.png&w=3840&q=75&dpl=dpl_3ec2qJCyXXB46oiNBQTThk7WiLea)
Higgsfield Cinema Studio v1.5 adds 6 cameras, 11 lenses – 220-credit trials accelerate DP-style workflows
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Higgsfield’s Cinema Studio v1.5 pushes AI video deeper into cinematography land: real f‑stop‑style aperture now governs depth‑of‑field and subject separation; DP‑curated aspect‑ratio presets cover social, TV, and scope formats; and a virtual camera library exposes six familiar cinema bodies plus 11 lenses and 15+ camera moves so users pick rigs, not vague “cinematic” filters. Sturdier project tools link shots into campaigns and trailers; creators showcase Stranger Things‑style lighting and parallel‑room grading as evidence the update targets directing and continuity, not one‑click clips. A 220‑credit promo is tuned to get filmmakers testing these controls at scale.
• Open AV speed and access (LTX‑2): Lightricks brands LTX‑2 “The Speed Leader,” citing up to 18× faster runs; RTX 4070 users report 10s 720p clips in ~3–5 minutes; ComfyUI ships a starter graph and Comfy Cloud flow; a 4K offline walkthrough and LTX‑2‑TURBO Hugging Face Space broaden entry points, while a StableDiffusion subreddit AMA fields roadmap questions.
• Speech‑native agents (Fun‑Audio‑Chat‑8B): Alibaba’s Tongyi open‑sources an 8B speech‑to‑speech model claiming ~50% GPU‑hour savings via 5 Hz dual‑resolution audio, adds speech function calling, and posts SOTA‑level scores on OpenAudioBench, VoiceBench, and UltraEval‑Audio; open weights land on GitHub, Hugging Face, and ModelScope.
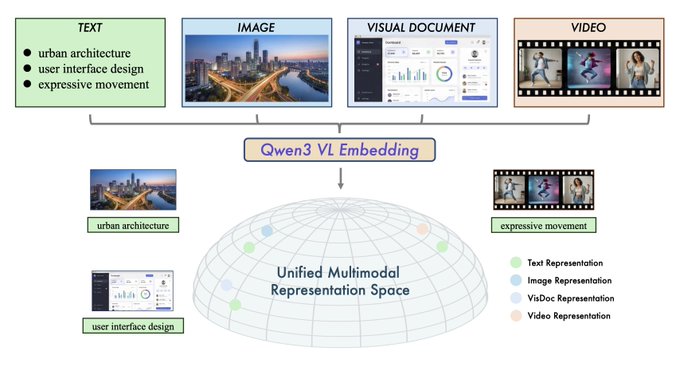
• Multimodal routing and retrieval (Qwen3, ATLAS): Qwen3‑VL‑Embedding plus a reranker unify text, images, and video across 30+ languages for visual search and multimodal RAG; the ATLAS router reports ~10–13% gains on complex reasoning benchmarks by learning which model or tool to invoke next, hinting at more orchestrated creative pipelines.
Across cameras, audio, and routing, today’s updates cluster around one theme: professional‑grade control—optical, vocal, and orchestration—being wired into open or semi‑open stacks, even as independent benchmarks for speed claims and long‑horizon agent reliability remain thin.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught
Top links today
- Higgsfield AI Stylist product page
- Krea LoRA trainers for Qwen and Z-Image
- LTX-2 open source video model release
- Run LTX-2 via Comfy Cloud
- Kling 2.6 Motion Control tutorial
- Story Grid multi-shot character tutorial
- Nano Banana Pro 2 character agent
- Glif Room Renovator AI agent
- Alibaba Wan AI video app on Android
- Klear unified audio-video generation paper
- ThinkRL-Edit reasoning-centric image editing paper
- Autodesk Flow Studio anime fight tutorial
- Pictory AI text-to-video creation
- Vidu AI set group photo video guide
Feature Spotlight
Cinema Studio v1.5: DP‑grade control lands in AI
Higgsfield’s Cinema Studio v1.5 adds true aperture control, DP‑curated aspect ratios, and stronger project management—pushing AI video from ‘demo’ to director‑level camera control.
Big new drop focused on real cinematography control: aperture/bokeh, unlocked aspect ratios with DP presets, plus sturdier project management. Heavy cross‑account demos and reactions today.
Jump to Cinema Studio v1.5: DP‑grade control lands in AI topicsTable of Contents
🎬 Cinema Studio v1.5: DP‑grade control lands in AI
Big new drop focused on real cinematography control: aperture/bokeh, unlocked aspect ratios with DP presets, plus sturdier project management. Heavy cross‑account demos and reactions today.
Higgsfield Cinema Studio v1.5 adds aperture, DP presets, and project tools
Cinema Studio v1.5 (Higgsfield): Higgsfield released Cinema Studio v1.5 with real aperture control for optical-style depth of field, DP-curated aspect ratio presets across “every” format, and sturdier project management, pushing its AI video tool closer to real cinematography workflows according to the launch details launch details and a creator recap that frames it as current AI filmmaking feature recap. The update also exposes a virtual camera stack—six named bodies (ARRI Alexa, RED, Panavision, Sony Venice, IMAX), 11 lenses, and 15+ camera moves—so filmmakers can pick familiar setups instead of generic filters, as outlined in the feature breakdown camera stack analysis.

Early tests, including a Stranger Things‑style mood clip that leans on split lighting and parallel-room grading style demo, position v1.5 less as a one-click generator and more as a director’s tool for controlled bokeh, framing, and multi-shot projects.
• DP-style control: Real f-stop-like aperture behavior now drives background blur and subject separation rather than vague “cinematic” sliders, according to the core update notes launch details.
• Production workflow: Expanded project management targets campaigns, trailers, and revisions instead of isolated one-offs, tying shots into a more traditional post-production workflow launch details.
• Virtual camera library: Presets tied to cinema camera brands and lens sets give creatives a fast way to match specific looks, as stressed in the breakdown for filmmakers camera stack analysis.
🎞️ Open AV video momentum: LTX‑2 speed and tooling
Continuing the open‑weights wave, today adds speed claims, local tests, and easy starts. Excludes Cinema Studio v1.5 (covered in the feature).
LTX-2 positions itself as fastest open AV model with real 4070 timings
LTX‑2 performance (Lightricks): Lightricks now markets LTX‑2 as “the fastest open‑source model in its class,” claiming up to 18× faster generation than competing systems in side‑by‑side charts and clips, following up on open weights where the team first released the full audio‑video stack for local use. The official reel emphasizes speed as a product feature rather than a benchmark footnote, branding LTX‑2 as “The Speed Leader” in open AV generation speed claim reel.

Real‑world user reports add texture to the marketing: one RTX 4070 (12 GB) owner quotes ~3 minutes to render a 10‑second, 720p clip with audio 4070 timing stat, while another pegs the same spec at around 5 minutes, suggesting performance varies with prompts and settings second 4070 run. Community sentiment skews strongly positive, with one creator calling LTX‑2 “a mic drop for local video gen,” framing the model as a serious option for desktop‑class cinematic work rather than cloud‑only experiments mic drop quote.
ComfyUI ships LTX-2 starter graph and Comfy Cloud click-to-try path
LTX‑2 tooling (ComfyUI): ComfyUI published a full “Get Started with LTX‑2” workflow graph that wires text prompts, Canny/Depth/Pose controls, built‑in upscaling, and prompt enhancement into a single node tree, extending the optimized RTX pipelines covered in RTX pipelines into a creator‑friendly starting point get started guide. The accompanying walkthrough targets cinematic use cases—multi‑modal control, dialogue, SFX, and music in one pass—rather than barebones T2V tests.

ComfyUI also highlights a browser‑based route: Comfy Cloud now exposes LTX‑2 as a ready‑made flow, so users can trigger audio‑video generations without setting up local VRAM or dependencies, via the hosted graph described in the comfy cloud quickstart and reinforced by a separate pointer to a dedicated LTX‑2 space on Comfy Cloud comfy cloud pointer. For AI filmmakers and designers, that combination—graph preset plus hosted runtime—reduces the gap between seeing LTX‑2 demos and running controlled shots with depth, pose, and upscaling in their own projects.
Creator walkthrough shows LTX-2 4K runs fully offline with Comfy integration
Local 4K use (community): Creator techhalla posts a detailed walkthrough of running LTX‑2 end‑to‑end on a personal rig—local, open weights, native 4K—expanding on the early PC tests summarized in PC demos with concrete prompts, VRAM notes, and install steps local 4k walkthrough. The thread stresses that Lightricks released not just an API but the full weights and training code, allowing creators to keep projects fully offline for privacy‑sensitive work local 4k walkthrough.

Later in the same sequence, techhalla links to a Git repo and instructions so users can clone the LTX‑2 Comfy pipeline and start generating locally “through this sponsored link,” tying the tutorial back to official docs on model capabilities and hardware needs comfy repo link and the broader product framing on the ltx-2 site overview. For independent filmmakers and designers, the practical takeaway is that a single consumer GPU can now host a 4K‑capable AV model plus a node‑based editor, turning desktop setups into mini‑studios rather than relying solely on cloud credits.
Community launches LTX-2-TURBO Hugging Face Space for faster trials
LTX‑2‑TURBO (community/Hugging Face): A community member spun up an LTX‑2‑TURBO Space on Hugging Face, framed as a faster variant of Lightricks’ distilled LTX‑2 model and exposed through an in‑browser UI for quick experimentation turbo space post. The Space runs on shared HF infrastructure and advertises itself as duplicated from Lightricks’ official distilled checkpoint, giving creatives a way to test prompts, motion styles, and audio‑video outputs without touching local installs or Comfy graphs, as outlined in the huggingface space. For storytellers who are still deciding whether to invest in a full local setup, this fills a lightweight “try before you wire it into your pipeline” slot in the growing LTX‑2 ecosystem.
🛠️ Directing via Motion Control: templates, tips, agents
Hands‑on directing with Kling 2.6 Motion Control—template flows, agent tutorials, and prompt tactics. Excludes Cinema Studio v1.5 feature.
Kling 2.6’s ‘Cute Baby Dance’ Motion Control preset gets official FAQ and 3‑minute recipe
Kling 2.6 Motion Control (Kling): Kling is now treating its viral Cute Baby Dance Motion Control preset as a structured entry point for new directors, publishing a short FAQ and tutorial that walk through uploading a character image and either pairing it with a video or choosing the built‑in template, while offering limited‑time subscriber discounts, as described in the Kling FAQ push, tutorial teaser , and template link. Following up on baby dances coverage of early meme clips, Techhalla adds a concrete 3‑minute walkthrough that shows the exact UI path—select model 2.6, tap Motion Control → Motion Library → Cute Baby Dance, then upload a reference image and generate without any prompt text, as demonstrated in the techhalla walkthrough.

• Template as pre‑choreographed rig: The combo of Kling’s FAQ and Techhalla’s screen recording makes Cute Baby Dance function like a pre‑built motion rig, so creatives can swap in their own character while inheriting tuned timing and camera behavior instead of keyframing from scratch Kling FAQ push, techhalla walkthrough .
• Zero‑prompt workflow: Emphasis on “no prompt needed” turns this into a repeatable recipe for non‑technical users, who only need a single sharp reference image and the right preset selection to produce trending vertical clips techhalla walkthrough.
HeyGlif formalizes Kling 2.6 Motion Control agents with concrete directing tips
Kling Motion Control agents (HeyGlif): HeyGlif is turning Kling 2.6 Motion Control into a more systematic directing toolkit, sharing “Keys to Success” such as physically acting out interactions with imaginary objects, matching the reference frame to the driving video composition, and keeping prompts blunt and specific, as outlined in the keys summary. Building on glif agent coverage of their earlier transitions stack, they also promote a dedicated Kling Motion Control agent plus a Nano Banana Pro 2 companion so users can generate a consistent character look and then animate it through Motion Control inside Glif, according to the nanobanana link and the agent details.

• Agent‑driven character animation: The “bring your characters to life” flow has creators feed a still reference image, a live‑action performance video of the subject, and a guiding prompt into the Kling Motion Control agent, which then maps the captured motion onto the stylized character, as shown in the character workflow and explained further in the motion guide.
• Packaged for reuse: HeyGlif exposes these setups as ready‑made agents—Nano Banana Pro 2 for consistent character boards and a Kling Motion Control agent for driving them—available directly on the agent page and the nanobanana agent, so directors and designers can reuse the same configuration across multiple shots instead of rebuilding pipelines each time.
Kling Motion Control recipes expand from cute loops to horror and Beethoven
Genre recipes for Motion Control (Kling + community): Creators are pushing Kling 2.6 Motion Control beyond meme dances into more directed genres, with community tips for cinematic horror jump‑scare scenes and portrait‑style resurrections of historic figures like Beethoven, as seen in Kling’s retweet of a Kling O1/2.6 “Cinematic Horror with Audio” tip thread horror retweet and Isaac Horror’s Beethoven demo Beethoven example. In the Beethoven clip, a detailed bust subtly turns and reacts to camera while the creator notes this makes it possible to "bring historic musicians like Beethoven back to life", underscoring how Motion Control can serve more serious music history, documentary, or education‑adjacent storytelling as well as playful content Beethoven example.

• From memes to mood pieces: The emerging horror and classical‑portrait recipes show that once directors grasp Motion Control’s reference‑image + motion‑clip model, they can pivot the same tooling from Cute Baby Dance‑style loops into carefully staged scares or reverent character studies horror retweet, Beethoven example .
📱 All‑in‑one creation goes mobile (Wan app)
A concentrated push to put full AI visual pipelines on phones—starring (ID+voice consistency), T2V/I2V with A/V sync, and multi‑shot tools. Excludes Cinema Studio v1.5.
Wan mobile app puts full AI video and image pipeline on phones
Wan App (Alibaba/Tongyi): Alibaba’s Tongyi Lab has launched the Wan AI creation app on both iOS and Android, packaging its Starring character system plus full text‑to‑video, image‑to‑video, and photoreal image editing stack into a phone‑first experience, as outlined in the wan launch and expanded in the analyst summary; distribution spans Apple’s App Store, Google Play, and a direct APK side‑load route according to the app store page, google play page, and apk download.
• Starring characters: The Starring feature lets users cast persistent characters into any video with identity and voice consistency and no retraining, targeting faceless creators and brands that want repeatable hosts and avatars wan launch, analyst summary .
• Multi-shot video tools: Wan’s video section covers text‑to‑video and image‑to‑video with more cinematic motion, native audio/video sync, and multi‑shot storytelling so creators can build sequences instead of isolated clips wan launch, analyst summary .
• On-device creative loop: The same app exposes photoreal image generation plus studio‑grade editing, keeping concept art, look exploration, and final social‑ready assets inside a single mobile workflow rather than bouncing between desktop tools wan launch.
For AI creatives, this concentrates a full character‑driven video and image pipeline into a mobile app that sits on top of Alibaba’s wider Tongyi model ecosystem and normal consumer app stores.
🖼️ Reusable looks: Midjourney styles and prompt packs
A fresh batch of shareable style refs and templates for stills—ink reportage, neon duotones, and concrete sculpture prompts.
Midjourney sref 3470974207 nails poetic narrative ink illustration
Narrative ink sref 3470974207 (Artedeingenio): Artedeingenio surfaces a Midjourney Style Creator code, 3470974207, that produces narrative ink illustrations with a limited accent color, sitting between reportage drawing, graphic art, and quiet visual storytelling—pitched for book interiors, literary covers, and editorial essays in the ink style ref.
The examples show a consistent recipe: hand‑drawn ink linework, subtle blue cross‑hatching or single accent tones, and lightly aged paper texture, so creatives can lock in a unified series look for whole publications or sequences of contemplative frames without re‑prompting from scratch.
Midjourney sref 6817491828 becomes go‑to storybook character sheet style
Storybook character sref 6817491828 (Artedeingenio): Artedeingenio highlights Midjourney style ref 6817491828, which yields expressive character sheets that look like pencil drawings washed with watercolor on aged paper, complete with margin notes and multiple poses, as outlined in the storybook sref.
Across examples—young heroine, bat‑winged girl, mustached gunslinger, green‑haired tinkerer—the style keeps consistent line quality, paper texture, and layout, giving artists a reusable base for turnarounds, concept packets, and illustrated story bibles without having to rebuild the sketchbook feel each time.
Concrete art prompt turns any subject into a textured sculpture series
Concrete art prompt (Azed AI): Azed AI shares a reusable "concrete art" text prompt that turns any subject into a front‑view, textured concrete sculpture with matte, rustic finish and soft ambient shadows, designed as a slot‑in template for creatives to adapt by changing the subject token, as described in the concrete prompt.
The format—"sculpture crafted from textured concrete, shaped like a [subject]" against a light blue background—gives designers a fast way to generate cohesive series of busts, mascots, or icons that all share the same lighting and material treatment, making it useful for branding explorations, gallery grids, or concept sculpts without manual look‑dev.
Midjourney sref 7721985153 offers bold blue–orange neon contour look
Neon duotone sref 7721985153 (Azed AI): A new Midjourney style reference, 7721985153, delivers a high‑contrast blue–orange duotone look where subjects are built from etched contour lines and semi‑translucent forms, showcased across crocodile skeletons, sculpted heads, and grouped figures in the neon contour style.
This sref dials in a distinctive graphic language—cool electric blues against hot oranges, with topographic line textures—that illustrators can reuse for album art, posters, or character line‑ups while keeping color palette and lighting behavior locked across a full set.
🧊 Modify in motion: Ray3 and anime 3D pipelines
3D and modify workflows get airtime—from Luma’s Ray3 restyles to Autodesk Flow Studio fight BTS. Excludes Kling Motion Control tips (covered elsewhere).
Ray3 Modify Video doubles as a virtual makeup restyling rig
Ray3 Modify Video (LumaLabsAI): Luma Labs highlights a "Virtual Makeup" test where a single face clip is restyled through multiple intense, graphic makeup looks entirely via Ray3 Modify inside Dream Machine, extending its earlier use for relighting interiors into full facial restyling, as seen in virtual relighting and the new virtual makeup clip. The demo cycles through several high‑contrast, animated looks on the same performance, signaling that Ray3 can now function as a non‑destructive makeup and art‑direction layer for portrait footage rather than only as an environment tool.

For AI filmmakers and beauty/fashion creators, this points toward AI pipelines where talent is shot once and makeup, face paint, or festival looks are iterated in post without reshoots.
Autodesk Flow Studio and 3ds Max power anime‑style fight previs in ‘Both of Me’
Flow Studio + 3ds Max (Autodesk): Animator Masahiro Yoshida shares behind‑the‑scenes footage of his short film Both of Me, showing how Autodesk’s Flow Studio and 3ds Max were used together to choreograph an anime‑style fight sequence—an evolution of the home‑shot combat previs seen in home fight previs and now applied to fully stylized characters Flow Studio BTS. The breakdown cuts between finished action shots and the Flow Studio/3ds Max interfaces, underscoring that AI‑assisted previs is starting to look like standard animation blocking rather than a novelty pass.

For teams building stylized action, the clip frames Flow Studio as glue between rough mocap, layout, and final anime rendering rather than a separate experimental pipeline.
Ray3 Modify becomes a playground for neon sci‑fi worlds and keyframe mixing
Ray3 Modify (LumaLabsAI): Creator Jon Finger shows Ray3 Modify being used not for polish passes but for pure play—roaming a neon, shifting city while experimenting with how keyframed camera moves and video modify interact inside Dream Machine, as shown in the Ray3 city demo. The follow‑up note about "mixing keyframes and Video modify" indicates people are starting to treat Ray3 less as a one‑off effect and more as a compositional tool they can iterate on shot rhythm with keyframe mixing note, with DreamLabLA amplifying the short as a creative exploration piece Dream Machine short.

The clip positions Ray3 as a way for small teams to block out whole worlds and camera paths in motion before committing to a final look pass.
🎙️ Speech‑to‑speech voices with empathy and control
S2S voice models that keep tone/prosody while following voice instructions—strong for dubbing, assistants, and character work.
Tongyi open-sources Fun-Audio-Chat-8B, an efficient emotional S2S voice model
Fun-Audio-Chat-8B (Alibaba Tongyi): Alibaba’s Tongyi Lab open-sourced Fun-Audio-Chat-8B, a speech-to-speech voice model that skips the usual ASR→LLM→TTS pipeline and operates directly on voice, claiming about 50% fewer GPU hours at similar speech quality and lower latency via dual‑resolution speech representations running at 5 Hz instead of 12.5–25 Hz, as described in the efficiency notes and launch overview. The model is designed for voice empathy, preserving tone, prosody, and emotion so that the same sentence spoken happily or sadly yields different responses, and it supports spoken style instructions like “speak like an excited esports commentator” or “start bored, then get more excited,” which matters for dubbing, assistants, and expressive character voices for creatives launch overview.

Tongyi notes that all Fun-Audio-Chat models are being released as open weights on GitHub, Hugging Face, and ModelScope, reinforcing this as an accessible S2S foundation for builders experimenting with emotional voice interfaces and narrative voice work efficiency notes.
Fun-Audio-Chat adds speech function calling and tops 8B voice benchmarks
Speech function calling (Fun-Audio-Chat, Alibaba Tongyi): The Fun-Audio-Chat stack is also positioned as a speech-native function-calling engine that can execute tasks from natural voice commands—examples include “Set a 25‑minute focus timer” and “Navigate from Alibaba campus to Hangzhou Zoo”—while achieving state-of-the-art results among ~8B-parameter models on OpenAudioBench, VoiceBench, and UltraEval‑Audio across voice empathy, spoken QA, audio understanding, function calling, and instruction following, according to the function calling update.
• Use cases: Tongyi highlights voice assistants with emotional awareness, customer support that can detect frustration or urgency, healthcare or therapy bots, and accessibility tools as primary targets, with Fun-Audio-Chat-Duplex announced as a coming extension for full-duplex, simultaneous two-way conversations function calling update.
• Open ecosystem: The team reiterates that Fun-Audio-Chat models are open-sourced across GitHub, Hugging Face, and ModelScope, making this S2S + function-calling combo available for custom agents, dubbing workflows, and interactive story experiences without relying on a closed API function calling update.
Together these details frame Fun-Audio-Chat not only as a creative dubbing tool but also as a general speech interface layer that can drive actions directly from expressive voice input.
🧰 Agent ops and nodes: building smarter creative rigs
Developer‑side boosts for creative pipelines: Claude Agent SDK practices and ComfyUI control nodes. Excludes LTX‑2 ‘getting started’ (covered under open AV).
Claude Agent SDK earns strong early praise from builders
Claude Agent SDK (Anthropic): Developers describe the Claude Agent SDK as opening a "whole world of capabilities" and being "OOMs better than anything else" for agent workflows, with one calling it "fucking fantastic" in back‑to‑back posts that frame it as meaningfully ahead of peers for building autonomous systems capability claim, strong praise . Another practitioner notes the SDK quietly shipped around November 24 but many heavy Claude users still missed it, urging Anthropic to promote it more clearly and even rename it from a "coding agent" to better reflect broader use cases release confusion. A separate comment that "I'm addicted to Claude Code" and loves being able to queue messages in the interface underscores how this stack is already shaping day‑to‑day dev loops rather than being a niche experiment code addiction.
Agent run-notes pattern emerges for Claude Agent SDK and Claude Code
Agent note-taking pattern (Anthropic): A concrete ops pattern is emerging around the Claude Agent SDK and Claude Code, where the agent writes notes to a file on every run—what worked, what failed, missing context—and a later Claude Code sweep reads those notes to automatically improve the harness and prompts notes pattern. This treats each execution as training data for the next, turning log files into a lightweight memory system and making the agent progressively better at handling complex, multi‑step creative tasks without manual post‑mortems.
ComfyUI TTP_toolset adds LTX‑2 first/last frame control node
TTP_toolset frame node (ComfyUI): The TTP_toolset for ComfyUI has been updated with a new node that exposes first‑ and last‑frame control for the latest LTX‑2 video model, giving graph builders much finer shot guidance than standard prompt‑only setups node update. For AI filmmakers working in node graphs, this means they can now pin bookend frames—locking in where a shot starts and ends—while still letting LTX‑2 handle motion in between, which is useful for matching storyboards, transitions, or edit decisions across multiple clips.
Custom Gradio camera-control component ships for LoRA-based image rigs
Camera control component (Gradio): A creator has built a custom camera control component for Gradio 6 that wraps camera‑control LoRAs, allowing users to adjust virtual camera parameters via an interactive UI instead of hard‑coding prompt tokens component demo. The author notes this was "super easy to build" thanks to Gradio 6’s new HTML component structure, and shares a live demo space showing how camera moves and angles can be manipulated in real time around a subject second share.
This pattern effectively turns LoRA‑driven camera behavior into a reusable node for creative rigs, making it easier for non‑technical artists to direct shots while still benefiting from model‑level camera conditioning.
Users push for scheduled runs and automation in Claude Code
Scheduled runs for Claude Code (Anthropic): Power users are starting to ask Anthropic for cron‑like scheduling inside Claude Code, explicitly wanting the ability to run tasks on a schedule from the UI instead of triggering agents manually schedule request. The request has been amplified through retweets retweet echo, signaling that once agents can handle nontrivial workflows, the next bottleneck for creative teams is unattended, recurring automation rather than one‑off interactive sessions.
🧠 Papers to watch: fine‑tuning, RL editing, multimodal AV
Mostly method/tooling advances useful to creatives: anti‑forgetting SFT, reasoning‑centric image edits, routing across tools, unified A/V gen, and stable video stylization.
Atlas routes across heterogeneous models and tools for complex multi‑domain tasks
Atlas (research): A proposed framework called ATLAS targets the "which model + which tool next" problem by combining training‑free cluster routing with RL‑based multi‑step routing, improving performance on complex reasoning benchmarks by about 10.1% in‑distribution and 13.1% out‑of‑distribution over prior routers, as described in the Atlas overview and the ArXiv paper. For creative stacks that already juggle multiple LLMs, image/video generators, and search tools, this is effectively a planner for which component to call when.
• Routing design: ATLAS first uses empirical priors to cluster models and tools by domain without extra training, then applies reinforcement learning to explore multi‑hop tool sequences, picking different trajectories for, say, visual reasoning vs. code synthesis.
• Relevance to creators: In pipelines where a single prompt might need story outlining, concept art, shot planning, and asset retrieval, a router that learns when to invoke which specialized model or search tool could reduce manual glue code and produce more coherent end‑to‑end results.
DreamStyle framed as practical multi‑mode video stylization tool
DreamStyle (ByteDance): Following up on the core DreamStyle paper—unifying text‑guided, style‑image‑guided, and first‑frame‑guided video stylization in one LoRA‑based framework video stylization—a new thread from Eugenio Fierro breaks down why this matters for real creative pipelines, highlighting reduced flicker and better style consistency across clips, as summarized in the DreamStyle overview. For creators working in anime, cinematic, cartoon, or brand‑locked looks, this framing pitches DreamStyle as a way to get stable, frame‑to‑frame style without juggling multiple ad‑hoc tricks.

• Unified conditions: The system can condition on plain text prompts, a style reference image, or the first frame of a clip, giving directors different entry points for short shots vs. longer sequences while still using one underlying backbone.
• LoRA detail: The paper’s use of token‑specific up matrices for LoRA (rather than a single shared matrix) is called out as a mechanism to reduce confusion between condition tokens and keep the style "locked" on the intended look over time.
• Data angle: The commentary stresses DreamStyle’s curated paired‑video dataset and data‑construction pipeline as a big part of why flicker and drift improve; weak or noisy style pairs are described as a main failure mode in older stylization methods.
Klear proposes single‑tower joint audio‑video generation with dense captions
Klear (research): A new joint audio‑video generative model called Klear tackles persistent issues like lip‑speech mismatch, audio‑visual asynchrony, and unimodal collapse by using a single‑tower DiT architecture with an Omni‑Full Attention scheme plus progressive multitask training, according to the Klear summary and ArXiv paper. The authors also build what they describe as the first large‑scale audio‑video dataset with dense captions to better align sound and visuals.
• Training recipe: Klear uses random modality masking and a multi‑stage curriculum to learn tightly aligned representations while preventing the model from degenerating into "just video" or "just audio" generation, which prior joint models often struggled with.
• Why this matters for AV work: For music videos, dialogue scenes, or performance pieces where gesture and sound must sync, a unified A/V backbone with higher alignment could mean fewer manual passes to fix timing, and it potentially gives future tools a better base for editing or re‑scoring footage using a single model.
Qwen3‑VL‑Embedding and Reranker target serious multimodal retrieval
Qwen3‑VL‑Embedding & Reranker (Alibaba): Alibaba’s Qwen team released a multimodal embedding model plus a paired reranker that place text, images, visual documents, and video in a unified representation space, then score fine‑grained relevance in a second stage, as outlined in the Qwen3 overview and amplified in the model mention. The models support 30+ languages and are aimed at tasks like visual search, screenshot Q&A, and multimodal RAG.
• Two‑stage design: The embedding model creates shared vectors across modalities, while the reranker computes more detailed relevance scores on candidates, mirroring the text‑only retriever + reranker pattern that already dominates production search systems.
• Creative and product use: For AI video, design, and documentation tools, this setup enables things like finding the right frame in a sequence by natural language, searching past style frames or layouts by sketch or screenshot, or building knowledge bases where users can query using a mix of text and images rather than plain keywords.
Entropy‑Adaptive Fine‑Tuning tackles catastrophic forgetting in SFT
Entropy‑Adaptive Fine‑Tuning (EAFT): A new SFT method proposes using token‑level entropy as a gate on gradient updates so the model can avoid "confident conflicts"—cases where high‑confidence prior knowledge is overwritten by new labels, which drives catastrophic forgetting in domain fine‑tunes, as explained in the EAFT summary and detailed in the ArXiv paper. For creatives and tool builders running continual fine‑tunes (e.g., style LoRAs, project‑specific assistants), this points toward training recipes that preserve general skills while still adapting to niche datasets.
• Method angle: EAFT measures entropy per token and down‑weights or skips updates where the model is already confident, aligning SFT updates more with the model’s internal belief distribution instead of blindly forcing labels, which the authors argue reduces destructive gradients and improves retention across tasks.
• Creative impact: In workflows where models are repeatedly re‑tuned for individual clients, shows, or brands, this kind of gating could help maintain base model creativity, language fluency, or coding competence while still locking in project‑specific direction and style notes.
ThinkRL‑Edit uses RL and chain‑of‑thought for reasoning‑centric image editing
ThinkRL‑Edit (research): A new framework for image editing leans on reinforcement learning and explicit chain‑of‑thought planning to handle "reasoning‑centric" edits—multi‑step instructions that require understanding relationships, counts, or logic instead of simple pixel tweaks, according to the ThinkRL-Edit summary and the ArXiv paper. The key idea is to decouple visual reasoning from actual image synthesis so the system can explore different edit plans before committing to a final render.
• Technique: The method samples reasoning chains with planning and reflection stages, then uses an unbiased chain preference grouping reward scheme to evaluate candidate edit plans, trying to stabilize noisy visual‑language‑model scores that prior RL‑for‑editing methods relied on.
• Why creatives care: For designers and storytellers who want "fix the lighting on the third character, then move the red car behind the blue one" instead of low‑level brushwork, this kind of reasoning engine is the layer that could eventually drive consistent, instruction‑based edits on top of existing diffusion or video models.
🎭 AI‑native shorts, transitions, and style tests
Micro‑shorts and motion experiments for narrative beats: metanarrative book transitions, painterly motion, anime vibes. Excludes Luma/Autodesk 3D (covered elsewhere).
Custom Midjourney anime style gets animated via Grok Imagine bike tests
Cross‑tool anime style (Midjourney + Grok Imagine): Artedeingenio unveils a new motorcycle‑centric anime style built in Midjourney’s Style Creator, teasing it with a “Street Hawk” bike racing through a futuristic city, then follows up by animating similarly drawn characters and vehicles with Grok Imagine to see how well the style survives motion Midjourney style tease and Cartoon to Grok test. The Midjourney style itself is being reserved for paying subscribers, but its behavior in video is visible in the public Grok tests.

• Style Creator to video pipeline: The workflow goes from a custom --sref anime style in Midjourney to static character sheets, then into Grok Imagine for motion clips where a hand‑drawn rider bursts through smoke or races across frame, showing how consistent the look remains between stills and animation Midjourney style tease and Cartoon to Grok test.
• Reusable cartoon language: A separate Grok Imagine post from the same creator shows a sketched character revving into full‑color animation, reinforcing that once a style is locked in, it can be applied across multiple characters and scenes rather than being a one‑off Cartoon to Grok test.
For creators exploring AI anime, these clips document a concrete pattern: author a style in Midjourney’s Style Creator, then stress‑test it in Grok Imagine loops before committing to longer sequences.
Kling 2.6 powers metanarrative “world becomes book” transition micro‑short
Metanarrative transition (Kling 2.6): Artedeingenio posts a ~10‑second micro‑short where a detailed 3D environment flattens into layered pages, the camera pulls back to reveal the world as an open book, and new scenes unfold as the pages turn, all driven by a single conceptual prompt in Kling 2.6 Motion Control Kling book prompt. The piece is explicitly framed as “better than a 3D pop‑up book,” signaling how creators are treating these tools as ways to prototype title sequences and conceptual transitions rather than full narratives.

• Transition as the subject: The prompt itself focuses on “environment flattening,” “depth compressing,” and “new environment unfolding from the next page,” which shows how creators can now design transitions as first‑class storytelling beats instead of afterthought edits Kling book prompt.
• Useful for openers and credits: The controlled camera pull‑back and smooth page turns point to applications in cold opens, chapter breaks, and metanarrative end cards where the world literally reveals itself as a designed object Kling book prompt.
The clip underlines that Kling 2.6 is being used not only for character dances and lip‑sync, but also for abstract, editorial transitions that motion designers usually had to build by hand.
Grok Imagine used for soft painterly tall‑grass motion study
Painterly motion test (Grok Imagine): Artedeingenio shares a ~6‑second Grok Imagine clip where a woman walks through tall grass under an overcast sky, with colors gently bleeding into one another frame by frame to create a calm, tactile painterly feel Painterly Grok test. The motion stays simple and slow so the focus is on how the model handles brush‑like textures, color bleed, and temporal coherence in a non‑photoreal style.

• Style focus over action: The prompt leans on “soft painterly scene,” “colors bleed slightly,” and “calm motion,” which turns the output into a controlled study of Grok’s handling of simulated paint and grain rather than a complex camera move Painterly Grok test.
• Signals for illustrators and cover artists: This kind of test hints at workflows where static book covers, album art, or editorial illustrations can be previewed as subtle looping motion without losing their hand‑painted look Painterly Grok test.
The experiment adds a different dimension to earlier Grok clips centered on anime linework or punchy branding, showing that the model can be pushed toward slower, mood‑driven painterly motion as well.
Cyberpunk “Dream City” anime micro‑short tests audience appetite for full series
Cyberpunk alley look test (Artedeingenio): A short “Dream City” clip from Artedeingenio drops viewers into a rain‑soaked, neon‑lit street and then cuts to a close‑up of a cyberpunk heroine, using bold title cards and fast pacing to ask outright whether people would watch a whole anime in this style Cyberpunk anime clip. The video runs only a few seconds but reads like a proof‑of‑concept opening for a larger series.

• Tight visual recipe: The piece combines wet asphalt reflections, dense signage, and a stylized character design that feels consistent with earlier AI anime work from the same creator, making it a compact test of color palette, lighting, and character readability in motion Cyberpunk anime clip.
• Audience testing in public: By framing the post as “Would you watch it?”, the creator uses social response around this micro‑short as an informal signal on which styles and tones might sustain a longer narrative Cyberpunk anime clip.
For anime‑focused builders, it highlights how a few seconds of on‑model motion can function as a live A/B test of a potential show’s look before committing to full episodes.
🗓️ Creator meetups and hack weekends
Community events for hands‑on learning and networking: new Runway meetups, Hailuo’s first Istanbul meetup, and a FLUX.2 hackathon in London.
FLUX.2 London hackathon brings together visual AI builders
FLUX.2 Hack (Runware / Black Forest Labs): Runware is co-hosting a two-day FLUX.2 hackathon in London on January 24–25 with Black Forest Labs, NVIDIA, Anthropic, and Dawn Capital, focused on building apps and visual experiences on top of the Flux.2 model, as announced in the hackathon tease. The event description notes that signups are full and on a waitlist, with prizes including NVIDIA GPUs and thousands in platform credits for teams that ship compelling generative media projects, per the waitlist update and hackathon page.

The schedule mixes model demos, talks from founders and artists working in visual intelligence, and time for teams to prototype Flux.2-powered tools, with art installations blending physical and digital work on display at the venue.
Runway expands global meetups program for AI video creators
Runway Meetups program (Runway): Runway is widening its community meetups program, inviting artists and filmmakers worldwide to RSVP for local events or apply to host their own, as shown in the meetups rollout and detailed on the meetups page. Events span cities like Lagos and Cape Town alongside past stops such as London, Berlin, Tokyo, and New York, framed as spaces to learn GenAI video workflows, show work, and meet other Runway users.

For AI creatives, these gatherings function as a low-friction way to see real production use of Runway’s models in the wild rather than only polished marketing examples.
Hailuo and Fal host first Istanbul meetup for AI filmmakers
Hailuo × Fal Istanbul meetup (Hailuo): Hailuo AI and Fal announced their first Istanbul meetup for AI-powered filmmaking and design, set for January 28 at QNBEYOND in Şişli at 7pm GMT+3, according to the meetup announcement and the later time reminder. The agenda combines networking with talks from local directors, technologists, and designers on how they use Hailuo and other generative tools in practice, with a speaker list including Ozan Sihay, Fatih Kadir Akın and others on the event agenda.
For regional creatives, it is positioned as a first chance to plug into Hailuo’s community in person rather than only through online reels and model drops.
LTX-2 team runs live Reddit AMA for open-source video model
LTX-2 Reddit AMA (Lightricks): The Lightricks team is hosting a live Ask Me Anything on r/StableDiffusion with CEO Zeev Farbman to field questions about the newly open-sourced LTX-2 audio–video model, its open weights, and future roadmap, according to the ama invite. The session is scheduled for 10:00 AM EST and explicitly invites questions on how LTX-2 compares to closed video systems, how creators can run it locally, and what improvements are planned next for cinematic control and audio sync.
For filmmakers and motion designers already experimenting with LTX-2 locally, the AMA is a direct channel to the model’s authors instead of learning only from second-hand benchmarks and community threads.
📣 Credits, promos, and creator calls
Engagement offers and promos across creative tools; mostly credits/discounts and how‑to pushes for faster content creation.
AI Stylist launch gets 215-credit engagement push from Higgsfield
AI Stylist credits (Higgsfield): To promote AI Stylist, Higgsfield is offering 215 credits to users who retweet, reply, follow, and like within a 9‑hour window, turning social engagement directly into generation budget as described in the announcement AI Stylist offer.

The tool itself lets creators upload one photo, pick from seven outfit categories, and customize backgrounds and poses so they can rapidly iterate production-ready character looks for posts, reels, and campaigns, with the credit promo framing it as a near-risk-free way to build a consistent visual pipeline AI Stylist offer.
Higgsfield offers 220 free credits to drive Cinema Studio v1.5 adoption
Cinema Studio v1.5 promo (Higgsfield): Higgsfield is dangling 220 platform credits to get filmmakers testing its new Cinema Studio v1.5 stack, asking users to retweet, reply, and follow in exchange for the giveaway according to the launch post Cinema Studio promo; this follows earlier Relight credit pushes, as noted in Relight credits, and keeps the focus on AI-native camera control for ARRI/RED/Panavision/Venice/IMAX-style work.
The promo positions credits as a low-friction way for creatives to try aperture-level bokeh, unlocked aspect ratios, and more advanced project management without paying up front, while Higgsfield gathers real-world usage around its "this is what AI filmmaking looks like now" message Cinema Studio promo.
Leonardo nudges creatives to start 2026 experiments on Seedream 4.5
Seedream 4.5 creator call (LeonardoAi): LeonardoAi is steering artists and designers toward Seedream 4.5 as a starting point for 2026 projects, pitching it as an upgraded model that improves aesthetics and keeps faces, lighting, and colors locked in across edits and variations Seedream overview.
• Reference‑driven editing: The post highlights stronger preservation of facial features and scene details while making creative changes to a base image, which matters for character continuity and layout-heavy work Seedream overview.
• Multi-image scenes: It also calls out workflows where multiple images are combined into a single scene or turned into dynamic iterations of a core key visual, plus more advanced composition and typography aimed at professional asset design Seedream overview.
For creatives, the message is that Seedream 4.5 is meant to cut rework on consistency-sensitive jobs like campaigns, cover art, and iterative brand visuals rather than being a purely experimental model.
Mitte AI feature pitch: one image plus voiceover becomes a full tutorial
Tutorial generator feature (Mitte AI): Creator Azed AI is spotlighting a Mitte AI feature that turns a single image plus a voiceover into a full demo video "in minutes," presenting it as a shift in how people produce tutorials by automating the visual side from a static asset Mitte feature tease.

The promotion leans on an Omnihuman-made video that explains how it was created on Mitte itself, reinforcing the idea that instructional content can now be generated by specifying narration and a reference frame rather than screen-recording or shooting footage from scratch Omnihuman meta demo.
🌡️ Distribution and leaderboards shape attention
Wider AI discourse that affects creative tool adoption: Gmail+Gemini’s reach, a new Chinese model in top‑10 vision, and a cautionary tale on agent traffic.
Gmail’s 3B-user base becomes a massive distribution surface for Gemini
Gmail + Gemini (Google): A viral take frames Gmail’s 3 billion users as the largest future distribution surface for Google’s Gemini assistant, arguing that deep integration will put AI in front of more people than any standalone model or app could reach distribution quote. The post calls distribution "king" and suggests that once Gemini is woven into inbox workflows, its usage may outscale competing AIs regardless of raw capability.

• Why creatives care: For anyone making AI-powered tools for writers, marketers, filmmakers, or musicians, this points to Gmail (and adjacent Workspace products) as a key discovery and habit channel, where summarization, drafting, and review flows may default to Gemini instead of third-party assistants.
• Attention shift: The framing implies that model choice for many end users may be decided by where they already live (email, docs, slides), not by leaderboard posts or standalone apps, which changes how new creative tools think about integrations and partnerships.
The post does not add timing or feature details, but it underlines how inbox-native assistants could quietly reshape which AI systems creatives touch every day.
Tailwind’s docs lose 40% traffic and 80% revenue as AI agents answer dev questions
Tailwind docs vs AI agents (Tailwind Labs): A widely shared comment from Tailwind’s co‑founder describes a sharp drop in documentation traffic and revenue he attributes to AI agents answering questions instead of sending developers to official docs—about a 40% traffic decline since early 2023 and revenue down close to 80%, leading to layoffs for 75% of the engineering team tailwind case. The note says Tailwind is "more popular than ever" but that AI-driven usage bypasses the docs funnel that historically converted users into paying customers.
• Docs as distribution: The post underlines how docs visits functioned as a key acquisition and upsell channel; when agents scrape or train on docs and then answer in‑chat, that traffic and monetization path breaks, even as the framework’s real-world usage grows tailwind case.
• Creator takeaway: For people publishing tutorials, documentation, or educational content around creative tools, it illustrates how AI assistants can hollow out the business side of open resources while still depending on them for training and inference.
The author says he wants LLM-optimized docs but is hesitant to ship anything that might make the revenue problem worse, framing this as an unresolved tension between accessibility through agents and financial sustainability for the tools they rely on.
Baidu’s ERNIE‑5.0 preview enters Vision Arena global top‑10
ERNIE‑5.0‑Preview‑1220 (Baidu): Baidu’s latest ERNIE‑5.0 preview model enters the LMArena Vision Arena global top‑10 with a score of 1226, marked as the only Chinese model in that tier and edging out several flagship Western systems on vision-heavy evaluations ernie overview. The same breakdown notes that this preview currently outperforms Gemini‑2.5‑Flash and GPT‑5‑Chat on vision tasks, while ranking #2 globally in creative writing behind Gemini‑3‑Pro ernie overview.
• Signal for creatives: Strong multimodal performance (text + images + video) is highlighted as crucial for "most real-world AI applications" that blend visual understanding with generation, which covers storyboarding, concept art, layout, and visually grounded copy work ernie overview.
• Geopolitical angle: The thread stresses that a Chinese model placing this high suggests the performance gap at the frontier between Chinese and U.S. systems is narrowing quickly, which may diversify the set of models serious creative teams evaluate—not only OpenAI and Google.
The leaderboard snapshot is still labeled preliminary with a ±15 confidence interval, so these rankings remain directional rather than definitive.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught