ElevenLabs on fal adds $0.90/min dubbing – TELUS cuts onboarding 20%
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
fal expanded its voice stack by shipping ElevenLabs endpoints as callable building blocks; Video Dubbing is listed at $0.90/min, Scribe v2 speech-to-text at $0.008 per input audio minute, and Voice Changer at $0.3/min; the move turns translation/dubbing, transcription, and voice conversion into pipeline steps without wiring ElevenLabs directly. Separately, TELUS Digital says it used ElevenLabs Agents simulations to cut onboarding time 20% for 20,000+ contact-center hires/year, claiming 50,000+ simulated customer conversations so far; TELUS cites latency, voice quality, and self-serve tooling, but shares no independent measurement artifacts.
• fal video gen: Wan 2.6 I2V Flash claims up to 15s clips with optional synced audio and “under 1 minute” runs; Vidu Q2 Reference-to-Video Pro adds multi-reference (images+videos) plus separate face ref.
• Workflow packaging: Freepik ships Custom Templates as shareable links for prompts/characters/models/refs; fal adds FLUX.2 [klein] trainers for 4B/9B plus edit LoRAs.
The throughline is commoditizing production glue—endpoints and templates—while outcome claims (training speedups; model latency) remain mostly vendor-reported.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught
Top links today
- Freepik Custom Templates announcement
- Freepik template gallery and builder
- Wan 2.6 image-to-video Flash on fal
- ElevenLabs Scribe v2 and dubbing on fal
- FLUX.2 [klein] LoRA trainer on fal
- FLUX.2 object removal LoRA playground
- FLUX.2 object removal LoRA weights
- ComfyUI VFX and games workflow survey
- FrankenMotion part-level human motion paper
- PhysRVG physics-aware video generation paper
- Hailuo 2.0 camera motion example thread
- Guide to Kling Motion Control workflow
- Higgsfield unlimited Kling motion control offer
- Veo 3.1 ingredients-to-video on Pollo AI
- HyperPages open-source web research writer
Feature Spotlight
Last‑chance creator deals (big ones only): unlimited Motion Control + Veo credits
Multiple creators amplified an end‑of‑window offer for a full month of unlimited Kling Motion Control—one of the few promos that can materially change how much video you can ship this week.
Today’s feed is dominated by time‑boxed access deals, especially a final-hours push for unlimited Kling Motion Control via Higgsfield. Also includes short window Veo 3.1 credit/discount promos; excludes non-urgent coupon noise.
Jump to Last‑chance creator deals (big ones only): unlimited Motion Control + Veo credits topicsTable of Contents
⏳ Last‑chance creator deals (big ones only): unlimited Motion Control + Veo credits
Today’s feed is dominated by time‑boxed access deals, especially a final-hours push for unlimited Kling Motion Control via Higgsfield. Also includes short window Veo 3.1 credit/discount promos; excludes non-urgent coupon noise.
Higgsfield pushes a final-hours “unlimited Kling Motion Control” month offer
Higgsfield (Kling Motion Control): A time-boxed “last 8 hours” offer is being promoted as 30 days of unlimited Kling Motion Control, bundled with “unlimited” access across Kling 2.6, Kling 2.5, Kling O1, and Kling Edit, according to the Final-hours offer.

The same thread also claims a 9-hour engagement window where “Retweet & reply” triggers 220 credits via DM, as described in the Final-hours offer. Amplification posts echo the urgency (“8 hours left”) in the Reminder clip, and repack the same deal as a “30 days with no limits” CTA in the Repost CTA.
Pollo AI runs a 24-hour Veo 3.1 credits promo alongside 50% off until Jan 23
Veo 3.1 on Pollo AI (Ingredients-to-Video): Pollo AI says Veo 3.1 Ingredients to Video is live, pitching short video generation from reference images plus a prompt, with 50% off for all users before Jan 23 and a 24-hour “Follow + RT + Comment = 199 free credits” window, as stated in the Promo details.

They frame the product deltas as: improved character/background/object consistency, native 9:16 and 16:9, 4K output (including “Fast mode”), and audio toggles (sound on/off), matching the What’s new list.
Lovart names 10 winners for its Veo 3.1 500-credit giveaway
Lovart (Veo 3.1 campaign): Following up on Credit giveaway (12-hour promo tied to the Veo 3.1 upgrade), Lovart posts a winners list and says 10 accounts will receive 500 credits each, telling recipients to check DMs in the Winners announcement.
The same post restates the Veo 3.1 pitch points—1080p and 4K upscaling, improved Ingredients-to-video consistency, and vertical support—inside the Winners announcement.
Hailuo AI closes its membership promo and says winner DMs are sent
Hailuo AI (membership giveaway): Hailuo says its promotional event is now over and that it has sent DMs to all winners for next steps, per the Event ended notice.
The referenced campaign copy included a bundle-style pitch (“Free now” access mentions Nano Banana Pro, Seedream 4.5, and GPT Image 1.5) plus a 56% off yearly plans claim, all summarized in the Event ended notice.
🧩 Repeatable AI film pipelines (multi‑tool): boards → refs → motion → finish
Multi-step creator pipelines show how teams are chaining image models, storyboards, and video generators into production-like workflows. Excludes the Higgsfield/Kling promo itself (covered in the feature) and focuses on process you can copy today.
ProperPrompter’s 3×3 storyboard grid pipeline: Nano Banana → Veo 3.1 → Kling 2.6
ProperPrompter (Nano Banana Pro + Veo 3.1 + Kling 2.6): Following up on Shot grid (grids as a continuity bridge), a detailed multi-step pipeline emerges: style-transfer a character in Nano Banana Pro, generate a 3×3 storyboard grid, pick 3 panels, run Veo 3.1 Ingredients, then finish with Kling 2.6 Motion Control for motion polish, as spelled out in the Workflow steps post.

• Where consistency comes from: the workflow uses a storyboard grid as an intermediate “anchor” (instead of jumping from single still → video), which is described explicitly in the Workflow steps thread and shown in the evolving outputs in Coffee prop clip.
• Audio as a patch layer: the creator notes they “had to edit in audio from another output,” treating sound as modular post rather than coupled to the final generation, per the Workflow steps description.
The thread is unusually candid about iteration cost (“many attempts”), which is often omitted from polished demo reels, as noted in Workflow steps.
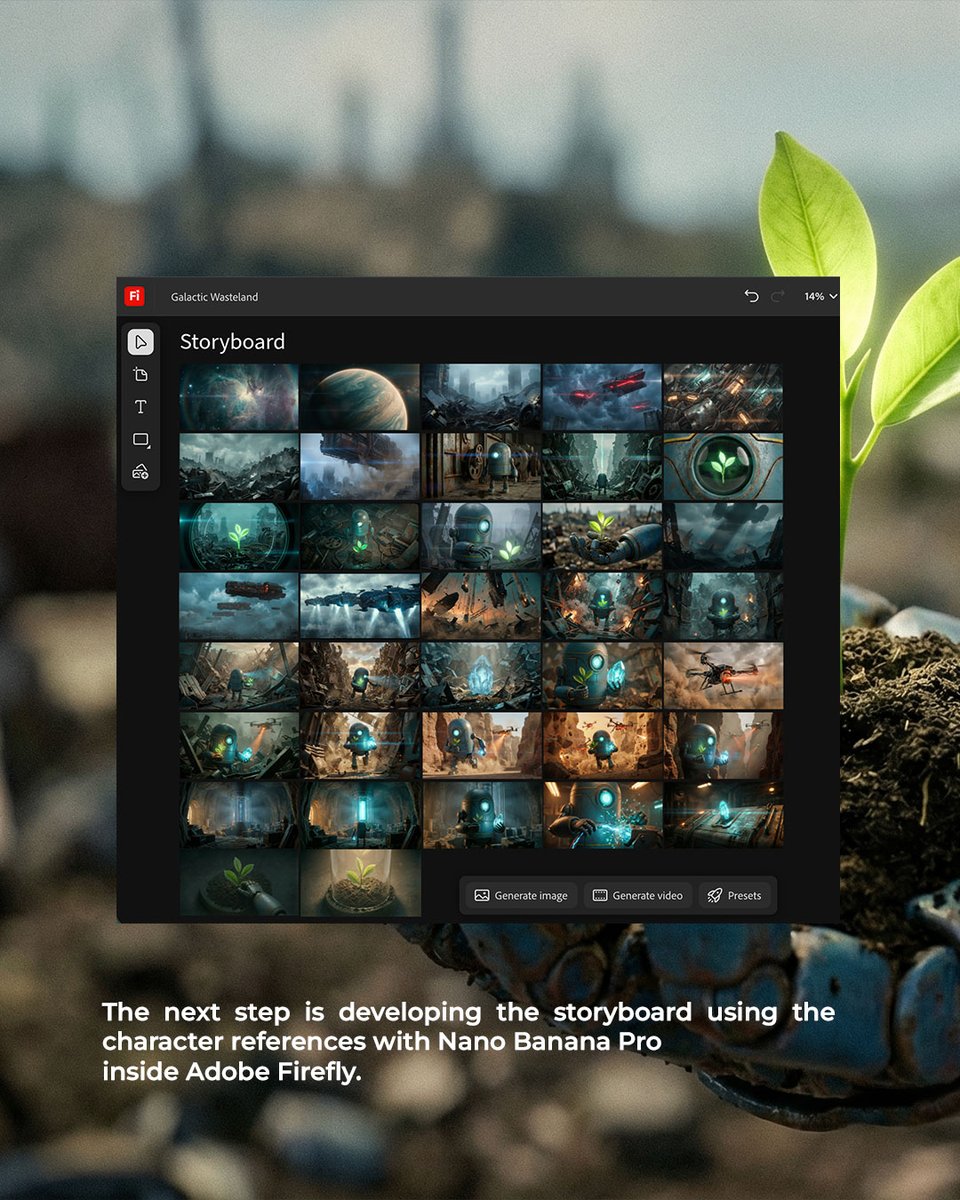
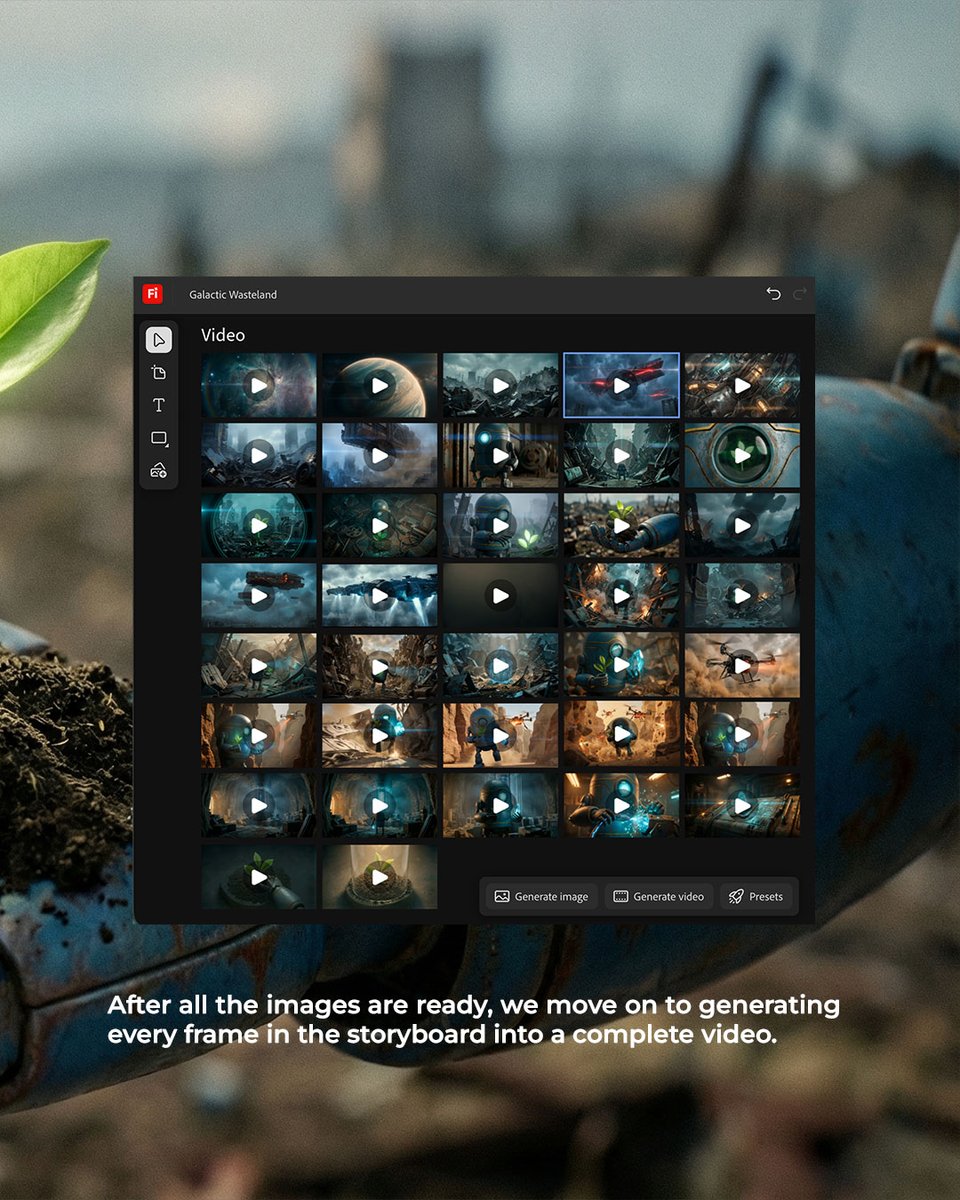
Adobe Firefly Boards: infinite-canvas storyboard to Topaz Astra finishing
Firefly Boards (Adobe): A concrete “boards-first” pipeline is shown: rebuild a concept inside Firefly Boards on a single infinite canvas to explore characters, mood, and storyboard, then enhance the locked frames using Topaz Astra upscaling within the same workspace, as demonstrated in the Boards workflow breakdown and reinforced in the Upscaling step note.

• Why Boards matters operationally: the pitch is reducing app-hopping—references + alignment + storyboard happen in one canvas, per the Boards workflow breakdown walkthrough.
• Finishing pass placement: Topaz Astra appears after storyboard lock (not mid-ideation), according to the Upscaling step note follow-up.
The example is framed as a remake workflow (“Galactic Wasteland”), suggesting Boards is being used as a pre-production control surface, not just a moodboard, per the Boards workflow breakdown.
Freepik Custom Templates package creative workflows into shareable links
Custom Templates (Freepik): Freepik announces Custom Templates that bundle prompts, characters, model choices, and reference assets into a single shareable link that can be reused across images, video, and audio, as shown in the Templates announcement and recapped with workflow standardization framing in the Why templates matter.

• What actually gets standardized: the template is described as carrying prompts, characters, models, and references together, per the Templates announcement description.
• Cross-media intent: the “same creative DNA across formats” claim (images/videos/audio) is repeated in the Why templates matter explainer.
It’s positioned less like “prompt saving” and more like a reproducibility primitive for teams and clients, as framed in the Why templates matter.
ImagineArt “Cinematic Workflow” pack organizes prompts by shot type for reuse
ImagineArt (Cinematic Workflow): A template-style workspace is shared that groups prompts by cinematic shot types—positioned as “plug-in” structure for iterating scenes (slow buildup, high action, zoom variants) without reorganizing every project, as described in the Workflow preview clip and expanded with access steps in the How to access steps.

• Reusable structure: the workflow is explicitly divided into sections like “Slow Buildup Scenes” and “High Action Scenes,” with zoom variants called out in the How to access steps thread.
• Porting across media: it’s framed as adaptable for both image and video prompts (keep core vibe, tweak per medium), per the How to access steps explanation.
The emphasis is on a repeatable shot taxonomy rather than a single prompt, which is the key difference versus typical one-off “cinematic prompt” drops, per the Workflow preview clip.
Dor Brothers hiring post reads like a modern AI filmmaking stack checklist
The Dor Brothers (AI filmmaking stack): A hiring call doubles as an explicit “baseline stack” list—Veo 3.1, HailuoAI / Minimax, Kling 2.6 / Kling Motion, Nano Banana Pro, Midjourney, plus traditional finishing tools like Photoshop, Premiere/DaVinci, and Topaz Video Enhance AI—with a requirement that portfolios include work made in the last 3 months, per the Hiring stack list.
The list is effectively a snapshot of what one studio thinks a full-time AI filmmaker must be fluent in right now, according to the Hiring stack list.
Lovart interior pipeline: room photo + wishlist into Nano Banana Pro and Veo 3.1
Lovart (Nano Banana Pro + Veo 3.1): A two-input creative workflow is demoed for interior redesign: upload a room photo plus wishlist items, then use Nano Banana Pro and Veo 3.1 to generate transformed room visuals, per the Room redesign demo.

The clip positions “wishlist items” as the constraint layer (objects to keep / insert) and the room photo as the layout anchor, as shown in the Room redesign demo.
Runway Story Panels as a three-shot storyboard for a game-vehicle revival
Runway (Story Panels): A storyboard-to-shot-planning pattern shows up via a three-panel sequence (garage reveal → launch → city drive) used to “revive” a favorite game vehicle, framed as iterating cinematic beats from panels rather than generating a full edit end-to-end, per the Story Panels example.
The panels read like a shot list with continuity baked in (lighting, angle, motion beat), as visible in the Story Panels example.
🧍 Identity & motion transfer: keeping a character stable under chaos
Continuity-focused posts today lean on motion transfer and reference stability—especially demonstrations of holding a visual motif through aggressive movement. Excludes pricing/“unlimited” chatter about Kling Motion Control (feature).
Kling 2.6 Motion Control keeps a hypnotic iris spiral stable under chaos
Kling 2.6 Motion Control (Kling): A creator stress-tested identity/continuity by asking Kling 2.6 to preserve a very specific visual motif—a hypnotic spiral iris—from a reference image while driving aggressive, chaotic movement, and reports it stayed readable even under heavy motion, as described in the chaotic motion note and reiterated in the workflow recap.

What matters for character stability work is the failure mode this avoids: small, high-frequency details (eye patterns, makeup, tattoos, logos) are usually the first thing to “melt” when motion gets energetic; this example suggests Kling’s motion transfer can sometimes keep those identity anchors intact, at least for short clips, as shown in the close-up iris render and echoed in the second clip example.
Luma Dream Machine Ray3 Modify demos fast recharacterization across styles
Ray3 Modify (Luma Dream Machine): LumaLabsAI shared a “choose your character” demo where a single figure is rapidly reimagined across multiple looks while keeping the underlying form coherent, as shown in the Ray3 Modify demo.

This lands as a continuity tool for pre-production: instead of generating new characters from scratch each time (and risking drift), the workflow implies iterating style/identity layers while keeping pose and silhouette more stable.
OpenArt shows a two-input motion-sync flow: motion video plus character reference
Motion-sync video (OpenArt): OpenArt is pitching a simplified “viral dance” continuity workflow: feed a source video for movement and a single reference image for the character look, then generate a motion-matched clip (powered by Kling 2.6 Motion Control), as shown in the motion-sync demo.

• Inputs stay atomic: motion comes from the source performance clip, while identity comes from the still reference—this separation is the core trick for keeping a consistent character while swapping dances.
• Where to try it: the flow is presented as a dedicated generator page, linked in the motion-sync page.
Apob AI markets motion-to-avatar transfer for rapid persona switching
Motion-to-avatar transfer (Apob AI): Apob AI is explicitly positioning its product around mapping your movements onto a digital avatar and spinning up “a new persona every single day,” per the motion-to-avatar pitch, with adjacent framing that “one clip” can become “thousand identities,” as shown in the identity scaling claim.

The creative relevance is straightforward: it treats performance capture as reusable source material, then swaps identity/character skin on top—useful for creators trying to maintain motion quality while iterating the “who” quickly.
Hailuo 2.0 gets singled out for “camera potential” in creator chatter
Hailuo 2.0 (Hailuo/Minimax): A reposted creator comment flags that Hailuo feels especially strong on camera behavior—“camera potential” is the phrase—suggesting shot movement/coherence is what’s standing out versus purely stylistic rendering, as seen in the camera potential comment. A separate Hailuo repost highlights experimentation with stop-motion/time-lapse assembly prompts, pointing at camera/temporal control as a creative lever, per the lego stop-motion prompt.
No performance metrics or settings are specified in the tweets, so treat this as directional signal rather than a verified feature claim.
🎬 Video models & generators: faster i2v, reference stacks, action tests
New and refreshed video generation options center on speed (sub‑1‑minute runs), longer clips, and richer reference control. Excludes identity-lock discussions (handled in Character Consistency).
fal ships Wan 2.6 Image-to-Video Flash with 15s clips and optional synced audio
Wan 2.6 Image-to-Video Flash (fal): fal says Wan 2.6 I2V Flash is now live—supporting videos up to 15 seconds, with optional synchronized audio, and a headline claim of under 1 minute generation time, per the launch post in Fal launch post.

For creative pipelines, this positions Wan 2.6 Flash as a “fast iteration” i2v option: longer-than-micro clips (15s) without the usual multi-minute wait, plus a single toggle decision on whether you want the model to emit audio or keep audio fully in your edit stack.
Vidu Q2 Reference-to-Video Pro lands on fal with multi-reference stacks
Vidu Q2 Reference-to-Video Pro (fal): fal is also putting Vidu Q2 Pro live as a reference-driven generator—explicitly supporting multiple videos and images as references, plus a split where you can use a character reference for full-body stability and a separate face reference for expressions, as described in Feature list.
The product surface fal points to is the model page linked in Model page, which frames this as more flexible than plain image-to-video (because you can stack references rather than “one source image + prompt”).
“Colossus” crime-drama reel is being used as an AI action proof clip (4K)
Colossus (Diesol): a short “gritty crime drama” reel is being positioned as evidence that current gen video models can hold up under fast action beats—gunplay, chases, explosions—per the showcase in Crime drama clip, with a separate callout to watch it in 4K in 4K link note.

This functions like an informal stress test: rapid motion + hard cuts + dark lighting, which are the spots where many generators still smear detail or lose coherence.
Kling “geologic time-lapse” prompt: volcanic vent to landmass in one clip
Kling prompt idea (time compression): a reposted prompt concept frames a big cinematic beat as a single continuous transformation—“from a single volcanic vent in a primordial ocean, land rises and cools; time compresses violently…”, as quoted in Prompt excerpt.
The creative takeaway is the structure of the beat: one clear starting state, one physical process, and explicit pacing language (“time compresses”)—useful when you want a montage-like arc without cutting between separate scenes.
Food “recipe” microfilms keep showing up as a repeatable Kling format
Nano Banana Pro + Kling (format signal): Kling is amplifying a “recipe” style short—framed as “powered by Google Nano Banana Pro + Kling AI”—as seen in the repost in Recipe repost.
The pattern here is less about a single model feature and more about a template creators can repeat: compact lifestyle/cooking spots where the edit rhythm (quick steps, punchy reveals) matches the strengths of short-form generation.
🖼️ Image makers in production mode: boards, concept art, and reference-ready frames
Image posts skew toward frames that can feed video pipelines (storyboards, character sheets, concept stills) rather than pure art dumps. Excludes prompt-only drops (those live in Prompts & Style Refs).
“Pro-Athlete” reads like a character sheet with detail cut-ins
Character concept stills (iamneubert): A full-body hero image plus a three-panel detail strip (arm build, portrait, spearhead) presents a cyber-prosthetics character in a sheet-like format, as posted in Pro-Athlete images.
The structure mirrors production references: one silhouette for read, then close-ups for materials/mechanics—useful when handing off to motion/3D or building consistent variants.
“Pure cinéma” still packs keep showing up as a publishable unit
Cinematic still packs: Another four-image “Pure cinéma” set leans into tight medieval close-ups—faces, armor detail, torch-lit contrast—continuing the still-pack-as-deliverable format following up on Still pack format (dark regalia gallery) and shown in Close-up set.
The new pack stays consistent in lighting language (warm practicals, shallow depth cues), which makes it easy to treat as a single cohesive reference block rather than isolated images.
A red-portal staircase frame lands as clean key art
Key art framing (Bri Guy AI): A stark concept still—dark stairwell leading to a bright red oval “exit”—circulates as a poster/thumbnail composition in Portal stair image.
The image’s value is its readability: one dominant shape, one subject scale cue, and a single accent color that survives heavy cropping.
Midjourney --sref 2773156114 anchors a modern storybook gothic look
Midjourney (Artedeingenio): A style reference pack shared with --sref 2773156114 emphasizes a cinematic storybook feel with a soft gothic edge, positioned as a reusable aesthetic in Style pack examples.
The sample set spans character, creature-scale contrast, and moody negative space—elements that translate into consistent boards when you need multiple scenes to “feel like the same film.”
Midjourney --sref 345035779 targets European comic editorial frames
Midjourney (Artedeingenio): A European comic-style digital illustration reference—framed as useful for slice-of-life, drama, and introspection—was shared with --sref 345035779 in Euro comic references.
The look leans on heavy outlines, simplified shapes, and muted palettes, which can help maintain character identity across multiple storyboard beats.
A Nokia 5110 SMS still shows the power of prop-driven frames
Prop-driven stills (fofrAI): A simple “photo of a Nokia 5110 showing a short sms message” prompt yields a period-specific insert shot—screen glow, table surface, and background clutter all doing the era work—per Nokia SMS frame.
This kind of prop close-up often functions as a bridge shot in storyboards (the object carries time/place without needing a wide scene).
A single crossover still delivers a whole scene premise
Scene-premise frames (fofrAI): A generated office/tableau places Mulder and Scully opposite Buffy with Giles exasperated in the back, plus the “I WANT TO BELIEVE” poster as a location stamp, as shown in Crossover still.
It’s a good example of “one frame, one joke, one room”: enough staging detail to blueprint a dialogue scene without generating coverage yet.
Niji 7 style ref pushes marbled, swirled materials on characters
Niji 7 (Mr_AllenT): A Niji 7 style reference using --sref 3557083389 highlights a distinctive marbled/swirl texture applied across face, hair, and armor, as shown in Niji style sample.
For production frames, this reads like a materials bible: the texture treatment is the identity, and the silhouette stays simple enough to reuse across poses.
A rusted archway frame lands as gritty environment reference
Environment frame (alillian): A decayed teal archway leading into red/green bokeh light functions as a gritty transitional environment still, as shared in Forgotten checkpoint image.
It’s the kind of “between locations” frame that can anchor an establishing beat or a chase corridor without needing complex set dressing.
Typography-covered garment becomes a costume lookdev reference
Fashion lookdev (Bri Guy AI): A night street fashion still centers a garment fully covered in glowing typography, paired with metallic boots and low-angle framing, as shown in Night fashion still.
The frame reads like a costume test: the pattern density, highlight behavior, and pose are the “spec,” more than the identity of the model.
📎 Copy‑paste prompts & style refs (Midjourney/Niji + cinematic text prompts)
Lots of immediately usable prompt payloads today: Midjourney srefs, Niji 7 prompt formulas, and cinematic audio-aware video prompts. This category is strictly for reusable text/settings, not general tool news.
Hand-forged metal figurine prompt template (aged copper/bronze/steel patina)
Prompt template (image gen): Azed shared a copy-paste prompt for a “hand‑forged metal figurine” look—aged copper/bronze/blackened steel, riveted joints, hammered texture, on a rough stone plinth with a dark charcoal backdrop—plus multiple subject examples in the prompt and examples.
The prompt text from the prompt and examples is:
“A hand-forged metal figurine of a [subject], assembled from aged copper, bronze, and blackened steel, riveted joints and hammered texture visible. Stands in a poised stance on a rough stone plinth, set against a dark charcoal backdrop with cool bluish shadows. Evokes an old-world artisan sculpture, rich in patina and character.”
Midjourney --sref 5890347778: high-contrast sketch portrait style pack
Midjourney (style reference): Azed shared a newly created style reference, --sref 5890347778, that consistently yields crisp, high-contrast ink/sketch character portraits (strong linework, minimal shading) as shown in the style ref gallery.
The examples in the style ref gallery make this useful for fast character studies, comic-keyframe lookdev, and storyboard-y portrait sheets where you want readable silhouettes over painterly realism.
Midjourney --sref 2773156114 for modern storybook + soft gothic illustration
Midjourney (style reference): Artedeingenio posted --sref 2773156114 as a “modern storybook” illustration look with a cinematic, soft-gothic touch, with multiple consistent samples in the style ref examples.
The style ref examples read well for indie animation pitch art and illustrated-book spreads where you want mood and staging without heavy texture noise.
Midjourney --sref 345035779 for European comic-style editorial illustration
Midjourney (style reference): Artedeingenio shared --sref 345035779 for a Franco‑Belgian / indie editorial comic look (heavy outlines, flat colors, slice‑of‑life framing), with reference images shown in the style ref samples.
The positioning in the style ref samples is geared toward dialogue-heavy scenes, urban narratives, and graphic-novel panel staging rather than glossy concept art.
Niji 7 character-sheet pack: Pirates of the Caribbean in One Piece style
Niji 7 (prompt pack): Artedeingenio shared a set of character re-designs that translate Pirates of the Caribbean characters into a One Piece‑like anime style, noting the exact prompts live in the ALT text of each image in the character sheet thread.
The character sheet thread is useful as a ready-made pattern for “franchise cast → unified anime universe” transformations, including aspect ratio flags (e.g., --ar 9:16) and a consistent style target (Niji 7).
Seedance 1.5 Pro: corrected handheld battlefield prompt with sound cues
Seedance 1.5 Pro (video prompt): Azed posted a corrected cinematic prompt that bakes in camera language plus sound design cues (shaky handheld follow, muffled gunfire, distant thuds), with the corrected text spelled out in the correct prompt and a short demo clip attached to the Seedance post.

The corrected prompt from the correct prompt is:
“A wide shot of soldiers advancing through a smoke-filled battlefield, cutting into a shaky handheld follow. Explosions thud heavily in the distance, debris raining down, muffled gunfire echoing unevenly. Wind pushes smoke across the frame, intense cinematic war atmosphere.”
Niji 7 --sref 3557083389: marbled swirl texture character look
Niji 7 (style reference): Mr_AllenT dropped a Niji look using --sref 3557083389 --niji 7, which produces a distinctive marbled/swirl texture mapped across faces and armor-like shapes, as shown in the single-image style example.
Because the single-image style example keeps form readable while stylizing surface detail, it’s a strong fit for character sheets and “alt skin” concept variants.
Niji 7 painterly pop-art prompt: art deco glamour poolside portraits
Niji 7 (prompt example): Artedeingenio highlighted a Niji 7 prompt that leans into art‑deco glamour / pop‑art portrait energy (Patrick Nagel adjacency), with the full copy‑paste prompt included in the ALT text of the first image in the poolside prompt example.
The ALT prompt shown in the poolside prompt example is:
“a painting of a girl lying by the pool, in the style of art deco glamour, patrick nagel, pop art influenced portraits, restrained serenity, bold manga lines, ivory, punctured canvases, captivating gaze --ar 16:9 --niji 7”
Niji 7 prompt: retro anime still photo collage (--chaos 10 --ar 3:4)
Niji 7 (prompt snippet): Mr_AllenT shared a compact collage formula aimed at “retro anime still” compositions with surreal snapshot layering, including the exact flags --chaos 10 --ar 3:4 --niji 7 in the prompt and collage outputs.
The prompt text in the prompt and collage outputs is:
“Retro anime still, [Subject], surreal, picture collage --chaos 10 --ar 3:4 --niji 7”
🪄 Finishing tools: LoRA-based edits, cleanup, and upscaling passes
Finishing and edit utilities show up as practical time savers: object removal/background removal LoRAs and upscaling inside storyboard tools. Excludes core generation and focuses on enhancement/compositing steps.
FLUX.2 [klein] 4B Object Remove LoRA is live with downloadable weights
FLUX.2 [klein] 4B Object Remove LoRA (fal): fal posted a dedicated release for an object removal LoRA (highlight/remove unwanted objects, then fill naturally) with a runnable fal Playground link and Hugging Face weights, as shared in the Object Remove LoRA post and linked via the live demo at fal playground plus the download page at model weights.
This is the kind of “last-mile” tool that matters when a shot is 90% right but has one distracting element—especially for thumbnails, posters, and product shots where manual cleanup time dominates.
fal ships FLUX.2 [klein] Trainers for fast LoRA-based personalization
FLUX.2 [klein] Trainers (fal): fal says it’s now possible to train custom LoRAs for FLUX.2 [klein] 4B Base, 4B Edit Base, 9B Base, and 9B Edit Base, framing it as a fast path to style/character/concept personalization for practical editing and cleanup workflows, per the trainer announcement.
The notable creator angle is that this positions “finishing passes” (outpaint/zoom/object cleanup/background extraction) as something teams can adapt to their own footage/style guide rather than treating as one-size-fits-all model behavior.
Firefly Boards workflow adds Topaz Astra upscaling after the storyboard is locked
Firefly Boards + Topaz Astra (Adobe/Topaz): a workflow breakdown shows using Adobe Firefly Boards as an “infinite canvas” for remixing references and locking a storyboard, then enhancing finalized frames with Topaz Astra upscaling inside the same Boards flow, per the Boards workflow breakdown and the follow-up note in Astra upscaling step.
This frames upscaling as a post-lock finishing pass (after creative direction is set), rather than something you do while still iterating on story and composition.
🎙️ Voice, dubbing, and agentic call centers (ElevenLabs everywhere)
Voice posts today are unusually concrete: enterprise training results plus new endpoints for transcription, voice conversion, and dubbing via fal. Excludes voice features inside video generators (those stay in Video).
TELUS Digital cites 20% onboarding-time drop using ElevenLabs Agents simulations
ElevenLabs Agents (ElevenLabs): TELUS Digital says it cut onboarding time by 20% for 20,000+ contact-center hires per year by using AI voice simulations, with 50,000+ simulated customer conversations completed so far, as described in the [training-results thread](t:60|training-results thread) and reinforced by the [quote post](t:111|quote post).

• Why it matters for voice teams: This is positioned as “pre-exposure” to real-world calls before new hires talk to customers, replacing hard-to-scale classroom/shadowing/roleplay, per the [training-results thread](t:60|training-results thread).
• Tooling signal: TELUS’ product lead frames ElevenLabs as having the “right balance of tooling… prototype… and go to market… fast,” as quoted in the [quote post](t:111|quote post).
The thread also says TELUS chose ElevenLabs for latency, voice quality, and self-serve tooling, but it doesn’t include independent measurement artifacts beyond those claims in the [training-results thread](t:60|training-results thread).
ElevenLabs Dubbing arrives on fal for audio-to-video localization
Video Dubbing (ElevenLabs on fal): fal added an ElevenLabs dubbing endpoint intended for language translation and dubbed output, announced in the [fal release post](t:62|fal release post) with a direct entry point in the [endpoint links](t:167|endpoint links).

The fal page shows $0.90 per minute pricing for dubbing, as listed on the [Dubbing endpoint page](link:167:2|Dubbing endpoint). This makes dubbing a single callable step in a pipeline (upload video → select languages → download dubbed version), which is the piece most teams end up re-building repeatedly for multi-language deliverables.
ElevenLabs Scribe v2 speech-to-text lands on fal as an endpoint
Scribe v2 (ElevenLabs on fal): fal added an ElevenLabs Scribe v2 speech-to-text endpoint positioned around “accurate” transcription, announced alongside other ElevenLabs endpoints in the [fal release post](t:62|fal release post), with the runnable endpoint linked in the [follow-up](t:167|endpoint links).
The fal model page lists usage pricing at $0.008 per input audio minute, as shown on the [Scribe v2 endpoint page](link:167:1|Scribe v2 endpoint). This turns Scribe into a straightforward step for captioning, edit transcripts, and searchable dailies, without needing to wire ElevenLabs directly.
ElevenLabs Voice Changer ships on fal for audio-to-audio conversion
Voice Changer (ElevenLabs on fal): fal made ElevenLabs’ Voice Changer available as an API-style endpoint (“any voice to any voice”), bundled in the same rollout as Scribe v2 and dubbing per the [fal release post](t:62|fal release post), with direct access linked in the [endpoint list](t:167|endpoint links).
The fal page shows pricing at $0.3 per minute of audio, as listed on the [Voice Changer endpoint page](link:167:0|Voice changer endpoint). In practice this is the utility layer for swapping VO takes, trying alt character reads, or matching a target voice for pickup lines, without re-recording.
🧰 Where creators run models: templates, hubs, and app-layer integrations
Today’s platform news is about packaging: turning workflows into reusable templates and exposing models through hubs like fal, Runware, Pollo, and Lovart. Excludes model capability deep-dives (covered in Image/Video categories) and excludes the Kling promo (feature).
Freepik adds Custom Templates for shareable prompt-to-output workflows
Freepik (Custom Templates): Freepik rolled out Custom Templates that package prompts, characters, model choices, and reference assets into a single shareable link across Images, Video, and Audio, aiming to stop teams from re-explaining the same workflow repeatedly, as shown in the feature launch and expanded in the workflow breakdown.
The practical shift is that “workflow DNA” becomes a portable object (a link) that collaborators can open and run without recreating setup decisions—especially useful when a studio wants consistent characters/styles across multiple outputs and formats.
fal ships FLUX.2 [klein] LoRA trainers and publishes edit LoRAs on Hugging Face
fal (FLUX.2 [klein] Trainers): fal announced a trainer suite for FLUX.2 [klein] covering 4B and 9B base/edit variants, framed as fast LoRA training for personalization (style/character/concept), according to the trainer announcement.
• Open LoRAs for common edit ops: fal also says it’s open-sourcing four LoRAs—Outpaint, Zoom, Object Remove, Background Remove—with weights hosted on Hugging Face, per the trainer announcement.
• One concrete artifact: The Object Remove LoRA has a dedicated Hugging Face listing, which fal points to in the weights page at weights page.
This lands as “production cleanup primitives as models,” not just one-off UI tools.
Pollo AI brings Veo 3.1 Ingredients-to-Video to the web with 4K and native ratios
Pollo AI (Veo 3.1 Ingredients to Video): Pollo AI says Veo 3.1 Ingredients to Video is live on its web product—generate short video from reference images plus a prompt, with emphasis on improved character/background/object consistency, as stated in the launch post and summarized in the what’s new list.
• Format and output knobs: The feature list calls out native 9:16 and 16:9 aspect ratios plus 4K availability, per the what’s new list.
• Offer window attached: The same post layers in a 50% off promo “before Jan 23” and a “24H” credit giveaway mechanic, as written in the launch post.
The tweets don’t include API/docs details, so it’s presented as an app-layer surface rather than a developer integration.
Runware adds Wan 2.6 Image with up to three reference images for guided edits
Runware (Wan 2.6 Image): Runware says Wan 2.6 Image is live, positioning it as “video-grade precision” for single-frame generation with support for up to 3 reference images to guide edits (style/background/subject), per the availability post and the model page described in model page.
Runware’s listing also publishes a concrete usage anchor—$0.03 per 1024×1024 image—in the pricing detail on model page, which matters if you’re budgeting high-iteration lookdev.
falcraft releases as a Minecraft mod for text-to-build generation
fal (falcraft): fal reposted that falcraft is now released as a Minecraft mod, letting players generate content in-game from text prompts, per the mod repost.
The tweet doesn’t include installation steps or supported operations (structures vs items vs terrain), so the actionable detail here is the new distribution surface: an in-game mod rather than a standalone web app.
💻 AI coding tools for creators: local models, desktop agents, and Claude Code mania
Developer-side tools in the feed are less about benchmarks and more about ‘ship faster’: Claude Code hype, desktop agent platforms with SaaS integrations, and new runnable local coding models. Excludes pure creative media generation.
Claude Code hype spikes as mainstream repeats “5× faster” anecdotes
Claude Code (Anthropic): Following up on Rate limits (agent swarms straining plans), a new wave of discussion frames Claude Code as a mainstream “productivity unlock,” with claims like “finished a year-long project in one week” and “five times more productive” attributed to business users in the Mainstream roundup; the mood is also getting pushback, with creators saying “Claude Code hype is out of control” in the Hype fatigue line.
• What’s actually being cited: The story bundles multiple anecdotes (Vercel CTO’s week-long sprint; a CEO scrapping hiring plans) and positions Claude Code as a step toward more autonomous agents, as described in the Mainstream roundup.
• Signal for creators who ship tools: The discourse is less about benchmarks and more about end-to-end throughput and non-coder adoption (“non-coders are building apps…”) per the Mainstream roundup, while the Hype fatigue line suggests expectations are running ahead of shared, repeatable workflows.
Kimi premium reportedly adds real Word/Excel/PPT editing and batch exports
Kimi (Moonshot): A reported premium-only update says Kimi can now edit and generate Word/Excel/PPT files with “real data,” including complex spreadsheet features like VLOOKUP and conditional formatting, plus batch operations like producing “37 PDFs in one go,” according to the Office-file capability claim.
• Workflow implication: The same post claims Kimi can convert large documents into presentation decks and embed charts/images inside office files, as described in the Office-file capability claim.
The tweet doesn’t show a full before/after export example, so the exact fidelity of formulas and formatting isn’t verifiable from the media provided.
Z AI claims GLM-4.7 Flash is a 30B coding model you can run locally
GLM-4.7-Flash (Z AI): Z AI is being framed as “just dropped” with GLM-4.7 Flash, described as a 30B-parameter coding model that can run locally in the Launch claim; a benchmark comparison image shows scores across SWE-bench Verified, t²-Bench, BrowseComp, AIME 25, GPQA, and HLE.
• Numbers shown in the chart: The image reports SWE-bench Verified at 59.2 and t²-Bench at 79.5 for GLM-4.7-Flash, alongside comparisons to Qwen3-30B-A3B-Thinking-2507 and GPT-OSS-20B, as shown in the Launch claim.
No weights, quantization guidance, or reproducible eval harness is linked in the tweets, so treat the chart as directional rather than definitive.
BytePlus ModelArk Coding Plans pitch multi-model access with “Auto” routing
ModelArk Coding Plans (BytePlus): BytePlus is promoting a coding plan that bundles multiple “top coding models” in one place and emphasizes model switching or “Auto mode” selection per task; the lineup named includes GLM-4.7, Deepseek-V3.2, GPT-OSS-120B, Kimi-K2-thinking, and ByteDance-Seed-Code in the Plan breakdown.
• Commercial framing: Pricing is described as starting at $5/month during a launch period (with “50% off” mentioned), and the pitch explicitly calls out compatibility with tools like Claude Code and Cursor, as written in the Plan breakdown.
The post reads like marketing copy and doesn’t include latency/cost tables, so the “Auto” routing behavior and savings aren’t measurable from today’s evidence.
Open-source “Claude Cowork” desktop agent claims 500+ SaaS integrations
Claude Cowork OSS-style desktop agent: A repo pitched as a leading open-source alternative to Claude Cowork is getting attention for “enterprise-level” desktop agent workflows—native macOS/Windows/Linux apps, persistent sessions, and tool integrations “connected with 500+ SaaS apps,” with rapid traction claims (“400+ stars in 4 days”) in the Desktop agent claim.

• Model switching pitch: The same tool is described as letting users swap between Claude, GPT-5, and Grok “seamlessly,” according to the Desktop agent claim.
The tweets don’t include an independent integration list or audit, so the “500+” figure should be treated as self-reported until the repo/docs are inspected.
“Ralph Claude Code” repo shows a sharp star spike past 3k
Ralph Claude Code (frankbria/ralph-claude-code): A viral “Have you tried Ralph Claude Code?” prompt is circulating in the Prompt to try Ralph, while a star-history screenshot shows a steep climb to above 3k stars for the repo, as shown in the Star history screenshot.
This looks like a “wrapper/tooling around Claude Code” micro-ecosystem signal rather than a documented product release, since the tweets don’t include feature lists or a changelog.
🕺 Motion research & 3D-adjacent generation (rigging, parts, physics)
A small but high-signal batch of animation research links landed today: part-level motion composition and physics-aware RL for video generation. Excludes general video model news and focuses on motion/rig realism methods.
FrankenMotion explores “motion Lego bricks” for part-level human animation
FrankenMotion (research): A new method frames human motion generation as something you can compose at the part level—think upper body, lower body, and other regions as independent “modules” that can be generated and then combined, as introduced in the FrankenMotion mention.

For AI filmmakers and character animators, the immediate promise is more direct control: instead of prompting “walk + wave” and hoping the model doesn’t muddle everything, you’d aim to author (or source) a clean walk cycle and then layer separate arm/torso performance on top, with the composition step doing the heavy lifting—see the visual examples in the FrankenMotion mention.
PhysRVG uses physics-aware RL to push video generation toward real collisions
PhysRVG (research): A paper proposes “physics-aware” reinforcement learning as a training/fine-tuning layer for video generators, explicitly targeting physical realism (notably collision rules and rigid-body motion) and pairing it with a new evaluation set called PhysRVGBench, as summarized in the PhysRVG paper post.
The authors describe a unified training setup (including a “Mimicry-Discovery Cycle”) that’s meant to keep models creative while still being penalized for physically impossible outcomes, per the ArXiv paper. For creators, this maps to a concrete failure mode: shots where props intersect hands, bodies slide, or impacts don’t transfer momentum—issues that are especially visible in action blocking and VFX-adjacent clips.
🔬 Research worth skimming: tool-use data, societies of thought, and optimization loops
Research links today cluster around how models reason and act: multi-agent “societies of thought,” synthesized tool-use trajectories, and RL-driven code optimization. Mostly papers + repo announcements, minimal creator-facing demos.
IterX uses RL loops to optimize code against a reward function
IterX (DeepReinforce): IterX is described as an automated deep code-optimization system that runs thousands of reward-driven iterations (rather than one-pass “optimize this” suggestions), with targets like measurable runtime/cost improvements; the launch is referenced in the IterX announcement RT and broken down in more detail in the IterX TLDR.
• What’s distinct: The pitch is that you define a reward function (runtime, cost, gas, etc.) and IterX iterates until it finds better-performing code—explicitly contrasting itself with single-pass IDE agents in the IterX TLDR.
• Where it’s shown working: The same thread claims demonstrated speedups on CUDA kernels and database queries, and mentions a “meta controller LLM” that switches between LoRA fine-tuning and RL evolution, per the IterX TLDR.
For creative teams shipping real-time video/audio pipelines, this kind of loop matters because “small % speedups” translate directly into cheaper renders and faster iteration—if the claims hold up outside the examples.
GEM pipeline synthesizes multi-turn tool-use trajectories from text
GEM (research): “Unlocking Implicit Experience” proposes extracting tool-use trajectories from ordinary text corpora—turning written procedures into multi-turn tool calls—so agent training doesn’t depend on expensive human-curated traces, per the paper thread and the paper page in ArXiv paper. For creative tooling, the obvious downstream is better tool-using assistants that can actually operate your stack (asset download → edit → render → publish) rather than stopping at “here’s what you should do.”
• Pipeline shape: The paper describes a four-stage synthesis path (relevance filtering → workflow/tool extraction → trajectory grounding → complexity refinement), and then trains a dedicated “Trajectory Synthesizer” via supervised fine-tuning to cut generation cost, as outlined in the paper thread.
No creator-facing demo in the tweets, but it’s a clean research direction: getting agent-like behavior from “how-to” text at scale.
Reasoning models may work by simulating a “society of thought”
Societies of thought (research): A new paper argues that the jump in reasoning-model performance comes less from “more thinking tokens” and more from internal multi-agent-like interactions—i.e., the model’s reasoning trace contains multiple competing perspectives that debate and reconcile, as summarized in the paper thread and detailed on the paper page in ArXiv paper. This is directly relevant to creative toolbuilders because it points to why “self-critique / debate / role” prompting sometimes improves plan quality: it may be aligning with what the model already does internally.
• What they measured: The authors claim models like DeepSeek-R1 and QwQ-32B show materially higher “perspective diversity” in traces than instruction-tuned baselines, and that this diversity correlates with better complex-task accuracy, per the analysis summary in paper thread.
Treat it as directional until you’ve read the methods, but it’s a useful mental model for anyone building multi-step creative agents (storyboarding, edit decisions, research-to-script) that depend on robust internal disagreement resolution.
RubricHub: ~110k-instance rubric dataset for open-ended generation models
RubricHub (dataset): A large rubric dataset (~110k instances) is circulating as training data for open-ended generation models, via the RubricHub mention RT. If this line of work lands, it’s a practical lever for creative LLMs (writing, ideation, critique) because rubrics are one of the few scalable ways to encode “what good looks like” without collapsing everything into single-score preference labels.
The tweet doesn’t include a link or examples, so details like license, rubric structure, and target tasks aren’t verifiable here; it’s still a useful signal that evaluation/teaching artifacts are becoming first-class datasets.
📉 Distribution reality: X feed quality collapse becomes the story
Community sentiment today centers on X’s recommendation quality: For You tab feels unusable for tech/AI, and even Following is described as degrading. This category is about reach and discovery conditions, not tool releases.
Creators say X’s For You (and even Following) became unreliable for AI discovery
X recommendations (distribution): Following up on Feed collapse (signal-to-noise complaints), multiple creators describe a recent break in X’s discovery loop for tech/AI—“the algorithm has ruined the ‘for you’ tab” as stated in For you complaint, with reports that carefully-trained feeds got “obliterated” over “the past 2 weeks” in Two-week shift. They also claim the degradation is no longer limited to For You: even the Following tab “turned into garbage” in Following tab issue, which matters because many creators were already using Following as the fallback discovery surface.
Timeline hygiene tactic: aggressively mute and mark unrelated short-form as Not interested
Feed cleanup workflow (X): As complaints about For You/Following quality stack up in For you complaint and Following tab issue, one concrete mitigation pattern shows up: aggressively muting patterns like “tap this post / open for a surprise” and repeatedly marking unrelated short-form as “not interested,” as described in Muting strategy. The practical implication for AI creators is that discoverability work now includes ongoing feed maintenance, not just posting and engagement tactics.
🧯 Tool friction & reliability gripes (what’s breaking flow)
Not many true outages, but clear complaints about degraded UX and discovery friction that affects how creators find useful AI work. This is more ‘workflow drag’ than technical incident reporting.
X discovery feels “obliterated” for tech/AI creators, even on Following
X timeline quality: Creators report that the For You tab has become unusable for finding tech and AI work, with one saying their carefully-trained feed got “obliterated” over the last ~2 weeks following up on feed collapse (signal-to-noise complaints) in the feed got obliterated and For You unusable posts. The practical failure mode they describe is fragile personalization—“you click on one thing and your feed is toast,” as described in feed got obliterated.
• Even Following isn’t a safe fallback: One creator says their Following feed “too turned into garbage,” suggesting the issue isn’t only recommendation drift but also what’s being surfaced/boosted across the whole product, per Following turned to garbage.
• Workarounds have their own drag: Lists and manual profile checks help, but heavy retweet behavior can overwhelm signal (“RTs clog their profile feed”), as noted in lists still scattershot.
Claude Code hype spike: mainstream narratives amplify “5× faster” expectations
Claude Code (Anthropic): Hype/expectations are becoming a topic themselves—“Claude Code hype is out of control,” as stated in hype out of control, with mainstream coverage piling on anecdotes about extreme productivity jumps in the mainstream Claude Code story.
• Expectation-setting risk: The story cites near-quotes like getting “Claude-pilled” and claims of “five times more productive,” plus a year-long project finished in a week, all attributed in mainstream Claude Code story. The net effect is a narrative where Claude Code is framed less as a coding tool and more as a general work accelerator—useful for visibility, but it can also inflate what new users think they’ll get on day one.
Feed hygiene tactic: aggressive “Not interested” + muting to purge short-form spam
Timeline cleanup (workflow drag): One concrete tactic circulating is to aggressively mute patterns like “tap this post / open for a surprise” bait, and repeatedly mark unrelated short-form videos as “not interested,” as laid out in muting and not interested. It’s a small workflow move, but it directly affects how quickly AI creatives can find prompts, model updates, and tool demos without context-switching.
Creators want Gemini to take actions on phones (not just chat)
Gemini on-device actions: A recurring friction point is that creators want Gemini to do things on the phone (tap, navigate, execute workflows), not only answer questions—“When are we getting that?” as asked in phone control request.
This matters for mobile-first creation and distribution loops (posting, clipping, template-based edits), where the bottleneck is often UI execution rather than ideation.
🏁 Finished drops: AIMVs, concept trailers, and short film proofs
A handful of ‘shippable’ releases stand out beyond WIP tests—music video launches and trailer-style proofs that position AI as film language, not just demos. Excludes random art shares without a named project/release hook.
Warner Music China releases ‘WU AI-HUA’ AIMV made with Kling AI
WU AI-HUA (Warner Music China × Kling AI): Warner Music China’s debut AIMV for its virtual idol AI-HUA is out, positioning a wuxia-coded character inside modern electronic/rap production, as announced by Kling in the release post.

The longer framing around the drop emphasizes it as “directed” rather than demo-ish—retro wuxia camera language, controlled pacing, and a character-first presentation—according to the project breakdown. For creators, it’s a clean proof that AI video tools can carry a full MV structure (identity, choreography, and coherent visual grammar) when the creative constraints are tight.
DarkSky International’s ‘DarkSky One’ concept-car spot uses generative AI
DarkSky One (DarkSky International): A 30-second campaign spot visualizes a concept car “before it physically exists,” using generative AI as the visualization layer for a light-pollution message, per the campaign thread.

This is an ad-shaped proof where AI is used to pre-visualize a product-world (vehicle + environments) without the usual physical build/shoot pipeline, while keeping the night sky as the central visual motif.
Noodles & Company turns real comments into AI ‘mini-epic’ ads
Steak Stroganoff mini-epics (Noodles & Company): The brand is running a campaign that screenshots real social posts about the limited-time dish, then blows them out into over-the-top AI-generated vignettes for CTV and social, as described in the campaign writeup.

The creative hook is the “comment → cinematic visualization” loop: authenticity comes from the source text, while the AI output is treated as stylized exaggeration rather than product-photorealism.
A Spider-Man fan concept trailer ships using Higgsfield and Kling
Spider-Man concept trailer (mhazandras): A finished, trailer-shaped proof for “The Amazing Spider-Man” was posted as being made with Higgsfield and Kling, leaning into the fan-trailer format rather than single-shot tests, as shown in the trailer post.

The piece is notable mainly as a packaging choice: quick beats, title-card rhythm, and montage continuity that reads like a trailer deliverable (not a tool demo).
James Yeung’s ‘Solitude’ series posts two new environment-driven frames
Solitude (James Yeung): Following up on Solitude series (named, repeatable single-figure motif), Yeung posted two new frames—one at a lit bus stop in heavy snow with a lone figure and dog in the scene, as shown in the bus stop post, and another titled “the Vault” set inside a dark industrial shaft with a single overhead light, per the vault post.
Both additions keep the series’ “one person vs architecture/light” grammar, but shift the emotional read by swapping setting scale (street-level shelter vs cavernous interior).
📚 Story craft signals: adaptive media, authorial intent, and “AI as companion” framing
Storytelling discourse today is less about new writing tools and more about what audiences will accept: adaptive narratives, the role of intent, and skepticism about LLM prose quality. This is the ‘meaning-making’ layer around the tools.
Showrunner leans into self-insertion characters and the “WITH vs BY AI” framing
Showrunner (Fable Simulation): New preview posts show Showrunner leaning hard into audience self-insertion—“you’ll be able to upload yourself and become a ruined Muppet billionaire”—while also reiterating the artistic fork of “win an Oscar WITH AI” vs “win an Oscar BY AI,” as framed in the Showrunner preview and echoing Oscar fork (AI as VFX layer vs AI as author).
The notable craft signal here is the product direction: identity upload becomes a native storytelling primitive (casting, personalization, participation), and the “WITH vs BY” framing functions as a public taste test for what kind of authorial intent audiences will accept, per the same Showrunner preview.
Adaptive movies expand from pacing to attention detection (phone-fiddling signal)
Adaptive media (Netflix): Following up on Realtime pacing (movies that watch viewers and adapt), rainisto suggests a concrete input signal—detecting when a viewer starts fiddling with their phone inside the Netflix app—and using that to dynamically adjust storytelling (speed up, slow down, reiterate, or simplify) as described in the Phone-fiddling adaptation idea.
The implication for creators is less about “branching endings” and more about a real-time editing layer: a film that changes its clarity and rhythm per viewer attention, closer to how a human storyteller modulates delivery mid‑story, per the same Phone-fiddling adaptation idea.
LLMs framed as story research companions, not prose engines
AI as companion (story research): Following up on Affleck clip (AI as tool, human collaboration as glue), cfryant sharpens the creative posture: “LLMs have never been good at writing… even… a haiku,” but they’re useful as a writing companion for quick research and story validation—specifically, checking whether details are period-appropriate in historical fiction—per the Period-accuracy companion framing.
This keeps “authorial intent” with the human while positioning AI as a fast plausibility checker (facts, era details, context), rather than the voice of the script, as described in the same Period-accuracy companion framing.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught