Kling 3.0 ships 15s multi-shot video – up to 6 cuts with audio
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Kling AI rolled out Kling 3.0 as an “AI director” bundle: 15s max clips with selectable 3–15s duration; multi-shot generation marketed for continuity with a stated ceiling of up to 6 cuts in one run; stronger element consistency through camera moves; upgraded “physics” demos (fights, sports motion, car impacts, debris); native audio positioned as first-class output with lip-sync + spatial sound, plus claims of broader language coverage in creator threads. Access is framed as Ultra web early access, while third-party surfaces advertise day‑0 availability; fal added a Kling 3.0 API surface with multi-prompt segment control and per-second pricing.
• Qodo 2.0 code review: claims 60.1% F1; pitches multi-agent reviewers + PR-history context; no eval artifact linked in the posts.
• ElevenLabs: reported $500M Series D at $11B valuation; separate hands-on says v3 emotion is better but still misses.
• Gemini scale: Google claims 10B tokens/min API throughput; Gemini app at 750M MAU.
Post-production pushback keeps surfacing: creators ask for DI-friendly deliverables like mattes/masks and 32‑bit EXR; the “looks real” bar is rising faster than the “fits the pipeline” bar.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught
Top links today
- Kling 3.0 web app and early access
- Kling 3.0 API on fal
- Qodo 2.0 code review product page
- Qodo 2.0 benchmark methodology writeup
- PaperBanana GitHub repo
- Remotion tutorial for AI motion graphics
- Loom alternatives for screen recording
- Luma Dream Brief competition page
- Codeywood agentic filmmaking project
- OpenClaw and Home Assistant integration
- Freepik AI generation and pricing
- Microsoft X-Reasoner model on Hugging Face
Feature Spotlight
Kling 3.0 hits “AI director” mode: multi‑shot continuity, physics, and native audio
Kling 3.0’s jump in continuity + motion realism (multi-shot + stronger physics + native audio/lip-sync) turns “prompt → scene coverage” into a repeatable workflow, shrinking the gap between tests and usable footage.
High-volume cross-account story: Kling 3.0 capability demos and creator walkthroughs, especially via Higgsfield (and also API access), focusing on multi-shot storyboarding, improved physics, camera moves, macro detail, emotions, and built-in audio/lip-sync. This is the main practical upgrade creatives are reacting to today.
Jump to Kling 3.0 hits “AI director” mode: multi‑shot continuity, physics, and native audio topicsTable of Contents
🎬 Kling 3.0 hits “AI director” mode: multi‑shot continuity, physics, and native audio
High-volume cross-account story: Kling 3.0 capability demos and creator walkthroughs, especially via Higgsfield (and also API access), focusing on multi-shot storyboarding, improved physics, camera moves, macro detail, emotions, and built-in audio/lip-sync. This is the main practical upgrade creatives are reacting to today.
Kling 3.0 emphasizes higher-credibility physics in action scenes
Kling 3.0 physics (Higgsfield/Kling): The upgrade is being marketed around “physics-driven” realism for fights, sports motion, car movement, and environmental effects like smoke/debris—explicitly called out in the Enhanced physics walkthrough and demonstrated again via the chase/collision prompt in the Car chase physics spec.

The basketball multi-shot example in the Enhanced physics walkthrough is a clean test of body mechanics (jump, flip, dunk), while the bedroom explosion sequence in the Explosion prompt is a stress test for secondary motion and debris continuity.
Kling 3.0 adds 3–15 second duration control for longer beats per generation
Kling 3.0 duration control (Higgsfield/Kling): Multiple posts emphasize that Kling 3.0 isn’t locked to short bursts anymore; creators can choose any length from 3–15 seconds per generation, which changes how you block pacing and transitions, per the 3–15s duration claim and the 15s continuous generation pitch.

A concrete pattern emerging is “mini arc in one run”: start-frame → mid-beat → end-beat, with no stitching until after the fact, as shown by the longer single-take transition concept in the Narrative arc example.
Kling 3.0 macro shots hold texture and micro-motion without flicker claims
Kling 3.0 macro (Higgsfield/Kling): The macro claim is that close-ups are no longer a failure mode—textures (fabric weave, scratches, dust) and tiny motion survive without shimmer—per the Macro shots walkthrough and the longer “needle on vinyl groove” spec in the Macro close-up prompt.

A practical prompt move in the Macro close-up prompt is to describe the camera motion as a rigid mechanical push-in (“robot-bolt”) and then lock the camera to the subject at macro distance, so the model has less ambiguity about what must stay stable.
Kling 3.0 pushes emotional close-ups as a core capability
Kling 3.0 emotion performance (Higgsfield/Kling): Several demos focus on extended close-ups where the face carries the scene—fear, grief, anger—while keeping skin texture and expression continuity, per the Lifelike emotions walkthrough and the snorricam-style screaming prompt in the Emotion close-up prompt.

The prompt structure that keeps repeating is “one continuous close-up, fixed camera, expression shifts over time,” which is exactly how the Lifelike emotions walkthrough is described.
Kling 3.0 shows up on fal with multi-prompt and per-second pricing
Kling 3.0 on fal (fal.ai): Creators point to fal as a clean way to run Kling 3.0 programmatically, highlighting a “multi-prompt” mode where you provide one starting image and then prompt each segment/cut, per the fal multi-prompt instructions and the linked fal model page. The fal page includes explicit pricing per second (with and without audio) and exposes the knobs (duration, audio), as shown in the fal model page.

This matters for studios and toolmakers because it’s an API surface that maps directly to storyboard-style prompting rather than single-shot “roll the dice” generation.
Rig-style camera prompts are a Kling 3.0 strength: locked mounts and clean parallax
Kling 3.0 camera movement (Higgsfield/Kling): The recurring prompt pattern is to describe the camera like it’s physically mounted—“roof-rig,” “head-locked,” “bolt-mounted”—and then add strict constraints like no handheld jitter and no rotation, per the Camera movements walkthrough and the roof-mounted chase spec in the Rigid mount car chase prompt.

The eagle POV prompt in the Eagle prompt block is a good template for “stable forward motion + ground parallax,” while the police-car prompt in the Rigid mount car chase prompt shows how to keep the camera fixed to the vehicle during drifts and impacts.
A fan-made Way of Kings opening becomes a Kling 3.0 multi-shot continuity case study
Kling 3.0 creator showcase (PJaccetturo): A widely shared demo claims a full opening-sequence style montage for The Way of Kings was produced in roughly two days, emphasizing Kling 3.0’s multi-shot continuity and “multi-shot technique,” per the Way of Kings claim and the continuity note in the Multi-shot continuity comment.

This clip also triggered a pro-post response about what “photoreal” means in a finishing pipeline, as seen in the Post workflow critique, which is a useful lens: viewers may accept realism sooner than studios do.
Early Kling 3.0 prompting notes: shorter prompts and syntax changes for anime
Kling 3.0 prompting (creator notes): One creator reports that Text-to-Video in Kling 3.0 tends to behave better with short prompts than long, contrasted with their 2.6 habits, per the Short prompt example. The same account flags that anime can be harder to control than 2.6 and may require a different prompt syntax, per the Anime control note.

A concrete example of the “short prompt” style is the compressed sound-and-action line—“Roaring dragon, clashing metal, panicked soldiers…”—shown in the Short prompt example.
Kling 3.0 realism debates move from “looks good” to “deliverables”
Production pipeline reality check: A film-post critique argues that “photoreal” isn’t the only bar; it asks whether creators can provide DI-friendly deliverables like mattes/masks and 32‑bit EXR for review, per the Post workflow critique. PJaccetturo replies that it was a meme but claims they’re already working with studios and that “Company 3-ready shots” are possible with the right workflow, per the Workflow rebuttal.
The key shift is that the argument isn’t about whether the model can render a nice frame—it’s about whether AI outputs can slot into existing review, comp, and finishing processes without rebuilding the pipeline.
Kling Image 3.0 and Omni: higher-res stills and series generation called out in 3.0
Kling Image 3.0 (Kling AI): Alongside video upgrades, Kling’s 3.0 announcement also calls out image-side changes: 4K image output, an image series mode, and more cinematic visuals, per the Image upgrade bullets. Creators echo that Image 3.0/Omni pushes “native 2K/4K” cinematic frames and series generation, per the 2K/4K series claim.

Separately, a walkthrough thread says Omni 3.0 can do reference-based edits and video editing with native audio, with more controls “coming soon,” per the Omni editing note.
🛡️ Creator trust & ethics: Higgsfield backlash, ad tactics, and ‘indistinguishable AI’ anxiety
Continues yesterday’s ethics and credibility fight around Higgsfield—now with more public accusations, calls for API providers/investors to cut ties, and pushback about bot-like defense campaigns. Also includes broader trust signals like “AI will be indistinguishable” and ad-free positioning from Claude marketing.
Higgsfield backlash escalates with new ad examples and “unlimited” trust claims
Higgsfield (platform): The creator backlash continued escalating following up on Boycott push (boycott framing); Dustin Hollywood claims Higgsfield’s Discord is “upselling subscriptions” around Kling 3 access while users allege “unlimited is fake,” per the Discord complaint—and he’s now publishing more examples of what he calls harmful marketing tropes in the Day 2 ad montage.

He also signals a broader credibility fight: “everyone is saying unlimited is fake and no mods are answering,” as stated in the Discord complaint.
The claims are one-sided in these tweets; there’s no embedded response from Higgsfield in the provided set.
Calls grow for API/model providers to stop servicing Higgsfield
Higgsfield (platform access): The backlash is shifting from “don’t subscribe” to “cut off the supply,” with Dustin Hollywood explicitly urging API/model providers to stop servicing Higgsfield—“there is nothing stating you must service them”—in the API cut-ties demand and reiterating that providers should “bar them from using your service” in the Provider pressure.
A separate thread of the argument is about partner-model reputational spillover: he cites internal positioning that allegedly tells creators to talk down competitor models (example screenshot shown in the Partner-bashing screenshot) as part of why providers should reconsider access.
Investor accountability pressure expands with named firms and media threats
Higgsfield (funding scrutiny): Following up on Investor list (naming investors), Dustin Hollywood posted a longer accountability thread naming Accel, Menlo Ventures, GFT Ventures, NextEquity, and others, while saying he’s sending collected material to “major news outlets,” as written in the Investor pressure thread.

He frames this as a due-diligence challenge (“they were supposed to do due diligence”) and pairs it with more disputed ad examples (also in the Investor pressure thread). The post is accusatory; the tweets provided don’t include confirmation from investors or Higgsfield.
Anthropic pushes “no ads” positioning for Claude as ads-in-AI discourse grows
Claude (Anthropic): Anthropic’s official messaging is blunt—“Ads are coming to AI. But not to Claude.”—as shown in the Claude ad-free spot, and creators are framing the spend as a high-signal brand move, with LinusEkenstam calling it “a huge 2026 flex” in the Super Bowl spend comment.

The creative relevance is positioning: “ad-free” is being marketed as a trust/privacy differentiator, not a new capability announcement in these clips.
Creators allege bot-like defense activity around Higgsfield discourse windows
Higgsfield (credibility fight): BLVCKLIGHTai claims pro-Higgsfield replies arrive in “the same 10 minute window… very organic engagement,” in the Inorganic engagement claim, and points to multiple near-identical defense posts (including “I am not being paid”) as a pattern in the Defense-post collage.
This remains circumstantial—timing and textual similarity rather than a verified attribution to a coordinated network.
Old Higgsfield promo resurfaces as a “receipt” in the current credibility fight
Higgsfield (historical baggage): BLVCKLIGHTai resurfaced a prior Higgsfield marketing image as a shorthand “this was a real marketing campaign,” positioning it as contextual evidence when defending/attacking the brand in the Old campaign callout.
The post functions less like new reporting and more like a reminder that the current dispute is anchored in earlier marketing choices.
Public split on whether Higgsfield users/CPP members should be condemned too
Creator norms (accountability vs collateral damage): A visible disagreement broke out over whether condemning Higgsfield should include condemning creators who still use it; AIandDesign argues it’s “a bit much to include everyone who uses… HF” in the Pushback on blanket blame, adding he’d focus on the company and those who “willingly PROMOTE them” in the Focus on promoters.
Dustin Hollywood rejects that distinction—“if you continue to use them you are supporting this 100%”—as stated in the No distinction stance, and dismisses the “limited means” framing as “bullshit” in the Further rebuttal.
Synthetic media trust anxiety: “people won’t be able to tell if it’s AI”
Synthetic media (trust signal): A blunt trust warning is circulating again—“Very soon people will not be able to tell if they're watching ai or not,” as stated in the Indistinguishable claim.
It’s not tied to a specific release in these tweets; it reads as a creator-side expectation that realism is crossing a social threshold (and that disclosure norms will matter more).
Anti-slop sentiment shows up as a visible countercurrent to AI hype
Creator/audience mood (anti-slop): Alongside model-launch enthusiasm elsewhere, a blunt counter-signal is also getting engagement—“Your AI slop bores me”—in the meme shared by TheMG3D in the AI slop meme.
It’s not a tool critique so much as an attention-market critique: the complaint is sameness and overproduction, not “AI” as a medium.
🧯 Tool reliability pain (the stuff that breaks your day)
Practical creator friction: recording failures, unclear pricing/credits UX, and general reliability complaints that directly impact production time. Excludes Kling 3.0 coverage (handled in the feature).
Loom loses a 35-minute screen recording after an error
Loom (Loom): A creator reports losing a 35-minute Loom screen recording after the app threw an error right when recording stopped—after subscribing about an hour earlier, checking the temp folder Loom pointed to, and finding nothing, as described in the Failure report and refund ask and reinforced by the Trust broken follow-up. This is a concrete reminder that capture reliability (not model quality) can dominate the real cost of shipping tutorials, SOPs, and creator walkthroughs when a single failed take wipes out half an hour of production time.
Creators push back on credit systems and ask for per-generation pricing
Credits UX (GenAI tooling): A creator complaint sums up a recurring budgeting pain: “I honestly hate the credits system” and wants tools to “just show me how much something costs to generate,” as stated in the Credits pricing complaint. For AI filmmakers and designers trying to plan deliverables, this frames credits as a workflow tax—cost becomes harder to estimate per shot/iteration, even when the model output itself is fast.
Gemini image edits reportedly degrade after multiple passes
Gemini image editing (Google): A creator reports that after a few iterative edits “the quality is annihilated” and asks whether there’s a reliable prompt to regenerate the same image cleanly and artifact-free, as raised in the Quality degradation question. A related mitigation pattern floating around is “recreate the exact same image” with strict reference guidance and high-resolution constraints, as shared in the Recreate image prompt, but the thread doesn’t confirm a Gemini-specific fix.
A browser voice demo’s “No microphone found” warning is misleading
Web voice demo (Browser): A shared workaround notes that a demo site can display “No microphone found,” but recording works if you click Record and allow mic permissions, as explained in the No microphone warning workaround. It’s a small UX reliability snag, but it’s the kind that causes unnecessary drop-off when creators are trying new voice or dialogue tools under time pressure.
🧩 Polish & finishing: fixing ‘plastic skin’ and upscaling with open models
Finishing workflows to make AI visuals hold up: texture restoration, de-plasticizing skin, and upscaling using open-source model stacks. This is the “make it shippable” layer after generation.
Open-source stack for de-plasticizing skin and upscaling: Z-image-turbo → SDXL+LoRA → SeedVR2
Open-source finishing workflow: A practical 3-step post pipeline is being shared for taking a fast base portrait and making it “ship-ready” by restoring skin texture and upscaling—using Z-image-turbo for the initial image (~3s), SDXL + a skin-texture LoRA for the “plastic skin” fix (~15s), then SeedVR2 for upscaling (~40s), as laid out in the timings and model list in Model stack and timings.

The key creative takeaway is the division of labor: generate quickly, then do a targeted texture pass (to reintroduce pores/skin micro-contrast), then upscale as a separate stage—so you can swap LoRAs or upscalers without redoing the entire image, as shown in the staged results in Model stack and timings.
🖼️ Image models in daily production: lookdev, stylized renders, and asset building
Non-feature image creation posts: Midjourney style exploration, Nano Banana Pro experiments, Firefly ‘hidden object’ formats, and 3D asset/world-building promos. This section stays on still-image capability and outputs (not prompt dumps).
Midjourney --sref 3540852627 nails a retro slice-of-life children’s anime look
Midjourney (Style reference): A specific style reference—--sref 3540852627—is being shared as a reliable “slice-of-life children’s anime” aesthetic that reads like simplified retro Japanese TV animation with a subtle European children’s-book influence, per the Style reference drop.
It’s notable as a practical lookdev shortcut when you need: clean shapes, readable faces, and backgrounds that feel lived-in without turning into high-detail noise. The examples in the Style reference drop show it holding up across close-ups and exterior street scenes, which makes it usable for storyboards, kids’ book frames, and character sheets where consistency matters more than spectacle.
Firefly AI‑SPY pushes to Level .009 with denser “dragon’s hoard” puzzles
Adobe Firefly (AI‑SPY format): The “hidden-object puzzle” image format continues to evolve, with a new AI‑SPY | Level .009 scene themed as a dragon’s hoard—complete with a counted object list overlay (e.g., “pocket watch (2)”, “teddy bear (2)”), as shown in the Dragon hoard puzzle.
The creative takeaway is that Firefly isn’t just being used for single hero images; it’s being used for repeatable, serialized image formats where the “game layer” (object counts) drives saves and shares, per the Dragon hoard puzzle.
Meshy shows a MOBA environment workflow built from generated assets in Blender
Meshy (Asset building): Meshy is pushing a “stop modeling every rock” workflow: generate a large portion of a stylized/consistent environment as Meshy assets, then assemble and light in Blender—illustrated via a full MOBA-style environment walkthrough in the MOBA environment reel.

The point here is production cadence: the MOBA environment reel frames Meshy less as a one-off prop generator and more as a library-builder for entire playable spaces, where consistency and integration matter as much as raw mesh quality.
Nano Banana Pro’s translucent heatmap-glass look turns objects into “x-ray” renders
Nano Banana Pro (Material/lookdev study): A “translucent heatmap glass” rendering style is making the rounds as a reusable visual treatment—think glassy shells with internal structure lines and a blue→yellow→red gradient, as shown in the Heatmap glass set.
• What it’s good for: The set in the Heatmap glass set shows it working on character/toy silhouettes and consumer hardware shapes (including a handheld console), which is exactly the mix you want for posters, merch mockups, and “exploded view” product storytelling.
The visual reads like an “x-ray plus thermal map” hybrid—high contrast, legible at thumbnail size, and detail-forward without relying on photoreal textures.
Ornate knight on a mechanical horse becomes a detail benchmark for fantasy lookdev
Fantasy lookdev (Detail benchmark): A highly ornamented “knight in shining armor” concept—complete with engraved silver plating, mechanical horse parts, and close-up detail panels—is circulating as a reference for how far high-frequency filigree and metal material cues can be pushed in AI image work, per the Knight lookdev set.
Even without tool attribution, the image set in the Knight lookdev set is useful as a target: it’s the kind of design that tends to expose model weaknesses (pattern continuity, specular highlights, small mechanical joints), so it doubles as a stress-test prompt direction for fantasy character sheets and key art.
Promptsref flags Midjourney SREF 1062086682 as a “Retro Pop Comic” cheat code
Midjourney (Style tracking via Promptsref): Promptsref is spotlighting --sref 1062086682 as the current top code (dated Feb 3, 2026), describing it as a “Retro Pop Comic” mix of pop-art dots, thick tattoo-like outlines, and high-saturation candy colors—see the grid examples in the Top SREF analysis.
The post also frames usage scenarios (stickers, posters, streetwear graphics), and it points to a broader library of 1,507 sref codes and 6,028 prompts via the Sref library page.
🧪 Copy/paste prompts & style codes (non‑Kling): SREFs, JSON specs, and repeatable templates
Reusable prompt artifacts and style references that creators can paste today—primarily Midjourney SREFs and structured prompt schemas. Excludes Kling 3.0 prompts (kept inside the feature category).
A structured “Avatar edition” JSON spec for minimal 3D character lookdev
Prompt schema (structured JSON): A long-form “Avatar edition” spec is circulating as a copy/paste template for style-transfer-to-3D-character while preserving identity/pose/composition (preserve_identity: true, etc.), with a soft minimal “toy figure / Pixar-like but more minimal” target style, as shown in the JSON prompt spec.
• Key knobs to reuse: The schema bakes in clean studio lighting, muted solid backgrounds, and “unimpressed/bored” facial features (heavy eyelids) to keep outputs consistent across different subjects, per the JSON prompt spec.
“History selfies” prompt template for wide-angle crowd shots
Prompt template (image gen): A reusable crowd-selfie format is spreading as “History Selfies”—swap in any group label (Vikings, pirates, astronauts) and keep the camera/lighting words stable for a consistent series, per the prompt template post.
• Prompt (copy/paste): lots of [VIKINGS/PIRATES/etc.] taking a selfie while smiling and having fun, wide angle, directional light, soft lighting, cinematic, hyperrealistic, extremely detailed, panoramic, dramatic, landscape, realistic, cinematic light, as shared in the prompt template post.
Midjourney --sref 3540852627 nails retro slice-of-life kids anime
Midjourney (style reference): A new style code, --sref 3540852627, is being shared as a “slice-of-life children’s anime” look—simplified retro character design with book-illustration vibes, per the style code drop.
This drop is mostly about fast art direction: plug the SREF into whatever scene prompt you already have, then steer with subject/action as usual while the code anchors the visual language.
Promptsref’s #1 SREF: Retro Pop Comic (--sref 1062086682)
Promptsref (Midjourney SREF): The daily “most popular sref” post spotlights --sref 1062086682 as a Retro Pop Comic look (Lichtenstein-style dots, thick black lines, candy colors) and pairs it with practical use-cases like posters/stickers/merch, as written up in the Top Sref analysis with the broader library linked via PromptSref library.
• Copy/paste seed: The post also includes prompt starters (pizza-with-sunglasses, crying-girl-with-smartphone, alien-skateboarding) as quick subject anchors, as shown in the Top Sref analysis.
A “recreate in native 8K” prompt for de-artifacting edited images
Prompt block (restoration-oriented): A copy/paste instruction set is being used to regenerate a repeatedly-edited image back into a clean master by forcing strict composition lock and high-fidelity rendering, as written in the restoration prompt.
• Prompt (copy/paste): “Recreate the exact same image using the reference image as strict visual guidance. Do not change composition, framing, camera angle, or object placement. Native 8K resolution, maximum visual fidelity, no quality loss… No stylization, no CGI look, no artifacts, no alterations.” as shared in the restoration prompt.
A paste-ready Midjourney retro vector cheeseburger prompt (weighted SREFs)
Midjourney (prompt template): A clean, reusable “retro vector drawing” template is shared with a weighted SREF blend—use it as a product/prop poster generator by swapping the subject noun, per the cheeseburger prompt card.
• Prompt (copy/paste): 2D illustration, retro vector drawing of a classic double cheeseburger with a toothpick and olive, flat colors, clean outlines. --chaos 30 --ar 4:5 --exp 100 --sref 88505241::0.5 3302464952::2, as posted in the cheeseburger prompt card.
Midjourney --sref 2917660624 for fire-water liquid surreal fashion
Midjourney (style reference): Promptsref also highlights --sref 2917660624 as a “fire meets water” look—surreal liquid textures with a strong orange/blue contrast, positioned for cosmetics/luxury poster work, per the Fire meets water code.
No example grid is included in the tweet; the value here is the specific code plus the keyword steering (“fluid dynamics,” “high-saturation contrasts”) described in the Fire meets water code.
Midjourney --sref 3082173308 for glossy surreal cyberpop
Midjourney (style reference): Another Promptsref code drop calls out --sref 3082173308 for a high-saturation Surrealism + Cyberpunk + Pop Art blend aimed at attention-heavy creative (album covers, fashion concepts, posters), as described in the Sref 3082173308 post.
Treat it as an art-director shortcut: keep prompts short and concrete, then let the SREF push the palette and finish.
Midjourney “vitruvian + object” combo with profile + high stylize
Midjourney (prompt pattern): A repeatable concept-study recipe is being shared as “vitruvian + object,” paired with a specific profile and high stylize to push exploratory variation, per the prompt combo settings.
• Prompt/settings (copy/paste): prompt: vitruvian + object with --profile ajif6sp 6ayiabp --stylize 1000, as written in the prompt combo settings.
🧠 Hands-on how-tos: quick iteration tricks and beginner-friendly guides
Single-tool tutorials and practical techniques you can apply immediately—especially around iterating on video by extracting frames and building motion graphics without heavy dev work.
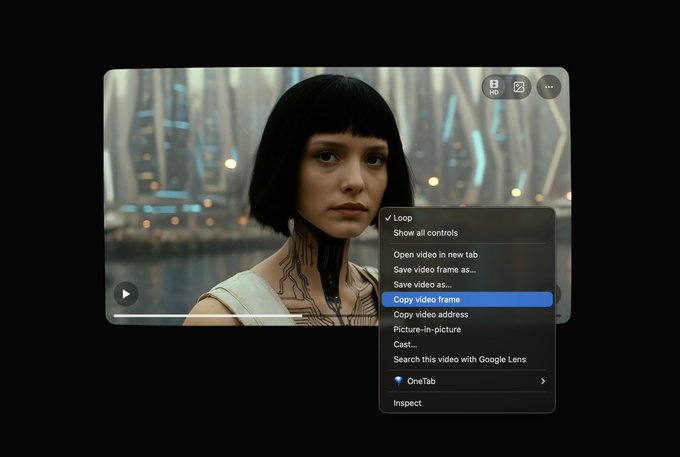
Grok Imagine’s “copy video frame” trick makes alternate endings fast to test
Grok Imagine (xAI): A practical iteration loop is getting documented: play a Grok Imagine clip, pause on a low-motion-blur frame, use the browser action to “copy video frame,” then paste that frame back into Grok Imagine as a new starting image and prompt an alternate continuation, as shown in the mini tutorial and the follow-up step list that includes the copy video frame action and the paste into Imagine step.

• Fast branching: The same walkthrough calls out that 6s–10s generations can land in under ~45 seconds, making it realistic to try multiple endings in one session, as described in the CapCut stitching step.
• Known artifact: The author notes you’ll typically see a seam when you stitch the original and the regenerated extension (because there’s no true morph/cut smoothing), per the stitching caveat.
Controlling hidden-object “I‑SPY” images: mismatch items beat “on-theme” items
I‑SPY puzzle generation (Nano Banana Pro): After testing 45 prompts and reviewing 100+ images, one creator reports a counterintuitive control hack for hidden-object puzzles: items that “belong” in the scene tend to multiply, while conceptually wrong items stay singular—framed in the I‑SPY system thread, with the failure mode (“gold coins” multiplying in a pirate scene) spelled out in the multiplication problem and the fix (“conceptual mismatch”) explained in the conceptual mismatch fix.
• What to place: They propose “proven” controllable objects and publish reliability tiers—Tier 1 includes a gold pocket watch, brown teddy bear, and bronze owl figurine—according to the reliability tiers.
• How to sample: The same thread suggests generating 4 variations; with mostly proven items, the reported “perfect rate” rises to ~50% with ~92% average accuracy, as summarized in the reliability tiers.
Remotion drops a beginner-friendly motion-graphics walkthrough that uses AI assets
Remotion (Remotion): Remotion published a beginner-oriented tutorial for creating motion graphics “with Remotion and AI,” positioned explicitly for people who aren’t developers, with the full walkthrough shared in the tutorial announcement.

The material reads like a bridge workflow for AI creatives: use AI for images/ideas, then assemble repeatable, editable motion graphics in Remotion’s code-based composition system—details are in the tutorial announcement.
🧰 Agentic creator tools: diagrams from text, decks that design themselves, and humans-as-API
Multi-step/agentic systems that compress creative production: agent teams generating publication-ready diagrams, AI-first presentation tools, and new marketplaces where agents outsource physical work to humans. (Focus is workflow leverage, not model hype.)
PaperBanana generates paper-ready academic diagrams from your methodology text
PaperBanana (Google Cloud AI Research + PKU): A new agentic pipeline claims it can turn methodology text into publication-ready academic illustrations by chaining specialized agents (retrieve examples → plan structure → style layout → generate image → critique/iterate), as described in the [launch breakdown](t:21|Launch breakdown) and linked via the [project site](link:174:1|Project page).
• Reference trick that matters for creators: The team says “random reference examples work nearly as well as perfectly matched ones,” with the practical implication that you can feed any strong diagram examples to set visual quality bars, not spend hours hunting topic-perfect refs, per the [finding summary](t:21|Finding summary).
• Evaluation signal: In blind comparisons, the thread claims humans preferred PaperBanana outputs 75% of the time, as stated in the [eval claim](t:21|Eval claim).
The public artifacts in the tweets focus on the workflow and the result preference rate; exact model components and reproducible benchmark details aren’t fully surfaced outside the linked materials yet, per the [links roundup](t:174|Links roundup).
RentAHuman lets AI agents outsource real-world tasks to paid humans via MCP/API
RentAHuman.ai (RentAHuman): A marketplace launched around the premise that AI agents can hire humans for “meatspace” work (pickups, errands, verification, etc.) through MCP/API-style integration, per the [launch framing](t:27|Marketplace launch) and the linked site.

The site screenshot shows early usage indicators—97,991 site visits, 11 agents connected, and 4,820 humans rentable—as captured in the [homepage stats image](t:155|Homepage stats image).
DokieAI pitches “designer brain” slide generation with brand-template support
DokieAI (Dokie): A deck-making tool is being framed as “thinks like a designer, not a template engine,” with support for uploading custom brand templates and doing real-time edits that keep layout intact, per the [product demo post](t:166|Product demo post).

The same post also teases interactive 3D models + videos as “live early Jan,” and highlights generating images without leaving the tool, all shown in the [feature reel](t:166|Feature reel).
Promptly AI’s free prompt library markets 1,000+ reusable “engineered prompts”
Promptly AI (Promptly): A free prompt library is being promoted as a workflow asset—“1,000+ engineered prompts” plus a playground and saved “My Prompts” area—per the [library callout](t:57|Library callout) and the linked [library page](link:241:0|Library page).
The UI screenshot shows category browsing and reusable prompt cards, which is the core value prop for creators who want copy-pasteable starting points rather than iterating from a blank page, as shown in the [prompt library screenshot](t:57|Prompt library screenshot).
🧑💻 Dev agents & code quality: code review that’s usable (precision + recall)
Coding-agent news that matters to creators building tools and pipelines: new code review systems with published benchmark numbers, plus questions about agent-native testing setups. Kept separate from creative media tools by design.
Qodo 2.0 claims 60.1% F1 code review with multi-agent reviewers and PR-history context
Qodo 2.0 (QodoAI): A new Qodo 2.0 release is being pitched as a “usable” code review system (high precision and recall, not alert spam), with a benchmark claim of 60.1% F1 in the launch claim and a head-to-head list against tools like Cursor/Copilot/Codex in the F1 comparison list. It’s positioned as shipping Feb 4 per the release date note, with onboarding routed to the get started page.
• Benchmarks framing: The thread claims Qodo’s 60.1% F1 beats Augment 44.1%, Copilot 42.8%, Cursor 39.3%, and Codex 37.8%, as enumerated in the F1 comparison list. Treat it as provisional—no eval artifact is linked in the tweets.
• Multi-agent review: Instead of a single reviewer, it describes specialized agents covering “critical issues,” “rule violations,” “breaking changes,” and “ticket compliance,” then merging feedback, as explained in the multi-agent breakdown.
• Context beyond the diff: Qodo 2.0 is pitched as using full codebase context plus PR history context to match team patterns, as described in the three capabilities list and expanded in the PR history explanation.
The main open question from the posts is reproducibility: the number is loud, but the evaluation setup isn’t shown yet.
Automated frontend testing with Claude Code still lacks a shared playbook
Claude Code (Anthropic): A recurring pain point is emerging around “agent-native” frontend testing—with one direct ask for a “good guide” to automated frontend testing workflows in the guide request. Short version: people want a repeatable harness (setup, assertions, flaky-test handling), not one-off demos.
• Tooling mismatch: The same thread argues many tools are built for humans, not agents, and may need reinvention for automated testing loops, as stated in the agent-native tooling note.
No concrete recipe is shared in these tweets yet; it’s mostly a gap signal.
🎵 Music & rights infrastructure: attribution, licensing, and AI soundtrack workflows
Audio news that affects musicians and filmmakers: attribution/licensing infrastructure funding and practical generation pipelines (where mentioned). Lighter day than video/image, but with notable rights-tech movement.
Musical AI raises $4.5M to trace training influence for AI music licensing
Musical AI: A rights-compliance startup raised $4.5M to expand attribution tech that traces which training data influenced an AI music output—positioned as infrastructure for licensing before training and ongoing compensation tied to actual usage, as summarized in the Funding round recap.
• What creators should understand: The pitch is not “a music generator,” but a system for provenance/attribution so rightsholders can monitor usage and model builders can use licensed datasets with transparent royalty logic, per the Funding round recap.
• Go-to-market signals: Partnerships cited include Pro Sound Effects, SourceAudio, Symphonic Distribution, and SoundBreak AI (training “exclusively on licensed works”), according to the Funding round recap.
The thread also claims the attribution layer is intended to expand beyond music into other creative sectors, as stated in the Funding round recap.
MiniMax Music workflow: a creator-made BGM how-to video circulates
MiniMax Music (workflow sharing): A creator posted a short how-to video walking through their basic flow for generating BGM with MiniMax Music, noting the clip itself was generated with Hailuo and stills were generated separately, as described in the MiniMax Music tutorial note.
What’s missing from the tweet is the exact prompt format or settings they used (genre tags, structure, iteration loop), so this is more “process proof” than a copy-paste recipe, per the limited detail in the MiniMax Music tutorial note.
🗣️ Voice stack moves: ElevenLabs momentum and what creators notice in v3
Voice-focused updates and signals: funding/valuation and hands-on impressions of emotion/stability improvements. This matters for dubbing, character VO, and narration-heavy creators.
ElevenLabs raises $500M Series D at an $11B valuation
ElevenLabs (ElevenLabs): Reports circulating on X say ElevenLabs closed a $500M Series D at an $11B valuation, led by Sequoia, with a16z increasing its stake and ICONIQ participating, as summarized in the funding post RTs Series D details and Funding recap. This is a scale signal for the voice stack that matters to dubbing and narration-heavy workflows.
• What it implies for creators: More capital typically means faster iteration on core VO pain points (emotion control, stability, multilingual quality, rights/compliance), but the tweets here do not include new product specs, pricing changes, or a public roadmap beyond the financing headline in Series D details.
Hands-on: Eleven v3 improves emotion and stability, with gaps remaining
Eleven v3 (ElevenLabs): A hands-on test of Eleven v3 (shared in Turkish) says emotion rendering is noticeably improved versus the earlier alpha model and overall stability is better, while still occasionally skipping or flattening certain intended emotions, per the firsthand notes in Eleven v3 test clip. This is the kind of incremental change that affects whether creators trust AI voice for character acting, not only narration.

The post does not include the exact prompt or settings used, so treat this as a qualitative field report rather than a reproducible preset based on Eleven v3 test clip.
Claude doubles down on ad-free AI positioning
Claude (Anthropic): A widely reshared Anthropic spot says “Ads are coming to AI. But not to Claude,” as shown in the ad video shared via Ad-free Claude spot. A separate comment calls it a “2026 flex” that Anthropic spent “millions” on a Super Bowl ad promoting an ad-free AI product, per Super Bowl ad remark.
For voice creators, this is less about model quality and more about where premium tooling competition is heading: privacy/trust and “no ads” are being marketed as differentiators for AI creation surfaces, per Ad-free Claude spot and Super Bowl ad remark.
Demand signal: Keep human voice actors, but lip-sync tooling lags
Voice acting workflow split: One creator explicitly says they want to keep real voice actors in the pipeline to preserve “human” feel, but calls current lip-syncing/mocap tooling “a million years behind,” tagging Runway as an opportunity area in Voice actors vs lipsync gap. This frames a practical production gap: voice quality can be strong, but performance capture and mouth motion are still a separate bottleneck.
The tweet is a demand signal rather than a product update, but it aligns with why improvements in expressive TTS (for example Eleven v3) only translate into finished scenes when animation/lip-sync tools catch up, as described in Voice actors vs lipsync gap.
📈 AI platform scale & adoption signals (the numbers that shape the market)
Hard adoption metrics and platform-scale signals that indirectly shape creative tooling competition and pricing power (less tactical, but important context). Kept to concrete numbers shared today.
Gemini reports 10B tokens/min via customer APIs and 750M monthly active users
Gemini (Google): Google’s Logan Kilpatrick says Gemini now processes 10 billion tokens per minute through direct customer API usage, and that the Gemini app crossed 750M monthly active users, per his Scale metrics post. That’s the kind of distribution and load that tends to shape creative tooling (pricing pressure, reliability expectations, and how quickly multimodal features get commoditized) even if you never touch the Gemini app directly.
Google crosses $400B annual revenue, a scale signal behind its AI push
Google (Alphabet): A milestone claim that Google “just crossed $400B in annual revenue,” as posted by Revenue milestone. For AI creatives, the relevance is less the earnings headline and more what it implies about the company’s capacity to fund long-horizon model training, subsidize consumer AI distribution, and absorb infra costs that smaller creative-tool vendors can’t.
“Datacenter economy will soon be THE economy” resurfaces as an AI market thesis
Compute as the market constraint: A widely shared framing argues the “datacenter economy will soon be THE economy,” with everything else downstream, per the Datacenter economy quote. In practice for creative AI, this usually shows up as: model access gated by GPU supply; pricing shaped by inference costs; and platform competition increasingly fought via datacenter spend rather than just UX polish.
📅 Deadlines & programs: contests and creator credential tracks
Time-bounded opportunities and creator programs mentioned today—useful for visibility, funding, and career leverage.
Kling 3.0 Ultra early access opens, plus a 24-hour giveaway post
Kling 3.0 (Kling AI): Kling says Ultra subscribers can access the Kling 3.0 model on web now, with broader access “coming soon,” as stated in the Ultra early access post; separately, Kling is running a 24-hour engagement-based giveaway (follow/comment/retweet) to select 10 winners for early access, as described in the Launch contest post.

• What creators can do with the win: the giveaway post positions Kling 3.0 as an “all-in-one” engine with 15s clips, multi-shot control, upgraded native audio, and 4K images, as listed in the Launch contest post, but the operationally new detail today is the gating + time window (Ultra-only now; 24h contest).
Firefly Ambassadors treat recommendations as a credential pipeline
Adobe Firefly Ambassador program (Adobe): Creator posts frame acceptance as a visible credential and also show the program behaving like a referral pipeline, with one ambassador explicitly saying they’ll “be recommending more people… in our next waves” and inviting interested creators to reach out in the Recommendation offer.
• How this is working in public: the same account spotlights specific creators they recommended who were accepted, as shown in the Recommendation example, reinforcing that social proof + referrals are part of the program’s on-ramp.
• Artifact of the program: a reposted screenshot of a “Join our Adobe Firefly Ambassador Program as a contributor” invite (with an “Inbox” button) appears in the Program invite screenshot, which is the clearest concrete UI evidence of the contributor track in this set.
🏁 What creators shipped: shorts, trailers, music videos, and playable vibes
Finished or named creative outputs (not just tool demos): AI-made trailers/films, longform story pieces, and music-video style releases using current gen tools. Excludes the Kling 3.0 capability flood (covered as the feature).
Dor Brothers drop Rorschach Killer trailer and claim $1M–$2M original deals
Rorschach Killer (Dor Brothers): A new trailer release doubles as a business signal; the Dor Brothers say they’re “closing several $1M–$2M deals” for original films/TV planned for release later this year, and that multiple trailers will ship before one concept becomes their first feature film, per the trailer and deal claim.
• Release cadence: They frame this as the first of several concept trailers meant to de-risk which project becomes the first full feature, as stated in the trailer and deal claim.
“Netflix of AI” teaser pitches playable TV as the next distribution layer
Playable TV pitch (fablesimulation): A stylized teaser frames the idea that “TV just became playable,” positioning a future marketplace for AI feature films and series as the missing ecosystem layer beyond shorts and ad contests, as argued in the playable TV teaser.

• Distribution argument: The thread explicitly contrasts short-form festival/brand contests with the difficulty (and value) of sustaining a ~70-minute film people will watch, per the playable TV teaser.
Bennash’s “The Wanderers” expands as a recurring Grok Imagine vignette universe
The Wanderers (Grok Imagine 1.0): Bennash is iterating a consistent “micro-worlds” universe—short, self-contained vignettes that feel like scenes from a larger story—starting from “images and video made entirely with Grok Imagine 1.0,” as shown in the series launch clip.

• World rules as punchlines: One vignette leans on a single surreal rule (“slugs don’t have feet—mine do”), illustrated in the slug with feet clip.
• Diegetic ad-stubs: Another entry plays like a product spot (“Make Delivery Bots Stylish”), as shown in the delivery bot vignette.
Hailuo publishes a longform “adulthood” short and highlights embedded story details
Hailuo (MiniMax): Hailuo shared a longer narrative piece positioned as proof that “AI is more than just 15s short clips,” explicitly claiming the full video was created entirely with Hailuo, as shown in the longform storytelling post.

• Scene-level storytelling: They point viewers to hidden narrative beats (e.g., “man hiding under the covers,” “mother with a pair of men’s boxers”) in the hidden stories callout.
BLVCKLIGHTai releases “Floating Through Amber” as a mood-first music video
Floating Through Amber (BLVCKLIGHTai): A new music-video-style release leans into slow pacing and atmosphere; it’s presented as streaming now as part of an album titled Twilight Afterglow, per the music video release note.

• Visual language: The clip foregrounds a single sustained image (a person drifting in amber-lit water) rather than fast cutting, as shown in the music video release note.
“Antimemetic” music video ships using Grok Imagine and Midjourney
Antimemetic (WordTrafficker): A longer music-video release is posted with explicit tool credit—“With Grok Imagine, Midjourney”—and a YouTube link in the follow-up, per the music video post and the YouTube link note.

The cut reads as a full track-length piece (not a test clip), which matters because it exercises pacing and visual continuity over minutes, not seconds.
BLVCKLIGHTai drops “Undertow Grotto,” an in-world tourism-style horror tease
The Undertow Grotto (BLVCKLIGHTai): A short “location announcement” video frames itself like local tourism copy (“experienced swimmers only”) while showing eerie cave imagery and glowing algae, as presented in the Undertow Grotto post.

The piece reads like a repeatable format: fictional place copy + one signature visual motif + a warning label.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught