LLM instances to brainstorm and cross-check the argument, and acknowledgments also mention Gemini 2.5 Pro and Qwen‑Max for verification, LaTeX help, and related explorations. This isn’t directly a product launch, but it’s a real-world example of LLMs co-authoring deep reasoning work, not just summarizing it. For you as a storyteller or systems builder, the takeaway is that structured multi-agent workflows (idea generator + critic) are already capable of proposing publishable arguments in niche domains—so similar patterns should be on the table for complex plot logic, puzzle design, or rule-heavy worldbuilding.
Mistral Large 3 tops LMArena’s open-source coding leaderboard
Mistral’s new Mistral Large 3 is now sitting at the top of LMArena’s open-source coding leaderboard, with a preliminary score of 1487 ±26 based on 535 votes and licensed under Apache‑2.0 Coding board snapshot.
For creative coders and tool builders, this makes Large 3 a prime candidate for on-prem or VPC-hosted code agents that sit behind your own UIs, story tools or asset pipelines. You get strong coding performance without SaaS lock-in, so you can, for instance, run a "shot fixer" agent that patches After Effects expressions or Blender scripts entirely on your own infra. The open license also means you can fine-tune or distill it into smaller assistants dedicated to tasks like screenplay formatting, dialogue linting, or batch data wrangling without worrying about restrictive terms.
Hyper-Research turns Claude Opus into a multi-URL research agent
Hyperbrowser has released Hyper-Research, an open-source tool that scrapes multiple URLs, then uses Claude Opus 4.5 to synthesize comparison tables, charts, and cross-source summaries for your questions Hyper-Research launch.

In the demo, a user drops several links into a project, hits analyze, and gets back structured insights across all sources instead of a single-page summary. For writers and producers, this is effectively a prebuilt research agent: you can feed in reference sites, brand decks, prior campaigns, or academic PDFs and ask things like "compare how each describes target audience" or "what visual motifs are shared". Because it’s open source, you can also fork it into an in-house "show bible reader" that reads old seasons’ scripts and style guides before it ever pitches you a new episode beat project page.
Model Finder app surfaces unreleased OpenAI model “gpt‑5.1‑codex‑max”
A screenshot from the community-built Model Finder app shows a new OpenAI model identifier, "gpt‑5.1‑codex‑max", listed under "NEW OpenAI Models" for the Responses API Model id screenshot.
There’s no official spec, pricing, or context window yet, but the name strongly suggests a high-budget coding or tools variant sitting alongside GPT‑5.1. For people building authoring agents—think "fix my script macro" bots, InDesign automation, or Unity cutscene generators—this is a signal to watch: OpenAI likely plans a more powerful, possibly more expensive, code-centric backend. If it follows past Codex patterns, expect better function calling and repo-scale understanding rather than big gains in prose style.
Gemini 3 Deep Think mode promoted again with benchmark reel
A follow-up thread again highlights Gemini 3 Deep Think for Google AI Ultra subscribers, this time focusing on a benchmark-heavy reel that flashes scores against GPT‑4 and Claude 3 Opus on reasoning, math, and coding tasks Deep Think demo.
This doesn’t add new capabilities beyond the earlier launch, but it does reinforce Google’s framing: Deep Think is for hard problems where you’re willing to pay with latency and tokens in exchange for extra passes of structured reasoning. If you’re scripting agents that decide when to "think harder"—for example, when a story puzzle doesn’t resolve or a production schedule has conflicting constraints—this is a good candidate for the slow path, with cheaper models handling first drafts and routine edits.
⚖️ Brand safety, scams, and legal discovery
Where AI meets audience trust and the courts: a luxury ad backlash over AI visuals, UK scam ads with AI storefronts, and a discovery order for 20M anonymized ChatGPT logs.
US judge orders OpenAI to hand over 20M anonymized ChatGPT logs
In the New York Times–led copyright lawsuit, US Magistrate Judge Ona Wang has ordered OpenAI to produce 20 million anonymized ChatGPT user logs within seven days, rejecting the company’s privacy objections as long as exhaustive de‑identification is applied. OpenAI logs report
The logs are meant to test whether ChatGPT reproduced copyrighted news content and how often, directly probing memorization and training‑data use. OpenAI logs report For AI storytellers and studios, this is a big signal: discovery can now reach deeply into model outputs, not just training PDFs, and courts are starting to treat generation logs as evidence. That’s likely to push platforms toward stricter retention policies, stronger privacy guarantees, and clearer answers on what exactly went into the models you’re building on.
HAVEN’s “I Run” AI vocal sparks removal, royalties fight, and labelling calls
The dance track “I Run” by HAVEN used Suno to turn producer Harrison Walker’s voice into a soulful female vocal that many listeners assumed was an unreleased Jorja Smith song; after it blew up on TikTok, labels pushed platforms to remove it from charts and streaming over deepfake‑style impersonation concerns. I Run case explainer

Jorja Smith’s label FAMM is now asking for a share of royalties and questioning whether the underlying AI models were trained on her catalogue, turning the case into a reference point for vocal likeness, training consent and compensation. I Run case explainer HAVEN later re‑released the song with a human singer, but the debate hasn’t cooled: artists and DJs are calling for clear AI‑vocal labels and guardrails so fans know what they’re hearing and whose voice—or data—made it possible. I Run case explainer
Meta accused of letting AI boutique scam ads run “wild” in the UK
A BBC and Which? investigation says Facebook and Instagram hosted dozens of scam boutiques built almost entirely with AI—perfect founders’ headshots, cozy shop photos and staged “UK” products—that actually shipped cheap items from Asia, misleading people who thought they were supporting local makers. Meta scam explainer Users reported the pages but often got no response until after the exposé, when Meta finally removed six of the companies. Meta scam explainer For designers and brand teams, this is a warning shot: AI‑polished imagery and backstories are now standard scam tools, and if your ads appear alongside this stuff, trust in the whole feed drops. It also raises the bar on visual authenticity signals—behind‑the‑scenes footage, verifiable addresses, or third‑party reviews—because glossy AI storefronts are no longer a sign of legitimacy.
Valentino’s AI DeVain bag ad slammed as “creepy” and off‑brand
Valentino’s new DeVain bag campaign, built around heavily AI‑generated visuals, is being roasted by fashion fans as “creepy”, “cheap” and “uninspired,” with many saying it feels totally misaligned with a luxury house that usually leans on craft and human artistry. Valentino backlash explainer

Commentators quoted by the BBC argue that when AI becomes part of a luxury brand’s visual identity, people worry efficiency is replacing artistry, so transparency alone doesn’t fix the perception problem. Valentino backlash explainer For creatives, the lesson is blunt: AI will amplify whatever idea you bring to it—if the core concept looks like low‑budget collage work, the tech makes that more obvious, not less.
🎁 Non‑Kling promos & credits to grab
Time‑limited perks for image/video creators beyond today’s Kling feature: Freepik’s big credit pool, holiday effects, and a Seedream‑powered plan discount.
Freepik Day 3 offers 800,000 AI credits to 100 creators
Freepik’s #Freepik24AIDays hits one of its best-value drops so far: today they’re giving away 800,000 AI credits split across 100 winners (8,000 credits each). day 3 promo

Following up on ai advent launch that outlined the 24‑day calendar, today’s Day 3 rules are simple: post your best Freepik AI creation, tag @Freepik, use the #Freepik24AIDays hashtag, and submit via the official form to enter. entry reminder You don’t need to be a power user yet; one strong piece that shows what you can do with their models is enough, and 100 winners means the odds are better than most contests right now. Creators who are already using Seedream 4.5 or Nano Banana Pro inside Freepik can treat this as effectively a year’s worth of experiments if they land the full 8k‑credit bundle. (Form link is in the announcement.) entry form
PolloAI’s Christmas Special adds 50+ AI effects with free uses and credits
PolloAI has switched on a "Christmas Special" tab powered by its Pollo 2.0 engine, packing 50+ new holiday effects, each with three free uses available until December 26. christmas special promo

For AI creators, this is a cheap way to knock out festive shorts, headers, and social posts: you can sample every effect three times before paying, which is plenty to find a few signature looks for a campaign. The team is also stacking a short 12‑hour push where anyone who follows, retweets, and comments "XmasMagic" gets 100 credits, which makes the pack even more attractive if you’re light on budget but heavy on client requests. speed promo
🧩 OSS turbulence: ComfyUI Nodes 2.0 feedback loop
Active community governance around a critical node‑based tool. Today: ComfyUI addresses pain points, promises fixes, keeps legacy canvas, and prioritizes custom node migration.
ComfyUI responds to Nodes 2.0 backlash, keeps legacy canvas and prioritizes custom nodes
ComfyUI’s core team publicly addressed the wave of frustration around the new Nodes 2.0 interface, stressing that the goal is to make ComfyUI "the most powerful and loved" open creative tool while acknowledging that the rollout has been bumpy. They reiterate a ship‑fast/fix‑fast philosophy and say they’re reading "every frustration, bug, and meme" from the community. nodes 2 update
In a follow‑up, they confirm that the legacy canvas mode is not being removed and can be switched back on in settings, so existing workflows won’t be forcibly broken. follow up thread They also call out custom node authors as "the heartbeat" of the ecosystem and say supporting third‑party nodes through the transition is a top priority, including working directly with maintainers so nothing people rely on gets left behind. For artists and pipeline builders who depend on ComfyUI graphs every day, the message is: expect rapid iteration on Nodes 2.0, but you can keep shipping on the old canvas while the new system matures.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught