
ComfyUI NVIDIA optimizations promise 2× speed – hits 100k GitHub stars
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
ComfyUI rolled out NVIDIA-focused performance changes that it says have been enabled by default since December; the headline claims are NVFP4 quantization up to 2× faster on Blackwell GPUs and async offload + pinned memory 10–50% faster when VRAM is tight, framed against a 2026 target of “1024×1024 in half the time.” Separately, ComfyUI crossed 100,000 GitHub stars and positioned itself as a top‑ranked open-source project; it’s a momentum signal more than a feature drop, but it usually correlates with faster node ecosystem churn.
• Comfy Cloud imports: Comfy Cloud now shows “paste a Civitai or Hugging Face link to import” into “My Models,” but docs still say Civitai-only and Creator tier; source support looks in flux.
• Anthropic Cowork: Anthropic previewed a Mac-only, approval-gated folder-access agent; an internal claim says Claude wrote “all” the Cowork code, but there’s no public audit.
Across stacks, the theme is fewer workflow frictions (speed, offload, model wrangling); independent benchmarks and rollout details remain thin.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught
Top links today
- Seed 1.8 on BytePlus ModelArk
- Crystal Video Upscaler on Replicate
- Freepik Change Camera 360 view tool
- ComfyUI performance optimizations documentation
- Higgsfield Mixed Media video stylization
- Higgsfield What’s Next image continuations
- Creatify Aurora v1 avatar video model
- Over-Searching in RAG LLMs paper
- Thinking with Map geolocalization agent paper
- VideoAuto-R1 video reasoning paper
- MMFormalizer multimodal autoformalization paper
- Molecular Structure of Thought reasoning topology
- AnyDepth depth estimation project
- End-to-end test-time training for long context
- RoboVIP multi-view video for robot manipulation
Feature Spotlight
Vibe-editing goes mainstream: Higgsfield Mixed Media + the week’s motion tools
Higgsfield Mixed Media spreads fast: turn any clip into 30+ cinematic styles in minutes (up to 4K, 4–24 FPS, tri-layer color control), shifting stylization from VFX grind to a repeatable edit step.
The dominant cross-account story is Higgsfield’s Mixed Media “vibe editing” (30+ looks, up to 4K, color-layer controls). Also includes other creator-facing video generators and motion-control clips circulating today (excluding still-image-only tools).
Jump to Vibe-editing goes mainstream: Higgsfield Mixed Media + the week’s motion tools topicsTable of Contents
🎬 Vibe-editing goes mainstream: Higgsfield Mixed Media + the week’s motion tools
The dominant cross-account story is Higgsfield’s Mixed Media “vibe editing” (30+ looks, up to 4K, color-layer controls). Also includes other creator-facing video generators and motion-control clips circulating today (excluding still-image-only tools).
Higgsfield launches Mixed Media for AI video stylization with 30+ looks, up to 4K
Mixed Media (Higgsfield): Higgsfield shipped Mixed Media as a clip-level stylization tool—turning existing footage into 30+ cinematic looks (e.g., sketch/noir/comic/hand-paint) with up to 4K output and color controls, as introduced in the launch teaser and reiterated in the feature list.

It’s being positioned as a replacement for manual frame-by-frame stylization for music videos and indie film workflows, with short input clips (often framed as 1–10 seconds) called out in the workflow recap and examples circulating via the 4K styles montage.
• Controls that matter for editors: Higgsfield highlights 4–24 FPS and tri-layer color control (background/mid/subject), as detailed in the feature list.
• What’s actually new in practice: instead of “filters per frame,” the pitch is coherent style across motion and lighting, which creators emphasize when describing “ditch frame-by-frame editing” in the creator breakdown.
Kling 2.6 Motion Control: dance trend uses character reference images to hold identity
Kling 2.6 (Kling): A recurring creator pattern today is “dance videos using character reference images,” with claims that Kling 2.6 Motion Control keeps face/body identity intact under complex choreography, as described in the dance trend thread.

• Setup being repeated: the described recipe is “upload character image → add a reference dance video → generate,” with the two-reference variation (two character refs at once) also claimed in the dance trend thread.
• Why it’s spreading: the thread attributes the trend’s reach to dance clips hitting “millions of views,” while emphasizing expression fidelity in the expression note; treat these as anecdotal since no consistent benchmark artifact is provided.
• Related control surface: separate reposts frame Kling 2.6 “Motion Brush” results as surprisingly strong in the motion brush repost, though the tweet doesn’t include comparable metrics or a standardized test.
Creatify Aurora v1 hits Runware: image + audio to realistic avatar video from ~$0.10/s
Aurora v1 (Creatify on Runware): Runware added Creatify Aurora v1 for audio-driven avatar video—one input image plus one audio track to produce a realistic talking/singing style output—priced starting around $0.10/s, as stated in the Runware availability post.

The positioning is squarely creator-commercial (ads, music videos, dubbing/localization, virtual humans), and Runware links to both a standard and “fast” model page in the model links, but there’s no additional quality/latency benchmarking in the tweets beyond the demo.
Mixed Media workflow: pick FPS/resolution and a style like Acid or Toxic with no prompts
Workflow pattern (Higgsfield Mixed Media): A creator walkthrough frames Mixed Media as a parameter-first workflow—upload a source clip, choose FPS and resolution, then apply a named look (e.g., “Acid” or “Toxic”) without prompting, as shown in the thread walkthrough.

The thread also claims fast rendering in practice and notes some styles require picking a color while others don’t, with the “Toxic” look called out directly in the thread walkthrough. Access/how-to links are being shared in the follow-up how to access post, but there’s no additional spec detail beyond the in-product selection flow shown on-screen.
Luma Dream Machine adds Ray3 Modify demo for time-of-day changes on footage
Ray3 Modify (Luma Dream Machine): Luma is pushing Ray3 Modify as a post-style transform for existing video—specifically changing “time of day” across the same scene, as shown in the Ray3 Modify clip.

The visible demo cycles identical shots through daylight/night/desert-like lighting variants, positioning Ray3 Modify as a lighting-and-mood knob for creators who already have motion but need alternate grades or narrative time shifts, per the Ray3 Modify clip.
Grok Imagine: creators keep iterating toward anime-style micro-animations
Grok Imagine (xAI): Creators are sharing ongoing iteration toward anime-style micro-animations, with “liking the anime I make … more and more” framing the current sentiment in the creator clip post.

There’s also a qualitative claim that “not just any video generator could render” this kind of animation in the follow-up comment, but the tweets don’t surface a reproducible workflow recipe or a model/version delta to anchor the improvement.
PixVerse v5.5 goes live on GMI Cloud with native audio-visual sync and multi-shot storytelling
PixVerse v5.5 (GMI Cloud / GMI Studio): PixVerse v5.5 is being promoted as live inside GMI Cloud and GMI Studio, with feature claims including native audio-visual sync and multi-shot storytelling, per the availability repost.
This is a distribution/update signal (where to run PixVerse v5.5) more than a spec release; the repost doesn’t include a demo clip, pricing, or an eval reference beyond the feature list in the availability repost.
Seedance 1.5 Pro prompt share: first-person bicycle downhill shot with natural shake
Seedance 1.5 Pro (Replicate): A POV filmmaking prompt is circulating for Seedance 1.5 Pro—first-person bicycle ride downhill at dawn with natural camera shake, wind feel, and edge motion blur—captured in the prompt share.

This is being presented as a reusable “cinematic urban realism” recipe (motion cues + blur constraints) rather than a new feature announcement, with the example output anchored in the prompt share.
🖼️ Image-generation demos: liminal realism, fake Street View, and Midjourney looks
Today’s image-side chatter skews toward “it looks real” demos (liminal spaces, Street View fakes) plus general Midjourney/Nano Banana Pro output showcases. This excludes reusable prompt dumps (covered in prompt_style_drops).
Nano Banana Pro liminal-space realism set becomes a new stress test
Nano Banana Pro (Google): A small set of “creepy liminal space” images is getting shared as a realism stress test—abandoned-feeling interiors (arches, fluorescents, empty corridors) with occasional motion-blur “ghost” artifacts, per the Liminal photo set and its Repost of set.
• Why creatives care: It’s the kind of output that reads like found photography for horror titles, ARGs, and “backrooms” sequences, because the spaces look physically plausible while still feeling wrong, as shown in the Liminal photo set.
Street View-style screenshot mockups jump from 1812 London to 2026 selfies
Workflow pattern: Creators are leaning into “Google Street View” UI mockups as a narrative container—complete with search bars, map insets, and timestamp overlays—spanning both historical and contemporary gags, as seen in the London 1812 Street View and the Street View selfie post.
• Period-piece framing: The “London, England — Google Street View — July 1812” interface turns a single image into an instant time-travel beat, as shown in the London 1812 Street View.
• Modern variant: A “caught posting on X” Street View selfie leans on the same UI-language (address bar, minimap, date stamp), with the author explicitly crediting Nano Banana Pro for the screenshot realism in the Street View selfie post.
ChatGPT 5.2 image prompt turns “relationship to the assistant” into a picture
ChatGPT 5.2 (OpenAI): A user shared a ChatGPT prompt—“Based on our conversation history, create a picture of how you feel I treat you”—and the resulting generated scene (a cozy study with a glowing energy sphere over an open book) is circulating as a compact demo of “personalized” image intent, as shown in the ChatGPT 5.2 screenshot and echoed in the Follow-up reaction.
It’s less about technical fidelity than the creative framing: using conversational context as the seed for a mood-board-style image, as shown in the ChatGPT 5.2 screenshot.
Midjourney sref 1462474833 channels DCAU and Samurai Jack energy
Midjourney: A creator is showcasing --sref 1462474833 as a Western action animation lane—explicitly citing Bruce Timm / DC Animated Universe and Genndy Tartakovsky (Samurai Jack) influence in the Style reference samples, alongside ongoing “I built a new style” posting in the Another style teaser.
The outputs emphasize sharp angles, heavy shadows, and graphic lighting—useful when you want animation-keyframe readability rather than painterly texture, as shown in the Style reference samples.
Midjourney sref 4517081602: red/black dissolution look goes shareable
Midjourney: A newly shared style reference, --sref 4517081602, is circulating with a consistent visual signature—minimal backgrounds, heavy negative space, and subjects “dissolving” into motion-blur or ink/smoke plumes, per the Sref style samples and the Repost samples.
• What it’s good for: The samples read like fashion/editorial key art (high-contrast silhouettes + controlled color accents), which is why it’s being treated more like a reusable art-direction preset than a one-off image set, as shown in the Sref style samples.
Midjourney close-up portrait posts push micro-texture realism
Midjourney: A hyper-close portrait crop (lips, pores, skin speculars) is being shared as a “can it do photoreal texture?” check, per the Close-up portrait crop, standing in contrast to the more graphic/stylized Midjourney lanes people are also trading today in the Sref style samples.
The demo’s value for designers is straightforward: it spotlights whether your current Midjourney settings can survive beauty-campaign scrutiny (where skin texture is the tell), as shown in the Close-up portrait crop.
🧪 Prompt & style drops: Midjourney srefs, Nano Banana recipes, and brand directives
Heavily prompt-driven day: multiple Midjourney --sref drops, long JSON-style Nano Banana Pro prompts, and reusable brand identity directives. Excludes multi-step pipelines (covered in creator_workflows_agents).
Nano Banana Pro prompt meme: “anti-memetic entity” for liminal, label-free photography
Nano Banana Pro (Nano Banana): A prompt meme is spreading for generating “impossible imperceptible anti-memetic entity” imagery—explicitly banning labels and overlays—to get a long-exposure/ghost artifact vibe as shown in the example output.
One iteration tightens the setting into “liminal space indoor underground theme park” with “90s disposable camera photography,” while keeping the “no dates, no text overlay” constraint per the prompt tweak.
Nano Banana Pro prompt: candid street-photo guitarist with headphones (85mm, f/4.5)
Nano Banana Pro (Nano Banana): A “candid street photography” prompt is being circulated with unusually specific capture settings (85mm, f/4.5, 1/250s, ISO 400) plus wardrobe/props (gig bag + over‑ear headphones) to push a believable campus/editorial vibe, as written in the prompt + example.
The notable pattern is using camera parameters as the primary control surface—background compression, mild bokeh, and motion freeze—rather than piling on style adjectives, per the prompt + example.
Nano Banana Pro prompt: fisheye “newspaper room” selective-color fashion set
Nano Banana Pro (Nano Banana): A prompt recipe for a box-room covered in newspaper wallpaper leans on fisheye distortion (10–12mm) and “selective color” art direction—everything grayscale except saturated reds—laid out in the prompt + output.
It’s a clean way to force graphic cohesion: lock the environment texture to one repeating pattern, then reserve color for a single story element (pants/glasses/shoes), as specified in the prompt + output.
Nano Banana Pro prompt: high-key studio K-pop “black textures” editorial look breakdown
Nano Banana Pro (Nano Banana): A high-key studio prompt is being shared that stays interesting by stacking black-on-black material cues (sequins, faux fur, patent boots, fishnet) against a pure white seamless, with full styling and camera settings (85mm, f/8, ISO 100) in the prompt + output.
The prompt’s control comes from wardrobe taxonomy (headwear, neckwear, outerwear, accessories) rather than abstract vibe words, as shown in the prompt + output.
Nano Banana Pro prompt: miniature person perched on a giant macro eye (lens/DoF spec)
Nano Banana Pro (Nano Banana): A detailed “macro composite” prompt is being shared that aims for high-fidelity realism by specifying lens (100mm macro), aperture (f/11), reflections, skin pores, and a grounded contact shadow—see the full structured prompt in the prompt + output.
The compositional trick is simple to reuse: treat an anatomical feature as a “ledge/bench,” then over-spec camera physics so the scene reads like a fashion-surreal editorial rather than a collage, per the prompt + output.
Seedance 1.5 Pro prompt share: FPV bike downhill at dawn with natural shake
Seedance 1.5 Pro (Replicate): A short prompt is circulating as a repeatable “cinematic realism” recipe for motion: first-person bike descent at dawn; natural camera shake synced to pedaling; wind rush; edge motion blur; steady forward momentum, per the prompt share + clip.
The key prompt ingredient is describing how the camera behaves (“shakes naturally,” “motion blur at the edges”) rather than only the scene, which matches the visible cadence in the prompt share + clip.
Veo 3.1 fast JSON prompt: K-pop idol BTS photoshoot with handheld orbit camera
Veo 3.1 fast (Google): A structured JSON prompt is being shared as a template for “idol photoshoot BTS” video direction—8s duration; hyper-real studio; orbiting handheld camera; dangling props with slight physics; and explicit wardrobe + set dressing—shown in the prompt + output clip.

The prompt reads like a shot list: subject action beats (three poses) plus camera path and environment constraints, which is visible in the consistent orbit and prop movement in the prompt + output clip.
Hailuo prompt recipe: chaining multiple camera moves in one shot (crane to shoulder mount)
Camera movement prompting (Hailuo): A prompt format is being reshared that explicitly sequences camera rigs inside a single generation—starting with an aerial crane move and transitioning into a shoulder-mounted feel—framed as “multiple camera movements” in the prompt repost.
This is less about a single scene idea and more about encoding shot grammar as text: specify the transition between camera modes, not just a static “camera moves,” as implied by the structure in the prompt repost.
Midjourney --p tlnt7wp moodboard prompt shared for glittery pastel-in-dark portrait lane
Midjourney --p tlnt7wp (Midjourney): A moodboard preset is being shared as a shorthand for a specific aesthetic lane—surreal, glitter-heavy portraits and props in dark settings with pastel/pink accents—framed in the moodboard share.
Unlike an --sref style ref, this reads as a “palette + subject matter” attractor: repeated motifs (glitter skin, pink monsters, neon hearts, NASA suit) suggest what the preset tends to pull toward, based on the moodboard share.
Midjourney custom style shared for children’s illustration and urban sketching looks
Midjourney (Midjourney): A creator-shared custom style is being positioned as dual-purpose—children’s illustration and loose urban sketching—based on a set of sample outputs in the style preview.
The examples consistently show ink-like outlines with watercolor washes and simplified shapes (street scenes, winter character vignettes), suggesting a dependable “line + wash” recipe rather than a hyper-detailed render lane, as shown in the style preview.
🧩 Workflow recipes & agents: brand boards, indie scenes, and product-shot automation
Multi-step creator pipelines dominate: Firefly Boards end-to-end branding, Freepik Spaces workflows for filmmakers, and agent-style automation for product visuals. Excludes single-tool prompts (prompt_style_drops) and tool outages (tool_issues_reliability).
Adobe Firefly Boards workflow turns a vague product idea into a full campaign in under 2 hours
Firefly Boards (Adobe): A full “brand-to-assets” workflow got documented end-to-end—moodboard → logo exploration → campaign visuals → short video outputs—claimed to be completed in under 2 hours inside a single Firefly Board, as shown in the workflow recap and expanded step-by-step in the board walkthrough.

The thread frames Boards as the organizing layer, then mixes partner models for each stage: Adobe Stock moodboarding per the moodboard step, logo ideation via Ideogram 3.0 in the logo generation step, campaign/key visuals using Nano Banana Pro + Flux 2 Pro according to the campaign visual step, and “first/second frame” control for animation using Veo 3.1 / Runway / Sora as described in the video step. It closes with Topaz Astra upscaling inside Boards per the upscaling step, plus a time-bound note about unlimited generations for specific Firefly plans through Jan 15 in the workflow recap.
Freepik Spaces workflow: generate character and setting refs, then drive action shots via Kling Motion Control
Spaces (Freepik): A repeatable indie-filmmaking pipeline is being shared: build a Space that links (1) a reference video, (2) generated character and environment reference images, then (3) Kling Motion Control to produce consistent action shots—using Spaces’ automatic frame extraction to avoid manual prep, as detailed in the step-by-step thread.

The creator pitch is that Spaces functions as the workflow glue (nodes + reusable setup) while Kling handles the motion step, with the overall approach introduced in the thread launch.
heyglif teases an agent that turns a product photo into deconstructed product shots using Claude tool selection
Deconstructed product shots agent (heyglif): A “bring your product image” agent is being teased that generates deconstructed visuals; the claim is that Claude builds the prompts and selects tools to recreate complex exploded-view/product breakdown shots, with access positioned as “coming soon” in the agent teaser.

A second clip reframes the same agent output beyond ads—showing multi-style component renders and recomposition—per the creative use demo.
Firefly Boards adds a handoff loop to Photoshop and Adobe Express Assistant for final edits
Firefly Boards (Adobe): A practical “last-mile” pattern is being pushed: generate inside Boards, then open outputs directly in Photoshop or Adobe Express for layout and cleanup—especially using Adobe Express Assistant for quick remove/recolor/resize passes, as described in the handoff workflow note.

The same workflow shows up in storyboard practice too: Flux 2 Pro generations move into Photoshop for 2×2 grid stacks and frame slicing, as explained in the Photoshop grid workflow.
Niji 7 → Nano Banana Pro → Grok Imagine emerges as a repeatable three-step remix chain
Cross-tool chain: A compact three-step remix pattern is getting reposted as a “do this, then this” workflow: generate a still in Niji 7, pass it through Nano Banana Pro, then animate/finish in Grok Imagine—shown as a labeled transformation chain in the Monday Road chain and echoed again in the Next train chain.

A similar “Niji 7 → Grok Imagine” bridge clip is also framed as a quick animation handoff in the workflow comparison clip, reinforcing the idea that creators are treating these as modular stages rather than single-model projects.
heyglif’s Room Renovator agent uses historical eras as a renovation storytelling layer
Room Renovator agent (heyglif): A lightweight storytelling workflow is being promoted for renovation/construction visuals: generate “before/after” by moving the same space through different historical eras, turning progress updates into a narrative device, as shown in the eras demo.

The agent is publicly accessible via the agent page, with the concept introduced in the eras demo.
🧍 Identity & continuity: single-image character sheets, multi-shot storytelling, and multi-angle views
Today’s continuity talk centers on using one reference to lock a character/world across outputs (character sheets, new characters in the same style) plus multi-angle and multi-shot features. Excludes generic image prompts and non-identity video styling.
Runway Render Engine turns one image into a character sheet plus world shots
Render Engine (Runway): A creator-built workflow inside Runway is demoing a tight continuity loop: upload 1 image (explicitly “no prompts”) and get a high-fidelity render plus a full character sheet, detail shots, and 9 cinematic images that expand the same world, as described in the Render Engine overview. It’s pitched as a way to lock identity and art direction early.
The follow-up samples lean into “character exploration” as the main value: keeping the same character’s face/wardrobe/tech-aesthetic stable while moving between clean sheet views and environmental frames, as shown in the Render Engine tests.
Runway Render Engine reuses an existing character to generate new castmates
Render Engine (Runway): A second continuity pattern is emerging: feed a previously generated character back in, and the system analyzes style to create new characters in the same world—the example shared is “male knights to accompany the previous heroes,” per the Same-world character expansion. This targets the common pain point of building a cast without the look drifting.
The outputs are framed as production-friendly: consistent armor/material language and facial rendering, plus cinematic scene placements that read like pre-vis stills rather than isolated portraits, as shown in the Same-world character expansion and reinforced by the environment-oriented presentation in the Gothic hall pairing.
🎙️ Voice stack updates: transcription, TTS, and enterprise scale signals
Voice news is a mix of business scale (ARR) plus new/updated transcription + TTS model mentions (mostly ElevenLabs and Alibaba Tongyi voice stack). No music-gen wave today.
ElevenLabs says it ended 2025 at $330M+ ARR, citing enterprise-scale voice deployments
ElevenLabs (ElevenLabs): The company says it closed 2025 at $330M+ ARR, framing the jump as enterprise-driven and tied to production voice workflows, per the ARR milestone post. This is a scale datapoint for teams budgeting dubbing, voice agents, and localization.

• Enterprise usage signals: ElevenLabs highlights deployments where agents handle 50,000+ calls per month and creative teams dub content across 30+ languages, as described in the ARR milestone post.
No customer names or unit economics were shared in these tweets.
Alibaba Tongyi highlights Fun-CosyVoice 3 (0.5B) for expressive TTS and zero-shot cloning
Fun-CosyVoice 3 0.5B (Tongyi Lab / Alibaba): In the same Tongyi “Fun” voice family update, the thread describes Fun-CosyVoice 3 (0.5B) as an open-source expressive TTS model with zero-shot voice cloning and cross-lingual voice generation, per the Voice stack overview and the Demo links note. No audio samples or MOS-style quality numbers were included in these tweets.
Alibaba Tongyi releases Fun-ASR (0.8B) as open-source, noise-robust multilingual ASR
Fun-ASR 0.8B (Tongyi Lab / Alibaba): A thread claims Alibaba’s Tongyi Lab open-sourced Fun-ASR (0.8B) for noise-robust, multilingual, real-time speech recognition, with the positioning summarized in the Model stack overview and expanded in the Demo links note. This is aimed at practical capture conditions (cafes/streets/offices). Short version: it’s trying to be usable outside studio audio.

Treat performance claims as provisional here—no benchmark tables were shown in the tweets.
Creatify Aurora v1 lands on Runware: one image + one audio track to realistic avatar video
Aurora v1 (Creatify on Runware): Runware says Creatify Aurora v1 is now available as an audio-driven avatar generator—one image + one audio track into a realistic talking/singing head video—priced from $0.10/s, as stated in the Runware availability post. The pitch is squarely commercial: ads, music videos, virtual humans, and dubbing/localization.
Runware also links to its hosted endpoints via the model pages in Model page and Fast variant page.
ElevenLabs Scribe v2 resurfaces as a batch transcription-focused accuracy push
Scribe v2 (ElevenLabs): A reposted mention describes Scribe v2 as ElevenLabs’ “most accurate transcription model so far,” positioned for batch transcription workflows in the Scribe v2 recap. Details like WER benchmarks, supported languages, and pricing weren’t included in the tweet.
🛠️ Finishing passes: upscalers, polish, and last-mile edits
Post tools show up mainly as “make it shippable” steps: video upscaling on Replicate, Topaz Astra inside Firefly workflows, and portrait finishers. Excludes generation features.
Replicate launches Crystal Video Upscaler for 4K-quality video upscaling
Crystal Video Upscaler (Replicate): Replicate says Crystal Video Upscaler is now live as a “high-precision” video upscaler tuned for portraits, faces, and products, as described in the Launch post. It also lines up with the underlying tool’s milestone that “Crystal Upscaler now works with videos” after ~2 months of work, per the Dev progress note.

This lands as a clean last-mile step for creators delivering social ads, product reels, and talking-head work where face detail is the thing people notice first.
Adobe Firefly Boards adds Topaz Astra as an in-app final video upscale step
Topaz Astra (Adobe Firefly Boards): A Firefly Boards workflow thread calls out a new “final step” that upscales generated video using Topaz Astra inside Boards—positioned as restoring fine texture and detail to make drafts usable as final assets, as shown in the Upscale step demo.

The practical implication for small teams is tighter handoff: generate, iterate, and finish in the same board surface, rather than exporting to a separate desktop upscaler just to hit delivery quality.
Adobe Express Assistant pitched as the last-mile edit layer for AI images
Adobe Express Assistant (Adobe): A Firefly Boards workflow share frames Adobe Express Assistant as the post step for fast cleanups—remove elements, recolor, and resize variants once the generated visuals are “ready,” as described in the Assistant handoff demo.
This is less about generation quality and more about production throughput: turning one approved visual into multiple shippable formats without reopening a full design file.
🏗️ Where creators build: hubs, team plans, and model marketplaces
Platform-layer updates: model hosting/import, team billing/credit pooling, and “all models in one place” offers. This is more about access and packaging than raw model capability.
Comfy Cloud adds one-link model imports and private “My Models” storage
Comfy Cloud (ComfyUI): ComfyUI says you can now import models into Comfy Cloud by pasting a Civitai or Hugging Face link—positioned as removing manual downloads and file management—per the Import feature demo.

• What you get: Imported weights appear under “My Models” and are not shared with other users, as described in the Import feature demo.
• Docs mismatch to watch: The current documentation says “the only supported source for model imports is Civitai,” as written in the Import docs, which conflicts with the broader “Civitai or Hugging Face” claim in the Import feature demo.
Net: the workflow is clearly “link in, model ready,” but the exact source support looks in flux based on the Import docs.
OpenArt runs January deal: up to 60% off across multiple top models
OpenArt (Pricing/marketplace): OpenArt is advertising a January promotion—“up to 60% off top models” and a pitch to “lock this price for the year”—covering models like NanoBanana Pro, Veo 3, Hailuo 2.3, Kling 2.6, and Seedream 4.5, as shown in the 2026 offer promo.

The plan details and tiers are pushed via the Pricing page, with the positioning explicitly being “one platform” access rather than new model capability per the 2026 offer promo.
Seed 1.8 arrives on BytePlus ModelArk with function calling and context management
Seed 1.8 (BytePlus ModelArk): BytePlus announced Seed 1.8 is now available on ModelArk, framing it as “production-ready” for visual intelligence and agentic workflows, with reliable function calling and built-in context management, according to the ModelArk availability post.
The post also spotlights intended deployments like multi-turn customer support, multimodal moderation, and physical-world monitoring/inspection, all as example “what you can build” packaging within ModelArk per the ModelArk availability post.
Hedra Team Plans add shared credits and shared billing
Hedra Team Plans (Hedra): Hedra introduced Team Plans where a single Pro account can fund a shared credit pool across a whole team, alongside shared billing and “content generation running 24/7,” as stated in the Team plans announcement.

For small studios, this reads as a packaging change more than a model change: the main shift is consolidating usage under one paid seat while still letting multiple collaborators generate continuously, per the Team plans announcement.
Producer opens a Spaces game challenge with up to 1,000 credits in prizes
Producer Spaces (Community challenge): Producer announced a Discord community challenge to create a game using Spaces, with “bonus points” for adding musical elements and prizes “up to 1,000 credits,” per the Challenge announcement.
Submissions must be shared as a Producer link to the Space by Monday, Jan 19 at 12:00 PM PT, as specified in the Deadline reminder.
Lovart posts a quick UI demo of its creator canvas
Lovart (App surface): Lovart shared a short “features worth discovering” UI walkthrough that frames Lovart as a mobile-first creative canvas/workflow surface, per the Lovart UI clip.

The clip is light on specifics (no pricing or model roster called out), but it’s clearly a platform packaging message—tool UX and creation surface—per the Lovart UI clip.
Pictory case study: scaling medical education videos via script/URL-to-video automation
Pictory (Creator automation case study): Pictory is promoting a case study about a medical creator scaling educational content, emphasizing automation from script or URL → video (voiceover, visuals, captions) and fast iteration by editing text, as described in the Case study teaser.
More detail lives in the Case study page, with the headline claim being the ability to produce “hundreds of videos with ease,” per the Case study teaser.
🧰 Agents for “real work”: Claude Cowork + creator-dev meta tooling
Creator-adjacent dev tools trend toward agentic desktop workflows (file access, planning scaffolds) rather than pure coding. This beat also captures how people are structuring Claude Code projects today.
Anthropic previews Cowork: Claude gets folder access for non-technical file work (Mac-only)
Cowork (Anthropic): Anthropic introduced Cowork as “Claude Code for the rest of your work,” giving Claude access to a user-selected folder so it can read, edit, and create files for everyday (non-coding) tasks, as described in the launch framing and the feature rundown. It’s positioned as a research preview and currently Mac-only, with explicit approval gates for major actions.
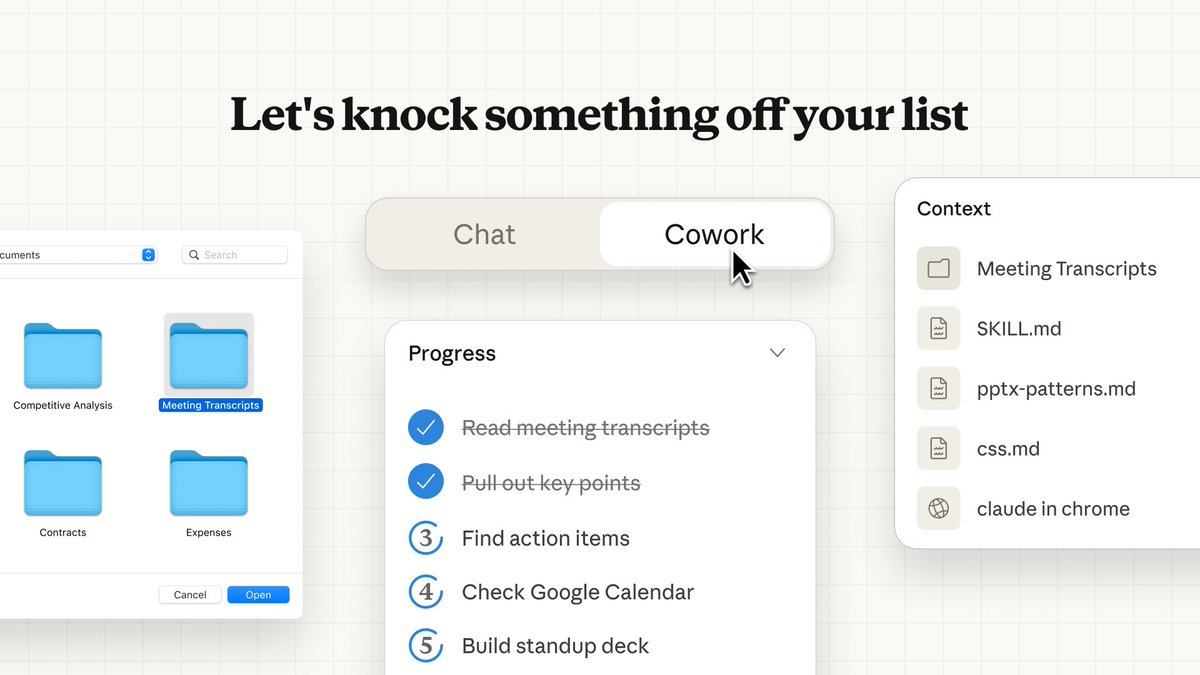
• Control model: Claude plans steps and asks for confirmation on bigger changes, according to the feature rundown.
• Surface area: It’s shown alongside existing connectors and “Claude in Chrome” style browser work, per the feature rundown.
Claude Code’s creator claims Claude wrote “all” the code for Cowork
Claude Code (Anthropic): A viral internal-dogfooding claim emerged alongside Cowork—Claude Code’s creator replied “All of it” to whether Claude Code wrote the code for Claude Cowork, as captured in the Boris Cherny screenshot and contextualized by the broader Cowork launch thread.
This is anecdotal (not a repo or audit), but it signals how Anthropic wants Cowork perceived: built with the same agentic tooling it’s shipping.
Claude Code usage expands into non-coding work like travel research and slide building
Claude Code (Anthropic): Anthropic is leaning into a broader “work agent” narrative: they’re highlighting that after launching Claude Code, users started applying it to non-coding tasks like “vacation research” and “building slides,” as echoed in the usage examples and reinforced by the Cowork positioning.
The creative implication is that “code-style” agent loops (plan → gather sources → draft → revise) are being marketed as a general workflow for files and documents, not just repositories.
DesignArena launches SVG Arena to compare models on prompt-to-SVG generation quality
SVG Arena (DesignArena): A new eval surface called SVG Arena is circulating for comparing prompt-to-SVG outputs, with a leaderboard-style UI showing ranked generations for the same prompt, as shown in the SVG Arena screenshot.
• What it’s measuring (implicitly): It’s less about “pretty images” and more about whether models can generate clean, faithful vector shapes (useful for designers shipping icons/logos/UI assets) under a consistent prompt-and-judge loop, per the SVG Arena screenshot.
Avthar shares the PSB method to structure Claude Code projects (Plan/Setup/Build)
PSB method (Claude Code workflow): A structured “Plan/Setup/Build” approach is being shared as a way to keep Claude Code projects from turning into spaghetti—starting with a spec doc (goals + milestones), then a checklist-style setup, then choosing between single-feature, issue-based, or parallel worktree builds, as outlined in the PSB breakdown.
• Setup discipline: The checklist explicitly calls out repo hygiene, secrets in a .env, documentation automation, and optional MCP/plugin plumbing, per the PSB breakdown.
It reads like a response to a real pain point: once agents can touch many files quickly, the project needs stronger scaffolding.
NotebookLM gets used to produce an explainer video about Google’s Universal Commerce Protocol
NotebookLM (Google): A creator posted a full explainer video made with NotebookLM to walk through Google’s Universal Commerce Protocol (UCP), highlighting NotebookLM as a “research → structured explanation → publishable video” pipeline, as shown in the NotebookLM explainer share.

The tweet frames this as lightly edited for YouTube, with the core production coming out of NotebookLM per the NotebookLM explainer share.
⚙️ Local stack performance: ComfyUI speed-ups and creator-grade GPU tricks
Compute news is concentrated in ComfyUI + NVIDIA optimizations: faster inference, better offloading when VRAM is tight, and defaults rolling out quietly. (No major new consumer GPU launches in the sample.)
ComfyUI ships NVIDIA GPU optimizations: NVFP4 up to 2× faster, async offload 10–50% faster
ComfyUI (ComfyUI + NVIDIA): New NVIDIA-focused performance work is now live, targeting “1024×1024 in half the time” as a 2026 goal, and it’s already been silently enabled by default since December according to the Optimization announcement. For Blackwell GPUs, ComfyUI is pitching NVFP4 quantization as “up to 2× faster,” and for memory-constrained setups it claims async offload + pinned memory yields “10–50% faster” performance across NVIDIA GPUs, per the same Optimization announcement.
• Blackwell-specific path: NVFP4 is framed as the main speed lever for owners of NVIDIA Blackwell cards, as described in the Optimization announcement.
• Low-VRAM path: Async offload + pinned memory is positioned as the broadly applicable boost when models don’t fit in VRAM, also per the Optimization announcement.
The operational detail that matters for local creators is the “enabled by default since December” claim in the Optimization announcement, which implies many people may already be benchmarking the new behavior without realizing it.
Comfy Cloud adds model import by pasting a Civitai/HF link (docs currently say Civitai only)
Comfy Cloud (ComfyUI): Comfy Cloud now lets users import models by pasting a model link instead of manually downloading and managing files, as shown in the Import announcement.
The announcement claims imports work from “Civitai or Hugging Face” in the Import announcement, but Comfy’s own documentation currently states “the only supported source for model imports is Civitai,” and that the feature is limited to Creator tier (or higher), as detailed in the Import models docs and echoed by the Docs pointer.
This is a workflow-level unlock for creators who keep a cloud Comfy setup alongside local: it removes the “model wrangling” step and keeps imported models private under “My Models,” per the Import announcement.
ComfyUI crosses 100k GitHub stars, now ranked 84th most popular GitHub project
ComfyUI (ComfyUI): ComfyUI passed 100,000 GitHub stars and was framed as the “84th most popular GitHub project of all time” in the 100k stars milestone. The signal here is less about a new feature and more about momentum: for local-first creators, this typically correlates with faster community debugging, more nodes/workflows, and more third-party infrastructure built around the same toolchain—though today’s post itself is purely the milestone note in the 100k stars milestone.
📚 Papers & toolkits creators should bookmark (reasoning, video, controllability)
Research links skew toward practical foundations: controllability, long-context/test-time training, video reasoning, and search-augmented behavior. Mostly paper drops; little benchmark drama.
End-to-end test-time training claims constant-latency long-context performance
End-to-End Test-Time Training for Long Context (TTT-E2E): This paper reframes long-context modeling as continual learning at test time, using next-token prediction to compress context into weights; it claims constant inference latency regardless of context length, per the paper share and the Paper page.
It also reports scaling results for a 3B-parameter model trained on 164B tokens, as described on the Paper page. That’s a useful reference point for teams building story bibles / long scripts / multi-scene projects where context windows are still the bottleneck.
Paper frames long chain-of-thought as “molecular structures” for stability
The Molecular Structure of Thought (Chen et al.): A new framing for long chain-of-thought (CoT) reliability models “good” long CoT trajectories as stable, molecule-like structures, aiming to explain why long reasoning can drift or collapse, as outlined in the paper share and detailed on the Paper page. It’s mainly interesting as a conceptual toolkit for anyone training or evaluating “long-thinking” agents where stability matters.
The paper argues these structures emerge more from fine-tuning long-CoT models than from copying human reasoning, per the Paper page.
VideoAuto-R1 trains video reasoning with “thinking once, answering twice”
VideoAuto-R1: A video understanding framework that trains a “Thinking Once, Answering Twice” behavior—generate an initial response, then refine via confidence and verifiable rewards—according to the paper share and the accompanying Paper page. It’s a direct attempt to make video QA-style reasoning more reliable without always paying the cost of full chain-of-thought at inference.
A notable claim is the “reason-when-necessary” strategy for efficiency, as described on the Paper page.
MMFormalizer links visual grounding to formal reasoning for “autoformalization”
MMFormalizer: A multimodal “autoformalization” approach that tries to turn natural-language + visual perception into grounded formal statements, aiming to reduce errors that come from missing constraints in diagrams or scenes; it’s summarized in the paper share and expanded on the Paper page.
The core mechanism is adaptive grounding (tying visual primitives to formal entities), which matters if you care about models that can justify structured decisions from images rather than only caption them, per the Paper page.
Thinking with Map proposes a map-in-the-loop agent for image geolocalization
Thinking with Map (MAPBench): This work pushes an explicit “agent-in-the-map loop” for image geolocalization—adding map reasoning to what vision-language models already infer from visual clues, as introduced in the paper share and described on the Paper page. It also introduces MAPBench, positioned as a benchmark built around up-to-date, real-world images.
The practical creative angle is evaluation: it’s a concrete way to test how well multimodal agents can ground place/scene claims when the workflow includes a map step rather than pure hallucination-prone recall.
🚧 Reliability & friction: Claude downtime reports and permission fatigue
The main reliability chatter is Claude availability plus “death by confirmations” in Claude Code’s permissions flow; on the video side, Veo 3.1 users complain about tail-end instability.
Claude users report an availability outage
Claude (Anthropic): Multiple users reported Claude being unavailable on Jan 12, with an initial “Is Claude down for anyone else?” check in Downtime question getting a quick “Yep” confirmation in Outage confirmation, suggesting it wasn’t just a single-account issue.
The tweets don’t include status-page detail, regions, or duration, so the scope remains unclear beyond user reports.
Claude Code Mac app users complain about repeated “Allow once” permission prompts
Claude Code (Anthropic): Following up on local file access (Claude Desktop file workflows), a user reports “death by confirmations” in the Claude Code Mac app—having to approve web fetch permissions “every 10 seconds” via repeated “Allow once” clicks during research-heavy sessions, and asking for a “dangerously skip permissions” option as shown in Permission prompt screenshot.
• What’s blocking flow: The prompt appears on each fetch attempt, which turns “over-use web search” workflows into constant interruption, per Permission prompt screenshot.
No official response or setting/workaround appears in the tweet set.
Veo 3.1 fast users report last-second instability in 8-second clips
Veo 3.1 fast (Google / Gemini app): A creator reports a recurring failure mode where Veo 3.1 fast “messed up” in the last 2–3 seconds of an 8-second generation, illustrated via a tandem drift donut clip shared in Tail-end glitch report.

The post doesn’t clarify whether the degradation is temporal coherence, motion artifacts, or scene drift, but it’s framed as repeat behavior rather than a one-off.
📈 Algorithm reality: slop vs quality, repost penalties, and delayed reach
Distribution discourse is the news today: creators quantify how low-effort ‘slop’ outperforms, debate whether quality is rewarded, and share heuristics about reposting and post timing.
Dor Brothers’ “Slop Culture” study claims low-effort volume can yield 50×–100× views
Slop culture (Dor Brothers): A new infographic thread argues that, on today’s social algorithms, high-frequency “slop” consistently beats produced work on raw distribution—citing a 50×–100× views advantage for low-quality, high-volume posting in the Slop culture thread.
• Why creatives care: the thread frames this as a structural incentive problem (“the system is built to reward frequency and immediacy”), which explains why polished shorts can underperform quick memes even when the craft is obvious, as shown in the Slop culture thread.
• Economic reality check: it also separates reach from earnings, claiming some multi‑million‑follower pages make “less than $15/month,” per the Slop culture thread.
Dor Brothers: “100 views from the right people” can beat a billion views for revenue
Client acquisition (Dor Brothers): A companion “Slop vs Quality” graphic claims their biggest revenue projects rarely come from their most viral posts; instead, “100 views from the right people” is positioned as the reliable path to high‑value clients, per the Slop vs quality graphic.
The claim is anecdotal (no underlying dataset shared in the tweets), but it’s a concrete framing for filmmakers and designers balancing portfolio pieces versus feed-maximizing output, as reinforced by the Observations comment.
Posting cadence observation: a new post may boost the previous one; delayed exposure is common
Timing and distribution (Artedeingenio): A thread claims that since a recent algorithm change, publishing a new post often boosts the prior post, and that many posts show delayed lift (weak first minutes, then take off hours later), based on repeated personal observation in the Posting cadence observation.
No hard metrics or screenshots are provided, so treat it as field-reporting rather than proof—but it’s a useful description of why “early likes” can be a misleading creative signal on X right now.
“Just post quality content” meme contrasts with a low-effort tweet hitting 924K views
Visibility narrative (cfryant): A viral counterexample screenshot shows a minimal “horses, don’t like em.” post reaching 924K views, used to mock the advice “just post quality content for visibility,” as shown in the Low-effort viral screenshot.
The post lands because it’s a crisp, visual datapoint that supports the Dor Brothers’ broader claim that algorithms often reward immediacy over effort, as argued in the Slop dominates argument.
Selective reposting advice: heavy reposting can tag you as “support/spam” and cut reach
Reposting behavior (Artedeingenio): A creator heuristic making the rounds says frequent reposting can cause the algorithm to classify an account as a “support account” (closer to spam than original creator), which then depresses distribution; the recommendation is to repost sparingly, per the Repost warning.
This is a platform-dynamics claim without platform confirmation, but it matches how many creators already treat reposts as a high-risk lever for identity and reach, as implied by the broader “slop vs quality” discussion in the Visibility meme.
“Post once, don’t reply” experiment: improved reach, worse creator experience
Engagement trade-off (bri_guy_ai): A small behavior experiment reports higher reach after doing one post and not replying (“didn’t interact with friends… had improved reach”), but also describes the approach as less enjoyable and less community-driven, per the Reach experiment.
It’s not a controlled test, but it captures a recurring tension in creator workflows: optimizing distribution can actively punish the social loop that keeps creatives posting.
🎞️ Creator drops: shorts, experiments, and narrative tests
A lighter showcase day: a few named/structured shorts and narrative experiments circulate (animation tests, AI film re-imaginings, and stylized concept clips). Excludes pure tool announcements.
“Houdini” escape-sequence AI short circulates as a personal project drop
HOUDINI (isaachorror): A short AI film re-imagining of Houdini’s escape imagery is shared as a personal project; the clip leans on a submerged, chained tank setup and fast-cut archival-style interstitials, as shown in the project clip.

The piece reads like a proof-of-tone test: establishing a period look, then using rapid montage to sell stakes and spectacle without a long runtime, per the same project clip.
Artedeingenio tests a “Satoshi Kon x Breaking Bad” mirror alter-ego scene
Breaking Bad anime concept (Artedeingenio): A crossover test imagines “Satoshi Kon made a Breaking Bad anime,” centering on Walter White facing an alter-ego in a broken mirror; the creator explicitly ties the mirror to “fractured personality” symbolism and show references, per the concept clip.

It functions like a compact narrative pitch: one iconic prop (mirror) + one readable emotional beat (self-confrontation) to prove the vibe without needing a full trailer, as described alongside the same concept clip.
A “lost on Street View” liminal theme-park screenshot becomes a micro-story
Liminal Street View micro-fiction: A “Got lost on Google Street View” post leans into an abandoned indoor theme-park vibe—carousel, small ferris wheel, mascot statue—reading as a self-contained horror-ish beat, as shown in the Street View screenshot.
In replies, the creator frames it as “a subtle challenge” prompt—i.e., the image itself is the narrative hook rather than the setup for a longer thread, per the follow-up line.
XCaliber resurfaces a personal AI animation scene from an 11-year story
XCaliber (indie story project): A short AI animation scene is reposted as a “special place in my heart” snippet tied to a story in development for 11 years, as echoed in the repost mention and duplicate repost.
The signal for other storytellers is less the technique (no workflow details in the reposts) and more the framing: AI as a way to finally render long-held scenes into shareable clips, per the repost mention.
Techhalla previews a larger project with a cinematic helicopter-rappel frame
ImagineArt (techhalla): A single high-drama still (helicopter rope insertion over a dense hillside city) is posted as a teaser for a “cinematic workflow” project-in-progress, per the still teaser.
Because it’s framed as “stay tuned” rather than a finished short, the post mainly signals aesthetic intent (scale, chaos, militarized action) and a likely longer sequence to come, as implied in the still teaser.
🛡️ Trust & ethics: high-risk AI answers get pulled + the hidden human supply chain
Policy/ethics signals today: Google reportedly removes AI Overviews in a high-risk query area after error reporting, while a separate thread spotlights outsourced human labor (labeling/moderation) as an often-hidden cost of “safe” AI.
Google pulls AI Overviews for some medical searches after reports flag dangerous errors
AI Overviews (Google): Google reportedly disabled AI Overviews for some health-related searches (example cited: liver blood tests) after reporting highlighted inaccurate, potentially harmful outputs, as summarized in the Report summary.
The immediate creator impact is less about search UI and more about distribution: if you rely on Google surfaces to route audiences to explanatory content, high-risk verticals can see sudden product-policy changes with little notice, and the removal itself becomes a signal that Google is treating these queries as a safety boundary rather than a “fix it later” quality issue.
“Hidden cost of AI” thread spotlights outsourced data work and content review in Nairobi
AI labor supply chain (Le Iene/Mediaset): A thread highlights a TV report alleging that parts of modern AI pipelines depend on outsourced workers in Nairobi doing data labeling, document checks, and sometimes disturbing content review under tight throughput and low pay, as described in the Hidden cost thread and linked via the Full segment page.

• Accountability and intermediaries: The post emphasizes that BPO-style layers can make it unclear who workers are “really” working for, which complicates responsibility when data or safety processes go wrong, per the Hidden cost thread.
• Data governance and psychological cost: It calls out provenance/consent for sensitive data and the mental-health burden of moderation work as real operational costs of “safe” AI, again per the Hidden cost thread.
The report framing is journalistic rather than audited, so specific claims remain hard to verify from tweets alone, but the thread shows this narrative continuing to shape how creators talk about “AI safety” beyond model cards and keynotes.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught




















































