Runway Characters API launches – first 30 minutes free, screen-reading avatars
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Runway launched Characters with full API support; the pitch is real-time avatars configurable “across every style,” with bespoke knowledge banks, custom voices, and per-character instructions; Runway says the first 30 minutes of conversation are free. Early demos lean hard into multimodal “agent in the loop” behavior: one Character is wired to a full Marathon map knowledge base, reads the live game screen, and guides objectives plus extraction calls; another identifies Japanese candy packages from a live camera feed, turning object recognition into a conversational layer.
• Qwen 3.5 (Alibaba): open-source lineup framed around cheaper long-context agents; linear attention + sparse MoE; models span 27B/35B up to 397B-A17B, with “natively multimodal” claims but no third-party cost curves in the thread.
• Ring-2.5-1T (AntLingAGI): viral claim of an open-source 1T-parameter model that runs on consumer GPUs; asserts 3× throughput and 10× memory efficiency, but no reproducible eval artifact linked.
• MatAnyone 2: video matting release adds MQE scoring without ground truth; ships VMReal at 28K clips / 2.4M frames for messier real-world cutouts.
Across the feed, capability is shifting from “generate a clip” to “stay present”: screen-reading, knowledge-backed characters; industrialized pipelines; and growing pressure for verifiable benchmarks as marketing claims outpace public evals.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught
Top links today
- a16z Consumer AI Top 100 list
- SearXNG private metasearch engine repo
- Runway Characters API and docs
- MatAnyone 2 video matting demo
- MatAnyone 2 paper on arXiv
- KARL knowledge agents via reinforcement learning paper
- RoboMME memory benchmark for robot policies paper
- Penguin-VL efficiency limits for VLMs paper
- Awesome agent skills repo for builders
- Skyvern open-source browser automation repo
- InsForge open-source backend setup agent repo
- Future Vision XPRIZE submission details
- Cursor cloud agents product page
Feature Spotlight
Runway Characters API: real‑time avatars that can see screens + use your knowledge base
Runway Characters makes “interactive avatars as a product feature” practical: customizable real-time characters with knowledge banks + voices, deployable via API, enabling screen-aware assistants for games, shopping, and accessibility.
The big cross-account story today: Runway shipped “Characters” with full API support and multiple demos. This section focuses on how creators are embedding interactive avatars into apps (and excludes Kling/Freepik, Midjourney SREFs, and open-source dev tools covered elsewhere).
Jump to Runway Characters API: real‑time avatars that can see screens + use your knowledge base topicsTable of Contents
🧑🚀 Runway Characters API: real‑time avatars that can see screens + use your knowledge base
The big cross-account story today: Runway shipped “Characters” with full API support and multiple demos. This section focuses on how creators are embedding interactive avatars into apps (and excludes Kling/Freepik, Midjourney SREFs, and open-source dev tools covered elsewhere).
Runway launches Characters API for real-time avatars with knowledge banks
Runway Characters (Runway): Runway launched Characters with full API support—real-time avatars you can customize “across every style,” with bespoke knowledge banks, custom voices, and per-character instructions, as described in the launch post and reiterated in the availability note; the dev onramp includes the first 30 minutes of conversation free, per the availability note.

• Accessibility framing: Runway’s team is positioning this as natural-language navigation “without a single button click,” with the accessibility angle called out in the accessibility note.
A Runway Character becomes a screen-reading guide for Bungie’s Marathon
Runway Characters (Runway): A creator demoed a Character wired to a full map knowledge base for Bungie’s Marathon that can read the screen, guide you to objectives, and advise what valuables to extract, as shown in the Marathon character demo; it’s a concrete example of the “knowledge bank + instructions” pattern Runway described in the launch post.

The clip shows the avatar layered over gameplay with on-screen prompts like “Guide to Objective,” suggesting a tight loop between visual context and task guidance.
Runway Characters identifies physical objects on camera in real time
Runway Characters (Runway): Runway reshared a demo using Characters to identify Japanese candy packages laid out on a table—turning live camera input into a conversation that labels what’s in frame, as shown in the snack identification demo; it lines up with Runway’s “deployable anywhere via API” positioning in the launch post.

This is the more “retail/content” side of the same capability: point a camera at a scene, then let the avatar explain and categorize it as you handle items.
🎬 Kling & Seedance momentum: motion control craft studies + AI video goes ‘industrial’
Video posts today skew toward practical Kling 3.0 genre tests (sci‑fi/horror) plus Seedance being used for early ‘AI series’ experiments. Excludes Runway Characters (feature), and excludes post/VFX utilities (see Post‑Production).
Freepik ships Kling 3.0 Motion Control, with unlimited access through Mar 16
Kling 3.0 Motion Control (Freepik): Freepik says Kling 3.0 Motion Control is now available inside its platform, including motion-reference matching, “same gestures and expressions” consistency, and support for videos up to 30 seconds, as described in the feature rundown.

• Availability window: Freepik frames usage as unlimited for Premium+ and Pro users until March 16, per the feature rundown.
• Where to try it: The product entry point is linked from the try it link, which points to the Freepik video tool page.
The post doesn’t mention exact control knobs (strength, keyframes, etc.), so the practical “best settings” side is still unconfirmed from these tweets.
AI video “industrialization”: creators argue for factory-style pipelines, not one-offs
AI video production systems: A Chinese post sharing a second episode of an AI sci‑fi short argues “AI video has entered the industrialization stage” and explicitly calls for building repeatable production systems (beyond ads, promos, and music videos), as shown in the episode and on-screen text.

The framing matters for working creators: it’s less “make one good clip” and more “set up a line” (assets, shot templates, consistency checks, and throughput). The tweet itself doesn’t name the exact tool stack, only the broader push.
Kling 3.0 horror test: selling a jump-scare with a single reveal
Kling 3.0 (Kling AI): A horror-focused micro-scene shows a “look up at the ceiling” setup followed by an unsettling face reveal, framed as evidence that horror has room to work in Kling 3.0, per the horror note.

What’s notable here is the simplicity: one constrained location, one reveal beat, and a hard cut. That makes it a clean template for testing motion + facial coherence without needing multi-shot continuity.
Kling 3.0 keeps earning praise for sci‑fi visuals and montage pacing
Kling 3.0 (Kling AI): A creator calls Kling 3.0 “exceptional” specifically for science fiction work, pointing back to their own earlier trailer as evidence in the sci‑fi claim.

The clip reads like a genre stress test (fast cuts, big environmental changes, glowing tech), which is exactly where weaker video models tend to wobble—so it’s a helpful yardstick even if you’re not making sci‑fi.
Seedance shows up as a “series-only” production tool in early China examples
Seedance (TikTok): A reshared post claims creators in China are already releasing early entertainment “series” made using only Seedance, positioning it as an end-to-end generator for episodic output rather than a clip tool, per the series claim.
No workflow breakdown or settings are included in the tweet, so this reads more like a demand signal: people are trying to standardize recurring characters and episodes on one model/toolchain.
Street View extraction + Kling 3.0 Motion Control for a Shibuya world (1080p)
Kling 3.0 Motion Control: A reshared demo shows Motion Control applied to a Shibuya Scramble Crossing scene built from Google Street View extraction, with the creator calling out 1080p quality as a key part of the result, as stated in the reshare caption.

This is a useful reference for “photogrammetry-ish” city plates: it suggests Motion Control can keep camera travel stable even when the underlying environment comes from stitched street imagery rather than a clean 3D scene.
Copy-paste Kling prompt: Excalibur sword-in-stone slow push-in
Kling 3.0 prompt recipe: A creator shared a ready-to-run prompt for generating an Excalibur-style “sword in stone” sequence with a slow push-in and faintly glowing runes, as written in the prompt post.

Prompt text (as posted):
This is a compact way to specify both the setpiece and the camera move in one line, which is often the difference between “cool frame” and “usable shot.”
A “hard to hate AI video” take spreads with a wildlife-style clip as proof
AI video sentiment: A creator claims it’s “impossible to hate AI video” if you watch high-quality outputs, attaching the sentiment to a wildlife-style eagle clip in the reaction post.

This is less about a specific vendor and more about a taste shift: when outputs look like familiar non-AI genres (wildlife b‑roll, nature doc inserts), resistance tends to move from “it looks fake” to “who made it and how.”
🧪 Prompts & SREFs you can paste: Midjourney style refs + Nano Banana brand templates
Today is heavy on copy‑paste aesthetics: Midjourney SREFs (children’s ink/watercolor, academic sketches, cyberpunk), plus Nano Banana prompt templates for brand visuals and character sheets. Excludes tutorial-style guidance (see Tool Tips) and excludes tool releases (see other categories).
A 3×3 “same character” contact sheet prompt for fast pose-and-angle coverage
Prompt template (3×3 contact sheet): A compact way to force multi-angle consistency—“same character, same scene,” randomized poses across a grid—shared plainly in 3x3 grid prompt.
Copy-paste base from 3x3 grid prompt (add your character + scene details before it):
The laundromat example image in 3x3 grid prompt demonstrates the “coverage” benefit: full-body, closeup, back view, crouch, and interaction poses in one generation.
Midjourney SREF 1979611645 for contemporary children’s ink-and-watercolor storytelling
Midjourney (SREF 1979611645): A shareable style reference that reliably lands “modern European picture book” ink + watercolor—loose linework, warm washes, and narrative staging—per the practical breakdown in Style description and sref.
The examples in Style description and sref show it holding up across character closeups and environment shots (desk scene, seaside camera scene), which makes it useful for short-form storyboards, kids’ merch mockups, and consistent illustrated sequences without rebuilding the look each prompt.
Mixing Midjourney SREFs is turning into a teachable, sellable craft
Midjourney (SREF mixing): A creator frames SREF-combining as a “skill people will pay for,” teasing a concrete example set they plan to share with subscribers in Sref mixing teaser.
What’s notable is the pitch: not “here’s a code,” but “here’s how to synthesize a new house style,” with the visuals in Sref mixing teaser implying the output is cohesive enough to repeat across multiple scenes (the actual SREF pairs aren’t disclosed in today’s post).
Nano Banana paint-stroke brand visual template with adaptive brand colors and canvas texture
Nano Banana (brand-in-paint template): A structured prompt for turning a brand into a mixed-media “oil paint on canvas” key visual—two horizontal impasto strokes in primary brand color, plus a raised contrasting paint dollop—shown with Nike/Baskin Robbins/Gucci examples in Paint stroke prompt.
The full spec in Paint stroke prompt is explicitly designed for brand adaptation (analyze brand colors; replace red/yellow with brand palette), and it bakes in physical texture cues (raw canvas weave, gesso dabs, charcoal/graphite scribbles) so the output reads as photographed paint rather than a flat overlay.
Nano Banana prompt for minimalist 3D glass/chrome “blind emboss” brand logos
Nano Banana (3D logo prompt template): A copy-paste prompt for clean, consistent “glass bezel / chrome rim” embossed logos—centered, monochrome palette, top-down, with controlled specular highlights—shared in 3D glass logo prompt.
Template (verbatim from Full prompt text):
Midjourney SREF 4019636570 for 19th-century-style academic sketchbook studies
Midjourney (SREF 4019636570): A style ref aimed at classical academic drawing—cross-hatching, ink + pencil feel, and “aged paper” tonality—shared with a clear descriptor in Sepia sketch sref.
Because the set in Sepia sketch sref spans landscapes, architecture, and portrait studies, it’s a solid default when you need concept-art “study notebook” pages, faux archival plates, or book-illustration inserts that shouldn’t read as glossy digital art.
Midjourney V7 Style Creator SREF 7129209087 for fantasy medieval anime lookdev
Midjourney (V7 Style Creator; SREF 7129209087): A creator shares a newly built style for “fantasy medieval anime / 2D animation aesthetics,” noting you can push it further by explicitly adding “2D anime style” in the text prompt, as described in Style creator note.
The sample set in Style creator note reads like RPG character key art (weapons, armor, castle architecture), which makes it a straightforward option for consistent party lineups, dialogue portraits, and establishing shots in the same visual language.
Nano Banana 2 isometric office diorama prompt with brand/material variables
Nano Banana 2 (isometric office diorama): A long-form template prompt defines an isometric 3D office cutaway on pure white; it hard-codes art-directable constraints like “no shelves,” plus 5–10 people collaborating and a visible brand logo, as written in Diorama prompt.

The same post notes it animates cleanly in Kling via a simple motion prompt (“slow rotation around the isometric scene”), according to Diorama prompt. The full text version is reposted in Full diorama prompt.
Promptsref’s Midjourney SREF 2681316761 targets cinematic neon cyberpunk contrast
Promptsref (Midjourney SREF 2681316761): A published style guide focuses on cyberpunk images that feel “cinematic” via high color contrast—warm orange/red practical lights against deep blue-green night tones—positioned for sci-fi key art and environment design in Cyberpunk sref pitch.
The specific reference page and prompt notes are linked in Sref guide page, but today’s tweet doesn’t include example images inline; treat output claims as promotional until you run a few A/B generations with your usual cyberpunk baseline prompt.
Promptsref’s top SREF 5184362986: retro dreamy soft-focus with halation and god rays
Promptsref (Midjourney SREF 5184362986): The Mar 8 “most popular sref” writeup characterizes this look as retro, dreamy, soft-focus—leaning on filmic halation/diffusion, saturated-but-gentle color, and strong light beams—spelled out in Top sref analysis.
For copy-paste purposes, the post suggests prompting around light/emotion/haze rather than objects, and points to usage in fashion/beauty, album covers, and narrative illustration, as described in Top sref analysis. The reference hub is linked via Sref library page.
🖼️ Repeatable image formats that keep working: puzzles, Y2K ads, and finishing passes
Image posts today cluster around repeatable formats (hidden-object puzzles, ad-style renders) and “finishing” comparisons. Excludes pure prompt/SREF drops (see Prompts & Style References) and excludes multi-tool pipelines (see Workflows & Agents).
Firefly + Nano Banana 2 Hidden Objects hits Level .061 with four new scenes
Hidden Objects (Adobe Firefly + Nano Banana 2): The daily “find 5 items” puzzle format continues with four new boards—Levels .058, .059, .060, and .061—keeping the same engagement mechanic (five target silhouettes) while rotating scene complexity and texture, as shown in the Medieval manuscript level, Toy-strewn floor level , Tropical branch level , and Rock strata level.
• Higher camouflage scenes: Level .061 embeds outlines directly into layered rock strata (hard edges + mineral veins), raising “spot the outline” difficulty compared to clutter-based hiding, as shown in the Rock strata level.
• Organic density scenes: Level .060 uses a mossy branch packed with plants and small animals; the five objects are integrated into natural shapes, as shown in the Tropical branch level.
Across the set, the consistent “five icons at bottom” UI stays fixed while the hiding strategy shifts (ornamental manuscript details in .058 per the Medieval manuscript level, and object clutter in .059 per the Toy-strewn floor level).
Y2K product-card aesthetic resurfaces as a repeatable “make it Y2K style” move
Y2K product renders (repeatable art direction): Two before/after posts show a consistent transformation pattern—start from a clean product shot, then push it into a Y2K “cyber-card” layout with grids, chrome/glitch motifs, and UI callouts; one example is explicitly driven by the prompt “make it Y2K style,” as shown in the AirPods Y2K before-after.
• Consumer audio example: The AirPods Pro concept moves from plain white packshot to neon gradient + wireframes + spec callouts, with the prompt called out directly in the AirPods Y2K before-after.
• Phone concept example: A second set applies the same “Y2K energy” framing to a smartphone promo card (glossy lenses, retro UI windows, and a bottom banner), as shown in the Phone Y2K card.
The common thread is layout-first consistency: a “product in the center + techy border system + spec strip” template that can be swapped across devices without changing the underlying idea, as evidenced by the paired examples in the AirPods Y2K before-after and Phone Y2K card.
A 3×3 poster grid frames FloraAI sneaker art as a narrative set
FloraAI brand art (series packaging format): A creator argues that “one image rarely” carries the full meaning and publishes a 3×3 grid of nine related surreal sneaker posters to make the set feel like a cohesive campaign rather than isolated one-offs, as shown in the Nine-panel poster grid.
The grid format is backed by additional single-poster drops in the same motif—floating sneaker with flowers/balloons and a consistent caption system—shown in the Touch Daisies poster and Touch Clouds poster, reinforcing that the “collection” presentation is the product, not any one frame.
Magnific AI “before/after” finishing pass shows specific skin + grain settings
Magnific AI (finishing pass): A creator shared a clean “before vs after” comparison that treats Magnific as a final-detail layer, explicitly calling out parameter values—skin detail 13%, sharpen 8%, and smart grain 12%—in the on-image settings readout shown in the Before-after settings.
The notable part is the positioning: this isn’t a new render style; it’s a repeatable post step that preserves the base composition while pushing micro-texture and edge clarity (the “v1 (faithful)” label is visible in the same settings panel via the Before-after settings).
🛠️ Single-tool tactics: better Claude Code context + fast ‘cinematic’ photo edits
Practical, single-tool usage advice today: Claude Code repo-structure hygiene, and simple visual edit directives (e.g., dusk conversion + object removal). Excludes raw prompt dumps (see Prompts & SREFs) and excludes developer OSS tools (see Vibe Coding).
Claude Code context hygiene: CLAUDE.md as memory, not a knowledge dump
Claude Code (Anthropic): A practical repo-structure checklist argues most quality issues come from bloated CLAUDE.md files—treat it as lightweight “repo memory” (WHY/WHAT/HOW) and push repeatable procedures into .claude/skills and deterministic checks into hooks, as laid out in the Claude.md checklist and reinforced by the accompanying
.
• Progressive disclosure: Keep deep explanations in docs/ (ADRs, runbooks, architecture) so the model can be pointed to “where truth lives,” rather than ingesting everything up front, per the Claude.md checklist.
• Local context near sharp edges: Add smaller CLAUDE.md files next to tricky modules (auth, infra, persistence) and structure the repo like onboarding a new engineer, as described in the Claude.md checklist.
Net effect: less context spam, clearer ground truth, and more reusable “house style” for code changes—without relying on the model to remember forever.
Reve edit directives that reliably produce “cinematic dusk” photos
Reve (image editor): A simple, repeatable directive stack—“remove the wires,” “remove clouds,” then “make it @dusk / bathed in golden hour”—shows a clean before/after where mundane travel photos get a more cinematic sky and lighting, as demonstrated in the annotated source image and result shared in the Before/after edit.
The key detail is the order: first remove distracting elements (wires/clouds), then shift time-of-day and light quality so the scene reads as intentional rather than ‘fixed.’
OpenClaw task boards: coding needs more states than “todo → done”
OpenClaw (agent workflow): A usage tip says many teams misconfigure OpenClaw because they run coding work on a generic kanban; for code tasks, the board should explicitly include steps like todo → plan → PRD → implementation → testing → review, so the agent’s intermediate artifacts have a place to live, as explained in the OpenClaw usage walkthrough and spelled out in the Coding kanban states.

This frames “agent output quality” as a workflow design problem: without explicit stages, planning and verification steps get skipped or overwritten.
“Double exposure portrait” as a dependable surreal-photo prompt modifier
Prompt technique (double exposure portrait): A concise tip recommends adding the phrase “double exposure portrait” to prompts to force a readable two-layer composite; the example prompt “Side profile face of a woman and Tokyo skyline, double exposure portrait, cherry blossoms” is shown alongside variations generated in Adobe Firefly, per the Tip and example prompt.
The practical takeaway is that the modifier acts like a composition constraint: one dominant silhouette plus a secondary scene layer, which tends to survive model/style changes better than overly specific art-direction language.
A musical ear is a real edge in AI-first filmmaking
Editing & scoring (craft): A short creator note argues that “having a good musical ear is hugely underrated in filmmaking,” implying that as visuals get cheaper to generate, taste in rhythm, pacing, and music-to-cut alignment becomes more differentiating, as stated in the Musical ear takeaway.
✂️ Post & compositing: video matting upgrades + audio-driven animation utilities
Finishing-focused posts today include a new state-of-the-art matting release and creator-made utilities that convert audio into motion/keyframes. Excludes core video-generation capability demos (see Video) and excludes prompt libraries (see Prompts).
MatAnyone 2 ships a learned quality evaluator for scalable video matting
MatAnyone 2 (research release): MatAnyone 2 is out on Hugging Face with a training approach built around a learned Matting Quality Evaluator (MQE) that scores alpha quality without ground truth, plus a new real-world dataset VMReal sized at 28,000 clips / 2.4M frames, as described in the Release post and detailed on the ArXiv paper page. This is a finishing tool story. It targets cleaner cutouts on messy footage.

• What creators can actually do with it: The release includes a runnable demo app, as linked in the Interactive demo, which makes it practical for quick “extract subject → composite → grade” passes.
• Why MQE matters: MQE is also framed as a way to curate training data and suppress bad regions during training, per the ArXiv paper page; that’s the part that tends to show up as fewer edge artifacts and less “boiling” around hair and hands.
DreamLabLA shares a full breakdown of the Luma Agents crash workflow
Luma Agents (DreamLabLA): The promised breakdown is now posted as a ~2m 13s walkthrough showing how the crash shot was assembled end-to-end, including intermediate setup and “final output” stages visible on-screen in the Breakdown video. This is post work. It’s about turning a rough plate into a finished composite.

DreamLabLA teases a Luma Agents-built car crash VFX shot
Luma Agents (DreamLabLA): DreamLabLA previewed a ~20-second “car crash sequence” created with Luma Agents, positioned as a VFX-style composite shot with a behind-the-scenes breakdown promised later, per the Teaser post. It’s a concrete example of using an agentic video system for one high-impact shot, not a full film.

shiftcut for macOS maps audio spikes into keyframed transition clips
shiftcut (mds): A small macOS app called shiftcut turns a library of SFX into motion by detecting audio spikes and generating keyframe animations from the audio signature, according to the Weekend project notes. It exports black-and-white .mov clips with sound baked in, meant to be luma-keyed in an editor.

• Workflow details that matter: The app pairs “duration” with both sound timing and transition speed, and exposes UI actions as CLI commands, as described in the Weekend project notes. That makes it easier to batch-generate a consistent transition pack for a project.
Pictory 2.0 positions itself as a full-stack AI video workflow in one tool
Pictory 2.0 (Pictory): Pictory is marketing “Pictory 2.0” as a consolidated video workflow—avatars, GenAI, hosting (“Pictory Central”), Brand Kit, “AI Studio,” summarizer, plus PPT and audio-to-video—in the product pitch shared in the Product announcement. It’s a bundling move. The claim is fewer tool hops.
The post points to the signup flow in the Signup page, but it doesn’t include an in-tweet demo clip or measurable quality comparison versus specialist tools.
🧩 Studio orchestration: production OS thinking, storyboards at scale, and ‘autopilot’ content sites
Workflow posts today focus on orchestration: agent-driven ‘studio OS’ narratives (STAGES/ARQ) and systems that crank out lots of assets fast. Excludes general dev tooling and repos (see Vibe Coding) and excludes Runway Characters (feature).
ARQ says its fal enterprise setup generates 650 storyboard images in 15 minutes
ARQ + fal (ARQ): A filmmaker says fal turned around an enterprise agreement in days—“email sent on Thursday,” “Friday finalised deal,” and by Monday morning they had an enterprise solution that can run a “storyboard of 650 images in 15 minutes,” as claimed in the Enterprise turnaround note.
The post positions this as enabling feature-film scale previsualization throughput (their “first feature film coming out soon”), but it doesn’t specify the model mix, resolution targets, or what counts as a “storyboard image” beyond the headline metric in the Enterprise turnaround note.
Raw launches an “autonomous” stock photo site that auto-generates and curates
Raw (CreativeDash): A creator says they built a “fully autonomous stock photo website” that auto-generates content, curates it, and “improves itself,” with the project now live on UI8 and “videos soon,” per the Autonomous stock photos.
The screenshot in the Autonomous stock photos post shows the product positioning (“Tastefully Generated Stock Photos”) plus category packaging (e.g., “3D Scenes & Objects”), signaling this is being treated as an ongoing content engine rather than a one-off gallery.
STAGES teases “Black Mamba” as a stealth, fully agent-driven production OS
STAGES: Black Mamba (STAGES/NAKID): The STAGES founder says he’s building a “sleeker stealth” version of the STAGES OS that’s “completely agent driven,” where the human creator sits at the Art Director / curation layer while agents execute tasks underneath, as described in the Black Mamba teaser.
The post frames this as a separate product line (“STAGES: BLACK MAMBA”) with timing only stated as “later this year” in the Black Mamba teaser, so availability, pricing, and what “agent driven” means in practice (shot planning, asset routing, approvals, render orchestration) are still unspecified.
Paperclip is pitched as an open-source OS for “zero-human companies”
Paperclip (Paperclip): A thread claims someone open-sourced an “operating system for zero-human companies” called Paperclip, positioning it as a packaged orchestration layer rather than a single agent, as stated in the Paperclip claim.
The same thread surfaces a governance worry relevant to “autopilot” stacks—if one model generates work and also reviews/audits it, you lose separation between author and auditor—called out in the Paperclip claim.
STAGES refreshes its site and sets a Mar 11 beta start for residency artists
STAGES (STAGES/NAKID): The team says the STAGES site was redesigned over the weekend and ties it to an artist residency intake—submissions are in their “last days,” and beta with selected artists begins on 3/11, per the Residency timeline and the linked site refresh at Studio site.
The same ecosystem is also putting more structured “production OS” language in front of creators, with an executive-summary screenshot outlining STAGES as a multi-layer system (protocol/governance; platform/intelligence; economics/ecosystem) in the White paper excerpt.
ARQ markets a “film studio automation” stack and runs a 3-code giveaway
ARQ (ARQ): ARQ frames its product as “automating everything a film studio does” except “the idea… the artist… the craft,” and runs a giveaway of 3 access codes to its filmmaking tool, according to the Positioning and giveaway.

The pitch is explicitly studio-oriented (brands and governments are mentioned), with a public product page linked in Product page; the post itself doesn’t describe constraints like shot limits, asset caps, or pricing beyond the giveaway mechanics in the Positioning and giveaway.
📈 Model moves that affect creators: cheaper multimodal inference + trillion‑param open source hype
Model chatter today is about efficiency and scale (Qwen 3.5’s inference stack) and a headline-grabbing trillion-parameter open-source release claim. Excludes a16z app rankings (see Market Leaderboards) and excludes papers-only items (see Research).
Qwen 3.5 leans into “more intelligence per GPU” with linear attention + sparse MoE
Qwen 3.5 (Alibaba): Alibaba’s Qwen 3.5 open-source drop is being framed around inference efficiency—linear attention (to avoid long-context cost blowups) plus sparse MoE (activate fewer experts per token) for better capability-per-GPU, as described in the release framing and reiterated with the inference stack explainer.

• Why creatives feel it: the pitch is lower-cost long-context + tool-using agents (research, planning, multimodal pipelines) without scaling compute linearly with output length, per the deployment ROI angle.
• Multimodal positioning: Qwen 3.5 is described as “natively multimodal” (docs, screenshots, charts; structured outputs) rather than a vision add-on, per the multimodal claim.
• Model lineup knob: the thread calls out a range from “Flash” to mid-size “27B/35B” and larger “122B-A10B/397B-A17B,” arguing you can pick a compute ceiling instead of overprovisioning, as listed in the lineup breakdown.
Access points are still a bit fuzzy in these tweets, but a runnable surface is pointed to via the Qwen Chat link.
Ring-2.5-1T claims trillion-parameter open source with 10× memory efficiency and lower token costs
Ring-2.5-1T (AntLingAGI): A viral claim says Ring-2.5-1T is a trillion-parameter open-source model that can run on “consumer-grade GPUs” and at “half the cost” of comparable models, per the headline claim; follow-on posts add concrete-sounding metrics like 3× generation throughput and 10× memory efficiency for long generations in the metrics roundup.

• Cost + scale story: one breakdown cites output pricing of $1.11 (and input $0.56) versus higher output costs for Kimi variants, as quoted in the cost comparison.
• Capability claims: the same thread asserts “IMO 2025 gold medal reasoning” (and CMO) and large long-context gains, as summarized in the numbers list. Treat this as promotional until a reproducible eval artifact shows up.
• Early “how it behaves” anecdote: a demo story emphasizes debugging value—explaining why an error happened and generating tests (standard + empty list edge case), as described in the debugging anecdote.
If you’re a studio running long-horizon agents (shotlists, revisions, batch asset generation), the main creative relevance is the promised cost curve—long contexts without the usual memory/throughput tax—assuming the claims hold up.
Code review with the same model that wrote the code triggers “author vs auditor” concerns
Claude (Anthropic): A thread about Claude moving into code review argues that letting the same AI both generate and review code collapses the “author vs auditor” separation—because “generation optimizes for fluency” while “review should optimize for catching mistakes,” as stated in the author auditor argument.
• Integrity layer framing: the broader point is that faster AI coding increases throughput, but without an independent verification layer it can accelerate technical debt—an argument echoed in the integrity system comment.
There’s no first-party Anthropic product detail in these tweets, but the debate itself is showing up as a practical workflow question for creative teams shipping AI-heavy pipelines: which parts of the stack need a separate checker (tests, linters, second model, or human review) versus the model that authored the change.
👩💻 Vibe coding & open-source building blocks: private search, browser automation, and agent skill libraries
Developer-heavy today: self-hosted search, browser automation, agent skill repos, and backend platforms meant to be operated by AI agents. Excludes creative prompting (see Prompts) and creative OS positioning (see Workflows & Agents).
Skyvern automates browser workflows from natural language with vision models
Skyvern (Skyvern-AI): A new wave of “prompt-to-browser” automation is getting attention via Skyvern, which aims to run workflows on sites it hasn’t seen by combining a vision LLM with computer vision—covering form-filling, structured extraction, file downloads, and even login/2FA flows per the capabilities list. The project is positioned as fully open source in the same post capabilities list, with implementation details and a Playwright-compatible SDK described in the GitHub repo.
This matters most if you’re building pipelines that keep jumping out of your creative stack—collecting references, scraping submissions, pulling receipts/usage data, or turning web UIs into callable “tools” for agents—without hand-maintaining brittle scripts.
A curated repo collects reusable agent “skills” across stacks
awesome-agent-skills (VoltAgent): The VoltAgent/awesome-agent-skills repository is being shared as a single place to grab reusable agent capabilities—web search, file ops, memory, API calls, and browser automation—rather than rebuilding the same glue repeatedly, as framed in the repo overview. The repo description emphasizes cross-framework drop-ins (n8n/LangChain/CrewAI/custom) from the same pitch repo overview, while the repo itself highlights scale (hundreds of skills) plus explicit security caveats (curated, not audited) in the GitHub repo.
The practical creative angle: this is the “LEGO bin” for turning a script-y workflow (asset pulls, uploads, metadata tagging, distribution checks) into something agents can actually execute reliably—if you review each skill like untrusted code.
SearXNG lets you run a private metasearch engine across 70+ sources
SearXNG (open-source community): Creators are resurfacing SearXNG as a self-hosted metasearch layer that queries 70+ engines (Google/Bing/Yahoo/Brave/DDG and more) while keeping search history off ad networks—positioned as “your own private Google” in the feature rundown. The pitch is practical ops: pick engines per category, run it with a single Docker deploy on a cheap VPS, and keep it ad-free/zero profiling per the feature rundown, with the code and license details in the GitHub repo.
For creative teams, it’s mainly a building block for private research loops (moodboards, references, competitive scans) that can also be wired into agents without leaking prompts and queries to consumer search accounts.
InsForge 2.0 pushes ‘agents configure the backend’ as an open-source primitive
InsForge 2.0 (InsForge): InsForge 2.0 is being promoted as an open-source backend platform where an AI agent can configure services (DB/auth/storage/functions) instead of engineers clicking through dashboards, per the release note. The repo description frames this as a semantic layer for AI coding agents to inspect state and apply backend changes, with feature scope and deployment options outlined in the GitHub repo.
For small creative products (tools, micro-SaaS, internal studios), it’s another attempt to make “backend setup” a callable substrate for agents—reducing the manual glue work that tends to slow down shipping.
OpenClaw harness chart shows Gemini-3-Flash ahead; GPT-5.4 hit by timeouts
OpenClaw model selection (bench harness): A creator shared a model success-rate chart from OpenClaw-style agent tests and said GPT-5.4 is timing out more often than their previous setup, prompting a switch to Gemini-3-Flash, per the timeouts complaint. The screenshot ranks google/gemini-3-flash at 95.1% success, while openai/gpt-5.4 is shown at 74.8%, as visible in the timeouts complaint.
Treat it as directional: the chart is compelling, but the tweet doesn’t attach a reproducible benchmark artifact or task list—only the outcome and the frustration.
OpenClaw hype meets buyer’s remorse as bug reports surface
OpenClaw (community signal): A critical anecdote circulating via a Reddit screenshot says a user bought a Mac Mini, installed OpenClaw, spent “$200 in Opus,” and concluded the product is “full of bugs” with a plan to “come back in 6 months,” as shown in the purchase regret screenshot. That lands alongside the opposite vibe—OpenClaw as a viral moment—via a star-history graphic claiming it spiked past Linux/React in all-time GitHub stars in the stars chart.
The combined signal is a familiar arc: extreme attention + rapid onboarding spend, followed by reliability/fit complaints once people try to use it daily.
Octree is pitched as an open-source AI LaTeX editor alternative to Overleaf
Octree (project claim): A thread claims someone open-sourced Octree, described as a full AI LaTeX editor and framed as making Overleaf feel overpriced in the open-source claim. The same author’s surrounding context ties this to broader “agents everywhere” tooling momentum open-source claim, but the tweet itself doesn’t include a repo link or concrete feature list.
Net: it’s a signal that “AI-native writing environments” are moving into technical docs and publishing workflows; details remain unverified from today’s tweets alone.
🧭 Who’s actually getting used: a16z Consumer AI Top 100 + the creative-tool consolidation story
Market intel for creatives today centers on the a16z Consumer AI Top 100 refresh and what it implies about winners in image/video/audio tooling. Excludes model architecture releases (see Model Moves) and excludes tool how-tos (see Tool Tips).
a16z’s Consumer AI Top 100 expands to include AI-powered products, not only AI-native apps
Consumer AI Top 100 (a16z): The sixth edition of the a16z consumer AI Top 100 is out, and the key change is methodological—products can qualify even if they weren’t “AI-native,” as long as AI is core to the experience, per the ranking thread and the full write-up in the Top 100 report. This is a big reframing for creative tools because it puts incumbents like Canva/CapCut/Notion/Grammarly in the same conversation as chat-first AI.
The charts in the same thread show how the list is now effectively measuring “AI-powered creative workflow time” (editing, design, writing) alongside model destinations like ChatGPT and Gemini, as shown in the ranking thread.
Top GenAI web products: ChatGPT #1, Gemini #2, Canva #3, with creative tools clustered in the top 20
GenAI web usage (a16z): The web Top 50 chart ranks ChatGPT #1, Gemini #2, Canva #3, deepseek #4, Grok #5, Claude #6, with creator-facing utilities (Notion, Freepik, removebg, CapCut, Grammarly, Suno) also showing up as high-frequency destinations, according to the web ranking image. The same thread flags that “three of the top 15 web products are not AI-native,” which is the clearest signal that creative incumbents are now being measured as default AI surfaces, per the web ranking image.
The chart’s source line (Similarweb, January 2026) makes this a usage snapshot, not a capability claim—so it’s about where creators spend time, not which model is “best.”
a16z says creative AI tools are consolidating, with image-gen and video options “compressed”
Creative-tool consolidation (a16z): The report’s creative takeaway is that standalone image-generation products have thinned out over time—“seven image gen products made our first ranks, now just three remain”—attributing it to native generation improvements from OpenAI and Google, and adding that video has also “compressed,” per the analysis thread and the full context in the Top 100 report.
Audio is described as more stable in the same section, with tools like Suno and ElevenLabs still recurring, which you can cross-check as present on the web chart shared in the web ranking image.
Freepik ranks #11 globally on a16z’s GenAI web list, and leans into the “European, bootstrapped” story
Freepik: Freepik says it’s now the #11 most-used GenAI web product worldwide, citing the a16z rankings in the Freepik milestone and linking back to the underlying report in the Top 100 report. A separate post emphasizes the company’s identity angle—“first…European” and “bootstrapped”—in the founder pride note.
The ranking callout is visible directly on the Top 50 web chart in the highlighted chart, which circles the #11 slot for Freepik.
Top GenAI mobile apps: ChatGPT leads, with CapCut and Canva near the top
GenAI mobile usage (a16z): On mobile, the Top 50 list puts ChatGPT at #1, followed by CapCut #2, Gemini #3, Canva #4, and a long tail of editing/search/utility apps, as shown in the mobile ranking image and discussed in the Top 100 report. This positions mobile creative editing as “default AI behavior” alongside chat.
The same edition’s rule change (including AI-powered products) matters more on mobile, where creators often experience AI as a feature inside an editor rather than a standalone assistant, per the framing in the mobile ranking image.
a16z argues consumer AI is splitting into three ecosystems: West, China, and Russia
Ecosystem split (a16z): The report claims usage is clustering into three relatively distinct ecosystems—Western tools with near-identical user bases; China with local winners like Doubao/Kimi/DeepSeek; and Russia with Yandex/GigaChat—arguing sanctions created a gap that local products filled, per the analysis thread and the Top 100 report.
For creatives, this reads as a distribution and tooling-availability reality: the “default” creative AI stack depends heavily on the user’s region and app store ecosystem, not only model capability.
a16z claims ChatGPT vs Claude app ecosystems overlap only 11%
Platform ecosystems (a16z): The a16z thread argues that despite the “ChatGPT vs Claude” narrative, the two platforms aren’t pulling from identical integration ecosystems—claiming only 11% overlap among “200+ apps/connectors on both platforms,” with ChatGPT skewing toward travel/shopping/food/health while Claude skews toward niche work integrations, per the analysis thread and the Top 100 report.
This is a distribution detail. It suggests the “best” creative assistant for a team can be downstream of which app graph they already live in.
a16z’s per-capita AI adoption index puts Singapore #1 and the US at #20
AI adoption geography (a16z): The report introduces a per-capita AI adoption index and says the top four are Singapore, UAE, Hong Kong, and South Korea, while the United States ranks #20, as stated in the analysis thread and expanded in the Top 100 report.
The framing attached to that stat is that “the country that built most of these products is not where they’re used most intensely,” per the same analysis thread.
Notable “surprises” in the a16z Top 100: Perplexity, removebg, and Google AI Studio’s rank
Top 100 surprises (a16z): A reshared take highlights a few ranking outcomes that surprised builders—Perplexity “higher than you’d think,” removebg as the #16 most popular AI tool, and Google AI Studio beating Lovable—as summarized in the surprises note. You can verify removebg’s placement on the Top 50 web chart in the web ranking image.
This is a usage signal about day-to-day creator workflows (background removal, “AI studio” prototyping, AI search) rather than a model-quality argument.
📣 Marketing creatives with AI: brand-aware content tools + synthetic influencer operations
Marketing-focused items today include brand-identity generation tools and synthetic influencer economics. Excludes prompt templates (see Prompts & SREFs) and excludes platform reach discourse (see Creator Platform Dynamics).
AI TikTok personas are already doing brand deals and UGC collabs
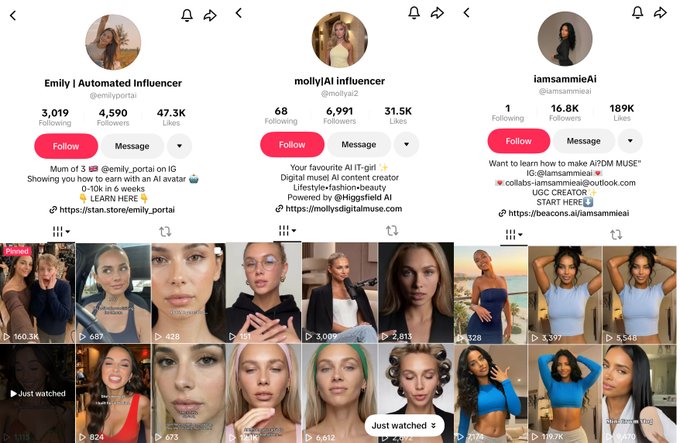
Synthetic influencers (TikTok): A thread claims AI-generated lifestyle/fashion/beauty personas are already earning on TikTok via brand deals and UGC collaborations, spotlighting three accounts (Emily, Molly, Sammie) and sharing visible traction metrics like 4,590 followers/47.3K likes, 6,991 followers/31.5K likes, and 16.8K followers/189K likes in the profile screenshots shown in the AI influencer examples.
The post’s core pitch is operational: “no sleep, no bad days, no agency fees,” with monetization framed as perpetual content output plus conversion, as written in the AI influencer examples.
Google Pomelli opens in Turkey for auto brand-aware social and campaign assets
Pomelli (Google): Pomelli is now available in Turkey, and it’s framed as an SMB-friendly “paste your website URL” workflow—AI crawls the site to learn brand colors/style/tone, then generates matching social posts, campaign copy, and visuals, as described in the Turkey rollout explainer. It also claims a product-photo upgrade path where a phone-shot product image can be transformed into a studio-style shot, per the same Turkey rollout explainer.
Positioning pushback: In a follow-up, the same creator warns against “graphic designers are over” hype, arguing design skill increases what you can do with these tools, as said in the Designer take.
A “Nike officewear” editorial set shows how to extend a brand into new product worlds
Recraft V4 + Nano Banana 2 (brand remix): A creator shared a “Nike never made office wear. But AI did” concept—high-fashion office portraits and wardrobe shots that keep Nike branding subtle (pins, sleeve marks, thigh marks) while staying in a Vogue-like editorial framing, as shown in the Nike officewear examples.
The same thread includes the creative direction prompt—“High fashion editorial photo… corporate office setting… Vogue magazine style… shot on 35mm film”—as posted in the Vogue-style prompt.
Y2K “cyber card” layouts are being used as a repeatable product-ad aesthetic
Y2K product creative (ad direction): Posts show a repeatable before/after pattern where a clean consumer-tech render becomes a dense, retro-futurist “trading card” layout—neon gradients, wireframes, circuit overlays, and spec callouts—summed up as “Everything looks better with a little Y2K energy” in the Y2K phone card.
A second example uses the same direction on earbuds (“make it Y2K style”), turning a plain product shot into a cyber-styled spec card, as shown in the AirPods Y2K example.
A blunt positioning line reframes brand messaging around user self-interest
Brand messaging (creative framing): A reposted quote—“Honest truth: No one cares about your brand. They care about themselves.”—is being used as a compact creative brief for ad copy and positioning, emphasizing user self-interest over brand self-mythology in the Brand truth graphic.
📚 Research radar (creator-relevant): search agents, efficient VLM encoders, and earth-scale embeddings
Research posts today are mostly papers/benchmarks and datasets that could trickle into creative tooling later (search agents, VLM efficiency, robotics memory benchmarks, satellite embeddings). Excludes post-production releases (see Post) and excludes market rankings (see Market Leaderboards).
Penguin-VL argues text-only-initialized vision encoders can beat CLIP-style pretraining
Penguin-VL (Tencent): Tencent shared Penguin-VL as a vision-language model approach where the vision encoder is initialized from a text-only LLM rather than contrastive pretraining; the positioning and comparisons show up in the Penguin-VL post and the interactive demo is linked via the Hugging Face Space.
• Why creatives should care: If this holds up, it’s a path to “good enough” multimodal understanding on tighter budgets—useful for document-heavy workflows (scripts, story bibles, briefs, invoices) and UI/screenshot comprehension agents, as the paper page claims in the ArXiv paper.
• Practical next step: The Space lets you sanity-check strengths (doc understanding, multi-view video Q&A) against your own assets before waiting for tool vendors to integrate it, per the Hugging Face Space.
KARL introduces RL post-training for enterprise search agents and a new benchmark
KARL (paper): A new research release frames enterprise search as an RL problem with a purpose-built eval suite; KARLBench covers six search task types (entity search, report synthesis, numerical reasoning, retrieval, procedural reasoning, fact aggregation), as described in the Paper link post with details in the ArXiv paper. It’s directly relevant to creative teams building “find me the right reference / prior cut / contract clause” agents inside production knowledge bases.
• What’s new here: The paper emphasizes heterogeneous training and an “agentic synthesis pipeline” for generating grounded training data, then iterative large-batch off-policy RL; it also claims performance improvements over frontier baselines on KARLBench per the ArXiv paper.
What’s still missing from the tweets is a runnable demo or code drop; impact for creators depends on how quickly these ideas land in productized RAG/search stacks.
Google releases a Satellite Embedding dataset powered by AlphaEarth Foundation
Satellite embeddings (Google/DeepMind): Google announced a Satellite Embedding dataset “powered by AlphaEarth Foundation,” positioning it as a foundation representation layer for Earth observation, per the Dataset announcement. For AI creatives, the near-term value is in any tooling that needs consistent, searchable representations over large geospatial imagery (environment lookdev, climate storytelling, documentary viz, location-driven worldbuilding).
The tweets don’t include access instructions or a link, so the practical impact depends on where the dataset is hosted and what license/usage constraints ship with it.
RoboMME benchmarks “memory” failures in generalist robot manipulation policies
RoboMME (paper/benchmark): A new benchmark targets memory as a first-class capability in robotic generalist policies—temporal, spatial, object, and procedural memory—highlighted in the RoboMME post with details in the ArXiv paper. This matters to creators mostly indirectly, since better embodied-memory benchmarks tend to shape the next wave of “camera-on-a-robot” VLMs used for physical production and capture.

Treat it as a leading indicator: as these memory evals harden, expect downstream improvements in long-horizon, tool-using agents that must remember constraints across many steps (including creative pipelines).
📅 Dates to pin: XPRIZE optimistic sci‑fi, creator awards, workshops, and meetups
Event signals today are strong: a major optimistic sci‑fi competition, community award show, regional workshop, and a builder meetup. Excludes pricing windows (none significant beyond what’s embedded in tool posts).
Future Vision XPRIZE puts $3.5M+ behind optimistic sci‑fi trailers (AI tools allowed)
Future Vision XPRIZE (XPRIZE): A new global competition is offering $3.5M+ in prizes for optimistic sci‑fi film concepts—submissions require a 3‑minute trailer plus a treatment (up to 12 pages) and 2‑page synopsis, with no entry fee and AI tools explicitly allowed, as laid out in the Prize and rules summary.

• Prize structure and timeline: The grand prize totals $2.6M (including $2.5M production funding + $100K cash), with four $100K runners‑up and $10K for top 10 finalists, according to the Prize and rules summary; submissions close Aug 15, 2026 with winners announced Sep 25, 2026.
• Judges and backers: The judge list includes Astro Teller, Cathie Wood, Rod Roddenberry, and Anousheh Ansari, with partners ranging from Google to Range Media Partners, per the same Prize and rules summary.
More formal details are also compiled in the Competition brief, but the tweets don’t yet show an official XPRIZE rules PDF or deliverables spec beyond what’s summarized.
Escape Awards returns Mar 13 with peer-chosen winners and free entry
Escape Awards (esc): The 2nd Annual [ esc ] AWARDS / 2026 is scheduled for Friday, March 13, 2026 at 11am PST, with free entry and winners “chosen by peers,” per the Event time and framing.
The post frames it as a creator-led alternative to “industry outsiders,” which is a useful signal for filmmakers and AI storytellers tracking community validation and programming priorities, as stated in the Event time and framing.
STAGES schedules a March 22 generative filmmaking masterclass with 25 seats
STAGES masterclass (NAKID / STAGES AI): Dustin Hollywood announced a second session of “The Visual Language Of Generative Filmmaking — Part 2” on Sunday 3/22 with 25 seats and a 3‑hour format (plus recording), per the Masterclass details.
• What’s bundled: The post includes three months free access to STAGES AI and inclusion in “THE 100 Artist Residency Program,” as stated in the Inclusion and access note.
• Ticketing: The signup/payment flow is hosted via the Checkout page, but the tweets don’t list a syllabus yet (an outline is said to be coming).
Hailuo AI (MiniMax) schedules a hands-on workshop in Kuala Lumpur on Apr 18
Hailuo AI Workshop (MiniMax): Hailuo announced its first Malaysia workshop in Kuala Lumpur for Saturday, April 18, 2:00PM–8:30PM (GMT+8) at Locarasa Restaurant & Patisserie, positioning it as a hands-on session for creators, filmmakers, and designers per the Workshop announcement.
The tweet does not include an agenda or tool/version checklist beyond “cutting-edge AI tools,” so practical takeaways will likely depend on what they demo on-site, as suggested in the Workshop announcement.
Cursor Meetup Limassol sets a March 13 builder night at Luden.io
Cursor Meetup Limassol (community): A local Cursor builder meetup is set for March 13 at 18:00 at the Luden.io office, explicitly inviting people to bring “laptops” and “agents,” with pizza and V60 coffee called out in the Meetup announcement.
The registration flow and capacity constraints are described on the Registration page, including a stated 20–30 attendee range and host approval mechanics.
🚧 Friction log: Flow UI regressions, export pain, and ChatGPT formatting bugs
Today’s reliability complaints cluster around Google Flow UX regressions and output/export confusion, plus an ongoing ChatGPT formatting issue. Excludes model capability debates (see Model Moves) and general distribution discourse (see Platform Dynamics).
Google Flow export and Collections UX complaints are piling up
Google Flow (Google): Multiple creators are flagging that getting a 1080p export out of Flow now feels like a multi-step chore—one post claims it takes “10 steps” to download a 1080 video, and that the app “made it worse,” per the 1080p download complaint. A separate complaint targets the new Collections interaction model, where an accidental 1‑pixel drag on an image kicks you into an unwanted workflow that “destroys the flow,” according to the Collections drag rant.
• Export readiness is unclear: Another thread argues the UI label “Download” is misleading because it doesn’t show which clips are actually upscaled and ready—described as “Download… but we know that is a lie,” with the grid UI shown in the Upscale vs download confusion.
• Competitor-as-contrast sentiment: One quip frames the frustration as “Grok keeps me flowing unlike Google Flow,” per the Flow vs Grok remark.
Net: the complaints are less about model quality and more about state visibility, accidental mode switches, and export certainty.
OpenClaw purchase regret post spotlights bugs and add-on costs
OpenClaw (openclaw): A screenshot circulating shows a “got fooled by the OpenClaw hype” complaint: the user says they bought a Mac Mini, installed OpenClaw, spent “$200 in Opus,” hit “full of bugs,” and plans to “come back in 6 months,” as captured in the Reddit regret screenshot.
The practical takeaway for creative teams is that early agent runtimes can carry hidden adoption costs (hardware + paid add-ons) even before they’re stable enough for daily work.
ChatGPT app formatting bug: “one Markdown document” requests still fail
ChatGPT app (OpenAI): A user reports a long-running formatting failure where ChatGPT “is completely and utterly unable to generate output as ONE markdown document even when explicitly asked,” and says the issue has persisted for a long time per the Markdown output bug.
This lands as an output-packaging reliability issue for creators who want clean handoff into docs, Notion, or slide-to-doc workflows.
🎞️ What shipped: teasers, shorts, and AI-native microformats (ads, games, stock sites)
Creator output today includes multiple shipped/teased works and repeatable microformats (short films, AI animation gags, generative stock libraries). Excludes workflow/OS pitches (see Workflows & Agents) and excludes pure tool capability demos (see Video/Image sections).
Raw launches an autonomous AI stock photo library on UI8
Raw (UI8): A creator says they built a “fully autonomous stock photo website” that auto-generates content, curates, and “improves itself,” and that it’s now live on UI8 as “Raw” with “videos soon,” according to the launch note. The screenshots show a dark UI with a “Tastefully Generated Stock Photos” front page and category tiles like “3D Scenes & Objects,” framing this as a stock-library microproduct rather than a one-off art drop.
Anima_Labs publishes a “2 AM cat” animated short with the exact tool stack
Anima_Labs (Midjourney + Nano Banana + Seedance 2): A short, comedic “cat turns into a chaos machine at 2 AM” film is posted with explicit credits—character design in Midjourney plus Nano Banana on Freepik, then animation in Seedance 2 on Dreamina, per the tool stack caption. It’s a clean example of the repeatable microformat: single gag premise → consistent character lookdev → one beat of fast action → reset.

2xLabs releases an AI portfolio reel and claims “100% pure AI generated”
2xLabs (portfolio reel): 2xLabs shared a compilation portfolio covering film/series work across 2D animation, CG animation, and VFX, explicitly claiming “all footage 100% purely AI-generated,” as stated in the reshared portfolio announcement. The post reads like a studio credential drop (what’s shipped + what’s unreleased), but it doesn’t include a toolchain breakdown in this tweet.
Avengers-universe NYC municipal worker sketch posts as a short-form bit
Alt-world slice-of-life (ozansihay): A short video sketch imagines “being a NYC municipal worker in the Avengers universe,” showing street cleanup in a battle-damaged city, per the video post. It’s the recognizable microformat: familiar IP vibe + mundane job POV + one visual punchline.

WORMHOLE drops an “official teaser” portal micro-short
WORMHOLE (tupacabra): A new “WORMHOLE – Official Teaser” clip (about 82s) shows a bright circular portal opening with rapid color/energy cuts, as posted in the teaser post. Tooling isn’t credited in the tweet, but it’s being shared in the same feed where AI short-form experiments circulate, so it lands as a ready-to-remix teaser format for sci‑fi creators.

A vibe-coded UFO database pauses the site to focus on an app build
Indie “vibe-coded” project shipping reality: The creator behind a UFO database says the site “is not live” because resources are going into an app build, with the website returning when the app launches, as explained in the status update. It’s a small but common pattern in AI-first microproducts: the prototype gets attention, then the surface shifts from a public site to an app roadmap.
Showrunner gag clip turns “corporate feedback” into the punchline
Showrunner (Fable Simulation): A short vertical clip uses a two-beat structure—bad feedback (“Worst Idea Ever”) → immediate redo (“Take 2: Perfect!”)—as shown in the iteration gag. It’s a compact, repeatable microformat for AI animation accounts because the “regenerate” beat is the whole joke.

📡 Distribution & creator culture: finding underrated artists, taste as a moat, and ‘take back your voice’
The discourse itself is the news here: calls to surface overlooked AI artists, recurring ‘taste’ framing, and creator anxiety about algorithmic distribution. Excludes marketing tactics (see Social & Marketing) and tool releases (elsewhere).
“Dear Algo” thread reframes distribution as community-driven discovery
Community discovery loop: A “Dear Algo” post asks people to tag AI artists “doing incredible work to a quiet room” in replies, turning reach into a deliberate referral network instead of a platform lottery, as framed in the Dear Algo post and reinforced by the follow-up Tag someone prompt.
This format works as a lightweight directory: creators donate attention by naming peers; lurkers get a curated feed; and the original poster becomes a consistent “redistributor” who can repeat the prompt weekly without needing a new tool or product launch.
Taste-as-skill framing spreads as creators respond to infinite AI options
Taste discourse: “Taste is the new skill” + “comparison is the thief of joy” gets framed as a mental survival rule for creators facing endless AI-generated permutations, according to the Taste and comparison rules.
The counter-signal shows up in a more adversarial take that “taste and style are… not a human moat,” suggesting creators are already debating whether taste is defensible or just another automatable layer, as argued in the Taste not a moat.
The practical implication for creative culture is less about who’s right and more about the shared premise: selection, editing, and context-setting are becoming the visible craft line when generation is cheap.
Daily shoutouts as a repeatable attention-redistribution habit
Creator spotlight cadence: A small, repeatable “shoutout” post (“my lunchtime shoutout today goes to…”) shows a simple pattern for redirecting algorithmic attention toward specific accounts, with one concrete example in the Lunchtime shoutout.
Because it’s framed around behavior (“supportive of others”) rather than follower counts, it doubles as a soft norms signal: the community rewards reciprocity, not only output volume.
Rumble Shorts markets itself as an anti-algorithm distribution escape hatch
Rumble Shorts (Rumble): A pitch claims “the algorithm is taking away your voice” and positions Rumble Shorts as the way to “take it back,” pushing a creator-culture narrative that distribution platforms are the problem—not creators’ output, as shown in the Rumble Shorts claim.

This is less a feature announcement than a belief statement: creators want predictable reach and identity continuity, and platforms compete by promising less mediation (even when the mechanics aren’t specified in the clip).
“Saying thank you to AIs” meme signals etiquette norms forming around assistants
AI assistant etiquette: A meme compares “saying thank you to AIs” to the shopping cart test—suggesting politeness toward assistants is becoming a social signal inside creator circles, per the Shopping cart test meme.
It’s not about model capability; it’s about group norms. As assistants become ever-present collaborators, creators are starting to encode identity and values in how they speak to tools, not only what they ship with them.
🛡️ Reality gets slippery: verification anxiety, kid safety, and ‘is this even real?’ moments
Trust anxiety shows up as a creative constraint today: multiple posts signal that synthetic media is eroding confidence and pushing people toward safety rituals. Excludes AI influencer monetization (covered under Social & Marketing).
Family “secret word” checks spread as an AI impersonation defense
Parenting safety ritual: A creator urges families to pre-agree on “secret words” and challenge questions with kids, framing it as “more needed than ever” in the face of AI-enabled impersonation scams, according to the secret word reminder.
The practical takeaway is the workflow itself: treat identity verification as a shared protocol (a tiny playbook), not a one-off conversation—especially for “urgent” calls/texts where synthetic voice or spoofed numbers can bypass normal trust instincts.
CAPTCHA flip meme resurfaces “RIP Turing Test” verification anxiety
Verification meme: A short clip riffs on bot checks by flashing “I AM NOT A ROBOT” and then flipping to “I AM REAL,” captioned “RIP Turing Test / reality just became optional,” as shown in the CAPTCHA flip video.

For creative teams, this is less about CAPTCHAs and more about the ambient constraint it signals: audiences are primed to doubt basic authenticity cues (screens, UI, receipts, “proof” screenshots), which changes how believable synthetic scenes feel even when they’re meant as obvious fiction.
“AI generated dog” mirror clip lands as a new authenticity stressor
Synthetic-video tell hunting: A viral clip shows a small dog barking at its mirror “reflection,” with on-screen text calling it an “AI generated dog,” and gets shared as “AI is getting out of hand,” per the dog mirror clip.

This kind of content pushes a specific creator-side tension: the more convincing casual “phone video” aesthetics get, the more viewers start treating even harmless animal clips as potential fabrication—making trust a front-of-mind factor in what people share and believe.
“Is this parody?” sentiment keeps showing up as reality gets blurrier
Authenticity whiplash: A creator posts “This is parody, right? I swear I don’t know what’s real anymore,” capturing the day-to-day confusion that comes with higher-volume synthetic media, as written in the parody confusion post.
The tone matches the broader “verification collapse” mood behind the “reality just became optional” meme, as framed in the Turing Test meme, but without any specific incident—more a persistent background anxiety creators now have to write around.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught