Runway real-time HD video hits <100ms first frame – $100K ad contest
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Runway previewed a real-time HD video model running on NVIDIA Vera Rubin; it claims time-to-first-frame under <100ms and frames the shift as interactive generation rather than queued renders, aligned with its General World Model (GWM-1) direction. The same feed shows gen-video maturing into brief-driven distribution: Runway also launched a Big Ad Contest with up to $100K prizes across 7 fictional briefs; meanwhile multi-shot directing stacks (Kling 3.0 Multi Shot in ComfyUI; Hedra Agent refs plus motion control) keep formalizing shot lists + timing into repeatable pipelines. No API tiers, pricing, or independent latency benchmarks were shared; the “research preview” label leaves the deployment timeline unclear.
• OpenArt Worlds: prompt/image→navigable 3D environment built with World Labs spatial AI; persistent scene consistency while exploring camera angles; “cast in scene” and “World Cam” workflows target multi-angle coverage without re-rolling sets.
• Agentic ops economics: token-cost math claims model choice can add ~$200k/mo at 20k DAU; concurrency tooling pitches per-agent Postgres “memory” (Deeplake) while NVIDIA open-sources NemoClaw (alpha) for sandboxed OpenClaw assistants.
Across tools, the unit of work is shifting from single outputs to interactive worlds, multi-shot sequences, and always-on agents; performance and controllability claims are ahead of audited evals.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught
Top links today
- OpenArt Worlds interactive 3D world builder
- Pictory webinar on AI video future
- Luma deadline extension details
- WorldCam paper on interactive 3D worlds
- SparkVSR interactive video super-resolution paper
- Qianfan-OCR document intelligence paper
- InCoder-32B code foundation model paper
- MiroThinker research-agent verification paper
- Hugging Face Papers skill for agents
- a16z take on competing with big labs
- Big Technology on OpenClaw and agents
- Runway Big Ad Contest entry page
Feature Spotlight
OpenArt Worlds makes “build once, shoot forever” 3D environments practical
OpenArt Worlds turns a single prompt/image into a walkable 3D world you can keep re-shooting—unlocking consistent scenes, controllable camera work, and studio-like iteration for solo creators.
A cross-account story today: OpenArt Worlds lets creators generate a navigable 3D environment from a prompt or image and keep scene consistency while exploring, framing shots, and iterating inside the same world (built with World Labs spatial AI).
Jump to OpenArt Worlds makes “build once, shoot forever” 3D environments practical topicsTable of Contents
🌍 OpenArt Worlds makes “build once, shoot forever” 3D environments practical
A cross-account story today: OpenArt Worlds lets creators generate a navigable 3D environment from a prompt or image and keep scene consistency while exploring, framing shots, and iterating inside the same world (built with World Labs spatial AI).
OpenArt Worlds launches prompt-to-navigable 3D worlds for consistent scenes
OpenArt Worlds (OpenArt): OpenArt shipped Worlds, letting you generate a fully navigable 3D environment from one prompt or image, then “step inside” to explore and shoot within the same consistent scene—positioned as a fix for re-rolling inconsistent shots, as described in the Launch thread and reinforced by the Spatial AI note (built with World Labs spatial AI).

• What you can do inside a world: Move freely to find angles; add characters/elements; capture “production-ready shots,” per the Launch thread.
• Where to try it: Access is linked via the Worlds product page.
The key creative shift is that the “unit of work” becomes the world, not a single frame.
Build-once world workflow replaces one-off shots for storyboards and ads
World-first shot workflow: Creators are framing OpenArt Worlds as a “build once, create inside it” loop—because single-image generation often yields lighting/angle/atmosphere drift between shots, a problem called out directly in the Shot isolation critique and contrasted with the Worlds approach in the Launch thread.

This maps cleanly to short-form ads and storyboards: lock an environment, then iterate camera and blocking instead of re-prompting from scratch.
Image-to-3D World: turn concept art or footage into an explorable set
OpenArt Worlds ingest mode: A practical entry point is “image to 3D world”—upload concept art (or even footage) and have it turned into a 3D scene you can navigate, as outlined in the Image to world step within the broader walkthrough in the Thread overview.

For filmmakers, this is basically pre-vis set building where shotfinding happens after the world exists, not before.
Cast in Scene: insert a character into an existing world for coverage
Cast in Scene (OpenArt Worlds): The workflow being shared is: create a character first, open/build a 3D world, set your camera position in the environment, then “cast” the character into that framing and generate a shot—steps described in the Cast in scene steps and consistent with the product claim that you can add characters/elements inside a persistent world in the Launch thread.
This is a straightforward way to generate multi-angle dialogue coverage without rebuilding the environment each time.
World Cam: shoot a still from your world and auto-enhance it
World Cam (OpenArt Worlds): OpenArt’s thread describes a “World Cam” mode where you open a 3D world, take a picture, and auto-enhance the still—called out explicitly in the World Cam note and paired with a short-film loop of explore → capture shots → enhance while keeping consistency in the Consistency workflow.

The practical result is a stills pipeline that stays anchored to one environment while you iterate composition and polish.
🤖 Agentic creator ops: memory layers, parallel agents, and “execution AI” in products
Creators and builders focused on agents that execute across apps: OpenClaw ecosystem extensions, agent memory/data runtimes, parallel coding swarms, and practical token-cost math. This is the ops layer behind faster creative output.
NVIDIA NemoClaw open-sources an OpenClaw sandbox plugin (alpha)
NemoClaw (NVIDIA): NVIDIA published NemoClaw, an open-source plugin that installs the OpenShell runtime (NVIDIA Agent Toolkit) as a sandbox for running OpenClaw “always-on assistants,” with the repo explicitly labeled alpha and warning it’s not production-ready, as shown in the Repo screenshot.
The repo text emphasizes sandbox orchestration and setup constraints (including “fresh installation” requirements) and notes inference is “routed through NVIDIA cloud” in the Repo screenshot, which is worth reconciling against social claims that it “keeps your files off the cloud” in the Repo screenshot. For creators building agentic pipelines, the practical artifact is the installable runtime + policy surface; the canonical reference point is the GitHub repo.
Token COGS math: one model swap can change burn by $200k/month
Inference unit economics: A thread walks through token-cost math (tokens per action × steps × DAU) and claims that at 20,000 DAU, choosing a pricier model tier can add roughly $200k/month in inference costs, then scales that spread to “$1M/month” at 100k DAU, as laid out in the Token math thread.
The pricing example contrasts “$3/M tokens” vs “$15/M tokens” with a concrete monthly delta in the Pricing comparison, framing this as an ops constraint for agentic products where each user action may trigger multiple tool-using steps.
Activeloop Deeplake pitches per-agent Postgres sandboxes for durable multimodal memory
Deeplake (Activeloop): A launch thread frames Deeplake as the missing “memory/data runtime” for agent systems: it spins up a sandboxed Postgres instance per agent “in seconds,” isolates sub-agents so they don’t collide, supports speculative branching, stores structured data plus images/video/PDFs, and “scales to zero when done,” according to the Deeplake runtime pitch.
The key creator-ops angle is concurrency: the thread calls out filesystems breaking when many agents run at once, and positions Deeplake as a single place to hold both relational state and multimodal artifacts (instead of a vector DB + S3 + JSON glue), per the Deeplake runtime pitch.
Vellum pitches a desktop-resident assistant that works while you sleep
Vellum: A creator-facing pitch describes Vellum as a desktop-based assistant that can operate with its own email and accounts and run tasks “while you sleep,” with “secure” positioning as a differentiator in the Vellum assistant pitch.

A follow-up claims 5,000+ signups for a “free setup session” showing email + app-building + video workflows, as stated in the Setup session details.
Hugging Face Papers becomes more agent-friendly with Markdown and a SKILL.md
Hugging Face Papers: Hugging Face’s Papers pages now serve Markdown automatically when fetched by agentic tools (to save tokens/clean parsing), and a new “paper-pages” SKILL.md is shared for agents to search papers and retrieve linked models/datasets/Spaces, as described in the Agent-friendly papers.
A separate announcement frames it as a copy-paste skill file for coding agents, per the Skill introduction.
SureThing switching story leans on “300,000 emails in one hour” and zero setup
SureThing: A promotional case study claims an early OpenClaw contributor switched to SureThing after failing with Claude/Codex on email triage; the headline anecdote is “300,000 unread emails…tamed in one hour,” emphasizing “no prompt engineering” and “works in 5 minutes,” per the Switching thread.
The thread’s core product claim is persistent memory without retraining (“I didn’t even have to tell it”), which is positioned as a UX wedge versus self-host/configure-heavy stacks; the on-ramp is linked in the Product page.
Tencent results highlight a “Chat AI” to “Execution AI” shift and agent embedding
Tencent “Execution AI” framing: A recap of Tencent’s Q4 and full-year 2025 results highlights management language shifting from “Chat AI” to “Execution AI,” alongside record investment lines (capex RMB 79.2B, R&D RMB 85.75B) and a narrative of rapidly turning agent demos into consumer/dev/enterprise products, as summarized in the Results breakdown.
The same thread claims agent products (e.g., WorkBuddy/QClaw) can be embedded into WeChat/WeCom/QQ “with one click,” and positions the competitive edge as workflow embedding rather than raw model strength, per the Results breakdown.
OpenClaw for LinkedIn launches with meeting reminder texts and app integrations
OpenClaw for LinkedIn: A launch note says OpenClaw for LinkedIn is live with integrations including Granola, Google Drive, HubSpot, and Slack, plus automated texting before meetings and appointment/call setup, as described in the LinkedIn launch note.
The creative-ops read is “distribution into a work surface”: pushing agent execution into a social/professional channel where outreach and scheduling already happen, per the LinkedIn launch note.
Durable pitches an AI business builder as a solo-income replacement
Durable: A promo thread positions Durable as an “AI business builder” that can replace 9–5 income, using the familiar “comment to get it built” growth loop in the Durable pitch.
No product details, pricing, or workflow proof are included in the tweet itself, so this reads as positioning rather than a verifiable capability drop, per the Durable pitch.
🎬 Real-time gen video + multi-shot directing: faster iteration, tighter control
Big creator-facing gains in speed and controllability: Runway previewed real-time HD generation (<100ms to first frame) and creators shared multi-shot Kling workflows plus agent-assisted reference generation for dialogue coverage.
Runway previews real-time HD video generation with sub-100ms first frame
Real-time video generation (Runway): Following up on frontier compute (Runway × NVIDIA signals), Runway says it trained a new real-time video model running on Vera Rubin that can output HD video instantly with time-to-first-frame under 100ms, as described in the GTC research preview; the team frames this as opening a different design space for video models and “world simulation,” tied to its General World Model (GWM-1) direction.

• What changes for iteration: the claim isn’t “faster renders,” it’s interactive generation where you can treat video like a responsive medium (think live blocking and camera exploration) rather than a queued job, per the GTC research preview.
• Why it’s plausible: Runway explicitly points to model–hardware co-design and continued investment “alongside advances in hardware,” as stated in the GTC research preview.
No API/tier details are shared here; it’s positioned as a research preview rather than a creator-facing product drop yet.
A ComfyUI workflow for Kling 3.0 Multi Shot that auto-writes prompts and timing
Kling 3.0 Multi Shot (workflow): Following up on Multi-shot recipe (manual multi-shot directing), a new ComfyUI setup formalizes Multi Shot into a repeatable pipeline: feed product/character images, choose total duration and number of scenes, have an LLM draft per-scene prompts plus timing, then manually edit before generation—outlined in the workflow breakdown with a share link in the ComfyUI page.

• Automation boundary: the LLM handles “first pass” shot list + timestamps, while the creator keeps final control by editing prompts/timing before render, per the workflow breakdown.
This is a concrete answer to the current bottleneck in multi-scene work: prompt and timing orchestration, not single-shot quality.
Hedra Agent + Kling 3.0 Motion Control: agent-built coverage, human-led performance
Hedra Agent (Hedra Labs): A creator describes a two-part directing loop where an agent generates the hard-to-grind prepro (characters, locations, and “all the angles” needed for dialogue coverage) and then human actors drive the final performance, as explained in the workflow description; they note the refs were generated with Hedra Agent using Nano Banana Pro plus Kling 3.0 Motion Control, as detailed in the tool stack note.

• Practical implication: it treats AI agents as a coverage planner (shots/angles/consistency) while keeping acting beats in human hands, matching the framing in the workflow description.
This is less about “one prompt → one clip” and more about building a repeatable dialogue unit (coverage + performance) that can survive revisions.
Freepik Speak lip-syncs a 45-second monologue from one still image
Speak lip sync (Freepik): Following up on Speak launch (music lip-sync positioning), a stress test shows Speak generating a 45-second output from a single static image plus a single 45-second audio file—with no direction controls beyond “image + audio,” as described in the long-audio test; the creator reports it adds subtle gestures (hands, breathing) in addition to mouth movement.

• Input constraints: the test explicitly notes Speak has no “direction” input for still images—upload image and audio together, then it processes end-to-end, per the long-audio test.
The open question is controllability (gesture blocking, eye lines, intensity), since the described workflow is intentionally hands-off.
Runway launches a spec-ad contest for fictional products with up to $100K prizes
Big Ad Contest (Runway): Runway announced a two-week contest to create ads for “products that don’t exist,” offering up to $100K in cash prizes across 7 briefs, with the positioning “no client notes” and “big ideas win big,” as stated in the contest announcement with rules/details on the contest page.

• Format constraints: entries are framed as brief-driven 30–60s ads (per the contest page) rather than open-ended short films, matching the structure implied in the contest announcement.
This is a clean signal that “spec ad” has become a first-class category for gen-video creators, not just portfolio filler.
Seedance 2 keeps proving the 2×2 grid as a compact “motion beat” format
Seedance 2 (pattern): Following up on 2×2 grid (grid-to-sequence trick), creators keep sharing new 2×2 grid examples that expand into a coherent animated beat, including a fresh “one more grid 2×2” clip in the new grid post and a related claim that the format can generate a “full sequence” in the grid sequence note.

This keeps surfacing as a practical unit for iteration: tiny storyboard-like inputs that yield temporally consistent motion without assembling a full shot list upfront.
A short sci-fi film ships as Grok Imagine–only production
Grok Imagine (xAI): A creator released “RE/BIRTH,” describing it as a short sci‑fi film made exclusively with Grok Imagine, as stated in the release post; the clip presents a cohesive sci‑fi sequence rather than isolated tests.

The notable part here is packaging: it’s presented as a finished short with a title card and consistent tone, which is a different bar than posting single-shot experiments.
Luma Dream Brief extends its deadline to March 27 as entries arrive
Dream Brief (Luma): Following up on Dream Brief (up to $1M ad-idea contest), Luma extended the submission deadline to March 27, as shown in the deadline extension post and detailed on the contest page; the team also shared that submissions are actively “rolling in” in the submissions post.

This is more time for teams building multi-shot ads, where the bottleneck is usually shot planning and assembly rather than single generations.
🛠️ Design & build tools: vibe design, Figma-to-app, Unity copilots, and Gemini API tricks
Practical creator tooling moved beyond chat: AI-assisted UI systems, prompt-to-prototype builders, and workflow-ready APIs (Gemini tools + grounding). This is where designers and makers get leverage without rebuilding stacks.
DeepMind Stitch turns prompts into a design system, prototype, and code
Stitch (Google DeepMind): Early-access testers describe Stitch as a prompt-to-UI agent that starts by generating a design system (fonts/colors/styles) and then iterates to a clickable prototype and code, with chat-based “vibe” changes updating the whole system coherently, according to the Early access demo and the Design system note.

The concrete novelty here is the design-system-first behavior: instead of producing one-off screens, it’s trying to keep an internal style contract stable as you iterate.
Figma Make generates functional prototypes from your Figma design system
Figma Make (Figma): A set of threads frames “static mockups” as over, with Figma Make generating clickable/functional prototypes from prompts while preserving your design system (fonts, colors, components), as described in the Feature rundown and reinforced by the Idea to demo framing.

• Prototype-to-app path: The same thread claims a Supabase connection enables auth, data storage, and private API connections—pushing outputs from demo toward “shippable web app” territory per the Idea to demo framing.
• Where to try: The entry link is shared via the Product page.
Gemini API adds built-in tools to function calling, plus context circulation and Maps grounding
Gemini API (Google): Following up on Tier upgrades (faster Tier 1→2 and spend controls), Google shipped a batch of “built-in tools” upgrades—built-in Search, Maps, and file search now work via function calling, “context circulation” is enabled with built-in tools for better performance across tool hops, and Google Maps grounding now works with Gemini 3, per the Shipping list.
• Tool-first app building: Built-ins working through function calling means you can treat Search/Maps/file search like first-class tools inside your agent loop, rather than bolt-on retrieval.
• Location-aware outputs: Maps grounding + Gemini 3 can tighten anything that depends on real POIs and routes (travel scenes, real-world references, production planning), as called out in the Shipping list.
Bezi AI: Unity-specialized assistant that works inside the editor via a plugin
Bezi AI (Unity assistant): A Unity-focused coding assistant is getting early praise for working directly in Unity via a plugin (no separate “Unity MCP” needed), showing higher feature-implementation hit rate than general coding models and successfully integrating Unity Asset Store packages (example: weather system), per the Early impressions.

The positioning here is specialization: the creator explicitly claims domain focus beats general models for Unity-specific workflows, as stated in the Early impressions.
Gamma Imagine pushes “context-aware” visual generation for decks and docs
Gamma Imagine (Gamma): Following up on Invite generator (a specific prompt+iteration workflow), a new launch thread claims Gamma Imagine generates visuals directly from a description—positioned as replacing the “open Canva → hunt templates → delete 80%” loop—per the Launch claim and the Workflow comparison.

• What it generates: The thread lists infographics, diagrams, posters, social graphics, logos, presentation visuals, and brand identity concepts per the Output list.
• Scale claim: The same thread asserts 70M users, 1M+ creations/day, and 4M new images/day, as stated in the Usage numbers.
Google AI Studio teases a rebuilt “vibe coding” experience
Google AI Studio (Google): A rebuilt “vibe coding experience” is scheduled to be unveiled “tomorrow,” with the team saying they spent 4 months rebuilding the flow “from scratch” to remove rough edges and make idea→output smoother, per the Rebuild announcement.
This is a tooling-surface story (not a model drop): if the rebuild lands, it likely changes the daily iteration loop for quick prototypes and experiments more than any single API feature.
UnslothAI Studio shows fine-tuning running on an A100 80GB with a live dashboard
UnslothAI Studio (Unsloth): A quick field report shows a fine-tune job running on an A100 80GB (explicitly “no H100 available”), with a live training UI showing step progress, loss, learning rate, and a GPU monitor, per the Training screen.
This is a practical “custom model” signal for teams that can’t count on top-tier GPUs every time, with the screenshot making clear it’s targeting Colab-class setups.
🖼️ Midjourney V8 alpha reality check: aesthetics, text, and regression debates
Today’s image chatter is dominated by practical MJ V8 alpha comparisons (V7 vs V8) and quality tradeoffs (sharpness/texture, prompt adherence, moderation), plus a few notable non-MJ image experiments. Excludes OpenArt Worlds (covered as the feature).
Midjourney V8 Alpha “soft focus” complaints cluster around texture and sharpness
Midjourney V8 Alpha (Midjourney): a recurring complaint is that portraits feel slightly soft—“like I didn’t put in my contact lenses”—with less micro-texture and crispness than expected, as noted in the V8 sharpness concern and reinforced by side-by-side experiments like the V8 vs V7 comparison. Midjourney’s own account responds by asking about parameter interactions (including trying --hd) in the Parameter suggestion, which frames the issue as potentially tunable rather than purely model-side.
• Parameter probing: one tester reports sticking to --p and finding --exp less helpful so far in the V8 vs V7 comparison, which is useful if you’re isolating whether softness is personalization-driven or general.
• Practical implication: if you’re doing close-up faces for posters or album art, you may need extra passes (or a different model) for texture-critical shots, based on the V8 sharpness concern.
Midjourney V8 Alpha regressions show up in “same prompt, same refs” comparisons
Midjourney V8 Alpha (Midjourney): a detailed side-by-side shows V7 on the left and V8 on the right using the same prompt and style references, with the creator arguing V8 loses the intended composition/detail in a late-night talk show / luxury interior setup, as shown in the V7 vs V8 interiors. Follow-up metadata (prompt trimming + job IDs) suggests they attempted to control variables tightly in the Job ID follow-up, framing this as more than “different seed” noise.
• Pattern to watch: scenes that rely on “off center, asymmetric” composition and rich interior set dressing may be where some users feel the downgrade most sharply, per the V7 vs V8 interiors.
Midjourney V8 Alpha testers report misgendering, proportion oddities, and clearer IP lookalikes
Midjourney V8 Alpha (Midjourney): early testers report a cluster of oddities—“a king” prompting female outputs, stronger-than-expected profile/personalization influence (“painter’s desk” look bleeding into everything), and recurring human proportion issues—summarized in the First impressions note. The same thread also claims recognizable franchise characters are appearing more clearly (GoT / Star Wars), which raises fresh IP leakage concerns if you’re generating client-facing concept art, as stated in the First impressions note.
• Why creatives care: misclassification and proportion drift are costly for character sheets and poster comps, while IP lookalikes can create review headaches when pitching, per the First impressions note.
Creators keep using Nano Banana 2 side-by-sides to pressure-test Midjourney V8
Nano Banana 2 (Freepik): multiple posts use direct comparison frames—Midjourney V8 Alpha vs Nano Banana 2/Pro—to decide which model to route a job to, especially for stylized fashion/editorial looks where NB outputs feel more “finished,” as shown in the V8 vs Nano Banana comparison and the Pipeline comparison. A separate example compares a dramatic scene (mushroom cloud beach chairs) and suggests the two tools are converging on similar composition while still differing in texture/rendering feel, as seen in the Explosion scene comparison.
• Common pattern: Midjourney generates the idea/variation; Nano Banana is used as a second pass when you want a cleaner, more animation-forward render, per the Pipeline comparison.
Midjourney V8 Alpha discourse hardens into “regression” vs “defenders” camps
Midjourney V8 Alpha (Midjourney): the social layer is getting louder—some call the release a “disasterclass” in the One-line critique or say “wake me up when v9 gets here” in the V9 wait joke, while others push back hard enough that it’s become a mini culture-war, as described in the Defenders debate clip. Another practitioner summary tries to split the difference—better prompt adherence, worse aesthetics—when describing what a “perfect” model blend would look like in the Prompt adherence take.

• Why it matters: if you’re running client work, the conversation itself is a signal about how risky V8 outputs may feel to stakeholders right now, as reflected across the Defenders debate clip and Prompt adherence take.
Midjourney V8 Alpha watercolor sketches shift style, but “handwritten notes” often fade out
Midjourney V8 Alpha (Midjourney): watercolor-style outputs are changing vs V7, but at least one tester doubts the claimed prompt adherence—especially when the prompt requires small, specific details like handwritten annotations, which end up barely visible in the Watercolor adherence critique. For illustrators using “travel journal” or “sketchbook” aesthetics, this is a concrete failure mode: the model may keep the vibe while dropping the instructive micro-elements.
• Where it breaks: prompts that depend on legible marginalia or timestamp-like scribbles don’t reliably hold up, according to the Watercolor adherence critique.
• What still works: the broader ink-and-wash mood appears consistent even when the “notes” constraint is missed, as visible in the Watercolor adherence critique.
Grok Imagine turns a static isometric illustration into a slow “drone” move
Grok Imagine (xAI): a creator demonstrates a “drone-style” shot generated from isometric art, effectively treating a still illustration as a space the camera can travel through, as shown in the Drone-style demo. The post positions this as an extension of the V7 “living city map” look—first get the dense isometric frame, then generate motion—following the workflow implied in the V7 SREF callout.

This sits in the same practical bucket as “image becomes shot” experiments: useful when you want motion without rebuilding scenes in 3D, as evidenced by the Drone-style demo.
Midjourney V7 “living city map” look resurfaces via SREF 3533283404
Midjourney V7 (Midjourney): amid V8 quality debates, a creator highlights a V7 style reference—--sref 3533283404—as a still-strong option for isometric, “living city” editorial illustrations (diorama viewpoint, clear linework, map-like storytelling), as described in the V7 SREF callout. For designers making explainer visuals, city guides, or storybook establishing shots, this is a concrete reminder that some pipelines may keep V7 as the “style generator” even if V8 wins elsewhere.
• What’s specific here: the value is the elevated viewpoint + dense micro-narrative city detail, not realism, per the V7 SREF callout.
Palette direction as story control: one base image, four emotional reads
Leonardo AI + Nano Banana Pro (Leonardo/Freepik): one creator demonstrates a workflow where you keep composition fixed and change only the color palette to steer narrative tone—nostalgia (warm amber), isolation (cool desaturated blue), tension (high contrast with a red accent), and late-night intimacy (candlelit warmth)—as explained across the Color storytelling thread and the follow-up reads in the Warm version note, Cool version note , and Red accent note.
The claim is that AI makes “palette as direction” fast enough to iterate like lighting tests in film, based on the framing in the Color storytelling thread.
Midjourney schedules Weekly Office Hours for March 18
Midjourney (Midjourney): Midjourney promoted its Weekly Office Hours session dated 3/18 in the Office hours announcement. In the middle of V8 Alpha testing debates, this is one of the few explicit “ask us live” surfaces for questions about parameters, rollout behavior, and how Midjourney wants creators to evaluate V8.
No agenda, notes, or clips were included in the Office hours announcement, so it’s unclear whether this session addresses the specific regression claims circulating today.
🧪 Copy/paste prompts & SREFs: Nano Banana libraries, retro logo recipes, and “glass portal” scenes
High-volume prompt sharing today: detailed Nano Banana prompt schemas/libraries and Midjourney SREF style breakdowns (risograph/neo-ink/stop-motion), plus reusable cinematic prompt templates. Excludes general MJ V8 capability debate (handled in Image Generation).
Nano Banana Pro/2 prompt library collects 400 high-fidelity, reusable prompts
Nano Banana Pro/2 (Promptsref library): A community-facing prompt library surfaced with “handpicked” examples and a claim of 400 prompts for Nano Banana Pro / Nano Banana 2, positioned as a fast way to grab proven recipes instead of writing from scratch, as shown in the Library post and linked via the prompt library in Prompt library. It’s heavy on structured, photography-like detail (pose, lighting, constraints, negative prompts), which matters if you’re trying to keep outputs consistent across a campaign or storyboards.
• What’s actually useful about it: Many entries are “production prompts” (camera, lighting, constraints) rather than short style blurbs, as you can see in the long-form schema examples shared in the Structured selfie schema and Cosplay schema.
The library pitch is promotional, but the prompts themselves are copy/paste-ready.
Nano Banana 2 CCTV-style prompt adds face boxes and a zoom inset
Nano Banana 2 (CCTV surveillance look): A highly specific “CCTV surveillance” recipe is being shared that asks the model to detect faces, draw white rectangular boxes, and add a large zoom-in inset connected by a line—complete with a reported cost of $0.07 per generation, according to the CCTV prompt and cost. This is a practical prop-generator for thriller/mystery storytelling (investigation boards, dossier frames, cold open shots).
• Copy/paste prompt core: “Create a high angle CCTV surveillance shot… draw a white rectangular bounding box around each face… for the most prominent person, add a large zoom in inset… keep the main image slightly noisy… no text, no timestamps,” as written in the CCTV prompt and cost.
The prompt is also a reminder that “no overlays except the boxes” needs to be explicit, otherwise models tend to invent UI elements.
Nano Banana 2 creators share JSON-style prompt schemas to reduce artifacts
Nano Banana 2 (Structured prompting pattern): Several creators are using long, JSON-like prompt schemas—subject/hair/body/pose/camera/vibe plus explicit constraints and negative_prompt lists—to push more stable anatomy and fewer “random” artifacts, as demonstrated in the Full prompt schema and reinforced by additional schema dumps like the Selfie schema example and Cosplay schema. This is less about “one magic sentence” and more about turning prompt-writing into a reusable spec.
• Template to steal: The repeated pattern is “must_keep” vs “avoid” plus a dedicated negative list (extra fingers, text, watermarks), which shows up explicitly in the Full prompt schema and Selfie schema example.
It’s verbose, but it’s also modular: you can swap only the subject block while keeping the camera+lighting blocks intact.
Niji SREF to Nano Banana 2: a copy/paste 2D-to-3D conversion prompt
Nano Banana 2 (2D→3D conversion prompt): A common pipeline is being codified as “generate 2D with niji SREF, then convert to a modern feature-animation 3D render in Nano Banana 2,” with a copy/paste conversion prompt explicitly shared in the 2D to 3D recipe. This matters for storytellers who want to keep a strong illustration style guide while moving into consistent 3D-ish frames for multi-shot sequences.
• Copy/paste prompt: “Convert this image into a modern feature-animation 3D render, clean appealing shapes… soft subsurface scattering… cinematic global illumination… preserve composition and color palette, no text, no logo,” as written in the 2D to 3D recipe.
• Where to run it: The same workflow is linked to a prompt playground in Prompt playground, which shows multiple model outputs around the same prompt.
The “preserve composition and color palette” line is doing a lot of work; it’s the difference between a style transfer and a full re-roll.
Promptsref posts a “top SREF” bundle for vintage line art + risograph texture
Midjourney SREF (Promptsref): A “most popular sref” post includes a multi-code bundle plus a fairly detailed style read—vintage line art, risograph texture, limited warm palette (gold/black/purple accents)—as described in the Style analysis post alongside a pointer to the SREF library in Sref library site. This is especially relevant for creators trying to make AI visuals feel printed/handmade rather than glossy.
• SREF bundle as shared: “--sref 36041825372 22455994504 5686881714 25315048022 42793793215 16399683882 --niji 6 --sv4,” per the Style analysis post.
Treat the “top 1” framing as community-popularity signal, not a quality benchmark; the value is the readable style breakdown + ready-to-run codes.
A hands-on-glass template for magical “portal reflections”
Adobe Firefly + Nano Banana 2 (Prompt template): A reusable magical-realism template is being shared for shots where a subject presses hands on cold glass (fingerprints + condensation) while the glass reflects an “impossible” alternate scene instead of the real surroundings, as written in the Prompt template. It’s the kind of repeatable setup that helps maintain a consistent visual motif across a music video or short film.
• Copy/paste template: “[SUBJECT] pressing hands against [GLASS TYPE] at night… fingerprints and condensation visible… [GLASS] reflecting [IMPOSSIBLE SCENE]… 35mm lens, deep focus… hyper-realistic, magical realism,” per the Prompt template.
The examples show it working across very different “impossible scenes,” which is the point of keeping the camera+glass details fixed.
Midjourney SREF 1836568042 for neo-Chinese ink poster layouts
Midjourney SREF 1836568042 (Neo-Chinese ink): A “New Oriental Aesthetic” recipe is being circulated around SREF 1836568042—negative space, ink diffusion, muted beige/gray palettes, and premium editorial composition—framed for book covers, exhibition posters, and packaging, as described in the Sref style notes with a full style guide linked in Style guide.
The post is more art-direction than parameters, but the constraints (“minimal but cinematic layouts”) are the part that helps keep generations on-brief.
Midjourney SREF 2846857487 targets a stop-motion miniature aesthetic
Midjourney SREF 2846857487 (Stop-motion miniature): A stop-motion “miniature set” look is being packaged as a repeatable recipe—matte metal, muted blue-gray tones, soft lighting, shallow depth of field—with the explicit shorthand “WALL‑E meets Laika,” as written in the Sref breakdown and expanded via the prompt guide in Prompt guide.
This is one of those styles that’s useful because it bakes in “tactile imperfections” (handmade textures) without needing to spell out every surface detail.
Nano Banana smart prompt turns modern logos into 80s-era variants
Nano Banana (Retro logo prompt pattern): A “smart prompt” workflow is being shared for turning brand marks into 80s-style logo treatments, with the key tactic being “change one variable, hit generate, get unlimited assets,” as shown in the 80s logo examples. It’s a practical pattern for album art packages, merch mockups, and throwback title cards where you need many variations quickly.
• How the prompt pattern is framed: Keep the core style fixed (“80’s era logo”) and swap the subject/brand variable; the examples in the 80s logo examples show Starbucks/Hermès-style treatments generated under the same aesthetic constraints.
The post is light on exact wording, but the visual result makes the “single-variable prompt” approach clear.
📅 Deadlines & stages: contests, brief programs, office hours, and creator meetups
Time-sensitive opportunities today include spec-ad contests, deadline extensions, and creator-facing live sessions. (Excludes OpenArt Worlds product details, covered as the feature.)
Luma extends Dream Brief deadline to March 27
Luma (Dream Brief): Luma extended the Dream Brief submission deadline to March 27, following up on Dream Brief (up to $1M in prizes) with the new date confirmed in the Deadline extended post.
Creators also appear to be actively shipping entries—Luma is reposting “submissions rolling in” proof via the Submissions showcase montage.
The mechanics and entry details live on the Dream Brief site, but the key operational change today is more time on the clock.
Runway opens a $100K spec-ad contest for fictional products
Runway (Big Ad Contest): Runway is running a brief-based spec-ad competition for “products that don’t exist,” with 7 fictional briefs and up to $100K in cash prizes, positioning it as a two‑week sprint with “no client notes,” per the Contest announcement.
• Submission format: The contest rules call for a 30–60 second ad generated in Runway (with watermark) and allow multiple entries, as detailed on the Contest rules page.
The brief structure is the useful part for teams practicing repeatable ad pipelines (boards → shots → assembly) under a fixed constraint set.
Art Basel HK exhibits an AI “Mary” that wanders and journals
Art Basel Hong Kong (Zero 10 / “Mary”): An installation named “Mary” is being shown at Art Basel Hong Kong; the framing is an AI entity with a “mind, body, journal” and no explicit goal beyond writing thoughts, described as “thinking in thousands of tokens per second” and “not knowing she is being observed,” per the Installation description.

This is less a tool release and more a live example of “agent-as-character” presentation—useful reference material for interactive storytelling and exhibition packaging.
Midjourney schedules Weekly Office Hours for March 18
Midjourney (Office Hours): Midjourney posted its Weekly Office Hours slot for 3/18, giving the community a recurring live forum to ask V8‑era questions (quality shifts, parameters, moderation behavior), as announced in the Office hours notice.
No agenda or notes were included in the tweets, so treat this as a calendar hook rather than a feature drop.
Pictory goes live with an AI video webinar at 11am PST
Pictory (Live webinar): Pictory is going live at 11 AM PST with its CEO and CMO to discuss “the future of AI video,” following up on Webinar invite with a “live in 1 hour” reminder in the Going live reminder.

Registration runs through the Zoom registration page, but the tweets don’t list specific product announcements planned for the session.
Topaz Labs onboards creators into its Creative Partners Program
Topaz Labs (Creative Partners): A creator posted they’ve joined Topaz Labs’ Creative Partners Program, signaling ongoing investment in creator distribution/affiliation around AI enhancement workflows, as shown in the Program welcome note.
The tweet doesn’t include program terms or benefits; it’s primarily a visibility/credential signal rather than a product capability update.
📣 AI marketing creatives: UGC-style ads, property videos, and ad-driven consumer AI economics
Creators are optimizing for distribution and revenue: AI-generated UGC ads, cheap listing videos, and the strategic debate about ads vs subscriptions for consumer AI. Practical focus: what converts, what scales, and what brands will buy.
UGC-style “camera roll” ads: AI-generated candid moments as a scaling template
UGC ad pattern: A creator claims $84k+/month ad performance is coming from ads that look like unpolished “camera roll” clips—ordinary setup, sudden interruption, real-feeling reaction—then notes AI can now generate the people, environment, and “endless little moments” while swapping scenarios for volume, as described in the Camera roll ad breakdown.

The practical creative ingredients are consistent: handheld framing, minimal staging, and a single surprise beat (here, a snowball hit) that reads as unscripted in the Camera roll ad breakdown.
Consumer AI monetization debate: ads may dwarf subscriptions (ARPU math vs Claude)
Consumer AI economics: A thread argues the undercovered battleground for “ChatGPT vs Claude” is ads; it cites Google at about $460/user/year in the U.S. (ads) and Meta at ~$250, then claims even matching Google’s ARPU would imply ~$152B/year if ads monetize the full U.S. population—versus ~$40B/year if 5% pay $200/month subscriptions, as laid out in the Ads vs subscriptions math.
It also asserts early data from a “very small rollout” shows ChatGPT ads outperforming Meta in effectiveness, but no underlying study is linked in the Ads vs subscriptions math, so treat the performance claim as directional rather than audited.
Vertical property listing videos: “photos in → marketing video out” in 15 minutes for $7
Real estate content workflow: One creator says they generated a vertical property listing video in 15 minutes for $7 by feeding in listing photos, positioning it as a repeatable solution for realtor social output and ad placements, per the Property video cost claim.

The pitch is less about “cinematic” and more about packaging: one render that can ship across vertical social, desktop, and Facebook ads, as stated in the Property video cost claim.
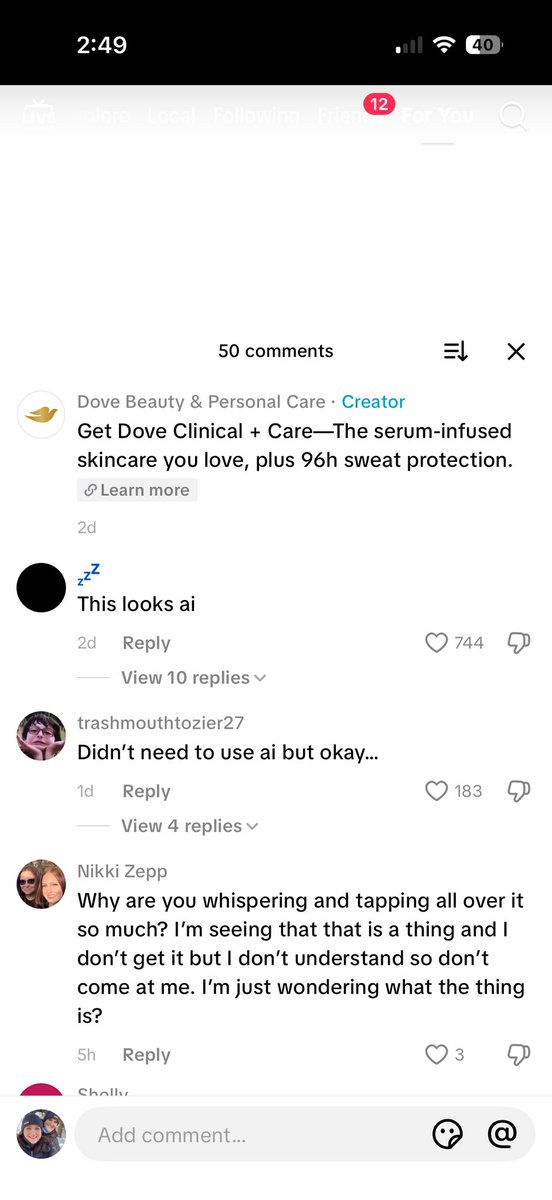
“This looks AI” comment wars are becoming a predictable ad engagement loop
AI detectability in marketing: A creator notes the current in-between phase—AI media is “good enough to be publishable” but not undetectable—so brand comment sections fill with fights over authenticity, as framed in the Publishable but detectable note.

A concrete example is a Dove ad thread where top comments include “This looks ai,” as shown in the Publishable but detectable note.
The near-term takeaway is that “looks AI but isn’t” and “looks real but is AI” are collapsing categories, per the Publishable but detectable note, which can change how UGC-style creative is evaluated by audiences.
Runway’s “Big Ad Contest” offers up to $100K for ads for fictional products
Runway (contest): Runway announced “Big Ad Contest For Products That Don’t Exist,” offering up to $100K in prizes with “no client notes,” seven briefs to choose from, and a two-week creation window, as stated in the Contest announcement.
• Rules and constraints: The contest page lists prize structure (including a $50K grand prize), 30–60s ad length, and requirements like using Runway tools and including the watermark, as detailed on the Contest rules page.
This is positioned as a spec-ad-friendly format where the “brief” replaces a brand client, per the Contest announcement.
Facebook launches creator program paying $1,000–$3,000/month to switch platforms
Facebook (Meta): A report says Facebook is launching a creator program that pays $1,000 to $3,000 per month for creators to switch platforms, according to the Creator program payout note.
Details like eligibility requirements are truncated in the tweet, but the key signal is direct distribution incentives becoming explicit cash offers in the Creator program payout note.
✨ Finishing & enhancement: super-resolution, neural upscaling demos, and creator-grade polish
A few concrete post tools surfaced: interactive video super-resolution research demos and DLSS-style “make it sharper/realer” experiments creators can try now. Quieter than video/image generation, but highly actionable for polish.
DLSS-5 Anything ships as a free Hugging Face upscaling playground
DLSS-5 Anything (community tool): A free Hugging Face Space is being shared as a quick way to try “DLSS-like” enhancement without needing an in-game integration, with the Space linked in the Space post via the Hugging Face Space.
The common usage pattern showing up is “before/after remaster” comps—see the off vs on example—which is exactly how many creators evaluate polish tools (does it recover faces/materials, or does it hallucinate new ones).
SparkVSR shows an interactive way to upscale video without temporal flicker
SparkVSR (research): A new interactive video super-resolution approach proposes sparse keyframe propagation to push detail through a clip while keeping temporal consistency, as introduced in the demo clip and detailed on the paper page.

For creators, the practical promise is “pick a few frames to get right, then propagate”—a finishing-style workflow that targets the usual frame-by-frame shimmer you get from naive upscalers.
Ad comment sections are now policing what ‘looks AI’—finishing gets strategic
Detectability discourse (marketing): Creators are calling out an in-between phase where AI media is “good enough to publish” but “not good enough to be perfectly undetectable,” and that tension is playing out directly in ad comment sections, per the detectability thread.
The screenshot in that post shows “This looks ai” getting heavy engagement on a brand ad, which turns finishing work (texture, motion, skin, lighting, micro-gestures) into a measurable part of performance and brand risk—not just aesthetics.
DLSS 5 off/on comps become a meme format for AI ‘restoration’ taste
DLSS 5 (meme format): “DLSS 5 Off vs On” comparisons are getting used as a fast visual language for AI-driven remastering—sometimes earnest, sometimes satire—as seen in the Crash Bandicoot comp and the bagel punchline.
• Aesthetic shorthand: Even non-game visuals get framed this way, like a chart “improving” its fit from R² 0.937 to 0.997 in the regression gag, which mirrors how creators talk about enhancement as “better than real” rather than merely sharper.
Net effect: it’s increasingly normal to judge finishing passes via exaggerated before/after framing, not subtle grading notes.
Topaz Labs keeps investing in creator distribution via its partners program
Topaz Labs (Creative Partners): A creator shared onboarding into the Topaz Labs Creative Partners Program, signaling Topaz’s continued push to recruit and distribute through creator-led enhancement workflows, as shown in the program welcome post.
No product feature drop is claimed in the tweet, but the partner onboarding itself is a useful signal that AI-assisted enhancement (upscaling/denoise/sharpen-style tooling) still has a marketing and community lane.
🧷 Likeness, anonymity, and the new consent fights in creative AI
Policy/ethics signals today center on identity: AI resurrected performances, voice/persona cloning for families, and media orgs targeting creator anonymity—issues that directly affect what creators can ship and how audiences react.
Val Kilmer’s AI-generated role puts posthumous consent back in the spotlight
As Deep as the Grave (film): Reports say an AI-generated performance of Val Kilmer will appear in the movie because he was too sick to film after being cast in 2020, and the production is proceeding “with the blessing of his daughter,” as described in the AI role explanation and detailed further in the Variety report. The immediate creator-side reaction pattern is familiar: consent is cited, but people still anticipate backlash, as reflected in the Backlash expectation post.
Pantio pitches “parent voice” cloning from old recordings into an advice-giving persona
Pantio (product): Pantio is being promoted as a way to clone a parent’s voice from voicemails, family videos, or social clips, then generate an AI persona that can “talk, joke, and give advice,” per the Voice cloning pitch post. The framing centers intergenerational access (“kids can meet grandparents they never got to know”), with the entry point summarized via the Pantio site reference.
AI media is publishable now, but still starts fights about what’s real
Detectability transition: Creators are describing a stable-feeling interim era where AI content is “good enough to publish” but not “perfectly undetectable,” which is driving comment-section arguments about what’s AI versus real, according to the Detectability argument post.
The dynamic shows up concretely in brand comments—one example screenshot shows a top reply of “This looks ai” with 744 likes on a Dove post, as captured in the Detectability argument.
The near-term creative consequence is less about generation quality and more about social acceptance and disclosure expectations: viewers are pattern-matching “AI-ness” as part of how they judge authenticity, even when the ad is otherwise watchable.
Banksy’s anonymity gets treated as a target, not part of the work
Anonymity as authorship: A thread argues that Banksy’s anonymity is integral to the art, and criticizes Reuters for spending effort trying to “derail” that anonymity, as stated in the Anonymity critique repost. In creative AI circles, this lands as a broader signal: identity management (real name vs pseudonym) is becoming a frontline constraint on what creators feel safe shipping—especially when visibility can trigger investigation, scraping, or unwanted attribution.
📚 Papers & open research creatives will feel soon (world models, OCR, alignment, decoding speed)
Research-heavy day: multiple papers and demos across interactive 3D worlds, document intelligence, diffusion alignment, and faster decoding—useful for forecasting what next-gen creative tools will ship.
Qianfan-OCR unifies document parsing and understanding with “Layout-as-Thought”
Qianfan-OCR (Baidu): A 4B vision-language OCR model is pitched as end-to-end document intelligence (parse/layout/understand) and can output image→Markdown; the paper highlights a “Layout-as-Thought” reasoning phase and reports top end-to-end scores on OmniDocBench v1.5 and OlmOCR Bench, as shown in the Paper card.
For creatives, the practical unlock is cleaner ingestion of scripts, treatments, shotlists, PDFs, and tables into downstream LLM workflows without brittle multi-stage OCR glue—Baidu also provides a hands-on sandbox in the HF demo, with more detail in the Paper page.
WorldCam turns camera pose into the control signal for interactive 3D world models
WorldCam (paper): A new paper proposes interactive autoregressive 3D “gaming worlds” where camera pose is the unifying geometric representation—keyboard/mouse actions map to continuous 6‑DoF camera motion, and global pose becomes the index for retrieving prior observations to keep long-horizon consistency, as shown in the Paper share.

This matters for previs and playable story prototypes because “action control” becomes “camera control,” which is exactly how creators explore a scene; the work positions pose-conditioned generation as a path to fewer continuity breaks during navigation, per the Paper page.
Mamba-3 upgrades state-space sequence modeling with complex state and MIMO decode
Mamba-3 (paper): A summary thread breaks down Mamba-3 as three core changes—new discretization (exponential-trapezoidal), complex-valued state updates (via data-dependent RoPE), and a MIMO inference formulation that boosts FLOPs utilization without increasing latency, as captured in the Summary screenshot.
The creative implication is “cheaper long-context assistants” if these architectures deliver Transformer-like quality with better inference efficiency, as outlined in the Paper page.
MiroThinker-1.7 & H1 emphasize verification for long-horizon research agents
MiroThinker-1.7 & H1 (MiroMind AI): Following up on agent family update with the paper artifact now circulating, MiroThinker-H1 is framed around local + global verification during inference for more reliable multi-step research, as shown in the Paper card and described in the Paper page.
For storytellers, this is a “fewer busted citations / stronger evidence chains” bet: verification becomes a first-class ingredient rather than a prompt trick.
MolmoPoint pushes “grounding tokens” for more reliable pointing in VLMs
MolmoPoint (models + paper): A new approach called MolmoPoint targets a persistent pain point in multimodal assistants—accurately pointing to the right UI element or image region—by introducing grounding tokens, as described in the combined paper thread shared in the Paper thread.
If this holds up, it’s a near-term enabler for creative agents that can mark up frames, design comps, and storyboards with fewer “wrong object” callouts (a bottleneck in art-direction-by-chat).
OpenIndex’s Hacker News dataset offers 47M+ items, updated every 5 minutes
open-index/hacker-news (dataset): OpenIndex published a “complete archive” dataset containing every Hacker News item since 2006; the dataset card claims 47,360,199 items spanning 2006‑10 through 2026‑03‑16 and a live pipeline that commits new items every 5 minutes as Parquet files, per the Dataset card screenshot.
This is immediately useful for creative+AI teams building trend-mining agents, “what developers are discussing” moodboards, or long-range product research corpora—without scraping and without losing historical context.
FlashSampling fuses exact token sampling into matmul to reduce decode overhead
FlashSampling (paper): A new method targets decode latency by avoiding full logits materialization—sampling is fused into the LM head matmul epilogue (tile-by-tile), aiming for exact sampling with less memory traffic, as linked from the ArXiv and HF share via the Paper page.
This is the kind of low-level optimization that tends to show up later as “the model feels snappier” in creative tools—especially for interactive assistants, timeline copilots, and anything doing long-form generation where tokens-per-second is user experience.
V-Co studies co-denoising to make pixel diffusion models more semantically aligned
V-Co (paper): A research paper digs into “visual co-denoising” for pixel-space diffusion—injecting pretrained visual features (e.g., DINOv2) during denoising—and argues specific architectural/training ingredients drive better semantic alignment, according to the Paper card and the linked Paper page.
The creative relevance is directional: if pixel diffusion regains traction, techniques like co-denoising are a concrete lever for prompt adherence and concept consistency without only scaling model size.
InCoder-32B targets industrial coding with 128K context and execution-grounded verification
InCoder-32B (paper): Beihang University researchers describe a 32B “industrial scenarios” code foundation model trained from scratch; they claim a staged recipe that extends context from 8K to 128K plus execution-grounded verification, aiming at chip design, GPU kernel optimization, embedded, compiler optimization, and 3D modeling workflows, as summarized in the Paper card.
For creative tech teams, the near-term signal is better model behavior on “hardware-aware” tasks (rendering, kernels, and toolchains) rather than app scripting, as detailed in the Paper page.
🎞️ What shipped: AI films, music videos, and playable experiments
A notable set of creator releases and demos: short films made with Grok Imagine, AI war-film episodic drops, and quick-build indie games using AI-generated 3D assets. This section is for finished outputs and public releases.
WAR FOREVER moves to Escape and tees up Part Two for June 6
WAR FOREVER (Dustin Hollywood / Escape): Following up on Part One release—long-form AI war episode drop—the project is now being distributed on Escape, with the post explicitly promising “special scenes” from a longer-format Part Two slated for June 6 (80th anniversary of D‑Day), as stated in the Escape release post alongside the linked Escape film page.

• Additional packaging: A separate “featurette” is also being posted exclusively to Escape, per the Featurette post, which reinforces the release strategy of shipping the episode plus behind-the-scenes or supplemental cuts as separate drops.
Treasure Island ships as a fast AI-asset indie game
Meshy (MeshyAI): A community creator shipped a playable game called “Treasure Island” built with Meshy + Three.js in “a few days,” with “all the models” described as AI-generated, per the Gameplay and build montage.

This is a concrete example of a workflow where the bottleneck shifts from modeling to integration (scene assembly, collisions, UI, and basic gameplay loop), because the 3D asset pipeline is being treated as the fast-moving part.
RE/BIRTH releases as a Grok Imagine-native short sci‑fi film
Grok Imagine (xAI): Creator _VVSVS released “RE/BIRTH” as a short sci‑fi film made “exclusively with” Grok Imagine, positioning it as a full tool-native example rather than a mixed pipeline, according to the Release post.
The visible cut leans into big atmospheric sci‑fi tableaux (hero figure, cosmic sky effects), which makes it a useful reference point for what Grok Imagine outputs look like when edited as a coherent short rather than a one-off shot.
A full music video cut from Midjourney V8 alpha clips
Midjourney V8 Alpha (Midjourney): bennash released “Why Me, God?” and describes it as a music video made from Midjourney V8 alpha video clips, per the Music video post.

The cut reads as an early “what you can ship today” example: abstract, high-texture sequences where coherence comes from editing and motif repetition rather than character continuity.
AFRO DUNE shows a fast Hedra meme-cinematic workflow
Hedra (Hedra Labs): tupacabra posted “AFRO DUNE” and claims the clip was made with Hedra “in 10min,” as stated in the Creation claim post and echoed in the follow-up Time-to-make note.

The surrounding posts frame it as a repeatable meme format (Dune-style power visuals with a recognizable character/handle), which is useful as a template for rapid-turnaround cinematic bits optimized for shareability rather than long continuity.
After Us: Volume 1 sets March 27
After Us (series release): A teaser announces “After Us. Volume 1.” with a March 27 date, as shown in the Teaser clip.

The framing (“Volume 1” + date card) is a clean packaging pattern for AI film projects: ship in labeled installments, not a single one-off, and make each drop feel like an episode with its own release moment.
My Cat So High music video posts publicly
AI music video (creator release): bennash posted “My Cat So High — the music video,” per the Music video post.

The release sits alongside other short-form music-video experiments in the thread, adding another reference cut for creators tracking what styles are getting shipped as complete videos rather than single shots.
🚧 What’s breaking (or regressing): MJ V8 rough edges and slow agent tooling
Creators reported multiple friction points: Midjourney V8 alpha regressions (quality, moderation, consistency) and performance complaints in coding-agent tools. These issues affect iteration speed and output reliability.
Midjourney V8 Alpha backlash consolidates into “disasterclass” and “wait for v9” memes
Midjourney V8 Alpha (Midjourney): The discourse itself is becoming a product signal: “distasterclass” reactions in the Backlash one-liner and “wake me up when v9 gets here” in the Wait for v9 post are spreading alongside “temperature check” posts like the V8 temperature check.
One secondary thread is the social split between critics and defenders; a creator explicitly notes “Midjourney defenders are rabid” in the Defenders reaction clip. For working creatives, this kind of polarized feedback usually means the tool is shipping real changes fast, but reliability is uneven across prompt families (portraits vs interiors vs illustration vs posters).
Midjourney V8 vs V7: same prompt+refs tests show composition/detail regressions
Midjourney V8 Alpha (Midjourney): Multiple creators are running controlled V7 vs V8 comparisons with the exact same prompt + style refs/personalization, and some are reporting clear regressions in layout and “finished” detail—especially on interior/scene prompts, as shown in a side-by-side from the V7 vs V8 comparison and follow-up metadata including job IDs in the Job ID note.
The practical pattern is straightforward: keep --ar, --raw, --stylize, and your profile/style references identical; only change the model version, then archive job IDs so you can re-run the test after model updates. The thread’s underlying frustration is summed up in the creator’s “same prompt and references” claim in the V7 vs V8 comparison, which is exactly the kind of reproducible check creative teams need before switching a production look to V8.
Midjourney V8 Alpha sharpness complaints: “contact lenses” softness and lost texture
Midjourney V8 Alpha (Midjourney): Portrait testers are repeatedly describing V8 output as softer and less textured—one user joked it felt like forgetting “contact lenses,” specifically calling out reduced sharpness/micro-texture in the V8 tests note, with an explicit V8-left/V7-right comparison shown in the V8 vs V7 portrait.
Midjourney staff are already probing for parameter-level fixes; in a reply, the official account asked whether the issue happens with plain prompts and suggested trying --hd, as seen in the Midjourney parameter question. For creators doing face-heavy work (poster key art, look-dev, character sheets), this softness becomes an iteration cost because you can’t tell whether the “look” is intentional style or model blur until late.
Midjourney V8 Alpha tradeoff: better prompt adherence, worse aesthetics in some tests
Midjourney V8 Alpha (Midjourney): A recurring take is that V8 follows instructions more literally, but the “Midjourney magic” (stylization/finish) can feel weaker; one tester summarizes it as “much better prompt adherence, but degraded aesthetic and image quality” in the Adherence vs quality take, while other posts frame V8 as “promising and incredibly fast” but still not there yet in the Early impression.
The synthesis creators keep circling is a hybrid wish-list—V7’s personalization/aesthetic engine plus V8’s instruction-following, as spelled out in the Adherence vs quality take. For design teams, that’s less about benchmarks and more about whether V8 can be trusted for consistent “brand look” without extra rerolls.
Midjourney V8 Alpha: improved text rendering but reports of stricter moderation
Midjourney V8 Alpha (Midjourney): Poster-prompt testing suggests the model is better at rendering text on posters, but creators are also reporting noticeably stricter moderation and more blocked/weaker outputs; one tester explicitly says “moderation has increased” and questions the censorship level in the Poster prompt thread.
This matters to filmmakers and storytellers because the “edgy but not explicit” middle ground (horror poster comps, thriller key art, tabloid-style layouts) is often where moderation changes quietly break a pipeline; the same thread also notes inconsistent quality across prompts, even when the typography improved, as described in the Poster prompt thread.
Claude Code slowdown complaint surfaces as an iteration blocker
Claude Code (Anthropic): A creator reports “Claude Code is slow AF right now” in the Performance complaint, which is the kind of small-seeming reliability issue that cascades when you’re mid-edit or mid-refactor and using the agent as the core loop.
No outage details or timestamps beyond the post are provided, but the key creative impact is immediate: latency turns agentic tools from “co-writer/co-editor” into a context-switch tax, as implied by the Performance complaint.
Midjourney V8 Alpha quirks: misgendering prompts and visible IP-like outputs reported
Midjourney V8 Alpha (Midjourney): Early testers are flagging basic prompt reliability issues (e.g., prompting “a king” yielding a woman) and also claiming more obvious franchise-looking outputs; one report calls out misgendering, human proportion problems, and “GoT characters and star wars characters very clearly in the output” in the First impressions issues.
There’s no clear reproduction recipe in the tweets, but the combination is operationally relevant: misgendering breaks character briefs, while anything that looks like recognizable IP is a legal/commercial risk for client work—even if it’s “just a test run,” as implied by the First impressions issues.
Midjourney schedules Weekly Office Hours on 3/18 as V8 Alpha feedback spikes
Midjourney (Midjourney): Midjourney announced “Weekly Office Hours - 3/18” in the Office hours post, giving the community an official slot to surface V8 Alpha issues (quality regressions, moderation changes, sharpness complaints) in real time.
No agenda or replay link is included in the tweet, but the timing matters because it overlaps with a wave of hands-on V8 testing and parameter-level troubleshooting discussed elsewhere today, including the official account’s prompt-parameter probing in the Midjourney parameter question.
📈 Distribution mood: algorithm fatigue, anti-algo yearnings, and “never leaving X” culture
The discourse itself is the news: creators are openly grappling with algorithmic reach, feed chaos, and calls for non-algorithmic platforms—signals that shape what formats and release strategies work.
AI filmmakers keep asking for non-algorithmic discovery surfaces
Distribution mood: A creator claims a “most realistic AI film” got minimal algorithmic sharing and uses that to argue for “non‑algo platforms,” as stated in the Non-algo platform ask. This is a direct continuation of Discovery gap (longform AI video lacking a home), but with a sharper “platform design” demand rather than format experimentation.
What’s missing from today’s evidence is any concrete alternative that can replace algorithmic reach at scale; the tweet is a demand signal, not a migration plan.
Algorithm backlash turns into inevitability math arguments
Algorithm anger: One rant frames recommendation algorithms as structurally extractive and claims reach will degrade as content supply grows (“more means less”), arguing the expected-value math only worsens over time, per the Algorithm inevitability rant.

The practical impact for AI creators is that “make better work” is no longer seen as a sufficient distribution strategy inside this worldview; the grievance is with ranking mechanics, not production quality.
Creators map X into subcultures, not a single audience
X creator culture: One meta-thread tries to explain day-to-day distribution reality as “multiple internets in one feed”—product-drop hype, live art, political pile-ons, Gen X “LinkedIn energy” mismatch, and loud commentators with “zero output,” as framed in the Feed fragmentation thread and repeated in the Repost of thread. It’s a creator-readable explanation for why posts that feel “obviously good” to you can still underperform: you’re often talking to (and being ranked by) a different corner than the one you think you’re in.
The same feed-sculpting theme shows up in smaller observations like “my For You is perfect right now” because it’s serving a narrow mix of debates and memes, as described in the For You feed snapshot.
Some creators prefer AI-generated feeds over influencer content
Instagram feed shift: One creator celebrates that “AI videos have replaced every single influencer on my IG feed,” calling it “exceptional content” and “a massive improvement,” as shown in the IG feed reaction.

This is a useful counter-signal to the usual “AI slop” framing: for at least some audiences, synthetic content isn’t a downgrade—it’s what they want the algorithm to serve.
Creators start treating weekly reach like a system problem
Creator ops pattern: A small but telling tactic—logging performance by weekday—shows up when one creator notes Wednesday is their worst-performing day “for the last 4 weeks” and suggests designing a midweek challenge to compensate, as described in the Weekday performance note. Following up on Reach drops (experimentation as a response), this is the more operational version: treat distribution dips as schedule/system design rather than as one-off bad posts.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught