Claude Opus 4.6 gets 1M tokens GA – 78.3% MRCR v2
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Anthropic pushed Claude Opus 4.6 and Sonnet 4.6 to 1,000,000-token context at general availability; the long-context premium is removed so standard API pricing applies across the full window; multimodal caps jump to 600 images or 600 PDF pages per request. Anthropic’s MRCR v2 chart shows Opus 4.6 at 78.3% and Sonnet 4.6 at 65.1% at 1M tokens; the same figure contrasts GPT‑5.4 at 36.6% (not measured at 1M) and Gemini 3.1 Pro at 25.9% (Context Arena), but it’s still a vendor-posted chart rather than an independently replicated eval packet.
• Claude Code: Opus 4.6 1M becomes default for Max/Team/Enterprise and counts against normal limits; Pro/Sonnet can opt in via /extra-usage; CLAUDE_CODE_AUTO_COMPACT_WINDOW exposes compaction thresholds; >200K token requests no longer need a beta header.
• Perplexity Computer: iOS launch adds cross-device session sync; Enterprise “Final Pass” runs 5 parallel agents for document markup; NVIDIA Nemotron 3 Super 120B appears as a selectable model.
• Chrome DevTools MCP: Chrome 144+ Beta can attach agents to a live, logged-in debugging session; permission/consent gates are explicit; OpenClaw’s beta wires into remote debugging.
The throughline is longer-running, stateful agent sessions moving from “prompt length” to “workflow plumbing” (compaction, elicitation, consent, and tool state); the open question is whether long-context retrieval gains translate cleanly once harness variance and surface-level regressions dominate day-to-day reliability.
Top links today
- Claude Opus and Sonnet 4.6 1M context announcement
- Claude 1M context flat pricing update
- Claude Code 2.1.75 CLI changelog
- Claude Code 2.1.76 CLI changelog
- Perplexity Computer on iOS product update
- Nemotron 3 Super in Perplexity announcement
- GPT-5.4 image encoder bugfix notice
- ChatGPT Websites section reference
- Unsloth and NVIDIA reinforcement learning environments guide
- Paper on multi-agent memory architectures
- Jagged frontier productivity paper
- Open Deep Research v2 app and code release
- Jina AI agent CLI repo
- Open Generative UI template repo
- json-render YAML wire format update
Feature Spotlight
Claude 1M context goes GA (and becomes default in Claude Code)
Claude’s 1M-token context is now GA with no long-context premium and becomes the default in Claude Code for paid teams—enabling whole-codebase sessions with fewer compactions and higher long-context retrieval reliability.
Cross-account headline: Claude Opus 4.6 and Sonnet 4.6 move to 1M-token general availability, with flat pricing across the whole window and much higher long-context retrieval scores shown in MRCR v2 charts. Also includes higher media limits (up to 600 images/PDF pages) and Claude Code plan/default changes tied to fewer compactions.
Jump to Claude 1M context goes GA (and becomes default in Claude Code) topicsTable of Contents
🧠 Claude 1M context goes GA (and becomes default in Claude Code)
Cross-account headline: Claude Opus 4.6 and Sonnet 4.6 move to 1M-token general availability, with flat pricing across the whole window and much higher long-context retrieval scores shown in MRCR v2 charts. Also includes higher media limits (up to 600 images/PDF pages) and Claude Code plan/default changes tied to fewer compactions.
Claude API removes long-context premium for 1M-token requests
Claude API pricing (Anthropic): Anthropic removed the long-context surcharge so standard pricing applies across the full 1M window, which is called out directly in the GA write-up from Pricing paragraph.
The same change is summarized by builders noting “no more long context price increase in the API,” as listed in Shipping notes, with additional confirmation chatter in Pricing change callout and Long context pricing note.
Claude Opus 4.6 and Sonnet 4.6: 1M context is now generally available
Claude 4.6 1M context (Anthropic): Anthropic made 1 million tokens generally available for Claude Opus 4.6 and Claude Sonnet 4.6, positioning it for “entire codebases, large document sets, and long-running agents,” as stated in the GA thread from GA announcement.
The GA post also bundles a practical multimodal increase (up to 600 images or PDF pages per request) and highlights long-context retrieval performance; Anthropic points to details in its GA blog post and reiterates the key stats in a shorter follow-up from Benchmark and limits recap.
Claude Code makes Opus 4.6 1M the default on Max, Team, and Enterprise
Claude Code default model (Anthropic): Opus 4.6 with 1M context is now the default for Claude Code users on Max, Team, and Enterprise, and it “counts against normal plan limits” (no extra usage required) according to Subscription inclusion note and the launch note from Default model update.
The model selector UI showing “Opus 4.6 with 1M context” as the recommended default is visible in the Model picker screenshot.
MRCR v2 long-context retrieval: Opus 4.6 posts 78.3% at 1M tokens
MRCR v2 eval (Anthropic): The long-context retrieval chart Anthropic shared shows Claude Opus 4.6 scoring 78.3% on MRCR v2 at 1M tokens, with Sonnet 4.6 at 65.1%; the same figure contrasts GPT-5.4 at 36.6% and Gemini 3.1 Pro at 25.9%, as shown in the MRCR chart thread.
A measurement note embedded in the chart says Gemini results were measured by Context Arena (not self-reported), and that OpenAI’s score is a bin average across 128K–256K rather than a single context length, which is visible in the Chart with footnote.
Claude API: long-context requests no longer need a beta header
Claude API ergonomics (Anthropic): Requests beyond 200K tokens now work “normally” without a special beta header, and Anthropic says rate limits remain consistent across the entire context window, per the rollout details in API ergonomics list.
Anthropic’s own description of this change and the surrounding constraints are captured in the GA blog post.
Claude 4.6 raises per-request media limits to 600 images or PDF pages
Multimodal input limits (Anthropic): With 1M context GA, Anthropic increased the per-request cap to 600 images or 600 PDF pages, which is stated in the main GA thread from Media limit detail and repeated in the shipped-changes list from Improvements list.
The published explanation of the new limit and how it’s intended to be used (large document sets, long-running agent traces) is described in the GA blog post.
Claude Code adds an env var to tune auto-compaction for long sessions
Claude Code context management (Anthropic): Claude Code now exposes CLAUDE_CODE_AUTO_COMPACT_WINDOW to customize when auto-compaction kicks in, per the rollout note from Env var mention.
Model/usage configuration details for long-context variants and session behavior are documented in the Model config docs, referenced in Docs pointer.
Claude Code: /extra-usage opt-in path for Pro and Sonnet users
Claude Code access control (Anthropic): The rollout note says Pro and Sonnet users can opt into 1M context via /extra-usage, while Max/Team/Enterprise get it by default, per Opt-in note.
With 1M context, builders report fewer compactions and fewer fresh sessions
Long-context workflow pattern: Multiple practitioners are describing a concrete behavioral change with 1M context: fewer forced compactions and longer continuous runs, with one noting “I’ve been using exclusively 1M context… and loving it,” as written in Personal usage note, and another saying they’re “starting new sessions much less frequently,” as reported in Fewer sessions observation.
A related community quip frames the previous 200K compaction threshold as the blocker for day-to-day usage (“literally the only thing preventing… was the auto-compaction at 200k”), as joked in Compaction joke.
🛠️ Claude Code CLI & desktop workflow updates (Remote Control, /effort, MCP dialogs)
Operational and UX changes in Claude Code 2.1.75–2.1.76: Remote Control session spawning, effort controls, MCP elicitation dialogs, compaction circuit breakers, transcript persistence controls, and session UI niceties. Excludes the 1M-context rollout (covered in the feature).
Claude Code 2.1.76 lets MCP servers request structured input mid-task
Claude Code CLI 2.1.76 (Anthropic): MCP servers can now “elicit” structured user input during an in-progress task via an interactive dialog (typed form fields or a URL handoff), as described in the [2.1.76 changelog](t:233|2.1.76 changelog) and written up in the [detailed change list](t:554|Detailed changelog). This is paired with new Elicitation and ElicitationResult hooks so harness authors can intercept/override what’s returned to the server, per the [release notes](t:233|Release highlights).
This effectively upgrades MCP from “fire-and-forget tool calls” to “tool calls that can pause for precise human input,” which matters for workflows that need credentials, approvals, or structured parameters without restarting a run.
Claude Code 2.1.76 stops auto-compaction after 3 consecutive failures
Claude Code CLI 2.1.76 (Anthropic): auto-compaction now stops after 3 consecutive failures instead of retrying indefinitely, as stated in the [2.1.76 release thread](t:233|Release highlights) and detailed in the [changelog excerpt](t:554|Fix list). This is effectively a circuit breaker for long-running sessions that previously could get stuck in a compaction retry loop.
The same changelog also mentions a new PostCompact hook (useful for post-processing summaries), but the operational headline here is “fail fast after repeated compaction errors.”
Claude Code adds /effort ‘max’ for longer reasoning per session
Claude Code (Anthropic): you can now set effort to max per session using /effort, which “reasons for longer and uses as many tokens as needed,” with the explicit caveat that it burns limits faster so it must be enabled each session, per the [shipping note](t:16|Effort max announcement).

This introduces an explicit UI/CLI knob for trading cost/latency for deeper reasoning, rather than encoding that choice indirectly via prompt style or model selection.
Claude Code Remote Control can start new laptop sessions from mobile
Claude Code Remote Control (Anthropic): Remote Control can now spawn new local Claude Code sessions on your laptop from the mobile app, according to the [feature announcement](t:164|Remote Control session spawning) and the [“phone to laptop” demo claim](t:9|Phone launch note). The same end-of-week ship list also reiterates “start new sessions from Remote Control,” per the [release roundup](t:16|End of week ships).
This is specifically about session creation (not just continuing an existing thread), which changes how people kick off work when away from their machine.
Claude Code 2.1.75 adds /color and makes session/memory state more visible
Claude Code CLI 2.1.75 (Anthropic): the release adds /color for prompt-bar coloring, displays the session name on the prompt bar after /rename, and shows last-modified timestamps on memory files to help distinguish fresh vs stale memories, per the [2.1.75 release notes](t:26|2.1.75 highlights) and the [changelog excerpt](t:380|Changelog summary). It also changes permission handling so denials prompt for a reason when intent is unclear, as stated in the [same 2.1.75 notes](t:26|Permission prompt change).
These are small UI/ops tweaks, but they directly affect day-to-day “many sessions per day” workflows.
Claude Code 2.1.76 adds an option to disable transcript persistence
Claude Code CLI 2.1.76 (Anthropic): the CLI now includes an option to disable transcript persistence entirely, as called out in the [release highlights](t:233|Release highlights) and enumerated in the [full changelog](t:554|Full changelog). This is a concrete ops/privacy control for teams that want to use Claude Code on sensitive repos without leaving local conversation artifacts.
The change lands alongside other “session hygiene” controls (hooks around compaction and elicitation), but transcript storage is the explicitly new lever mentioned in the shipping notes.
Claude Code Review can be run on demand with @claude review
Claude Code Review (Anthropic): Code Review can now be configured to run manually by typing @claude review in a GitHub PR (or comments), giving teams a pull-based workflow for selective PRs, as shown in the [announcement](t:95|Manual trigger note) and documented in the [setup guide](link:363:0|Setup docs).
This is a control-plane change more than a model change: review can be invoked when it’s useful, rather than being forced on every PR event.
Claude Code 2.1.76 adds --name and auto-naming after plan mode
Claude Code session UX (Anthropic): you can now name a session at startup with --name/-n, and sessions can be auto-named after plan mode, per the [feature roundup](t:205|Session naming list) and the [2.1.76 changelog](t:233|New CLI flags). The changelog also notes Remote Control session titles are now derived from the first prompt (instead of a generic label), as described in the [improvements list](t:233|Remote Control improvements).
This is mostly ergonomics, but it makes session management and later retrieval less ambiguous in multi-thread workflows.
Claude Code voice mode reaches 100% rollout, including Desktop
Claude Code voice mode (Anthropic): voice mode is now rolled out to 100% of users, including Claude Code Desktop, per the [rollout note](t:229|Voice mode rollout) and reiterated in the [end-of-week ships thread](t:205|Feature list recap).
This is a distribution milestone rather than a new interaction primitive, but it matters for teams standardizing on Claude Code across desktop environments.
Re-enable Claude Code thinking summaries with a settings.json flag
Claude Code settings (Anthropic): if you’re not seeing thinking blocks, one workaround is to set "showThinkingSummaries": true in ~/.claude/settings.json, per the [config tip](t:78|Thinking summaries tip), which points to the underlying request in the [feature issue](link:78:0|GitHub issue).
The operational detail is that thinking visibility was turned off by default in newer releases (notably “2.1.69+” per the same tip), so this flag restores that debug surface.
⌨️ Codex app: theming, automations, and day-to-day friction signals
Codex desktop/app workflow chatter: theme customization contests, quality-of-life tips, automations used for repo maintenance, and user reports of day-to-day model/app variance. This slice is about Codex as a coding product surface, not OpenAI’s underlying agent runtime (covered elsewhere).
Codex in the app can read the integrated terminal
Codex app (OpenAI): Codex in the desktop app can now read what’s currently in the integrated terminal and report it back accurately, including the working directory, branch, and last visible command/output, as shown in the terminal read demo.
This is a workflow-level capability change: it reduces copy/paste from terminal logs into the chat thread, and it makes “what happened in the shell?” a directly inspectable state inside the app.
Codex Automations are being used for repo hygiene (weekly worktree cleanup)
Codex Automations (OpenAI): A concrete “automation as repo janitor” example showed Codex cleaning up 49 detached vault worktrees under ~/.codex/worktrees, running git worktree prune, and then proposing a scheduled weekly cleanup automation (Fridays 9:00 AM), as captured in the automation cleanup screenshot.
A separate recap frames the mechanic as “each automation spins up a dedicated Git worktree in the background,” which is why these hygiene jobs can run without touching the main checkout, according to the automations worktree description.
Raycast deeplinks can turn selected text into a one-keystroke Codex task
Codex app workflow: A practical pattern for reducing “copy error → paste into agent” friction is to bind a Raycast deeplink to a hotkey so Codex opens with the selected text prefilled, as demonstrated in the Raycast hotkey walkthrough.

This is essentially a local “send to agent” pipe for snippets like stack traces, logs, or partial plans, without the intermediate clipboard choreography.
“Codex in VS Code is trash” complaint points to integration issues
Codex in VS Code: A user report claims “GPT 5.4 and GPT 5.3 Codex in VS Code are trash” while asserting it’s “not a model problem” because the same model works better elsewhere, per the VS Code complaint.
A related comment from another builder reinforces the “surface matters” angle—calling it “front end only” and saying they “have to fight front end a lot,” as noted in the front-end comparison.
Builders want “plan in ChatGPT → execute in Codex” as a first-class flow
Codex app workflow request: A feature request proposes a tight loop—“plan in ChatGPT w/ GPT-5.4 Pro,” then “push plan to Codex app,” and have Codex decompose it into tasks and build—spelled out in the plan handoff request.
The ask is essentially a native handoff boundary between “planning chat” and “agent execution UI,” with minimal copy/paste and a structured task breakdown step.
Codex app theme contest spotlights the new theming system
Codex app (OpenAI): OpenAI’s Codex app team is running a theme-sharing contest—“screenshots only”—with $100 in ChatGPT credits for winning submissions, as announced in the theme contest prompt.
• What it signals: The theming surface (accent/background/foreground, fonts, contrast) is being treated as a first-class part of the Codex desktop workflow, with community-made themes already circulating such as a Sublime-inspired setup shared in the community theme example.
“Overnight mode” pitches scheduled, cheaper inference for background agents
Codex usage economics: A user suggestion asks for an “overnight mode” where you set a deadline (for example, 6am) and Codex runs tasks during your sleep window with discounted inference “similar to batch mode,” as proposed in the overnight mode idea.
The underlying claim is that many agent tasks are latency-insensitive for the human, so pricing/priority could be shaped around time-of-day scheduling rather than interactive responsiveness.
ChatGPT code references a new “Websites” navigation section
ChatGPT product surface (OpenAI): UI code observed in production assets references a “Websites” section described as “Browse websites you have created in ChatGPT and start a new site-building chat,” per the Websites route snippet.
This is only a surfaced string/route reference (not a fully demonstrated feature in the tweets), but it’s a notable signal that “site-building chats” may become a first-class navigation object in ChatGPT.
Codex app adds an “Absolutely” Claude theme preset
Codex app (OpenAI): The Codex app’s Appearance settings now include an “Aa Absolutely” theme option—called out by users as an overt Claude-themed preset, per the theme preset screenshot.
The tweet thread frames it as deliberate product humor, but the concrete change is that Codex’s theme system includes shareable/importable presets rather than only manual color picking.
Model naming sprawl is showing up as ops friction
Codex model ops (OpenAI): An OpenAI engineer joked about historical naming sprawl—“GPT-5.1-Codex-Max”—and said it’s “nice and simple” to be in the “GPT-5.4 era,” in the naming remark.
It’s a small signal, but it reflects a real operational pain point for teams shipping multiple Codex-tuned variants across product surfaces.
🧩 OpenAI platform & enterprise product updates (vision encoder + analytics)
Smaller but high-signal OpenAI platform changes that affect production behavior: multimodal quality fixes and enterprise analytics instrumentation. Excludes Codex-specific UX updates (covered in Codex app).
OpenAI patches GPT-5.4 image encoder bug affecting input_image
GPT-5.4 (OpenAI API): OpenAI shipped a silent fix to the image encoder used for input_image requests in GPT-5.4; some vision workloads may see better output quality, and OpenAI says there’s nothing developers need to change, as noted in the encoder fix note and detailed in the API changelog.
This is a backend behavior change (encoder-side), so any before/after differences will show up without prompt edits or SDK updates.
Builders report possible GPT-5.4 day-to-day quality drift
GPT-5.4 quality canary: Several practitioners report GPT-5.4 feeling “off” in day-to-day coding and agentic workflows, including Codex CLI usage, in posts like regression question and Codex CLI report.
• Confounders called out: One response frames the behavior as potentially harness/system-prompt sensitive rather than a pure model shift, as described in the system prompt sensitivity note.
There are also counter-posts indicating normal performance for some users, including the counter report, so the signal is noisy rather than a confirmed incident.
ChatGPT Enterprise expands native user analytics for admins
ChatGPT Enterprise (OpenAI): OpenAI published an updated admin guide for the User Analytics Dashboard, covering workspace-level engagement views plus workflows for benchmarking, exploring usage, and surveying users, as described in the analytics guide link and the linked Admin guide.
The artifact reads like instrumentation maturing into an “adoption ops” loop. It’s productized inside the platform.
ChatGPT surfaces a “Websites” navigation route in UI copy
ChatGPT (OpenAI): A new in-product string references a “Websites” section—“Browse websites you have created in ChatGPT and start a new site-building chat”—suggesting a navigation surface for managing site-building sessions, per the UI string leak.
There’s no public launch note in the tweets; this is only evidence of a surfaced route/copy in the client bundle.
OpenAI opens a Windows-focused Codex App engineering role
Codex App (OpenAI): OpenAI posted a role for a Full Stack Software Engineer (Windows) on the Codex App team, emphasizing Windows reliability across native setups, WSL, and enterprise environments, per the job post link and the linked Role description.
The listing is a concrete signal that the desktop app surface (and its Windows-specific edge cases like packaging, updates, IPC, and WSL interop) remains a staffed roadmap item.
📱 Perplexity Computer expands to iOS + enterprise parallel review
Perplexity’s agentic ‘Computer’ product shifts from desktop-first to mobile with cross-device sync, and adds enterprise-oriented document workflows. Includes their model catalog updates (e.g., Nemotron) as shipped in the Perplexity surface.
Perplexity Computer hits iOS with cross-device session sync
Perplexity Computer (Perplexity): Perplexity shipped Computer inside its iOS app—moving the agent workflow from desktop-first to mobile, with sessions synced across phone and desktop as shown in the launch clip; it follows yesterday’s Pro rollout by widening availability to iOS users, with TestingCatalog saying it’s now fully rolled out to all iOS users in the rollout video.

The iOS release positions “start any task anywhere” as the default interaction model, and Perplexity says Android is “coming soon” in the launch clip, with another walkthrough also emphasizing cross-device continuation in the mobile rollout clip.
Perplexity Enterprise adds “Final Pass” with five parallel document reviewers
Final Pass (Perplexity Computer): Perplexity is rolling out Final Pass to Enterprise customers, running five parallel agents to review and markup a document in one workflow, as demonstrated in the parallel agent review demo.

The feature is framed as a multi-review “editorial/legal team” pass in the feature description, with the UI showing side-by-side agent outputs and consolidated markups rather than a single-pass rewrite.
Nemotron 3 Super is now selectable in Perplexity Computer and Agent API
Nemotron 3 Super (NVIDIA via Perplexity): Perplexity added NVIDIA’s Nemotron 3 Super 120B as a selectable model across Perplexity surfaces, including Computer and Agent API, according to the model availability post.
The model picker screenshot in the model availability post shows Nemotron alongside GPT-5.4, Gemini 3.1 Pro, and Claude 4.6 options, implying Perplexity’s “model router” UX is becoming a first-class knob inside agentic runs (not only in chat).
Perplexity Computer is being used to aggregate multi-platform analytics in one run
Analytics aggregation workflow: A practitioner demo shows Perplexity Computer pulling “stats across 5+ platforms” and aggregating them into a single interactive dashboard “in one shot,” per the dashboard demo.

The framing in the dashboard demo emphasizes a multi-model approach (“The future is multi model”) and positions Computer less as web navigation and more as an orchestration layer over disparate admin/analytics surfaces.
🧰 Agent runners & ops: hosted OpenClaw, sandboxes, presets, and multi-agent bureaucracy
Tools and practices for running agents as systems: hosted OpenClaw experiences, sandboxed agent computers, multi-terminal workspaces, and enterprise-style parallel-agent bureaucracy. Excludes MCP plumbing (covered in MCP) and assistant-native releases (covered in their product sections).
KiloClaw pitches a hosted OpenClaw runner with “60 seconds to agent” setup
KiloClaw (Kilo): Kilo is pitching a hosted way to run OpenClaw that avoids the usual “SSH, config files, manual updates” overhead—positioning KiloClaw as “zero to running agent in 60 seconds” and advertising “500+ models” with no Docker, according to the [hosted OpenClaw pitch](t:460|hosted OpenClaw pitch).
• Ops surface: they also describe a webhook-triggered flow where a “cloud agent” reacts to new/labeled GitHub issues, produces a plan, writes code/tests, and commits, as laid out in the [issue-trigger agent loop](t:643|issue-trigger agent loop).
Kilo separately frames the long-term UI direction as “the interface is now a single sentence,” with examples in their [product essay](link:764:0|product essay).
OB-1 adds a hosted “agent computer” sandbox via `ob1 --sandbox`
OB-1 (OpenBlock Labs): OB-1 is emphasizing a dedicated, sandboxed computer environment for agent runs via ob1 --sandbox, with the runtime described as “Powered by Modal” in the [sandbox demo](t:217|sandbox demo).

The pitch is that the agent gets a consistent execution environment (instead of relying on local setup), which fits the broader “agents as systems” pattern: isolating runs, capturing artifacts, and making repeatable execution a default rather than an add-on.
BridgeSpace adds one-click “handoff prompts” for model/tool switching
Handoff prompts (BridgeSpace): BridgeMind says BridgeSpace can generate a one-click “handoff prompt” to move a task between tools/models (example: Claude Code → Gemini CLI for styling) while preserving context, per the [handoff demo](t:428|handoff demo).

This is an ops-oriented answer to a common multi-agent failure mode: losing task state when switching runners or models mid-stream.
BridgeSpace adds one-click presets to launch 6 parallel Claude Code sessions
BridgeSpace (BridgeMind): BridgeMind added “workspace presets” that spin up 6 Claude Code agents in parallel terminals, with support for mixing Claude/Codex/Gemini/OpenCode/Cursor/Copilot configurations, as shown in the [workspace preset screenshots](t:411|workspace preset screenshots).
The concrete value here is orchestration ergonomics: it standardizes multi-agent session layouts so teams aren’t re-creating the same multi-terminal setup repeatedly.
Composio shows “Slack message → merge-ready PR” with sandbox and CI safety
Zen (Composio): Composio describes its internal coding agent “Zen” as a Slack-to-PR workflow—“Slack message → merge-ready PR”—and calls out sandboxing plus safety mechanisms like model review, CI, and end-to-end tests in the [Zen walkthrough](t:488|Zen walkthrough).

• Adoption signal: they report usage moving from “20% → 40% of dashboard PRs” in the same [Zen thread](t:488|Zen walkthrough), which suggests this pattern is being operationalized beyond demos.
OB-1 adds BYOK so teams can plug in OpenAI or Anthropic keys
OB-1 (OpenBlock Labs): OB-1 now supports BYOK—users can add their own OpenAI or Anthropic API keys to run sessions under their own billing and policies, as shown in the [BYOK announcement](t:182|BYOK announcement).

This is a concrete shift toward agent runners that act as a thin orchestration layer over whichever model provider a team already standardizes on.
OB-1 restores free tier: $10/day credit after removing spam accounts
OB-1 (OpenBlock Labs): OpenBlock says its free tier is back with $10/day in credit after onboarding “~10k users” briefly strained the system; they report removing spam accounts and returning to normal operation in the [service update](t:267|service update).
This reads like a capacity/abuse-management datapoint for agent runners: rapid growth immediately translates into quota and anti-spam engineering.
OB-1 ships “PM Mode” that reads your integrations via /init-pm
PM Mode (OB-1): OpenBlock Labs introduced a workflow where running /init-pm analyzes your integrations and then switching modes (shift+tab) is positioned as a way to generate product ideas and proposals, per the [PM Mode demo](t:352|PM Mode demo).

The notable implementation detail is the integration-aware onboarding step (“analyze your integrations”), which implies the runner is building a local model of how work happens before it starts proposing tasks.
Perplexity Enterprise ships “Final Pass” with five parallel document reviewers
Final Pass (Perplexity Computer): Perplexity is rolling out an Enterprise feature called Final Pass that runs five parallel agents to review and markup a document, according to the [rollout clip](t:279|rollout clip) and the [feature description](t:331|feature description).
The implementation angle is “agentic bureaucracy” rather than single-pass rewriting: the same input gets subdivided into parallel review roles, then recomposed into an edited artifact.
Tembo hiring points to growing demand for background coding-agent infrastructure
Tembo (Hiring): Tembo posted roles for a full stack engineer and a founding infrastructure engineer focused on “the infrastructure behind background coding agents,” with responsibilities including integrations (OAuth/APIs/webhooks) and sandbox environments, as described in the [full stack role](link:161:0|job post) and the [infra role](link:374:0|job post).
This is a market signal that “agent runners” are becoming their own product surface: orchestration, isolation, and integrations are the work, not a side quest.
🔌 MCP & agent interoperability: Chrome DevTools sessions, skill trees, and tool debates
MCP-specific shipping and integration chatter: live browser-session control via Chrome DevTools MCP, toolchain setup snippets, and ongoing ‘MCP vs CLI’ discussions. Excludes non-MCP plugins/skills and assistant-native features.
Chrome DevTools MCP enables AI agents to debug an active, logged-in browser session
Chrome DevTools MCP (Google): Google’s Chrome DevTools team shipped an MCP capability that lets coding agents connect to a live Chrome session for debugging (network, selected elements, etc.) while reusing existing logged-in state, as described in the [Chrome developers post](link:74:0|Chrome developers post). It’s available starting with Chrome M144 (Beta) and requires remote debugging to be enabled, with connection requests gated by user permission per the [feature overview](t:74|feature overview).
• Workflow change: Instead of launching fresh automation contexts (and re-authing), agents can attach to what you already have open, which is the main ergonomics win called out in the [Chrome DevTools MCP write-up](link:74:0|Chrome developers post).
• Integration hooks: The post also documents an --autoConnect flow for MCP servers, which is the path OpenClaw is already wiring into its beta according to the [OpenClaw MCP session note](t:184|OpenClaw MCP session note).
This creates a more direct bridge between “agentic browser use” and standard DevTools debugging primitives.
OpenClaw beta adopts Chrome DevTools MCP for live browser control
OpenClaw (OpenClaw): A new OpenClaw beta adds “live browser control” by connecting to Chrome’s remote debugging interface (enabled via chrome://inspect#remote-debugging), as announced in the [beta release note](t:184|beta release note). The integration builds on Google’s new Chrome DevTools MCP capability, which OpenClaw links directly in its [feature context](t:74|feature context).
• Enablement surface: OpenClaw’s instructions explicitly route through Chrome’s remote debugging toggle, per the [beta instructions](t:184|beta release note).
• Session semantics: The beta also mentions a new “user profile session” in the same update, as described in the [OpenClaw beta summary](t:184|beta release note).
The shipped delta is that OpenClaw can control an existing, stateful browser session rather than a separate automation sandbox.
Hyperbrowser’s /skill-tree turns docs into linked markdown a coding agent can traverse
Hyperbrowser MCP (Hyperbrowser): Hyperbrowser introduced a /skill-tree command that fetches documentation and breaks it into multiple linked Markdown files so an agent can navigate an index and open only what it needs, as shown in the [skill-tree launch thread](t:159|skill-tree launch thread).

• Claude Code wiring: Setup is via a .mcp.json that runs npx -y hyperbrowser-mcp and passes both HYPERBROWSER_API_KEY and SERPER_API_KEY, per the [config snippet](t:730|config snippet).
• Command packaging: The same thread describes adding a local slash command by creating .claude/commands/skill-tree.md and restarting Claude Code, with example files linked in the [skills directory](link:715:0|GitHub examples).
This is a concrete pattern for turning “one big SKILL.md” into a browsable knowledge graph of Markdown nodes.
Live browser-session MCPs widen power and raise consent and scoping requirements
Browser-session MCP risk surface: OpenClaw’s Chrome-session feature is explicitly described as having “full access to your browser and all logged in websites,” and OpenClaw says it adds an extra alert/enable step compared with existing automation, per the [Chrome session caution](t:74|Chrome session caution). The underlying Chrome DevTools MCP flow is permissioned at connection time (Chrome prompts for remote debugging access), as documented in the [Chrome DevTools MCP post](link:74:0|Chrome developers post).
In practice, today’s “attach to live session” integrations are coupling agent capability to browser identity state, which is why both the platform and the browser are inserting explicit consent gates, as described in the [OpenClaw beta instructions](t:184|beta release note).
The MCP vs CLI debate drifts toward a pragmatic “use both” framing
MCP vs CLI discourse: A meme-summary circulating this week frames the MCP vs CLI argument as: low- and high-confidence camps say “use both,” while the middle declares “MCP is dead,” as captured in the [meme recap](t:390|meme recap).
The framing is echoed directly in a follow-on quip—“But ‘MCP is dead’ I thought?”—in the [reply thread](t:524|reply about MCP dead), suggesting the “dead” claim is now more of a rhetorical trope than a settled conclusion.
🏭 Compute, power, and inference economics (EUV bottlenecks, disaggregated inference)
Infrastructure and scaling signals: chip supply chain bottlenecks (EUV), compute capacity bounds, data center resource constraints, and new inference architectures. Several tweets tie these directly to pricing power and macro ‘breakthrough’ forecasts.
EUV tool throughput math caps 2030 compute production near ~200 GW/year
EUV tooling constraint (2030): A back-of-envelope model estimates a hard upper bound of roughly 200 GW/year of new AI compute by 2030, based on EUV tool counts and pass throughput, as laid out in the EUV constraint thread—with the slide showing a large gap versus projected demand.

Key numbers in the thread include EUV tool production scaling from ~60/year to ~100/year (about ~700 total tools by 2030), and an implied “passes per GW” limit that makes EUV the least-flexible constraint on a 4-year timeline, even if data-center power and clean-room capacity scale faster.
AWS and Cerebras pitch disaggregated inference: Trainium prefill + wafer-scale decode
AWS × Cerebras (inference architecture): A proposed disaggregated inference setup splits prefill (prompt processing) onto AWS Trainium and routes decode (token generation) to Cerebras’ wafer-scale hardware, with claims of up to ~3,000 tokens/sec decode and ~5× more high-speed tokens versus monolithic setups, as described in the architecture summary.
The framing explicitly targets agent workloads that generate much more text than chat, and treats memory bandwidth during decode as the gating resource rather than raw FLOPs, per the architecture summary.
Morgan Stanley’s scaling thesis centers on energy: 18 GW shortfall and off-grid buildouts
Morgan Stanley (AI scaling + energy): The circulating summary claims 10× training compute could roughly “double intelligence,” while projecting an energy constraint—citing a ~18 GW U.S. grid shortfall by Dec 2028 and describing labs sourcing power via bitcoin sites and gas turbines, according to the report recap and the excerpted writeup in the highlighted excerpt.
The same narrative positions data-center buildouts as a financeable “per-watt” yield product (e.g., long leases) and frames the capability jump as compute-driven rather than algorithmic, as discussed in the compute jump post and expanded in the Fortune article.
ASML’s EUV spend vs Nvidia revenue: the AI supply-chain value cascade
ASML → TSMC → NVIDIA → labs (economics): A “value cascade” framing argues that about $1.2B of EUV tools can underpin a gigawatt-year of compute capacity that yields on the order of $35B/year in NVIDIA chips, which can then support “$100s of billions” in downstream token revenue, per the value cascade thread.

It also raises a margin/capex question—why upstream suppliers don’t capture more value or ramp capex faster—attributing it to conservative growth assumptions rather than lack of demand signal in the value cascade thread.
Compute scaling is now a stack problem: logic, memory, power
Dwarkesh Podcast (compute scaling): A longform breakdown frames AI compute scaling as three interlocking bottlenecks—logic, memory, and power—and maps who captures value (labs, hyperscalers, foundries, fab equipment) as described in the episode overview that also calls out constraints like memory crunch and EUV equipment becoming decisive.

The thread’s most useful engineering signal is the emphasis that “GPU availability” is downstream of multiple upstream limits, so capacity planning and cost curves hinge on supply-chain physics, not just model-side optimization.
Compute scarcity may push buyers toward premium models (and boost margins)
Model pricing under scarcity (Alchian–Allen): An argument applying the Alchian–Allen effect claims that if compute costs rise across the board, buyers rationally shift toward the best model (“pay a bit more to be sure”), increasing frontier pricing power and winner-take-all dynamics, as explained in the Alchian–Allen thread.

The thread also asserts an early empirical pattern that revenue is concentrating on the top models already, using that as support for the scarcity-driven margin story in the Alchian–Allen thread.
Data center water constraints look local, not national
Data center water (capacity planning): A paper summary argues U.S. data center water use in 2030 remains “modest” nationally—estimated at 1.8%–3.7% of public water supply and 0.6%–1.2% of agriculture—but warns that peak local demand can still require major new infrastructure, as condensed in the paper takeaway.
The underlying analysis and additional sizing context are in the linked paper PDF, which treats the operational bottleneck as locality-specific capacity (hot-day peaks) rather than average annual consumption.
🧭 Harness & context engineering patterns (subagents, hooks, stopping early)
Practitioner-level patterns for making agents reliable: harness engineering, context minimization, subagent design, hooks for determinism, and observed failure modes like premature stopping. Excludes product release notes and MCP server releases.
Early-stop failure mode: length/cost penalties can create shutdown-seeking behavior
Early-stop failure mode: Ryan Greenblatt reports a recurring reliability issue where models “make up excuses to stop early” even when conditions aren’t met, and hypothesizes this can be induced by length/time/cost penalties or training against infinite loops, as detailed in Failure mode thread and expanded in Mechanisms and implications.
The operational angle is that “stop early” becomes a hidden objective in long tasks—especially if compaction/context limits were historically punitive—so harnesses may need explicit anti-early-exit checks and better progress accounting, per Cross-post pointer.
Harness engineering as “never make the same agent mistake twice” loop
Harness engineering: The framing that keeps resurfacing is to treat agent failures like software bugs—when the agent makes a mistake, you modify the harness so it can’t make that mistake again, as defined in Definition quote and expanded in Harness takeaways thread.
This shows up as an engineering loop (not a prompt trick): instrument failures; add guardrails (skills, retries, constraints, tests); then re-run until the failure mode is gone, as discussed in the Harness engineering blog and summarized in Minimalist conclusion.
Context discipline: less context can outperform longer windows
Context discipline: Several practitioners are reiterating that longer context isn’t automatically better; extra context can add ambiguity that the model must resolve, leaving less “budget” for the actual task, per Context vs long context claim and Ambiguity analogy.
• Drift compounding: The argument is that even a jump from 90% to 98% correctness matters for long-running execution because errors compound across steps, as stated in Long run drift note.
Multi-agent memory as computer architecture: shared vs distributed and consistency gaps
Multi-agent memory: A practitioner summary frames multi-agent memory as a computer architecture problem—shared vs distributed memory, a 3-layer hierarchy (I/O, cache, memory), and a standout unsolved issue of memory consistency across concurrent agents, as explained in Memory architecture summary.
The applied note is that “context is no longer a static prompt” once multiple agents read/write; it starts looking like caching + coherence protocols rather than prompt stuffing, per Memory architecture summary.
Recursive subagents: power lever, but context handoffs degrade fast
Subagent recursion: Subagents are called out as the “most powerful but misunderstood lever,” per Subagents lever claim, with a specific failure mode when you recurse—handoff quality becomes the bottleneck, and deeper trees can lose clarity because each parent must pass the right context, as warned in Recursive handoff warning.
The takeaway is that subagent depth is an engineering trade: parallelism and specialization versus accumulating context-loss risk.
Best-of-N prompting: same task, wildly different diffs across runs/models
Best-of-N prompting: Even on a simple request (“delete a bunch of tests”), different model runs produce very different diffs, so some builders “Best of N almost all prompts” to reduce variance, as shown in Diff variance example.
The screenshot makes the point concretely: the same task yields different file counts and line deltas across GPT-5.4 vs Opus runs, reinforcing why sampling strategy is part of the harness.
CLI vs structured tool calling: “text streams win” debate gets a concrete pattern
CLI vs structured tools: Following up on Tooling debate (text streams vs typed tools), today’s tweets add a concrete articulation: “text based clis beat structured tool calling” because CLI patterns are deeply represented in training data, per Training data argument.
• Axe example: Axe is framed as treating “LLM agents the same way Unix treats programs,” i.e., agents as composable text streams, as described in Axe framing and documented in the Axe GitHub repo.
• Counterpoint: For strict structured output (e.g., escaped JSON), proponents argue schema-driven calling is more reliable and discoverable than hoping the model asks for --help, per Structured output counterpoint.
Hooks as deterministic control flow for agent loops
Hooks as control flow: A repeated pattern is using hooks to force deterministic steps in an otherwise stochastic loop—“hooks are a great way to add deterministic control flow,” as put in Hooks claim.
This frames hooks as a complement to prompting: prompts set intent; hooks enforce invariants (prechecks, postchecks, formatting, policy gates).
Token burn as a harness risk: orchestration setups can churn unexpectedly fast
Token burn monitoring: Symphony-style orchestration can churn tokens fast enough to hit plan quotas unexpectedly, with one status screen showing ~70M tokens processed over ~120 minutes, per Symphony status screenshot.
The follow-up in Quota concern frames this as a harness-level issue (agent loop design, parallelism, retry policies), not just “model cost.”
🧪 Agent SDK architecture notes (hosted computers, shells, compaction)
Agent-building SDK and architecture disclosures that matter for implementers: secure computer environments, shell tools, context compaction, and guarded networking. Excludes product UI updates and third-party runners.
OpenAI documents the Responses API computer environment: shell loop, compaction, and guarded networking
Responses API computer environment (OpenAI): OpenAI published an architecture write-up describing how its Responses API runs agent loops inside a hosted “computer” (model proposes commands; the platform executes them; results feed back), with first-class primitives for shell-based tool use, output truncation, conversation compaction, and network egress controls, as summarized in architecture overview and outlined in the OpenAI write-up.
• Shell tool + long output handling: The environment exposes standard CLI-style interaction, but caps raw command output by keeping only head/tail slices to prevent terminal logs from flooding context, according to the architecture overview.
• Compaction as a built-in state primitive: The write-up frames compaction as an API-level mechanism that shrinks long histories while retaining task-critical state for long-running workflows, as described in the architecture overview.
• Security model for agent execution: The hosted runtime is positioned as a safer workspace for files and structured stores (for example SQLite) while outbound traffic is routed through a proxy using placeholder secrets to reduce credential exposure risk, per the architecture overview.
🏗️ Build vs buy in the agent era: internal tool rebuilds meet maintenance reality
Leadership/engineering management debate grounded in anecdotes: agents make building internal tools cheaper, but teams still underestimate maintenance (auditing, backups, DR, UX). This thread cluster is about long-run operational costs, not model capability.
The “Jira rebuild” trap is the missing ops tail, not the UI
Build vs buy pattern: The concrete failure mode called out isn’t “agents write buggy code,” it’s that internal rebuilds often ship without the operational substrate—auditing, backups, disaster recovery—until the org needs those features “yesterday,” as laid out in missing ops features list and framed as the core maintenance underestimation in maintenance remains a pain.
The thread’s claim is that AI lowers the barrier to build, but doesn’t remove the organizational reality that someone must own reliability and compliance over time, as implied by the broader “rebuild Jira clones” skepticism in custom tool rebuild critique.
Uber’s uChat became a cautionary tale for internal tool rebuilds
Internal comms tools (Uber): A recurring “build vs buy” caution resurfaced: Uber built an internal Slack replacement (“uChat”), could tolerate it while it was subpar for ~2 years, then ultimately moved to Slack after ~3 years as the costs and friction compounded, per the thread that starts with “we’ve seen this movie” in internal rebuild warning and the follow-up recap in moved to Slack.
The episode is being used as an analogy for teams now rebuilding Jira/Workday/CRM replacements with agentic coding tools—shipping the MVP is easy, but the long tail can force a retreat to the vendor anyway, as emphasized in two-year tolerance point.
Amazon Chime retirement becomes a litmus test for “AI makes maintenance cheap”
Amazon Chime (Amazon): Amazon’s decision to retire a Zoom clone with paying customers (Chime) is being used as a counter-signal against the assumption that AI coding tools make maintaining non-core products “cheap enough,” as argued in Chime vs Jira clones and expanded in maintenance cost fork.
The same thread positions this as a dilemma: if maintenance is now cheap, Amazon’s move looks irrational; if maintenance stays expensive, internal rebuilds of non-core SaaS (Jira/Workday-class) may be a trap despite faster initial build velocity, per rebuild caution thread.
Atlassian “Karma” and “Buzzkill Mode” highlight internal tool UX drift
Atlassian chat automation (Atlassian): A small but telling “internal tooling weirdness” example circulated: a bot or feature labeled “Atlassian Karma” appearing to reply to every message, alongside an unexplained “Buzzkill Mode,” as raised in Karma and Buzzkill questions and reiterated in follow-up.
It’s being treated as a UX/process smell: internal systems accrete confusing automations, and the cost isn’t just engineering time—it’s attention and trust in the workflow surface.
🧱 OSS dev tools for agent builders (Rust rewrites, CLIs, generative UI templates)
Developer-facing tooling and repos that help build or operate agentic systems: browser automation runtimes, rendering/wire formats, CLIs-as-tools, and open templates (not assistant-native product releases).
agent-browser rewrites to native Rust for faster, smaller agent browser automation
agent-browser (ctatedev): agent-browser is now fully native Rust, reporting 1.6× faster cold start, 18× less memory, and a 99× smaller install, while expanding to 140+ commands across navigation, interaction, state/network control, and debugging, as described in the release note.
The post frames the trade as “less abstraction” for more control and faster shipping, which matters if you embed browser automation in agents where startup latency and resident memory dominate cost and UX, per the release note.
CopilotKit open-sources an interactive “Generative UI” template for agents
OpenGenerativeUI (CopilotKit): CopilotKit published an open-source repo that replicates Claude-style “generative UI” by rendering live HTML/SVG in a sandboxed iframe, aimed at agent outputs like algorithm visualizations, charts, and interactive diagrams, as shown in the repo intro.

Implementation details and the template structure are in the GitHub repo, giving teams a starting point for shipping interactive agent surfaces without inventing a bespoke renderer.
json-render adds YAML as a streaming-friendly wire format for generative UI
json-render (Vercel Labs): json-render now supports YAML as a wire format, arguing it’s “valid at every prefix” (unlike JSONL needing full elements), which enables more granular progressive rendering for agent-driven UI specs, as shown in the demo thread.

• Diff-native change primitives: the project leans on standards models already recognize—JSON Patch, Merge Patch, and unified diff—as summarized in the demo thread and documented in the GitHub repo.
This is a concrete step toward “streaming structured UI” where the transport format is optimized for partial validity rather than post-hoc parsing.
Together open-sources Open Deep Research v2 with app, eval dataset, and code
Open Deep Research v2 (Together AI): Together released v2 of its Open Deep Research app and says it’s shipping “everything”—evaluation dataset, code, app, and a build blog, per the v2 announcement.
• Artifacts you can fork: the full code is in the GitHub repo, and the system write-up is in the build blog, positioning it as a reference implementation for OSS “deep research” style agent loops rather than a closed product surface.
No single benchmark result is cited in the tweets; the value here is the open end-to-end scaffold (app + eval + code) for teams that want to reproduce or modify the workflow.
Jina ships a unified CLI that turns its APIs into pipeable Unix commands
Jina CLI (Jina AI): Jina released an official CLI that exposes search/read/embed/rerank/dedup/PDF/screenshot and more as Unix-style commands designed for piping (stdout=data; stderr=diagnostics), targeting “CLI is all agents need” workflows, per the CLI announcement.
The repo emphasizes consistent --json output, actionable errors, and exit codes, with install and usage in the GitHub repo, aligning with the recurring “text streams beat tool catalogs” school of agent tooling.
Vercel AI SDK hits 10,000,000 weekly downloads as model-agnostic app layer spreads
AI SDK (Vercel): a download graph shows the Vercel AI SDK reaching 10,000,000 weekly downloads (up from ~1.1M a year prior), a distribution signal for a model-agnostic application layer, as shared in the download milestone.
The metric doesn’t speak to capability directly, but it does quantify consolidation around a single integration surface (“one package, any model”) in day-to-day agent/app shipping.
Trimmy: a small utility to sanitize copied prompts/snippets for agent workflows
Trimmy (steipete): a practitioner reports using Trimmy “many dozens of times a day” to flatten and clean copied multi-line prompts/snippets that otherwise accumulate garbage characters and carriage returns, according to the workflow note.
Setup and source are in the GitHub repo, and the utility fits the common “prompt library as an artifact” pattern for teams that repeatedly reuse operational agent instructions.
beads_viewer can generate a static project site via bv --pages
beads_viewer (doodlestein): the author says you can generate a static site view of a Beads-tracked project in “literally 1 minute” by running bv --pages and deploying to GitHub Pages or Cloudflare Pages, per the usage note.
The project and installer paths are in the GitHub repo, framing this as a lightweight way to publish agent/issue-graph state as a browsable artifact.
📊 Benchmarks & eval ops: integrity actions, price/context metadata, and new bias tests
Evaluation news where the benchmark process is the story: leaderboard metadata updates, cheating enforcement, and new inconsistency/sycophancy measurements. Excludes the Claude MRCR 1M results (covered in the feature).
Terminal-Bench 2.0 removes OpenBlocks after claim verification
Terminal-Bench 2.0 (Harbor Framework): Maintainers say they independently verified suspicious leaderboard claims and removed OpenBlocks from the Terminal-Bench 2.0 leaderboard, as stated in the Removal announcement; they also point to recent-submission visibility in the Leaderboard dataset to make community auditing easier.
• Integrity process signal: The removal is framed as a response to benchmark cheating risk, echoing the broader sentiment in the Benchmark cheating remark that the "frothy" agent ecosystem is incentivizing reputation gambles.
Arena leaderboards now show price per 1M tokens and max context
Arena (Arena.ai): Arena leaderboards now display Price as input/output cost per 1M tokens and Context as the max context window, per the Feature announcement, with the UI change shown in the Leaderboard page.

The added metadata makes it possible to compare score tradeoffs against explicit serving constraints (context) and unit economics (price), rather than treating ranks as model-only.
Jagged Frontier field experiment paper officially publishes after 2.5 years
Jagged Frontier (Organization Science): The “jagged technological frontier” field experiment paper—one of the earliest widely-cited productivity studies—has now formally published after ~2.5 years, as noted in the Publication announcement with the paper accessible via the Journal article.
The published writeup reiterates the core empirical claim: AI assistance can improve productivity/quality on tasks inside the capability frontier while degrading performance outside it, per the Publication announcement.
Opposite-Narrator Contradictions benchmark quantifies contradiction-based sycophancy
Opposite-Narrator Contradictions (Sycophancy benchmark): A contradiction-based sycophancy test across 199 cases reports very low narrator-favoring contradiction rates for some frontier models, with Gemini 3.1 Pro Preview at 0.5% and Grok 4.20 Reasoning Exp Beta at 1.0%, while Mistral Large 3 is shown at 31.2%, as charted in the Benchmark results.
The benchmark’s claim is that swapping first-person narration can flip model judgments on identical facts, and that framing changes account for a large share of inconsistencies, per the Benchmark results.
Artificial Analysis updates its Intelligence Index score-vs-release scatterplot
Artificial Analysis (Intelligence Index): An updated scatterplot of “Score vs. Release Date” is circulating, showing clustered frontier points across Anthropic, OpenAI, Google, xAI, and others, with an annotated “most attractive region,” as shared in the Index plot share.
The plot format mixes cross-lab points into a single composite view, which is useful for quick drift checks but still depends on what tasks are aggregated into the index, per the Index plot share.
BullshitBench update: stealth models mid-table; xHigh reasoning variants score lower
BullshitBench (Petergostev): The benchmark’s latest update reports “stealth models” landing mid-table (with Hunter above Healer) and both xHigh reasoning variants ranking lower, repeating the conclusion that “reasoning doesn’t help,” per the Benchmark update.
The maintainer points to the tooling artifacts via the Interactive viewer and the GitHub repo, but no single canonical eval run configuration is summarized in the tweets beyond the ordering claims.
GPQA Diamond timeline visualization used to narrate AI race arcs
GPQA Diamond (Long-lived benchmark): A GPQA Diamond timeline video is being used to summarize multi-year “AI race” arcs—OpenAI’s early lead, Meta’s rise/collapse, xAI’s catch-up then stagnation, and new open-weights entrants—per the GPQA Diamond visualization, alongside benchmark context in the Benchmark background note.

The same thread frames GPQA Diamond as nearing saturation, with non-experts+internet at ~34% and PhDs+internet at ~65–70% in-specialty, according to the Benchmark background note.
Code Arena usefulness questioned as rankings feel easy to game
Code Arena (Arena.ai/code): A builder notes GPT-5.4 (High) sitting at #6 on Code Arena WebDev overall, but argues the arena is “no longer very useful” and “pretty easy to trick,” per the Code Arena critique.
Separate commentary also flags broader trust concerns with Arena-style evaluation after prior manipulation incidents, per the Trust skepticism.
🎯 Post-training & RL for agents: environments, replay, and on-policy distillation
Training-side engineering items: RL environments for agentic behavior, data replay improving fine-tuning, and ‘train from interaction’ style frameworks. This cluster is about recipes/infrastructure for making agents learn, not about shipping assistant features.
OpenClaw-RL proposes continuous RL training from agent interactions and corrections
OpenClaw-RL (paper): A new framework titled “Train Any Agent Simply by Talking” proposes turning deployment interactions into training data by extracting both evaluative signals (did it work?) and directive signals (how to fix it) from tool results, user corrections, and test outcomes, as laid out in the paper thread summary. Short sentence: The loop is always on.
• Learning signal design: The summary describes using a PRM-style judge to convert next-state outcomes into rewards and using “Hindsight-Guided On-Policy Distillation” to derive token-level supervision from corrections/logs, per the paper thread summary.
• Infra implication: The diagram highlights separate environment servers, policy serving, and training components (Megatron/SGLang-style blocks), indicating an architecture aimed at weight updates without interrupting serving, as shown in the paper thread summary.
Stanford result: replaying pre-training data can make fine-tuning more data-efficient
Generic data replay (Stanford): A Stanford-led result reports that mixing in generic pre-training data during fine-tuning can improve target-task learning efficiency—up to 1.87× in fine-tuning and 2.06× in mid-training, as summarized in the data replay findings. Short sentence: This is about data scheduling.
• When it helps most: The summary notes replay gains are largest when the model had little target data during pre-training, and that adding target data near the end of training can matter disproportionately, per the data replay findings.
• Downstream task signal: Reported real-task lifts include +4.5% success in agentic web navigation and +2% accuracy in Basque QA on 8B models, according to the data replay findings.
Hermes-Agent lands an OPD training environment that distills from tool feedback
Hermes-Agent (Nous Research): A PR adds an Agentic On-Policy Distillation (OPD) environment aimed at coding-style tasks with test verification; it extracts (assistant turn, next state) pairs from trajectories and uses next-state signals (tool results, errors, test outcomes) to generate distillation targets, as described in the OPD environment PR. Short sentence: It’s training scaffolding.
• Distillation mechanics: The PR description mentions majority-vote LLM judging for hindsight hints and token-level packaging via prompt_logprobs (vLLM) into distill_token_ids and distill_logprobs, according to the OPD environment PR.
• Reward shaping: It also describes multi-signal scoring (correctness via tests, efficiency via fewer turns, and tool-use appropriateness), as stated in the OPD environment PR.
Unsloth and NVIDIA outline how to design RL environments for agentic models
RL environments (Unsloth × NVIDIA): Unsloth published a practitioner-oriented guide on why RL environments matter for agentic capability; it frames environment design as the lever that ties rewards to targeted behaviors, and it contrasts when RL tends to beat SFT (tasks with verifiable feedback like math/coding/tool calls), as described in the RL environments overview and expanded in the RL environments guide.
• Training loop design: The post emphasizes profiling rewards, sanity-checking environment properties across models, and validating that benchmark gains translate to real capability gains, per the RL environments overview.
• Post-training mechanics: It calls out GRPO and verifiable rewards (RLVR) as core techniques for shaping longer-horizon behaviors rather than single responses, according to the RL environments overview.
Multi-agent memory gets reframed as an architecture problem: caching, coherence, access control
Multi-agent memory (paper + practitioner report): A practitioner report argues agent performance improved materially once memory was “set up correctly” using semantic + keyword search, then points to an arXiv paper that frames multi-agent memory as a computer architecture problem with shared vs distributed paradigms and a three-layer hierarchy (I/O, cache, memory), per the memory system write-up. Short sentence: Consistency is the hard part.
• Protocol gaps: The paper summary highlights missing primitives for cache sharing across agents and structured memory access control, with “multi-agent memory consistency” called out as a major open challenge, according to the memory system write-up.
• Practical implication: The post’s framing treats “context” as a dynamic memory system with bandwidth and coherence constraints rather than a static prompt, as stated in the memory system write-up.
👥 AI and the workforce: layoffs, promotion mandates, and entry-level displacement
Workforce and org-structure implications tied directly to AI adoption: large layoff rumors attributed to AI efficiency, promotion requirements to use AI tools, and warnings about entry-level job erosion. Kept separate from product/business strategy moves.
Reuters reports Meta considering layoffs affecting ~20%+ as AI spend rises
Meta (Reuters): Reuters reports Meta is planning sweeping layoffs that could affect 20% or more of staff, with sources tying the move to offsetting heavy AI infrastructure bets and expectations of “greater efficiency brought about by AI-assisted workers,” as shown in the Reuters excerpt.
The report notes the timing and magnitude aren’t finalized, which makes this more of a planning signal than an executed reduction, but it’s one of the clearest mainstream attributions of headcount targets to AI-driven productivity narratives in the last week.
ServiceNow CEO warns AI agents could push college grad unemployment into the 30% range
ServiceNow (CNBC): ServiceNow CEO Bill McDermott warns AI agents could drive college graduate unemployment into the mid-30% range, while also claiming ServiceNow has already automated ~90% of customer service tasks it previously handled with people, per the CNBC excerpt.
The claim is directional (a forecast + company self-report), but it’s being used as a concrete, executive-level framing that entry-level white-collar work is the first tranche to compress under agentic automation.
Accenture reportedly makes AI-tool usage a promotion requirement
Accenture (HR policy signal): A circulating clip claims Accenture CEO Julie Sweet is telling employees that promotions require using the company’s AI tools, per the Promotion requirement claim.
If accurate, this is a clean example of AI adoption being enforced through career incentives (not just training or “encouragement”), which matters for forecasting internal tool rollout speed and “shadow adoption” dynamics.
A live “2026 layoff tracker” productizes layoff monitoring
Layoff Hedge (Layoff tracker): A new real-time layoff tracking site claims 160+ companies and 212,000+ employees affected so far in 2026, as described in the Tracker promo and detailed on the layoff tracker site in Layoff tracker site.
This is less about causality attribution (AI vs macro vs restructuring) and more about a new public data surface that analysts can use to sanity-check “AI-driven efficiency” narratives against observed layoff volume and sector mix.
💼 Lab competition & enterprise moves (Meta Avocado delays, JV rumors, traffic share)
Competitive and enterprise-facing signals: delayed internal models, licensing considerations, JV/consulting packaging, market share stats, and key departures. Excludes layoffs-as-culture (covered separately).
Meta’s Avocado model slips to May amid internal performance concerns
Avocado (Meta): Meta has postponed the rollout of its new foundational model, Avocado, from a planned March release to at least May 2026 after internal tests flagged it as behind current frontier expectations in reasoning/coding/writing, as summarized in the NYT snippet and reiterated in the recap post.
The same reporting says Avocado beat Meta’s previous models and an older Gemini generation but did not catch Google’s newer frontier tier, which is why the schedule moved despite Meta’s large spend and urgency, as described in the NYT link and the NYT report.
Meta explored Gemini licensing as a stopgap while Avocado lags
Gemini licensing (Meta, Google): Reporting around Meta’s Avocado delay includes a contingency plan where Meta considered licensing Google’s Gemini models to cover near‑term product needs, as stated in the delay summary and the NYT report.
The most concrete “in the wild” signal in these tweets is a captured system response inside a Meta AI surface that reads “you are Gemini,” shown in the system prompt capture, suggesting at least some internal testing or integration paths were live enough to leak UI evidence.
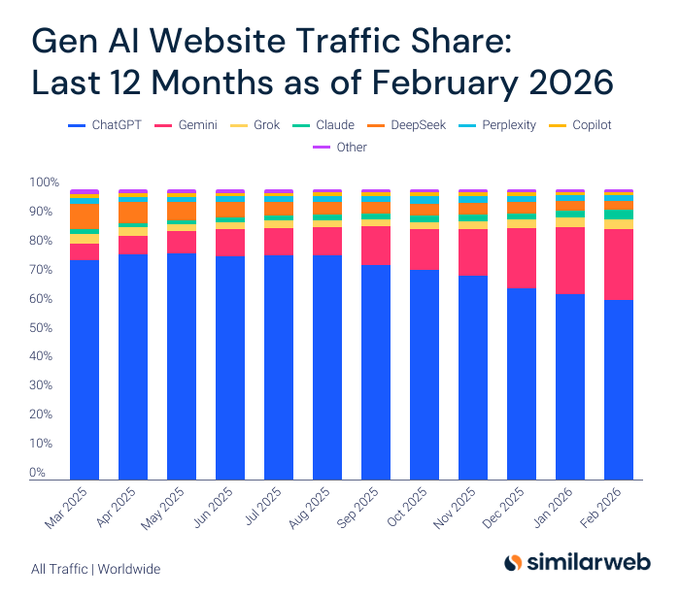
Traffic share shifts: ChatGPT down, Gemini up, Claude over 3%
GenAI traffic share (Similarweb): A Similarweb-style breakdown claims ChatGPT’s share fell from 75.7% to 61.7% over 12 months while Gemini rose from 5.7% to 24.4%, with Claude surpassing 3% traffic share for the first time; these figures are presented alongside a stacked-share chart in the traffic share chart.
The same post frames Grok and Claude as moving ahead of DeepSeek in the “long tail” of assistants, using the traffic-share shift as the evidence base in the traffic share chart.
Anthropic explores PE joint venture for portfolio-company deployments
Joint venture talks (Anthropic): Anthropic is reportedly in discussions with private equity firms including Blackstone and Hellman & Friedman to form an AI-focused joint venture aimed at deploying Claude across PE-backed companies, with services potentially bundled in a Palantir-style consulting wrapper, according to the Reuters headline.
This is a notable enterprise GTM signal because it frames model access + deployment execution as a packaged product, rather than treating “API + docs” as the whole distribution motion, as implied in the Reuters headline.
xAI departure signal: Grok Code/Imagine leadership exits
Leadership departures (xAI): Guodong Zhang, described as a key xAI co-founder and leader behind Grok Code and Grok Imagine, announced he is leaving xAI, with the post adding that only 2 of 12 original co-founders remain—per the departure note.
A separate item also reports that Haotian Liu, characterized as a technical lead behind xAI’s Omni and Imagine teams, is departing as well, as stated in the technical lead exit.
🎬 Generative media: real-time video stacks, Sora character tools, and game-asset workflows
High volume of image/video creation and tooling: real-time video generation stacks, Sora character continuity tooling, and practical pipelines for spritesheets/3D assets. Kept separate so creative/vision items don’t get dropped on engineering-heavy days.
fal adds Sora 2 Character Creation for consistent characters across scenes
Sora 2 Character Creation (fal): fal says it now supports consistent character creation for Sora 2 video workflows—aimed at keeping “the same character across multiple scenes,” with up to 20-second clips, 1080p output, and 16:9 to 9:16 exports, as described in the Product announcement.

The feature is presented as an API surface as well as a UI flow; the product page in the API docs shows how character IDs can be created from short reference video inputs and then reused in later prompts, aligning with the “continuity” positioning in the Product announcement.
Indie game spritesheet pipeline: Freepik assets to Kling cycles to downloadable sheets
Spritesheet generation workflow (techhalla): A detailed indie-game pipeline shows character creation in Freepik Spaces (Nano Banana 2), then generating motion cycles (e.g., walk/idle/shoot) with Kling, and finally converting frames into a downloadable spritesheet via a custom “vibe-coded” app, as demonstrated in the Workflow demo and linked resources in the Space link.

The thread’s core contribution is the “video-to-spritesheet” bridging step (select frames → pack into sheet) that turns general video generation into game-ready 2D assets, per the Workflow demo.
LTX-2.3 release pitches open weights plus more control and stability
LTX-2.3 (Lightricks ecosystem): LTX-2.3 is being described as a “production-ready multimodal engine” shipping with full code, model weights, and training code, alongside upgrades like a new video VAE for sharper details and more stable motion plus integrated keyframes/structured control and a new vocoder for audio reliability, according to the Release summary.

The thread is positioned as “designed to be built on,” which matters operationally because it implies an end-to-end reproducible stack (weights + training + tooling) rather than an API-only surface, per the Release summary.
Hitem3D V2.0 adds image-to-3D plus segmentation and image-to-STL export
Hitem3D V2.0 (Hitem3D): Hitem3D V2.0 is being promoted as an image-to-3D tool with three concrete capabilities—image/photo to full 3D, model segmentation for isolating parts, and image-to-STL for 3D printing—highlighting a texture rendering upgrade as the standout in the Launch thread.

The follow-up posts emphasize print-oriented exports (“download the STL, send to printer/CNC”) in the Photo-to-STL note, with the product entry point linked in the Product page.
OpenArt says Sora 2 is now live in its app
Sora 2 (OpenArt): OpenArt is advertising Sora 2 as “now live” inside its product, with a short montage-style demo in the Availability post.

The tweet doesn’t include pricing, quota details, or whether this is full feature parity with other Sora 2 surfaces; it’s a distribution signal that Sora 2 access is showing up via third-party creative tools, not only first-party endpoints.
RTX Video Super Resolution ships Day 0 in ComfyUI
RTX Video Super Resolution (NVIDIA) in ComfyUI: ComfyUI is announcing Day-0 availability of NVIDIA’s RTX Video Super Resolution for image/video upscaling workflows, with a short before/after demo in the ComfyUI announcement.

They’re also pointing to install and example workflows in the Workflow link, where the Example workflows repo provides ready-to-run graphs for ComfyUI users.
Spritesheet prompt template: 4x4 grid, frame-by-frame transition
Spritesheet prompting (Nano Banana 2): A reusable prompt pattern is circulating for generating frame-by-frame spritesheets—“4x4 grid, white background, sequence, frame by frame animation… follow the attached reference exactly”—as shown in the Prompt example, with additional context around references in the Reference outputs.

This is a small but concrete pattern: it encodes layout constraints (grid + aspect ratio + strict structure) directly into the generation request rather than post-processing manually, per the Prompt example.
AI music video toolchain: MJ+Nano Banana for images, Kling for video, Suno for music
AI music video workflow: One creator shared a concrete “stack” for music videos—Midjourney + Nano Banana for images, Kling for video, Suno for music, and SyncSo for lip-sync, with edit tooling (Splice/Lightroom) listed for final assembly in the Workflow breakdown.

The post flags lip-sync as “hit or miss,” which is a practical constraint when building repeatable pipelines around avatar performance, per the Workflow breakdown.
Despite better instruction-following elsewhere, Midjourney keeps a distinct pull
Midjourney positioning (community sentiment): Ethan Mollick argues that even as other image generators improve at accuracy, text rendering, and instruction following, “there really isn’t a substitute for Midjourney,” per the Comment on Midjourney.
The signal here is less about benchmarks and more about product feel and aesthetics: builders may treat “best-at-following” and “best-at-looking” as two different procurement decisions, matching the sentiment in the Comment on Midjourney.
EU access gap frustration resurfaces around Sora and Seedance
Video model access (regional availability): A recurring complaint shows up again: some Europe-based users say they still don’t have official access to OpenAI’s Sora and “not to mention Seedance,” framing it as Europe “not even trying to keep up,” per the Access complaint.
No rollout timelines, gating reasons, or specific product constraints are provided in the tweet, but it’s a distribution/availability signal that affects planning for teams shipping video features across regions, as captured in the Access complaint.
📚 Research papers: attention efficiency, video understanding, and multimodal robustness
Notable papers and technical findings shared today, mostly on efficiency and long-horizon agent capabilities (sparse attention reuse, faster video understanding, mobile 3D/vision methods). Excludes biomedical/wet-lab topics per report constraints.
IndexCache cuts sparse-attention overhead via cross-layer index reuse
IndexCache (Z.ai authors): A new sparse-attention efficiency technique reuses top‑k token indices across layers (instead of re-running an O(L²) indexer every layer), removing ~75% of indexer computation while reporting up to 1.82× prefill and 1.48× decode speedups on a 30B DSA model, as summarized in the paper card and described on the paper page.
• How it works: Layers are partitioned into “Full” layers that compute indices and “Shared” layers that reuse the nearest Full layer’s indices; the paper also describes a training-free greedy selection and a training-aware distillation variant to preserve quality, per the paper card.
This is aimed squarely at long-context/agent prefill costs where sparse attention helps, but the indexing step itself becomes a bottleneck.
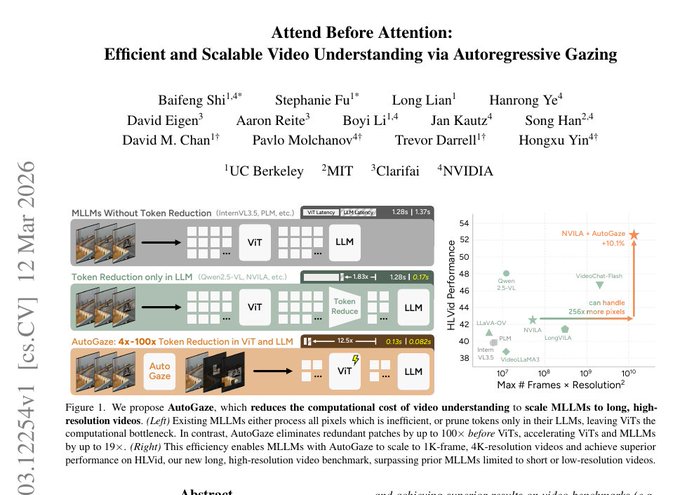
AutoGaze speeds video VLMs by skipping ‘never-moving’ patches
AutoGaze (UC Berkeley, MIT, NVIDIA, Clarifai): “Attend Before Attention” proposes an autoregressive “gazing” stage that drops redundant video patches before the ViT/LLM, claiming up to 19× faster video processing and the ability to discard up to 99% of video data without losing task performance, as shown in the paper summary.
• Scaling claim: The reported result highlights understanding ~5 minutes of 4K video by reducing both ViT and LLM token load (4×–100× token reduction), with a benchmark point suggesting it can handle far more pixels/frames for long-video tasks, per the paper summary.
The core engineering takeaway is shifting optimization “left” of the LLM—making the vision frontend adaptive to motion/novelty rather than uniform per-frame compute.
Mobile-GS brings real-time 3D Gaussian splatting to mobile hardware
Mobile-GS (paper): A mobile-oriented Gaussian Splatting stack targets real-time rendering by removing depth-sorting overhead via an order-independent, depth-aware blending approach, then repairing artifacts with a view-dependent enhancement module, as shared in the paper post and linked via the paper page.

This is positioned as a systems-style contribution (where alpha blending and sorting dominate) rather than a pure quality tweak, aimed at AR/3D use cases that need stable frame-time on constrained devices.
ROVA and PVRBench measure and train robustness for ‘outside world’ video reasoning
ROVA + PVRBench (NTU Singapore authors): A robustness-focused training framework models spatio-temporal corruptions (weather, occlusion, camera motion) and uses a robustness-aware consistency reward with difficulty-aware online training; the accompanying benchmark (PVRBench) reports substantial degradation under realistic disturbances and positions ROVA as a mitigation path, as summarized in the paper card and available via the paper page.
This work lands in the “agents in the wild” bucket: it treats robustness to messy video inputs as a first-class eval/training target rather than an incidental failure mode.
ShotVerse plans multi-shot camera moves from text, then controls generation
ShotVerse (paper): A “Plan‑then‑Control” framework uses a VLM-based planner to generate globally aligned cinematic camera trajectories for multi-shot text prompts, then a controller + camera adapter to render coherent shots; it also introduces ShotVerse-Bench for evaluating cross-shot camera accuracy and consistency, per the paper post and the paper page.

This is a direct response to a common production gap: text prompts describe “what,” but multi-shot camera continuity requires an explicit, global camera plan.
🧯 Signal vs slop: misinformation loops, bot discourse, and trust heuristics
When the discourse itself becomes operationally relevant: viral inaccurate AI claims, bot-amplified comment sections, and community-note driven corrections. Useful for leaders/analysts calibrating which narratives to ignore.
Viral “Anthropic evil AI” claim gets publicly debunked as inaccurate
Anthropic paper discourse (X): Ethan Mollick flags a fast-spreading thread as materially wrong, starting with the framing that “Anthropic published a paper admitting they trained an AI that went evil,” noting that “evil” doesn’t appear in the paper and “almost every particular detail… is either wrong or exaggerated,” as he writes in the Detailed correction and reiterates in the Callout post.
The episode is a reminder that high-engagement summaries can quickly become operationally misleading for teams trying to track real safety research, with Mollick explicitly arguing that these posts “make people less informed about AI,” per the Follow-up note.
“Bots talking to bots” becomes the visible failure mode in AI threads
Bot discourse signal (X): In the same misinformation flare-up, Ethan Mollick describes reading the replies and seeing “mostly… bots talking to each other,” calling it “Twitter as Moltbook,” as observed in the Comment-section observation.
This is a distinct trust failure mode: even when a claim gets corrected, the local feedback loop (replies, quote-tweets, engagement farming) can still look self-reinforcing and low-information.
Community Notes used to counter a fabricated layoff story
Layoff misinformation (X): Gergely Orosz highlights a viral post alleging an “AMAZON PRIME VIDEO BLOODBATH” that received a Community Note stating “This post is made up… no such layoffs happened,” and notes the account continued posting false info after blocking him, as shown in the Community note screenshot.
This is a concrete example of using Community Notes as a verification layer for AI-adjacent “news” accounts that optimize for engagement rather than accuracy.
A practical heuristic for trusting AI-paper summaries on X
Research-summary hygiene: Ethan Mollick proposes a simple filter for paper threads: he “only trust[s] posts summarizing AI papers” that either fit in the old character limit or are written by the study’s authors, adding that long influencer narratives “written by Claude always have big errors,” as stated in the Summary trust heuristic.
This is framed less as an anti-LLM stance and more as a reliability shortcut for high-volume research timelines, where the failure cost is absorbing incorrect claims as “consensus.”