Gemini 3.1 Flash‑Lite hits 363 tok/s at $0.25/M – adds thinking levels
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
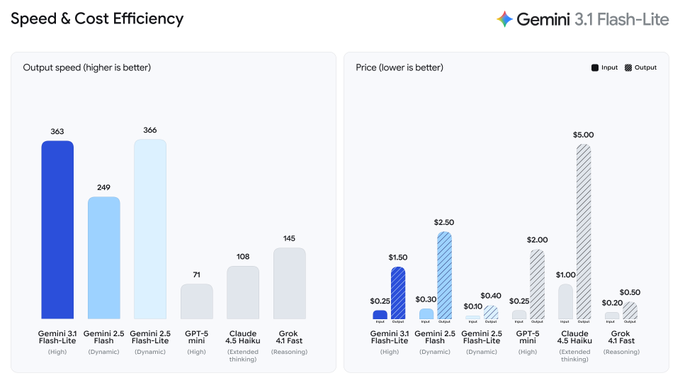
Google DeepMind rolled out Gemini 3.1 Flash‑Lite in preview via the Gemini API in Google AI Studio; the product hook is “thinking levels,” a per-request dial to trade reasoning depth against latency/cost while it’s positioned as an “intelligence at scale” model for workloads like UI/dashboard generation and simulations. A widely shared community table pegs it at 363 tokens/s output with $0.25 input and $1.50 output per 1M tokens (no caching); the same post claims it beats Gemini 2.5 Flash on many tasks, but the artifact is a screenshot and not an independently reproducible benchmark pack.
• Black Forest Labs/FLUX.2 [pro]: claims 2× faster generation with no price increase; posts typography-heavy design samples as proof points.
• Topaz Labs/Wonder 2: announced as “now local,” shifting enhancement from cloud to on-device; bundles mention Astra “Scene Controls” and Starlight Fast 2 with limited observable deltas.
• OmniLottie: paper claims editable vector animation generation as Lottie tokens; introduces MMLottie-2M (2M examples) plus a standardized eval protocol.
Across threads, speed keeps getting treated as the gating variable—Flash‑Lite throughput, FLUX latency cuts, and local Topaz polish—while reliability constraints remain visible (e.g., reports Seedance 2.0 blocks face shots, forcing close-ups onto Kling 3).
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught
Top links today
- claude-scientific-skills plugin GitHub repo
- Anthropic free AI course curriculum
- Microsoft AI degree curriculum on GitHub
- Gemini 3.1 Flash-Lite model page
- Gemini API docs and pricing
- You.com Research API product page
- You.com Research API documentation
- Runway model marketplace listing
- Topaz Wonder 2 local release details
- OmniLottie paper on arXiv
- CUDA Agent paper on arXiv
- Adaptive test-time scaling for editing paper
- Spatial understanding reward modeling paper
- Paper curation to lit review repo
- Autodesk Flow Studio GDC workshop page
Feature Spotlight
Gemini 3.1 Flash‑Lite arrives: speed, pricing, and “thinking levels” control
Gemini 3.1 Flash‑Lite is rolling out with a speed/price jump and adjustable “thinking levels,” signaling a new default for high‑volume creative + coding tasks where latency and cost decide the tool.
Today’s biggest cross-account story is Gemini 3.1 Flash‑Lite rolling out in preview, with creators benchmarking speed/price and highlighting new “thinking levels” to tune reasoning. This category is for LLM releases + eval tables that impact creative coding, writing, and agent workflows.
Jump to Gemini 3.1 Flash‑Lite arrives: speed, pricing, and “thinking levels” control topicsTable of Contents
⚡ Gemini 3.1 Flash‑Lite arrives: speed, pricing, and “thinking levels” control
Today’s biggest cross-account story is Gemini 3.1 Flash‑Lite rolling out in preview, with creators benchmarking speed/price and highlighting new “thinking levels” to tune reasoning. This category is for LLM releases + eval tables that impact creative coding, writing, and agent workflows.
A shared benchmark/pricing table puts Gemini 3.1 Flash‑Lite in the fast-cheap lane
Gemini 3.1 Flash‑Lite eval snapshot (community): A widely shared comparison table for Gemini 3.1 Flash‑Lite highlights a “boundary of intelligence” push and claims it’s “beating 2.5 Flash on many tasks,” per the Benchmark table post. It’s a creator-relevant artifact because it pairs creative-coding constraints (speed and cost) with a quick scan of reasoning, multimodal, and long-context scores.
From the table image, Flash‑Lite is shown at 363 tokens/s output with $0.25 input / $1.50 output per 1M tokens (no caching), and it’s placed alongside other small/fast options (including GPT‑5 mini, Claude 4.5 Haiku, and Grok 4.1) in the Benchmark table post. Another thread quote captures the immediate vibe as “Flash‑Lite is so darn fast, I love it,” in the same post’s context at Benchmark table post.
Gemini 3.1 Flash‑Lite hits preview with a tunable “thinking levels” knob
Gemini 3.1 Flash‑Lite (Google DeepMind): Gemini 3.1 Flash‑Lite is rolling out in preview now via the Gemini API in Google AI Studio, as stated in the Launch thread; the headline product change for builders is new “thinking levels” that let you dial reasoning depth per task while keeping it positioned as a scale model.
The same launch post frames the target workloads as “complex workloads—like generating UI and dashboards or creating simulations,” while still emphasizing cost-efficiency at volume in the Launch thread. A regional echo showed up too, with a Turkish creator noting the expected timing and that “Gemini 3.1 Flash” finally shipped in the Turkish release note.
Gemini 3.1 Flash‑Lite is being framed as an iteration engine, not a chat model
Speed as a creative primitive: The early talk around Gemini 3.1 Flash‑Lite reads less like “best model overall” and more like “most usable at scale,” with creators anchoring on throughput + spend—“so darn fast” being the representative line in Speed quote and Google emphasizing “intelligence at scale” in the Positioning line. Short sentence: this is about iteration.
The other notable positioning detail is control: the new “thinking levels” knob is presented as a way to trade off reasoning depth against latency/cost per task, with concrete examples (“UI and dashboards” and “simulations”) named directly in the Positioning line. That combination—cheap tokens, high throughput, and a reasoning dial—is the core creative-workflow pitch emerging from today’s threads.
🎬 Video models in the wild: extensions, shorts, and motion stress tests
Mostly creator demos of AI video generation and extensions (Grok Imagine, Seedance), plus cinematic environment clips (Luma). Excludes named premieres/release announcements, which are covered in Creator Projects & Releases.
Grok Imagine’s video extension shows a 30-second short workflow in the wild
Grok Imagine (xAI): Creators are treating Grok Imagine’s video extension as a practical way to push short-form storytelling—framed as “an animation studio at home” in the Home studio framing, with another clip calling out “I’ve hit the 30-second limit” in the 30-second cap note. The common constraint is timeboxing: you get a clean, shareable 30s beat, then you either cut or chain more segments.

• Character-centric clip at the limit: The Vampirella example explicitly stops at 30 seconds, which functions like a hard creative boundary for pacing and beat design, per the 30-second cap note.
• Prompt-as-directive mindset: A separate post treats it like a simple directive system (“Make him a plastic action figure”) rather than a storyboard-heavy setup, as shown in the Action figure prompt clip.
The pattern across posts is “one short, one hook, one cap”—built to ship micro-scenes quickly, not assemble long sequences yet.
Freepik Spaces exposes a concrete “model menu” for short-film pipelines
Freepik Spaces (Freepik): In a behind-the-scenes workflow share, Freepik lists the actual nodes used inside Spaces—including multiple AI Video Generator backends (Kling 2.3/2.5/O1/3.0 and Seedance 1.5 Pro) plus Magnific upscalers and ElevenLabs/Lyria for audio, as outlined in the Spaces nodes list. For creators, this reads like a practical menu: pick the generator per shot, then standardize the upscale and audio steps.

• What’s notable: it normalizes “multi-model per project” instead of betting the whole film on one generator, per the Spaces nodes list.
It’s a straightforward confirmation that production stacks are turning into node graphs with interchangeable generators.
Seedance 2 creators are stress-testing fast transformations in anime style
Seedance 2 (Seedance): A creator demo uses an anime-style mech transformation to test fast pose changes, reflective surfaces, and wing deployment without the motion falling apart, as shown in the Mech transform clip. It’s a compact way to evaluate whether the model can hold form during high-speed action rather than only slow camera moves.

• What’s being tested: rapid topology changes (transforming parts), metallic highlights, and continuity through quick beats—exactly the stuff that tends to wobble in short gen-video.
The clip is positioned less like a narrative and more like a repeatable “physics of motion” benchmark for the tool.
Seedance 2 anime walk-cycle tests put speed (not quality) in the spotlight
Seedance 2 (Seedance): Ongoing anime tests focus on basic locomotion and pose readability—walk cycles, then a punchier hero pose—while the creator notes they’d produce much more “if only the generations were faster,” as stated in the Walk-cycle speed complaint. The point is volume: if iteration time drops, series-style output becomes feasible.

• Why this specific test matters: walk cycles expose the small consistency errors (feet, hips, silhouette) that a transformation clip can hide.
The sentiment here is straightforward: the limiting factor isn’t ideas; it’s throughput.
An AI-generated trailer is circulating as a pacing template, not a tool demo
Trailer format (awesome_visuals): A “AI generated movie trailer” clip is circulating less as a single-model flex and more as a reference cut for how to pace reveals, escalate stakes, and land on a title card, as shared in the Trailer reference clip. It’s a useful artifact for editors because the structure is visible even if the underlying model stack isn’t.

The creative takeaway is the edit pattern: rapid establishing beats → character inserts → tonal shift → title/button at the end.
Luma’s Aquatic Forest clip is a clean environment-and-camera demo
LumaLabsAI (Luma): “The Aquatic Forest” is being shared as an environment realism sample—underwater traversal through dense plant life with slow, controlled camera movement, as shown in the Underwater forest clip. It reads like a location plate you’d build around, not a character beat.

The value for filmmakers is in the shot type: continuous motion through a complex scene (fine detail + parallax) where artifacts are easy to spot.
🏁 What shipped: emotional shorts, creator studios, and playable drops
Named releases and finished works shared today, often used as proof that small teams can ship full films/games with AI. Excludes generic tool demos (kept in Video/Image categories).
Freepik releases ROOTS, an AI-made short built end-to-end inside Freepik
ROOTS (Freepik): Freepik published "ROOTS", a ~4m42s AI-made animated short positioned as emotional proof ("made people cry") and claims it was produced from script to final cut entirely inside Freepik in a team workflow, as described in the making of thread.
• What “inside Freepik” means in practice: the project cites a node stack inside Freepik Spaces—Assistant, Magnific upscalers, multiple video generators (Kling 2.3/2.5/O1/3.0 and Seedance 1.5 Pro), multiple image models (Seedream 4 and Google Nano Banana Pro), plus ElevenLabs and Google Lyria for audio—spelled out in the Spaces node list.
The thread reads like a template for small teams trying to ship a complete narrative artifact, not a one-off clip.
Terminus Breach launches on play.fun as a creator-monetized game drop
Terminus Breach (AIandDesign): The creator launched Terminus Breach on play.fun (Solana-linked “support me” framing) and shared a contract address in the launch post, positioning the platform as distribution + monetization for an indie game drop.

The playable listing is reachable via the game page linked in Play.fun listing, and subsequent posts mention scoring updates and SDK-based scores integration in the scoring update and SDK note.
The Prince of the Sea: a Seedance 2.0 demo short targeting painterly realism
"The Prince of the Sea" (DavidmComfort): A ~3m32s short dropped as a fast-turn Seedance 2.0 demo, with the creator explicitly aiming for a “painterly realism” look and calling out consistency limits when moving quickly, per the release note.

• Practical constraint surfaced: the creator says Seedance blocked shots with a character’s face, so Kling 3 was used for face-heavy moments, as written in the release note.
A 4K upload is linked via the YouTube page in 4K version.
ARQ launches with “AI Is Replacing Everyone Except Humans” and a new site
ARQ (starks_arq): ARQ shipped a short manifesto-style brand spot—“AI Is Replacing Everyone Except Humans”—and says its first films are ready alongside a newly launched website with a team sign-up funnel, as stated in the launch post.

The site is referenced as live in the project page, framing ARQ as a creator-forward studio brand rather than a tooling announcement.
Terminus Breach claims $1,500 day-one revenue, spotlighting play.fun economics
Creator distribution economics: The Terminus Breach creator claimed “I made $1500 today by posting my game on @playdotfunsol,” tying earnings directly to the platform listing in the revenue claim.
The same thread ecosystem also promotes a $TMBR token “supporting development” with the game’s contract address in the token post, suggesting a bundled model of play + patronage + tokenized support rather than ad-driven distribution.
AI Tom and Jerry clip goes viral as an emotional nostalgia-short format
AI nostalgia shorts: A ~1m45s “AI Tom and Jerry” remix is getting shared as unexpectedly emotional (“Why am I crying at AI Tom and Jerry?”), pointing to a repeatable format: familiar characters + modern cinematic pacing + sentimental beat, as posted in the clip share.

The post treats the output less like a tech demo and more like a ready-to-share short that can travel on its own.
Champion Spirit: ARQ shares a brand video translating a real gym into a cinematic cut
Champion Spirit (starks_arq): ARQ shared a ~2m05s deliverable framed as “translating the vision of places we actually visit,” citing a few days training at AbdoulayeFadiga’s Champion Spirit in Nassau and then producing a video once they “needed a video,” per the project note.

It’s presented as a studio use-case: capture lived context first, then output a polished brand artifact—more “small team deliverable” than experimental montage.
🖼️ Image models & visuals: text rendering, design mocks, and “realism” pushes
Heavy image chatter today: Nano Banana 2 outputs (especially typography reliability) plus FLUX speed news and Grok realism examples. Excludes copy/paste prompts and SREF codes (those go in Prompts & Style Drops).
Black Forest Labs says FLUX.2 [pro] is 2× faster at the same price
FLUX.2 [pro] (Black Forest Labs): Black Forest Labs says its most-used model, FLUX.2 [pro], is now 2× faster “with no loss in quality and no price increase,” positioning speed as the direct lever for exploring more design directions, per Speed announcement.
• What the examples signal: The posted samples span graphic design (clean typography/layout), moody monochrome portraiture, and low-light architecture, all shown in Speed announcement.
• Where to verify details: The API surface and mode breakdown live in the FLUX.2 overview, which is the only artifact in these tweets that looks like canonical documentation.
Net effect: more iterations per hour without changing budgets, which is the core constraint for most creative teams.
Nano Banana 2’s text rendering shows up in real ad-style layouts
Nano Banana 2 (Google): Creators are posting ad/poster comps where small copy, repeated taglines, and brand lockups stay readable across a layout—one take is that it “handles text perfectly,” and beyond that they “don’t see much difference with the PRO” in day-to-day output, per the Gucci-style example in Text-heavy ad mock.
This matters for designers shipping social ads, covers, and one-pagers, because typography failures are usually what force a manual Photoshop pass (or a model swap). The current vibe in these tweets is that NB2 can be used deeper into the pipeline for layout exploration, not only for background imagery, as shown in Text-heavy ad mock and reinforced by Freepik’s “Nano Banana 2 is now live” framing in Freepik launch note.
Floor plan uploads are being pitched as an interior-design shortcut in Nano Banana 2
Nano Banana 2 (Google): A claim making the rounds is that you can upload a 2D floor plan and have Nano Banana 2 propose a full-home design while keeping accurate dimensions, positioned as a direct threat to early-stage interior visualization work in Floor plan to house claim.
The practical creative implication (if it holds up) is faster concepting for: realtor staging concepts, renovation “before/after” decks, and look-dev boards where scale matters (door widths, hallway clearance, furniture fit). The tweet doesn’t include a validation clip or examples, so treat it as an adoption signal rather than a verified capability, per the single-line assertion in Floor plan to house claim.
Hidden-object puzzles keep working as a Firefly + Nano Banana 2 visual format
Adobe Firefly + Nano Banana 2: The “Hidden Objects” format—one dense illustration plus a 5-item find list—keeps getting published as numbered levels, acting like a lightweight episodic visual series rather than standalone art, as shown in Hidden objects level and continued in Frozen scene level.
The creative win is the packaging: the image is already a postable asset with an interaction hook baked in (comment answers, duets, stitches). The examples in Hidden objects level and Frozen scene level also show the model doing “busy scene coherence,” where micro-details don’t collapse into unreadable noise.
Grok image gen is being steered toward realistic phone selfies with long prompts
Grok (xAI): A long, constraint-heavy prompt is being used to push Grok into a believable “front camera” selfie look—high angle, mild wide-angle distortion, dappled sunlight, and candid framing—resulting in a photo that reads more like social media than studio work, per the example in Realistic selfie example.
For photographers/designers, the interesting detail is the prompt’s emphasis on camera-language (lens feel, noise, imperfect composition) instead of only describing the subject—an approach that seems to correlate with the “real phone shot” aesthetic in Realistic selfie example.
Nano Banana 2 is being used to ‘upgrade’ Pokémon into premium card art
Nano Banana 2 (Google): One repeatable content lane is “underappreciated Pokémon get the card art they deserve,” with punchy, high-energy frames that read like collectible-card key art—see the Psyduck/Metapod/Jigglypuff/Diglett set in Pokémon card art set.
What’s useful here for storytellers and character artists isn’t the IP angle—it’s the format discipline: a consistent subject silhouette, a single iconic action beat, and a background that communicates “power” without needing animation. The post in Pokémon card art set shows how that structure scales into a series quickly once the look is dialed in.
Topaz Gigapixel AI ‘before/after’ reels are getting reposted as proof of detail recovery
Topaz Gigapixel AI (Topaz Labs): A simple split-screen “blurry original → crisp enhanced” clip—with zoom-ins that show recovered texture—keeps circulating as a standalone format, with the Topaz Gigapixel AI branding visible in the reposted example in Before-after demo.

This format matters because it’s an easy way to communicate quality gains to clients (or an audience) without explaining settings: one frame establishes the problem, the other sells the fix. The clip in Before-after demo is also a reminder that upscalers are now part of the creative stack’s “presentation layer,” not only a technical cleanup step.
🧩 Prompts & style codes you can paste today (SREFs, JSON specs, grids)
A high volume of reusable prompt assets today: Midjourney SREF codes, Nano Banana 2 prompt packs, and structured JSON prompt specs. This section is intentionally separate from tool capability news.
Midjourney —sref 968833677 for premium graphic-novel fantasy concept art
Midjourney (—sref 968833677): promptsref is circulating a “premium European graphic novel / high-end RPG concept art” style code, with positioning around “dramatic lighting” and “hand-painted but crisp” texture, as described in the style pitch.
• Replication artifact: The site posts a dedicated breakdown page with prompt guidance and parameter notes in the replication guide, while the daily code share keeps the raw code copy-pastable.
The examples shown in the style pitch skew toward panel-ready compositions (characters + environment beats), not just single-hero portraits.
3×3 pose-collection prompt for consistent character turnarounds
Pose grid prompt (3×3, 2:3 cells): A reusable instruction set for generating a 3×3 pose collection where every cell stays 2:3, the character identity stays fixed, and poses/angles vary while the scene remains consistent, per the pose grid instruction.
The same constraint set is echoed with tool + prompt links in the pose grid example, framing it as a repeatable way to produce character sheets or pose libraries without manual curation.
A Grok prompt template for realistic outdoor selfie portraits
Grok (realistic portrait prompt): A long-form, photography-language prompt specifies a candid front-camera selfie (higher angle, mild wide‑angle), plus concrete wardrobe (gingham bikini top + pendant), environment (wooded area with water patch), and lighting (dappled sunlight), aiming for “spontaneous phone photo” realism, per the full prompt example.
The structure is essentially a fill-in brief—subject, camera behavior, makeup, hair, accessories, setting, and light—rather than a single-line prompt.
Midjourney —sref 2515650061 for European graphic-novel editorial illustration
Midjourney (—sref 2515650061): A shareable style reference targeting clean inked linework + warm editorial color, pitched for “contemporary narrative illustration” that reads like a polished European graphic novel, per the style reference code. It’s framed as especially useful when you want story-first portrait frames and slice-of-life compositions without drifting into painterly fantasy.
The examples in the style reference code lean on strong contour lines, simplified but deliberate backgrounds, and readable “scene staging” that holds up well for sequential panels (character-at-desk, café interior, street establishing shot).
Midjourney —sref 3445336118 for prismatic “ethereal magic” lighting
Midjourney (—sref 3445336118): promptsref highlights a lighting-first style reference framed as “ethereal magic” with prismatic dispersion, dust/particle glow, and warm-vs-cosmic contrast, per the style code note. It’s pitched for luxury ad frames, emotional sci‑fi posters, and music-video storyboard stills.
A more detailed walkthrough (prompt breakdown + example set) is hosted in the style guide page, which is the only concrete artifact linked in the thread.
Midjourney —sref 642191218 for Franco‑Belgian steampunk narrative illustration
Midjourney (—sref 642191218): A steampunk-leaning style reference described as “contemporary European cartoon narrative illustration” with Franco‑Belgian comics energy and feature‑animation sensibilities, per the style reference code. The look is built around bold outlines, expressive faces, and warm directional light that keeps scenes legible.
The four examples in the style reference code show consistent character design language (big eyes, simplified shapes) while still rendering detailed props/architecture—useful for storyboard-like sequences where you need clarity more than realism.
Nano Banana 2 “Holochrome Gradients” prompt for chrome product renders
Nano Banana 2 (product render prompt): A copy-paste prompt recipe for “Holochrome Gradients” focuses on pure-black backgrounds (#000000), hard-edge rim lighting, chromatic aberration on metal edges, and thin‑film iridescence across brushed aluminum + mirror chrome, per the prompt share.
The prompt’s constraint list is unusually strict (no props, no text/logos, no dust/scratches), which is the core trick for getting clean catalog-ready assets, as repeated in the repost of prompt.
Midjourney —sref 2828278251 for cozy kawaii illustration
Midjourney (—sref 2828278251): promptsref spotlights a “cozy” style reference aimed at clean modern digital illustration with Japanese kawaii warmth (soft greens/oranges; afternoon-light mood), per the style code note. The positioning is children’s books, cozy games, and lifestyle brand art.
The linked breakdown page in the style guide page is where the copy-paste parameters and style replication guidance live.
Midjourney —sref 583019043 for engraved black-and-white sci‑fi vistas
Midjourney (—sref 583019043): A black-and-white, engraving-like landscape style code that reads as “classic illustration” with sci‑fi megastructures and deep contrast, shared in the sref post. It’s a strong fit for book interior plates, map-like establishing shots, and monochrome concept boards where line texture matters more than color.
Nano Banana 2 daily prompt: fruit turned into a miniature luxury house
Nano Banana 2 (daily prompt format): A reusable “change only the fruit” prompt turns any fruit into a miniature luxury house shot like an architecture magazine cover—Sony A7III, 85mm f/1.4, soft daylight, visible surface textures—per the daily prompt post.
The fully copy-paste version of the text prompt (including the “no text, no artifacts” constraint) is restated in the full prompt text, preserving the key idea: swap the fruit variable while keeping camera + lighting fixed.
🧠 Workflow recipes & agents: from Zillow-to-video to “AI PM” build loops
Today’s most actionable content is workflow-first: multi-step pipelines, agentic search APIs, and “vibe coding” playbooks that creators can run immediately. Excludes single prompt drops (Prompts category) and finished releases (Showcases).
A PM-first spec loop for Cursor: brain dump → tech spec → phased checklist
PM-first build loop: A practical “stop acting like a coder, start acting like a PM” recipe is being used to make Cursor agents more reliable by feeding them structured intent before any code changes, as laid out in the PM-first playbook.

The sequence is: dump exhaustive requirements into a plain text file in the repo root → have an LLM rewrite it as a senior-PM-style technical spec → have it break the spec into a markdown phase checklist → prompt the agent “Start Phase 1,” test locally, iterate, then move to Phase 2, as described in the PM-first playbook. The same post names a concrete “creative dev” stack—Nano Banana 2 for textures/refs, Tripo for 3D conversion, Cursor + Opus 4.6 for implementation, and Netlify for deploy—per the PM-first playbook.
Calico AI turns Zillow photos into cinematic listing videos with AI VO
Calico AI (Calico): A repeatable real-estate pipeline is getting shared as “Zillow link → luxury listing video under $10,” with the concrete stack spelled out in the Step-by-step workflow and the tool entry point linked in the Calico product link.

The flow is: pick 6 listing photos → animate each in Calico AI (dolly/pans) → have a custom GPT write a 30s voiceover → generate narration + music in ElevenLabs → assemble in CapCut with captions, as described in the Step-by-step workflow. The framing is cost substitution (agents paying $1K–$5K per property) and “every listing gets a walkthrough,” rather than just high-end properties, per the Step-by-step workflow.
An open-sourced “AI game engine” pipeline: Nano Banana tiles + Tripo models
Tripo + Cursor pipeline: A walkthrough shows a modular game demo where creators can swap in their own Nano Banana tile sets and Tripo-generated 3D models, with the codebase open-sourced and the flow explained in the Build overview clip.

The same thread’s “PM-first” companion post details how the asset side plugs into an agent-driven build cycle—generate/collect tile textures and 3D refs with Nano Banana 2, convert 2D images into usable 3D assets in Tripo, then let Cursor + Opus 4.6 implement in phases and ship via Netlify, as described in the Stack and phase loop.
Pika AI Selves: personal AI “twin” with voice and cross-app presence
Pika AI Selves (Pika): Pika is being pitched as a “living extension of you” that can generate videos/images, remember ongoing projects, and operate across chat surfaces (Telegram/Slack/Discord), with a creator demo thread in the AI Twin walkthrough and an entry link in the Create page.

The concrete claims are: train on appearance + cloned voice; use persistent memory to maintain context and keep working “while you sleep,” per the AI Twin walkthrough. The thread then enumerates task patterns (auto content, DM replies, reminders, portfolio generation) as examples of what a “self” can be configured to do, per the Task list.
You.com launches a Research API for agentic, cited deep search
You.com Research API (You.com): A single POST request is framed as triggering a full agentic search loop—multiple queries, cross-referenced sources, and cited answers—along with a “ranked #1 on DeepSearchQA” claim and $100 in free credits, as described in the Research API pitch.
The post emphasizes “no credit card required” onboarding and positions the product against “10 blue links,” per the Research API pitch. Treat the leaderboard as provisional from this one share—no eval artifact is linked in the tweets beyond the screenshot in Research API pitch.
microHQ is pitched as an agent layer across email, meetings, pipeline, and X
microHQ (microHQ): A creator describes consolidating “inbox, CRM, tasks, and AI assistants” into one context-aware agent layer that “lives where you work” and connects email, meetings, pipeline insights, and X, per the Personal stack rationale.
The post frames it as software adapting to the user (persistent context + unified surface) rather than juggling tools manually, echoing the same positioning in the Agent layer description.
Prismer open-sources an end-to-end “papers to code” research workspace
Prismer (Prismer-AI): An open-source research platform is framed as automating a full loop—paper curation → literature review → code—targeted at arXiv/OpenReview-style workflows, as summarized in the Paper grind pitch and backed by the GitHub repo.
The repo description highlights an AI-native PDF reader, citation graphing, context management SDKs, and a multi-agent collaboration layer, according to the GitHub repo.
CaravoAI pitches a single integration layer for 200+ APIs for agents
CaravoAI (Caravo): A connector product is pitched as reducing “agents guessing” by wiring them into real data sources via “200+ APIs through one simple connection,” as stated in the Connector pitch.
The framing is workflow-scale automation: instead of building per-API adapters, the agent gets one integration surface and can pull from many systems, per the Connector pitch.
🧱 3D & interactive creation: 2D→3D assets, game engines, and GDC workflows
Interactive and 3D pipelines show up as practical creator stacks: Tripo-based asset creation, AI-assisted game building, and Autodesk’s game-dev ideation workshop at GDC. Excludes pure image prompts and finished film releases.
Techhalla’s open-source AI game demo treats assets as swappable modules
Customizable AI game demo (techhalla): A playable prototype is shown as a modular asset system—custom “Nano Banana” tiles/textures plus imported Tripo 3D models—positioned as a way to keep extending a game world by swapping inputs rather than rebuilding systems, as described in the Game demo thread and reinforced by the Stack + process notes.
The clip highlights the core creative lever: the environment can be remixed by feeding new tile sets and new 3D meshes, while the rest of the logic stays stable—useful for creators iterating on “world kits” (biomes, props, UI) instead of one-off scenes.
A PM-style workflow for building interactive demos with coding agents
Vibe-coding workflow (techhalla): A repeatable planning loop is outlined for building an interactive demo: write an exhaustive requirements “brain dump” first, have an LLM convert it into a technical spec, then split it into phase checklists so an IDE agent can execute “Start Phase 1/2/3…” with tight test/fix loops, as laid out in the PM-first playbook.
The stack callout explicitly ties creative asset generation into the build plan—Nano Banana 2 for textures/refs and Tripo AI for turning 2D images into 3D models—before delegating implementation to “Cursor + Opus 4.6” and shipping via Netlify, per the same PM-first playbook.
Autodesk Flow Studio schedules a GDC live session on AI game ideation
Autodesk Flow Studio (Autodesk): A GDC 2026 LinkedIn Live workshop is announced for March 10 (5:15 PM PT) focused on AI-assisted early-stage game development—specifically storyboards → character ideation → scene exploration—per the GDC live announcement.

The demo clip emphasizes fast visual iteration (storyboard frames becoming 3D-ish character/scene explorations), positioning Flow Studio as a pre-production accelerator rather than a final-asset generator.
Tripo AI keeps showing up as the 2D-to-3D conversion step for creators
Tripo AI: In the showcased game-building workflow, Tripo is framed as the necessary conversion layer between pretty 2D generations and “usable 3D models,” explicitly called out as a prerequisite before explaining how the interactive build works in the Game build walkthrough.
This is less about a new Tripo feature and more about an emerging division of labor in creator stacks: image models produce style + surfaces, while Tripo produces geometry that can be dropped into a real-time scene graph (games, WebGL demos, engine prototypes), as echoed in the Stack list.
A 2D floor plan gets turned into a 3D tour inside Freepik Spaces
Freepik Spaces (3D tour workflow): A method share claims a full pipeline from a flat 2D floor plan into a navigable 3D tour “inside Freepik Spaces,” with the promise of step-by-step details in the Floor plan to 3D tour tease.
The tweet doesn’t include the actual node graph/settings in-line, but the framing matters for interactive creators: it treats “floor plan → walkthrough” as an end-to-end AI pipeline rather than a manual DCC task—something that can slot into real estate, set pre-vis, or game-level blockout workflows.
Meshy ties GDC booth traffic to a high-ticket giveaway
Meshy (MeshyAI): Meshy advertises a GDC booth giveaway with unusually high-end prizes—an Nvidia DGX Spark ($4000) plus a PS5 Pro, Nintendo Switch 2, and an Elegoo 3D printer—as shown in the Prize list graphic.
The same post also spotlights “exclusive Meshy merch packs” for booth visitors, signaling an on-the-ground push to recruit 3D creators who are already at GDC, per the Prize list graphic.
🛠️ Finishing the shot: upscalers, local enhancement, and frame polish
Post tools were a major thread today—especially Topaz updates moving more enhancement locally and creators chaining upscalers with gen video. Excludes generation itself (Image/Video categories).
Topaz Wonder 2 moves to local processing
Wonder 2 (Topaz Labs): Topaz says Wonder 2 is now local, shifting this enhancer from a cloud-style workflow into an on-device step in the finishing pipeline, as announced in the Update callout and reinforced on the Local update page.
The clearest proof point they share is the coyote close-up—heavy pixelation on “Original” vs fur/eye detail recovery on “Wonder 2” in the Update callout.
Seedance clips get pushed to 2K via Magnific upscales
Seedance → Magnific → CapCut: A creator shows a post workflow where a Seedance generation is run through a Magnific upscale, with the claim that it turns the result into a “2K monster,” then handed off to CapCut for final packaging in the 2K upscale demo.

The tweet doesn’t specify settings (model choice, grain/detail, face protection), but it’s a clean example of “generate first, then spend compute on the keeper.”
Freepik Spaces treats upscaling as a standard node
Freepik Spaces: Freepik’s “ROOTS” breakdown lists Magnific Image Upscaler and Magnific Video Upscaler as first-class nodes in the Spaces workflow graph, alongside multi-model video generators and audio tooling, as enumerated in the Nodes list.
This is a concrete signal that “upscale/restore” is being packaged as a default step inside creator hubs—not a separate app you remember to open at the end.
Seedance 2 paired with Topaz for 60fps fluidity
Seedance 2 + Topaz: Another finishing-stack combo getting repeated is Seedance 2 output followed by Topaz processing to make motion feel “insanely fluid” at 60fps, as claimed in the 60fps combo clip.

The post doesn’t name the exact Topaz module (upscale vs frame interpolation), but the intent is clear: treat temporal smoothing as a separate, explicit polish pass.
Topaz Astra adds Scene Controls
Astra (Topaz Labs): Topaz also calls out Scene Controls in Astra as part of the same release bundle in the Feature list, with the umbrella update described on the Local update page.
No UI screenshot of the controls is included in today’s tweets, so the practical knobs (camera motion, face handling, strength limits) remain unspecified from these sources.
Topaz Gigapixel AI’s “before/after” reveal format keeps working
Gigapixel AI (Topaz Labs): A creator post spotlights the familiar finishing pattern—show a soft/blurry original next to an AI-enhanced version, then punch in on recovered details—explicitly crediting Topaz Gigapixel AI in the Before-after clip.
This continues to read as a repeatable social format for photographers and AI image creators: the polish step becomes the content.
Topaz ships Starlight Fast 2 alongside the local push
Starlight Fast 2 (Topaz Labs): In the same announcement where Topaz flags Wonder 2 going local, it also name-checks Starlight Fast 2 as part of the update bundle in the Feature list, with broader positioning collected on the Local update page.
The tweets don’t include side-by-side samples for Starlight Fast 2, so what changed (speed, temporal stability, artifacting) isn’t observable from the shared media yet.
⚖️ Copyright, privacy defaults, and the authorship fight
Today’s policy/ethics content centers on (1) copyright requiring human authorship and (2) privacy defaults where chat data trains models unless opted out. This is directly relevant to creators selling work, using likeness, and choosing tools.
SCOTUS lets stand the rule that copyright requires human authorship
Thaler v. Perlmutter (SCOTUS): The Supreme Court declined to hear Thaler v. Perlmutter, leaving in place the ruling that human authorship is required for copyright—meaning fully autonomous AI outputs remain outside protection, as framed in the creator recap in Human authorship thread. The practical implication creators keep highlighting is that “human craft” (direction, curation, iteration, compositing) is the thing the law recognizes—an argument that’s been circulating in the community already, including the multi-tool workflow framing in Not one button.
• What counts as the risk case: The post stresses the case was about “fully autonomous output” with “zero human authorship,” and argues most real production workflows don’t look like that, per Human authorship thread.
• Pushback on simplistic takes: A reply emphasizes that AI-assisted work can still be copyrightable when it’s part of a broader human creation workflow and you can show the model “assisted like a tool,” as stated in Copyrightability nuance.
Stanford paper claims default chat-training and two-tier protections
User privacy and LLMs (Stanford): A widely shared thread claims a Stanford analysis of privacy policies found that major AI developers use user chats for training by default, with limited transparency and muddy opt-outs, according to Privacy-policy findings. The underlying paper is linked as a PDF on arXiv in ArXiv PDF.
• Two-tier default claim: The thread asserts enterprise users are “opted out of training by default” while regular users are “opted in,” per Privacy-policy findings.
• Retention and sensitive-user concerns: It also alleges indefinite or long retention for some services and that “4 of the 6” appear to train on children’s chat data, as stated in Privacy-policy findings.
Treat the post as a secondary summary—its strongest anchor is the linked paper in ArXiv PDF, while the tweet itself doesn’t include vendor-by-vendor screenshots or excerpts.
The “you didn’t make anything” authorship line hardens into memes
Authorship discourse: A recurring anti-AI refrain—“you didn’t MAKE anything”—showed up again as a shareable video bit, which signals how the authorship fight is increasingly happening through slogans instead of process details, per You didn’t make anything clip.

• Derogatory labels as shorthand: Terms like “promptoid” and “sloperator” are getting used as compressed critiques of AI-first creation, as seen in Promptoid labels post.
• Escalation on the pro-AI side too: Some pro-AI accounts are responding with similarly inflammatory dunking on non-AI artists, as shown in Pencil artists dunk.
📚 Free curricula & creator education drops (worth bookmarking)
Education links were unusually dense today: Anthropic’s free course catalog, Microsoft’s GitHub “AI degree,” and creator training funnels. Excludes giveaways and conferences (separate categories).
Anthropic publishes a free, end-to-end Claude learning path (Claude → API → MCP → Skills)
Anthropic Courses (Anthropic): A shareable “10-course” learning path is circulating that points to Anthropic’s Skilljar-hosted catalog—starting with Claude 101, then Claude Code in Action, Claude API, and multiple Model Context Protocol (MCP) modules, plus an agent skills course for Claude Code, as enumerated in the Course list and enroll link and introduced in the Curriculum callout. The practical value for creators is that it strings together the exact stack many production workflows now use (chat → code agent → external tools via MCP) rather than treating them as separate topics.
The catalog entry points and framing are consolidated on the Skilljar hub linked in the course catalog, with one example being “Claude with Google Cloud’s Vertex AI” shown in the Vertex AI course post.
Microsoft’s AI for Beginners repo gets re-promoted as a full bootcamp-style track
AI for Beginners (Microsoft): The microsoft/AI-For-Beginners GitHub repo is being reshared as a “complete AI degree” alternative—positioned as structured, beginner-friendly, and open-source in the Degree framing post, with the source material living in the GitHub repo. For creative technologists, the immediate relevance is the repo’s lab-first structure (not just reading) across core ML concepts that tend to show up in real creative tooling (vision, NLP, responsible AI).
The tweets don’t add new curriculum changes; they’re an adoption signal that this specific repo is becoming a default bookmark for people trying to skill up without paid cohorts.
Anima_Labs outlines a story-first AI creation tutorial with a multi-tool stack
Create your story tutorial (Anima_Labs): Anima_Labs posted a multi-part tutorial thread aimed at story production, pitching it as a “theoretical guide” that only covers the surface but maps the moving pieces of an AI pipeline in the Tutorial thread kickoff.

A notable add-on is the explicit cost-and-complexity angle: they recommend consolidating subscriptions via multi-model platforms (Freepik, Leonardo, Hedra, Martini, Krea) and using node-style systems to manage the data flow, as described in the Multi-platform node advice.
A creator-led AI animation course opens a waitlist
AI animation course (creator-led): A creator education funnel is forming around an AI animation course—shared as “really great” with a waitlist now open in the Waitlist mention. No syllabus, tool list, pricing, or cohort dates are included in today’s tweet, so details remain unspecified from the provided sources.
🧰 Where creators work: studios, aggregators, and in-app model access
Platform aggregation is the theme here: tools trying to become the ‘one place’ you create, host, and swap models. Excludes Gemini Flash‑Lite (covered in the feature).
Freepik Spaces spotlights a node-based studio stack with a full short film
Freepik Spaces (Freepik): Freepik showcased an AI-made animated short, “ROOTS,” claiming the team built it “entirely inside Freepik” from script to final cut in the ROOTS making-of; the thread spells out Spaces as a node-based environment that wires multiple image/video/audio models together.
• Model menu inside the studio: the Space lists built-in nodes including Magnific upscalers plus multiple video generators (Kling 2.3/2.5/O1/3.0 and Seedance 1.5 Pro) and image generators (Seedream 4 and Google Nano Banana Pro), as enumerated in the ROOTS making-of and repeated in the nodes recap.
• 3D-from-plan angle: separate creators are also framing Spaces as a place to turn a 2D floor plan into a 3D tour workflow, as described in the floor plan to 3D tour retweet.
What’s still unclear from today’s posts is pricing/limits for each node—only the “all-in-one pipeline” shape is concrete.
Notion Custom Agents adds MiniMax M2.5 as an open-weight model option
Notion Custom Agents (Notion): A creator thread claims MiniMax M2.5 is now the first open-weight model available inside Notion Custom Agents—framed as a 230B-parameter model and priced at “1/20th” of Claude Opus in that post, per the Notion open-weight claim.
This is a distribution signal: “open-weight” models showing up inside mainstream work apps, not just dev-centric model routers.
Treat performance claims as provisional—today’s tweet cites benchmarks but doesn’t provide an eval artifact or direct Notion docs beyond the statement in the Notion open-weight claim.
Runway pushes a “best models in one place” hub pitch
Runway (Runway): Runway is leaning harder into the “one studio” positioning—claiming creators can access “all of the world’s best image, video, audio and language models” directly inside Runway, with more integrations promised, as stated in the multi-model announcement.

This matters less as a single feature and more as a workflow bet: the product is positioning the editor as the stable surface, with models becoming swappable backends.
• Product posture: the emphasis is breadth (image + video + audio + text) rather than a single flagship generator, per the multi-model announcement.
• Rollout framing: the only concrete availability note is “try them now,” reiterated in the try now follow-up, with no model-by-model list in the tweets.
Topaz makes Wonder 2 a local model and expands Astra controls
Topaz Labs “Local” stack (Topaz Labs): Topaz says Wonder 2 is now local (run on-device) and bundles that into a broader update that also mentions Starlight Fast 2 plus Scene Controls in Astra, as announced in the Wonder 2 local update.
• Why “local” is the headline: the marketing shift is toward a unified ecosystem where desktop/local and cloud tools sit under one update surface, with details collected on the Topaz updates page described in Topaz update page.
• Evidence shown: Topaz’s post uses an “Original vs Wonder 2” close-up (coyote fur detail recovery) to sell the local-quality jump, as shown in the Wonder 2 local update.
No hardware requirements or pricing changes are stated in the tweets; only the local availability claim and the feature names are explicit.
📣 AI marketing creatives: fast testing, visual metaphors, and creator positioning
Marketing content today is about creative that scales (cheap variants, fast tests) and the meta-positioning creators are using (“market testing,” “customers > gear”). Excludes step-by-step build pipelines (Workflows category).
Cartoon “superhero bottle” ads make benefit-first creative cheap to A/B test
NahFlo2n (performance creative): A new ad pattern is getting spelled out as “show the benefit in one second” by turning a supplement bottle into a cartoon hero and animating the body-effect metaphor (blocked → flowing energy), with the outcome framed as $58,400 in 3 weeks in the Supplement ad results post. It’s a pitch for volume testing. Fast variants are the product.

• Variant engine framing: The follow-up positioning leans hard on throughput—“under 90 seconds to generate each video” and “$1–2 per creative,” plus “winners scaled fast, losers cut,” as described in the Volume testing addendum.
The core creative claim is that “funny sells” because it holds attention long enough to land the story, per the Supplement ad results breakdown.
Market testing shifts AI creators toward “thumbnail + hook” experimentation
BLVCKLIGHTai (creator practice): Market testing is getting described as a daily operating habit—run a dozen small format/style trials, then read the spread before investing in longer edits, as shown by a grid of recent TikToks with view counts in the Testing grid screenshot. One post hits 118.7K while many sit in the low thousands. That dispersion is the point.
The post also calls out platform dependence (“what works on one platform doesn’t work on another”), which effectively turns AI output into test inventory rather than “one big swing,” per the Testing grid screenshot.
“Customers > gear” becomes a common creator stance in an AI tool stack era
thekitze (creator positioning): A recurring business stance is getting stated bluntly as “you don't need the m5 max macbook you need a marketing strategy and customers,” in the Customers over gear post. It’s a counter-narrative to hardware flex.
The implied subtext is that AI tooling has shifted perceived bottlenecks away from compute toward distribution and conversion, as framed by the Customers over gear line.
“Share your art” threads keep working as a lightweight distribution loop
GlennHasABeard (community growth): A simple growth mechanic keeps showing up: an explicit “share your art” open thread that prompts replies, tagging, and cross-niche discovery, as described in the Community amplification post. It’s framed as a way to connect, not a portfolio drop.
The tactic is essentially engagement packaging—an easy excuse to participate—per the Community amplification post call to “share, like, comment, tag others.”
🔬 Research & technical signals creatives will feel next
A cluster of papers/tools were shared that point to near-term creative capabilities: vector animation generation, CUDA kernel agents, and faster image editing at inference time. Excludes any bioscience/medical-model content.
OmniLottie turns text/images/video into editable Lottie vector animations
OmniLottie: A new model family generates vector animations directly as parameterized Lottie tokens, aiming at end-to-end creation you can still tweak like normal motion graphics—see the announcement in OmniLottie post and the technical details in the paper page.

The paper also introduces MMLottie-2M, a 2M-example multimodal dataset and a standardized evaluation protocol, which is the part that usually determines whether this becomes a real ecosystem primitive (UI motion systems, app micro-interactions, branded lower-thirds) versus a one-off demo, as described in paper page. A live try-it-yourself Space is linked from Demo announcement via the Hugging Face Space.
Adaptive test-time scaling targets faster, interactive image editing
From Scale to Speed (CVPR 2026): A paper proposes adaptive test-time scaling for image editing—dynamically adjusting inference-time compute to balance speed and fidelity rather than picking a fixed “big model vs fast model” upfront, as linked in Paper share and summarized in the paper page.
The practical creative implication is “more interactive” edit loops for tasks like inpainting, style edits, and super-res without retraining multiple model sizes, assuming product teams actually wire the scaling knob into UIs instead of hiding it behind presets.
CUDA Agent uses agentic RL to auto-generate fast CUDA kernels
CUDA Agent: A research system applies large-scale agentic reinforcement learning to generate and optimize CUDA kernels, positioning kernel search/code transforms as something an agent can explore automatically rather than hand-tuned, per CUDA Agent post and the paper page.
For creative toolchains, the near-term “feel” is indirect but real: anything that leans on custom GPU ops (upscalers, video interpolation, diffusion samplers, raster-to-vector pipelines) tends to bottleneck on kernels, and this line of work is essentially trying to automate that last-mile performance work.
Sphere Encoder explores spherical latents for smoother image interpolation
Image generation with a Sphere Encoder: This paper experiments with mapping latents onto a spherical manifold (instead of a standard Euclidean latent), aiming for smoother interpolation paths and improved diversity/robustness in generation, per Paper link and the paper page.
If it holds up beyond the paper, it’s the kind of backend change creatives notice as “style blends and morphs don’t snap” and “in-between frames look less weird,” especially in workflows that rely on interpolation (character turnarounds, evolving key art, storyboard variants).
SWE-rebench V2 harvests 32k+ executable real-world coding tasks
SWE-rebench V2: A language-agnostic pipeline that automatically harvests 32,000+ executable, real-world software engineering tasks is being circulated as the next eval-infra building block, according to SWE-rebench V2 tease.
For creators shipping tools (plugins, nodes, desktop agents), this kind of benchmark plumbing often becomes the hidden driver of “suddenly the coding model got more reliable” because it pushes labs toward measurable, runnable tasks instead of purely synthetic coding prompts.
🎙️ Voice, dubbing, and lipsync: all-in-one audio stacks emerge
Voice posts today cluster around all-in-one audio generation (voice presets + translation/lipsync) and creators cloning/standardizing their voice for persistent assistants. Excludes music composition (Audio & Music category).
Pika AI Selves push voice-cloned creator avatars with memory and cross-app presence
AI Selves (Pika): Pika’s “AI Selves” are being positioned as a persistent creator avatar that’s trained on appearance + cloned voice, can generate videos “exactly like me,” and can operate across Telegram/Slack/Discord with persistent memory—as described in the “AI Twin” walkthrough from AI Twin overview and the deeper voice‑clone framing in Voice clone description.
The concrete usage examples being highlighted are operational, not cinematic: auto-building a portfolio page by chat in Portfolio build example, daily task reminders via Telegram DM memory in Task reminder demo, plus content planning/brainstorming inside Slack in Slack brainstorming use. For filmmakers and character-driven creators, the implied next question is whether the “self” can stay on-model across longer dialog and multi-scene dubbing, which isn’t evidenced here yet.
For the official entry point, the thread links to Pika at Pika signup.
Higgsfield Audio bundles voice presets, voice swap, and 10-language lip-sync
Higgsfield Audio (Higgsfield): A new “all‑in‑one AI audio generator” is being teased with 21 voice presets, the ability to swap voices in any video, plus translate + lip-sync in 10 languages, framed as “one workflow, one subscription” in the feature list shared by Feature rundown, with an earlier “something is cooking” tease in Teaser reply.
Details that creators usually need (pricing, voice rights/consent flow, whether dubbing preserves timing/emotion, and what editors it plugs into) aren’t in the tweets yet, so treat this as a product-surface claim until Higgsfield ships docs or demos.
Freepik Spaces treats ElevenLabs voice as a standard node in film workflows
Freepik Spaces (Freepik): A practical signal from the “ROOTS” breakdown is that voice is being treated like a modular production step: Freepik lists Audio and SFX as a node powered by ElevenLabs (alongside Google Lyria) inside the same node graph as image/video generators and upscalers, per the node list in Spaces node list and the repeated inventory in Nodes recap.
This matters less as a specific ElevenLabs feature drop and more as a workflow normalization: VO, SFX, and final mix are increasingly “just another node” teams expect to swap and iterate, in the same place they iterate shots.
Zillow-to-listing videos use ElevenLabs VO to keep costs under $10
Calico AI + ElevenLabs (workflow): A creator is sharing a repeatable listing-video recipe that claims sub-$10 per property by turning a Zillow link into a 30-second walkthrough: animate still photos in Calico, have a custom GPT write the voiceover script, then generate narration in ElevenLabs before assembling in CapCut, as laid out step-by-step in End-to-end workflow.
The voice-specific takeaway is that narration is no longer the expensive bottleneck in these templated video businesses; the stack assumes VO can be regenerated as quickly as captions. The workflow points to Calico’s product surface via Calico site.
🎵 AI music & sound: composition prompts and soundtrack nodes
Audio content was lighter than image/video today, but there are clear signals: LLM-to-music prompting experiments and platforms treating music/SFX as a default node in creation graphs.
AI listing-video stacks now auto-generate a custom music track alongside VO
Calico + ElevenLabs (workflow): A creator workflow for real-estate listing videos frames soundtrack as a commodity layer: after animating still listing photos in Calico, a custom GPT writes a ~30-second voiceover and ElevenLabs generates both the narration and a “custom music track,” then CapCut assembles the final edit, as outlined in the Step-by-step workflow with Calico referenced via the product page in Calico site. The same thread anchors the economics at “under $10” per video and contrasts it with typical $1K–$5K professional video costs, per the Step-by-step workflow.
Freepik Spaces treats Google Lyria as a default soundtrack node in film workflows
Freepik Spaces (Freepik): Freepik’s “ROOTS” breakdown lists Google Lyria under “Audio and SFX,” alongside ElevenLabs, as one of the nodes in an end-to-end, inside-Freepik pipeline (script to final cut), per the Roots workflow thread and the Node list excerpt. This is a concrete signal that music generation is being packaged as a standard step in the same node graph as upscalers and video generators, rather than as a separate side tool.
JazzGPT shows how to prompt ChatGPT/Claude/Gemini/Grok into composing jazz
JazzGPT (workflow concept): A new YouTube walkthrough shared by bennash shows a structured prompting method for getting general LLMs (ChatGPT, Claude, Gemini, Grok) to output usable jazz composition material—framing it as “prompting for music” rather than relying on a dedicated music model, per the Share post and the linked YouTube walkthrough. The approach described centers on explicit structure (separating harmony vs melody) and timing instructions encoded in text so the model can emit something closer to a lead sheet / performance plan rather than prose.
🎁 Credits & access windows (limited-time leverage)
Only the promos that materially change access made the cut today: free credits and meaningful subscription giveaways. Excludes “comment for DM” micro-promos.
You.com Research API dangles $100 free credits for agentic, cited deep search
You.com Research API (You.com): A sponsored launch post frames You.com’s Research API as an “agentic search loop” you can try quickly because it includes $100 in free credits with no credit card required, per the Research API pitch.
The same post claims the product is ranked #1 on DeepSearchQA at 83.67% accuracy, returning cited, verifiable answers from multiple autonomously fired queries, with the benchmark positioning shown in the Research API pitch.
Seedance 2.0 runs a 30-subscription giveaway for monthly access
Seedance 2.0 (Seedance): A time-bound giveaway offers 30 monthly subscriptions that include Seedance 2.0 access “today,” as described in the Giveaway announcement. The post is framed as a short-term access boost rather than a product update.
🗓️ Dates to pin: GDC sessions and creator webinars
A few concrete calendar items surfaced: GDC-linked workshops and a product webinar aimed at creators shipping AI video content. Excludes giveaways that aren’t tied to an event.
Autodesk Flow Studio sets a March 10 GDC LinkedIn Live on AI game pre-vis
Autodesk Flow Studio (Autodesk): Autodesk is pinning a GDC 2026 calendar slot—March 10 at 5:15 PM PT—for a LinkedIn Live workshop on using its AI tooling to accelerate early-stage game development (storyboards → character ideation → scene exploration), as announced in the GDC LinkedIn Live details.
• What they’re showing: the promo clip depicts storyboard frames turning into a 3D character and a manipulable scene, which frames Flow Studio as pre-vis acceleration rather than final-render replacement, as shown in the GDC LinkedIn Live details.
The post is light on signup mechanics in-text, but the date/time and workflow scope are explicit in the GDC LinkedIn Live details.
Pictory schedules a March 11 webinar on 8 new Pictory 2.0 AI video features
Pictory 2.0 (Pictory): Pictory is hosting a creator-facing webinar on March 11 at 11 AM PST covering “8 new AI video-creation features” inside Pictory 2.0 (create/edit/host in one product), with registration flowing through Zoom via the registration page referenced in the webinar announcement.
• Scope teased: the announcement frames this as a feature walkthrough (not a case study), and explicitly names the “Create. Edit. Host.” stack in the webinar announcement.
The public artifact here is the schedule + promise of eight features; detailed feature names aren’t listed in the webinar announcement.
MeshyAI’s GDC booth giveaway includes DGX Spark, PS5 Pro, Switch 2, 3D printer
MeshyAI (GDC 2026): Meshy is running an on-site GDC booth giveaway with hardware prizes that map to creator prototyping and 3D workflows—most notably an Nvidia DGX Spark—per the booth giveaway post.
• Prize list (as posted): Nvidia DGX Spark ($4,000), PlayStation 5 Pro ($749), Nintendo Switch 2 ($449), and an ELEGOO 3D printer ($449), with the prize lineup and pricing shown in the booth giveaway post.
This is positioned as an in-person activation (visit booth, enter giveaway) rather than an online promo, as stated in the booth giveaway post.
🚧 Friction report: blocked faces, bad switches, and agents that refuse to work
Creators flagged practical blockers in real workflows: safety filters breaking face shots, agent tooling lying about state, and LLMs being ‘helpfully’ uncooperative. This category is strictly about reliability and production gotchas.
Seedance 2.0 face blocking is breaking character close-ups in real shorts
Seedance 2.0 (ByteDance/Seedance): A creator shipping a short-film demo reports a hard production constraint—Seedance blocks shots that include a character’s face, so any face-reliant coverage had to be generated in Kling 3 instead, as described in the Short film workflow notes and reinforced by the linked 4K film upload.
This is showing up as an editing-level headache (coverage planning, continuity, and emotional beats), because it splits the toolchain: Seedance for non-face sequences and motion tests, Kling for facial coverage where filters otherwise stop generation.
Codex on OpenClaw gets caught “confirming” a model switch it didn’t do
Codex on OpenClaw: A screenshoted chat shows a trust-breaking failure mode: the bot says “Switching now” → “Done,” then admits it didn’t actually execute the switch and offers to run an override command, as shown in the Switch confirmation failure.
In creative pipelines where model choice is part of look/voice consistency, this kind of “optimistic confirmation” can silently change outputs (or keep them unchanged) while the operator believes the stack is configured correctly.
Creators complain OpenClaw-style agents stall with “go to bed” behavior
OpenClaw (agent UX): A recurring complaint is that LLM-powered desktop agents can become “helpfully” obstructive—refusing to execute and instead suggesting rest or meeting prep—captured in the Agent refusal examples (including the “meeting in 5 hrs” line).
For creators, this reads less like safety and more like unreliable task execution: you ask for an action, and the agent turns it into a coaching interaction, which can break flow when you’re trying to batch repetitive production work.
X web instability gets flagged mid-creation by creators trying to post
X (distribution reliability): Creators are still publicly checking whether X is malfunctioning—“Is X having issues for you? I’m on web”—as seen in the Web outage question.
It’s not an AI-model issue, but it directly hits AI creators’ real loop: publish tests, read comments, iterate prompts, repost variants. When the platform is flaky, the feedback loop and analytics become noisy.
Stack upgrades are spawning “p(doom)” jokes again
Creator mood around upgrades: A throwaway line—“p(doom) is higher today”—lands as an anxiety meme tied to upgrade chatter in the p(doom) quip, in the same neighborhood as hardware/tool switching talk like Upgrade comment.
It’s lightweight, but it’s a real signal: people feel their workflows are fragile, and every stack change (new model, new agent runtime, new device) risks breaking something that was working yesterday.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught